The ability to quickly build and deploy machine learning (ML) models is becoming increasingly important in today’s data-driven world. However, building ML models requires significant time, effort, and specialized expertise. From data collection and cleaning to feature engineering, model building, tuning, and deployment, ML projects often take months for developers to complete. And experienced data scientists can be hard to come by.
This is where the AWS suite of low-code and no-code ML services becomes an essential tool. With just a few clicks using Amazon SageMaker Canvas, you can take advantage of the power of ML without needing to write any code.
As a strategic systems integrator with deep ML experience, Deloitte utilizes the no-code and low-code ML tools from AWS to efficiently build and deploy ML models for Deloitte’s clients and for internal assets. These tools allow Deloitte to develop ML solutions without needing to hand-code models and pipelines. This can help speed up project delivery timelines and enable Deloitte to take on more client work.
The following are some specific reasons why Deloitte uses these tools:
- Accessibility for non-programmers – No-code tools open up ML model building to non-programmers. Team members with just domain expertise and very little coding skills can develop ML models.
- Rapid adoption of new technology – Availability and constant improvement on ready-to-use models and AutoML helps ensure that users are constantly using leading-class technology.
- Cost-effective development – No-code tools help reduce the cost and time required for ML model development, making it more accessible to clients, which can help them achieve a higher return on investment.
Additionally, these tools provide a comprehensive solution for faster workflows, enabling the following:
- Faster data preparation – SageMaker Canvas has over 300 built-in transformations and the ability to use natural language that can accelerate data preparation and making data ready for model building.
- Faster model building – SageMaker Canvas offers ready-to-use models or Amazon AutoML technology that enables you to build custom models on enterprise data with just a few clicks. This helps speed up the process compared to coding models from the ground up.
- Easier deployment – SageMaker Canvas offers the ability to deploy production-ready models to an Amazon Sagmaker endpoint in a few clicks while also registering it in Amazon SageMaker Model Registry.
Vishveshwara Vasa, Cloud CTO for Deloitte, says:
“Through AWS’s no-code ML services such as SageMaker Canvas and SageMaker Data Wrangler, we at Deloitte Consulting have unlocked new efficiencies, enhancing the speed of development and deployment productivity by 30–40% across our client-facing and internal projects.”
In this post, we demonstrate the power of building an end-to-end ML model with no code using SageMaker Canvas by showing you how to build a classification model for predicting if a customer will default on a loan. By predicting loan defaults more accurately, the model can help a financial services company manage risk, price loans appropriately, improve operations, provide additional services, and gain a competitive advantage. We demonstrate how SageMaker Canvas can help you rapidly go from raw data to a deployed binary classification model for loan default prediction.
SageMaker Canvas offers comprehensive data preparation capabilities powered by Amazon SageMaker Data Wrangler in the SageMaker Canvas workspace. This enables you to go through all the phases of a standard ML workflow, from data preparation to model building and deployment, on a single platform.
Data preparation is typically the most time-intensive phase of the ML workflow. To reduce time spent on data preparation, SageMaker Canvas allows you to prepare your data using over 300 built-in transformations. Alternatively, you can write natural language prompts, such as “drop the rows for column c that are outliers,” and be presented with the code snippet necessary for this data preparation step. You can then add this to your data preparation workflow in a few clicks. We show you how to use that in this post as well.
Solution overview
The following diagram describes the architecture for a loan default classification model using SageMaker low-code and no-code tools.
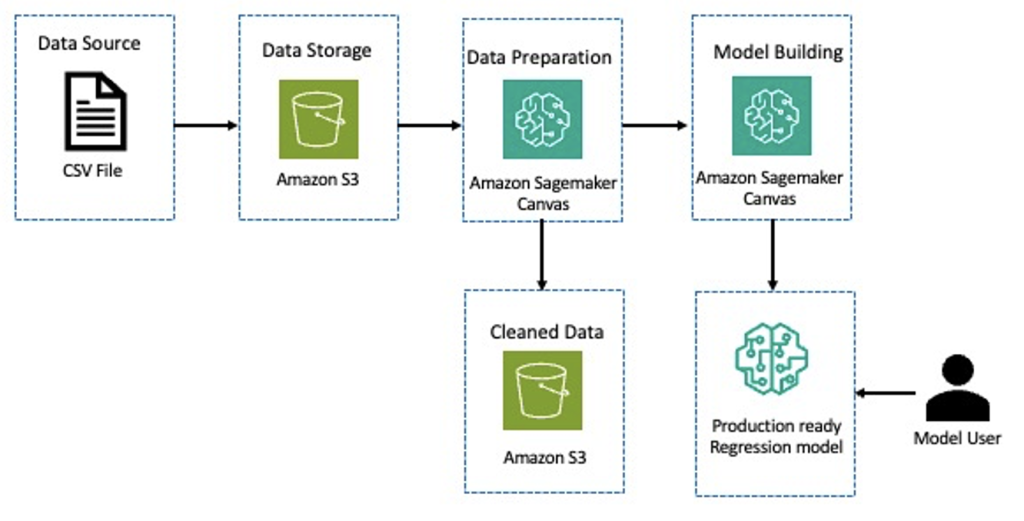
Starting with a dataset that has details about loan default data in Amazon Simple Storage Service (Amazon S3), we use SageMaker Canvas to gain insights about the data. We then perform feature engineering to apply transformations such as encoding categorical features, dropping features that are not needed, and more. Next, we store the cleansed data back in Amazon S3. We use the cleaned dataset to create a classification model for predicting loan defaults. Then we have a production-ready model for inference.
Prerequisites
Make sure that the following prerequisites are complete and that you have enabled the Canvas Ready-to-use models option when setting up the SageMaker domain. If you have already set up your domain, edit your domain settings and go to Canvas settings to enable the Enable Canvas Ready-to-use models option. Additionally, set up and create the SageMaker Canvas application, then request and enable Anthropic Claude model access on Amazon Bedrock.
Dataset
We use a public dataset from kaggle that contains information about financial loans. Each row in the dataset represents a single loan, and the columns provide details about each transaction. Download this dataset and store this in an S3 bucket of your choice. The following table lists the fields in the dataset.
| Column Name | Data Type | Description |
Person_age |
Integer | Age of the person who took a loan |
Person_income |
Integer | Income of the borrower |
Person_home_ownership |
String | Home ownership status (own or rent) |
Person_emp_length |
Decimal | Number of years they are employed |
Loan_intent |
String | Reason for loan (personal, medical, educational, and so on) |
Loan_grade |
String | Loan grade (A–E) |
Loan_int_rate |
Decimal | Interest rate |
Loan_amnt |
Integer | Total amount of the loan |
Loan_status |
Integer | Target (whether they defaulted or not) |
Loan_percent_income |
Decimal | Loan amount compared to the percentage of the income |
Cb_person_default_on_file |
Integer | Previous defaults (if any) |
Cb_person_credit_history_length |
String | Length of their credit history |
Simplify data preparation with SageMaker Canvas
Data preparation can take up to 80% of the effort in ML projects. Proper data preparation leads to better model performance and more accurate predictions. SageMaker Canvas allows interactive data exploration, transformation, and preparation without writing any SQL or Python code.
Complete the following steps to prepare your data:
- On the SageMaker Canvas console, choose Data preparation in the navigation pane.
- On the Create menu, choose Document.
- For Dataset name, enter a name for your dataset.
- Choose Create.

- Choose Amazon S3 as the data source and connect it to the dataset.
- After the dataset is loaded, create a data flow using that dataset.

- Switch to the analyses tab and create a Data Quality and Insights Report.
This is a recommended step to analyze the quality of the input dataset. The output of this report produces instant ML-powered insights such as data skew, duplicates in the data, missing values, and much more. The following screenshot shows a sample of the generated report for the loan dataset.


By generating these insights on your behalf, SageMaker Canvas provides you with a set of issues in the data that need remediation in the data preperation phase. To pick the top two issues identified by SageMaker Canvas, you need to encode the categorical features and remove the duplicate rows so your model quality is high. You can do both of these and more in a visual workflow with SageMaker Canvas.
- First, one-hot encode the
loan_intent,loan_grade, andperson_home_ownership - You can drop the
cb_person_cred_history_lengthcolumn because that column has the least predicting power, as shown in the Data Quality and Insights Report.
SageMaker Canvas recently added a Chat with data option. This feature uses the power of foundation models to interpret natural language queries and generate Python-based code to apply feature engineering transformations. This feature is powered by Amazon Bedrock, and can be configured to run entirely in a your VPC so that data never leaves the your environment. - To use this feature to remove duplicate rows, choose the plus sign next to the Drop column transform, then choose Chat with data.

- Enter your query in natural language (for example, “Remove duplicate rows from the dataset”).
- Review the generated transformation and choose Add to steps to add the transformation to the flow.

- Finally, export the output of these transformations to Amazon S3 or optionally Amazon SageMaker Feature Store to use these features across multiple projects.
You can also add another step to create an Amazon S3 destination for the dataset to scale the workflow for a large dataset. The following diagram shows the SageMaker Canvas data flow after adding visual transformations.

You have completed the entire data processing and feature engineering step using visual workflows in SageMaker Canvas. This helps reduce the time a data engineer spends on cleaning and making the data ready for model development from weeks to days. The next step is to build the ML model.
Build a model with SageMaker Canvas
Amazon SageMaker Canvas provides a no-code end-to-end workflow for building, analyzing, testing, and deploying this binary classification model. Complete the following steps:
- Create a dataset in SageMaker Canvas.
- Specify either the S3 location that was used to export the data or the S3 location that’s on the destination of the SageMaker Canvas job.

Now you’re ready to build the model. - Choose Models in the navigation pane and choose New model.
- Name the model and select Predictive analysis as the model type.
- Choose the dataset created in the previous step.

The next step is configuring the model type. - Choose the target column and the model type will be automatically set as 2 category prediction.
- Choose your build type, Standard build or Quick build.

SageMaker Canvas displays the expected build time as soon as you start building the model. Standard build usually takes between 2–4 hours; you can use the Quick build option for smaller datasets, which only takes 2–15 minutes. For this particular dataset, it should take around 45 minutes to complete the model build. SageMaker Canvas keeps you informed of the progress of the build process. - After the model is built, you can look at the model performance.

SageMaker Canvas provides various metrics like accuracy, precision, and F1 score depending on the type of the model. The following screenshot shows the accuracy and a few other advanced metrics for this binary classification model. - The next step is to make test predictions.
SageMaker Canvas allows you to make batch predictions on multiple inputs or a single prediction to quickly verify the model quality. The following screenshot shows a sample inference.
- The last step is to deploy the trained model.
SageMaker Canvas deploys the model on SageMaker endpoints, and now you have a production model ready for inference. The following screenshot shows the deployed endpoint.
After the model is deployed, you can call it through the AWS SDK or AWS Command Line Interface (AWS CLI) or make API calls to any application of your choice to confidently predict the risk of a potential borrower. For more information about testing your model, refer to Invoke real-time endpoints.
Clean up
To avoid incurring additional charges, log out of SageMaker Canvas or delete the SageMaker domain that was created. Additionally, delete the SageMaker model endpoint and delete the dataset that was uploaded to Amazon S3.
Conclusion
No-code ML accelerates development, simplifies deployment, doesn’t require programming skills, increases standardization, and reduces cost. These benefits made no-code ML attractive to Deloitte to improve its ML service offerings, and they have shortened their ML model build timelines by 30–40%.
Deloitte is a strategic global systems integrator with over 17,000 certified AWS practitioners across the globe. It continues to raise the bar through participation in the AWS Competency Program with 25 competencies, including Machine Learning. Connect with Deloitte to start using AWS no-code and low-code solutions to your enterprise.
About the authors
 Chida Sadayappan leads Deloitte’s Cloud AI/Machine Learning practice. He brings strong thought leadership experience to engagements and thrives in supporting executive stakeholders achieve performance improvement and modernization goals across industries using AI/ML. Chida is a serial tech entrepreneur and an avid community builder in the startup and developer ecosystems.
Chida Sadayappan leads Deloitte’s Cloud AI/Machine Learning practice. He brings strong thought leadership experience to engagements and thrives in supporting executive stakeholders achieve performance improvement and modernization goals across industries using AI/ML. Chida is a serial tech entrepreneur and an avid community builder in the startup and developer ecosystems.
 Kuldeep Singh, a Principal Global AI/ML leader at AWS with over 20 years in tech, skillfully combines his sales and entrepreneurship expertise with a deep understanding of AI, ML, and cybersecurity. He excels in forging strategic global partnerships, driving transformative solutions and strategies across various industries with a focus on generative AI and GSIs.
Kuldeep Singh, a Principal Global AI/ML leader at AWS with over 20 years in tech, skillfully combines his sales and entrepreneurship expertise with a deep understanding of AI, ML, and cybersecurity. He excels in forging strategic global partnerships, driving transformative solutions and strategies across various industries with a focus on generative AI and GSIs.
 Kasi Muthu is a senior partner solutions architect focusing on data and AI/ML at AWS based out of Houston, TX. He is passionate about helping partners and customers accelerate their cloud data journey. He is a trusted advisor in this field and has plenty of experience architecting and building scalable, resilient, and performant workloads in the cloud. Outside of work, he enjoys spending time with his family.
Kasi Muthu is a senior partner solutions architect focusing on data and AI/ML at AWS based out of Houston, TX. He is passionate about helping partners and customers accelerate their cloud data journey. He is a trusted advisor in this field and has plenty of experience architecting and building scalable, resilient, and performant workloads in the cloud. Outside of work, he enjoys spending time with his family.