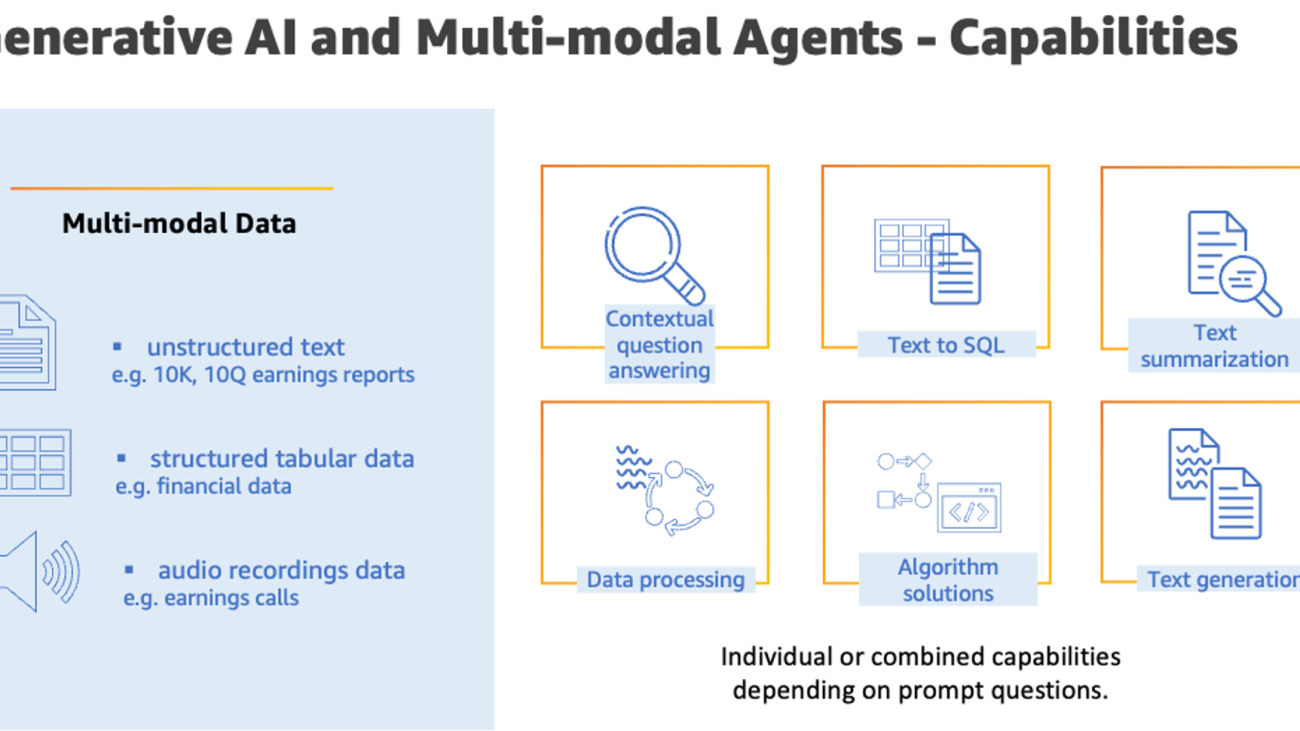
Multi-modal data is a valuable component of the financial industry, encompassing market, economic, customer, news and social media, and risk data. Financial organizations generate, collect, and use this data to gain insights into financial operations, make better decisions, and improve performance. However, there are challenges associated with multi-modal data due to the complexity and lack of standardization in financial systems and data formats and quality, as well as the fragmented and unstructured nature of the data. Financial clients have frequently described the operational overhead of gaining financial insights from multi-modal data, which necessitates complex extraction and transformation logic, leading to bloated effort and costs. Technical challenges with multi-modal data further include the complexity of integrating and modeling different data types, the difficulty of combining data from multiple modalities (text, images, audio, video), and the need for advanced computer science skills and sophisticated analysis tools.
One of the ways to handle multi-modal data that is gaining popularity is the use of multi-modal agents. Multi-modal agents are AI systems that can understand and analyze data in multiple modalities using the right tools in their toolkit. They are able to connect insights across these diverse data types to gain a more comprehensive understanding and generate appropriate responses. Multi-modal agents, in conjunction with generative AI, are finding a wide spread application in financial markets. The following are a few popular use cases:
- Smart reporting and market intelligence – AI can analyze various sources of financial information to generate market intelligence reports, aiding analysts, investors, and companies to stay updated on trends. Multi-modal agents can summarize lengthy financial reports quickly, saving analysts significant time and effort.
- Quantitative modeling and forecasting – Generative models can synthesize large volumes of financial data to train machine learning (ML) models for applications like stock price forecasting, portfolio optimization, risk modeling, and more. Multi-modal models that understand diverse data sources can provide more robust forecasts.
- Compliance and fraud detection – This solution can be extended to include monitoring tools that analyze communication channels like calls, emails, chats, access logs, and more to identify potential insider trading or market manipulation. Detecting fraudulent collusion across data types requires multi-modal analysis.
A multi-modal agent with generative AI boosts the productivity of a financial analyst by automating repetitive and routine tasks, freeing time for analysts to focus on high-value work. Multi-modal agents can amplify an analyst’s ability to gain insights by assisting with research and analysis. Multi-modal agents can also generate enhanced quantitative analysis and financial models, enabling analysts to work faster and with greater accuracy.
Implementing a multi-modal agent with AWS consolidates key insights from diverse structured and unstructured data on a large scale. Multi-modal agents can easily combine the power of generative AI offerings from Amazon Bedrock and Amazon SageMaker JumpStart with the data processing capabilities from AWS Analytics and AI/ML services to provide agile solutions that enable financial analysts to efficiently analyze and gather insights from multi-modal data in a secure and scalable manner within AWS. Amazon offers a suite of AI services that enable natural language processing (NLP), speech recognition, text extraction, and search:
- Amazon Comprehend is an NLP service that can analyze text for key phrases and analyze sentiment
- Amazon Textract is an intelligent document processing service that can accurately extract text and data from documents
- Amazon Transcribe is an automatic speech recognition service that can convert speech to text
- Amazon Kendra is an enterprise search service powered by ML to find the information across a variety of data sources, including documents and knowledge bases

In this post, we showcase a scenario where a financial analyst interacts with the organization’s multi-modal data, residing on purpose-built data stores, to gather financial insights. In the interaction, we demonstrate how multi-modal agents plan and run the user query and retrieve the results from the relevant data sources. All this is achieved using AWS services, thereby increasing the financial analyst’s efficiency to analyze multi-modal financial data (text, speech, and tabular data) holistically.

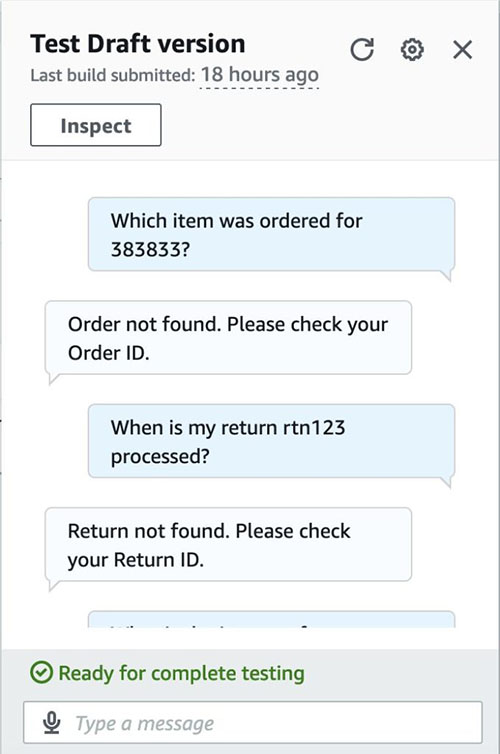
The following screenshot shows an example of the UI.

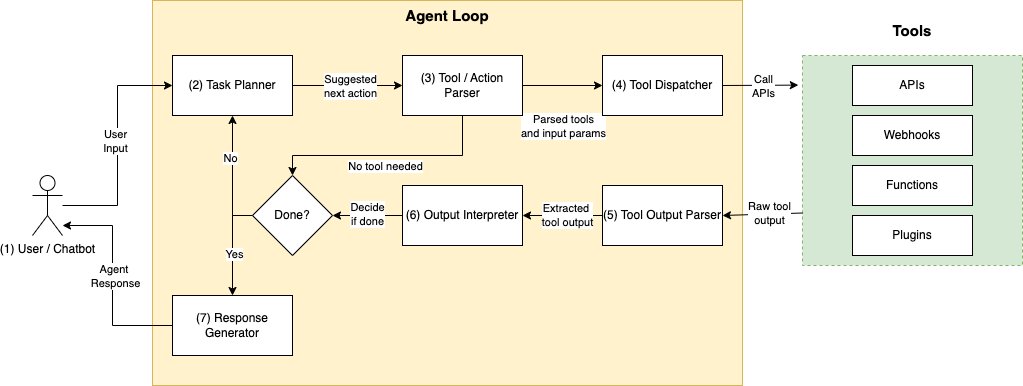
Solution overview
The following diagram illustrates the conceptual architecture to use generative AI with multi-modal data using agents. The steps involved are as follows:
- The financial analyst poses questions via a platform such as chatbots.
- The platform uses a framework to determine the most suitable multi-modal agent tool to answer the question.
- Once identified, the platform runs the code that is linked to the previously identified tool.
- The tool generates an analysis of the financial data as requested by the financial analyst.
- In summarizing the results, large language models retrieve and report back to the financial analyst.

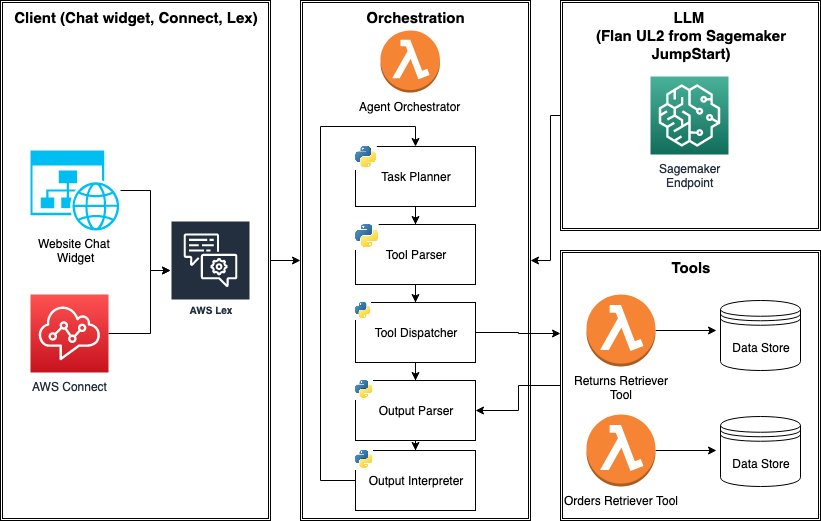
Technical architecture
The multi-modal agent orchestrates various tools based on natural language prompts from business users to generate insights. For unstructured data, the agent uses AWS Lambda functions with AI services such as Amazon Textract for document analysis, Amazon Transcribe for speech recognition, Amazon Comprehend for NLP, and Amazon Kendra for intelligent search. For structured data, the agent uses the SQL Connector and SQLAlchemy to analyze databases, which includes Amazon Athena. The agent also utilizes Python in Lambda and the Amazon SageMaker SDK for computations and quantitative modeling. The agent also has long-term memory for storing prompts and results in Amazon DynamoDB. The multi-modal agent resides in a SageMaker notebook and coordinates these tools based on English prompts from business users in a Streamlit UI.

The key components of the technical architecture are as follows:
- Data storage and analytics – The quarterly financial earning recordings as audio files, financial annual reports as PDF files, and S&P stock data as CSV files are hosted on Amazon Simple Storage Service (Amazon S3). Data exploration on stock data is done using Athena.
- Large language models – The large language models (LLMs) are available via Amazon Bedrock, SageMaker JumpStart, or an API.
- Agents – We use LangChain’s agents for a non-predetermined chain of calls as user input to LLMs and other tools. In these types of chains, there is an agent that has access to a suite of tools. Each tool has been built for a specific task. Depending on the user input, the agent decides the tool or a combination of tools to call to answer the question. We created the following purpose-built agent tools for our scenario:
- Stocks Querying Tool – To query S&P stocks data using Athena and SQLAlchemy.
- Portfolio Optimization Tool – To build a portfolio based on the chosen stocks.
- Financial Information Lookup Tool – To search for financial earnings information stored in multi-page PDF files using Amazon Kendra.
- Python Calculation Tool – To use for mathematical calculations.
- Sentiment Analysis Tool – To identify and score sentiments on a topic using Amazon Comprehend.
- Detect Phrases Tool – To find key phrases in recent quarterly reports using Amazon Comprehend.
- Text Extraction Tool – To convert the PDF versions of quarterly reports to text files using Amazon Textract.
- Transcribe Audio Tool – To convert audio recordings to text files using Amazon Transcribe.
The agent memory that holds the chain of user interactions with the agent is saved in DynamoDB.
The following sections explain some of the primary steps with associated code. To dive deeper into the solution and code for all the steps shown here, refer to the GitHub repo.
Prerequisites
To run this solution, you must have an API key to an LLM such as Anthropic Claud2, or have access to Amazon Bedrock foundation models.
To generate responses from structured and unstructured data using LLMs and LangChain, you need access to LLMs through either Amazon Bedrock, SageMaker JumpStart, or API keys, and to use databases that are compatible with SQLAlchemy. AWS Identity and Access Management (IAM) policies are also required, the details which you can find in the GitHub repo.
Key components of a multi-modal agent
There are a few key components components of the multi-modal agent:
- Functions defined for tools of the multi-modal agent
- Tools defined for the multi-modal agent
- Long-term memory for the multi-modal agent
- Planner-executor based multi-modal agent (defined with tools, LLMs, and memory)
In this section, we illustrate the key components with associated code snippets.
Functions defined for tools of the multi-modal agent
The multi-modal agent needs to use various AI services to process different types of data—text, speech, images, and more. Some of these functions may need to call AWS AI services like Amazon Comprehend to analyze text, Amazon Textract to analyze images and documents, and Amazon Transcribe to convert speech to text. These functions can either be called locally within the agent or deployed as Lambda functions that the agent can invoke. The Lambda functions internally call the relevant AWS AI services and return the results to the agent. This approach modularizes the logic and makes the agent more maintainable and extensible.
The following function defines how to calculate the optimized portfolio based on the chosen stocks. One way to convert a Python-based function to an LLM tool is to use the BaseTool wrapper.
The following is the code for Lambda calling the AWS AI service (Amazon Comprehend, Amazon Textract, Amazon Transcribe) APIs:
Tools defined for the multi-modal agent
The multi-modal agent has access to various tools to enable its functionality. It can query a stocks database to answer questions on stocks. It can optimize a portfolio using a dedicated tool. It can retrieve information from Amazon Kendra, Amazon’s enterprise search service. A Python REPL tool allows the agent to run Python code. An example of the structure of the tools, including their names and descriptions, is shown in the following code. The actual tool box of this post has eight tools: Stocks Querying Tool, Portfolio Optimization Tool, Financial Information Lookup Tool, Python Calculation Tool, Sentiment Analysis Tool, Detect Phrases Tool, Text Extraction Tool, and Transcribe Audio Tool.
Long-term memory for the multi-modal agent
The following code illustrates the configuration of long-term memory for the multi-modal agent. In this code, DynamoDB table is added as memory to store prompts and answers for future reference.
Planner-executor based multi-modal agent
The planner-executor based multi-modal agent architecture has two main components: a planner and an executor. The planner generates a high-level plan with steps required to run and answer the prompt question. The executor then runs this plan by generating appropriate system responses for each plan step using the language model with necessary tools. See the following code:
Example scenarios based on questions asked by financial analyst
In this section, we explore two example scenarios to illustrate the end-to-end steps performed by the multi-modal agent based on questions asked by financial analyst.
Scenario 1: Questions by financial analyst related to structured data
In this scenario, the financial analyst asks a question in English related to companies’ stocks to the multi-modal agent. The multi-modal LangChain agent comes up with a multi-step plan and decides what tools to use for each step. The following diagram illustrates an example workflow with the following steps:
- The financial analyst asks a financial question in English through the UI to the multi-modal agent.
- The agent identifies that it requires the database tool to answer the question. It generates a SQL query using an LLM based on the question and queries the Athena database.
- Athena runs the SQL query, retrieves the relevant result (stock price time series of the five companies), and passes the result with relevant data to the agent.
- The agent identifies that it requires a second tool to answer the question. It passes the retrieved data to the Python tool for portfolio optimization.
- The Python tool calculates the required optimal portfolio, including weights, and passes the answer to the LLM within the agent.
- The agent compiles the required information and calculations using the LLM and answers the financial analysist via the UI in English.

The financial analyst asks the following question:
“What are the closing prices of stocks AAAA, WWW, DDD in year 2018? Can you build an optimized portfolio using these three stocks?”
The following code shows the steps identified by the planner of the multi-modal agent:
The agent translated the question prompt into the following SQL query:
The following code shows the final answer by the multi-modal agent based on the question:
Scenario 2: Questions by financial analyst related to unstructured data
In this scenario, a financial analyst asks multiple questions about the company’s financial health to the multi-modal agent. The agent invokes two tool agents, Amazon Kendra with unstructured data and a Python compute tool, to gather information and perform the necessary calculations. The agent then compiles the information from the tools using its language model and provides the full answer to the analyst. The key of this scenario is that the agent can remember the questions and answers of the previous questions, and incorporates the context into the conversation. The following diagram illustrates the workflow, which consists of the following steps:
- The financial analyst asks a financial question in English through the UI to the multi-modal agent.
- The agent identifies that it requires the Amazon Kendra tool to answer the question and invokes the Amazon Kendra agent tool.
- Amazon Kendra searches the unstructured data corpus in Amazon S3 and retrieves the relevant document containing the answer.
- Using Retrieval Augmented Generation (RAG), Amazon Kendra passes the answer from the relevant document to the LLM within the agent.
- The agent identifies that it requires a second tool to answer the second part of the question. It passes information from the first tool to the Python compute tool.
- The Python tool calculates the required ratio and passes the answer to the LLM within the agent.
- The agent compiles the required information and calculations using the LLM and answers the financial analyst via the UI.

The following are questions and answers between the analyst and multi-modal agent.
The agent answers the question “What is Amazon’s net loss for fiscal year ending in December 2022?” with “Amazon reported total net sales of $514.0 billion and a net loss of $2.7 billion for fiscal year 2022.” The source is the Amazon 10K report for the fiscal year ending December 2022, retrieved using the Retrive_Kendra Tool.
For the question “What is the net loss for the same year ?” the agent answers “$2.7 billion.” The source is the Amazon 10K report for the fiscal year ending December 2022, retrieved using the Retrive_Kendra Tool. Note that even though the question is similar to the second question, this question didn’t specify the company name or the year number. However, the agent was able to use the correct company name and year based on the context in conversation memory.
For the question “What is the formula for Net Profit Margin Ratio which is a type of profitability ratio ?” the agent answers “Amazon reported total net sales of $514.0 billion and a net loss of $2.7 billion for fiscal year 2022. The Net Profit Margin Ratio for Amazon for fiscal year 2022 is -0.5%.” The source is Retrieve_Kendra and PythonREPLTool().
Dive deeper into the solution
To dive deeper into the solution and the code shown in this post, check out the GitHub repo.
In the GitHub repo, you will be able to find a Python notebook that has the end-to-end solution, an AWS CloudFormation template for provisioning the infrastructure, unstructured data (earnings reports PDF files, earnings call audio files), and structured data (stocks time series).
In the appendix at the end, different questions asked by financial analyst, agent tools invoked, and the answer from the multi-modal agent has been tabulated.
Clean up
After you run the multi-modal agent, make sure to clean up any resources that won’t be utilized. Shut down and delete the databases used (Athena). In addition, delete the data in Amazon S3 and stop any SageMaker Studio notebook instances to not incur any further charges. Delete the Lambda functions and DynamoDB tables as part of long-term memory that aren’t used. If you used SageMaker JumpStart to deploy an LLM as a SageMaker real-time endpoint, delete the endpoint through either the SageMaker console or SageMaker Studio.
Conclusion
This post demonstrated the wide range of AWS storage, AI/ML, and compute services that you can use to build an advanced multi-modal AI solution along with the LangChain framework and generative AI. By integrating NLP, speech recognition, and ML technologies, the multi-modal agent developed in this scenario is able to analyze diverse financial data modalities (structured and unstructured) and respond to prompts in natural language (English). This boosts the productivity and efficiency of financial analysts, allowing them to focus on high-value, strategic work. Multi-modal AI solutions powered by AWS have the potential to transform financial markets by automating repetitive tasks, enhancing human capabilities, and generating data-driven insights efficiently. For structured data, a modern data architecture with multiple databases can be incorporated with generative AI and LLM. For more details, refer to Reinventing the data experience: Use generative AI and modern data architecture to unlock insights. Also, refer to Amazon Bedrock for use cases on generative AI, foundation models, and large language models.
Appendix
The following table contains example questions by a financial analyst to ask the multi-modal agent based on structured and unstructured data.
| Question Purpose | Question asked by financial analysts through UI | Agent tools invoked | Primary AWS services used by Agent tools | Answer from multi-modal agent |
| Prompt the LangChain agent to preprocess and extract information from the collected data | Convert the Amazon`s recent quarters 10k and 10q files to text format |
1. Text Extraction Tool |
|
The text files containing Amazon's financial filings have been cleaned and are ready for analysis. |
| Prompt the LangChain agent to transcribe the audio recordings to texts | Can you transcribe most recent quaterly audio recording of earnings call to text format? |
|
|
I have the earnings call transcripts, now I can extract key phrases. |
| Prompt the LangChain agent to analyze the company’s financial health and performance | Analyze Amazon's financial health based on the 10k report. Calculate important financial ratios. Please limit your answer to 5 sentences. |
|
|
Here is a summary of Amazon’s financial health in 5 sentences: Amazon has a low profit margin indicating low profitability relative to revenue. However, Amazon has a high return on assets indicating efficient use of assets to generate profits. Amazon has a low debt-to-equity ratio indicating low financial leverage and risk. Amazon has a high current ratio indicating good short-term liquidity position and ability to pay off short-term obligations. Overall, Amazon seems to be in a good financial position with efficient operations and low risk. |
| Prompt the LangChain agent to analyze the company’s financial performance from company’s earnings reports | What were the main drivers of the company’s revenue growth in the quarter? Please limit your answers to 5 sentences. |
|
|
Here is a summary of the main drivers of revenue growth in 5 sentences: Amazon's revenue grew due to an increase in subscription and support revenue from new customers. Existing customer accounts also expanded, contributing to revenue growth. Higher net sales drove increased revenue for the company. Although I could not calculate the exact revenue growth percentage, the key phrases and information extracted point to revenue growth being driven primarily by new subscriptions, existing customer expansion, and greater net sales. |
| Prompt the LangChain agent to analyze the company’s management team and their plans for the future from company’s earnings reports | What are the company's top priorities for the coming year? What are the biggest risks facing the company? Please limit your answers to 5 sentences. |
|
|
Here is a summary response in 5 sentences: Amazon's priorities are investing in growth and expanding into new markets. However, risks like changes in consumer demand and competition threaten their business. By analyzing key phrases in financial reports, their focus on fulfillment, technology, and new products emerges, as do risks around suppliers, exchange rates, and retail competition. Though facing pressures, Amazon aims to innovate, improve customer experience, and strengthen their position. Continuous progress on price, speed, and selection will drive their competitive advantage. |
| Prompt the LangChain agent to analyze the company’s strategy from company’s earnings reports | What are company’s financial and business goals for upcoming financial year/quarter? Please limit your answers to 5 sentences. |
|
|
Here is a summary of Amazon's main goals in 5 sentences: Amazon seeks to grow by improving infrastructure and entering new markets. They will invest in fulfillment and technology to enable expansion. By moving into groceries, healthcare, and entertainment, Amazon can diversify their offerings. Focusing on the customer through competitive pricing, selection, and innovation is key. If Amazon achieves operational excellence and continuous progress, they will strengthen their position. |
| Prompt the LangChain agent to perform sentiment analysis on the earnings call recordings | What is the sentiment around inflation in Amazon's earnings call? |
|
|
The sentiment of mentions of 'inflation' in the Amazon earnings call transcript is negative. Justification: Quote 1: "We're seeing inflationary pressures, especially in fuel and transportation costs." Quote 2: "Inflation is a concern and we're seeing cost inflation, which is an unusual thing for us. |
| Prompt the LangChain agent to build an optimal portfolio using the collected data | What are the closing prices of stocks AAAA, WWW, DDD in year 2018? Can you build an optimized portfolio using these three stocks? |
|
|
The closing stock prices for AAAA, WWW and DDD in 2018 are:AAAA: $172.44WWW: $85.91DDD: $9.82The optimized portfolio allocation for stocks AAAA, WWW and DDD is:AAAA: 55%WWW: 45%DDD: 0%' |
About the Authors
 Sovik Kumar Nath is an AI/ML solution architect with AWS. He has extensive experience designing end-to-end machine learning and business analytics solutions in finance, operations, marketing, healthcare, supply chain management, and IoT. Sovik has published articles and holds a patent in ML model monitoring. He has double masters degrees from the University of South Florida, University of Fribourg, Switzerland, and a bachelors degree from the Indian Institute of Technology, Kharagpur. Outside of work, Sovik enjoys traveling, taking ferry rides, and watching movies.
Sovik Kumar Nath is an AI/ML solution architect with AWS. He has extensive experience designing end-to-end machine learning and business analytics solutions in finance, operations, marketing, healthcare, supply chain management, and IoT. Sovik has published articles and holds a patent in ML model monitoring. He has double masters degrees from the University of South Florida, University of Fribourg, Switzerland, and a bachelors degree from the Indian Institute of Technology, Kharagpur. Outside of work, Sovik enjoys traveling, taking ferry rides, and watching movies.
 Mohan Musti is Senior Technical Account Manger based out of Dallas. Mohan helps customers architect and optimize applications on AWS. Mohan has Computer Science and Engineering from JNT University ,India. In his spare time, he enjoys spending time with his family and camping.
Mohan Musti is Senior Technical Account Manger based out of Dallas. Mohan helps customers architect and optimize applications on AWS. Mohan has Computer Science and Engineering from JNT University ,India. In his spare time, he enjoys spending time with his family and camping.
 Jia (Vivian) Li is a Senior Solutions Architect in AWS, with specialization in AI/ML. She currently supports customers in financial industry. Prior to joining AWS in 2022, she had 7 years of experience supporting enterprise customers use AI/ML in the cloud to drive business results. Vivian has a BS from Peking University and a PhD from University of Southern California. In her spare time, she enjoys all the water activities, and hiking in the beautiful mountains in her home state, Colorado.
Jia (Vivian) Li is a Senior Solutions Architect in AWS, with specialization in AI/ML. She currently supports customers in financial industry. Prior to joining AWS in 2022, she had 7 years of experience supporting enterprise customers use AI/ML in the cloud to drive business results. Vivian has a BS from Peking University and a PhD from University of Southern California. In her spare time, she enjoys all the water activities, and hiking in the beautiful mountains in her home state, Colorado.
 Uchenna Egbe is an AIML Solutions Architect who enjoys building reusable AIML solutions. Uchenna has an MS from the University of Alaska Fairbanks. He spends his free time researching about herbs, teas, superfoods, and how to incorporate them into his daily diet.
Uchenna Egbe is an AIML Solutions Architect who enjoys building reusable AIML solutions. Uchenna has an MS from the University of Alaska Fairbanks. He spends his free time researching about herbs, teas, superfoods, and how to incorporate them into his daily diet.
 Navneet Tuteja is a Data Specialist at Amazon Web Services. Before joining AWS, Navneet worked as a facilitator for organizations seeking to modernize their data architectures and implement comprehensive AI/ML solutions. She holds an engineering degree from Thapar University, as well as a master’s degree in statistics from Texas A&M University.
Navneet Tuteja is a Data Specialist at Amazon Web Services. Before joining AWS, Navneet worked as a facilitator for organizations seeking to modernize their data architectures and implement comprehensive AI/ML solutions. She holds an engineering degree from Thapar University, as well as a master’s degree in statistics from Texas A&M University.
 Praful Kava is a Sr. Specialist Solutions Architect at AWS. He guides customers to design and engineer Cloud scale Analytics pipelines on AWS. Outside work, he enjoys travelling with his family and exploring new hiking trails.
Praful Kava is a Sr. Specialist Solutions Architect at AWS. He guides customers to design and engineer Cloud scale Analytics pipelines on AWS. Outside work, he enjoys travelling with his family and exploring new hiking trails.













 Adir Sharabi is a Principal Solutions Architect with Amazon Web Services. He works with AWS customers to help them architect secure, resilient, scalable and high performance applications in the cloud. He is also passionate about Data and helping customers to get the most out of it.
Adir Sharabi is a Principal Solutions Architect with Amazon Web Services. He works with AWS customers to help them architect secure, resilient, scalable and high performance applications in the cloud. He is also passionate about Data and helping customers to get the most out of it. Omer Haim is a Senior Startup Solutions Architect at Amazon Web Services. He helps startups with their cloud journey, and is passionate about containers and ML. In his spare time, Omer likes to travel, and occasionally game with his son.
Omer Haim is a Senior Startup Solutions Architect at Amazon Web Services. He helps startups with their cloud journey, and is passionate about containers and ML. In his spare time, Omer likes to travel, and occasionally game with his son. Dmitry Zadorozhny is a data analyst at
Dmitry Zadorozhny is a data analyst at  Fuad Babaev serves as a Data Science Specialist at Virtuswap (
Fuad Babaev serves as a Data Science Specialist at Virtuswap (















 Dhaval Shah is a Senior Solutions Architect at AWS, specializing in Machine Learning. With a strong focus on digital native businesses, he empowers customers to leverage AWS and drive their business growth. As an ML enthusiast, Dhaval is driven by his passion for creating impactful solutions that bring positive change. In his leisure time, he indulges in his love for travel and cherishes quality moments with his family.
Dhaval Shah is a Senior Solutions Architect at AWS, specializing in Machine Learning. With a strong focus on digital native businesses, he empowers customers to leverage AWS and drive their business growth. As an ML enthusiast, Dhaval is driven by his passion for creating impactful solutions that bring positive change. In his leisure time, he indulges in his love for travel and cherishes quality moments with his family. Ninad Joshi is a Senior Solutions Architect at AWS, helping global AWS customers design secure, scalable, and cost effective solutions in cloud to solve their complex real-world business challenges. His work in Machine Learning (ML) covers a wide range of AI/ML use cases, with a primary focus on End-to-End ML, Natural Language Processing, and Computer Vision. Prior to joining AWS, Ninad worked as a software developer for 12+ years. Outside of his professional endeavors, Ninad enjoys playing chess and exploring different gambits.
Ninad Joshi is a Senior Solutions Architect at AWS, helping global AWS customers design secure, scalable, and cost effective solutions in cloud to solve their complex real-world business challenges. His work in Machine Learning (ML) covers a wide range of AI/ML use cases, with a primary focus on End-to-End ML, Natural Language Processing, and Computer Vision. Prior to joining AWS, Ninad worked as a software developer for 12+ years. Outside of his professional endeavors, Ninad enjoys playing chess and exploring different gambits.

 Raju Rangan is a Senior Solutions Architect at Amazon Web Services (AWS). He works with government sponsored entities, helping them build AI/ML solutions using AWS. When not tinkering with cloud solutions, you’ll catch him hanging out with family or smashing birdies in a lively game of badminton with friends.
Raju Rangan is a Senior Solutions Architect at Amazon Web Services (AWS). He works with government sponsored entities, helping them build AI/ML solutions using AWS. When not tinkering with cloud solutions, you’ll catch him hanging out with family or smashing birdies in a lively game of badminton with friends. Sherry Ding is a senior AI/ML specialist solutions architect at Amazon Web Services (AWS). She has extensive experience in machine learning with a PhD degree in computer science. She mainly works with public sector customers on various AI/ML-related business challenges, helping them accelerate their machine learning journey on the AWS Cloud. When not helping customers, she enjoys outdoor activities.
Sherry Ding is a senior AI/ML specialist solutions architect at Amazon Web Services (AWS). She has extensive experience in machine learning with a PhD degree in computer science. She mainly works with public sector customers on various AI/ML-related business challenges, helping them accelerate their machine learning journey on the AWS Cloud. When not helping customers, she enjoys outdoor activities.






 John Hwang is a Generative AI Architect at AWS with special focus on Large Language Model (LLM) applications, vector databases, and generative AI product strategy. He is passionate about helping companies with AI/ML product development, and the future of LLM agents and co-pilots. Prior to joining AWS, he was a Product Manager at Alexa, where he helped bring conversational AI to mobile devices, as well as a derivatives trader at Morgan Stanley. He holds B.S. in computer science from Stanford University.
John Hwang is a Generative AI Architect at AWS with special focus on Large Language Model (LLM) applications, vector databases, and generative AI product strategy. He is passionate about helping companies with AI/ML product development, and the future of LLM agents and co-pilots. Prior to joining AWS, he was a Product Manager at Alexa, where he helped bring conversational AI to mobile devices, as well as a derivatives trader at Morgan Stanley. He holds B.S. in computer science from Stanford University.



 Sandeep Singh is a Senior Data Scientist with AWS Professional Services. He is passionate about helping customers innovate and achieve their business objectives by developing state-of-the-art AI/ML powered solutions. He is currently focused on Generative AI, LLMs, prompt engineering, and scaling Machine Learning across enterprises. He brings recent AI advancements to create value for customers.
Sandeep Singh is a Senior Data Scientist with AWS Professional Services. He is passionate about helping customers innovate and achieve their business objectives by developing state-of-the-art AI/ML powered solutions. He is currently focused on Generative AI, LLMs, prompt engineering, and scaling Machine Learning across enterprises. He brings recent AI advancements to create value for customers. Yanyan Zhang is a Senior Data Scientist in the Energy Delivery team with AWS Professional Services. She is passionate about helping customers solve real problems with AI/ML knowledge. Recently, her focus has been on exploring the potential of Generative AI and LLM. Outside of work, she loves traveling, working out and exploring new things.
Yanyan Zhang is a Senior Data Scientist in the Energy Delivery team with AWS Professional Services. She is passionate about helping customers solve real problems with AI/ML knowledge. Recently, her focus has been on exploring the potential of Generative AI and LLM. Outside of work, she loves traveling, working out and exploring new things. Wrick Talukdar is a Senior Architect with the Amazon Comprehend Service team. He works with AWS customers to help them adopt machine learning on a large scale. Outside of work, he enjoys reading and photography.
Wrick Talukdar is a Senior Architect with the Amazon Comprehend Service team. He works with AWS customers to help them adopt machine learning on a large scale. Outside of work, he enjoys reading and photography.