New approach reduces the number of ancillary qubits required to implement the crucial T gate by at least an order of magnitude.Read More
NeurIPS reinforcement-learning-challenge winners announced
AWS sponsored the challenge and provided resources for participants to prepare and process data and then train, deploy, and test their models.Read More
How Alexa’s new Live Translation for conversations works
Parallel speech recognizers, language ID, and translation models geared to conversational speech are among the modifications that make Live Translation possible.Read More
Exploratory data analysis, feature engineering, and operationalizing your data flow into your ML pipeline with Amazon SageMaker Data Wrangler
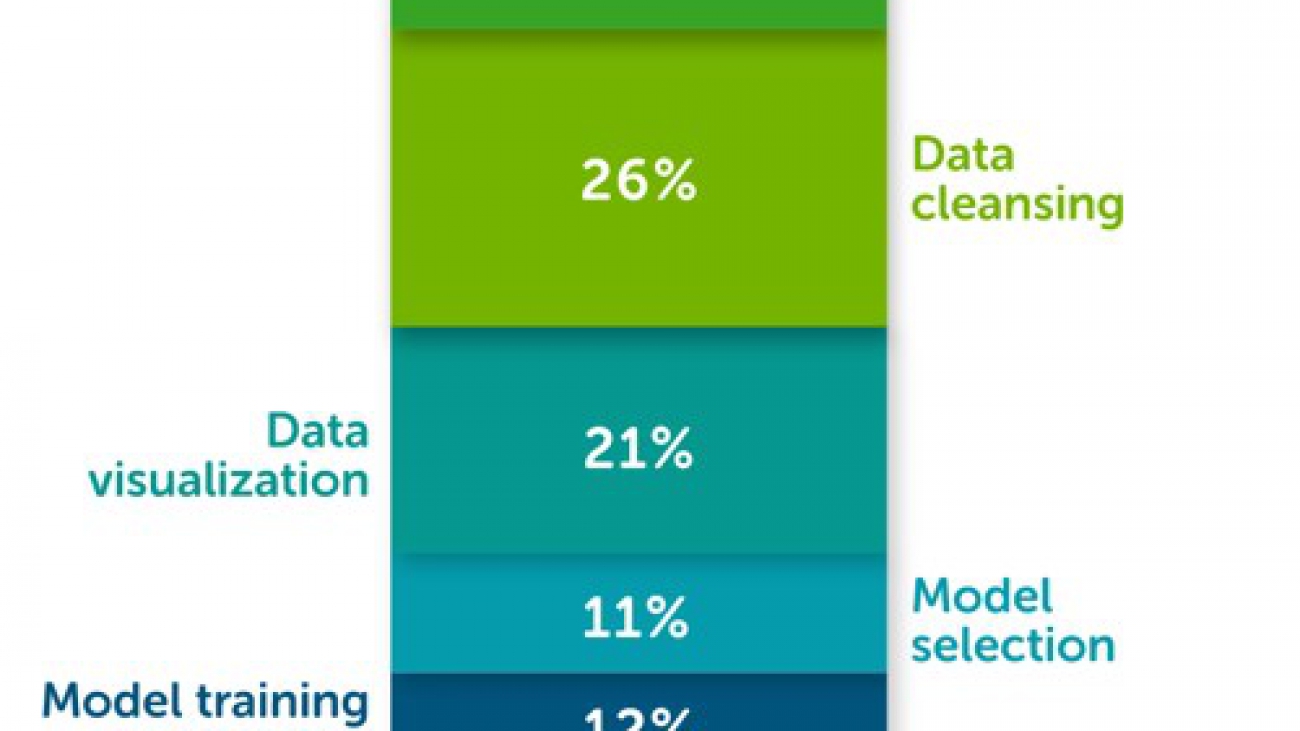
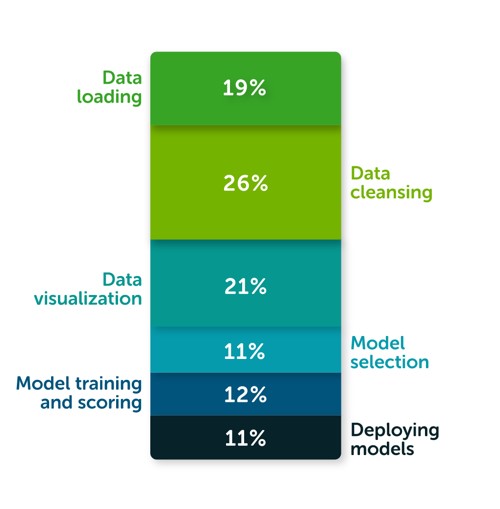
According to The State of Data Science 2020 survey, data management, exploratory data analysis (EDA), feature selection, and feature engineering accounts for more than 66% of a data scientist’s time (see the following diagram).
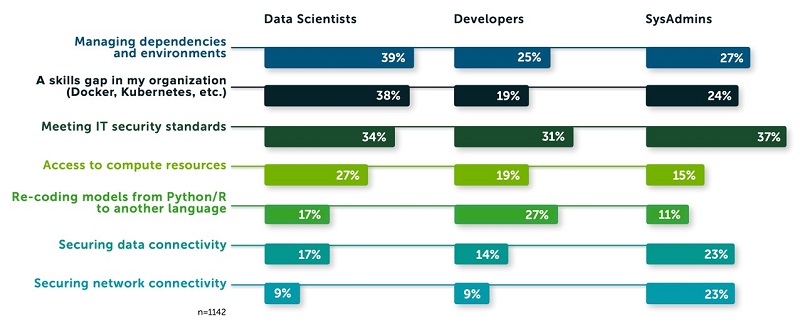
The same survey highlights that the top three biggest roadblocks to deploying a model in production are managing dependencies and environments, security, and skill gaps (see the following diagram).
The survey posits that these struggles result in fewer than half (48%) of the respondents feeling able to illustrate the impact data science has on business outcomes.
Enter Amazon SageMaker Data Wrangler, the fastest and easiest way to prepare data for machine learning (ML). SageMaker Data Wrangler gives you the ability to use a visual interface to access data, perform EDA and feature engineering, and seamlessly operationalize your data flow by exporting it into an Amazon SageMaker pipeline, Amazon SageMaker Data Wrangler job, Python file, or SageMaker feature group.
SageMaker Data Wrangler also provides you with over 300 built-in transforms, custom transforms using a Python, PySpark or SparkSQL runtime, built-in data analysis such as common charts (like scatterplot or histogram), custom charts using the Altair library, and useful model analysis capabilities such as feature importance, target leakage, and model explainability. Finally, SageMaker Data Wrangler creates a data flow file that can be versioned and shared across your teams for reproducibility.
Solution overview
In this post, we use the retail demo store example and generate a sample dataset. We use three files: users.csv, items.csv, and interactions.csv. We first prepare the data in order to predict the customer segment based on past interactions. Our target is the field called persona, which we later transform and rename to USER_SEGMENT.
The following code is a preview of the users dataset:
id,username,email,first_name,last_name,addresses,age,gender,persona
1,user1,nathan.smith@example.com,Nathan,Smith,"[{""first_name"": ""Nathan"", ""last_name"": ""Smith"", ""address1"": ""049 Isaac Stravenue Apt. 770"", ""address2"": """", ""country"": ""US"", ""city"": ""Johnsonmouth"", ""state"": ""NY"", ""zipcode"": ""12758"", ""default"": true}]",28,M,electronics_beauty_outdoors
2,user2,kevin.martinez@example.com,Kevin,Martinez,"[{""first_name"": ""Kevin"", ""last_name"": ""Martinez"", ""address1"": ""074 Jennifer Flats Suite 538"", ""address2"": """", ""country"": ""US"", ""city"": ""East Christineview"", ""state"": ""MI"", ""zipcode"": ""49758"", ""default"": true}]",19,M,electronics_beauty_outdoorsThe following code is a preview of the items dataset:
ITEM_ID,ITEM_URL,ITEM_SK,ITEM_NAME,ITEM_CATEGORY,ITEM_STYLE,ITEM_DESCRIPTION,ITEM_PRICE,ITEM_IMAGE,ITEM_FEATURED,ITEM_GENDER_AFFINITY
36,http://dbq4nocqaarhp.cloudfront.net/#/product/36,,Exercise Headphones,electronics,headphones,These stylishly red ear buds wrap securely around your ears making them perfect when exercising or on the go.,19.99,5.jpg,true,
49,http://dbq4nocqaarhp.cloudfront.net/#/product/49,,Light Brown Leather Lace-Up Boot,footwear,boot,Sturdy enough for the outdoors yet stylish to wear out on the town.,89.95,11.jpg,,The following code is a preview of the interactions dataset:
ITEM_ID,USER_ID,EVENT_TYPE,TIMESTAMP
2,2539,ProductViewed,1589580300
29,5575,ProductViewed,1589580305
4,1964,ProductViewed,1589580309
46,5291,ProductViewed,1589580309This post is not intended to be a step-by-step guide, but rather describe the process of preparing a training dataset and highlight some of the transforms and data analysis capabilities using SageMaker Data Wrangler. You can download the .flow files if you want to download, upload, and retrace the full example in your SageMaker Studio environment.
At a high level, we perform the following steps:
- Connect to Amazon Simple Storage Service (Amazon S3) and import the data.
- Transform the data, including type casting, dropping unneeded columns, imputing missing values, label encoding, one hot encoding, and custom transformations to extract elements from a JSON formatted column.
- Create table summaries and charts for data analysis. We use the quick model option to get a sense of which features are adding predictive power as we progress with our data preparation. We also use the built-in target leakage capability and get a report on any features that are at risk of leaking.
- Create a data flow, in which we combine and join the three tables to perform further aggregations and data analysis.
- Iterate by performing additional feature engineering or data analysis on the newly added data.
- Export our workflow to a SageMaker Data Wrangler job.
Prerequisites
Make sure you don’t have any quota limits on the m5.4xlarge instance type part of your Studio application before creating a new data flow. For more information about prerequisites, see Getting Started with Data Wrangler.
Importing the data
We import our three CSV files from Amazon S3. SageMaker Data Wrangler supports CSV and Parquet files. It also allows you to sample the data in case the data is too large to fit in your studio application. The following screenshot shows a preview of the users dataset.
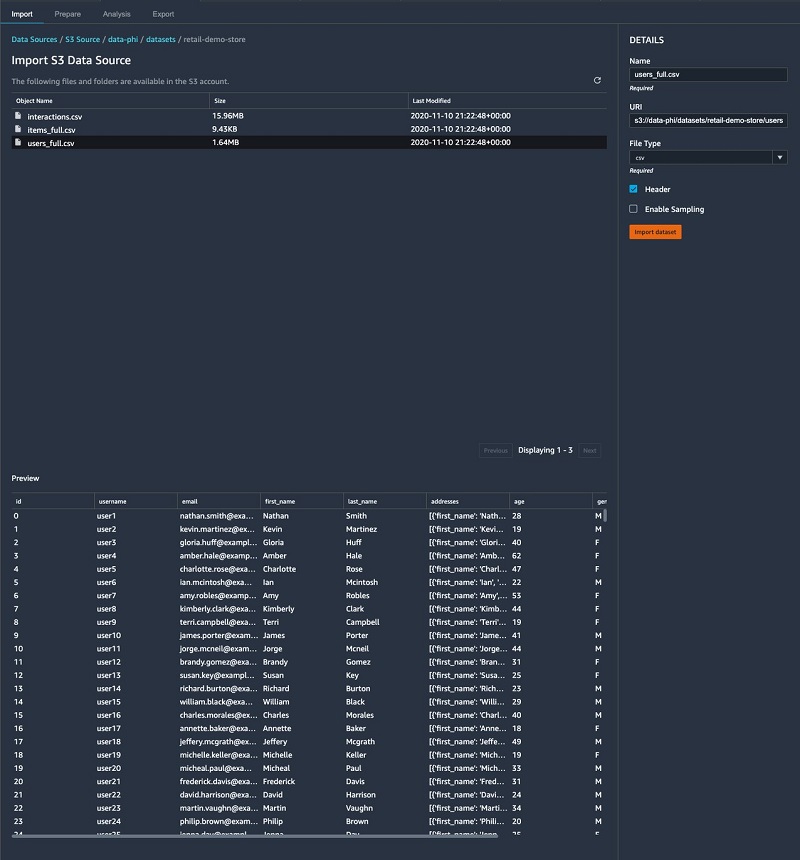
After importing our CSV files, our datasets look like the following screenshot in SageMaker Data Wrangler.
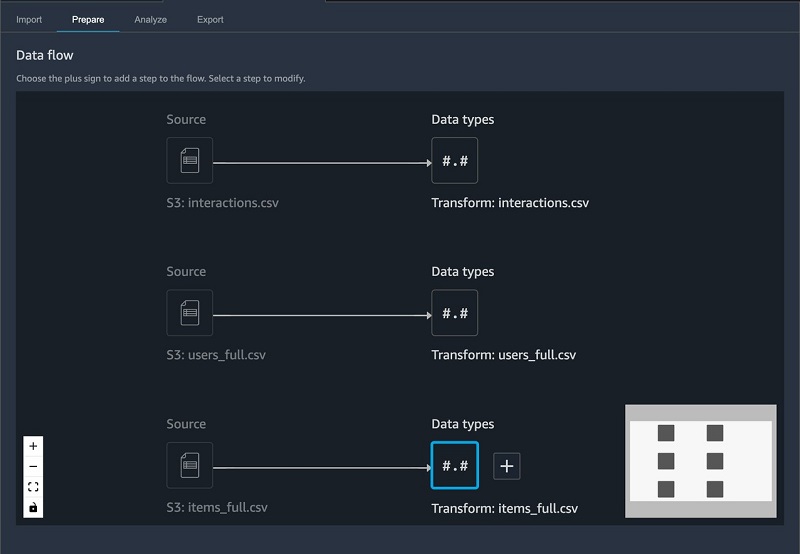
We can now add some transforms and perform data analysis.
Transforming the data
For each table, we check the data types and make sure that it was inferred correctly.
Items table
To perform transforms on the items table, complete the following steps:
- On the SageMaker Data Wrangler UI, for the items table, choose +.
- Choose Edit data types.
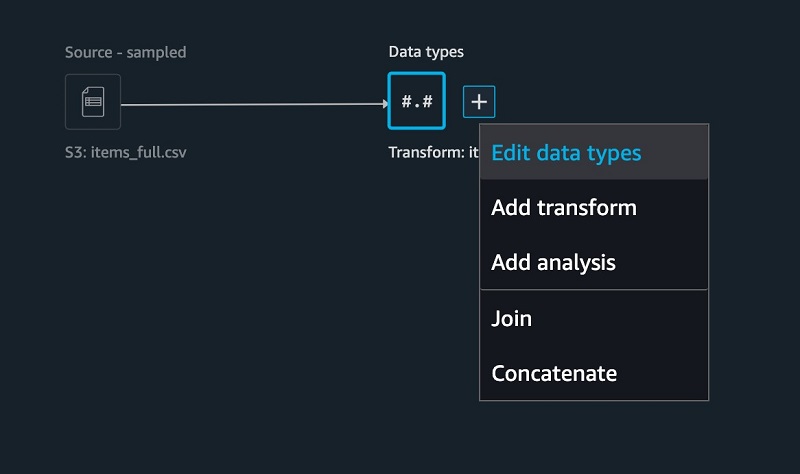
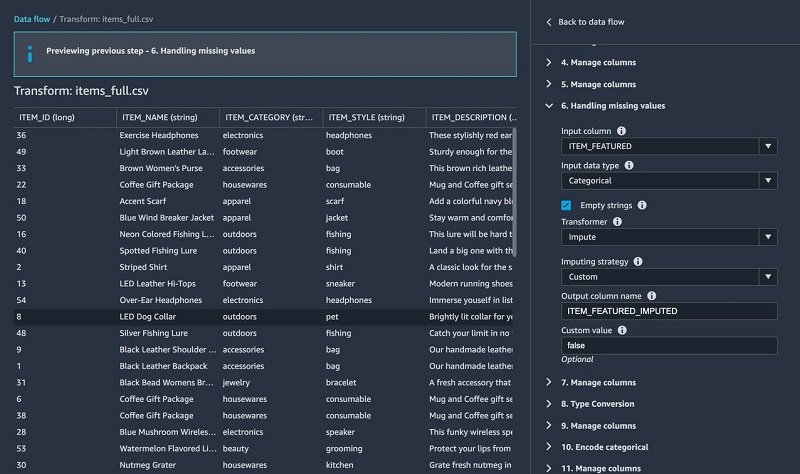
Most of the columns were inferred properly, except for one. The ITEM_FEATURED column is missing values and should really be casted as a Boolean.
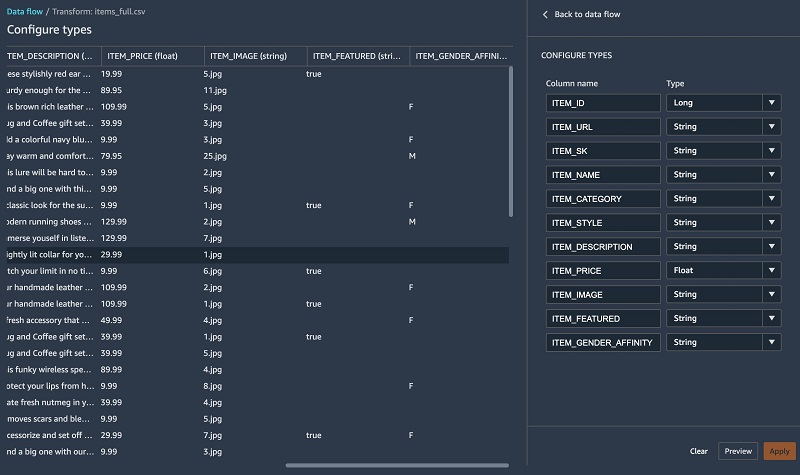
For the items table, we perform the following transformations:
- Fill missing values with
falsefor theITEM_FEATUREDcolumn - Drop unneeded columns such as
URL,SK,IMAGE,NAME,STYLE,ITEM_FEATUREDandDESCRIPTION - Rename
ITEM_FEATURED_IMPUTEDtoITEM_FEATURED - Cast the
ITEM_FEATUREDcolumn as Boolean - Encode the
ITEM_GENDER_AFFINITYcolumn
- To add a new transform, choose + and choose Add transform.
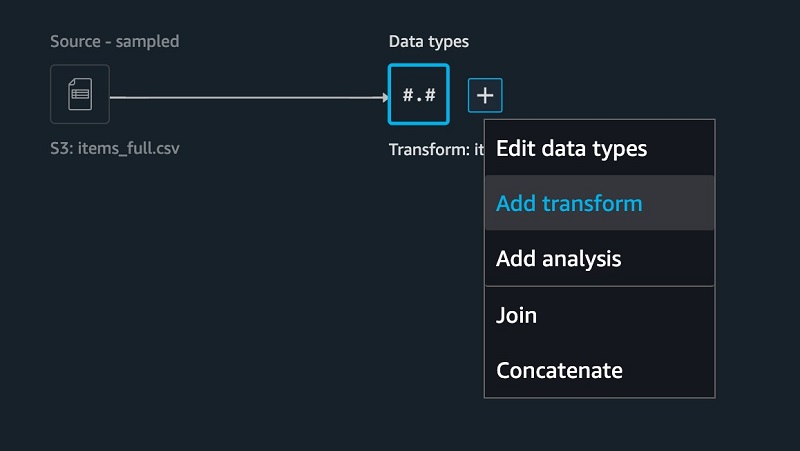
- Fill in missing values using the built-in Handling missing values transform.
- To drop columns, under Manage columns, For Input column, choose ITEM_URL.
- For Required column operator, choose Drop column.

- Repeat this step for
SK,IMAGE,NAME,STYLE,ITEM_FEATURED, andDESCRIPTION
- For Required column operator, choose Drop column.
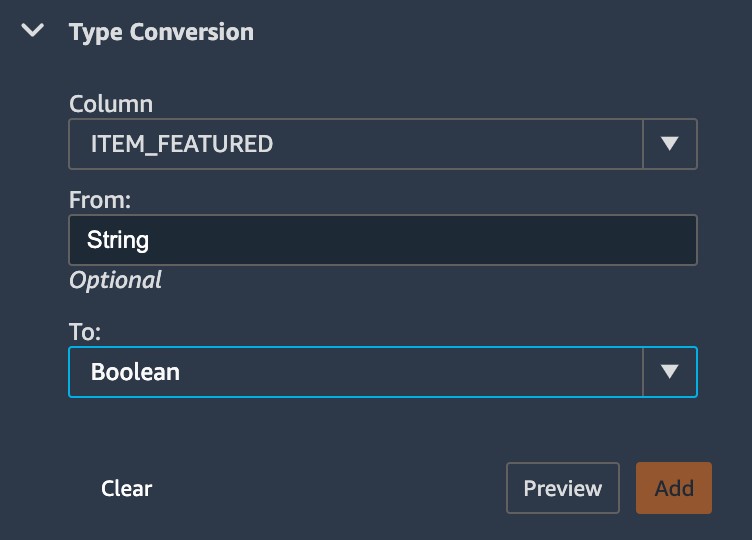
- Under Type Conversion, for Column, choose ITEM_FEATURED.
- for To, choose Boolean.
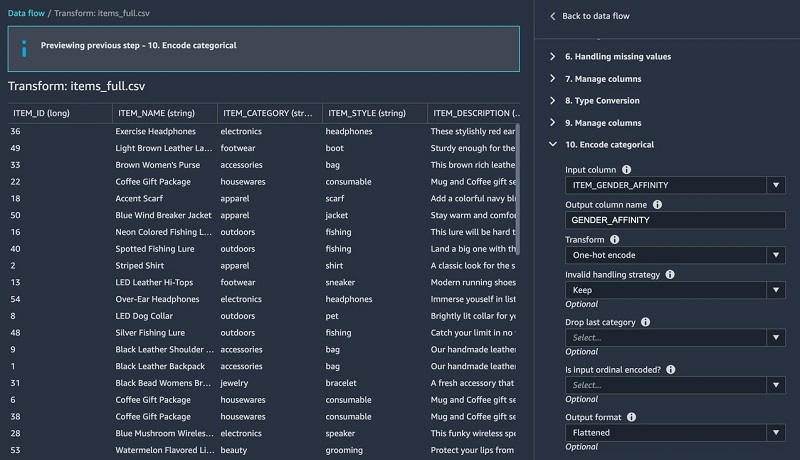
- Under Encore categorical, add a one hot encoding transform to the
ITEM_GENDER_AFFINITYcolumn.
- Rename our column from
ITEM_FEATURED_IMPUTED to ITEM_FEATURED. - Run a table summary.
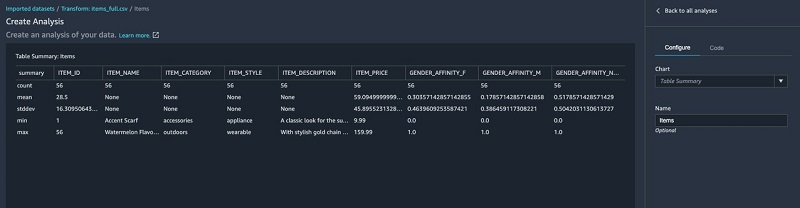
The table summary data analysis doesn’t provide information on all the columns.
- Run the
df.info()function as a custom transform. - Choose Preview to verify that our
ITEM_FEATUREDcolumn comes as a Boolean data type.
DataFrame.info() prints information about the DataFrame including the data types, non-null values, and memory usage.
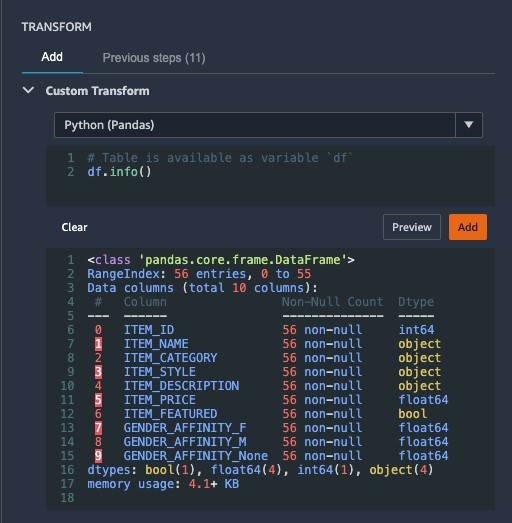
- Check that the
ITEM_FEATUREDcolumn has been casted properly and doesn’t have any null values.
Let’s move on to the users table and prepare our dataset for training.
Users table
For the users table, we perform the following steps:
- Drop unneeded columns such as
username,email,first_name, andlast_name. - Extract elements from a JSON column such as zip code, state, and city.
The addresse column containing a JSON string looks like the following code:
[{ "first_name": "Nathan",
"last_name": "Smith",
"address1": "049 Isaac Stravenue Apt. 770",
"address2": "",
"country": "US",
"city": "Johnsonmouth",
"state": "NY",
"zipcode": "12758",
"default": true
}]
To extract relevant location elements for our model, we apply several transforms and save them in their respective columns. The following screenshot shows an example of extracting the user zip code.
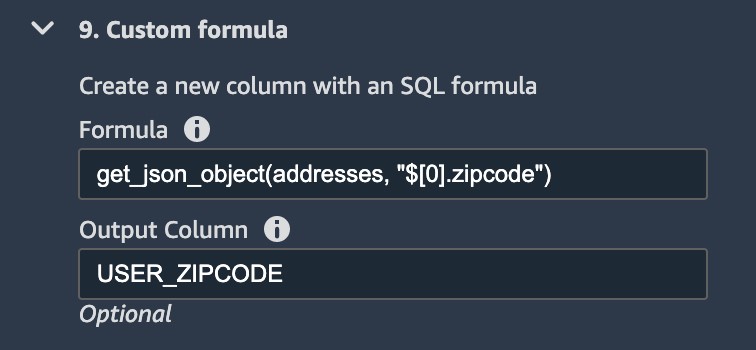
We apply the same transform to extract city and state, respectively.
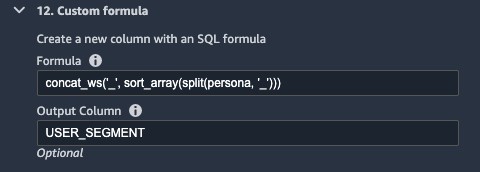
- In the following transform, we split and rearrange the different personas (such as
electronics_beauty_outdoors) and save it asUSER_SEGMENT.
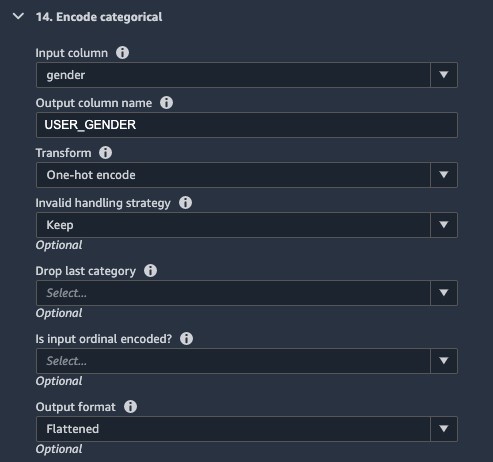
- We also perform a one hot encoding on the
USER_GENDERcolumn.
Interactions table
Finally, in the interactions table, we complete the following steps:
- Perform a custom transform to extract the event date and time from a timestamp.
Custom transforms are quite powerful because they allow you to insert a snippet of code and run the transform using different runtime engines such as PySpark, Python, or SparkSQL. All you have to do is to start your transform with df, which denotes the DataFrame.
The following code is an example using a custom PySpark transform to extract the date and time from the timestamp:
from pyspark.sql.functions import from_unixtime, to_date, date_format
df = df.withColumn('DATE_TIME', from_unixtime('TIMESTAMP'))
df = df.withColumn( 'EVENT_DATE', to_date('DATE_TIME')).withColumn( 'EVENT_TIME', date_format('DATE_TIME', 'HH:mm:ss'))
- Perform a one hot encoding on the EVENT_TYPE
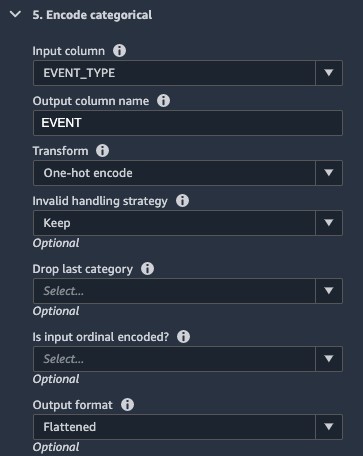
- Lastly, drop any columns we don’t need.
Performing data analysis
In addition to common built-in data analysis such as scatterplots and histograms, SageMaker Data Wrangler gives you the ability to build custom visualizations using the Altair library.
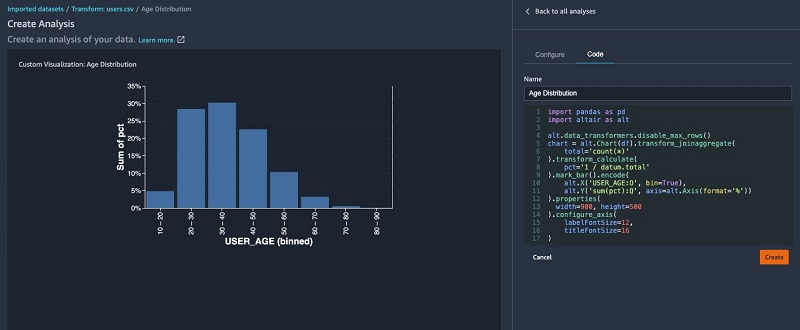
In the following histogram chart, we binned the user by age ranges on the x axis and the total percentage of users on the y axis.
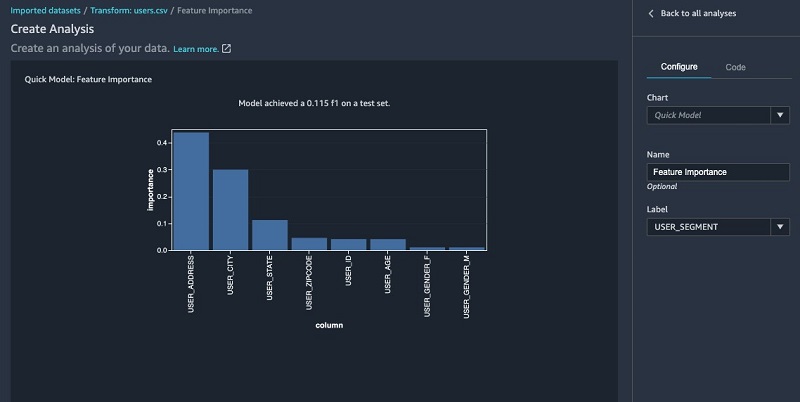
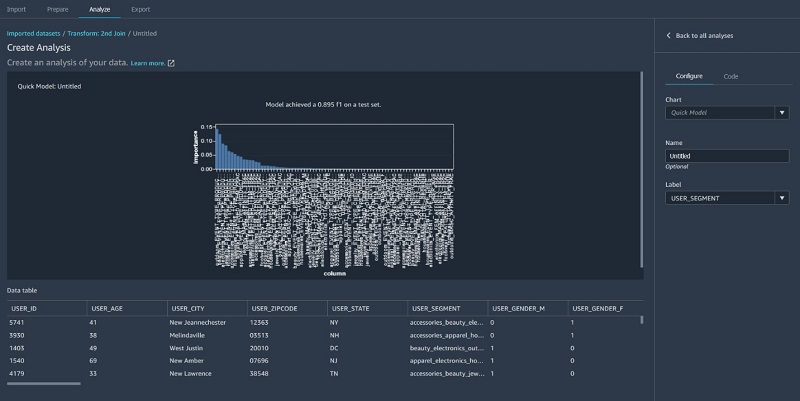
We can also use the quick model functionality to show feature importance. The F1 score indicating the model’s predictive accuracy is also shown in the following visualization. This enables you to iterate by adding new datasets and performing additional features engineering to incrementally improve model accuracy.
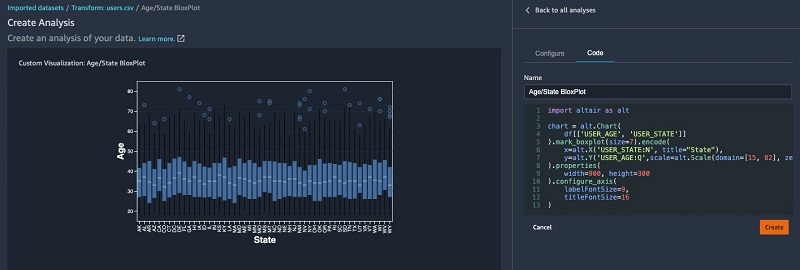
The following visualization is a box plot by age and state. This is particularly useful to understand the interquartile range and possible outliers.
Building a data flow
SageMaker Data Wrangler builds a data flow and keeps the dependencies of all the transforms, data analysis, and table joins. This allows you to keep a lineage of your exploratory data analysis but also allows you to reproduce past experiments consistently.
In this section, we join our interactions and items tables.
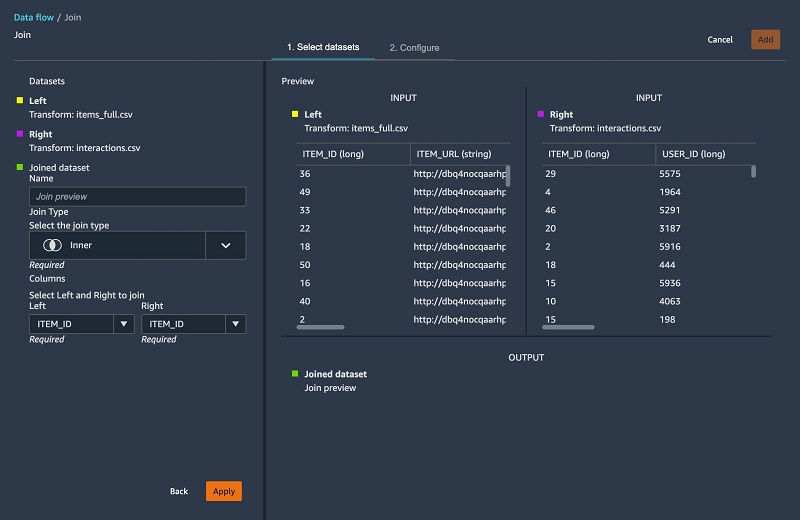
- Join our tables using the
ITEM_IDkey. - Use a custom transform to aggregate our dataset by
USER_IDand generate other features by pivoting theITEM_CATEGORYandEVENT_TYPE:
import pyspark.sql.functions as F
df = df.groupBy(["USER_ID"]).pivot("ITEM_CATEGORY")
.agg(F.sum("EVENT_TYPE_PRODUCTVIEWED").alias("EVENT_TYPE_PRODUCTVIEWED"),
F.sum("EVENT_TYPE_PRODUCTADDED").alias("EVENT_TYPE_PRODUCTADDED"),
F.sum("EVENT_TYPE_CARTVIEWED").alias("EVENT_TYPE_CARTVIEWED"),
F.sum("EVENT_TYPE_CHECKOUTSTARTED").alias("EVENT_TYPE_CHECKOUTSTARTED"),
F.sum("EVENT_TYPE_ORDERCOMPLETED").alias("EVENT_TYPE_ORDERCOMPLETED"),
F.sum(F.col("ITEM_PRICE") * F.col("EVENT_TYPE_ORDERCOMPLETED")).alias("TOTAL_REVENUE"),
F.avg(F.col("ITEM_FEATURED").cast("integer")).alias("FEATURED_ITEM_FRAC"),
F.avg("GENDER_AFFINITY_F").alias("FEM_AFFINITY_FRAC"),
F.avg("GENDER_AFFINITY_M").alias("MASC_AFFINITY_FRAC")).fillna(0)
- Join our dataset with the
userstables.
The following screenshot shows what our DAG looks like after joining all the tables together.
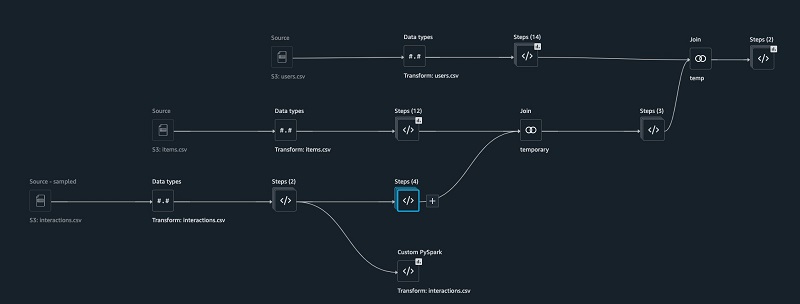
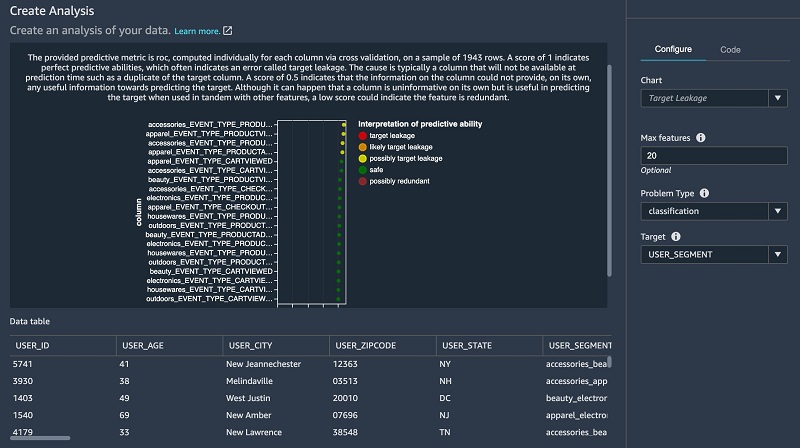
- Now that we have combined all three tables, run data analysis for target leakage.
Target leakage or data leakage is one of the most common and difficult problems when building a model. Target leakages mean that you use features as part of training your model that aren’t available upon inference time. For example, if you try to predict a car crash and one of the features is airbag_deployed, you don’t know if the airbag has been deployed until the crash happened.
The following screenshot shows that we don’t have a strong target leakage candidate after running the data analysis.
- Finally, we run a quick model on the joined dataset.
The following screenshot shows that our F1 score is 0.89 after joining additional data and performing further feature transformations.
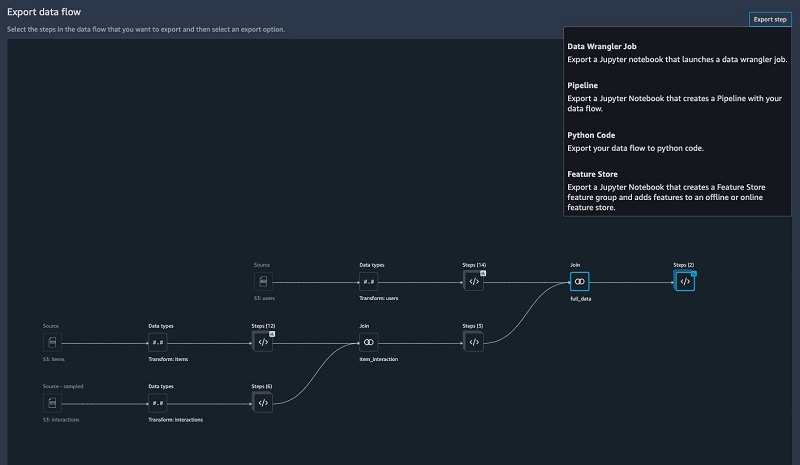
Exporting your data flow
SageMaker Data Wrangler gives you the ability to export your data flow into a Jupyter notebook with code pre-populated for the following options:
- SageMaker Data Wrangler job
- SageMaker Pipelines
- SageMaker Feature Store
SageMaker Data Wrangler can also output a Python file.
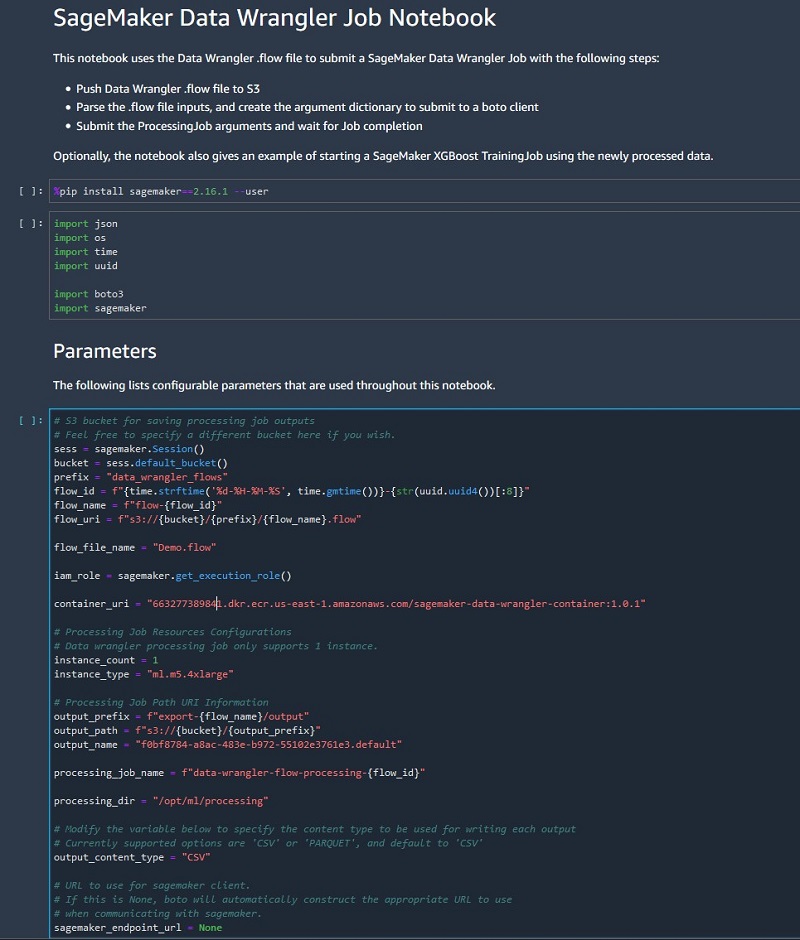
The SageMaker Data Wrangler job pre-populated in a Jupyter notebook ready to be run.
Conclusion
SageMaker Data Wrangler makes it easy to ingest data and perform data preparation tasks such as exploratory data analysis, feature selection, feature engineering, and more advanced data analysis such as feature importance, target leakage, and model explainability using an easy and intuitive user interface. SageMaker Data Wrangler makes the transition of converting your data flow into an operational artifact such as a SageMaker Data Wrangler job, SageMaker feature store, or SageMaker pipeline very easy with one click of a button.
Log in into your Studio environment, download the .flow file, and try SageMaker Data Wrangler today.
About the Authors
 Phi Nguyen is a solution architect at AWS helping customers with their cloud journey with a special focus on data lake, analytics, semantics technologies and machine learning. In his spare time, you can find him biking to work, coaching his son’s soccer team or enjoying nature walk with his family.
Phi Nguyen is a solution architect at AWS helping customers with their cloud journey with a special focus on data lake, analytics, semantics technologies and machine learning. In his spare time, you can find him biking to work, coaching his son’s soccer team or enjoying nature walk with his family.
 Roberto Bruno Martins is a Machine Learning Specialist Solution Architect, helping customers from several industries create, deploy and run machine learning solutions. He’s been working with data since 1994, and has no plans to stop any time soon. In his spare time he plays games, practices martial arts and likes to try new food.
Roberto Bruno Martins is a Machine Learning Specialist Solution Architect, helping customers from several industries create, deploy and run machine learning solutions. He’s been working with data since 1994, and has no plans to stop any time soon. In his spare time he plays games, practices martial arts and likes to try new food.
Multi-agent reinforcement learning for an uncertain world
With a new method, agents can cope better with the differences between simulated training environments and real-world deployment.Read More
Identifying training bottlenecks and system resource under-utilization with Amazon SageMaker Debugger
At AWS re:Invent 2020, AWS released the profiling functionality for Amazon SageMaker Debugger. In this post, we expand on the importance of profiling deep neural network (DNN) training, review some of the common performance bottlenecks you might encounter, and demonstrate how to use the profiling feature in Debugger to detect such bottlenecks.
In the context of DNN training, performance profiling refers to the art of analyzing the manner in which your training application is utilizing your training resources. Training resources are expensive, and your goal should always be to maximize their utilization. This is particularly true of your GPUs, which are typically the most expensive system resource in deep learning training tasks. Through performance profiling, we seek to answer questions such as:
- To what degree are we utilizing our CPU, GPU, network, and memory resources? Can we increase their utilization, and if so, how?
- What is our current speed of training, as measured, for example, by the training throughput, or the number of training iterations per second? Can we increase the throughout, and if so, how?
- Are there any performance bottlenecks that are preventing us from increasing the training throughput, and if so, what are they?
- Are we using the most ideal training instance types? Might a different choice of instance type speed up our training, or be more cost-effective?
Performance analysis is an integral step of performance optimization, in which we seek to increase system utilization and increase throughput. A typical strategy for performance optimization is to iterate the following two steps until you’re satisfied with the system utilization and throughput:
- Profiling the training performance to identify bottlenecks in the pipeline and under-utilized resources
- Addressing bottlenecks to increase resource utilization
Effective profiling analysis and optimization can lead to meaningful savings in time and cost. If you’re content with 50% GPU utilization, you’re wasting your (your company’s) money. Not to mention that you could probably be delivering your product much sooner. It’s essential that you have strong tools for profiling performance, and that you incorporate performance analysis and optimization as an integral part of your team’s development cycle.
That’s where the newly announced profiling capability of Debugger comes in.
Debugger is a feature of Amazon SageMaker training that makes it easy to train machine learning (ML) models faster by capturing real-time metrics such as learning gradients and weights. This provides transparency into the training process, so you can correct anomalies such as losses, overfitting, and overtraining. Debugger provides built-in rules to easily analyze emitted data, including tensors that are critical for the success of training jobs.
With the newly introduced profiling capability, Debugger now automatically monitors system resources such as CPU, GPU, network, I/O, and memory, providing a complete resource utilization view of training jobs. You can profile your entire training job or portions thereof to emit detailed framework metrics during different phases of the training job. You can reallocate resources based on recommendations from the profiling capability. Metrics and insights are captured and monitored programmatically using the SageMaker Python SDK or visually through Amazon SageMaker Studio.
Let’s demonstrate how to use Debugger to profile the performance of a ResNet50 model. Full documentation of this example is available in the following Jupyter notebook.
Configuring a training job
To configure profiling on a SageMaker training job, we first create an instance of the ProfileConfig object, in which we specify the profiling frequency. The profiler supports a number of optional settings for controlling the level and scope of profiling, including Python profiling and DataLoader profiling. For more information about the API, see Amazon SageMaker Debugger.
The ProfileConfig instance is applied to SageMaker Estimator. In the following code, we set the system monitoring interval 500 milliseconds. We also set batch_size to 64.
from sagemaker.profiler import ProfilerConfig, FrameworkProfile
profiler_config = ProfilerConfig(
system_monitor__interval_millis=500,
framework_profiling_params=FrameworkProfile(start_step=5, num_steps=2)
)
estimator = TensorFlow(
role=sagemaker.get_execution_role(),
instance_count=1,
instance_type='ml.p2.xlarge',
entry_point='train_tf.py',
source_dir='demo',
framework_version='2.3.',
py_version='py37',
profiler_config=profiler_config,
script_mode=True,
hyperparameters={'batch_size':64}When the training session starts, Debugger collects and uploads profiling data to a secured Amazon Simple Storage Service (Amazon S3) bucket that you own and control. This enables investigation of performance issues while the training is still ongoing. You can view the profiling data in Studio. In addition, Debugger provides APIs for loading and analyzing the data programmatically.
Throughout the training, a diagnostic report is automatically generated and periodically updated, with a summary of the profiling results of the training session and recommendations for how to improve resource utilization. You can view the report in Studio or pull it from Amazon S3 in HTML format for offline analysis. Debugger generates a notebook (profiler-report.ipynb) that you can use to adjust the profiler report as needed.
Reviewing profiling results in Studio
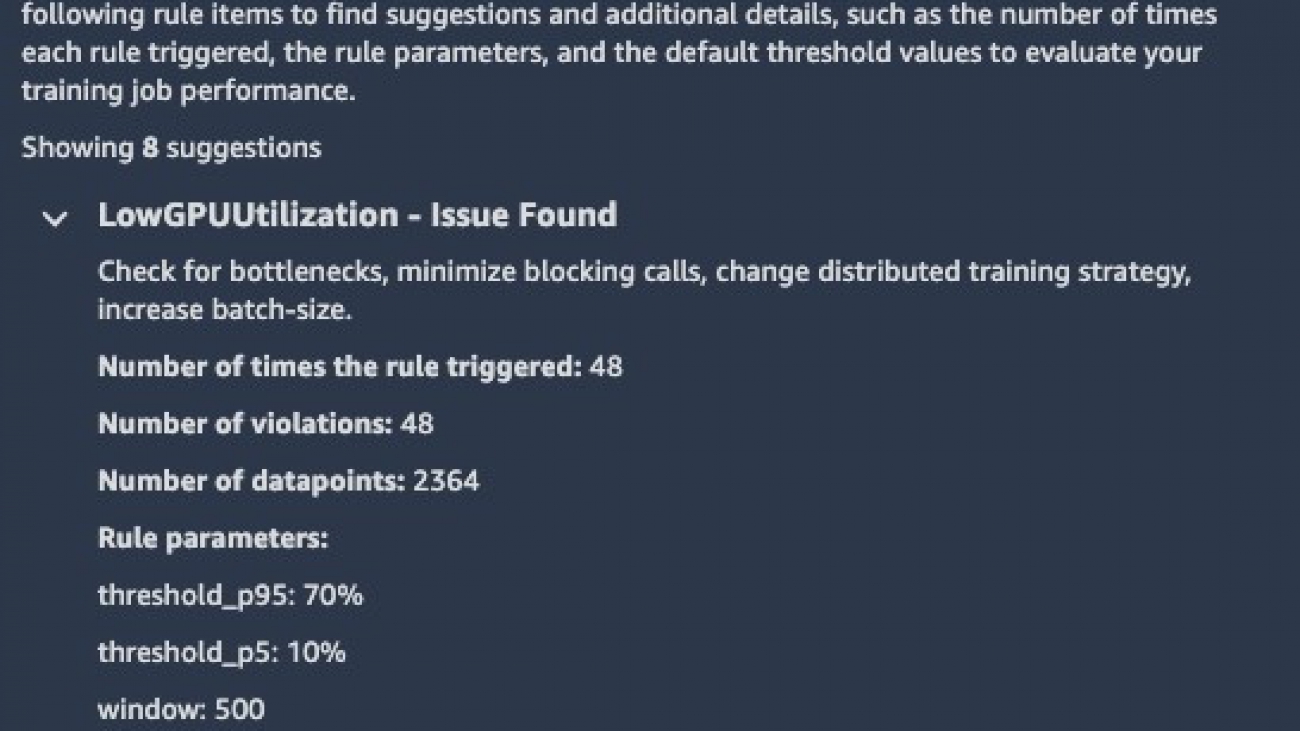
You can view the collected performance metrics in Studio. The Overview tab of the Debugger Insights page provides a summary report of the profiling analysis. For more information about what issues are automatically analyzed and reported, see List of Debugger Built-in Rules.
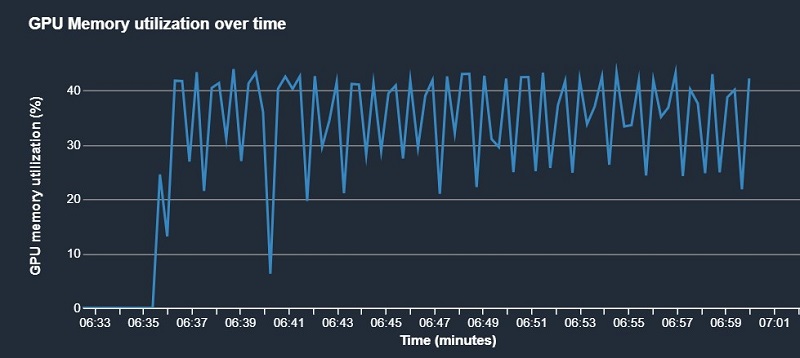
In our example, it has identified low utilization of the GPU and advises us to check for bottlenecks or increase the batch size. The low GPU utilization should raise a red flag for us. As we mentioned earlier, the GPU is typically the most expensive resource you use, and you should always strive to maximize its use.
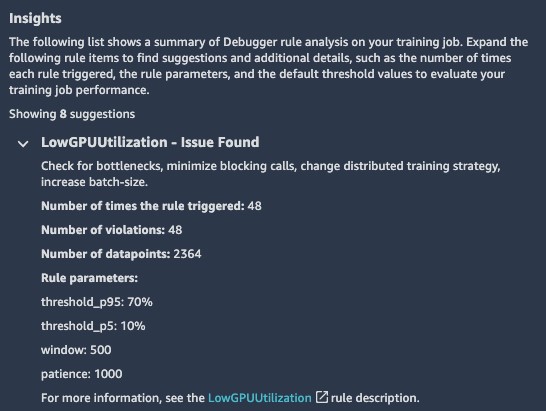
The Nodes tab includes plots of the system utilization and framework metrics. This is available as soon as the training starts, and Debugger begins to upload the collected data to Amazon S3.
The following plots show that although there are no bottlenecks in the system, both the GPU and GPU memory are highly under-utilized.
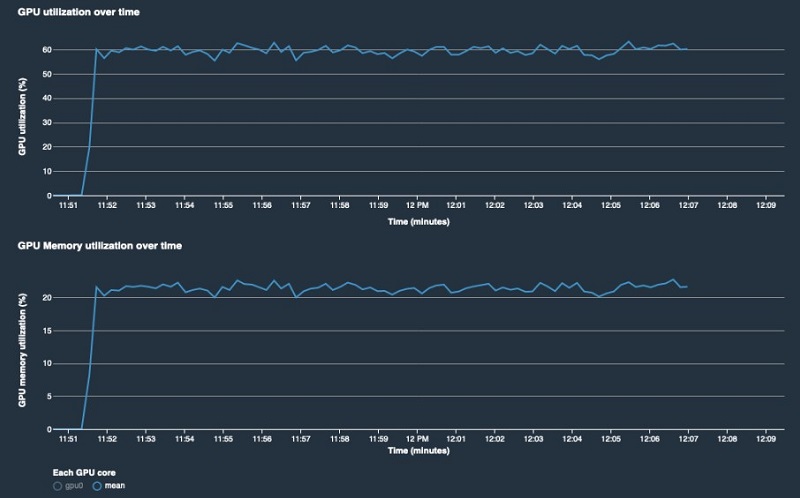
These results are clear indications that the batch size we chose is leading to under-utilization of the system resources, and that we can increase training efficiency by increasing the batch size. When we rerun the job with the batch size set to 1024, we see much better GPU utilization.
Performing advanced performance analysis using Debugger profiling
In some cases, there may be clear issues with your training, but the reasons for them might not be immediately apparent from the Studio report. In these cases, you can use the profiling analysis APIs of Debugger to deep dive into the training behavior. In the following code, we demonstrate how to load the collected system and framework metrics into a Pandas DataFrame for processing. This provides you flexibility in analyzing issues.
from smdebug.profiler.analysis.notebook_utils.training_job import TrainingJob
from smdebug.profiler.analysis.utils.profiler_data_to_pandas import PandasFrame
tj = TrainingJob(training_job_name, region)
pf = PandasFrame(tj.profiler_s3_output_path)
system_metrics_df = pf.get_all_system_metrics()
framework_metrics_df = pf.get_all_framework_metrics()For more information about the API, see the interactive_analysis.ipynb notebook.
This section showed a simple example of how we can use the profiling functionality of Debugger to identify system resource under-utilization resulting from a small batch size. Another common cause of under-utilization is when there is a bottleneck somewhere in the training pipeline, which we address later in this post. We first highlight some of the unique features of the profiling function of Debugger.
Unique features of the Debugger profiling function
The profiler collects both system and framework metrics. Other than the inherent value in having a broad range of statistics (such as step duration, data-loading, preprocessing, and operator runtime on CPU and GPU), this enables deep learning developers or engineers to easily correlate between system resource utilization metrics and training progression, and glean deeper insights into potential issues. For example, in the following image, we use the profiling analysis APIs in Debugger to plot both GPU utilization and train step times on the same graph. This enables us to identify a clear connection between every fiftieth train step (marked in yellow) and severe dips in the GPU utilization.
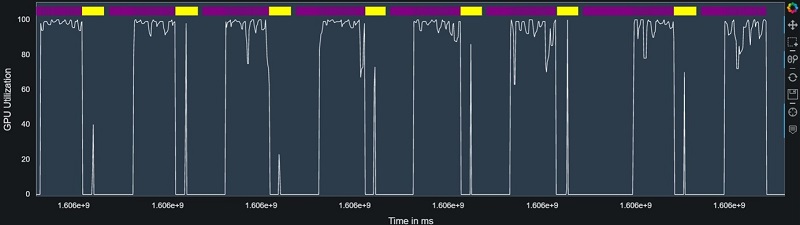
Debugger collects performance metrics on the entire end-to-end training session. Other profilers often limit their activity to a limited number of training steps, and therefore run the risk of missing performance issues that occur outside the chosen window. In contrast, Debugger collects metrics and statistics on the entire training session, making it easier to catch performance issues that occur less regularly.
Debugger provides APIs for managing the information-interference tradeoff, which refers to the simple observation that the more we change the original pipeline to extract meaningful performance data, the less meaningful that data actually is. The more we increase the frequency at which we poll the system for utilization metrics, the more the activity of the actual profiling begins to overshadow the activity of the training loop, essentially deeming the captured data useless. Finding the right balance is not always so easy. A complete performance analysis strategy should include profiling at different levels of invasion in order to get as clear a picture as possible of what is going on.
In the next section, we review some of the potential bottlenecks in a typical training pipeline, and how to detect them using the profiling function of Debugger.
The training pipeline and potential bottlenecks
To facilitate the discussion on the possible bottlenecks within a training session, we present the following diagram of a typical training pipeline. The training is broken down into eight steps, each of which can potentially impede the training flow.
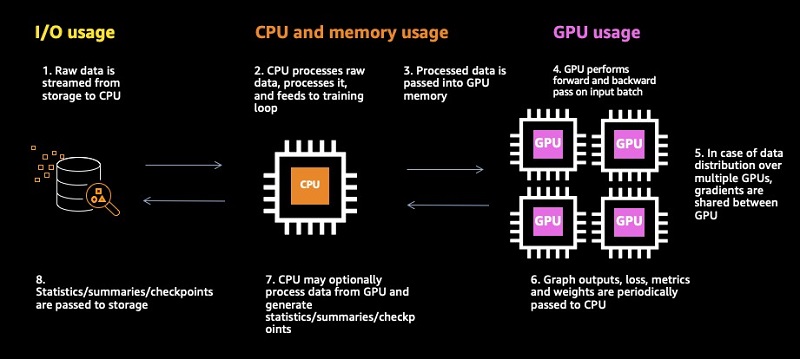
Let’s dive into a few of the potential bottlenecks and demonstrate how we can use the profiling functionality of Debugger to identify them.
Raw data input
Unless you’re auto-generating your training data, you’re likely loading it from storage. This might be from local storage such as Amazon Elastic Block Store (Amazon EBS) or local NVMe SSD disks, or it might be over the network via Amazon Elastic File System (Amazon EFS), Amazon FSx for Lustre, or Amazon S3. In either case, you’re using system resources that could potentially block the pipeline. If the amount of raw data per training sample is particularly large, if your I/O interface has high latency, or if the network bandwidth of your training instance is low, you may find your CPU sitting idly as it waits for the raw data to come in.
A classic example of this is when you train with SageMaker using File input mode. In File input mode, all the training data is downloaded to the local file systems of the training instances before the training starts. If you have a lot of data, you could be waiting a while before the first epoch starts.
The alternative SageMaker option is to use Pipe input mode. This allows you to stream data directly from an S3 bucket into your input data pipeline, thus avoiding the huge bottleneck to training startup. But even in the case of Pipe input mode, you can easily run up on resource limitations. For example, if your instance type supports network I/O of up to 10 Gbs, and each sample requires 100 Mb of raw data, you have an upper limit of 100 training samples per second, no matter how fast your GPU is. The way to overcome such issues is to reduce your raw data, compress some of the data, use a binary dataset format like TFRecord or RecordIO instead of raw data files, or choose an instance type with a higher network I/O bandwidth.
For our example, the limitation comes from the network I/O bandwidth of the instance, but it can also come from a bandwidth on the amount of data that you can pull from Amazon S3 or from somewhere else along the line. (If you’re pulling data from Amazon S3 without using Pipe mode, make sure to choose an instance type with Elastic Network Adapter enabled.)
A common footprint of a bottleneck caused by the NetworkIn bandwidth is low GPU utilization, combined with high (maximum) network utilization. The following chart shows the GPU utilization reported by the Debugger profiler and displayed in Studio. In this case, we have artificially increased the network traffic by blowing up the size of each incoming data record with 1 MB of zeros. As a result, the GPU remains mostly idle, while it waits for the training samples to come in.

Data preprocessing
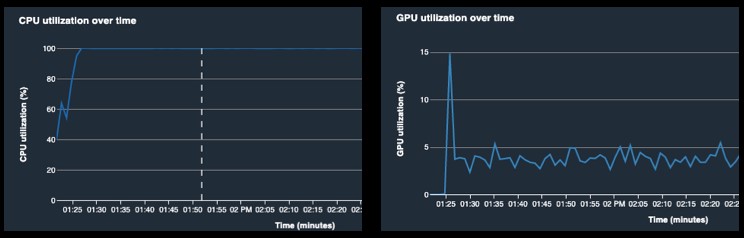
The next step in the training pipeline is the data preprocessing. In this stage, typically performed on the CPU, the raw data is prepared for entry to the training loop. This might include applying augmentations to input data, inserting masking elements, batching, filtering, and more. In the case of TensorFlow, tf.data functions include built-in functionality for parallelizing the processing operations within the CPU (for example, the num_parallel_calls argument in the tf.data.dataset.map routine), and also for running the CPU in parallel with the GPU (for example, tf.data.dataset.prefetch). Similarly, the PyTorch APIs allow for multi-process data loading and automatic memory pinning. However, if you’re running heavy or memory-intensive computation in this stage, you might still find yourself with your GPU idle as it waits for data input.
For more information about how to use Debugger to identify a bottleneck in the data input pipeline, see the dataset_bottleneck.ipynb notebook.
A common footprint of this bottleneck is low GPU utilization, along with high CPU utilization (see the following visualizations).
Model output processing
The CPU might perform some processing on the output data received from the GPU. In TensorFlow, this processing often occurs within TensorFlow callbacks. You can use these to evaluate tensors, create image summaries, collect statistics, update the learning rate, and more. There are different ways in which this could reduce the training throughput:
- If the processing is computation or memory intensive, this may become a performance bottleneck. If the processing is independent of the model GPU state, you might want to try running in a separate (non-blocking) thread.
- If your callbacks are processing output on frequent iterations, you’re also likely slowing down the throughput. Consider reducing the frequency of the processing or adding the processing to the GPU model graph.
For more information about how to use Debugger to identify a bottleneck from a training callback, see the callback_bottleneck.ipynb notebook.
A common footprint of this bottleneck are periodic dips in GPU utilization, which can be correlated with heavy callback activity (see the following visualization).
Conclusion
The newly announced profiling functionality of SageMaker Debugger offers essential tools for identifying training bottlenecks and under-utilization of system resources. You can use these tools to increase your training efficiency and reduce training costs. In this post, we demonstrated a few simple use cases. The configuration APIs include controls for a wide variety of low-level profiling features, which provide coverage for a broad range of potential issues. For more information, see the Debugger profiling examples in the GitHub repo.
For additional resources about TensorFlow, and deep learning performance tips on PyTorch or Apache MXNet, see the following:
- TensorFlow Performance Analysis
- Deep Learning Computation: GPUs
- Choosing the right GPU for deep learning on AWS
About the Authors
 Muhyun Kim is a data scientist at Amazon Machine Learning Solutions Lab. He solves customer’s various business problems by applying machine learning and deep learning, and also helps them gets skilled.
Muhyun Kim is a data scientist at Amazon Machine Learning Solutions Lab. He solves customer’s various business problems by applying machine learning and deep learning, and also helps them gets skilled.
 Chaim Rand is a Machine Learning Algorithm Developer working on Autonomous Vehicle technologies at Mobileye, an Intel Company.
Chaim Rand is a Machine Learning Algorithm Developer working on Autonomous Vehicle technologies at Mobileye, an Intel Company.
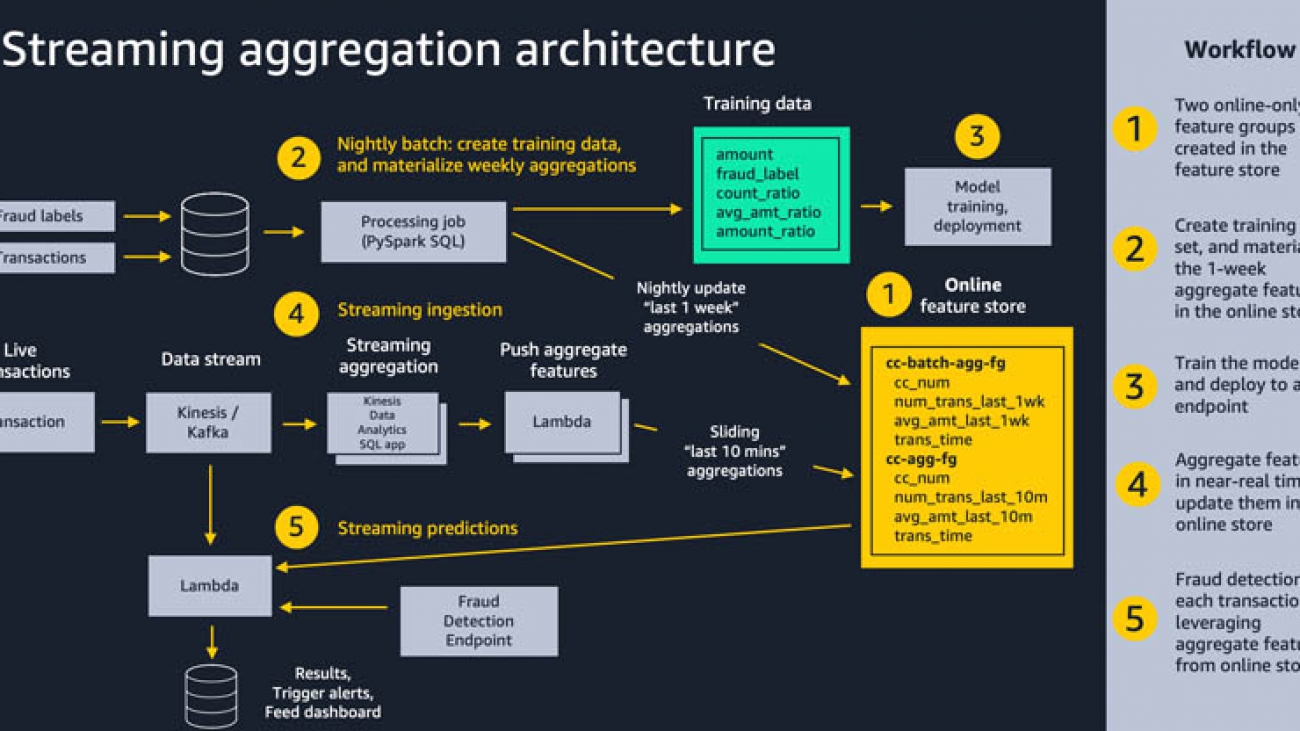
Using streaming ingestion with Amazon SageMaker Feature Store to make ML-backed decisions in near-real time
Businesses are increasingly using machine learning (ML) to make near-real time decisions, such as placing an ad, assigning a driver, recommending a product, or even dynamically pricing products and services. ML models make predictions given a set of input data known as features, and data scientists easily spend more than 60% of their time designing and building these features. Furthermore, highly accurate predictions depend on timely access to feature values that change quickly over time, adding even more complexity to the job of building a highly available and accurate solution. For example, a model for a ride sharing app can choose the best price for a ride from the airport, but only if it knows the number of ride requests received in the past 10 minutes and the number of passengers projected to land in the next 10 minutes. A routing model in a call center app can pick the best available agent for an incoming call, but it is only effective if it knows the customer’s latest web session clicks.
Although the business value of near real time ML predictions is enormous, the architecture required to deliver them reliably, securely, and with good performance is complicated. Solutions need high-throughput updates and low latency retrieval of the most recent feature values in milliseconds, something most data scientists are not prepared to deliver. As a result, some enterprises have spent millions of dollars inventing their own proprietary infrastructure for feature management. Other firms have limited their ML applications to simpler patterns like batch scoring until ML vendors provide more comprehensive off-the-shelf solutions for online feature stores.
To address these challenges, Amazon SageMaker Feature Store provides a fully managed central repository for ML features, making it easy to securely store and retrieve features, without having to build and maintain your own infrastructure. Amazon SageMaker Feature Store lets you define groups of features, use batch ingestion and streaming ingestion, retrieve the latest feature values with single-digit millisecond latency for highly accurate online predictions, and extract point-in-time correct datasets for training. Instead of building and maintaining these infrastructure capabilities, you get a fully managed service that scales as your data grows, enables sharing features across teams, and lets your data scientists focus on building great ML models aimed at game-changing business use cases. Teams can now deliver robust features once, and reuse them many times in a variety of models that may be built by different teams.
This post walks through a complete example of how you can couple streaming feature engineering with Amazon SageMaker Feature Store to make ML-backed decisions in near-real time. We show a credit card fraud detection use case that updates aggregate features from a live stream of transactions and uses low-latency feature retrievals to help detect fraudulent transactions. Try it out for yourself by visiting our code repo.
Credit card fraud use case
Stolen credit card numbers can be bought in bulk on the dark web from previous leaks or hacks of organizations that store this sensitive data. Fraudsters buy these card lists and attempt to make as many transactions as possible with the stolen numbers until the card is blocked. These fraud attacks typically happen in a short time frame, and this can be easily spotted in historical transactions because the velocity of transactions during the attack differs significantly from the cardholder’s usual spending pattern.
The following table shows a sequence of transactions from one credit card where the cardholder first has a genuine spending pattern and then experiences a fraud attack starting on November 4th.
| cc_num | trans_time | amount | fraud_label |
| …1248 | Nov-01 14:50:01 | 10.15 | 0 |
| … 1248 | Nov-02 12:14:31 | 32.45 | 0 |
| … 1248 | Nov-02 16:23:12 | 3.12 | 0 |
| … 1248 | Nov-04 02:12:10 | 1.01 | 1 |
| … 1248 | Nov-04 02:13:34 | 22.55 | 1 |
| … 1248 | Nov-04 02:14:05 | 90.55 | 1 |
| … 1248 | Nov-04 02:15:10 | 60.75 | 1 |
| … 1248 | Nov-04 13:30:55 | 12.75 | 0 |
For this post, we train an ML model to spot this kind of behavior by engineering features that describe an individual card’s spending pattern, such as the number of transactions or the average transaction amount from that card in a certain time window. This model protects cardholders from fraud at the point of sale by detecting and blocking suspicious transactions before the payment can complete. The model makes predictions in a low-latency, real-time context and relies on receiving up-to-the-minute feature calculations, so it can respond to an ongoing fraud attack. In a real-world scenario, features related to cardholder spending patterns would only form part of the model’s feature set, and we can include information about the merchant, the cardholder, the device used to make the payment, and any other data that may be relevant to detecting fraud.
Because our use case relies on profiling an individual card’s spending patterns, it’s crucial that we can identify credit cards in a transaction stream. Most publicly available fraud detection datasets don’t provide this information, so we use the Python Faker library to generate a set of transactions covering a 5-month period. This dataset contains 5.4 million transactions spread across 10,000 unique (and fake) credit card numbers and is intentionally imbalanced to match the reality of credit card fraud (only 0.25% of the transactions are fraudulent). We vary the number of transactions per day per card, as well as the transaction amounts. See our code repo for more detail.
Overview of the solution
We want our fraud detection model to classify credit card transactions by noticing a burst of recent transactions that differs significantly from the cardholder’s usual spending pattern. Sounds simple enough, but how do we build it?
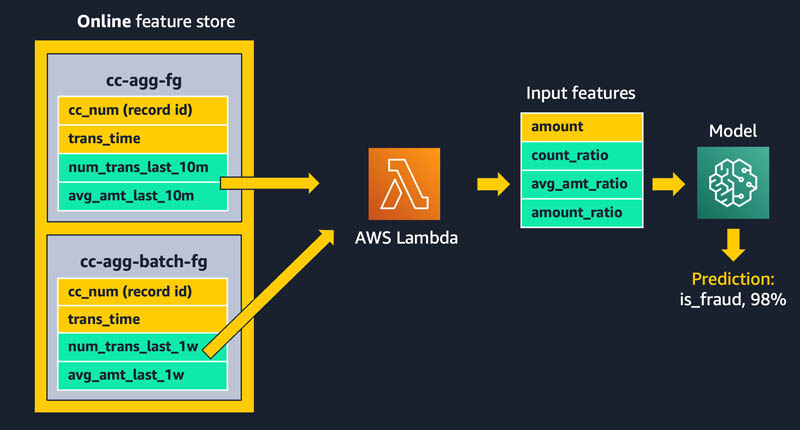
The following diagram shows our overall solution architecture. We feel that this same pattern will work well for a variety of streaming aggregation use cases. At a high level, the pattern involves the following five pieces. We dive into more detail on these in subsequent sections:
- Feature store – We use Amazon SageMaker Feature Store to provide a repository of features with high-throughput writes and secure low-latency reads, using feature values that are organized into multiple feature groups.
- Batch ingestion – Batch ingestion takes labeled historical credit card transactions and creates the aggregate features and ratios needed for training the fraud detection model. We use an Amazon SageMaker Processing job and the built-in Spark container to calculate aggregate weekly counts and transaction amount averages and ingest them into the feature store for use in online inference.
- Model training and deployment – This aspect of our solution is straightforward. We use Amazon SageMaker to train a model using the built-in XGBoost algorithm on aggregated features created from historical transactions. The model is deployed to a SageMaker endpoint, where it handles fraud detection requests on live transactions.
- Streaming ingestion – An Amazon Kinesis Data Analytics application calculates aggregated features from a transaction stream, and an AWS Lambda function updates the online feature store.
- Streaming predictions – Lastly, we make fraud predictions on a stream of transactions, using AWS Lambda to pull aggregate features from the online feature store. We use the latest feature data to calculate transaction ratios and then call the fraud detection endpoint.

Feature store
ML models rely on well-engineered features coming from a variety of data sources, with transformations as simple as calculations, or as complicated as a multi-step pipeline that takes hours of compute time and complex coding. Amazon SageMaker Feature Store enables the reuse of these features across teams and models which improves data scientist productivity, speeds time to market, and ensures consistency of model input.
Each feature inside SageMaker Feature Store is organized into a logical grouping called a feature group. You decide which feature groups you need for your models. Each one can have dozens, hundreds, or even thousands of features. Feature groups are managed and scaled independently, but they’re all available for search and discovery across teams of data scientists responsible for many independent ML models and use cases.
ML models often require features from multiple feature groups. A key aspect of a feature group is how often its feature values need to be updated or materialized for downstream training or inference. You refresh some features hourly, nightly, or weekly, and a subset of features must be streamed to the feature store in near-real time. Streaming all feature updates would lead to unnecessary complexity, and could even lower the quality of data distributions by not giving you the chance to remove outliers.
In our use case, we create a feature group called cc-agg-batch-fg for aggregated credit card features updated in batch, and one called cc-agg-fg for streaming features. The batch feature group is updated nightly, and provides aggregate features looking back over a one-week time window. Recalculating one-week aggregations on streaming transactions does not offer meaningful signals, and would be a waste of resources.
Conversely, our cc-agg-fg feature group must be updated in a streaming fashion, because it offers the latest transaction counts and average transaction amounts looking back over a 10-minute time window. Without streaming aggregation, we could not spot the typical fraud attack pattern of a rapid sequence of purchases.
By isolating features that are recalculated nightly, we can improve ingestion throughput for our streaming features. Separation lets us optimize the ingestion for each group independently. When designing for your use cases, keep in mind that models requiring features from a large number of feature groups may want to make multiple retrievals from the feature store in parallel to avoid adding excessive latency to a real time prediction workflow.
The feature groups for our use case are seen in the following diagram.

Each feature group must have one feature used as a record identifier (for this post, the credit card number). The record identifier acts as a primary key for the feature group, enabling fast lookups as well as joins across feature groups. An event time feature is also required, which enables the feature store to track the history of feature values over time. This becomes important when looking back at the state of features at a specific point in time.
In each feature group, we track the number of transactions per unique credit card and its average transaction amount. The only difference between our two groups is the time window used for aggregation. We use a 10-minute window for streaming aggregation, and a 1-week window for batch aggregation.
With Amazon SageMaker Feature Store, you have the flexibility to create feature groups that are offline only, online only, or both online and offline. An online store provides high-throughput writes and low-latency retrievals of feature values, ideal for online inference. An offline store is provided using Amazon S3, giving firms a highly scalable repository, with a full history of feature values, partitioned by feature group. The offline store is ideal for training and batch scoring use cases.
When you enable a feature group to provide both online and offline stores, SageMaker automatically synchronizes feature values to an offline store, continuously appending the latest values to give you a full history of values over time. Another benefit of feature groups that are both online and offline is to help avoid the problem of training and inference skew. SageMaker lets you feed both training and inference with the same transformed feature values, ensuring consistency to drive more accurate predictions. The focus in our post is to demonstrate online feature streaming, so we implemented online-only feature groups.
Batch ingestion
To materialize our batch features, we create a feature pipeline that is run as an Amazon SageMaker Processing job that is executed nightly. The job has two responsibilities: producing the dataset for training our model, and populating the batch feature group with the most up-to-date values for aggregate 1-week features, as shown in the following diagram:
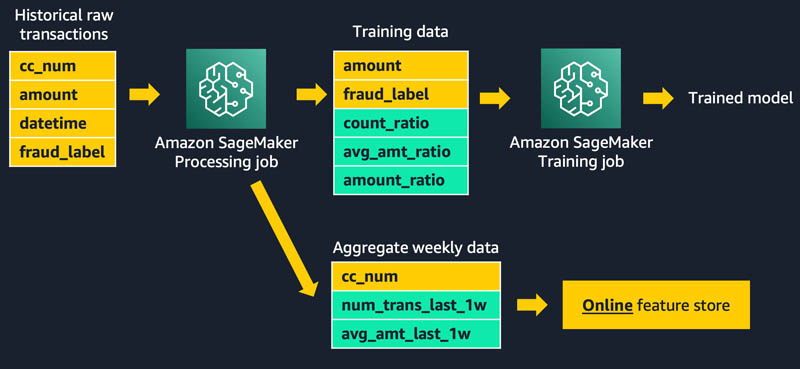
Each historical transaction used in the training set is enriched with aggregated features for the specific credit card involved in the transaction. We look back over two separate sliding time windows: 1 week back, and the preceding 10 minutes. The actual features used to train the model include the following ratios of these aggregated values:
amt_ratio1 = avg_amt_last_10m / avg_amt_last_1wamt_ratio2 = transaction_amount / avg_amt_last_1wcount_ratio = num_trans_last_10m / num_trans_last_1w
For example, the third ratio is the transaction count from the prior 10 minutes divided by the transaction count from the last week. Our ML model can learn patterns of normal activity versus fraudulent activity from these ratios, rather than relying on raw counts and transaction amounts. Spending patterns on different cards vary greatly, so normalized ratios provide a better signal to the model than the aggregated amounts themselves.
You may be wondering why our batch job is computing features with a 10-minute lookback. Isn’t that only relevant for online inference? We need the 10-minute window on historical transactions to create an accurate training dataset. This is critical for ensuring consistency with the 10-minute streaming window that will be used in near real time to support online inference.
The resulting training dataset from the processing job can be saved directly as a CSV for model training, or it can be bulk ingested into an offline feature group that can be used for other models and by other data science teams to address a wide variety of other use cases. For example, we can create and populate a feature group called cc-transactions-fg. Our training job can then pull a specific training dataset based on the needs for our specific model, selecting specific date ranges and a subset of features of interest. This approach enables multiple teams to reuse feature groups and maintain fewer feature pipelines, leading to significant cost savings and productivity improvements over time. This example notebook demonstrates the pattern of using SageMaker Feature Store as a central repository that data scientists can extract training datasets from.
In addition to creating a training dataset, we use the PutRecord API to put the 1-week feature aggregations into the online feature store nightly. The following code demonstrates putting a record into an online feature group given specific feature values, including a record identifier and an event time:
record = [{'FeatureName': 'cc_num',
'ValueAsString': str(cc_num)},
{'FeatureName':'avg_amt_last_1w',
'ValueAsString': str(avg_amt_last_1w)},
{'FeatureName':'num_trans_last_1w',
'ValueAsString': str(num_trans_last_1w)}]
event_time_feature = {
'FeatureName': 'trans_time',
'ValueAsString': str(int(round(time.time())))}
record.append(event_time_feature)
response = feature_store_client.put_record(
FeatureGroupName=’cc-agg-batch-fg’, Record=record)
ML engineers often build a separate version of feature engineering code for online features based on the original code written by data scientists for model training. This can deliver the desired performance, but is an extra development step and introduces more chance for training and inference skew. In our use case, we show how using SQL for aggregations can enable a data scientist to provide the same code for both batch and streaming.
Streaming ingestion
Amazon SageMaker Feature Store delivers single-digit millisecond retrieval of pre-calculated features, and it can also play an effective role in solutions requiring streaming ingestion. Our use case demonstrates both. Weekly lookback is handled as a pre-calculated feature group, materialized nightly as shown earlier. Now let’s dive into how we calculate features aggregated on the fly over a 10-minute window and ingest them into the feature store for later online inference.
You can perform streaming ingestion by tapping into an Apache Kafka topic or an Amazon Kinesis Data Stream, applying feature transformation and aggregation, and pushing the result to the feature store. For teams comfortable with Java, Apache Flink is a popular framework for streaming aggregation. However, for data scientists with limited Java skills, SQL is a much more accessible option.
In our use case, we listen to a Kinesis data stream of credit card transactions, and use a simple Kinesis Data Analytics SQL application to create aggregate features. An AWS Lambda function ingests those features into the feature store for subsequent use at inference time. Establishing the SQL app is straightforward. You choose a source stream, define a SQL query, and identify a destination (for our use case, a Lambda function).
To produce aggregate counts and average amounts looking back over a 10-minute window, we use the following SQL query on the input stream:
| cc_num | amount | datetime | num_trans_last_10m | avg_amt_last_10m |
| …1248 | 50.00 | Nov-01,22:01:00 | 1 | 74.99 |
| …9843 | 99.50 | Nov-01,22:02:30 | 1 | 99.50 |
| …7403 | 100.00 | Nov-01,22:03:48 | 1 | 100.00 |
| …1248 | 200.00 | Nov-01,22:03:59 | 2 | 125.00 |
| …0732 | 26.99 | Nov01, 22:04:15 | 1 | 26.99 |
| …1248 | 50.00 | Nov-01,22:04:28 | 3 | 100.00 |
| …1248 | 500.00 | Nov-01,22:05:05 | 4 | 200.00 |
SELECT STREAM "cc_num",
COUNT(*) OVER LAST_10_MINUTES,
AVG("amount") OVER LAST_10_MINUTES
FROM transactions WINDOW LAST_10_MINUTES AS (PARTITION BY "cc_num" RANGE INTERVAL '10' MINUTE PRECEDING)
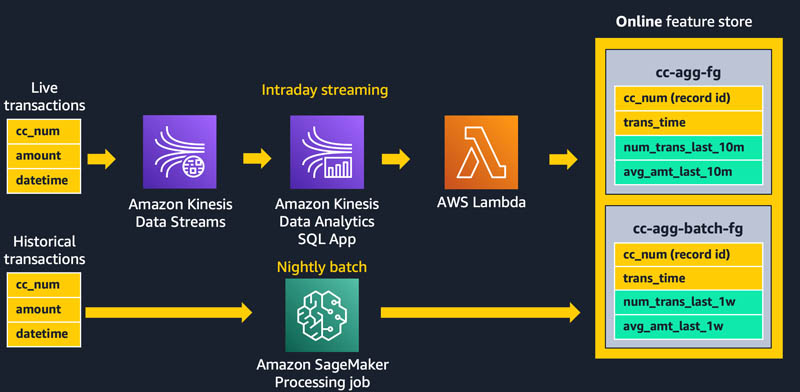
In this example, notice that the final row has a count of four transactions in the last 10 minutes from the credit card ending with 1248, and a corresponding average transaction amount of $200.00. The SQL query is consistent with the one used to drive creation of our training dataset, helping to avoid training and inference skew.
As transactions stream into the SQL app, the app sends the aggregate results to our Lambda function, as shown in the following diagram. The Lambda function takes these features and populates the cc-agg-fg feature group.
Updating feature values in the feature store from Lambda is done using a simple call to the PutRecord API. The following is the core piece of Python code for storing the aggregate features:
record = [{'FeatureName': 'cc_num',
'ValueAsString': str(cc_num)},
{'FeatureName':'avg_amt_last_10m',
'ValueAsString': str(avg_amt_last_10m)},
{'FeatureName':'num_trans_last_10m',
'ValueAsString': str(num_trans_last_10m)},
{'FeatureName': 'evt_time',
'ValueAsString': str(int(round(time.time())))}]
featurestore_runtime.put_record(FeatureGroupName='cc-agg-fg',
Record=record)
We prepare the record as a list of named value pairs, including the current time as the event time. The SageMaker Feature Store API ensures that this new record follows the schema that we identified when we created the feature group. If a record for this primary key already existed, it is now overwritten in the online store.
Streaming predictions
Now that we have streaming ingestion keeping the feature store up to date with the latest feature values, let’s look at how we make fraud predictions.
We create a second Lambda function that uses a Kinesis data stream as a trigger. For each new transaction event, we retrieve batch and streaming features from SageMaker Feature Store, calculate ratios, and invoke the SageMaker model endpoint to make the prediction as shown in the following diagram.
We use the following code to retrieve feature values on demand from the feature store before calling the SageMaker model endpoint:
featurestore_runtime =
boto3.client(service_name='sagemaker-featurestore-runtime')
response = featurestore_runtime.get_record(
FeatureGroupName=feature_group_name,
RecordIdentifierValueAsString=record_identifier_value)
Finally, with the model input feature vector assembled, we call the model endpoint to predict if a specific credit card transaction is fraudulent:
sagemaker_runtime =
boto3.client(service_name='runtime.sagemaker')
request_body = ','.join(features)
response = sagemaker_runtime.invoke_endpoint(
EndpointName=ENDPOINT_NAME,
ContentType='text/csv',
Body=request_body)
probability = json.loads(response['Body'].read().decode('utf-8'))
In the example above, the model came back with a probability of 98% that the specific transaction was fraudulent, and it was able to leverage near real-time aggregated input features, based on the most recent 10 minutes of transactions on that credit card.
Seeing it work end to end
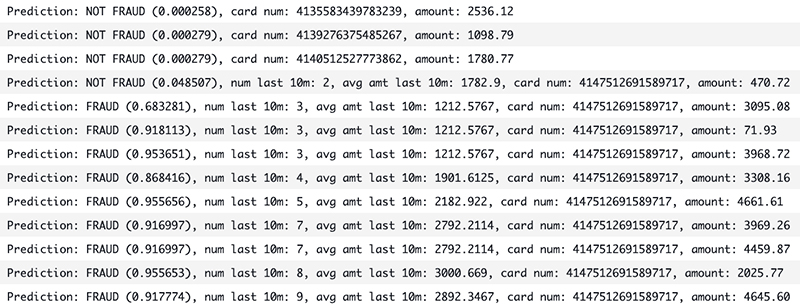
To demonstrate the full end-to-end workflow of our solution, we simply send credit card transactions into our Kinesis data stream. Our automated streaming feature aggregation takes over from there, maintaining a near real time view of transaction counts and amounts in SageMaker Feature Store, with a sliding 10-minute lookback window. These features are combined with the 1-week aggregate features that were already ingested to the feature store in batch, letting us make fraud predictions on each transaction.
We send a single transaction from three different credit cards. We then simulate a fraud attack on a fourth credit card by sending many back-to-back transactions in seconds. The output from our Lambda function is shown below. As expected, the first three one-off transactions are predicted as NOT FRAUD. Of the 10 fraudulent transactions, the first is predicted as NOT FRAUD, and the rest are all correctly identified as FRAUD. Notice how the aggregate features are kept current, helping drive more accurate predictions.
Conclusion
We have shown how Amazon SageMaker Feature Store can play a key role in the solution architecture for critical operational workflows that need streaming aggregation and low latency inference. With an enterprise-ready feature store in place, you can use both batch ingestion and streaming ingestion to feed feature groups, and access feature values on demand to perform online predictions for significant business value. ML features can now be shared at scale across many teams of data scientists and thousands of ML models, improving data consistency, model accuracy, and data scientist productivity. Amazon SageMaker Feature Store is available now, and you can try out this entire example. Let us know what you think.
About the Authors
 Paul Hargis is an AI/ML Specialist, Solutions Architect at Amazon Web Services (AWS). Prior to this role, he was lead architect for Amazon Exports and Expansions helping amazon.com improve experience for international shoppers. Paul likes to help customers expand their machine learning initiatives to solve real-world problems. He is married and has one daughter who runs in Cross Country and Track teams in high school.
Paul Hargis is an AI/ML Specialist, Solutions Architect at Amazon Web Services (AWS). Prior to this role, he was lead architect for Amazon Exports and Expansions helping amazon.com improve experience for international shoppers. Paul likes to help customers expand their machine learning initiatives to solve real-world problems. He is married and has one daughter who runs in Cross Country and Track teams in high school.
 Megan Leoni is an AI/ML Specialist Solutions Architect for AWS helping customers across Europe, Middle East, and Africa design and implement ML Solutions. Prior to joining AWS, Megan worked as a data scientist building and deploying real time fraud detection models.
Megan Leoni is an AI/ML Specialist Solutions Architect for AWS helping customers across Europe, Middle East, and Africa design and implement ML Solutions. Prior to joining AWS, Megan worked as a data scientist building and deploying real time fraud detection models.
 Mark Roy is a Principal Machine Learning Architect for AWS, helping AWS customers design and build AI/ML solutions. Mark’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including Insurance, Financial Services, Media and Entertainment, Healthcare, Utilities, and Manufacturing. Mark holds 6 AWS certifications, including the ML Specialty Certification. Prior to joining AWS, Mark was an architect, developer, and technology leader for 25+ years, including 19 years in financial services.
Mark Roy is a Principal Machine Learning Architect for AWS, helping AWS customers design and build AI/ML solutions. Mark’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including Insurance, Financial Services, Media and Entertainment, Healthcare, Utilities, and Manufacturing. Mark holds 6 AWS certifications, including the ML Specialty Certification. Prior to joining AWS, Mark was an architect, developer, and technology leader for 25+ years, including 19 years in financial services.
 Arunprasath Shankar is an Artificial Intelligence and Machine Learning (AI/ML) Specialist Solutions Architect with AWS, helping global customers scale their AI solutions effectively and efficiently in the cloud. In his spare time, Arun enjoys watching sci-fi movies and listening to classical music.
Arunprasath Shankar is an Artificial Intelligence and Machine Learning (AI/ML) Specialist Solutions Architect with AWS, helping global customers scale their AI solutions effectively and efficiently in the cloud. In his spare time, Arun enjoys watching sci-fi movies and listening to classical music.
AWS and NVIDIA achieve the fastest training times for Mask R-CNN and T5-3B
Note: At the AWS re:Invent Machine Learning Keynote we announced performance records for T5-3B and Mask-RCNN. This blog post includes updated numbers with additional optimizations since the keynote aired live on 12/8.
At re:Invent 2019, we demonstrated the fastest training times on the cloud for Mask R-CNN, a popular instance segmentation model, and BERT, a popular natural language processing (NLP) model. Over the past several months, we have worked in collaboration with NVIDIA to significantly improve the underlying infrastructure, network, machine learning (ML) framework, and model code to once again achieve the best training times for state-of-the-art models used by our customers. Today, we’re excited to share with you the fastest training times for Mask R-CNN on TensorFlow and PyTorch and T5-3B (NLP) on PyTorch, and dive deep into the technology stack, our optimizations, and how you can leverage these capabilities to train large models quickly with Amazon SageMaker.
Summary results
Our customers training deep neural network models in PyTorch and TensorFlow have asked for help with problems they face with training speed and model size. First, customers told us they wanted to train models faster without waiting days or weeks for results. Data scientists need to iterate daily to get ML applications to market faster. Second, customers told us they struggled to apply the latest research in NLP because these model architectures didn’t fit in a single NVIDIA GPU’s memory during training. Customers knew they could get higher accuracy from these larger models with billions of parameters. But there was no easy way to automatically and efficiently split a model across multiple NVIDIA GPUs.
To solve these problems, AWS released new SageMaker distributed training libraries, which provide the easiest and fastest way to train deep learning models. The SageMaker data parallelism library provides better scaling efficiency than Horovod or PyTorch’s Distributed Data Parallel (DDP), and its model parallelism library automatically splits large models across multiple GPUs. In this post, we describe how this underlying technology was used to achieve record training times for Mask R-CNN and T5-3B.
Mask R-CNN
Object detection algorithms form the backbone of many deep learning applications. Self-driving cars, security systems, and image processing all incorporate object detection. In particular, Mask R-CNN is ubiquitous in this field. Mask R-CNN takes in an image and then isolates and identifies objects within that image, providing both a bounding box and object mask. Since it was first proposed in 2017, training Mask R-CNN on the COCO dataset has become the standard benchmark for object detection models, and many of our customers use this as their baseline to build their own models.
One issue with Mask R-CNN is its complexity. The model incorporates multiple different neural networks performing different tasks. One network identifies candidate objects, while two others are responsible for identifying objects and generating masks. In addition, the model must perform operations like non-max suppression and sample selection, which can be difficult to optimize on the GPU. In the original 2017 paper, Mask R-CNN took 32 hours to train on 8 GPUs with the COCO data. Since then, training time has significantly improved. In 2019, we demonstrated the fastest training times in the cloud for Mask R-CNN—27 minutes with PyTorch and 28 minutes with TensorFlow. In 2020, we collaborated with NVIDIA to bring this down to 6:45 minutes on PyTorch and 6:12 minutes on TensorFlow. To our knowledge, this is the fastest time to train Mask R-CNN in the cloud and a 75% reduction from our record last year.
Mask-RCNN Technology stack and performance
Achieving these results required optimizations to the underlying hardware, networking, and software stack. We added GPU implementations of some operations that are central to training Mask R-CNN. We also added new data pipelining utilities to speed up pre-processing and avoid any degradation in GPU utilization. In collaboration with NVIDIA, we deployed a new optimizer, NovoGrad, to push the boundaries further on large batch training. All of these optimizations are available in SageMaker, the AWS Deep Learning Containers, and the AWS Deep Learning AMIs. The result is that our training times this year are more than twice as fast on a single-node workload, and more than three times as fast on a multi-node workload, as compared to 2019.
Next, we scaled this optimized single-node workload to a cluster of 64 p3dn.24xlarge instances, each with 8 NVIDIA V100 GPUs. Efficiently scaling to 512 V100 GPUs requires fully utilizing the available bandwidth and topology between Amazon Elastic Compute Cloud (Amazon EC2) instances. At SC20 this year, we demonstrated a reimagined parameter server at scale that was designed from scratch to use the AWS Elastic Fabric Adapter (EFA) and node-to-node communication between EC2 instances. This technology is available to developers as of today with the SageMaker data parallelism library, with native framework APIs for both TensorFlow and PyTorch.
Distributed training generally uses one of two distribution strategies: parameter servers or AllReduce. Although parameter servers can perform gradient reduction with less communication than AllReduce (2 hops vs. 2(n-1) hops, respectively) and can perform asynchronous parameter updates, parameter servers tend to suffer from uneven bandwidth allocation and network congestion. Both drawbacks become more apparent with larger clusters. As a result, AllReduce is more often used. However, AllReduce has its own drawbacks. In addition to the increased number of hops, AllReduce requires synchronous updates between nodes, meaning all training is impacted by a single straggler node.
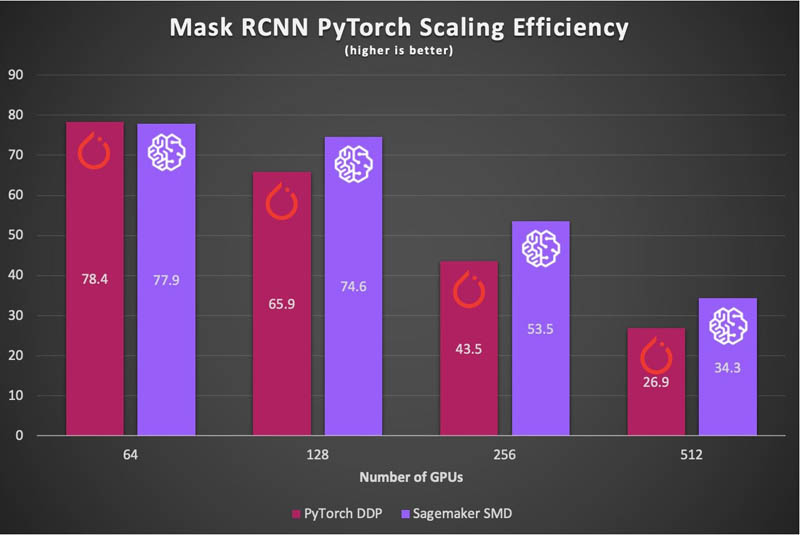
We can use EFA to overcome network congestion by spreading communication evenly across multiple routes between nodes. In addition, SageMaker introduces a balanced fusion buffer, which collects gradients on each GPU and shards them evenly to each parameter server, ensuring a balanced workload across the entire cluster. The results show significantly improved scaling efficiency, and reduced training times on larger clusters. With SageMaker, along with new large batch optimizations, we can efficiently scale both TensorFlow and PyTorch to 512 A100 GPUs, while scaling almost linearly. With these new tools, we can train Mask R-CNN to convergence in just above 6 minutes on both frameworks, beating last year’s best time by more than 75%. The following charts show the improvement in scaling efficiency using SageMaker’s data parallelism library when training Mask-RCNN relative to DDP and Horovod.
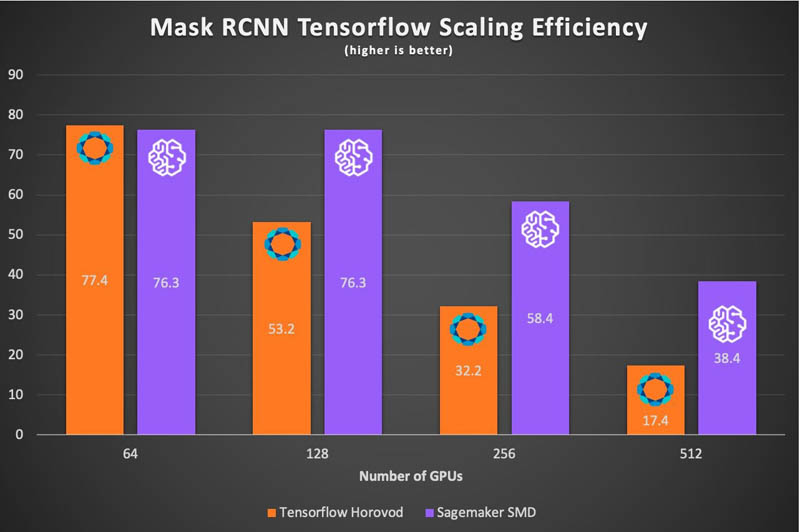
T5-3B: Text-to-Text Transfer Transformer
We’ve seen rapid progress in NLP model accuracy in the past few years. In 2017, we saw the invention of the transformer layer, a novel way for models to identify the portion of the text to focus on. We then saw state-of-the-art models such as BERT, RoBERTa, ALBERT, and DistilBERT. Now we see researchers achieving record accuracy and zero- or few-shot learning with large models that have billions or hundreds of billions of parameters.
Empirical results from OpenAI show that optimal performance comes from scaling up in three dimensions: model size, dataset size, and training steps. Model size is the primary bottleneck, and for smaller models such as BERT, data parallelism alone has been sufficient. Yet scaling to extreme language model sizes has been prohibitively difficult for developers and researchers because models can no longer fit onto a single GPU’s memory, preventing any data parallelism from taking place.
T5 is 15 times larger than the original BERT model and achieved near-human performance on the SuperGLUE benchmark. In addition, sequence-to-sequence models can perform machine translation, text summarization, and open-domain question-answering. In collaboration with NVIDIA, who supplied the base technology for T5 pre-training and fine-tuning tasks [1], we trained T5-3B in 4.86 days on 2,048 A100 GPUs on 256 p4d.24xlarge instances. The technologies for automatic and efficient splitting of large models across multiple GPU devices are now available in SageMaker.
T5-3B Technology stack and performance
SageMaker splits the model into multiple partitions that each fit on a single GPU. The freed memory can then be used to scale to larger batch sizes, further increasing training throughput and speeding up convergence. SageMaker also implements pipelined execution that splits data into smaller micro-batches and interleaves execution to increase GPU utilization.
The following figure illustrates an example execution schedule for the interleaved pipeline over two GPUs. F0 represents the forward pass for micro-batch 0, and B1 represents the backward pass for micro-batch 1. “Update” represents the optimizer update of the parameters. The figure shows that GPU0 always prioritizes backward passes whenever possible (for instance, running B0 before F2), which allows for clearing the memory used for activations earlier.

To train T5-3B, SageMaker performed 8-way model parallel training combined with 256-way data parallel training. We further improved training time by using the new p4d.24xlarge instances, equipped with 8 NVIDIA A100 GPUs and supporting 400 Gbps network bandwidth. We reduced the training time to 4.86 days by efficiently scaling out to 256 instances. We used EFA to optimize network communication over large clusters. We achieved the best training performance by using SageMaker, 256 p4d.24xlarge instances, and EFA.
To evaluate model performance, we fine-tuned the pre-trained checkpoints on a downstream natural language inference task. We used the Multi-Genre Natural Language Inference (MNLI) corpus for fine-tuning. The corpus contains around 433,000 hypothesis/premise sentence pairs and covers a range of genres of spoken and written text with support for cross-genre evaluation. We obtained a score of 91.19 for in-genre (matched) and a score of 91.25 for cross-genre (mismatched) in only 4.86 days time to train.
Conclusion
With these new record-breaking training times, AWS continues to be the industry leader in cloud ML. These models are now available for everyone to use in AWS by leveraging the new SageMaker data parallelism and model parallelism libraries. You can get started with distributed training on SageMaker using the following examples. For further information, please feel free to reach out to Aditya Bindal directly at bindala@amazon.com.
Editor’s Note: All of the following contributors were essential to our ability to achieve this year’s results and to the writing of this post: Abhinav Sharma, Anurag Singh, Gautam Kumar, Harsh Patel, Lai Wei, Rahul Huilgol, Rejin Joy, Roshani Nagmote, Sami Kama, Sam Oshin, Qinggang Zhou, Yu Liu
About the Authors
 Aditya Bindal is a Senior Product Manager for AWS Deep Learning. He works on products that make it easier for customers to train deep learning models on AWS. In his spare time, he enjoys spending time with his daughter, playing tennis, reading historical fiction, and traveling.
Aditya Bindal is a Senior Product Manager for AWS Deep Learning. He works on products that make it easier for customers to train deep learning models on AWS. In his spare time, he enjoys spending time with his daughter, playing tennis, reading historical fiction, and traveling.
 Ben Snyder is an applied scientist with AWS Deep Learning. His research interests include computer vision models, reinforcement learning, and distributed optimization. Outside of work, he enjoys cycling and backcountry camping.
Ben Snyder is an applied scientist with AWS Deep Learning. His research interests include computer vision models, reinforcement learning, and distributed optimization. Outside of work, he enjoys cycling and backcountry camping.
 Derya Cavdar is currently working as a software engineer at AWS AI in Palo Alto, CA. She received her PhD in Computer Engineering from Bogazici University, Istanbul, Turkey, in 2016. Her research interests are deep learning, distributed training optimization, large-scale machine learning systems, and performance modeling.
Derya Cavdar is currently working as a software engineer at AWS AI in Palo Alto, CA. She received her PhD in Computer Engineering from Bogazici University, Istanbul, Turkey, in 2016. Her research interests are deep learning, distributed training optimization, large-scale machine learning systems, and performance modeling.
 Jared Nielsen is an Applied Scientist with AWS Deep Learning. His research interests include natural language processing, reinforcement learning, and large-scale training optimizations. He is a passionate rock climber outside of work.
Jared Nielsen is an Applied Scientist with AWS Deep Learning. His research interests include natural language processing, reinforcement learning, and large-scale training optimizations. He is a passionate rock climber outside of work.
 Khaled ElGalaind is the engineering manager for AWS Deep Engine Benchmarking, focusing on performance improvements for AWS machine learning customers. Khaled is passionate about democratizing deep learning. Outside of work, he enjoys volunteering with the Boy Scouts, BBQ, and hiking in Yosemite.
Khaled ElGalaind is the engineering manager for AWS Deep Engine Benchmarking, focusing on performance improvements for AWS machine learning customers. Khaled is passionate about democratizing deep learning. Outside of work, he enjoys volunteering with the Boy Scouts, BBQ, and hiking in Yosemite.
Brian Pickering is the VP of Sales & Business Development – Amazon Relationship at NVIDIA. He joined NVIDIA in 2016 to manage NVIDIA’s relationship with Amazon. Prior to NVIDIA, Brian was at F5 Networks, where he led their Cloud Sales and Cloud Partner Ecosystem. In 2012, while at AWS and responsible for leading the AWS Consulting Partner Ecosystem program and teams, CRN recognized Brian as one of the top 100 “People You Don’t Know But Should for Channel.” Prior to AWS, Brian lead various strategic business efforts, including winning the first non-MS OS OEM deal with Dell while at Red Hat.
Anish Mohan is a Machine Learning Architect at NVIDIA and the technical lead for ML/DL engagements with key NVIDIA customers in the greater Seattle region. Before NVIDIA, he was at Microsoft’s AI Division, working to develop and deploy AI/ML algorithms and solutions.
Customizing and reusing models generated by Amazon SageMaker Autopilot
Amazon SageMaker Autopilot automatically trains and tunes the best machine learning (ML) models for classification or regression problems while allowing you to maintain full control and visibility. This not only allows data analysts, developers, and data scientists to train, tune, and deploy models with little to no code, but you can also review a generated notebook that outlines all the steps that Autopilot took to generate the model. In some cases, you might also want to customize pipelines generated by Autopilot with your own custom components.
This post shows you how to create and use models with Autopilot in a couple of clicks, then outlines how to adapt the SageMaker Autopilot generated code with your own feature selectors and custom transformers to add domain-specific features. We also use the dry run capability of Autopilot, in which Autopilot only generates code for data preprocessors, algorithms, and algorithm parameter settings. This can be done by simply choosing the option run a pilot to create a notebook with candidate definitions.
Customizing Autopilot
Customizing Autopilot models is, in most cases, not necessary. Autopilot creates high-quality models that can be deployed without the need for customization. Autopilot automatically performs exploratory analysis of your data and decides which features may produce the best results. As such, it presents a low barrier of entry to ML for a wide range of users, from data analysts to developers, wishing to add AI/ML capabilities to their project.
However, more advanced users can take advantage of Autopilot’s transparent approach to AutoML to dramatically reduce the undifferentiated heavy lifting prevalent in ML projects. For example, you may want Autopilot to use custom feature transformations that your company uses, or custom imputation techniques that work better in the context of your data. You can preprocess your data before bringing it to SageMaker Autopilot, but that would involve going outside Autopilot and maintaining a separate preprocessing pipeline. Alternatively, you can use Autopilot’s data processing pipeline to direct Autopilot to use your custom transformations and imputations. The advantage to this approach is that you can focus on data collection, and let Autopilot do the heavy lifting to apply your desired feature transformations and imputations, and then find and deploy the best model.
Preparing your data and Autopilot job
Let’s start by creating an Autopilot experiment using the Forest Cover Type dataset.
- Download the dataset and upload it to Amazon Simple Storage Service (Amazon S3).
Make sure that you create your Amazon SageMaker Studio user in the same Region as the S3 bucket.
- Open SageMaker Studio.
- Create a job, providing the following information:
- Experiment name
- Training dataset location
- S3 bucket for saving Autopilot output data
- Type of ML problem
Your Autopilot job is now ready to run. Instead of running a complete experiment, we choose to let Autopilot generate a notebook with candidate definitions.

Inspecting the Autopilot-generated pipelines
SageMaker Autopilot automates the key tasks in an ML pipeline. It explores hundreds of models comprised of different features, algorithms, and hyperparameters to find the one that best fits your data. It also provides a leader board of 250 models so you can see how each model candidate performed and pick the best one to deploy. We explore this in more depth in the final section of this post.
When the experiment is complete, you can inspect your generated candidate pipelines. Candidate refers to the combination of data preprocessing steps and algorithm selection used to train the 250 models. The candidate generation notebook contains Python code that Autopilot used to generate these candidates.
- Choose Open candidate generation notebook.
- Open your notebook.
- Choose Import to import the notebook into your workspace.
- When prompted, choose Python 3 (Data Science) as the kernel.
- Inside the notebook, run all the cells in the SageMaker Setup
This copies the data preparation code that Autopilot generated into your workspace.
In your root SageMaker Studio directory, you should now see a folder with the name of your Autopilot experiment. The folder’s name should be <Your Experiment Name>–artifacts. That directory contains two sub-directories: generated_module and sagemaker_automl. The generated_module directory contains the data processing artifacts that Autopilot generated.
So far, the Autopilot job has analyzed the dataset and generated ML candidate pipelines that contain a set of feature transformers and an ML algorithm. Navigate down the generated_module folder to the candidate_data_processors directory, which contains 12 files:
- dpp0.py–dpp9.py – Data processing candidates that Autopilot generated
- trainer.py – Script that runs the data processing candidates
- sagemaker_serve.py – Script for running the preprocessing pipeline at inference time
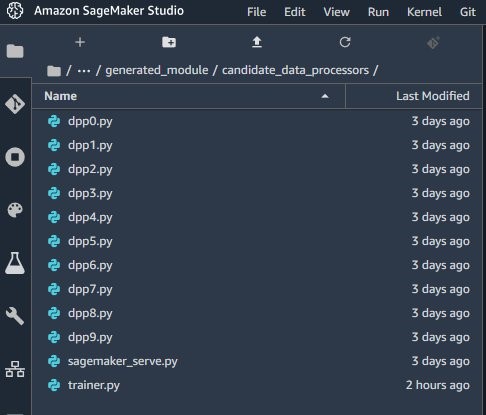
If you examine any of the dpp*.py files, you can observe that Autopilot generated code that builds sckit-learn pipelines, which you can easily extend with your own transformations. You can do this by either modifying the existing dpp*.py files directly or extending the pipelines after they’re instantiated in the trainer.py file, in which you define a transformer that can be called inside existing dpp*.py files. The second approach is recommended because it’s more maintainable and allows you to extend all the proposed processing pipelines at once as opposed to modifying each one individually.
Using specific transformers
You may wish to call a specific transformer from sckit-learn or use one implemented in the open-source package sagemaker-scikit-learn-extension. The latter provides a number of scikit-learn-compatible estimators and transformers that you can use. For instance, it implements the Weight of Evidence (WoE) encoder, an often-used encoding for categorical features in the context of binary classification.
To use additional transformers, first extend the import statements in the trainer.py file. For our use case, we add the following code:
from sklearn.pipeline import FeatureUnion, Pipeline
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import SelectFromModel
from sagemaker_sklearn_extension.preprocessing import RobustStandardScalerIf, upon modifying trainer.py, you encounter errors when running the notebook cell containing automl_interactive_runner.fit_data_transformers(...), you can get debugging information from Amazon CloudWatch under the log group /aws/sagemaker/TrainingJobs.
Implementing custom transformers
Going back to the forest cover type use case, we have features for the vertical and horizontal distance to hydrology. We want to extend this with an additional feature transform that calculates the straight line distance to hydrology. We can do this by adding an additional file into the candidate_data_processors directory where we define our custom transform. See the following code:
# additional_features.py
import numpy as np
from sklearn.base import BaseEstimator, TransformerMixin
class HydrologyDistance(BaseEstimator, TransformerMixin):
def __init__(self, feature_index):
self._feature_index = feature_index
def fit(self, X, y = None):
return self
def transform(self, X, y = None):
X = X.copy().astype(np.float32)
a, b = np.split(X[:, self._feature_index ], 2, axis=1)
return np.hypot(a,b).reshape(-1,1)Inside the trainer.py file, we then import the additional_features module and add our HydrologyDistance transformer as a parallel pipeline to the existing generated ones.
In addition to our additional feature transformer, we also add a feature selector to our pipeline to select only the features with the highest importance as determined by a RandomForestClassifier:
def update_feature_transformer(header, feature_transformer):
"""Customize the feature transformer. Default returns
header: sagemaker_sklearn_extension.externals.Header
Object of class Header, used to map the column names to the appropriate index
feature_transformer : obj
transformer applied to the features
Returns
-------
feature_transformer : obj
updated transformer to be applied to the features
"""
features_to_transform = header.as_feature_indices(
[
'Horizontal_Distance_To_Hydrology',
'Vertical_Distance_To_Hydrology'
]
)
# new pipeline with custom transforms
additional_pipeline = Pipeline([("distance", HydrologyDistance(features_to_transform)),
("scaleDistance",RobustStandardScaler())
])
# combine with the AutoPilot generated pipeline
combined_transformer = FeatureUnion([("additional", additional_pipeline),
("existing", feature_transformer)]
)
# perform feature selection on the combined pipeline
feature_selector = SelectFromModel(RandomForestClassifier(n_estimators = 10))
feature_transformer = Pipeline([("feature_engineering", combined_transformer),
("feature_selection",feature_selector)]
)
return feature_transformerfrom additional_features import *Running inferences
Next we need to copy our additional_features.py file into the model directory to make it available at inference time. A serialize_code function is provided specifically for this. Modify the function as per the following example code to make sure that it’s included with the model artifact. The line of code that requires modification is highlighted.
def serialize_code(dest_dir, processor_file):
"""Copies the code required for inference to the destination directory
By default, sagemaker_serve.py and the processor module's file are copied.
To serialize any additional .py file for custom transformer, add it to the
list files_to_serialize.
dest_dir: str
destination where the python files would be serialized
"""
files_to_serialize = [
os.path.join(os.path.dirname(__file__), 'sagemaker_serve.py'),
processor_file]
# Include the custom transformer code in the model directory
files_to_serialize.append(os.path.join(os.path.dirname(__file__), 'additional_features.py'))
os.makedirs(dest_dir, exist_ok=True)
for source in files_to_serialize:
shutil.copy(source, os.path.join(dest_dir, os.path.basename(source)))Finally, we need to modify the model_fn function in sagemaker_serve.py to copy the additional_features.py file into the current working directory so that the scikit-learn pipeline can import the file at inference time:
import shutil # make sure this is imported so that file can be copied
def model_fn(model_dir):
"""Loads the model.
The SageMaker Scikit-learn model server loads model by invoking this method.
Parameters
----------
model_dir: str
the directory where the model files reside
Returns
-------
: AutoMLTransformer
deserialized model object that can be used for model serving
"""
shutil.copyfile(os.path.join(model_dir, 'additional_features.py'), 'additional_features.py')
return load(filename=os.path.join(model_dir, 'model.joblib'))When you finish all these steps, you can return to the candidate definition notebook and run the remaining cells. The additional transforms you defined are applied across all the selected data processing pipeline candidates and are also included in the inference pipeline.
Deploying the best model
As Autopilot runs the candidate pipelines, it iterates over 250 combinations of processing pipelines, algorithm types, and model hyperparameters. When the process is complete, you can navigate to the final section of the notebook (Model Selection and Deployment) and view a leaderboard of the models Autopilot generated. Running the remaining notebook cells automatically deploys the model that produced the best results and exposes it as a RSET API endpoint.
Conclusions
In this post, we demonstrated how to customize an Autopilot training and inference pipeline with your own feature engineering code. We first let Autopilot generate candidate definitions without running the actual training and hyperparameter tuning. Then we implemented custom transformers that represent custom feature engineering that we want to bring to Autopilot. For more information about Autopilot, see Amazon SageMaker Autopilot.
About the Authors
 Simon Zamarin is an AI/ML Solutions Architect whose main focus is helping customers extract value from their data assets. In his spare time, Simon enjoys spending time with family, reading sci-fi, and working on various DIY house projects.
Simon Zamarin is an AI/ML Solutions Architect whose main focus is helping customers extract value from their data assets. In his spare time, Simon enjoys spending time with family, reading sci-fi, and working on various DIY house projects.
 Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his Ph.D. in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently he helps customers in the financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his Ph.D. in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently he helps customers in the financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
 Piali Das is a Senior Software Engineer in the AWS SageMaker Autopilot team. She previously contributed to building SageMaker Algorithms. She enjoys scientific programming in general and has developed an interest in machine learning and distributed systems.
Piali Das is a Senior Software Engineer in the AWS SageMaker Autopilot team. She previously contributed to building SageMaker Algorithms. She enjoys scientific programming in general and has developed an interest in machine learning and distributed systems.

Making sense of your health data with Amazon HealthLake
We’re excited to announce Amazon HealthLake, a new HIPAA-eligible service for healthcare providers, health insurance companies, and pharmaceutical companies to securely store, transform, query, analyze, and share health data in the cloud, at petabyte scale. HealthLake uses machine learning (ML) models trained to automatically understand and extract meaningful medical data from raw, disparate data, such as medications, procedures, and diagnoses. This revolutionizes a process that is traditionally manual, error-prone, and costly. HealthLake tags and indexes all the data and structures it in Fast Healthcare Interoperability Resources (FHIR) to provide a complete view of each patient and a consistent way to query and share the data. It integrates with services like Amazon QuickSight and Amazon SageMaker to visualize and understand relationships in the data, identify trends, and make predictions. Because HealthLake automatically structures all of a healthcare organization’s data into the FHIR industry format, the information can be easily and securely shared between health systems and with third-party applications, enabling providers to collaborate more effectively and allowing patients unfettered access to their medical information.
Every healthcare provider, payer, and life sciences company is trying to solve the problem of organizing and structuring their data in order to make better patient support decisions, design better clinical trials, operate more efficiently, understand population health trends, and share data securely. It all starts with making sense of health data.
Let’s look at one specific example—imagine you have a diabetic patient whom you’re trying to manage, and 2 months later their glucose level is still not responding to the treatment that you prescribed. With HealthLake, you can easily create a cohort of diabetic patients and their demographics, treatments, blood glucose readings, tests, and clinical observations and export this data. You can then create an interactive dashboard with QuickSight and compare that patient to a population with similar treatment options to see what helped improve their health outcome. You can use SageMaker to train and tune the best ML models to help you identify which subset of these diabetic patients are at increased risk of complications like high blood pressure so you can intervene early and introduce a second line of medications in addition to preventive measures, like special diets.
Health data is complex
Healthcare organizations are doing some amazing things with ML today, but health data remains complex and difficult to work with (data is siloed, spread out across multiple systems in incompatible formats). Over the past decade, we’ve witnessed a digital transformation in healthcare, with organizations capturing huge volumes of patient data every day, from family history and clinical observations to diagnoses and medications. The vast majority of this data is contained in unstructured medical records such as clinical notes, laboratory reports (PDFs), insurance claims (forms), recorded conversations (audio), X-rays (images), and more.
Before leveraging healthcare data for effective care, it all needs to be securely ingested, stored, and aggregated. Relevant attributes need to be extracted, tagged, indexed, and structured before you can start analyzing it. The cost and operational complexity of doing all this work well is prohibitive to most healthcare organizations and takes weeks, or even months. The FHIR standard is a start toward the goal of standardizing a data structure and exchange for healthcare, but the data still needs to be transformed to enable advanced analytics via queries, visualizations, and ML tools and techniques. This means analysis effectively remains hard to reach for almost all providers.
Create a complete view of a patient’s medical history, in minutes
With HealthLake, we’re demystifying a set of challenges for our healthcare and life sciences customers by removing the heavy lifting needed to tag, index, structure, and organize this data, providing a complete view of each patient’s medical history in minutes, instead of weeks or months. HealthLake makes it easy for you to copy your on-premises data to AWS. HealthLake transforms raw, disparate data with integrated medical natural language processing (NLP), which uses specialized ML models that have been trained to automatically understand and extract meaningful medical information, such as medications, procedures, and diagnoses, from raw, disparate data. HealthLake tags each patients’ record, indexes every data element using standardized labels, structures each data element in interoperable standards, and organizes the data in a timeline view for each patient. HealthLake presents data on each patient in chronological order of medical events so that you can look at trends like disease progression over time, giving you new tools to improve care and intervene earlier.
Your data in HealthLake is secure, compliant, and auditable. Data versioning is enabled to protect data against accidental deletion, and per FHIR specification, if you delete a piece of data, it’s only hidden from analysis and results—not deleted from the service, only versioned. Your data is encrypted using customer managed keys (CMKs) in a single-tenant architecture to provide an additional level of protection when data is accessed or searched, so that the same key isn’t shared by multiple customers. You retain ownership and control of your data, along with the ability to encrypt it, protect it, move it, and delete it in alignment with your organization’s security policies.
Identify trends and make predictions to manage your entire population
Today, the most widely used clinical models to predict disease risk lack personalization and often use a very limited number of commonly collected data points, which is problematic because the resulting models may produce imprecise predictions. However, if you look at an individual’s medical record, there may be hundreds of thousands of data points, and the majority of that is untapped data stored in doctors’ notes. With your health data structured and organized chronologically by medical events, you can easily query, perform analytics, and build ML models to observe health trends across an entire population.
You can use other AWS services that work seamlessly with HealthLake, such as QuickSight or SageMaker. For example, you can create an interactive dashboard with QuickSight to observe population health trends, and zoom in on a smaller group of patients with a similar state to compare their treatments and health outcomes. You can also build, train, and deploy your own ML models with SageMaker to track the progression of at-risk patients over the course of many years against a similar cohort of patients. This enables you to identify early warning signs that need to be addressed proactively and would be missed without the complete clinical picture provided by HealthLake.
Bringing it all together
Now, your health data is tagged, indexed, structured, and organized in chronological order of medical events, so it can be easily searched and analyzed. You can securely share patient’s data across health systems in a consistent, compatible FHIR format across multiple applications. You now have the ability to make point-of-care or population health decisions that are driven by evidence from the overall data.
AWS customers are excited about the innovation that HealthLake offers and the opportunity to make sense of their health data to deliver personalized treatments, understand population health trends, and identify patients for clinical trial enrollment. This offers an unprecedented opportunity to close gaps in care and provide the high quality and personalized care every patient deserves.
Cerner Corporation, a global healthcare technology company, is focused on using data to help solve issues at the speed of innovation—evolving healthcare to enhance clinical and operational outcomes, help resolve clinician burnout, and improve health equity.
“At Cerner, we are committed to transforming the future of healthcare through cloud delivery, machine learning, and AI. Working alongside AWS, we are in a position to accelerate innovation in healthcare. That starts with data. We are excited about the launch of HealthLake and its potential to quickly ingest patient data from diverse sources, unlock new insights through advanced analytics, and serve many of our initiatives across population health.”
—Ryan Hamilton, SVP & Chief Architect, Cerner
Konica Minolta Precision Medicine (KMPM) is a life science company dedicated to the advancement of precision medicine to more accurately predict, detect, treat, and ultimately cure disease.
“We are building a multi-modal platform at KMPM to handle a significant amount of health data inclusive of pathology, imaging, and genetic information. HealthLake will allow us to unlock the real power of this multi-modal approach to find novel associations and signals in our data. It will provide our expert team of data scientists and developers the ability to integrate, label, and structure this data faster and discover insights that our clinicians and pharmaceutical partners require to truly drive precision medicine.”
—Kiyotaka Fujii, President, Global Healthcare, Konica Minolta, & Chairman, Ambry Genetics
Orion Health is a global, award-winning provider of health information technology, advancing population health and precision medicine solutions for the delivery of care across the entire health ecosystem.
“At Orion Health, we believe that there is significant untapped potential to transform the healthcare sector by improving how technology is used and providing insights into the data being generated. Data is frequently messy and incomplete, which is costly and time consuming to clean up. We are excited to work alongside AWS to use HealthLake to help deliver new ways for patients to interact with the healthcare system, supporting initiatives such as the 21st Century Cures Act, designed to make healthcare more accessible and affordable, and Digital Front Door, which aims to improve health outcomes by helping patients receive the perfect care for them from the comfort of their home.”
—Anne O’Hanlon, Product Director, Orion Health
Conclusion
What was once just a pile of disparate and unstructured data looking like a patchwork quilt—an incomplete health history stitched together with limited data—is now structured to be easily read and searched. For every healthcare provider, health insurer, and life sciences company, there is now a purpose-built service enabled by ML they can use to aggregate and organize previously unusable health data, so that it can be analyzed in a secure and compliant single-tenant location in the cloud. HealthLake represents a significant leap forward for these organizations to learn from all their data to proactively manage their patients and population, improve the quality of patient care, optimize hospital efficiency, and reduce cost.
About the Authors
 Dr. Taha Kass-Hout, is director of machine learning and chief medical officer at Amazon Web Services (AWS), where he leads initiatives such as as Amazon HealthLake and Amazon Comprehend Medical. A physician and bioinformatician, Taha has previously pioneered the use of emerging technologies and cloud at both the CDC (in electronic disease surveillance) and the FDA, where he was the Agency’s first Chief Health Informatics Officer, and established both the OpenFDA and PrecisionFDA data sharing initiatives.
Dr. Taha Kass-Hout, is director of machine learning and chief medical officer at Amazon Web Services (AWS), where he leads initiatives such as as Amazon HealthLake and Amazon Comprehend Medical. A physician and bioinformatician, Taha has previously pioneered the use of emerging technologies and cloud at both the CDC (in electronic disease surveillance) and the FDA, where he was the Agency’s first Chief Health Informatics Officer, and established both the OpenFDA and PrecisionFDA data sharing initiatives.
 Dr. Matt Wood is Vice President of Product Management and leads our vertical AI efforts on the ML team, including Personalize, Forecast, Poirot, and Colossus, along with our thought leadership projects such as DeepRacer. In his spare time Matt also serves as the chief science geek for the scalable COVID testing initiative at Amazon; providing guidance on scientific and technical development, including test design, lab sciences, regulatory oversight, and the evaluation and implementation of emerging testing technologies.
Dr. Matt Wood is Vice President of Product Management and leads our vertical AI efforts on the ML team, including Personalize, Forecast, Poirot, and Colossus, along with our thought leadership projects such as DeepRacer. In his spare time Matt also serves as the chief science geek for the scalable COVID testing initiative at Amazon; providing guidance on scientific and technical development, including test design, lab sciences, regulatory oversight, and the evaluation and implementation of emerging testing technologies.