Guido Imbens elected to the National Academy of Sciences; Alberto Abadie elected to American Academy of Arts and Sciences.Read More
Detect social media fake news using graph machine learning with Amazon Neptune ML
In recent years, social media has become a common means for sharing and consuming news. However, the spread of misinformation and fake news on these platforms has posed a major challenge to the well-being of individuals and societies. Therefore, it is imperative that we develop robust and automated solutions for early detection of fake news on social media. Traditional approaches rely purely on the news content (using natural language processing) to mark information as real or fake. However, the social context in which the news is published and shared can provide additional insights into the nature of fake news on social media and improve the predictive capabilities of fake news detection tools. In this post, we demonstrate how to use Amazon Neptune ML to detect fake news based on the content and social context of the news on social media.
Neptune ML is a new capability of Amazon Neptune that uses graph neural networks (GNNs), a machine learning (ML) technique purpose-built for graphs, to make easy, fast, and accurate predictions using graph data. Making accurate predictions on graphs with billions of relationships requires expertise. Existing ML approaches such as XGBoost can’t operate effectively on graphs because they’re designed for tabular data. As a result, using these methods on graphs can take time, require specialized skills, and produce suboptimal predictions.
Neptune ML uses the Deep Graph Library (DGL), an open-source library to which AWS contributes, and Amazon SageMaker to build and train GNNs, including Relational Graph Convolutional Networks (R-GCNs) for tasks such as node classification, node regression, link prediction, or edge classification.
The DGL makes it easy to apply deep learning to graph data, and Neptune ML automates the heavy lifting of selecting and training the best ML model for graph data. It provides fast and memory-efficient message passing primitives for training GNNs. Neptune ML uses the DGL to automatically choose and train the best ML model for your workload. This enables you to make ML-based predictions on graph data in hours instead of weeks. For more information, see Amazon Neptune ML for machine learning on graphs.
Amazon SageMaker is a fully managed service that provides every developer and data scientist with the ability to prepare, build, train, and deploy ML models quickly.
Overview of GNNs
GNNs are neural networks that take graphs as input. These models operate on the relational information in data to produce insights not possible in other neural network architectures and algorithms. A graph (sometimes called a network) is a data structure that highlights the relationships between components in the data. It consists of nodes (or vertices) and edges (or links) that act as connections between the nodes. Such a data structure has an advantage when dealing with entities that have multiple relationships. Graph data structures have been around for centuries, with a wide variety of modern use cases.
GNNs are emerging as an important class of deep learning (DL) models. GNNs learn embeddings on nodes, edges, and graphs. GNNs have been around for about 20 years, but interest in them has dramatically increased in the last 5 years. In this time, we’ve seen new architectures emerge, novel applications realized, and new platforms and libraries enter the scene. There are several potential research and industry use cases for GNNs, including the following:
- Computer vision – Generating scene graphs
- Forecasting – Predicting traffic volume
- Node classification – Implementing targeted campaigns, detecting fake news
- Graph classification – Predicting the properties of a chemical compound
- Link prediction – Building recommendation systems
- Other – Predicting adversarial attacks

Dataset
For this post, we use the BuzzFeed dataset from the 2018 version of FakeNewsNet. The BuzzFeed dataset consists of a sample of news articles shared on Facebook from nine news agencies over 1 week leading up to the 2016 US election. Every post and the corresponding news article have been fact-checked by BuzzFeed journalists. The following table summarizes key statistics about the BuzzFeed dataset from FakeNewsNet.
| Category | Amount |
| Users | 15,257 |
| Authors | 126 |
| Publishers | 28 |
| Social Links | 634,750 |
| Engagements | 25,240 |
| News Articles | 182 |
| Fake News | 91 |
| Real News | 91 |
To get the raw data, you can complete the following steps:
- Clone the FakeNewsNet repository from GitHub.
- Check out the old version branch.
- Change the directory to
Data/BuzzFeed.
Each row in the Users.txt file provides a UUID for the corresponding user.

Each row in the News.txt file provides a name and ID for the corresponding news in the dataset.

In the BuzzFeedNewsUser.txt file, the news_id in the first column is posted or shared by the user_id in the second column n times, where n is the value in the third column.

In the BuzzFeedUserUser.txt file, the user_id in the first column follows the user_id in the second column.

User features such as age, gender, and historical social media activities (109,626 features for each user) are made available in UserFeature.mat file. Sample news content files, shown in the following screenshot, contain information such as news title, news text, author name, and publisher web address.

We processed the raw data from the FakeNewsNet repository and converted it into CSV format for vertices and edges in a heterogeneous property graph that can be readily loaded into a Neptune database with Apache TinkerPop Gremlin. The constructed property graph is composed of four vertex types and five edge types, as demonstrated in the following schematic, which together describe the social context in which each news item is published and shared. The News vertices have two properties: news_title and news_type (Fake or Real). The edges connecting News and User vertices have a weight property describing how many times the user has shared the news. The User vertices have a 100-dimension property representing user features such as age, gender, and historical social media activities (reduced from 109,626 to 100 using principal coordinate analysis).
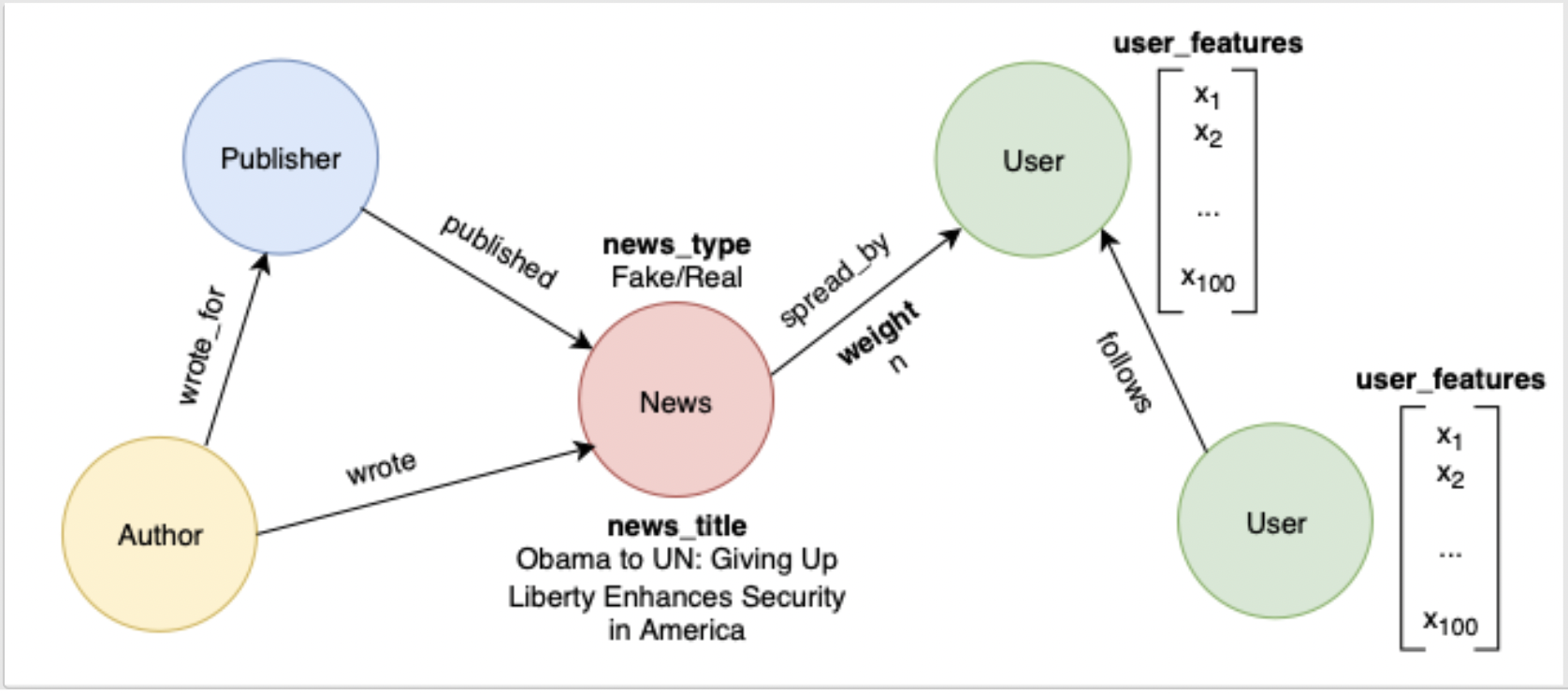
The following screenshot shows the first 10 rows of the processed nodes.csv file.

The following screenshot shows the first 10 rows of the processed edges.csv file.

To follow along with this post, start by using the following AWS CloudFormation quick-start template to quickly spin up an associated Neptune cluster and AWS graph notebook, and set up all the configurations needed to work with Neptune ML in a graph notebook. You then need to download and save the sample dataset in the default Amazon Simple Storage Service (Amazon S3) bucket associated with your SageMaker session, or in an S3 bucket of your choice. For rapid experimentation and initial data exploration, you can save a copy of the dataset under the home directory of the local volume attached to your SageMaker notebook instance, and follow the create_graph_dataset.ipynb Jupyter notebook. After you generate the processed nodes and edges files, you can run the following commands to upload the transformed graph data to Amazon S3:
You can use the %load magic command, which is available as part of the AWS graph notebook, to bulk load data to Neptune:
You can use the %graph_notebook_config magic command to see information about the Neptune cluster associated with your graph notebook. You can also use the %status magic command to see the status of your Neptune cluster, as shown in the following screenshot.

Solution overview
Neptune ML uses graph neural network technology to automatically create, train, and deploy ML models on your graph data. Neptune ML supports common graph prediction tasks, such as node classification and regression, edge classification and regression, and link prediction. In our solution, we use node classification to classify news nodes according to the news_type property.
The following diagram illustrates the high-level process flow to develop the best model for fake news detection.

Graph ML with Neptune ML involves five main steps:
-
Export and configure the data – The data export step uses the Neptune-Export service to export data from Neptune into Amazon S3 in CSV format. A configuration file named
training-data-configuration.jsonis automatically generated, which specifies how the exported data can be loaded into a trainable graph. - Preprocess the data – The exported dataset is preprocessed using standard techniques to prepare it for model training. Feature normalization can be performed for numeric data, and text features can be encoded using word2vec. At the end of this step, a DGL graph is generated from the exported dataset for the model training step. This step is implemented using a SageMaker processing job, and the resulting data is stored in an Amazon S3 location that you have specified.
-
Train the model – This step trains the ML model that will be used for predictions. Model training is done in two stages:
- The first stage uses a SageMaker processing job to generate a model training strategy configuration set that specifies what type of model and model hyperparameter ranges are used for the model training.
- The second stage uses a SageMaker model tuning job to try different hyperparameter configurations and select the training job that produced the best-performing model. The tuning job runs a pre-specified number of model training job trials on the processed data. At the end of this stage, the trained model parameters of the best training job are used to generate model artifacts for inference.
- Create an inference endpoint in SageMaker – The inference endpoint is a SageMaker endpoint instance that is launched with the model artifacts produced by the best training job. The endpoint is able to accept incoming requests from the graph database and return the model predictions for inputs in the requests.
- Query the ML model using Gremlin – You can use extensions to the Gremlin query language to query predictions from the inference endpoint.
Before we proceed with the first step of machine learning, let’s verify that the graph dataset is loaded in the Neptune cluster. Run the following Gremlin traversal to see the count of nodes by label:
If nodes are loaded correctly, the output is as follows:
- 126
authornodes - 182
newsnodes - 28
publishernodes - 15,257
usernodes
Use the following code to see the count edges by label:
If edges are loaded correctly, the output is as follows:
- 634,750
followsedges - 174
publishededges - 250
wroteedges - 250
wrote_foredges
Now let’s go through the ML development process in detail.
Export and configure the data
The export process is triggered by calling to the Neptune-Export service endpoint. This call contains a configuration object that specifies the type of ML model to build, in our case node classification, as well as any feature configurations required.
The configuration options provided to the Neptune-Export service are broken into two main sections: selecting the target and configuring features. Here we want to classify news nodes according to the news_type property.
The second section of the configuration, configuring features, is where we specify details about the types of data stored in our graph and how the ML model should interpret that data. When data is exported from Neptune, all properties of all nodes are included. Each property is treated as a separate feature for the ML model. Neptune ML does its best to infer the correct type of feature for a property, but in many cases, the accuracy of the model can be improved by specifying information about the property used for a feature. We use word2vec to encode the news_title property of news nodes, and the numerical type for user_features property of user nodes. See the following code:
Start the export process by running the following command:

Preprocess the data
When the export job is complete, we’re ready to train our ML model. There are three machine learning steps in Neptune ML. The first step (data processing) processes the exported graph dataset using standard feature preprocessing techniques to prepare it for use by the DGL. This step performs functions such as feature normalization for numeric data and encoding text features using word2vec. At the conclusion of this step, the dataset is formatted for model training. This step is implemented using a SageMaker processing job, and data artifacts are stored in a pre-specified Amazon S3 location when the job is complete. Run the following code to create the data processing configuration and begin the processing job:

Train the model
Now that you have the data processed in the desired format, this step trains the ML model that is used for predictions. The model training is done in two stages. The first stage uses a SageMaker processing job to generate a model training strategy. A model training strategy is a configuration set that specifies what type of model and model hyperparameter ranges are used for the model training. After the first stage is complete, the SageMaker processing job launches a SageMaker hyperparameter tuning job. The hyperparameter tuning job runs a pre-specified number of model training job trials on the processed data, and stores the model artifacts generated by the training in the output Amazon S3 location. When all the training jobs are complete, the hyperparameter tuning job also notes the training job that produced the best performing model.
We use the following training parameters:

The hyperparameter tuning finds the best version of a model by running many training jobs on the dataset. You can summarize hyperparameters of the five best training jobs and their respective model performance as follows:

We can see that the best performing training job achieved an accuracy of approximately 94%. This training job will be automatically selected by Neptune ML for creating an endpoint in the next step.
Create an endpoint
The final step of machine learning is to create an inference endpoint, which is a SageMaker endpoint instance that is launched with the model artifacts produced by the best training job. We use this endpoint in our graph queries to return the model predictions for the inputs in the request. After the endpoint is created, it stays active until it’s manually deleted. Create the endpoint with the following code:

Our new endpoint is now up and running.
Query the ML model
Now let’s query your trained graph to see how the model predicts news_type for one unseen news node:
If your graph is continuously changing, you may need to update ML predictions frequently using the newest data. Although you can do this simply by rerunning the earlier steps (from data export and configuration to creating your inference endpoint), Neptune ML supports simpler ways to update your ML predictions using new data. See Workflows for handling evolving graph data for more details.
Conclusion
In this post, we showed how Neptune ML and GNNs can help detect social media fake news using node classification on graph data by combining information from the complex interaction patterns in the graph. For instructions on implementing this solution, see the GitHub repo. You can also clone and extend this solution with additional data sources for model retraining and tuning. We encourage you to reach out and discuss your use cases with the authors via your AWS account manager.
Additional references
For more information related to Neptune ML and detecting fake news in social media, see the following resources:
- Beyond News Contents: The Role of Social Context for Fake News Detection
- FakeNewsNet
- Graph-based recommendation system with Neptune ML: An illustration on social network link prediction challenges
- Analyzing social media feeds using Amazon Neptune
About the Authors
 Hasan Shojaei is a Data Scientist with AWS Professional Services, where he helps customers across different industries such as sports, insurance, and financial services solve their business challenges through the use of big data, machine learning, and cloud technologies. Prior to this role, Hasan led multiple initiatives to develop novel physics-based and data-driven modeling techniques for top energy companies. Outside of work, Hasan is passionate about books, hiking, photography, and ancient history.
Hasan Shojaei is a Data Scientist with AWS Professional Services, where he helps customers across different industries such as sports, insurance, and financial services solve their business challenges through the use of big data, machine learning, and cloud technologies. Prior to this role, Hasan led multiple initiatives to develop novel physics-based and data-driven modeling techniques for top energy companies. Outside of work, Hasan is passionate about books, hiking, photography, and ancient history.
 Sarita Joshi is a Senior Data Science Manager with the AWS Professional Services Intelligence team. Together with her team, Sarita plays a strategic role for our customers and partners by helping them achieve their business outcomes through machine learning and artificial intelligence solutions at scale. She has several years of experience as a consultant advising clients across many industries and technical domains, including AI, ML, analytics, and SAP. She holds a master’s degree in Computer Science, Specialty Data Science from Northeastern University.
Sarita Joshi is a Senior Data Science Manager with the AWS Professional Services Intelligence team. Together with her team, Sarita plays a strategic role for our customers and partners by helping them achieve their business outcomes through machine learning and artificial intelligence solutions at scale. She has several years of experience as a consultant advising clients across many industries and technical domains, including AI, ML, analytics, and SAP. She holds a master’s degree in Computer Science, Specialty Data Science from Northeastern University.
Optimize F1 aerodynamic geometries via Design of Experiments and machine learning
FORMULA 1 (F1) cars are the fastest regulated road-course racing vehicles in the world. Although these open-wheel automobiles are only 20–30 kilometers (or 12–18 miles) per-hour faster than top-of-the-line sports cars, they can speed around corners up to five times as fast due to the powerful aerodynamic downforce they create. Downforce is the vertical force generated by the aerodynamic surfaces that presses the car towards the road, increasing the grip from the tires. F1 aerodynamicists must also monitor the air resistance or drag, which limits straight-line speed.
The F1 engineering team is in charge of designing the next generation of F1 cars and putting together the technical regulation for the sport. Over the last 3 years, they have been tasked with designing a car that maintains the current high levels of downforce and peak speeds, but is also not adversely affected by driving behind another car. This is important because the previous generation of cars can lose up to 50% of their downforce when racing closely behind another car due to the turbulent wake generated by wings and bodywork.
Instead of relying on time-consuming and costly track or wind tunnel tests, F1 uses Computational Fluid Dynamics (CFD), which provides a virtual environment to study the flow of fluids (in this case the air around the F1 car) without ever having to manufacture a single part. With CFD, F1 aerodynamicists test different geometry concepts, assess their aerodynamic impact, and iteratively optimize their designs. Over the past 3 years, the F1 engineering team has collaborated with AWS to set up a scalable and cost-efficient CFD workflow that has tripled the throughput of CFD runs and cut the turnaround time per run by half.
F1 is in the process of looking into AWS machine learning (ML) services such as Amazon SageMaker to help optimize the design and performance of the car by using the CFD simulation data to build models with additional insights. The aim is to uncover promising design directions and reduce the number of CFD simulations, thereby reducing the time taken to converge to optimal designs.
In this post, we explain how F1 collaborated with the AWS Professional Services team to develop a bespoke Design of Experiments (DoE) workflow powered by ML to advise F1 aerodynamicists on which design concepts to test in CFD to maximize learning and performance.
Problem statement
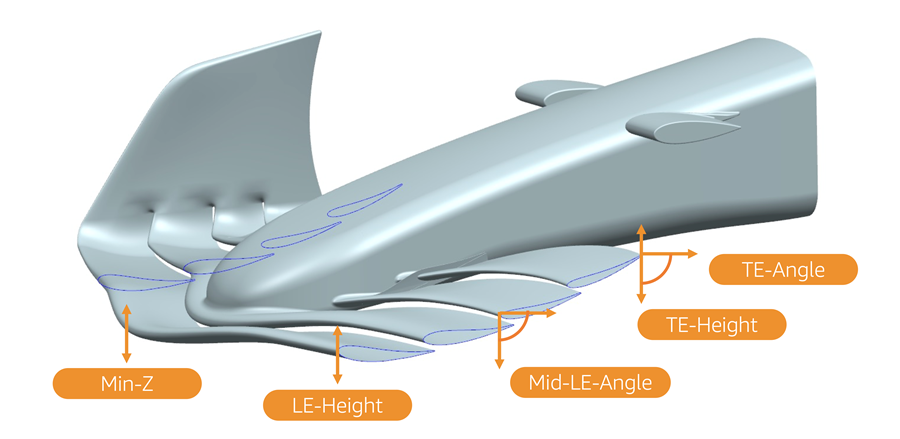
When exploring new aerodynamic concepts, F1 aerodynamicists sometimes employ a process called Design of Experiments (DoE). This process systematically studies the relationship between multiple factors. In the case of a rear wing, this might be wing chord, span, or camber, with respect to aerodynamic metrics such as downforce or drag. The goal of a DoE process is to efficiently sample the design space and minimize the number of candidates tested before converging to an optimal result. This is achieved by iteratively changing multiple design factors, measuring the aerodynamic response, studying the impact and relationship between factors, and then continuing testing in the most optimum or informative direction. In the following figure, we present an example rear wing geometry that F1 has kindly shared with us from their UNIFORM baseline. Four design parameters which F1 aerodynamicists could investigate in a DoE routine are labeled.

In this project, F1 worked with AWS Professional Services to investigate using ML to enhance DoE routines. Traditional DoE methods require a well-populated design space in order to understand the relationship between design parameters and therefore rely on a large number of upfront CFD simulations. ML regression models could use the results from previous CFD simulations to predict the aerodynamic response given the set of design parameters, as well as give you an indication of the relative importance of each design variable. You could use these insights to predict optimal designs and help designers converge to optimum solutions with fewer upfront CFD simulations. Secondly, you could use data science techniques to understand which regions in the design space haven’t been explored and could potentially hide optimal designs.
To illustrate the bespoke ML-powered DoE workflow, we walk through a real example of designing a front wing.
Designing a front wing
F1 cars rely on wings such as the front and rear wings to generate most of their downforce, which we refer to throughout this example by the coefficient Cz. Throughout this example, the downforce values have been normalized. In this example, F1 aerodynamicists used their domain expertise to parameterize the wing geometry as follows (refer to the following figure for a visual representation):
- LE-Height – Leading edge height
- Min-Z – Minimum ground clearance
- Mid-LE-Angle – Leading edge angle of the third element
- TE-Angle – Trailing edge angle
- TE-Height – Trailing edge height
This front wing geometry was shared by F1 and is part of the UNIFORM baseline.
These parameters were selected because they are sufficient to describe the main aspects of the geometry efficiently and because in the past, aerodynamic performance has shown notable sensitivity with respect to these parameters. The goal of this DoE routine was to find the combination of the five design parameters that would maximize aerodynamic downforce (Cz). The design freedom is also limited by setting maximum and minimum values to the design parameters, as shown in the following table.
| . | Minimum | Maximum |
| TE-Height | 250.0 | 300.0 |
| TE-Angle | 145.0 | 165.0 |
| Mid-LE-Angle | 160.0 | 170.0 |
| Min-Z | 5.0 | 50.0 |
| LE-Height | 100.0 | 150.0 |
Having established the design parameters, the target output metric, and the bounds of our design space, we have all we need to get started with the DoE routine. A workflow diagram of our solution is presented in the following image. In the following section, we dive deep into the different stages.
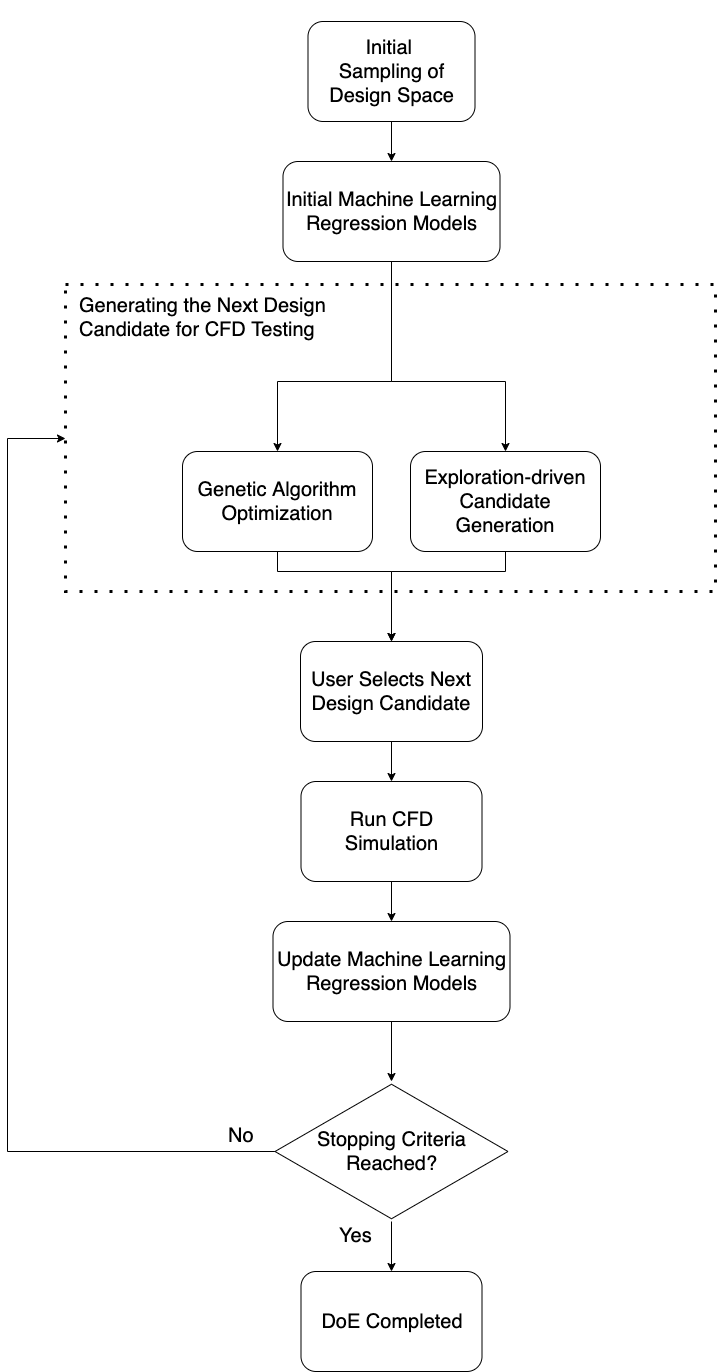
Initial sampling of the design space
The first step of the DoE workflow is to run in CFD an initial set of candidates that efficiently sample the design space and allow us to build the first set of ML regression models to study the influence of each feature. First, we generate a pool of N samples ![]() using Latin Hypercube Sampling (LHS) or a regular grid method. Then, we select k candidates to test in CFD by means of a greedy inputs algorithm, which aims to maximize the exploration of the design space. Starting with a baseline candidate (the current design), we iteratively select candidates furthest away from all the previously tested candidates. Suppose that we already tested k designs; for the remaining design candidates, we find the minimum distance d with respect to the tested k designs:
using Latin Hypercube Sampling (LHS) or a regular grid method. Then, we select k candidates to test in CFD by means of a greedy inputs algorithm, which aims to maximize the exploration of the design space. Starting with a baseline candidate (the current design), we iteratively select candidates furthest away from all the previously tested candidates. Suppose that we already tested k designs; for the remaining design candidates, we find the minimum distance d with respect to the tested k designs:
![]()
The greedy inputs algorithm selects the candidate that maximizes the distance in the feature space to the previously tested candidates:
![]()
In this DoE, we selected three greedy inputs candidates and ran those in CFD to assess their aerodynamic downforce (Cz). The greedy inputs candidates explore the bounds of the design space and at this stage, none of them proved superior to the baseline candidate in terms of aerodynamic downforce (Cz). The results of this initial round of CFD testing together with the design parameters are displayed in the following table.
| . | TE-Height | TE-Angle | Mid-LE-Angle | Min-Z | LE-Height | Normalized Cz |
| Baseline | 292.25 | 154.86 | 166 | 5 | 130 | 0.975 |
| GI 0 | 250 | 165 | 160 | 50 | 100 | 0.795 |
| GI 1 | 300 | 145 | 170 | 50 | 100 | 0.909 |
| GI 2 | 250 | 145 | 170 | 5 | 100 | 0.847 |
Initial ML regression models
The goal of the regression model is to predict Cz for any combination of the five design parameters. With such a small dataset, we prioritized simple models, applied model regularization to avoid overfitting, and combined the predictions of different models where possible. The following ML models were constructed:
- Ordinary Least Squares (OLS)
- Support Vector Regression (SVM) with an RBF kernel
- Gaussian Process Regression (GP) with a Matérn kernel
- XGBoost
In addition, a two-level stacked model was built, where the predictions of the GP, SVM, and XGBoost models are assimilated by a Lasso algorithm to produce the final response. This model is referred to throughout this post as the stacked model. To rank the predictive capabilities of the five models we described, a repeated k-fold cross validation routine was implemented.
Generating the next design candidate to test in CFD
Selecting which candidate to test next requires careful consideration. The F1 aerodynamicist must balance the benefit of exploiting options predicted by the ML model to provide high downforce with the cost of failing to explore uncharted regions of the design space, which may provide even higher downforce. For that reason, in this DoE routine, we propose three candidates: one performance-driven and two exploration-driven. The purpose of the exploration-driven candidates is also to provide additional data points to the ML algorithm in regions of the design space where the uncertainty around the prediction is highest. This in turn leads to more accurate predictions in the next round of design iteration.
Genetic algorithm optimization to maximize downforce
To obtain the candidate with the highest expected aerodynamic downforce, we could run a prediction over all possible design candidates. However, this wouldn’t be efficient. For this optimization problem, we use a genetic algorithm (GA). The goal is to efficiently search through a huge solution space (obtained via the ML prediction of Cz) and return the most optimal candidate. GAs are advantageous when the solution space is complex and non-convex, so that classical optimization methods such as gradient descent are an ineffective means to find a global solution. GA is a subset of evolutionary algorithms and inspired by concepts from natural selection, genetic crossover, and mutation to solve the search problem. Over a series of iterations (known as generations), the best candidates of an initially randomly selected set of design candidates are combined (much like reproduction). Eventually, this mechanism allows you to find the most optimal candidates in an efficient manner. For more information about GAs, refer to Using genetic algorithms on AWS for optimization problems.
Generating exploration-driven candidates
In generating what we term exploration-driven candidates, a good sampling strategy must be able to adapt to a situation of effect sparsity, where only a subset of the parameters significantly affects the solution. Therefore, the sampling strategy should spread out the candidates across the input design space but also avoid unnecessary CFD runs, changing variables that have little effect on performance. The sampling strategy must take into account the response surface predicted by the ML regressor. Two sampling strategies were employed to obtain exploration-driven candidates.
In the case of Gaussian Process Regressors (GP), the standard deviation ![]() of the predicted response surface can be used as an indication of the uncertainty of the model. The sampling strategy consists of selecting out of the pool of N samples
of the predicted response surface can be used as an indication of the uncertainty of the model. The sampling strategy consists of selecting out of the pool of N samples ![]() , the candidate that maximizes
, the candidate that maximizes ![]() . By doing so, we’re sampling in the region of the design space where the regressor is least confident about its prediction. In mathematical terms, we select the candidate that satisfies the following equation:
. By doing so, we’re sampling in the region of the design space where the regressor is least confident about its prediction. In mathematical terms, we select the candidate that satisfies the following equation:
![]()
Alternatively, we employ a greedy inputs and outputs sampling strategy, which maximizes both the distances in the feature space and in the response space between the proposed candidate and the already tested designs. This tackles the effect sparsity situation because candidates that modify a design parameter of little relevance have a similar response, and therefore the distances in the response surface are minimal. In mathematical terms, we select the candidate that satisfies the following equation, where the function f is the ML regression model:
![]()
![]()
![]()
Candidate selection, CFD testing, and optimization loop
At this stage, the user is presented with both performance-driven and exploration-driven candidates. The next step consists of selecting a subset of the proposed candidates, running CFD simulations with those design parameters, and recording the aerodynamic downforce response.
After this, the DoE workflow retrains the ML regression models, runs the genetic algorithm optimization, and proposes a new set of performance-driven and exploration-driven candidates. The user runs a subset of the proposed candidates and continues iterating in this fashion until the stopping criteria is met. The stopping criteria is generally met when a candidate deemed optimum is obtained.
Results
In the following figure, we record the normalized aerodynamic downforce (Cz) from the CFD simulation (blue) and the one predicted beforehand using the ML regression model of choice (pink) for each iteration of the DoE workflow. The goal was to maximize aerodynamic downforce (Cz). The first four runs (to the left of the red line) were the baseline and the three greedy inputs candidates outlined previously. From there on, a combination of performance-driven and exploration-driven candidates were tested. In particular, the candidates at iterations 6 and 8 were exploratory candidates, both showing lower levels of downforce than the baseline candidate (iteration 1). As expected, as we recorded more candidates, the ML prediction became increasingly accurate, as denoted by the decreasing distance between the predicted and actual Cz. At iteration 9, the DoE workflow managed to find a candidate with a similar performance to the baseline, and at iteration 12, the DoE workflow was concluded when the performance-driven candidate surpassed the baseline.

The final design parameters together with the resultant normalized downforce value is presented in the following table. The normalized downforce level for the baseline candidate was 0.975, whereas the optimum candidate for the DoE workflow recorded a normalized downforce level of 1.000. This is an important 2.5% relative increase.
For context, a traditional DoE approach with five variables would require 25 upfront CFD simulations before achieving a good enough fit to predict an optimum. On the other hand, this active learning approach converged to an optimum in 12 iterations.
| . | TE-Height | TE-Angle | Mid-LE-Angle | Min-Z | LE-Height | Normalized Cz |
| Baseline | 292.25 | 154.86 | 166 | 5 | 130 | 0.975 |
| Optimal | 299.97 | 156.79 | 166.27 | 5.01 | 135.26 | 1.000 |
Feature importance
Understanding the relative feature importance for a predictive model can provide a useful insight into the data. It can help feature selection with less important variables being removed, thereby reducing the dimensionality of the problem and potentially improving the predictive powers of the regression model, particularly in the small data regime. In this design problem, it provides F1 aerodynamicists an insight into which variables are the most sensitive and therefore require more careful tuning.
In this routine, we implemented a model-agnostic technique called permutation importance. The relative importance of each variable is measured by calculating the increase in the model’s prediction error after randomly shuffling the values for that variable alone. If a feature is important for the model, the prediction error increases greatly, and vice versa for lesser important features. In the following figure, we present the permutation importance for a Gaussian Process Regressor (GP) predicting aerodynamic downforce (Cz). The trailing edge height (TE-Height) was deemed the most important.

Conclusion
In this post, we explained how F1 aerodynamicists are using ML regression models in DoE workflows when designing novel aerodynamic geometries. The ML-powered DoE workflow developed by AWS Professional Services provides insights into which design parameters will maximize performance or explore uncharted regions in the design space. As opposed to iteratively testing candidates in CFD in a grid search fashion, the ML-powered DoE workflow is able to converge to optimal design parameters in fewer iterations. This saves both time and resources because fewer CFD simulations are required.
Whether you’re a pharmaceutical company looking to speed up chemical composition optimization or a manufacturing company looking to find the design dimensions for the most robust designs, DoE workflows can help reach optimal candidates more efficiently. AWS Professional Services is ready to supplement your team with specialized ML skills and experience to develop the tools to streamline DoE workflows and help you achieve better business outcomes. For more information, see AWS Professional Services, or reach out through your account manager to get in touch.
About the Authors
 Pablo Hermoso Moreno is a Data Scientist in the AWS Professional Services Team. He works with clients across industries using Machine Learning to tell stories with data and reach more informed engineering decisions faster. Pablo’s background is in Aerospace Engineering and having worked in the motorsport industry he has an interest in bridging physics and domain expertise with ML. In his spare time, he enjoys rowing and playing guitar.
Pablo Hermoso Moreno is a Data Scientist in the AWS Professional Services Team. He works with clients across industries using Machine Learning to tell stories with data and reach more informed engineering decisions faster. Pablo’s background is in Aerospace Engineering and having worked in the motorsport industry he has an interest in bridging physics and domain expertise with ML. In his spare time, he enjoys rowing and playing guitar.
Build a risk management machine learning workflow on Amazon SageMaker with no code
Since the global financial crisis, risk management has taken a major role in shaping decision-making for banks, including predicting loan status for potential customers. This is often a data-intensive exercise that requires machine learning (ML). However, not all organizations have the data science resources and expertise to build a risk management ML workflow.
Amazon SageMaker is a fully managed ML platform that allows data engineers and business analysts to quickly and easily build, train, and deploy ML models. Data engineers and business analysts can collaborate using the no-code/low-code capabilities of SageMaker. Data engineers can use Amazon SageMaker Data Wrangler to quickly aggregate and prepare data for model building without writing code. Then business analysts can use the visual point-and-click interface of Amazon SageMaker Canvas to generate accurate ML predictions on their own.
In this post, we show how simple it is for data engineers and business analysts to collaborate to build an ML workflow involving data preparation, model building, and inference without writing code.
Solution overview
Although ML development is a complex and iterative process, you can generalize an ML workflow into the data preparation, model development, and model deployment stages.

Data Wrangler and Canvas abstract the complexities of data preparation and model development, so you can focus on delivering value to your business by drawing insights from your data without being an expert in code development. The following architecture diagram highlights the components in a no-code/low-code solution.
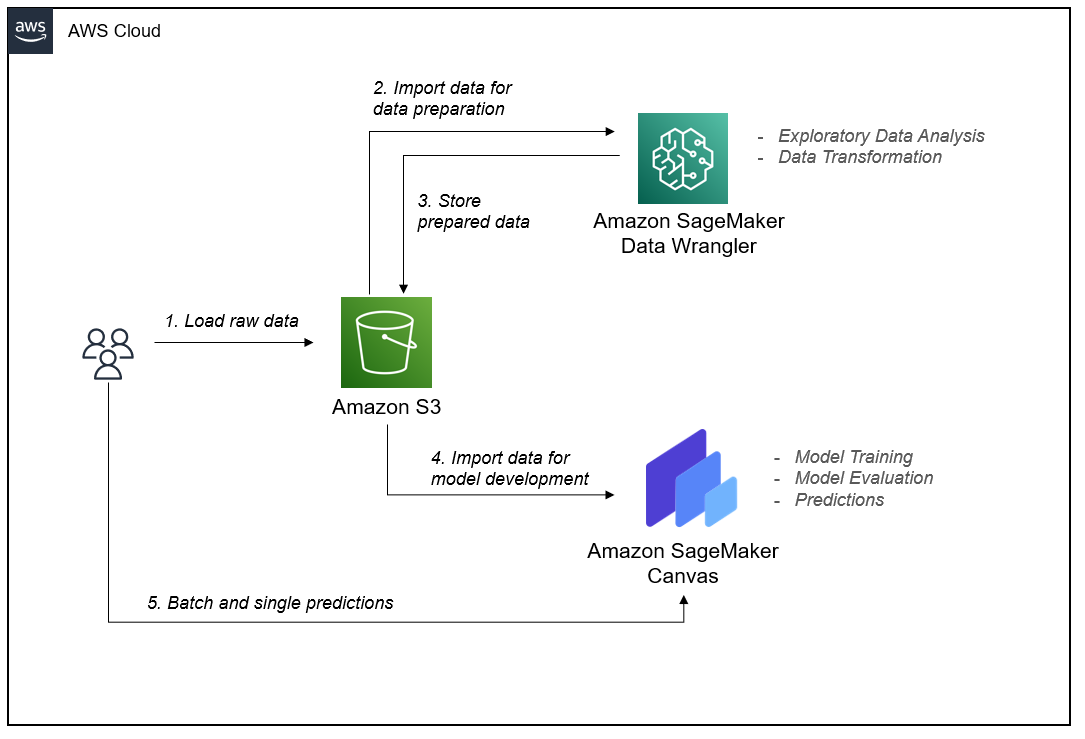
Amazon Simple Storage Service (Amazon S3) acts as our data repository for raw data, engineered data, and model artifacts. You can also choose to import data from Amazon Redshift, Amazon Athena, Databricks, and Snowflake.
As data scientists, we then use Data Wrangler for exploratory data analysis and feature engineering. Although Canvas can run feature engineering tasks, feature engineering usually requires some statistical and domain knowledge to enrich a dataset into the right form for model development. Therefore, we give this responsibility to data engineers so they can transform data without writing code with Data Wrangler.
After data preparation, we pass model building responsibilities to data analysts, who can use Canvas to train a model without having to write any code.
Finally, we make single and batch predictions directly within Canvas from the resulting model without having to deploy model endpoints ourselves.
Dataset overview
We use SageMaker features to predict the status of a loan using a modified version of Lending Club’s publicly available loan analysis dataset. The dataset contains loan data for loans issued through 2007–2011. The columns describing the loan and the borrower are our features. The column loan_status is the target variable, which is what we’re trying to predict.
To demonstrate in Data Wrangler, we split the dataset in two CSV files: part one and part two. We’ve removed some columns from Lending Club’s original dataset to simplify the demo. Our dataset contains over 37,000 rows and 21 feature columns, as described in the following table.
| Column name | Description |
loan_status |
Current status of the loan (target variable). |
loan_amount |
The listed amount of the loan applied for by the borrower. If the credit department reduces the loan amount, it’s reflected in this value. |
funded_amount_by_investors |
The total amount committed by investors for that loan at that time. |
term |
The number of payments on the loan. Values are in months and can be either 36 or 60. |
interest_rate |
Interest rate on the loan. |
installment |
The monthly payment owed by the borrower if the loan originates. |
grade |
LC assigned loan grade. |
sub_grade |
LC assigned loan subgrade. |
employment_length |
Employment length in years. Possible values are between 0–10, where 0 means less than one year and 10 means ten or more years. |
home_ownership |
The home ownership status provided by the borrower during registration. Our values are RENT, OWN, MORTGAGE, and OTHER. |
annual_income |
The self-reported annual income provided by the borrower during registration. |
verification_status |
Indicates if income was verified or not by the LC. |
issued_amount |
The month at which the loan was funded. |
purpose |
A category provided by the borrower for the loan request. |
dti |
A ratio calculated using the borrower’s total monthly debt payments on the total debt obligations, excluding mortgage and the requested LC loan, divided by the borrower’s self-reported monthly income. |
earliest_credit_line |
The month the borrower’s earliest reported credit line was opened. |
inquiries_last_6_months |
The number of inquiries in the past 6 months (excluding auto and mortgage inquiries). |
open_credit_lines |
The number of open credit lines in the borrower’s credit file. |
derogatory_public_records |
The number of derogatory public records. |
revolving_line_utilization_rate |
Revolving line utilization rate, or the amount of credit the borrower is using relative to all available revolving credit. |
total_credit_lines |
The total number of credit lines currently in the borrower’s credit file. |
We use this dataset for our data preparation and model training.
Prerequisites
Complete the following prerequisite steps:
- Upload both loan files to an S3 bucket of your choice.
- Make sure you have the necessary permissions. For more information, refer to Get Started with Data Wrangler.
- Set up a SageMaker domain configured to use Data Wrangler. For instructions, refer to Onboard to Amazon SageMaker Domain.
Import the data
Create a new Data Wrangler data flow from the Amazon SageMaker Studio UI.
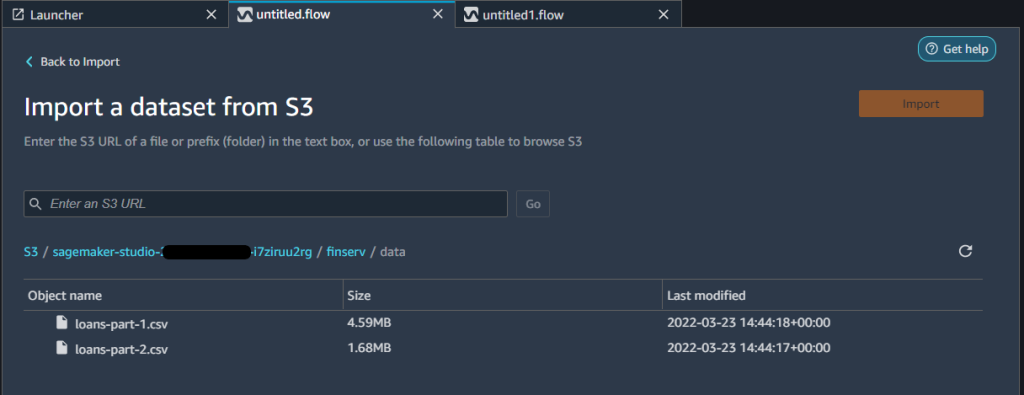
Import data from Amazon S3 by selecting the CSV files from the S3 bucket where you placed your dataset. After you import both files, you can see two separate workflows in the Data flow view.
You can choose several sampling options when importing your data in a Data Wrangler flow. Sampling can help when you have a dataset that is too large to prepare interactively, or when you want to preserve the proportion of rare events in your sampled dataset. Because our dataset is small, we don’t use sampling.
Prepare the data
For our use case, we have two datasets with a common column: id. As a first step in data preparation, we want to combine these files by joining them. For instructions, refer to Transform Data.
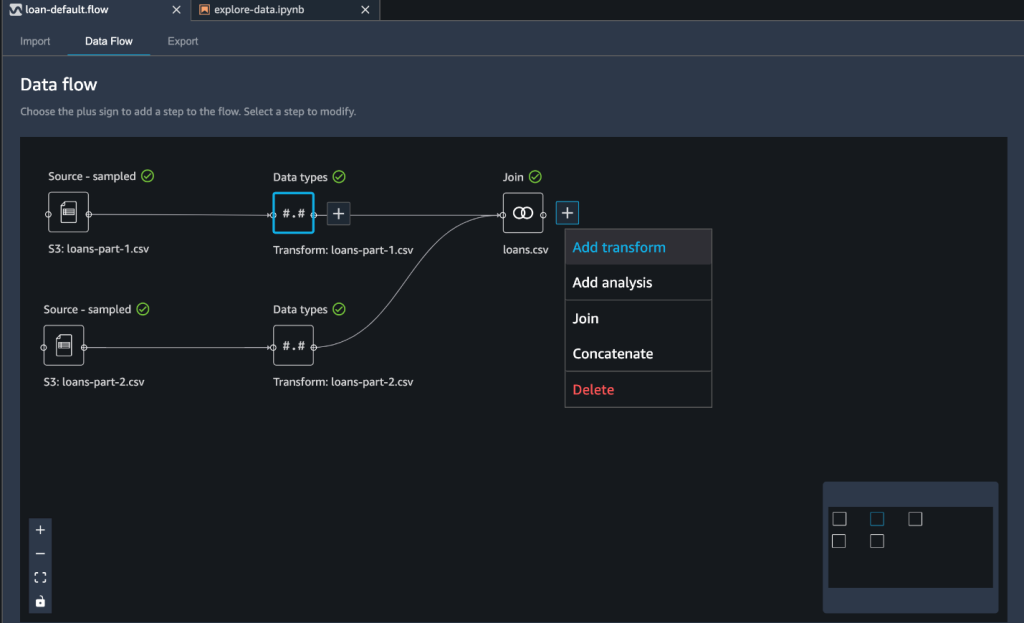
We use the Join data transformation step and use the Inner join type on the id column.
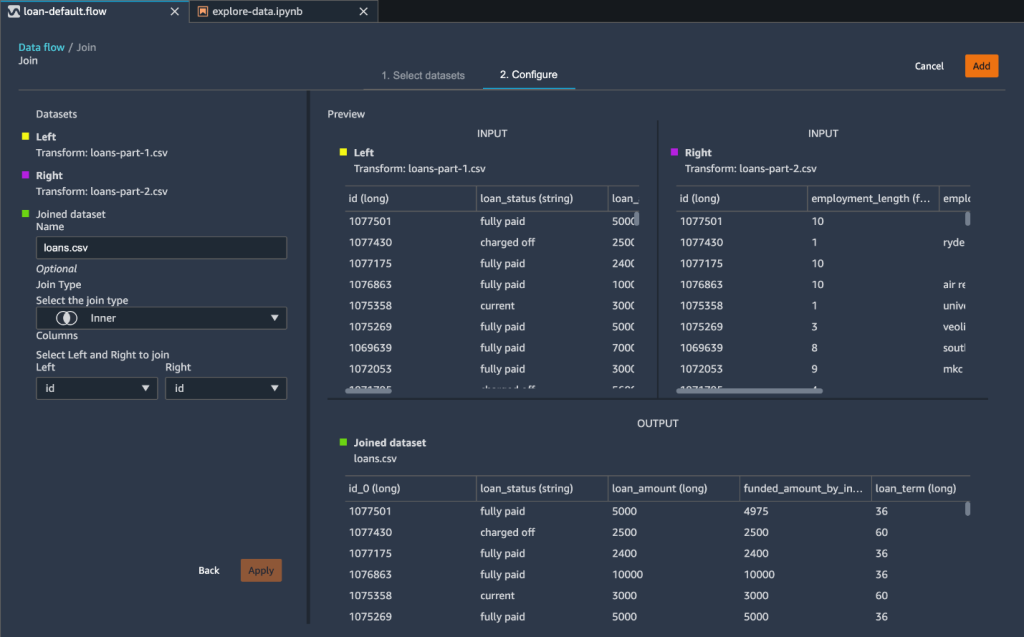
As a result of our join transformation, Data Wrangler creates two additional columns: id_0 and id_1. However, these columns are unnecessary for our model building purposes. We drop these redundant columns using the Manage columns transform step.


We’ve imported our datasets, joined them, and removed unnecessary columns. We’re now ready to enrich our data through feature engineering and prepare for model building.
Perform feature engineering
We used Data Wrangler for preparing data. You can also use the Data Quality and Insights Report feature within Data Wrangler to verify your data quality and detect abnormalities in your data. Data scientists often need to use these data insights to efficiently apply the right domain knowledge to engineering features. For this post, we assume we’ve completed these quality assessments and can move on to feature engineering.
In this step, we apply a few transformations to numeric, categorical, and text columns.
We first normalize the interest rate to scale the values between 0–1. We do this using the Process numeric transform to scale the interest_rate column using a min-max scaler. The purpose for normalization (or standardization) is to eliminate bias from our model. Variables that are measured at different scales won’t contribute equally to the model learning process. Therefore, a transformation function like a min-max scaler transform helps normalize features.
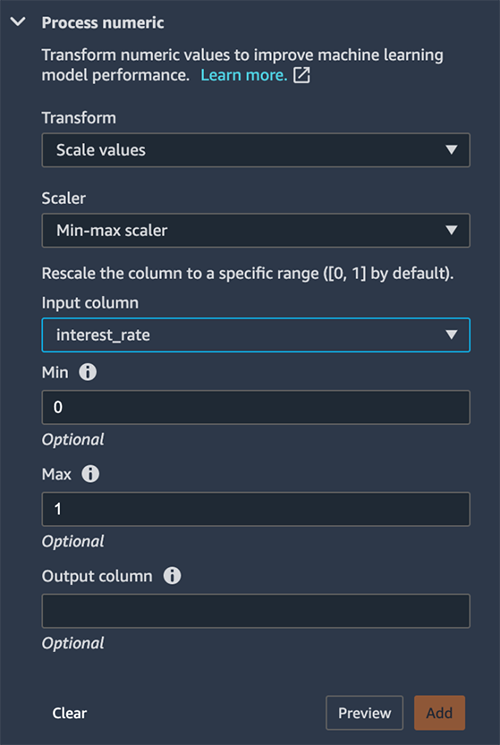
To convert a categorial variable into a numeric value, we use one-hot encoding. We choose the Encode categorical transform, then choose One-hot encode. One-hot encoding improves an ML model’s predictive ability. This process converts a categorical value into a new feature by assigning a binary value of 1 or 0 to the feature. As a simple example, if you had one column that held either a value of yes or no, one-hot encoding would convert that column to two columns: a Yes column and a No column. A yes value would have 1 in the Yes column and a 0 in the No column. One-hot encoding makes our data more useful because numeric values can more easily determine a probability for our predictions.
Finally, we featurize the employer_title column to transform its string values into a numerical vector. We apply the Count Vectorizer and a standard tokenizer within the Vectorize transform. Tokenization breaks down a sentence or series of text into words, whereas a vectorizer converts text data into a machine-readable form. These words are represented as vectors.
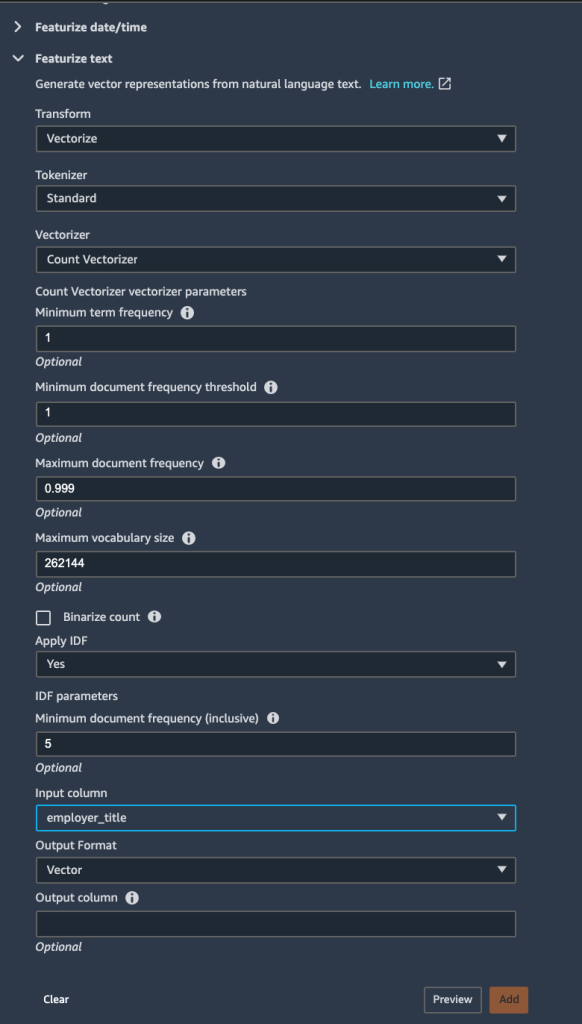
With all feature engineering steps complete, we can export the data and output the results into our S3 bucket. Alternatively, you can export your flow as Python code, or a Jupyter notebook to create a pipeline with your view using Amazon SageMaker Pipelines. Consider this when you want to run your feature engineering steps at scale or as part of an ML pipeline.

We can now use the Data Wrangler output file as our input for Canvas. We reference this as a dataset in Canvas to build our ML model.
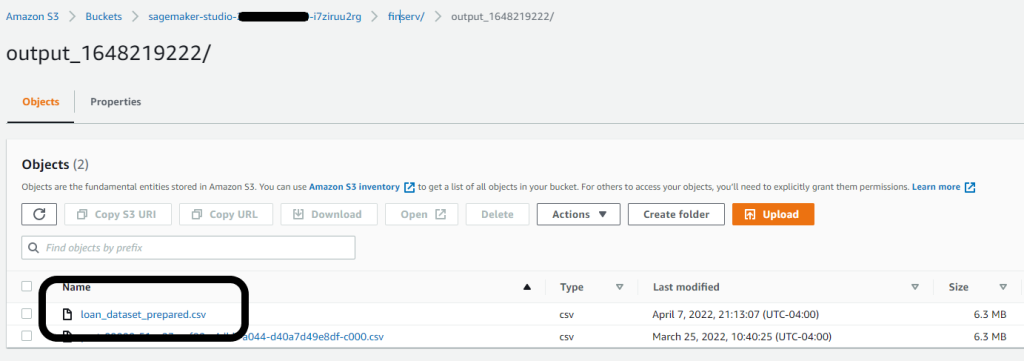
In our case, we exported our prepared dataset to the default Studio bucket with an output prefix. We reference this dataset location when loading the data into Canvas for model building next.
Build and train your ML model with Canvas
On the SageMaker console, launch the Canvas application. To build an ML model from the prepared data in the previous section, we perform the following steps:
- Import the prepared dataset to Canvas from the S3 bucket.
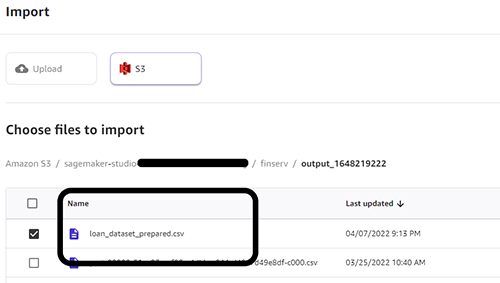
We reference the same S3 path where we exported the Data Wrangler results from the previous section.
- Create new model in Canvas and name it
loan_prediction_model. - Select the imported dataset and add it to the model object.

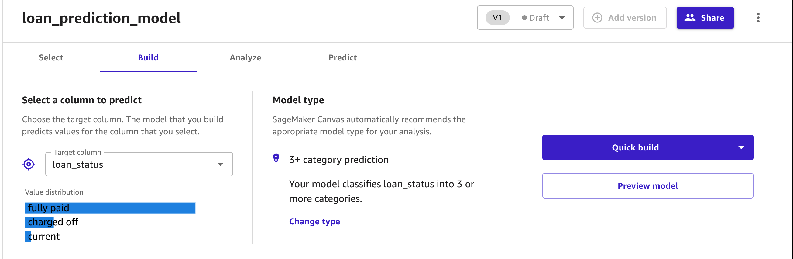
To have Canvas build a model, we must select the target column.
- Because our goal is to predict the probability of a lender’s ability to repay a loan, we choose the
loan_statuscolumn.
Canvas automatically identifies the type of ML problem statement. At the time of writing, Canvas supports regression, classification, and time series forecasting problems. You can specify the type of problem or have Canvas automatically infer the problem from your data.
- Choose your option to start the model building process: Quick build or Standard build.
The Quick build option uses your dataset to train a model within 2–15 minutes. This is useful when you’re experimenting with a new dataset to determine if the dataset you have will be sufficient to make predictions. We use this option for this post.
The Standard build option choses accuracy over speed and uses approximately 250 model candidates to train the model. The process usually takes 1–2 hours.
After the model is built, you can review the results of the model. Canvas estimates that your model is able to predict the right outcome 82.9% of the time. Your own results may vary due to the variability in training models.
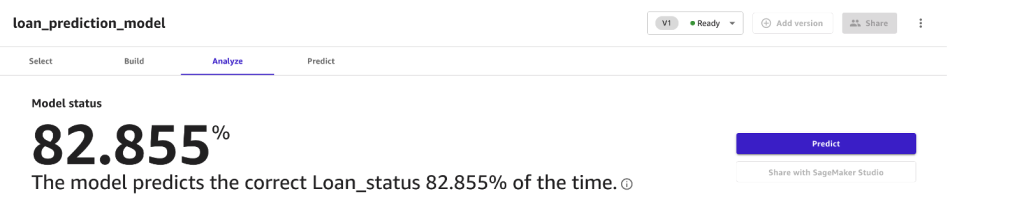
In addition, you can dive deep into details analysis of the model to learn more about the model.
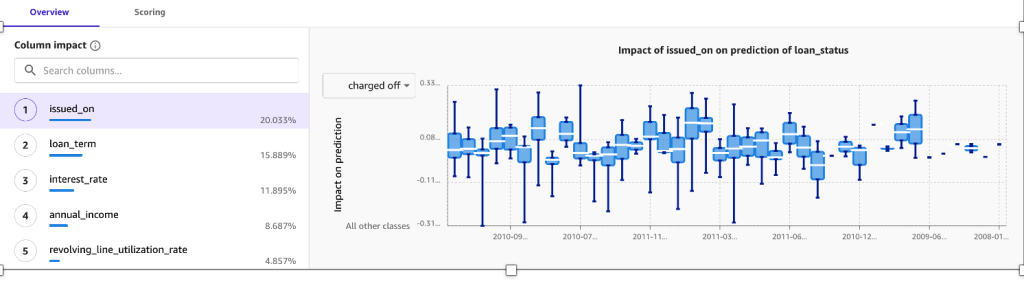
Feature importance represents the estimated importance of each feature in predicting the target column. In this case, the credit line column has the most significant impact in predicting if a customer will pay back the loan amount, followed by interest rate and annual income.
The confusion matrix in the Advanced metrics section contains information for users that want a deeper understanding of their model performance.

Before you can deploy your model for production workloads, use Canvas to test the model. Canvas manages our model endpoint and allows us to make predictions directly in the Canvas user interface.
- Choose Predict and review the findings on either the Batch prediction or Single prediction tab.
In the following example, we make a single prediction by modifying values to predict our target variable loan_status in real time

We can also select a larger dataset and have Canvas generate batch predictions on our behalf.
Conclusion
End-to-end machine learning is complex and iterative, and often involves multiple personas, technologies, and processes. Data Wrangler and Canvas enable collaboration between teams without requiring these teams to write any code.
A data engineer can easily prepare data using Data Wrangler without writing any code and pass the prepared dataset to a business analyst. A business analyst can then easily build accurate ML models with just a few click using Canvas and get accurate predictions in real time or in batch.
Get started with Data Wrangler using these tools without having to manage any infrastructure. You can set up Canvas quickly and immediately start creating ML models to support your business needs.
About the Authors
 Peter Chung is a Solutions Architect for AWS, and is passionate about helping customers uncover insights from their data. He has been building solutions to help organizations make data-driven decisions in both the public and private sectors. He holds all AWS certifications as well as two GCP certifications.
Peter Chung is a Solutions Architect for AWS, and is passionate about helping customers uncover insights from their data. He has been building solutions to help organizations make data-driven decisions in both the public and private sectors. He holds all AWS certifications as well as two GCP certifications.
 Meenakshisundaram Thandavarayan is a Senior AI/ML specialist with AWS. He helps hi-tech strategic accounts on their AI and ML journey. He is very passionate about data-driven AI.
Meenakshisundaram Thandavarayan is a Senior AI/ML specialist with AWS. He helps hi-tech strategic accounts on their AI and ML journey. He is very passionate about data-driven AI.
 Dan Ferguson is a Solutions Architect at AWS, based in New York, USA. As a machine learning services expert, Dan works to support customers on their journey to integrating ML workflows efficiently, effectively, and sustainably.
Dan Ferguson is a Solutions Architect at AWS, based in New York, USA. As a machine learning services expert, Dan works to support customers on their journey to integrating ML workflows efficiently, effectively, and sustainably.
Speeding database queries by rewriting redundancies
Amazon Athena reduces query execution time by 14% by eliminating redundant operations.Read More
Use Amazon Lex to capture street addresses
Amazon Lex provides automatic speech recognition (ASR) and natural language understanding (NLU) technologies to transcribe user input, identify the nature of their request, and efficiently manage conversations. Lex lets you create sophisticated conversations, streamline your user experience to improve customer satisfaction (CSAT) scores, and increase containment in your contact centers.
Natural, effective customer interactions require that the Lex virtual agent accurately interprets the information provided by the customer. One scenario that can be particularly challenging is capturing a street address during a call. For example, consider a customer who has recently moved to a new city and calls in to update their street address for their wireless account. Even a single United States zip code can contain a wide range of street names. Getting the right address over the phone can be difficult, even for human agents.
In this post, we’ll demonstrate how you can use Amazon Lex and the Amazon Location Service to provide an effective user experience for capturing their address via voice or text.
Solution overview
For this example, we’ll use an Amazon Lex bot that provides self-service capabilities as part of an Amazon Connect contact flow. When the user calls in on their phone, they can ask to change their address, and the bot will ask them for their customer number and their new address. In many cases, the new address will be captured correctly in the first try. For more challenging addresses, the bot may ask them to restate their street name, spell their street name, or repeat their zip code or address number to capture the correct address.
Here’s a sample user interaction to model our Lex bot:
IVR: Hi, welcome to ACME bank customer service. How can I help? You can check account balances, order checks, or change your address.
User: I want to change my address.
IVR: Can you please tell me your customer number?
User: 123456.
IVR: Thanks. Please tell me your new zip code.
User: 32312.
IVR: OK, what’s your new street address?
User: 6800 Thomasville Road, Suite 1-oh-1.
IVR: Thank you. To make sure I get it right, can you tell me just the name of your street?
User: Thomasville Road.
IVR: OK, your new address is 6800 Thomasville Road, Suite 101, Tallahassee Florida 32312, USA. Is that right?
User: Yes.
IVR: OK, your address has been updated. Is there anything else I can help with?
User: No thanks.
IVR: Thank you for reaching out. Have a great day!
As an alternative approach, you can capture the whole address in a single turn, rather than asking for the zip code first:
IVR: Hi, welcome to ACME bank customer service. How can I help? You can check account balances, order checks, or change your address.
User: I want to update my address.
IVR: Can you please tell me your customer number?
User: 123456.
IVR: Thanks. Please tell me your new address, including the street, city, state, and zip code.
User: 6800 Thomasville Road, Suite 1-oh-1, Tallahassee Florida, 32312.
IVR: Thank you. To make sure I get it right, can you tell me just the name of your street?
User: Thomasville Road.
IVR: OK, your new address is 6800 Thomasville Road, Suite 101, Tallahassee Florida 32312, US. Is that right?
User: Yes.
IVR: OK, your address has been updated. Is there anything else I can help with?
User: No thanks.
IVR: Thank you for reaching out. Have a great day!
Solution architecture
We’ll use an Amazon Lex bot integrated with Amazon Connect in this solution. When the user calls in and provides their new address, Lex uses automatic speech recognition to transcribe their speech to text. Then, it uses an AWS Lambda fulfillment function to send the transcribed text to Amazon Location Service, which performs address lookup and returns a normalized address.
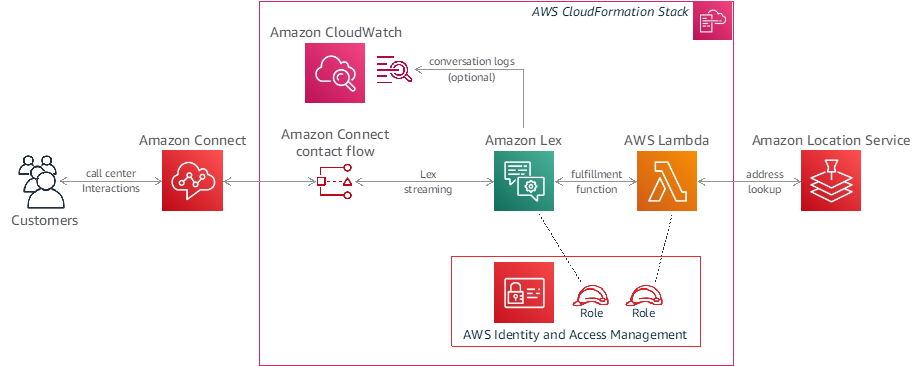
As part of the AWS CloudFormation stack, you can also create an optional Amazon CloudWatch Logs log group for capturing Lex conversation logs, which can be used to create a conversation analytics dashboard to visualize the results (see the post Building a business intelligence dashboard for your Amazon Lex bots for one way to do this).
How it works
This solution combines several techniques to create an effective user experience, including:
- Amazon Lex automatic speech recognition technology to convert speech to text.
- Integration with Amazon Location Service for address lookup and normalization.
- Lex spelling styles, to implement a “say-spell” approach when voice inputs are not clear (for example, ask the user to say their street name, and then if necessary, to spell it).
The first step is to make sure that the required slots have been captured.
In the first code section that follows, we prompt the user for their zip code and street address using the Lex ElicitSlot dialog action. The elicit_slot_with_retries() function prompts the user based on a set of configurable prompts.
The last section of code above uses a helper function parse_address.parse() that converts spoken numbers into digits (for example, it converts “sixty eight hundred” to “6800”).
Then, we send the user’s utterance to Amazon Location Service and inspect the response. We discard any entries that don’t have a street, a street number, or have an incorrect zip code. In cases where we have to re-prompt for a street name or number, we also discard any previously suggested addresses.
Once we have a resolved address, we confirm it with the user.
If we don’t get a resolved address back from the Amazon Location Service, or if the user says the address that we suggested wasn’t right, then we re-prompt for some additional information, and try again. The additional information slots include:
- StreetName: slot type AMAZON.StreetName
- SpelledStreetName: slot type AMAZON.AlphaNumeric (using Amazon Lex spelling styles)
- StreetAddressNumber: slot type AMAZON.Number
The logic to re-prompt is controlled by the next_retry() function, which consults a list of actions to try:
The next_retry() function will try these actions in order. You can modify the sequence of prompts by changing the order in the RETRY_ACTIONS list. You can also configure different prompts for scenarios where Amazon Location Service doesn’t find a match, versus when the user says that the suggested address wasn’t correct. As you can see, we may ask the user to restate their street name, and failing that, to spell it using Amazon Lex spelling styles. We refer to this as a “say-spell” approach, and it’s similar to how a human agent would interact with a customer in this scenario.
To see this in action, you can deploy it in your AWS account.
Prerequisites
You can use the CloudFormation link that follows to deploy the solution in your own AWS account. Before deploying this solution, you should confirm that you have the following prerequisites:
- An available AWS account where you can deploy the solution.
- Access to the following AWS services:
- Amazon Lex
- AWS Lambda, for integration with Amazon Location Service
- Amazon Location Service, for address lookup
- AWS Identity and Access Management (IAM), for creating the necessary policies and roles
- CloudWatch Logs, to create log groups for the Lambda function and optionally for capturing Lex conversation logs
- CloudFormation to create the stack
- An Amazon Connect instance (for instructions on setting one up, see Create an Amazon Connect instance).
The following AWS Regions support Amazon Lex, Amazon Connect, and Amazon Location Service: US East (N. Virginia), US West (Oregon), Europe (Frankfurt), Asia Pacific (Singapore), Asia Pacific (Sydney) Region, and Asia Pacific (Tokyo).
Deploying the sample solution
Sign in to the AWS Management Console in your AWS account, and select the following link to deploy the sample solution:
![]()
This will create a new CloudFormation stack.
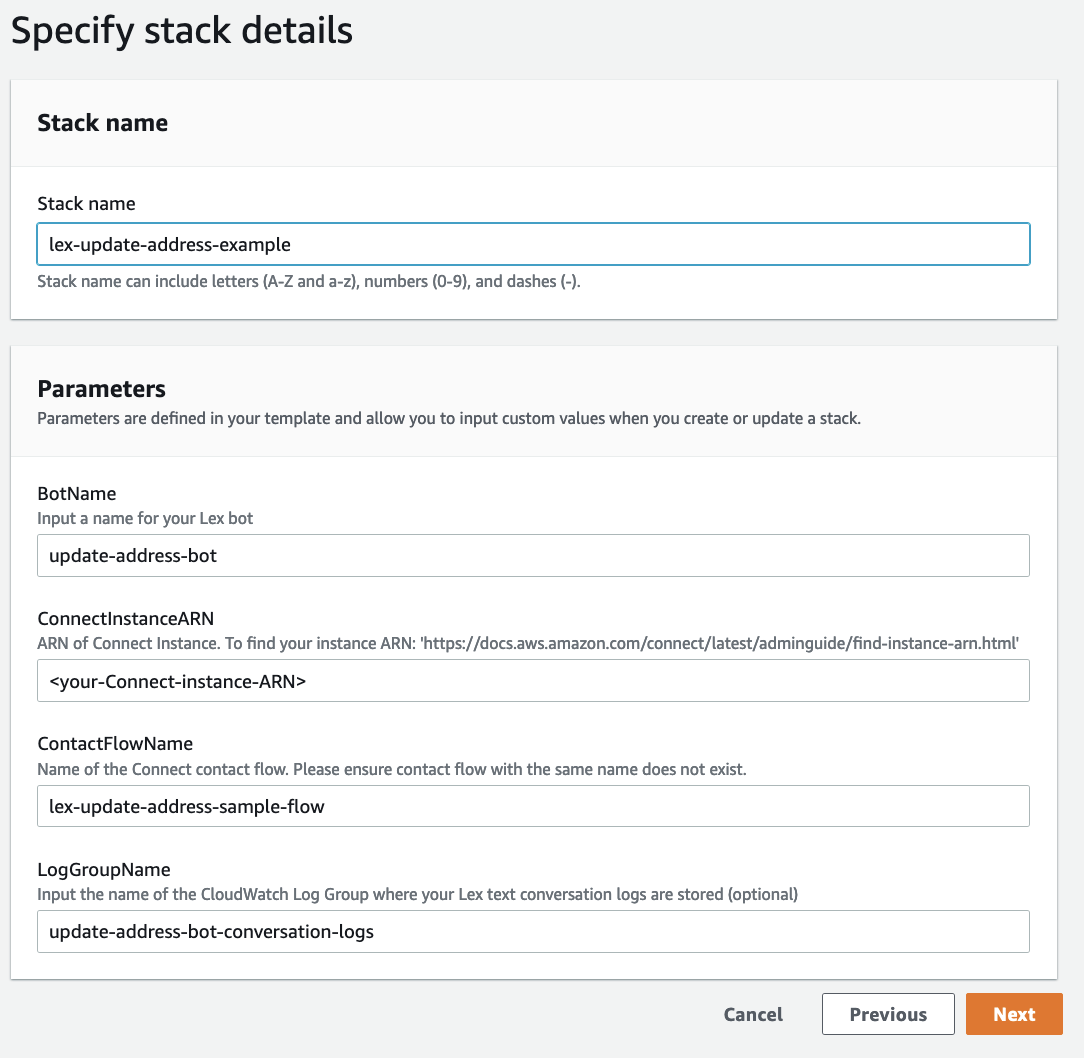
Enter a Stack name, such as lex-update-address-example. Enter the ARN (Amazon Resource Name) for the Amazon Connect instance that you’ll use for testing the solution. You can keep the default values for the other parameters, or change them to suit your needs. Choose Next, and add any tags that you may want for your stack (optional). Choose Next again, review the stack details, select the checkbox to acknowledge that IAM resources will be created, and then choose Create stack.
After a few minutes, your stack will be complete, and include the following resources:
- A Lex bot, including a published version with an alias (
Development-Alias) - A Lambda fulfillment function for the bot (
BotHandler) - A CloudWatch Logs log group for Lex conversation logs
- Required Amazon IAM roles
- A custom resource that adds a sample contact flow to your Connect instance
At this point, you can try the example interaction above in the Lex V2 console. You should see the sample bot with the name that you specified in the CloudFormation template (e.g., update-address-bot).
Choose this bot, choose Bot versions in the left-side navigation panel, choose the Version 1 version, and then choose Intents in the left-side panel. You’ll see the list of intents, as well as a Test button.
To test, select the Test button, select Development-Alias, and then select Confirm to open the test window.
Try “I want to change my address” to get started. This will use the UpdateAddressZipFirst intent to capture an address, starting by asking for the zip code, and then asking for the street address.
You can also say “I want to update my address” to try the UpdateAddress intent, which captures an address all at once with a single utterance.
Testing with Amazon Connect
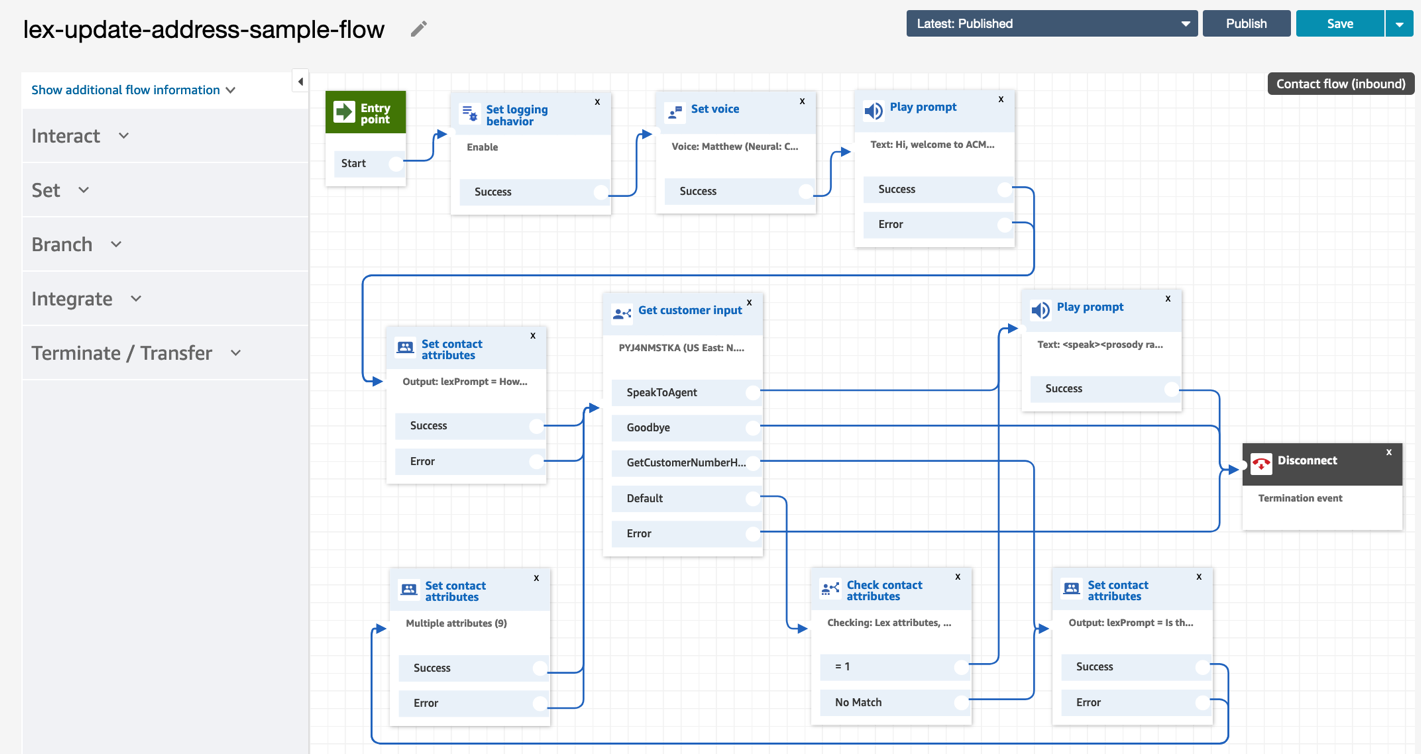
Now let’s try this with voice using a Connect instance. A sample contact flow was already configured in your Connect instance:
All you need to do is set up a phone number, and associate it with this contact flow. To do this, follow these steps:
- Launch Amazon Connect in the AWS Console.
- Open your Connect instance by selecting the Access URL, and logging in to the instance.
- In Dashboard, select View phone numbers.
- Select Claim a number, choose a country from the Country drop-down, and choose a number.

- Enter a Description, such as “Example flow to update an address with Amazon Lex”, and select the contact flow that you just created.

- Choose Save.
Now you’re ready to call in to your Connect instance to test your bot using voice. Just dial the number on your phone, and try some US addresses. To try the zip code first approach, say “change my address”. To try the change address in one turn approach, say “update my address”. You can also just say, “my new address is”, followed by a valid US address.
But wait… there’s more
Another challenging use case for voice scenarios is capturing a user’s email address. This is often needed for user verification purposes, or simply to let the user change their email address on file. Lex has built-in support for email addresses using the AMAZON.EmailAddress built-in slot type, which also supports Lex spelling styles.
Using a “say-spell” approach for capturing email addresses can be very effective, and since the approach is similar to the user experience in the street address capture scenarios that we described above, we’ve included it here. Give it a try!
Clean up
You may want to clean up the resources created as part of the CloudFormation template when you’re done using the bot to avoid incurring ongoing charges. To do this, delete the CloudFormation Stack.
Conclusion
Amazon Lex offers powerful automated speech recognition and natural language understanding capabilities that can be used to capture the information needed from your users to provide automated, self-service functionality. Capturing a customer’s address via speech recognition can be challenging due to the range of names for streets, cities, and towns. However, you can easily integrate Amazon Lex with the Amazon Location Service to look up the correct address, based on the customer’s input. You can incorporate this technique in your own Lex conversation flows.
About the Author
 Brian Yost is a Senior Technical Program manager on the AWS Lex team. In his spare time, he enjoys mountain biking, home brewing, and tinkering with technology.
Brian Yost is a Senior Technical Program manager on the AWS Lex team. In his spare time, he enjoys mountain biking, home brewing, and tinkering with technology.
Amazon Redshift: Ten years of continuous reinvention
Two authors of Amazon Redshift research paper that will be presented at leading international forum for database researchers reflect on how far the first petabyte scale cloud data warehouse has advanced since it was announced ten years ago.Read More
Customize pronunciation using lexicons in Amazon Polly
Amazon Polly is a text-to-speech service that uses advanced deep learning technologies to synthesize natural-sounding human speech. It is used in a variety of use cases, such as contact center systems, delivering conversational user experiences with human-like voices for automated real-time status check, automated account and billing inquiries, and by news agencies like The Washington Post to allow readers to listen to news articles.
As of today, Amazon Polly provides over 60 voices in 30+ language variants. Amazon Polly also uses context to pronounce certain words differently based upon the verb tense and other contextual information. For example, “read” in “I read a book” (present tense) and “I will read a book” (future tense) is pronounced differently.
However, in some situations you may want to customize the way Amazon Polly pronounces a word. For example, you may need to match the pronunciation with local dialect or vernacular. Names of things (e.g., Tomato can be pronounced as tom-ah-to or tom-ay-to), people, streets, or places are often pronounced in many different ways.
In this post, we demonstrate how you can leverage lexicons for creating custom pronunciations. You can apply lexicons for use cases such as publishing, education, or call centers.
Customize pronunciation using SSML tag
Let’s say you stream a popular podcast from Australia and you use the Amazon Polly Australian English (Olivia) voice to convert your script into human-like speech. In one of your scripts, you want to use words that are unknown to Amazon Polly voice. For example, you want to send Mātariki (Māori New Year) greetings to your New Zealand listeners. For such scenarios, Amazon Polly supports phonetic pronunciation, which you can use to achieve a pronunciation that is close to the correct pronunciation in the foreign language.
You can use the <phoneme> Speech Synthesis Markup Language (SSML) tag to suggest a phonetic pronunciation in the ph attribute. Let me show you how you can use <phoneme> SSML tag.
First, login into your AWS console and search for Amazon Polly in the search bar at the top. Select Amazon Polly and then choose Try Polly button.
In the Amazon Polly console, select Australian English from the language dropdown and enter following text in the Input text box and then click on Listen to test the pronunciation.
I’m wishing you all a very Happy Mātariki.
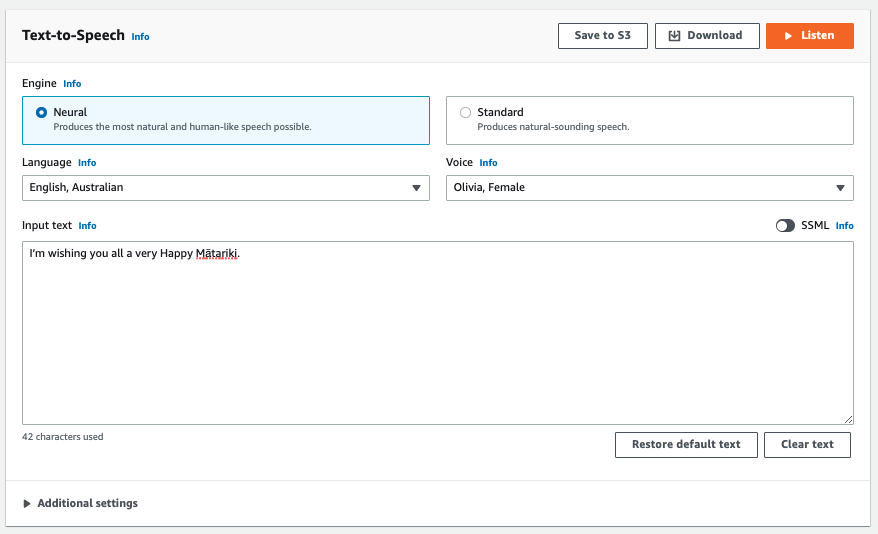
Sample speech without applying phonetic pronunciation:
If you hear the sample speech above, you can notice that the pronunciation of Mātariki – a word which is not part of Australian English – isn’t quite spot-on. Now, let’s look at how in such scenarios we can use phonetic pronunciation using <phoneme> SSML tag to customize the speech produced by Amazon Polly.
To use SSML tags, turn ON the SSML option in Amazon Polly console. Then copy and paste following SSML script containing phonetic pronunciation for Mātariki specified inside the ph attribute of the <phoneme> tag.
With the <phoneme> tag, Amazon Polly uses the pronunciation specified by the ph attribute instead of the standard pronunciation associated by default with the language used by the selected voice.
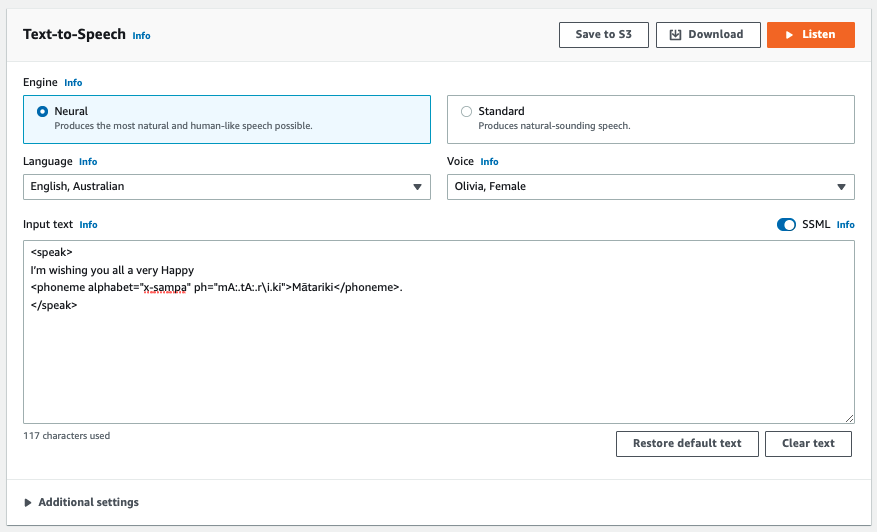
Sample speech after applying phonetic pronunciation:
If you hear the sample sound, you’ll notice that we opted for a different pronunciation for some of vowels (e.g., ā) to make Amazon Polly synthesize the sounds that are closer to the correct pronunciation. Now you might have a question, how do I generate the phonetic transcription “mA:.tA:.ri.ki” for the word Mātariki?
You can create phonetic transcriptions by referring to the Phoneme and Viseme tables for the supported languages. In the example above we have used the phonemes for Australian English.
Amazon Polly offers support in two phonetic alphabets: IPA and X-Sampa. Benefit of X-Sampa is that they are standard ASCII characters, so it is easier to type the phonetic transcription with a normal keyboard. You can use either of IPA or X-Sampa to generate your transcriptions, but make sure to stay consistent with your choice, especially when you use a lexicon file which we’ll cover in the next section.
Each phoneme in the phoneme table represents a speech sound. The bolded letters in the “Example” column of the Phoneme/Viseme table in the Australian English page linked above represent the part of the word the “Phoneme” corresponds to. For example, the phoneme /j/ represents the sound that an Australian English speaker makes when pronouncing the letter “y” in “yes.”
Customize pronunciation using lexicons
Phoneme tags are suitable for one-off situations to customize isolated cases, but these are not scalable. If you process huge volume of text, managed by different editors and reviewers, we recommend using lexicons. Using lexicons, you can achieve consistency in adding custom pronunciations and simultaneously reduce manual effort of inserting phoneme tags into the script.
A good practice is that after you test the custom pronunciation on the Amazon Polly console using the <phoneme> tag, you create a library of customized pronunciations using lexicons. Once lexicons file is uploaded, Amazon Polly will automatically apply phonetic pronunciations specified in the lexicons file and eliminate the need to manually provide a <phoneme> tag.
Create a lexicon file
A lexicon file contains the mapping between words and their phonetic pronunciations. Pronunciation Lexicon Specification (PLS) is a W3C recommendation for specifying interoperable pronunciation information. The following is an example PLS document:
Make sure that you use correct value for the xml:lang field. Use en-AU if you’re uploading the lexicon file to use with the Amazon Polly Australian English voice. For a complete list of supported languages, refer to Languages Supported by Amazon Polly.
To specify a custom pronunciation, you need to add a <lexeme> element which is a container for a lexical entry with one or more <grapheme> element and one or more pronunciation information provided inside <phoneme> element.
The <grapheme> element contains the text describing the orthography of the <lexeme> element. You can use a <grapheme> element to specify the word whose pronunciation you want to customize. You can add multiple <grapheme> elements to specify all word variations, for example with or without macrons. The <grapheme> element is case-sensitive, and during speech synthesis Amazon Polly string matches the words inside your script that you’re converting to speech. If a match is found, it uses the <phoneme> element, which describes how the <lexeme> is pronounced to generate phonetic transcription.
You can also use <alias> for commonly used abbreviations. In the preceding example of a lexicon file, NZ is used as an alias for New Zealand. This means that whenever Amazon Polly comes across “NZ” (with matching case) in the body of the text, it’ll read those two letters as “New Zealand”.
For more information on lexicon file format, see Pronunciation Lexicon Specification (PLS) Version 1.0 on the W3C website.
You can save a lexicon file with as a .pls or .xml file before uploading it to Amazon Polly.
Upload and apply the lexicon file
Upload your lexicon file to Amazon Polly using the following instructions:
- On the Amazon Polly console, choose Lexicons in the navigation pane.
- Choose Upload lexicon.
- Enter a name for the lexicon and then choose a lexicon file.
- Choose the file to upload.
- Choose Upload lexicon.
If a lexicon by the same name (whether a .pls or .xml file) already exists, uploading the lexicon overwrites the existing lexicon.
Now you can apply the lexicon to customize pronunciation.
- Choose Text-to-Speech in the navigation pane.
- Expand Additional settings.
- Turn on Customize pronunciation.
- Choose the lexicon on the drop-down menu.
You can also choose Upload lexicon to upload a new lexicon file (or a new version).
It’s a good practice to version control the lexicon file in a source code repository. Keeping the custom pronunciations in a lexicon file ensures that you can consistently refer to phonetic pronunciations for certain words across the organization. Also, keep in mind the pronunciation lexicon limits mentioned on Quotas in Amazon Polly page.
Test the pronunciation after applying the lexicon
Let’s perform quick test using “Wishing all my listeners in NZ, a very Happy Mātariki” as the input text.
We can compare the audio files before and after applying the lexicon.
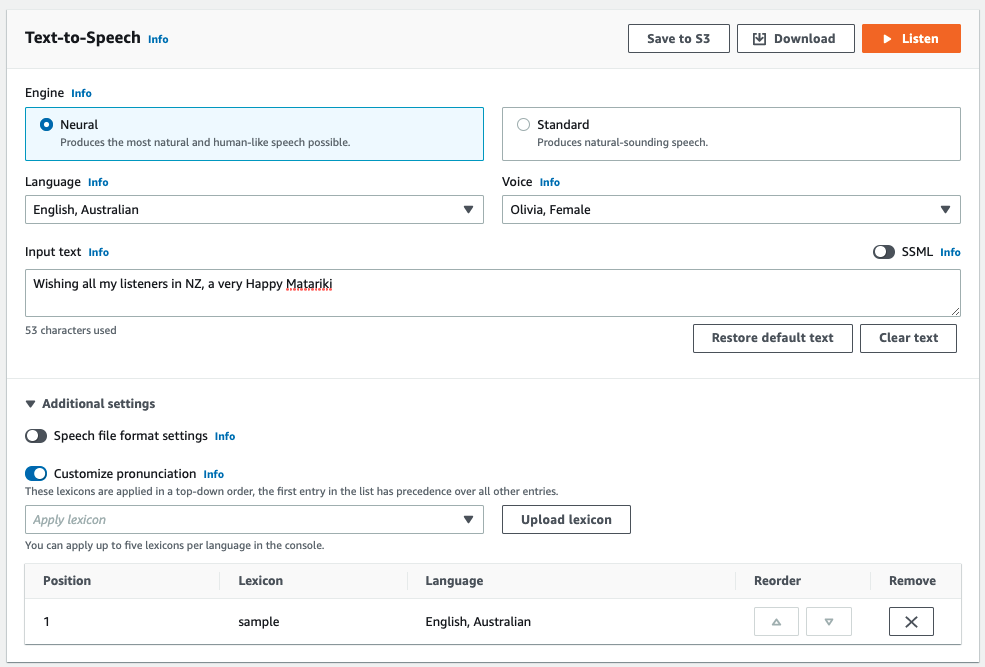
Before applying the lexicon:
After applying the lexicon:
Conclusion
In this post, we discussed how you can customize pronunciations of commonly used acronyms or words not found in the selected language in Amazon Polly. You can use <phoneme> SSML tag which is great for inserting one-off customizations or testing purposes. We recommend using Lexicon to create a consistent set of pronunciations for frequently used words across your organization. This enables your content writers to spend time on writing instead of the tedious task of adding phonetic pronunciations in the script repetitively. You can try this in your AWS account on the Amazon Polly console.
Summary of resources
About the Authors
 Ratan Kumar is a Solutions Architect based out of Auckland, New Zealand. He works with large enterprise customers helping them design and build secure, cost-effective, and reliable internet scale applications using the AWS cloud. He is passionate about technology and likes sharing knowledge through blog posts and twitch sessions.
Ratan Kumar is a Solutions Architect based out of Auckland, New Zealand. He works with large enterprise customers helping them design and build secure, cost-effective, and reliable internet scale applications using the AWS cloud. He is passionate about technology and likes sharing knowledge through blog posts and twitch sessions.
 Maciek Tegi is a Principal Audio Designer and a Product Manager for Polly Brand Voices. He has worked in professional capacity in the tech industry, movies, commercials and game localization. In 2013, he was the first audio engineer hired to the Alexa Text-To- Speech team. Maciek was involved in releasing 12 Alexa TTS voices across different countries, over 20 Polly voices, and 4 Alexa celebrity voices. Maciek is a triathlete, and an avid acoustic guitar player.
Maciek Tegi is a Principal Audio Designer and a Product Manager for Polly Brand Voices. He has worked in professional capacity in the tech industry, movies, commercials and game localization. In 2013, he was the first audio engineer hired to the Alexa Text-To- Speech team. Maciek was involved in releasing 12 Alexa TTS voices across different countries, over 20 Polly voices, and 4 Alexa celebrity voices. Maciek is a triathlete, and an avid acoustic guitar player.
Amazon Text-to-Speech group’s research at ICASSP 2022
Papers focus on speech conversion and data augmentation — and sometimes both at once.Read More
Personalize your machine translation results by using fuzzy matching with Amazon Translate
A person’s vernacular is part of the characteristics that make them unique. There are often countless different ways to express one specific idea. When a firm communicates with their customers, it’s critical that the message is delivered in a way that best represents the information they’re trying to convey. This becomes even more important when it comes to professional language translation. Customers of translation systems and services expect accurate and highly customized outputs. To achieve this, they often reuse previous translation outputs—called translation memory (TM)—and compare them to new input text. In computer-assisted translation, this technique is known as fuzzy matching. The primary function of fuzzy matching is to assist the translator by speeding up the translation process. When an exact match can’t be found in the TM database for the text being translated, translation management systems (TMSs) often have the option to search for a match that is less than exact. Potential matches are provided to the translator as additional input for final translation. Translators who enhance their workflow with machine translation capabilities such as Amazon Translate often expect fuzzy matching data to be used as part of the automated translation solution.
In this post, you learn how to customize output from Amazon Translate according to translation memory fuzzy match quality scores.
Translation Quality Match
The XML Localization Interchange File Format (XLIFF) standard is often used as a data exchange format between TMSs and Amazon Translate. XLIFF files produced by TMSs include source and target text data along with match quality scores based on the available TM. These scores—usually expressed as a percentage—indicate how close the translation memory is to the text being translated.
Some customers with very strict requirements only want machine translation to be used when match quality scores are below a certain threshold. Beyond this threshold, they expect their own translation memory to take precedence. Translators often need to apply these preferences manually either within their TMS or by altering the text data. This flow is illustrated in the following diagram. The machine translation system processes the translation data—text and fuzzy match scores— which is then reviewed and manually edited by translators, based on their desired quality thresholds. Applying thresholds as part of the machine translation step allows you to remove these manual steps, which improves efficiency and optimizes cost.
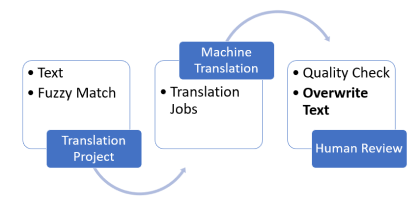
Figure 1: Machine Translation Review Flow
The solution presented in this post allows you to enforce rules based on match quality score thresholds to drive whether a given input text should be machine translated by Amazon Translate or not. When not machine translated, the resulting text is left to the discretion of the translators reviewing the final output.
Solution Architecture
The solution architecture illustrated in Figure 2 leverages the following services:
-
Amazon Simple Storage Service – Amazon S3 buckets contain the following content:
- Fuzzy match threshold configuration files
- Source text to be translated
- Amazon Translate input and output data locations
- AWS Systems Manager – We use Parameter Store parameters to store match quality threshold configuration values
-
AWS Lambda – We use two Lambda functions:
- One function preprocesses the quality match threshold configuration files and persists the data into Parameter Store
- One function automatically creates the asynchronous translation jobs
- Amazon Simple Queue Service – An Amazon SQS queue triggers the translation flow as a result of new files coming into the source bucket
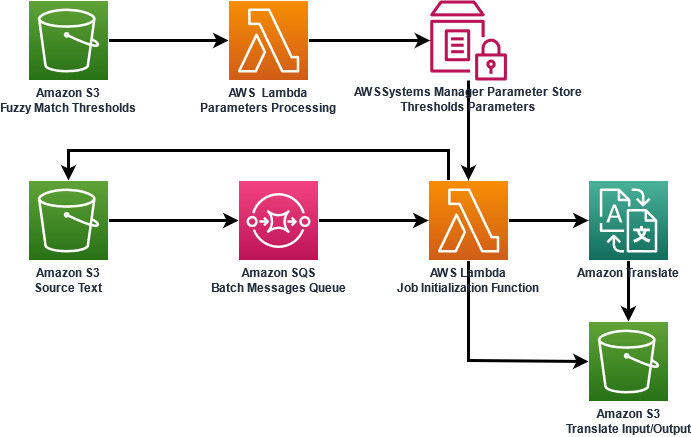
Figure 2: Solution Architecture
You first set up quality thresholds for your translation jobs by editing a configuration file and uploading it into the fuzzy match threshold configuration S3 bucket. The following is a sample configuration in CSV format. We chose CSV for simplicity, although you can use any format. Each line represents a threshold to be applied to either a specific translation job or as a default value to any job.
The specifications of the configuration file are as follows:
- Column 1 should be populated with the name of the XLIFF file—without extension—provided to the Amazon Translate job as input data.
- Column 2 should be populated with the quality match percentage threshold. For any score below this value, machine translation is used.
- For all XLIFF files whose name doesn’t match any name listed in the configuration file, the default threshold is used—the line with the keyword
defaultset in Column 1.
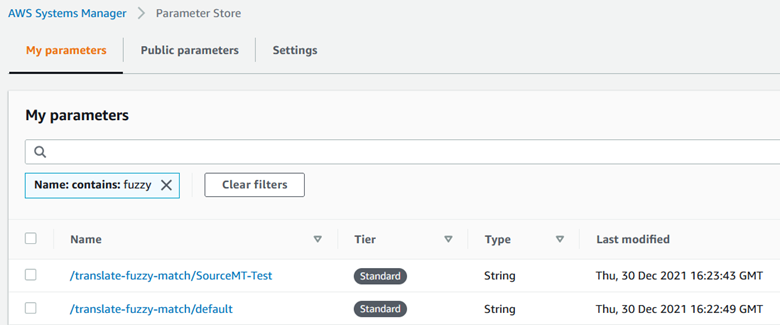
Figure 3: Auto-generated parameter in Systems Manager Parameter Store
When a new file is uploaded, Amazon S3 triggers the Lambda function in charge of processing the parameters. This function reads and stores the threshold parameters into Parameter Store for future usage. Using Parameter Store avoids performing redundant Amazon S3 GET requests each time a new translation job is initiated. The sample configuration file produces the parameter tags shown in the following screenshot.
The job initialization Lambda function uses these parameters to preprocess the data prior to invoking Amazon Translate. We use an English-to-Spanish translation XLIFF input file, as shown in the following code. It contains the initial text to be translated, broken down into what is referred to as segments, represented in the source tags.
The source text has been pre-matched with the translation memory beforehand. The data contains potential translation alternatives—represented as <alt-trans> tags—alongside a match quality attribute, expressed as a percentage. The business rule is as follows:
- Segments received with alternative translations and a match quality below the threshold are untouched or empty. This signals to Amazon Translate that they must be translated.
- Segments received with alternative translations with a match quality above the threshold are pre-populated with the suggested target text. Amazon Translate skips those segments.
Let’s assume the quality match threshold configured for this job is 80%. The first segment with 99% match quality isn’t machine translated, whereas the second segment is, because its match quality is below the defined threshold. In this configuration, Amazon Translate produces the following output:
In the second segment, Amazon Translate overwrites the target text initially suggested (Selección) with a higher quality translation: Visita de selección.
One possible extension to this use case could be to reuse the translated output and create our own translation memory. Amazon Translate supports customization of machine translation using translation memory thanks to the parallel data feature. Text segments previously machine translated due to their initial low-quality score could then be reused in new translation projects.
In the following sections, we walk you through the process of deploying and testing this solution. You use AWS CloudFormation scripts and data samples to launch an asynchronous translation job personalized with a configurable quality match threshold.
Prerequisites
For this walkthrough, you must have an AWS account. If you don’t have an account yet, you can create and activate one.
Launch AWS CloudFormation stack
- Choose Launch Stack:

- For Stack name, enter a name.
- For ConfigBucketName, enter the S3 bucket containing the threshold configuration files.
- For ParameterStoreRoot, enter the root path of the parameters created by the parameters processing Lambda function.
- For QueueName, enter the SQS queue that you create to post new file notifications from the source bucket to the job initialization Lambda function. This is the function that reads the configuration file.
- For SourceBucketName, enter the S3 bucket containing the XLIFF files to be translated. If you prefer to use a preexisting bucket, you need to change the value of the CreateSourceBucket parameter to No.
- For WorkingBucketName, enter the S3 bucket Amazon Translate uses for input and output data.
- Choose Next.

Figure 4: CloudFormation stack details
- Optionally on the Stack Options page, add key names and values for the tags you may want to assign to the resources about to be created.
- Choose Next.
- On the Review page, select I acknowledge that this template might cause AWS CloudFormation to create IAM resources.
- Review the other settings, then choose Create stack.
AWS CloudFormation takes several minutes to create the resources on your behalf. You can watch the progress on the Events tab on the AWS CloudFormation console. When the stack has been created, you can see a CREATE_COMPLETE message in the Status column on the Overview tab.
Test the solution
Let’s go through a simple example.
- Download the following sample data.
- Unzip the content.
There should be two files: an .xlf file in XLIFF format, and a threshold configuration file with .cfg as the extension. The following is an excerpt of the XLIFF file.
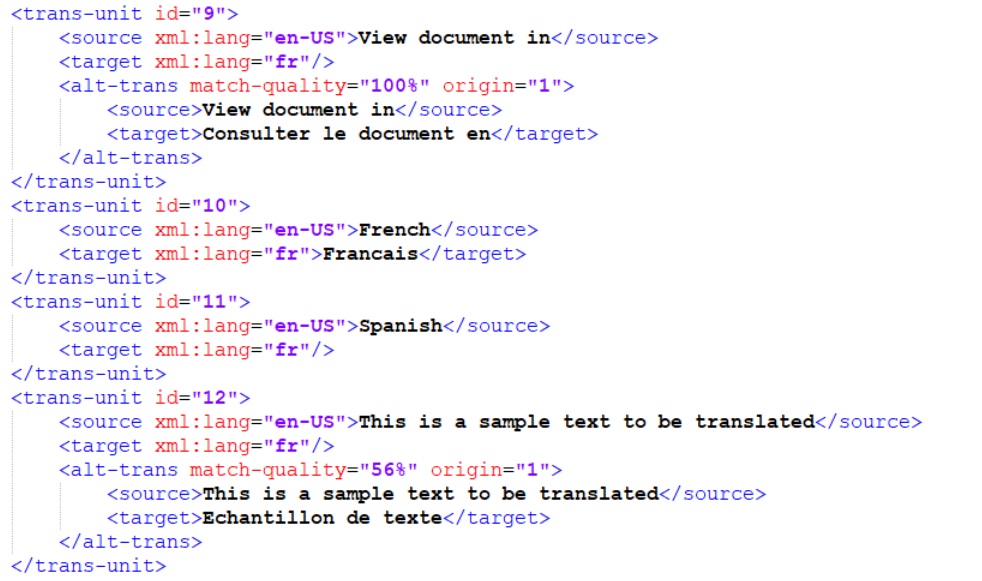
Figure 5: English to French sample file extract
- On the Amazon S3 console, upload the quality threshold configuration file into the configuration bucket you specified earlier.
The value set for test_En_to_Fr is 75%. You should be able to see the parameters on the Systems Manager console in the Parameter Store section.
- Still on the Amazon S3 console, upload the .xlf file into the S3 bucket you configured as source. Make sure the file is under a folder named
translate(for example,<my_bucket>/translate/test_En_to_Fr.xlf).
This starts the translation flow.
- Open the Amazon Translate console.
A new job should appear with a status of In Progress.

Figure 6: In progress translation jobs on Amazon Translate console
- Once the job is complete, click into the job’s link and consult the output. All segments should have been translated.
All segments should have been translated. In the translated XLIFF file, look for segments with additional attributes named lscustom:match-quality, as shown in the following screenshot. These custom attributes identify segments where suggested translation was retained based on score.

Figure 7: Custom attributes identifying segments where suggested translation was retained based on score
These were derived from the translation memory according to the quality threshold. All other segments were machine translated.
You have now deployed and tested an automated asynchronous translation job assistant that enforces configurable translation memory match quality thresholds. Great job!
Cleanup
If you deployed the solution into your account, don’t forget to delete the CloudFormation stack to avoid any unexpected cost. You need to empty the S3 buckets manually beforehand.
Conclusion
In this post, you learned how to customize your Amazon Translate translation jobs based on standard XLIFF fuzzy matching quality metrics. With this solution, you can greatly reduce the manual labor involved in reviewing machine translated text while also optimizing your usage of Amazon Translate. You can also extend the solution with data ingestion automation and workflow orchestration capabilities, as described in Speed Up Translation Jobs with a Fully Automated Translation System Assistant.
About the Authors
 Narcisse Zekpa is a Solutions Architect based in Boston. He helps customers in the Northeast U.S. accelerate their adoption of the AWS Cloud, by providing architectural guidelines, design innovative, and scalable solutions. When Narcisse is not building, he enjoys spending time with his family, traveling, cooking, and playing basketball.
Narcisse Zekpa is a Solutions Architect based in Boston. He helps customers in the Northeast U.S. accelerate their adoption of the AWS Cloud, by providing architectural guidelines, design innovative, and scalable solutions. When Narcisse is not building, he enjoys spending time with his family, traveling, cooking, and playing basketball.
 Dimitri Restaino is a Solutions Architect at AWS, based out of Brooklyn, New York. He works primarily with Healthcare and Financial Services companies in the North East, helping to design innovative and creative solutions to best serve their customers. Coming from a software development background, he is excited by the new possibilities that serverless technology can bring to the world. Outside of work, he loves to hike and explore the NYC food scene.
Dimitri Restaino is a Solutions Architect at AWS, based out of Brooklyn, New York. He works primarily with Healthcare and Financial Services companies in the North East, helping to design innovative and creative solutions to best serve their customers. Coming from a software development background, he is excited by the new possibilities that serverless technology can bring to the world. Outside of work, he loves to hike and explore the NYC food scene.