Learn about the development, operational, and process improvements that can be incorporated by organizations to improve the explainability of models while adhering to regulatory requirements.Read More
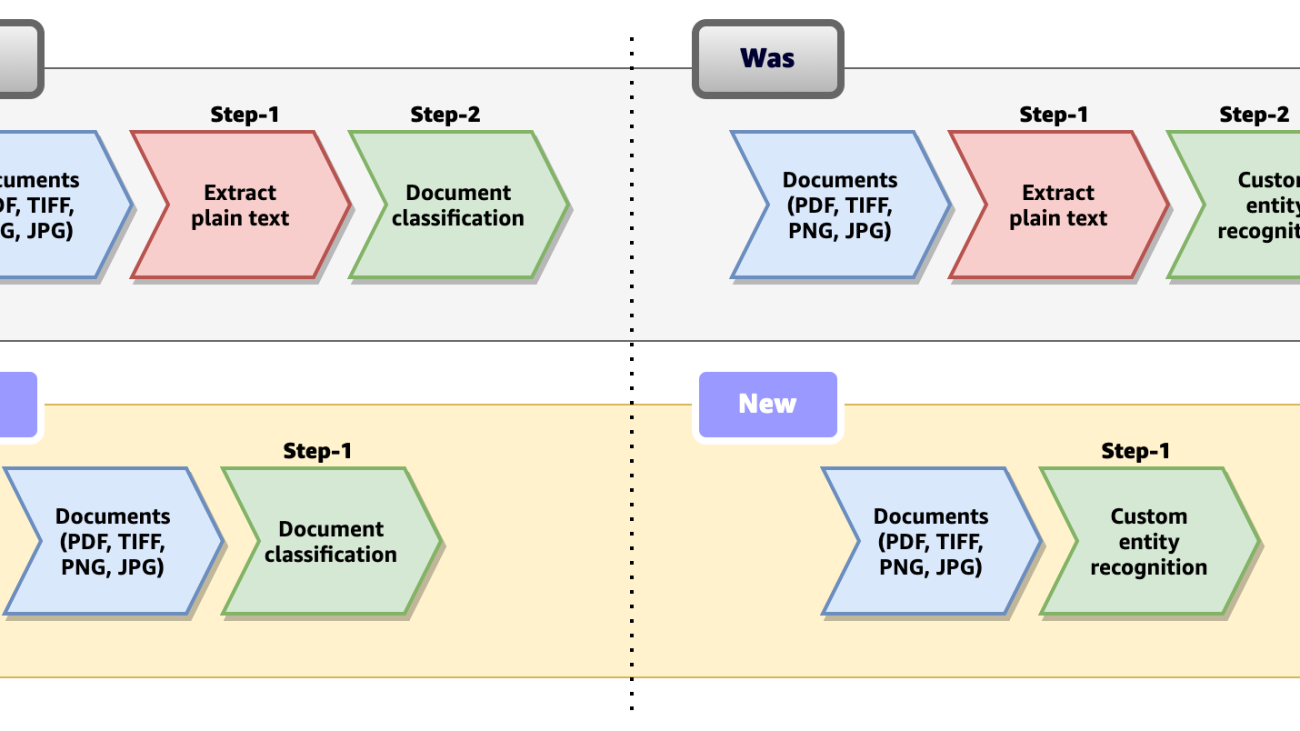
Introducing one-step classification and entity recognition with Amazon Comprehend for intelligent document processing
“Intelligent document processing (IDP) solutions extract data to support automation of high-volume, repetitive document processing tasks and for analysis and insight. IDP uses natural language technologies and computer vision to extract data from structured and unstructured content, especially from documents, to support automation and augmentation.” – Gartner
The goal of Amazon’s intelligent document processing (IDP) is to automate the processing of large amounts of documents using machine learning (ML) in order to increase productivity, reduce costs associated with human labor, and provide a seamless user experience. Customers spend a significant amount of time and effort identifying documents and extracting critical information from them for various use cases. Today, Amazon Comprehend supports classification for plain text documents, which requires you to preprocess documents in semi-structured formats (scanned, digital PDF or images such as PNG, JPG, TIFF) and then use the plain text output to run inference with your custom classification model. Similarly, for custom entity recognition in real time, preprocessing to extract text is required for semi-structured documents such as PDF and image files. This two-step process introduces complexities in document processing workflows.
Last year, we announced support for native document formats with custom named entity recognition (NER) asynchronous jobs. Today, we are excited to announce one-step document classification and real-time analysis for NER for semi-structured documents in native formats (PDF, TIFF, JPG, PNG) using Amazon Comprehend. Specifically, we are announcing the following capabilities:
- Support for documents in native formats for custom classification real-time analysis and asynchronous jobs
- Support for documents in native formats for custom entity recognition real-time analysis
With this new release, Amazon Comprehend custom classification and custom entity recognition (NER) supports documents in formats such as PDF, TIFF, PNG, and JPEG directly, without the need to extract UTF8 encoded plain text from them. The following figure compares the previous process to the new procedure and support.
This feature simplifies document processing workflows by eliminating any preprocessing steps required to extract plain text from documents, and reduces the overall time required to process them.
In this post, we discuss a high-level IDP workflow solution design, a few industry use cases, the new features of Amazon Comprehend, and how to use them.
Overview of solution
Let’s start by exploring a common use case in the insurance industry. A typical insurance claim process involves a claim package that may contain multiple documents. When an insurance claim is filed, it includes documents like insurance claim form, incident reports, identity documents, and third-party claim documents. The volume of documents to process and adjudicate an insurance claim can run up to hundreds and even thousands of pages depending on the type of claim and business processes involved. Insurance claim representatives and adjudicators typically spend hundreds of hours manually sifting, sorting, and extracting information from hundreds or even thousands of claim filings.
Similar to the insurance industry use case, the payment industry also processes large volumes of semi-structured documents for cross-border payment agreements, invoices, and forex statements. Business users spend the majority of their time on manual activities such as identifying, organizing, validating, extracting, and passing required information to downstream applications. This manual process is tedious, repetitive, error prone, expensive, and difficult to scale. Other industries that face similar challenges include mortgage and lending, healthcare and life sciences, legal, accounting, and tax management. It is extremely important for businesses to process such large volumes of documents in a timely manner with a high level of accuracy and nominal manual effort.
Amazon Comprehend provides key capabilities to automate document classification and information extraction from a large volume of documents with high accuracy, in a scalable and cost-effective way. The following diagram shows an IDP logical workflow with Amazon Comprehend. The core of the workflow consists of document classification and information extraction using NER with Amazon Comprehend custom models. The diagram also demonstrates how the custom models can be continuously improved to provide higher accuracies as documents and business processes evolve.
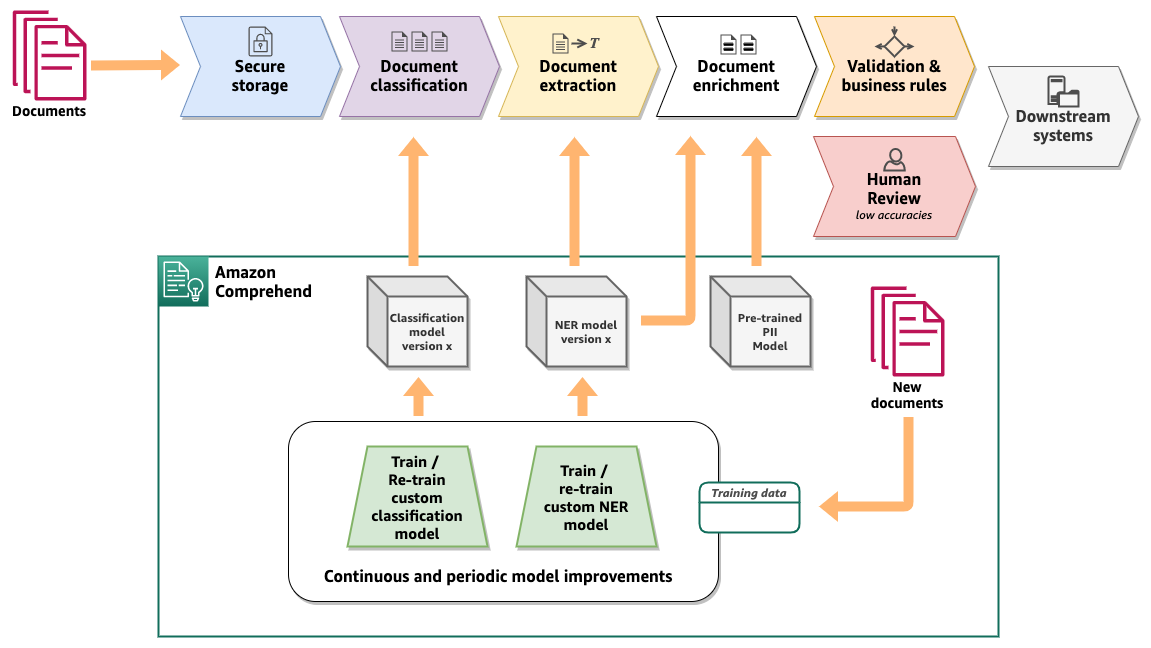
Custom document classification
With Amazon Comprehend custom classification, you can organize your documents into predefined categories (classes). At a high level, the following are the steps to set up a custom document classifier and perform document classification:
- Prepare training data to train a custom document classifier.
- Train a customer document classifier with the training data.
- After the model is trained, optionally deploy a real-time endpoint.
- Perform document classification with either an asynchronous job or in real time using the endpoint.
Steps 1 and 2 are typically done at the beginning of an IDP project after the document classes relevant to the business process are identified. A custom classifier model can then be periodically retrained to improve accuracy and introduce new document classes. You can train a custom classification model either in multi-class mode or multi-label mode. Training can be done for each in one of two ways: using a CSV file, or using an augmented manifest file. Refer to Preparing training data for more details on training a custom classification model. After a custom classifier model is trained, a document can be classified either using real-time analysis or an asynchronous job. Real-time analysis requires an endpoint to be deployed with the trained model and is best suited for small documents depending on the use case. For a large number of documents, an asynchronous classification job is best suited.
Train a custom document classification model
To demonstrate the new feature, we trained a custom classification model in multi-label mode, which can classify insurance documents into one of seven different classes. The classes are INSURANCE_ID, PASSPORT, LICENSE, INVOICE_RECEIPT, MEDICAL_TRANSCRIPTION, DISCHARGE_SUMMARY, and CMS1500. We want to classify sample documents in native PDF, PNG, and JPEG format, stored in an Amazon Simple Storage Service (Amazon S3) bucket, using the classification model. To start an asynchronous classification job, complete the following steps:
- On the Amazon Comprehend console, choose Analysis jobs in the navigation pane.
- Choose Create job.

- For Name, enter a name for your classification job.
- For Analysis type¸ choose Custom classification.
- For Classifier model, choose the appropriate trained classification model.
- For Version, choose the appropriate model version.

In the Input data section, we provide the location where our documents are stored.
- For Input format, choose One document per file.
- For Document read mode¸ choose Force document read action.
- For Document read action, choose Textract detect document text.
This enables Amazon Comprehend to use the Amazon Textract DetectDocumentText API to read the documents before running the classification. The DetectDocumentText API is helpful in extracting lines and words of text from the documents. You may also choose Textract analyze document for Document read action, in which case Amazon Comprehend uses the Amazon Textract AnalyzeDocument API to read the documents. With the AnalyzeDocument API, you can choose to extract Tables, Forms, or both. The Document read mode option enables Amazon Comprehend to extract the text from documents behind the scenes, which helps reduce the extra step of extracting text from the document, which is required in our document processing workflow.
The Amazon Comprehend custom classifier can also process raw JSON responses generated by the DetectDocumentText and AnalyzeDocument APIs, without any modification or preprocessing. This is useful for existing workflows where Amazon Textract is involved in extracting text from the documents already. In this case, the JSON output from Amazon Textract can be fed directly to the Amazon Comprehend document classification APIs.
- In the Output data section, for S3 location, specify an Amazon S3 location where you want the asynchronous job to write the results of the inference.
- Leave the remaining options as default.
- Choose Create job to start the job.

You can view the status of the job on the Analysis jobs page.
When the job is complete, we can view the output of the analysis job, which is stored in the Amazon S3 location provided during the job configuration. The classification output for our single-page PDF sample CMS1500 document is as follows. The output is a file in JSON lines format, which has been formatted to improve readability.
The preceding sample is a single-page PDF document; however, custom classification can also handle multi-page PDF documents. In the case of multi-page documents, the output contains multiple JSON lines, where each line is the classification result of each of the pages in a document. The following is a sample multi-page classification output:
Custom entity recognition
With an Amazon Comprehend custom entity recognizer, you can analyze documents and extract entities like product codes or business-specific entities that fit your particular needs. At a high level, the following are the steps to set up a custom entity recognizer and perform entity detection:
- Prepare training data to train a custom entity recognizer.
- Train a custom entity recognizer with the training data.
- After the model is trained, optionally deploy a real-time endpoint.
- Perform entity detection with either an asynchronous job or in real time using the endpoint.
A custom entity recognizer model can be periodically retrained to improve accuracy and to introduce new entity types. You can train a custom entity recognizer model with either entity lists or annotations. In both cases, Amazon Comprehend learns about the kind of documents and the context where the entities occur to build an entity recognizer model that can generalize to detect new entities. Refer to Preparing the training data to learn more about preparing training data for custom entity recognizer.
After a custom entity recognizer model is trained, entity detection can be done either using real-time analysis or an asynchronous job. Real-time analysis requires an endpoint to be deployed with the trained model and is best suited for small documents depending on the use case. For a large number of documents, an asynchronous classification job is best suited.
Train a custom entity recognition model
To demonstrate the entity detection in real time, we trained a custom entity recognizer model with insurance documents and augmented manifest files using custom annotations and deployed the endpoint using the trained model. The entity types are Law Firm, Law Office Address, Insurance Company, Insurance Company Address, Policy Holder Name, Beneficiary Name, Policy Number, Payout, Required Action, and Sender. We want to detect entities from sample documents in native PDF, PNG, and JPEG format, stored in an S3 bucket, using the recognizer model.
Note that you can use a custom entity recognition model that is trained with PDF documents to extract custom entities from PDF, TIFF, image, Word, and plain text documents. If your model is trained using text documents and an entity list, you can only use plain text documents to extract the entities.
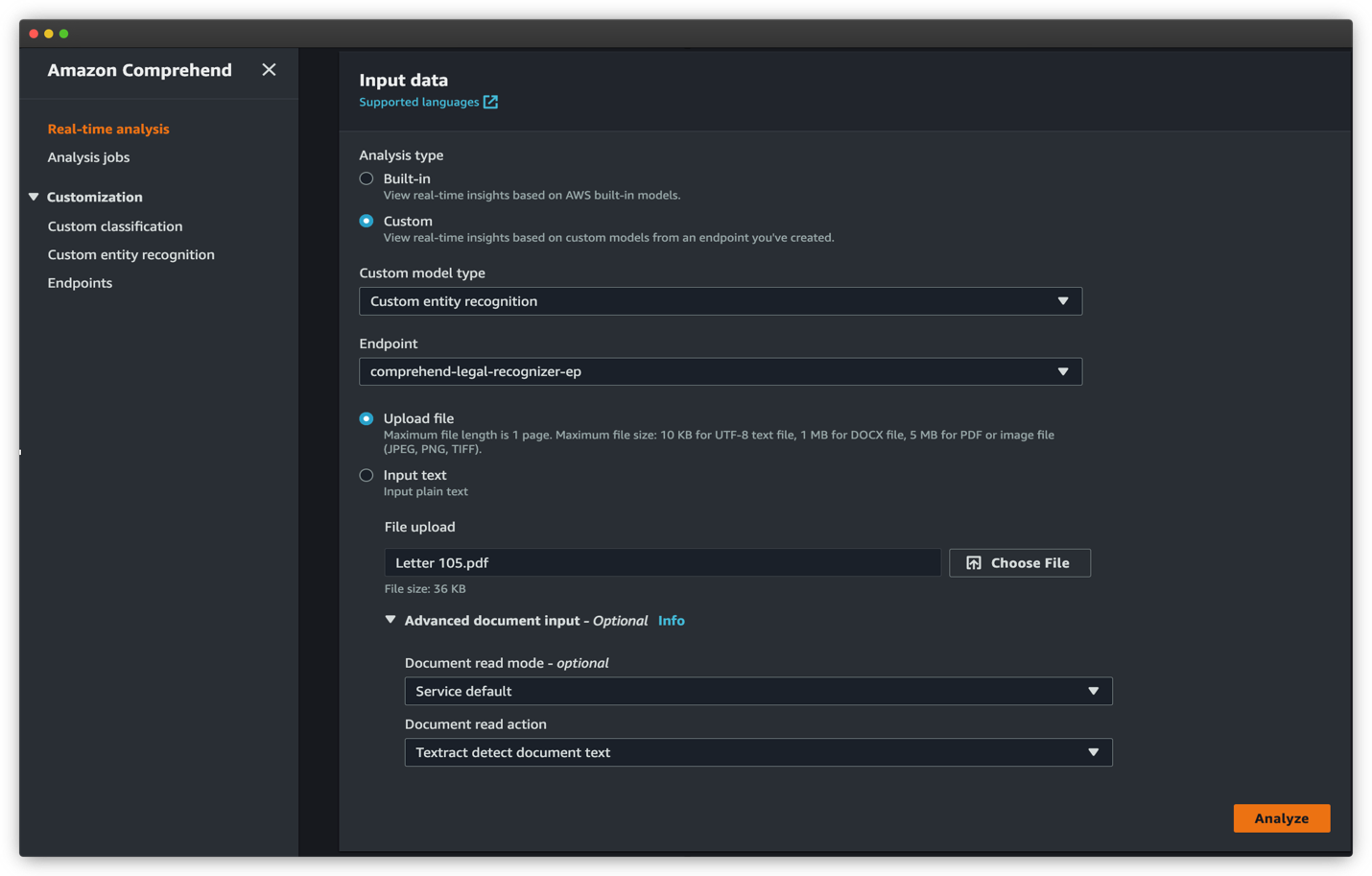
We need to detect entities from a sample document in any native PDF, PNG, and JPEG format using the recognizer model. To start a synchronous entity detection job, complete the following steps:
- On the Amazon Comprehend console, choose Real-time analysis in the navigation pane.
- Under Analysis type, select Custom.
- For Custom entity recognition, choose the custom model type.
- For Endpoint, choose the real-time endpoint that you created for your entity recognizer model.
- Select Upload file and choose Choose File to upload the PDF or image file for inference.
- Expand the Advanced document input section and for Document read mode, choose Service default.
- For Document read action, choose Textract detect document text.
- Choose Analyze to analyze the document in real time.
The recognized entities are listed in the Insights section. Each entity contains the entity value (the text), the type of entity as defined by your during the training process, and the corresponding confidence score.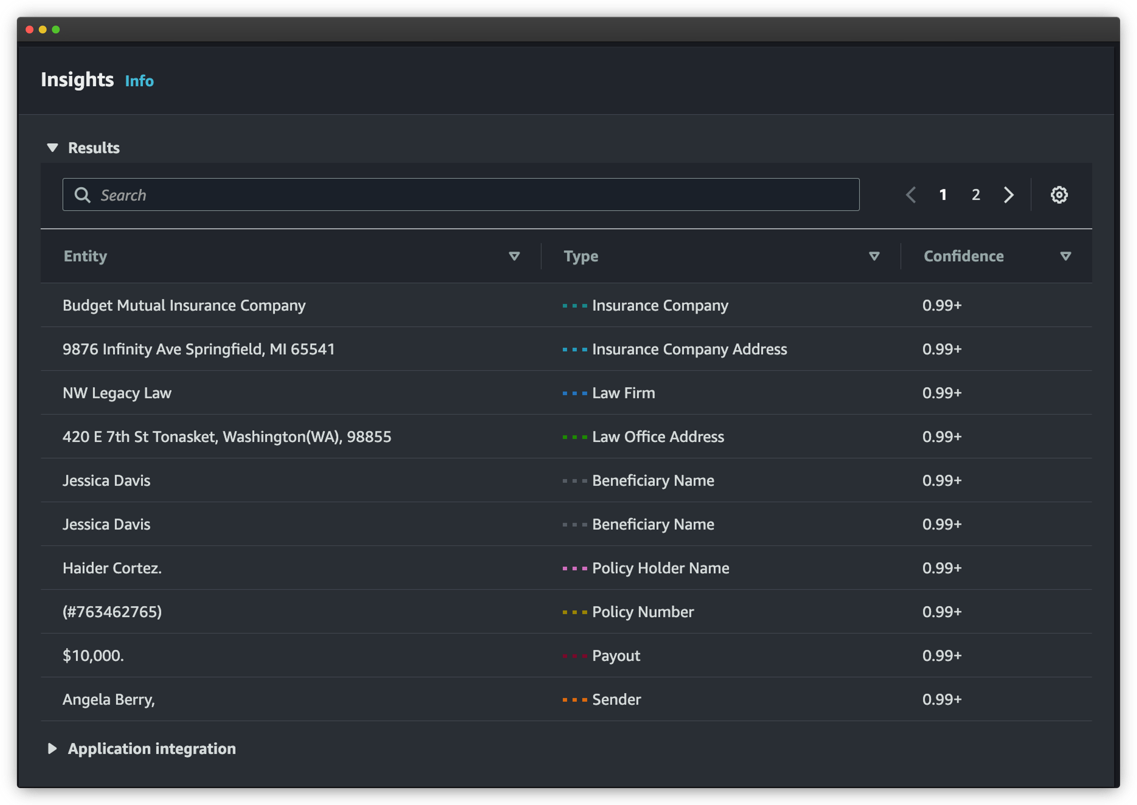
For more details and a complete walkthrough on how to train a custom entity recognizer model and use it to perform asynchronous inference using asynchronous analysis jobs, refer to Extract custom entities from documents in their native format with Amazon Comprehend.
Conclusion
This post demonstrated how you can classify and categorize semi-structured documents in their native format and detect business-specific entities from them using Amazon Comprehend. You can use real-time APIs for low-latency use cases, or use asynchronous analysis jobs for bulk document processing.
As a next step, we encourage you to visit the Amazon Comprehend GitHub repository for full code samples to try out these new features. You can also visit the Amazon Comprehend Developer Guide and Amazon Comprehend developer resources for videos, tutorials, blogs, and more.
About the authors
 Wrick Talukdar is a Senior Architect with the Amazon Comprehend Service team. He works with AWS customers to help them adopt machine learning on a large scale. Outside of work, he enjoys reading and photography.
Wrick Talukdar is a Senior Architect with the Amazon Comprehend Service team. He works with AWS customers to help them adopt machine learning on a large scale. Outside of work, he enjoys reading and photography.
 Anjan Biswas is a Senior AI Services Solutions Architect with a focus on AI/ML and Data Analytics. Anjan is part of the world-wide AI services team and works with customers to help them understand and develop solutions to business problems with AI and ML. Anjan has over 14 years of experience working with global supply chain, manufacturing, and retail organizations, and is actively helping customers get started and scale on AWS AI services.
Anjan Biswas is a Senior AI Services Solutions Architect with a focus on AI/ML and Data Analytics. Anjan is part of the world-wide AI services team and works with customers to help them understand and develop solutions to business problems with AI and ML. Anjan has over 14 years of experience working with global supply chain, manufacturing, and retail organizations, and is actively helping customers get started and scale on AWS AI services.
 Godwin Sahayaraj Vincent is an Enterprise Solutions Architect at AWS who is passionate about machine learning and providing guidance to customers to design, deploy, and manage their AWS workloads and architectures. In his spare time, he loves to play cricket with his friends and tennis with his three kids.
Godwin Sahayaraj Vincent is an Enterprise Solutions Architect at AWS who is passionate about machine learning and providing guidance to customers to design, deploy, and manage their AWS workloads and architectures. In his spare time, he loves to play cricket with his friends and tennis with his three kids.
USC and Amazon select five new faculty research projects
Faculty projects are focused on various aspects of trustworthy machine learning.Read More
Illustrative notebooks in Amazon SageMaker JumpStart
Amazon SageMaker JumpStart is the Machine Learning (ML) hub of SageMaker providing pre-trained, publicly available models for a wide range of problem types to help you get started with machine learning.
JumpStart also offers example notebooks that use Amazon SageMaker features like spot instance training and experiments over a large variety of model types and use cases. These example notebooks contain code that shows how to apply ML solutions by using SageMaker and JumpStart. They can be adapted to match to your own needs and can thus speed up application development.
Recently, we added 10 new notebooks to JumpStart in Amazon SageMaker Studio. This post focuses on these new notebooks. As of this writing, JumpStart offers 56 notebooks, ranging from using state-of-the-art natural language processing (NLP) models to fixing bias in datasets when training models.
The 10 new notebooks can help you in the following ways:
- They offer example code for you to run as is from the JumpStart UI in Studio and see how the code works
- They show the usage of various SageMaker and JumpStart APIs
- They offer a technical solution that you can further customize based on your own needs
The number of notebooks that are offered through JumpStart increase on a regular basis as more notebooks are added. These notebooks are also available on github.

Notebooks overview
The 10 new notebooks are as follows:
- In-context learning with AlexaTM 20B – Demonstrates how to use AlexaTM 20B for in-context learning with zero-shot and few-shot learning on five example tasks: text summarization, natural language generation, machine translation, extractive question answering, and natural language inference and classification.
- Fairness linear learner in SageMaker – There have recently been concerns about bias in ML algorithms as a result of mimicking existing human prejudices. This notebook applies fairness concepts to adjust model predictions appropriately.
- Manage ML experimentation using SageMaker Search – Amazon SageMaker Search lets you quickly find and evaluate the most relevant model training runs from potentially hundreds and thousands of SageMaker model training jobs.
- SageMaker Neural Topic Model – SageMaker Neural Topic Model (NTM) is an unsupervised learning algorithm that attempts to describe a set of observations as a mixture of distinct categories.
- Predict driving speed violations – The SageMaker DeepAR algorithm can be used to train a model for multiple streets simultaneously, and predict violations for multiple street cameras.
- Breast cancer prediction – This notebook uses UCI’S breast cancer diagnostic dataset to build a predictive model of whether a breast mass image indicates a benign or malignant tumor.
- Ensemble predictions from multiple models – By combining or averaging predictions from multiple sources and models, we typically get an improved forecast. This notebook illustrates this concept.
- SageMaker asynchronous inference – Asynchronous inference is a new inference option for near-real-time inference needs. Requests can take up to 15 minutes to process and have payload sizes of up to 1 GB.
- TensorFlow bring your own model – Learn how to train a TensorFlow model locally and deploy on SageMaker using this notebook.
- Scikit-learn bring your own model – This notebook shows how to use a pre-trained Scikit-learn model with the SageMaker Scikit-learn container to quickly create a hosted endpoint for that model.
Prerequisites
To use these notebooks, make sure that you have access to Studio with an execution role that allows you to run SageMaker functionality. The short video below will help you navigate to JumpStart notebooks.
In the following sections, we go through each of the 10 new solutions and discuss some of their interesting details.
In-context learning with AlexaTM 20B
AlexaTM 20B is a multitask, multilingual, large-scale sequence-to-sequence (seq2seq) model, trained on a mixture of Common Crawl (mC4) and Wikipedia data across 12 languages, using denoising and Causal Language Modeling (CLM) tasks. It achieves state-of-the-art performance on common in-context language tasks such as one-shot summarization and one-shot machine translation, outperforming decoder only models such as Open AI’s GPT3 and Google’s PaLM, which are over eight times bigger.
In-context learning, also known as prompting, refers to a method where you use an NLP model on a new task without having to fine-tune it. A few task examples are provided to the model only as part of the inference input, a paradigm known as few-shot in-context learning. In some cases, the model can perform well without any training data at all, only given an explanation of what should be predicted. This is called zero-shot in-context learning.
This notebook demonstrates how to deploy AlexaTM 20B through the JumpStart API and run inference. It also demonstrates how AlexaTM 20B can be used for in-context learning with five example tasks: text summarization, natural language generation, machine translation, extractive question answering, and natural language inference and classification.
 |
 |
The notebook demonstrates the following:
- One-shot text summarization, natural language generation, and machine translation using a single training example for each of these tasks
- Zero-shot question answering and natural language inference plus classification using the model as is, without the need to provide any training examples.
Try running your own text against this model and see how it summarizes text, extracts Q&A, or translates from one language to another.
Fairness linear learner in SageMaker
There have recently been concerns about bias in ML algorithms as a result of mimicking existing human prejudices. Nowadays, several ML methods have strong social implications, for example they are used to predict bank loans, insurance rates, or advertising. Unfortunately, an algorithm that learns from historical data will naturally inherit past biases. This notebook presents how to overcome this problem by using SageMaker and fair algorithms in the context of linear learners.
It starts by introducing some of the concepts and math behind fairness, then it downloads data, trains a model, and finally applies fairness concepts to adjust model predictions appropriately.
 |
 |
The notebook demonstrates the following:
- Running a standard linear model on UCI’s Adult dataset.
- Showing unfairness in model predictions
- Fixing data to remove bias
- Retraining the model
Try running your own data using this example code and detect if there is bias. After that, try removing bias, if any, in your dataset using the provided functions in this example notebook.
Manage ML experimentation using SageMaker Search
SageMaker Search lets you quickly find and evaluate the most relevant model training runs from potentially hundreds and thousands of SageMaker model training jobs. Developing an ML model requires continuous experimentation, trying new learning algorithms, and tuning hyperparameters, all while observing the impact of such changes on model performance and accuracy. This iterative exercise often leads to an explosion of hundreds of model training experiments and model versions, slowing down the convergence and discovery of a winning model. In addition, the information explosion makes it very hard down the line to trace back the lineage of a model version—the unique combination of datasets, algorithms, and parameters that brewed that model in the first place.
This notebook shows how to use SageMaker Search to quickly and easily organize, track, and evaluate your model training jobs on SageMaker. You can search on all the defining attributes from the learning algorithm used, hyperparameter settings, training datasets used, and even the tags you have added on the model training jobs. You can also quickly compare and rank your training runs based on their performance metrics, such as training loss and validation accuracy, thereby creating leaderboards for identifying the winning models that can be deployed into production environments. SageMaker Search can quickly trace back the complete lineage of a model version deployed in a live environment, right up until the datasets used in training and validating the model.
 |
 |
The notebook demonstrates the following:
- Training a linear model three times
- Using SageMaker Search to organize and evaluate these experiments
- Visualizing the results in a leaderboard
- Deploying a model to an endpoint
- Tracing lineage of the model starting from the endpoint
In your own development of predictive models, you may be running several experiments. Try using SageMaker Search in such experiments and experience how it can help you in multiple ways.
SageMaker Neural Topic Model
SageMaker Neural Topic Model (NTM) is an unsupervised learning algorithm that attempts to describe a set of observations as a mixture of distinct categories. NTM is most commonly used to discover a user-specified number of topics shared by documents within a text corpus. Here each observation is a document, the features are the presence (or occurrence count) of each word, and the categories are the topics. Because the method is unsupervised, the topics aren’t specified up-front and aren’t guaranteed to align with how a human may naturally categorize documents. The topics are learned as a probability distribution over the words that occur in each document. Each document, in turn, is described as a mixture of topics.
This notebook uses the SageMaker NTM algorithm to train a model on the 20NewsGroups dataset. This dataset has been widely used as a topic modeling benchmark.
 |
 |
The notebook demonstrates the following:
- Creating a SageMaker training job on a dataset to produce an NTM model
- Using the model to perform inference with a SageMaker endpoint
- Exploring the trained model and visualizing learned topics
You can easily modify this notebook to run on your text documents and divide them into various topics.
Predict driving speed violations
This notebook demonstrates time series forecasting using the SageMaker DeepAR algorithm by analyzing the city of Chicago’s Speed Camera Violation dataset. The dataset is hosted by Data.gov, and is managed by the U.S. General Services Administration, Technology Transformation Service.
These violations are captured by camera systems and are available to improve the lives of the public through the city of Chicago data portal. The Speed Camera Violation dataset can be used to discern patterns in the data and gain meaningful insights.
The dataset contains multiple camera locations and daily violation counts. Each daily violation count for a camera can be considered a separate time series. You can use the SageMaker DeepAR algorithm to train a model for multiple streets simultaneously, and predict violations for multiple street cameras.
 |
 |
The notebook demonstrates the following:
- Training the SageMaker DeepAR algorithm on the time series dataset using spot instances
- Making inferences on the trained model to make traffic violation predictions
With this notebook, you can learn how time series problems can be solved using the DeepAR algorithm in SageMaker and try applying it on your own time series datasets.
Breast cancer prediction
This notebook takes an example for breast cancer prediction using UCI’S breast cancer diagnostic dataset. It uses this dataset to build a predictive model of whether a breast mass image indicates a benign or malignant tumor.
 |
 |
The notebook demonstrates the following:
- Basic setup for using SageMaker
- Converting datasets to Protobuf format used by the SageMaker algorithms and uploading to Amazon Simple Storage Service (Amazon S3)
- Training a SageMaker linear learner model on the dataset
- Hosting the trained model
- Scoring using the trained model
You can go through this notebook to learn how to solve a business problem using SageMaker, and understand the steps involved for training and hosting a model.
Ensemble predictions from multiple models
In practical applications of ML on predictive tasks, one model often doesn’t suffice. Most prediction competitions typically require combining forecasts from multiple sources to get an improved forecast. By combining or averaging predictions from multiple sources or models, we typically get an improved forecast. This happens because there is considerable uncertainty in the choice of the model and there is no one true model in many practical applications. Therefore, it’s beneficial to combine predictions from different models. In the Bayesian literature, this idea is referred to as Bayesian model averaging, and has been shown to work much better than just picking one model.
This notebook presents an illustrative example to predict if a person makes over $50,000 a year based on information about their education, work experience, gender, and more.
 |
 |
The notebook demonstrates the following:
- Preparing your SageMaker notebook
- Loading a dataset from Amazon S3 using SageMaker
- Investigating and transforming the data so that it can be fed to SageMaker algorithms
- Estimating a model using the SageMaker XGBoost (Extreme Gradient Boosting) algorithm
- Hosting the model on SageMaker to make ongoing predictions
- Estimating a second model using the SageMaker linear learner method
- Combining the predictions from both models and evaluating the combined prediction
- Generating final predictions on the test dataset
Try running this notebook on your dataset and using multiple algorithms. Try experimenting with various combination of models offered by SageMaker and JumpStart and see which combination of model ensembling gives the best results on your own data.
SageMaker asynchronous inference
SageMaker asynchronous inference is a new capability in SageMaker that queues incoming requests and processes them asynchronously. SageMaker currently offers two inference options for customers to deploy ML models: a real-time option for low-latency workloads, and batch transform, an offline option to process inference requests on batches of data available up-front. Real-time inference is suited for workloads with payload sizes of less than 6 MB and require inference requests to be processed within 60 seconds. Batch transform is suitable for offline inference on batches of data.
Asynchronous inference is a new inference option for near-real-time inference needs. Requests can take up to 15 minutes to process and have payload sizes of up to 1 GB. Asynchronous inference is suitable for workloads that don’t have subsecond latency requirements and have relaxed latency requirements. For example, you might need to process an inference on a large image of several MBs within 5 minutes. In addition, asynchronous inference endpoints let you control costs by scaling down endpoint instance count to zero when they’re idle, so you only pay when your endpoints are processing requests.
 |
 |
The notebook demonstrates the following:
- Creating a SageMaker model
- Creating an endpoint using this model and asynchronous inference configuration
- Making predictions against this asynchronous endpoint
This notebook shows you a working example of putting together an asynchronous endpoint for a SageMaker model.
TensorFlow bring your own model
A TensorFlow model is trained locally on a classification task where this notebook is being run. Then it’s deployed on a SageMaker endpoint.
 |
 |
The notebook demonstrates the following:
- Training a TensorFlow model locally on the IRIS dataset
- Importing that model into SageMaker
- Hosting it on an endpoint
If you have TensorFlow models that you developed yourself, this example notebook can help you host your model on a SageMaker managed endpoint.
Scikit-learn bring your own model
SageMaker includes functionality to support a hosted notebook environment, distributed, serverless training, and real-time hosting. It works best when all three of these services are used together, but they can also be used independently. Some use cases may only require hosting. Maybe the model was trained prior to SageMaker existing, in a different service.

The notebook demonstrates the following:
- Using a pre-trained Scikit-learn model with the SageMaker Scikit-learn container to quickly create a hosted endpoint for that model
If you have Scikit-learn models that you developed yourself, this example notebook can help you host your model on a SageMaker managed endpoint.
Clean up resources
After you’re done running a notebook in JumpStart, make sure to Delete all resources so that all the resources that you created in the process are deleted and your billing is stopped. The last cell in these notebooks usually deletes endpoints that are created.
Summary
This post walked you through 10 new example notebooks that were recently added to JumpStart. Although this post focused on these 10 new notebooks, there are a total of 56 available notebooks as of this writing. We encourage you to log in to Studio and explore the JumpStart notebooks yourselves, and start deriving immediate value out of them. For more information, refer to Amazon SageMaker Studio and SageMaker JumpStart.
About the Author
 Dr. Raju Penmatcha is an AI/ML Specialist Solutions Architect in AI Platforms at AWS. He received his PhD from Stanford University. He works closely on the low/no-code suite services in SageMaker that help customers easily build and deploy machine learning models and solutions.
Dr. Raju Penmatcha is an AI/ML Specialist Solutions Architect in AI Platforms at AWS. He received his PhD from Stanford University. He works closely on the low/no-code suite services in SageMaker that help customers easily build and deploy machine learning models and solutions.
AWS CodeWhisperer creates computer code from natural language
At re:Invent, AWS announces that the CodeWhisperer preview has added support for two new programming languages.Read More
AWS CodeWhisperer creates computer code from natural language
At re:Invent, AWS announces that the CodeWhisperer preview has added support for two new programming languages.Read More
Interactive data prep widget for notebooks powered by Amazon SageMaker Data Wrangler
According to a 2020 survey of data scientists conducted by Anaconda, data preparation is one of the critical steps in machine learning (ML) and data analytics workflows, and often very time consuming for data scientists. Data scientists spend about 66% of their time on data preparation and analysis tasks, including loading (19%), cleaning (26%), and visualizing data (21%).
Amazon SageMaker Studio is the first fully integrated development environment (IDE) for ML. With a single click, data scientists and developers can quickly spin up Studio notebooks to explore datasets and build models. If you prefer a GUI-based and interactive interface, you can use Amazon SageMaker Data Wrangler, with over 300 built in visualizations, analyses, and transformations to efficiently process data backed by Spark without writing a single line of code.
Data Wrangler now offers a built-in data preparation capability in Amazon SageMaker Studio Notebooks that allows ML practitioners to visually review data characteristics, identify issues, and remediate data-quality problems—in just a few clicks directly within the notebooks.
In this post, we show you how the Data Wrangler data prep widget automatically generates key visualizations on top of a Pandas data frame to understand data distribution, detect data quality issues, and surface data insights such as outliers for each feature. It helps interact with the data and discover insights that may go unnoticed with ad hoc querying. It also recommends transformations to remediate, enables you to apply data transformations on the UI and automatically generate code in the notebook cells. This feature is available in all regions where SageMaker Studio is available.
Solution overview
Let’s further understand how this new widget makes data exploration significantly easier and provides a seamless experience to improve the overall data preparation experience for data engineers and practitioners. For our use case, we use of a modified version of the Titanic dataset, a popular dataset in the ML community, which has now been added as a sample dataset so you can get started with SageMaker Data Wrangler quickly. The original dataset was obtained from OpenML, and modified to add synthetic data quality issues by Amazon for this demo. You can download the modified version of dataset from public S3 path s3://sagemaker-sample-files/datasets/tabular/dirty-titanic/titanic-dirty-4.csv.
Prerequisites
To get hands-on experience with all the features described in this post, complete the following prerequisites:
- Ensure that you have an AWS account, secure access to log in to the account via the AWS Management Console, and AWS Identity and Access Management (IAM) permissions to use Amazon SageMaker and Amazon Simple Storage Service (Amazon S3) resources.
- Use the sample dataset from public S3 path
s3://sagemaker-sample-files/datasets/tabular/dirty-titanic/titanic-dirty-4.csvor alternatively upload it to an S3 bucket in your account. - Onboard to a SageMaker domain and access Studio to use notebooks. For instructions, refer to Onboard to Amazon SageMaker Domain. If you’re using existing Studio, upgrade to the latest version of Studio.
Enable the data exploration widget
When you’re using Pandas data frames, Studio notebook users can manually enable the data exploration widget so that new visualizations are displayed by default on top of each column. The widget shows a histogram for numerical data and a bar chart for other types of data. These representations allow you to quickly comprehend the data distribution and discover missing values and outliers without having to write boilerplate methods for each and every column. You can hover over the bar in each visual to get a quick understanding of the distribution.
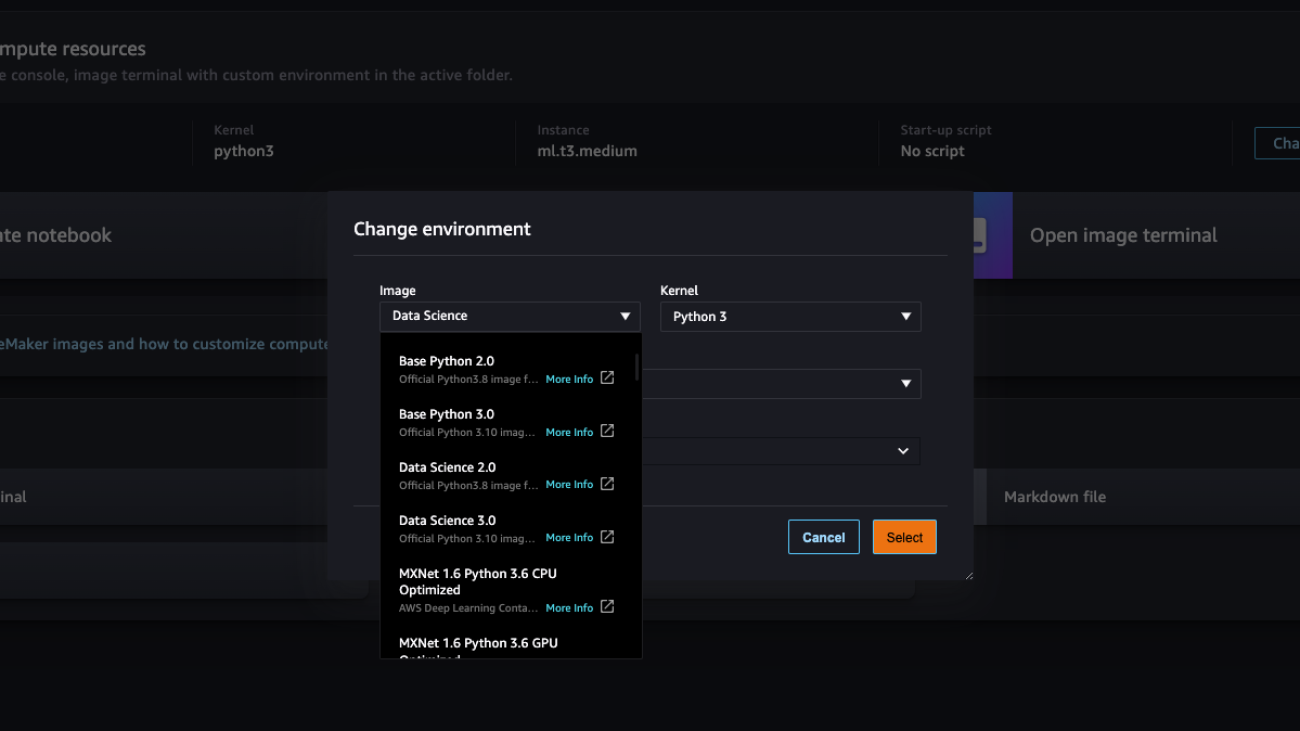
Open Studio and create a new Python 3 notebook. Make sure to choose the Data Science 3.0 image from SageMaker images by clicking Change environment button.

The data exploration widget is available in the following images. For the list of default SageMaker images, refer to Available Amazon SageMaker Images.
- Python 3 (Data Science) with Python 3.7
- Python 3 (Data Science 2.0) with Python 3.8
- Python 3 (Data Science 3.0) with Python 3.10
- Spark Analytics 1.0 and 2.0
To use this widget, import the SageMaker_DataWrangler library. Load the modified version of the Titanic dataset from S3://sagemaker-sample-files/datasets/tabular/dirty-titanic/titanic-dirty-4.csv and read the CSV with the Pandas library:

Visualize the data
After the data is loaded in the Pandas data frame, you can view the data by just using df or display(df). Along with listing the row, the data prep widget produces insights, visualizations, and advice on data quality. You don’t need to write any additional code to generate feature and target insights, distribution information, or rendering data quality checks. You can choose the data frame table’s header to view the statistical summary showing the data quality warnings, if any.

Each column shows a bar chart or histogram based on the data type. By default, the widget samples up to 10,000 observations for generating meaningful insights. It also provides the option to run the insight analysis on the entire dataset.
As shown in the following screenshot, this widget identifies whether a column has categorical or quantitative data.

For categorical data, the widget generates the bar chart with all the categories. In the following screenshot, for example, the column Sex identifies the categories on the data. You can hover over the bar (male in this case) to see the details of these categories, like the total number of rows with the value male and its distribution in the total visualized dataset (64.07% in this example). It also highlights the total percentage of missing values in a different color for categorical data. For quantitative data like the ticket column, it shows distribution along with the percentage of invalid values.
 |
 |
 |
If you want to see a standard Pandas visualization in the notebook, you can choose View the Pandas table and toggle between the widget and the Pandas representation, as shown in the following screenshot.


To get more detailed insights about the data in the column, choose the column’s header to open a side panel dedicated to the column. Here you can observe two tabs: Insights and Data quality.

In the following sections, we explore these two options in more detail.
Insights
The Insights tab provides details with descriptions for each column. This section lists aggregated statistics, such as mode, number of uniques, ratios and counts for missing/invalid values, etc., as well as visualize data distribution with help of a histogram or a bar chart. In the following screenshots, you can check out the data insights and distribution information displayed with easily understandable visualizations generated for the selected column survived.
 |
 |
 |
Data quality
The studio data prep widget highlights identified data quality issues with the warning sign in the header. Widget can identify the whole spectrum of data quality issues from basics (missing values, constant column, etc.) to more ML specific (target leakage, low predictive score features, etc.). Widget highlights the cells causing the data quality issue and reorganize the rows to put the problematic cells at the top. To remedy the data quality issue widget provides several transformers, applicable on a click of a button.
To explore the data quality section, choose the column header, and in the side panel, choose the Data quality tab. You should see the following in your Studio environment.

Let’s look at the different options available on the Data quality tab. For this example, we choose the age column, which is detected as a quantitative column based on the data. As we can see in the following screenshot, this widget suggests different type of transformations that you could apply, including the most common actions, such as Replace with new value, Drop missing, Replace with median, or Replace with mean. You can choose any of those for your dataset based on the use case (the ML problem you’re trying to solve). It also gives you the Drop column option if you want to remove the feature altogether.

When you choose Apply and export code, the transform is applied to the deep copy of the data frame. After the transform is applied successfully, the data table is refreshed with the insights and visualizations. The transform code is generated after the existing cell in the notebook. You can run this exported code later on to apply the transformation on your datasets, and extend it as per your needs. You can customize the transformation by directly modifying the generated code. If we apply the Drop missing option in the Age column, the following transformation code is applied to the dataset, and code is also generated in a cell below the widget:
The following is another example of a code snippet for Replace with median:
Now let’s look at the data prep widget’s target insight capability. Assume you want to use the survived feature to predict if a passenger will survive. Choose the survived column header. In the side panel, choose Select as target column. The ideal data distribution for the survived feature should have only two classes: yes (1) or no (0), which helps classify the Titanic crash survival chances. However, due to data inconsistencies in the chosen target column, the survived feature has 0, 1, ?, unknown, and yes.

Choose the problem type based on the selected target column, which can be either Classification or Regression. For the survived column, the problem type is classification. Choose Run to generate insights for the target column.

The data prep widget lists the target column insights with recommendations and sample explanations to solve the issues with the target column data quality. It also automatically highlights the anomalous data in the column.

We choose the recommended transform Drop rare target values, because there are fewer observations for the rare target values.

The chosen transform is applied to the Pandas data frame and the uncommon target values were eliminated from the survived column. See the following code:
The results of the applied transform are immediately visible on the data frame. To track the data preparation activities applied using the data prep widget, the transformed code is also generated in the following notebook cell.
Conclusion
In this post, we provided guidance on how the Studio data prep widget can help you analyze data distributions, explore data quality insights generated by the tool, and uncover potential issues such as outliers for each critical feature. This helps improve the overall data quality to help you train high-quality models, and it removes the undifferentiated heavy lifting by allowing you to transform data on the user interface and generate code for the notebook cells automatically. You can then use this code in your MLOps pipelines to build reproducibility, avoid wasting time on repetitive tasks, and reduce compatibility problems by quickening the construction and deployment of data wrangling pipelines.
If you’re new to SageMaker Data Wrangler or Studio, refer to Get Started with SageMaker Data Wrangler. If you have any questions related to this post, please add it in the comments section.
About the Authors
 Parth Patel is a Solutions Architect at AWS in the San Francisco Bay Area. Parth guides customers to accelerate their journey to the cloud and help them adopt and grow on the AWS Cloud successfully. He focuses on machine learning, environmental sustainability, and application modernization.
Parth Patel is a Solutions Architect at AWS in the San Francisco Bay Area. Parth guides customers to accelerate their journey to the cloud and help them adopt and grow on the AWS Cloud successfully. He focuses on machine learning, environmental sustainability, and application modernization.
 Isha Dua is a Senior Solutions Architect based in the San Francisco Bay Area. She helps AWS Enterprise customers grow by understanding their goals and challenges, and guiding them on how they can architect their applications in a cloud-native manner while making sure they are resilient and scalable. She’s passionate about machine learning technologies and environmental sustainability.
Isha Dua is a Senior Solutions Architect based in the San Francisco Bay Area. She helps AWS Enterprise customers grow by understanding their goals and challenges, and guiding them on how they can architect their applications in a cloud-native manner while making sure they are resilient and scalable. She’s passionate about machine learning technologies and environmental sustainability.
 Hariharan Suresh is a Senior Solutions Architect at AWS. He is passionate about databases, machine learning, and designing innovative solutions. Prior to joining AWS, Hariharan was a product architect, core banking implementation specialist, and developer, and worked with BFSI organizations for over 11 years. Outside of technology, he enjoys paragliding and cycling.
Hariharan Suresh is a Senior Solutions Architect at AWS. He is passionate about databases, machine learning, and designing innovative solutions. Prior to joining AWS, Hariharan was a product architect, core banking implementation specialist, and developer, and worked with BFSI organizations for over 11 years. Outside of technology, he enjoys paragliding and cycling.
 Dani Mitchell is an AI/ML Specialist Solutions Architect at Amazon Web Services. He is focused on Computer Vision use cases and helping customers across EMEA to accelerate their ML journey.
Dani Mitchell is an AI/ML Specialist Solutions Architect at Amazon Web Services. He is focused on Computer Vision use cases and helping customers across EMEA to accelerate their ML journey.
Run notebooks as batch jobs in Amazon SageMaker Studio Lab
Recently, the Amazon SageMaker Studio launched an easy way to run notebooks as batch jobs that can run on a recurring schedule. Amazon SageMaker Studio Lab also supports this feature, enabling you to run notebooks that you develop in SageMaker Studio Lab in your AWS account. This enables you to quickly scale your machine learning (ML) experiments with bigger datasets and more powerful instances, without having to learn anything new or change one line of code.
In this post, we walk you through the one time prerequisite to connect your Studio Lab environment to an AWS account. After that, we walk you through the steps to run notebooks as a batch job from Studio Lab.
Solution overview
Studio Lab incorporated the same extension as Studio, which is based on the Jupyter open-source extension for scheduled notebooks. This extension has additional AWS-specific parameters, like the compute type. In Studio Lab, a scheduled notebook is first copied to an Amazon Simple Storage Service (Amazon S3) bucket in your AWS account, then run at the scheduled time with the selected compute type. When the job is complete, the output is written to an S3 bucket, and the AWS compute is completely halted, preventing ongoing costs.
Prerequisites
To use Studio Lab notebook jobs, you need administrative access to the AWS account you’re going to connect with (or assistance from someone with this access). In the rest of this post, we assume that you’re the AWS administrator, if that’s not the case, ask your administrator or account owner to review these steps with you.
Create a SageMaker execution role
We need to ensure that the AWS account has an AWS Identity and Access Management (IAM) SageMaker execution role. This role is used by SageMaker resources within the account, and provides access from SageMaker to other resources in the AWS account. In our case, our notebook jobs run with these permissions. If SageMaker has been used previously in this account, then a role may already exist, but it may not have all the permissions required. So let’s go ahead and make a new one.
The following steps only need to be done once, regardless of how many SageMaker Studio Lab environments will access this AWS account.
- On the IAM console, choose Roles in the navigation pane.
- Choose Create role.
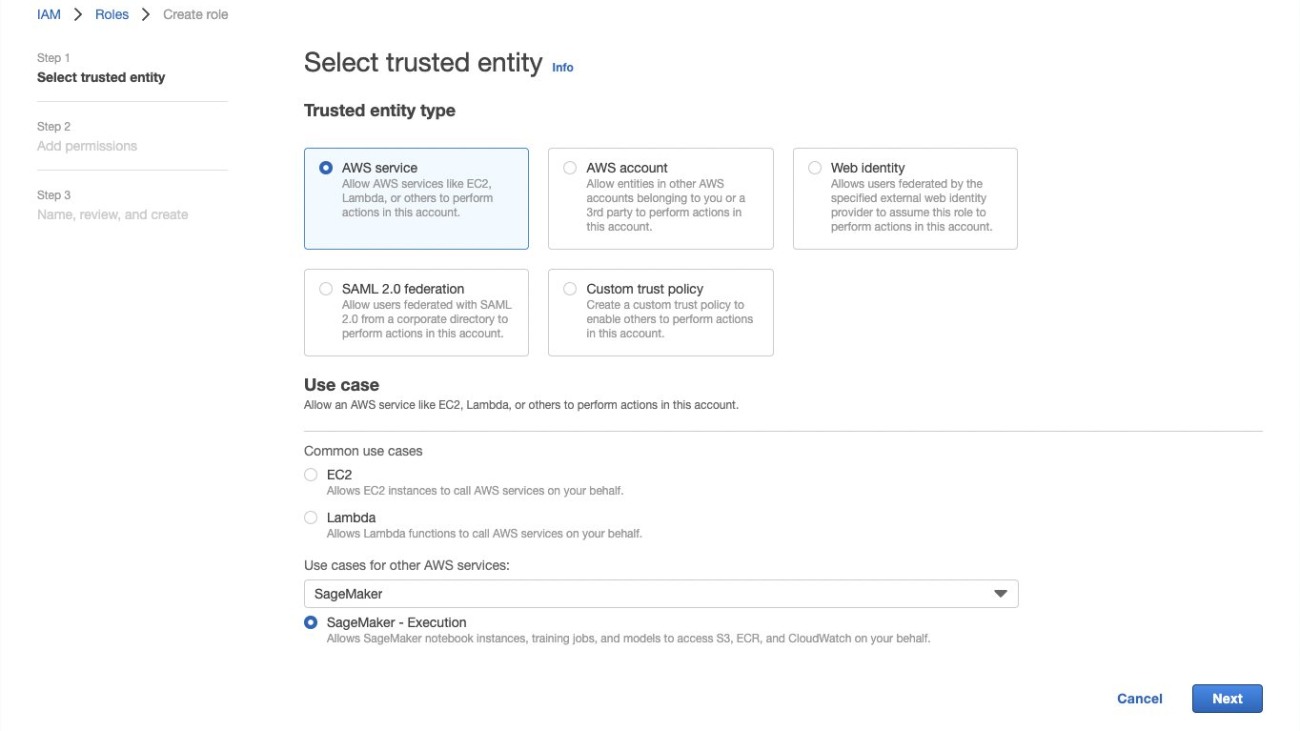
- For Trusted entity type, select AWS service.
- For Use cases for other AWS Services, choose SageMaker.
- Select SageMaker – Execution.
- Choose Next.

- Review the permissions, then choose Next.

- For Role name, enter a name (for this post, we use
sagemaker-execution-role-notebook-jobs). - Choose Create role.
- Make a note of the role ARN.
The role ARN will be in the format of arn:aws:iam::[account-number]:role/service-role/[role-name] and is required in the Studio Lab setup.
Create an IAM user
For a Studio Lab environment to access AWS, we need to create an IAM user within AWS and grant it necessary permissions. We then need to create a set of access keys for that user and provide them to the Studio Lab environment.
This step should be repeated for each SageMaker Studio Lab environment that will access this AWS account.
Note that administrators and AWS account owners should ensure that to the greatest extent possible, well-architected security practices are followed. For example, user permissions should always be scoped down, and access keys should be rotated regularly to minimize the impact of credential compromise.
In this blog we show how to use the AmazonSageMakerFullAccess managed policy. This policy provides broad access to Amazon SageMaker that may go beyond what is required. Details about AmazonSageMakerFullAccess can be found here.
Although Studio Lab employs enterprise security, it should be noted that Studio Lab user credentials don’t form part of your AWS account, and therefore, for example, are not subject to your AWS password or MFA policies.
To scope down permissions as much as possible, we create a user profile specifically for this access.
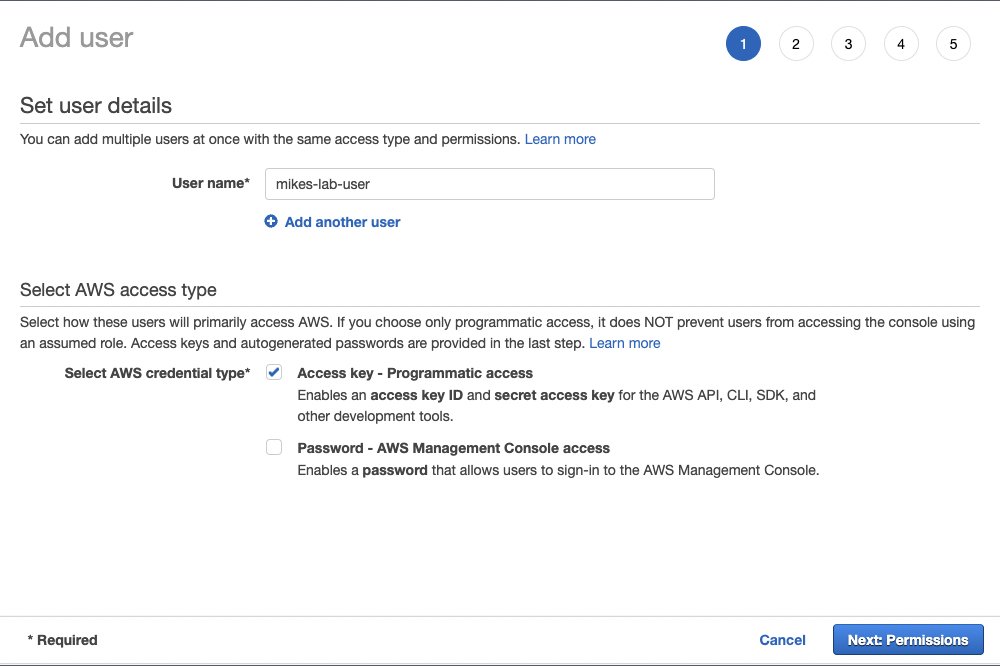
- On the IAM console, choose Users in the navigation pane.
- Choose Add users.
- For User name, enter a name.It’s good practice to use a name that is linked to an individual person who will be using this account; this helps if reviewing audit logs.
- For Select AWS access type, select Access key – Programmatic access.
- Choose Next: Permissions.
- Choose Attach existing policies directly.
- Search for and select
AmazonSageMakerFullAccess.
- Search for and select
AmazonEventBridgeFullAccess.
- Choose Next: Tags.
- Choose Next: Review.
- Confirm your policies, then choose Create user.
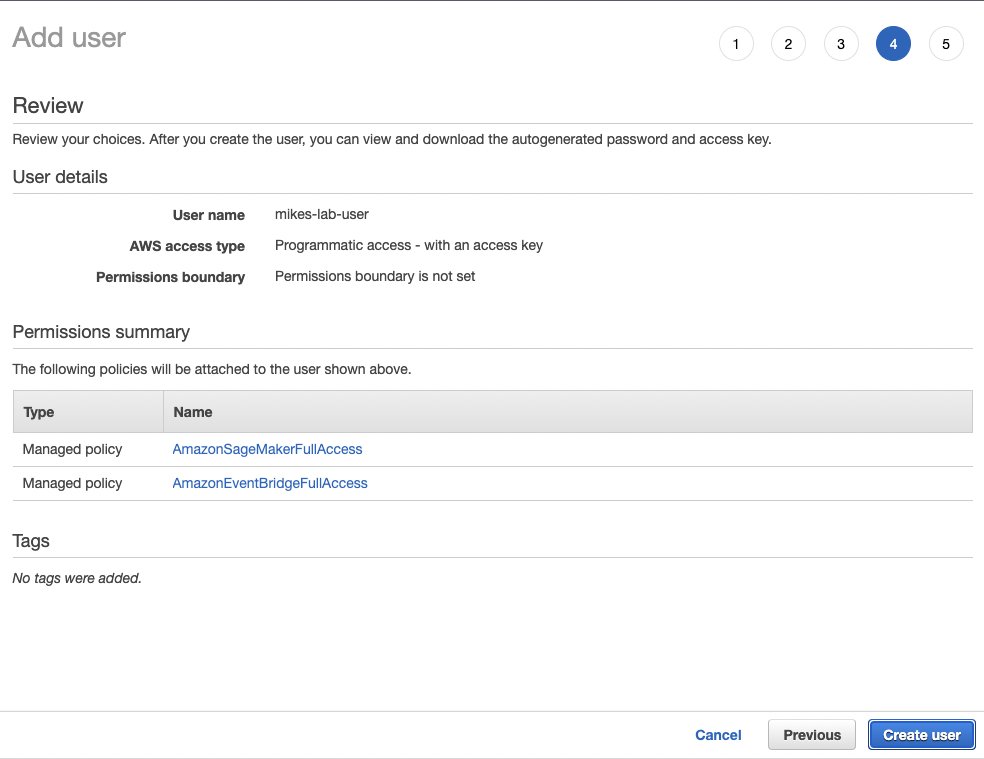 The final page of the user creation process should show you the user’s access keys. Leave this tab open, because we can’t navigate back here and we need these details.
The final page of the user creation process should show you the user’s access keys. Leave this tab open, because we can’t navigate back here and we need these details. - Open a new browser tab in Studio Lab.
- On the File menu, choose New Launcher, then choose Terminal.

- At the command line, enter the following code:
- Enter the following code:
- Enter the values from the IAM console page for your access key ID and secret access key.
- For
Default region name, enterus-west-2. - Leave
Default output formatastext.
Congratulations, your Studio Lab environment should now be configured to access the AWS account. To test the connection, issue the following command:
This command should return details about the IAM user your configured to use.
Create a notebook job
Notebook jobs are created using Jupyter notebooks within Studio Lab. If your notebook runs in Studio Lab, then it can run as a notebook job (with more resources and access to AWS services). However, there are a couple of things to watch for.
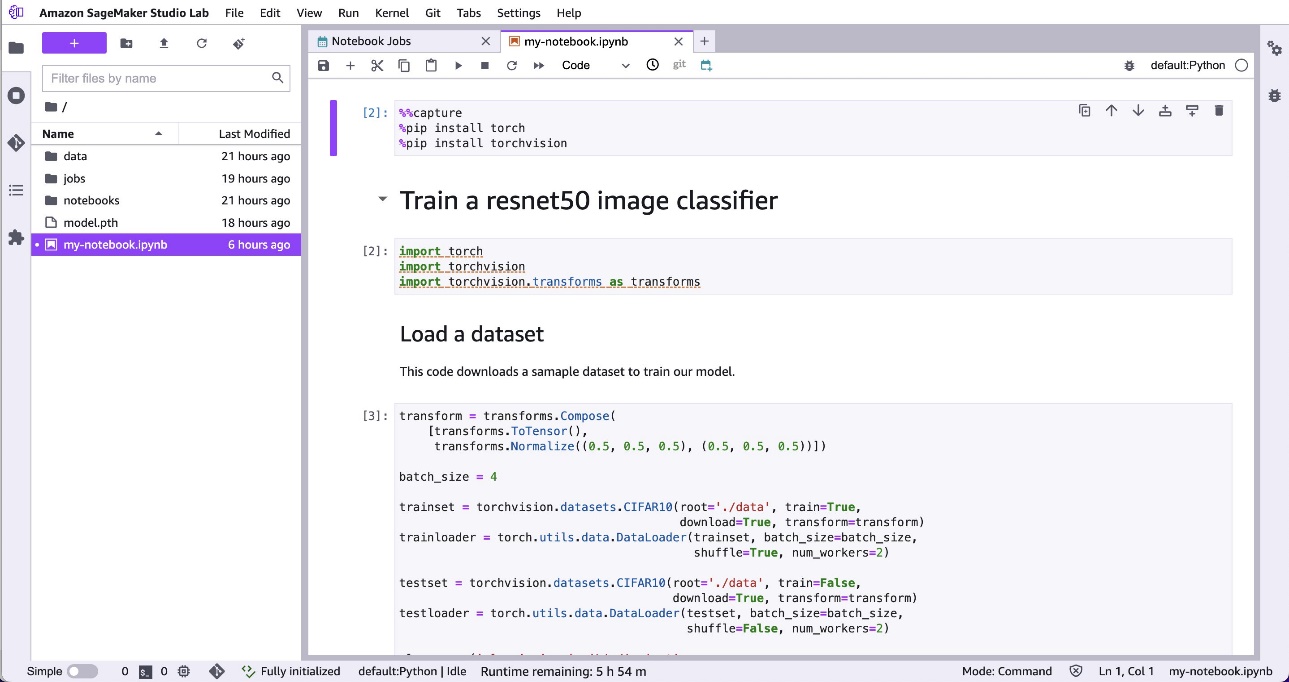
If you have installed packages to get your notebook working, add commands to load these packages in a cell at the top of your notebook. By using a & symbol at the start of each line, the code will be sent to the command line to run. In the following example, the first cell uses pip to install PyTorch libraries:
Our notebook will generate a trained PyTorch model. With our regular code, we save the model to the file system in Studio Labs.
When we run this as a notebook job, we need to save the model somewhere we can access it afterwards. The easiest way to do this is to save the model in Amazon S3. We created an S3 bucket to save our models, and use another command line cell to copy the object into the bucket.


We use the AWS Command Line Interface (AWS CLI) here to copy the object. We could also use the AWS SDK for Python (Boto3) if we wanted to have a more sophisticated or automated control of the file name. For now, we will ensure that we change the file name each time we run the notebook so the models don’t get overwritten.
Now we are ready to create the notebook job.
- Choose (right-click) the notebook name, then choose Create Notebook Job.
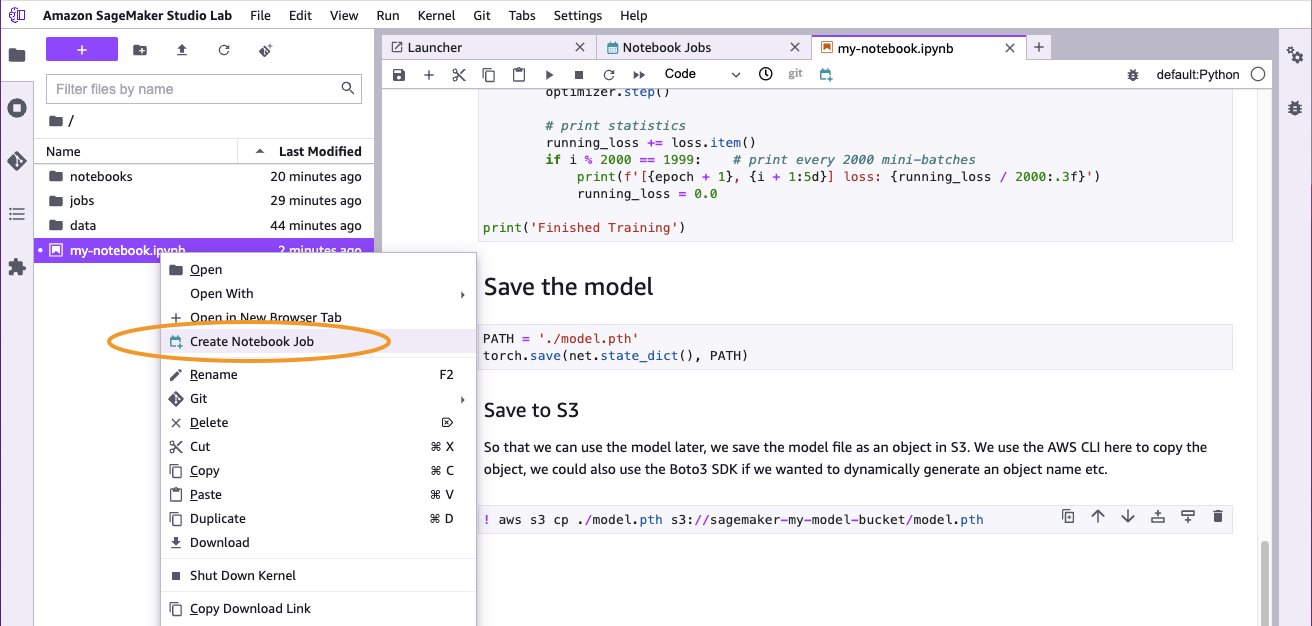
If this menu option is missing, you may need to refresh your Studio Lab environment. To do this, open Terminal from the launcher and run the following code: - Next, restart your JupyterLab instance by choosing Amazon SageMaker Studio Lab from the top menu, then choose Restart JupyterLab.Alternatively, go to the project page, and shut down and restart the runtime.
- On the Create job page, for Compute type, choose the compute type that suites your job.
For more information on the different types of compute capacity, including the cost, see Amazon SageMaker Pricing (choose On-Demand Pricing and navigate to the Training tab. You may also need to check the quota availability of the compute type in your AWS account. For more information about service quotas, see: AWS service quotas.For this example, we’ve selected an ml.p3.2xlarge instance, which offers 8 vCPU, 61 GB of memory and a Tesla V100 GPU.
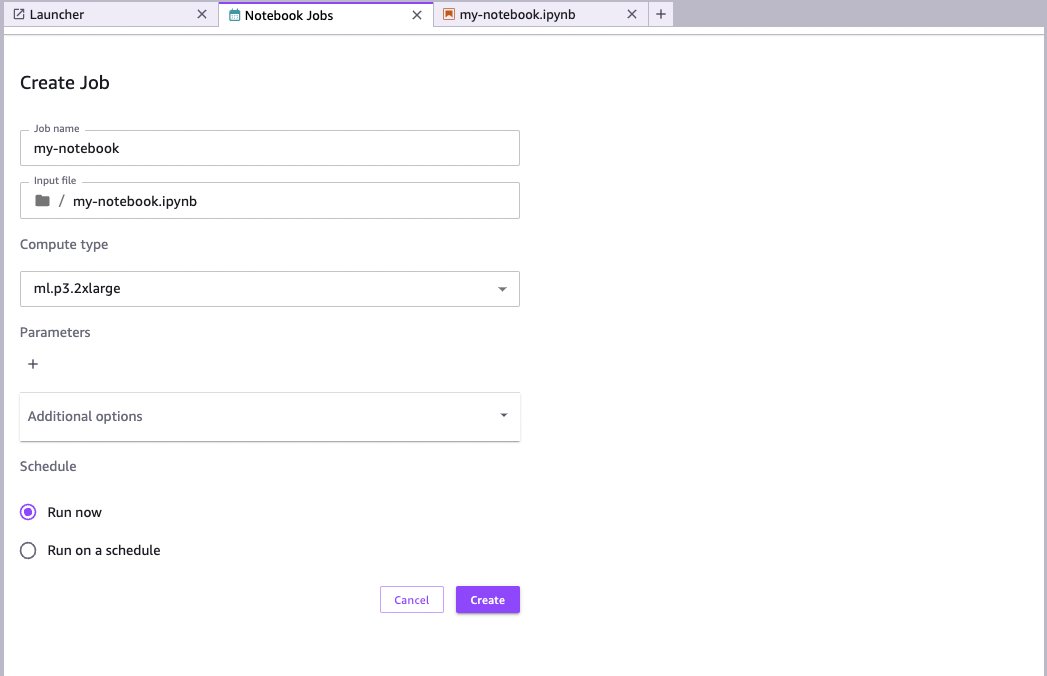
If there are no warnings on this page, you should be ready to go. If there are warnings, check to ensure the correct role ARN is specified in Additional options. This role should match the ARN of the SageMaker execution role we created earlier.The ARN is in the format
arn:aws:iam::[account-number]:role/service-role/[role-name].There are other options available within Additional options; for example, you can select a particular image and kernel that may already have the configuration you need without the need to install additional libraries.
- If you want to run this notebook on a schedule, select Run on a schedule and specify how often you want the job to run.
 We want this notebook to run once, so we select Run now.
We want this notebook to run once, so we select Run now. - Choose Create.

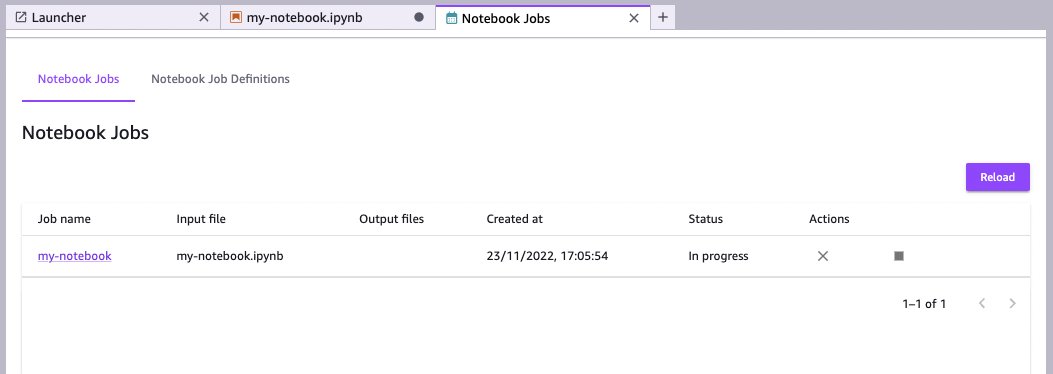
Notebook jobs list
The Notebook Jobs page lists all the jobs currently running and those that ran in the past. You can find this list from the Launcher (choose, File, New Launcher), then choose Notebook Jobs in the Other section.
When the notebook job is complete, you will see the status change to Completed (use the Reload option if required). You can then choose the download icon to access the output files.
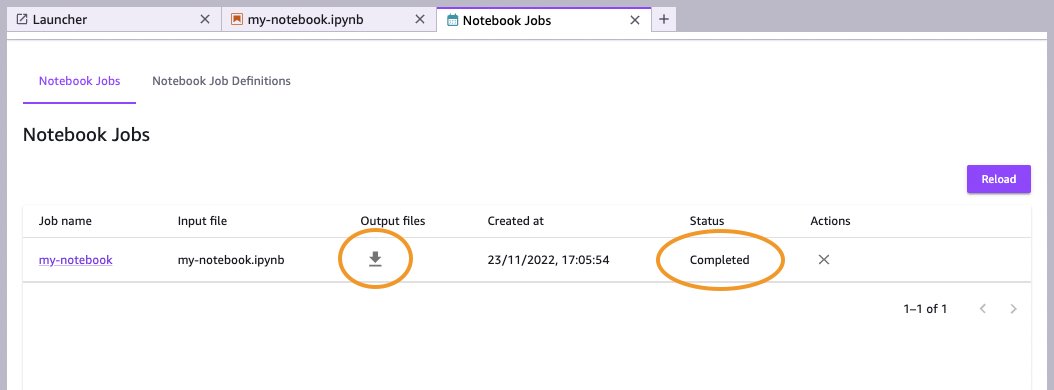
When the files have downloaded, you can review the notebook along with the code output and output log. In our case, because we added code to time the run of the training cell, we can see how long the training job took—16 minutes and 21 seconds, which is much faster than if the code had run inside of Studio Lab (1 hour, 38 minutes, 55 seconds). In fact, the whole notebook ran in 1,231 seconds (just over 20 minutes) at a cost of under $1.30 (USD).
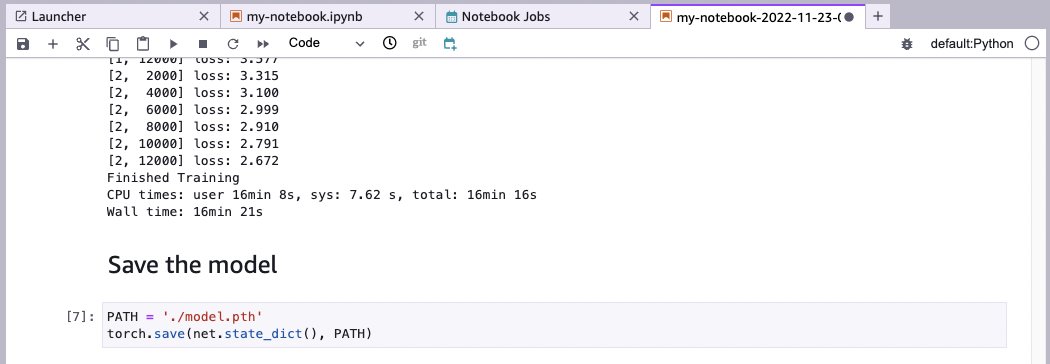
W can now increase the number of epochs and adjust the hyperparameters to improve the loss value of the model, and submit another notebook job.
Conclusion
In this post, we showed how to use Studio Lab notebook jobs to scale out the code we developed in Studio Lab and run it with more resources in an AWS account.
By adding AWS credentials to our Studio Lab environment, not only can we access notebook jobs, but we can also access other resources from an AWS account right from within our Studio Lab notebooks. Take a look at the AWS SDK for Python.
This extra capability of Studio Lab lifts the limits of the kinds and sizes of projects you can achieve. Let us know what you build with this new capability!
About the authors
 Mike Chambers is a Developer Advocate for AI and ML at AWS. He has spent the last 7 years helping builders to learn cloud, security and ML. Originally from the UK, Mike is a passionate tea drinker and Lego builder.
Mike Chambers is a Developer Advocate for AI and ML at AWS. He has spent the last 7 years helping builders to learn cloud, security and ML. Originally from the UK, Mike is a passionate tea drinker and Lego builder.
 Michele Monclova is a principal product manager at AWS on the SageMaker team. She is a native New Yorker and Silicon Valley veteran. She is passionate about innovations that improve our quality of life.
Michele Monclova is a principal product manager at AWS on the SageMaker team. She is a native New Yorker and Silicon Valley veteran. She is passionate about innovations that improve our quality of life.
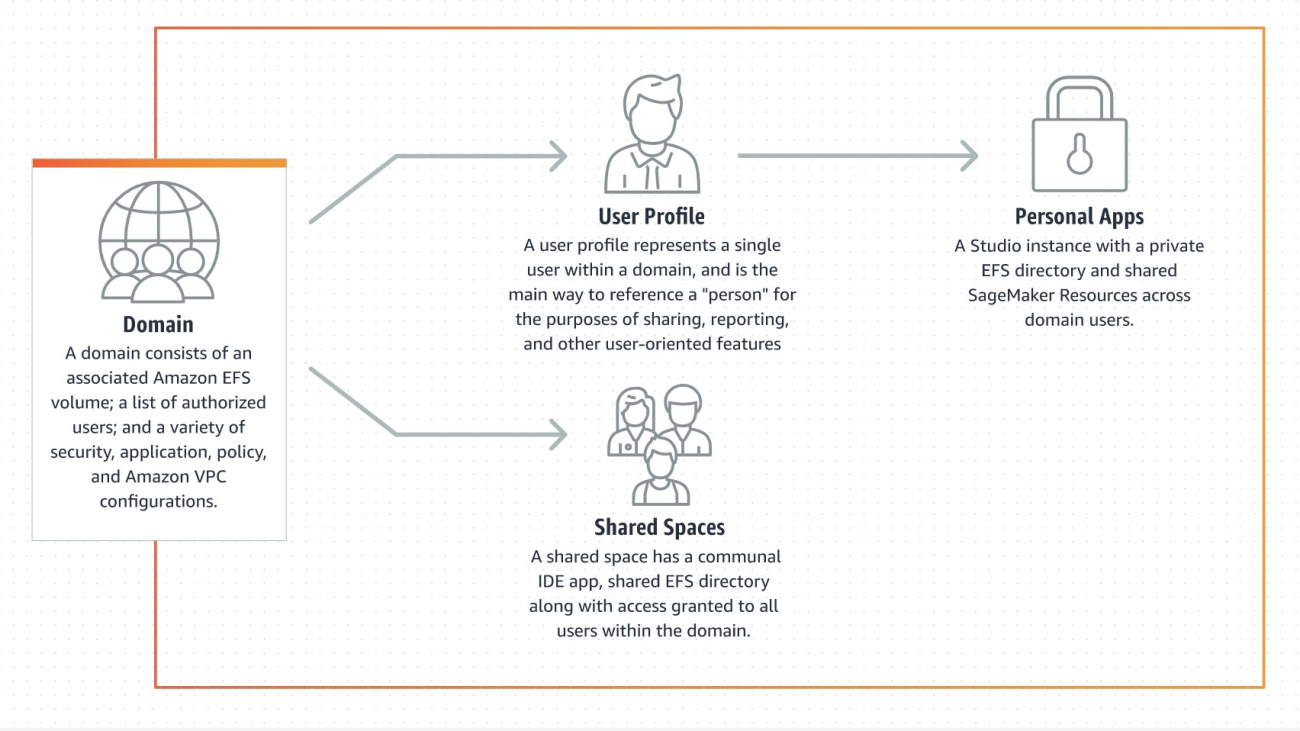
Organize machine learning development using shared spaces in SageMaker Studio for real-time collaboration
Amazon SageMaker Studio is the first fully integrated development environment (IDE) for machine learning (ML). It provides a single, web-based visual interface where you can perform all ML development steps, including preparing data and building, training, and deploying models.
Within an Amazon SageMaker Domain, users can provision a personal Amazon SageMaker Studio IDE application, which runs a free JupyterServer with built‑in integrations to examine Amazon SageMaker Experiments, orchestrate Amazon SageMaker Pipelines, and much more. Users only pay for the flexible compute on their notebook kernels. These personal applications automatically mount a respective user’s private Amazon Elastic File System (Amazon EFS) home directory so they can keep code, data, and other files isolated from other users. Amazon SageMaker Studio already supports sharing of notebooks between private applications, but the asynchronous mechanism can slow down the iteration process.
Now with shared spaces in Amazon SageMaker Studio, users can organize collaborative ML endeavors and initiatives by creating a shared IDE application that users utilize with their own Amazon SageMaker user profile. Data workers collaborating in a shared space get access to an Amazon SageMaker Studio environment where they can access, read, edit, and share their notebooks in real time, which gives them the quickest path to start iterating with their peers on new ideas. Data workers can even collaborate on the same notebook concurrently using real-time collaboration capabilities. The notebook indicates each co-editing user with a different cursor that shows their respective user profile name.
Shared spaces in SageMaker Studio automatically tag resources, such as Training jobs, Processing jobs, Experiments, Pipelines, and Model Registry entries created within the scope of a workspace with their respective sagemaker:space-arn. The space filters those resources within the Amazon SageMaker Studio user interface (UI) so users are only presented with SageMaker Experiments, Pipelines, and other resources that are pertinent to their ML endeavor.
Solution overview
Since shared spaces automatically tags resources, administrators can easily monitor costs associated with an ML endeavor and plan budgets using tools such as AWS Budgets and AWS Cost Explorer. As an administrator you’ll only need to attach a cost allocation tag for sagemaker:space-arn.
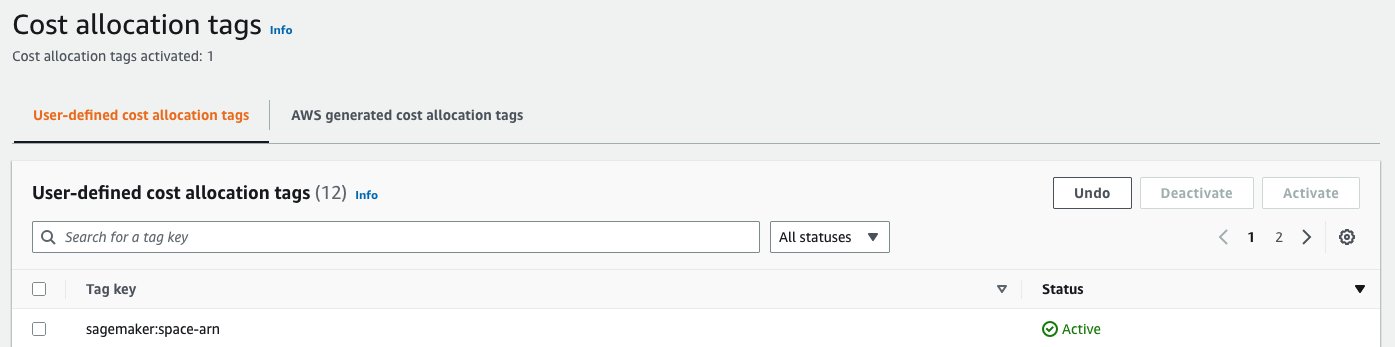
Once that’s complete, you can use AWS Cost Explorer to identify how much individual ML projects are costing your organization.
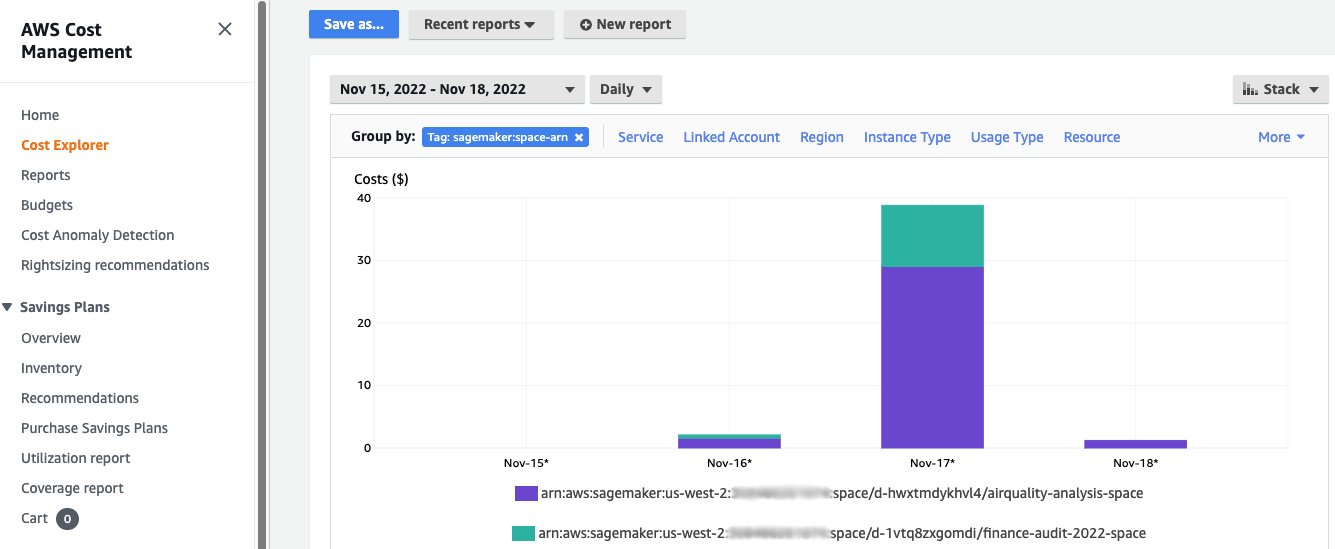
Get started with shared spaces in Amazon SageMaker Studio
In this section, we’ll analyze the typical workflow for creating and utilizing shared spaces in Amazon SageMaker Studio.
Create a shared space in Amazon SageMaker Studio
You can use the Amazon SageMaker Console or the AWS Command Line Interface (AWS CLI) to add support for spaces to an existing domain. For the most up to date information, please check Create a shared space. Shared spaces only work with a JupyterLab 3 SageMaker Studio image and for SageMaker Domains using AWS Identity and Access Management (AWS IAM) authentication.
Console creation
To create a space within a designated Amazon SageMaker Domain, you’ll first need to set a designated space default execution role. From the Domain details page, select the Domain settings tab and select Edit. Then you can set a space default execution role, which only needs to be completed once per Domain, as shown in the following diagram:

Next, you can go to the Space management tab within your domain and select the Create button, as shown in the following diagram:
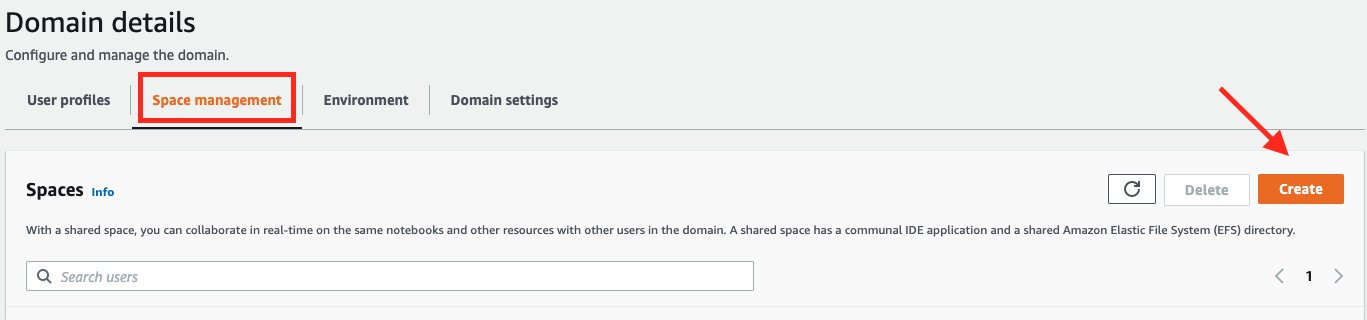
AWS CLI creation
You can also set a default Domain space execution role from the AWS CLI. In order to determine your region’s JupyterLab3 image ARN, check Setting a default JupyterLab version.
Once that’s been completed for your Domain, you can create a shared space from the CLI.
Launch a shared space in Amazon SageMaker Studio
Users can launch a shared space by selecting the Launch button next to their user profile within the AWS Console for their Amazon SageMaker Domain.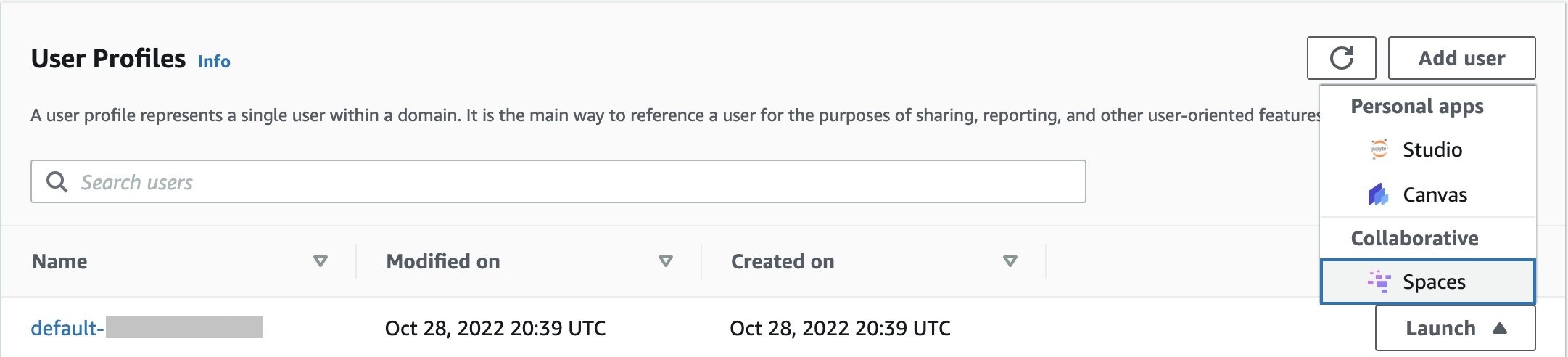
After selecting Spaces under the Collaborative section, then select which Space to launch: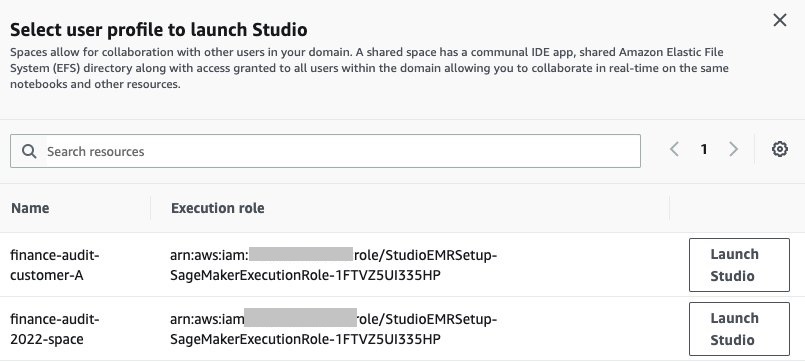
Alternatively, users can generate a pre-signed URL to launch a space through the AWS CLI:
Real time collaboration
Once the Amazon SageMaker Studio shared space IDE has been loaded, users can select the Collaborators tab on the left panel to see which users are actively working in your space and on what notebook. If more than one person is working on the same notebook, then you’ll see a cursor with the other user’s profile name where they are editing:
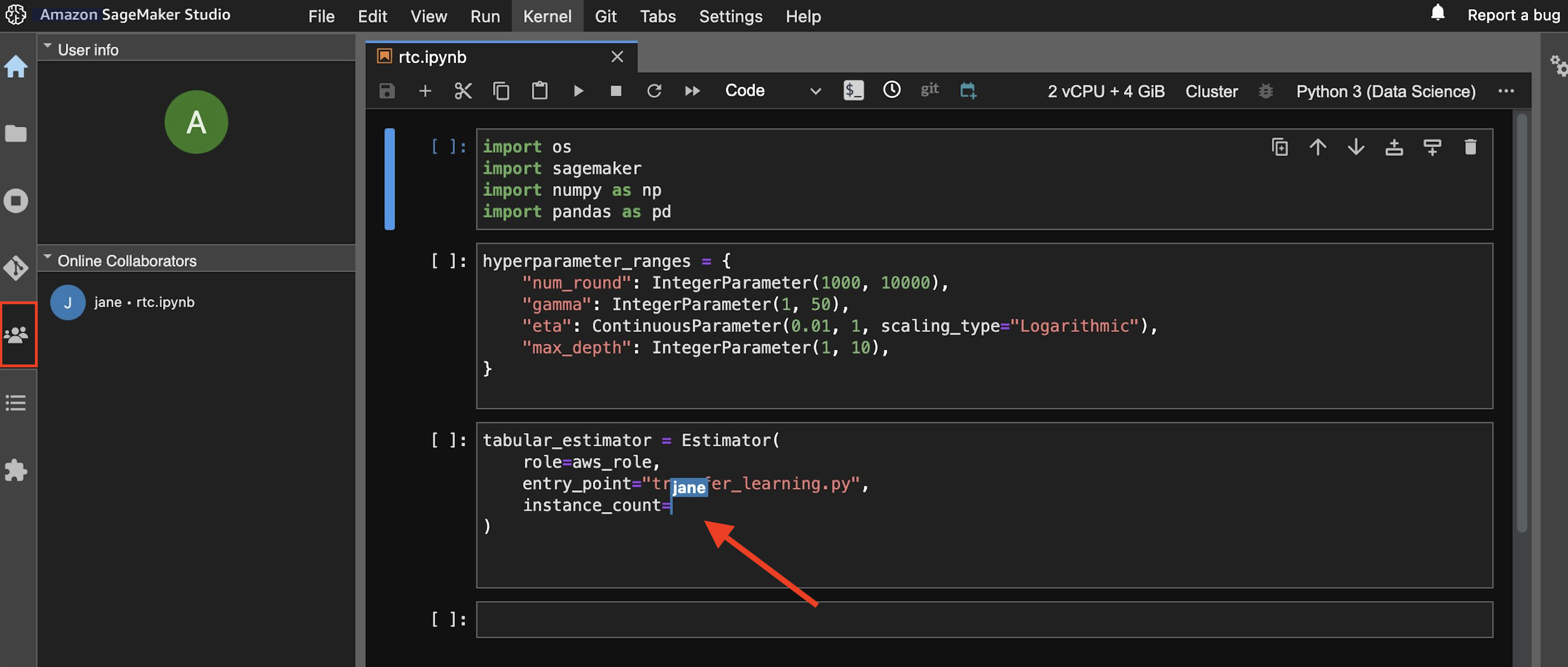
In the following screenshot, you can see the different user experiences for someone editing and viewing the same notebook: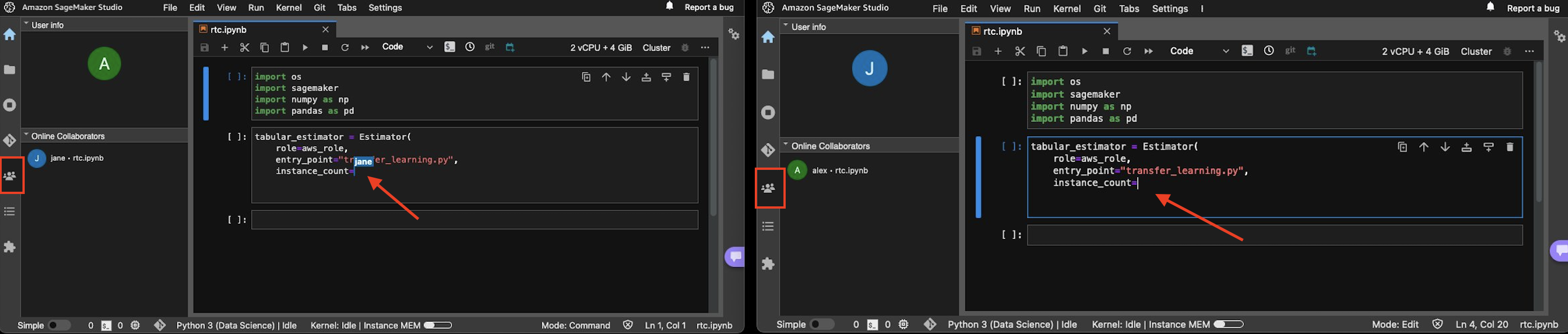
Conclusion
In this post, we showed you how shared spaces in SageMaker Studio adds a real-time collaborative IDE experience to Amazon SageMaker Studio. Automated tagging helps users scope and filter their Amazon SageMaker resources, which includes: experiments, pipelines, and model registry entries to maximize user productivity. Additionally, administrators can use these applied tags to monitor the costs associated with a given space and set appropriate budgets using AWS Cost Explorer and AWS Budgets.
Accelerate your team’s collaboration today by setting up shared spaces in Amazon SageMaker Studio for your specific machine learning endeavors!
About the authors
 Sean Morgan is an AI/ML Solutions Architect at AWS. He has experience in the semiconductor and academic research fields, and uses his experience to help customers reach their goals on AWS. In his free time, Sean is an active open-source contributor/maintainer and is the special interest group lead for TensorFlow Add-ons.
Sean Morgan is an AI/ML Solutions Architect at AWS. He has experience in the semiconductor and academic research fields, and uses his experience to help customers reach their goals on AWS. In his free time, Sean is an active open-source contributor/maintainer and is the special interest group lead for TensorFlow Add-ons.
 Han Zhang is a Senior Software Engineer at Amazon Web Services. She is part of the launch team for Amazon SageMaker Notebooks and Amazon SageMaker Studio, and has been focusing on building secure machine learning environments for customers. In her spare time, she enjoys hiking and skiing in the Pacific Northwest.
Han Zhang is a Senior Software Engineer at Amazon Web Services. She is part of the launch team for Amazon SageMaker Notebooks and Amazon SageMaker Studio, and has been focusing on building secure machine learning environments for customers. In her spare time, she enjoys hiking and skiing in the Pacific Northwest.
 Arkaprava De is a Senior Software Engineer at AWS. He has been at Amazon for over 7 years and is currently working on improving the Amazon SageMaker Studio IDE experience. You can find him on LinkedIn.
Arkaprava De is a Senior Software Engineer at AWS. He has been at Amazon for over 7 years and is currently working on improving the Amazon SageMaker Studio IDE experience. You can find him on LinkedIn.
 Kunal Jha is a Senior Product Manager at AWS. He is focused on building Amazon SageMaker Studio as the IDE of choice for all ML development steps. In his spare time, Kunal enjoys skiing and exploring the Pacific Northwest. You can find him on LinkedIn.
Kunal Jha is a Senior Product Manager at AWS. He is focused on building Amazon SageMaker Studio as the IDE of choice for all ML development steps. In his spare time, Kunal enjoys skiing and exploring the Pacific Northwest. You can find him on LinkedIn.
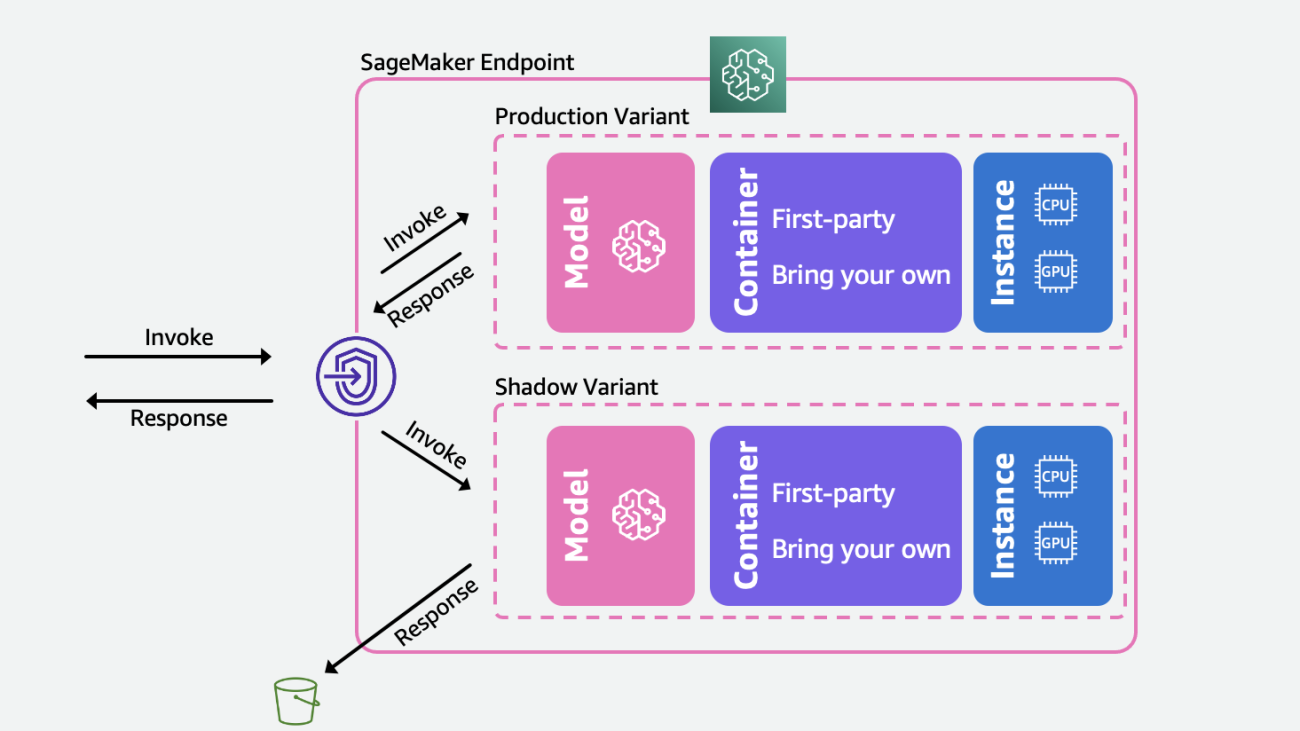
Minimize the production impact of ML model updates with Amazon SageMaker shadow testing
Amazon SageMaker now allows you to compare the performance of a new version of a model serving stack with the currently deployed version prior to a full production rollout using a deployment safety practice known as shadow testing. Shadow testing can help you identify potential configuration errors and performance issues before they impact end-users. With SageMaker, you don’t need to invest in building your shadow testing infrastructure, allowing you to focus on model development. SageMaker takes care of deploying the new version alongside the current version serving production requests, routing a portion of requests to the shadow version. You can then compare the performance of the two versions using metrics such as latency and error rate. This gives you greater confidence that production rollouts to SageMaker inference endpoints won’t cause performance regressions, and helps you avoid outages due to accidental misconfigurations.
In this post, we demonstrate this new SageMaker capability. The corresponding sample notebook is available in this GitHub repository.
Overview of solution
Your model serving infrastructure consists of the machine learning (ML) model, the serving container, or the compute instance. Let’s consider the following scenarios:
- You’re considering promoting a new model that has been validated offline to production, but want to evaluate operational performance metrics, such as latency, error rate, and so on, before making this decision.
- You’re considering changes to your serving infrastructure container, such as patching vulnerabilities or upgrading to newer versions, and want to assess the impact of these changes prior to promotion to production.
- You’re considering changing your ML instance and want to evaluate how the new instance would perform with live inference requests.
The following diagram illustrates our solution architecture.

For each of these scenarios, select a production variant you want to test against and SageMaker automatically deploys the new variant in shadow mode and routes a copy of the inference requests to it in real time within the same endpoint. Only the responses of the production variant are returned to the calling application. You can choose to discard or log the responses of the shadow variant for offline comparison. Optionally, you can monitor the variants through a built-in dashboard with a side-by-side comparison of the performance metrics. You can use this capability either through SageMaker inference update-endpoint APIs or through the SageMaker console.
Shadow variants build on top of the production variant capability in SageMaker inference endpoints. To reiterate, a production variant consists of the ML model, serving container, and ML instance. Because each variant is independent of others, you can have different models, containers, or instance types across variants. SageMaker lets you specify auto scaling policies on a per-variant basis so they can scale independently based on incoming load. SageMaker supports up to 10 production variants per endpoint. You can either configure a variant to receive a portion of the incoming traffic by setting variant weights, or specify the target variant in the incoming request. The response from the production variant is forwarded back to the invoker.
A shadow variant(new) has the same components as a production variant. A user-specified portion of the requests, known as the traffic sampling percentage, is forwarded to the shadow variant. You can choose to log the response of the shadow variant in Amazon Simple Storage Service (Amazon S3) or discard it.
Note that SageMaker supports a maximum of one shadow variant per endpoint. For an endpoint with a shadow variant, there can be a maximum of one production variant.
After you set up the production and shadow variants, you can monitor the invocation metrics for both production and shadow variants in Amazon CloudWatch under the AWS/SageMaker namespace. All updates to the SageMaker endpoint are orchestrated using blue/green deployments and occur without any loss in availability. Your endpoints will continue responding to production requests as you add, modify, or remove shadow variants.
You can use this capability in one of two ways:
- Managed shadow testing using the SageMaker Console – You can leverage the console for a guided experience to manage the end-to-end journey of shadow testing. This lets you setup shadow tests for a predefined duration of time, monitor the progress through a live dashboard, clean up upon completion, and act on the results.
- Self-service shadow testing using the SageMaker Inference APIs – If your deployment workflow already uses create/update/delete-endpoint APIs, you can continue using them to manage Shadow Variants.
In the following sections, we walk through each of these scenarios.
Scenario 1 – Managed shadow testing using the SageMaker Console
If you wish to choose SageMaker to manage the end-to-end workflow of creating, managing, and acting on the results of the shadow tests, consider using the Shadow tests’ capability in the Inference section of the SageMaker Console. As stated earlier, this enables you to setup shadow tests for a predefined duration of time, monitor the progress through a live dashboard, presents clean up options upon completion, and act on the results. To learn more, please visit the shadow tests section of our documentation for a step-by-step walkthrough of this capability.
Pre-requisites
The models for production and shadow need to be created on SageMaker. Please refer to the CreateModel API here.
Step 1 – Create a shadow test
Navigate to the Inference section of the left navigation panel of the SageMaker console and then choose Shadow tests. This will take you to a dashboard with all the scheduled, running, and completed shadow tests. Click ‘create a shadow test’. Enter a name for the test and choose next.
This will take you to the shadow test settings page. You can choose an existing IAM role or create one that has the AmazonSageMakerFullAccess IAM policy attached. Next, choose ‘Create a new endpoint’ and enter a name (xgb-prod-shadow-1). You can add one production and one shadow variant associated with this endpoint by clicking on ‘Add’ in the Variants section. You can select the models you have created in the ‘Add Model’ dialog box. This creates a production or variant. Optionally, you can change the instance type and count associated with each variant.
All the traffic goes to the production variant andit responds to invocation requests. You can control a portion of the requests that is routed to the shadow variant by changing the Traffic Sampling Percentage.
You can control the duration of the test from one hour to 30 days. If unspecified, it defaults to 7 days. After this period, the test is marked complete. If you are running a test on an existing endpoint, it will be rolled back to the state prior to starting the test upon completion.
You can optionally capture the requests and responses of the Shadow variant using the Data Capture options. If left unspecified, the responses of the shadow variant are discarded.


Step 2 – Monitor a shadow test
You can view the list of shadow tests by navigating to the Shadow Tests section under Inference. Click on the shadow test created in the previous step to view the details of a shadow test and monitor it while it is in progress or after it has completed.

The Metrics section provides a comparison of the key metrics and provides overlaid graphs between the production and shadow variants, along with descriptive statistics. You can compare invocation metrics such as ModelLatency and Invocation4xxErrors as well as instance metrics such as CPUUtilization and DiskUtilization.

Step 3 – Promote the Shadow variant to the new production variant
Upon comparing, you can either choose to promote the shadow variant to be the new production variant or remove the shadow variant. For both these options, select ‘Mark Complete’ on the top of the page. This presents you with an option to either promote or remove the shadow variant.
If you choose to promote, you will be taken to a deployment page, where you can confirm the variant settings prior to deployment. Prior to deployment, we recommend sizing your shadow variants to be able to handle 100% of the invocation traffic. If you are not using shadow testing to evaluate alternate instance types or sizes, you can use the choose the ‘retain production variant settings. Otherwise, you can choose to ‘retain shadow variant settings. If you choose this option, please ensure that your traffic sampling is set at 100%. Alternatively, you can specify the instance type and count if you wish to override these settings.
Once you confirm the deployment, SageMaker will initiate an update to your endpoint to promote the shadow variant to the new production variant. As with SageMaker all updates, your endpoint will still be operational during the update.


Scenario 2: Shadow testing using SageMaker inference APIs
This section covers how to use the existing SageMaker create/update/delete-endpoint APIs to deploy shadow variants.
For this example, we have two XGBoost models that represent two different versions of the models that have been pre-trained. model.tar.gz is the model currently deployed in production. model2 is the newer model, and we want to test its performance in terms of operational metrics such as latency before deciding to use it in production. We deploy model2 as a shadow variant of model.tar.gz. Both pre-trained models are stored in the public S3 bucket s3://sagemaker-sample-files. We firstdownload the modelour local compute instance and then upload to S3.
The models in this example are used to predict the probability of a mobile customer leaving their current mobile operator. The dataset we use is publicly available and was mentioned in the book Discovering Knowledge in Data by Daniel T. Larose. These models were trained using the XGB Churn Prediction Notebook in SageMaker. You can also use your own pre-trained models, in which case you can skip downloading from s3://sagemaker-sample-files and copy your own models directly to model/ folder.
Step 1 – Create models
We upload the model files to our own S3 bucket and create two SageMaker models. See the following code:
Step 2 – Deploy the two models as production and shadow variants to a real-time inference endpoint
We create an endpoint config with the production and shadow variants. The ProductionVariants and ShadowProductionVariants are of particular interest. Both these variants have ml.m5.xlarge instances with 4 vCPUs and 16 GiB of memory, and the initial instance count is set to 1. See the following code:
Lastly, we create the production and shadow variant:
Step 3 – Invoke the endpoint for testing
After the endpoint has been successfully created, you can begin invoking it. We send about 3,000 requests in a sequential way:
Step 4 – Compare metrics
Now that we have deployed both the production and shadow models, let’s compare the invocation metrics. For a list of invocation metrics available for comparison, refer to Monitor Amazon SageMaker with Amazon CloudWatch. Let’s start by comparing invocations between the production and shadow variants.
The InvocationsPerInstance metric refers to the number of invocations sent to the production variant. A fraction of these invocations, specified in the variant weight, are sent to the shadow variant. The invocation per instance is calculated by dividing the total number of invocations by the number of instances in a variant. As shown in the following charts, we can confirm that both the production and shadow variants are receiving invocation requests according to the weights specified in the endpoint config.


Next, let’s compare the model latency (ModelLatency metric) between the production and shadow variants. Model latency is the time taken by a model to respond as viewed from SageMaker. We can observe how the model latency of the shadow variant compares with the production variant without exposing end-users to the shadow variant.

We expect the overhead latency (OverheadLatency metric) to be comparable across production and shadow variants. Overhead latency is the interval measured from the time SageMaker receives the request until it returns a response to the client, minus the model latency.

Step 5- Promote your shadow variant
To promote the shadow model to production, create a new endpoint configuration with current ShadowProductionVariant as the new ProductionVariant and remove the ShadowProductionVariant. This will remove the current ProductionVariant and promote the shadow variant to become the new production variant. As always, all SageMaker updates are orchestrated as blue/green deployments under the hood, and there is no loss of availability while performing the update.
Optionally, you can leverage Deployment Guardrails if you want to use all-at-once traffic shifting and auto rollbacks during your update.
Step 6 – Clean Up
If you do not plan to use this endpoint further, you should delete the endpoint to avoid incurring additional charges and clean up other resources created in this blog.
Conclusion
In this post, we introduced a new capability of SageMaker inference to compare the performance of new version of a model serving stack with the currently deployed version prior to a full production rollout using a deployment safety practice known as shadow testing. We walked you through the advantages of using shadow variants and methods to configure the variants with an end-to-end example. To learn more about shadow variants, refer to shadow tests documentation.
About the Authors
 Raghu Ramesha is a Machine Learning Solutions Architect with the Amazon SageMaker Service team. He focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his spare time, he enjoys traveling and photography.
Raghu Ramesha is a Machine Learning Solutions Architect with the Amazon SageMaker Service team. He focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his spare time, he enjoys traveling and photography.
 Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his Ph.D. in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently he helps customers in the financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his Ph.D. in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently he helps customers in the financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
 Qiyun Zhao is a Senior Software Development Engineer with the Amazon SageMaker Inference Platform team. He is the lead developer of the Deployment Guardrails and Shadow Deployments, and he focuses on helping customers to manage ML workloads and deployments at scale with high availability. He also works on platform architecture evolutions for fast and secure ML jobs deployment and running ML online experiments at ease. In his spare time, he enjoys reading, gaming and traveling.
Qiyun Zhao is a Senior Software Development Engineer with the Amazon SageMaker Inference Platform team. He is the lead developer of the Deployment Guardrails and Shadow Deployments, and he focuses on helping customers to manage ML workloads and deployments at scale with high availability. He also works on platform architecture evolutions for fast and secure ML jobs deployment and running ML online experiments at ease. In his spare time, he enjoys reading, gaming and traveling.
 Tarun Sairam is a Senior Product Manager for Amazon SageMaker Inference. He is interested in learning about the latest trends in machine learning and helping customers leverage them. In his spare time, he enjoys biking, skiing, and playing tennis.
Tarun Sairam is a Senior Product Manager for Amazon SageMaker Inference. He is interested in learning about the latest trends in machine learning and helping customers leverage them. In his spare time, he enjoys biking, skiing, and playing tennis.