Amazon Kendra is a highly accurate and easy-to-use intelligent search service powered by machine learning (ML). To make it simple to search data across multiple content repositories, Amazon Kendra offers a number of native data source connectors to help get your documents easily ingested and indexed.
This post describes how you can use the Amazon Kendra ServiceNow connector. To allow the connector to access your ServiceNow site, you need to know your ServiceNow version, the Amazon Kendra index, the ServiceNow host URL, and the credentials of a user with the ServiceNow admin role attached to it. The ServiceNow credentials needed for the Amazon Kendra ServiceNow connector to work are securely stored in AWS Secrets Manager, and can be entered during the connector setup.
Currently, Amazon Kendra has two provisioning editions: the Amazon Kendra Developer Edition for building proof of concepts (POCs), and the Amazon Kendra Enterprise Edition. Amazon Kendra connectors work with both these editions.
The Amazon Kendra ServiceNow Online connector indexes Service Catalog items and public articles that have a published state, so a knowledge base article must have the public role under Can Read, and Cannot Read must be null or not set.
Prerequisites
To get started, you need the following:
- The ServiceNow host URL
- Username and Password of a user with the admin role
- Know your ServiceNow version
The user that you use for the connector needs to have the admin role in ServiceNow. This is defined on ServiceNow’s User Administration page (see the section Insufficient Permissions for more information).
When setting up the ServiceNow connector, we need to define if our build is London or a different ServiceNow version. To obtain our build name, we can go on the System Diagnostics menu and choose Stats.
In the following screenshot, my build name is Orlando, so I indicate on the connector that my version is Others.

Creating a ServiceNow connector in the Amazon Kendra console
The following section describes the process of deploying an Amazon Kendra index and configuring a ServiceNow connector.
- Create your index. For instructions, see Getting started with the Amazon Kendra SharePoint Online connector.
If you already have an index, you can skip this step.
The next step is to set up the data sources. One of the advantages of implementing Amazon Kendra is that you can use a set of pre-built connectors for data sources, such as Amazon Simple Storage Service (Amazon S3), Amazon Relational Database Service (Amazon RDS), Salesforce, ServiceNow, and SharePoint Online, among others.
For this post, we use the ServiceNow connector.
- On the Amazon Kendra console, choose Indexes.
- Choose MyServiceNowindex.
- Choose Add data sources.

- Choose ServiceNow Online.

- For Name, enter a connector name.
- For Description, enter an optional description.
- For Tags¸ you can optionally assign tags to your data source.
- Choose Next.

In this next step, we define targets.
- For ServiceNow host, enter the host name.
- For ServiceNow version, enter your version (for this post, we choose Others).
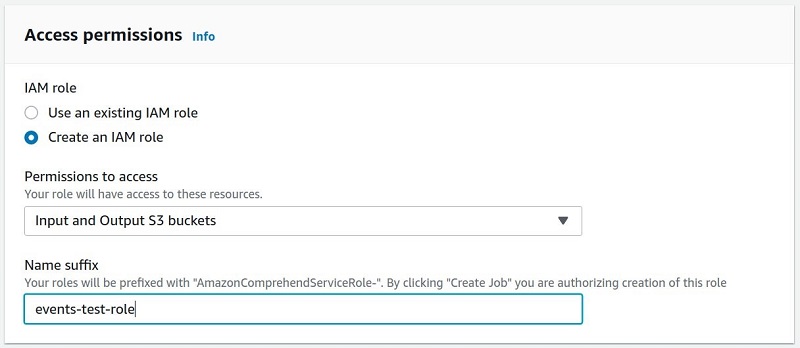
- For IAM role, we can create a new AWS Identity and Access Management (IAM) role or use an existing one.
For more information, see IAM role for ServiceNow data sources.
This role has four functions:
If you use an existing IAM role, you have to grant permissions to this secret in Secrets Manager. If you create a new IAM and a new secret, no further action is required.
- Choose Next.

You then need to define ServiceNow authentication details, the content to index, and the synchronization schedule.
The ServiceNow user you provide for the connector needs to have the admin role.
- In the Authentication section, for Type of authentication, choose an existing secret or create a new one. For this post, we choose New.
- Enter your secret’s name, username, and password.

- In the ServiceNow configuration section, we define the content types we need to index: Knowledge articles, Service catalog items, or both.
- You also define if it include the item attachments.
Amazon Kendra only indexes public articles that have a published state, so a knowledge base article must have the public role under Can Read, and Cannot Read must be null or not set.

- You can include or exclude some file extensions (for example, for Microsoft Word, we have six different types of extensions).

- For Frequency, choose Run on demand.

- Add field mappings.
Even though this is an optional step, it’s a good idea to add this extra layer of metadata to our documents from ServiceNow. This metadata enables you to improve accuracy through manual tuning, filtering, and faceting. There is no way to add metadata to already ingested documents, so if you want to add metadata later, you need to delete this data source and recreate a data source with metadata and ingest your documents again.
If you map fields through the console when setting up the ServiceNow connector for the first time, these fields are created automatically. If you configure the connector via the API, you need update your index first and define those new fields.
You can map ServiceNow properties to Amazon Kendra index fields. The following table is the list of fields that we can map.
| ServiceNow Field Name |
Suggested Amazon Kendra Field Name |
| content |
_document_body |
| displayUrl |
sn_display_url |
| first_name |
sn_ka_first_name |
| kb_category |
sn_ka_category |
| kb_catagory_name |
_category |
| kb_knowledge_base |
sn_ka_knowledge_base |
| last_name |
sn_ka_last_name |
| number |
sn_kb_number |
| published |
sn_ka_publish_date |
| repItemType |
sn_repItemType |
| short_description |
_document_title |
| sys_created_by |
sn_createdBy |
| sys_created_on |
_created_at |
| sys_id |
sn_sys_id |
| sys_updated_by |
sn_updatedBy |
| sys_updated_on |
_last_updated_at |
| url |
sn_url |
| user_name |
sn_ka_user_name |
| valid_to |
sn_ka_valid_to |
| workflow_state |
sn_ka_workflow_state |
Even though there are suggested Kendra field names you can define, you can map a field into a different name.
The following table summarizes the available service catalog fields.
| ServiceNow Field Name |
Suggested Amazon Kendra Field Name |
| category |
sn_sc_category |
| category_full_name |
sn_sc_category_full_name |
| category_name |
_category |
| description |
_document_body |
| displayUrl |
sn_display_url |
| repItemType |
sn_repItemType |
| sc_catalogs |
sn_sc_catalogs |
| sc_catalogs_name |
sn_sc_catalogs_name |
| short_description |
_document_body |
| sys_created_by |
sn_createdBy |
| sys_created_on |
_created_at |
| sys_id |
sn_sys_id |
| sys_updated_by |
sn_updatedBy |
| sys_updated_on |
_last_updated_at |
| title |
_document_title |
| url |
sn_url |
For this post, our Amazon Kendra index has a custom index field called MyCustomUsername, which you can use to map the Username field from different data sources. This custom field was created under the index’s facet definition. The following screenshot shows a custom mapping.

- Review the settings and choose Create data source.
After your ServiceNow data source is created, you see a banner similar to the following screenshot.
- Choose Sync now to start the syncing and document ingestion process.

If everything goes as expected, you can see the status as Succeeded.

Testing
Now that you have synced your ServiceNow site you can test it on the Amazon Kendra’s search console.
In my case, my ServiceNow site has the demo examples, so I asked what is the storage on the ipad 3, which returned information from a service catalog item:

Creating a ServiceNow connector with Python
We saw how to create an index on the Amazon Kendra console; now we create a new Amazon Kendra index and a ServiceNow connector and sync it by using the AWS SDK for Python (Boto3). Boto3 makes it easy to integrate your Python application, library, or script with AWS services, including Amazon Kendra.
My personal preference to test my Python scripts is to spin up an Amazon SageMaker notebook instance, a fully managed ML Amazon Elastic Compute Cloud (Amazon EC2) instance that runs the Jupyter Notebook app. For instructions, see Create an Amazon SageMaker Notebook Instance.
To create an index using the AWS SDK, we need to have the policy AmazonKendraFullAccess attached to the role we use.
Also, Amazon Kendra requires different roles to operate:
- IAM roles for indexes, which are needed by Amazon Kendra to write to Amazon CloudWatch Logs.
- IAM roles for data sources, which are needed when we use the
CreateDataSource These roles require a specific set of permissions depending on the connector we use. Because we use ServiceNow data sources, it must provide permissions to:
- Secrets Manager, where the ServiceNow online credentials are stored.
- Permission to use the AWS Key Management Service (AWS KMS) customer master Key (CMK) to decrypt the credentials by Secrets Manager.
- Permission to use the
BatchPutDocument and BatchDeleteDocument operations to update the index.
For more information, see IAM access roles for Amazon Kendra.
Our current requirements are:
- Amazon SageMaker Notebooks execution role with permission to create an Amazon Kendra index using an Amazon SageMaker notebook
- Amazon Kendra IAM role for CloudWatch
- Amazon Kendra IAM role for ServiceNow connector
- ServiceNow credentials stored on Secrets Manager
To create an index, we use the following code:
import boto3
from botocore.exceptions import ClientError
import pprint
import time
kendra = boto3.client("kendra")
print("Creating an index")
description = <YOUR_INDEX_DESCRIPTION>
index_name = <YOUR_NEW_INDEX_NAME>
role_arn = <KENDRA_ROLE_WITH_CLOUDWATCH_PERMISSIONS ROLE>
try:
index_response = kendra.create_index(
Description = <DESCRIPTION>,
Name = index_name,
RoleArn = role_arn,
Edition = "DEVELOPER_EDITION",
Tags=[
{
'Key': 'Project',
'Value': 'SharePoint Test'
}
]
)
pprint.pprint(index_response)
index_id = index_response['Id']
print("Wait for Kendra to create the index.")
while True:
# Get index description
index_description = kendra.describe_index(
Id = index_id
)
# If status is not CREATING quit
status = index_description["Status"]
print(" Creating index. Status: "+status)
if status != "CREATING":
break
time.sleep(60)
except ClientError as e:
print("%s" % e)
print("Done creating index.")
While our index is being created, we obtain regular updates (every 60 seconds to be exact, check line 38) until the process is finished. See the following code:
Creating an index
{'Id': '3311b507-bfef-4e2b-bde9-7c297b1fd13b',
'ResponseMetadata': {'HTTPHeaders': {'content-length': '45',
'content-type': 'application/x-amz-json-1.1',
'date': 'Wed, 12 Aug 2020 12:58:19 GMT',
'x-amzn-requestid': 'a148a4fc-7549-467e-b6ec-6f49512c1602'},
'HTTPStatusCode': 200,
'RequestId': 'a148a4fc-7549-467e-b6ec-6f49512c1602',
'RetryAttempts': 2}}
Wait for Kendra to create the index.
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: ACTIVE
Done creating index
The preceding code indicates that our index has been created and our new index ID is 3311b507-bfef-4e2b-bde9-7c297b1fd13b (your ID is different from our example code). This information is included as ID in the response.
Our Amazon Kendra index is up and running now.
If you have metadata attributes associated with your ServiceNow articles, you want to do three things:
- Determine the Amazon Kendra attribute name you want for each of your ServiceNow metadata attributes. By default, Amazon Kendra has six reserved fields (
_category, created_at, _file_type, _last_updated_at, _source_uri, and _view_count).
- Update the index with the UpdateIndex API call with the Amazon Kendra attribute names.
- Map each ServiceNow metadata attribute to each Amazon Kendra metadata attribute.
You can find a table with metadata attributes and the suggested Amazon Kendra fields under step 20 on the previous section.
For this post, I have the metadata attribute UserName associated with my ServiceNow article and I want to map it to the field MyCustomUsername on my index. The following code shows how to add the attribute MyCustomUsername to my Amazon Kendra index. After we create this custom field in our index, we map our field Username from ServiceNow to it. See the following code:
try:
update_response = kendra.update_index(
Id='3311b507-bfef-4e2b-bde9-7c297b1fd13b',
RoleArn='arn:aws:iam::<MY-ACCOUNT-NUMBER>:role/service-role/AmazonKendra-us-east-1-KendraRole',
DocumentMetadataConfigurationUpdates=[
{
'Name': <MY_CUSTOM_FIELD_NAME>,
'Type': 'STRING_VALUE',
'Search': {
'Facetable': True,
'Searchable': True,
'Displayable': True
}
}
]
)
except ClientError as e:
print('%s' % e)
pprint.pprint(update_response)
If everything goes well, we receive a 200 response:
{'ResponseMetadata': {'HTTPHeaders': {'content-length': '0',
'content-type': 'application/x-amz-json-1.1',
'date': 'Wed, 12 Aug 2020 12:17:07 GMT',
'x-amzn-requestid': '3eba66c9-972b-4757-8d92-37be17c8f8a2},
'HTTPStatusCode': 200,
'RequestId': '3eba66c9-972b-4757-8d92-37be17c8f8a2',
'RetryAttempts': 0}}
}
We also need to have GetSecretValue for our secret stored in Secrets Manager.
If you need to create a new secret in Secrets Manager to store your ServiceNow credentials, make sure the role you use has permissions to CreateSecret and tagging for Secrets Manager. The policy should look like the following code:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "SecretsManagerWritePolicy",
"Effect": "Allow",
"Action": [
"secretsmanager:UntagResource",
"secretsmanager:CreateSecret",
"secretsmanager:TagResource"
],
"Resource": "*"
}
]
}
The following code creates a secret in Secrets Manager:
secretsmanager = boto3.client('secretsmanager')
SecretName = <YOURSECRETNAME>
SharePointCredentials = "{'username': <YOUR_SERVICENOW_SITE_USERNAME>, 'password': <YOUR_SERVICENOW_SITE_PASSWORD>}"
try:
create_secret_response = secretsmanager.create_secret(
Name=SecretName,
Description='Secret for a servicenow data source connector',
SecretString=SharePointCredentials,
Tags=[
{
'Key': 'Project',
'Value': 'ServiceNow Test'
}
]
)
except ClientError as e:
print('%s' % e)
pprint.pprint(create_secret_response)
If everything goes well, you get a response with your secret’s ARN:
{'ARN':<YOUR_SECRETS_ARN>,
'Name': <YOUR_SECRET_NAME>,
'ResponseMetadata': {'HTTPHeaders': {'connection': 'keep-alive',
'content-length': '161',
'content-type': 'application/x-amz-json-1.1',
'date': 'Sat, 22 Aug 2020 14:44:13 GMT',
'x-amzn-requestid': '68c9a153-c08e-42df-9e6d-8b82550bc412'},
'HTTPStatusCode': 200,
'RequestId': '68c9a153-c08e-42df-9e6d-8b82550bc412',
'RetryAttempts': 0},
'VersionId': 'bee74dab-6beb-4723-a18b-4829d527aad8'}
Now that we have our Amazon Kendra index, our custom field, and our ServiceNow credentials, we can proceed with creating our data source.
To ingest documents from this data source, we need an IAM role with Kendra:BatchPutDocument and kendra:BatchDeleteDocument permissions. For more information, see IAM roles for Microsoft SharePoint Online data sources. We use the ARN for this IAM role when invoking the CreateDataSource API.
Make sure the role you use for your data source connector has a trust relationship with Amazon Kendra. It should look like the following code:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "kendra.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
The following code is the policy structure we need:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"secretsmanager:GetSecretValue"
],
"Resource": [
"arn:aws:secretsmanager:region:account ID:secret:secret ID"
]
},
{
"Effect": "Allow",
"Action": [
"kms:Decrypt"
],
"Resource": [
"arn:aws:kms:region:account ID:key/key ID"
]
},
{
"Effect": "Allow",
"Action": [
"kendra:BatchPutDocument",
"kendra:BatchDeleteDocument"
],
"Resource": [
"arn:aws:kendra:<REGION>:<account_ID>:index/<index_ID>"
],
"Condition": {
"StringLike": {
"kms:ViaService": [
"kendra.amazonaws.com"
]
}
}
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::<BUCKET_NAME>/*"
]
}
]
}
Finally, the following code is my role’s ARN:
arn:aws:iam::<MY_ACCOUNT_NUMBER>:role/Kendra-Datasource
Following the least privilege principle, we only allow our role to put and delete documents in our index, and read the secrets to connect to our ServiceNow site.
One detail we can specify when creating a data source is the sync schedule, which indicates how often our index syncs with the data source we create. This schedule is defined on the Schedule key of our request. You can use schedule expressions for rules to define how often you want to sync your data source. For this post, I use the ScheduleExpression 'cron(0 11 * * ? *)', which means that our data source is synced every day at 11:00 AM.
I use the following code. Make sure you match your SiteURL and SecretARN, as well as your IndexID. Additionally, FieldMappings is where you map between the ServiceNow attribute names with the Amazon Kendra index attribute names. I chose the same attribute name in both, but you can call the Amazon Kendra attribute whatever you’d like.
For more details, see create_data_source(**kwargs).
print('Create a data source')
SecretArn= "<YOUR_SERVICENOW_ONLINE_USER_AND_PASSWORD_SECRETS_ARN>"
SiteUrl = "<YOUR_SERVICENOW_SITE_URL>"
DSName= "<YOUR_NEW_DATASOURCE_NAME>"
IndexId= "<YOUR_INDEX_ID>"
DSRoleArn= "<YOUR_DATA_SOURCE_ROLE>"
ScheduleExpression='cron(0 11 * * ? *)'
try:try:
datasource_response = kendra.create_data_source(
Name=DSName,
IndexId=IndexId,
Type='SERVICENOW',
Configuration={
'ServiceNowConfiguration': {
'HostUrl': SiteUrl,
'SecretArn': SecretArn,
'ServiceNowBuildVersion': 'OTHERS',
'KnowledgeArticleConfiguration':
{
'CrawlAttachments': True,
'DocumentDataFieldName': 'content',
'DocumentTitleFieldName': 'short_description',
'FieldMappings':
[
{
'DataSourceFieldName': 'sys_created_on',
'DateFieldFormat': 'yyyy-MM-dd hh:mm:ss',
'IndexFieldName': '_created_at'
},
{
'DataSourceFieldName': 'sys_updated_on',
'DateFieldFormat': 'yyyy-MM-dd hh:mm:ss',
'IndexFieldName': '_last_updated_at'
},
{
'DataSourceFieldName': 'kb_category_name',
'IndexFieldName': '_category'
},
{
'DataSourceFieldName': 'sys_created_by',
'IndexFieldName': 'MyCustomUsername'
}
],
'IncludeAttachmentFilePatterns':
[
'.*\.(dotm|ppt|pot|pps|ppa)$',
'.*\.(doc|dot|docx|dotx|docm)$',
'.*\.(pptx|ppsx|pptm|ppsm|html)$',
'.*\.(txt)$',
'.*\.(hml|xhtml|xhtml2|xht|pdf)$'
]
},
'ServiceCatalogConfiguration': {
'CrawlAttachments': True,
'DocumentDataFieldName': 'description',
'DocumentTitleFieldName': 'title',
'FieldMappings':
[
{
'DataSourceFieldName': 'sys_created_on',
'DateFieldFormat': 'yyyy-MM-dd hh:mm:ss',
'IndexFieldName': '_created_at'
},
{
'DataSourceFieldName': 'sys_updated_on',
'DateFieldFormat': 'yyyy-MM-dd hh:mm:ss',
'IndexFieldName': '_last_updated_at'
},
{
'DataSourceFieldName': 'category_name',
'IndexFieldName': '_category'
}
],
'IncludeAttachmentFilePatterns':
[
'.*\.(dotm|ppt|pot|pps|ppa)$',
'.*\.(doc|dot|docx|dotx|docm)$',
'.*\.(pptx|ppsx|pptm|ppsm|html)$',
'.*\.(txt)$',
'.*\.(hml|xhtml|xhtml2|xht|pdf)$'
]
},
},
},
Description='My ServiceNow Datasource',
RoleArn=DSRoleArn,
Schedule=ScheduleExpression,
Tags=[
{
'Key': 'Project',
'Value': 'ServiceNow Test'
}
])
pprint.pprint(datasource_response)
print('Waiting for Kendra to create the DataSource.')
datasource_id = datasource_response['Id']
while True:
# Get index description
datasource_description = kendra.describe_data_source(
Id=datasource_id,
IndexId=IndexId
)
# If status is not CREATING quit
status = datasource_description["Status"]
print(" Creating index. Status: "+status)
if status != "CREATING":
break
time.sleep(60)
except ClientError as e:
pprint.pprint('%s' % e)
pprint.pprint(datasource_response)
If everything goes well, we should receive a 200 status response:
Create a DataSource
{'Id': '507686a5-ff4f-4e82-a356-32f352fb477f',
'ResponseMetadata': {'HTTPHeaders': {'content-length': '45',
'content-type': 'application/x-amz-json-1.1',
'date': 'Sat, 22 Aug 2020 15:50:08 GMT',
'x-amzn-requestid': '9deaea21-1d38-47b0-a505-9bb2efb0b74f'},
'HTTPStatusCode': 200,
'RequestId': '9deaea21-1d38-47b0-a505-9bb2efb0b74f',
'RetryAttempts': 0}}
Waiting for Kendra to create the DataSource.
Creating index. Status: CREATING
Creating index. Status: ACTIVE
{'Id': '507686a5-ff4f-4e82-a356-32f352fb477f',
'ResponseMetadata': {'HTTPHeaders': {'content-length': '45',
'content-type': 'application/x-amz-json-1.1',
'date': 'Sat, 22 Aug 2020 15:50:08 GMT',
'x-amzn-requestid': '9deaea21-1d38-47b0-a505-9bb2efb0b74f'},
'HTTPStatusCode': 200,
'RequestId': '9deaea21-1d38-47b0-a505-9bb2efb0b74f',
'RetryAttempts': 0}}
Even though we have defined a schedule for syncing my data source, we can sync on demand by using the method start_data_source_sync_job:
DSId=<YOUR DATA SOURCE ID>
IndexId=<YOUR INDEX ID>
try:
ds_sync_response = kendra.start_data_source_sync_job(
Id=DSId,
IndexId=IndexId
)
except ClientError as e:
print('%s' % e)
pprint.pprint(ds_sync_response)
The response should look like the following code:
{'ExecutionId': '3d11e6ef-3b9e-4283-bf55-f29d0b10e610',
'ResponseMetadata': {'HTTPHeaders': {'content-length': '54',
'content-type': 'application/x-amz-json-1.1',
'date': 'Sat, 22 Aug 2020 15:52:36 GMT',
'x-amzn-requestid': '55d94329-50af-4ad5-b41d-b173f20d8f27'},
'HTTPStatusCode': 200,
'RequestId': '55d94329-50af-4ad5-b41d-b173f20d8f27',
'RetryAttempts': 0}}
Testing
Finally, we can query our index. See the following code:
response = kendra.query(
IndexId=<YOUR_INDEX_ID>,
QueryText='Is there a service that has 11 9s of durability?')
if response['TotalNumberOfResults'] > 0:
print(response['ResultItems'][0]['DocumentExcerpt']['Text'])
print("More information: "+response['ResultItems'][0]['DocumentURI'])
else:
print('No results found, please try a different search term.')
Common errors
In this section, we discuss errors that may occur, whether using the Amazon Kendra console or the Amazon Kendra API.
You should look at CloudWatch logs and error messages returned in the Amazon Kendra console or via the Amazon Kendra API. The CloudWatch logs help you determine the reason for a particular error, whether you experience it using the console or programmatically.
Common errors when trying to access ServiceNow as a data source are:
- Insufficient permissions
- Invalid credentials
- Secrets Manager error
Insufficient permissions
A common scenario you may come across is when you have the right credentials but your user doesn’t have enough permissions for the Amazon Kendra ServiceNow connector to crawl your knowledge base and service catalog items.
You receive the following error message:
We couldn't sync the following data source: 'MyServiceNowOnline', at start time Sep 12, 2020, 1:08 PM CDT. Amazon Kendra can't connect to the ServiceNow server with the specified credentials. Check your credentials and try your request again.
If you can log in to your ServiceNow instance, make sure that the user you designed for the connector has the admin role.
- On your ServiceNow instance, under User Administration, choose Users.

- On the users list, choose the user ID of the user you want to use for the connector.

- On the Roles tab, verify that your user has the admin

- If you don’t have that role attached to your user, choose Edit to add it.

- On the Amazon Kendra console, on your connector configuration page, choose Sync now.

Invalid credentials
You may encounter an error with the following message:
We couldn't sync the following data source: 'MyServiceNowOnline', at start time Jul 28, 2020, 3:59 PM CDT. Amazon Kendra can't connect to the ServiceNow server with the specified credentials. Check your credentials and try your request again.
To investigate, complete the following steps:
- Choose the error message to review the CloudWatch logs.

You’re redirected CloudWatch Logs Insights.
- Choose Run Query to start analyzing the logs.

We can verify our credentials by going to Secrets Manager and reviewing our credentials stored in the secret.
- Choose your secret name.

- Choose Retrieve secret value.

- If your password doesn’t match, choose Edit,

- And the username or password and choose Save.

- Go back to your data source in Amazon Kendra, and choose Sync now.

Secrets Manager error
You may encounter an error stating that the customer’s secret can’t be fetched. This may happen if you use an existing secret and the IAM role used for syncing your ServiceNow data source doesn’t have permissions to access the secret.
To address this issue, first we need our secret’s ARN.
- On the Secrets Manager console, choose your secret’s name (for this post,
AmazonKendra-ServiceNow-demosite).
- Copy the secret’s ARN.
- On the IAM console, search for the role we use to sync our ServiceNow data source (for this post,
AmazonKendra-servicenow-role).
- For Permissions, choose Add inline policy.
- Following the least privilege principle, for Service, choose Secrets Manager.
- For Access Level, choose Read and GetSecretValue.
- For Resources, enter our secret’s ARN.
Your settings should look similar to the following screenshot.

- Enter a name for your policy.
- Choose Create Policy.
After your policy has been created and attached to your data source role, try to sync again.
Conclusion
You have now learned how to ingest the documents from your ServiceNow site into your Amazon Kendra index. We hope this post helps you take advantage of the intelligent search capabilities in Amazon Kendra to find accurate answers from your enterprise content.
For more information about Amazon Kendra, see AWS re:Invent 2019 – Keynote with Andy Jassy on YouTube, Amazon Kendra FAQs, and What is Amazon Kendra?
About the Authors
 David Shute is a Senior ML GTM Specialist at Amazon Web Services focused on Amazon Kendra. When not working, he enjoys hiking and walking on a beach.
David Shute is a Senior ML GTM Specialist at Amazon Web Services focused on Amazon Kendra. When not working, he enjoys hiking and walking on a beach.
 Juan Pablo Bustos is an AI Services Specialist Solutions Architect at Amazon Web Services, based in Dallas, TX. Outside of work, he loves spending time writing and playing music as well as trying random restaurants with his family.
Juan Pablo Bustos is an AI Services Specialist Solutions Architect at Amazon Web Services, based in Dallas, TX. Outside of work, he loves spending time writing and playing music as well as trying random restaurants with his family.
Read More


 Jorge Alfaro Hidalgo is an Enterprise Solutions Architect in AWS Mexico with more than 20 years of experience in IT industry, he is passionate about helping enterprises to AWS cloud journey building innovative solutions to achieve their business objectives.
Jorge Alfaro Hidalgo is an Enterprise Solutions Architect in AWS Mexico with more than 20 years of experience in IT industry, he is passionate about helping enterprises to AWS cloud journey building innovative solutions to achieve their business objectives. Mauricio Zajbert has more than 30 years of experience in the IT industry and a fully recovered infrastructure professional; he’s currently Solutions Architecture Manager for Enterprise accounts in AWS Mexico leading a team that helps customers in their cloud journey. He’s lived through several technology waves and deeply believes none has offered the benefits of the cloud.
Mauricio Zajbert has more than 30 years of experience in the IT industry and a fully recovered infrastructure professional; he’s currently Solutions Architecture Manager for Enterprise accounts in AWS Mexico leading a team that helps customers in their cloud journey. He’s lived through several technology waves and deeply believes none has offered the benefits of the cloud.




 Graham Horwood is a data scientist at Amazon AI. His work focuses on natural language processing technologies for customers in the public and commercial sectors.
Graham Horwood is a data scientist at Amazon AI. His work focuses on natural language processing technologies for customers in the public and commercial sectors. Ben Snively is an AWS Public Sector Specialist Solutions Architect. He works with government, non-profit, and education customers on big data/analytical and AI/ML projects, helping them build solutions using AWS.
Ben Snively is an AWS Public Sector Specialist Solutions Architect. He works with government, non-profit, and education customers on big data/analytical and AI/ML projects, helping them build solutions using AWS. Sameer Karnik is a Sr. Product Manager leading product for Amazon Comprehend, AWS’s natural language processing service.
Sameer Karnik is a Sr. Product Manager leading product for Amazon Comprehend, AWS’s natural language processing service.






 Nick Minaie is an Artificial Intelligence and Machine Learning (AI/ML) Specialist Solution Architect, helping customers on their journey to well-architected machine learning solutions at scale. In his spare time, Nick enjoys family time, abstract painting, and exploring nature.
Nick Minaie is an Artificial Intelligence and Machine Learning (AI/ML) Specialist Solution Architect, helping customers on their journey to well-architected machine learning solutions at scale. In his spare time, Nick enjoys family time, abstract painting, and exploring nature. Sam Liu is a product manager at Amazon Web Services (AWS). His current focus is the infrastructure and tooling of machine learning and artificial intelligence. Beyond that, he has 10 years of experience building machine learning applications in various industries. In his spare time, he enjoys making short videos for technical education or animal protection.
Sam Liu is a product manager at Amazon Web Services (AWS). His current focus is the infrastructure and tooling of machine learning and artificial intelligence. Beyond that, he has 10 years of experience building machine learning applications in various industries. In his spare time, he enjoys making short videos for technical education or animal protection.





 Blake DeLee is a Rochester, NY-based conversational AI consultant with AWS Professional Services. He has spent five years in the field of conversational AI and voice, and has experience bringing innovative solutions to dozens of Fortune 500 businesses. Blake draws on a wide-ranging career in different fields to build exceptional chatbot and voice solutions.
Blake DeLee is a Rochester, NY-based conversational AI consultant with AWS Professional Services. He has spent five years in the field of conversational AI and voice, and has experience bringing innovative solutions to dozens of Fortune 500 businesses. Blake draws on a wide-ranging career in different fields to build exceptional chatbot and voice solutions. As a Product Manager on the Amazon Lex team, Harshal Pimpalkhute spends his time trying to get machines to engage (nicely) with humans.
As a Product Manager on the Amazon Lex team, Harshal Pimpalkhute spends his time trying to get machines to engage (nicely) with humans. Esther Lee is a Product Manager for AWS Language AI Services. She is passionate about the intersection of technology and education. Out of the office, Esther enjoys long walks along the beach, dinners with friends and friendly rounds of Mahjong.
Esther Lee is a Product Manager for AWS Language AI Services. She is passionate about the intersection of technology and education. Out of the office, Esther enjoys long walks along the beach, dinners with friends and friendly rounds of Mahjong.






 Watson G. Srivathsan is the Sr. Product Manager for Amazon Translate, AWS’s natural language processing service. On weekends you will find him exploring the outdoors in the Pacific Northwest.
Watson G. Srivathsan is the Sr. Product Manager for Amazon Translate, AWS’s natural language processing service. On weekends you will find him exploring the outdoors in the Pacific Northwest. Xingyao Wang is the Software Develop Engineer for Amazon Translate, AWS’s natural language processing service. She likes to hang out with her cats at home.
Xingyao Wang is the Software Develop Engineer for Amazon Translate, AWS’s natural language processing service. She likes to hang out with her cats at home.

 Anuj Gupta is the Product Manager for Amazon Augmented AI. He is focusing on delivering products that make it easier for customers to adopt machine learning. In his spare time, he enjoys road trips and watching Formula 1.
Anuj Gupta is the Product Manager for Amazon Augmented AI. He is focusing on delivering products that make it easier for customers to adopt machine learning. In his spare time, he enjoys road trips and watching Formula 1.







 Frank Wang is a Startup Senior Solutions Architect at AWS. He has worked with a wide range of customers with focus on Independent Software Vendors (ISVs) and now startups. He has several years of engineering leadership, software architecture, and IT enterprise architecture experiences, and now focuses on helping customers through their cloud journey on AWS.
Frank Wang is a Startup Senior Solutions Architect at AWS. He has worked with a wide range of customers with focus on Independent Software Vendors (ISVs) and now startups. He has several years of engineering leadership, software architecture, and IT enterprise architecture experiences, and now focuses on helping customers through their cloud journey on AWS. Shishuai Wang is an ML Specialist Solutions Architect working with the AWS WWSO team. He works with AWS customers to help them adopt machine learning on a large scale. He enjoys watching movies and traveling around the world.
Shishuai Wang is an ML Specialist Solutions Architect working with the AWS WWSO team. He works with AWS customers to help them adopt machine learning on a large scale. He enjoys watching movies and traveling around the world. Yu Zhang is a staff software engineer and the technical lead of the Deep Learning platform at DeepMap. His research interests include Large-Scale Image Concept Learning, Image Retrieval, and Geo and Climate Informatic
Yu Zhang is a staff software engineer and the technical lead of the Deep Learning platform at DeepMap. His research interests include Large-Scale Image Concept Learning, Image Retrieval, and Geo and Climate Informatic Tom Wang is a founding team member and Director of Engineering at DeepMap, managing their cloud infrastructure, backend services, and map pipelines. Tom has 20+ years of industry experience in database storage systems, distributed big data processing, and map data infrastructure. Prior to DeepMap, Tom was a tech lead at Apple Maps and key contributor to Apple’s map data infrastructure and map data validation platform. Tom holds an MS degree in computer science from the University of Wisconsin-Madison.
Tom Wang is a founding team member and Director of Engineering at DeepMap, managing their cloud infrastructure, backend services, and map pipelines. Tom has 20+ years of industry experience in database storage systems, distributed big data processing, and map data infrastructure. Prior to DeepMap, Tom was a tech lead at Apple Maps and key contributor to Apple’s map data infrastructure and map data validation platform. Tom holds an MS degree in computer science from the University of Wisconsin-Madison.