In 2021, we launched AWS Support Proactive Services as part of the AWS Enterprise Support offering. Since its introduction, we have helped hundreds of customers optimize their workloads, set guardrails, and improve the visibility of their machine learning (ML) workloads’ cost and usage.
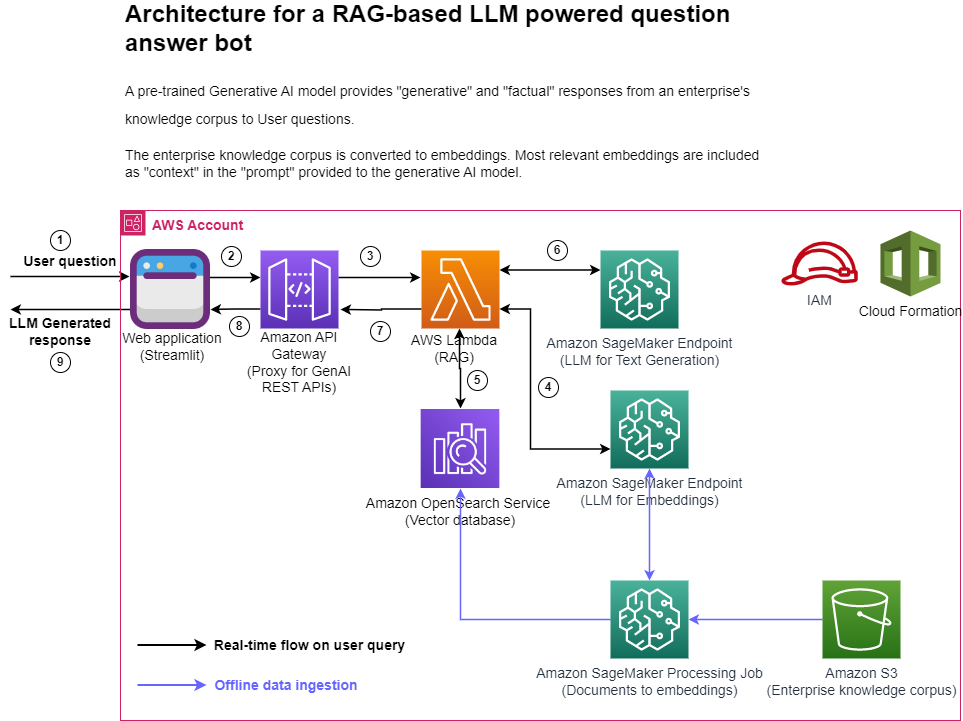
In this series of posts, we share lessons learned about optimizing costs in Amazon SageMaker. In Part 1, we showed how to get started using AWS Cost Explorer to identify cost optimization opportunities in SageMaker. In this post, we focus on various ways to analyze SageMaker usage and identify cost optimization opportunities for SageMaker notebook instances and Amazon SageMaker Studio.
| Analyze Amazon SageMaker spend and determine cost optimization opportunities based on usage:
|
SageMaker notebook instances
A SageMaker notebook instance is a fully managed compute instance running the Jupyter Notebook app. SageMaker manages creating the instance and related resources. Notebooks contain everything needed to run or recreate an ML workflow. You can use Jupyter notebooks in your notebook instance to prepare and process data, write code to train models, deploy models to SageMaker Hosting, and test or validate your models. SageMaker notebook instances’ cost is based on the instance-hours consumed while the notebook instance is running, as well as the cost of GB-month of provisioned storage, as outlined in Amazon SageMaker Pricing.
In Cost Explorer, you can filter notebook costs by applying a filter on Usage type. The names of these usage types are structured as follows:
REGION-Notebk:instanceType (for example, USE1-Notebk:ml.g4dn.8xlarge)REGION-Notebk:VolumeUsage.gp2 (for example, USE2-Notebk:VolumeUsage.gp2)
Filtering by the usage type Notebk: will show you a list of notebook usage types in an account. As shown in the following screenshot, you can select Select All and choose Apply to display the cost breakdown of your notebook usage.

To see the cost breakdown of the selected notebook usage type by the number of usage hours, you need to de-select all the REGION-Notebk:VolumeUsage.gp2 usage types from the preceding list and choose Apply to apply the filter. The following screenshot shows the cost and usage graphs for the selected notebook usage types.

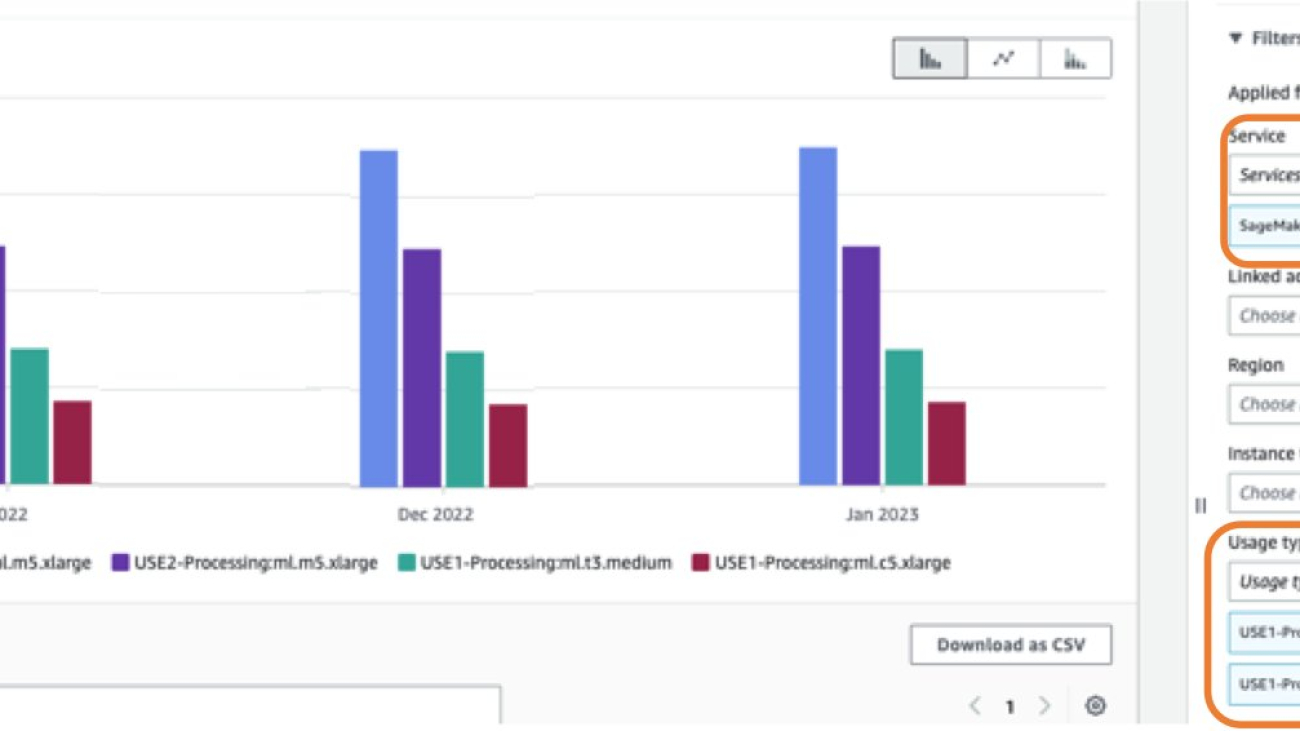
You can also apply additional filters such as account number, Amazon Elastic Compute Cloud (Amazon EC2) instance type, cost allocation tag, Region, and more. Changing the granularity to Daily gives you daily cost and usage charts based on the selected usage types and dimension, as shown in the following screenshot.

In the preceding example, the notebook instance of type ml.t2.medium in the USE2 Region is reporting a daily usage of 24 hours between the period of July 2 and September 26. Similarly, the notebook instance of type ml.t3.medium in the USE1 Region is reporting a daily usage of 24 hours between August 3 and September 26, and a daily usage of 48 hours between September 26 and December 31. Daily usage of 24 hours or more for multiple consecutive days could indicate that a notebook instance has been left running for multiple days but is not in active use. This type of pattern could benefit from applying cost control guardrails such as manual or auto-shutdown of notebook instances to prevent idle runtime.
Although Cost Explorer helps you understand cost and usage data at the granularity of the instance type, you can use AWS Cost and Usage Reports (AWS CUR) to get data at the granularity of a resource such as notebook ARN. You can build custom queries to look up AWS CUR data using standard SQL. You can also include cost-allocation tags in your query for an additional level of granularity. The following query returns notebook resource usage for the last 3 months from your AWS CUR data:
SELECT
bill_payer_account_id,
line_item_usage_account_id,
line_item_resource_id AS notebook_arn,
line_item_usage_type,
DATE_FORMAT((line_item_usage_start_date),'%Y-%m-%d') AS day_line_item_usage_start_date,
SUM(CAST(line_item_usage_amount AS DOUBLE)) AS sum_line_item_usage_amount,
line_item_unblended_rate,
SUM(CAST(line_item_unblended_cost AS DECIMAL(16,8))) AS sum_line_item_unblended_cost,
line_item_blended_rate,
SUM(CAST(line_item_blended_cost AS DECIMAL(16,8))) AS sum_line_item_blended_cost,
line_item_line_item_description,
line_item_line_item_type
FROM
{$table_name}
WHERE
line_item_usage_start_date >= date_trunc('month',current_date - interval '3' month)
AND line_item_product_code = 'AmazonSageMaker'
AND line_item_line_item_type IN ('DiscountedUsage', 'Usage', 'SavingsPlanCoveredUsage')
AND line_item_usage_type like '%Notebk%'
AND line_item_operation = 'RunInstance'
AND bill_payer_account_id = 'xxxxxxxxxxxx'
GROUP BY
bill_payer_account_id,
line_item_usage_account_id,
line_item_resource_id,
line_item_usage_type,
line_item_unblended_rate,
line_item_blended_rate,
line_item_line_item_type,
DATE_FORMAT((line_item_usage_start_date),'%Y-%m-%d'),
line_item_line_item_description
ORDER BY
line_item_resource_id, day_line_item_usage_start_date
The following screenshot shows the results obtained from running the AWS CUR query using Amazon Athena. For more information about using Athena, refer to Querying Cost and Usage Reports using Amazon Athena.

The result of the query shows that notebook dev-notebook running on an ml.t2.medium instance is reporting 24 hours of usage for multiple consecutive days. The instance rate is $0.0464/hour and the daily cost for running for 24 hours is $1.1136.
AWS CUR query results can help you identify patterns of notebooks running for consecutive days, which can be analyzed for cost optimization. More information and example queries can be found in the AWS CUR Query Library.
You can also feed AWS CUR data into Amazon QuickSight, where you can slice and dice it any way you’d like for reporting or visualization purposes. For instructions on ingesting AWS CUR data into QuickSight, see How do I ingest and visualize the AWS Cost and Usage Report (CUR) into Amazon QuickSight.
Optimize notebook instance cost
SageMaker notebooks are suitable for ML model development, which includes interactive data exploration, script writing, prototyping of feature engineering, and modeling. Each of these tasks may have varying computing resource requirements. Estimating the right type of computing resources to serve various workloads is challenging, and may lead to over-provisioning of resources, resulting in increased cost.
For ML model development, the size of a SageMaker notebook instance depends on the amount of data you need to load in-memory for meaningful exploratory data analyses (EDA) and the amount of computation required. We recommend starting small with general-purpose instances (such as T or M families) and scaling up as needed. For example, ml.t2.medium is sufficient for most basic data processing, feature engineering, and EDA that deals with small datasets that can be held within 4 GB memory. If your model development involves heavy computational work (such as image processing), you can stop your smaller notebook instance and change the instance type to the desired larger instance, such as ml.c5.xlarge. You can switch back to the smaller instance when you no longer need a larger instance. This will help keep the compute costs down.
Consider the following best practices to help reduce the cost of your notebook instances.
CPU vs. GPU
Considering CPU vs. GPU notebook instances is important for instance right-sizing. CPUs are best at handling single, more complex calculations sequentially, whereas GPUs are better at handling multiple but simple calculations in parallel. For many use cases, a standard current generation instance type from an instance family such as M provides enough computing power, memory, and network performance for notebooks to perform well.
GPUs provide a great price/performance ratio if you take advantage of them effectively. For example, if you are training your deep learning model on a SageMaker notebook and your neural network is relatively big, performing a large number of calculations involving hundreds of thousands of parameters, then your model can take advantage of the accelerated compute and hardware parallelism offered by GPU instances such as P instance families. However, it’s recommended to use GPU instances only when you really need them because they’re expensive and GPU communication overhead might even degrade performance if your notebook doesn’t need them. We recommend using notebooks with instances that are smaller in compute for interactive building and leaving the heavy lifting to ephemeral training, tuning, and processing jobs with larger instances, including GPU-enabled instances. This way, you don’t keep a large instance (or a GPU) constantly running with your notebook. If you need accelerated computing in your notebook environment, you can stop your m* family notebook instance, switch to a GPU-enabled P* family instance, and start it again. Don’t forget to switch it back when you no longer need that extra boost in your development environment.
Restrict user access to specific instance types
Administrators can restrict users from creating notebooks that are too large through AWS Identity and Access Management (IAM) policies. For example, the following sample policy only allows users to create smaller t3 SageMaker notebook instances:
{
"Action": [
"sagemaker:CreateNotebookInstances"
],
"Resource": [
"*"
],
"Effect": "Deny",
"Sid": "BlockLargeNotebookInstances",
"Condition": {
"ForAnyValue:StringNotLike": {
"sagemaker:InstanceTypes": [
"ml.t3.medium",
"ml.t3.large"
]
}
}
}
Administrators can also use AWS Service Catalog to allow for self-service of SageMaker notebooks. This allows you to restrict the instance types that are available to users when creating a notebook. For more information, see Enable self-service, secured data science using Amazon SageMaker notebooks and AWS Service Catalog and Launch Amazon SageMaker Studio using AWS Service Catalog and AWS SSO in AWS Control Tower Environment.
Stop idle notebook instances
To keep your costs down, we recommend stopping your notebook instances when you don’t need them and starting them when you do need them. Consider auto-detecting idle notebook instances and managing their lifecycle using a lifecycle configuration script. For example, auto-stop-idle is a sample shell script that stops a SageMaker notebook when it’s idle for more than 1 hour.
AWS maintains a public repository of notebook lifecycle configuration scripts that address common use cases for customizing notebook instances, including a sample bash script for stopping idle notebooks.
Schedule automatic start and stop of notebook instances
Another approach to save on notebooks cost is to automatically start and stop your notebooks at specific times. You can accomplish this by using Amazon EventBridge rules and AWS Lambda functions. For more information about configuring your Lambda functions, see Configuring Lambda function options. After you have created the functions, you can create rules to trigger these functions on a specific schedule, for example, start the notebooks every weekday at 7:00 AM. See Creating an Amazon EventBridge rule that runs on a schedule for instructions. For the scripts to start and stop notebooks with a Lambda function, refer to Ensure efficient compute resources on Amazon SageMaker.
SageMaker Studio
Studio provides a fully managed solution for data scientists to interactively build, train, and deploy ML models. Studio notebooks are one-click collaborative Jupyter notebooks that can be spun up quickly because you don’t need to set up compute instances and file storage beforehand. You are charged for the compute instance type you choose to run your notebooks on, based on the duration of use. There is no additional charge for using Studio. The costs incurred for running Studio notebooks, interactive shells, consoles, and terminals are based on ML compute instance usage.
When launched, the resource is run on an ML compute instance of the chosen instance type. If an instance of that type was previously launched and is available, the resource is run on that instance. For CPU-based images, the default suggested instance type is ml.t3.medium. For GPU-based images, the default suggested instance type is ml.g4dn.xlarge. Billing occurs per instance and starts when the first instance of a given instance type is launched.
If you want to create or open a notebook without the risk of incurring charges, open the notebook from the File menu and choose No Kernel from the Select Kernel dialog. You can read and edit a notebook without a running kernel, but you can’t run cells. You are billed separately for each instance. Billing ends when all the KernelGateway apps on the instance are shut down, or the instance is shut down. For information about billing along with pricing examples, see Amazon SageMaker Pricing.
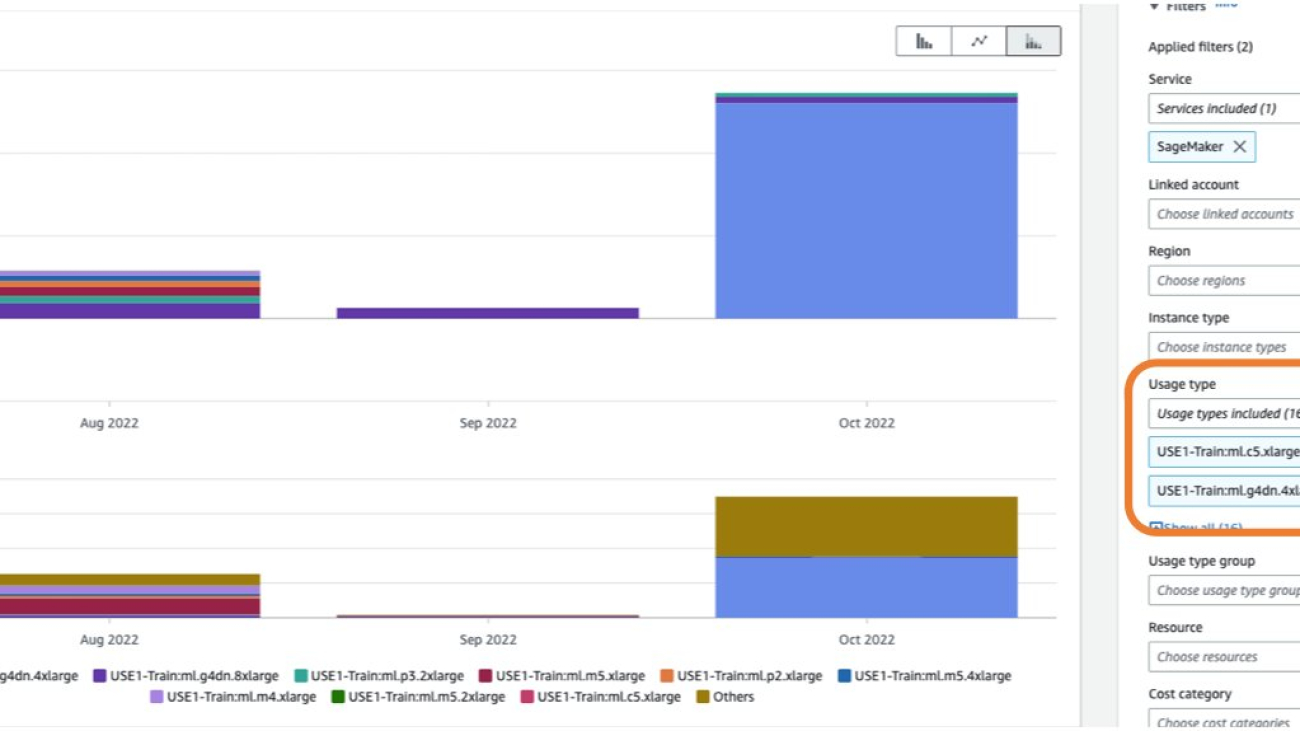
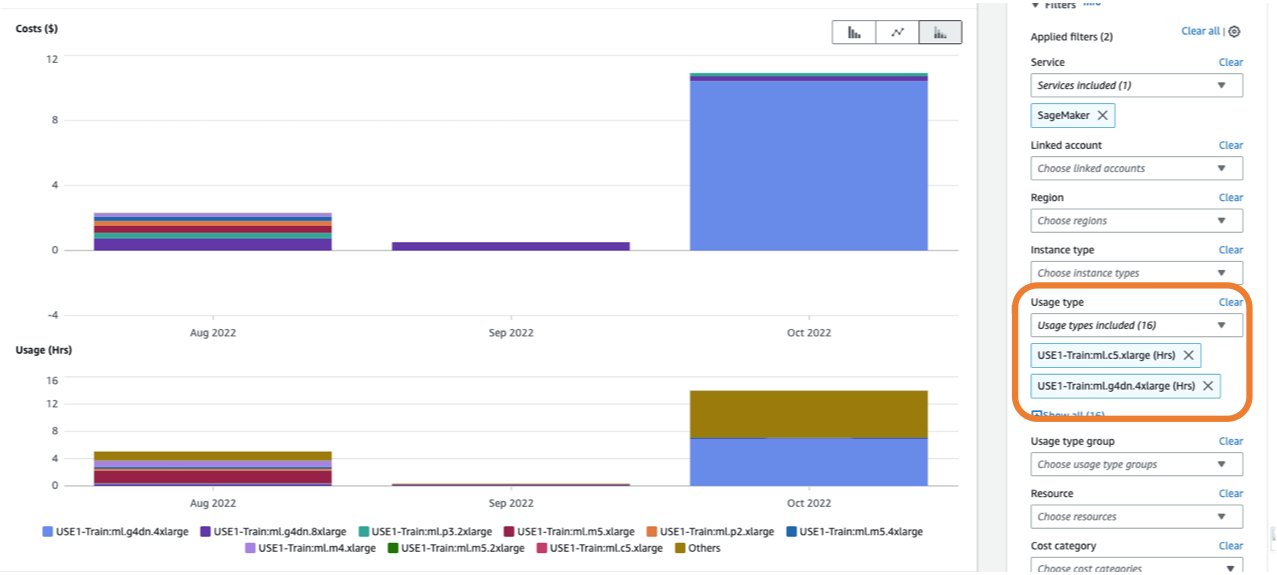
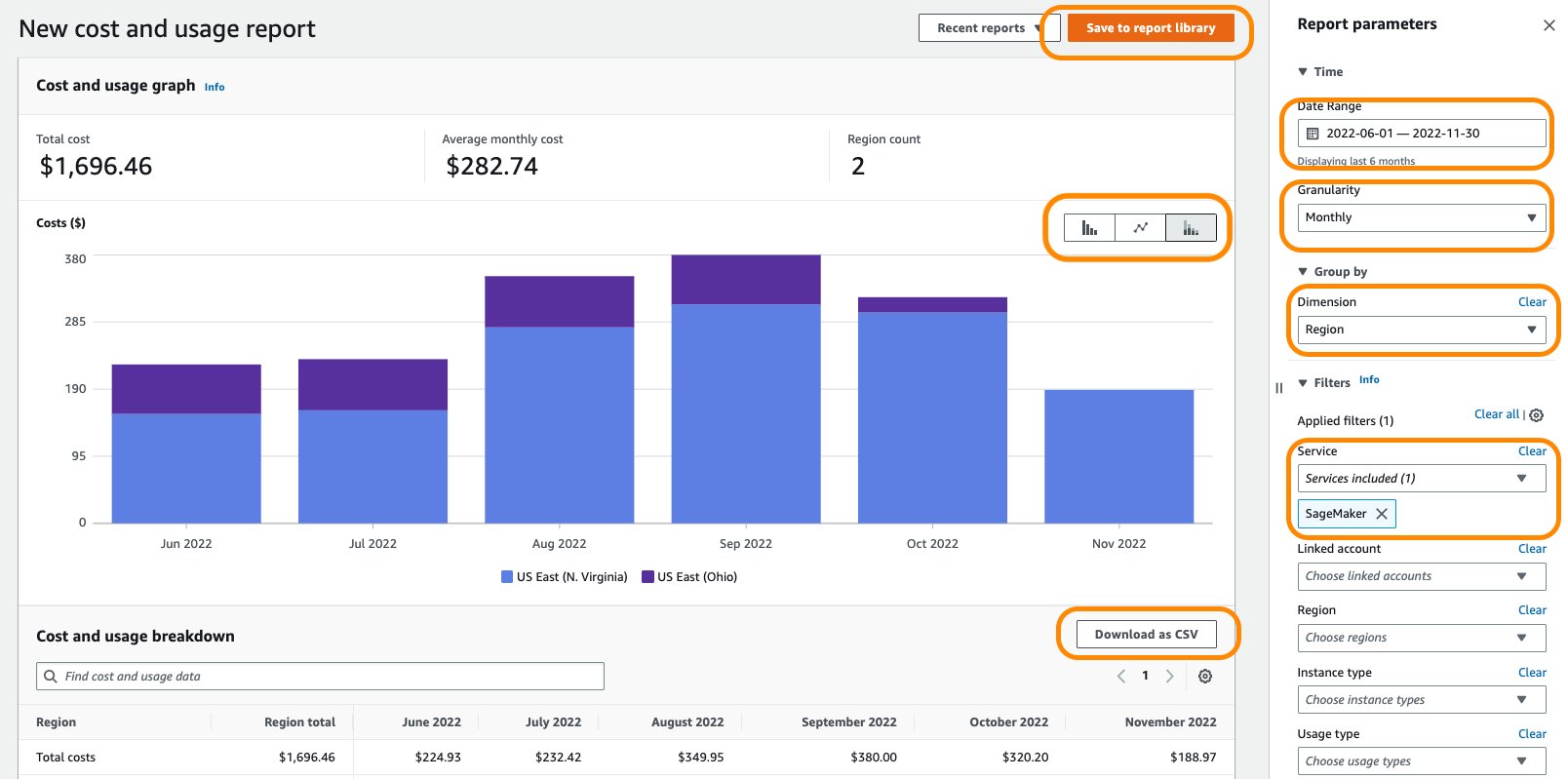
In Cost Explorer, you can filter Studio notebook costs by applying a filter on Usage type. The name of this usage types is structured as: REGION-studio:KernelGateway-instanceType (for example, USE1-Studio:KernelGateway-ml.m5.large)
Filtering by the usage type studio: in Cost Explorer will show you the list of Studio usage types in an account. You can select the necessary usage types, or select Select All and choose Apply to display the cost breakdown of Studio app usage. The following screenshot shows the selection all the studio usage types for cost analysis.

You can also apply additional filters such as Region, linked account, or instance type for more granular cost analysis. Changing the granularity to Daily gives you daily cost and usage charts based selected usage types and dimension, as shown in the following screenshot.

In the preceding example, the Studio KernelGateway instance of type ml.t3.medium in the USE1 Region is reporting a daily usage of 48 hours between the period of January 1 and January 24, followed by a daily usage of 24 hours until February 11. Similarly, Studio KernelGateway instance of type ml.m5.large in USE1 Region is reporting 24 hours of daily usage of between January 1 and January 23. A daily usage of 24 hours or more for multiple consecutive days indicates a possibility of Studio notebook instances running continuously for multiple days. This type of pattern could benefit from applying cost control guardrails such as manual or automatic shutdown of Studio apps when not in use.
As mentioned earlier, you can use AWS CUR to get data at the granularity of a resource and build custom queries to look up AWS CUR data using standard SQL. You can also include cost-allocation tags in your query for an additional level of granularity. The following query returns Studio KernelGateway resource usage for the last 3 months from your AWS CUR data:
SELECT
bill_payer_account_id,
line_item_usage_account_id,
line_item_resource_id AS studio_notebook_arn,
line_item_usage_type,
DATE_FORMAT((line_item_usage_start_date),'%Y-%m-%d') AS day_line_item_usage_start_date,
SUM(CAST(line_item_usage_amount AS DOUBLE)) AS sum_line_item_usage_amount,
line_item_unblended_rate,
SUM(CAST(line_item_unblended_cost AS DECIMAL(16,8))) AS sum_line_item_unblended_cost,
line_item_blended_rate,
SUM(CAST(line_item_blended_cost AS DECIMAL(16,8))) AS sum_line_item_blended_cost,
line_item_line_item_description,
line_item_line_item_type
FROM
customer_all
WHERE
line_item_usage_start_date >= date_trunc('month',current_date - interval '3' month)
AND line_item_product_code = 'AmazonSageMaker'
AND line_item_line_item_type IN ('DiscountedUsage', 'Usage', 'SavingsPlanCoveredUsage')
AND line_item_usage_type like '%Studio:KernelGateway%'
AND line_item_operation = 'RunInstance'
AND bill_payer_account_id = 'xxxxxxxxxxxx'
GROUP BY
bill_payer_account_id,
line_item_usage_account_id,
line_item_resource_id,
line_item_usage_type,
line_item_unblended_rate,
line_item_blended_rate,
line_item_line_item_type,
DATE_FORMAT((line_item_usage_start_date),'%Y-%m-%d'),
line_item_line_item_description
ORDER BY
line_item_resource_id, day_line_item_usage_start_date
The following screenshot shows the results obtained from running the AWS CUR query using Athena.

The result of the query shows that the Studio KernelGateway app named datascience-1-0-ml-t3-medium-1abf3407f667f989be9d86559395 running in account 111111111111, Studio domain d-domain1234, and user profile user1 on an ml.t3.medium instance is reporting 24 hours of usage for multiple consecutive days. The instance rate is $0.05/hour and the daily cost for running for 24 hours is $1.20.
AWS CUR query results can help you identify patterns of resources running for consecutive days at a granular level of hourly or daily usage, which can be analyzed for cost optimization. As with SageMaker notebooks, you can also feed AWS CUR data into QuickSight for reporting or visualization purposes.
SageMaker Data Wrangler
Amazon SageMaker Data Wrangler is a feature of Studio that helps you simplify the process of data preparation and feature engineering from a low-code visual interface. The usage type name for a Studio Data Wrangler app is structured as REGION-Studio_DW:KernelGateway-instanceType (for example, USE1-Studio_DW:KernelGateway-ml.m5.4xlarge).
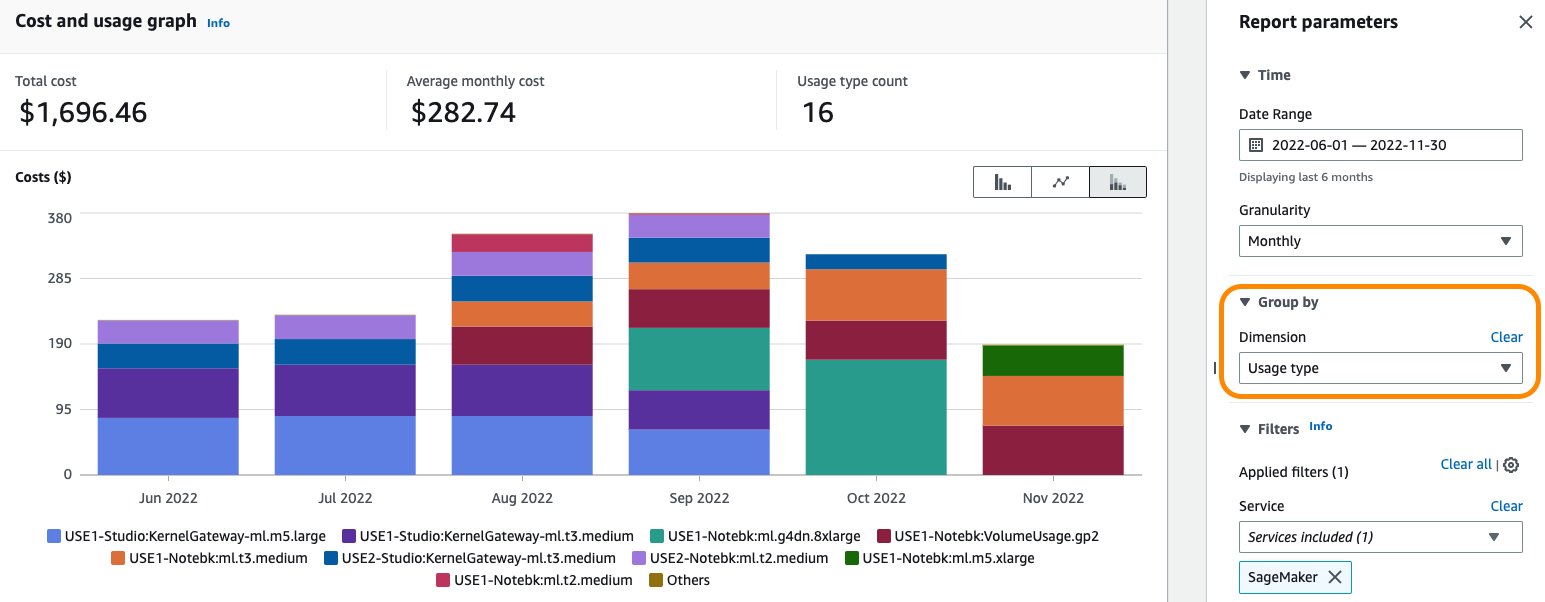
Filtering by the usage type studio_DW: in Cost Explorer will show you the list of Studio Data Wrangler usage types in an account. You can select the necessary usage types, or select Select All and choose Apply to display the cost breakdown of Studio Data Wrangler app usage. The following screenshot shows the selection all the studio_DW usage types for cost analysis.

As noted earlier, you can also apply additional filters for more granular cost analysis. For example, the following screenshot shows 24 hours of daily usage of the Studio Data Wrangler instance type ml.m5.4xlarge in the USE1 Region for multiple days and its associated cost. Insights like this can be used to apply cost control measures such as shutting down Studio apps when not in use.

You can obtain resource-level information from AWS CUR, and build custom queries to look up AWS CUR data using standard SQL. The following query returns Studio Data Wrangler app resource usage and associated cost for the last 3 months from your AWS CUR data:
SELECT
bill_payer_account_id,
line_item_usage_account_id,
line_item_resource_id AS studio_notebook_arn,
line_item_usage_type,
DATE_FORMAT((line_item_usage_start_date),'%Y-%m-%d') AS day_line_item_usage_start_date,
SUM(CAST(line_item_usage_amount AS DOUBLE)) AS sum_line_item_usage_amount,
line_item_unblended_rate,
SUM(CAST(line_item_unblended_cost AS DECIMAL(16,8))) AS sum_line_item_unblended_cost,
line_item_blended_rate,
SUM(CAST(line_item_blended_cost AS DECIMAL(16,8))) AS sum_line_item_blended_cost,
line_item_line_item_description,
line_item_line_item_type
FROM
{$table_name}
WHERE
line_item_usage_start_date >= date_trunc('month',current_date - interval '3' month)
AND line_item_product_code = 'AmazonSageMaker'
AND line_item_line_item_type IN ('DiscountedUsage', 'Usage', 'SavingsPlanCoveredUsage')
AND line_item_usage_type like '%Studio_DW:KernelGateway%'
AND line_item_operation = 'RunInstance'
AND bill_payer_account_id = 'xxxxxxxxxxxx'
GROUP BY
bill_payer_account_id,
line_item_usage_account_id,
line_item_resource_id,
line_item_usage_type,
line_item_unblended_rate,
line_item_blended_rate,
line_item_line_item_type,
DATE_FORMAT((line_item_usage_start_date),'%Y-%m-%d'),
line_item_line_item_description
ORDER BY
line_item_resource_id, day_line_item_usage_start_date
The following screenshot shows the results obtained from running the AWS CUR query using Athena.

The result of the query shows that the Studio Data Wrangler app named sagemaker-data-wrang-ml-m5-4xlarge-b741c1a025d542c78bb538373f2d running in account 111111111111, Studio domain d-domain1234, and user profile user1 on an ml.m5.4xlarge instance is reporting 24 hours of usage for multiple consecutive days. The instance rate is $0.922/hour and the daily cost for running for 24 hours is $22.128.
Optimize Studio cost
Studio notebooks are charged for the instance type you choose, based on the duration of use. You must shut down the instance to stop incurring charges. If you shut down the notebook running on the instance but don’t shut down the instance, you will still incur charges. When you shut down the Studio notebook instances, any additional resources, such as SageMaker endpoints, Amazon EMR clusters, and Amazon Simple Storage Service (Amazon S3) buckets created from Studio are not deleted. Delete those resources if they are no longer needed to stop accrual of charges. For more details about shutting down Studio resources, refer to Shut Down Resources. If you’re using Data Wrangler, it’s important to shut it down after your work is done to save cost. For details, refer to Shut Down Data Wrangler.
Consider the following best practices to help reduce the cost of your Studio notebooks.
Automatically stop idle Studio notebook instances
You can automatically stop idle Studio notebook resources with lifecycle configurations in Studio. You can also install and use a JupyterLab extension available on GitHub as a Studio lifecycle configuration. For detailed instructions on the Studio architecture and adding the extension, see Save costs by automatically shutting down idle resources within Amazon SageMaker Studio.
Resize on the fly
The benefit of Studio notebooks over notebook instances is that with Studio, the underlying compute resources are fully elastic and you can change the instance on the fly. This allows you to scale the compute up and down as your compute demand changes, for example from ml.t3.medium to ml.m5.4xlarge, without interrupting your work or managing infrastructure. Moving from one instance to another is seamless, and you can continue working while the instance launches. With on-demand notebook instances, you need to stop the instance, update the setting, and restart with the new instance type. For more information, see Learn how to select ML instances on the fly in Amazon SageMaker Studio.
Restrict user access to specific instance types
Administrators can use IAM condition keys as an effective way to restrict certain instance types, such as GPU instances, for specific users, thereby controlling costs. For example, in the following sample policy, access is denied for all instances except ml.t3.medium and ml.g4dn.xlarge. Note that you need to allow the system instance for the default Jupyter Server apps.
{
"Action": [
"sagemaker:CreateApp"
],
"Resource": [
"*"
],
"Effect": "Deny",
"Sid": "BlockSagemakerLargeInstances",
"Condition": {
"ForAnyValue:StringNotLike": {
"sagemaker:InstanceTypes": [
"ml.t3.medium",
"ml.g4dn.xlarge",
"system"
]
}
}
}
For comprehensive guidance on best practices to optimize Studio cost, refer to Ensure efficient compute resources on Amazon SageMaker.
Use tags to keep track of Studio cost
In Studio, you can assign custom tags to your Studio domain as well as users who are provisioned access to the domain. Studio will automatically copy and assign these tags to the Studio notebooks created by the users, so you can easily track and categorize the cost of Studio notebooks and create cost chargeback models for your organization.
By default, SageMaker automatically tags new SageMaker resources such as training jobs, processing jobs, experiments, pipelines, and model registry entries with their respective sagemaker:domain-arn. SageMaker also tags the resource with the sagemaker:user-profile-arn or sagemaker:space-arn to designate the resource creation at an even more granular level.
Administrators can use automated tagging to easily monitor costs associated with their line of business, teams, individual users, or individual business problems by using tools such as AWS Budgets and Cost Explorer. For example, you can attach a cost allocation tag for the sagemaker:domain-arn tag.

This allows you to utilize Cost Explorer to visualize the Studio notebook spend for a given domain.

Consider storage costs
When the first member of your team onboards to Studio, SageMaker creates an Amazon Elastic File System (Amazon EFS) volume for the team. When this member, or any member of the team, opens Studio, a home directory is created in the volume for the member. A storage charge is incurred for this directory. Subsequently, additional storage charges are incurred for the notebooks and data files stored in the member’s home directory. For more information, see Amazon EFS Pricing.
Conclusion
In this post, we provided guidance on cost analysis and best practices when building ML models using notebook instances and Studio. As machine learning establishes itself as a powerful tool across industries, training and running ML models needs to remain cost-effective. SageMaker offers a wide and deep feature set for facilitating each step in the ML pipeline and provides cost optimization opportunities without impacting performance or agility.
| Refer to the following posts in this series for more information about optimizing cost for SageMaker:
|
About the Authors
 Deepali Rajale is a Senior AI/ML Specialist at AWS. She works with enterprise customers providing technical guidance with best practices for deploying and maintaining AI/ML solutions in the AWS ecosystem. She has worked with a wide range of organizations on various deep learning use cases involving NLP and computer vision. She is passionate about empowering organizations to leverage generative AI to enhance their use experience. In her spare time, she enjoys movies, music, and literature.
Deepali Rajale is a Senior AI/ML Specialist at AWS. She works with enterprise customers providing technical guidance with best practices for deploying and maintaining AI/ML solutions in the AWS ecosystem. She has worked with a wide range of organizations on various deep learning use cases involving NLP and computer vision. She is passionate about empowering organizations to leverage generative AI to enhance their use experience. In her spare time, she enjoys movies, music, and literature.
 Uri Rosenberg is the AI & ML Specialist Technical Manager for Europe, Middle East, and Africa. Based out of Israel, Uri works to empower enterprise customers on all things ML to design, build, and operate at scale. In his spare time, he enjoys cycling, hiking, breakfast, lunch and dinner.
Uri Rosenberg is the AI & ML Specialist Technical Manager for Europe, Middle East, and Africa. Based out of Israel, Uri works to empower enterprise customers on all things ML to design, build, and operate at scale. In his spare time, he enjoys cycling, hiking, breakfast, lunch and dinner.
Read More












 Jesse Manders is a Senior Product Manager in the AWS AI/ML human in the loop services team. He works at the intersection of AI and human interaction with the goal of creating and improving AI/ML products and services to meet our needs. Previously, Jesse held leadership roles in engineering at Apple and Lumileds, and was a senior scientist in a Silicon Valley startup. He has an M.S. and Ph.D. from the University of Florida, and an MBA from the University of California, Berkeley, Haas School of Business.
Jesse Manders is a Senior Product Manager in the AWS AI/ML human in the loop services team. He works at the intersection of AI and human interaction with the goal of creating and improving AI/ML products and services to meet our needs. Previously, Jesse held leadership roles in engineering at Apple and Lumileds, and was a senior scientist in a Silicon Valley startup. He has an M.S. and Ph.D. from the University of Florida, and an MBA from the University of California, Berkeley, Haas School of Business. Romi Datta is a Senior Manager of Product Management in the Amazon SageMaker team responsible for Human in the Loop services. He has been in AWS for over 4 years, holding several product management leadership roles in SageMaker, S3 and IoT. Prior to AWS he worked in various product management, engineering and operational leadership roles at IBM, Texas Instruments and Nvidia. He has an M.S. and Ph.D. in Electrical and Computer Engineering from the University of Texas at Austin, and an MBA from the University of Chicago Booth School of Business.
Romi Datta is a Senior Manager of Product Management in the Amazon SageMaker team responsible for Human in the Loop services. He has been in AWS for over 4 years, holding several product management leadership roles in SageMaker, S3 and IoT. Prior to AWS he worked in various product management, engineering and operational leadership roles at IBM, Texas Instruments and Nvidia. He has an M.S. and Ph.D. in Electrical and Computer Engineering from the University of Texas at Austin, and an MBA from the University of Chicago Booth School of Business. Jonathan Buck is a Software Engineer at Amazon Web Services working at the intersection of machine learning and distributed systems. His work involves productionizing machine learning models and developing novel software applications powered by machine learning to put the latest capabilities in the hands of customers.
Jonathan Buck is a Software Engineer at Amazon Web Services working at the intersection of machine learning and distributed systems. His work involves productionizing machine learning models and developing novel software applications powered by machine learning to put the latest capabilities in the hands of customers. Alex Williams is an applied scientist in the human-in-the-loop science team at AWS AI where he conducts interactive systems research at the intersection of human-computer interaction (HCI) and machine learning. Before joining Amazon, he was a professor in the Department of Electrical Engineering and Computer Science at the University of Tennessee where he co-directed the People, Agents, Interactions, and Systems (PAIRS) research laboratory. He has also held research positions at Microsoft Research, Mozilla Research, and the University of Oxford. He regularly publishes his work at premier publication venues for HCI, such as CHI, CSCW, and UIST. He holds a PhD from the University of Waterloo.
Alex Williams is an applied scientist in the human-in-the-loop science team at AWS AI where he conducts interactive systems research at the intersection of human-computer interaction (HCI) and machine learning. Before joining Amazon, he was a professor in the Department of Electrical Engineering and Computer Science at the University of Tennessee where he co-directed the People, Agents, Interactions, and Systems (PAIRS) research laboratory. He has also held research positions at Microsoft Research, Mozilla Research, and the University of Oxford. He regularly publishes his work at premier publication venues for HCI, such as CHI, CSCW, and UIST. He holds a PhD from the University of Waterloo. Sarah Gao is a Software Development Manager in Amazon SageMaker Human In the Loop (HIL) responsible for building the ML based labeling platform. Sarah has been in AWS for over 4 years, holding several software management leadership roles in EC2 security and SageMaker. Prior to AWS she worked in various engineering management roles at Oracle and Sun Microsystem.
Sarah Gao is a Software Development Manager in Amazon SageMaker Human In the Loop (HIL) responsible for building the ML based labeling platform. Sarah has been in AWS for over 4 years, holding several software management leadership roles in EC2 security and SageMaker. Prior to AWS she worked in various engineering management roles at Oracle and Sun Microsystem. Erran Li is the applied science manager at human-in-the-loop services, AWS AI, Amazon. His research interests are 3D deep learning, and vision and language representation learning. Previously he was a senior scientist at Alexa AI, the head of machine learning at Scale AI and the chief scientist at Pony.ai. Before that, he was with the perception team at Uber ATG and the machine learning platform team at Uber working on machine learning for autonomous driving, machine learning systems and strategic initiatives of AI. He started his career at Bell Labs and was adjunct professor at Columbia University. He co-taught tutorials at ICML’17 and ICCV’19, and co-organized several workshops at NeurIPS, ICML, CVPR, ICCV on machine learning for autonomous driving, 3D vision and robotics, machine learning systems and adversarial machine learning. He has a PhD in computer science at Cornell University. He is an ACM Fellow and IEEE Fellow.
Erran Li is the applied science manager at human-in-the-loop services, AWS AI, Amazon. His research interests are 3D deep learning, and vision and language representation learning. Previously he was a senior scientist at Alexa AI, the head of machine learning at Scale AI and the chief scientist at Pony.ai. Before that, he was with the perception team at Uber ATG and the machine learning platform team at Uber working on machine learning for autonomous driving, machine learning systems and strategic initiatives of AI. He started his career at Bell Labs and was adjunct professor at Columbia University. He co-taught tutorials at ICML’17 and ICCV’19, and co-organized several workshops at NeurIPS, ICML, CVPR, ICCV on machine learning for autonomous driving, 3D vision and robotics, machine learning systems and adversarial machine learning. He has a PhD in computer science at Cornell University. He is an ACM Fellow and IEEE Fellow.












 Simon Zamarin is an AI/ML Solutions Architect whose main focus is helping customers extract value from their data assets. In his spare time, Simon enjoys spending time with family, reading sci-fi, and working on various DIY house projects.
Simon Zamarin is an AI/ML Solutions Architect whose main focus is helping customers extract value from their data assets. In his spare time, Simon enjoys spending time with family, reading sci-fi, and working on various DIY house projects. Vikram Elango is a Sr. AI/ML Specialist Solutions Architect at AWS, based in Virginia, US. He is currently focused on generative AI, LLMs, prompt engineering, large model inference optimization, and scaling ML across enterprises. Vikram helps financial and insurance industry customers with design and architecture to build and deploy ML applications at scale. In his spare time, he enjoys traveling, hiking, cooking, and camping with his family.
Vikram Elango is a Sr. AI/ML Specialist Solutions Architect at AWS, based in Virginia, US. He is currently focused on generative AI, LLMs, prompt engineering, large model inference optimization, and scaling ML across enterprises. Vikram helps financial and insurance industry customers with design and architecture to build and deploy ML applications at scale. In his spare time, he enjoys traveling, hiking, cooking, and camping with his family. João Moura is an AI/ML Specialist Solutions Architect at AWS, based in Spain. He helps customers with deep learning model training and inference optimization, and more broadly building large-scale ML platforms on AWS. He is also an active proponent of ML-specialized hardware and low-code ML solutions.
João Moura is an AI/ML Specialist Solutions Architect at AWS, based in Spain. He helps customers with deep learning model training and inference optimization, and more broadly building large-scale ML platforms on AWS. He is also an active proponent of ML-specialized hardware and low-code ML solutions. Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.
Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.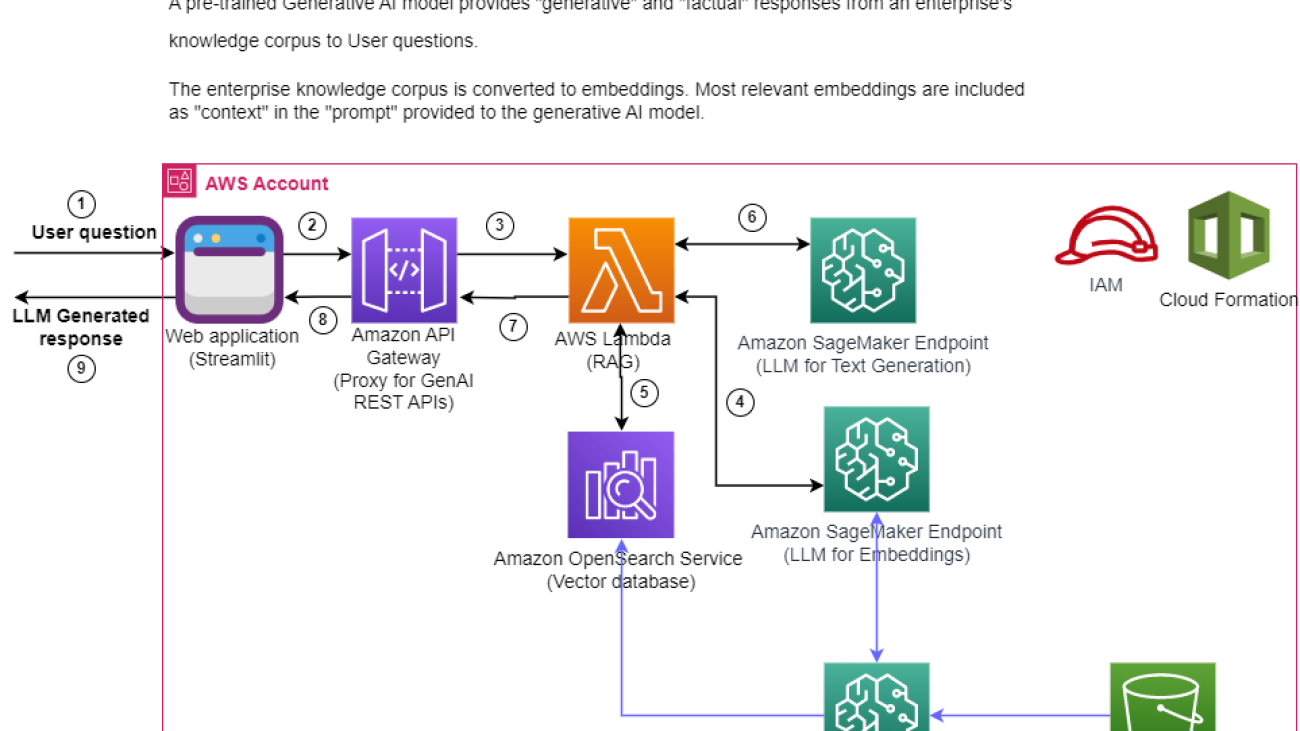





 Amit Arora is an AI and ML Specialist Architect at Amazon Web Services, helping enterprise customers use cloud-based machine learning services to rapidly scale their innovations. He is also an adjunct lecturer in the MS data science and analytics program at Georgetown University in Washington D.C.
Amit Arora is an AI and ML Specialist Architect at Amazon Web Services, helping enterprise customers use cloud-based machine learning services to rapidly scale their innovations. He is also an adjunct lecturer in the MS data science and analytics program at Georgetown University in Washington D.C. Dr. Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A.
Dr. Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A. Navneet Tuteja is a Data Specialist at Amazon Web Services. Before joining AWS, Navneet worked as a facilitator for organizations seeking to modernize their data architectures and implement comprehensive AI/ML solutions. She holds an engineering degree from Thapar University, as well as a master’s degree in statistics from Texas A&M University.
Navneet Tuteja is a Data Specialist at Amazon Web Services. Before joining AWS, Navneet worked as a facilitator for organizations seeking to modernize their data architectures and implement comprehensive AI/ML solutions. She holds an engineering degree from Thapar University, as well as a master’s degree in statistics from Texas A&M University.


















 Genta Watanabe is a Senior Technical Account Manager at Amazon Web Services. He spends his time working with strategic automotive customers to help them achieve operational excellence. His areas of interest are machine learning and artificial intelligence. In his spare time, Genta enjoys spending time with his family and traveling.
Genta Watanabe is a Senior Technical Account Manager at Amazon Web Services. He spends his time working with strategic automotive customers to help them achieve operational excellence. His areas of interest are machine learning and artificial intelligence. In his spare time, Genta enjoys spending time with his family and traveling. Abhijit Kalita is a Senior AI/ML Evangelist at Amazon Web Services. He spends his time working with public sector partners in Asia Pacific, enabling them on their AI/ML workloads. He has many years of experience in data analytics, AI, and machine learning across different verticals such as automotive, semiconductor manufacturing, and financial services. His areas of interest are machine learning and artificial intelligence, especially NLP and computer vision. In his spare time, Abhijit enjoys spending time with his family, biking, and playing with his little hamster.
Abhijit Kalita is a Senior AI/ML Evangelist at Amazon Web Services. He spends his time working with public sector partners in Asia Pacific, enabling them on their AI/ML workloads. He has many years of experience in data analytics, AI, and machine learning across different verticals such as automotive, semiconductor manufacturing, and financial services. His areas of interest are machine learning and artificial intelligence, especially NLP and computer vision. In his spare time, Abhijit enjoys spending time with his family, biking, and playing with his little hamster.





 Brian Curry is currently a founder and Head of Products at OCX Cognition, where we are building a machine learning platform for customer analytics. Brian has more than a decade of experience leading cloud solutions and design-centered product organizations.
Brian Curry is currently a founder and Head of Products at OCX Cognition, where we are building a machine learning platform for customer analytics. Brian has more than a decade of experience leading cloud solutions and design-centered product organizations. Sandhya M N is part of Infogain and leads the Data Science team for OCX. She is a seasoned software development leader with extensive experience across multiple technologies and industry domains. She is passionate about staying up to date with technology and using it to deliver business value to customers.
Sandhya M N is part of Infogain and leads the Data Science team for OCX. She is a seasoned software development leader with extensive experience across multiple technologies and industry domains. She is passionate about staying up to date with technology and using it to deliver business value to customers. Prashanth Ganapathy is a Senior Solutions Architect in the Small Medium Business (SMB) segment at AWS. He enjoys learning about AWS AI/ML services and helping customers meet their business outcomes by building solutions for them. Outside of work, Prashanth enjoys photography, travel, and trying out different cuisines.
Prashanth Ganapathy is a Senior Solutions Architect in the Small Medium Business (SMB) segment at AWS. He enjoys learning about AWS AI/ML services and helping customers meet their business outcomes by building solutions for them. Outside of work, Prashanth enjoys photography, travel, and trying out different cuisines. Sabha Parameswaran is a Senior Solutions Architect at AWS with over 20 years of deep experience in enterprise application integration, microservices, containers and distributed systems performance tuning, prototyping, and more. He is based out of the San Francisco Bay Area. At AWS, he is focused on helping customers in their cloud journey and is also actively involved in microservices and serverless-based architecture and frameworks.
Sabha Parameswaran is a Senior Solutions Architect at AWS with over 20 years of deep experience in enterprise application integration, microservices, containers and distributed systems performance tuning, prototyping, and more. He is based out of the San Francisco Bay Area. At AWS, he is focused on helping customers in their cloud journey and is also actively involved in microservices and serverless-based architecture and frameworks. Vaishnavi Ganesan is a Solutions Architect at AWS based in the San Francisco Bay Area. She is focused on helping Commercial Segment customers on their cloud journey and is passionate about security in the cloud. Outside of work, Vaishnavi enjoys traveling, hiking, and trying out various coffee roasters.
Vaishnavi Ganesan is a Solutions Architect at AWS based in the San Francisco Bay Area. She is focused on helping Commercial Segment customers on their cloud journey and is passionate about security in the cloud. Outside of work, Vaishnavi enjoys traveling, hiking, and trying out various coffee roasters. Ajay Swaminathan is an Account Manager II at AWS. He is an advocate for Commercial Segment customers, providing the right financial, business innovation, and technical resources in accordance with his customers’ goals. Outside of work, Ajay is passionate about skiing, dubstep and drum and bass music, and basketball.
Ajay Swaminathan is an Account Manager II at AWS. He is an advocate for Commercial Segment customers, providing the right financial, business innovation, and technical resources in accordance with his customers’ goals. Outside of work, Ajay is passionate about skiing, dubstep and drum and bass music, and basketball.