
In our previous blog posts, we explored various techniques such as fine-tuning large language models (LLMs), prompt engineering, and Retrieval Augmented Generation (RAG) using Amazon Bedrock to generate impressions from the findings section in radiology reports using generative AI. Part 1 focused on model fine-tuning. Part 2 introduced RAG, which combines LLMs with external knowledge bases to reduce hallucinations and improve accuracy in medical applications. Through real-time retrieval of relevant medical information, RAG systems can provide more reliable and contextually appropriate responses, making them particularly valuable for healthcare applications where precision is crucial. In both previous posts, we used traditional metrics like ROUGE scores for performance evaluation. This metric is suitable for evaluating general summarization tasks, but can’t effectively assess whether a RAG system successfully integrates retrieved medical knowledge or maintains clinical accuracy.
In Part 3, we’re introducing an approach to evaluate healthcare RAG applications using LLM-as-a-judge with Amazon Bedrock. This innovative evaluation framework addresses the unique challenges of medical RAG systems, where both the accuracy of retrieved medical knowledge and the quality of generated medical content must align with stringent standards such as clear and concise communication, clinical accuracy, and grammatical accuracy. By using the latest models from Amazon and the newly released RAG evaluation feature for Amazon Bedrock Knowledge Bases, we can now comprehensively assess how well these systems retrieve and use medical information to generate accurate, contextually appropriate responses.
This advancement in evaluation methodology is particularly crucial as healthcare RAG applications become more prevalent in clinical settings. The LLM-as-a-judge approach provides a more nuanced evaluation framework that considers both the quality of information retrieval and the clinical accuracy of generated content, aligning with the rigorous standards required in healthcare.
In this post, we demonstrate how to implement this evaluation framework using Amazon Bedrock, compare the performance of different generator models, including Anthropic’s Claude and Amazon Nova on Amazon Bedrock, and showcase how to use the new RAG evaluation feature to optimize knowledge base parameters and assess retrieval quality. This approach not only establishes new benchmarks for medical RAG evaluation, but also provides practitioners with practical tools to build more reliable and accurate healthcare AI applications that can be trusted in clinical settings.
Overview of the solution
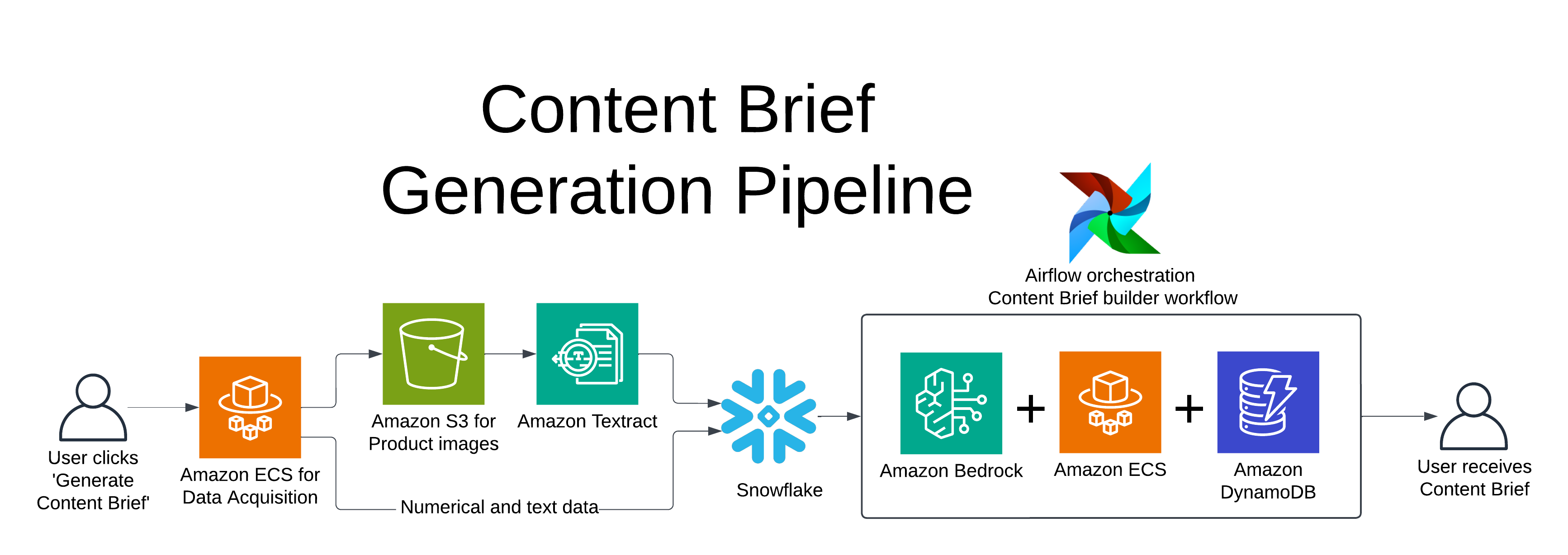
The solution uses Amazon Bedrock Knowledge Bases evaluation capabilities to assess and optimize RAG applications specifically for radiology findings and impressions. Let’s examine the key components of this architecture in the following figure, following the data flow from left to right.

The workflow consists of the following phases:
- Data preparation – Our evaluation process begins with a prompt dataset containing paired radiology findings and impressions. This clinical data undergoes a transformation process where it’s converted into a structured JSONL format, which is essential for compatibility with the knowledge base evaluation system. After it’s prepared, this formatted data is securely uploaded to an Amazon Simple Storage Service (Amazon S3) bucket, providing accessibility and data security throughout the evaluation process.
- Evaluation processing – At the heart of our solution lies an Amazon Bedrock Knowledge Bases evaluation job. This component processes the prepared data while seamlessly integrating with Amazon Bedrock Knowledge Bases. This integration is crucial because it enables the system to create specialized medical RAG capabilities specifically tailored for radiology findings and impressions, making sure that the evaluation considers both medical context and accuracy.
- Analysis – The final stage empowers healthcare data scientists with detailed analytical capabilities. Through an advanced automated report generation system, professionals can access detailed analysis of performance metrics of the summarization task for impression generation. This comprehensive reporting system enables thorough assessment of both retrieval quality and generation accuracy, providing valuable insights for system optimization and quality assurance.
This architecture provides a systematic and thorough approach to evaluating medical RAG applications, providing both accuracy and reliability in healthcare contexts where precision and dependability are paramount.
Dataset and background
The MIMIC Chest X-ray (MIMIC-CXR) database v2.0.0 is a large, publicly available dataset of chest radiographs in DICOM format with free-text radiology reports. We used the MIMIC CXR dataset consisting of 91,544 reports, which can be accessed through a data use agreement. This requires user registration and the completion of a credentialing process.
During routine clinical care, clinicians trained in interpreting imaging studies (radiologists) will summarize their findings for a particular study in a free-text note. The reports were de-identified using a rule-based approach to remove protected health information. Because we used only the radiology report text data, we downloaded just one compressed report file (mimic-cxr-reports.zip) from the MIMIC-CXR website. For evaluation, 1,000 of the total 2,000 reports from a subset of MIMIC-CXR dataset were used. This is referred to as the dev1 dataset. Another set of 1,000 of the total 2,000 radiology reports (referred to as dev2) from the chest X-ray collection from the Indiana University hospital network were also used.
RAG with Amazon Bedrock Knowledge Bases
Amazon Bedrock Knowledge Bases helps take advantage of RAG, a popular technique that involves drawing information from a data store to augment the responses generated by LLMs. We used Amazon Bedrock Knowledge Bases to generate impressions from the findings section of the radiology reports by enriching the query with context that is received from querying the knowledge base. The knowledge base is set up to contain findings and corresponding impression sections of 91,544 MIMIC-CXR radiology reports as {prompt, completion} pairs.
LLM-as-a-judge and quality metrics
LLM-as-a-judge represents an innovative approach to evaluating AI-generated medical content by using LLMs as automated evaluators. This method is particularly valuable in healthcare applications where traditional metrics might fail to capture the nuanced requirements of medical accuracy and clinical relevance. By using specialized prompts and evaluation criteria, LLM-as-a-judge can assess multiple dimensions of generated medical content, providing a more comprehensive evaluation framework that aligns with healthcare professionals’ standards.
Our evaluation framework encompasses five critical metrics, each designed to assess specific aspects of the generated medical content:
- Correctness – Evaluated on a 3-point Likert scale, this metric measures the factual accuracy of generated responses by comparing them against ground truth responses. In the medical context, this makes sure that the clinical interpretations and findings align with the source material and accepted medical knowledge.
- Completeness – Using a 5-point Likert scale, this metric assesses whether the generated response comprehensively addresses the prompt holistically while considering the ground truth response. It makes sure that critical medical findings or interpretations are not omitted from the response.
- Helpfulness – Measured on a 7-point Likert scale, this metric evaluates the practical utility of the response in clinical contexts, considering factors such as clarity, relevance, and actionability of the medical information provided.
- Logical coherence – Assessed on a 5-point Likert scale, this metric examines the response for logical gaps, inconsistencies, or contradictions, making sure that medical reasoning flows naturally and maintains clinical validity throughout the response.
- Faithfulness – Scored on a 5-point Likert scale, this metric specifically evaluates whether the response contains information not found in or quickly inferred from the prompt, helping identify potential hallucinations or fabricated medical information that could be dangerous in clinical settings.
These metrics are normalized in the final output and job report card, providing standardized scores that enable consistent comparison across different models and evaluation scenarios. This comprehensive evaluation framework not only helps maintain the reliability and accuracy of medical RAG systems, but also provides detailed insights for continuous improvement and optimization. For details about the metric and evaluation prompts, see Evaluator prompts used in a knowledge base evaluation job.
Prerequisites
Before proceeding with the evaluation setup, make sure you have the following:
- An active AWS account with appropriate permissions
- Amazon Bedrock model access enabled in your preferred AWS Region
- An S3 bucket with CORS enabled for storing evaluation data
- An Amazon Bedrock knowledge base
- An AWS Identity and Access Management (IAM) role with necessary permissions for Amazon S3 and Amazon Bedrock
The solution code can be found at the following GitHub repo.
Make sure that your knowledge base is fully synced and ready before initiating an evaluation job.
Convert the test dataset into JSONL for RAG evaluation
In preparation for evaluating our RAG system’s performance on radiology reports, we implemented a data transformation pipeline to convert our test dataset into the required JSONL format. The following code shows the format of the original dev1 and dev2 datasets:
{
"prompt": "value of prompt key",
"completion": "value of completion key"
}
Output Format
{
"conversationTurns": [{
"referenceResponses": [{
"content": [{
"text": "value from completion key"
}]
}],
"prompt": {
"content": [{
"text": "value from prompt key"
}]
}
}]
}
Drawing from Wilcox’s seminal paper The Written Radiology Report, we carefully structured our prompt to include comprehensive guidelines for generating high-quality impressions:
import json
import random
import boto3
# Initialize the S3 client
s3 = boto3.client('s3')
# S3 bucket name
bucket_name = "<BUCKET_NAME>"
# Function to transform a single record
def transform_record(record):
return {
"conversationTurns": [
{
"referenceResponses": [
{
"content": [
{
"text": record["completion"]
}
]
}
],
"prompt": {
"content": [
{
"text": """You're given a radiology report findings to generate a concise radiology impression from it.
A Radiology Impression is the radiologist's final concise interpretation and conclusion of medical imaging findings, typically appearing at the end of a radiology report.
n Follow these guidelines when writing the impression:
n- Use clear, understandable language avoiding obscure terms.
n- Number each impression.
n- Order impressions by importance.
n- Keep impressions concise and shorter than the findings section.
n- Write for the intended reader's understanding.n
Findings: n""" + record["prompt"]
}
]
}
}
]
}
The script processes individual records, restructuring them to include conversation turns with both the original radiology findings and their corresponding impressions, making sure each report maintains the professional standards outlined in the literature. To maintain a manageable dataset size set used by this feature, we randomly sampled 1,000 records from the original dev1 and dev2 datasets, using a fixed random seed for reproducibility:
# Read from input file and write to output file
def convert_file(input_file_path, output_file_path, sample_size=1000):
# First, read all records into a list
records = []
with open(input_file_path, 'r', encoding='utf-8') as input_file:
for line in input_file:
records.append(json.loads(line.strip()))
# Randomly sample 1000 records
random.seed(42) # Set the seed first
sampled_records = random.sample(records, sample_size)
# Write the sampled and transformed records to the output file
with open(output_file_path, 'w', encoding='utf-8') as output_file:
for record in sampled_records:
transformed_record = transform_record(record)
output_file.write(json.dumps(transformed_record) + 'n')
# Usage
input_file_path = '<INPUT_FILE_NAME>.jsonl' # Replace with your input file path
output_file_path = '<OUTPUT_FILE_NAME>.jsonl' # Replace with your desired output file path
convert_file(input_file_path, output_file_path)
# File paths and S3 keys for the transformed files
transformed_files = [
{'local_file': '<OUTPUT_FILE_NAME>.jsonl', 'key': '<FOLDER_NAME>/<OUTPUT_FILE_NAME>.jsonl'},
{'local_file': '<OUTPUT_FILE_NAME>.jsonl', 'key': '<FOLDER_NAME>/<OUTPUT_FILE_NAME>.jsonl'}
]
# Upload files to S3
for file in transformed_files:
s3.upload_file(file['local_file'], bucket_name, file['key'])
print(f"Uploaded {file['local_file']} to s3://{bucket_name}/{file['key']}")
Set up a RAG evaluation job
Our RAG evaluation setup begins with establishing core configurations for the Amazon Bedrock evaluation job, including the selection of evaluation and generation models (Anthropic’s Claude 3 Haiku and Amazon Nova Micro, respectively). The implementation incorporates a hybrid search strategy with a retrieval depth of 10 results, providing comprehensive coverage of the knowledge base during evaluation. To maintain organization and traceability, each evaluation job is assigned a unique identifier with timestamp information, and input data and results are systematically managed through designated S3 paths. See the following code:
import boto3
from datetime import datetime
# Generate unique name for the job
job_name = f"rag-eval-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}"
# Configure knowledge base and model settings
knowledge_base_id = "<KNOWLEDGE_BASE_ID>"
evaluator_model = "anthropic.claude-3-haiku-20240307-v1:0"
generator_model = "amazon.nova-micro-v1:0"
role_arn = "<IAM_ROLE_ARN>"
# Specify S3 locations
input_data = "<INPUT_S3_PATH>"
output_path = "<OUTPUT_S3_PATH>"
# Configure retrieval settings
num_results = 10
search_type = "HYBRID"
# Create Bedrock client
bedrock_client = boto3.client('bedrock')
With the core configurations in place, we initiate the evaluation job using the Amazon Bedrock create_evaluation_job API, which orchestrates a comprehensive assessment of our RAG system’s performance. The evaluation configuration specifies five key metrics—correctness, completeness, helpfulness, logical coherence, and faithfulness—providing a multi-dimensional analysis of the generated radiology impressions. The job is structured to use the knowledge base for retrieval and generation tasks, with the specified models handling their respective roles: Amazon Nova Micro for generation and Anthropic’s Claude 3 Haiku for evaluation, and the results are systematically stored in the designated S3 output location for subsequent analysis. See the following code:
retrieve_generate_job = bedrock_client.create_evaluation_job(
jobName=job_name,
jobDescription="Evaluate retrieval and generation",
roleArn=role_arn,
applicationType="RagEvaluation",
inferenceConfig={
"ragConfigs": [{
"knowledgeBaseConfig": {
"retrieveAndGenerateConfig": {
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
"knowledgeBaseId": knowledge_base_id,
"modelArn": generator_model,
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"numberOfResults": num_results,
"overrideSearchType": search_type
}
}
}
}
}
}]
},
outputDataConfig={
"s3Uri": output_path
},
evaluationConfig={
"automated": {
"datasetMetricConfigs": [{
"taskType": "Custom",
"dataset": {
"name": "RagDataset",
"datasetLocation": {
"s3Uri": input_data
}
},
"metricNames": [
"Builtin.Correctness",
"Builtin.Completeness",
"Builtin.Helpfulness",
"Builtin.LogicalCoherence",
"Builtin.Faithfulness"
]
}],
"evaluatorModelConfig": {
"bedrockEvaluatorModels": [{
"modelIdentifier": evaluator_model
}]
}
}
}
)
Evaluation results and metrics comparisons
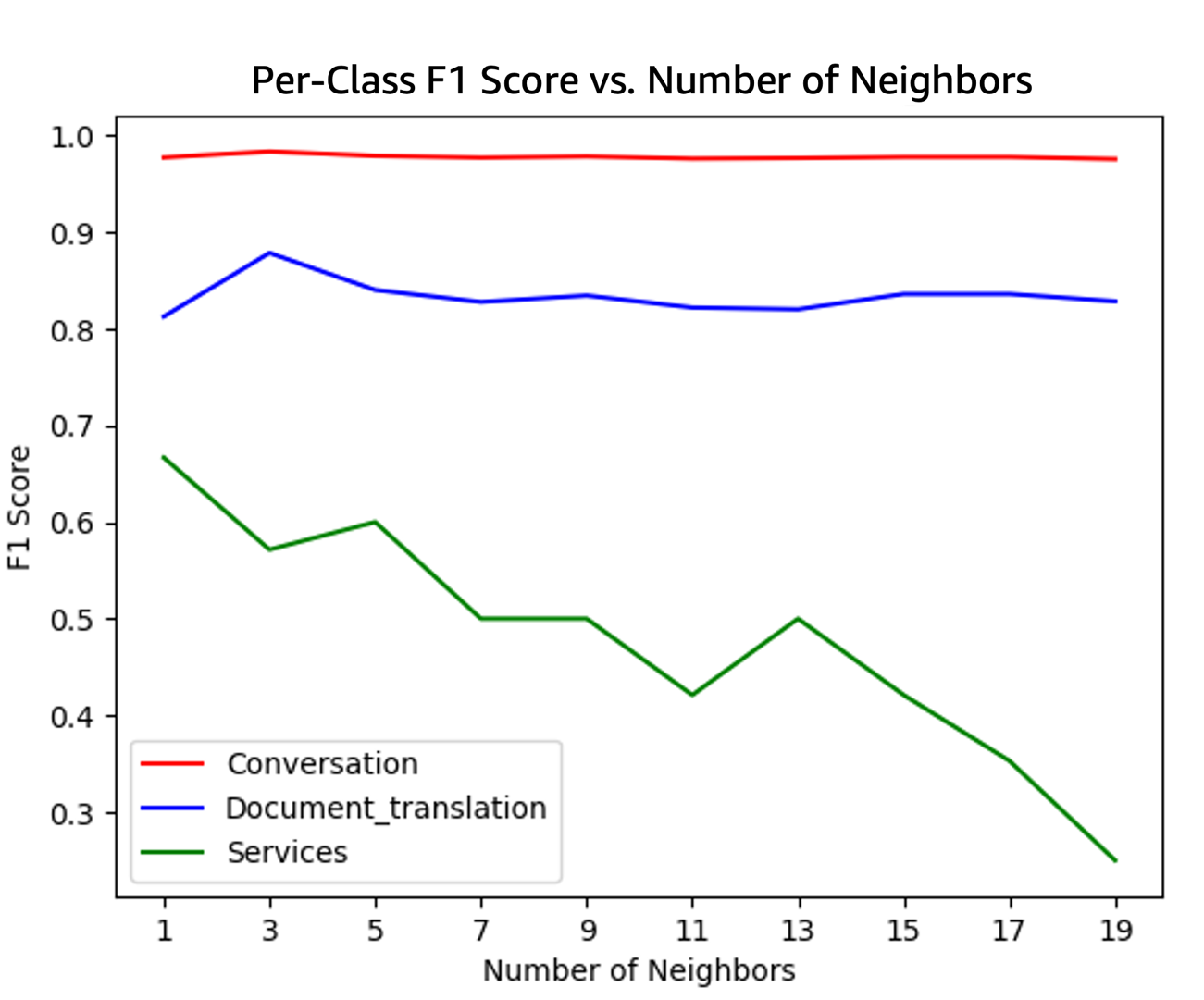
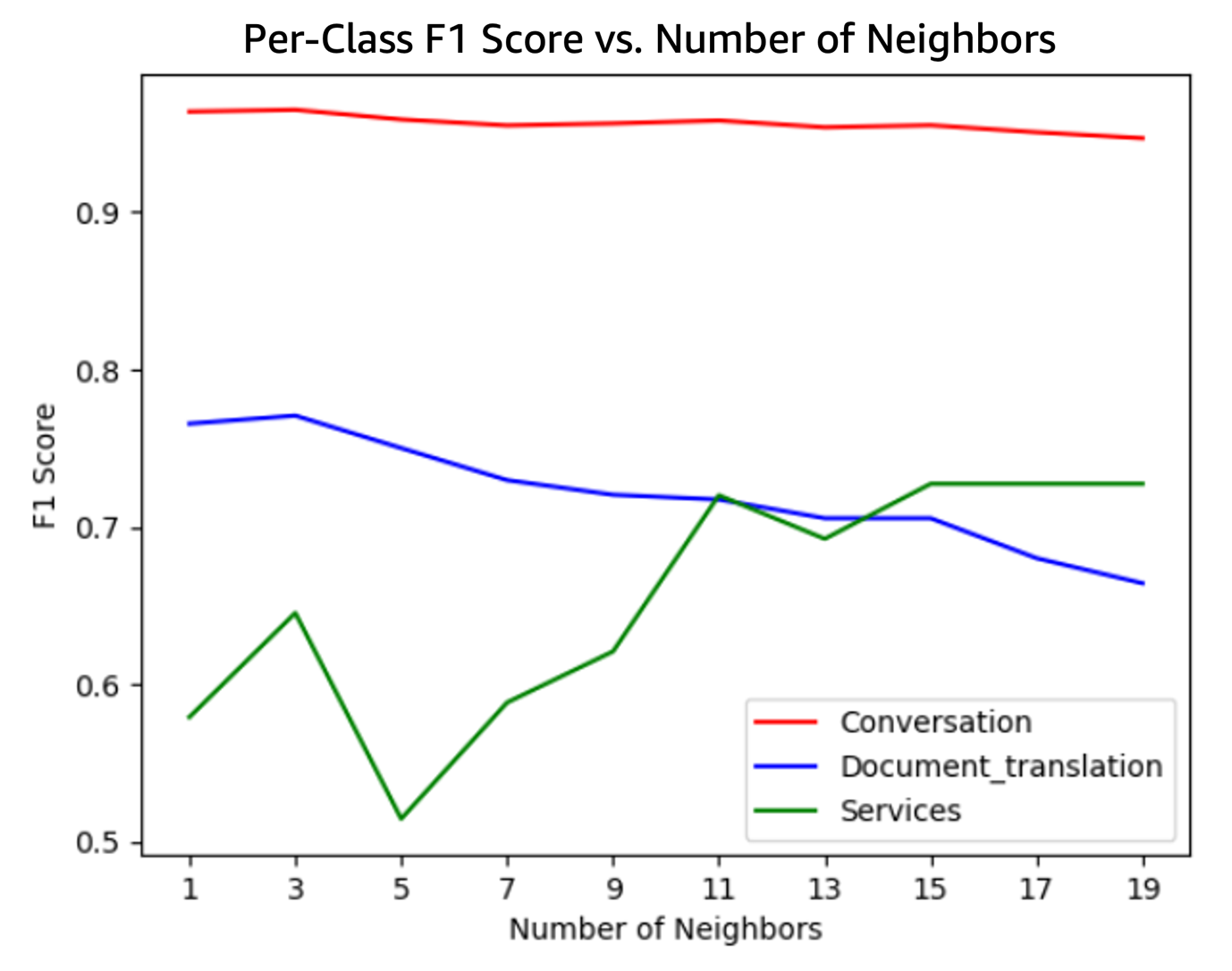
The evaluation results for the healthcare RAG applications, using datasets dev1 and dev2, demonstrate strong performance across the specified metrics. For the dev1 dataset, the scores were as follows: correctness at 0.98, completeness at 0.95, helpfulness at 0.83, logical coherence at 0.99, and faithfulness at 0.79. Similarly, the dev2 dataset yielded scores of 0.97 for correctness, 0.95 for completeness, 0.83 for helpfulness, 0.98 for logical coherence, and 0.82 for faithfulness. These results indicate that the RAG system effectively retrieves and uses medical information to generate accurate and contextually appropriate responses, with particularly high scores in correctness and logical coherence, suggesting robust factual accuracy and logical consistency in the generated content.
The following screenshot shows the evaluation summary for the dev1 dataset.

The following screenshot shows the evaluation summary for the dev2 dataset.

Additionally, as shown in the following screenshot, the LLM-as-a-judge framework allows for the comparison of multiple evaluation jobs across different models, datasets, and prompts, enabling detailed analysis and optimization of the RAG system’s performance.

Additionally, you can perform a detailed analysis by drilling down and investigating the outlier cases with least performance metrics such as correctness, as shown in the following screenshot.

Metrics explainability
The following screenshot showcases the detailed metrics explainability interface of the evaluation system, displaying example conversations with their corresponding metrics assessment. Each conversation entry includes four key columns: Conversation input, Generation output, Retrieved sources, and Ground truth, along with a Score column. The system provides a comprehensive view of 1,000 examples, with navigation controls to browse through the dataset. Of particular note is the retrieval depth indicator showing 10 for each conversation, demonstrating consistent knowledge base utilization across examples.
The evaluation framework enables detailed tracking of generation metrics and provides transparency into how the knowledge base arrives at its outputs. Each example conversation presents the complete chain of information, from the initial prompt through to the final assessment. The system displays the retrieved context that informed the generation, the actual generated response, and the ground truth for comparison. A scoring mechanism evaluates each response, with a detailed explanation of the decision-making process visible through an expandable interface (as shown by the pop-up in the screenshot). This granular level of detail allows for thorough analysis of the RAG system’s performance and helps identify areas for optimization in both retrieval and generation processes.

In this specific example from the Indiana University Medical System dataset (dev2), we see a clear assessment of the system’s performance in generating a radiology impression for chest X-ray findings. The knowledge base successfully retrieved relevant context (shown by 10 retrieved sources) to generate an impression stating “Normal heart size and pulmonary vascularity 2. Unremarkable mediastinal contour 3. No focal consolidation, pleural effusion, or pneumothorax 4. No acute bony findings.” The evaluation system scored this response with a perfect correctness score of 1, noting in the detailed explanation that the candidate response accurately summarized the key findings and correctly concluded there was no acute cardiopulmonary process, aligning precisely with the ground truth response.

In the following screenshot, the evaluation system scored this response with a low score of 0.5, noting in the detailed explanation the ground truth response provided is “Moderate hiatal hernia. No definite pneumonia.” This indicates that the key findings from the radiology report are the presence of a moderate hiatal hernia and the absence of any definite pneumonia. The candidate response covers the key finding of the moderate hiatal hernia, which is correctly identified as one of the impressions. However, the candidate response also includes additional impressions that are not mentioned in the ground truth, such as normal lung fields, normal heart size, unfolded aorta, and degenerative changes in the spine. Although these additional impressions might be accurate based on the provided findings, they are not explicitly stated in the ground truth response. Therefore, the candidate response is partially correct and partially incorrect based on the ground truth.
Clean up
To avoid incurring future charges, delete the S3 bucket, knowledge base, and other resources that were deployed as part of the post.
Conclusion
The implementation of LLM-as-a-judge for evaluating healthcare RAG applications represents a significant advancement in maintaining the reliability and accuracy of AI-generated medical content. Through this comprehensive evaluation framework using Amazon Bedrock Knowledge Bases, we’ve demonstrated how automated assessment can provide detailed insights into the performance of medical RAG systems across multiple critical dimensions. The high-performance scores across both datasets indicate the robustness of this approach, though these metrics are just the beginning.
Looking ahead, this evaluation framework can be expanded to encompass broader healthcare applications while maintaining the rigorous standards essential for medical applications. The dynamic nature of medical knowledge and clinical practices necessitates an ongoing commitment to evaluation, making continuous assessment a cornerstone of successful implementation.
Through this series, we’ve demonstrated how you can use Amazon Bedrock to create and evaluate healthcare generative AI applications with the precision and reliability required in clinical settings. As organizations continue to refine these tools and methodologies, prioritizing accuracy, safety, and clinical utility in healthcare AI applications remains paramount.
About the Authors
 Adewale Akinfaderin is a Sr. Data Scientist–Generative AI, Amazon Bedrock, where he contributes to cutting edge innovations in foundational models and generative AI applications at AWS. His expertise is in reproducible and end-to-end AI/ML methods, practical implementations, and helping global customers formulate and develop scalable solutions to interdisciplinary problems. He has two graduate degrees in physics and a doctorate in engineering.
Adewale Akinfaderin is a Sr. Data Scientist–Generative AI, Amazon Bedrock, where he contributes to cutting edge innovations in foundational models and generative AI applications at AWS. His expertise is in reproducible and end-to-end AI/ML methods, practical implementations, and helping global customers formulate and develop scalable solutions to interdisciplinary problems. He has two graduate degrees in physics and a doctorate in engineering.
 Priya Padate is a Senior Partner Solution Architect supporting healthcare and life sciences worldwide at Amazon Web Services. She has over 20 years of healthcare industry experience leading architectural solutions in areas of medical imaging, healthcare related AI/ML solutions and strategies for cloud migrations. She is passionate about using technology to transform the healthcare industry to drive better patient care outcomes.
Priya Padate is a Senior Partner Solution Architect supporting healthcare and life sciences worldwide at Amazon Web Services. She has over 20 years of healthcare industry experience leading architectural solutions in areas of medical imaging, healthcare related AI/ML solutions and strategies for cloud migrations. She is passionate about using technology to transform the healthcare industry to drive better patient care outcomes.
 Dr. Ekta Walia Bhullar is a principal AI/ML/GenAI consultant with AWS Healthcare and Life Sciences business unit. She has extensive experience in development of AI/ML applications for healthcare especially in Radiology. During her tenure at AWS she has actively contributed to applications of AI/ML/GenAI within lifescience domain such as for clinical, drug development and commercial lines of business.
Dr. Ekta Walia Bhullar is a principal AI/ML/GenAI consultant with AWS Healthcare and Life Sciences business unit. She has extensive experience in development of AI/ML applications for healthcare especially in Radiology. During her tenure at AWS she has actively contributed to applications of AI/ML/GenAI within lifescience domain such as for clinical, drug development and commercial lines of business.









 Parker Bradshaw is an Enterprise SA at AWS who focuses on storage and data technologies. He helps retail companies manage large data sets to boost customer experience and product quality. Parker is passionate about innovation and building technical communities. In his free time, he enjoys family activities and playing pickleball.
Parker Bradshaw is an Enterprise SA at AWS who focuses on storage and data technologies. He helps retail companies manage large data sets to boost customer experience and product quality. Parker is passionate about innovation and building technical communities. In his free time, he enjoys family activities and playing pickleball.

 Hrushikesh Gangur is a Principal Solutions Architect at AWS. Based in San Francisco, California, Hrushikesh is an expert in AWS machine learning. As a thought leader in the field of generative AI, Hrushikesh has contributed to AWS’s efforts in helping startups and ISVs build and deploy AI applications. His expertise extends to various AWS services, including Amazon SageMaker, Amazon Bedrock, and accelerated computing which are crucial for building AI applications.
Hrushikesh Gangur is a Principal Solutions Architect at AWS. Based in San Francisco, California, Hrushikesh is an expert in AWS machine learning. As a thought leader in the field of generative AI, Hrushikesh has contributed to AWS’s efforts in helping startups and ISVs build and deploy AI applications. His expertise extends to various AWS services, including Amazon SageMaker, Amazon Bedrock, and accelerated computing which are crucial for building AI applications. Sai Darahas Akkineni is a Software Development Engineer at AWS. He holds a master’s degree in Computer Engineering from Cornell University, where he worked in the Autonomous Systems Lab with a specialization in computer vision and robot perception. Currently, he helps deploy large language models to optimize throughput and latency.
Sai Darahas Akkineni is a Software Development Engineer at AWS. He holds a master’s degree in Computer Engineering from Cornell University, where he worked in the Autonomous Systems Lab with a specialization in computer vision and robot perception. Currently, he helps deploy large language models to optimize throughput and latency. Prashant Patel is a Senior Software Development Engineer in AWS. He’s passionate about scaling large language models for enterprise applications. Prior to joining AWS, he worked at IBM on productionizing large-scale AI/ML workloads on Kubernetes. Prashant has a master’s degree from NYU Tandon School of Engineering. While not at work, he enjoys traveling and playing with his dogs.
Prashant Patel is a Senior Software Development Engineer in AWS. He’s passionate about scaling large language models for enterprise applications. Prior to joining AWS, he worked at IBM on productionizing large-scale AI/ML workloads on Kubernetes. Prashant has a master’s degree from NYU Tandon School of Engineering. While not at work, he enjoys traveling and playing with his dogs.




 Wangpeng An, Principal Algorithm Engineer at TikTok, specializes in multimodal LLMs for video understanding, advertising, and recommendations. He has led key projects in model acceleration, content moderation, and Ads LLM pipelines, enhancing TikTok’s real-time machine learning systems.
Wangpeng An, Principal Algorithm Engineer at TikTok, specializes in multimodal LLMs for video understanding, advertising, and recommendations. He has led key projects in model acceleration, content moderation, and Ads LLM pipelines, enhancing TikTok’s real-time machine learning systems. Haotian Zhang is a Tech Lead MLE at TikTok, specializing in content understanding, search, and recommendation. He received an ML PhD from University of Waterloo. At TikTok, he leads a group of engineers to improve the efficiency, robustness, and effectiveness of training and inference for LLMs and multimodal LLMs, especially for large distributed ML systems.
Haotian Zhang is a Tech Lead MLE at TikTok, specializing in content understanding, search, and recommendation. He received an ML PhD from University of Waterloo. At TikTok, he leads a group of engineers to improve the efficiency, robustness, and effectiveness of training and inference for LLMs and multimodal LLMs, especially for large distributed ML systems. Xiaojie Ding is a senior engineer at TikTok, focusing on content moderation system development, model resource and deployment optimization, and algorithm engineering stability construction. In his free time, he likes to play single-player games.
Xiaojie Ding is a senior engineer at TikTok, focusing on content moderation system development, model resource and deployment optimization, and algorithm engineering stability construction. In his free time, he likes to play single-player games. Nachuan Yang is a senior engineer at TikTok, focusing on content security and moderation. He has successively been engaged in the construction of moderation systems, model applications, and deployment and performance optimization.
Nachuan Yang is a senior engineer at TikTok, focusing on content security and moderation. He has successively been engaged in the construction of moderation systems, model applications, and deployment and performance optimization. Kairong Sun is a Senior SRE on the AML Team at ByteDance. His role focuses on maintaining the seamless operation and efficient allocation of resources within the cluster, specializing in cluster machine maintenance and resource optimization.
Kairong Sun is a Senior SRE on the AML Team at ByteDance. His role focuses on maintaining the seamless operation and efficient allocation of resources within the cluster, specializing in cluster machine maintenance and resource optimization.
 Xavier Vizcaino is the head of the DataLab, in the Digital Solutions department of Applus IDIADA. DataLab is the unit focused on the development of solutions for generating value from the exploitation of data through artificial intelligence.
Xavier Vizcaino is the head of the DataLab, in the Digital Solutions department of Applus IDIADA. DataLab is the unit focused on the development of solutions for generating value from the exploitation of data through artificial intelligence. Diego Martín Montoro is an AI Expert and Machine Learning Engineer at Applus+ Idiada Datalab. With a Computer Science degree and a Master’s in Data Science, Diego has built his career in the field of artificial intelligence and machine learning. His experience includes roles as a Machine Learning Engineer at companies like AppliedIT and Applus+ IDIADA, where he has worked on developing advanced AI systems and anomaly detection solutions.
Diego Martín Montoro is an AI Expert and Machine Learning Engineer at Applus+ Idiada Datalab. With a Computer Science degree and a Master’s in Data Science, Diego has built his career in the field of artificial intelligence and machine learning. His experience includes roles as a Machine Learning Engineer at companies like AppliedIT and Applus+ IDIADA, where he has worked on developing advanced AI systems and anomaly detection solutions. Jordi Sánchez Ferrer is the current Product Owner of the Datalab at Applus+ Idiada. A Computer Engineer with a Master’s degree in Data Science, Jordi’s trajectory includes roles as a Business Intelligence developer, Machine Learning engineer, and lead developer in Datalab. In his current role, Jordi combines his technical expertise with product management skills, leading strategic initiatives that align data science and AI projects with business objectives at Applus+ Idiada.
Jordi Sánchez Ferrer is the current Product Owner of the Datalab at Applus+ Idiada. A Computer Engineer with a Master’s degree in Data Science, Jordi’s trajectory includes roles as a Business Intelligence developer, Machine Learning engineer, and lead developer in Datalab. In his current role, Jordi combines his technical expertise with product management skills, leading strategic initiatives that align data science and AI projects with business objectives at Applus+ Idiada. Daniel Colls is a professional with more than 25 years of experience who has lived through the digital transformation and the transition from the on-premises model to the cloud from different perspectives in the IT sector. For the past 3 years, as a Solutions Architect at AWS, he has made this experience available to his customers, helping them successfully implement or move their workloads to the cloud.
Daniel Colls is a professional with more than 25 years of experience who has lived through the digital transformation and the transition from the on-premises model to the cloud from different perspectives in the IT sector. For the past 3 years, as a Solutions Architect at AWS, he has made this experience available to his customers, helping them successfully implement or move their workloads to the cloud.






 Akhil Raj Yallamelli is a Cloud Infrastructure Architect at AWS, specializing in architecting cloud infrastructure solutions for enhanced data security and cost efficiency. He is experienced in integrating technical solutions with business strategies to create scalable, reliable, and secure cloud environments. Akhil enjoys developing solutions focusing on customer business outcomes, incorporating generative AI (Gen AI) technologies to drive innovation and cloud enablement. He holds an MS degree in Computer Science. Outside of his professional work, Akhil enjoys watching and playing sports.
Akhil Raj Yallamelli is a Cloud Infrastructure Architect at AWS, specializing in architecting cloud infrastructure solutions for enhanced data security and cost efficiency. He is experienced in integrating technical solutions with business strategies to create scalable, reliable, and secure cloud environments. Akhil enjoys developing solutions focusing on customer business outcomes, incorporating generative AI (Gen AI) technologies to drive innovation and cloud enablement. He holds an MS degree in Computer Science. Outside of his professional work, Akhil enjoys watching and playing sports. Ebbey Thomas is a Senior Generative AI Specialist Solutions Architect at AWS. He designs and implements generative AI solutions that address specific customer business problems. He is recognized for simplifying complexity and delivering measurable business outcomes for clients. Ebbey holds a BS in Computer Engineering and an MS in Information Systems from Syracuse University.
Ebbey Thomas is a Senior Generative AI Specialist Solutions Architect at AWS. He designs and implements generative AI solutions that address specific customer business problems. He is recognized for simplifying complexity and delivering measurable business outcomes for clients. Ebbey holds a BS in Computer Engineering and an MS in Information Systems from Syracuse University.





































 Gene Arnold is a Product Architect with Alation’s Forward Deployed Engineering team. A curious learner with over 25 years of experience, Gene focuses how to sharpen selling skills and constantly explores new product lines.
Gene Arnold is a Product Architect with Alation’s Forward Deployed Engineering team. A curious learner with over 25 years of experience, Gene focuses how to sharpen selling skills and constantly explores new product lines. Prabhakar Chandrasekaran is a Senior Technical Account Manager with AWS Enterprise Support. Prabhakar enjoys helping customers build cutting-edge AI/ML solutions on the cloud. He also works with enterprise customers providing proactive guidance and operational assistance, helping them improve the value of their solutions when using AWS. Prabhakar holds eight AWS and seven other professional certifications. With over 21 years of professional experience, Prabhakar was a data engineer and a program leader in the financial services space prior to joining AWS.
Prabhakar Chandrasekaran is a Senior Technical Account Manager with AWS Enterprise Support. Prabhakar enjoys helping customers build cutting-edge AI/ML solutions on the cloud. He also works with enterprise customers providing proactive guidance and operational assistance, helping them improve the value of their solutions when using AWS. Prabhakar holds eight AWS and seven other professional certifications. With over 21 years of professional experience, Prabhakar was a data engineer and a program leader in the financial services space prior to joining AWS. Sindhu Jambunathan is a Senior Solutions Architect at AWS, specializing in supporting ISV customers in the data and generative AI vertical to build scalable, reliable, secure, and cost-effective solutions on AWS. With over 13 years of industry experience, she joined AWS in May 2021 after a successful tenure as a Senior Software Engineer at Microsoft. Sindhu’s diverse background includes engineering roles at Qualcomm and Rockwell Collins, complemented by a Master’s of Science in Computer Engineering from the University of Florida. Her technical expertise is balanced by a passion for culinary exploration, travel, and outdoor activities.
Sindhu Jambunathan is a Senior Solutions Architect at AWS, specializing in supporting ISV customers in the data and generative AI vertical to build scalable, reliable, secure, and cost-effective solutions on AWS. With over 13 years of industry experience, she joined AWS in May 2021 after a successful tenure as a Senior Software Engineer at Microsoft. Sindhu’s diverse background includes engineering roles at Qualcomm and Rockwell Collins, complemented by a Master’s of Science in Computer Engineering from the University of Florida. Her technical expertise is balanced by a passion for culinary exploration, travel, and outdoor activities. Prateek Jain is a Sr. Solutions Architect with AWS, based out of Atlanta Georgia. He is passionate about GenAI and helping customers build amazing solutions on AWS. In his free time, he enjoys spending time with Family and playing tennis.
Prateek Jain is a Sr. Solutions Architect with AWS, based out of Atlanta Georgia. He is passionate about GenAI and helping customers build amazing solutions on AWS. In his free time, he enjoys spending time with Family and playing tennis.








 Niithiyn Vijeaswaran is a Generative AI Specialist Solutions Architect with the Third-Party Model Science team at AWS. His area of focus is AWS AI accelerators (AWS Neuron). He holds a Bachelor’s degree in Computer Science and Bioinformatics.
Niithiyn Vijeaswaran is a Generative AI Specialist Solutions Architect with the Third-Party Model Science team at AWS. His area of focus is AWS AI accelerators (AWS Neuron). He holds a Bachelor’s degree in Computer Science and Bioinformatics. Preston Tuggle is a Sr. Specialist Solutions Architect working on generative AI.
Preston Tuggle is a Sr. Specialist Solutions Architect working on generative AI. Shane Rai is a Principal Generative AI Specialist with the AWS World Wide Specialist Organization (WWSO). He works with customers across industries to solve their most pressing and innovative business needs using the breadth of cloud-based AI/ML services offered by AWS, including model offerings from top tier foundation model providers.
Shane Rai is a Principal Generative AI Specialist with the AWS World Wide Specialist Organization (WWSO). He works with customers across industries to solve their most pressing and innovative business needs using the breadth of cloud-based AI/ML services offered by AWS, including model offerings from top tier foundation model providers. Avan Bala is a Solutions Architect at AWS. His area of focus is AI for DevOps and machine learning. He holds a bachelor’s degree in Computer Science with a minor in Mathematics and Statistics from the University of Maryland. Avan is currently working with the Enterprise Engaged East Team and likes to specialize in projects about emerging AI technologies.
Avan Bala is a Solutions Architect at AWS. His area of focus is AI for DevOps and machine learning. He holds a bachelor’s degree in Computer Science with a minor in Mathematics and Statistics from the University of Maryland. Avan is currently working with the Enterprise Engaged East Team and likes to specialize in projects about emerging AI technologies. Banu Nagasundaram leads product, engineering, and strategic partnerships for Amazon SageMaker JumpStart, the machine learning and generative AI hub provided by SageMaker. She is passionate about building solutions that help customers accelerate their AI journey and unlock business value.
Banu Nagasundaram leads product, engineering, and strategic partnerships for Amazon SageMaker JumpStart, the machine learning and generative AI hub provided by SageMaker. She is passionate about building solutions that help customers accelerate their AI journey and unlock business value.


 Dian Xu is the Senior Director of Engineering in Data at Rocket Companies, where she leads transformative initiatives to modernize enterprise data platforms and foster a collaborative, data-first culture. Under her leadership, Rocket’s data science, AI & ML platforms power billions of automated decisions annually, driving innovation and industry disruption. A passionate advocate for Gen AI and cloud technologies, Xu is also a sought-after speaker at global forums, inspiring the next generation of data professionals. Outside of work, she channels her love of rhythm into dancing, embracing styles from Bollywood to Bachata as a celebration of cultural diversity.
Dian Xu is the Senior Director of Engineering in Data at Rocket Companies, where she leads transformative initiatives to modernize enterprise data platforms and foster a collaborative, data-first culture. Under her leadership, Rocket’s data science, AI & ML platforms power billions of automated decisions annually, driving innovation and industry disruption. A passionate advocate for Gen AI and cloud technologies, Xu is also a sought-after speaker at global forums, inspiring the next generation of data professionals. Outside of work, she channels her love of rhythm into dancing, embracing styles from Bollywood to Bachata as a celebration of cultural diversity. Joel Hawkins is a Principal Data Scientist at Rocket Companies, where he is responsible for the data science and MLOps platform. Joel has decades of experience developing sophisticated tooling and working with data at large scales. A driven innovator, he works hand in hand with data science teams to ensure that we have the latest technologies available to provide cutting edge solutions. In his spare time, he is an avid cyclist and has been known to dabble in vintage sports car restoration.
Joel Hawkins is a Principal Data Scientist at Rocket Companies, where he is responsible for the data science and MLOps platform. Joel has decades of experience developing sophisticated tooling and working with data at large scales. A driven innovator, he works hand in hand with data science teams to ensure that we have the latest technologies available to provide cutting edge solutions. In his spare time, he is an avid cyclist and has been known to dabble in vintage sports car restoration. Venkata Santosh Sajjan Alla is a Senior Solutions Architect at AWS Financial Services. He partners with North American FinTech companies like Rocket and other financial services organizations to drive cloud and AI strategy, accelerating AI adoption at scale. With deep expertise in AI & ML, Generative AI, and cloud-native architecture, he helps financial institutions unlock new revenue streams, optimize operations, and drive impactful business transformation. Sajjan collaborates closely with Rocket Companies to advance its mission of building an AI-fueled homeownership platform to Help Everyone Home. Outside of work, he enjoys traveling, spending time with his family, and is a proud father to his daughter.
Venkata Santosh Sajjan Alla is a Senior Solutions Architect at AWS Financial Services. He partners with North American FinTech companies like Rocket and other financial services organizations to drive cloud and AI strategy, accelerating AI adoption at scale. With deep expertise in AI & ML, Generative AI, and cloud-native architecture, he helps financial institutions unlock new revenue streams, optimize operations, and drive impactful business transformation. Sajjan collaborates closely with Rocket Companies to advance its mission of building an AI-fueled homeownership platform to Help Everyone Home. Outside of work, he enjoys traveling, spending time with his family, and is a proud father to his daughter. Alak Eswaradass is a Principal Solutions Architect at AWS based in Chicago, IL. She is passionate about helping customers design cloud architectures using AWS services to solve business challenges and is enthusiastic about solving a variety of ML use cases for AWS customers. When she’s not working, Alak enjoys spending time with her daughters and exploring the outdoors with her dogs.
Alak Eswaradass is a Principal Solutions Architect at AWS based in Chicago, IL. She is passionate about helping customers design cloud architectures using AWS services to solve business challenges and is enthusiastic about solving a variety of ML use cases for AWS customers. When she’s not working, Alak enjoys spending time with her daughters and exploring the outdoors with her dogs.