A remarkable characteristic of human intelligence is our ability to learn tasks
quickly. Most humans can learn reasonably complex skills like tool-use and
gameplay within just a few hours, and understand the basics after only a few
attempts. This suggests that data-efficient learning may be a meaningful part
of developing broader intelligence.
On the other hand, Deep Reinforcement Learning (RL) algorithms can achieve
superhuman performance on games like Atari, Starcraft, Dota, and Go, but
require large amounts of data to get there. Achieving superhuman performance on
Dota took over 10,000 human years of gameplay. Unlike simulation, skill
acquisition in the real-world is constrained to wall-clock time. In order to
see similar breakthroughs to AlphaGo in real-world settings, such as robotic
manipulation and autonomous vehicle navigation, RL algorithms need to be
data-efficient — they need to learn effective policies within a reasonable
amount of time.
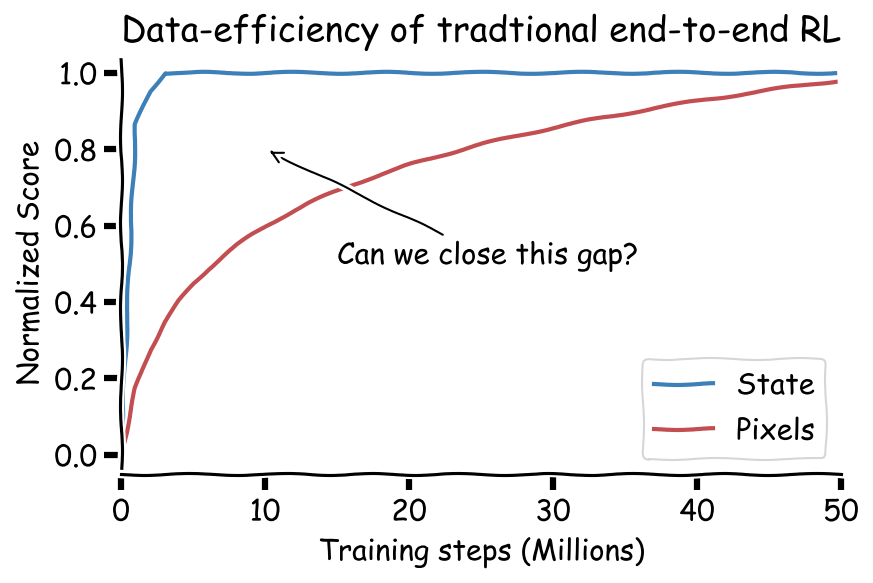
To date, it has been commonly assumed that RL operating on coordinate state is
significantly more data-efficient than pixel-based RL. However, coordinate
state is just a human crafted representation of visual information. In
principle, if the environment is fully observable, we should also be able to
learn representations that capture the state.
Recent advances in data-efficient RL
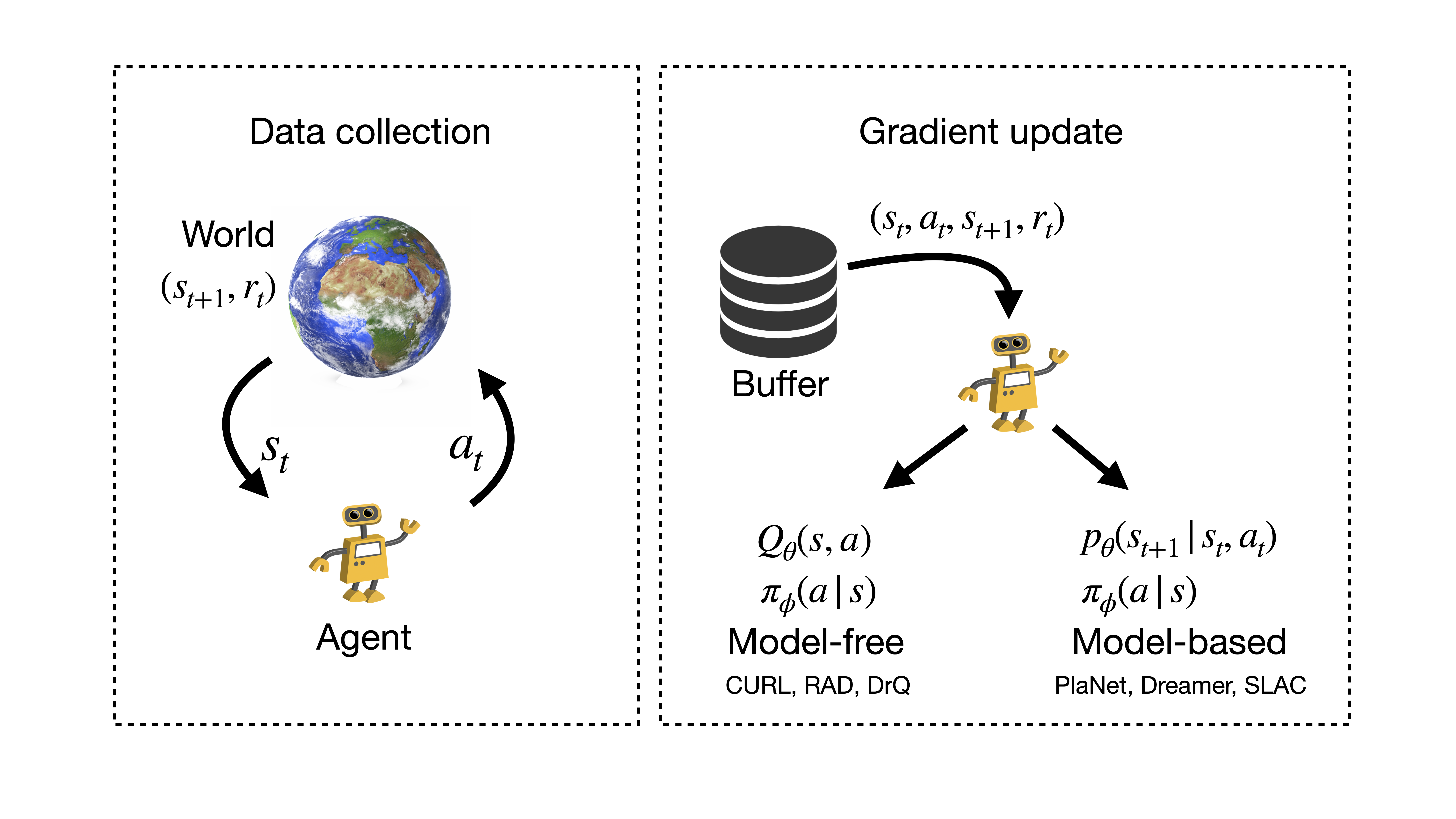
Recently, there have been several algorithmic advances in Deep RL that have
improved learning policies from pixels. The methods fall into two categories:
(i) model-free algorithms and (ii) model-based (MBRL) algorithms. The main
difference between the two is that model-based methods learn a forward
transition model $p(s_{t+1}|,s_t,a_t)$ while model-free ones do not. Learning a
model has several distinct advantages. First, it is possible to use the model
to plan through action sequences, generate fictitious rollouts as a form of
data augmentation, and temporally shape the latent space by learning a model.
However, a distinct disadvantage of model-based RL is complexity. Model-based
methods operating on pixels require learning a model, an encoding scheme, a
policy, various auxiliary tasks such as reward prediction, and stitching these
parts together to make a whole algorithm. Visual MBRL methods have a lot of
moving parts and tend to be less stable. On the other hand, model-free methods
such as Deep Q Networks (DQN), Proximal Policy Optimization (PPO), and Soft
Actor-Critic (SAC) learn a policy in an end-to-end manner optimizing for one
objective. While traditionally, the simplicity of model-free RL has come at the
cost of sample-efficiency, recent improvements have shown that model-free
methods can in fact be more data-efficient than MBRL and, more surprisingly,
result in policies that are as data efficient as policies trained on coordinate
state. In what follows we will focus on these recent advances in pixel-based
model-free RL.
Why now?
Over the last few years, two trends have converged to make data-efficient
visual RL possible. First, end-to-end RL algorithms have become increasingly
more stable through algorithms like the Rainbow DQN, TD3, and SAC. Second,
there has been tremendous progress in label-efficient learning for image
classification using contrastive unsupervised representations (CPCv2, MoCo,
SimCLR) and data augmentation (MixUp, AutoAugment, RandAugment). In recent work
from our lab at BAIR (CURL, RAD), we combined contrastive learning and data
augmentation techniques from computer vision with model-free RL to show
significant data-efficiency gains on common RL benchmarks like Atari, DeepMind
control, ProcGen, and OpenAI gym.
Contrastive Learning in RL Setting
CURL was inspired by recent advances in contrastive representation learning in
computer vision (CPC, CPCv2, MoCo, SimCLR). Contrastive learning aims to
maximize / minimize similarity between two similar / dissimilar representations
of an image. For example, in MoCo and SimCLR, the objective is to maximize
agreement between two data-augmented versions of the same image and minimize it
between all other images in the dataset, where optimization is performed with a
Noise Contrastive Estimation loss. Through data augmentation, these
representations internalize powerful inductive biases about invariance in the
dataset.
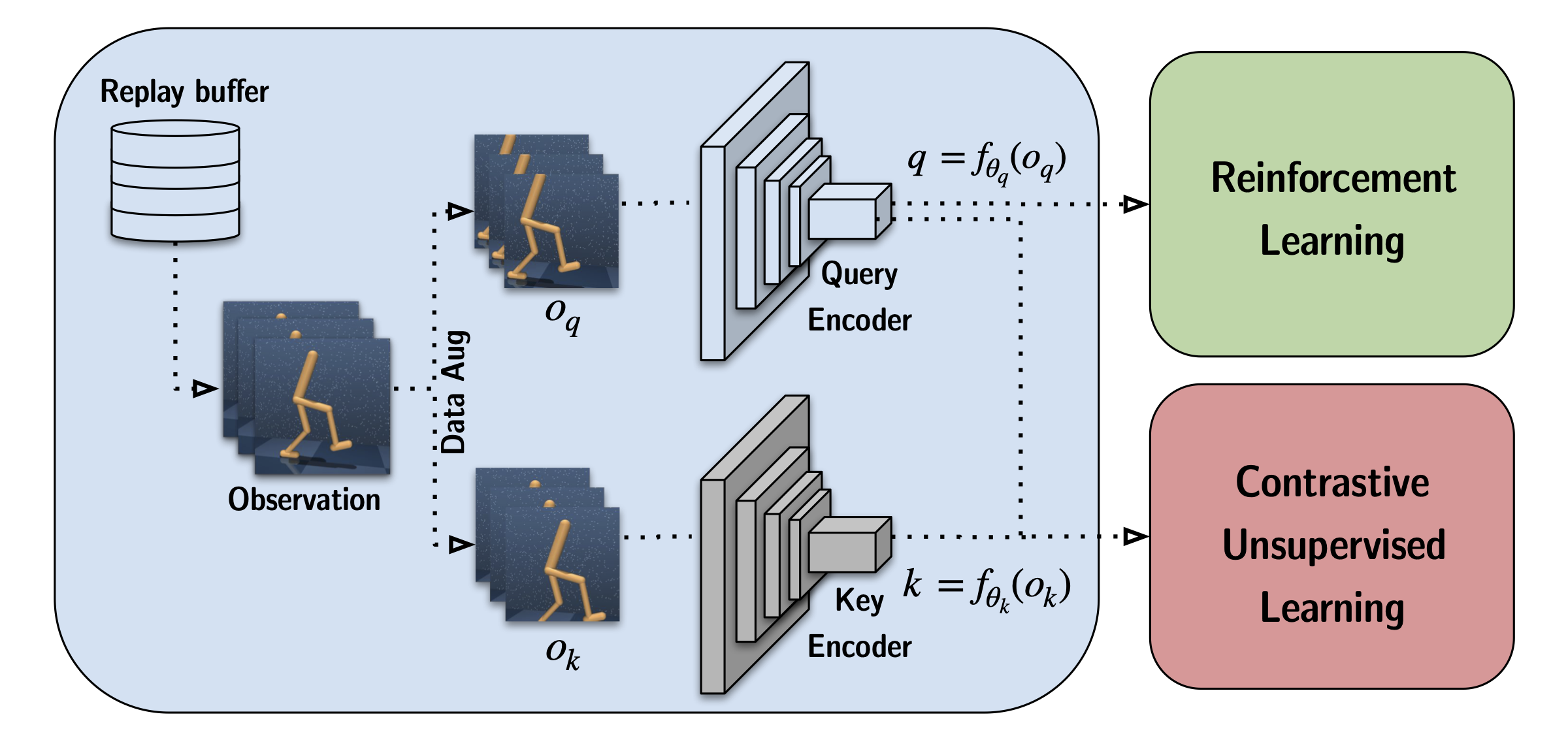
In the RL setting, we opted for a similar approach and adopted the momentum
contrast (MoCo) mechanism, a popular contrastive learning method in computer
vision that uses a moving average of the query encoder parameters (momentum) to
encode the keys to stabilize training. There are two main differences in setup:
(i) the RL dataset changes dynamically and (ii) visual RL is typically
performed on stacks of frames to access temporal information like velocities.
Rather than separating contrastive learning from the downstream task as done in
vision, we learn contrastive representations jointly with the RL objective.
Instead of discriminating across single images, we discriminate across the
stack of frames.
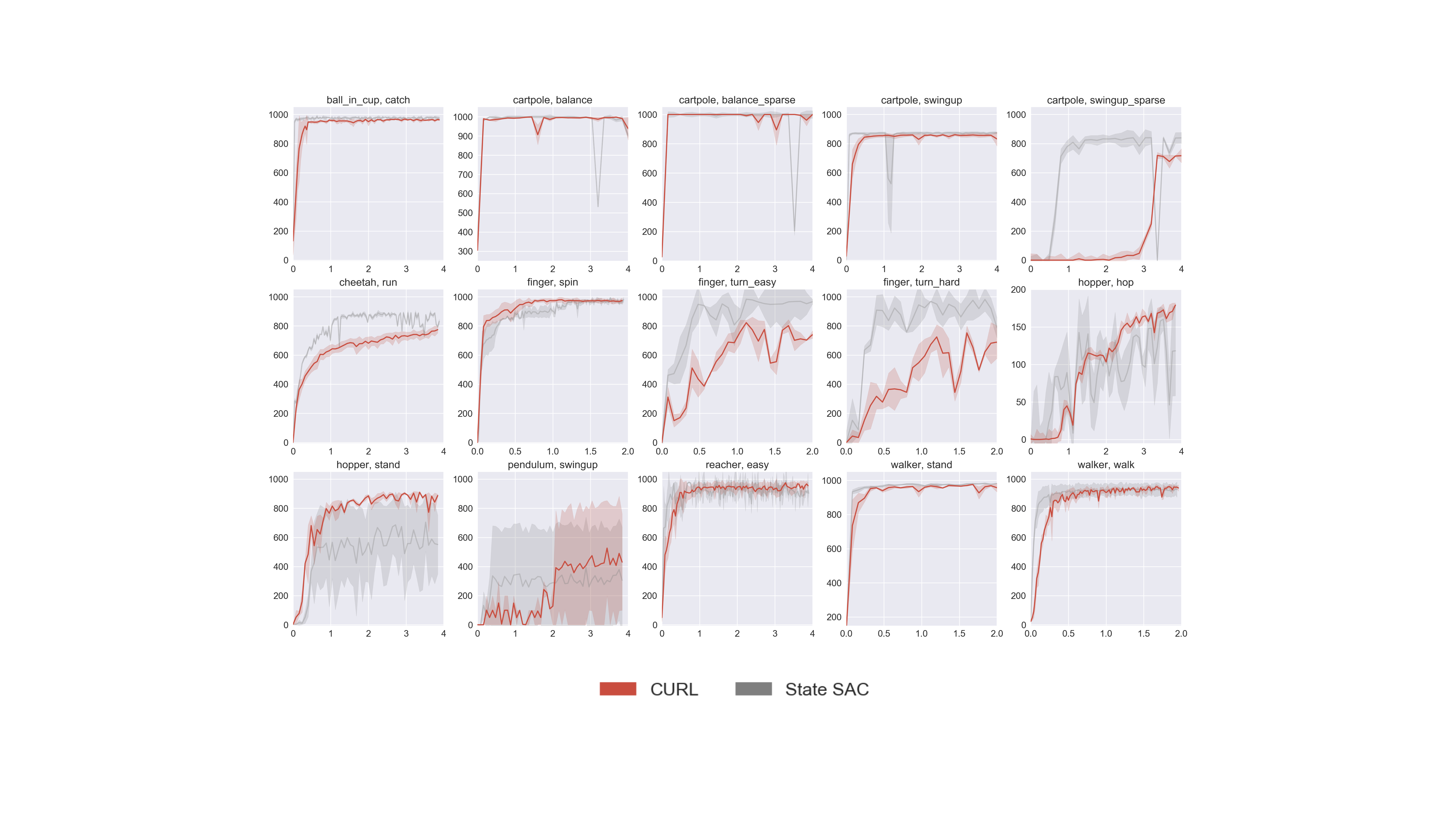
By combining contrastive learning with Deep RL in the above manner we found,
for the first time, that pixel-based RL can be nearly as data-efficient as
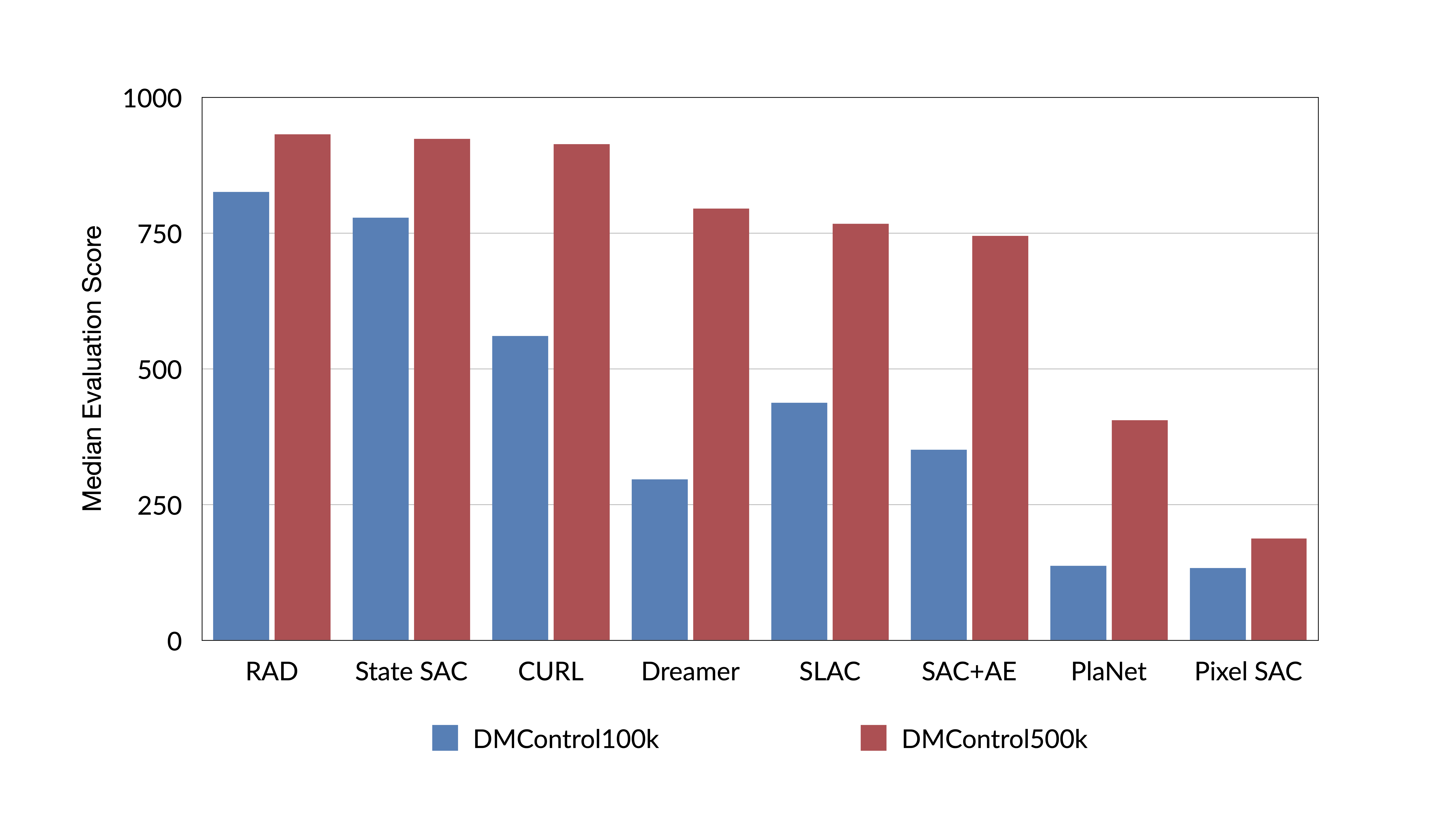
state-based RL on the DeepMind control benchmark suite. In the figure below,
we show learning curves for DeepMind control tasks where contrastive learning
is coupled with SAC (red) and compared to state-based SAC (gray).
We also demonstrate data-efficiency gains on the Atari 100k step benchmark. In
this setting, we couple CURL with an Efficient Rainbow DQN (Eff. Rainbow) and
show that CURL outperforms the prior state-of-the-art (Eff. Rainbow, SimPLe) on
20 out of 26 games tested.
RL with Data Augmentation
Given that random cropping was a crucial component in CURL, it is natural to
ask — can we achieve the same results with data augmentation alone? In
Reinforcement Learning with Augmented Data (RAD), we performed the first
extensive study of data augmentation in Deep RL and found that for the DeepMind
control benchmark the answer is yes. Data augmentation alone can outperform
prior competing methods, match, and sometimes surpass the efficiency of
state-based RL. Similar results were also shown in concurrent work – DrQ.
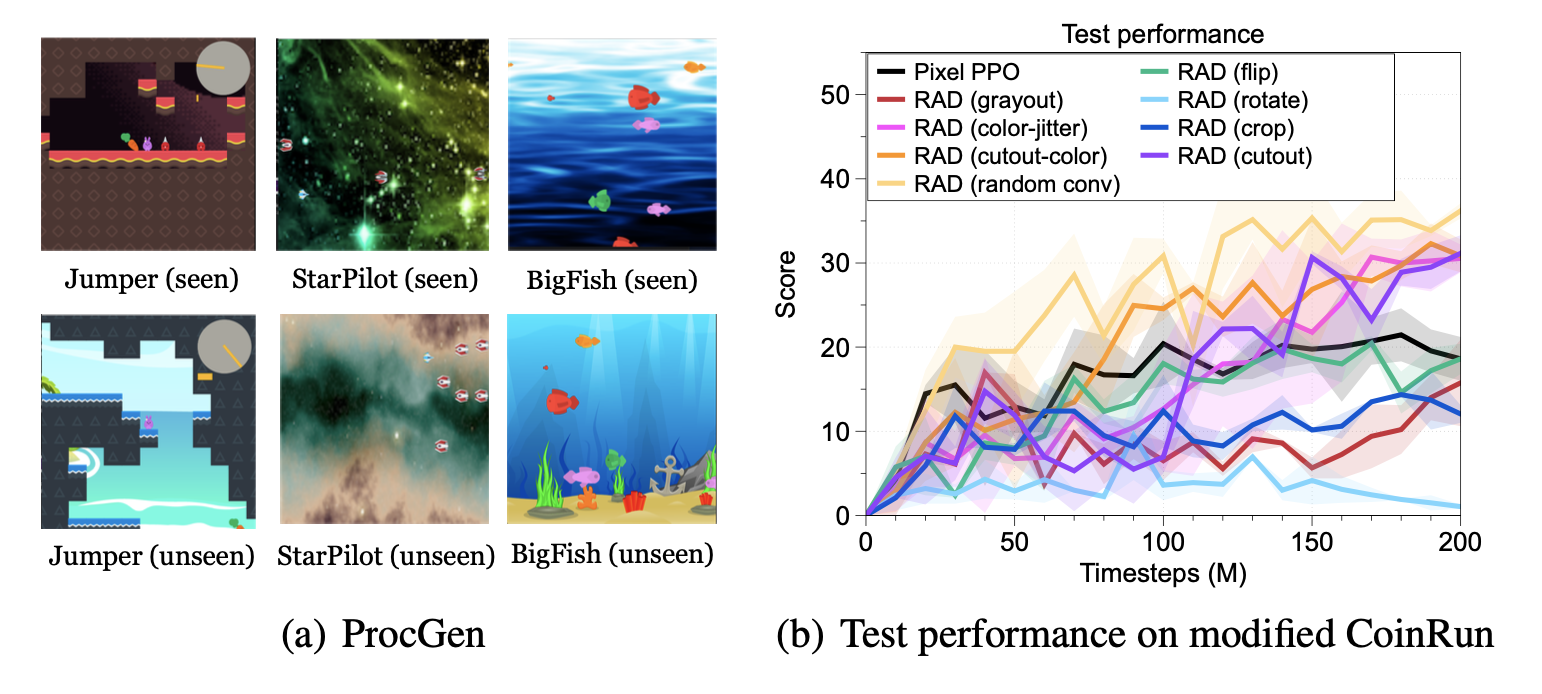
We found that RAD also improves generalization on the ProcGen game suite,
showing that data augmentation is not limited to improving data-efficiency but
also helps RL methods generalize to test-time environments.
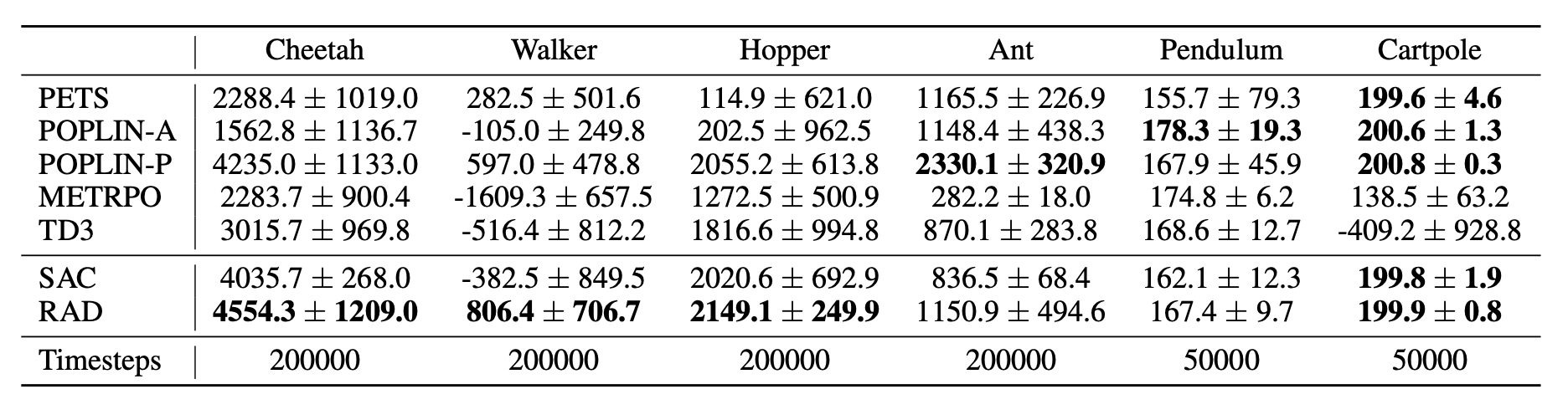
If data augmentation works for pixel-based RL, can it also improve state-based
methods? We introduced a new state-based augmentation — random amplitude
scaling — and showed that simple RL with state-based data augmentation
achieves state-of-the-art results on OpenAI gym environments and outperforms
more complex model-free and model-based RL algorithms.
Contrastive Learning vs Data Augmentation
If data augmentation with RL performs so well, do we need unsupervised
representation learning? RAD outperforms CURL because it only optimizes for
what we care about, which is the task reward. CURL, on the other hand, jointly
optimizes the reinforcement and contrastive learning objectives. If the metric
used to evaluate and compare these methods is the score attained on the task at
hand, a method that purely focuses on reward optimization is expected to be
better as long as it implicitly ensures similarity consistencies on the
augmented views.
However, many problems in RL cannot be solved with data augmentations alone.
For example, RAD would not be applicable to environments with sparse-rewards or
no rewards at all, because it learns similarity consistency implicitly through
the observations coupled to a reward signal. On the other hand, the contrastive
learning objective in CURL internalizes invariances explicitly and is therefore
able to learn semantic representations from high dimensional observations
gathered from any rollout regardless of the reward signal. Unsupervised
representation learning may therefore be a better fit for real-world tasks,
such as robotic manipulation, where the environment reward is more likely to be
sparse or absent.
This post is based on the following papers:
-
CURL: Contrastive Unsupervised Representations for Reinforcement Learning
Michael Laskin*, Aravind Srinivas*, Pieter Abbeel
Thirty-seventh International Conference Machine Learning (ICML), 2020.
arXiv, Project Website -
Reinforcement Learning with Augmented Data
Michael Laskin*, Kimin Lee*, Adam Stooke, Lerrel Pinto, Pieter Abbeel, Aravind Srinivas
arXiv, Project Website
References
- Hafner et al. Learning Latent Dynamics for Planning from Pixels. ICML 2019.
- Hafner et al. Dream to Control: Learning Behaviors by Latent Imagination. ICLR 2020.
- Kaiser et al. Model-Based Reinforcement Learning for Atari. ICLR 2020.
- Lee et al. Stochastic Latent Actor-Critic: Deep Reinforcement Learning with a Latent Variable Model. arXiv 2019.
- Henaff et al. Data-Efficient Image Recognition with Contrastive Predictive Coding. ICML 2020.
- He et al. Momentum Contrast for Unsupervised Visual Representation Learning. CVPR 2020.
- Chen et al. A Simple Framework for Contrastive Learning of Visual Representations. ICML 2020.
- Kostrikov et al. Image Augmentation Is All You Need: Regularizing Deep Reinforcement Learning from Pixels. arXiv 2020.