Professorship named after influential former University of Michigan professor.Read More
Amazon Scholar contributes to best student paper award
Paper proposes a method to better and more equitably place COVID vaccine clinics to encourage more vaccinations.Read More
Control access to Amazon SageMaker Feature Store offline using AWS Lake Formation
You can establish feature stores to provide a central repository for machine learning (ML) features that can be shared with data science teams across your organization for training, batch scoring, and real-time inference. Data science teams can reuse features stored in the central repository, avoiding the need to reengineer feature pipelines for different projects and as a result eliminating rework and duplication.
To satisfy security and compliance needs, you may need granular control over how these shared ML features are accessed. These needs often go beyond table- and column-level access control to individual row-level access control. For example, you may want to let account representatives see rows from a sales table for only their accounts and mask the prefix of sensitive data like credit card numbers. Fine-grained access controls are needed to protect feature store data and grant access based on an individual’s role. This is specifically important for customers and stakeholders in industries that are required to audit access to feature data and ensure the right level of security is in place.
In this post, we provide an overview of how to implement granular access control to feature groups and features stored in an offline feature store using Amazon SageMaker Feature Store and AWS Lake Formation. If you’re new to Feature Store, you may want to refer to Understanding the key capabilities of Amazon SageMaker Feature Store for additional background before diving into the rest of this post. Note that for the online feature store, you can use AWS Identity and Access Management (IAM) policies with conditions to restrict user access against feature groups.
Solution overview
The following architecture uses Lake Formation to implement row-, column-, or cell-level access to limit which feature groups or features within a feature group can be accessed by a data scientist working in Amazon SageMaker Studio. Although we focus on restricting access to users working in Studio, the same approach is applicable for users accessing the offline feature store using services like Amazon Athena.
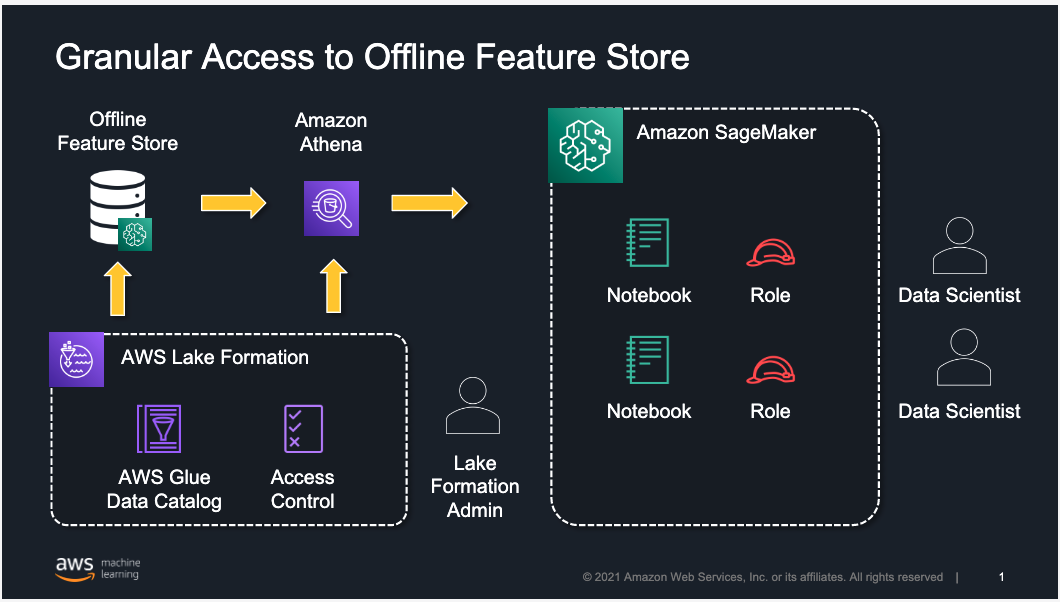
Feature Store is a purpose-built solution for ML feature management that helps data science teams reuse ML features across teams and models, serve features for model predictions at scale with low latency, and train and deploy new models more quickly and effectively.
Lake Formation is a fully managed service that helps you build, secure, and manage data lakes, and provide access control for data in the data lake. Lake Formation supports the following security levels:
- Row-level permissions – Restricts access to specific rows based on data compliance and governance policies
- Column-level permissions – Restricts access to specific columns based on data filters
- Cell-level permissions – Combines both row- and column-level controls by allowing you access to specific rows and columns on the database tables
Lake Formation also provides centralized auditing and compliance reporting by identifying which principals accessed what data, when, and through which services.
By combining Feature Store and Lake Formation, you can implement granular access to ML features on your existing offline feature store.
In this post, we provide an approach for use cases in which you have created feature groups in Feature Store and need to provide access to your data science teams for feature exploration and creating models for their projects. At a high level, a Lake Formation admin defines and creates a permission model in Lake Formation and assigns it to individual Studio users or groups of users.
We walk you through the following steps:
- Register the offline feature store in Lake Formation.
- Create the Lake Formation data filters for fine-grained access control.
- Grant feature groups (tables) and features (columns) permissions.
Prerequisites
To implement this solution, you need to create a Lake Formation admin user in IAM and sign in as that admin user. For instructions, refer to Create a Data Lake Administrator.
We begin with setting up test data using synthetic grocery orders from synthetically generated customer lists using the Faker Python library. You can try it yourself by following the module on GitHub. For each customer, the notebook generates between 1–10 orders, with products purchased in each order. Then you can use the following notebook to create the three feature groups for the customers, products, and orders datasets in the feature store. Before creating the feature groups, make sure that your Studio environment is set up in your AWS account. For instructions, refer to Onboard to Amazon SageMaker Domain.
The goal is to illustrate how to use Feature Store to store the features and use Lake Formation to control access to these features. The following screenshot shows the definition of the orders feature group using the Studio console.
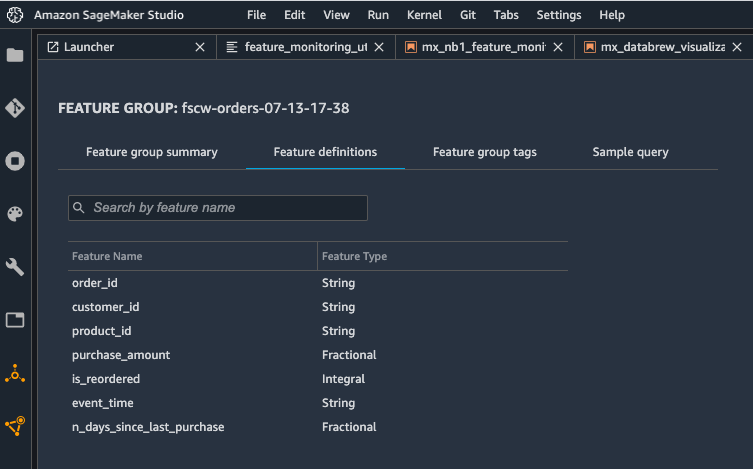
Feature Store uses an Amazon Simple Storage Service (Amazon S3) bucket in your account to store offline data. You can use query engines like Athena against the offline data store in Amazon S3 to extract training datasets or to analyze feature data, and you can join more than one feature group in a single query. Feature Store automatically builds the AWS Glue Data Catalog for feature groups during feature group creation, which allows you to use this catalog to access and query the data from the offline store using Athena or open-source tools like Presto.
Register the offline feature store in Lake Formation
To start using Lake Formation permissions with your existing Feature Store databases and tables, you must revoke the Super permission from the IAMAllowedPrincipals group on the database and the associated feature group tables in Lake Formation.
- Sign in to the AWS Management Console as a Lake Formation administrator.
- In the navigation pane, under Data Catalog, choose Databases.
- Select the database
sagemaker_featurestore, which is the database associated to the offline feature store.
Because Feature Store automatically builds an AWS Glue Data Catalog when you create the feature groups, the offline feature store is visible as a database in Lake Formation.

- On the Actions menu, choose Edit.
- On the Edit database page, if you want Lake Formation permissions to work for newly created feature groups too and not have to revoke the
IAMAllowedPrincipalsfor each table, deselect Use only IAM access control for new tables in this database, then choose Save. - On the Databases page, select the
sagemaker_featurestoredatabase. - On the Actions menu, choose View permissions.

- Select the
IAMAllowedPrincipalsgroup and choose Revoke.

Similarly, you need to perform these steps for all feature group tables that are associated to your offline feature store.
- In the navigation pane, under Data Catalog, choose Tables.
- Select table with your feature group name.
- On the Actions menu, choose View permissions.
- Select the
IAMAllowedPrincipalsgroup and choose Revoke.
To switch the offline feature store to the Lake Formation permission model, you need to turn on Lake Formation permissions for the Amazon S3 location of the offline feature store. For this, you have to register the Amazon S3 location.
- In the navigation pane, under Register and Ingest, choose Data lake locations.
- Choose Register location.
- Select the location of the offline feature store in Amazon S3 for the Amazon S3 path.
The location is the S3Uri that was provided in the feature group’s offline store configuration and can be found in the DescribeFeatureGroup API’s ResolvedOutputS3Uri field.
- Select the default
AWSServiceRoleForLakeFormationDataAccessIAM role and choose Register location.

Lake Formation integrates with AWS Key Management Service (AWS KMS); this approach also works with Amazon S3 locations that have been encrypted with an AWS managed key or with the recommended approach of a customer managed key. For further reading, refer to Registering an encrypted Amazon S3 location.
Create Lake Formation data filters for fine-grained access control
You can implement row-level and cell-level security by creating data filters. You select a data filter when you grant the SELECT Lake Formation permission on tables. In this case, we use this capability to implement a set of filters that limit access to feature groups and specific features within a feature group.
Let’s use the following figure to explain how data filters work. The figure shows two feature groups: customers and orders. A row-level data filter is applied to the customers feature group, resulting in only records where feature1 = ‘12’ is being returned. Similarly, access to the orders feature group is restricted using a cell-level data filter to only feature records where feature2 = ‘22’, as well as excluding feature 1 from the resulting dataset.
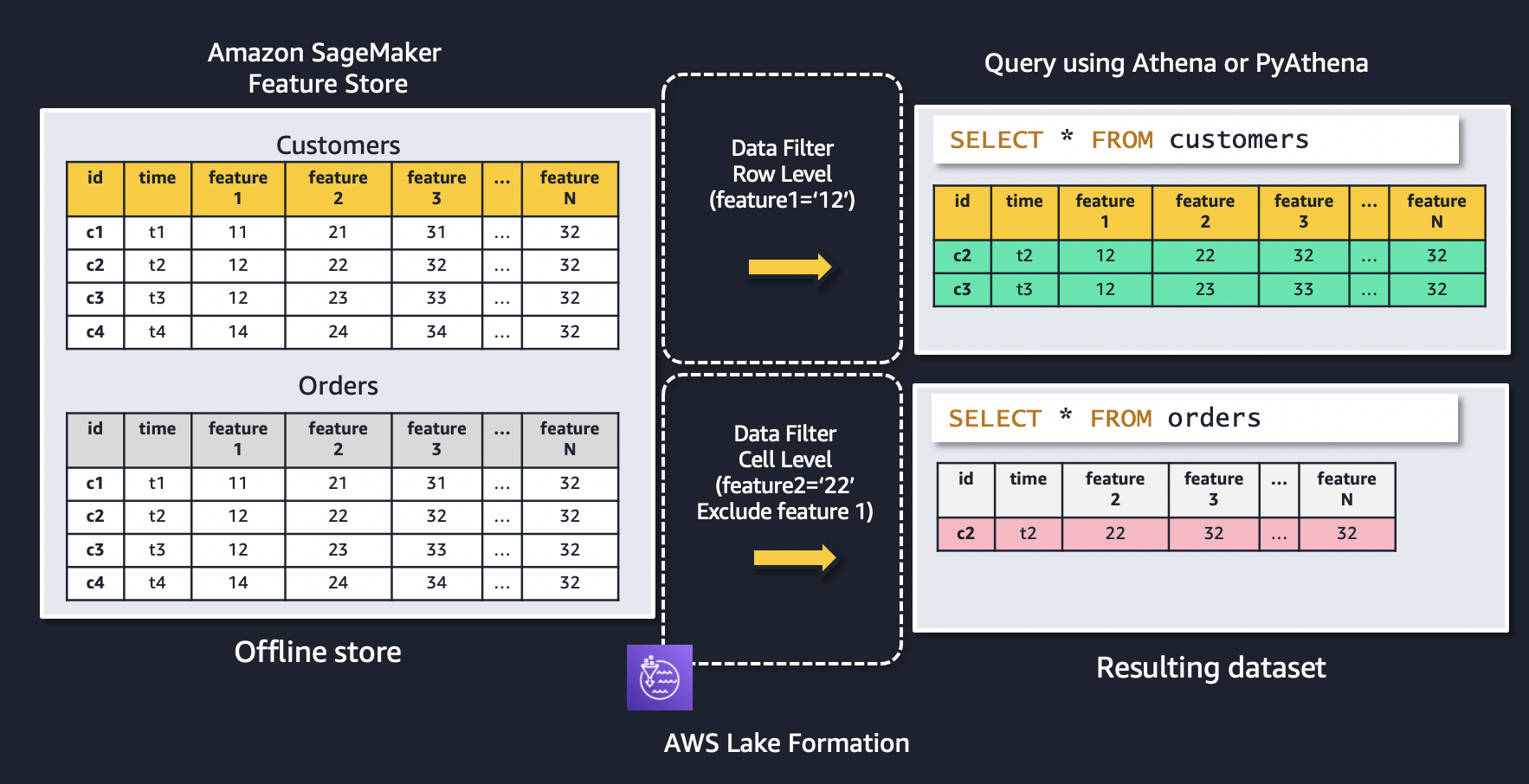
To create a new data filter, in the navigation pane on the Lake Formation console, under Data Catalog, choose Data filters and then choose Create new filter.
When you select Access to all columns and provide a row filter expression, you’re establishing row-level security (row filtering) only. In this example, we create a filter that limits access to a data scientist to only records in the orders feature group based on the value of the feature customer_id ='C7782'.

When you include or exclude specific columns and also provide a row filter expression, you’re establishing cell-level security (cell filtering). In this example, we create a filter that limits access to a data scientist to certain features of a feature group (we exclude sex and is_married) and a subset of the records in the customers feature group based on the value of the feature (customer_id ='C3126').

The following screenshot shows the data filters created.

Grant feature groups (tables) and features (columns) permission
In this section, you grant granular access control and permissions defined in Lake Formation to a SageMaker user by assigning the data filter to the SageMaker execution role associated to the user who originally created the feature groups. The SageMaker execution role is created as part of the SageMaker Studio domain setup and by default starts with AmazonSageMaker-ExecutionRole-*. You need to give this role permissions on Lake Formation APIs (GetDataAccess, StartQueryPlanning, GetQueryState, GetWorkUnits, and GetWorkUnitResults) and AWS Glue APIs (GetTables and GetDatabases) in IAM in order for it to be able to access the data.
Create the following policy in IAM, name the policy LakeFormationDataAccess, and attach it to the SageMaker execution role. You also need to attach the AmazonAthenaFullAccess policy to access Athena.
Next, you need to grant access to the Feature Store database and specific feature group table to the SageMaker execution role and assign it one of the data filters created previously. To grant data permissions inside Lake Formation, in the navigation pane, under Permissions, choose Data Lake Permissions, then choose Grant. The following screenshot demonstrates how to grant permissions with a data filter for row-level access to a SageMaker execution role.

Similarly, you can grant permissions with the data filter created for cell-level access to the SageMaker execution role.
Test Feature Store access
In this section, you validate the access controls set up in Lake Formation using a Studio notebook. This implementation uses the Feature Store Python SDK and Athena to query data from the offline feature store that has been registered in Lake Formation.
First, you test row-level access by creating an Athena query for your feature group orders with the following code. The table_name is the AWS Glue table that is automatically generated by Feature Store.
You query all records from the orders using the following query string:
Only records with customer_id = ‘C7782’ are returned as per the data filters created in Lake Formation.

Secondly, you test cell-level access by creating an Athena query for your feature group customers with the following code. The table_name is the AWS Glue table that is automatically generated by Feature Store.
You query all records from the orders using the following query string:
Only records with customer_id ='C3126' are returned as per the data filters created in Lake Formation. In addition, the features sex and is_married aren’t visible.

With this approach, you can implement granular permission access control to an offline feature store. With the Lake Formation permission model, you can limit access to certain feature groups or specific features within a feature group for individuals based on their role in the organization.
To explore the complete code example, and to try it out in your own account, see the GitHub repo.
Conclusion
SageMaker Feature Store provides a purpose-built feature management solution to help organizations scale ML development across business units and data science teams. In this post, we explained how you can use Lake Formation to implement fine-grained access control for your offline feature store. Give it a try, and let us know what you think in comments.
About the Authors
 Arnaud Lauer is a Senior Partner Solutions Architect in the Public Sector team at AWS. He enables partners and customers to understand how best to use AWS technologies to translate business needs into solutions. He brings more than 16 years of experience in delivering and architecting digital transformation projects across a range of industries, including the public sector, energy, and consumer goods. Artificial intelligence and machine learning are some of his passions. Arnaud holds 12 AWS certifications, including the ML Specialty Certification.
Arnaud Lauer is a Senior Partner Solutions Architect in the Public Sector team at AWS. He enables partners and customers to understand how best to use AWS technologies to translate business needs into solutions. He brings more than 16 years of experience in delivering and architecting digital transformation projects across a range of industries, including the public sector, energy, and consumer goods. Artificial intelligence and machine learning are some of his passions. Arnaud holds 12 AWS certifications, including the ML Specialty Certification.
 Ioan Catana is an Artificial Intelligence and Machine Learning Specialist Solutions Architect at AWS. He helps customers develop and scale their ML solutions in the AWS Cloud. Ioan has over 20 years of experience, mostly in software architecture design and cloud engineering.
Ioan Catana is an Artificial Intelligence and Machine Learning Specialist Solutions Architect at AWS. He helps customers develop and scale their ML solutions in the AWS Cloud. Ioan has over 20 years of experience, mostly in software architecture design and cloud engineering.
 Swagat Kulkarni is a Senior Solutions Architect at AWS and an AI/ML enthusiast. He is passionate about solving real-world problems for customers with cloud-native services and machine learning. Swagat has over 15 years of experience delivering several digital transformation initiatives for customers across multiple domains including retail, travel and hospitality and healthcare. Outside of work, Swagat enjoys travel, reading, and meditating.
Swagat Kulkarni is a Senior Solutions Architect at AWS and an AI/ML enthusiast. He is passionate about solving real-world problems for customers with cloud-native services and machine learning. Swagat has over 15 years of experience delivering several digital transformation initiatives for customers across multiple domains including retail, travel and hospitality and healthcare. Outside of work, Swagat enjoys travel, reading, and meditating.
 Charu Sareen is a Sr. Product Manager for Amazon SageMaker Feature Store. Prior to AWS, she was leading growth and monetization strategy for SaaS services at VMware. She is a data and machine learning enthusiast and has over a decade of experience spanning product management, data engineering, and advanced analytics. She has a bachelor’s degree in Information Technology from National Institute of Technology, India and an MBA from University of Michigan, Ross School of Business.
Charu Sareen is a Sr. Product Manager for Amazon SageMaker Feature Store. Prior to AWS, she was leading growth and monetization strategy for SaaS services at VMware. She is a data and machine learning enthusiast and has over a decade of experience spanning product management, data engineering, and advanced analytics. She has a bachelor’s degree in Information Technology from National Institute of Technology, India and an MBA from University of Michigan, Ross School of Business.
Manage dialog to elicit Amazon Lex slots in Amazon Connect contact flows
Amazon Lex can add powerful automation to contact center solutions, so you can enable self-service via interactive voice response (IVR) interactions or route calls to the appropriate agent based on caller input. These capabilities can increase customer satisfaction by streamlining the user experience, and improve containment rates in the contact center.
In both the self-service and call routing scenarios, you may need to configure the bot so that it can obtain information commonly required in customer service calls. For example, to enable a self-service experience when the caller requests a transfer from their checking account to their savings account, you may have to first get their account ID.
Bots are more effective at processing a response if they know the related request or prompt (for example, “What is your account ID?”). Amazon Lex provides comprehensive dialog management capabilities, so that context can be maintained across a conversation. However, sometimes the initial prompt may occur before the Amazon Lex bot is engaged.
In the case of an IVR solution, for example, the welcome prompt (“Welcome to ACME bank. To get started, can you tell me your account ID?”) may be defined in the client (Amazon Connect) contact flow. In this case, the Amazon Lex bot isn’t aware that you already prompted the user for their account ID. This could be a source of ambiguity for the bot (imagine if someone called you and started a conversation by saying, “123456”).
To create the best customer experience in cases like this, we recommend that you provide your Amazon Lex bot with details about the prompt. In this post, we show a simple way to inform Amazon Lex about details such as a prior prompt already provided to the user.
Solution overview
For this example, we use an Amazon Lex bot that provides self-service capabilities as part of an Amazon Connect contact flow. When the user calls in on their phone, they’re prompted for their account ID (for example, a six-digit number). We demonstrate how the Amazon Connect contact flow passes context about the information requested (in this case, the AccountId slot) to the Amazon Lex bot. As a best practice, we recommend setting the Amazon Lex dialog state to “slot elicitation” any time a user is prompted for a slot value.
We use the following sample banking interaction to model our Amazon Lex bot:
IVR: Hi, welcome to ACME bank customer service. To get started, please tell me your account ID.
User: 123456.
IVR: Thanks. How can I help? You can check account balances, transfer funds, and order checks.
User: What’s my balance in checking?
IVR: The balance for your checking account is $875. Is there anything else I can help you with?
User: No thanks, that’s it.
IVR: Okay, thanks for contacting us today. We appreciate your business!
Let’s deploy an Amazon Lex bot to see how this works.
Solution architecture
In this sample solution, we use AWS CloudFormation to deploy an Amazon Lex bot with an AWS Lambda fulfillment function, along with an example Amazon Connect contact flow that is integrated with the bot. The welcome prompt (“Welcome to ACME bank. To get started, please tell me your account ID.”) is configured in a “Play prompt” block in the contact flow.

The contact flow uses a Lambda helper function to inform Amazon Lex that the user has been prompted for a slot value. This is done via an “Invoke AWS Lambda function” block in the contact flow. The helper function makes a call to the Amazon Lex put-session API, to tell Amazon Lex to elicit for the account ID slot value. See the following code:
Next, control passes to the “Get customer input” block in the contact flow to trigger the Amazon Lex bot. Because the bot is ready for the account ID slot, the conversation is more efficient. You can also handle scenarios where the caller doesn’t have the requested information, by creating an intent to respond to inputs such as “I don’t know.” Although the bot is expecting a number (account ID), if the user provides a different response, the appropriate intent is triggered.
Prerequisites
Before deploying this solution, you should have the following prerequisites:
- An AWS account where you can deploy the solution
- Access to the following AWS services:
- Amazon Lex to create bots
- Lambda for the business logic functions
- AWS Identity and Access Management (IAM) with access to create policies and roles
- Amazon CloudWatch Logs to create log groups
- AWS CloudFormation to run the stack
- An Amazon Connect instance (for instructions on setting one up, see Create an Amazon Connect instance)
Deploy the sample solution
To deploy the solution, complete the following steps:
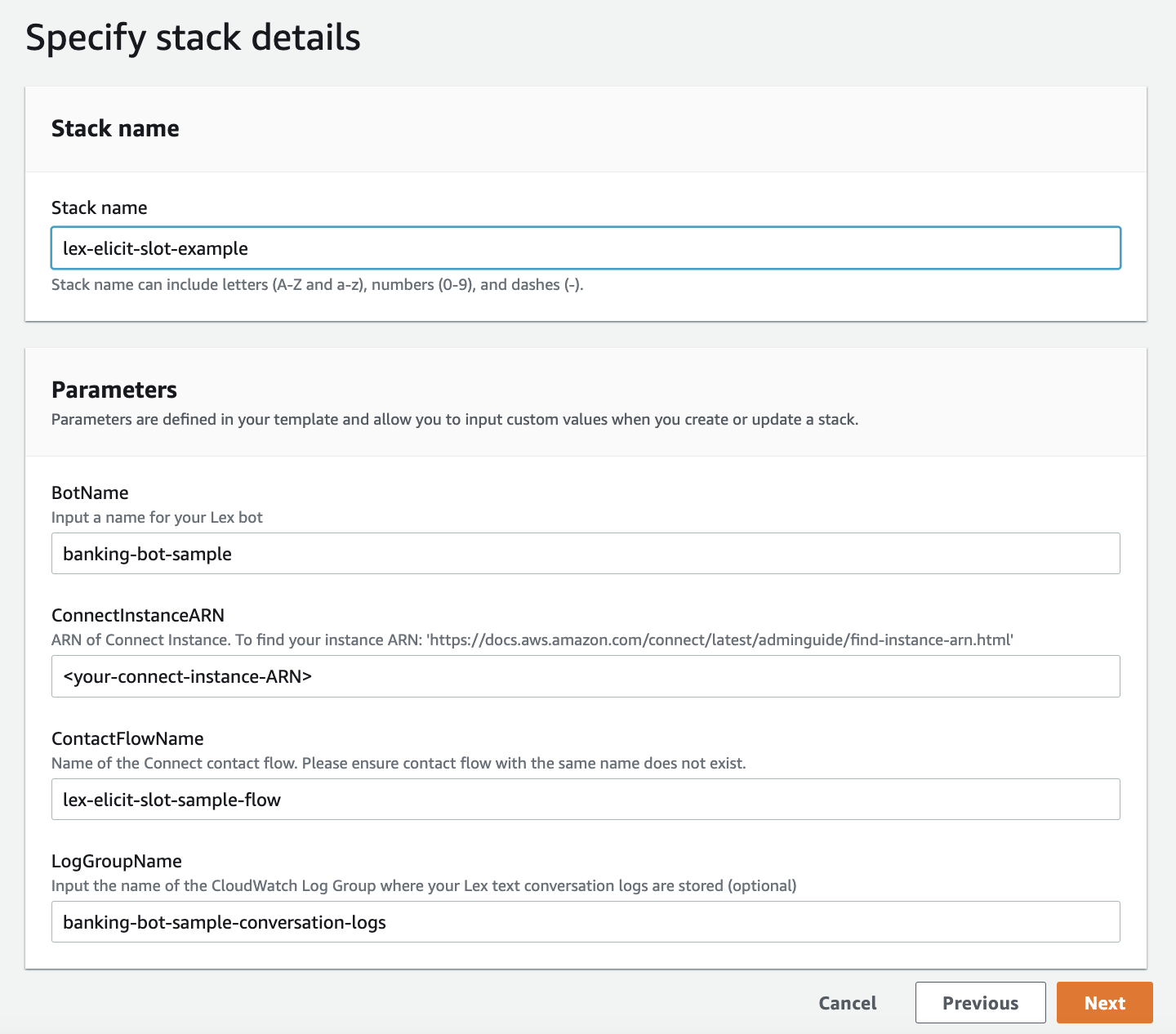
- Sign in to the AWS Management Console in your AWS account, and choose the following link:

This launches a new CloudFormation stack to create the example banking bot.
- For Stack name, enter a name (for example,
lex-elicit-slot-example). - For ConnectInstanceARN, enter the ARN (Amazon Resource Name) for the Amazon Connect instance you’ll use for testing the solution.
- Leave the other parameters at their default or change them as needed.
- Choose Next.
- Add any tags you may want for your stack (this step is optional).
- Choose Next.
- Review the stack details and select the check box to acknowledge that IAM resources will be created.
- Choose Create stack.
After a few minutes, your stack is complete, and includes the following resources:
- A Lex bot, including a published version with an alias (
Development-Alias) - A Lambda fulfillment function for the bot (
BotHandler) - A Lambda helper function, which calls the Amazon Lex
put-sessionAPI to enable slot elicitation mode (SlotElicitor) - A CloudWatch Logs log group for Amazon Lex conversation logs (optional)
- Required IAM roles
- A custom resource that adds a sample contact flow to your Amazon Connect instance
Test the bot on the Amazon Lex console
At this point, you can try the example interaction on the Amazon Lex console. You should see the sample bot with the name that you specified in the CloudFormation template (banking-bot-sample).
- On the Amazon Lex console, choose this bot and choose Bot versions in the navigation pane.
- Choose Version 1, then choose Intents in the navigation pane.
You can see a list of intents.
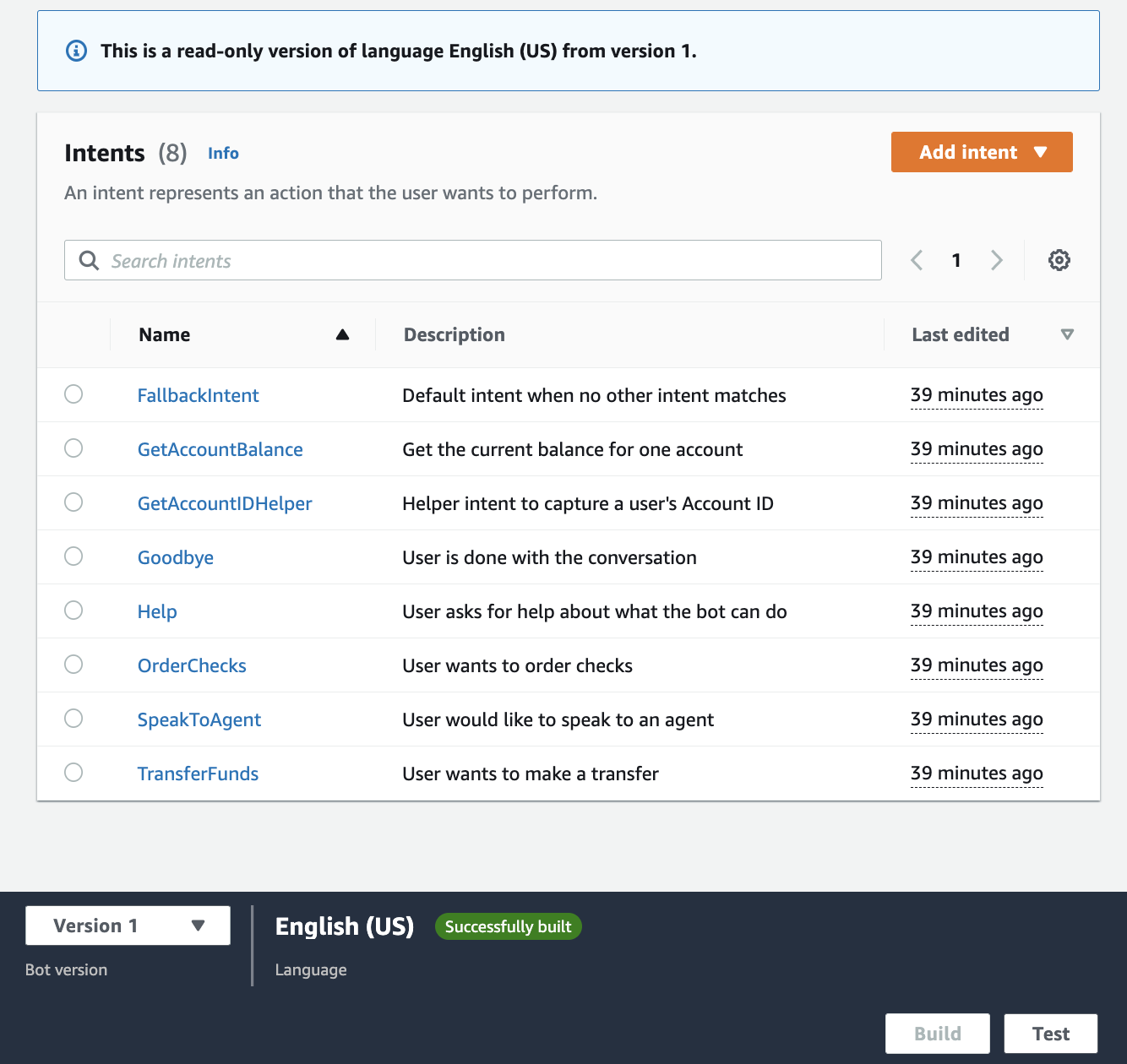
- Choose Test.
- Select Development-Alias and choose Confirm.
The test window opens.
- Try “What’s my balance?” to get started. You can also say “order some checks,” “transfer 100 dollars,” and “goodbye.”
You will be prompted for an account ID.
Test the bot with Amazon Connect
Now let’s try this with voice using an Amazon Connect instance. We have already configured a sample contact flow in your Amazon Connect instance.
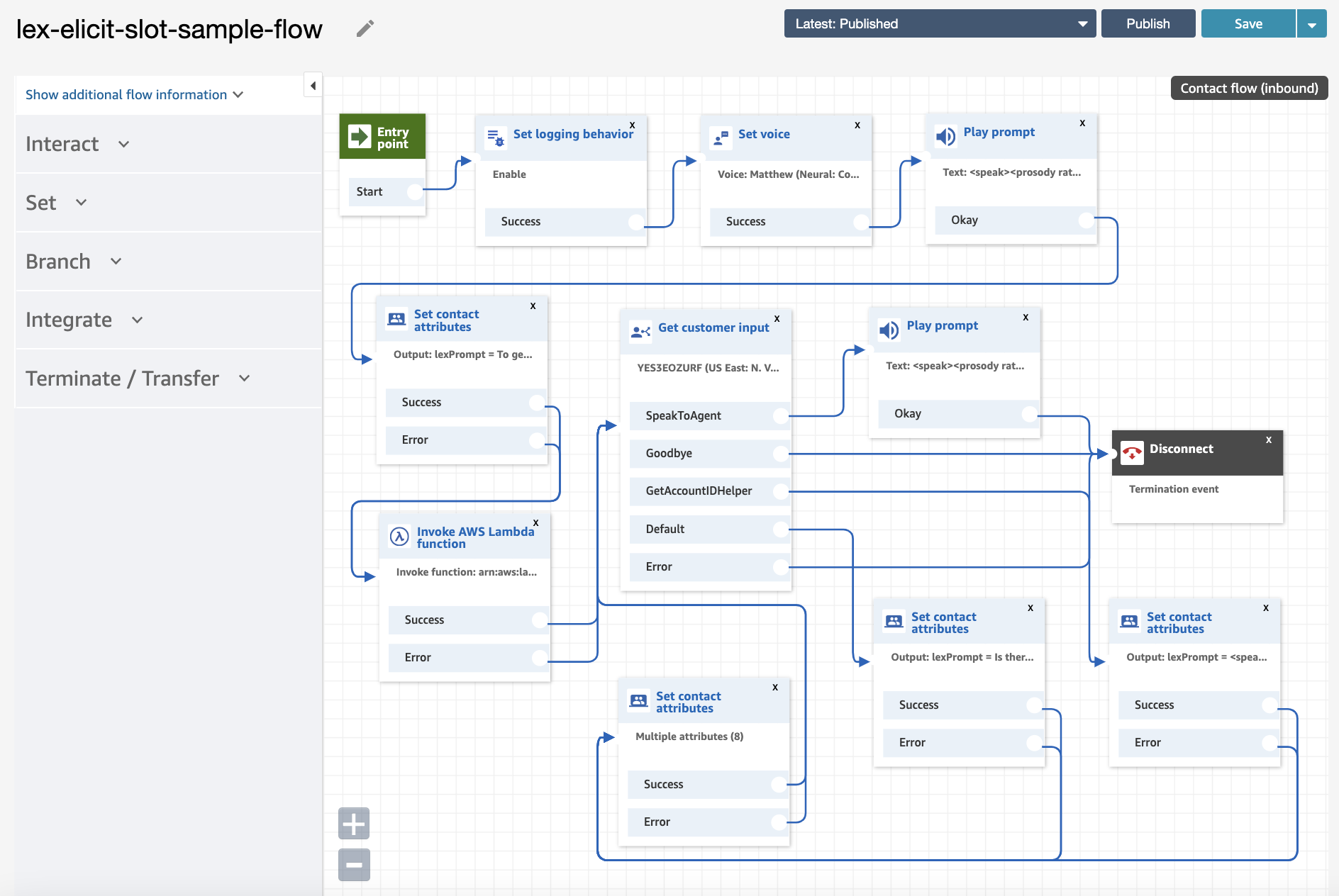
All you need to do is set up a phone number and associate it with this contact flow. To do this, follow these steps:
- On the Amazon Connect console, open your instance by choosing Access URL and logging in to the instance.
- On the Dashboard, choose View phone numbers.

- Choose Claim a number.
- Choose a country on the Country drop-down menu, and choose a number.

- For Description, enter a description, such as
Example contact flow that elicits a slot with Amazon Lex. - For Contact flow, choose the contact flow you just created.
- Choose Save.

You’re now ready to call in to your Amazon Connect instance to test your bot using voice. Just dial the number on your phone and give it a try!
Clean up
You may want to clean up the resources created as part of the CloudFormation template when you’re done using the bot, to avoid incurring ongoing charges. To do this, delete the CoudFormation Stack.
Conclusion
Amazon Lex offers powerful automated speech recognition (ASR) and natural language understanding (NLU) capabilities that you can use to capture information from your users to provide automated, self-service functionality, or to route callers to the right agents. Amazon Lex uses slot elicitation to collect information commonly needed in a customer service call. It’s important to provide the bot details on the type of information it should be expecting at the right times—in some cases, even on the first turn of a conversation. You can incorporate this technique in your own Amazon Lex conversation flows.
About the Authors
 Brian Yost is a Senior Technical Program manager on the AWS Lex team. In his spare time, he enjoys mountain biking, home brewing, and tinkering with technology.
Brian Yost is a Senior Technical Program manager on the AWS Lex team. In his spare time, he enjoys mountain biking, home brewing, and tinkering with technology.
Luciana Buriol’s quest for scientific joy
The principal research scientist shares lessons learned during her life journey from a small farm to working on optimizing Amazon’s distribution network.Read More
New method for “editing” fabricated chips enables more-efficient designs
Reducing the energy of ion beams used for editing eliminates the need for “sacrificial” areas between electrical components and improves precision.Read More
Luxembourg
Scientists in Luxembourg solve problems for our global customers and collaborate with teams worldwide. Much of the work in Luxembourg is focused on surfacing the right products to Amazon retail customers and delivering them as efficiently as possible.Read More
London and Cambridge
Scientists in London and nearby Cambridge work on Amazon experiences including Amazon retail, Prime Video, Alexa, Ring, Halo, Echo Show, and others.Read More
Edinburgh
Scientists in Edinburgh conduct research related to a variety of Amazon products and experiences, including machine learning, talent recruitment, and other consumer-facing services. Scientists here focus on real-world problems and own solutions end-to-end, from research to production.Read More