A well-designed CI/CD pipeline is essential to scale any software development workflow effectively. When designing production CI/CD pipelines, AWS recommends leveraging multiple accounts to isolate resources, contain security threats and simplify billing-and data science pipelines are no different. At AWS, we’re continuing to innovate to simplify the MLOps workflow.
In this post, we discuss some of the newer cross-account features to Amazon SageMaker that allow you to better share and manage model groups as well as manage model versions. For an example account structure to follow organizational unit best practices to host models using SageMaker endpoints across accounts, refer to MLOps Workload Orchestrator.
Solution overview
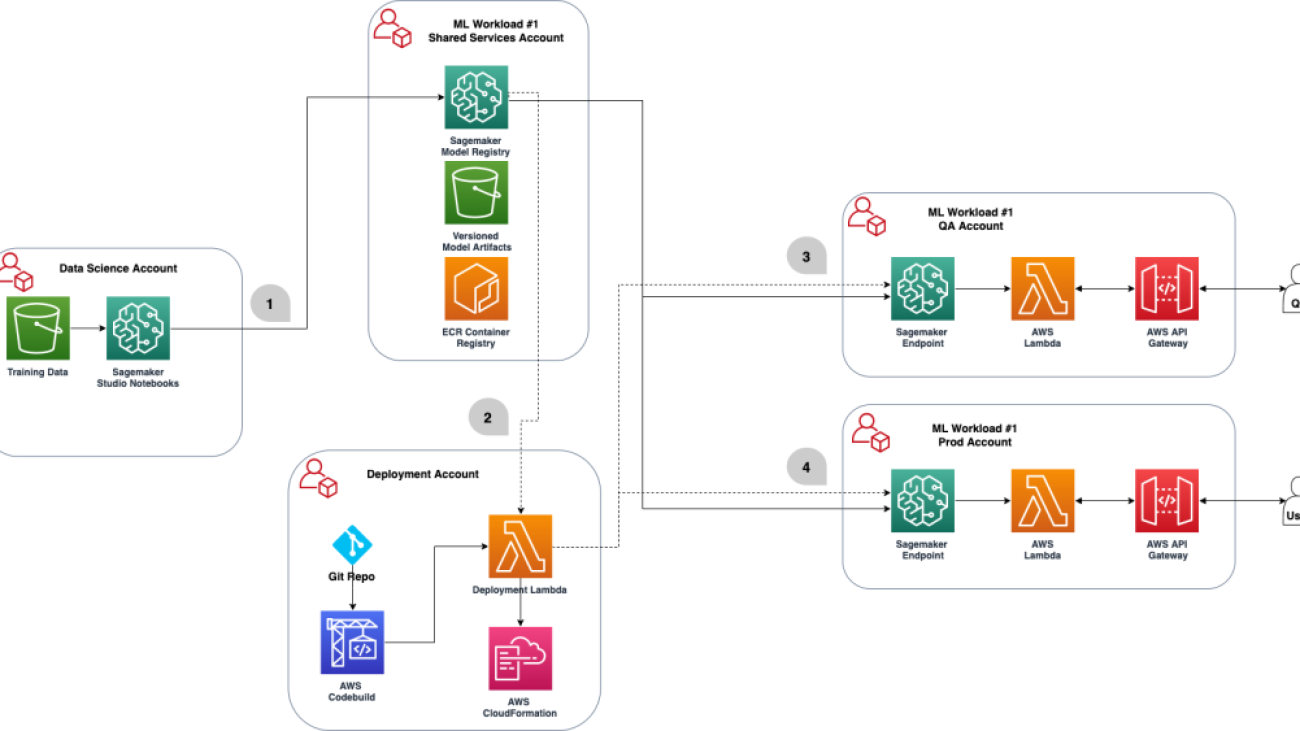
The following diagram illustrates our shared model registry architecture.

Some things to note in the preceding architecture:
The following steps correspond to the diagram:
- A data scientist registers a model from the data science account into the shared services SageMaker model registry in a
PendingManualApproval state. The model artifact is created in the shared services account Amazon Simple Storage Service (Amazon S3) bucket.
- Upon a new model version registration, someone with the authority to approve the model based on the metrics should approve or reject the model.
- After the model is approved, the CI/CD pipeline in deployment account is triggered to deploy the updated model details in the QA account and update the stage as QA.
- Upon passing the testing process, you can either choose to have a manual approval step within your CI/CD process or have your CI/CD pipeline directly deploy the model to production and update the stage as Prod.
- The production environment references the approved model and code, perhaps doing an A/B test in production. In case of an audit or any issue with the model, you can use Amazon SageMaker ML Lineage Tracking. It creates and stores information about the steps of a machine learning (ML) workflow from data preparation to model deployment. With the tracking information, you can reproduce the workflow steps, track the model and dataset lineage, and establish model governance and audit standards.
Throughout the whole process, the shared model registry retains the older model versions. This allows the team to roll back changes, or even host production variants.
Prerequisites
Make sure you have the following prerequisites:
- A provisioned multi-account structure – For instructions, see Best Practices for Organizational Units with AWS Organizations. For the purposes of this blog we are leveraging the following accounts:
- Data science account – An account where data scientists have access to the training data and create the models.
- Shared services account – A central account for storing the model artifacts (as shown in the architecture diagram) to be accessed across the different workload accounts.
- Deployment account – An account responsible for deploying changes to the various accounts.
- Workload accounts – These are commonly QA and prod environments where software engineers are able to build applications to consume the ML model.
- A deployment account with appropriate permissions – For more information about best practices with a multi-account OU structure, refer to Deployments OU. This account is responsible for pointing the workload accounts to the desired model in the shared services account’s model registry.
Define cross-account policies
In following the principle of least privilege, first we need to add cross-account resource policies to the shared services resources to grant access from the other accounts.
Because the model artifacts are stored in the shared services account’s S3 bucket, the data science account needs Amazon S3 read/write access to push trained models to Amazon S3. The following code illustrates this policy, but don’t add it to the shared services account yet:
#Data Science account's policy to access Shared Services' S3 bucket
{
'Version': '2012-10-17',
'Statement': [{
'Sid': 'AddPerm',
'Effect': 'Allow',
'Principal': {
'AWS': 'arn:aws:iam::<data_science_account_id>:root'
},
"Action": [
's3:PutObject',
's3:PutObjectAcl',
's3:GetObject',
's3:GetObjectVersion'
], #read/write
'Resource': 'arn:aws:s3:::<shared_bucket>/*'
}]
}
The deployment account only needs to be granted read access to the S3 bucket, so that it can use the model artifacts to deploy to SageMaker endpoints. We also need to attach the following policy to the shared services S3 bucket:
#Deployment account's policy to access Shared Services' S3 bucket
{
'Version': '2012-10-17',
'Statement': [{
'Sid': 'AddPerm',
'Effect': 'Allow',
'Principal': {
'AWS': 'arn:aws:iam::<deployment_account_id>:root'
},
'Action': [
's3:GetObject',
's3:GetObjectVersion'
], #read
'Resource': 'arn:aws:s3:::<shared_bucket>/*'
}]
}
We combine both policies to get the following final policy. Create this policy in the shared services account after replacing the appropriate account IDs:
{
"Version": "2012-10-17",
"Statement": [{
"Sid": "AddPerm",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::<data_science_account_id>:root"
},
"Action": [
"s3:PutObject",
"s3:PutObjectAcl",
"s3:GetObject",
"s3:GetObjectVersion" ],
"Resource": "arn:aws:s3:::<shared_bucket>/*"
},
{
"Sid": "AddPermDeployment",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::<deployment_account_id>:root"
},
"Action": [
"s3:GetObject",
"s3:GetObjectVersion" ],
"Resource": "arn:aws:s3:::<shared_bucket>/*"
}
]
}
To be able to deploy a model created in a different account, the user must have a role that has access to SageMaker actions, such as a role with the AmazonSageMakerFullAccess managed policy. Refer to Deploy a Model Version from a Different Account for additional details.
We need to define the model group that contains the model versions we want to deploy. Also, we want to grant permissions to the data science account. This can be accomplished in the following steps. We refer to the accounts as follows:
- shared_services_account_id – The account where the model registry is and where we want the model to be
- data_science_account_id – The account where we will be training and therefore creating the actual model artifact
- deployment_account_id – The account where we want to host the endpoint for this model
First we need to ensure the model package groups exists. You can use Boto3 APIs as shown the following example, or you can use the AWS Management Console to create the model package. Refer to Create Model Package Group for more details. This assumes you have the Boto3 installed.
model_package_group_name = "cross-account-example-model"
sm_client = boto3.Session().client("sagemaker")
create_model_package_group_response = sm_client.create_model_package_group(
ModelPackageGroupName=model_package_group_name,
ModelPackageGroupDescription="Cross account model package group",
Tags=[
{
'Key': 'Name',
'Value': 'cross_account_test'
},
]
)
print('ModelPackageGroup Arn : {}'.format(create_model_package_group_response['ModelPackageGroupArn']))
For the permissions for this model package group, you can create a JSON document resembling the following code. Replace the actual account IDs and model package group name with your own values.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AddPermModelPackageGroupCrossAccount",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::<data_science_account_id>:root"
},
"Action": [
"sagemaker:DescribeModelPackageGroup"
],
"Resource": "arn:aws:sagemaker:<region>:<shared_services_account_id>:model-package-group/<model_package_group_name>"
},
{
"Sid": "AddPermModelPackageVersionCrossAccount",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::<data_science_account_id>:root"
},
"Action": [
"sagemaker:DescribeModelPackage",
"sagemaker:ListModelPackages",
"sagemaker:UpdateModelPackage",
"sagemaker:CreateModelPackage",
"sagemaker:CreateModel"
],
"Resource": "arn:aws:sagemaker:<region>:<shared_services_account_id>:model-package/<model_package_group_name>/*"
}
]
}
Finally, apply the policy to the model package group. You can’t associate this policy with the package group via the console. You need the SDK or AWS Command Line Interface (AWS CLI) access. For example, the following code uses Boto3:
# Convert the policy from JSON dict to string
model_package_group_policy = dict(<put-above-json-policy-after-subsitute> )
model_package_group_policy = json.dumps(model_package_group_policy)
# Set the new policy
sm_client = boto3.Session().client("sagemaker")
response = sm_client.put_model_package_group_policy(
ModelPackageGroupName = model_package_group_name,
ResourcePolicy = model_package_group_policy)
We also need a custom AWS Key Management Service (AWS KMS) key to encrypt the model while storing it in Amazon S3. This needs to be done using the data science account. On the AWS KMS console, navigate to the Define key usage permissions page. In the Other AWS accounts section, choose Add another AWS account. Enter the AWS account number for the deployment account. You use this KMS key for the SageMaker training job. If you don’t specify a KMS key for the training job, SageMaker defaults to an Amazon S3 server-side encryption key. A default Amazon S3 server-side encryption key can’t be shared with or used by another AWS account.
The policy and permissions follow this pattern:
- The Amazon S3 policy specified in
shared_services_account gives permissions to the data science account and deployments account
- The KMS key policy specified in
shared_services_account gives permissions to the data science account and deployments account
We need to ensure that the shared services account and deployment account have access to the Docker images that were used for training the model. These images are generally hosted in AWS accounts, and your account admin can help you get access, if you don’t have access already. For this post, we don’t create any custom Docker images after training the model and therefore we don’t need any specific Amazon ECR policies for the images.
In the workload accounts (QA or prod), we need to create two AWS Identity and Access Management (IAM) policies similar to the following. These are inline policies, which means that they’re embedded in an IAM identity. This gives these accounts access to model registry.
The first inline policy allows a role to access the Amazon S3 resource in the shared services account that contains the model artifact. Provide the name of the S3 bucket and your model:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::<bucket-name>/sagemaker/<cross-account-example-model>/output/model.tar.gz"
}
]
}
The second inline policy allows a role, which we create later, to use the KMS key in the shared services account. Specify the account ID for the shared services account and KMS key ID:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowUseOfTheKey",
"Effect": "Allow",
"Action": [
"kms:Decrypt"
],
"Resource": [
"arn:aws:kms:us-east-1:<data_science_account_id>:key/{xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx}"
]
}
]
}
Finally, we need to create an IAM role for SageMaker. This role has the AmazonSageMakerFullAccess policy attached. We then attach these two inline policies to the role we created. If you’re using an existing SageMaker execution role, attach these two policies to that role. For instructions, refer to Creating roles and attaching policies (console).
Now that we have defined the policies of each account, let’s use an example to see it in action.
Build and train a model using a SageMaker pipeline
We first create a SageMaker pipeline in the data science account for carrying out data processing, model training, and evaluation. We use the California housing dataset obtained from the StatLib library. In the following code snippet, we use a custom preprocessing script preprocess.py to perform some simple feature transformation such as feature scaling, which can be generated using the following notebook. This script also splits the dataset into training and test datasets.
We create a SKLearnProcessor object to run this preprocessing script. In the SageMaker pipeline, we create a processing step (ProcessingStep) to run the processing code using SKLearnProcessor. This processing code is called when the SageMaker pipeline is initialized. The code creating the SKLearnProcessor and ProcessingStep are shown in the following code. Note that all the code in this section is run in the data science account.
# Useful SageMaker variables - Create a Pipeline session which will lazy init resources
session = PipelineSession()
framework_version = "0.23-1"
# Create SKlearn processor object,
# The object contains information about what instance type to use, the IAM role to use etc.
# A managed processor comes with a preconfigured container, so only specifying version is required.
sklearn_processor = SKLearnProcessor(
framework_version=framework_version,
role=role,
instance_type=processing_instance_type,
instance_count=1,
base_job_name="tf2-california-housing-processing-job",
sagemaker_session=session
)
# Use the sklearn_processor in a SageMaker pipelines ProcessingStep
step_preprocess_data = ProcessingStep(
name="Preprocess-California-Housing-Data",
processor=sklearn_processor,
inputs=[
ProcessingInput(source=input_data, destination="/opt/ml/processing/input"),
],
outputs=[
ProcessingOutput(output_name="train", source="/opt/ml/processing/train"),
ProcessingOutput(output_name="test", source="/opt/ml/processing/test"),
],
code="preprocess.py",
)
We need a custom KMS key to encrypt the model while storing it to Amazon S3. See the following code:
kms_client = boto3.client('kms')
response = kms_client.describe_key(
KeyId='alias/sagemaker/outkey',
)
key_id = response['KeyMetadata']['KeyId']
To train the model, we create a TensorFlow estimator object. We pass it the KMS key ID along with our training script train.py, training instance type, and count. We also create a TrainingStep to be added to our pipeline, and add the TensorFlow estimator to it. See the following code:
model_path = f"s3://{bucket}/{prefix}/model/"
hyperparameters = {"epochs": training_epochs}
tensorflow_version = "2.4.1"
python_version = "py37"
tf2_estimator = TensorFlow(
source_dir="code",
entry_point="train.py",
instance_type=training_instance_type,
instance_count=1,
framework_version=tensorflow_version,
role=role,
base_job_name="tf2-california-housing-train",
output_path=model_path,
output_kms_key=key_id,
hyperparameters=hyperparameters,
py_version=python_version,
sagemaker_session=session
)
# Use the tf2_estimator in a SageMaker pipelines ProcessingStep.
# NOTE how the input to the training job directly references the output of the previous step.
step_train_model = TrainingStep(
name="Train-California-Housing-Model",
estimator=tf2_estimator,
inputs={
"train": TrainingInput(
s3_data=step_preprocess_data.properties.ProcessingOutputConfig.Outputs[
"train"
].S3Output.S3Uri,
content_type="text/csv",
),
"test": TrainingInput(
s3_data=step_preprocess_data.properties.ProcessingOutputConfig.Outputs[
"test"
].S3Output.S3Uri,
content_type="text/csv",
),
},
)
In addition to training, we need to carry out model evaluation, for which we use mean squared error (MSE) as the metric in this example. The earlier notebook also generates evaluate.py, which we use to evaluate our a model using MSE. We also create a ProcessingStep to initialize the model evaluation script using a SKLearnProcessor object. The following code creates this step:
from sagemaker.workflow.properties import PropertyFile
# Create SKLearnProcessor object.
# The object contains information about what container to use, what instance type etc.
evaluate_model_processor = SKLearnProcessor(
framework_version=framework_version,
instance_type=processing_instance_type,
instance_count=1,
base_job_name="tf2-california-housing-evaluate",
role=role,
sagemaker_session=session
)
# Create a PropertyFile
# A PropertyFile is used to be able to reference outputs from a processing step, for instance to use in a condition step.
# For more information, visit https://docs.aws.amazon.com/sagemaker/latest/dg/build-and-manage-propertyfile.html
evaluation_report = PropertyFile(
name="EvaluationReport", output_name="evaluation", path="evaluation.json"
)
# Use the evaluate_model_processor in a SageMaker pipelines ProcessingStep.
step_evaluate_model = ProcessingStep(
name="Evaluate-California-Housing-Model",
processor=evaluate_model_processor,
inputs=[
ProcessingInput(
source=step_train_model.properties.ModelArtifacts.S3ModelArtifacts,
destination="/opt/ml/processing/model",
),
ProcessingInput(
source=step_preprocess_data.properties.ProcessingOutputConfig.Outputs[
"test"
].S3Output.S3Uri,
destination="/opt/ml/processing/test",
),
],
outputs=[
ProcessingOutput(output_name="evaluation", source="/opt/ml/processing/evaluation"),
],
code="evaluate.py",
property_files=[evaluation_report],
)
After model evaluation, we also need a step to register our model with the model registry, if the model performance meets the requirements. This is shown in the following code using the RegisterModel step. Here we need to specify the model package that we had declared in the shared services account. Replace the Region, account, and model package with your values. The model name used here is modeltest, but you can use any name of your choice.
# Create ModelMetrics object using the evaluation report from the evaluation step
# A ModelMetrics object contains metrics captured from a model.
model_metrics = ModelMetrics(
model_statistics=MetricsSource(
s3_uri=evaluation_s3_uri,
content_type="application/json",
)
)
# Create a RegisterModel step, which registers the model with SageMaker Model Registry.
model = Model(
image_uri=tf2_estimator.training_image_uri(),
model_data=training_step.properties.ModelArtifacts.S3ModelArtifacts,
source_dir=tf2_estimator.source_dir,
entry_point=tf2_estimator.entry_point,
role=role_arn,
sagemaker_session=session
)
model_registry_args = model.register(
content_types=['text/csv'],
response_types=['application/json'],
inference_instances=['ml.t2.medium', 'ml.m5.xlarge'],
transform_instances=['ml.m5.xlarge'],
model_package_group_name=model_package_group_name,
approval_status='PendingManualApproval',
model_metrics=model_metrics
)
step_register_model= ModelStep(
name='RegisterModel',
step_args=model_registry_args
)
We also need to create the model artifacts so that it can be deployed (using the other account). For creating the model, we create a CreateModelStep, as shown in the following code:
from sagemaker.inputs import CreateModelInput
from sagemaker.workflow.model_step import ModelStep
step_create_model = ModelStep(
name="Create-California-Housing-Model",
step_args=model.create(instance_type="ml.m5.large",accelerator_type="ml.eia1.medium"),
)
Adding conditions to the pipeline is done with a ConditionStep. In this case, we only want to register the new model version with the model registry if the new model meets an accuracy condition. See the following code:
from sagemaker.workflow.conditions import ConditionLessThanOrEqualTo
from sagemaker.workflow.condition_step import (
ConditionStep,
JsonGet,
)
# Create accuracy condition to ensure the model meets performance requirements.
# Models with a test accuracy lower than the condition will not be registered with the model registry.
cond_lte = ConditionLessThanOrEqualTo(
left=JsonGet(
step=step_evaluate_model,
property_file=evaluation_report,
json_path="regression_metrics.mse.value",
),
right=accuracy_mse_threshold,
)
# Create a SageMaker Pipelines ConditionStep, using the preceding condition.
# Enter the steps to perform if the condition returns True / False.
step_cond = ConditionStep(
name="MSE-Lower-Than-Threshold-Condition",
conditions=[cond_lte],
if_steps=[step_register_model, step_create_model],
else_steps=[step_higher_mse_send_email_lambda],
)
Finally, we want to orchestrate all the pipeline steps so that the pipeline can be initialized:
from sagemaker.workflow.pipeline import Pipeline
# Create a SageMaker Pipeline.
# Each parameter for the pipeline must be set as a parameter explicitly when the pipeline is created.
# Also pass in each of the preceding steps.
# Note that the order of execution is determined from each step's dependencies on other steps,
# not on the order they are passed in.
pipeline = Pipeline(
name=pipeline_name,
parameters=[
processing_instance_type,
training_instance_type,
input_data,
training_epochs,
accuracy_mse_threshold,
endpoint_instance_type,
],
steps=[step_preprocess_data, step_train_model, step_evaluate_model, step_cond],
)
Deploy a model version from a different account
Now that the model has been registered in the shared services account, we need to deploy into our workload accounts using the CI/CD pipeline in the deployment account. We have already configured the role and the policy in an earlier step. We use the model package ARN to deploy the model from the model registry. The following code runs in the deployment account and is used to deploy approved models to QA and prod:
from sagemaker import ModelPackage
from time import gmtime, strftime
sagemaker_session = sagemaker.Session(boto_session=sess)
model_package_arn = 'arn:aws:sagemaker:<region>:<shared_services_account>:<model_group_package>/modeltest/version_number'
model = ModelPackage(role=role,
model_package_arn=model_package_arn,
sagemaker_session=sagemaker_session)
model.deploy(initial_instance_count=1, instance_type='ml.m5.xlarge')
Conclusion
In this post, we demonstrated how to set up the policies needed for a multi-account setup for ML based on the principle of least privilege. Then we showed the process of building and training the models in the data science account. Finally, we used the CI/CD pipeline in the deployment account to deploy the latest version of approved models to QA and production accounts. Additionally, you can view the deployment history of models and build triggers in AWS CodeBuild.
You can scale the concepts in this post to host models in Amazon Elastic Compute Cloud (Amazon EC2) or Amazon Elastic Kubernetes Service (Amazon EKS), as well as build out a batch inference pipeline.
To learn more about having separate accounts that build ML models in AWS, see Best Practices for Organizational Units with AWS Organizations and Safely update models in production.
About the Authors
 Sandeep Verma is a Sr. Prototyping Architect with AWS. He enjoys diving deep into customer challenges and building prototypes for customers to accelerate innovation. He has a background in AI/ML, founder of New Knowledge, and generally passionate about tech. In his free time, he loves traveling and skiing with his family.
Sandeep Verma is a Sr. Prototyping Architect with AWS. He enjoys diving deep into customer challenges and building prototypes for customers to accelerate innovation. He has a background in AI/ML, founder of New Knowledge, and generally passionate about tech. In his free time, he loves traveling and skiing with his family.
 Mani Khanuja is an Artificial Intelligence and Machine Learning Specialist SA at Amazon Web Services (AWS). She helps customers using machine learning to solve their business challenges using the AWS. She spends most of her time diving deep and teaching customers on AI/ML projects related to computer vision, natural language processing, forecasting, ML at the edge, and more. She is passionate about ML at edge, therefore, she has created her own lab with self-driving kit and prototype manufacturing production line, where she spend lot of her free time.
Mani Khanuja is an Artificial Intelligence and Machine Learning Specialist SA at Amazon Web Services (AWS). She helps customers using machine learning to solve their business challenges using the AWS. She spends most of her time diving deep and teaching customers on AI/ML projects related to computer vision, natural language processing, forecasting, ML at the edge, and more. She is passionate about ML at edge, therefore, she has created her own lab with self-driving kit and prototype manufacturing production line, where she spend lot of her free time.
 Saumitra Vikram is a Software Developer on the Amazon SageMaker team and is based in Chennai, India. Outside of work, he loves spending time running, trekking and motor bike riding through the Himalayas.
Saumitra Vikram is a Software Developer on the Amazon SageMaker team and is based in Chennai, India. Outside of work, he loves spending time running, trekking and motor bike riding through the Himalayas.
 Sreedevi Srinivasan is an engineering leader in AWS SageMaker. She is passionate and excited about enabling ML as a platform that is set to transform every day lives. She currently focusses on SageMaker Feature Store. In her free time, she likes to spend time with her family.
Sreedevi Srinivasan is an engineering leader in AWS SageMaker. She is passionate and excited about enabling ML as a platform that is set to transform every day lives. She currently focusses on SageMaker Feature Store. In her free time, she likes to spend time with her family.
 Rupinder Grewal is a Sr Ai/ML Specialist Solutions Architect with AWS. He currently focuses on serving of models and MLOps on SageMaker. Prior to this role he has worked as Machine Learning Engineer building and hosting models. Outside of work he enjoys playing tennis and biking on mountain trails.
Rupinder Grewal is a Sr Ai/ML Specialist Solutions Architect with AWS. He currently focuses on serving of models and MLOps on SageMaker. Prior to this role he has worked as Machine Learning Engineer building and hosting models. Outside of work he enjoys playing tennis and biking on mountain trails.
 Farooq Sabir is a Senior Artificial Intelligence and Machine Learning Specialist Solutions Architect at AWS. He holds PhD and MS degrees in Electrical Engineering from The University of Texas at Austin and a MS in Computer Science from Georgia Institute of Technology. At AWS, he helps customers formulate and solve their business problems in data science, machine learning, computer vision, artificial intelligence, numerical optimization and related domains. He has over 16 years of work experience and is also an adjunct faculty member at The University of Texas at Dallas, where he teaches a graduate course on Applied Machine Learning. Based in Dallas, Texas, he and his family love to travel and make long road trips.
Farooq Sabir is a Senior Artificial Intelligence and Machine Learning Specialist Solutions Architect at AWS. He holds PhD and MS degrees in Electrical Engineering from The University of Texas at Austin and a MS in Computer Science from Georgia Institute of Technology. At AWS, he helps customers formulate and solve their business problems in data science, machine learning, computer vision, artificial intelligence, numerical optimization and related domains. He has over 16 years of work experience and is also an adjunct faculty member at The University of Texas at Dallas, where he teaches a graduate course on Applied Machine Learning. Based in Dallas, Texas, he and his family love to travel and make long road trips.
Read More





 Dr. Raju Penmatcha is an AI/ML Specialist Solutions Architect in AI Platforms at AWS. He received his PhD from Stanford University. He works closely on the low/no-code suite of services in SageMaker, which help customers easily build and deploy machine learning models and solutions. When not helping customers, he likes traveling to new places.
Dr. Raju Penmatcha is an AI/ML Specialist Solutions Architect in AI Platforms at AWS. He received his PhD from Stanford University. He works closely on the low/no-code suite of services in SageMaker, which help customers easily build and deploy machine learning models and solutions. When not helping customers, he likes traveling to new places. Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.




 Then from your AWS Cloud9 environment, choose the plus sign and open new terminal.
Then from your AWS Cloud9 environment, choose the plus sign and open new terminal.