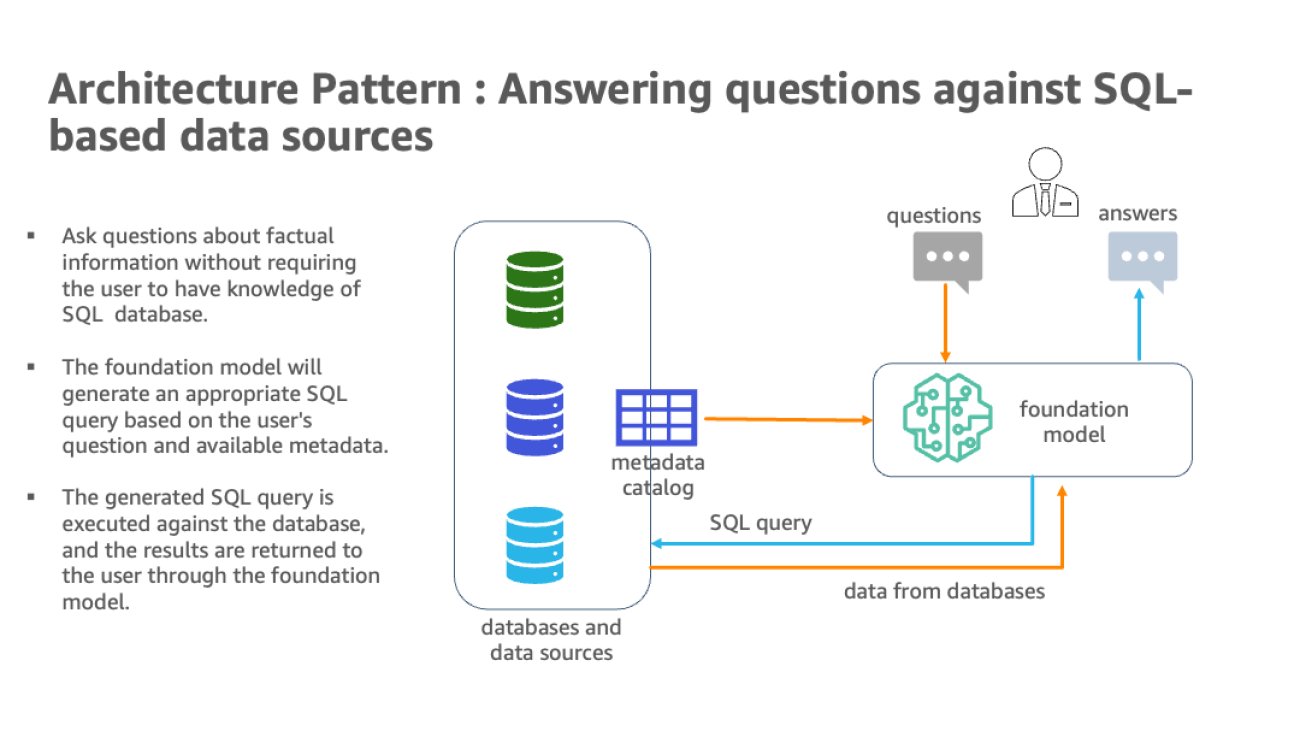
Implementing a modern data architecture provides a scalable method to integrate data from disparate sources. By organizing data by business domains instead of infrastructure, each domain can choose tools that suit their needs. Organizations can maximize the value of their modern data architecture with generative AI solutions while innovating continuously.
The natural language capabilities allow non-technical users to query data through conversational English rather than complex SQL. However, realizing the full benefits requires overcoming some challenges. The AI and language models must identify the appropriate data sources, generate effective SQL queries, and produce coherent responses with embedded results at scale. They also need a user interface for natural language questions.
Overall, implementing a modern data architecture and generative AI techniques with AWS is a promising approach for gleaning and disseminating key insights from diverse, expansive data at an enterprise scale. The latest offering for generative AI from AWS is Amazon Bedrock, which is a fully managed service and the easiest way to build and scale generative AI applications with foundation models. AWS also offers foundation models through Amazon SageMaker JumpStart as Amazon SageMaker endpoints. The combination of large language models (LLMs), including the ease of integration that Amazon Bedrock offers, and a scalable, domain-oriented data infrastructure positions this as an intelligent method of tapping into the abundant information held in various analytics databases and data lakes.
In the post, we showcase a scenario where a company has deployed a modern data architecture with data residing on multiple databases and APIs such as legal data on Amazon Simple Storage Service (Amazon S3), human resources on Amazon Relational Database Service (Amazon RDS), sales and marketing on Amazon Redshift, financial market data on a third-party data warehouse solution on Snowflake, and product data as an API. This implementation aims to enhance the productivity of the enterprise’s business analytics, product owners, and business domain experts. All this achieved through the use of generative AI in this domain mesh architecture, which enables the company to achieve its business objectives more efficiently. This solution has the option to include LLMs from JumpStart as a SageMaker endpoint as well as third-party models. We provide the enterprise users with a medium of asking fact-based questions without having an underlying knowledge of data channels, thereby abstracting the complexities of writing simple to complex SQL queries.
Solution overview
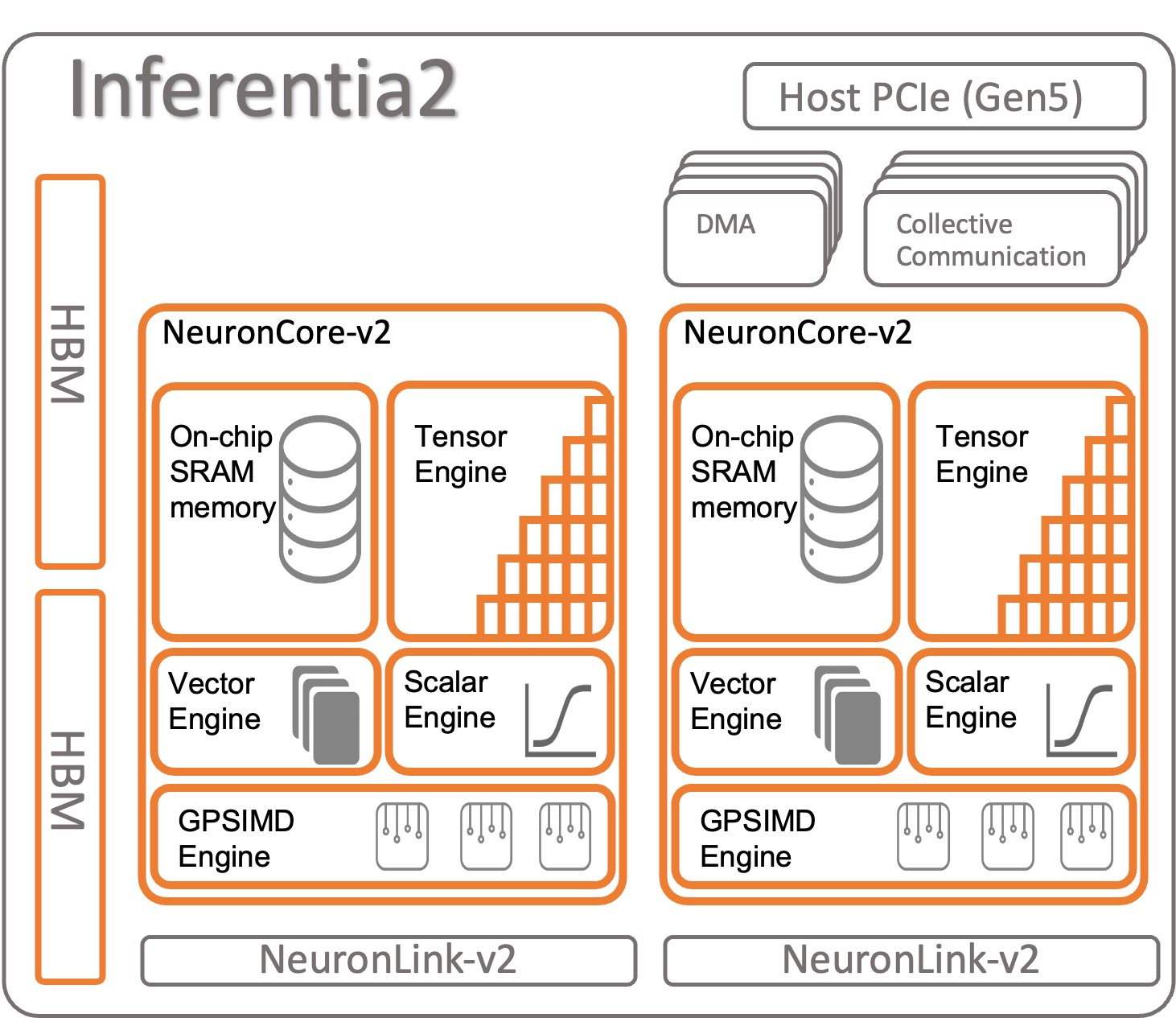
A modern data architecture on AWS applies artificial intelligence and natural language processing to query multiple analytics databases. By using services such as Amazon Redshift, Amazon RDS, Snowflake, Amazon Athena, and AWS Glue, it creates a scalable solution to integrate data from various sources. Using LangChain, a powerful library for working with LLMs, including foundation models from Amazon Bedrock and JumpStart in Amazon SageMaker Studio notebooks, a system is built where users can ask business questions in natural English and receive answers with data drawn from the relevant databases.
The following diagram illustrates the architecture.
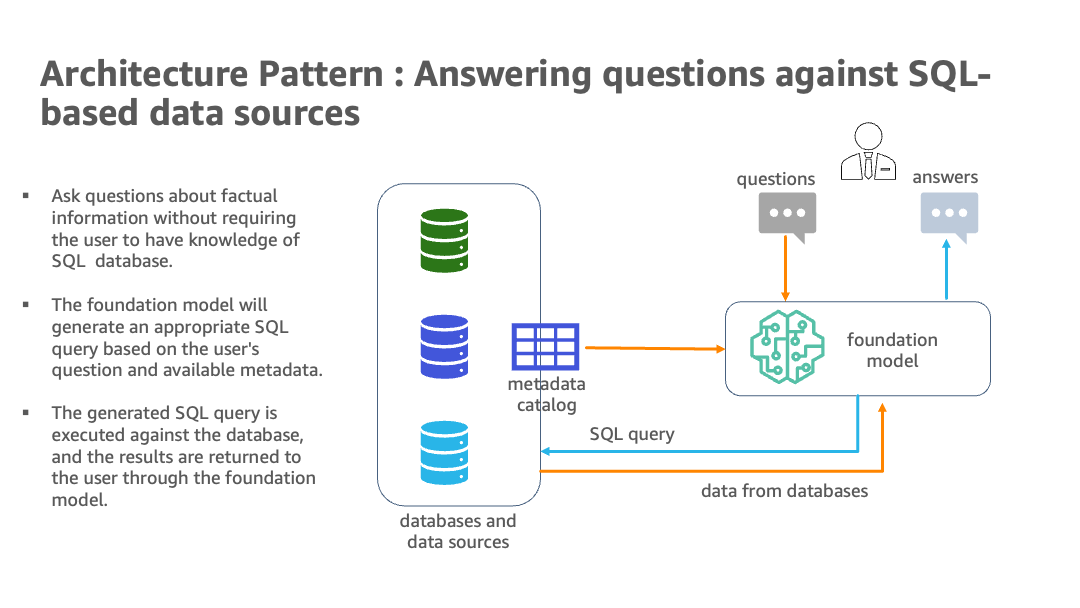
The hybrid architecture uses multiple databases and LLMs, with foundation models from Amazon Bedrock and JumpStart for data source identification, SQL generation, and text generation with results.
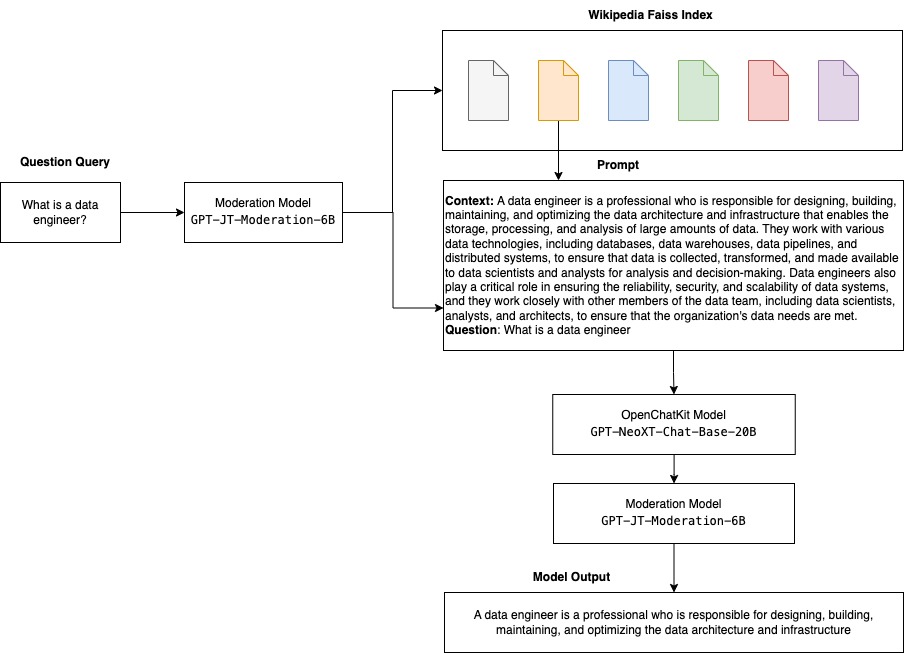
The following diagram illustrates the specific workflow steps for our solution.
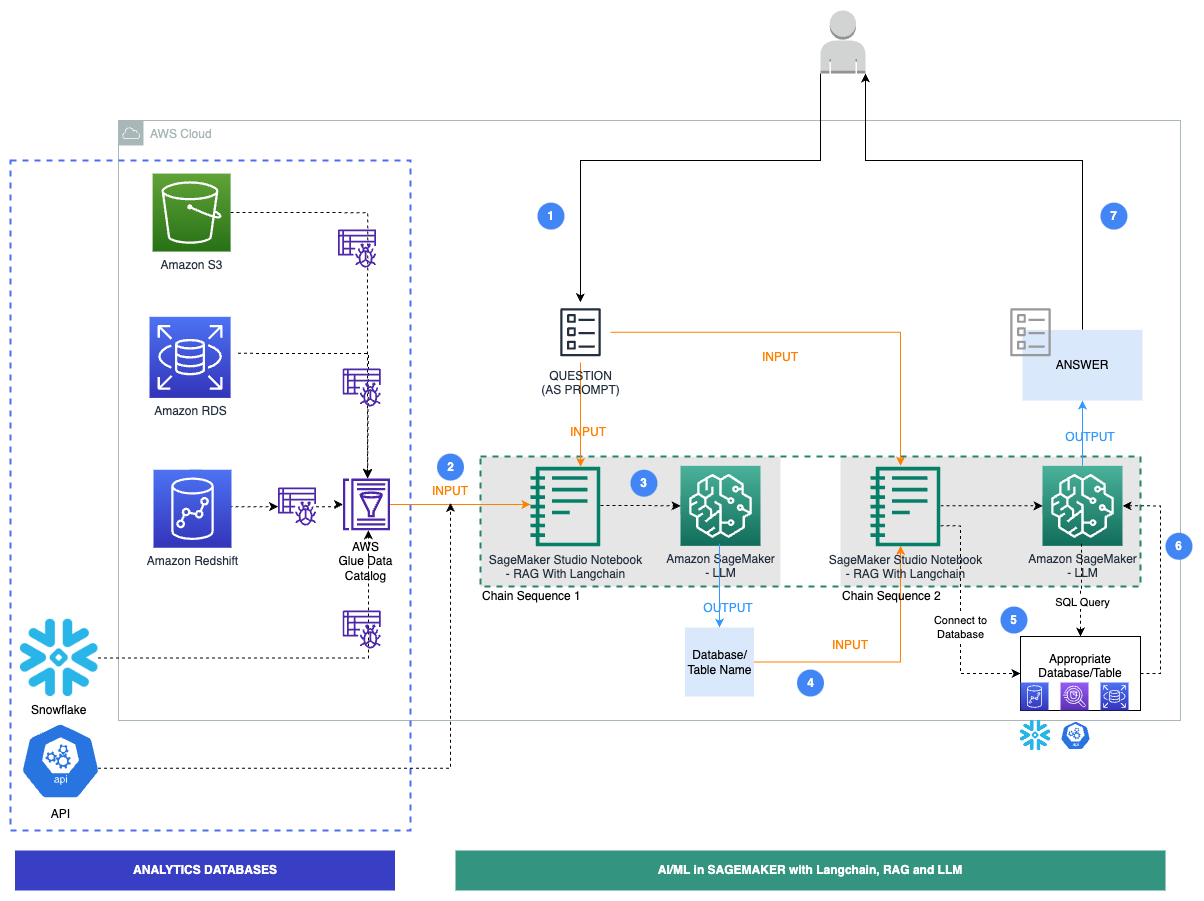
The steps are follows:
- A business user provides an English question prompt.
- An AWS Glue crawler is scheduled to run at frequent intervals to extract metadata from databases and create table definitions in the AWS Glue Data Catalog. The Data Catalog is input to Chain Sequence 1 (see the preceding diagram).
- LangChain, a tool to work with LLMs and prompts, is used in Studio notebooks. LangChain requires an LLM to be defined. As part of Chain Sequence 1, the prompt and Data Catalog metadata are passed to an LLM, hosted on a SageMaker endpoint, to identify the relevant database and table using LangChain.
- The prompt and identified database and table are passed to Chain Sequence 2.
- LangChain establishes a connection to the database and runs the SQL query to get the results.
- The results are passed to the LLM to generate an English answer with the data.
- The user receives an English answer to their prompt, querying data from different databases.
This following sections explain some of the key steps with associated code. To dive deeper into the solution and code for all steps shown here, refer to the GitHub repo. The following diagram shows the sequence of steps followed:

Prerequisites
You can use any databases that are compatible with SQLAlchemy to generate responses from LLMs and LangChain. However, these databases must have their metadata registered with the AWS Glue Data Catalog. Additionally, you will need to have access to LLMs through either JumpStart or API keys.
Connect to databases using SQLAlchemy
LangChain uses SQLAlchemy to connect to SQL databases. We initialize LangChain’s SQLDatabase function by creating an engine and establishing a connection for each data source. The following is a sample of how to connect to an Amazon Aurora MySQL-Compatible Edition serverless database and include only the employees table:
Next, we build prompts used by Chain Sequence 1 to identify the database and the table name based on the user question.
Generate dynamic prompt templates
We use the AWS Glue Data Catalog, which is designed to store and manage metadata information, to identify the source of data for a user query and build prompts for Chain Sequence 1, as detailed in the following steps:
- We build a Data Catalog by crawling through the metadata of multiple data sources using the JDBC connection used in the demonstration.
- With the Boto3 library, we build a consolidated view of the Data Catalog from multiple data sources. The following is a sample on how to get the metadata of the employees table from the Data Catalog for the Aurora MySQL database:
A consolidated Data Catalog has details on the data source, such as schema, table names, and column names. The following is a sample of the output of the consolidated Data Catalog:
- We pass the consolidated Data Catalog to the prompt template and define the prompts used by LangChain:
Chain Sequence 1: Detect source metadata for the user query using LangChain and an LLM
We pass the prompt template generated in the previous step to the prompt, along with the user query to the LangChain model, to find the best data source to answer the question. LangChain uses the LLM model of our choice to detect source metadata.
Use the following code to use an LLM from JumpStart or third-party models:
The generated text contains information such as the database and table names against which the user query is run. For example, for the user query “Name all employees with birth date this month,” generated_text has the information database == rdsmysql and database.table == rdsmysql.employees.
Next, we pass the details of the human resources domain, Aurora MySQL database, and employees table to Chain Sequence 2.
Chain Sequence 2: Retrieve responses from the data sources to answer the user query
Next, we run LangChain’s SQL database chain to convert text to SQL and implicitly run the generated SQL against the database to retrieve the database results in a simple readable language.
We start with defining a prompt template that instructs the LLM to generate SQL in a syntactically correct dialect and then run it against the database:
Finally, we pass the LLM, database connection, and prompt to the SQL database chain and run the SQL query:
For example, for the user query “Name all employees with birth date this month,” the answer is as follows:
Clean up
After you run the modern data architecture with generative AI, make sure to clean up any resources that won’t be utilized. Shut down and delete the databases used (Amazon Redshift, Amazon RDS, Snowflake). In addition, delete the data in Amazon S3 and stop any Studio notebook instances to not incur any further charges. If you used JumpStart to deploy an LLM as a SageMaker real-time endpoint, delete endpoint through either the SageMaker console or Studio.
Conclusion
In this post, we integrated a modern data architecture with generative AI and LLMs within SageMaker. This solution uses various text-to-text foundation models from JumpStart as well as third-party models. This hybrid approach identifies data sources, writes SQL queries, and generates responses with query results. It uses Amazon Redshift, Amazon RDS, Snowflake, and LLMs. To improve the solution, you could add more databases, a UI for English queries, prompt engineering, and data tools. This could become an intelligent, unified way to get insights from multiple data stores. To dive deeper into the solution and the code shown in this post, check out the GitHub repo . Also, refer to Amazon Bedrock for use cases on generative AI, foundation models, and large language models.
Appendix
Example prompts
| Domain | Database/API | Prompt | SQL (Generated by LLM) | Output |
| Sales & Marketing | Amazon RedShift | How many ticket sales are there? | SELECT COUNT(*) AS total_salesFROM tickit.sales; |
There are 172,456 ticket sales. |
| Sales & Marketing | Amazon RedShift | What was the total commission for the ticket sales in the year 2008? | SELECT SUM(commission) AS total_commissionFROM tickit.salesWHERE EXTRACT(YEAR FROM saletime) = 2008 |
The total commission for ticket sales in the year 2008 was $16,614,814.65. |
| Legal | S3 | How many frauds happened in the year 2023? | SELECT count(*)FROM claimsWHERE extract(year from write_time) = 2023 AND fraud = 1; |
There were 164 fraud claims in 2023. |
| Legal | S3 | How many policies were claimed this year? | SELECT count(*)FROM claims; |
There were 5000 claims made this year. |
| Human Resources | Amazon Aurora MySQL | Name all employees with birth date this month | SELECT * FROM employeesWHERE MONTH(birth_date) = MONTH(CURRENT_DATE()); |
The employees with birthdays this month are:Christian KoblickTzvetan ZielinskiKazuhito CappellettiYinghua Dredge |
| Human Resources | Amazon Aurora MySQL | How many employees were hired before 1990? | SELECT COUNT(*) AS 'Number of employees hired before 1990'FROM employeesWHERE hire_date < '1990-01-01' |
29 employees were hired before 1990. |
| Finance and Investments | Snowflake | Which stock performed the best and the worst in May of 2013? | SELECT name, MAX(close) AS max_close, MIN(close) AS min_closeFROM all_stocks_5yrWHERE date BETWEEN '2013-05-01' AND '2013-05-31'GROUP BY nameORDER BY max_close DESC, min_close ASC |
The stock that performed the best in May 2013 was AnySock1 (ASTOCK1) with a maximum closing price of $842.50. The stock that performed the worst was AnySock2 (ASTOCK2) with a minimum closing price of $3.22. |
| Finance and Investments | Snowflake | What is the average volume stocks traded in July of 2013? | SELECT AVG(volume) AS average_volumeFROM all_stocks_5yrWHERE date BETWEEN '2013-07-01' AND '2013-07-31' |
The average volume of stocks traded in July 2013 was 4,374,177 |
| Product – Weather | API | What is the weather like right now in New York City in degrees Fahrenheit? |
About the Authors
 Navneet Tuteja is a Data Specialist at Amazon Web Services. Before joining AWS, Navneet worked as a facilitator for organizations seeking to modernize their data architectures and implement comprehensive AI/ML solutions. She holds an engineering degree from Thapar University, as well as a master’s degree in statistics from Texas A&M University.
Navneet Tuteja is a Data Specialist at Amazon Web Services. Before joining AWS, Navneet worked as a facilitator for organizations seeking to modernize their data architectures and implement comprehensive AI/ML solutions. She holds an engineering degree from Thapar University, as well as a master’s degree in statistics from Texas A&M University.
 Sovik Kumar Nath is an AI/ML solution architect with AWS. He has extensive experience designing end-to-end machine learning and business analytics solutions in finance, operations, marketing, healthcare, supply chain management, and IoT. Sovik has published articles and holds a patent in ML model monitoring. He has double masters degrees from the University of South Florida, University of Fribourg, Switzerland, and a bachelors degree from the Indian Institute of Technology, Kharagpur. Outside of work, Sovik enjoys traveling, taking ferry rides, and watching movies.
Sovik Kumar Nath is an AI/ML solution architect with AWS. He has extensive experience designing end-to-end machine learning and business analytics solutions in finance, operations, marketing, healthcare, supply chain management, and IoT. Sovik has published articles and holds a patent in ML model monitoring. He has double masters degrees from the University of South Florida, University of Fribourg, Switzerland, and a bachelors degree from the Indian Institute of Technology, Kharagpur. Outside of work, Sovik enjoys traveling, taking ferry rides, and watching movies.





 James Park is a Solutions Architect at Amazon Web Services. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In h is spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends.You can find him on
James Park is a Solutions Architect at Amazon Web Services. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In h is spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends.You can find him on  Abhi Shivaditya is a Senior Solutions Architect at AWS, working with strategic global enterprise organizations to facilitate the adoption of AWS services in areas such as Artificial Intelligence, distributed computing, networking, and storage. His expertise lies in Deep Learning in the domains of Natural Language Processing (NLP) and Computer Vision. Abhi assists customers in deploying high-performance machine learning models efficiently within the AWS ecosystem.
Abhi Shivaditya is a Senior Solutions Architect at AWS, working with strategic global enterprise organizations to facilitate the adoption of AWS services in areas such as Artificial Intelligence, distributed computing, networking, and storage. His expertise lies in Deep Learning in the domains of Natural Language Processing (NLP) and Computer Vision. Abhi assists customers in deploying high-performance machine learning models efficiently within the AWS ecosystem.
 Evandro Franco is an AI/ML Specialist Solutions Architect working on Amazon Web Services. He helps AWS customers overcome business challenges related to AI/ML on top of AWS. He has more than 15 years working with technology, from software development, infrastructure, serverless, to machine learning.
Evandro Franco is an AI/ML Specialist Solutions Architect working on Amazon Web Services. He helps AWS customers overcome business challenges related to AI/ML on top of AWS. He has more than 15 years working with technology, from software development, infrastructure, serverless, to machine learning.
 Frank Liu is a Software Engineer for AWS Deep Learning. He focuses on building innovative deep learning tools for software engineers and scientists. In his spare time, he enjoys hiking with friends and family.
Frank Liu is a Software Engineer for AWS Deep Learning. He focuses on building innovative deep learning tools for software engineers and scientists. In his spare time, he enjoys hiking with friends and family.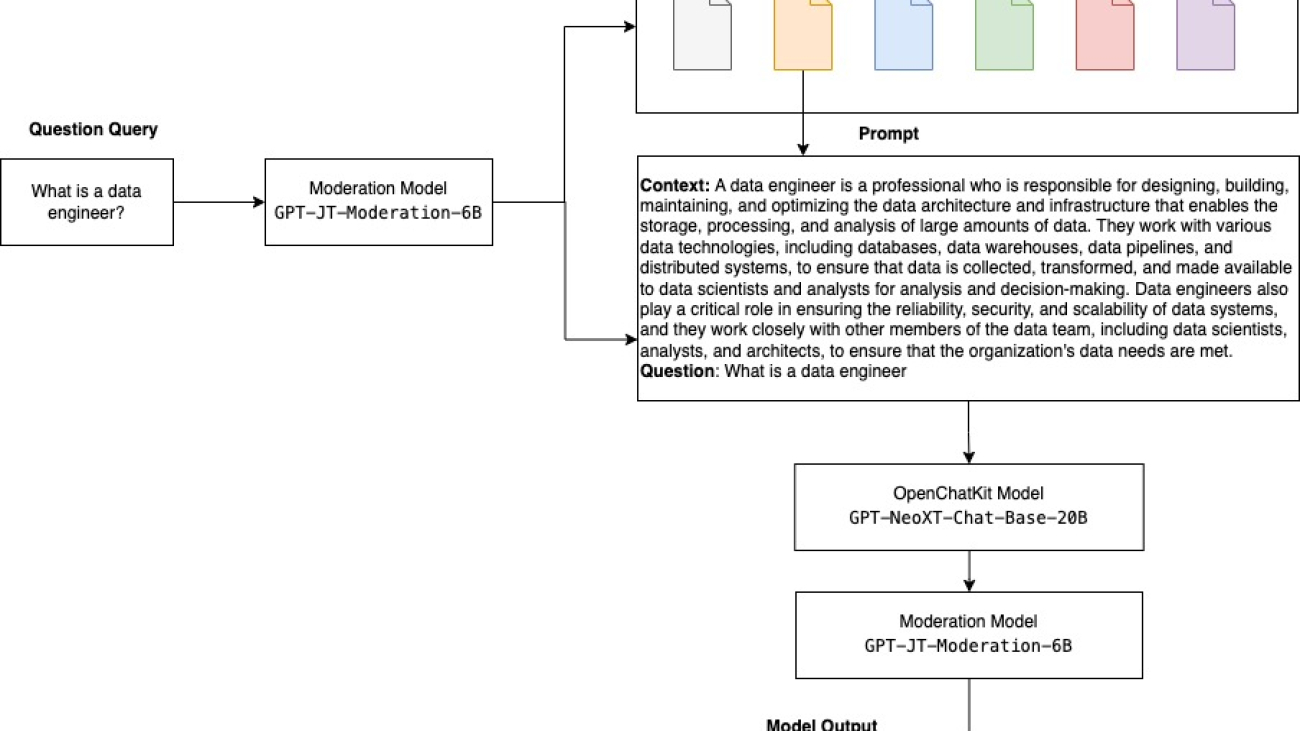
 Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker. Vikram Elango is a Sr. AIML Specialist Solutions Architect at AWS, based in Virginia, US. He is currently focused on generative AI, LLMs, prompt engineering, large model inference optimization, and scaling ML across enterprises. Vikram helps financial and insurance industry customers with design and thought leadership to build and deploy machine learning applications at scale. In his spare time, he enjoys traveling, hiking, cooking, and camping with his family.
Vikram Elango is a Sr. AIML Specialist Solutions Architect at AWS, based in Virginia, US. He is currently focused on generative AI, LLMs, prompt engineering, large model inference optimization, and scaling ML across enterprises. Vikram helps financial and insurance industry customers with design and thought leadership to build and deploy machine learning applications at scale. In his spare time, he enjoys traveling, hiking, cooking, and camping with his family. Andrew Smith is a Cloud Support Engineer in the SageMaker, Vision & Other team at AWS, based in Sydney, Australia. He supports customers using many AI/ML services on AWS with expertise in working with Amazon SageMaker. Outside of work, he enjoys spending time with friends and family as well as learning about different technologies.
Andrew Smith is a Cloud Support Engineer in the SageMaker, Vision & Other team at AWS, based in Sydney, Australia. He supports customers using many AI/ML services on AWS with expertise in working with Amazon SageMaker. Outside of work, he enjoys spending time with friends and family as well as learning about different technologies.












 Rupinder Grewal is a Sr Ai/ML Specialist Solutions Architect with AWS. He currently focuses on serving of models and MLOps on SageMaker. Prior to this role he has worked as Machine Learning Engineer building and hosting models. Outside of work he enjoys playing tennis and biking on mountain trails.
Rupinder Grewal is a Sr Ai/ML Specialist Solutions Architect with AWS. He currently focuses on serving of models and MLOps on SageMaker. Prior to this role he has worked as Machine Learning Engineer building and hosting models. Outside of work he enjoys playing tennis and biking on mountain trails.


 Da Zheng is a senior applied scientist at AWS AI/ML research leading a graph machine learning team to develop techniques and frameworks to put graph machine learning in production. Da got his PhD in computer science from the Johns Hopkins University.
Da Zheng is a senior applied scientist at AWS AI/ML research leading a graph machine learning team to develop techniques and frameworks to put graph machine learning in production. Da got his PhD in computer science from the Johns Hopkins University. Florian Saupe is a Principal Technical Product Manager at AWS AI/ML research supporting advanced science teams like the graph machine learning group and improving products like Amazon DataZone with ML capabilities. Before joining AWS, Florian lead technical product management for automated driving at Bosch, was a strategy consultant at McKinsey & Company, and worked as a control systems/robotics scientist – a field in which he holds a phd.
Florian Saupe is a Principal Technical Product Manager at AWS AI/ML research supporting advanced science teams like the graph machine learning group and improving products like Amazon DataZone with ML capabilities. Before joining AWS, Florian lead technical product management for automated driving at Bosch, was a strategy consultant at McKinsey & Company, and worked as a control systems/robotics scientist – a field in which he holds a phd.