In a keynote address at the latest Amazon Machine Learning Conference, Amazon Visiting Academic, Stanford professor, and recent Nobel laureate Guido Imbens offered insights on the estimation of causal effects in “panel data” settings.Read More
Multi-tenant RAG with Amazon Bedrock Knowledge Bases
Organizations are continuously seeking ways to use their proprietary knowledge and domain expertise to gain a competitive edge. With the advent of foundation models (FMs) and their remarkable natural language processing capabilities, a new opportunity has emerged to unlock the value of their data assets.
As organizations strive to deliver personalized experiences to customers using generative AI, it becomes paramount to specialize the behavior of FMs using their own—and their customers’—data. Retrieval Augmented Generation (RAG) has emerged as a simple yet effective approach to achieve a desired level of specialization.
Amazon Bedrock Knowledge Bases is a fully managed capability that simplifies the management of the entire RAG workflow, empowering organizations to give FMs and agents contextual information from company’s private data sources to deliver more relevant and accurate responses tailored to their specific needs.
For organizations developing multi-tenant products, such as independent software vendors (ISVs) creating software as a service (SaaS) offerings, the ability to personalize experiences for each of their customers (tenants in their SaaS application) is particularly significant. This personalization can be achieved by implementing a RAG approach that selectively uses tenant-specific data.
In this post, we discuss and provide examples of how to achieve personalization using Amazon Bedrock Knowledge Bases. We focus particularly on addressing the multi-tenancy challenges that ISVs face, including data isolation, security, tenant management, and cost management. We focus on scenarios where the RAG architecture is integrated into the ISV application and not directly exposed to tenants. Although the specific implementations presented in this post use Amazon OpenSearch Service as a vector database to store tenants’ data, the challenges and architecture solutions proposed can be extended and tailored to other vector store implementations.
Multi-Tenancy design considerations
When architecting a multi-tenanted RAG system, organizations need to take several considerations into account:
- Tenant isolation – One crucial consideration in designing multi-tenanted systems is the level of isolation between the data and resources related to each tenant. These resources include data sources, ingestion pipelines, vector databases, and RAG client application. The level of isolation is typically governed by security, performance, and the scalability requirements of your solution, together with your regulatory requirements. For example, you may need to encrypt the data related to each of your tenants using a different encryption key. You may also need to make sure that high activity generated by one of the tenants doesn’t affect other tenants.
- Tenant variability – A similar yet distinct consideration is the level of variability of the features provided to each tenant. In the context of RAG systems, tenants might have varying requirements for data ingestion frequency, document chunking strategy, or vector search configuration.
- Tenant management simplicity – Multi-tenant solutions need a mechanism for onboarding and offboarding tenants. This dimension determines the degree of complexity for this process, which might involve provisioning or tearing down tenant-specific infrastructure, such as data sources, ingestion pipelines, vector databases, and RAG client applications. This process could also involve adding or deleting tenant-specific data in its data sources.
- Cost-efficiency – The operating costs of a multi-tenant solution depend on the way it provides the isolation mechanism for tenants, so designing a cost-efficient architecture for the solution is crucial.
These four considerations need to be carefully balanced and weighted to suit the needs of the specific solution. In this post, we present a model to simplify the decision-making process. Using the core isolation concepts of silo, pool, and bridge defined in the SaaS Tenant Isolation Strategies whitepaper, we propose three patterns for implementing a multi-tenant RAG solution using Amazon Bedrock Knowledge Bases, Amazon Simple Storage Service (Amazon S3), and OpenSearch Service.
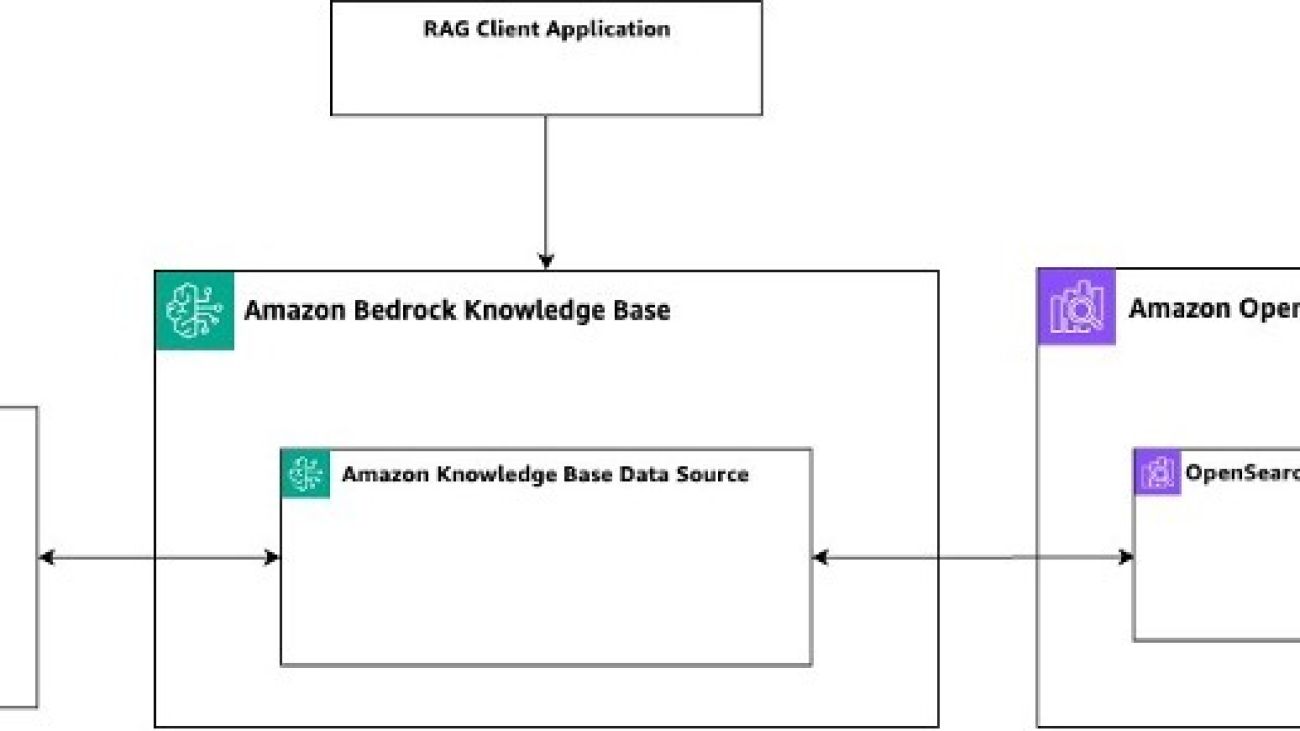
A typical RAG solution using Amazon Bedrock Knowledge Bases is composed of several components, as shown in the following figure:
- A data source, such as an S3 bucket
- A knowledge base including a data source
- A vector database such as an Amazon OpenSearch Serverless collection and index or other supported vector databases
- A RAG client application

The main challenge in adapting this architecture for multi-tenancy is determining how to provide isolation between tenants for each of the components. We propose three prescriptive patterns that cater to different use cases and offer carrying levels of isolation, variability, management simplicity, and cost-efficiency. The following figure illustrates the trade-offs between these three architectural patterns in terms of achieving tenant isolation, variability, cost-efficiency, and ease of tenant management.

Multi-tenancy patterns
In this section, we describe the implementation of these three different multi-tenancy patterns in a RAG architecture based on Amazon Bedrock Knowledge Bases, discussing their use cases as well as their pros and cons.
Silo
The silo pattern, illustrated in the following figure, offers the highest level of tenant isolation, because the entire stack is deployed and managed independently for each single tenant.

In the context of the RAG architecture implemented by Amazon Bedrock Knowledge Bases, this pattern prescribes the following:
- A separate data source per tenant – In this post, we consider the scenario in which tenant documents to be vectorized are stored in Amazon S3, therefore a separate S3 bucket is provisioned per tenant. This allows for per-tenant AWS Key Management Service (AWS KMS) encryption keys, as well as per-tenant S3 lifecycle policies to manage object expiration, and object versioning policies to maintain multiple versions of objects. Having separate buckets per tenant provides isolation and allows for customized configurations based on tenant requirements.
- A separate knowledge base per tenant – This allows for a separate chunking strategy per tenant, and it’s particularly useful if you envision the document basis of your tenants to be different in nature. For example, one of your tenants might have a document base composed of flat text documents, which can be treated with fixed-size chunking, whereas another tenant might have a document base with explicit sections, for which semantic chunking would be better suited to section. Having a different knowledge base per tenant also lets you decide on different embedding models, giving you the possibility to choose different vector dimensions, balancing accuracy, cost, and latency. You can choose a different KMS key per tenant for the transient data stores, which Amazon Bedrock uses for end-to-end per-tenant encryption. You can also choose per-tenant data deletion policies to control whether your vectors are deleted from the vector database when a knowledge base is deleted. Separate knowledge bases also mean that you can have different ingestion schedules per tenants, allowing you to agree to different data freshness standards with your customers.
- A separate OpenSearch Serverless collection per tenant – Having a separate OpenSearch Serverless collection per tenant allows you to have a separate KMS encryption key per tenant, maintaining per-tenant end-to-end encryption. For each tenant-specific collection, you can create a separate vector index, therefore choosing for each tenant the distance metric between Euclidean and dot product, so that you can choose how much importance to give to the document length. You can also choose the specific settings for the HNSW algorithm per tenant to control memory consumption, cost, and indexing time. Each vector index, in conjunction with the setup of metadata mappings in your knowledge base, can have a different metadata set per tenant, which can be used to perform filtered searches. Metadata filtering can be used in the silo pattern to restrict the search to a subset of documents with a specific characteristic. For example, one of your tenants might be uploading dated documents and wants to filter documents pertaining to a specific year, whereas another tenant might be uploading documents coming from different company divisions and wants to filter over the documentation of a specific company division.
Because the silo pattern offers tenant architectural independence, onboarding and offboarding a tenant means creating and destroying the RAG stack for that tenant, composed of the S3 bucket, knowledge base, and OpenSearch Serverless collection. You would typically do this using infrastructure as code (IaC). Depending on your application architecture, you may also need to update the log sinks and monitoring systems for each tenant.
Although the silo pattern offers the highest level of tenant isolation, it is also the most expensive to implement, mainly due to creating a separate OpenSearch Serverless collection per tenant for the following reasons:
- Minimum capacity charges – Each OpenSearch Serverless collection encrypted with a separate KMS key has a minimum of 2 OpenSearch Compute Units (OCUs) charged hourly. These OCUs are charged independently from usage, meaning that you will incur charges for dormant tenants if you choose to have a separate KMS encryption key per tenant.
- Scalability overhead – Each collection separately scales OCUs depending on usage, in steps of 6 GB of memory, and associated vCPUs and fast access storage. This means that resources might not be fully and optimally utilized across tenants.
When choosing the silo pattern, note that a maximum of 100 knowledge bases are supported in each AWS account. This makes the silo pattern favorable for your largest tenants with specific isolation requirements. Having a separate knowledge base per tenant also reduces the impact of quotas on concurrent ingestion jobs (maximum one concurrent job per KB, five per account), job size (100 GB per job), and data sources (maximum of 5 million documents per data source). It also improves the performance fairness as perceived by your tenants.
Deleting a knowledge base during offboarding a tenant might be time-consuming, depending on the size of the data sources and the synchronization process. To mitigate this, you can set the data deletion policy in your tenants’ knowledge bases to RETAIN. This way, the knowledge base deletion process will not delete your tenants’ data from the OpenSearch Service index. You can delete the index by deleting the OpenSearch Serverless collection.
Pool
In contrast with the silo pattern, in the pool pattern, illustrated in the following figure, the whole end-to-end RAG architecture is shared by your tenants, making it particularly suitable to accommodate many small tenants.

The pool pattern prescribes the following:
- Single data source – The tenants’ data is stored within the same S3 bucket. This implies that the pool model supports a shared KMS key for encryption at rest, not offering the possibility of per-tenant encryption keys. To identify tenant ownership downstream for each document uploaded to Amazon S3, a corresponding JSON metadata file has to be generated and uploaded. The metadata file generation process can be asynchronous, or even batched for multiple files, because Amazon Bedrock Knowledge Bases requires an explicit triggering of the ingestion job. The metadata file must use the same name as its associated source document file, with
.metadata.jsonappended to the end of the file name, and must be stored in the same folder or location as the source file in the S3 bucket. The following code is an example of the format:
In the preceding JSON structure, the key tenantId has been deliberately chosen, and can be changed to a key you want to use to express tenancy. The tenancy field will be used at runtime to filter documents belonging to a specific tenant, therefore the filtering key at runtime must match the metadata key in the JSON used to index the documents. Additionally, you can include other metadata keys to perform further filtering that isn’t based on tenancy. If you don’t upload the object.metadata.json file, the client application won’t be able to find the document using metadata filtering.
- Single knowledge base – A single knowledge base is created to handle the data ingestion for your tenants. This means that your tenants will share the same chunking strategy and embedding model, and share the same encryption at-rest KMS key. Moreover, because ingestion jobs are triggered per data source per KB, you will be restricted to offer to your tenants the same data freshness standards.
- Single OpenSearch Serverless collection and index – Your tenant data is pooled in a single OpenSearch Service vector index, therefore your tenants share the same KMS encryption key for vector data, and the same HNSW parameters for indexing and query. Because tenant data isn’t physically segregated, it’s crucial that the query client be able to filter results for a single tenant. This can be efficiently achieved using either the Amazon Bedrock Knowledge Bases
RetrieveorRetrieveAndGenerate, expressing the tenant filtering condition as part of the retrievalConfiguration (for more details, see Amazon Bedrock Knowledge Bases now supports metadata filtering to improve retrieval accuracy). If you want to restrict the vector search to return results fortenant_1, the following is an example client implementation performingRetrieveAndGeneratebased on the AWS SDK for Python (Boto3):
text contains the original user query that needs to be answered. Taking into account the document base, <YOUR_KNOWLEDGEBASE_ID> needs to be substituted with the identifier of the knowledge base used to pool your tenants, and <FM_ARN> needs to be substituted with the Amazon Bedrock model Amazon Resource Name (ARN) you want to use to reply to the user query. The client presented in the preceding code has been streamlined to present the tenant filtering functionality. In a production case, we recommend implementing session and error handling, logging and retry logic, and separating the tenant filtering logic from the client invocation to make it inaccessible to developers.
Because the end-to-end architecture is pooled in this pattern, onboarding and offboarding a tenant doesn’t require you to create new physical or logical constructs, and it’s as simple as starting or stopping and uploading specific tenant documents to Amazon S3. This implies that there is no AWS managed API that can be used to offboard and end-to-end forget a specific tenant. To delete the historical documents belonging to a specific tenant, you can just delete the relevant objects in Amazon S3. Typically, customers will have an external application that maintains the list of available tenants and their status, facilitating the onboarding and offboarding process.
Sharing the monitoring system and logging capabilities in this pattern reduces the complexity of operations with a large number of tenants. However, it requires you to collect the tenant-specific metrics from the client side to perform specific tenant attribution.
The pool pattern optimizes the end-to-end cost of your RAG architecture, because sharing OCUs across tenants maximizes the use of each OCU and minimizes the tenants’ idle time. Sharing the same pool of OCUs across tenants means that this pattern doesn’t offer performance isolation at the vector store level, so the largest and most active tenants might impact the experience of other tenants.
When choosing the pool pattern for your RAG architecture, you should be aware that a single ingestion job can ingest or delete a maximum of 100 GB. Additionally, the data source can have a maximum of 5 million documents. If the solution has many tenants that are geographically distributed, consider triggering the ingestion job multiple times a day so you don’t hit the ingestion job size limit. Also, depending on the number and size of your documents to be synchronized, the time for ingestion will be determined by the embedding model invocation rate. For example, consider the following scenario:
- Number of tenants to be synchronized = 10
- Average number of documents per tenant = 100
- Average size per document = 2 MB, containing roughly 200,000 tokens divided in 220 chunks of 1,000 tokens to allow for overlap
- Using Amazon Titan Embeddings v2 on demand, allowing for 2,000 RPM and 300,000 TPM
This would result in the following:
- Total embeddings requests = 10*100*220 = 220,000
- Total tokens to process = 10*100*1,000=1,000,000
- Total time taken to embed is dominated by the RPM, therefore 220,000/2,000 = 1 hour, 50 minutes
This means you could trigger an ingestion job 12 times per day to have a good time distribution of data to be ingested. This calculation is a best-case scenario and doesn’t account for the latency introduced by the FM when creating the vector from the chunk. If you expect having to synchronize a large number of tenants at the same time, consider using provisioned throughput to decrease the time it takes to create vector embeddings. This approach will also help distribute the load on the embedding models, limiting throttling of the Amazon Bedrock runtime API calls.
Bridge
The bridge pattern, illustrated in the following figure, strikes a balance between the silo and pool patterns, offering a middle ground that balances tenant data isolation and security.

The bridge pattern delivers the following characteristics:
- Separate data source per tenant in a common S3 bucket – Tenant data is stored in the same S3 bucket, but prefixed by a tenant identifier. Although having a different prefix per tenant doesn’t offer the possibility of using per-tenant encryption keys, it does create a logical separation that can be used to segregate data downstream in the knowledge bases.
- Separate knowledge base per tenant – This pattern prescribes creating a separate knowledge base per tenant similar to the silo pattern. Therefore, the considerations in the silo pattern apply. Applications built using the bridge pattern usually share query clients across tenants, so they need to identify the specific tenant’s knowledge base to query. They can identify the knowledge base by storing the tenant-to-knowledge base mapping in an external database, which manages tenant-specific configurations. The following example shows how to store this tenant-specific information in an Amazon DynamoDB table:
In a production setting, your application will store tenant-specific parameters belonging to other functionality in your data stores. Depending on your application architecture, you might choose to store
knowledgebaseIdandmodelARNalongside the other tenant-specific parameters, or create a separate data store (for example, thetenantKbConfigtable) specifically for your RAG architecture.This mapping can then be used by the client application by invoking the
RetrieveAndGenerateAPI. The following is an example implementation: - Separate OpenSearch Service index per tenant – You store data within the same OpenSearch Serverless collection, but you create a vector index per tenant. This implies your tenants share the same KMS encryption key and the same pool of OCUs, optimizing the OpenSearch Service resources usage for indexing and querying. The separation in vector indexes gives you the flexibility of choosing different HNSM parameters per tenant, letting you tailor the performance of your k-NN indexing and querying for your different tenants.
The bridge pattern supports up to 100 tenants, and onboarding and offboarding a tenant requires the creation and deletion of a knowledge base and OpenSearch Service vector index. To delete the data pertaining to a particular tenant, you can delete the created resources and use the tenant-specific prefix as a logical parameter in your Amazon S3 API calls. Unlike the silo pattern, the bridge pattern doesn’t allow for per-tenant end-to-end encryption; it offers the same level of tenant customization offered by the silo pattern while optimizing costs.
Summary of differences
The following figure and table provide a consolidated view for comparing the characteristics of the different multi-tenant RAG architecture patterns. This comprehensive overview highlights the key attributes and trade-offs associated with the pool, bridge, and silo patterns, enabling informed decision-making based on specific requirements.
The following figure illustrates the mapping of design characteristics to components of the RAG architecture.

The following table summarizes the characteristics of the multi-tenant RAG architecture patterns.
| Characteristic | Attribute of | Pool | Bridge | Silo |
| Per-tenant chunking strategy | Amazon Bedrock Knowledge Base Data Source | No | Yes | Yes |
| Customer managed key for encryption of transient data and at rest | Amazon Bedrock Knowledge Base Data Source | No | No | Yes |
| Per-tenant distance measure | Amazon OpenSearch Service Index | No | Yes | Yes |
| Per-tenant ANN index configuration | Amazon OpenSearch Service Index | No | Yes | Yes |
| Per-tenant data deletion policies | Amazon Bedrock Knowledge Base Data Source | No | Yes | Yes |
| Per-tenant vector size | Amazon Bedrock Knowledge Base Data Source | No | Yes | Yes |
| Tenant performance isolation | Vector database | No | No | Yes |
| Tenant onboarding and offboarding complexity | Overall solution | Simplest, requires management of new tenants in existing infrastructure | Medium, requires minimal management of end-to-end infrastructure | Hardest, requires management of end-to-end infrastructure |
| Query client implementation | Original Data Source | Medium, requires dynamic filtering | Hardest, requires external tenant mapping table | Simplest, same as single-tenant implementation |
| Amazon S3 tenant management complexity | Amazon S3 buckets and objects | Hardest, need to maintain tenant specific metadata files for each object | Medium, each tenant needs a different S3 path | Simplest, each tenant requires a different S3 bucket |
| Cost | Vector database | Lowest | Medium | Highest |
| Per-tenant FM used to create vector embeddings | Amazon Bedrock Knowledge Base | No | Yes | Yes |
Conclusion
This post explored three distinct patterns for implementing a multi-tenant RAG architecture using Amazon Bedrock Knowledge Bases and OpenSearch Service. The silo, pool, and bridge patterns offer varying levels of tenant isolation, variability, management simplicity, and cost-efficiency, catering to different use cases and requirements. By understanding the trade-offs and considerations associated with each pattern, organizations can make informed decisions and choose the approach that best aligns with their needs.
Get started with Amazon Bedrock Knowledge Bases today.
About the Authors
 Emanuele Levi is a Solutions Architect in the Enterprise Software and SaaS team, based in London. Emanuele helps UK customers on their journey to refactor monolithic applications into modern microservices SaaS architectures. Emanuele is mainly interested in event-driven patterns and designs, especially when applied to analytics and AI, where he has expertise in the fraud-detection industry.
Emanuele Levi is a Solutions Architect in the Enterprise Software and SaaS team, based in London. Emanuele helps UK customers on their journey to refactor monolithic applications into modern microservices SaaS architectures. Emanuele is mainly interested in event-driven patterns and designs, especially when applied to analytics and AI, where he has expertise in the fraud-detection industry.
 Mehran Nikoo is a Generative AI Go-To-Market Specialist at AWS. He leads the generative AI go-to-market strategy for UK and Ireland.
Mehran Nikoo is a Generative AI Go-To-Market Specialist at AWS. He leads the generative AI go-to-market strategy for UK and Ireland.
 Dani Mitchell is a Generative AI Specialist Solutions Architect at AWS. He is focused on computer vision use case and helps AWS customers in EMEA accelerate their machine learning and generative AI journeys with Amazon SageMaker and Amazon Bedrock.
Dani Mitchell is a Generative AI Specialist Solutions Architect at AWS. He is focused on computer vision use case and helps AWS customers in EMEA accelerate their machine learning and generative AI journeys with Amazon SageMaker and Amazon Bedrock.
How Amazon trains sequential ensemble models at scale with Amazon SageMaker Pipelines
Amazon SageMaker Pipelines includes features that allow you to streamline and automate machine learning (ML) workflows. This allows scientists and model developers to focus on model development and rapid experimentation rather than infrastructure management
Pipelines offers the ability to orchestrate complex ML workflows with a simple Python SDK with the ability to visualize those workflows through SageMaker Studio. This helps with data preparation and feature engineering tasks and model training and deployment automation. Pipelines also integrates with Amazon SageMaker Automatic Model Tuning which can automatically find the hyperparameter values that result in the best performing model, as determined by your chosen metric.
Ensemble models are becoming popular within the ML communities. They generate more accurate predictions through combining the predictions of multiple models. Pipelines can quickly be used to create and end-to-end ML pipeline for ensemble models. This enables developers to build highly accurate models while maintaining efficiency, and reproducibility.
In this post, we provide an example of an ensemble model that was trained and deployed using Pipelines.
Use case overview
Sales representatives generate new leads and create opportunities within Salesforce to track them. The following application is a ML approach using unsupervised learning to automatically identify use cases in each opportunity based on various text information, such as name, description, details, and product service group.
Preliminary analysis showed that use cases vary by industry and different use cases have a very different distribution of annualized revenue and can help with segmentation. Hence, a use case is an important predictive feature that can optimize analytics and improve sales recommendation models.
We can treat the use case identification as a topic identification problem and we explore different topic identification models such as Latent Semantic Analysis (LSA), Latent Dirichlet Allocation (LDA), and BERTopic. In both LSA and LDA, each document is treated as a collection of words only and the order of the words or grammatical role does not matter, which may cause some information loss in determining the topic. Moreover, they require a pre-determined number of topics, which was hard to determine in our data set. Since, BERTopic overcame the above problem, it was used in order to identify the use case.
The approach uses three sequential BERTopic models to generate the final clustering in a hierarchical method.
Each BERTopic model consists of four parts:
- Embedding – Different embedding methods can be used in BERTopic. In this scenario, input data comes from various areas and is usually inputted manually. As a result, we use sentence embedding to ensure scalability and fast processing.
- Dimension reduction – We use Uniform Manifold Approximation and Projection (UMAP), which is an unsupervised and nonlinear dimension reduction method, to reduce high dimension text vectors.
- Clustering – We use the Balanced Iterative Reducing and Clustering using Hierarchies (BIRCH) method to form different use case clusters.
- Keyword identification – We use class-based TF-IDF to extract the most representative words from each cluster.
Sequential ensemble model
There is no predetermined number of topics, so we set an input for the number of clusters to be 15–25 topics. Upon observation, some of the topics are wide and general. Therefore, another layer of the BERTopic model is applied individually to them. After combining all of the newly identified topics in the second-layer model and together with the original topics from first-layer results, postprocessing is performed manually to finalize topic identification. Lastly, a third layer is used for some of the clusters to create sub-topics.
To enable the second- and third-layer models to work effectively, you need a mapping file to map results from previous models to specific words or phrases. This helps make sure that the clustering is accurate and relevant.
We’re using Bayesian optimization for hyperparameter tuning and cross-validation to reduce overfitting. The data set contains features like opportunity name, opportunity details, needs, associated product name, product details, product groups. The models are evaluated using a customized loss function, and the best embedding model is selected.
Challenges and considerations
Here are some of the challenges and considerations of this solution:
- The pipeline’s data preprocessing capability is crucial for enhancing model performance. With the ability to preprocess incoming data prior to training, we can make sure that our models are fed with high-quality data. Some of the preprocessing and data cleaning steps include converting all text column to lower case, removing template elements, contractions, URLs, emails, etc. removing non-relevant NER labels, and lemmatizing combined text. The result is more accurate and reliable predictions.
- We need a compute environment that is highly scalable so that we can effortlessly handle and train millions of rows of data. This allows us to perform large-scale data processing and modeling tasks with ease and reduces development time and costs.
- Because every step of the ML workflow requires varying resource requirements, a flexible and adaptable pipeline is essential for efficient resource allocation. We can reduce the overall processing time, resulting in faster model development and deployment, by optimizing resource usage for each step.
- Running custom scripts for data processing and model training requires the availability of required frameworks and dependencies.
- Coordinating the training of multiple models can be challenging, especially when each subsequent model depends on the output of the previous one. The process of orchestrating the workflow between these models can be complex and time-consuming.
- Following each training layer, it’s necessary to revise a mapping that reflects the topics produced by the model and use it as an input for the subsequent model layer.
Solution overview
In this solution, the entry point is Amazon SageMaker Studio, which is a web-based integrated development environment (IDE) provided by AWS that enables data scientists and ML developers to build, train, and deploy ML models at scale in a collaborative and efficient manner.
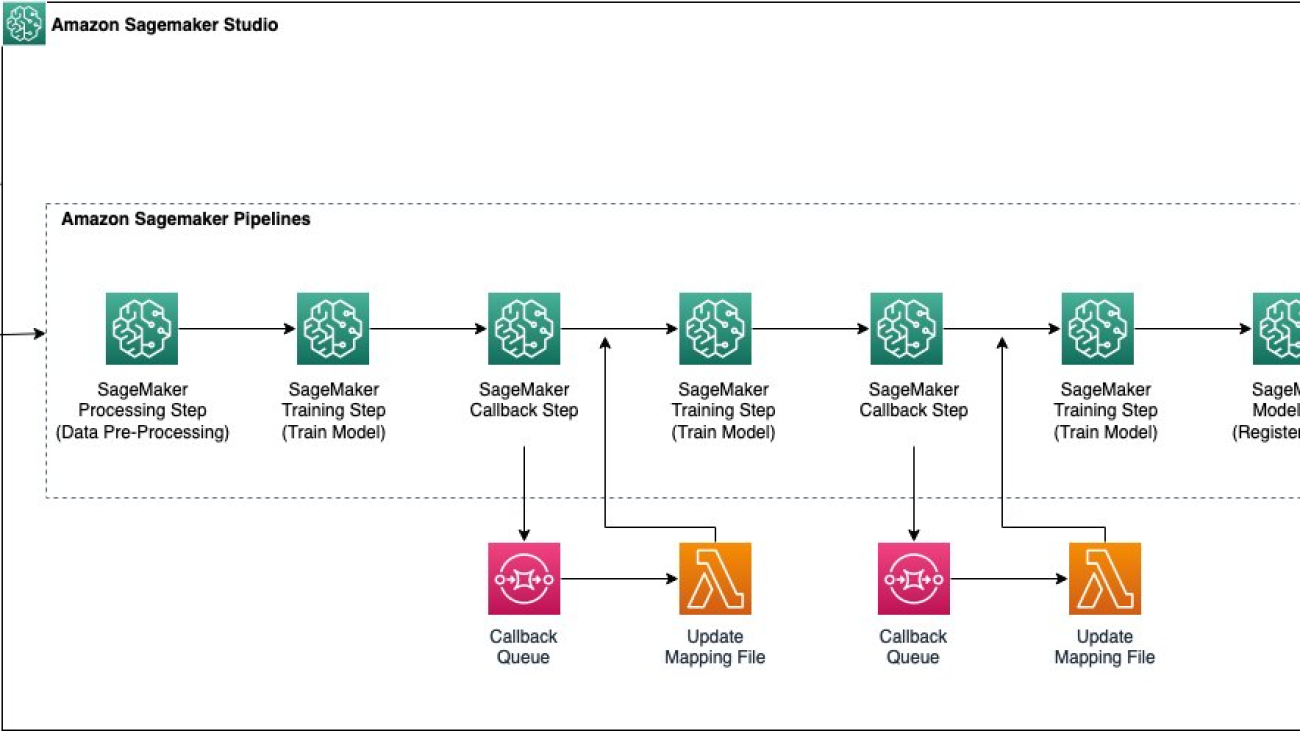
The following diagrams illustrates the high-level architecture of the solution.

As part of the architecture, we’re using the following SageMaker pipeline steps:
- SageMaker Processing – This step allows you to preprocess and transform data before training. One benefit of this step is the ability to use built-in algorithms for common data transformations and automatic scaling of resources. You can also use custom code for complex data preprocessing, and it allows you to use custom container images.
- SageMaker Training – This step allows you to train ML models using SageMaker-built-in algorithms or custom code. You can use distributed training to accelerate model training.
- SageMaker Callback – This step allows you to run custom code during the ML workflow, such as sending notifications or triggering additional processing steps. You can run external processes and resume the pipeline workflow on completion in this step.
- SageMaker Model – This step allows you to create or register model to Amazon SageMaker
Implementation Walkthrough
First, we set up the Sagemaker pipeline:
import boto3
import sagemaker
# create a Session with custom region (e.g. us-east-1), will be None if not specified
region = "<your-region-name>"
# allocate default S3 bucket for SageMaker session, will be None if not specified
default_bucket = "<your-s3-bucket>"
boto_session = boto3.Session(region_name=region
sagemaker_client = boto_session.client("sagemaker")
Initialize a SageMaker Session
sagemaker_session = sagemaker.session.Session(boto_session=boto_session, sagemaker_client=sagemaker_client, default_bucket= default_bucket,)
Set Sagemaker execution role for the session
role = sagemaker.session.get_execution_role(sagemaker_session)
Manage interactions under Pipeline Context
pipeline_session = sagemaker.workflow.pipeline_context.PipelineSession(boto_session=boto_session, sagemaker_client=sagemaker_client, default_bucket=default_bucket,)
Define base image for scripts to run on
account_id = role.split(":")[4]
# create a base image that take care of dependencies
ecr_repository_name = "<your-base-image-to-run-script>".
tag = "latest"
container_image_uri = "{0}.dkr.ecr.{1}.amazonaws.com/{2}:{3}".format(account_id, region, ecr_repository_name, tag)
The following is a detailed explanation of the workflow steps:
- Preprocess the data – This involves cleaning and preparing the data for feature engineering and splitting the data into train, test, and validation sets.
import os
BASE_DIR = os.path.dirname(os.path.realpath(__file__))
from sagemaker.workflow.parameters import ParameterString
from sagemaker.workflow.steps import ProcessingStep
from sagemaker.processing import (
ProcessingInput,
ProcessingOutput,
ScriptProcessor,
)
processing_instance_type = ParameterString(
name="ProcessingInstanceType",
# choose an instance type suitable for the job
default_value="ml.m5.4xlarge"
)
script_processor = ScriptProcessor(
image_uri=container_image_uri,
command=["python"],
instance_type=processing_instance_type,
instance_count=1,
role=role,
)
# define the data preprocess job
step_preprocess = ProcessingStep(
name="DataPreprocessing",
processor=script_processor,
inputs=[
ProcessingInput(source=BASE_DIR, destination="/opt/ml/processing/input/code/")
],
outputs=[
ProcessingOutput(output_name="data_train", source="/opt/ml/processing/data_train"), # output data and dictionaries etc for later steps
]
code=os.path.join(BASE_DIR, "preprocess.py"),
)- Train layer 1 BERTopic model – A SageMaker training step is used to train the first layer of the BERTopic model using an Amazon Elastic Container Registry (Amazon ECR) image and a custom training script.
base_job_prefix="OppUseCase"
from sagemaker.workflow.steps import TrainingStep
from sagemaker.estimator import Estimator
from sagemaker.inputs import TrainingInput
training_instance_type = ParameterString(
name="TrainingInstanceType",
default_value="ml.m5.4xlarge"
)
# create an estimator for training job
estimator_first_layer = Estimator(
image_uri=container_image_uri,
instance_type=training_instance_type,
instance_count=1,
output_path= f"s3://{default_bucket}/{base_job_prefix}/train_first_layer", # S3 bucket where the training output be stored
role=role,
entry_point = "train_first_layer.py"
)
# create training job for the estimator based on inputs from data-preprocess step
step_train_first_layer = TrainingStep(
name="TrainFirstLayerModel",
estimator = estimator_first_layer,
inputs={
TrainingInput(
s3_data=step_preprocess.properties.ProcessingOutputConfig.Outputs[ "data_train" ].S3Output.S3Uri,
),
},
)- Use a callback step – This involves sending a message to an Amazon Simple Queue Service (Amazon SQS) queue, which triggers an AWS Lambda function. The Lambda function updates the mapping file in Amazon Simple Storage Service (Amazon S3) and sends a success token back to the pipeline to resume its run.
from sagemaker.workflow.callback_step import CallbackStep, CallbackOutput, CallbackOutputTypeEnum
first_sqs_queue_to_use = ParameterString(
name="FirstSQSQueue",
default_value= <first_queue_url>, # add queue url
)
first_callback_output = CallbackOutput(output_name="s3_mapping_first_update", output_type=CallbackOutputTypeEnum.String)
step_first_mapping_update = CallbackStep(
name="FirstMappingUpdate",
sqs_queue_url= first_sqs_queue_to_use,
# Input arguments that will be provided in the SQS message
inputs={
"input_location": f"s3://{default_bucket}/{base_job_prefix}/mapping",
"output_location": f"s3://{default_bucket}/{base_job_prefix}/ mapping_first_update "
},
outputs=[
first_callback_output,
],
)
step_first_mapping_update.add_depends_on([step_train_first_layer]) # call back is run after the step_train_first_layer
- Train layer 2 BERTopic model – Another SageMaker TrainingStep is used to train the second layer of the BERTopic model using an ECR image and a custom training script.
estimator_second_layer = Estimator(
image_uri=container_image_uri,
instance_type=training_instance_type, # same type as of first train layer
instance_count=1,
output_path=f"s3://{bucket}/{base_job_prefix}/train_second_layer", # S3 bucket where the training output be stored
role=role,
entry_point = "train_second_layer.py"
)
# create training job for the estimator based on inputs from preprocessing, output of previous call back step and first train layer step
step_train_second_layer = TrainingStep(
name="TrainSecondLayerModel",
estimator = estimator_second_layer,
inputs={
TrainingInput(
s3_data=step_preprocess.properties.ProcessingOutputConfig.Outputs[ "data_train"].S3Output.S3Uri,
),
TrainingInput(
# Output of the previous call back step
s3_data= step_first_mapping_update.properties.Outputs["s3_mapping_first_update"],
),
TrainingInput(
s3_data=f"s3://{bucket}/{base_job_prefix}/train_first_layer"
),
}
)
- Use a callback step – Similar to Step 3, this involves sending a message to an SQS queue which triggers a Lambda function. The Lambda function updates the mapping file in Amazon S3 and sends a success token back to the pipeline to resume its run.
second_sqs_queue_to_use = ParameterString(
name="SecondSQSQueue",
default_value= <second_queue_url>, # add queue url
)
second_callback_output = CallbackOutput(output_name="s3_mapping_second_update", output_type=CallbackOutputTypeEnum.String)
step_second_mapping_update = CallbackStep(
name="SecondMappingUpdate",
sqs_queue_url= second_sqs_queue_to_use,
# Input arguments that will be provided in the SQS message
inputs={
"input_location": f"s3://{default_bucket}/{base_job_prefix}/mapping_first_update ",
"output_location": f"s3://{default_bucket}/{base_job_prefix}/mapping_second_update "
},
outputs=[
second_callback_output,
],
)
step_second_mapping_update.add_depends_on([step_train_second_layer]) # call back is run after the step_train_second_layer
- Train layer 3 BERTopic model – This involves fetching the mapping file from Amazon S3 and training the third layer of the BERTopic model using an ECR image and a custom training script.
estimator_third_layer = Estimator(
image_uri=container_image_uri,
instance_type=training_instance_type, # same type as of prvious two train layers
instance_count=1,
output_path=f"s3://{default_bucket}/{base_job_prefix}/train_third_layer", # S3 bucket where the training output be stored
role=role,
entry_point = "train_third_layer.py"
)
# create training job for the estimator based on inputs from preprocess step, second callback step and outputs of previous two train layers
step_train_third_layer = TrainingStep(
name="TrainThirdLayerModel",
estimator = estimator_third_layer,
inputs={
TrainingInput(
s3_data=step_preprocess.properties.ProcessingOutputConfig.Outputs["data_train"].S3Output.S3Uri,
),
TrainingInput(
# s3_data = Output of the previous call back step
s3_data= step_second_mapping_update.properties.Outputs[' s3_mapping_second_update’],
),
TrainingInput(
s3_data=f"s3://{default_bucket}/{base_job_prefix}/train_first_layer"
),
TrainingInput(
s3_data=f"s3://{default_bucket}/{base_job_prefix}/train_second_layer"
),
}
)
- Register the model – A SageMaker model step is used to register the model in the SageMaker model registry. When the model is registered, you can use the model through a SageMaker inference pipeline.
from sagemaker.model import Model
from sagemaker.workflow.model_step import ModelStep
model = Model(
image_uri=container_image_uri,
model_data=step_train_third_layer.properties.ModelArtifacts.S3ModelArtifacts,
sagemaker_session=sagemaker_session,
role=role,
)
register_args = model.register(
content_types=["text/csv"],
response_types=["text/csv"],
inference_instances=["ml.c5.9xlarge", "ml.m5.xlarge"],
model_package_group_name=model_package_group_name,
approval_status=model_approval_status,
)
step_register = ModelStep(name="OppUseCaseRegisterModel", step_args=register_args)
To effectively train a BERTopic model and BIRCH and UMAP methods, you need a custom training image which can provide additional dependencies and framework required to run the algorithm. For a working sample of a custom docker image, refer to Create a custom Docker container Image for SageMaker
Conclusion
In this post, we explained how you can use wide range of steps offered by SageMaker Pipelines with custom images to train an ensemble model. For more information on how to get started with Pipelines using an existing ML Operations (MLOps) template, refer to Building, automating, managing, and scaling ML workflows using Amazon SageMaker Pipelines.
About the Authors
 Bikramjeet Singh is a Applied Scientist at AWS Sales Insights, Analytics and Data Science (SIADS) Team, responsible for building GenAI platform and AI/ML Infrastructure solutions for ML scientists within SIADS. Prior to working as an AS, Bikram worked as a Software Development Engineer within SIADS and Alexa AI.
Bikramjeet Singh is a Applied Scientist at AWS Sales Insights, Analytics and Data Science (SIADS) Team, responsible for building GenAI platform and AI/ML Infrastructure solutions for ML scientists within SIADS. Prior to working as an AS, Bikram worked as a Software Development Engineer within SIADS and Alexa AI.
 Rahul Sharma is a Senior Specialist Solutions Architect at AWS, helping AWS customers build ML and Generative AI solutions. Prior to joining AWS, Rahul has spent several years in the finance and insurance industries, helping customers build data and analytics platforms.
Rahul Sharma is a Senior Specialist Solutions Architect at AWS, helping AWS customers build ML and Generative AI solutions. Prior to joining AWS, Rahul has spent several years in the finance and insurance industries, helping customers build data and analytics platforms.
 Sachin Mishra is a seasoned professional with 16 years of industry experience in technology consulting and software leadership roles. Sachin lead the Sales Strategy Science and Engineering function at AWS. In this role, he was responsible for scaling cognitive analytics for sales strategy, leveraging advanced AI/ML technologies to drive insights and optimize business outcomes.
Sachin Mishra is a seasoned professional with 16 years of industry experience in technology consulting and software leadership roles. Sachin lead the Sales Strategy Science and Engineering function at AWS. In this role, he was responsible for scaling cognitive analytics for sales strategy, leveraging advanced AI/ML technologies to drive insights and optimize business outcomes.
 Nada Abdalla is a research scientist at AWS. Her work and expertise span multiple science areas in statistics and ML including text analytics, recommendation systems, Bayesian modeling and forecasting. She previously worked in academia and obtained her M.Sc and PhD from UCLA in Biostatistics. Through her work in academia and industry she published multiple papers at esteemed statistics journals and applied ML conferences. In her spare time she enjoys running and spending time with her family.
Nada Abdalla is a research scientist at AWS. Her work and expertise span multiple science areas in statistics and ML including text analytics, recommendation systems, Bayesian modeling and forecasting. She previously worked in academia and obtained her M.Sc and PhD from UCLA in Biostatistics. Through her work in academia and industry she published multiple papers at esteemed statistics journals and applied ML conferences. In her spare time she enjoys running and spending time with her family.
Implementing login node load balancing in SageMaker HyperPod for enhanced multi-user experience
Amazon SageMaker HyperPod is designed to support large-scale machine learning (ML) operations, providing a robust environment for training foundation models (FMs) over extended periods. Multiple users — such as ML researchers, software engineers, data scientists, and cluster administrators — can work concurrently on the same cluster, each managing their own jobs and files without interfering with others.
When using HyperPod, you can use familiar orchestration options such as Slurm or Amazon Elastic Kubernetes Service (Amazon EKS). This blog post specifically applies to HyperPod clusters using Slurm as the orchestrator. In these clusters, the concept of login nodes is available, which cluster administrators can add to facilitate user access. These login nodes serve as the entry point through which users interact with the cluster’s computational resources. By using login nodes, users can separate their interactive activities, such as browsing files, submitting jobs, and compiling code, from the cluster’s head node. This separation helps prevent any single user’s activities from affecting the overall performance of the cluster.
However, although HyperPod provides the capability to use login nodes, it doesn’t provide an integrated mechanism for load balancing user activity across these nodes. As a result, users manually select a login node, which can lead to imbalances where some nodes are overutilized while others remain underutilized. This not only affects the efficiency of resource usage but can also lead to uneven performance experiences for different users.
In this post, we explore a solution for implementing load balancing across login nodes in Slurm-based HyperPod clusters. By distributing user activity evenly across all available nodes, this approach provides more consistent performance, better resource utilization, and a smoother experience for all users. We guide you through the setup process, providing practical steps to achieve effective load balancing in your HyperPod clusters.
Solution overview
In HyperPod, login nodes serve as access points for users to interact with the cluster’s computational resources so they can manage their tasks without impacting the head node. Although the default method for accessing these login nodes is through AWS Systems Manager, there are cases where direct Secure Shell (SSH) access is more suitable. SSH provides a more traditional and flexible way of managing interactions, especially for users who require specific networking configurations or need features such as TCP load balancing, which Systems Manager doesn’t support.
Given that HyperPod is typically deployed in a virtual private cloud (VPC) using private subnets, direct SSH access to the login nodes requires secure network connectivity into the private subnet. There are several options to achieve this:
- AWS Site-to-Site VPN – Establishes a secure connection between your on-premises network and your VPC, suitable for enterprise environments
- AWS Direct Connect – Offers a dedicated network connection for high-throughput and low-latency needs
- AWS VPN Client – A software-based solution that remote users can use to securely connect to the VPC, providing flexible and easy access to the login nodes
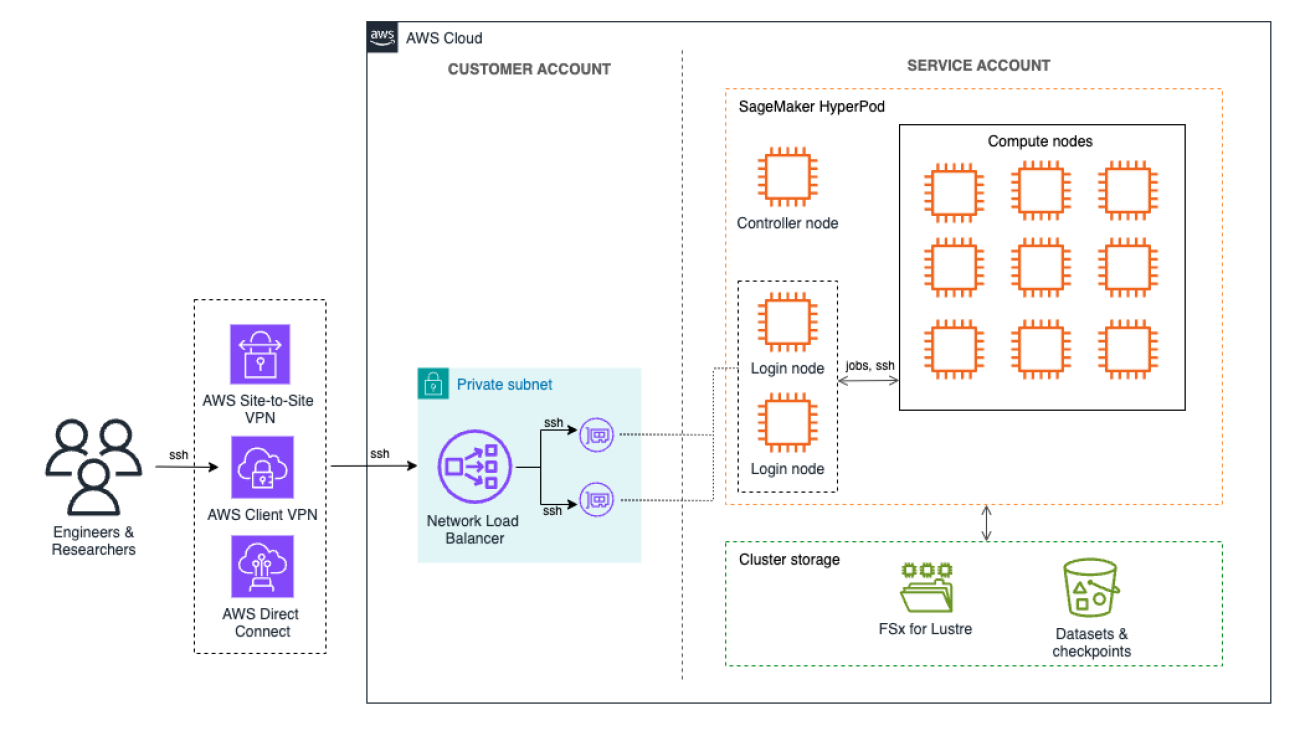
This post demonstrates how to use the AWS VPN Client to establish a secure connection to the VPC. We set up a Network Load Balancer (NLB) within the private subnet to evenly distribute SSH traffic across the available login nodes and use the VPN connection to connect to the NLB in the VPC. The NLB ensures that user sessions are balanced across the nodes, preventing any single node from becoming a bottleneck and thereby improving overall performance and resource utilization.
For environments where VPN connectivity might not be feasible, an alternative option is to deploy the NLB in a public subnet to allow direct SSH access from the internet. In this configuration, the NLB can be secured by restricting access through a security group that allows SSH traffic only from specified, trusted IP addresses. As a result, authorized users can connect directly to the login nodes while maintaining some level of control over access to the cluster. However, this public-facing method is outside the scope of this post and isn’t recommended for production environments, as exposing SSH access to the internet can introduce additional security risks.
The following diagram provides an overview of the solution architecture.
Prerequisites
Before following the steps in this post, make sure you have the foundational components of a HyperPod cluster setup in place. This includes the core infrastructure for the HyperPod cluster and the network configuration required for secure access. Specifically, you need:
- HyperPod cluster – This post assumes you already have a HyperPod cluster deployed. If not, refer to Getting started with SageMaker HyperPod and the HyperPod workshop for guidance on creating and configuring your cluster.
- VPC, subnets, and security group – Your HyperPod cluster should reside within a VPC with associated subnets. To deploy a new VPC and subnets, follow the instructions in the Own Account section of the HyperPod workshop. This process includes deploying an AWS CloudFormation stack to create essential resources such as the VPC, subnets, security group, and an Amazon FSx for Lustre volume for shared storage.
Setting up login nodes for cluster access
Login nodes are dedicated access points that users can use to interact with the HyperPod cluster’s computational resources without impacting the head node. By connecting through login nodes, users can browse files, submit jobs, and compile code independently, promoting a more organized and efficient use of the cluster’s resources.
If you haven’t set up login nodes yet, refer to the Login Node section of the HyperPod Workshop, which provides detailed instructions on adding these nodes to your cluster configuration.
Each login node in a HyperPod cluster has an associated network interface within your VPC. A network interface, also known as an elastic network interface, represents a virtual network card that connects each login node to your VPC, allowing it to communicate over the network. These interfaces have assigned IPv4 addresses, which are essential for routing traffic from the NLB to the login nodes.
To proceed with the load balancer setup, you need to obtain the IPv4 addresses of each login node. You can obtain these addresses from the AWS Management Console or by invoking a command on your HyperPod cluster’s head node.
Using the AWS Management Console
To set up login nodes for cluster access using the AWS Management Console, follow these steps:
- On the Amazon EC2 console, select Network interfaces in the navigation pane
- In the Search bar, select VPC ID = (Equals) and choose the VPC id of the VPC containing the HyperPod cluster
- In the Search bar, select Description : (Contains) and enter the name of the instance group that includes your login nodes (typically, this is login-group)
For each login node, you will find an entry in the list, as shown in the following screenshot. Note down the IPv4 addresses for all login nodes of your cluster.

Using the HyperPod head node
Alternatively, you can also retrieve the IPv4 addresses by entering the following command on your HyperPod cluster’s head node:
Create a Network Load Balancer
The next step is to create a NLB to manage traffic across your cluster’s login nodes.
For the NLB deployment, you need the IPv4 addresses of the login nodes collected earlier and the appropriate security group configurations. If you deployed your cluster using the HyperPod workshop instructions, a security group that permits communication between all cluster nodes should already be in place.
This security group can be applied to the load balancer, as demonstrated in the following instructions. Alternatively, you can opt to create a dedicated security group that grants access specifically to the login nodes.
Create target group
First, we create the target group that will be used by the NLB.
- On the Amazon EC2 console, select Target groups in the navigation pane
- Choose Create target group
- Create a target group with the following parameters:
- For Choose a target type, choose IP addresses
- For Target group name, enter smhp-login-node-tg
- For Protocol : Port, choose TCP and enter 22
- For IP address type, choose IPv4
- For VPC, choose SageMaker HyperPod VPC (which was created with the CloudFormation template)
- For Health check protocol, choose TCP
- Choose Next, as shown in the following screenshot

- In the Register targets section, register the login node IP addresses as the targets
- For Ports, enter 22 and choose Include as pending below, as shown in the following screenshot

- The login node IPs will appear as targets with Pending health status. Choose Create target group, as shown in the following screenshot

Create load balancer
To create the load balancer, follow these steps:
- On the Amazon EC2 console, select Load Balancers in the navigation pane
- Choose Create load balancer
- Choose Network Load Balancer and choose Create, as shown in the following screenshot

- Provide a name (for example, smhp-login-node-lb) and choose Internal as Scheme

- For network mapping, select the VPC that contains your HyperPod cluster and an associated private subnet, as shown in the following screenshot

- Select a security group that allows access on port 22 to the login nodes. If you deployed your cluster using the HyperPod workshop instructions, you can use the security group from this deployment.
- Select the Target group that you created before and choose TCP as Protocol and 22 for Port, as shown in the following screenshot

- Choose Create load balancer
After the load balancer has been created, you can find its DNS name on the load balancer’s detail page, as shown in the following screenshot.

Making sure host keys are consistent across login nodes
When using multiple login nodes in a load-balanced environment, it’s crucial to maintain consistent SSH host keys across all nodes. SSH host keys are unique identifiers that each server uses to prove its identity to connecting clients. If each login node has a different host key, users will encounter “WARNING: SSH HOST KEY CHANGED” messages whenever they connect to a different node, causing confusion and potentially leading users to question the security of the connection.
To avoid these warnings, configure the same SSH host keys on all login nodes in the load balancing rotation. This setup makes sure that users won’t receive host key mismatch alerts when routed to a different node by the load balancer.
You can enter the following script on the cluster’s head node to copy the SSH host keys from the first login node to the other login nodes in your HyperPod cluster:
Create AWS Client VPN endpoint
Because the NLB has been created with Internal scheme, it’s only accessible from within the HyperPod VPC. To access the VPC and send requests to the NLB, we use AWS Client VPN in this post.
AWS Client VPN is a managed client-based VPN service that enables secure access to your AWS resources and resources in your on-premises network.
We’ll set up an AWS Client VPN endpoint that provides clients with access to the HyperPod VPC and uses mutual authentication. With mutual authentication, Client VPN uses certificates to perform authentication between clients and the Client VPN endpoint.
To deploy a client VPN endpoint with mutual authentication, you can follow the steps outlined in Get started with AWS Client VPN. When configuring the client VPN to access the HyperPod VPC and the login nodes, keep these adaptations to the following steps in mind:
- Step 2 (create a Client VPN endpoint) – By default, all client traffic is routed through the Client VPN tunnel. To allow internet access without routing traffic through the VPN, you can enable the option Enable split-tunnel when creating the endpoint. When this option is enabled, only traffic destined for networks matching a route in the Client VPN endpoint route table is routed through the VPN tunnel. For more details, refer to Split-tunnel on Client VPN endpoints.
- Step 3 (target network associations) – Select the VPC and private subnet used by your HyperPod cluster, which contains the cluster login nodes.
- Step 4 (authorization rules) – Choose the Classless Inter-Domain Routing (CIDR) range associated with the HyperPod VPC. If you followed the HyperPod workshop instructions, the CIDR range is 10.0.0.0/16.
- Step 6 (security groups) – Select the security group that you previously used when creating the NLB.
Connecting to the login nodes
After the AWS Client VPN is configured, clients can establish a VPN connection to the HyperPod VPC. With the VPN connection in place, clients can use SSH to connect to the NLB, which will route them to one of the login nodes.
ssh -i /path/to/your/private-key.pem user@<NLB-IP-or-DNS>
To allow SSH access to the login nodes, you must create user accounts on the cluster and add their public keys to the authorized_keys file on each login node (or on all nodes, if necessary). For detailed instructions on managing multi-user access, refer to the Multi-User section of the HyperPod workshop.
In addition to using the AWS Client VPN, you can also access the NLB from other AWS services, such as Amazon Elastic Compute Cloud (Amazon EC2) instances, if they meet the following requirements:
- VPC connectivity – The EC2 instances must be either in the same VPC as the NLB or able to access the HyperPod VPC through a peering connection or similar network setup.
- Security group configuration – The EC2 instance’s security group must allow outbound connections on port 22 to the NLB security group. Likewise, the NLB security group should be configured to accept inbound SSH traffic on port 22 from the EC2 instance’s security group.
Clean up
To remove deployed resources, you can clean them up in the following order:
- Delete the Client VPN endpoint
- Delete the Network Load Balancer
- Delete the target group associated with the load balancer
If you also want to delete the HyperPod cluster, follow these additional steps:
- Delete the HyperPod cluster
- Delete the CloudFormation stack, which includes the VPC, subnets, security group, and FSx for Lustre volume
Conclusion
In this post, we explored how to implement login node load balancing for SageMaker HyperPod clusters. By using a Network Load Balancer to distribute user traffic across login nodes, you can optimize resource utilization and enhance the overall multi-user experience, providing seamless access to cluster resources for each user.
This approach represents only one way to customize your HyperPod cluster. Because of the flexibility of SageMaker HyperPod you can adapt configurations to your unique needs while benefiting from a managed, resilient environment. Whether you need to scale foundation model workloads, share compute resources across different tasks, or support long-running training jobs, SageMaker HyperPod offers a versatile solution that can evolve with your requirements.
For more details on making the most of SageMaker HyperPod, dive into the HyperPod workshop and explore further blog posts covering HyperPod.
About the Authors
 Janosch Woschitz is a Senior Solutions Architect at AWS, specializing in AI/ML. With over 15 years of experience, he supports customers globally in leveraging AI and ML for innovative solutions and building ML platforms on AWS. His expertise spans machine learning, data engineering, and scalable distributed systems, augmented by a strong background in software engineering and industry expertise in domains such as autonomous driving.
Janosch Woschitz is a Senior Solutions Architect at AWS, specializing in AI/ML. With over 15 years of experience, he supports customers globally in leveraging AI and ML for innovative solutions and building ML platforms on AWS. His expertise spans machine learning, data engineering, and scalable distributed systems, augmented by a strong background in software engineering and industry expertise in domains such as autonomous driving.
 Giuseppe Angelo Porcelli is a Principal Machine Learning Specialist Solutions Architect for Amazon Web Services. With several years of software engineering and an ML background, he works with customers of any size to understand their business and technical needs and design AI and ML solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. He has worked on projects in different domains, including MLOps, computer vision, and NLP, involving a broad set of AWS services. In his free time, Giuseppe enjoys playing football.
Giuseppe Angelo Porcelli is a Principal Machine Learning Specialist Solutions Architect for Amazon Web Services. With several years of software engineering and an ML background, he works with customers of any size to understand their business and technical needs and design AI and ML solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. He has worked on projects in different domains, including MLOps, computer vision, and NLP, involving a broad set of AWS services. In his free time, Giuseppe enjoys playing football.
How Clearwater Analytics is revolutionizing investment management with generative AI and Amazon SageMaker JumpStart
This post was written with Darrel Cherry, Dan Siddall, and Rany ElHousieny of Clearwater Analytics.
As global trading volumes rise rapidly each year, capital markets firms are facing the need to manage large and diverse datasets to stay ahead. These datasets aren’t just expansive in volume; they’re critical in driving strategy development, enhancing execution, and streamlining risk management. The explosion of data creation and utilization, paired with the increasing need for rapid decision-making, has intensified competition and unlocked opportunities within the industry. To remain competitive, capital markets firms are adopting Amazon Web Services (AWS) Cloud services across the trade lifecycle to rearchitect their infrastructure, remove capacity constraints, accelerate innovation, and optimize costs.
Generative AI, AI, and machine learning (ML) are playing a vital role for capital markets firms to speed up revenue generation, deliver new products, mitigate risk, and innovate on behalf of their customers. A great example of such innovation is our customer Clearwater Analytics and their use of large language models (LLMs) hosted on Amazon SageMaker JumpStart, which has propelled asset management productivity and delivered AI-powered investment management productivity solutions to their customers.
In this post, we explore Clearwater Analytics’ foray into generative AI, how they’ve architected their solution with Amazon SageMaker, and dive deep into how Clearwater Analytics is using LLMs to take advantage of more than 18 years of experience within the investment management domain while optimizing model cost and performance.
About Clearwater Analytics
Clearwater Analytics (NYSE: CWAN) stands at the forefront of investment management technology. Founded in 2004 in Boise, Idaho, Clearwater has grown into a global software-as-a-service (SaaS) powerhouse, providing automated investment data reconciliation and reporting for over $7.3 trillion in assets across thousands of accounts worldwide. With a team of more than 1,600 professionals and a long-standing relationship with AWS dating back to 2008, Clearwater has consistently pushed the boundaries of financial technology innovation.
In May 2023, Clearwater embarked on a journey into the realm of generative AI, starting with a private, secure generative AI chat-based assistant for their internal workforce, enhancing client inquiries through Retrieval Augmented Generation (RAG). As a result, Clearwater was able to increase assets under management (AUM) over 20% without increasing operational headcount. By September of the same year, Clearwater unveiled its generative AI customer offerings at the Clearwater Connect User Conference, marking a significant milestone in their AI-driven transformation.
About SageMaker JumpStart
Amazon SageMaker JumpStart is an ML hub that can help you accelerate your ML journey. With SageMaker JumpStart, you can evaluate, compare, and select foundation models (FMs) quickly based on predefined quality and responsibility metrics to perform tasks such as article summarization and image generation. Pre-trained models are fully customizable for your use case with your data, and you can effortlessly deploy them into production with the user interface or AWS SDK. You can also share artifacts, including models and notebooks, within your organization to accelerate model building and deployment, and admins can control which models are visible to users within their organization.
Clearwater’s generative AI solution architecture
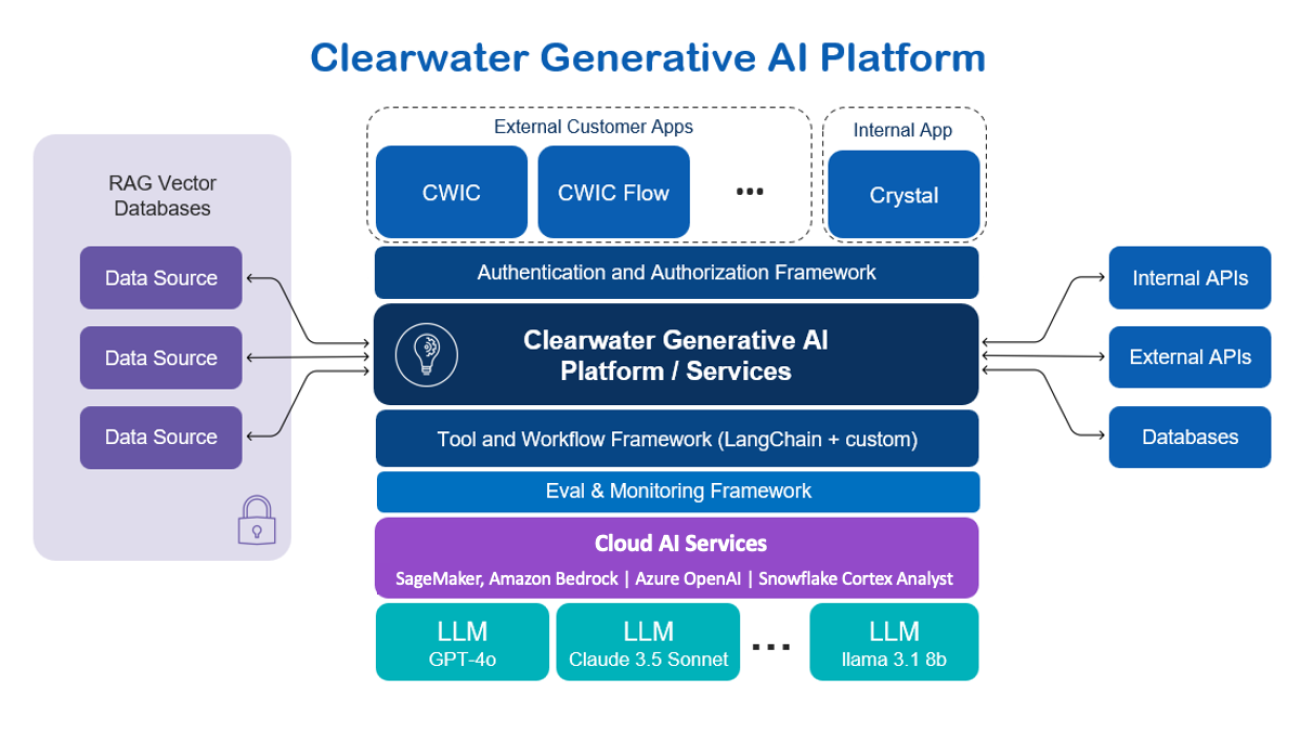
Clearwater Analytics’ generative AI architecture supports a wide array of vertical solutions by merging extensive functional capabilities through the LangChain framework, domain knowledge through RAG, and customized LLMs hosted on Amazon SageMaker. This integration has resulted in a potent asset for both Clearwater customers and their internal teams.
The following image illustrates the solution architecture.

As of September 2024, the AI solution supports three core applications:
- Clearwater Intelligent Console (CWIC) – Clearwater’s customer-facing AI application. This assistant framework is built upon three pillars:
- Knowledge awareness – Using RAG, CWIC compiles and delivers comprehensive knowledge that is crucial for customers from intricate calculations of book value to period-end reconciliation processes.
- Application awareness – Transforming novice users into power users instantly, CWIC guides clients to inquire about Clearwater’s applications and receive direct links to relevant investment reports. For instance, if a client needs information on their yuan exposure, CWIC employs its tool framework to identify and provide links to the appropriate currency exposure reports.
- Data awareness – Digging deep into portfolio data, CWIC adeptly manages complex queries, such as validating book yield tie-outs, by accessing customer-specific data and performing real-time calculations.The following image shows a snippet of the generative AI assistance within the CWIC.

- Crystal – Clearwater’s advanced AI assistant with expanded capabilities that empower internal teams’ operations. Crystal shares CWIC’s core functionalities but benefits from broader data sources and API access. Enhancements driven by Crystal have achieved efficiency gains between 25% and 43%, improving Clearwater’s ability to manage substantial increases in AUM without increases in staffing.
- CWIC Specialists – Their most recent solution CWIC Specialists are domain-specific generative AI agents equipped to handle nuanced investment tasks, from accounting to regulatory compliance. These agents can work in single or multi-agentic workflows to answer questions, perform complex operations, and collaborate to solve various investment-related tasks. These specialists assist both internal teams and customers in domain specific areas, such as investment accounting, regulatory requirements, and compliance information. Each specialist is underpinned by thousands of pages of domain documentation, which feeds into the RAG system and is used to train smaller, specialized models with Amazon SageMaker JumpStart. This approach enhances cost-effectiveness and performance to promote high-quality interactions.
In the next sections, we dive deep into how Clearwater analytics is using Amazon SageMaker JumpStart to fine-tune models for productivity improvement and to deliver new AI services.
Clearwater’s Use of LLMs hosted on Amazon SageMaker JumpStart
Clearwater employs a two-pronged strategy for using LLMs. This approach addresses both high-complexity scenarios requiring powerful language models and domain-specific applications demanding rapid response times.
- Advanced foundation models – For tasks involving intricate reasoning or creative output, Clearwater uses state-of-the-art pre-trained models such as Anthropic’s Claude or Meta’s Llama. These models excel in handling complex queries and generating innovative solutions.
- Fine-tuned models for specialized knowledge – In cases where domain-specific expertise or swift responses are crucial, Clearwater uses fine-tuned models. These customized LLMs are optimized for industries or tasks that require accuracy and efficiency.
Fine-tuned models through domain adaptation with Amazon SageMaker JumpStart
Although general LLMs are powerful, their accuracy can be put to the test in specialized domains. This is where domain adaptation, also known as continued pre-training, comes into play. Domain adaptation is a sophisticated form of transfer learning that allows a pre-trained model to be fine-tuned for optimal performance in a different, yet related, target domain. This approach is particularly valuable when there’s a scarcity of labeled data in the target domain but an abundance in a related source domain.
These are some of the key benefits for domain adaptation:
- Cost-effectiveness – Creating a curated set of questions and answers for instruction fine-tuning can be prohibitively expensive and time-consuming. Domain adaptation eliminates the need for thousands of manually created Q&As.
- Comprehensive learning – Unlike instruction tuning, which only learns from provided questions, domain adaptation extracts information from entire documents, resulting in a more thorough understanding of the subject matter.
- Efficient use of expertise – Domain adaptation frees up human experts from the time-consuming task of generating questions so they can focus on their primary responsibilities.
- Faster deployment – With domain adaptation, specialized AI models can be developed and deployed more quickly, accelerating time to market for AI-powered solutions.
AWS has been at the forefront of domain adaptation, creating a framework to allow creating powerful, specialized AI models. Using this framework, Clearwater has been able to train smaller, faster models tailored to specific domains without the need for extensive labeled datasets. This innovative approach allows Clearwater to power digital specialists with a finely tuned model trained on a particular domain. The result? More responsive LLMs that form the backbone of their cutting-edge generative AI services.
The evolution of fine-tuning with Amazon SageMaker JumpStart
Clearwater is collaborating with AWS to enhance their fine-tuning processes. Amazon SageMaker JumpStart offered them a framework for domain adaptation. During the year, Clearwater has witnessed significant improvements in the user interface and effortlessness of fine-tuning using SageMaker JumpStart.
For instance, the code required to set up and fine-tune a GPT-J-6B model has been drastically streamlined. Previously, it required a data scientist to write over 100 lines of code within an Amazon SageMaker Notebook to identify and retrieve the proper image, set the right training script, and import the right hyperparameters. Now, using SageMaker JumpStart and advancements in the field, the process has streamlined to a few lines of code:
A fine-tuning example: Clearwater’s approach
For Clearwater’s AI, the team successfully fine-tuned a GPT-J-6B (huggingface-textgeneration1-gpt-j- 6bmodel) model with domain adaptation using Amazon SageMaker JumpStart. The following are the concrete steps used for the fine-tuning process to serve as a blueprint for others to implement similar strategies. A detailed tutorial can found in this amazon-sagemaker-examples repo.
- Document assembly – Gather all relevant documents that will be used for training. This includes help content, manuals, and other domain-specific text. The data Clearwater used for training this model is public help content which contains no client data. Clearwater exclusively uses client data, with their collaboration and approval, to fine-tune a model dedicated solely to the specific client. Curation, cleaning and de-identification of data is necessary for training and subsequent tuning operations.
- Test set creation – Develop a set of questions and answers that will be used to evaluate the model’s performance before and after fine-tuning. Clearwater has implemented a sophisticated model evaluation system for additional assessment of performance for open source and commercial models. This is covered more in the Model evaluation and optimization section later in this post.
- Pre-trained model deployment – Deploy the original, pre-trained GPT-J-6B model.
- Baseline testing – Use the question set to test the pre-trained model, establishing a performance baseline.
- Pre-trained model teardown – Remove the pre-trained model to free up resources.
- Data preparation – Upload the assembled documents to an S3 bucket, making sure they’re in a format suitable for the fine-tuning process.
- Fine-tuning – Train the new model using the uploaded documents, adjusting hyperparameters as needed.
- Fine-tuned model testing – Evaluate the fine-tuned model using the same question set used for the baseline.
- Fine-tuned model teardown – If not immediately needed, tear down the fine-tuned model to optimize resource usage.
- RAG comparison – Test a RAG-based system using the same question set for an additional point of comparison.
- Performance evaluation – Analyze the results from all tests to assess the effectiveness of the fine-tuning process.
This is how the results look before tuning an open source model (GGPT-J-6B), after tuning, and using a commercial model with a larger context window (Claude-3.5-Sonnet).
Prompt
What does Clearwater Compliance module do?
Reference Answer
The Clearwater Compliance module supports client investment policies, providing daily updates, including compliance warnings and violations. Clearwater’s Compliance module monitors various portfolio characteristics, including asset and security type allocation, sector exposure, investment time horizon, and credit quality. The Compliance module enables users to establish and update investment policies, monitor changes to accounts, and provide audit reporting. Rules provide flexibility to evaluate data from the individual security-level to aggregate values at the portfolio-level. User-identified investments can also be prohibited. Multiple investment policies can be applied to individual accounts and aggregates of accounts.
| GPT-J-6B pre-trained | GPT-J-6B fine-tuned | Claude-3.5-Sonnet with RAG |
| The Clearwater Compliance module is an integrated set of controls you can use to manage your compliance with the federal and state requirements for the handling and transportation of hazardous materials. |
The Clearwater Compliance module is a suite of tools designed to help clients monitor and manage their compliance policies and procedures. · Compliance Overview dashboard – Provides a high-level view of compliance policies and a history of compliance policy changes. · Compliance Settings tool – Users can update compliance settings, such as the frequency at which compliance policies are checked and the level of compliance required to access a compliance-restricted area of the website. · Compliance Audit report – Provides a detailed list of policies and rules that weren’t met. The report includes a breakdown of rule violations and the actions required to bring the policies into compliance. · Compliance Notifications tool – Sends notifications to designated recipients, such as the client’s compliance officer, when a compliance rule is about to expire or has been violated. · Compliance Documents tool – Users can upload and manage compliance policies and rules. |
The Clearwater Compliance module is a sophisticated tool designed to support and monitor client investment policies. Here’s what it does: · Daily Monitoring – Provides daily updates, including compliance warnings and violations, to foster ongoing adherence to investment policies. · Portfolio characteristic tracking –Monitors various aspects of portfolios, including asset and security type allocation, sector exposure, investment time horizon, and credit quality. · Policy management – Users can establish, update, and manage investment policies through the module. · Flexible rule application – Allows for the evaluation of compliance rules at both individual security and portfolio levels. · Custom policy creation – Clearwater works with clients to create compliance rules based on their specific investment policies and interpretations. · Multi-account support – Multiple investment policies can be applied to individual accounts or aggregates of accounts. · Reporting and auditing – Generates audit reports and provides tools for monitoring account changes. · Risk mitigation – Offers integrated, customized daily reports on the Clearwater Reporting Site, to proactively manage risk. · Regulatory compliance – Includes external and regulatory policies when provided by the client, providing broader compliance coverage. · Violation tracking – Identifies compliance rule violations, tracks the number of days in violation, and allows for resolution statements. |
Although the Compliance module is comprehensive, it has some limitations. It only supports objective rules using data available within the Clearwater system and doesn’t cover areas such as pre-trade compliance, investments without publicly available data, or scenario testing.
Overall, the Clearwater Compliance module serves as a robust tool for maintaining investment policy compliance, offering daily monitoring, customization, and reporting features to support effective risk management and regulatory adherence.
Model evaluation and optimization
Clearwater employs a sophisticated evaluation system to assess the performance of new models available on Amazon SageMaker JumpStart. This means that only models demonstrating superior capabilities are integrated into the production environment.
Clearwater’s LLM operations (LLMOps) pipeline plays a crucial role in this process, automating the evaluation and seamless integration of new models. This commitment to using the most effective LLMs for each unique task with cutting-edge technology and optimal performance is the cornerstone of Clearwater’s approach.
The evaluation phase is crucial for determining the success of the fine-tuning process. As you determine the evaluation process and framework that should be used, you need to make sure they fit the criteria for their domain. At Clearwater, we designed our own internal evaluation framework to meet the specific needs of our investment management and accounting domains.
Here are key considerations:
- Performance comparison – The fine-tuned model should outperform the pre-trained model on domain-specific tasks. If it doesn’t, it might indicate that the pre-trained model already had significant knowledge in this area.
- RAG benchmark – Compare the fine-tuned model’s performance against a RAG system using a pre-trained model. If the fine-tuned model doesn’t at least match RAG performance, troubleshooting is necessary.
- Troubleshooting checklist:
- Data format suitability for fine-tuning
- Completeness of the training dataset
- Hyperparameter optimization
- Potential overfitting or underfitting
- Cost-benefit analysis. That is, estimate the operational costs of using a RAG system with a pre-tuned model (for example, Claude-3.5 Sonnet) compared with deploying the fine-tuned model at production scale.
- Advance considerations:
- Iterative fine-tuning – Consider multiple rounds of fine-tuning, gradually introducing more specific or complex data.
- Multi-task learning – If applicable, fine-tune the model on multiple related domains simultaneously to improve its versatility.
- Continual learning – Implement strategies to update the model with new information over time without full retraining.
Conclusion
For businesses and organizations seeking to harness the power of AI in specialized domains, domain adaptation presents significant opportunities. Whether you’re in healthcare, finance, legal services, or any other specialized field, adapting LLMs to your specific needs can provide a significant competitive advantage.
By following this comprehensive approach with Amazon SageMaker, organizations can effectively adapt LLMs to their specific domains, achieving better performance and potentially more cost-effective solutions than generic models with RAG systems. However, the process requires careful monitoring, evaluation, and optimization to achieve the best results.
As we’ve observed with Clearwater’s success, partnering with an experienced AI company such as AWS can help navigate the complexities of domain adaptation and unlock its full potential. By embracing this technology, you can create AI solutions that are not just powerful, but also truly tailored to your unique requirements and expertise.
The future of AI isn’t just about bigger models, but smarter, more specialized ones. Domain adaptation is paving the way for this future, and those who harness its power will emerge as leaders in their respective industries.
Get started with Amazon SageMaker JumpStart on your fine-tuning LLM journey today.
About the Authors
 Darrel Cherry is a Distinguished Engineer with over 25 years of experience leading organizations to create solutions for complex business problems. With a passion for emerging technologies, he has architected large cloud and data processing solutions, including machine learning and deep learning AI applications. Darrel holds 19 US patents and has contributed to various industry publications. In his current role at Clearwater Analytics, Darrel leads technology strategy for AI solutions, as well as Clearwater’s overall enterprise architecture. Outside the professional sphere, he enjoys traveling, auto racing, and motorcycling, while also spending quality time with his family.
Darrel Cherry is a Distinguished Engineer with over 25 years of experience leading organizations to create solutions for complex business problems. With a passion for emerging technologies, he has architected large cloud and data processing solutions, including machine learning and deep learning AI applications. Darrel holds 19 US patents and has contributed to various industry publications. In his current role at Clearwater Analytics, Darrel leads technology strategy for AI solutions, as well as Clearwater’s overall enterprise architecture. Outside the professional sphere, he enjoys traveling, auto racing, and motorcycling, while also spending quality time with his family.
 Dan Siddall, a Staff Data Scientist at Clearwater Analytics, is a seasoned expert in generative AI and machine learning, with a comprehensive understanding of the entire ML lifecycle from development to production deployment. Recognized for his innovative problem-solving skills and ability to lead cross-functional teams, Dan leverages his extensive software engineering background and strong communication abilities to bridge the gap between complex AI concepts and practical business solutions.
Dan Siddall, a Staff Data Scientist at Clearwater Analytics, is a seasoned expert in generative AI and machine learning, with a comprehensive understanding of the entire ML lifecycle from development to production deployment. Recognized for his innovative problem-solving skills and ability to lead cross-functional teams, Dan leverages his extensive software engineering background and strong communication abilities to bridge the gap between complex AI concepts and practical business solutions.
 Rany ElHousieny is an Engineering Leader at Clearwater Analytics with over 30 years of experience in software development, machine learning, and artificial intelligence. He has held leadership roles at Microsoft for two decades, where he led the NLP team at Microsoft Research and Azure AI, contributing to advancements in AI technologies. At Clearwater, Rany continues to leverage his extensive background to drive innovation in AI, helping teams solve complex challenges while maintaining a collaborative approach to leadership and problem-solving.
Rany ElHousieny is an Engineering Leader at Clearwater Analytics with over 30 years of experience in software development, machine learning, and artificial intelligence. He has held leadership roles at Microsoft for two decades, where he led the NLP team at Microsoft Research and Azure AI, contributing to advancements in AI technologies. At Clearwater, Rany continues to leverage his extensive background to drive innovation in AI, helping teams solve complex challenges while maintaining a collaborative approach to leadership and problem-solving.
 Pablo Redondo is a Principal Solutions Architect at Amazon Web Services. He is a data enthusiast with over 18 years of FinTech and healthcare industry experience and is a member of the AWS Analytics Technical Field Community (TFC). Pablo has been leading the AWS Gain Insights Program to help AWS customers achieve better insights and tangible business value from their data analytics and AI/ML initiatives. In his spare time, Pablo enjoys quality time with his family and plays pickleball in his hometown of Petaluma, CA.
Pablo Redondo is a Principal Solutions Architect at Amazon Web Services. He is a data enthusiast with over 18 years of FinTech and healthcare industry experience and is a member of the AWS Analytics Technical Field Community (TFC). Pablo has been leading the AWS Gain Insights Program to help AWS customers achieve better insights and tangible business value from their data analytics and AI/ML initiatives. In his spare time, Pablo enjoys quality time with his family and plays pickleball in his hometown of Petaluma, CA.
 Prashanth Ganapathy is a Senior Solutions Architect in the Small Medium Business (SMB) segment at AWS. He enjoys learning about AWS AI/ML services and helping customers meet their business outcomes by building solutions for them. Outside of work, Prashanth enjoys photography, travel, and trying out different cuisines.
Prashanth Ganapathy is a Senior Solutions Architect in the Small Medium Business (SMB) segment at AWS. He enjoys learning about AWS AI/ML services and helping customers meet their business outcomes by building solutions for them. Outside of work, Prashanth enjoys photography, travel, and trying out different cuisines.
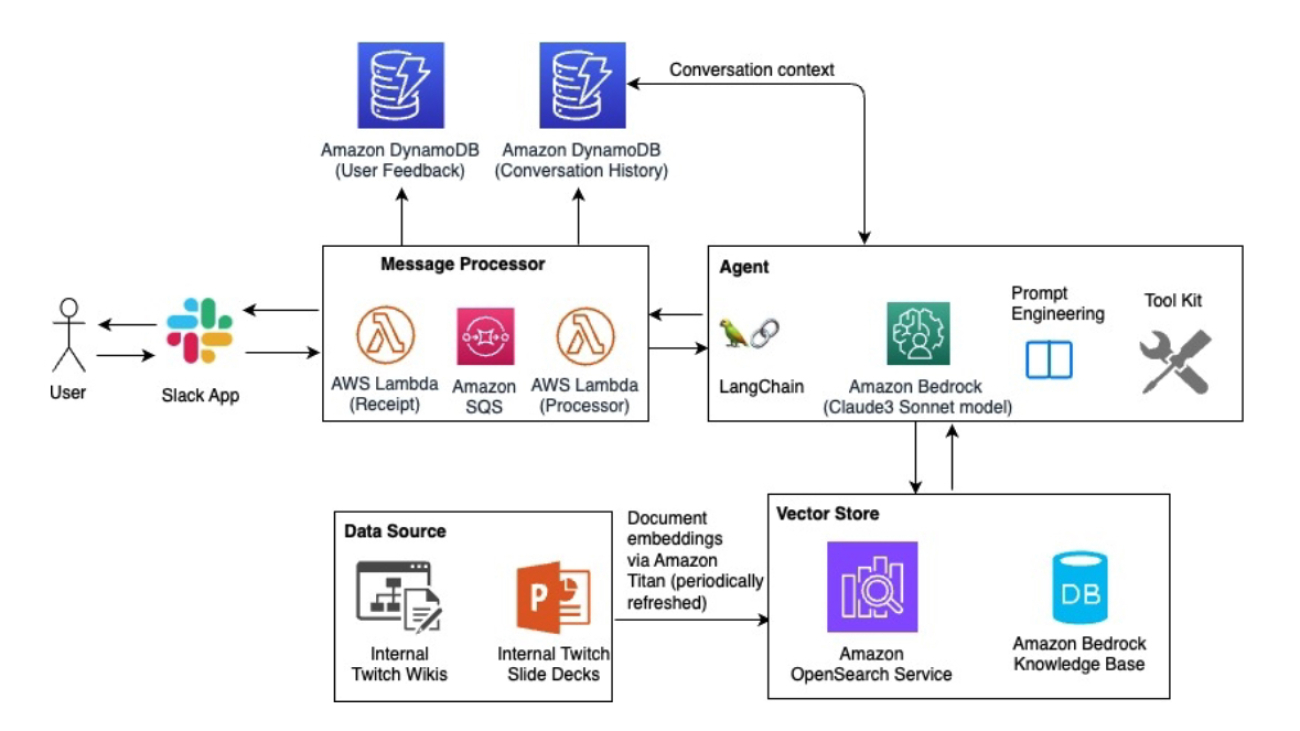
How Twitch used agentic workflow with RAG on Amazon Bedrock to supercharge ad sales
Twitch, the world’s leading live-streaming platform, has over 105 million average monthly visitors. As part of Amazon, Twitch advertising is handled by the ad sales organization at Amazon. New ad products across diverse markets involve a complex web of announcements, training, and documentation, making it difficult for sales teams to find precise information quickly. In early 2024, Amazon launched a major push to harness the power of Twitch for advertisers globally. This necessitated the ramping up of Twitch knowledge to all of Amazon ad sales. The task at hand was especially challenging to internal sales support teams. With a ratio of over 30 sellers per specialist, questions posed in public channels often took an average of 2 hours for an initial reply, with 20% of questions not being answered at all. All in all, the entire process from an advertiser’s request to the first campaign launch could stretch up to 7 days.
In this post, we demonstrate how we innovated to build a Retrieval Augmented Generation (RAG) application with agentic workflow and a knowledge base on Amazon Bedrock. We implemented the RAG pipeline in a Slack chat-based assistant to empower the Amazon Twitch ads sales team to move quickly on new sales opportunities. We discuss the solution components to build a multimodal knowledge base, drive agentic workflow, use metadata to address hallucinations, and also share the lessons learned through the solution development using multiple large language models (LLMs) and Amazon Bedrock Knowledge Bases.
Solution overview
A RAG application combines an LLM with a specialized knowledge base to help answer domain-specific questions. We developed an agentic workflow with RAG solution that revolves around a centralized knowledge base that aggregates Twitch internal marketing documentation. This content is then transformed into a vector database optimized for efficient information retrieval. In the RAG pipeline, the retriever taps into this vector database to surface relevant information, and the LLM generates tailored responses to Twitch user queries submitted through a Slack assistant. The solution architecture is presented in the following diagram.

The key architectural components driving this solution include:
- Data sources – A centralized repository containing marketing data aggregated from various sources such as wikis and slide decks, using web crawlers and periodic refreshes
- Vector database – The marketing contents are first embedded into vector representations using Amazon Titan Multimodal Embeddings G1 on Amazon Bedrock, capable of handling both text and image data. These embeddings are then stored in an Amazon Bedrock knowledge bases.
- Agentic workflow – The agent acts as an intelligent dispatcher. It evaluates each user query to determine the appropriate course of action, whether refusing to answer off-topic queries, tapping into the LLM, or invoking APIs and data sources such as the vector database. The agent uses chain-of-thought (CoT) reasoning, which breaks down complex tasks into a series of smaller steps then dynamically generates prompts for each subtask, combines the results, and synthesizes a final coherent response.
- Slack integration – A message processor was implemented to interface with users through a Slack assistant using an AWS Lambda function, providing a seamless conversational experience.
Lessons learned and best practices
The process of designing, implementing, and iterating a RAG application with agentic workflow and a knowledge base on Amazon Bedrock produced several valuable lessons.
Processing multimodal source documents in the knowledge base
An early problem we faced was that Twitch documentation is scattered across the Amazon internal network. Not only is there no centralized data store, but there is also no consistency in the data format. Internal wikis contain a mixture of image and text, and training materials to sales agents are often in the form of PowerPoint presentations. To make our chat assistant the most effective, we needed to coalesce all of this information together into a single repository the LLM could understand.
The first step was making a wiki crawler that uploaded all the relevant Twitch wikis and PowerPoint slide decks to Amazon Simple Storage Service (Amazon S3). We used that as the source to create a knowledge base on Amazon Bedrock. To handle the combination of images and text in our data source, we used the Amazon Titan Multimodal Embeddings G1 model. For the documents containing specific information such as demographic context, we summarized multiple slides to ensure this information is included in the final contexts for LLM.
In total, our knowledge base contains over 200 documents. Amazon Bedrock knowledge bases are easy to amend, and we routinely add and delete documents based on changing wikis or slide decks. Our knowledge base is queried from time to time every day, and metrics, dashboards, and alarms are inherently supported in Amazon Web Services (AWS) through Amazon CloudWatch. These tools provide complete transparency into the health of the system and allow fully hands-off operation.
Agentic workflow for a wide range of user queries
As we observed our users interact with our chat assistant, we noticed that there were some questions the standard RAG application couldn’t answer. Some of these questions were overly complex, with multiple questions combined, some asked for deep insights into Twitch audience demographics, and some had nothing to do with Twitch at all.
Because the standard RAG solution could only answer simple questions and couldn’t handle all these scenarios gracefully, we invested in an agentic workflow with RAG solution. In this solution, an agent breaks down the process of answering questions into multiple steps, and uses different tools to answer different types of questions. We implemented an XML agent in LangChain, choosing XML because the Anthropic Claude models available in Amazon Bedrock are extensively trained on XML data. In addition, we engineered our prompts to instruct the agent to adopt a specialized persona with domain expertise in advertising and the Twitch business realm. The agent breaks down queries, gathers relevant information, analyzes context, and weighs potential solutions. The flow for our chat agent is shown in the following diagram. In the follow, when the agent reads a user question, the first step is to decide whether the question is related to Twitch – if it isn’t, the agent politely refuses to answer. If the question is related to Twitch, the agent ‘thinks’ about which tool is best suited to answer the question. For instance, if the question is related to audience forecasting, the agent will invoke Amazon internal Audience Forecasting API. If the question is related to Twitch advertisement products, the agent will invoke its advertisement knowledge base. Once the agent fetches the results from the appropriate tool, the agent will consider the results and think whether it now has enough information to answer the question. If it doesn’t, the agent will invoke its toolkit again (maximum of 3 attempts) to gain more context. Once its finished gathering information, the agent will generate a final response and send it to the user.
 |
One of the chief benefits of agentic AI is the ability to integrate with multiple data sources. In our case, we use an internal forecasting API to fetch data related to the available Amazon and Twitch audience supply. We also use Amazon Bedrock Knowledge Bases to help with questions about static data, such as features of Twitch ad products. This greatly increased the scope of questions our chatbot could answer, which the initial RAG couldn’t support. The agent is intelligent enough to know which tool to use based on the query. You only need to provide high-level instructions about the tool purpose, and it will invoke the LLM to make a decision. For example,
Even better, LangChain logs the agent’s thought process in CloudWatch. This is what a log statement looks like when the agent decides which tool to use:
The agent helps keep our RAG flexible. Looking towards the future, we plan to onboard additional APIs, build new vector stores, and integrate with chat assistants in other Amazon organizations. This is critical to helping us expand our product, maximizing its scope and impact.
Contextual compression for LLM invocation
During the document retrieval, we found that our internal wikis varied greatly in size. This meant that often a wiki would contain hundreds or even thousands of lines of text, but only a small paragraph was relevant to answering the question. To reduce the size of context and input token to the LLM, we used another LLM to perform contextual compression to extract the relevant portions of the returned documents. Initially, we used Anthropic Claude Haiku because of its superior speed. However, we found that Anthropic Claude Sonnet boosted the result accuracy, while being only 20% slower than Haiku (from 8 seconds to 10 seconds). As a result, we chose Sonnet for our use case because providing the best quality answers to our users is the most important factor. We’re willing to take an additional 2 seconds latency, comparing to the 2-day turn-around time in the traditional manual process.
Address hallucinations by document metadata
As with any RAG solution, our chat assistant occasionally hallucinated incorrect answers. While this is a well-recognized problem with LLMs, it was particularly pronounced in our system, because of the complexity of the Twitch advertising domain. Because our users relied on the chatbot responses to interact with their clients, they were reluctant to trust even its correct answers, despite most answers being correct.
We increased the users’ trust by showing them where the LLM was getting its information from for each statement made. This way, if a user is skeptical of a statement, they can check the references the LLM used and read through the authoritative documentation themselves. We achieved this by adding the source URL of the retrieved documents as metadata in our knowledge base, which Amazon Bedrock directly supports. We then instructed the LLM to read the metadata and append the source URLs as clickable links in its responses.
Here’s an example question and answer with citations:
Note that the LLM responds with two sources. The first is from a sales training PowerPoint slide deck, and the second is from an internal wiki. For the slide deck, the LLM can provide the exact slide number it pulled the information from. This is especially useful because some decks contain over 100 slides.
After adding citations, our user feedback score noticeably increased. Our favorable feedback rate increased by 40% and overall assistant usage increased by 20%, indicating that users gained more trust in the assistant’s responses due to the ability to verify the answers.
Human-in-the-loop feedback collection
When we launched our chat assistant in Slack, we had a feedback form that users could fill out. This included several questions to rate aspects of the chat assistant on a 1–5 scale. While the data was very rich, hardly anyone used it. After switching to a much simpler thumb up or thumb down button that a user could effortlessly select (the buttons are appended to each chatbot answer), our feedback rate increased by eightfold.
Conclusion
Moving fast is important in the AI landscape, especially because the technology changes so rapidly. Often engineers will have an idea about a new technique in AI and want to test it out quickly. Using AWS services helped us learn fast about what technologies are effective and what aren’t. We used Amazon Bedrock to test multiple foundation models (FMs), including Anthropic Claude Haiku and Sonnet, Meta Llama 3, Cohere embedding models, and Amazon Titan Multimodal Embeddings. Amazon Bedrock Knowledge Bases helped us implement RAG with agentic workflow efficiently without building custom integrations to our various multimodal data sources and data flows. Using dynamic chunking and metadata filtering let us retrieve the needed contents more accurately. All these together allowed us to spin up a working prototype in a few days instead of months. After we deployed the changes to our customers, we continued to adopt Amazon Bedrock and other AWS services in the application.
Since the Twitch Sales Bot launch in February 2024, we have answered over 11,000 questions about the Twitch sales process. In addition, Amazon sellers who used our generative AI solution delivered 25% more Twitch revenue year-to-date when compared with sellers who didn’t, and delivered 120% more revenue when compared to self-service accounts. We will continue expanding our chat assistant’s agentic capabilities—using Amazon Bedrock along with other AWS services—to solve new problems for our users and increase Twitch bottom line. We plan to incorporate distinct Knowledge Bases across Amazon portfolio of 1P Publishers like Prime Video, Alexa, and IMDb as a fast, accurate, and comprehensive generative AI solution to supercharge ad sales.
For your own project, you can follow our architecture and adopt a similar solution to build an AI assistant to address your own business challenge.
About the Authors
 Bin Xu is a Senior Software Engineer at Amazon Twitch Advertising and holds a Master’s degree in Data Science from Columbia University. As the visionary creator behind TwitchBot, Bin successfully introduced the proof of concept in 2023. Bin is currently leading a team in Twitch Ads Monetization, focusing on optimizing video ad delivery, improving sales workflows, and enhancing campaign performance. Also leading efforts to integrate AI-driven solutions to further improve the efficiency and impact of Twitch ad products. Outside of his professional endeavors, Bin enjoys playing video games and tennis.
Bin Xu is a Senior Software Engineer at Amazon Twitch Advertising and holds a Master’s degree in Data Science from Columbia University. As the visionary creator behind TwitchBot, Bin successfully introduced the proof of concept in 2023. Bin is currently leading a team in Twitch Ads Monetization, focusing on optimizing video ad delivery, improving sales workflows, and enhancing campaign performance. Also leading efforts to integrate AI-driven solutions to further improve the efficiency and impact of Twitch ad products. Outside of his professional endeavors, Bin enjoys playing video games and tennis.
 Nick Mariconda is a Software Engineer at Amazon Advertising, focused on enhancing the advertising experience on Twitch. He holds a Master’s degree in Computer Science from Johns Hopkins University. When not staying up to date with the latest in AI advancements, he enjoys getting outdoors for hiking and connecting with nature.
Nick Mariconda is a Software Engineer at Amazon Advertising, focused on enhancing the advertising experience on Twitch. He holds a Master’s degree in Computer Science from Johns Hopkins University. When not staying up to date with the latest in AI advancements, he enjoys getting outdoors for hiking and connecting with nature.
 Frank Zhu is a Senior Product Manager at Amazon Advertising, located in New York City. With a background in programmatic ad-tech, Frank helps connect the business needs of advertisers and Amazon publishers through innovative advertising products. Frank has a BS in finance and marketing from New York University and outside of work enjoys electronic music, poker theory, and video games.
Frank Zhu is a Senior Product Manager at Amazon Advertising, located in New York City. With a background in programmatic ad-tech, Frank helps connect the business needs of advertisers and Amazon publishers through innovative advertising products. Frank has a BS in finance and marketing from New York University and outside of work enjoys electronic music, poker theory, and video games.
 Yunfei Bai is a Principal Solutions Architect at AWS. With a background in AI/ML, data science, and analytics, Yunfei helps customers adopt AWS services to deliver business results. He designs AI/ML and data analytics solutions that overcome complex technical challenges and drive strategic objectives. Yunfei has a PhD in Electronic and Electrical Engineering. Outside of work, Yunfei enjoys reading and music.
Yunfei Bai is a Principal Solutions Architect at AWS. With a background in AI/ML, data science, and analytics, Yunfei helps customers adopt AWS services to deliver business results. He designs AI/ML and data analytics solutions that overcome complex technical challenges and drive strategic objectives. Yunfei has a PhD in Electronic and Electrical Engineering. Outside of work, Yunfei enjoys reading and music.
 Cathy Willcock is a Principal Technical Business Development Manager located in Seattle, WA. Cathy leads the AWS technical account team supporting Amazon Ads adoption of AWS cloud technologies. Her team works across Amazon Ads enabling discovery, testing, design, analysis, and deployments of AWS services at scale, with a particular focus on innovation to shape the landscape across the AdTech and MarTech industry. Cathy has led engineering, product, and marketing teams and is an inventor of ground-to-air calling (1-800-RINGSKY).
Cathy Willcock is a Principal Technical Business Development Manager located in Seattle, WA. Cathy leads the AWS technical account team supporting Amazon Ads adoption of AWS cloud technologies. Her team works across Amazon Ads enabling discovery, testing, design, analysis, and deployments of AWS services at scale, with a particular focus on innovation to shape the landscape across the AdTech and MarTech industry. Cathy has led engineering, product, and marketing teams and is an inventor of ground-to-air calling (1-800-RINGSKY).
Acknowledgments
We would also like to acknowledge and express our gratitude to our leadership team: Abhoy Bhaktwatsalam (VP, Amazon Publisher Monetization), Carl Petersen (Director, Twitch, Audio & Podcast Monetization), Cindy Barker (Senior Principal Engineer, Amazon Publisher Insights & Analytics), and Timothy Fagan (Principal Engineer, Twitch Monetization), for their invaluable insights and support. Their expertise and backing were instrumental for the successful development and implementation of this innovative solution.

Accelerate your ML lifecycle using the new and improved Amazon SageMaker Python SDK – Part 2: ModelBuilder
In Part 1 of this series, we introduced the newly launched ModelTrainer class on the Amazon SageMaker Python SDK and its benefits, and showed you how to fine-tune a Meta Llama 3.1 8B model on a custom dataset. In this post, we look at the enhancements to the ModelBuilder class, which lets you seamlessly deploy a model from ModelTrainer to a SageMaker endpoint, and provides a single interface for multiple deployment configurations.
In November 2023, we launched the ModelBuilder class (see Package and deploy models faster with new tools and guided workflows in Amazon SageMaker and Package and deploy classical ML and LLMs easily with Amazon SageMaker, part 1: PySDK Improvements), which reduced the complexity of initial setup of creating a SageMaker endpoint such as creating an endpoint configuration, choosing the container, serialization and deserialization, and more, and helps you create a deployable model in a single step. The recent update enhances usability of the ModelBuilder class for a wide range of use cases, particularly in the rapidly evolving field of generative AI. In this post, we deep dive into the enhancements made to the ModelBuilder class, and show you how to seamlessly deploy the fine-tuned model from Part 1 to a SageMaker endpoint.
Improvements to the ModelBuilder class
We’ve made the following usability improvements to the ModelBuilder class:
- Seamless transition from training to inference – ModelBuilder now integrates directly with SageMaker training interfaces to make sure that the correct file path to the latest trained model artifact is automatically computed, simplifying the workflow from model training to deployment.
- Unified inference interface – Previously, the SageMaker SDK offered separate interfaces and workflows for different types of inference, such as real-time, batch, serverless, and asynchronous inference. To simplify the model deployment process and provide a consistent experience, we have enhanced ModelBuilder to serve as a unified interface that supports multiple inference types.
- Ease of development, testing, and production handoff – We are adding support for local mode testing with ModelBuilder so that users can effortlessly debug and test their processing and inference scripts with faster local testing without including a container, and a new function that outputs the latest container image for a given framework so you don’t have to update the code each time a new LMI release comes out.
- Customizable inference preprocessing and postprocessing – ModelBuilder now allows you to customize preprocessing and postprocessing steps for inference. By enabling scripts to filter content and remove personally identifiable information (PII), this integration streamlines the deployment process, encapsulating the necessary steps within the model configuration for better management and deployment of models with specific inference requirements.
- Benchmarking support – The new benchmarking support in ModelBuilder empowers you to evaluate deployment options—like endpoints and containers—based on key performance metrics such as latency and cost. With the introduction of a Benchmarking API, you can test scenarios and make informed decisions, optimizing your models for peak performance before production. This enhances efficiency and provides cost-effective deployments.
In the following sections, we discuss these improvements in more detail and demonstrate how to customize, test, and deploy your model.
Seamless deployment from ModelTrainer class
ModelBuilder integrates seamlessly with the ModelTrainer class; you can simply pass the ModelTrainer object that was used for training the model directly to ModelBuilder in the model parameter. In addition to the ModelTrainer, ModelBuilder also supports the Estimator class and the result of the SageMaker Core TrainingJob.create() function, and automatically parses the model artifacts to create a SageMaker Model object. With resource chaining, you can build and deploy the model as shown in the following example. If you followed Part 1 of this series to fine-tune a Meta Llama 3.1 8B model, you can pass the model_trainer object as follows:
Customize the model using InferenceSpec
The InferenceSpec class allows you to customize the model by providing custom logic to load and invoke the model, and specify any preprocessing logic or postprocessing logic as needed. For SageMaker endpoints, preprocessing and postprocessing scripts are often used as part of the inference pipeline to handle tasks that are required before and after the data is sent to the model for predictions, especially in the case of complex workflows or non-standard models. The following example shows how you can specify the custom logic using InferenceSpec:
Test using local and in process mode
Deploying a trained model to a SageMaker endpoint involves creating a SageMaker model and configuring the endpoint. This includes the inference script, any serialization or deserialization required, the model artifact location in Amazon Simple Storage Service (Amazon S3), the container image URI, the right instance type and count, and more. The machine learning (ML) practitioners need to iterate over these settings before finally deploying the endpoint to SageMaker for inference. The ModelBuilder offers two modes for quick prototyping:
- In process mode – In this case, the inferences are made directly within the same inference process. This is highly useful in quickly testing the inference logic provided through
InferenceSpecand provides immediate feedback during experimentation. - Local mode – The model is deployed and run as a local container. This is achieved by setting the mode to
LOCAL_CONTAINERwhen you build the model. This is helpful to mimic the same environment as the SageMaker endpoint. Refer to the following notebook for an example.
The following code is an example of running inference in process mode, with a custom InferenceSpec:
As the next steps, you can test it in local container mode as shown in the following code, by adding the image_uri. You will need to include the model_server argument when you include the image_uri.
Deploy the model
When testing is complete, you can now deploy the model to a real-time endpoint for predictions by updating the mode to mode.SAGEMAKER_ENDPOINT and providing an instance type and size:
In addition to real-time inference, SageMaker supports serverless inference, asynchronous inference, and batch inference modes for deployment. You can also use InferenceComponents to abstract your models and assign CPU, GPU, accelerators, and scaling policies per model. To learn more, see Reduce model deployment costs by 50% on average using the latest features of Amazon SageMaker.
After you have the ModelBuilder object, you can deploy to any of these options simply by adding the corresponding inference configurations when deploying the model. By default, if the mode is not provided, the model is deployed to a real-time endpoint. The following are examples of other configurations:
- Deploy the model to a serverless endpoint:
from sagemaker.serverless.serverless_inference_config import ServerlessInferenceConfig
predictor = model_builder.deploy(
endpoint_name="serverless-endpoint",
inference_config=ServerlessInferenceConfig(memory_size_in_mb=2048))- Deploy the model to an asynchronous endpoint:
- Run a batch transform job for offline inference on a dataset:
- Deploy a multi-model endpoint using
InferenceComponent:
Clean up
If you created any endpoints when following this post, you will incur charges while it is up and running. As best practice, delete any endpoints if they are no longer required, either using the AWS Management Console, or using the following code:
Conclusion
In this two-part series, we introduced the ModelTrainer and the ModelBuilder enhancements in the SageMaker Python SDK. Both classes aim to reduce the complexity and cognitive overhead for data scientists, providing you with a straightforward and intuitive interface to train and deploy models, both locally on your SageMaker notebooks and to remote SageMaker endpoints.
We encourage you to try out the SageMaker SDK enhancements (SageMaker Core, ModelTrainer, and ModelBuilder) by referring to the SDK documentation and sample notebooks on the GitHub repo, and let us know your feedback in the comments!
About the Authors
 Durga Sury is a Senior Solutions Architect on the Amazon SageMaker team. Over the past 5 years, she has worked with multiple enterprise customers to set up a secure, scalable AI/ML platform built on SageMaker.
Durga Sury is a Senior Solutions Architect on the Amazon SageMaker team. Over the past 5 years, she has worked with multiple enterprise customers to set up a secure, scalable AI/ML platform built on SageMaker.
 Shweta Singh is a Senior Product Manager in the Amazon SageMaker Machine Learning (ML) platform team at AWS, leading SageMaker Python SDK. She has worked in several product roles in Amazon for over 5 years. She has a Bachelor of Science degree in Computer Engineering and a Masters of Science in Financial Engineering, both from New York University.
Shweta Singh is a Senior Product Manager in the Amazon SageMaker Machine Learning (ML) platform team at AWS, leading SageMaker Python SDK. She has worked in several product roles in Amazon for over 5 years. She has a Bachelor of Science degree in Computer Engineering and a Masters of Science in Financial Engineering, both from New York University.

Accelerate your ML lifecycle using the new and improved Amazon SageMaker Python SDK – Part 1: ModelTrainer
Amazon SageMaker has redesigned its Python SDK to provide a unified object-oriented interface that makes it straightforward to interact with SageMaker services. The new SDK is designed with a tiered user experience in mind, where the new lower-level SDK (SageMaker Core) provides access to full breadth of SageMaker features and configurations, allowing for greater flexibility and control for ML engineers. The higher-level abstracted layer is designed for data scientists with limited AWS expertise, offering a simplified interface that hides complex infrastructure details.
In this two-part series, we introduce the abstracted layer of the SageMaker Python SDK that allows you to train and deploy machine learning (ML) models by using the new ModelTrainer and the improved ModelBuilder classes.
In this post, we focus on the ModelTrainer class for simplifying the training experience. The ModelTrainer class provides significant improvements over the current Estimator class, which are discussed in detail in this post. We show you how to use the ModelTrainer class to train your ML models, which includes executing distributed training using a custom script or container. In Part 2, we show you how to build a model and deploy to a SageMaker endpoint using the improved ModelBuilder class.
Benefits of the ModelTrainer class
The new ModelTrainer class has been designed to address usability challenges associated with Estimator class. Moving forward, ModelTrainer will be the preferred approach for model training, bringing significant enhancements that greatly improve the user experience. This evolution marks a step towards achieving a best-in-class developer experience for model training. The following are the key benefits:
- Improved intuitiveness – The ModelTrainer class reduces complexity by consolidating configurations into just few core parameters. This streamlining minimizes cognitive overload, allowing users to focus on model training rather than configuration intricacies. Additionally, it employs intuitive config classes for straightforward platform interactions.
- Simplified script mode and BYOC – Transitioning from local development to cloud training is now seamless. The ModelTrainer automatically maps source code, data paths, and parameter specifications to the remote execution environment, eliminating the need for special handshakes or complex setup processes.
- Simplified distributed training – The ModelTrainer class provides enhanced flexibility for users to specify custom commands and distributed training strategies, allowing you to directly provide the exact command you want to run in your container through the
commandparameter in theSourceCodeThis approach decouples distributed training strategies from the training toolkit and framework-specific estimators. - Improved hyperparameter contracts – The ModelTrainer class passes the training job’s hyperparameters as a single environment variable, allowing the you to load the hyperparameters using a single
SM_HPSvariable.
To further explain each of these benefits, we demonstrate with examples in the following sections, and finally show you how to set up and run distributed training for the Meta Llama 3.1 8B model using the new ModelTrainer class.
Launch a training job using the ModelTrainer class
The ModelTrainer class simplifies the experience by letting you customize the training job, including providing a custom script, directly providing a command to run the training job, supporting local mode, and much more. However, you can spin up a SageMaker training job in script mode by providing minimal parameters—the SourceCode and the training image URI.
The following example illustrates how you can launch a training job with your own custom script by providing just the script and the training image URI (in this case, PyTorch), and an optional requirements file. Additional parameters such as the instance type and instance size are automatically set by the SDK to preset defaults, and parameters such as the AWS Identity and Access Management (IAM) role and SageMaker session are automatically detected from the current session and user’s credentials. Admins and users can also overwrite the defaults using the SDK defaults configuration file. For the detailed list of pre-set values, refer to the SDK documentation.
With purpose-built configurations, you can now reuse these objects to create multiple training jobs with different hyperparameters, for example, without having to re-define all the parameters.
Run the job locally for experimentation
To run the preceding training job locally, you can simply set the training_mode parameter as shown in the following code:
The training job runs remotely because training_mode is set to Mode.LOCAL_CONTAINER. If not explicitly set, the ModelTrainer runs a remote SageMaker training job by default. This behavior can also be enforced by changing the value to Mode.SAGEMAKER_TRAINING_JOB. For a full list of the available configs, including compute and networking, refer to the SDK documentation.
Read hyperparameters in your custom script
The ModelTrainer supports multiple ways to read the hyperparameters that are passed to a training job. In addition to the existing support to read the hyperparameters as command line arguments in your custom script, ModelTrainer also supports reading the hyperparameters as individual environment variables, prefixed with SM_HPS_<hyperparameter-key>, or as a single environment variable dictionary, SM_HPS.
Suppose the following hyperparameters are passed to the training job:
You have the following options:
- Option 1 – Load the hyperparameters into a single JSON dictionary using the
SM_HPSenvironment variable in your custom script:
- Option 2 – Read the hyperparameters as individual environment variables, prefixed by
SM_HPas shown in the following code (you need to explicitly specify the correct input type for these variables):
- Option 3 – Read the hyperparameters as AWS CLI arguments using
parse.args:
Run distributed training jobs
SageMaker supports distributed training to support training for deep learning tasks such as natural language processing and computer vision, to run secure and scalable data parallel and model parallel jobs. This is usually achieved by providing the right set of parameters when using an Estimator. For example, to use torchrun, you would define the distribution parameter in the PyTorch Estimator and set it to "torch_distributed": {"enabled": True}.
The ModelTrainer class provides enhanced flexibility for users to specify custom commands directly through the command parameter in the SourceCode class, and supports torchrun, torchrun smp, and the MPI strategies. This capability is particularly useful when you need to launch a job with a custom launcher command that is not supported by the training toolkit.
In the following example, we show how to fine-tune the latest Meta Llama 3.1 8B model using the default launcher script using Torchrun on a custom dataset that’s preprocessed and saved in an Amazon Simple Storage Service (Amazon S3) location:
If you wanted to customize your torchrun launcher script, you can also directly provide the commands using the command parameter:
For more examples and end-to-end ML workflows using the SageMaker ModelTrainer, refer to the GitHub repo.
Conclusion
The newly launched SageMaker ModelTrainer class simplifies the user experience by reducing the number of parameters, introducing intuitive configurations, and supporting complex setups like bringing your own container and running distributed training. Data scientists can also seamlessly transition from local training to remote training and training on multiple nodes using the ModelTrainer.
We encourage you to try out the ModelTrainer class by referring to the SDK documentation and sample notebooks on the GitHub repo. The ModelTrainer class is available from the SageMaker SDK v2.x onwards, at no additional charge. In Part 2 of this series, we show you how to build a model and deploy to a SageMaker endpoint using the improved ModelBuilder class.
About the Authors
Durga Sury is a Senior Solutions Architect on the Amazon SageMaker team. Over the past 5 years, she has worked with multiple enterprise customers to set up a secure, scalable AI/ML platform built on SageMaker.
Shweta Singh is a Senior Product Manager in the Amazon SageMaker Machine Learning (ML) platform team at AWS, leading SageMaker Python SDK. She has worked in several product roles in Amazon for over 5 years. She has a Bachelor of Science degree in Computer Engineering and a Masters of Science in Financial Engineering, both from New York University.
Amazon Q Apps supports customization and governance of generative AI-powered apps
We are excited to announce new features that allow creation of more powerful apps, while giving more governance control using Amazon Q Apps, a capability within Amazon Q Business that allows you to create generative AI-powered apps based on your organization’s data. These features enhance app customization options that let business users tailor solutions to their specific individual or organizational requirements. We have introduced new governance features for administrators to endorse user-created apps with app verification, and to organize app libraries with customizable label categories that reflect their organizations. App creators can now share apps privately and build data collection apps that can collate inputs across multiple users. These additions are designed to improve how companies use generative AI in their daily operations by focusing on admin controls and capabilities that unlock new use cases.
In this post, we examine how these features enhance the capabilities of Amazon Q Apps. We explore the new customization options, detailing how these advancements make Amazon Q Apps more accessible and applicable to a wider range of enterprise customers. We focus on key features such as custom labels, verified apps, private sharing, and data collection apps (preview).
Endorse quality apps and customize labels in the app library
To help with discoverability of published Amazon Q Apps and address questions about quality of user-created apps, we have launched verified apps. Verified apps are endorsed by admins, indicating they have undergone approval based on your company’s standards. Admins can endorse published Amazon Q Apps by updating their status from Default to Verified directly on the Amazon Q Business console. Admins can work closely with their business stakeholders to determine the criteria for verifying apps, based on their organization’s specific needs and policies. This admin-led labeling capability is a reactive approach to endorsing published apps, without gating the publishing process for app creators.
When users access the library, they will see a distinct blue checkmark icon on any apps that have been marked as Verified by admins (as shown in the following screenshot). Additionally, verified apps are automatically surfaced to the top of the app list within each category, making them easily discoverable. To learn more about verifying apps, refer to Understanding and managing Verified Amazon Q Apps.

The next feature we discuss is custom labels. Admins can create custom category labels for app users to organize and classify apps in the library to reflect their team functions or organizational structure. This feature enables admins to create and manage these labels on the Amazon Q Business console, and end-users can use them at app creation and to discover relevant apps in the library. Admins can update the category labels at any time to tailor towards specific business needs depending on their use cases. For example, admins that manage Amazon Q Business app environments for marketing organizations might add labels like Product Marketing, PR, Ads, or Sales solely for the users on the marketing team to use (see the following screenshot).

Users on the marketing team who create apps can use the custom labels to slot their app in the right category, which will help other users discover apps in the library based on their focus area (as shown in the following screenshot). To learn more about custom labels, see Custom labels for Amazon Q Apps.

Share your apps with select users
App creators can now use advanced sharing options to create more granular controls over apps and facilitate collaboration within their organizations. With private sharing, you have the option to share an app with select individuals or with all app users (which was previously possible). Sharing of any extent will still display the app in the library, but with private sharing, it will only be visible to app users with whom it has been shared. This means the library continues to be the place where users discover apps that they have access to. This feature unlocks the ability to enable apps only to the intended audience and helps reduce “noise” in the library from apps that aren’t necessarily relevant for all users. App creators have the ability to test updates before they are ready to publish changes, helping make sure app iterations and refinements aren’t shared before they are ready to widely publish the revised version.
To share an app with specific users, creators can add each user using their full email address (see the following screenshot). Users are only added after the email address match is found, making sure creators don’t unknowingly give access to someone who doesn’t have access to that Amazon Q Business app environment. To learn more about private sharing, see Sharing Amazon Q Apps.

Unlock new use cases with data collection
The last feature we share in this post is data collection apps (preview), a new capability that allows you to record inputs provided by other app users, resulting in a new genre of Amazon Q Apps such as team surveys and project retrospectives. This enhancement enables you to collate data across multiple users within your organization, further enhancing the collaborative quality of Amazon Q Apps for various business needs. These apps can further use generative AI to analyze the collected data, identify common themes, summarize ideas, and provide actionable insights.
After publishing a data collection app to the library, creators can share the unique link to invite their colleagues to participate. You must share the unique link to get submissions for your specific data collection. When app users open the data collection app from the library, it triggers a fresh data collection with its own unique shareable link, for which they are the designated owner. As the owner of a data collection, you can start new rounds and manage controls to start and stop accepting new data submissions, as well as reveal or hide the collected data. To learn more about data collection apps, see Data collection in Amazon Q Apps.

Conclusion
In this post, we discussed how these new features for Amazon Q Apps in Amazon Q Business make generative AI more customizable and governable for enterprise users. From custom labels and verified apps to private sharing and data collection capabilities, these innovations enable organizations to create, manage, and share AI-powered apps that align with their specific business needs while maintaining appropriate controls.
For more information, see Creating purpose-built Amazon Q Apps.
About the Author
 Tiffany Myers is a Product Manager at AWS, where she leads bringing in new capabilities while maintaining the simplicity of Amazon Q Business and Amazon Q Apps, drawing inspiration from the adaptive intelligence of amphibians in nature to help customers transform and evolve their businesses through generative AI.
Tiffany Myers is a Product Manager at AWS, where she leads bringing in new capabilities while maintaining the simplicity of Amazon Q Business and Amazon Q Apps, drawing inspiration from the adaptive intelligence of amphibians in nature to help customers transform and evolve their businesses through generative AI.
Answer questions from tables embedded in documents with Amazon Q Business
Amazon Q Business is a generative AI-powered assistant that can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in your enterprise systems. A large portion of that information is found in text narratives stored in various document formats such as PDFs, Word files, and HTML pages. Some information is also stored in tables (such as price or product specification tables) embedded in those same document types, CSVs, or spreadsheets. Although Amazon Q Business can provide accurate answers from narrative text, getting answers from these tables requires special handling of more structured information.
On November 21, 2024, Amazon Q Business launched support for tabular search, which you can use to extract answers from tables embedded in documents ingested in Amazon Q Business. Tabular search is a built-in feature in Amazon Q Business that works seamlessly across many domains, with no setup required from admin or end users.
In this post, we ingest different types of documents that have tables and show you how Amazon Q Business responds to questions related to the data in the tables.
Prerequisites
To follow along with this walkthrough, you need to have the following prerequisites in place:
- An AWS Account where you can follow the instructions in this post.
- At least one Amazon Q Business user is required. For information, refer to Amazon Q Business pricing.
- Requires cross-Region inference enabled on the Amazon Q application.
- Amazon Q Business applications created on or after November 21, 2024, will automatically benefit from the new capability. If your application was created before this date, you are required to reingest your content to update their indexes.
Overview of tabular search
Tabular search extends Amazon Q Business capabilities to find answers beyond text paragraphs, analyzing tables embedded in enterprise documents so you can get answers to a wide range of queries, including factual lookup from tables.
With tabular search in Amazon Q Business, you can ask questions such as, “what’s the credit card with the lowest APR and no annual fees?” or “which credit cards offer travel insurance?” where the answers may be found in a product-comparison table, inside a marketing PDF stored in an internal repository, or on a website.
This feature supports a wide range of file formats, including PDF, Word documents, CSV files, Excel spreadsheets, HTML, and SmartSheet (via SmartSheet connector). Notably, tabular search can also extract data from tables represented as images within PDFs and retrieve information from single or multiple cells. Additionally, it can perform aggregations on numerical data, providing users with valuable insights.
Ingest documents in Amazon Q Business
To create an Amazon Q Business application, retriever, and index to pull data in real time during a conversation, follow the steps under the Create and configure your Amazon Q application section in the AWS Machine Learning Blog post, Discover insights from Amazon S3 with Amazon Q S3 connector.
For this post, we use The World’s Billionaires, which lists the world’s top 10 billionaires from 1987 through 2024 in a tabular format. You can download this data as a PDF from Wikipedia using the Tools menu. Upload the PDF to an Amazon Simple Storage Service (Amazon S3) bucket and use it as a data source in your Amazon Q Business application.
Run queries with Amazon Q
You can start asking questions to Amazon Q using the Web experience URL, which can be found on the Applications page, as shown in the following screenshot.

Suppose we want to know the ratio of men to women who appeared on the Forbes 2024 list of the world’s billionaires. As you can tell from the following screenshot of The World’s Billionaires PDF, there were 383 women and 2398 men.

To use Amazon Q Business to elicit that information from the PDF, enter the following in the web experience chatbot
“In 2024, what is the ratio of men to women who appeared in the Forbes 2024 billionaire’s list?”

Amazon Q Business supplies the answer, as shown in the following screenshot.
The following screenshot is a list of the top 10 Billionaires from 2009.

We enter “How many of the top 10 billionaires in 2009 were from countries outside the United States?”
Amazon Q Business provides an answer, as shown in the following screenshot.

Next, to demonstrate how Amazon Q Business can pull data from a CSV file, we used the example of crime statistics found here.

We enter the question, “How many incidents of crime were reported in Hollywood?”
Amazon Q Business provides the answer, as shown in the following screenshot.

Metadata boosting
To improve the accuracy of responses from Amazon Q Business application with CSV files, you can add metadata to documents in an S3 bucket by using a metadata file. Metadata is additional information about a document describing it further in order to improve retrieval accuracy for context-poor document formats for example, a CSV with cryptic column names. Additional fields such as its title and the date and time it was created can also be useful if you want to search the titles or want documents from certain time period.
You can do this by following Enable document attributes for search in Amazon Q Business.
Additional details about metadata boosting can be found at Configuring document attributes for boosting in Amazon Q Business in the Amazon Q User Guide.
Clean up
To avoid incurring future charges and to clean out unused roles and policies, delete the resources you created: the Amazon Q application, data sources, and corresponding IAM roles.
To delete the Amazon Q application, follow these steps:
- On the Amazon Q console, choose Applications and then select your application.
- On the Actions drop-down menu, choose Delete.
- To confirm deletion, enter delete in the field and choose Delete. Wait until you get the confirmation message; the process can take up to 15 minutes.
To delete the S3 bucket created in Prepare your S3 bucket as a data source, follow these steps:
- Follow the instructions in Emptying a bucket
- Follow the steps in Deleting a bucket
To delete the IAM Identity center instance you created as part of the prerequisites, follow the steps at Delete your IAM Identity Center instance.
Conclusion
By following this post, you can ingest different types of documents that contain tables in them. Then, you can ask Amazon Q questions related to information in the table and have Amazon Q provide you answers in natural language.
To learn about metadata search, refer to Configuring metadata controls in Amazon Q Business.
For S3 data source setup refer to Set up Amazon Q Business application with S3 data source.
About the author
 Jiten Dedhia is a Sr. AIML Solutions Architect with over 20 years of experience in the software industry. He has helped Fortune 500 companies with their AIML/Generative AI needs.
Jiten Dedhia is a Sr. AIML Solutions Architect with over 20 years of experience in the software industry. He has helped Fortune 500 companies with their AIML/Generative AI needs.
 Sapna Maheshwari is a Sr. Solutions Architect at AWS, with a passion for designing impactful tech solutions. She is an engaging speaker who enjoys sharing her insights at conferences.
Sapna Maheshwari is a Sr. Solutions Architect at AWS, with a passion for designing impactful tech solutions. She is an engaging speaker who enjoys sharing her insights at conferences.