We recently announced Amazon SageMaker Pipelines, the first purpose-built, easy-to-use continuous integration and continuous delivery (CI/CD) service for machine learning (ML). SageMaker Pipelines is a native workflow orchestration tool for building ML pipelines that take advantage of direct Amazon SageMaker integration. Three components improve the operational resilience and reproducibility of your ML workflows: pipelines, model registry, and projects. These workflow automation components enable you to easily scale your ability to build, train, test, and deploy hundreds of models in production, iterate faster, reduce errors due to manual orchestration, and build repeatable mechanisms.
SageMaker projects introduce MLOps templates that automatically provision the underlying resources needed to enable CI/CD capabilities for your ML development lifecycle. You can use a number of built-in templates or create your own custom template. You can use SageMaker Pipelines independently to create automated workflows; however, when used in combination with SageMaker projects, the additional CI/CD capabilities are provided automatically. The following screenshot shows how the three components of SageMaker Pipelines can work together in an example SageMaker project.
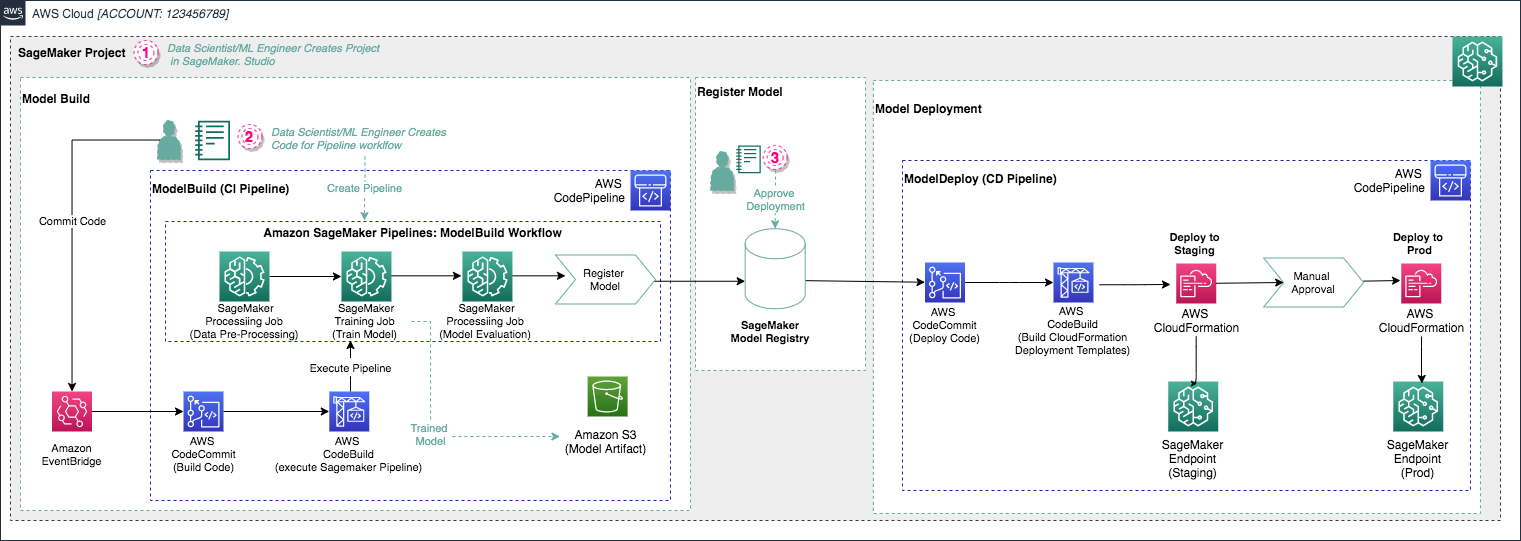
This post focuses on using an MLOps template to bootstrap your ML project and establish a CI/CD pattern from sample code. We show how to use the built-in build, train, and deploy project template as a base for a customer churn classification example. This base template enables CI/CD for training ML models, registering model artifacts to the model registry, and automating model deployment with manual approval and automated testing.
MLOps template for building, training, and deploying models
We start by taking a detailed look at what AWS services are launched when this build, train, and deploy MLOps template is launched. Later, we discuss how to modify the skeleton for a custom use case.
To get started with SageMaker projects, you must first enable it on the Amazon SageMaker Studio console. This can be done for existing users or while creating new ones. For more information, see SageMaker Studio Permissions Required to Use Projects.
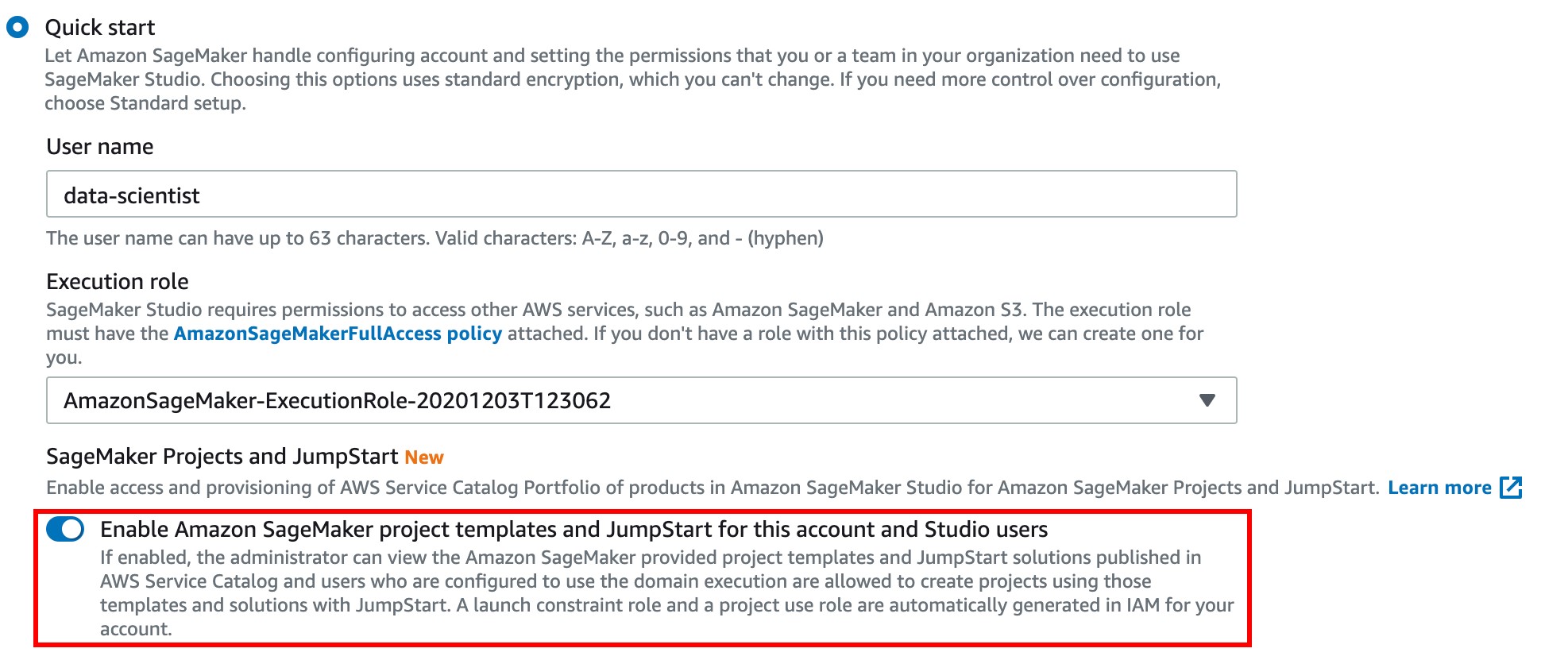
In SageMaker Studio, you can now choose the Projects menu on the Components and registries menu.
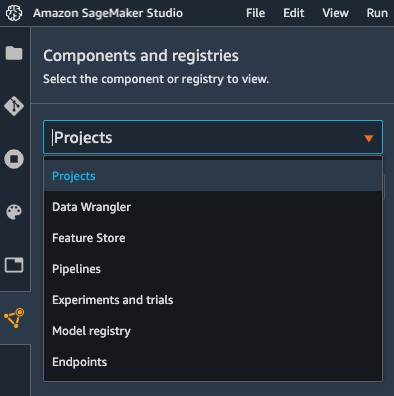
On the projects page, you can launch a preconfigured SageMaker MLOps template. For this post, we choose MLOps template for model building, training, and deployment.
Launching this template starts a model building pipeline by default, and while there is no cost for using SageMaker Pipelines itself, you will be charged for the services launched. Cost varies by Region. A single run of the model build pipeline in us-east-1 is estimated to cost less than $0.50. Models approved for deployment incur the cost of the SageMaker endpoints (test and production) for the Region using an ml.m5.large instance.
After the project is created from the MLOps template, the following architecture is deployed.
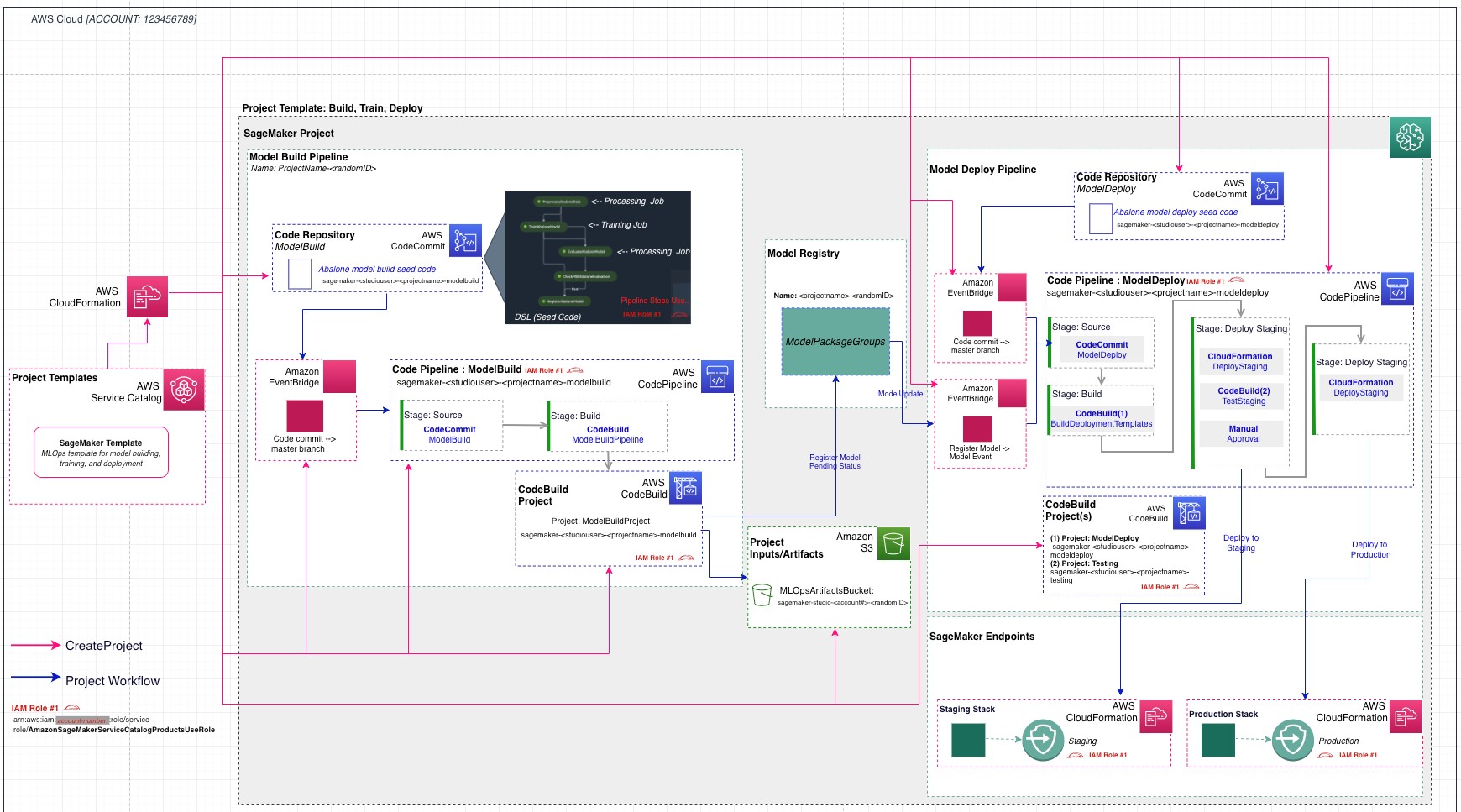
Included in the architecture are the following AWS services and resources:
- The MLOps templates that are made available through SageMaker projects are provided via an AWS Service Catalog portfolio that automatically gets imported when a user enables projects on the Studio domain.
- Two repositories are added to AWS CodeCommit:
- The first repository provides scaffolding code to create a multi-step model building pipeline including the following steps: data processing, model training, model evaluation, and conditional model registration based on accuracy. As you can see in the
pipeline.pyfile, this pipeline trains a linear regression model using the XGBoost algorithm on the well-known UCI Abalone dataset. This repository also includes a build specification file, used by AWS CodePipeline and AWS CodeBuild to run the pipeline automatically. - The second repository contains code and configuration files for model deployment, as well as test scripts required to pass the quality gate. This repo also uses CodePipeline and CodeBuild, which run an AWS CloudFormation template to create model endpoints for staging and production.
- The first repository provides scaffolding code to create a multi-step model building pipeline including the following steps: data processing, model training, model evaluation, and conditional model registration based on accuracy. As you can see in the
- Two CodePipeline pipelines:
- The
ModelBuildpipeline automatically triggers and runs the pipeline from end to end whenever a new commit is made to theModelBuildCodeCommit repository. - The
ModelDeploypipeline automatically triggers whenever a new model version is added to the model registry and the status is marked asApproved. Models that are registered withPendingorRejectedstatuses aren’t deployed.
- The
- An Amazon Simple Storage Service (Amazon S3) bucket is created for output model artifacts generated from the pipeline.
- SageMaker Pipelines uses the following resources:
- This workflow contains the directed acyclic graph (DAG) that trains and evaluates our model. Each step in the pipeline keeps track of the lineage and intermediate steps can be cached for quickly re-running the pipeline. Outside of templates, you can also create pipelines using the SDK.
- Within SageMaker Pipelines, the SageMaker model registry tracks the model versions and respective artifacts, including the lineage and metadata for how they were created. Different model versions are grouped together under a model group, and new models registered to the registry are automatically versioned. The model registry also provides an approval workflow for model versions and supports deployment of models in different accounts. You can also use the model registry through the boto3 package.
- Two SageMaker endpoints:
- After a model is approved in the registry, the artifact is automatically deployed to a staging endpoint followed by a manual approval step.
- If approved, it’s deployed to a production endpoint in the same AWS account.
All SageMaker resources, such as training jobs, pipelines, models, and endpoints, as well as AWS resources listed in this post, are automatically tagged with the project name and a unique project ID tag.
Modifying the sample code for a custom use case
After your project has been created, the architecture described earlier is deployed and the visualization of the pipeline is available on the Pipelines drop-down menu within SageMaker Studio.
To modify the sample code from this launched template, we first need to clone the CodeCommit repositories to our local SageMaker Studio instance. From the list of projects, choose the one that was just created. On the Repositories tab, you can select the hyperlinks to locally clone the CodeCommit repos.

ModelBuild repo
The ModelBuild repository contains the code for preprocessing, training, and evaluating the model. The sample code trains and evaluates a model on the UCI Abalone dataset. We can modify these files to solve our own customer churn use case. See the following code:
|-- codebuild-buildspec.yml
|-- CONTRIBUTING.md
|-- pipelines
| |-- abalone
| | |-- evaluate.py
| | |-- __init__.py
| | |-- pipeline.py
| | |-- preprocess.py
| |-- get_pipeline_definition.py
| |-- __init__.py
| |-- run_pipeline.py
| |-- _utils.py
| |-- __version__.py
|-- README.md
|-- sagemaker-pipelines-project.ipynb
|-- setup.cfg
|-- setup.py
|-- tests
| -- test_pipelines.py
|-- tox.iniWe now need a dataset accessible to the project.
- Open a new SageMaker notebook inside Studio and run the following cells:
!wget http://dataminingconsultant.com/DKD2e_data_sets.zip !unzip -o DKD2e_data_sets.zip !mv "Data sets" Datasets import os import boto3 import sagemaker prefix = 'sagemaker/DEMO-xgboost-churn' region = boto3.Session().region_name default_bucket = sagemaker.session.Session().default_bucket() role = sagemaker.get_execution_role() RawData = boto3.Session().resource('s3') .Bucket(default_bucket).Object(os.path.join(prefix, 'data/RawData.csv')) .upload_file('./Datasets/churn.txt') print(os.path.join("s3://",default_bucket, prefix, 'data/RawData.csv'))
- Rename the abalone directory to
customer_churn. This requires us to modify the path inside codebuild-buildspec.yml as shown in the sample repository. See the following code:run-pipeline --module-name pipelines.customer-churn.pipeline
- Replace the
preprocess.pycode with the customer churn preprocessing script found in the sample repository. - Replace the
pipeline.pycode with the customer churn pipeline script found in the sample repository.- Be sure to replace the “
InputDataUrl” default parameter with the Amazon S3 URL obtained in step 1:input_data = ParameterString( name="InputDataUrl", default_value=f"s3://YOUR_BUCKET/RawData.csv", ) - Update the conditional step to evaluate the classification model:
# Conditional step for evaluating model quality and branching execution cond_lte = ConditionGreaterThanOrEqualTo( left=JsonGet(step=step_eval, property_file=evaluation_report, json_path="binary_classification_metrics.accuracy.value"), right=0.8 )
One last thing to note is the default
ModelApprovalStatusis set toPendingManualApproval. If our model has greater than 80% accuracy, it’s added to the model registry, but not deployed until manual approval is complete. - Be sure to replace the “
- Replace the
evaluate.pycode with the customer churn evaluation script found in the sample repository. One piece of the code we’d like to point out is that, because we’re evaluating a classification model, we need to update the metrics we’re evaluating and associating with trained models:report_dict = { "binary_classification_metrics": { "accuracy": { "value": acc, "standard_deviation" : "NaN" }, "auc" : { "value" : roc_auc, "standard_deviation": "NaN" }, }, } evaluation_output_path = '/opt/ml/processing/evaluation/evaluation.json' with open(evaluation_output_path, 'w') as f: f.write(json.dumps(report_dict))
The JSON structure of these metrics are required to match the format of sagemaker.model_metrics for complete integration with the model registry.
ModelDeploy repo
The ModelDeploy repository contains the AWS CloudFormation buildspec for the deployment pipeline. We don’t make any modifications to this code because it’s sufficient for our customer churn use case. It’s worth noting that model tests can be added to this repo to gate model deployment. See the following code:
├── build.py
├── buildspec.yml
├── endpoint-config-template.yml
├── prod-config.json
├── README.md
├── staging-config.json
└── test
├── buildspec.yml
└── test.pyTriggering a pipeline run
Committing these changes to the CodeCommit repository (easily done on the Studio source control tab) triggers a new pipeline run, because an Amazon EventBridge event monitors for commits. After a few moments, we can monitor the run by choosing the pipeline inside the SageMaker project.
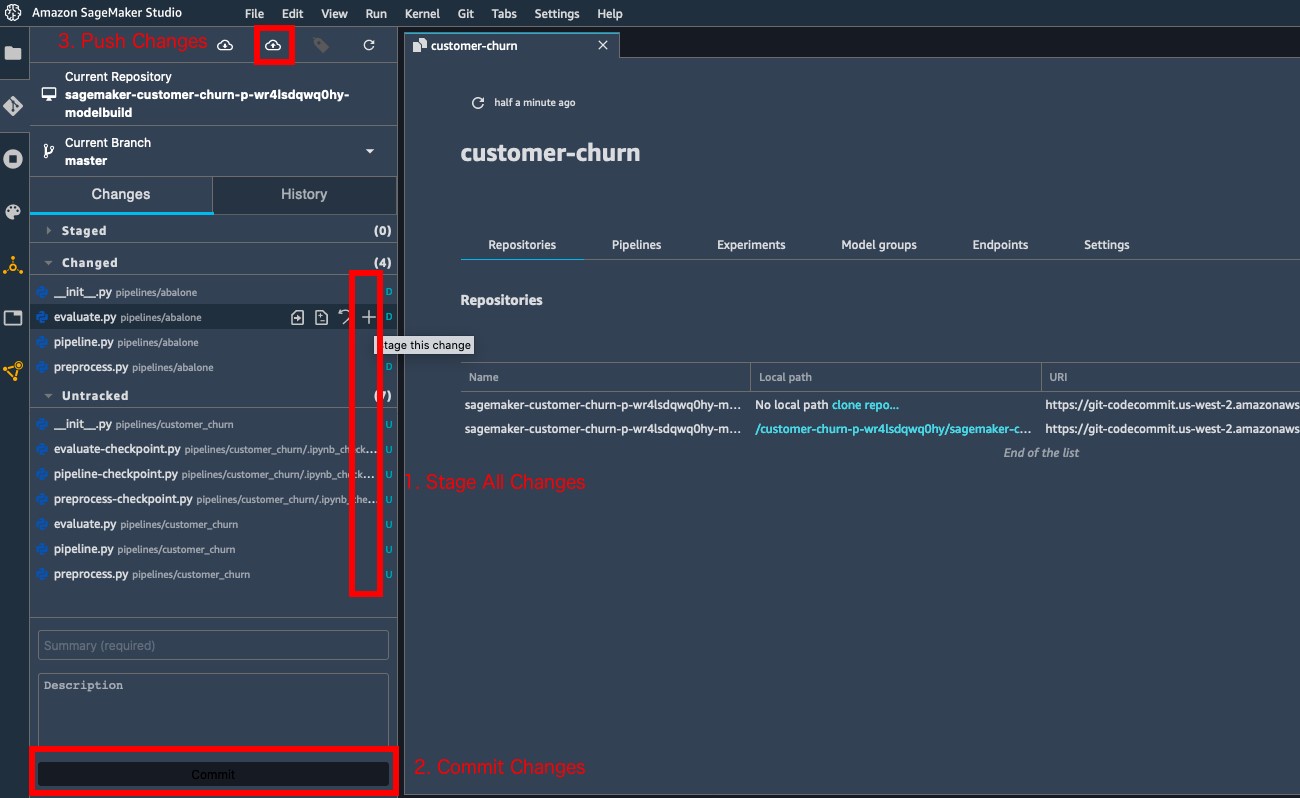 The following screenshot shows our pipeline details.
The following screenshot shows our pipeline details. Choosing the pipeline run displays the steps of the pipeline, which you can monitor.
Choosing the pipeline run displays the steps of the pipeline, which you can monitor.
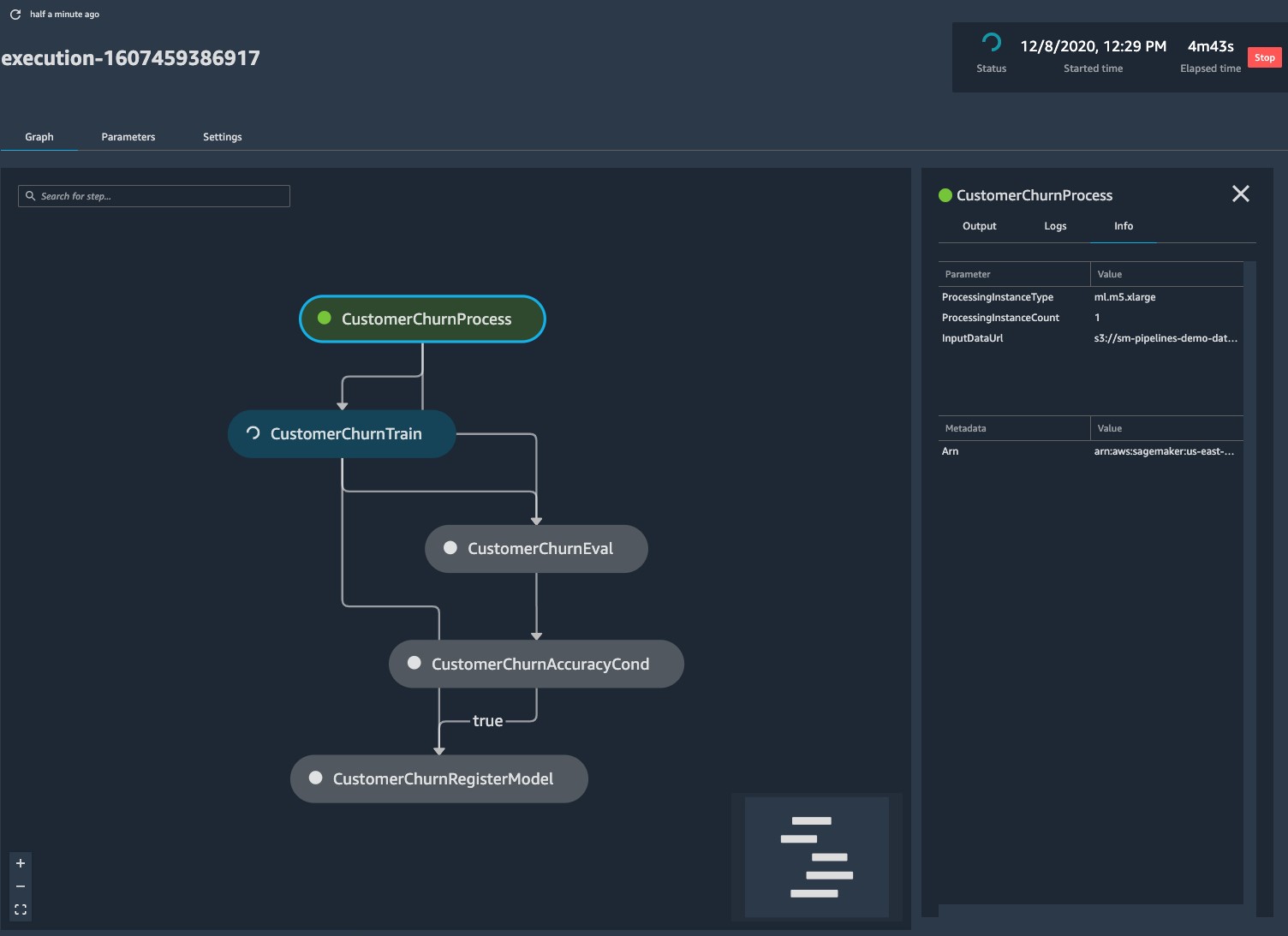
When the pipeline is complete, you can go to the Model groups tab inside the SageMaker project and inspect the metadata attached to the model artifacts.

If everything looks good, we can manually approve the model.
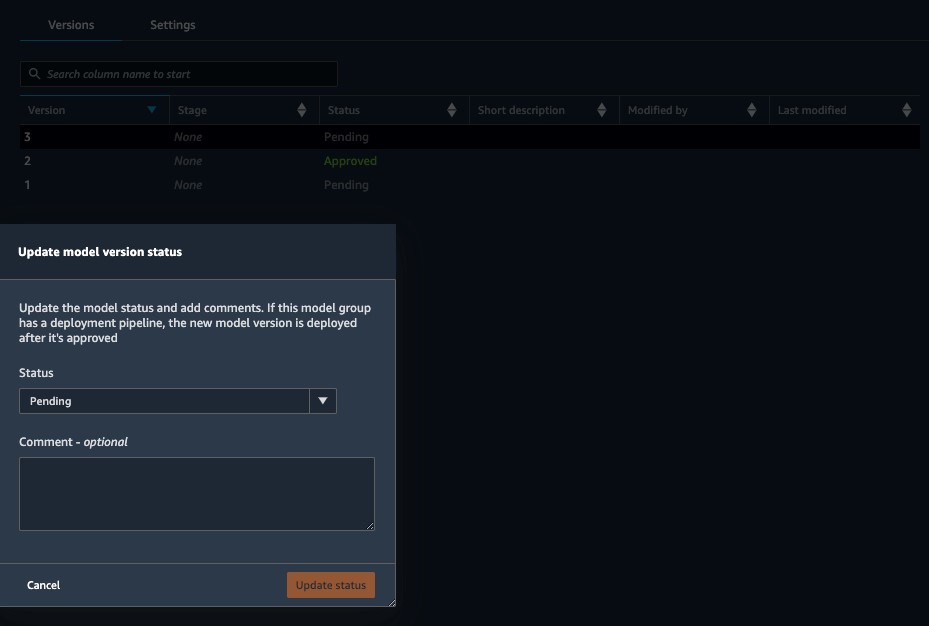
This approval triggers the ModelDeploy pipeline and exposes an endpoint for real-time inference.
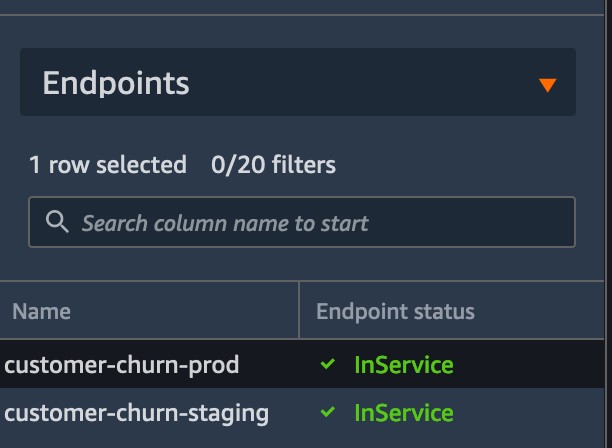
Conclusion
SageMaker Pipelines enables teams to leverage best practice CI/CD methods within their ML workflows. In this post, we showed how a data scientist can modify a preconfigured MLOps template for their own modeling use case. Among the many benefits is that the changes to the source code can be tracked, associated metadata can be tied to trained models for deployment approval, and repeated pipeline steps can be cached for reuse. To learn more about SageMaker Pipelines, check out the website and the documentation. Try SageMaker Pipelines in your own workflows today.
About the Authors
 Sean Morgan is an AI/ML Solutions Architect at AWS. He previously worked in the semiconductor industry, using computer vision to improve product yield. He later transitioned to a DoD research lab where he specialized in adversarial ML defense and network security. In his free time, Sean is an active open-source contributor and maintainer, and is the special interest group lead for TensorFlow Addons.
Sean Morgan is an AI/ML Solutions Architect at AWS. He previously worked in the semiconductor industry, using computer vision to improve product yield. He later transitioned to a DoD research lab where he specialized in adversarial ML defense and network security. In his free time, Sean is an active open-source contributor and maintainer, and is the special interest group lead for TensorFlow Addons.
 Hallie Weishahn is an AI/ML Specialist Solutions Architect at AWS, focused on leading global standards for MLOps. She previously worked as an ML Specialist at Google Cloud Platform. She works with product, engineering, and key customers to build repeatable architectures and drive product roadmaps. She provides guidance and hands-on work to advance and scale machine learning use cases and technologies. Troubleshooting top issues and evaluating existing architectures to enable integrations from PoC to a full deployment is her strong suit.
Hallie Weishahn is an AI/ML Specialist Solutions Architect at AWS, focused on leading global standards for MLOps. She previously worked as an ML Specialist at Google Cloud Platform. She works with product, engineering, and key customers to build repeatable architectures and drive product roadmaps. She provides guidance and hands-on work to advance and scale machine learning use cases and technologies. Troubleshooting top issues and evaluating existing architectures to enable integrations from PoC to a full deployment is her strong suit.
 Shelbee Eigenbrode is an AI/ML Specialist Solutions Architect at AWS. Her current areas of depth include DevOps combined with ML/AI. She has been in technology for 23 years, spanning multiple roles and technologies. With over 35 patents granted across various technology domains, her passion for continuous innovation combined with a love of all things data turned her focus to the field of d ata science. Combining her backgrounds in data, DevOps, and machine learning, her current passion is helping customers to not only embrace data science but also ensure all models have a path to production by adopting MLOps practices. In her spare time, she enjoys reading and spending time with family, including her fur family (aka dogs), as well as friends.
Shelbee Eigenbrode is an AI/ML Specialist Solutions Architect at AWS. Her current areas of depth include DevOps combined with ML/AI. She has been in technology for 23 years, spanning multiple roles and technologies. With over 35 patents granted across various technology domains, her passion for continuous innovation combined with a love of all things data turned her focus to the field of d ata science. Combining her backgrounds in data, DevOps, and machine learning, her current passion is helping customers to not only embrace data science but also ensure all models have a path to production by adopting MLOps practices. In her spare time, she enjoys reading and spending time with family, including her fur family (aka dogs), as well as friends.