Tens of thousands of AWS customers use AWS machine learning (ML) services to accelerate their ML development with fully managed infrastructure and tools. For customers who have been developing ML models on premises, such as their local desktop, they want to migrate their legacy ML models to the AWS Cloud to fully take advantage of the most comprehensive set of ML services, infrastructure, and implementation resources available on AWS.
The term legacy code refers to code that was developed to be manually run on a local desktop, and is not built with cloud-ready SDKs such as the AWS SDK for Python (Boto3) or Amazon SageMaker Python SDK. In other words, these legacy codes aren’t optimized for cloud deployment. The best practice for migration is to refactor these legacy codes using the Amazon SageMaker API or the SageMaker Python SDK. However, in some cases, organizations with a large number of legacy models may not have the time or resources to rewrite all those models.
In this post, we share a scalable and easy-to-implement approach to migrate legacy ML code to the AWS Cloud for inference using Amazon SageMaker and AWS Step Functions, with a minimum amount of code refactoring required. You can easily extend this solution to add more functionality. We demonstrate how two different personas, a data scientist and an MLOps engineer, can collaborate to lift and shift hundreds of legacy models.
Solution overview
In this framework, we run the legacy code in a container as a SageMaker Processing job. SageMaker runs the legacy script inside a processing container. The processing container image can either be a SageMaker built-in image or a custom image. The underlying infrastructure for a Processing job is fully managed by SageMaker. No change to the legacy code is required. Familiarity with creating SageMaker Processing jobs is all that is required.
We assume the involvement of two personas: a data scientist and an MLOps engineer. The data scientist is responsible for moving the code into SageMaker, either manually or by cloning it from a code repository such as AWS CodeCommit. Amazon SageMaker Studio provides an integrated development environment (IDE) for implementing various steps in the ML lifecycle, and the data scientist uses it to manually build a custom container that contains the necessary code artifacts for deployment. The container will be registered in a container registry such as Amazon Elastic Container Registry (Amazon ECR) for deployment purposes.
The MLOps engineer takes ownership of building a Step Functions workflow that we can reuse to deploy the custom container developed by the data scientist with the appropriate parameters. The Step Functions workflow can be as modular as needed to fit the use case, or it can consist of just one step to initiate a single process. To minimize the effort required to migrate the code, we have identified three modular components to build a fully functional deployment process:
- Preprocessing
- Inference
- Postprocessing
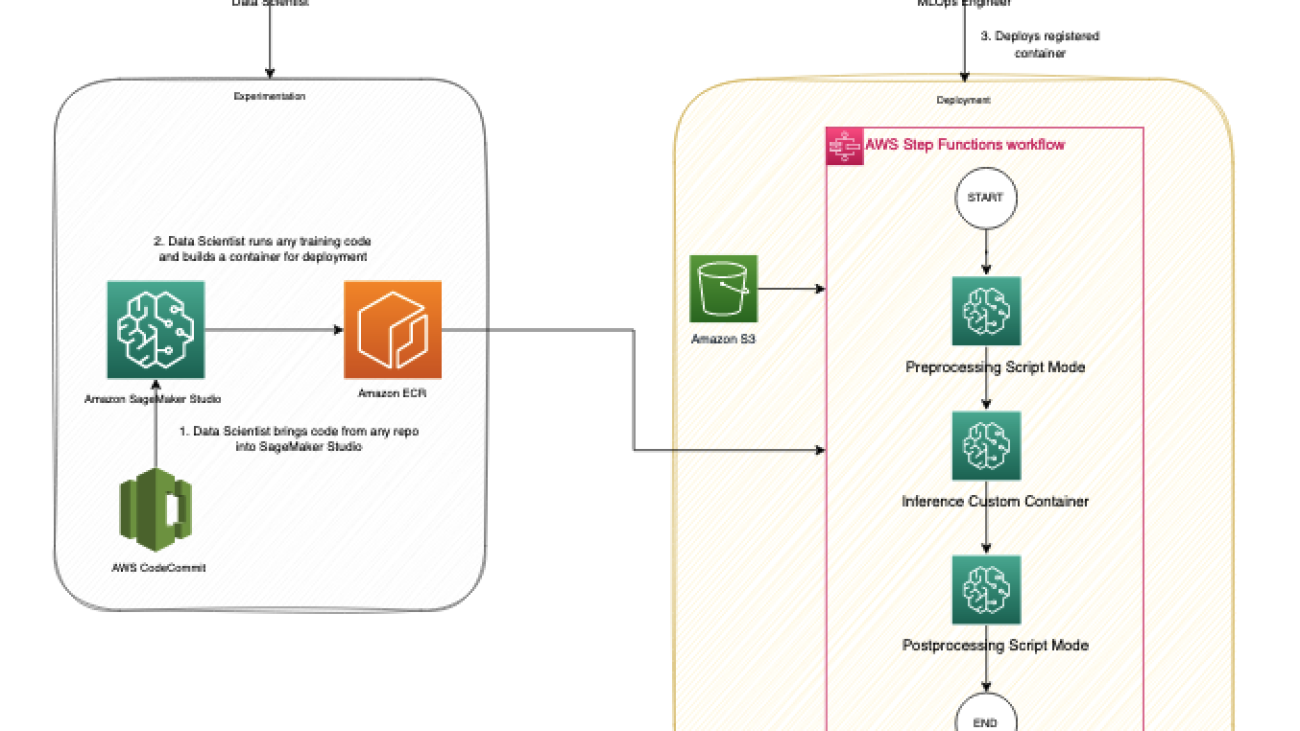
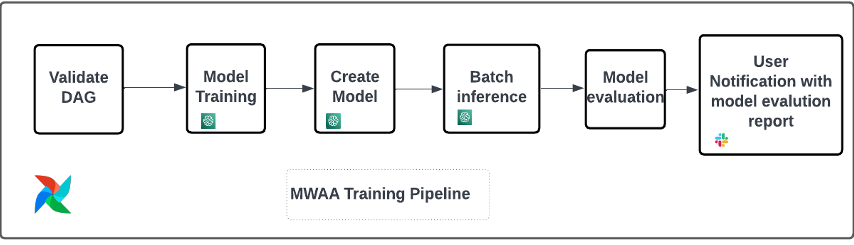
The following diagram illustrates our solution architecture and workflow.

The following steps are involved in this solution:
- The data scientist persona uses Studio to import legacy code through cloning from a code repository, and then modularizing the code into separate components that follow the steps of the ML lifecycle (preprocessing, inference, and postprocessing).
- The data scientist uses Studio, and specifically the Studio Image Build CLI tool provided by SageMaker, to build a Docker image. This CLI tool allows the data scientist to build the image directly within Studio and automatically registers the image into Amazon ECR.
- The MLOps engineer uses the registered container image and creates a deployment for a specific use case using Step Functions. Step Functions is a serverless workflow service that can control SageMaker APIs directly through the use of the Amazon States Language.
SageMaker Processing job
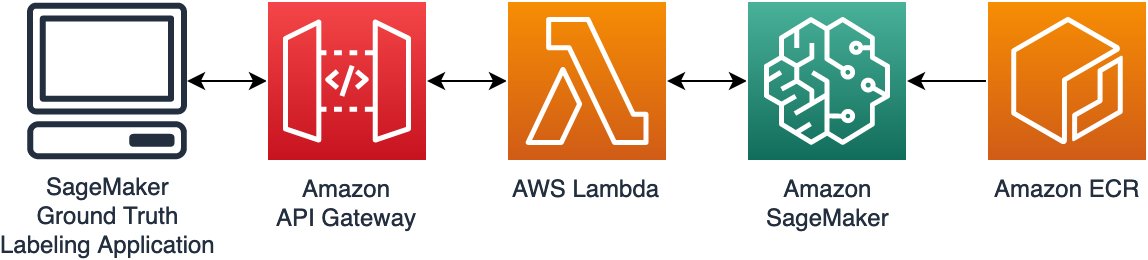
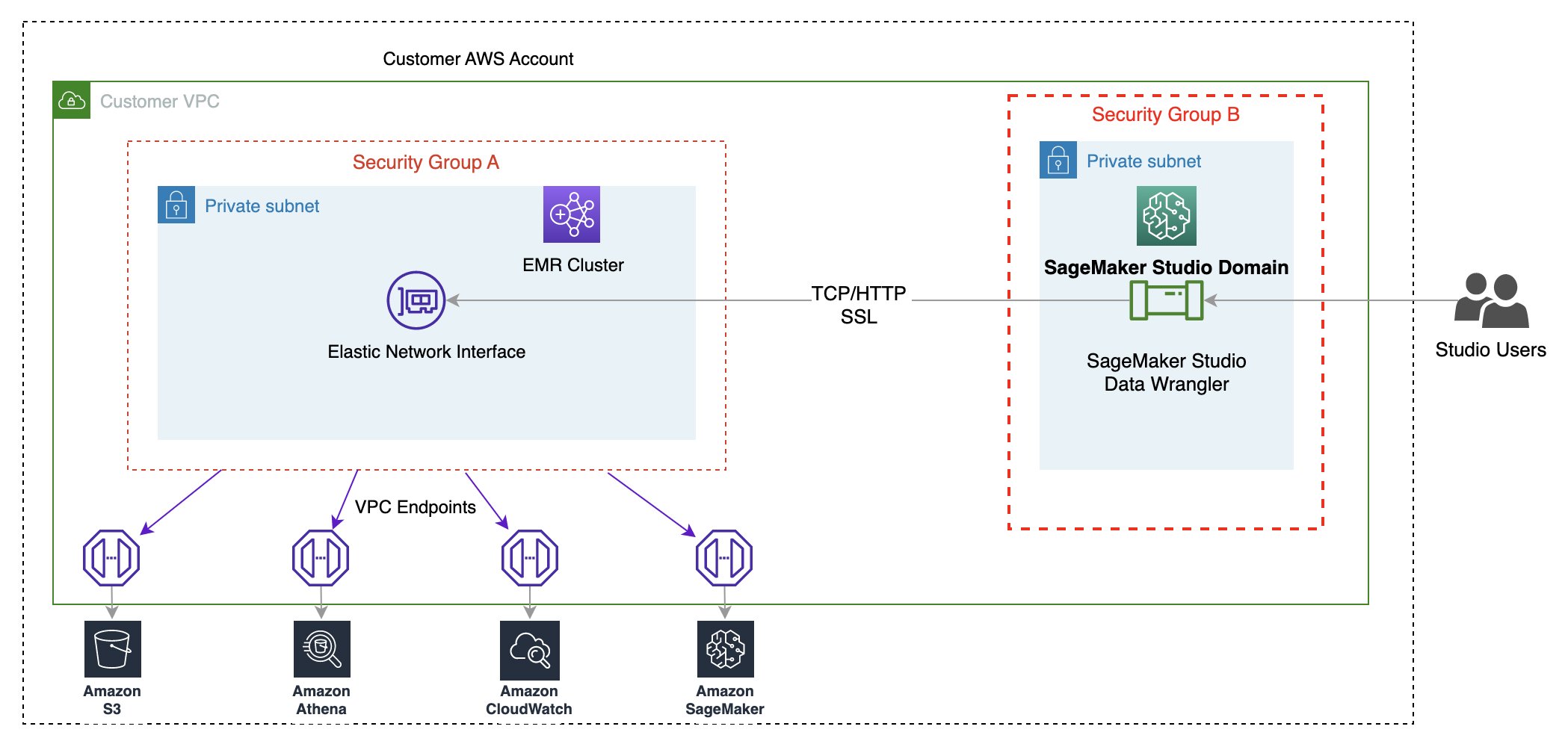
Let’s understand how a SageMaker Processing job runs. The following diagram shows how SageMaker spins up a Processing job.

SageMaker takes your script, copies your data from Amazon Simple Storage Service (Amazon S3), and then pulls a processing container. The processing container image can either be a SageMaker built-in image or a custom image that you provide. The underlying infrastructure for a Processing job is fully managed by SageMaker. Cluster resources are provisioned for the duration of your job, and cleaned up when a job is complete. The output of the Processing job is stored in the S3 bucket you specified. To learn more about building your own container, refer to Build Your Own Processing Container (Advanced Scenario).
The SageMaker Processing job sets up your processing image using a Docker container entrypoint script. You can also provide your own custom entrypoint by using the ContainerEntrypoint and ContainerArguments parameters of the AppSpecification API. If you use your own custom entrypoint, you have the added flexibility to run it as a standalone script without rebuilding your images.
For this example, we construct a custom container and use a SageMaker Processing job for inference. Preprocessing and postprocessing jobs utilize the script mode with a pre-built scikit-learn container.
Prerequisites
To follow along this post, complete the following prerequisite steps:
- Create a Studio domain. For instructions, refer to Onboard to Amazon SageMaker Domain Using Quick setup.
- Create an S3 bucket.
- Clone the provided GitHub repo into Studio.
The GitHub repo is organized into different folders that correspond to various stages in the ML lifecycle, facilitating easy navigation and management:

Migrate the legacy code
In this step, we act as the data scientist responsible for migrating the legacy code.
We begin by opening the build_and_push.ipynb notebook.
The initial cell in the notebook guides you in installing the Studio Image Build CLI. This CLI simplifies the setup process by automatically creating a reusable build environment that you can interact with through high-level commands. With the CLI, building an image is as easy as telling it to build, and the result will be a link to the location of your image in Amazon ECR. This approach eliminates the need to manage the complex underlying workflow orchestrated by the CLI, streamlining the image building process.
Before we run the build command, it’s important to ensure that the role running the command has the necessary permissions, as specified in the CLI GitHub readme or related post. Failing to grant the required permissions can result in errors during the build process.
See the following code:
To streamline your legacy code, divide it into three distinct Python scripts named preprocessing.py, predict.py, and postprocessing.py. Adhere to best programming practices by converting the code into functions that are called from a main function. Ensure that all necessary libraries are imported and the requirements.txt file is updated to include any custom libraries.
After you organize the code, package it along with the requirements file into a Docker container. You can easily build the container from within Studio using the following command:
By default, the image will be pushed to an ECR repository called sagemakerstudio with the tag latest. Additionally, the execution role of the Studio app will be utilized, along with the default SageMaker Python SDK S3 bucket. However, these settings can be easily altered using the appropriate CLI options. See the following code:
Now that the container has been built and registered in an ECR repository, it’s time to dive deeper into how we can use it to run predict.py. We also show you the process of using a pre-built scikit-learn container to run preprocessing.py and postprocessing.py.
Productionize the container
In this step, we act as the MLOps engineer who productionizes the container built in the previous step.
We use Step Functions to orchestrate the workflow. Step Functions allows for exceptional flexibility in integrating a diverse range of services into the workflow, accommodating any existing dependencies that may exist in the legacy system. This approach ensures that all necessary components are seamlessly integrated and run in the desired sequence, resulting in an efficient and effective workflow solution.
Step Functions can control certain AWS services directly from the Amazon States Language. To learn more about working with Step Functions and its integration with SageMaker, refer to Manage SageMaker with Step Functions. Using the Step Functions integration capability with SageMaker, we run the preprocessing and postprocessing scripts using a SageMaker Processing job in script mode and run inference as a SageMaker Processing job using a custom container. We do so using AWS SDK for Python (Boto3) CreateProcessingJob API calls.
Preprocessing
SageMaker offers several options for running custom code. If you only have a script without any custom dependencies, you can run the script as a Bring Your Own Script (BYOS). To do this, simply pass your script to the pre-built scikit-learn framework container and run a SageMaker Processing job in script mode using the ContainerArguments and ContainerEntrypoint parameters in the AppSpecification API. This is a straightforward and convenient method for running simple scripts.
Check out the “Preprocessing Script Mode” state configuration in the sample Step Functions workflow to understand how to configure the CreateProcessingJob API call to run a custom script.
Inference
You can run a custom container using the Build Your Own Processing Container approach. The SageMaker Processing job operates with the /opt/ml local path, and you can specify your ProcessingInputs and their local path in the configuration. The Processing job then copies the artifacts to the local container and starts the job. After the job is complete, it copies the artifacts specified in the local path of the ProcessingOutputs to its specified external location.
Check out the “Inference Custom Container” state configuration in the sample Step Functions workflow to understand how to configure the CreateProcessingJob API call to run a custom container.
Postprocessing
You can run a postprocessing script just like a preprocessing script using the Step Functions CreateProcessingJob step. Running a postprocessing script allows you to perform custom processing tasks after the inference job is complete.
Create the Step Functions workflow
For quickly prototyping, we use the Step Functions Amazon States Language. You can edit the Step Functions definition directly by using the States Language. Refer to the sample Step Functions workflow.
You can create a new Step Functions state machine on the Step Functions console by selecting Write your workflow in code.

Step Functions can look at the resources you use and create a role. However, you may see the following message:
“Step Functions cannot generate an IAM policy if the RoleArn for SageMaker is from a Path. Hardcode the SageMaker RoleArn in your state machine definition, or choose an existing role with the proper permissions for Step Functions to call SageMaker.”
To address this, you must create an AWS Identity and Access Management (IAM) role for Step Functions. For instructions, refer to Creating an IAM role for your state machine. Then attach the following IAM policy to provide the required permissions for running the workflow:
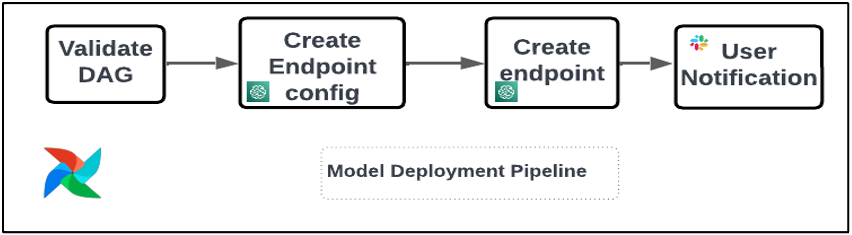
The following figure illustrates the flow of data and container images into each step of the Step Functions workflow.

The following is a list of minimum required parameters to initialize in Step Functions; you can also refer to the sample input parameters JSON:
- input_uri – The S3 URI for the input files
- output_uri – The S3 URI for the output files
- code_uri – The S3 URI for script files
- custom_image_uri – The container URI for the custom container you have built
- scikit_image_uri – The container URI for the pre-built scikit-learn framework
- role – The execution role to run the job
- instance_type – The instance type you need to use to run the container
- volume_size – The storage volume size you require for the container
- max_runtime – The maximum runtime for the container, with a default value of 1 hour
Run the workflow
We have broken down the legacy code into manageable parts: preprocessing, inference, and postprocessing. To support our inference needs, we constructed a custom container equipped with the necessary library dependencies. Our plan is to utilize Step Functions, taking advantage of its ability to call the SageMaker API. We have shown two methods for running custom code using the SageMaker API: a SageMaker Processing job that utilizes a pre-built image and takes a custom script at runtime, and a SageMaker Processing job that uses a custom container, which is packaged with the necessary artifacts to run custom inference.
The following figure shows the run of the Step Functions workflow.

Summary
In this post, we discussed the process of migrating legacy ML Python code from local development environments and implementing a standardized MLOps procedure. With this approach, you can effortlessly transfer hundreds of models and incorporate your desired enterprise deployment practices. We presented two different methods for running custom code on SageMaker, and you can select the one that best suits your needs.
If you require a highly customizable solution, it’s recommended to use the custom container approach. You may find it more suitable to use pre-built images to run your custom script if you have basic scripts and don’t need to create your custom container, as described in the preprocessing step mentioned earlier. Furthermore, if required, you can apply this solution to containerize legacy model training and evaluation steps, just like how the inference step is containerized in this post.
About the Authors
 Bhavana Chirumamilla is a Senior Resident Architect at AWS with a strong passion for data and machine learning operations. She brings a wealth of experience and enthusiasm to help enterprises build effective data and ML strategies. In her spare time, Bhavana enjoys spending time with her family and engaging in various activities such as traveling, hiking, gardening, and watching documentaries.
Bhavana Chirumamilla is a Senior Resident Architect at AWS with a strong passion for data and machine learning operations. She brings a wealth of experience and enthusiasm to help enterprises build effective data and ML strategies. In her spare time, Bhavana enjoys spending time with her family and engaging in various activities such as traveling, hiking, gardening, and watching documentaries.
 Shyam Namavaram is a senior artificial intelligence (AI) and machine learning (ML) specialist solutions architect at Amazon Web Services (AWS). He passionately works with customers to accelerate their AI and ML adoption by providing technical guidance and helping them innovate and build secure cloud solutions on AWS. He specializes in AI and ML, containers, and analytics technologies. Outside of work, he loves playing sports and experiencing nature with trekking.
Shyam Namavaram is a senior artificial intelligence (AI) and machine learning (ML) specialist solutions architect at Amazon Web Services (AWS). He passionately works with customers to accelerate their AI and ML adoption by providing technical guidance and helping them innovate and build secure cloud solutions on AWS. He specializes in AI and ML, containers, and analytics technologies. Outside of work, he loves playing sports and experiencing nature with trekking.
 Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his PhD in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently, he helps customers in the financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his PhD in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently, he helps customers in the financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
 Srinivasa Shaik is a Solutions Architect at AWS based in Boston. He helps enterprise customers accelerate their journey to the cloud. He is passionate about containers and machine learning technologies. In his spare time, he enjoys spending time with his family, cooking, and traveling.
Srinivasa Shaik is a Solutions Architect at AWS based in Boston. He helps enterprise customers accelerate their journey to the cloud. He is passionate about containers and machine learning technologies. In his spare time, he enjoys spending time with his family, cooking, and traveling.

 Arun Kumar Lokanatha is a Senior ML Solutions Architect with the Amazon SageMaker Service team. He focuses on helping customers build, train, and migrate ML production workloads to SageMaker at scale. He specializes in Deep Learning especially in the area of NLP and CV. Outside of work, he enjoys Running and hiking.
Arun Kumar Lokanatha is a Senior ML Solutions Architect with the Amazon SageMaker Service team. He focuses on helping customers build, train, and migrate ML production workloads to SageMaker at scale. He specializes in Deep Learning especially in the area of NLP and CV. Outside of work, he enjoys Running and hiking. Mark Yu is a Software Engineer in AWS SageMaker. He focuses on building large-scale distributed training systems, optimizing training performance, and developing high-performance ml training hardwares, including SageMaker trainium. Mark also has in-depth knowledge on the machine learning infrastructure optimization. In his spare time, he enjoys hiking, and running.
Mark Yu is a Software Engineer in AWS SageMaker. He focuses on building large-scale distributed training systems, optimizing training performance, and developing high-performance ml training hardwares, including SageMaker trainium. Mark also has in-depth knowledge on the machine learning infrastructure optimization. In his spare time, he enjoys hiking, and running. Omri Fuchs is a Software Development Manager at AWS SageMaker. He is the technical leader responsible for SageMaker training job platform, focusing on optimizing SageMaker training performance, and improving training experience. He has a passion for cutting-edge ML and AI technology. In his spare time, he likes cycling, and hiking.
Omri Fuchs is a Software Development Manager at AWS SageMaker. He is the technical leader responsible for SageMaker training job platform, focusing on optimizing SageMaker training performance, and improving training experience. He has a passion for cutting-edge ML and AI technology. In his spare time, he likes cycling, and hiking. Gal Oshri is a Senior Product Manager on the Amazon SageMaker team. He has 7 years of experience working on Machine Learning tools, frameworks, and services.
Gal Oshri is a Senior Product Manager on the Amazon SageMaker team. He has 7 years of experience working on Machine Learning tools, frameworks, and services.
 Deepak Mettem is a Senior Engineering Manager in VMware, Carbon Black Unit. He and his team work on building the streaming based applications and services that are highly available, scalable and resilient to bring customers machine learning based solutions in real-time. He and his team are also responsible for creating tools necessary for data scientists to build, train, deploy and validate their ML models in production.
Deepak Mettem is a Senior Engineering Manager in VMware, Carbon Black Unit. He and his team work on building the streaming based applications and services that are highly available, scalable and resilient to bring customers machine learning based solutions in real-time. He and his team are also responsible for creating tools necessary for data scientists to build, train, deploy and validate their ML models in production. Mahima Agarwal is a Machine Learning Engineer in VMware, Carbon Black Unit.
Mahima Agarwal is a Machine Learning Engineer in VMware, Carbon Black Unit. Vamshi Krishna Enabothala is a Sr. Applied AI Specialist Architect at AWS. He works with customers from different sectors to accelerate high-impact data, analytics, and machine learning initiatives. He is passionate about recommendation systems, NLP, and computer vision areas in AI and ML. Outside of work, Vamshi is an RC enthusiast, building RC equipment (planes, cars, and drones), and also enjoys gardening.
Vamshi Krishna Enabothala is a Sr. Applied AI Specialist Architect at AWS. He works with customers from different sectors to accelerate high-impact data, analytics, and machine learning initiatives. He is passionate about recommendation systems, NLP, and computer vision areas in AI and ML. Outside of work, Vamshi is an RC enthusiast, building RC equipment (planes, cars, and drones), and also enjoys gardening. Sahil Thapar is an Enterprise Solutions Architect. He works with customers to help them build highly available, scalable, and resilient applications on the AWS Cloud. He is currently focused on containers and machine learning solutions.
Sahil Thapar is an Enterprise Solutions Architect. He works with customers to help them build highly available, scalable, and resilient applications on the AWS Cloud. He is currently focused on containers and machine learning solutions.


 Jonathan Buck is a Software Engineer at Amazon Web Services working at the intersection of machine learning and distributed systems. His work involves productionizing machine learning models and developing novel software applications powered by machine learning to put the latest capabilities in the hands of customers.
Jonathan Buck is a Software Engineer at Amazon Web Services working at the intersection of machine learning and distributed systems. His work involves productionizing machine learning models and developing novel software applications powered by machine learning to put the latest capabilities in the hands of customers. Li Erran Li is the applied science manager at humain-in-the-loop services, AWS AI, Amazon. His research interests are 3D deep learning, and vision and language representation learning. Previously he was a senior scientist at Alexa AI, the head of machine learning at Scale AI and the chief scientist at Pony.ai. Before that, he was with the perception team at Uber ATG and the machine learning platform team at Uber working on machine learning for autonomous driving, machine learning systems and strategic initiatives of AI. He started his career at Bell Labs and was adjunct professor at Columbia University. He co-taught tutorials at ICML’17 and ICCV’19, and co-organized several workshops at NeurIPS, ICML, CVPR, ICCV on machine learning for autonomous driving, 3D vision and robotics, machine learning systems and adversarial machine learning. He has a PhD in computer science at Cornell University. He is an ACM Fellow and IEEE Fellow.
Li Erran Li is the applied science manager at humain-in-the-loop services, AWS AI, Amazon. His research interests are 3D deep learning, and vision and language representation learning. Previously he was a senior scientist at Alexa AI, the head of machine learning at Scale AI and the chief scientist at Pony.ai. Before that, he was with the perception team at Uber ATG and the machine learning platform team at Uber working on machine learning for autonomous driving, machine learning systems and strategic initiatives of AI. He started his career at Bell Labs and was adjunct professor at Columbia University. He co-taught tutorials at ICML’17 and ICCV’19, and co-organized several workshops at NeurIPS, ICML, CVPR, ICCV on machine learning for autonomous driving, 3D vision and robotics, machine learning systems and adversarial machine learning. He has a PhD in computer science at Cornell University. He is an ACM Fellow and IEEE Fellow.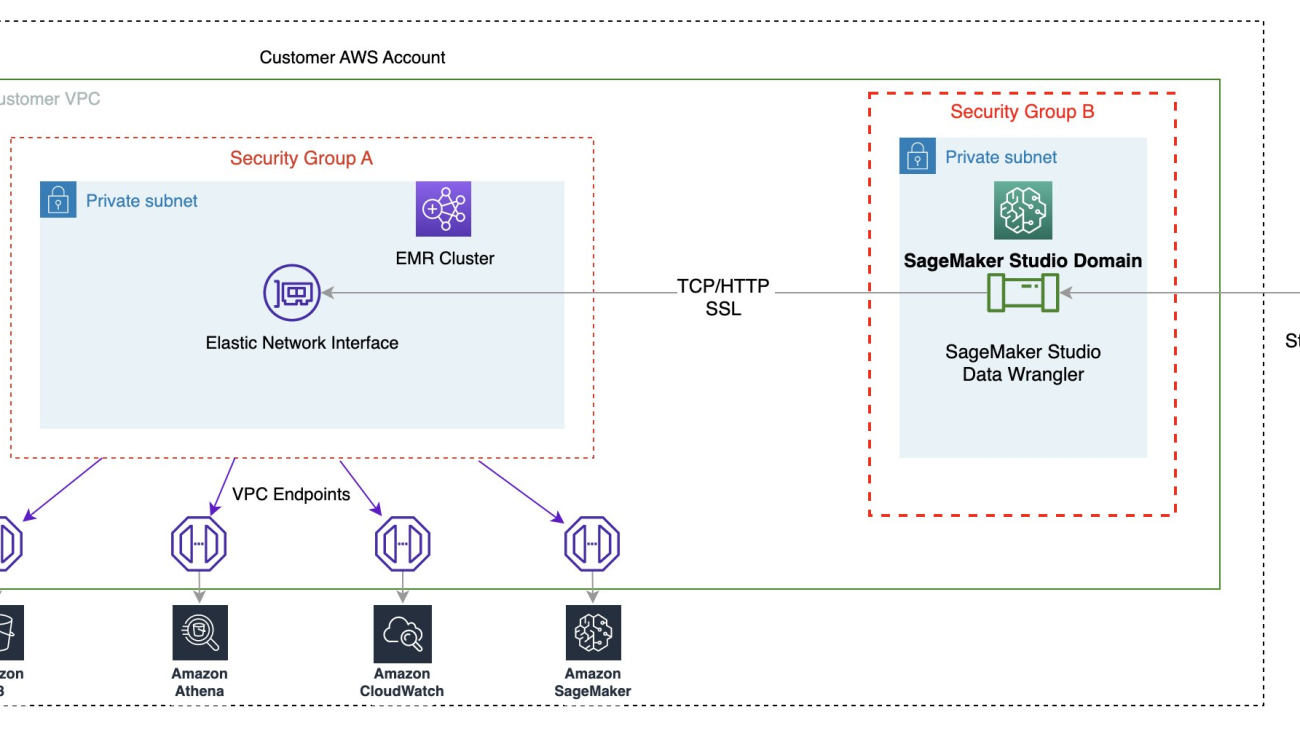


















 Ajjay Govindaram is a Senior Solutions Architect at AWS. He works with strategic customers who are using AI/ML to solve complex business problems. His experience lies in providing technical direction as well as design assistance for modest to large-scale AI/ML application deployments. His knowledge ranges from application architecture to big data, analytics, and machine learning. He enjoys listening to music while resting, experiencing the outdoors, and spending time with his loved ones.
Ajjay Govindaram is a Senior Solutions Architect at AWS. He works with strategic customers who are using AI/ML to solve complex business problems. His experience lies in providing technical direction as well as design assistance for modest to large-scale AI/ML application deployments. His knowledge ranges from application architecture to big data, analytics, and machine learning. He enjoys listening to music while resting, experiencing the outdoors, and spending time with his loved ones. Isha Dua is a Senior Solutions Architect based in the San Francisco Bay Area. She helps AWS enterprise customers grow by understanding their goals and challenges, and guides them on how they can architect their applications in a cloud-native manner while ensuring resilience and scalability. She’s passionate about machine learning technologies and environmental sustainability.
Isha Dua is a Senior Solutions Architect based in the San Francisco Bay Area. She helps AWS enterprise customers grow by understanding their goals and challenges, and guides them on how they can architect their applications in a cloud-native manner while ensuring resilience and scalability. She’s passionate about machine learning technologies and environmental sustainability. Varun Mehta is a Solutions Architect at AWS. He is passionate about helping customers build Enterprise-Scale Well-Architected solutions on the AWS Cloud. He works with strategic customers who are using AI/ML to solve complex business problems.
Varun Mehta is a Solutions Architect at AWS. He is passionate about helping customers build Enterprise-Scale Well-Architected solutions on the AWS Cloud. He works with strategic customers who are using AI/ML to solve complex business problems.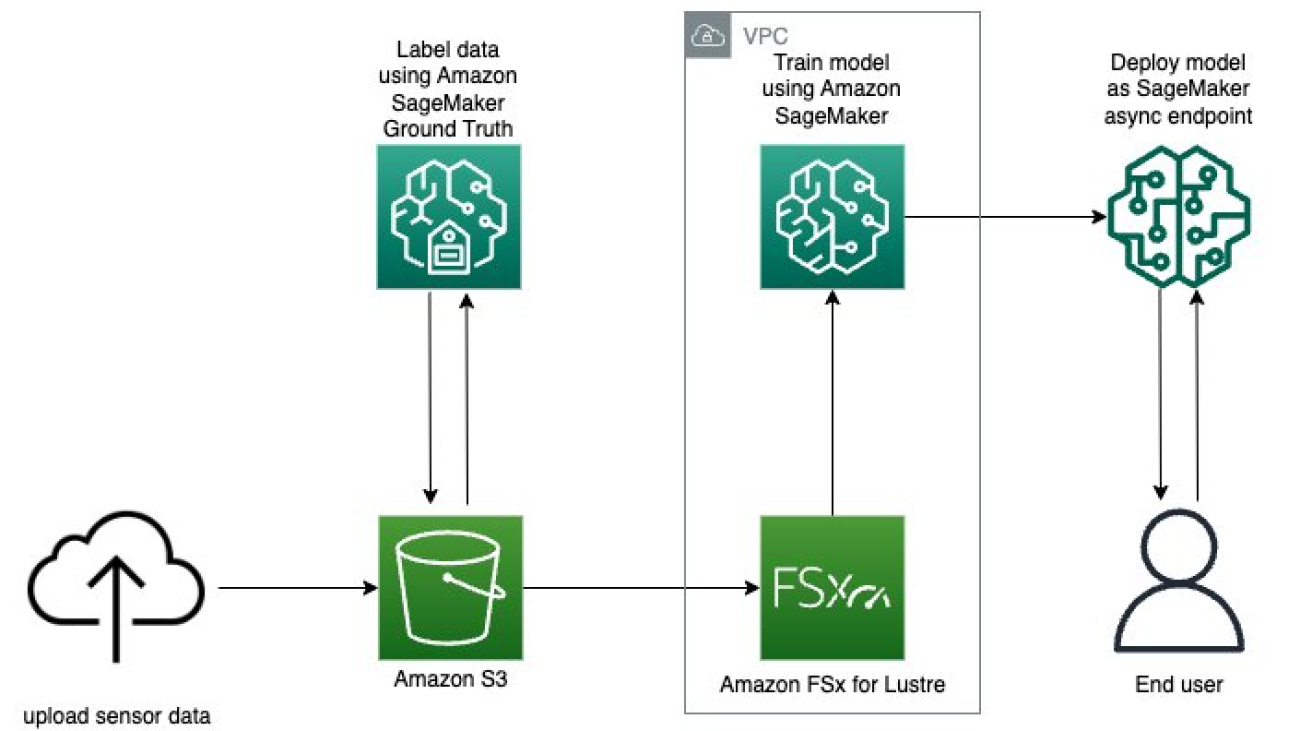













 Isaac Privitera is a Senior Data Scientist at the
Isaac Privitera is a Senior Data Scientist at the  Vidya Sagar Ravipati is Manager at the
Vidya Sagar Ravipati is Manager at the  Jeremy Feltracco is a Software Development Engineer with th
Jeremy Feltracco is a Software Development Engineer with th 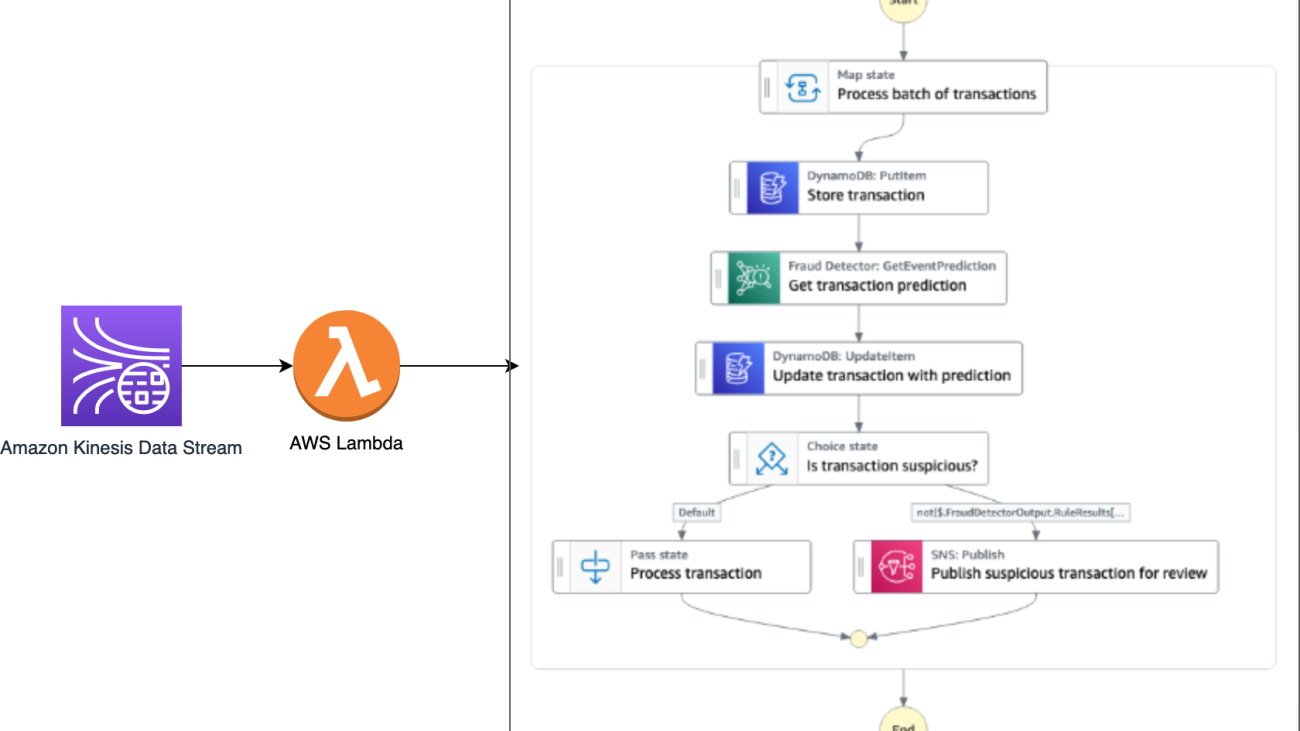



 Veda Raman is a Senior Specialist Solutions Architect for machine learning based in Maryland. Veda works with customers to help them architect efficient, secure and scalable machine learning applications. Veda is interested in helping customers leverage serverless technologies for Machine learning.
Veda Raman is a Senior Specialist Solutions Architect for machine learning based in Maryland. Veda works with customers to help them architect efficient, secure and scalable machine learning applications. Veda is interested in helping customers leverage serverless technologies for Machine learning. Giedrius Praspaliauskas is a Senior Specialist Solutions Architect for serverless based in California. Giedrius works with customers to help them leverage serverless services to build scalable, fault-tolerant, high-performing, cost-effective applications.
Giedrius Praspaliauskas is a Senior Specialist Solutions Architect for serverless based in California. Giedrius works with customers to help them leverage serverless services to build scalable, fault-tolerant, high-performing, cost-effective applications.