From training new models to deploying them in production, Amazon SageMaker offers the most complete set of tools for startups and enterprises to harness the power of machine learning (ML) and Deep Learning.
With its Transformers open-source library and ML platform, Hugging Face makes transfer learning and the latest ML models accessible to the global AI community, reducing the time needed for data scientists and ML engineers in companies around the world to take advantage of every new scientific advancement.
Applying Transformers to new NLP tasks or domains requires fine-tuning of large language models, a technique leveraging the accumulated knowledge of pre-trained models to adapt them to a new task or specific type of documents in an additional, efficient training process.
Fine-tuning the model to produce accurate predictions for the business problem at hand requires the training of large Transformers models, for example, BERT, BART, RoBERTa, T5, which can be challenging to perform in a scalable way.
Hugging Face has been working closely with SageMaker to deliver ready-to-use Deep Learning Containers (DLCs) that make training and deploying the latest Transformers models easier and faster than ever. Because features such as SageMaker Data Parallel (SMDP), SageMaker Model Parallel (SMMP), S3 pipe mode, are integrated into the container, using these drastically reduces the time for companies to create Transformers-based ML solutions such as question-answering, generating text and images, optimizing search results, and improves customer support automation, conversational interfaces, semantic search, document analyses, and many more applications.
In this post, we focus on the deep integration of SageMaker distributed libraries with Hugging Face, which enables data scientists to accelerate training and fine-tuning of Transformers models from days to hours, all in SageMaker.
Overview of distributed training
ML practitioners and data scientists face two scaling challenges when training models: scaling model size (number of parameters and layers) and scaling training data. Scaling either the model size or training data can result in better accuracy, but there can be cases in deep learning where the amount of memory on the accelerator (CPU or GPU) limits the combination of the size of the training data and the size of the model. For example, when training a large language model, the batch size is often limited to a small number of samples, which can result in a less accurate model.
Distributed training can split up the workload to train the model among multiple processors, called workers. These workers operate in parallel to speed up model training.
Based on what we want to scale (model or data) there are two approaches to distributed training: data parallel and model parallel.
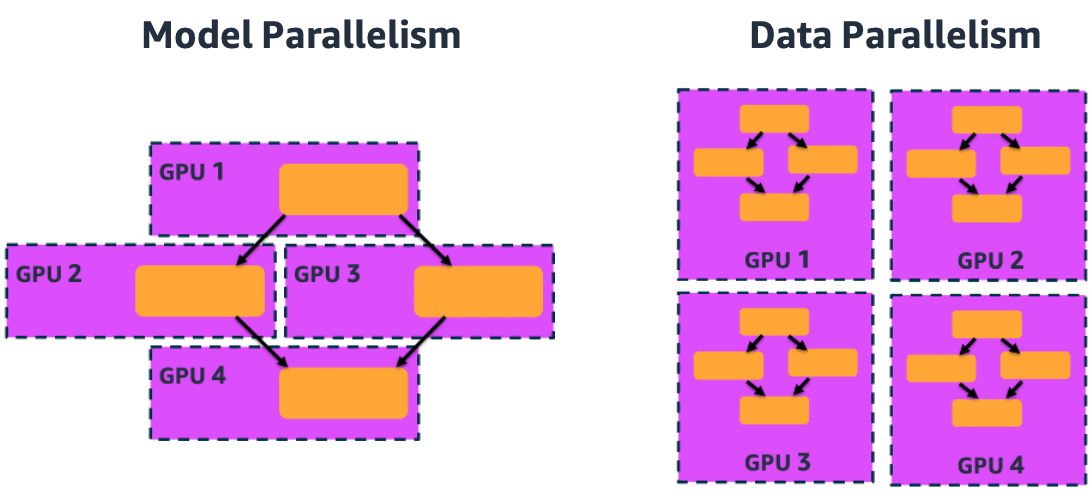
Data parallel is the most common approach to distributed training. Data parallelism entails creating a copy of the model architecture and weights on different accelerators. Then, rather than passing in the entire training set to a single accelerator, we can partition the training set across the different accelerators, and get through the training set faster. Although this adds the step of the accelerators needing to communicate their gradient information back to a parameter server, this time is more than offset by the speed boost of iterating over a fraction of the entire dataset per accelerator. Because of this, data parallelism can significantly help reduce training times. For example, training a single model without parallelization takes 4 hours. Using distributed training can reduce that to 24 minutes. SageMaker distributed training also implements cutting-edge techniques in gradient updates.
A model parallel approach is used with large models too large to fit on one accelerator (GPU). This approach implements a parallelization strategy where the model architecture is divided into shards and placed onto different accelerators. The configuration of each of these shards is neural network architecture dependent, and typically includes several layers. The communication between the accelerators occurs each time the training data passes from one of the shards to the next.
To summarize, you should use distributed training data parallelism for time-intensive tasks due to large datasets or when you want to accelerate your training experiments. You should use model parallelism when your model can’t fit onto one accelerator.
Prerequisites
To perform distributed training of Hugging Face Transformers models in SageMaker, you need to complete the following prerequisites:
- Sign up for an AWS account. For more information, see Set Up Amazon SageMaker Prerequisites.
- Get started using either Amazon SageMaker Studio (see Onboard to Amazon SageMaker Domain), SageMaker notebook instances, or a local environment with the SageMaker Python SDK installed.
- Set up the right AWS Identity and Access Management (IAM) permissions.
- Upgrade to the latest SageMaker version that includes the libraries of Hugging Face and distributed training:
Implement distributed training
The Hugging Face Transformers library provides a Trainer API that is optimized to train or fine-tune the models the library provides. You can also use it on your own models if they work the same way as Transformers models; see Trainer for more details. This API is used in our example scripts, which show how to preprocess the data for various NLP tasks, which you can take as models to write a script solving your own custom problem. The promise of the Trainer API is that this script works out of the box on any distributed setup, including SageMaker.
The Trainer API takes everything needed for the training. This includes your datasets, your model (or a function that returns your model), a compute_metrics function that returns the metrics you want to track from the arrays of predications and labels, your optimizer and learning rate scheduler (good defaults are provided), as well as all the hyperparameters you can tune for your training grouped in a data class called TrainingArguments. With all of that, it exposes three methods—train, evaluate, and predict—to train your model, get the metric results on any dataset, or get the predictions on any dataset. To learn more about the Trainer object, refer to Fine-tuning a model with the Trainer API and the video The Trainer API, which walks you through a simple example.
Behind the scenes, the Trainer API starts by analyzing the environment in which you are launching your script when you create the TrainingArguments. For instance, if you launched your training with SageMaker, it looks at the SM_FRAMEWORK_PARAMS variable in the environment to detect if you enabled SageMaker data parallelism or model parallelism. Then it gets the relevant variables (such as the rank of the process or the world size) from the environment before performing the necessary initialization steps (such as smdistributed.dataparallel.torch.distributed.init_process_group()).
The Trainer contains the whole training loop, so it can adjust the necessary steps to make sure the smdistributed.dataparallel backend is used when necessary without you having to change a line of code in your script. It can still run (albeit much slower) on your local machine for debugging. It handles sharding your dataset such that each process sees different samples automatically, with a reshuffle at each epoch, synchronizing your gradients before the optimization step, mixed precision training if you activated it, gradient accumulation if you can’t fit a big batch size on your GPUs, and many more optimizations.
If you activated model parallelism, it makes sure the processes that have to see the same data (if their dp_rank is the same) get the same batches, and that processes with different dp_rank don’t see the same samples, again with a reshuffle at each epoch. It makes sure the state dictionaries of the model or optimizers are properly synchronized when checkpointing, and again handles all the optimizations such as mixed precision and gradient accumulation.
When using the evaluate and predict methods, the Trainer performs a distributed evaluation, to take advantage of all your GPUs. It properly handles splitting your data for each process (process of the same dp_rank if model parallelism is activated) and makes sure that the predictions are properly gathered in the same order as the dataset you’re using before they are sent to the compute_metrics function or just returned. Using the Trainer API is not mandatory. Users can still use Keras or PyTorch within Hugging Face. However, the Trainer API can provide a helpful abstraction layer.
Train a model using SageMaker Hugging Face Estimators
An Estimator is a high-level interface for SageMaker training and handles end-to-end SageMaker training and deployment tasks. The training of your script is invoked when you call fit on a HuggingFace Estimator. In the Estimator, you define which fine-tuning script to use as entry_point, which instance_type to use, and which hyperparameters are passed in. For more information about HuggingFace parameters, see Hugging Face Estimator.
Distributed training: Data parallel
In this example, we use the new Hugging Face DLCs and SageMaker SDK to train a distributed Seq2Seq-transformer model on the question and answering task using the Transformers and datasets libraries. The bert-large-uncased-whole-word-masking model is fine-tuned on the squad dataset.
The following code samples show you steps of creating a HuggingFace estimator for distributed training with data parallelism.
- Choose a Hugging Face Transformers script:
When you create a HuggingFace Estimator, you can specify a training script that is stored in a GitHub repository as the entry point for the Estimator, so you don’t have to download the scripts locally. You can use git_config to run the Hugging Face Transformers examples scripts and right ‘branch’ if your transformers_version needs to be configured. For example, if you use transformers_version 4.6.1, you have to use ‘branch':'v4.6.1‘.
- Configure training hyperparameters that are passed into the training job:
As a hyperparameter, we can define any Seq2SeqTrainingArguments and the ones defined in the training script.
- Define the distribution parameters in the
HuggingFaceEstimator:
You can use the SageMaker data parallelism library out of the box for distributed training. We added the functionality of data parallelism directly into the Trainer. To enable data parallelism, you can simply add a single parameter to your HuggingFace Estimator to let your Trainer-based code use it automatically.
- Create a
HuggingFaceEstimator including parameters defined in previous steps and start training:
The Hugging Face Transformers repository contains several examples and scripts for fine-tuning models on tasks from language modeling to token classification. In our case, we use run_qa.py from the examples/pytorch/question-answering examples.
smdistributed.dataparallel supports model training on SageMaker with the following instance types only. For best performance, we recommend using an instance type that supports Elastic Fabric Adapter (EFA):
- ml.p3.16xlarge
- ml.p3dn.24xlarge (Recommended)
- ml.p4d.24xlarge (Recommended)
To get the best performance and the most out of SMDataParallel, you should use at least two instances, but you can also use one for testing this example.
The following example notebook provides more detailed step-by-step guidance.
Distributed training: Model parallel
For distributed training with model parallelism, we use the Hugging Face Transformers and datasets library together with the SageMaker SDK for sequence classification on the General Language Understanding Evaluation (GLUE) benchmark on a multi-node, multi-GPU cluster using the SageMaker model parallelism library.
As with data parallelism, we first set the git configuration, training hyperparameters, and distribution parameters in the HuggingFace Estimator:
The model parallelism library internally uses MPI, so to use model parallelism, MPI must be enabled using the distribution parameter. “processes_per_host” in the preceding code specifies the number of processes MPI should launch on each host. We suggest these for development and testing. At production time, you can contact AWS Support if requesting extensive GPU capacity. For more information, see Run a SageMaker Distributed Model Parallel Training Job.
The following example notebook contains the complete code scripts.
Spot Instances
With the Hugging Face framework extension for the SageMaker Python SDK, we can also take advantage of fully managed Amazon Elastic Compute Cloud (Amazon EC2) Spot Instances and save up to 90% of our training cost.
Unless your training job will complete quickly, we recommend you use checkpointing with managed spot training, therefore you need to define checkpoint_s3_uri.
To use Spot Instances with the HuggingFace Estimator, we have to set the use_spot_instances parameter to True and define your max_wait and max_run time. For more information about the managed spot training lifecycle, see Managed Spot Training in Amazon SageMaker.
The following is a code snippet for setting up a spot training Estimator:
The following notebook contains the complete code scripts.
Conclusion
In this post, we discussed distributed training of Hugging Face Transformers using SageMaker. We first reviewed the use cases for data parallelism vs. model parallelism. Data parallelism is typically more appropriate but not necessarily restricted to when training is bottlenecked by compute, whereas you can use model parallelism when a model can’t fit within the memory provided on a single accelerator. We then showed how to train with both methods.
In the data parallelism use case we discussed, training a model on a single p3.2xlarge instance (with a single GPU) takes 4 hours and costs roughly $15 at the time of this writing. With data parallelism, we can train the same model in 24 minutes at a cost of $28. Although the cost has doubled, this has reduced the training time by a factor of 10. For a situation in which you need to train many models within a short period of time, data parallelism can enable this at a relatively low cost increase. As for the model parallelism use case, it adds the ability to train models that could not have been previously trained at all due to hardware limitations. Both features enable new workflows for ML practitioners, and are readily accessible through the HuggingFace Estimator as a part of the SageMaker Python SDK. Deploying these models to hosted endpoints follows the same procedure as for other Estimators.
This integration enables other features that are part of the SageMaker ecosystem. For example, you can use Spot Instances by adding a simple flag to the Estimator for additional cost-optimization. As a next step, you can find and run the training demo and example notebook.
About the Authors
 Archis Joglekar is an AI/ML Partner Solutions Architect in the Emerging Technologies team. He is interested in performant, scalable deep learning and scientific computing using the building blocks at AWS. His past experiences range from computational physics research to machine learning platform development in academia, national labs, and startups. His time away from the computer is spent playing soccer and with friends and family.
Archis Joglekar is an AI/ML Partner Solutions Architect in the Emerging Technologies team. He is interested in performant, scalable deep learning and scientific computing using the building blocks at AWS. His past experiences range from computational physics research to machine learning platform development in academia, national labs, and startups. His time away from the computer is spent playing soccer and with friends and family.
 James Yi is a Sr. AI/ML Partner Solutions Architect in the Emerging Technologies team at Amazon Web Services. He is passionate about working with enterprise customers and partners to design, deploy and scale AI/ML applications to derive their business values. Outside of work, he enjoys playing soccer, traveling and spending time with his family.
James Yi is a Sr. AI/ML Partner Solutions Architect in the Emerging Technologies team at Amazon Web Services. He is passionate about working with enterprise customers and partners to design, deploy and scale AI/ML applications to derive their business values. Outside of work, he enjoys playing soccer, traveling and spending time with his family.
 Philipp Schmid is a Machine Learning Engineer and Tech Lead at Hugging Face, where he leads the collaboration with the Amazon SageMaker team. He is passionate about democratizing, optimizing, and productionizing cutting-edge NLP models and improving the ease of use for Deep Learning.
Philipp Schmid is a Machine Learning Engineer and Tech Lead at Hugging Face, where he leads the collaboration with the Amazon SageMaker team. He is passionate about democratizing, optimizing, and productionizing cutting-edge NLP models and improving the ease of use for Deep Learning.
 Sylvain Gugger is a Research Engineer at Hugging Face and one of the main maintainers of the Transformers library. He loves open source software and help the community use it.
Sylvain Gugger is a Research Engineer at Hugging Face and one of the main maintainers of the Transformers library. He loves open source software and help the community use it.
 Jeff Boudier builds products at Hugging Face, creator of Transformers, the leading open-source ML library. Previously Jeff was a co-founder of Stupeflix, acquired by GoPro, where he served as director of Product Management, Product Marketing, Business Development and Corporate Development.
Jeff Boudier builds products at Hugging Face, creator of Transformers, the leading open-source ML library. Previously Jeff was a co-founder of Stupeflix, acquired by GoPro, where he served as director of Product Management, Product Marketing, Business Development and Corporate Development.
























 Phi Nguyen is a solutions architect at AWS helping customers with their cloud journey with a special focus on data lake, analytics, semantics technologies and machine learning. In his spare time, you can find him biking to work, coaching his son’s soccer team or enjoying nature walk with his family.
Phi Nguyen is a solutions architect at AWS helping customers with their cloud journey with a special focus on data lake, analytics, semantics technologies and machine learning. In his spare time, you can find him biking to work, coaching his son’s soccer team or enjoying nature walk with his family.