Amazon SageMaker Studio is a web-based integrated development environment (IDE) for machine learning (ML) that lets you build, train, debug, deploy, and monitor your ML models. Each onboarded user in Studio has their own dedicated set of resources, such as compute instances, a home directory on an Amazon Elastic File System (Amazon EFS) volume, and a dedicated AWS Identity and Access Management (IAM) execution role.
One of the most common real-world challenges in setting up user access for Studio is how to manage multiple users, groups, and data science teams for data access and resource isolation.
Many customers implement user management using federated identities with AWS Single Sign-On (AWS SSO) and an external identity provider (IdP), such as Active Directory (AD) or AWS Managed Microsoft AD directory. It’s aligned with the AWS recommended practice of using temporary credentials to access AWS accounts.
An Amazon SageMaker domain supports AWS SSO and can be configured in AWS SSO authentication mode. In this case, each entitled AWS SSO user has their own Studio user profile. Users given access to Studio have a unique sign-in URL that directly opens Studio, and they sign in with their AWS SSO credentials. Organizations manage their users in AWS SSO instead of the SageMaker domain. You can assign multiple users access to the domain at the same time. You can use Studio user profiles for each user to define their security permissions in Studio notebooks via an IAM role attached to the user profile, called an execution role. This role controls permissions for SageMaker operations according to its IAM permission policies.
In AWS SSO authentication mode, there is always one-to-one mapping between users and user profiles. The SageMaker domain manages the creation of user profiles based on the AWS SSO user ID. You can’t create user profiles via the AWS Management Console. This works well in the case when one user is a member of only one data science team or if users have the same or very similar access requirements across their projects and teams. In a more common use case, when a user can participate in multiple ML projects and be a member of multiple teams with slightly different permission requirements, the user requires access to different Studio user profiles with different execution roles and permission policies. Because you can’t manage user profiles independently of AWS SSO in AWS SSO authentication mode, you can’t implement a one-to-many mapping between users and Studio user profiles.
If you need to establish a strong separation of security contexts, for example for different data categories, or need to entirely prevent the visibility of one group of users’ activity and resources to another, the recommended approach is to create multiple SageMaker domains. At the time of this writing, you can create only one domain per AWS account per Region. To implement the strong separation, you can use multiple AWS accounts with one domain per account as a workaround.
The second challenge is to restrict access to the Studio IDE to only users from inside a corporate network or a designated VPC. You can achieve this by using IAM-based access control policies. In this case, the SageMaker domain must be configured with IAM authentication mode, because the IAM identity-based polices aren’t supported by the sign-in mechanism in AWS SSO mode. The post Secure access to Amazon SageMaker Studio with AWS SSO and a SAML application solves this challenge and demonstrates how to control network access to a SageMaker domain.
This solution addresses these challenges of AWS SSO user management for Studio for a common use case of multiple user groups and a many-to-many mapping between users and teams. The solution outlines how to use a custom SAML 2.0 application as the mechanism to trigger the user authentication for Studio and support multiple Studio user profiles per one AWS SSO user.
You can use this approach to implement a custom user portal with applications backed by the SAML 2.0 authorization process. Your custom user portal can have maximum flexibility on how to manage and display user applications. For example, the user portal can show some ML project metadata to facilitate identifying an application to access.
You can find the solution’s source code in our GitHub repository.
Solution overview
The solution implements the following architecture.

The main high-level architecture components are as follows:
- Identity provider – Users and groups are managed in an external identity source, for example in Azure AD. User assignments to AD groups define what permissions a particular user has and which Studio team they have access to. The identity source must by synchronized with AWS SSO.
- AWS SSO – AWS SSO manages SSO users, SSO permission sets, and applications. This solution uses a custom SAML 2.0 application to provide access to Studio for entitled AWS SSO users. The solution also uses SAML attribute mapping to populate the SAML assertion with specific access-relevant data, such as user ID and user team. Because the solution creates a SAML API, you can use any IdP supporting SAML assertions to create this architecture. For example, you can use Okta or even your own web application that provides a landing page with a user portal and applications. For this post, we use AWS SSO.
- Custom SAML 2.0 applications – The solution creates one application per Studio team and assigns one or multiple applications to a user or a user group based on entitlements. Users can access these applications from within their AWS SSO user portal based on assigned permissions. Each application is configured with the Amazon API Gateway endpoint URL as its SAML backend.
- SageMaker domain – The solution provisions a SageMaker domain in an AWS account and creates a dedicated user profile for each combination of AWS SSO user and Studio team the user is assigned to. The domain must be configured in IAM authentication mode.
- Studio user profiles – The solution automatically creates a dedicated user profile for each user-team combination. For example, if a user is a member of two Studio teams and has corresponding permissions, the solution provisions two separate user profiles for this user. Each profile always belongs to one and only one user. Because you have a Studio user profile for each possible combination of a user and a team, you must consider your account limits for user profiles before implementing this approach. For example, if your limit is 500 user profiles, and each user is a member of two teams, you consume that limit 2.5 times faster, and as a result you can onboard 250 users. With a high number of users, we recommend implementing multiple domains and accounts for security context separation. To demonstrate the proof of concept, we use two users, User 1 and User 2, and two Studio teams, Team 1 and Team 2. User 1 belongs to both teams, whereas User 2 belongs to Team 2 only. User 1 can access Studio environments for both teams, whereas User 2 can access only the Studio environment for Team 2.
- Studio execution roles – Each Studio user profile uses a dedicated execution role with permission polices with the required level of access for the specific team the user belongs to. Studio execution roles implement an effective permission isolation between individual users and their team roles. You manage data and resource access for each role and not at an individual user level.
The solution also implements an attribute-based access control (ABAC) using SAML 2.0 attributes, tags on Studio user profiles, and tags on SageMaker execution roles.
In this particular configuration, we assume that AWS SSO users don’t have permissions to sign in to the AWS account and don’t have corresponding AWS SSO-controlled IAM roles in the account. Each user signs in to their Studio environment via a presigned URL from an AWS SSO portal without the need to go to the console in their AWS account. In a real-world environment, you might need to set up AWS SSO permission sets for users to allow the authorized users to assume an IAM role and to sign in to an AWS account. For example, you can provide data scientist role permissions for a user to be able to interact with account resources and have the level of access they need to fulfill their role.
Solution architecture and workflow
The following diagram presents the end-to-end sign-in flow for an AWS SSO user.

An AWS SSO user chooses a corresponding Studio application in their AWS SSO portal. AWS SSO prepares a SAML assertion (1) with configured SAML attribute mappings. A custom SAML application is configured with the API Gateway endpoint URL as its Assertion Consumer Service (ACS), and needs mapping attributes containing the AWS SSO user ID and team ID. We use ssouserid and teamid custom attributes to send all needed information to the SAML backend.
The API Gateway calls an SAML backend API. An AWS Lambda function (2) implements the API, parses the SAML response to extract the user ID and team ID. The function uses them to retrieve a team-specific configuration, such as an execution role and SageMaker domain ID. The function checks if a required user profile exists in the domain, and creates a new one with the corresponding configuration settings if no profile exists. Afterwards, the function generates a Studio presigned URL for a specific Studio user profile by calling CreatePresignedDomainUrl API (3) via a SageMaker API VPC endpoint. The Lambda function finally returns the presigned URL with HTTP 302 redirection response to sign the user in to Studio.
The solution implements a non-production sample version of an SAML backend. The Lambda function parses the SAML assertion and uses only attributes in the <saml2:AttributeStatement> element to construct a CreatePresignedDomainUrl API call. In your production solution, you must use a proper SAML backend implementation, which must include a validation of an SAML response, a signature, and certificates, replay and redirect prevention, and any other features of an SAML authentication process. For example, you can use a python3-saml SAML backend implementation or OneLogin open-source SAML toolkit to implement a secure SAML backend.
Dynamic creation of Studio user profiles
The solution automatically creates a Studio user profile for each user-team combination, as soon as the AWS SSO sign-in process requests a presigned URL. For this proof of concept and simplicity, the solution creates user profiles based on the configured metadata in the AWS SAM template:
You can configure own teams, custom settings, and tags by adding them to the metadata configuration for the AWS CloudFormation resource GetUserProfileMetadata.
For more information on configuration elements of UserSettings, refer to create_user_profile in boto3.
IAM roles
The following diagram shows the IAM roles in this solution.

The roles are as follows:
- Studio execution role – A Studio user profile uses a dedicated Studio execution role with data and resource permissions specific for each team or user group. This role can also use tags to implement ABAC for data and resource access. For more information, refer to SageMaker Roles.
-
SAML backend Lambda execution role – This execution role contains permission to call the
CreatePresignedDomainUrlAPI. You can configure the permission policy to include additional conditional checks usingConditionkeys. For example, to allow access to Studio only from a designated range of IP addresses within your private corporate network, use the following code:For more examples on how to use conditions in IAM policies, refer to Control Access to the SageMaker API by Using Identity-based Policies.
- SageMaker – SageMaker assumes the Studio execution role on your behalf, as controlled by a corresponding trust policy on the execution role. This allows the service to access data and resources, and perform actions on your behalf. The Studio execution role must contain a trust policy allowing SageMaker to assume this role.
- AWS SSO permission set IAM role – You can assign your AWS SSO users to AWS accounts in your AWS organization via AWS SSO permission sets. A permission set is a template that defines a collection of user role-specific IAM policies. You manage permission sets in AWS SSO, and AWS SSO controls the corresponding IAM roles in each account.
- AWS Organizations Service Control Policies – If you use AWS Organizations, you can implement Service Control Policies (SCPs) to centrally control the maximum available permissions for all accounts and all IAM roles in your organization. For example, to centrally prevent access to Studio via the console, you can implement the following SCP and attach it to the accounts with the SageMaker domain:
Solution provisioned roles
The AWS CloudFormation stack for this solution creates three Studio execution roles used in the SageMaker domain:
SageMakerStudioExecutionRoleDefaultSageMakerStudioExecutionRoleTeam1SageMakerStudioExecutionRoleTeam2
None of the roles have the AmazonSageMakerFullAccess policy attached, and each has only a limited set of permissions. In your real-world SageMaker environment, you need to amend the role’s permissions based on your specific requirements.
SageMakerStudioExecutionRoleDefault has only the custom policy SageMakerReadOnlyPolicy attached with a restrictive list of allowed actions.
Both team roles, SageMakerStudioExecutionRoleTeam1 and SageMakerStudioExecutionRoleTeam2, additionally have two custom polices, SageMakerAccessSupportingServicesPolicy and SageMakerStudioDeveloperAccessPolicy, allowing usage of particular services and one deny-only policy, SageMakerDeniedServicesPolicy, with explicit deny on some SageMaker API calls.
The Studio developer access policy enforces the setting of the Team tag equal to the same value as the user’s own execution role for calling any SageMaker Create* API:
Furthermore, it allows using delete, stop, update, and start operations only on resources tagged with the same Team tag as the user’s execution role:
For more information on roles and polices, refer to Configuring Amazon SageMaker Studio for teams and groups with complete resource isolation.
Network infrastructure
The solution implements a fully isolated SageMaker domain environment with all network traffic going through AWS PrivateLink connections. You may optionally enable internet access from the Studio notebooks. The solution also creates three VPC security groups to control traffic between all solution components such as the SAML backend Lambda function, VPC endpoints, and Studio notebooks.

For this proof of concept and simplicity, the solution creates a SageMaker subnet in a single Availability Zone. For your production setup, you must use multiple private subnets across multiple Availability Zones and ensure that each subnet is appropriately sized, assuming minimum five IPs per user.
This solution provisions all required network infrastructure. The CloudFormation template ./cfn-templates/vpc.yaml contains the source code.
Deployment steps
To deploy and test the solution, you must complete the following steps:
- Deploy the solution’s stack via an AWS Serverless Application Model (AWS SAM) template.
- Create AWS SSO users, or use existing AWS SSO users.
- Create custom SAML 2.0 applications and assign AWS SSO users to the applications.
The full source code for the solution is provided in our GitHub repository.
Prerequisites
To use this solution, the AWS Command Line Interface (AWS CLI), AWS SAM CLI, and Python3.8 or later must be installed.
The deployment procedure assumes that you enabled AWS SSO and configured for the AWS Organizations in the account where the solution is deployed.
To set up AWS SSO, refer to the instructions in GitHub.
Solution deployment options
You can choose from several solution deployment options to have the best fit for your existing AWS environment. You can also select the network and SageMaker domain provisioning options. For detailed information about the different deployment choices, refer to the README file.
Deploy the AWS SAM template
To deploy the AWS SAM template, complete the following steps:
- Clone the source code repository to your local environment:
- Build the AWS SAM application:
- Deploy the application:
- Provide stack parameters according to your existing environment and desired deployment options, such as existing VPC, existing private and public subnets, and existing SageMaker domain, as discussed in the Solution deployment options chapter of the README file.
You can leave all parameters at their default values to provision new network resources and a new SageMaker domain. Refer to detailed parameter usage in the README file if you need to change any default settings.
Wait until the stack deployment is complete. The end-to-end deployment including provisioning all network resources and a SageMaker domain takes about 20 minutes.
To see the stack output, run the following command in the terminal:
Create SSO users
Follow the instructions to add AWS SSO users to create two users with names User1 and User2 or use any two of your existing AWS SSO users to test the solution. Make sure you use AWS SSO in the same AWS Region in which you deployed the solution.
Create custom SAML 2.0 applications
To create the required custom SAML 2.0 applications for Team 1 and for Team 2, complete the following steps:
- Open the AWS SSO console in the AWS management account of your AWS organization, in the same Region where you deployed the solution stack.
- Choose Applications in the navigation pane.
- Choose Add a new application.
- Choose Add a custom SAML 2.0 application.
- For Display name, enter an application name, for example
SageMaker Studio Team 1. - Leave Application start URL and Relay state empty.
- Choose If you don’t have a metadata file, you can manually enter your metadata values.
- For Application ACS URL, enter the URL provided in the
SAMLBackendEndpointkey of the AWS SAM stack output. - For Application SAML audience, enter the URL provided in the
SAMLAudiencekey of the AWS SAM stack output. - Choose Save changes.

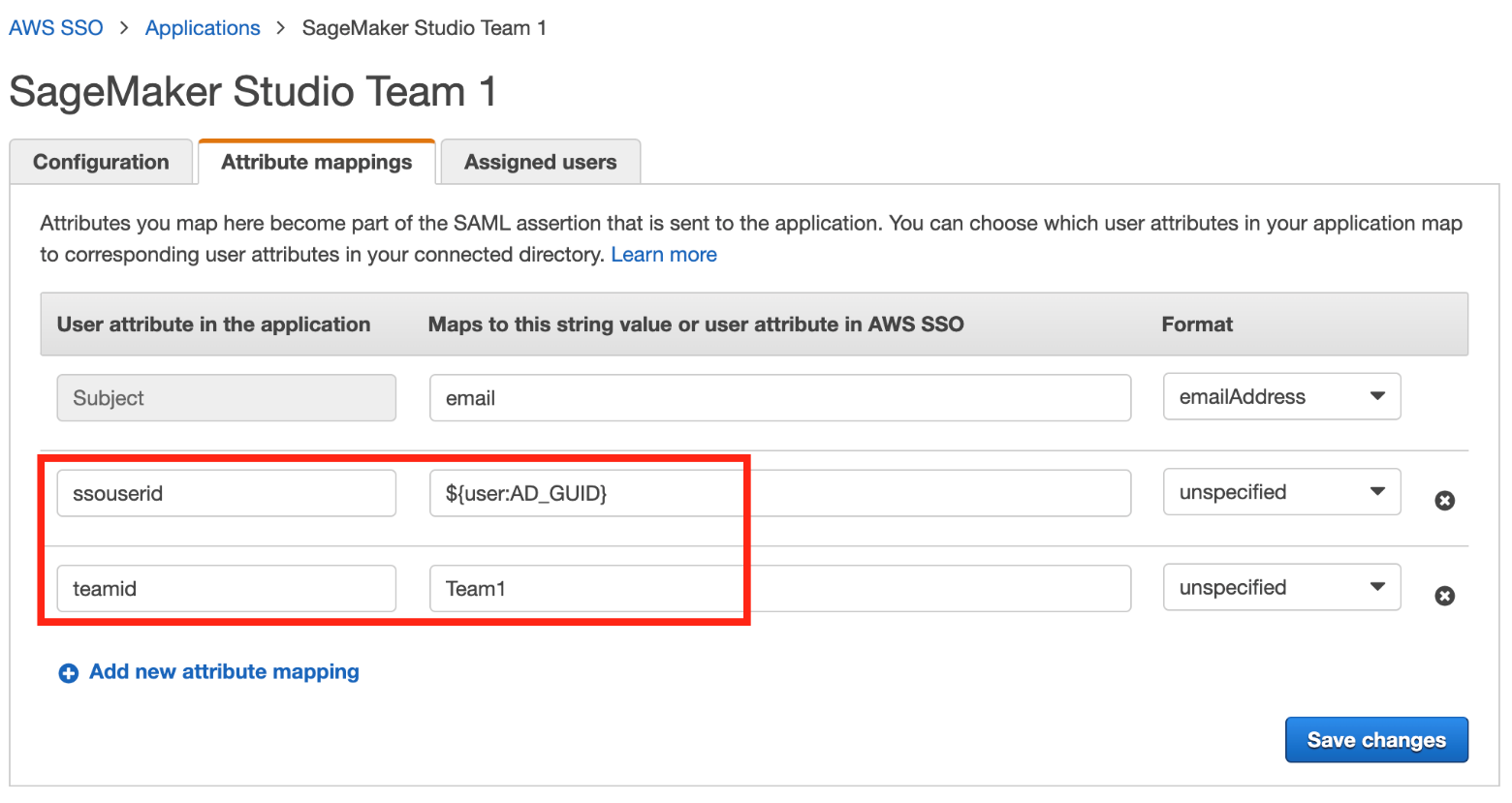
- Navigate to the Attribute mappings tab.
- Set the Subject to email and Format to emailAddress.
- Add the following new attributes:
-
ssouseridset to${user:AD_GUID} -
teamidset toTeam1orTeam2, respectively, for each application
-
- Choose Save changes.
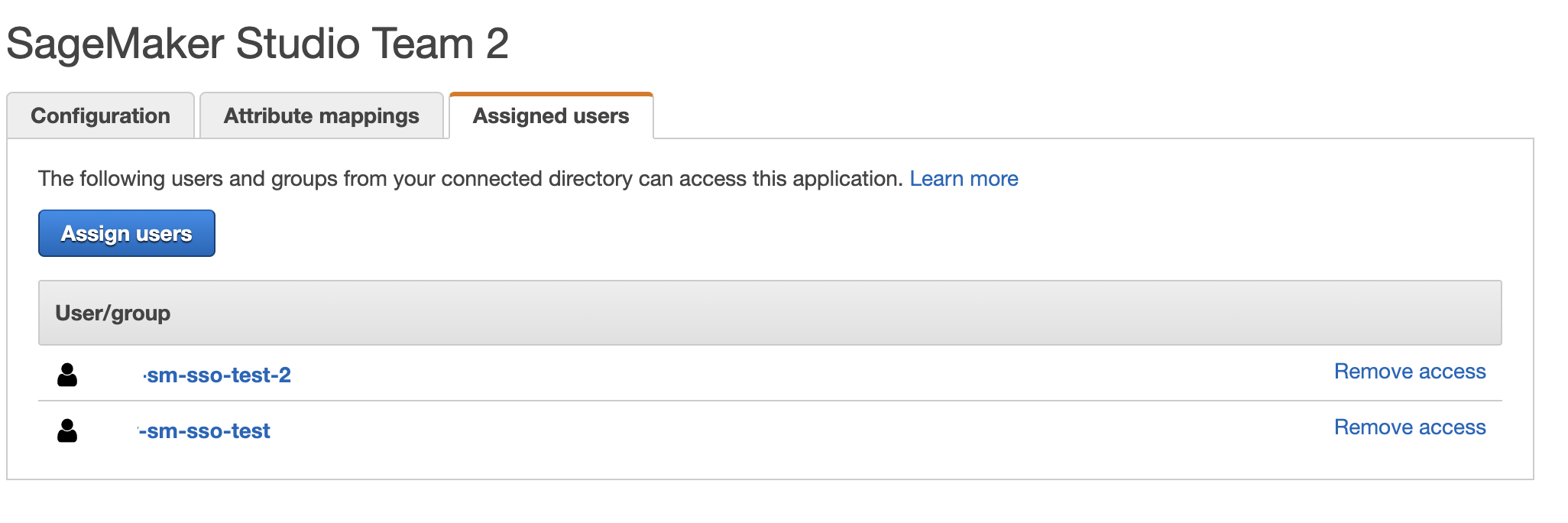
- On the Assigned users tab, choose Assign users.
- Choose User 1 for the Team 1 application and both User 1 and User 2 for the Team 2 application.
- Choose Assign users.
Test the solution
To test the solution, complete the following steps:
- Go to AWS SSO user portal
https://<Identity Store ID>.awsapps.com/startand sign as User 1.
Two SageMaker applications are shown in the portal.
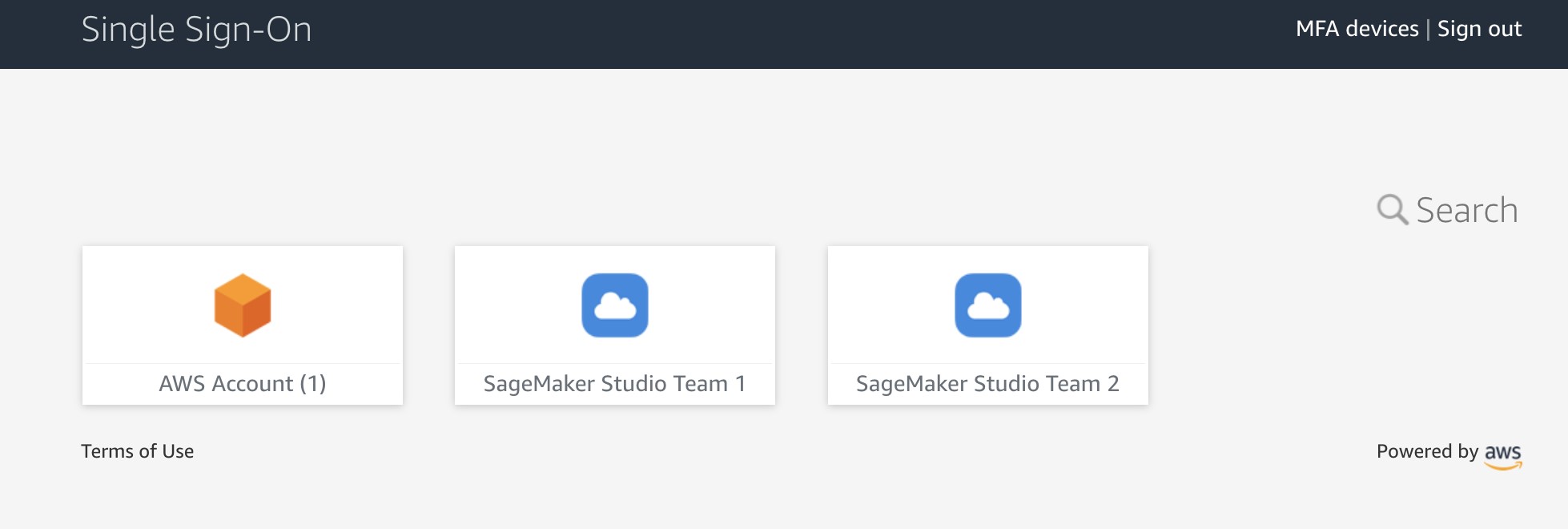
- Choose SageMaker Studio Team 1.
You’re redirected to the Studio instance for Team 1 in a new browser window.
 The first time you start Studio, SageMaker creates a JupyterServer application. This process takes few minutes.
The first time you start Studio, SageMaker creates a JupyterServer application. This process takes few minutes.

- In Studio, on the File menu, choose New and Terminal to start a new terminal.
- In the terminal command line, enter the following command:
The command returns the Studio execution role.

In our setup, this role must be different for each team. You can also check that each user in each instance of Studio has their own home directory on a mounted Amazon EFS volume.
- Return to the AWS SSO portal, still logged as User 1, and choose SageMaker Studio Team 2.
You’re redirected to a Team 2 Studio instance.
 The start process can again take several minutes, because SageMaker starts a new JupyterServer application for User 2.
The start process can again take several minutes, because SageMaker starts a new JupyterServer application for User 2. - Sign as User 2 in the AWS SSO portal.
User 2 has only one application assigned: SageMaker Studio Team 2.

If you start an instance of Studio via this user application, you can verify that it uses the same SageMaker execution role as User 1’s Team 2 instance. However, each Studio instance is completely isolated. User 2 has their own home directory on an Amazon EFS volume and own instance of JupyterServer application. You can verify this by creating a folder and some files for each of the users and see that each user’s home directory is isolated.
Now you can sign in to the SageMaker console and see that there are three user profiles created.

You just implemented a proof of concept solution to manage multiple users and teams with Studio.
Clean up
To avoid charges, you must remove all project-provisioned and generated resources from your AWS account. Use the following SAM CLI command to delete the solution CloudFormation stack:
For security reasons and to prevent data loss, the Amazon EFS mount and the content associated with the Studio domain deployed in this solution are not deleted. The VPC and subnets associated with the SageMaker domain remain in your AWS account. For instructions to delete the file system and VPC, refer to Deleting an Amazon EFS file system and Work with VPCs, respectively.
To delete the custom SAML application, complete the following steps:
- Open the AWS SSO console in the AWS SSO management account.
- Choose Applications.
- Select SageMaker Studio Team 1.
- On the Actions menu, choose Remove.
- Repeat these steps for SageMaker Studio Team 2.
Conclusion
This solution demonstrated how you can create a flexible and customizable environment using AWS SSO and Studio user profiles to support your own organization structure. The next possible improvement steps towards a production-ready solution could be:
- Implement automated Studio user profile management as a dedicated microservice to support an automated profile provisioning workflow and to handle metadata and configuration for user profiles, for example in Amazon DynamoDB.
- Use the same mechanism in a more general case of multiple SageMaker domains and multiple AWS accounts. The same SAML backend can vend a corresponding presigned URL redirecting to a user profile-domain-account combination according to your custom logic based on user entitlements and team setup.
- Implement a synchronization mechanism between your IdP and AWS SSO and automate creation of custom SAML 2.0 applications.
- Implement scalable data and resource access management with attribute-based access control (ABAC).
If you have any feedback or questions, please leave them in the comments.
Further reading
Documentation
Blog posts
- Onboarding Amazon SageMaker Studio with AWS SSO and Okta Universal Directory
- Configuring Amazon SageMaker Studio for teams and groups with complete resource isolation
- Secure access to Amazon SageMaker Studio with AWS SSO and a SAML application
About the Author
 Yevgeniy Ilyin is a Solutions Architect at AWS. He has over 20 years of experience working at all levels of software development and solutions architecture and has used programming languages from COBOL and Assembler to .NET, Java, and Python. He develops and codes cloud native solutions with a focus on big data, analytics, and data engineering.
Yevgeniy Ilyin is a Solutions Architect at AWS. He has over 20 years of experience working at all levels of software development and solutions architecture and has used programming languages from COBOL and Assembler to .NET, Java, and Python. He develops and codes cloud native solutions with a focus on big data, analytics, and data engineering.