Combining acoustic and lexical information improves real-time voice sentiment analysis.Read More
Generate a counterfactual analysis of corn response to nitrogen with Amazon SageMaker JumpStart solutions
In his book The Book of Why, Judea Pearl advocates for teaching cause and effect principles to machines in order to enhance their intelligence. The accomplishments of deep learning are essentially just a type of curve fitting, whereas causality could be used to uncover interactions between the systems of the world under various constraints without testing hypotheses directly. This could provide answers that lead us to AGI (artificial generalized intelligence).
This solution proposes a causal inference framework using Bayesian networks to represent causal dependencies and draw causal conclusions based on observed satellite imagery and experimental trial data in the form of simulated weather and soil conditions. The case study is the causal relationship between nitrogen-based fertilizer application and the corn yields.
The satellite imagery is processed using purpose-built Amazon SageMaker geospatial capabilities and enriched with custom-built Amazon SageMaker Processing operations. The causal inference engine is deployed with Amazon SageMaker Asynchronous Inference.
In this post, we demonstrate how to create this counterfactual analysis using Amazon SageMaker JumpStart solutions.
Solution overview
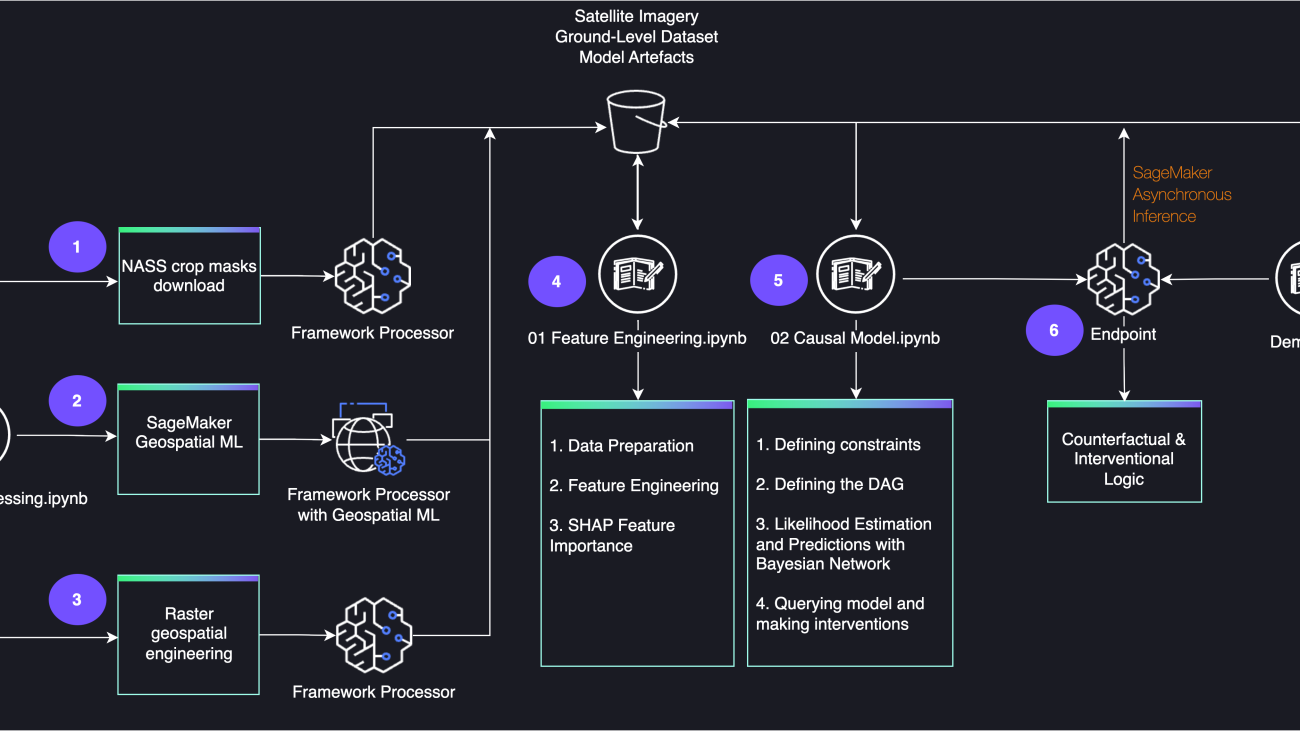
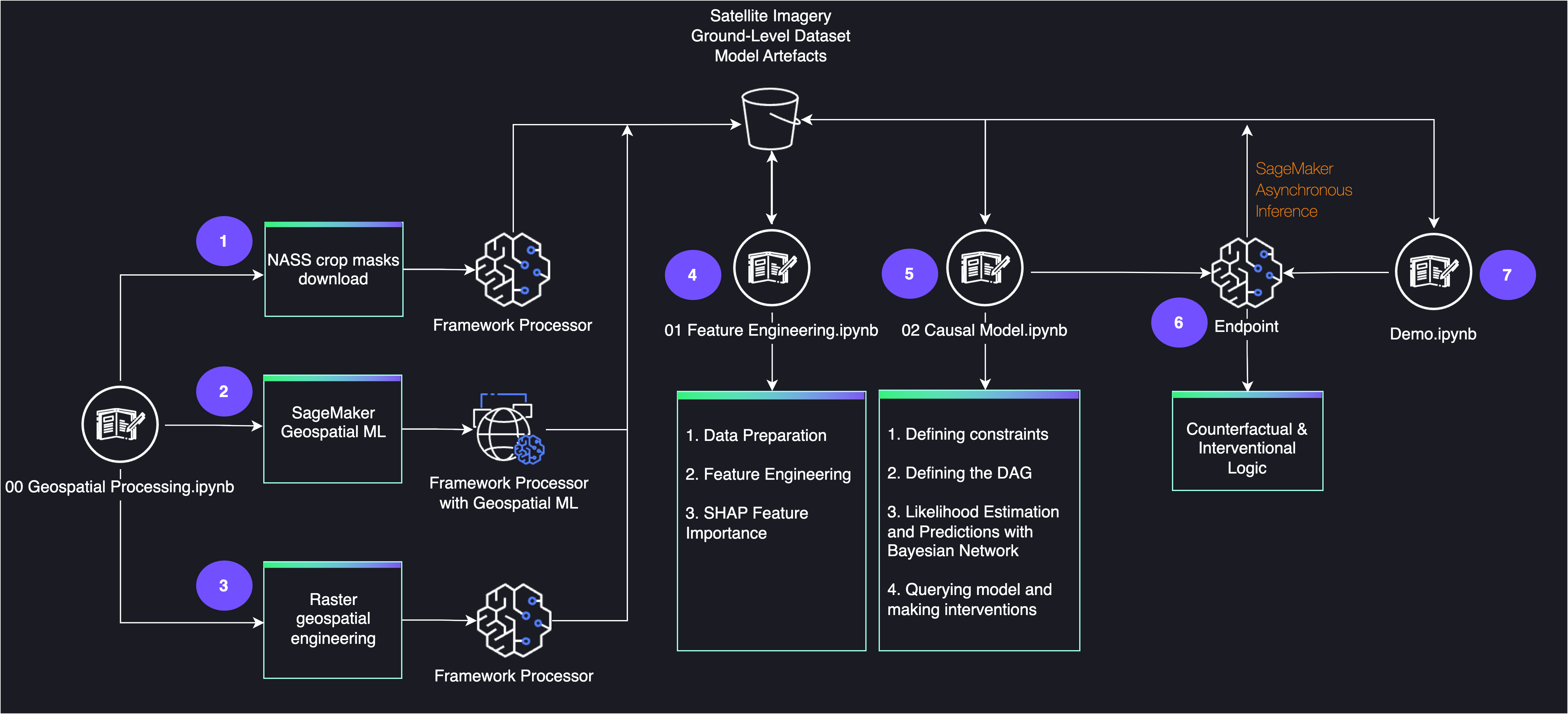
The following diagram shows the architecture for the end-to-end workflow.
Prerequisites
You need an AWS account to use this solution.
To run this JumpStart 1P Solution and have the infrastructure deployed to your AWS account, you need to create an active Amazon SageMaker Studio instance (refer to Onboard to Amazon SageMaker Domain). When your Studio instance is ready, follow the instructions in SageMaker JumpStart to launch the Crop Yield Counterfactuals solution.
Note that this solution is currently available in the US West (Oregon) Region only.
Causal inference
Causality is all about understanding change, but how to formalize this in statistics and machine learning (ML) is not a trivial exercise.
In this crop yield study, the nitrogen added as fertilizer and the yield outcomes might be confounded. Similarly, the nitrogen added as a fertilizer and the nitrogen leaching outcomes could be confounded as well, in the sense that a common cause can explain their association. However, association is not causation. If we know which observed factors confound the association, we account for them, but what if there are other hidden variables responsible for confounding? Reducing the amount of fertilizer won’t necessarily reduce residual nitrogen; similarly, it might not drastically diminish the yield, whereas the soil and climatic conditions could be the observed factors that confound the association. How to handle confounding is the central problem of causal inference. A technique introduced by R. A. Fisher called randomized controlled trial aims to break possible confounding.
However, in the absence of randomized control trials, there is a need for causal inference purely from observational data. There are ways to connect the causal questions to data in observational studies by writing the causal graphical model on what we postulate as how things happen. This involves claiming the corresponding traverses will capture the corresponding dependencies, while satisfying the graphical criterion for conditional ignorability (to what extent we can treat causation as association based on the causal assumptions). After we have postulated the structure, we can use the implied invariances to learn from observational data and plug in causal questions, inferring causal claims without randomized control trials.
This solution uses both data from simulated randomized control trials (RCTs) as well as observational data from satellite imagery. A series of simulations conducted over thousands of fields and multiple years in Illinois (United States) are used to study the corn response to increasing nitrogen rates for a broad combination of weather and soil variation seen in the region. It addresses the limitation of using trial data limited in the number of soils and years it can explore by using crop simulations of various farming scenarios and geographies. The database was calibrated and validated using data from more than 400 trials in the region. Initial nitrogen concentration in the soil was set randomly among a reasonable range.
Additionally, the database is enhanced with observations from satellite imagery, whereas zonal statistics are derived from spectral indices in order to represent spatio-temporal changes in vegetation, seen across geographies and phenological phases.
Causal inference with Bayesian networks
Structural causal models (SCMs) use graphical models to represent causal dependencies by incorporating both data-driven and human inputs. A particular type of structure causal model called Bayesian networks is proposed to model the crop phenology dynamics using probabilistic expressions by representing variables as nodes and relationships between variables as edges. Nodes are indicators of crop growth, soil and weather conditions, and the edges between them represent spatio-temporal causal relationships. The parent nodes are field-related parameters (including the day of sowing and area planted), and the child nodes are yield, nitrogen uptake, and nitrogen leaching metrics.
For more information, refer to the database characterization and the guide for identifying the corn growth stages.
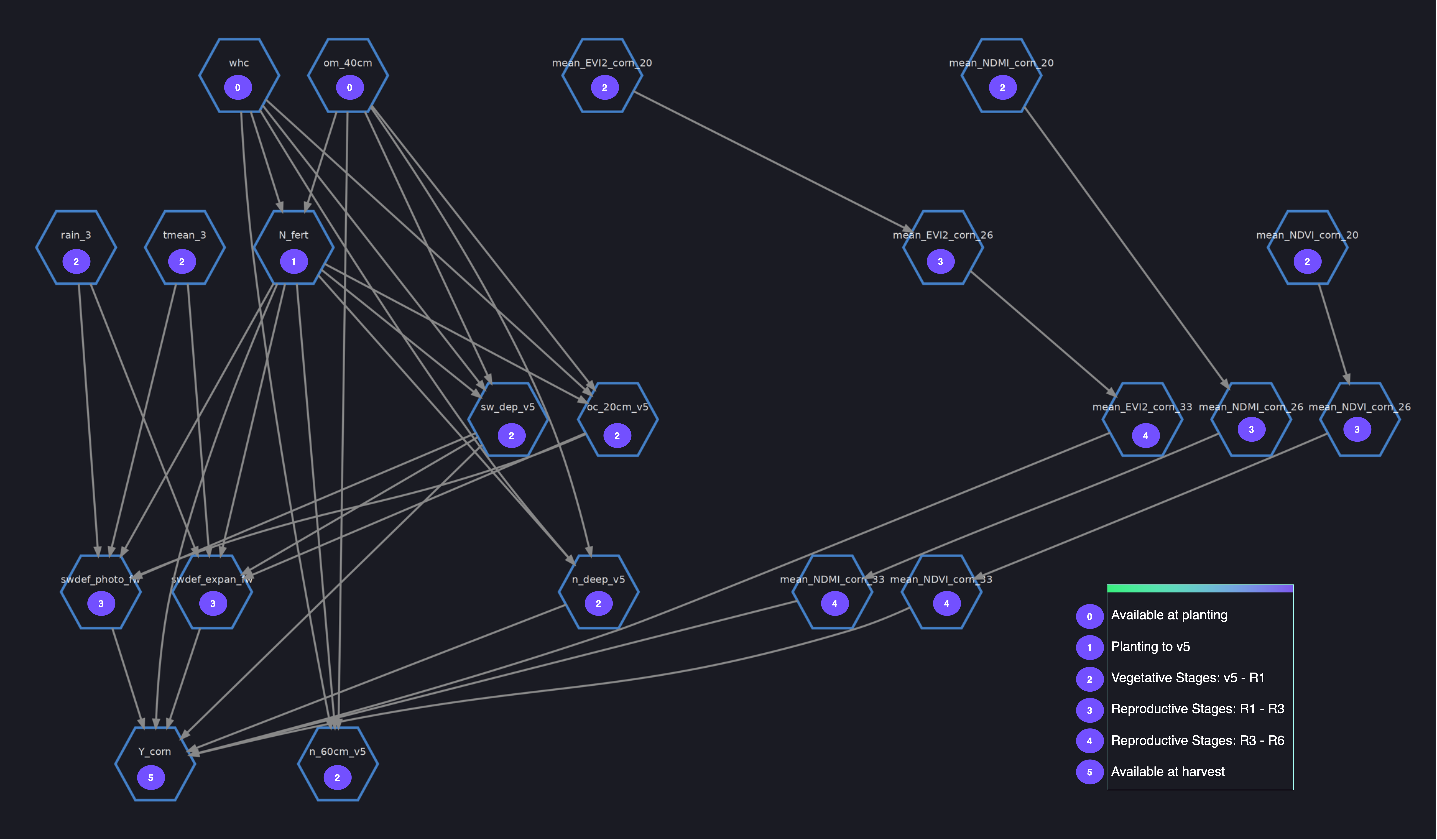
A few steps are required to build a Bayesian networks model (with CausalNex) before we can use it for counterfactual and interventional analysis. The structure of the causal model is initially learned from data, whereas subject matter expertise (trusted literature or empirical beliefs) is used to postulate additional dependencies and independencies between random variables and intervention variables, as well as asserting the structure is causal.
Using NO TEARS, a continuous optimization algorithm for structure learning, the graph structure describing conditional dependencies between variables is learned from data, with a set of constraints imposed on edges, parent nodes, and child nodes that are not allowed in the causal model. This preserves the temporal dependencies between variables. See the following code:
"""
tabu_edges: Imposing edges that are not allowed in the causal model
tabu_parents: Imposing parent nodes that are not allowed in the causal model
tabu_child: Imposing child nodes that are not allowed in the causal model
"""
from causalnex.structure.notears import from_pandas
g_learned = from_pandas(
X,
tabu_edges=tabu_edges,
tabu_parent_nodes=tabu_parents,
tabu_child_nodes=tabu_child,
max_iter=100,
)
The next step encodes domain knowledge in models and captures phenology dynamics, while avoiding spurious relationships. Multicollinearity analysis, variation inflation factor analysis, and global feature importance using SHAP analysis are conducted to extract insights and constraints on water stress variables (expansion, phenology, and photosynthesis around flowering), weather and soil variables, spectral indices, and the nitrogen-based indicators:
"""
edges: Modifying the structure by imposing constraints on edges
"""
from causalnex.structure import StructureModel
g = StructureModel()
g.add_edges_from(
edges,
origin="expert"
)
Bayesian networks in CausalNex support only discrete distributions. Any continuous features, or features with a large number of categories, are discretized prior to fitting the Bayesian network:
from causalnex.discretiser.discretiser_strategy import (
DecisionTreeSupervisedDiscretiserMethod,
MDLPSupervisedDiscretiserMethod
)
discretiser = DecisionTreeSupervisedDiscretiserMethod(
mode="single",
tree_params={"max_depth": 2, "random_state": 2022},
)
discretiser.fit(
feat_names=features,
dataframe=df,
target_continuous=True,
target=target,
)After the structure is reviewed, the conditional probability distribution of each variable given its parents can be learned from data, in a step called likelihood estimation:
from causalnex.network import BayesianNetwork
bn = BayesianNetwork(g)
bn = bn.fit_node_states(discretised_data)
bn = bn.fit_cpds(
train,
method="BayesianEstimator",
bayes_prior="K2",
)
Finally, the structure and likelihoods are used to perform observational inference on the fly, following a deterministic Junction Tree algorithm (JTA), and making interventions using do-calculus. SageMaker Asynchronous Inference allows queuing incoming requests and processes them asynchronously. This option is ideal for both observational and counterfactual inference scenarios, where the process can’t be parallelized, thereby taking significant time to update the probabilities throughout the network, although multiple queries can be run in parallel. See the following code:
"""
Query the marginal likelihood of states in the graph given some observations.
These observations can be made anywhere in the network,
and their impact will be propagated through to the node of interest.
"""
from causalnex.inference import InferenceEngine
ie = InferenceEngine(bn)
pseudo_observation = [{"day_sow":0}, {"day_sow":1}, {"day_sow":2}]
marginals_multi = ie.query(
pseudo_observation,
parallel=True,
num_cores=multiprocessing.cpu_count(),
)
# distribution before intervention
marginals_before = ie.query()["Y_corn"]
# updating a node distribution
ie.do_intervention("N_fert", 0)
# effect of do on marginals
marginals_after = ie.query()["Y_corn"]
# Resetting the node distribution
ie.reset_do("N_fert")
For further details, refer to the inference script.
The causal model notebook is a step-by-step guide on running the preceding steps.
Geospatial data processing
Earth Observation Jobs (EOJs) are chained together to acquire and transform satellite imagery, whereas purpose-built operations and pre-trained models are used for cloud removal, mosaicking, band math operations, and resampling. In this section, we discuss in more detail the geospatial processing steps.
Area of interest
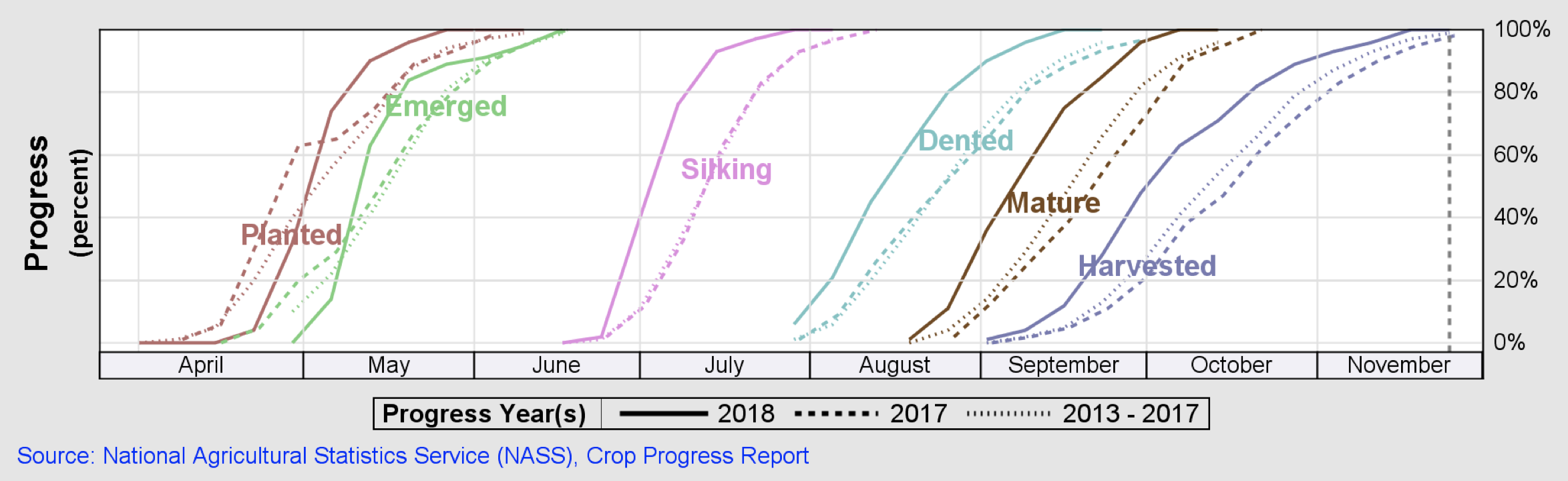
In the following figure, green polygons are the selected counties, the orange grid is the database map (a grid of 10 x 10 km cells where trials are conducted in the region), and the grid of grayscale squares is the 100 km x 100 km Sentinel-2 UTM tiling grid.
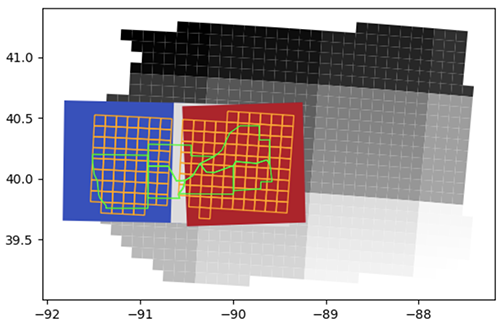
Spatial files are used to map the simulated database with corresponding satellite imagery, overlaying polygons of 10 km x 10 km cells that divide the state of Illinois (where trials are conducted in the region), counties polygons, and 100 km x 100 km Sentinel-2 UTM tiles. To optimize the geospatial data processing pipeline, a few nearby Sentinel-2 tiles are first selected. Next, the aggregated geometries of tiles and cells are overlayed in order to obtain the region of interest (RoI). The counties and the cell IDs that are fully observed within the RoI are selected to form the polygon geometry passed onto the EOJs.
Time range
For this exercise, the corn phenology cycle is divided into three stages: the vegetative stages v5 to R1 (emergence, leaf collars, and tasseling), the reproductive stages R1 to R4 (silking, blister, milk, and dough) and the reproductive stages R5 (dented) and R6 (physiological maturity). Consecutive satellite visits are acquired for each phenology stage within a time range of 2 weeks and a predefined area of interest (selected counties), enabling spatial and temporal analysis of satellite imagery. The following figure illustrates these metrics.
Cloud removal
Cloud removal for Sentinel-2 data uses an ML-based semantic segmentation model to identify clouds in the image, where cloudy pixels are replaced by with value -9999 (nodata value):
request_polygon_coordinates = [[(-90.571754, 39.839326), (-90.893651, 39.84092), (-90.916609, 39.845075), (-90.916071, 39.757168), (-91.147678, 39.75707), (-91.265848, 39.757258), (-91.365125, 39.758723), (-91.367962, 39.759124), (-91.365396, 39.777266), (-91.432919, 39.840554), (-91.446385, 39.870394), (-91.455887, 39.945538), (-91.460287, 39.980333), (-91.494865, 40.037421), (-91.510322, 40.127994), (-91.512974, 40.181062), (-91.510332, 40.201142), (-91.258828, 40.197299), (-90.911969, 40.193088), (-90.909756, 40.284394), (-90.450227, 40.276335), (-90.451502, 40.188892), (-90.199556, 40.183945), (-90.118966, 40.235263), (-90.033026, 40.377806), (-89.92468, 40.435921), (-89.717104, 40.435655), (-89.714927, 40.319218), (-89.602979, 40.320129), (-89.601604, 40.122432), (-89.578289, 39.976127), (-89.698259, 39.975309), (-89.701864, 39.916787), (-89.994506, 39.901925), (-89.994405, 39.87286), (-90.583534, 39.87675), (-90.582435, 39.854574), (-90.571754, 39.839326)]]
start_time = '2018-08-15T00:00:00Z'
end_time = '2018-09-15T00:00:00Z'
eoj_input_config = {
"RasterDataCollectionQuery": {
"RasterDataCollectionArn": 'arn:aws:sagemaker-geospatial:us-west-2:378778860802:raster-data-collection/public/nmqj48dcu3g7ayw8',
"AreaOfInterest": {
"AreaOfInterestGeometry": {
"PolygonGeometry": {"Coordinates": request_polygon_coordinates}
}
},
"TimeRangeFilter": {"StartTime": start_time, "EndTime": end_time},
"PropertyFilters": {
"Properties": [{"Property": {"EoCloudCover":
{"LowerBound": 0, "UpperBound": 10}}}],
"LogicalOperator": "AND",
},
}
}
eoj_config = {
"JobConfig": {
"CloudRemovalConfig": {
"AlgorithmName": "INTERPOLATION",
"InterpolationValue": "-9999",
"TargetBands": ["red", "green", "blue", "nir", "swir16"],
},
}
}
eojParams = {
"Name": "cloudremoval",
"InputConfig": eoj_input_config,
**eoj_config,
"ExecutionRoleArn": role_arn,
}
eoj_response = sg_client.start_earth_observation_job(**eojParams)
After the EOJ is created, the ARN is returned and used to perform the subsequent geomosaic operation.
To get the status of a job, you can run sg_client.get_earth_observation_job(Arn = response['Arn']).
Geomosaic
The geomosaic EOJ is used to merge images from multiple satellite visits into a large mosaic, by overwriting nodata or transparent pixels (including the cloudy pixels) with pixels from other timestamps:
eoj_config = {"JobConfig": {"GeoMosaicConfig": {"AlgorithmName": "NEAR"}}}
eojParams = {
"Name": "geomosaic",
"InputConfig": {"PreviousEarthObservationJobArn": eoj_arn},
**eoj_config,
"ExecutionRoleArn": role_arn,
}
eoj_response = sg_client.start_earth_observation_job(**eojParams)
After the EOJ is created, the ARN is returned and used to perform the subsequent resampling operation.
Resampling
Resampling is used to downscale the resolution of the geospatial image in order to match the resolution of the crop masks (10–30 m resolution rescaling):
eoj_config = {
"JobConfig": {
"ResamplingConfig": {
"OutputResolution": {"UserDefined": {"Value": 30, "Unit": "METERS"}},
"AlgorithmName": "NEAR",
},
}
}
eojParams = {
"Name": "resample",
"InputConfig": {"PreviousEarthObservationJobArn": eoj_arn},
**eoj_config,
"ExecutionRoleArn": role_arn,
}
eoj_response = sg_client.start_earth_observation_job(**eojParams)
After the EOJ is created, the ARN is returned and used to perform the subsequent band math operation.
Band math
Band math operations are used for transforming the observations from multiple spectral bands to a single band. It includes the following spectral indices:
- EVI2 – Two-Band Enhanced Vegetation Index
- GDVI – Generalized Difference Vegetation Index
- NDMI – Normalized Difference Moisture Index
- NDVI – Normalized Difference Vegetation Index
- NDWI – Normalized Difference Water Index
See the following code:
spectral_indices = [['EVI2', ' 2.5 * ( nir - red ) / ( nir + 2.4 * red + 1.0 ) '],
['GDVI', ' ( ( nir * * 2.0 ) - ( red * * 2.0 ) ) / ( ( nir * * 2.0 ) + ( red * * 2.0 ) ) '],
['NDMI', ' ( nir - swir16 ) / ( nir + swir16 ) '],
['NDVI', ' ( nir - red ) / ( nir + red ) '],
['NDWI', ' ( green - nir ) / ( green + nir ) ']]
eoj_config = {
"JobConfig": {
"BandMathConfig": {"CustomIndices": {"Operations": []}},
}
}
for indices in spectral_indices:
eoj_config["JobConfig"]["BandMathConfig"]["CustomIndices"]["Operations"].append(
{"Name": indices[0], "Equation": indices[1][1:-1]}
)
eojParams = {
"Name": "bandmath",
"InputConfig": {"PreviousEarthObservationJobArn": eoj_arn},
**eoj_config,
"ExecutionRoleArn": role_arn,
}
eoj_response = sg_client.start_earth_observation_job(**eojParams)
Zonal statistics
The spectral indices are further enriched using Amazon SageMaker Processing, where GDAL-based custom logic is used to do the following:
- Merge the spectral indices into a single multi-channel mosaic
- Reproject the mosaic to the crop mask‘s projection
- Apply the crop mask and reproject the mosaic to the cells polygons’s CRC
- Calculate zonal statistics for selected polygons (10 km x 10 km cells)
With parallelized data distribution, manifest files (for each crop phenological stage) are distributed across several instances using the ShardedByS3Key S3 data distribution type. For further details, refer to the feature extraction script.
The geospatial processing notebook is a step-by-step guide on running the preceding steps.
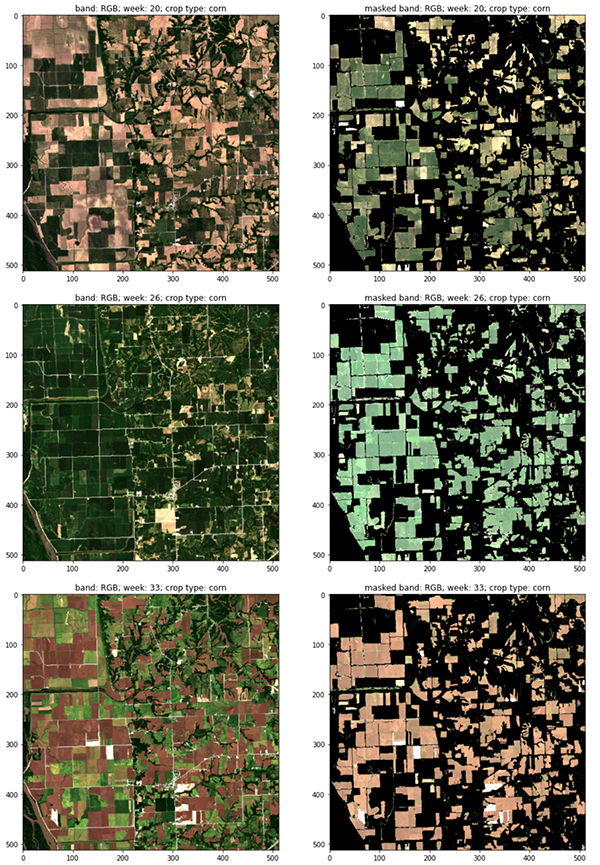
The following figure shows RGB channels of consecutive satellite visits representing the vegetative and reproductive stages of the corn phenology cycle, with (right) and without (left) crop masks (CW 20, 26 and 33, 2018 Central Illinois).
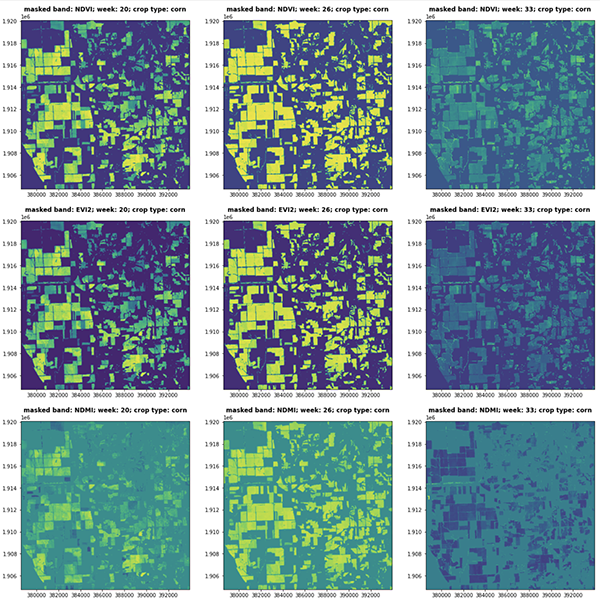
In the following figure, spectral indices (NDVI, EVI2, NDMI) of consecutive satellite visits represent the vegetative and reproductive stages of the corn phenology cycle (CW 20, 26 and 33, 2018 Central Illinois).
Clean up
If you no longer want to use this solution, you can delete the resources it created. After the solution is deployed in Studio, choose Delete all resources to automatically delete all standard resources that were created when launching the solution, including the S3 bucket.
Conclusion
This solution provides a blueprint for use cases where causal inference with Bayesian networks are the preferred methodology for answering causal questions from a combination of data and human inputs. The workflow includes an efficient implementation of the inference engine, which queues incoming queries and interventions and processes them asynchronously. The modular aspect enables the reuse of various components, including geospatial processing with purpose-built operations and pre-trained models, enrichment of satellite imagery with custom-built GDAL operations, and multimodal feature engineering (spectral indices and tabular data).
In addition, you can use this solution as a template for building gridded crop models where nitrogen fertilizer management and environmental policy analysis are conducted.
For more information, refer to Solution Templates and follow the guide to launch the Crop Yield Counterfactuals solution in the US West (Oregon) Region. The code is available in the GitHub repo.
Citations
German Mandrini, Sotirios V. Archontoulis, Cameron M. Pittelkow, Taro Mieno, Nicolas F. Martin,
Simulated dataset of corn response to nitrogen over thousands of fields and multiple years in Illinois,
Data in Brief, Volume 40, 2022, 107753, ISSN 2352-3409
Useful resources
- Getting started with Amazon SageMaker
- Amazon SageMaker Developer Guide
- Amazon SageMaker Python SDK
- Amazon SageMaker geospatial capabilities
- Asynchronous inference
About the Authors
 Paul Barna is a Senior Data Scientist with the Machine Learning Prototyping Labs at AWS.
Paul Barna is a Senior Data Scientist with the Machine Learning Prototyping Labs at AWS.
Zero-shot prompting for the Flan-T5 foundation model in Amazon SageMaker JumpStart
The size and complexity of large language models (LLMs) have exploded in the last few years. LLMs have demonstrated remarkable capabilities in learning the semantics of natural language and producing human-like responses. Many recent LLMs are fine-tuned with a powerful technique called instruction tuning, which helps the model perform new tasks or generate responses to novel prompts without prompt-specific fine-tuning. An instruction-tuned model uses its understanding of related tasks or concepts to generate predictions to novel prompts. Because this technique doesn’t involve updating model weights, it avoids the time-consuming and computationally expensive process required to fine-tune a model for a new, previously unseen task.
In this post, we show how you can access and deploy an instruction-tuned Flan T5 model from Amazon SageMaker Jumpstart. We also demonstrate how you can engineer prompts for Flan-T5 models to perform various natural language processing (NLP) tasks. Furthermore, these tasks can be performed with zero-shot learning, where a well-engineered prompt can guide the model towards desired results. For example, consider providing a multiple-choice question and asking the model to return the appropriate answer from the available choices. We cover prompts for the following NLP tasks:
- Text summarization
- Common sense reasoning
- Question answering
- Sentiment classification
- Translation
- Pronoun resolution
- Text generation based on article
- Imaginary article based on title
Code for all the steps in this demo is available in the following notebook.
JumpStart is the machine learning (ML) hub of Amazon SageMaker that offers a one-click access to over 350 built-in algorithms; pre-trained models from TensorFlow, PyTorch, Hugging Face, and MXNet; and pre-built solution templates. JumpStart also provides pre-trained foundation models like Stability AI’s Stable Diffusion text-to-image model, BLOOM, Cohere’s Generate, Amazon’s AlexaTM and more.
Instruction tuning
Instruction tuning is a technique that involves fine-tuning a language model on a collection of NLP tasks using instructions. In this technique, the model is trained to perform tasks by following textual instructions instead of specific datasets for each task. The model is fine-tuned with a set of input and output examples for each task, allowing the model to generalize to new tasks that it hasn’t been explicitly trained on as long as prompts are provided for the tasks. Instruction tuning helps improve the accuracy and effectiveness of models and is helpful in situations where large datasets aren’t available for specific tasks.
A myriad of instruction tuning research has been performed since 2020, producing a collection of various tasks, templates, and methods. One of the most prominent instruction tuning methods, Finetuning language models (Flan), aggregates these publicly available collections into a Flan Collection to produce fine-tuned models on a wide variety of instructions. In this way, the multi-task Flan models are competitive with the same models independently fine-tuned on each specific task and can generalize beyond the specific instructions seen during training to following instructions in general.
Zero-shot learning
Zero-shot learning in NLP allows a pre-trained LLM to generate responses to tasks that it hasn’t been specifically trained for. In this technique, the model is provided with an input text and a prompt that describes the expected output from the model in natural language. The pre-trained models can use its knowledge to generate coherent and relevant responses even for prompts it hasn’t specifically been trained on. Zero-shot learning can reduce the time and data required while improving efficiency and accuracy of NLP tasks. Zero-shot learning is used in a variety of NLP tasks, such as question answering, summarization, and text generation.
Few-shot learning involves training a model to perform new tasks by providing only a few examples. This is useful where limited labeled data is available for training. Although this post primarily focuses on zero-shot learning, the referenced models are also capable of generating responses to few-shot learning prompts.
Flan-T5 model
A popular encoder-decoder model known as T5 (Text-to-Text Transfer Transformer) is one such model that was subsequently fine-tuned via the Flan method to produce the Flan-T5 family of models. Flan-T5 is an instruction-tuned model and therefore is capable of performing various zero-shot NLP tasks, as well as few-shot in-context learning tasks. With appropriate prompting, it can perform zero-shot NLP tasks such as text summarization, common sense reasoning, natural language inference, question answering, sentence and sentiment classification, translation, and pronoun resolution. The examples provided in this post are generated with the Flan-T5 family.
JumpStart provides convenient deployment of this model family through Amazon SageMaker Studio and the SageMaker SDK. This includes Flan-T5 Small, Flan-T5 Base, Flan-T5 Large, Flan-T5 XL, and Flan-T5 XXL. Furthermore, JumpStart provides three versions of Flan-T5 XXL at different levels of quantization:
- Flan-T5 XXL – The full model, loaded in single-precision floating-point format (FP32).
- Flan-T5 XXL FP16 – A half-precision floating-point format (FP16) version of the full model. This implementation consumes less GPU memory and performs faster inference than the FP32 version.
- Flan-T5 XXL BNB INT8 – An 8-bit quantized version of the full model, loaded onto the GPU context using the
accelerateandbitsandbyteslibraries. This implementation provides accessibility to this LLM on instances with less compute, such as a single-GPU ml.g5.xlarge instance.
Prompt engineering for zero-shot NLP tasks on Flan-T5 models
Prompt engineering deals with creating high-quality prompts to guide the model towards the desired responses. Prompts need to be designed based on the specific task and dataset being used. The goal here is to provide the model with necessary information to generate high-quality responses while minimizing noise. This could involve keywords, additional contexts, questions, and more. For example, see the following code:
A well-designed prompt can make the model more creative and generalized so that it can easily adapt to new tasks. Prompts can also help incorporate domain knowledge on specific tasks and improve interpretability. Prompt engineering can greatly improve the performance of zero-shot and few-shot learning models. Creating high-quality prompts requires careful consideration of the task at hand, as well as a deep understanding of the model’s strengths and limitations.
In the provided example notebook, each task demonstrates at least seven prompt templates and a comprehensive set of parameters to control the model output, such as maximum sequence length, number of return sequences, and number of beams. In addition, the prompt templates used are from the Flan T5 GitHub repository, which consists of many templates used within the Flan Collection. This collection of templates is helpful to explore when you perform your own prompt engineering.
In the following table, the Flan-T5 XXL model is used to generate responses for various zero-shot NLP tasks. The first column shows the task, the second column contains the prompt provided to the model (where the template text is bold and the non-bold text is the example input), and the third column is the response from the model when queried against the prompt.
Take the summarization task for an example: to create a model prompt, you can concatenate the template Briefly summarize this paragraph: with the text example you want to summarize. All tasks in this table used the same payload parameters: max_length=150 to provide an upper limit on the number of response tokens, no_repeat_ngram_size=5 to discourage n-gram repetition, and do_sample=False to disable sampling for repeatability. We discuss available payload parameter options when querying the endpoint in more detail later.
| Task | Prompt (template in bold) | Model output |
| Summarization | Briefly summarize this paragraph: Amazon Comprehend uses natural language processing (NLP) to extract insights about the content of documents. It develops insights by recognizing the entities, key phrases, language, sentiments, and other common elements in a document. Use Amazon Comprehend to create new products based on understanding the structure of documents. For example, using Amazon Comprehend you can search social networking feeds for mentions of products or scan an entire document repository for key phrases. You can access Amazon Comprehend document analysis capabilities using the Amazon Comprehend console or using the Amazon Comprehend APIs. You can run real-time analysis for small workloads or you can start asynchronous analysis jobs for large document sets. You can use the pre-trained models that Amazon Comprehend provides, or you can train your own custom models for classification and entity recognition. All of the Amazon Comprehend features accept UTF-8 text documents as the input. In addition, custom classification and custom entity recognition accept image files, PDF files, and Word files as input. Amazon Comprehend can examine and analyze documents in a variety of languages, depending on the specific feature. For more information, see Languages supported in Amazon Comprehend. Amazon Comprehend’s Dominant language capability can examine documents and determine the dominant language for a far wider selection of languages. |
Understand the capabilities of Amazon Comprehend |
| Common sense reasoning or natural language reasoning | The world cup has kicked off in Los Angeles, United States.nnBased on the paragraph above can we conclude that ”The world cup takes place in United States.”?nn[”yes”, ”no”] | yes |
| question answering |
Answer based on context:nnThe newest and most innovative Kindle yet lets you take notes on millions of books and documents, write lists and journals, and more. For readers who have always wished they could write in their eBooks, Amazon’s new Kindle lets them do just that. The Kindle Scribe is the first Kindle for reading and writing and allows users to supplement their books and documents with notes, lists, and more. Here’s everything you need to know about the Kindle Scribe, including frequently asked questions. The Kindle Scribe makes it easy to read and write like you would on paper The Kindle Scribe features a 10.2-inch, glare-free screen (the largest of all Kindle devices), crisp 300 ppi resolution, and 35 LED front lights that automatically adjust to your environment. Further personalize your experience with the adjustable warm light, font sizes, line spacing, and more. It comes with your choice of the Basic Pen or the Premium Pen, which you use to write on the screen like you would on paper. They also attach magnetically to your Kindle and never need to be charged. The Premium Pen includes a dedicated eraser and a customizable shortcut button. The Kindle Scribe has the most storage options of all Kindle devices: choose from 8 GB, 16 GB, or 32 GB to suit your level of reading and writing.nnwhat are the key features of new Kindle? |
10.2-inch, glare-free screen |
| Sentence or sentiment classification | Review:nThis moive is so great and once again dazzles and delights usnIs this movie review sentence negative or positive?nOPTIONS:n-positive n-negative | positive |
| Translation | My name is ArthurnnTranslate to German | Mein Name ist Arthur |
| Pronoun resolution | Allen made his friend, Xin, laugh when he told a funny joke.nnWho is he referring to?nn(A)Allen n(B)Xin | Allen |
| Title generation based on an article |
The newest and most innovative Kindle yet lets you take notes on millions of books and documents, write lists and journals, and more. For readers who have always wished they could write in their eBooks, Amazon’s new Kindle lets them do just that. The Kindle Scribe is the first Kindle for reading and writing and allows users to supplement their books and documents with notes, lists, and more. Here’s everything you need to know about the Kindle Scribe, including frequently asked questions. The Kindle Scribe makes it easy to read and write like you would on paper The Kindle Scribe features a 10.2-inch, glare-free screen (the largest of all Kindle devices), crisp 300 ppi resolution, and 35 LED front lights that automatically adjust to your environment. Further personalize your experience with the adjustable warm light, font sizes, line spacing, and more. It comes with your choice of the Basic Pen or the Premium Pen, which you use to write on the screen like you would on paper. They also attach magnetically to your Kindle and never need to be charged. The Premium Pen includes a dedicated eraser and a customizable shortcut button. The Kindle Scribe has the most storage options of all Kindle devices: choose from 8 GB, 16 GB, or 32 GB to suit your level of reading and writing. nnGive me a good title for the article above. |
Everything You Need to Know About the New Kindle Scribe |
| Imaginary article generation based on a title | Title: ”University has new facility coming up“\nGiven the above title of an imaginary article, imagine the article.n | The University of the Philippines (UP) is set to construct a new building for its College of Medicine and Health Sciences (CMHS) in the campus of the University of Santo Tomas (UST) in Bacolod City. The CMHS building, which will be located at the UST campus, will be the first building constructed by the university in the UST campus. The CMMS building will be the first of its kind in the country, according to UP Vice President for Administration and Finance Dr. Jose L. Alcala. The CMMH building will be the second building constructed by the UP in the UST. The first building, which was completed in 2008, is the UP |
Access Flan-T5 instruction-tuned models in SageMaker
JumpStart provides three avenues to get started using these instruction-tuned Flan models: JumpStart foundation models, Studio, and the SageMaker SDK. The following sections illustrate what each of these avenues look like and describe how to access them.
JumpStart foundation models
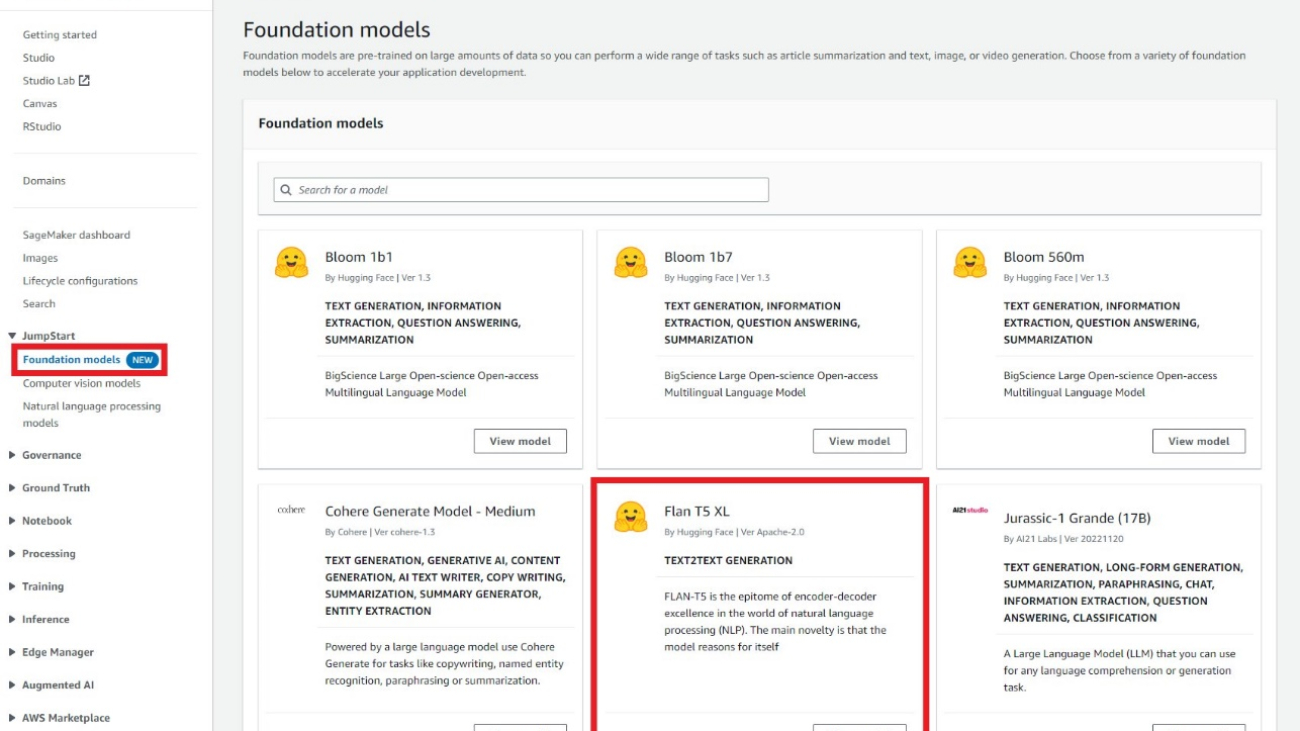
Developers can use the visual interface of the JumpStart foundation models, accessed via the SageMaker console, to test instruction-tuned Flan models without writing a single line of code. This playground provides an input prompt textbox along with controls for various parameters used during inference. This feature is currently in a gated preview, and you will see Request Access button instead of models if you don’t have access. As seen in the following screenshots, you can access foundation models in the navigation pane of the SageMaker console. Choose View model on the Flan-T5 XL model card to access the user interface.

You can use this flexible user interface to try a demo of the model.

SageMaker Studio
You can also access these models through the JumpStart landing page in Studio. This page lists available end-to-end ML solutions, pre-trained models, and example notebooks.

You can choose a Flan-T5 model card to deploy a model endpoint through the user interface.

After your endpoint is successfully launched, you can launch an example Jupyter notebook that demonstrates how to query that endpoint.

SageMaker Python SDK
Finally, you can programmatically deploy an endpoint through the SageMaker SDK. You will need to specify the model ID of your desired model in the SageMaker model hub and the instance type used for deployment. The model URI, which contains the inference script, and the URI of the Docker container are obtained through the SageMaker SDK. These URIs are provided by JumpStart and can be used to initialize a SageMaker model object for deployment. See the following code:
Now that the endpoint is deployed, you can query the endpoint to produce generated text. Consider a summarization task as an example, where you want to produce a summary of the following text:
You should supply this text within a JSON payload when invoking the endpoint. This JSON payload can include any desired inference parameters that help control the length, sampling strategy, and output token sequence restrictions. While the transformers library defines a full list of available payload parameters, many important payload parameters are defined as follows:
- max_length – The model generates text until the output length (which includes the input context length) reaches
max_length. If specified, it must be a positive integer. - num_return_sequences – The number of output sequences returned. If specified, it must be a positive integer.
- num_beams – The number of beams used in the greedy search. If specified, it must be an integer greater than or equal to
num_return_sequences. - no_repeat_ngram_size – The model ensures that a sequence of words of
no_repeat_ngram_sizeis not repeated in the output sequence. If specified, it must be a positive integer greater than 1. - temperature – Controls the randomness in the output. Higher temperature results in output sequence with low-probability words, and lower temperature results in output sequence with high-probability words. If
temperatureequals 0, it results in greedy decoding. If specified, it must be a positive float. - early_stopping – If
True, text generation is finished when all beam hypotheses reach the end of stence token. If specified, it must be Boolean. - do_sample – If
True, sample the next word as per the likelihood. If specified, it must be Boolean. - top_k – In each step of text generation, sample from only the
top_kmost likely words. If specified, it must be a positive integer. - top_p – In each step of text generation, sample from the smallest possible set of words with cumulative probability
top_p. If specified, it must be a float between 0–1. - seed – Fix the randomized state for reproducibility. If specified, it must be an integer.
We can specify any subset of these parameters while invoking an endpoint. Next, we show an example of how to invoke an endpoint with these arguments:
This code block generates an output sequence sample that resembles the following text:
Clean up
To avoid ongoing charges, delete the SageMaker inference endpoints. You can delete the endpoints via the SageMaker console or from the Studio notebook using the following commands:
Conclusion
In this post, we gave an overview of the benefits of zero-shot learning and described how prompt engineering can improve the performance of instruction-tuned models. We also showed how to easily deploy an instruction-tuned Flan T5 model from JumpStart and provided examples to demonstrate how you can perform different NLP tasks using the deployed Flan T5 model endpoint in SageMaker.
We encourage you to deploy a Flan T5 model from JumpStart and create your own prompts for NLP use cases.
To learn more about JumpStart, check out the following:
- Run text generation with Bloom and GPT models on Amazon SageMaker JumpStart
- Generate images from text with the stable diffusion model on Amazon SageMaker JumpStart
- Run image segmentation with Amazon SageMaker JumpStart
- Run text classification with Amazon SageMaker JumpStart using TensorFlow Hub and Hugging Face models
- Amazon SageMaker JumpStart models and algorithms now available via API
- Incremental training with Amazon SageMaker JumpStart
- Transfer learning for TensorFlow object detection models in Amazon SageMaker
- Transfer learning for TensorFlow text classification models in Amazon SageMaker
- Transfer learning for TensorFlow image classification models in Amazon SageMaker
About the authors
 Dr. Xin Huang is an Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A journal.
Dr. Xin Huang is an Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A journal.
 Vivek Gangasani is a Senior Machine Learning Solutions Architect at Amazon Web Services. He works with Machine Learning Startups to build and deploy AI/ML applications on AWS. He is currently focused on delivering solutions for MLOps, ML Inference and low-code ML. He has worked on projects in different domains, including Natural Language Processing and Computer Vision.
Vivek Gangasani is a Senior Machine Learning Solutions Architect at Amazon Web Services. He works with Machine Learning Startups to build and deploy AI/ML applications on AWS. He is currently focused on delivering solutions for MLOps, ML Inference and low-code ML. He has worked on projects in different domains, including Natural Language Processing and Computer Vision.
 Dr. Kyle Ulrich is an Applied Scientist with the Amazon SageMaker built-in algorithms team. His research interests include scalable machine learning algorithms, computer vision, time series, Bayesian non-parametrics, and Gaussian processes. His PhD is from Duke University and he has published papers in NeurIPS, Cell, and Neuron.
Dr. Kyle Ulrich is an Applied Scientist with the Amazon SageMaker built-in algorithms team. His research interests include scalable machine learning algorithms, computer vision, time series, Bayesian non-parametrics, and Gaussian processes. His PhD is from Duke University and he has published papers in NeurIPS, Cell, and Neuron.
Reduce call hold time and improve customer experience with self-service virtual agents using Amazon Connect and Amazon Lex
This post was co-written with Tony Momenpour and Drew Clark from KYTC.
Government departments and businesses operate contact centers to connect with their communities, enabling citizens and customers to call to make appointments, request services, and sometimes just ask a question. When there are more calls than agents can answer, callers get placed on hold with a message such as the following: “We are experiencing higher than usual call volumes. Your call is very important to us, please stay on the line and your call will be answered in the order it was received.”
Unless the hold music is particularly good, callers don’t typically enjoy having to wait—it wastes time and money. Some contact centers play automated messages to encourage the caller to leave a voicemail, visit the website, or call back later. These options are unsatisfying to callers who just want to ask an agent a question to get an answer quickly.
One solution is to have enough trained agents available to take all the calls right away, even during times of unusually high call volumes. This would eliminate hold times and ensure that callers receive fast responses. The key to making this approach practical is to augment human agents with scalable, AI-powered virtual agents that can address callers’ needs for at least some of the incoming calls. When a virtual agent successfully addresses a caller’s enquiry, the result is a happy caller, lower average hold times for all callers, and lower costs. Gartner’s Customer Service and Support Leader poll estimates that live channels such as phone and live chat cost an average of $8.01 per contact, while self-service channels cost about $0.10 per contact—a virtual agent can potentially save $7.91 (98%) for every call it successfully handles.
A virtual agent doesn’t have to handle every call, and it probably shouldn’t try—some portion of calls are likely served best with a human touch, so a good virtual agent should know its own limitations, and quickly transfer the caller to a human agent when needed.
In this post, we share how the Kentucky Transportation Cabinet’s (KYTC) Department of Vehicle Regulations (DVR) reduced call hold time and improved customer experience with self-service virtual agents using Amazon Connect and Amazon Lex.
KYTC DVR’s challenges
The KYTC DVR supports, assists and provides information related to vehicle registration, driver licenses, and commercial vehicle credentials to nearly 5 million constituents.
“In a recent survey conducted with Kentucky citizens, more than 50% actually wanted help without speaking to someone,” says Drew Clark, Business Analyst and Project Manager at KYTC.
There were several challenges the KYTC team faced that made it necessary for them to replace the existing system with Amazon Connect and Amazon Lex. The lack of flexibility in the existing customer service system prevented them from providing their customers the best user experience and from innovating further by introducing features like the ability to handle redundant queries via chat. Also, the introduction of federal REAL ID requirements in 2019 resulted in increased call volumes from drivers with questions. Call volumes increased further in 2020 when the COVID-19 pandemic struck and driver licensing regional offices closed. Callers experienced an average handle time of 5 minutes or longer—an undesirable situation for both the callers and the DVR contact center professionals. In addition, there was an over-reliance on the callback feature, resulting in a below par customer experience.
Solution overview
To tackle these challenges, the KYTC team reviewed several contact center solutions and collaborated with the AWS ProServe team to implement a cloud-based contact center and a virtual agent named Max. Currently, customers can interact with the contact center via voice and chat channels. The contact center is powered by Amazon Connect, and Max, the virtual agent, is powered by Amazon Lex and the AWS QnABot solution.
Amazon Connect directs some incoming calls to the virtual agent (Max) by identifying the caller number. Max uses natural language processing (NLP) to find the best answer to a caller’s question from the DVR’s knowledge base of questions and answers, and responds to the caller using a natural and human-like synthesized voice (powered by Amazon Polly), supplemented when appropriate with an SMS text message containing links to webpages that provide relevant detailed information. With Amazon Lex, the department was able to automate tasks like providing information on REAL IDs, and renewing driver’s licenses or vehicle registrations. If the caller can’t find the desired answer, the call is transferred to a live agent.
The KYTC DVR reports that with the new system, they can handle the same or greater call volumes at a lower operational cost than the previous system. The call handling time has been reduced by 33%. They consistently see 90% of the QnABot traffic routing through the self-service option on the website. The QnABot is now handling close to 35% of the incoming phone calls without the need for human intervention, during regular business hours and after hours as well! In addition, agent training time was reduced to 2 weeks from 4 weeks due to Amazon Connect’s intuitive design and ease of use. Not only did DVR improve the customer and agent experience, but they also avoided high up-front costs and reduced their overall operational cost.
Amazon Lex and the AWS QnABot
Amazon Lex is an AWS service for creating conversational interfaces. You can use Amazon Lex to build capable self-service virtual agents for your contact center to automate a wide variety of caller experiences, such as claims, quotes, payments, purchases, appointments, and more.
The AWS QnABot is an open-source solution that uses Amazon Lex along with other AWS services to automate question answering use cases.
QnABot allows you to quickly deploy a conversational AI virtual agent into your contact centers, websites, and messaging channels, with no coding experience required. You configure curated answers to frequently asked questions using an integrated content management system that supports rich text and rich voice responses optimized for each channel. You can expand the solution’s knowledge base to include searching existing documents and webpage content using Amazon Kendra. QnABot uses Amazon Translate to support user interaction in many languages.
Integrated user feedback and monitoring provide visibility into customer queries, concerns, and sentiment. This enables you to tune and enrich your content, effectively teaching your virtual agent so it gets smarter all the time.
Conclusion
The KYTC DVR contact center has achieved impressive customer experience and cost-efficiency improvements by deploying an Amazon Connect cloud-based contact center, along with a virtual agent built with Amazon Lex and the open-source AWS QnABot solution.
Curious to see if you can benefit from the same approaches that worked for the KYTC DVR? Check out these short demo videos:
Try Amazon Lex or the QnABot for yourself in your own AWS account. You can follow the steps in the implementation guide for automated deployment, or explore the AWS QnABot workshop.
We’d love to hear from you. Let us know what you think in the comments section.
About the Authors
 Tony Momenpour is a systems consultant within the Kentucky Transportation Cabinet. He has worked for the Commonwealth of Kentucky for 19 years in various roles. His focus is to assist the Commonwealth with being able to provide its citizens a great customer service experience.
Tony Momenpour is a systems consultant within the Kentucky Transportation Cabinet. He has worked for the Commonwealth of Kentucky for 19 years in various roles. His focus is to assist the Commonwealth with being able to provide its citizens a great customer service experience.
 Drew Clark is a business analyst/project manager for the Kentucky Transportation Cabinet’s Office of Information Technology. He is focusing on system architecture, application platforms, and modernization for the cabinet. He has been with the Transportation Cabinet since 2016 working in various IT roles.
Drew Clark is a business analyst/project manager for the Kentucky Transportation Cabinet’s Office of Information Technology. He is focusing on system architecture, application platforms, and modernization for the cabinet. He has been with the Transportation Cabinet since 2016 working in various IT roles.
 Rajiv Sharma is a Domain Lead – Contact Center in the AWS Data and Machine Learning team. Rajiv works with our customers to deliver engagements using Amazon Connect and Amazon Lex.
Rajiv Sharma is a Domain Lead – Contact Center in the AWS Data and Machine Learning team. Rajiv works with our customers to deliver engagements using Amazon Connect and Amazon Lex.
 Thomas Rindfuss is a Sr. Solutions Architect on the Amazon Lex team. He invents, develops, prototypes, and evangelizes new technical features and solutions for Language AI services that improves the customer experience and eases adoption.
Thomas Rindfuss is a Sr. Solutions Architect on the Amazon Lex team. He invents, develops, prototypes, and evangelizes new technical features and solutions for Language AI services that improves the customer experience and eases adoption.
 Bob Strahan is a Principal Solutions Architect in the AWS Language AI Services team.
Bob Strahan is a Principal Solutions Architect in the AWS Language AI Services team.
Amazon, MIT research symposium focused on cutting-edge technology
Attendees explored new avenues of research in areas including robotics and conversational AI via roundtables moderated by researchers from Amazon.Read More
Build end-to-end document processing pipelines with Amazon Textract IDP CDK Constructs
Intelligent document processing (IDP) with AWS helps automate information extraction from documents of different types and formats, quickly and with high accuracy, without the need for machine learning (ML) skills. Faster information extraction with high accuracy can help you make quality business decisions on time, while reducing overall costs. For more information, refer to Intelligent document processing with AWS AI services: Part 1.
However, complexity arises when implementing real-world scenarios. Documents are often sent out of order, or they may be sent as a combined package with multiple form types. Orchestration pipelines need to be created to introduce business logic, and also account for different processing techniques depending on the type of form inputted. These challenges are only magnified as teams deal with large document volumes.
In this post, we demonstrate how to solve these challenges using Amazon Textract IDP CDK Constructs, a set of pre-built IDP constructs, to accelerate the development of real-world document processing pipelines. For our use case, we process an Acord insurance document to enable straight-through processing, but you can extend this solution to any use case, which we discuss later in the post.
Acord document processing at scale
Straight-through processing (STP) is a term used in the financial industry to describe the automation of a transaction from start to finish without the need for manual intervention. The insurance industry uses STP to streamline the underwriting and claims process. This involves the automatic extraction of data from insurance documents such as applications, policy documents, and claims forms. Implementing STP can be challenging due to the large amount of data and the variety of document formats involved. Insurance documents are inherently varied. Traditionally, this process involves manually reviewing each document and entering the data into a system, which is time-consuming and prone to errors. This manual approach is not only inefficient but can also lead to errors that can have a significant impact on the underwriting and claims process. This is where IDP on AWS comes in.
To achieve a more efficient and accurate workflow, insurance companies can integrate IDP on AWS into the underwriting and claims process. With Amazon Textract and Amazon Comprehend, insurers can read handwriting and different form formats, making it easier to extract information from various types of insurance documents. By implementing IDP on AWS into the process, STP becomes easier to achieve, reducing the need for manual intervention and speeding up the overall process.
This pipeline allows insurance carriers to easily and efficiently process their commercial insurance transactions, reducing the need for manual intervention and improving the overall customer experience. We demonstrate how to use Amazon Textract and Amazon Comprehend to automatically extract data from commercial insurance documents, such as Acord 140, Acord 125, Affidavit of Home Ownership, and Acord 126, and analyze the extracted data to facilitate the underwriting process. These services can help insurance carriers improve the accuracy and speed of their STP processes, ultimately providing a better experience for their customers.
Solution overview
The solution is built using the AWS Cloud Development Kit (AWS CDK), and consists of Amazon Comprehend for document classification, Amazon Textract for document extraction, Amazon DynamoDB for storage, AWS Lambda for application logic, and AWS Step Functions for workflow pipeline orchestration.
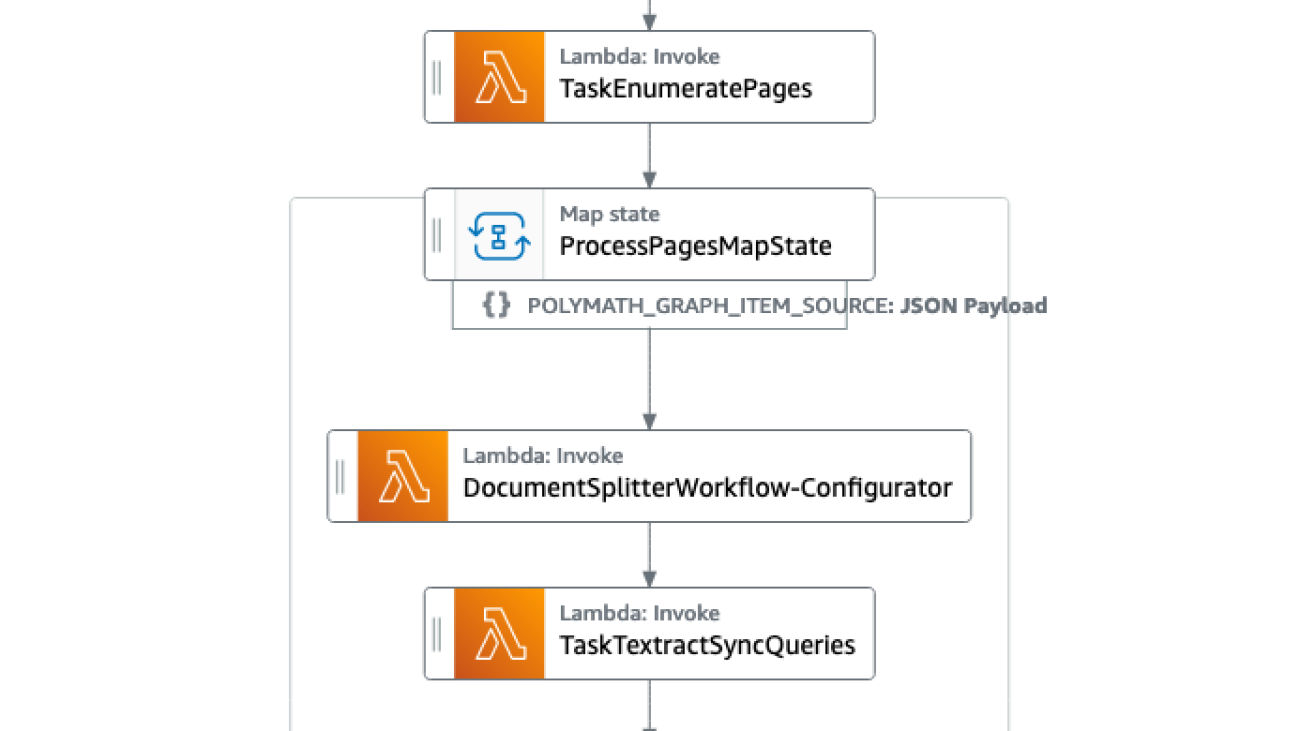
The pipeline consists of the following phases:
- Split the document packages and classification of each form type using Amazon Comprehend.
- Run the processing pipelines for each form type or page of form with the appropriate Amazon Textract API (Signature Detection, Table Extraction, Forms Extraction, or Queries).
- Perform postprocessing of the Amazon Textract output into machine-readable format.
The following screenshot of the Step Functions workflow illustrates the pipeline.
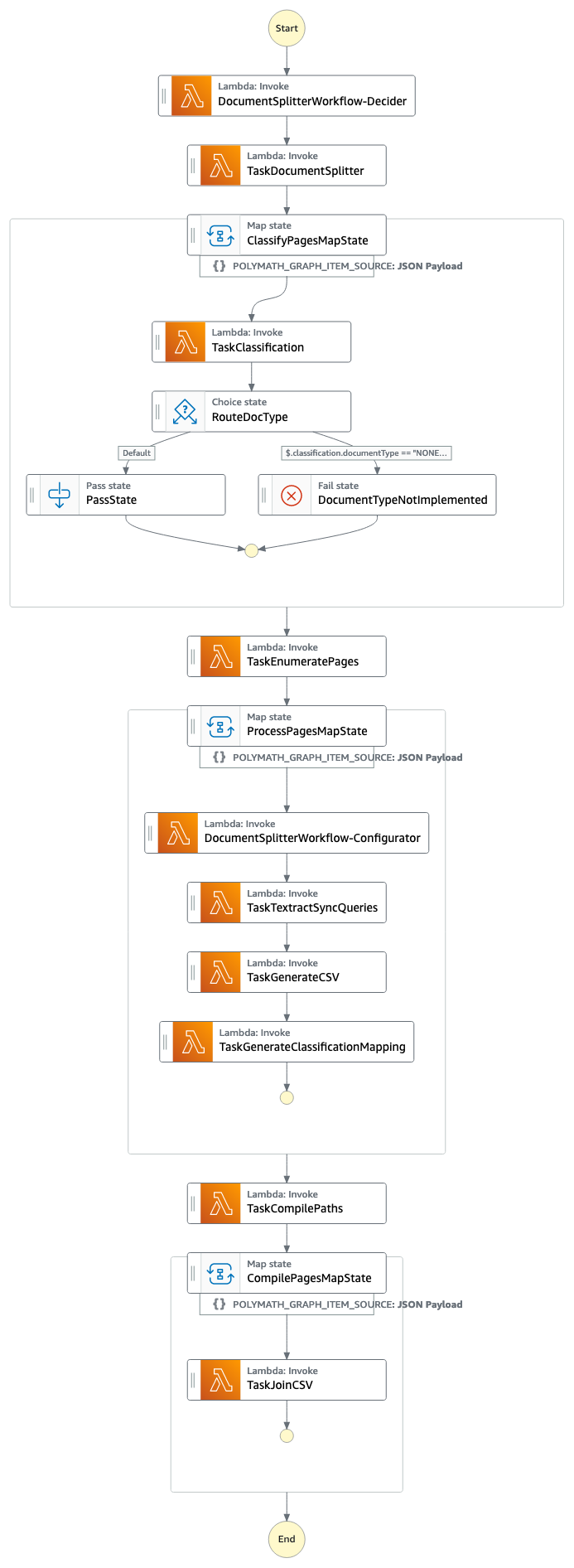
Prerequisites
To get started with the solution, ensure you have the following:
- AWS CDK version 2 installed
- Docker installed and running on your machine
- Appropriate access to Step Functions, DynamoDB, Lambda, Amazon Simple Queue Service (Amazon SQS), Amazon Textract, and Amazon Comprehend
Clone the GitHub repo
Start by cloning the GitHub repository:
Create an Amazon Comprehend classification endpoint
We first need to provide an Amazon Comprehend classification endpoint.
For this post, the endpoint detects the following document classes (ensure naming is consistent):
acord125acord126acord140property_affidavit
You can create one by using the comprehend_acord_dataset.csv sample dataset in the GitHub repository. To train and create a custom classification endpoint using the sample dataset provided, follow the instructions in Train custom classifiers. If you would like to use your own PDF files, refer to the first workflow in the post Intelligently split multi-form document packages with Amazon Textract and Amazon Comprehend.
After training your classifier and creating an endpoint, you should have an Amazon Comprehend custom classification endpoint ARN that looks like the following code:
Navigate to docsplitter/document_split_workflow.py and modify lines 27–28, which contain comprehend_classifier_endpoint. Enter your endpoint ARN in line 28.
Install dependencies
Now you install the project dependencies:
Initialize the account and Region for the AWS CDK. This will create the Amazon Simple Storage Service (Amazon S3) buckets and roles for the AWS CDK tool to store artifacts and be able to deploy infrastructure. See the following code:
Deploy the AWS CDK stack
When the Amazon Comprehend classifier and document configuration table are ready, deploy the stack using the following code:
Upload the document
Verify that the stack is fully deployed.
Then in the terminal window, run the aws s3 cp command to upload the document to the DocumentUploadLocation for the DocumentSplitterWorkflow:
We have created a sample 12-page document package that contains the Acord 125, Acord 126, Acord 140, and Property Affidavit forms. The following images show a 1-page excerpt from each document.
All data in the forms is synthetic, and the Acord standard forms are the property of the Acord Corporation, and are used here for demonstration only.
 |
 |
 |
 |
Run the Step Functions workflow
Now open the Step Function workflow. You can get the Step Function workflow link from the document_splitter_outputs.json file, the Step Functions console, or by using the following command:
Depending on the size of the document package, the workflow time will vary. The sample document should take 1–2 minutes to process. The following diagram illustrates the Step Functions workflow.

When your job is complete, navigate to the input and output code. From here you will see the machine-readable CSV files for each of the respective forms.
To download these files, open getfiles.py. Set files to be the list outputted by the state machine run. You can run this function by running python3 getfiles.py. This will generate the csvfiles_<TIMESTAMP> folder, as shown in the following screenshot.

Congratulations, you have now implemented an end-to-end processing workflow for a commercial insurance application.
Extend the solution for any type of form
In this post, we demonstrated how we could use the Amazon Textract IDP CDK Constructs for a commercial insurance use case. However, you can extend these constructs for any form type. To do this, we first retrain our Amazon Comprehend classifier to account for the new form type, and adjust the code as we did earlier.
For each of the form types you trained, we must specify its queries and textract_features in the generate_csv.py file. This customizes each form type’s processing pipeline by using the appropriate Amazon Textract API.
Queries is a list of queries. For example, “What is the primary email address?” on page 2 of the sample document. For more information, see Queries.
textract_features is a list of the Amazon Textract features you want to extract from the document. It can be TABLES, FORMS, QUERIES, or SIGNATURES. For more information, see FeatureTypes.
Navigate to generate_csv.py. Each document type needs its classification, queries, and textract_features configured by creating CSVRow instances.
For our example we have four document types: acord125, acord126, acord140, and property_affidavit. In in the following we want to use the FORMS and TABLES features on the acord documents, and the QUERIES and SIGNATURES features for the property affidavit.
Refer to the GitHub repository for how this was done for the sample commercial insurance documents.
Clean up
To remove the solution, run the cdk destroy command. You will then be prompted to confirm the deletion of the workflow. Deleting the workflow will delete all the generated resources.
Conclusion
In this post, we demonstrated how you can get started with Amazon Textract IDP CDK Constructs by implementing a straight-through processing scenario for a set of commercial Acord forms. We also demonstrated how you can extend the solution to any form type with simple configuration changes. We encourage you to try the solution with your respective documents. Please raise a pull request to the GitHub repo for any feature requests you may have. To learn more about IDP on AWS, refer to our documentation.
About the Authors
 Raj Pathak is a Senior Solutions Architect and Technologist specializing in Financial Services (Insurance, Banking, Capital Markets) and Machine Learning. He specializes in Natural Language Processing (NLP), Large Language Models (LLM) and Machine Learning infrastructure and operations projects (MLOps).
Raj Pathak is a Senior Solutions Architect and Technologist specializing in Financial Services (Insurance, Banking, Capital Markets) and Machine Learning. He specializes in Natural Language Processing (NLP), Large Language Models (LLM) and Machine Learning infrastructure and operations projects (MLOps).
 Aditi Rajnish is a Second-year software engineering student at University of Waterloo. Her interests include computer vision, natural language processing, and edge computing. She is also passionate about community-based STEM outreach and advocacy. In her spare time, she can be found rock climbing, playing the piano, or learning how to bake the perfect scone.
Aditi Rajnish is a Second-year software engineering student at University of Waterloo. Her interests include computer vision, natural language processing, and edge computing. She is also passionate about community-based STEM outreach and advocacy. In her spare time, she can be found rock climbing, playing the piano, or learning how to bake the perfect scone.
 Enzo Staton is a Solutions Architect with a passion for working with companies to increase their cloud knowledge. He works closely as a trusted advisor and industry specialist with customers around the country.
Enzo Staton is a Solutions Architect with a passion for working with companies to increase their cloud knowledge. He works closely as a trusted advisor and industry specialist with customers around the country.
Snapper provides machine learning-assisted labeling for pixel-perfect image object detection
Bounding box annotation is a time-consuming and tedious task that requires annotators to create annotations that tightly fit an object’s boundaries. Bounding box annotation tasks, for example, require annotators to ensure that all edges of an annotated object are enclosed in the annotation. In practice, creating annotations that are precise and well-aligned to object edges is a laborious process.
In this post, we introduce a new interactive tool called Snapper, powered by a machine learning (ML) model that reduces the effort required of annotators. The Snapper tool automatically adjusts noisy annotations, reducing the time required to annotate data at a high-quality level.
Overview of Snapper
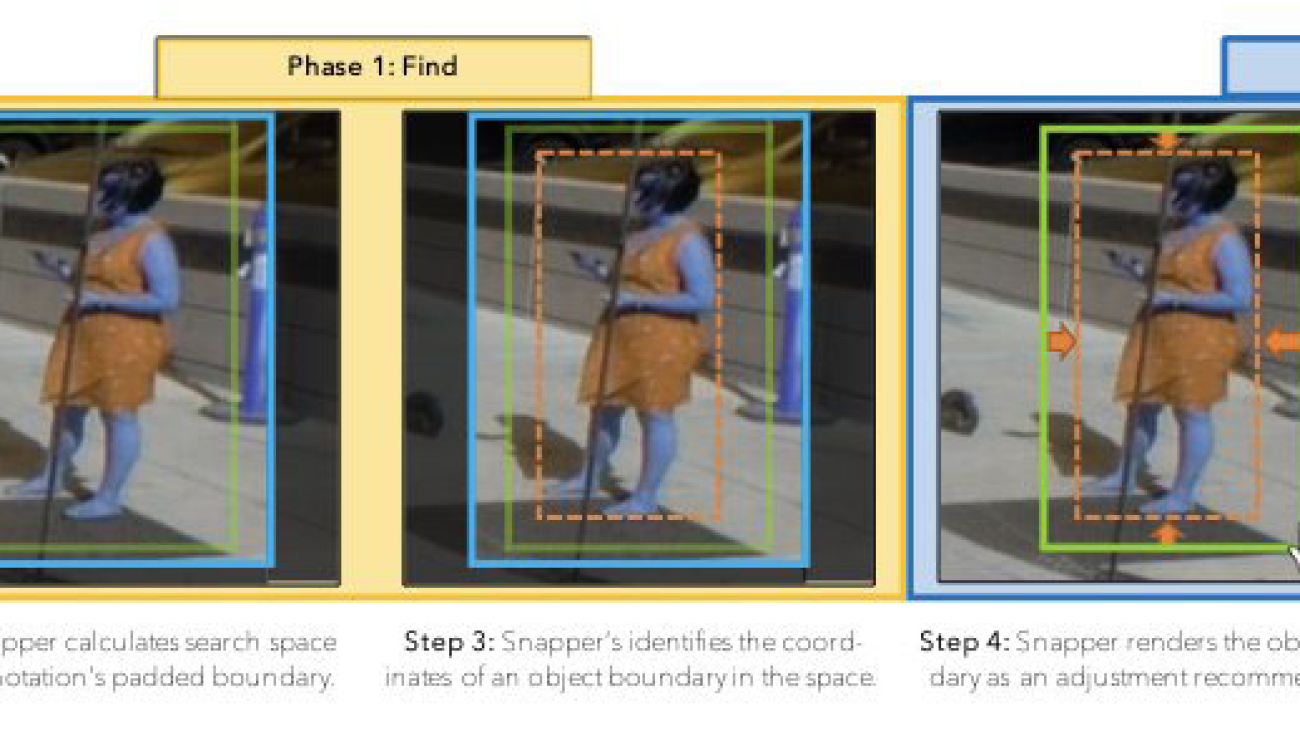
Snapper is an interactive and intelligent system that automatically “snaps” object annotations to image-based objects in real time. With Snapper, annotators place bounding box annotations by drawing boxes, and then see immediate and automatic adjustments to their bounding box to better fit the bounded object.
The Snapper system is composed of two subsystems. The first subsystem is a front-end ReactJS component that intercepts annotation-related mouse events and handles the rendering of the model’s predictions. We integrate this front end with our Amazon SageMaker Ground Truth annotation UI. The second subsystem consists of the model backend, which receives requests from the front-end client, routes the requests to an ML model to generate adjusted bounding box coordinates, and sends the data back to the client.

ML model optimized for annotators
A tremendous number of high-performing object detection models have been proposed by the computer vision community in recent years. However, these state-of-the-art models are typically optimized for unguided object detection. To facilitate Snapper’s “snapping” functionality for adjusting users’ annotations, the input to our model is an initial bounding box, provided by the annotator, which can serve as a marker for the presence of an object. Furthermore, because the system has no intended object class it aims to support, Snapper’s adjustment model should be object-agnostic such that the system performs well on a range of object classes.
In general, these requirements diverge substantially from the use cases of typical ML object detection models. We note that the traditional object detection problem is formulated as “detect the object center, then regress the dimensions.” This is counterintuitive, because accurate predictions of bounding box edges rely crucially on first finding an accurate box center, and then trying to establish scalar distances to edges. Moreover, it doesn’t provide good confidence estimates that focus on the uncertainties of the edge locations, because only the classifier score is available for use.
To give our Snapper model the ability to adjust users’ annotations, we design and implement an ML model custom designed for bounding box adjustment. As input, the model takes an image and a corresponding bounding box annotation. The model extracts features from the image using a convolutional neural network. Following feature extraction, directional spatial pooling is applied to each dimension to aggregate the information needed to identify an appropriate edge location.
We formulate location prediction for bounding boxes as a classification problem over different locations. While seeing the whole object, we ask the machine to reason about the presence or absence of an edge directly at each pixel’s location as a classification task. This improves accuracy, as the reasoning for each edge uses image features from the immediate local neighborhood. Moreover, the scheme decouples the reasoning between different edges, which prevents unambiguous edge locations from being affected by the uncertain ones. Additionally, it provides us with edge-wise intuitive confidence estimates, as our model considers each edge of the object independently (like human annotators would) and provides an interpretable distribution (or uncertainty estimate) for each edge’s location. This allows us to highlight less confident edges for more efficient and precise human review.
Benchmarking and evaluating the Snapper tool
In practice, we find that the Snapper tool streamlines the bounding box annotation task and is very intuitive for users to pick up. We also conducted a quantitative analysis of Snapper to characterize the tool objectively. We evaluated Snapper’s adjustment model using a type of evaluation standard to object detection models that employs two measures to examine validity: Intersection over Union (IoU), and edge and corner deviance. IoU calculates the alignment between two annotations by dividing the annotations’ area of overlap by the annotations’ area of union, yielding a metric that ranges from 0–1. Edge deviance and corner deviance are calculated by taking the fraction of edges and corners that deviate from the ground truth by a pixel value.
To evaluate Snapper, we dynamically generated noisy annotation data by randomly adjusting the COCO ground truth bounding box coordinates with jitter. Our procedure for adding jitter first shifts the center of the bounding box by up to 10% of the corresponding bounding box dimension on each axis and then rescales the dimensions of the bounding box by a randomly sampled ratio between 0.9–1.1. Here, we apply these metrics to the validation set from the official MS-COCO dataset used for training. We specifically calculate the fraction of bounding boxes with IoU exceeding 90% alongside the fraction of edge deviations and corner deviations that deviate less than one or three pixels from the corresponding ground truth. The following table summarizes our findings.

As shown in the preceding table, Snapper’s adjustment model significantly improved the two sources of noisy data across each of the three metrics. With an emphasis on high precision annotations, we observe that applying Snapper to the jittered MS COCO dataset increases the fraction of bounding boxes with IoU exceeding 90% by upwards of 40%.
Conclusion
In this post, we introduced a new ML-powered annotation tool called Snapper. Snapper consists of a SageMaker model backend as well as a front-end component that we integrate into the Ground Truth labeling UI. We evaluated Snapper on simulated noisy bounding box annotations and found that it can successfully refine imperfect bounding boxes. The use of Snapper in labeling tasks can significantly reduce cost and increase accuracy.
To learn more, visit Amazon SageMaker Data Labeling and schedule a consultation today.
About the authors
 Jonathan Buck is a Software Engineer at Amazon Web Services working at the intersection of machine learning and distributed systems. His work involves productionizing machine learning models and developing novel software applications powered by machine learning to put the latest capabilities in the hands of customers.
Jonathan Buck is a Software Engineer at Amazon Web Services working at the intersection of machine learning and distributed systems. His work involves productionizing machine learning models and developing novel software applications powered by machine learning to put the latest capabilities in the hands of customers.
 Alex Williams is an applied scientist in the human-in-the-loop science team at AWS AI where he conducts interactive systems research at the intersection of human-computer interaction (HCI) and machine learning. Before joining Amazon, he was a professor in the Department of Electrical Engineering and Computer Science at the University of Tennessee where he co-directed the People, Agents, Interactions, and Systems (PAIRS) research laboratory. He has also held research positions at Microsoft Research, Mozilla Research, and the University of Oxford. He regularly publishes his work at prem
Alex Williams is an applied scientist in the human-in-the-loop science team at AWS AI where he conducts interactive systems research at the intersection of human-computer interaction (HCI) and machine learning. Before joining Amazon, he was a professor in the Department of Electrical Engineering and Computer Science at the University of Tennessee where he co-directed the People, Agents, Interactions, and Systems (PAIRS) research laboratory. He has also held research positions at Microsoft Research, Mozilla Research, and the University of Oxford. He regularly publishes his work at prem
 Min Bai is an applied scientist at AWS, with a current specialization in 2D / 3D computer vision, with a focus on the fields of autonomous driving and user-friendly AI tools. When not at work, he enjoys exploring nature, especially off the beaten track.
Min Bai is an applied scientist at AWS, with a current specialization in 2D / 3D computer vision, with a focus on the fields of autonomous driving and user-friendly AI tools. When not at work, he enjoys exploring nature, especially off the beaten track.
 Kumar Chellapilla is a General Manager and Director at Amazon Web Services and leads the development of ML/AI Services such as human-in-loop systems, AI DevOps, Geospatial ML, and ADAS/Autonomous Vehicle development. Prior to AWS, Kumar was a Director of Engineering at Uber ATG and Lyft Level 5 and led teams using machine learning to develop self-driving capabilities such as perception and mapping. He also worked on applying machine learning techniques to improve search, recommendations, and advertising products at LinkedIn, Twitter, Bing, and Microsoft Research.
Kumar Chellapilla is a General Manager and Director at Amazon Web Services and leads the development of ML/AI Services such as human-in-loop systems, AI DevOps, Geospatial ML, and ADAS/Autonomous Vehicle development. Prior to AWS, Kumar was a Director of Engineering at Uber ATG and Lyft Level 5 and led teams using machine learning to develop self-driving capabilities such as perception and mapping. He also worked on applying machine learning techniques to improve search, recommendations, and advertising products at LinkedIn, Twitter, Bing, and Microsoft Research.
 Patrick Haffner is a Principal Applied Scientist with the AWS Sagemaker Ground Truth team. He has been working on human-in-the-loop optimization since 1995, when he applied the LeNet Convolutional Neural Network to check recognition. He is interested in holistic approaches where ML algorithms and labeling UIs are optimized together to minimize the labeling cost.
Patrick Haffner is a Principal Applied Scientist with the AWS Sagemaker Ground Truth team. He has been working on human-in-the-loop optimization since 1995, when he applied the LeNet Convolutional Neural Network to check recognition. He is interested in holistic approaches where ML algorithms and labeling UIs are optimized together to minimize the labeling cost.
 Erran Li is the applied science manager at humain-in-the-loop services, AWS AI, Amazon. His research interests are 3D deep learning, and vision and language representation learning. Previously he was a senior scientist at Alexa AI, the head of machine learning at Scale AI and the chief scientist at Pony.ai. Before that, he was with the perception team at Uber ATG and the machine learning platform team at Uber working on machine learning for autonomous driving, machine learning systems and strategic initiatives of AI. He started his career at Bell Labs and was adjunct professor at Columbia University. He co-taught tutorials at ICML’17 and ICCV’19, and co-organized several workshops at NeurIPS, ICML, CVPR, ICCV on machine learning for autonomous driving, 3D vision and robotics, machine learning systems and adversarial machine learning. He has a PhD in computer science at Cornell University. He is an ACM Fellow and IEEE Fellow.
Erran Li is the applied science manager at humain-in-the-loop services, AWS AI, Amazon. His research interests are 3D deep learning, and vision and language representation learning. Previously he was a senior scientist at Alexa AI, the head of machine learning at Scale AI and the chief scientist at Pony.ai. Before that, he was with the perception team at Uber ATG and the machine learning platform team at Uber working on machine learning for autonomous driving, machine learning systems and strategic initiatives of AI. He started his career at Bell Labs and was adjunct professor at Columbia University. He co-taught tutorials at ICML’17 and ICCV’19, and co-organized several workshops at NeurIPS, ICML, CVPR, ICCV on machine learning for autonomous driving, 3D vision and robotics, machine learning systems and adversarial machine learning. He has a PhD in computer science at Cornell University. He is an ACM Fellow and IEEE Fellow.
Recommend top trending items to your users using the new Amazon Personalize recipe
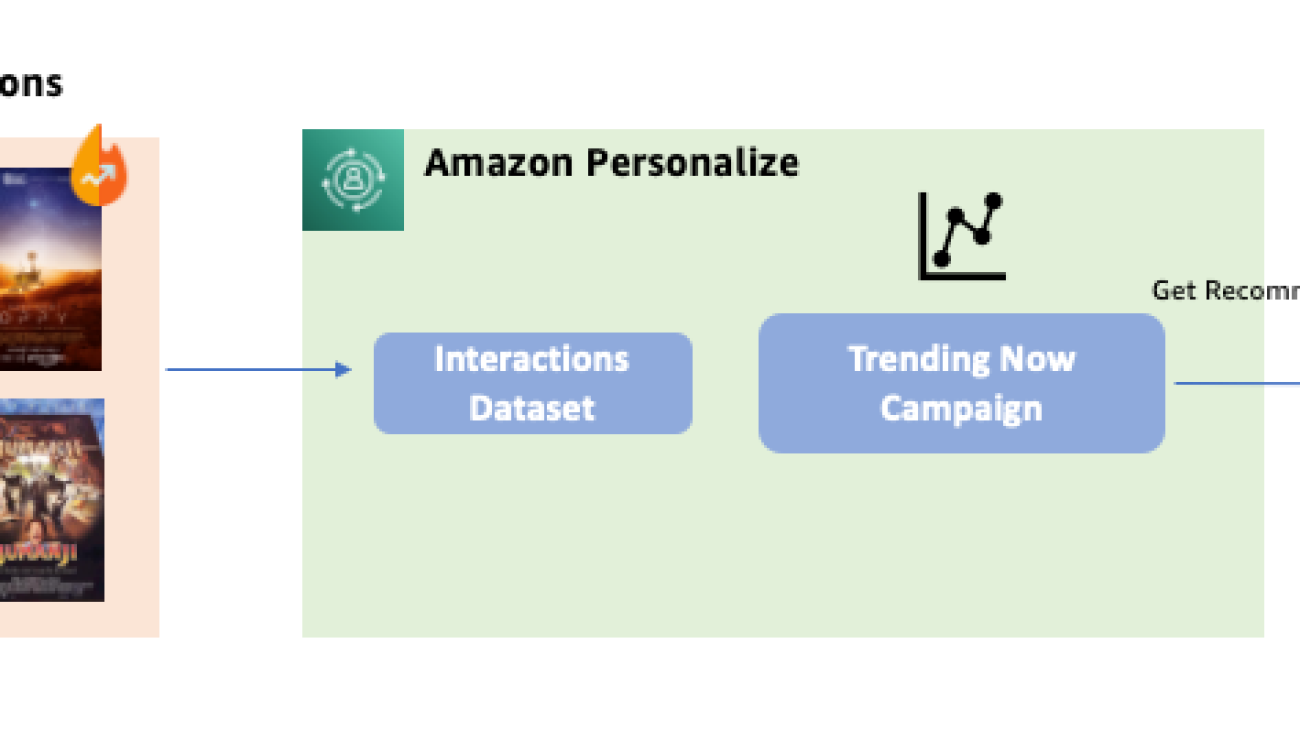
Amazon Personalize is excited to announce the new Trending-Now recipe to help you recommend items gaining popularity at the fastest pace among your users.
Amazon Personalize is a fully managed machine learning (ML) service that makes it easy for developers to deliver personalized experiences to their users. It enables you to improve customer engagement by powering personalized product and content recommendations in websites, applications, and targeted marketing campaigns. You can get started without any prior ML experience, using APIs to easily build sophisticated personalization capabilities in a few clicks. All your data is encrypted to be private and secure, and is only used to create recommendations for your users.
User interests can change based on a variety of factors, such as external events or the interests of other users. It’s critical for websites and apps to tailor their recommendations to these changing interests to improve user engagement. With Trending-Now, you can surface items from your catalog that are rising in popularity with higher velocity than other items, such as trending news, popular social content, or newly released movies. Amazon Personalize looks for items that are rising in popularity at a faster rate than other catalog items to help users discover items that are engaging their peers. Amazon Personalize also allows you to define the time periods over which trends are calculated depending on their unique business context, with options for every 30 minutes, 1 hour, 3 hours, or 1 day, based on the most recent interactions data from users.
In this post, we show how to use this new recipe to recommend top trending items to your users.
Solution overview
Trending-Now identifies the top trending items by calculating the increase in interactions that each item has over configurable intervals of time. The items with the highest rate of increase are considered trending items. The time is based on timestamp data in your interactions dataset. You can specify the time interval by providing a trend discovery frequency when you create your solution.
The Trending-Now recipe requires an interactions dataset, which contains a record of the individual user and item events (such as clicks, watches, or purchases) on your website or app along with the event timestamps. You can use the parameter Trend discovery frequency to define the time intervals over which trends are calculated and refreshed. For example, if you have a high traffic website with rapidly changing trends, you can specify 30 minutes as the trend discovery frequency. Every 30 minutes, Amazon Personalize looks at the interactions that have been ingested successfully and refreshes the trending items. This recipe also allows you to capture and surface any new content that has been introduced in the last 30 minutes and has seen a higher degree of interest from your user base than any preexisting catalog items. For any parameter values that are greater than 2 hours, Amazon Personalize automatically refreshes the trending item recommendations every 2 hours to account for new interactions and new items.
Datasets that have low traffic but use a 30-minute value can see poor recommendation accuracy due to sparse or missing interactions data. The Trending-Now recipe requires that you provide interaction data for at least two past time periods (this time period is your desired trend discovery frequency). If interaction data doesn’t exist for the last 2 time periods, Amazon Personalize will replace the trending items with popular items until the required minimum data is available.
The Trending-Now recipe is available for both custom dataset groups as well as video-on-demand domain dataset groups. In this post, we demonstrate how to tailor your recommendations for the fast-changing trends in user interest with this new Trending-Now feature for a media use case with a custom dataset group. The following diagram illustrates the solution workflow.

For example, in video-on-demand applications, you can use this feature to show what movies are trending in the last 1 hour by specifying 1 hour for your trend discovery frequency. For every 1 hour of data, Amazon Personalize identifies the items with the greatest rate of increase in interactions since the last evaluation. Available frequencies include 30 minutes, 1 hour, 3 hours, and 1 day.
Prerequisites
To use the Trending-Now recipe, you first need to set up Amazon Personalize resources on the Amazon Personalize console. Create your dataset group, import your data, train a solution version, and deploy a campaign. For full instructions, see Getting started.
For this post, we have followed the console approach to deploy a campaign using the new Trending-Now recipe. Alternatively, you can build the entire solution using the SDK approach with this provided notebook. For both approaches, we use the MovieLens public dataset.
Prepare the dataset
Complete the following steps to prepare your dataset:
- Create a dataset group.
- Create an interactions dataset using the following schema:
- Import the interactions data to Amazon Personalize from Amazon Simple Storage Service (Amazon S3).
For the interactions data, we use ratings history from the movies review dataset, MovieLens.
Please use below python code to curate interactions dataset from the MovieLens public dataset.
The MovieLens dataset contains the user_id, rating, item_id, interactions between the users and items, and the time this interaction took place (a timestamp, which is given as UNIX epoch time). The dataset also contains movie title information to map the movie ID to the actual title and genres. The following table is a sample of the dataset.
| USER_ID | ITEM_ID | TIMESTAMP | TITLE | GENRES |
| 116927 | 1101 | 1105210919 | Top Gun (1986) | Action|Romance |
| 158267 | 719 | 974847063 | Multiplicity (1996) | Comedy |
| 55098 | 186871 | 1526204585 | Heal (2017) | Documentary |
| 159290 | 59315 | 1485663555 | Iron Man (2008) | Action|Adventure|Sci-Fi |
| 108844 | 34319 | 1428229516 | Island, The (2005) | Action|Sci-Fi|Thriller |
| 85390 | 2916 | 953264936 | Total Recall (1990) | Action|Adventure|Sci-Fi|Thriller |
| 103930 | 18 | 839915700 | Four Rooms (1995) | Comedy |
| 104176 | 1735 | 985295513 | Great Expectations (1998) | Drama|Romance |
| 97523 | 1304 | 1158428003 | Butch Cassidy and the Sundance Kid (1969) | Action|Western |
| 87619 | 6365 | 1066077797 | Matrix Reloaded, The (2003) | Action|Adventure|Sci-Fi|Thriller|IMAX |
The curated dataset includes USER_ID, ITEM_ID (movie ID), and TIMESTAMP to train the Amazon Personalize model. These are the mandatory required fields to train a model with the Trending-Now recipe. The following table is a sample of the curated dataset.
| USER_ID | ITEM_ID | TIMESTAMP |
| 48953 | 529 | 841223587 |
| 23069 | 1748 | 1092352526 |
| 117521 | 26285 | 1231959564 |
| 18774 | 457 | 848840461 |
| 58018 | 179819 | 1515032190 |
| 9685 | 79132 | 1462582799 |
| 41304 | 6650 | 1516310539 |
| 152634 | 2560 | 1113843031 |
| 57332 | 3387 | 986506413 |
| 12857 | 6787 | 1356651687 |
Train a model
After the dataset import job is complete, you’re ready to train your model.
- On the Solutions tab, choose Create solution.
- Choose the
new aws-trending-nowrecipe. - In the Advanced configuration section, set Trend discovery frequency to 30 minutes.
- Choose Create solution to start training.

Create a campaign
In Amazon Personalize, you use a campaign to make recommendations for your users. In this step, you create a campaign using the solution you created in the previous step and get the Trending-Now recommendations:
- On the Campaigns tab, choose Create campaign.
- For Campaign name, enter a name.
- For Solution, choose the solution
trending-now-solution. - For Solution version ID, choose the solution version that uses the
aws-trending-nowrecipe. - For Minimum provisioned transactions per second, leave it at the default value.
- Choose Create campaign to start creating your campaign.

Get recommendations
After you create or update your campaign, you can get a recommended list of items that are trending, sorted from highest to lowest. On the campaign (trending-now-campaign) Personalization API tab, choose Get recommendations.

The following screenshot shows the campaign detail page with results from a GetRecommendations call that includes the recommended items and the recommendation ID.

The results from the GetRecommendations call includes the IDs of recommended items. The following table is a sample after mapping the IDs to the actual movie titles for readability. The code to perform the mapping is provided in the attached notebook.
| ITEM_ID | TITLE |
| 356 | Forrest Gump (1994) |
| 318 | Shawshank Redemption, The (1994) |
| 58559 | Dark Knight, The (2008) |
| 33794 | Batman Begins (2005) |
| 44191 | V for Vendetta (2006) |
| 48516 | Departed, The (2006) |
| 195159 | Spider-Man: Into the Spider-Verse (2018) |
| 122914 | Avengers: Infinity War – Part II (2019) |
| 91974 | Underworld: Awakening (2012) |
| 204698 | Joker (2019) |
Get trending recommendations
After you create a solution version using the aws-trending-now recipe, Amazon Personalize will identify the top trending items by calculating the increase in interactions that each item has over configurable intervals of time. The items with the highest rate of increase are considered trending items. The time is based on timestamp data in your interactions dataset.
Now let’s provide the latest interactions to Amazon Personalize to calculate the trending items. We can provide the latest interactions using real-time ingestion by creating an event tracker or through a bulk data upload with a dataset import job in incremental mode. In the notebook, we have provided sample code to individually import the latest real-time interactions data into Amazon Personalize using the event tracker.
For this post we will provide the latest interactions as a bulk data upload with a dataset import job in incremental mode. Please use below python code to generate dummy incremental interactions and upload the incremental interactions data using a dataset import job.
We have synthetically generated these interactions by randomly selecting a few values for USER_ID and ITEM_ID, and generating interactions between those users and items with latest timestamps. The following table contains the randomly selected ITEM_ID values that are used for generating incremental interactions.
| ITEM_ID | TITLE |
| 153 | Batman Forever (1995) |
| 260 | Star Wars: Episode IV – A New Hope (1977) |
| 1792 | U.S. Marshals (1998) |
| 2363 | Godzilla (Gojira) (1954) |
| 2407 | Cocoon (1985) |
| 2459 | Texas Chainsaw Massacre, The (1974) |
| 3948 | Meet the Parents (2000) |
| 6539 | Pirates of the Caribbean: The Curse of the Bla… |
| 8961 | Incredibles, The (2004) |
| 61248 | Death Race (2008) |
Upload the incremental interactions data by selecting Append to current dataset (or use incremental mode if using APIs), as shown in the following snapshot.

After the import job of incremental interactions dataset is complete, wait for the length of the trend discovery frequency time that you configured for the new recommendations to get reflected.
Choose Get recommendations on the campaign API page to get the latest recommended list of items that are trending.

Now we see the latest list of recommended items. The following table contains the data after mapping the IDs to the actual movie titles for readability. The code to perform the mapping is provided in the attached notebook.
| ITEM_ID | TITLE |
| 260 | Star Wars: Episode IV – A New Hope (1977) |
| 6539 | Pirates of the Caribbean: The Curse of the Bla… |
| 153 | Batman Forever (1995) |
| 3948 | Meet the Parents (2000) |
| 1792 | U.S. Marshals (1998) |
| 2459 | Texas Chainsaw Massacre, The (1974) |
| 2363 | Godzilla (Gojira) (1954) |
| 61248 | Death Race (2008) |
| 8961 | Incredibles, The (2004) |
| 2407 | Cocoon (1985) |
The preceding GetRecommendations call includes the IDs of recommended items. Now we see the ITEM_ID values recommended are from the incremental interactions dataset that we had provided to the Amazon Personalize model. This is not surprising because these are the only items that gained interactions in the most recent 30 minutes from our synthetic dataset.
You have now successfully trained a Trending-Now model to generate item recommendations that are becoming popular with your users and tailor the recommendations according to user interest. Going forward, you can adapt this code to create other recommenders.
You can also use filters along with the Trending-Now recipe to differentiate the trends between different types of content, like long vs. short videos, or apply promotional filters to explicitly recommend specific items based on rules that align with your business goals.
Clean up
Make sure you clean up any unused resources you created in your account while following the steps outlined in this post. You can delete filters, recommenders, datasets, and dataset groups via the AWS Management Console or using the Python SDK.
Summary
The new aws-trending-now recipe from Amazon Personalize helps you identify the items that are rapidly becoming popular with your users and tailor your recommendations for the fast-changing trends in user interest.
For more information about Amazon Personalize, see the Amazon Personalize Developer Guide.
About the authors
 Vamshi Krishna Enabothala is a Sr. Applied AI Specialist Architect at AWS. He works with customers from different sectors to accelerate high-impact data, analytics, and machine learning initiatives. He is passionate about recommendation systems, NLP, and computer vision areas in AI and ML. Outside of work, Vamshi is an RC enthusiast, building RC equipment (planes, cars, and drones), and also enjoys gardening.
Vamshi Krishna Enabothala is a Sr. Applied AI Specialist Architect at AWS. He works with customers from different sectors to accelerate high-impact data, analytics, and machine learning initiatives. He is passionate about recommendation systems, NLP, and computer vision areas in AI and ML. Outside of work, Vamshi is an RC enthusiast, building RC equipment (planes, cars, and drones), and also enjoys gardening.
 Anchit Gupta is a Senior Product Manager for Amazon Personalize. She focuses on delivering products that make it easier to build machine learning solutions. In her spare time, she enjoys cooking, playing board/card games, and reading.
Anchit Gupta is a Senior Product Manager for Amazon Personalize. She focuses on delivering products that make it easier to build machine learning solutions. In her spare time, she enjoys cooking, playing board/card games, and reading.
 Abhishek Mangal is a Software Engineer for Amazon Personalize and works on architecting software systems to serve customers at scale. In his spare time, he likes to watch anime and believes ‘One Piece’ is the greatest piece of story-telling in recent history.
Abhishek Mangal is a Software Engineer for Amazon Personalize and works on architecting software systems to serve customers at scale. In his spare time, he likes to watch anime and believes ‘One Piece’ is the greatest piece of story-telling in recent history.

Bundesliga Match Fact Ball Recovery Time: Quantifying teams’ success in pressing opponents on AWS
In football, ball possession is a strong predictor for team success. It’s hard to control the game without having control over the ball. In the past three Bundesliga seasons, as well as in the current season (at the time of this writing), Bayern Munich is ranked first in the table and in ball possession percentage, followed by Dortmund being second in both. The active tactics and playing styles that facilitate high possession values through ball retention have been widely discussed. Terms like Tiki-Taka were established to describe a playing style that is characterized by a precise short passing game with frequent long ball possessions of the attacking team. However, in order to arrive at high possession rates, teams also need to adapt their defense to quickly win back a ball lost to the opponent. Terms like high-press, middle-press, and low-press are often used to describe the amount of room a defending team is allowing their opponents when moving towards their goal before applying pressure on the ball.
The recent history of Bundesliga club FC Köln emphasizes the effect of different pressing styles on a team’s success. Since Steffen Baumgart took over as coach at FC Köln in 2021, the team has managed to lift themselves from the bottom and has established a steady position in the middle of the table. When analyzing the team statistics after the switch in coaches, one aspect stands our specifically: with 54 pressing situations per game, the team was ranked first in the league, being able to win the ball back in a third of those situations. This proved especially successful when attacking in the opponent’s half of the pitch. With an increased number of duels per match (+10% compared to previous season), the Billy Goats managed to finish the last season on a strong seventh place, securing a surprising spot in the UEFA Europa Conference League.
Our previous Bundesliga Match Fact (BMF) Pressure Handling sheds light on how successful different players and teams are in withstanding this pressure while retaining the ball. To facilitate the understanding of how active and successful a defending team applies pressure, we need to understand how long it takes them to win back a lost ball. Which Bundesliga teams are fastest in winning back lost possessions? How does a team’s ability to quickly regain possession develop over the course of a match? Are their recovery times diminished when playing stronger teams? And finally, are short recovery times a necessary ingredient to a winning formula?
Introducing the new Bundesliga Match Fact: Ball Recovery Time.
 |
 |
 |
How it works
Ball Recovery Time (BRT) calculates the amount of time it takes for a team to regain possession of the ball. It indicates how hungry a team is at winning the ball back and is measured in average ball recovery time in seconds.
Throughout a match, the positions of the players and the ball are tracked by cameras around the pitch and stored as coordinates in a positional data stream. This allows us to calculate which player has ball possession at any given moment in time. It’s no surprise that the ball possession alternates between the two teams over the course of a match. However, less obvious are the times where the ball possession is contested and can’t be directly assigned to any particular team. The timer for ball recovery starts counting from the moment the team loses possession until they regain it. The time when the ball’s possession is not clear is included in the timer, incentivizing teams to favor clear and fast recoveries.
The following example shows a sequence of alternating ball possessions between team A and B. At some point, team A loses ball possession to team B, which starts the ball recovery time for team A. The ball recovery time is calculated until team A regains the ball.

As already mentioned, FC Cologne has been the league leader in the number of pressing situations since Steffen Baumgart took office. This style of play is also evident when you look at the ball recovery times for the first 24 match days in the 2022/23 season. Cologne achieved an incredible ball recovery time of 13.4 seconds, which is the fourth fastest in the league. On average, it took them only 1.4 seconds longer to recover a lost ball than the fastest team in the league, Bayern Munich, who got the ball back from their opponents after an average of 12 seconds.

Let’s look at certain games played by Cologne in the 2022/23 season. The following chart shows the ball recovery times of Cologne for various games. At least two games stand out in particular. On the first match day, they faced FC Schalke—also known as the Miners—and managed an exceptionally low BRT of 8.3 seconds. This was aided by a red card for Schalke in the first half when the game was still tied 0:0. Cologne’s quick recovery of the ball subsequently helped them prevail a 3:1 against the Miners.

Also worth mentioning is the Cologne derby against Borussia Mönchengladbach on the ninth match day. In that game, Cologne took 21.6 seconds to recover the ball, which is around 60% slower than their season average of 13.4 seconds. A yellow-red card just before halftime certainly made it difficult for the Billy Goats to speed up recovering the ball from their local rival Borussia. At the same time, Borussia managed to win the ball back from Cologne on average after just 13.7 seconds, resulting in a consistent 5:2 win for Borussia over their perennial rivals from Cologne.
How it’s implemented
Positional data from an ongoing match, which is recorded at a sampling rate of 25 Hz, is utilized to determine the time taken to recover the ball. To ensure real-time updates of ball recovery times, we have implemented Amazon Managed Streaming for Apache Kafka (Amazon MSK) as a central solution for data streaming and messaging. This allows for seamless communication of positional data and various outputs of Bundesliga Match Facts between containers in real time.
The following diagram illustrates the end-to-end workflow for Ball Recovery Time.

The match-related data is collected and ingested using DFL’s DataHub. Metadata of the match is processed within the AWS Lambda function MetaDataIngestion, while positional data is ingested using the AWS Fargate container called MatchLink. Both the Lambda function and the Fargate container publish the data for further consumption in the relevant MSK topics. The core of the Ball Recovery Time BMF resides within a dedicated Fargate container called BMF BallRecoveryTime. This container operates throughout the corresponding match and obtains all necessary data continuously through Amazon MSK. Its logic responds instantly to positional changes and constantly computes the current ball recovery times.
After the ball recovery times have been computed, they’re transmitted back to the DataHub for distribution to other consumers of Bundesliga Match Facts. Additionally, the ball recovery times are sent to a specific topic in the MSK cluster, where they can be accessed by other Bundesliga Match Facts. A Lambda function retrieves all recovery times from the relevant Kafka topic and stores them in an Amazon Aurora Serverless database. This data is then utilized to create interactive, near-real-time visualizations with Amazon QuickSight.
Summary

In this post, we demonstrated how the new Bundesliga Match Fact Ball Recovery Time makes it possible to quantify and objectively compare the speed of different Bundesliga teams in winning back a lost ball possession. This allows commentators and fans to understand how early and successful teams apply pressure to their opponents.
The new Bundesliga Match Fact is the result of an in-depth analysis by a team of football experts and data scientists from the Bundesliga and AWS. Noteworthy ball recovery times are shown in the live ticker of the respective matches in the official Bundesliga app and website. During live matches, ball recovery times are also provided to commentators through the data story finder and visually shown to fans at key moments in broadcast.
We hope that you enjoy this brand-new Bundesliga Match Fact and that it provides you with new insights into the game. To learn more about the partnership between AWS and Bundesliga, visit Bundesliga on AWS!
We’re excited to learn what patterns you will uncover. Share your insights with us: @AWScloud on Twitter, with the hashtag #BundesligaMatchFacts.
About the Authors
Javier Poveda-Panter is a Senior Data Scientist for EMEA sports customers within the AWS Professional Services team. He enables customers in the area of spectator sports to innovate and capitalize on their data, delivering high-quality user and fan experiences through machine learning and data science. He follows his passion for a broad range of sports, music, and AI in his spare time.
Tareq Haschemi is a consultant within AWS Professional Services. His skills and areas of expertise include application development, data science, machine learning, and big data. He supports customers in developing data-driven applications within the cloud. Prior to joining AWS, he was also a consultant in various industries such as aviation and telecommunications. He is passionate about enabling customers on their data/AI journey to the cloud.
Jean-Michel Lourier is a Senior Data Scientist within AWS Professional Services. He leads teams implementing data driven applications side by side with AWS customers to generate business value out of their data. He’s passionate about diving into tech and learning about AI, machine learning, and their business applications. He is also an enthusiastic cyclist, taking long bike-packing trips.
Fotinos Kyriakides is an ML Engineer with AWS Professional Services. He focuses his efforts in the fields of machine learning, MLOps, and application development, in supporting customers to develop applications in the cloud that leverage and innovate on insights generated from data. In his spare time, he likes to run and explore nature.
Luuk Figdor is a Principal Sports Technology Advisor in the AWS Professional Services team. He works with players, clubs, leagues, and media companies such as the Bundesliga and Formula 1 to help them tell stories with data using machine learning. In his spare time, he likes to learn all about the mind and the intersection between psychology, economics, and AI.
Bundesliga Match Fact Keeper Efficiency: Comparing keepers’ performances objectively using machine learning on AWS
The Bundesliga is renowned for its exceptional goalkeepers, making it potentially the most prominent among Europe’s top five leagues in this regard. Apart from the widely recognized Manuel Neuer, the Bundesliga has produced remarkable goalkeepers who have excelled in other leagues, including the likes of Marc-André ter Stegen, who is a superstar at Barcelona. In view of such steep competition, people are split on the question of who the most remarkable sweeper in the German top league is. As demonstrated by Yann Sommer’s stunning 19 saves (Bundesliga record) against Bayern Munich last summer that aided his former club Mönchengladbach to pull a draw on the Bavarians, this league’s keepers are fiercely vying for the top spot.
We have witnessed time and time again that a keeper can make or break a win, yet it remains challenging to objectively quantify their effect on a team’s success. Who is the most efficient goal keeper in the Bundesliga? Who prevents more goals than the average? How can we even compare keepers with different playing styles? It’s about time to shed some light on our guardians’ achievements. Enter the brand-new Bundesliga Match Fact: Keeper Efficiency.
When talking about the best of the best shot-stoppers in the Bundesliga, the list is long and rarely complete. In recent years, one name has been especially dominant: Kevin Trapp. For years, Trapp has been regarded as one of the finest goalies in the Bundesliga. Not only was he widely considered the top-rated goalkeeper in the league during the 2021/22 season, but he also held that title back in 2018/19 when Eintracht Frankfurt reached the Europa League semifinals. Similar to Yann Sommer, Trapp often delivered his best performances on nights when his team was up against the Bavarians.
Many football enthusiasts would argue that Yann Sommer is the best keeper in Germany’s top league, despite being also the smallest. Sommer is highly skilled with the ball at his feet and has demonstrated his ability to produce jaw-dropping saves that are on par with others in the world elite. Although Sommer can genuinely match any goalkeeper’s level on his best days, he hasn’t had enough of those best days frequently in the past. Although he has improved his consistency over time, he still makes occasional errors that can frustrate fans. While being the well-deserved Switzerland’s #1 since 2016, time will tell whether he pushes Manuel Neuer off the throne in Munich.
And let’s not forget about Gregor Kobel. Since joining Borussia Dortmund, Kobel, who has previously played for Hoffenheim, Augsburg, and VfB Stuttgart, has been a remarkable signing for the club. Although Jude Bellingham has possibly overtaken him as the team’s highest valued player, there is still a valid argument that Kobel is the most important player for Dortmund. At only 25 years old, Kobel is among the most promising young goalkeepers globally, with the ability to make quality saves and face a significant number of shots in the Bundesliga. The pressure to perform at Dortmund is immense, second only to their fierce rivals Bayern Munich (at the time of this writing), and Kobel doesn’t have the same defensive protection as any Bayern keeper would. In 2022/23 so far, he has almost secured a clean sheet every other match for Die Schwarzgelben, despite the team’s inconsistency and often poor midfield performance.
As these examples show, the ways in which keepers shine and compete are manifold. Therefore, it’s no surprise that determining the proficiency of goalkeepers in preventing the ball from entering the net is considered one of the most difficult tasks in football data analysis. Bundesliga and AWS have collaborated to perform an in-depth examination to study the quantification of achievements of Bundesliga’s keepers. The result is a machine learning (ML)-powered insight that allows fans to easily evaluate and compare the goalkeepers’ proficiencies. We’re excited to announce the new Bundesliga Match Fact: Keeper Efficiency.

How it works
The new Bundesliga Match Fact Keeper Efficiency allows fans to evaluate the proficiency of goalkeepers in terms of their ability to prevent shooters from scoring. Although tallying the total number of saves a goalkeeper makes during a match can be informative, it doesn’t account for variations in the difficulty of the shots faced. To avoid treating a routine catch of a 30-meter shot aimed directly at the goalkeeper as being equivalent to an exceptional save made from a shot taken from a distance of 5 meters, we assign each shot a value known as xSaves, which measures the probability that a shot will be saved by a Keeper. In other words, a shot with an xSaves value of 0.9 would be saved 9 out of 10 times.
An ML model is trained through Amazon SageMaker, using data from four seasons of the first and second Bundesliga, encompassing all shots that landed on target (either resulting in a goal or being saved). Using derived characteristics of a shot, the model generates the probability that the shot will be successfully saved by the goalkeeper. Some of the factors considered by the model are: distance to goal, distance to goalkeeper, shot angle, number of players between the shot location and the goal, goalkeeper positioning, and predicted shot trajectory. We utilize an extra model to predict the trajectory of the shot using the initial few frames of the observed shot. With the predicted trajectory of the shot and the goalkeeper’s position, the xSaves model can evaluate the probability of the goalkeeper saving the ball.
Adding up all xSaves values of saved and conceded shots by a goalkeeper yields the expected number of saves a goalkeeper should have during a match or season. Comparing that against the actual number of saves yields the Keeper Efficiency. In other words, a goalkeeper with a positive Keeper Efficiency rating indicates that the goalkeeper has saved more shots than expected.

Keeper Efficiency in action
The following are a few estimates to showcase the Keeper Efficiency.
Example 1
Due to the large distance to the goal, and the relatively low distance and large number of defenders covering the goal, the probability that the shot will result in a goal is low. Because the goalkeeper saved the shot, he will receive a small increase in the Keeper Efficiency ranking.
Example 2
In this example, the striker is much closer to the goal, with only one defender between him and the goalkeeper, resulting in a lower save probability.
Example 3
In this example, the speed of the ball is much higher and the ball is higher off the ground, resulting in a very low probability that the ball will be saved. The goal was conceded, and therefore the goalkeeper will see a small decrease in his Keeper Efficiency statistic.
What makes a good save
The preceding video shows a medium difficulty shot with approximately a 50/50 chance of being saved, meaning that half the keepers in the league would save it and the other half concede the goal. What makes this save remarkable is the goalkeeper’s positioning, instinct, and reflexes. The goalkeeper remains focused on the ball even when his vision is obstructed by the defenders and changes his positioning multiple times according to where he thinks the biggest opening lies. Looking at it frame by frame, as soon as the attacking player winds up to take the shot, the goalkeeper makes a short hop backwards to better position himself for the jump to save the shot. The keeper’s reflexes are perfect, landing precisely at the moment when the striker kicks the ball. If he lands too late, he would be mid-air as the ball is flying towards the goal, wasting precious time. With both feet planted on the grass, he makes a strong jump, managing to save the shot.
How Keeper Efficiency is implemented
This Bundesliga Match Fact consumes both event and positional data. Positional data is information gathered by cameras on the positions of the players and ball at any moment during the match (x-y coordinates), arriving at 25Hz. Event data consists of hand-labelled event descriptions with useful attributes, such as shot on target. When a shot on target (a scored or saved goal) event is received, it queries the stored positional data and finds a sync frame—a frame during which the timing and position of the ball match with the event. This frame is used to synchronize the event data with the positional data. Having synchronized, the subsequent frames that track the ball trajectory are used to predict where the ball will enter the goal. Additionally, the goalkeeper position at the time of the shot is considered, as well as a number of other features such as the number of defenders between the ball and the goalpost and the speed of the ball. All this data is then passed to an ML model (xGBoost), which is deployed on Amazon SageMaker Serverless Inference to generate a prediction on the probability of the shot being saved.
The BMF logic itself (except for the ML model) runs on an AWS Fargate container. For every xSaves prediction, it produces a message with the prediction as a payload, which then gets distributed by a central message broker running on Amazon Managed Streaming for Apache Kafka (Amazon MSK). The information also gets stored in a data lake for future auditing and model improvements. The contents of the Kafka messages then get written via an AWS Lambda function to an Amazon Aurora Serverless database to be presented in an Amazon QuickSight dashboard. The following diagram illustrates this architecture.

Summary

The new Bundesliga Match Fact Keeper Efficiency measures the shot-stopping skills of the Bundesliga’s goalies, which are considered to be among the finest in the world. This gives fans and commentators the unique opportunity to understand quantitatively how much a goalkeeper’s performance has contributed to a team’s match result or seasonal achievements.
This Bundesliga Match Fact was developed among a team of Bundesliga and AWS experts. Noteworthy goalkeeper performances are pushed into the Bundesliga live ticker in the mobile app and on the webpage. Match commentators can observe exceptional Keeper Efficiency through the data story finder, and visuals are presented to the fans as part of broadcasting streams.
We hope that you enjoy this brand-new Bundesliga Match Fact and that it provides you with new insights into the game. To learn more about the partnership between AWS and Bundesliga, visit Bundesliga on AWS!
We’re excited to learn what patterns you will uncover. Share your insights with us: @AWScloud on Twitter, with the hashtag #BundesligaMatchFacts.
About the Authors
Javier Poveda-Panter is a Senior Data Scientist for EMEA sports customers within the AWS Professional Services team. He enables customers in the area of spectator sports to innovate and capitalize on their data, delivering high-quality user and fan experiences through machine learning and data science. He follows his passion for a broad range of sports, music, and AI in his spare time.
Tareq Haschemi is a consultant within AWS Professional Services. His skills and areas of expertise include application development, data science, machine learning, and big data. He supports customers in developing data-driven applications within the cloud. Prior to joining AWS, he was also a consultant in various industries such as aviation and telecommunications. He is passionate about enabling customers on their data/AI journey to the cloud.
Jean-Michel Lourier is a Senior Data Scientist within AWS Professional Services. He leads teams implementing data-driven applications side by side with AWS customers to generate business value out of their data. He’s passionate about diving into tech and learning about AI, machine learning, and their business applications. He is also an enthusiastic cyclist, taking long bike-packing trips.
Fotinos Kyriakides is an ML Engineer with AWS Professional Services. He focuses his efforts in the fields of machine learning, MLOps, and application development, in supporting customers to develop applications in the cloud that leverage and innovate on insights generated from data. In his spare time, he likes to run and explore nature.
Uwe Dick is a Data Scientist at Sportec Solutions AG. He works to enable Bundesliga clubs and media to optimize their performance using advanced stats and data—before, after, and during matches. In his spare time, he settles for less and just tries to last the full 90 minutes for his recreational football team.
Luuk Figdor is a Principal Sports Technology Advisor in the AWS Professional Services team. He works with players, clubs, leagues, and media companies such as the Bundesliga and Formula 1 to help them tell stories with data using machine learning. In his spare time, he likes to learn all about the mind and the intersection between psychology, economics, and AI.