Amazon distinguished scientist, and Max Planck Institute director receives honor from German newspaper WELT.Read More
Alexa’s new speech recognition abilities showcased at Interspeech
Director of speech recognition Shehzad Mevawalla highlights recent advances in on-device processing, speaker ID, and semi-supervised learning.Read More

Using Amazon SageMaker inference pipelines with multi-model endpoints
Businesses are increasingly deploying multiple machine learning (ML) models to serve precise and accurate predictions to their consumers. Consider a media company that wants to provide recommendations to its subscribers. The company may want to employ different custom models for recommending different categories of products—such as movies, books, music, and articles. If the company wants to add personalization to the recommendations by using individual subscriber information, the number of custom models further increases. Hosting each custom model on a distinct compute instance is not only cost prohibitive, but also leads to underutilization of the hosting resources if not all models are frequently used.
Amazon SageMaker is a fully managed service that enables developers and data scientists to quickly and easily build, train, and deploy ML models at any scale. After you train an ML model, you can deploy it on Amazon SageMaker endpoints that are fully managed and can serve inferences in real time with low latency. Amazon SageMaker multi-model endpoints (MMEs) are a cost-effective solution to deploy a large number of ML models or per-user models. You can deploy multiple models on a single multi-model enabled endpoint such that all models share the compute resources and the serving container. You get significant cost savings and also simplify model deployments and updates. For more information about MME, see Save on inference costs by using Amazon SageMaker multi-model endpoints.
The following diagram depicts how MMEs work.

Multiple model artifacts are persisted in an Amazon S3 bucket. When a specific model is invoked, Amazon SageMaker dynamically loads it onto the container hosting the endpoint. If the model is already loaded in the container’s memory, invocation is faster because Amazon SageMaker doesn’t need to download and load it.
Until now, you could use MME with several frameworks, such as TensorFlow, PyTorch, MXNet, SKLearn, and build your own container with a multi-model server. This post introduces the following feature enhancements to MME:
- MME support for Amazon SageMaker built-in algorithms – MME is now supported natively in the following popular Amazon SageMaker built-in algorithms: XGBoost, linear learner, RCF, and KNN. You can directly use the Amazon SageMaker provided containers while using these algorithms without having to build your own custom container.
- MME support for Amazon SageMaker inference pipelines – The Amazon SageMaker inference pipeline model consists of a sequence of containers that serve inference requests by combining preprocessing, predictions, and postprocessing data science tasks. An inference pipeline allows you to reuse the same preprocessing code used during model training to process the inference request data used for predictions. You can now deploy an inference pipeline on an MME where one of the containers in the pipeline can dynamically serve requests based on the model being invoked.
- IAM condition keys for granular access to models – Prior to this enhancement, an AWS Identity and Access Management (IAM) principal with
InvokeEndpointpermission on the endpoint resource could invoke all the models hosted on that endpoint. Now, we support granular access to models using IAM condition keys. For example, the following IAM condition restricts the principal’s access to a model persisted in the Amazon Simple Storage Service (Amazon S3) bucket withcompany_aorcommonprefixes:
Condition": {
"StringLike": {
"sagemaker:TargetModel": ["company_a/*", "common/*"]
}
}
We also provide a fully functional notebook to demonstrate these enhancements.
Walkthrough overview
To demonstrate these capabilities, the notebook discusses the use case of predicting house prices in multiple cities using linear regression. House prices are predicted based on features like number of bedrooms, number of garages, square footage, and more. Depending on the city, the features affect the house price differently. For example, small changes in the square footage cause a drastic change in house prices in New York City when compared to price changes in Houston.
For accurate house price predictions, we train multiple linear regression models, with a unique location-specific model per city. Each location-specific model is trained on synthetic housing data with randomly generated characteristics. To cost-effectively serve the multiple housing price prediction models, we deploy the models on a single multi-model enabled endpoint, as shown in the following diagram.

The walkthrough includes the following high-level steps:
- Examine the synthetic housing data generated.
- Preprocess the raw housing data using Scikit-learn.
- Train regression models using the built-in Amazon SageMaker linear learner algorithm.
- Create an Amazon SageMaker model with multi-model support.
- Create an Amazon SageMaker inference pipeline with an Sklearn model and multi-model enabled linear learner model.
- Test the inference pipeline by getting predictions from the different linear learner models.
- Update the MME with new models.
- Monitor the MME with Amazon CloudWatch
- Explore fine-grained access to models hosted on the MME using IAM condition keys.
Other steps necessary to import libraries, set up IAM permissions, and use utility functions are defined in the notebook, which this post doesn’t discuss. You can walk through and run the code with the following notebook on the GitHub repo.
Examining the synthetic housing data
The dataset consists of six numerical features that capture the year the house was built, house size in square feet, number of bedrooms, number of bathrooms, lot size, number of garages, and two categorical features: deck and front porch, indicating whether these are present or not.
To see the raw data, enter the following code:
_houses.head()The following screenshot shows the results.

You can now preprocess the categorical variables (front_porch and deck) using Scikit-learn.
Preprocessing the raw housing data
To preprocess the raw data, you first create an SKLearn estimator and use the sklearn_preprocessor.py script as the entry_point:
#Create the SKLearn estimator with the sklearn_preprocessor.py as the script
from sagemaker.sklearn.estimator import SKLearn
script_path = 'sklearn_preprocessor.py'
sklearn_preprocessor = SKLearn(
entry_point=script_path,
role=role,
train_instance_type="ml.c4.xlarge",
sagemaker_session=sagemaker_session_gamma)
You then launch multiple Scikit-learn training jobs to process the raw synthetic data generated for multiple locations. Before running the following code, take the training instance limits in your account and cost into consideration and adjust the PARALLEL_TRAINING_JOBS value accordingly:
preprocessor_transformers = []
for index, loc in enumerate(LOCATIONS[:PARALLEL_TRAINING_JOBS]):
print("preprocessing fit input data at ", index , " for loc ", loc)
job_name='scikit-learn-preprocessor-{}'.format(strftime('%Y-%m-%d-%H-%M-%S', gmtime()))
sklearn_preprocessor.fit({'train': train_inputs[index]}, job_name=job_name, wait=True)
##Once the preprocessor is fit, use tranformer to preprocess the raw training data and store the transformed data right back into s3.
transformer = sklearn_preprocessor.transformer(
instance_count=1,
instance_type='ml.m4.xlarge',
assemble_with='Line',
accept='text/csv'
)
preprocessor_transformers.append(transformer)
When the preprocessors are properly fitted, preprocess the training data using batch transform to directly preprocess the raw data and store back into Amazon S3:
preprocessed_train_data_path = []
for index, transformer in enumerate(preprocessor_transformers):
transformer.transform(train_inputs[index], content_type='text/csv')
print('Launching batch transform job:
{}'.format(transformer.latest_transform_job.job_name))
preprocessed_train_data_path.append(transformer.output_path)
Training regression models
In this step, you train multiple models, one for each location.
Start by accessing the built-in linear learner algorithm:
from sagemaker.amazon.amazon_estimator import get_image_uri
container = get_image_uri(boto3.Session().region_name, 'linear-learner')
container
Depending on the Region you’re using, you receive output similar to the following:
382416733822.dkr.ecr.us-east-1.amazonaws.com/linear-learner:1Next, define a method to launch a training job for a single location using the Amazon SageMaker Estimator API. In the hyperparameter configuration, you use predictor_type='regressor' to indicate that you’re using the algorithm to train a regression model. See the following code:
def launch_training_job(location, transformer):
"""Launch a linear learner traing job"""
train_inputs = '{}/{}'.format(transformer.output_path, "train.csv")
val_inputs = '{}/{}'.format(transformer.output_path, "val.csv")
print("train_inputs:", train_inputs)
print("val_inputs:", val_inputs)
full_output_prefix = '{}/model_artifacts/{}'.format(DATA_PREFIX, location)
s3_output_path = 's3://{}/{}'.format(BUCKET, full_output_prefix)
print("s3_output_path ", s3_output_path)
s3_output_path = 's3://{}/{}/model_artifacts/{}'.format(BUCKET, DATA_PREFIX, location)
linear_estimator = sagemaker.estimator.Estimator(
container,
role,
train_instance_count=1,
train_instance_type='ml.c4.xlarge',
output_path=s3_output_path,
sagemaker_session=sagemaker_session)
linear_estimator.set_hyperparameters(
feature_dim=10,
mini_batch_size=100,
predictor_type='regressor',
epochs=10,
num_models=32,
loss='absolute_loss')
DISTRIBUTION_MODE = 'FullyReplicated'
train_input = sagemaker.s3_input(s3_data=train_inputs,
distribution=DISTRIBUTION_MODE, content_type='text/csv;label_size=1')
val_input = sagemaker.s3_input(s3_data=val_inputs,
distribution=DISTRIBUTION_MODE, content_type='text/csv;label_size=1')
remote_inputs = {'train': train_input, 'validation': val_input}
linear_estimator.fit(remote_inputs, wait=False)
return linear_estimator.latest_training_job.name
You can now start multiple model training jobs, one for each location. Make sure to choose the correct value for PARALLEL TRAINING_JOBS, taking your AWS account service limits and cost into consideration. In the notebook, this value is set to 4. See the following code:
training_jobs = []
for transformer, loc in zip(preprocessor_transformers, LOCATIONS[:PARALLEL_TRAINING_JOBS]):
job = launch_training_job(loc, transformer)
training_jobs.append(job)
print('{} training jobs launched: {}'.format(len(training_jobs), training_jobs))
You receive output similar to the following:
4 training jobs launched: [(<sagemaker.estimator.Estimator object at 0x7fb54784b6d8>, 'linear-learner-2020-06-03-03-51-26-548'), (<sagemaker.estimator.Estimator object at 0x7fb5478b3198>, 'linear-learner-2020-06-03-03-51-26-973'), (<sagemaker.estimator.Estimator object at 0x7fb54780dbe0>, 'linear-learner-2020-06-03-03-51-27-775'), (<sagemaker.estimator.Estimator object at 0x7fb5477664e0>, 'linear-learner-2020-06-03-03-51-31-457')]Wait until all training jobs are complete before proceeding to the next step.
Creating an Amazon SageMaker model with multi-model support
When the training jobs are complete, you’re ready to create an MME.
First, define a method to copy model artifacts from the training job output to a location in Amazon S3 where the MME dynamically loads individual models:
def deploy_artifacts_to_mme(job_name):
print("job_name :", job_name)
response = sm_client.describe_training_job(TrainingJobName=job_name)
source_s3_key,model_name = parse_model_artifacts(response['ModelArtifacts']['S3ModelArtifacts'])
copy_source = {'Bucket': BUCKET, 'Key': source_s3_key}
key = '{}/{}/{}/{}.tar.gz'.format(DATA_PREFIX, MULTI_MODEL_ARTIFACTS, model_name, model_name)
print('Copying {} modeln from: {}n to: {}...'.format(model_name, source_s3_key, key))
s3_client.copy_object(Bucket=BUCKET, CopySource=copy_source, Key=key)
Copy the model artifacts from all the training jobs to this location:
## Deploy all but the last model trained to MME
for job_name in training_jobs[:-1]:
deploy_artifacts_to_mme(job_name)
You receive output similar to the following:
linear-learner-2020-06-03-03-51-26-973
Copying LosAngeles_CA model
from: DEMO_MME_LINEAR_LEARNER/model_artifacts/LosAngeles_CA/linear-learner-2020-06-03-03-51-26-973/output/model.tar.gz
to: DEMO_MME_LINEAR_LEARNER/multi_model_artifacts/LosAngeles_CA/LosAngeles_CA.tar.gz...
linear-learner-2020-06-03-03-51-27-775
Copying Chicago_IL model
from: DEMO_MME_LINEAR_LEARNER/model_artifacts/Chicago_IL/linear-learner-2020-06-03-03-51-27-775/output/model.tar.gz
to: DEMO_MME_LINEAR_LEARNER/multi_model_artifacts/Chicago_IL/Chicago_IL.tar.gz...
linear-learner-2020-06-03-03-51-31-457
Create the Amazon SageMaker model entity using the MultiDataModel API:
MODEL_NAME = '{}-{}'.format(HOUSING_MODEL_NAME, strftime('%Y-%m-%d-%H-%M-%S', gmtime()))
_model_url = 's3://{}/{}/{}/'.format(BUCKET, DATA_PREFIX, MULTI_MODEL_ARTIFACTS)
ll_multi_model = MultiDataModel(
name=MODEL_NAME,
model_data_prefix=_model_url,
image=container,
role=role,
sagemaker_session=sagemaker
Creating an inference pipeline
Set up an inference pipeline with the PipelineModel API. This sets up a list of models in a single endpoint; for this post, we configure our pipeline model with the fitted Scikit-learn inference model and the fitted MME linear learner model. See the following code:
from sagemaker.model import Model
from sagemaker.pipeline import PipelineModel
import boto3
from time import gmtime, strftime
timestamp_prefix = strftime("%Y-%m-%d-%H-%M-%S", gmtime())
scikit_learn_inference_model = sklearn_preprocessor.create_model()
model_name = '{}-{}'.format('inference-pipeline', timestamp_prefix)
endpoint_name = '{}-{}'.format('inference-pipeline-ep', timestamp_prefix)
sm_model = PipelineModel(
name=model_name,
role=role,
sagemaker_session=sagemaker_session,
models=[
scikit_learn_inference_model,
ll_multi_model])
sm_model.deploy(initial_instance_count=1, instance_type='ml.m4.xlarge', endpoint_name=endpoint_name)
The MME is now ready to take inference requests and respond with predictions. With the MME, the inference request should include the target model to invoke.
Testing the inference pipeline
You can now get predictions from the different linear learner models. Create a RealTimePredictor with the inference pipeline endpoint:
from sagemaker.predictor import json_serializer, csv_serializer, json_deserializer, RealTimePredictor
from sagemaker.content_types import CONTENT_TYPE_CSV, CONTENT_TYPE_JSON
predictor = RealTimePredictor(
endpoint=endpoint_name,
sagemaker_session=sagemaker_session,
serializer=csv_serializer,
content_type=CONTENT_TYPE_CSV,
accept=CONTENT_TYPE_JSON)
Define a method to get predictions from the RealTimePredictor:
def predict_one_house_value(features, model_name, predictor_to_use):
print('Using model {} to predict price of this house: {}'.format(model_name,
features))
body = ','.join(map(str, features)) + 'n'
start_time = time.time()
response = predictor_to_use.predict(features, target_model=model_name)
response_json = json.loads(response)
predicted_value = response_json['predictions'][0]['score']
duration = time.time() - start_time
print('${:,.2f}, took {:,d} msn'.format(predicted_value, int(duration * 1000)))
With MME, the models are dynamically loaded into the container’s memory of the instance hosting the endpoint when invoked. Therefore, the model invocation may take longer when it’s invoked for the first time. When the model is already in the instance container’s memory, the subsequent invocations are faster. If an instance memory utilization is high and a new model needs to be loaded, unused models are unloaded. The unloaded models remain in the instance’s storage volume and can be loaded into container’s memory later without being downloaded from the S3 bucket again. If the instance’s storage volume is full, unused models are deleted from storage volume.
Amazon SageMaker fully manages the loading and unloading of the models, without you having to take any specific actions. However, it’s important to understand this behavior because it has implications on the model invocation latency.
Iterate through invocations with random inputs against a random model and show the predictions and the time it takes for the prediction to come back:
for i in range(10):
model_name = LOCATIONS[np.random.randint(1, len(LOCATIONS[:PARALLEL_TRAINING_JOBS]))]
full_model_name = '{}/{}.tar.gz'.format(model_name,model_name)
predict_one_house_value(gen_random_house()[1:], full_model_name,runtime_sm_client)
You receive output similar to the following:
Using model Chicago_IL/Chicago_IL.tar.gz to predict price of this house: [1993, 2728, 6, 3.0, 0.7, 1, 'y', 'y']
$439,972.62, took 1,166 ms
Using model Houston_TX/Houston_TX.tar.gz to predict price of this house: [1989, 1944, 5, 3.0, 1.0, 1, 'n', 'y']
$280,848.00, took 1,086 ms
Using model LosAngeles_CA/LosAngeles_CA.tar.gz to predict price of this house: [1968, 2427, 4, 3.0, 1.0, 2, 'y', 'n']
$266,721.31, took 1,029 ms
Using model Chicago_IL/Chicago_IL.tar.gz to predict price of this house: [2000, 4024, 2, 1.0, 0.82, 1, 'y', 'y']
$584,069.88, took 53 ms
Using model LosAngeles_CA/LosAngeles_CA.tar.gz to predict price of this house: [1986, 3463, 5, 3.0, 0.9, 1, 'y', 'n']
$496,340.19, took 43 ms
Using model Chicago_IL/Chicago_IL.tar.gz to predict price of this house: [2002, 3885, 4, 3.0, 1.16, 2, 'n', 'n']
$626,904.12, took 39 ms
Using model Chicago_IL/Chicago_IL.tar.gz to predict price of this house: [1992, 1531, 6, 3.0, 0.68, 1, 'y', 'n']
$257,696.17, took 36 ms
Using model Chicago_IL/Chicago_IL.tar.gz to predict price of this house: [1992, 2327, 2, 3.0, 0.59, 3, 'n', 'n']
$337,758.22, took 33 ms
Using model LosAngeles_CA/LosAngeles_CA.tar.gz to predict price of this house: [1995, 2656, 5, 1.0, 1.16, 0, 'y', 'n']
$390,652.59, took 35 ms
Using model LosAngeles_CA/LosAngeles_CA.tar.gz to predict price of this house: [2000, 4086, 2, 3.0, 1.03, 3, 'n', 'y']
$632,995.44, took 35 ms
The output that shows the predicted house price and the time it took for the prediction.
You should consider two different invocations of the same model. The second time, you don’t need to download from Amazon S3 because they’re already present on the instance. You see the inferences return in less time than before. For this use case, the invocation time for the Chicago_IL/Chicago_IL.tar.gz model reduced from 1,166 milliseconds the first time to 53 milliseconds the second time. Similarly, the invocation time for the LosAngeles_CA /LosAngeles_CA.tar.gz model reduced from 1,029 milliseconds to 43 milliseconds.
Updating an MME with new models
To deploy a new model to an existing MME, copy a new set of model artifacts to the same Amazon S3 location you set up earlier. For example, copy the model for the Houston location with the following code:
## Copy the last model
last_training_job=training_jobs[PARALLEL_TRAINING_JOBS-1]
deploy_artifacts_to_mme(last_training_job)
Now you can make predictions using the last model. See the following code:
model_name = LOCATIONS[PARALLEL_TRAINING_JOBS-1]
full_model_name = '{}/{}.tar.gz'.format(model_name,model_name)
predict_one_house_value(gen_random_house()[:-1], full_model_name,predictor)
Monitoring MMEs with CloudWatch metrics
Amazon SageMaker provides CloudWatch metrics for MMEs so you can determine the endpoint usage and the cache hit rate and optimize your endpoint. To analyze the endpoint and the container behavior, you invoke multiple models in this sequence:
##Create 200 copies of the original model and save with different names.
copy_additional_artifacts_to_mme(200)
##Starting with no models loaded into the container
##Invoke the first 100 models
invoke_multiple_models_mme(0,100)
##Invoke the same 100 models again
invoke_multiple_models_mme(0,100)
##This time invoke all 200 models to observe behavior
invoke_multiple_models_mme(0,200)
The following chart shows the behavior of the CloudWatch metrics LoadedModelCount and MemoryUtilization corresponding to these model invocations.

The LoadedModelCount metric continuously increases as more models are invoked, until it levels off at 121. The MemoryUtilization metric of the container also increased correspondingly to around 79%. This shows that the instance chosen to host the endpoint could only maintain 121 models in memory when 200 model invocations were made.
The following chart adds the ModelCacheHit metric to the previous two.

As the number of models loaded to the container memory increase, the ModelCacheHit metric improves. When the same 100 models are invoked the second time, ModelCacheHit reaches 1. When new models not yet loaded are invoked, ModelCacheHit decreases again.
You can use CloudWatch charts to help make ongoing decisions on the optimal choice of instance type, instance count, and number of models that a given endpoint should host.
Exploring granular access to models hosted on an MME
Because of the role attached to the notebook instance, it can invoke all models hosted on the MME. However, you can restrict this model invocation access to specific models by using IAM condition keys. To explore this, you create a new IAM role and IAM policy with a condition key to restrict access to a single model. You then assume this new role and verify that only a single target model can be invoked.
The role assigned to the Amazon SageMaker notebook instance should allow IAM role and IAM policy creation for the next steps to be successful.
Create an IAM role with the following code:
#Create a new role that can be assumed by this notebook. The roles should allow access to only a single model.
path='/'
role_name="{}{}".format('allow_invoke_ny_model_role', strftime('%Y-%m-%d-%H-%M-%S', gmtime()))
description='Role that allows invoking a single model'
action_string = "sts:AssumeRole"
trust_policy={
"Version": "2012-10-17",
"Statement": [
{
"Sid": "statement1",
"Effect": "Allow",
"Principal": {
"AWS": role
},
"Action": "sts:AssumeRole"
}
]
}
response = iam_client.create_role(
Path=path,
RoleName=role_name,
AssumeRolePolicyDocument=json.dumps(trust_policy),
Description=description,
MaxSessionDuration=3600
)
print(response)
Create an IAM policy with a condition key to restrict access to only the NewYork model:
managed_policy = {
"Version": "2012-10-17",
"Statement": [
{
"Sid": "SageMakerAccess",
"Action": "sagemaker:InvokeEndpoint",
"Effect": "Allow",
"Resource":endpoint_resource_arn,
"Condition": {
"StringLike": {
"sagemaker:TargetModel": ["NewYork_NY/*"]
}
}
}
]
}
response = iam_client.create_policy(
PolicyName='allow_invoke_ny_model_policy',
PolicyDocument=json.dumps(managed_policy)
)
Attach the IAM policy to the IAM role:
iam_client.attach_role_policy(
PolicyArn=policy_arn,
RoleName=role_name
)
Assume the new role and create a RealTimePredictor object runtime client:
## Invoke with the role that has access to only NY model
sts_connection = boto3.client('sts')
assumed_role_limited_access = sts_connection.assume_role(
RoleArn=role_arn,
RoleSessionName="MME_Invoke_NY_Model"
)
assumed_role_limited_access['AssumedRoleUser']['Arn']
#Create sagemaker runtime client with assumed role
ACCESS_KEY = assumed_role_limited_access['Credentials']['AccessKeyId']
SECRET_KEY = assumed_role_limited_access['Credentials']['SecretAccessKey']
SESSION_TOKEN = assumed_role_limited_access['Credentials']['SessionToken']
runtime_sm_client_with_assumed_role = boto3.client(
service_name='sagemaker-runtime',
aws_access_key_id=ACCESS_KEY,
aws_secret_access_key=SECRET_KEY,
aws_session_token=SESSION_TOKEN,
)
#SageMaker session with the assumed role
sagemakerSessionAssumedRole = sagemaker.Session(sagemaker_runtime_client=runtime_sm_client_with_assumed_role)
#Create a RealTimePredictor with the assumed role.
predictorAssumedRole = RealTimePredictor(
endpoint=endpoint_name,
sagemaker_session=sagemakerSessionAssumedRole,
serializer=csv_serializer,
content_type=CONTENT_TYPE_CSV,
accept=CONTENT_TYPE_JSON)
Now invoke the NewYork_NY model:
full_model_name = 'NewYork_NY/NewYork_NY.tar.gz'
predict_one_house_value(gen_random_house()[:-1], full_model_name, predictorAssumedRole)
You receive output similar to the following:
Using model NewYork_NY/NewYork_NY.tar.gz to predict price of this house: [1992, 1659, 2, 2.0, 0.87, 2, 'n', 'y']
$222,008.38, took 154 ms
Next, try to invoke a different model (Chicago_IL/Chicago_IL.tar.gz). This should throw an error because the assumed role isn’t authorized to invoke this model. See the following code:
full_model_name = 'Chicago_IL/Chicago_IL.tar.gz'
predict_one_house_value(gen_random_house()[:-1], full_model_name,predictorAssumedRole)
You receive output similar to the following:
ClientError: An error occurred (AccessDeniedException) when calling the InvokeEndpoint operation: User: arn:aws:sts::xxxxxxxxxxxx:assumed-role/allow_invoke_ny_model_role/MME_Invoke_NY_Model is not authorized to perform: sagemaker:InvokeEndpoint on resource: arn:aws:sagemaker:us-east-1:xxxxxxxxxxxx:endpoint/inference-pipeline-ep-2020-07-01-15-46-51Conclusion
Amazon SageMaker MMEs are a very powerful tool for teams developing multiple ML models to save significant costs and lower deployment overhead for a large number of ML models. This post discussed the new capabilities of Amazon SageMaker MMEs: native integration with Amazon SageMaker built-in algorithms (such as linear learner and KNN), native integration with inference pipelines, and fine-grained controlled access to the multiple models hosted on a single endpoint using IAM condition keys.
The notebook included with the post provided detailed instructions on training multiple linear learner models for house price predictions for multiple locations, hosting all the models on a single MME, and controlling access to the individual models.When considering multi-model enabled endpoints, you should balance the cost savings and the latency requirements.
Give Amazon SageMaker MMEs a try and leave your feedback in the comments.
About the Author
 Sireesha Muppala is a AI/ML Specialist Solutions Architect at AWS, providing guidance to customers on architecting and implementing machine learning solutions at scale. She received her Ph.D. in Computer Science from University of Colorado, Colorado Springs. In her spare time, Sireesha loves to run and hike Colorado trails.
Sireesha Muppala is a AI/ML Specialist Solutions Architect at AWS, providing guidance to customers on architecting and implementing machine learning solutions at scale. She received her Ph.D. in Computer Science from University of Colorado, Colorado Springs. In her spare time, Sireesha loves to run and hike Colorado trails.
 Michael Pham is a Software Development Engineer in the Amazon SageMaker team. His current work focuses on helping developers efficiently host machine learning models. In his spare time he enjoys Olympic weightlifting, reading, and playing chess.
Michael Pham is a Software Development Engineer in the Amazon SageMaker team. His current work focuses on helping developers efficiently host machine learning models. In his spare time he enjoys Olympic weightlifting, reading, and playing chess.
Time series forecasting using unstructured data with Amazon Forecast and the Amazon SageMaker Neural Topic Model
As the volume of unstructured data such as text and voice continues to grow, businesses are increasingly looking for ways to incorporate this data into their time series predictive modeling workflows. One example use case is transcribing calls from call centers to forecast call handle times and improve call volume forecasting. In the retail or media industry, companies are interested in using related information about products or content to forecast popularity of existing or new products or content from unstructured information such as product type, description, audience reviews, or social media feeds. However, combining this unstructured data with time series is challenging because most traditional time series models require numerical inputs for forecasting. In this post, we describe how you can combine Amazon SageMaker with Amazon Forecast to include unstructured text data into your time series use cases.
Solution overview
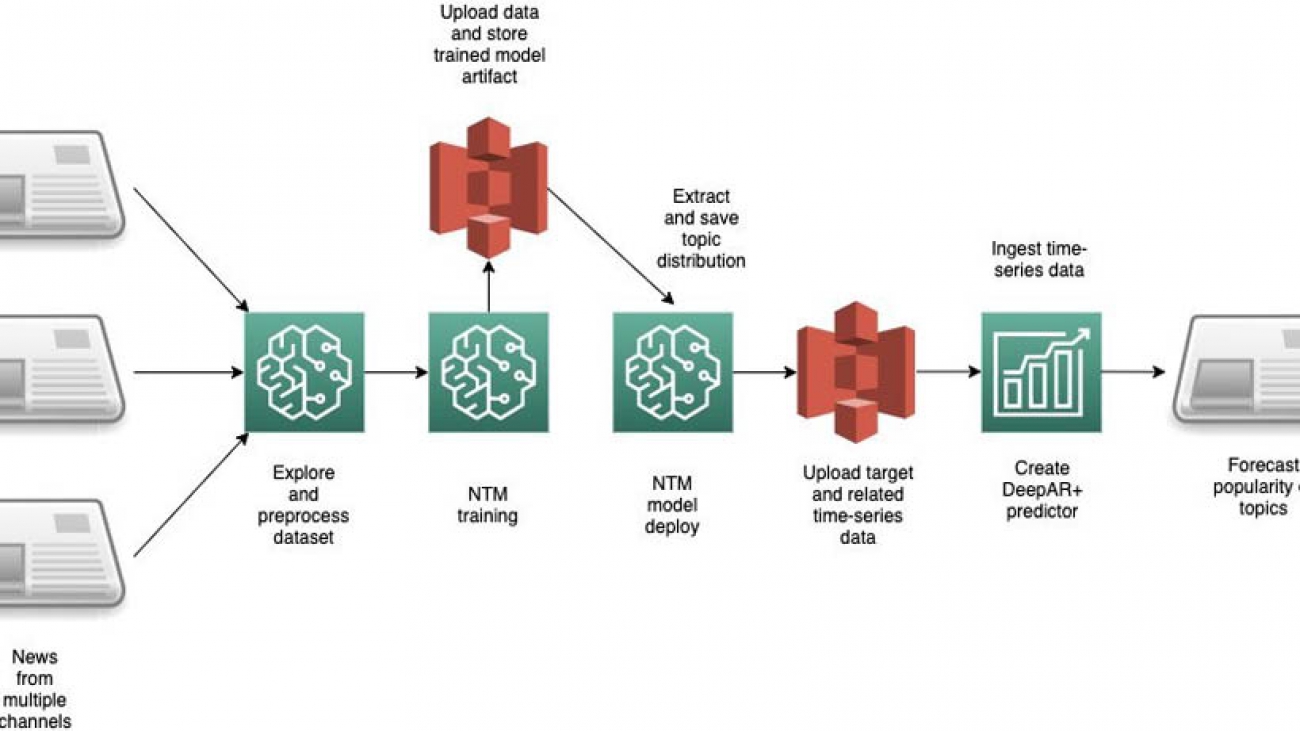
For our use case, we predict the popularity of news articles based on their topics looking forward over a 15 day horizon. You first download and preprocess the data and then run the NTM algorithm to generate topic vectors. After generating the topic vectors, you save them and use these vectors as a related time series to create the forecast.
The following diagram illustrates the architecture of this solution.

AWS services
Forecast is a fully managed service that uses machine learning (ML) to generate highly accurate forecasts without requiring any prior ML experience. Forecast is applicable in a wide variety of use cases, including energy demand forecasting, estimating product demand, workforce planning, and computing cloud infrastructure usage.
With Forecast, there are no servers to provision or ML models to build manually. Additionally, you only pay for what you use, and there is no minimum fee or upfront commitment. To use Forecast, you only need to provide historical data for what you want to forecast, and, optionally, any related data that you believe may impact your forecasts. This related data may include time-varying data (such as price, events, and weather) and categorical data (such as color, genre, or region). The service automatically trains and deploys ML models based on your data and provides you with a custom API to retrieve forecasts.
Amazon SageMaker is a fully managed service that provides every developer and data scientist with the ability to build, train, and deploy ML models quickly. The Neural Topic Model (NTM) algorithm is an unsupervised learning algorithm that can organize a collection of documents into topics that contain word groupings based on their statistical distribution. For example, documents that contain frequent occurrences of words such as “bike,” “car,” “train,” “mileage,” and “speed” are likely to share a topic on “transportation.” You can use topic modeling to classify or summarize documents based on the topics detected. You can also use it to retrieve information and recommend content based on topic similarities.
The derived topics that NTM learns are characterized as a latent representation because they are inferred from the observed word distributions in the collection. The semantics of topics are usually inferred by examining the top ranking words they contain. Because the method is unsupervised, only the number of topics, not the topics themselves, are pre-specified. In addition, the topics aren’t guaranteed to align with how a human might naturally categorize documents. NTM is one of the built-in algorithms you can train and deploy using Amazon SageMaker.
Prerequisites
To follow along with this post, you must create the following:
- An AWS Identity and Access Management (IAM role)
- An Amazon SageMaker notebook instance
- An Amazon Simple Storage Service (Amazon S3) bucket
To create the aforementioned resources and clone the forecast-samples GitHub repo into the notebook instance, launch the following AWS CloudFormation stack:
![]()
In the Parameters section, enter unique names for your S3 bucket and notebook and leave all other settings at their default.

When the CloudFormation script is complete, you can view the created resources on the Resources tab of the stack.

Navigate to Sagemaker and open the notebook instance created from the CloudFormation template. Open Jupyter and continue to the /notebooks/blog_materials/Time_Series_Forecasting_with_Unstructured_Data_and_Amazon_SageMaker_Neural_Topic_Model/ folder and start working your way through the notebooks.
Creating the resources manually
For the sake of completeness, we explain in detail the steps necessary to create the resources that the CloudFormation script creates automatically.
- Create an IAM role that can do the following:
- Has permission to access Forecast and Amazon S3 to store the training and test datasets.
- Has an attached trust policy to give Amazon SageMaker permission to assume the role.
- Allows Forecast to access Amazon S3 to pull the stored datasets into Forecast.
For more information, see Set Up Permissions for Amazon Forecast.
- Create an Amazon SageMaker notebook instance.
- Attach the IAM role you created for Amazon SageMaker to this notebook instance.
- Create an S3 bucket to store the outputs of your human workflow.
- Copy the ARN of the bucket to use in the accompanying Jupyter notebook.
This project consists of three notebooks, available in the GitHub repo. They cover the following:
- Preprocessing the dataset
- NTM with Amazon SageMaker
- Using Amazon Forecast to predict the topic’s popularity on various social media platforms going forward
Training and deploying the forecast
In the first notebook, 1_preprocess.ipynb, you download the New Popularity in Multiple Social Media Platforms dataset from the University of California Irvine (UCI) Machine Learning Repository using the requests library [1]. The following screenshot shows a sample of the dataset, where we have anonymized the topic names without loss of generality. It consists of news articles and their popularity on various social channels.

Because we’re focused on predictions based on the Headline and Title columns, we drop the Source and IDLink columns. We examine the current state of the data with a simple histogram plot. The following plot depicts the popularity of a subset of articles on Facebook.

The following plot depicts the popularity of a subset of articles on GooglePlus.

The distributions are heavily skewed towards a very small number of views; however, there are a few outlier articles that have an extremely high popularity.
Preprocessing the data
You may notice the popularity of the articles is extremely skewed. To convert this into a usable time series for ML, we need to convert the PublishDate column, which is read in as a string type, to a datetime type using the Pandas to_datetime method:
df['PublishDate'] = pd.to_datetime(df['PublishDate'], infer_datetime_format=True)We then group by topic and save the preprocessed.csv to be used by the next notebook, 2_NTM.ipynb. In the directory /data, you should see a file called NewsRatingsdataset.csv. You can now move to the next notebook, where you build a neural topic model to extract topic vectors from the processed dataset.
Before creating the topic model, it’s helpful to explore the data some more. In the following code, we plot the daily time series for the popularity of a given topic across the three social media channels, as well as a daily time series for the sentiment of a topic based on news article titles and headlines:
topic = 1 # Change this to any of [0, 1, 2, 3]
subdf = df[(df['Topic']==topic)&(df['PublishDate']>START_DATE)]
subdf = subdf.reset_index().set_index('PublishDate')
subdf.index = pd.to_datetime(subdf.index)
subdf.head()
subdf[["LinkedIn", 'GooglePlus', 'Facebook']].resample("1D").mean().dropna().plot(figsize=(15, 4))
subdf[["SentimentTitle", 'SentimentHeadline']].resample("1D").mean().dropna().plot(figsize=(15, 4))
The following are the plots for the topic Topic_1.

The dataset still needs a bit more cleaning before it’s ready for the NTM algorithm to use. Not much data exists before October 13, 2015, so you can drop the data before that date and reset the indexes accordingly. Moreover, some of the headlines and ratings contain missing values, denoted by NaN and -1, respectively. You can use regex to find and replace those headlines with empty strings and convert these ratings to zeros. There is a difference in scale for the popularity of a topic on Facebook vs. LinkedIn vs. GooglePlus. For this post, you focus on forecasting popularity on Facebook only.
Topic modeling
Now you use the built-in NTM algorithm on Amazon SageMaker to extract topics from the news headlines. When preparing a corpus of documents for NTM, you must clean and standardize the data by converting the text to lower case, remove stop words, remove any numeric characters that may not be meaningful to your corpus, and tokenize the document’s text.
We use the Natural Language Toolkit and sklearn Python libraries to convert the headlines into tokens and create vectors of the token’s counts. Also, we drop the Title column in the dataframe, but store the titles in a separate dataframe. This is because the Headline column contains similar information as the Title column, but the headlines are longer and more descriptive, and we want to use the titles later on as a validation set for our NTM during training.
Lastly, we type cast the vectors into a sparse array in order to reduce the amount of memory utilization, because the bag-of-words matrix can quickly become quite large and memory intensive. For more information, see the notebook or Build a semantic content recommendation system with Amazon SageMaker.
Training an NTM
To extract text vectors, you convert each headline into a 20 (NUM_TOPICS)-dimensional topic vector. This can be viewed as an effective lower-dimensional embedding of all the text in the corpus into some predefined topics. Each topic has a representation as a vector, and related topics have a related vector representation. This topic is a derived topic and is not to be confused with the original Topic field in the raw dataset. Assuming that there is some correlation between topics from one day to the next (for example, the top topics don’t change very frequently on a daily basis), you can represent all the text in the dataset as a collection of 20 topics.
You then set the training dataset and trained model artifact location in Amazon S3 and upload the data. To train the model, you can use one or more instances (specified by the parameter train_instance_count) and choose a strategy to either fully replicate the data on each instance or use ShardedByS3Key, which only puts certain data shards on each instance. This speeds up training at the cost of each instance only seeing a fraction of the data.
To reduce overfitting, it’s helpful to introduce a validation dataset in addition to the training dataset. The hyperparameter num_patience_epochs controls the early stopping behavior, which makes sure the training is stopped if the change in the loss is less than the specified tolerance (set by tolerance) consistently for num_patience_epochs. The epochs hyperparameter specifies the total number of epochs to run the job. For this post, we chose hyperparameters to balance the tradeoff between accuracy and training time:
%time
from sagemaker.session import s3_input
sess = sagemaker.Session()
ntm = sagemaker.estimator.Estimator(container,
role,
train_instance_count=1,
train_instance_type='ml.c4.xlarge',
output_path=output_path,
sagemaker_session=sess)
ntm.set_hyperparameters(num_topics=NUM_TOPICS, feature_dim=vocab_size, mini_batch_size=128,
epochs=100, num_patience_epochs=5, tolerance=0.001)
s3_train = s3_input(s3_train_data, distribution='FullyReplicated')
ntm.fit({'train': s3_train})
To further improve the model performance, you can take advantage of hyperparameter tuning in Amazon SageMaker.
Deploying and testing the model
To generate the feature vectors for the headlines, you first deploy the model and run inferences on the entire training dataset to obtain the topic vectors. An alternative option is to run a batch transform job.
To ensure that the topic model works as expected, we show the extracted topic vectors from the titles, and check if the topic distribution of the title is similar to that of the corresponding headline. Remember that the model hasn’t seen the titles before. As a measure of similarity, we compute the cosine similarity for a random title and associated headline. A high cosine similarity indicates that titles and headlines have a similar representation in this low-dimensional embedding space.
You can also use a cosine similarity of the title-headline as a feature: well-written titles that correlate well with the actual headline may obtain a higher popularity score. You could use this to check if titles and headlines represent the content of the document accurately, but we don’t explore this further in this notebook [2].
Finally, you store the results of the headlines mapped across the extracted NUM_TOPICS (20) back into a dataframe and save the dataframe as preprocessed_data.csv in data/ for use in subsequent notebooks.
The following code tests the vector similarity:
ntm_predictor = ntm.deploy(initial_instance_count=1, instance_type='ml.m4.xlarge')
topic_data = np.array(topic_vectors.tocsr()[:10].todense())
topic_vecs = []
for index in range(10):
results = ntm_predictor.predict(topic_data[index])
predictions = np.array([prediction['topic_weights'] for prediction in results['predictions']])
topic_vecs.append(predictions)
from sklearn.metrics.pairwise import cosine_similarity
comparisonvec = []
for i, idx in enumerate(range(10)):
comparisonvec.append([df.Headline[idx], title_column[idx], cosine_similarity(topic_vecs[i], [pred_array_cc[idx]])[0][0]])
pd.DataFrame(comparisonvec, columns=['Headline', 'Title', 'CosineSimilarity'])
The following screenshot shows the output.

Visualizing headlines
Another way to visualize the results is to plot a T-SNE graph. T-SNE uses a nonlinear embedding model by attempting to check if the nearest neighbor joint probability distribution in the high-dimensional space (for this use case, NUM_TOPICS) matches the equivalent lower-dimensional (2) joint distribution by minimizing a loss known as the Kullback-Leibler divergence [3]. Essentially, this is a dimensionality reduction technique that can map high-dimensional vectors to a lower-dimensional space.
Computing the T-SNE can take quite some time, especially for large datasets, so we shuffle the dataset and extract only 10,000 headline embeddings for the T-SNE plot. For more information about the advantages and pitfalls of using T-SNE in topic modeling, see How to Use t-SNE Effectively.
The following T-SNE plot shows a few large topics (indicated by the similar color clusters—red green, purple, blue, and brown), which is consistent with the dataset containing four primary topics. But by expanding the dimensionality of the topic vectors to NUM_TOPICS = 20, we allow the NTM model to capture additional semantic information between the headlines than is captured by a single topic token.

With our topic modeling complete and our data saved, you can now delete the endpoint to avoid incurring any charges.
Forecasting topic popularity
Now you run the third and final notebook, where you use the Forecast DeepAR+ algorithm to forecast the popularity of the topics. First, you establish a Forecast session using the Forecast SDK. It’s very important the region of your bucket is in the same region as the session.
After this step, you read in preprocessed_data.csv into a dataframe for some additional preprocessing. Drop the Headline column and replace the index of the dataframe with the publish date of the news article. You do this so you can easily aggregate the data on a daily basis. The following screenshot shows your results.

Creating the target and related time series
For this post, you want to forecast the Facebook ratings for each of the four topics in the Topic column of the dataset. In Forecast, we need to define a target time series that consists of the item ID, timestamp, and the value we want to forecast.
Additionally, as of this writing, you can provide a related time series, which can include up to 13 dynamic features, which in our use case are the SentimentHeadline and the topic vectors. Because we can only choose 13 features in Forecast, we choose 10 out of the 20 topic vectors to illustrate building the Forecast model. Currently, the CNN-QR, DeepAR+ algorithm (which we use in this post), and Prophet algorithm support related time series.
As before, we start forecasting from 2015-11-01 and end our training data at 2016-06-21. Using this, we forecast for 15 days into the future. The following screenshot shows our target time series.

The following screenshot shows our related time series.

Upload the datasets to the S3 bucket.
Defining the dataset schemas and dataset group to ingest into Forecast
Forecast has several predefined domains that come with predefined schemas for data ingestion. Because we’re interested in web traffic, you can choose the WEB_TRAFFIC domain. For more information about dataset domains, see Predefined Dataset Domains and Dataset Types.
This provides a predefined schema and attribute types for the attributes you include in the target and related time series. The WEB_TRAFFIC domain doesn’t have item metadata; only target and related time series data is allowed.
Define the schema for the target time series with the following code:
# Set the dataset name to a new unique value. If it already exists, go to the Forecast console and delete any existing
# dataset ARNs and datasets.
datasetName = 'webtraffic_forecast_NLP'
schema ={
"Attributes":[
{
"AttributeName":"item_id",
"AttributeType":"string"
},
{
"AttributeName":"timestamp",
"AttributeType":"timestamp"
},
{
"AttributeName":"value",
"AttributeType":"float"
}
]
}
try:
response = forecast.create_dataset(
Domain="WEB_TRAFFIC",
DatasetType='TARGET_TIME_SERIES',
DatasetName=datasetName,
DataFrequency=DATASET_FREQUENCY,
Schema = schema
)
datasetArn = response['DatasetArn']
print('Success')
except Exception as e:
print(e)
datasetArn = 'arn:aws:forecast:{}:{}:dataset/{}'.format(REGION_NAME, ACCOUNT_NUM, datasetName)
Define the schema for the related time series with the following code:
# Set the dataset name to a new unique value. If it already exists, go to the Forecast console and delete any existing
# dataset ARNs and datasets.
datasetName = 'webtraffic_forecast_related_NLP'
schema ={
"Attributes":[{
"AttributeName":"item_id",
"AttributeType":"string"
},
{
"AttributeName":"timestamp",
"AttributeType":"timestamp"
},
{
"AttributeName":"SentimentHeadline",
"AttributeType":"float"
}]
+
[{
"AttributeName":"Headline_{}".format(x),
"AttributeType":"float"
} for x in range(10)]
}
try:
response=forecast.create_dataset(
Domain="WEB_TRAFFIC",
DatasetType='RELATED_TIME_SERIES',
DatasetName=datasetName,
DataFrequency=DATASET_FREQUENCY,
Schema = schema
)
related_datasetArn = response['DatasetArn']
print('Success')
except Exception as e:
print(e)
related_datasetArn = 'arn:aws:forecast:{}:{}:dataset/{}'.format(REGION_NAME, ACCOUNT_NUM, datasetName)
Before ingesting any data into Forecast, we need to combine the target and related time series into a dataset group:
datasetGroupName = 'webtraffic_forecast_NLPgroup'
#try:
create_dataset_group_response = forecast.create_dataset_group(DatasetGroupName=datasetGroupName,
Domain="WEB_TRAFFIC",
DatasetArns= [datasetArn, related_datasetArn]
)
datasetGroupArn = create_dataset_group_response['DatasetGroupArn']
except Exception as e:
datasetGroupArn = 'arn:aws:forecast:{}:{}:dataset-group/{}'.format(REGION_NAME, ACCOUNT_NUM, datasetGroupName)
Ingesting the target and related time series data from Amazon S3
Next you import the target and related data previously stored in AmazonS3 to create a Forecast dataset. You provide the location of the training data in Amazon S3 and the ARN of the dataset placeholder you created.
Ingest the target and related time series with the following code:
s3DataPath = 's3://{}/{}/target_time_series.csv'.format(bucket, prefix)
datasetImportJobName = 'forecast_DSIMPORT_JOB_TARGET'
try:
ds_import_job_response=forecast.create_dataset_import_job(DatasetImportJobName=datasetImportJobName,
DatasetArn=datasetArn,
DataSource= {
"S3Config" : {
"Path":s3DataPath,
"RoleArn": role_arn
}
},
TimestampFormat=TIMESTAMP_FORMAT
)
ds_import_job_arn=ds_import_job_response['DatasetImportJobArn']
target_ds_import_job_arn = copy.copy(ds_import_job_arn) #used to delete the resource during cleanup
except Exception as e:
print(e)
ds_import_job_arn='arn:aws:forecast:{}:{}:dataset-import-job/{}/{}'.format(REGION_NAME, ACCOUNT_NUM, datasetArn, datasetImportJobName)
s3DataPath = 's3://{}/{}/related_time_series.csv'.format(bucket, prefix)
datasetImportJobName = 'forecast_DSIMPORT_JOB_RELATED'
try:
ds_import_job_response=forecast.create_dataset_import_job(DatasetImportJobName=datasetImportJobName,
DatasetArn=related_datasetArn,
DataSource= {
"S3Config" : {
"Path":s3DataPath,
"RoleArn": role_arn
}
},
TimestampFormat=TIMESTAMP_FORMAT
)
ds_import_job_arn=ds_import_job_response['DatasetImportJobArn']
related_ds_import_job_arn = copy.copy(ds_import_job_arn) #used to delete the resource during cleanup
except Exception as e:
print(e)
ds_import_job_arn='arn:aws:forecast:{}:{}:dataset-import-job/{}/{}'.format(REGION_NAME, ACCOUNT_NUM, related_datasetArn, datasetImportJobName)
Creating the predictor
The Forecast DeepAR+ algorithm is a supervised learning algorithm for forecasting scalar (one-dimensional) time series using recurrent neural networks (RNNs). Classic forecasting methods, such as ARIMA or exponential smoothing (ETS), fit a single model to each individual time series. In contrast, DeepAR+ creates a global model (one model for all the time series) with the potential benefit of learning across time series.
The DeepAR+ model is particularly useful when working with a large collection (over thousands) of target time series, in which certain time series have a limited amount of information. For example, as a generalization of this use case, global models such as DeepAR+ can use the information from related topics with strong statistical signals to predict the popularity of new topics with little historical data. Importantly, DeepAR+ also allows you to include related information such as the topic vectors in a related time series.
To create the predictor, use the following code:
try:
create_predictor_response=forecast.create_predictor(PredictorName=predictorName,
ForecastHorizon=forecastHorizon,
AlgorithmArn=algorithmArn,
PerformAutoML=False, # change to true if want to perform AutoML
PerformHPO=False, # change to true to perform HPO
EvaluationParameters= {"NumberOfBacktestWindows": 1,
"BackTestWindowOffset": 15},
InputDataConfig= {"DatasetGroupArn": datasetGroupArn},
FeaturizationConfig= {"ForecastFrequency": "D",
}
)
predictorArn=create_predictor_response['PredictorArn']
except Exception as e:
predictorArn = 'arn:aws:forecast:{}:{}:predictor/{}'.format(REGION_NAME, ACCOUNT_NUM, predictorName)
When you call the create_predictor() method, it takes several minutes to complete.
Backtesting is a method of testing an ML model trained on and designed to predict time series data. Due to the sequential nature of time series data, training and test data can’t be randomized. Moreover, the most recent time series data is generally considered the most relevant for testing purposes. Therefore, backtesting uses the most recent windows that were unseen by the model during training to test the model and collect metrics. Amazon Forecast lets you choose up to five windows for backtesting. For more information, see Evaluating Predictor Accuracy.
For this post, we evaluate the DeepAR+ model for both the MAPE error, which is a common error metric in time series forecasting, and the root mean square error (RMSE), which penalizes larger deviations even more. The RMSE is an average deviation from the forecasted value and actual value in the same units as the dependent variable (in this use case, topic popularity on Facebook).
Creating and querying the forecast
When you’re satisfied with the accuracy metrics from your trained Forecast model, it’s time to generate a forecast. You can do this by creating a forecast for each item in the target time series used to train the predictor. Query the results to find out the popularity of the different topics in the original dataset.
The following is the result for Topic 0.

The following is the result for Topic 1.

The following is the result for Topic 2.

The following is the result for Topic 3.

Forecast accuracy
As an example, the RMSE for Topic 1 is 22.047559071991657. Although the actual range of popularity values in the ground truth set over the date range of the forecast is quite large [3:331], this RMSE does not in and of itself indicate if the model is production ready or not. The RMSE metric is simply an additional data point that should be used in the evaluation of the efficacy of your model.
Cleaning up
To avoid incurring future charges, delete each Forecast component. Also delete any other resources used in the notebook such as the Amazon SageMaker NTM endpoint, any S3 buckets used for storing data, and finally the Amazon SageMaker notebooks.
Conclusion
In this post, you learned how to build a forecasting model using unstructured raw text data. You also learned how to train a topic model and use the generated topic vectors as related time series for Forecast. Although this post is intended to demonstrate how you can combine these models together, you can improve the model accuracy by training on much larger datasets by having many more topics than in this dataset, using the same methodology. Amazon Forecast also supports other deep learning models for time series forecasting such as CNN-Qr. To read more about how you can build an end-to-end operational workflow with Amazon Forecast and AWS StepFunctions, see here.
References
[1] Multi-Source Social Feedback of Online News Feeds, N. Moniz and L. Torgo, arXiv:1801.07055 (2018). [2] Learning to determine the quality of news headlines, Omidvar, A. et al. arXiv:1911.11139. [3] “Visualizing data using T-SNE”, L., Van der Maaten and G. Hinton, Journal of Machine Learning Research 9 2579-2605 (2008).About the Authors
 David Ehrlich is a Machine Learning Specialist at Amazon Web Services. He is passionate about helping customers unlock the true potential of their data. In his spare time, he enjoys exploring the different neighborhoods in New York City, going to comedy clubs, and traveling.
David Ehrlich is a Machine Learning Specialist at Amazon Web Services. He is passionate about helping customers unlock the true potential of their data. In his spare time, he enjoys exploring the different neighborhoods in New York City, going to comedy clubs, and traveling.
 Stefan Natu is a Sr. Machine Learning Specialist at Amazon Web Services. He is focused on helping financial services customers build end-to-end machine learning solutions on AWS. In his spare time, he enjoys reading machine learning blogs, playing the guitar, and exploring the food scene in New York City.
Stefan Natu is a Sr. Machine Learning Specialist at Amazon Web Services. He is focused on helping financial services customers build end-to-end machine learning solutions on AWS. In his spare time, he enjoys reading machine learning blogs, playing the guitar, and exploring the food scene in New York City.
Performing batch fraud predictions using Amazon Fraud Detector, Amazon S3, and AWS Lambda
Amazon Fraud Detector is a fully managed service that makes it easy to identify potentially fraudulent online activities, such as the creation of fake accounts or online payment fraud. Unlike general-purpose machine learning (ML) packages, Amazon Fraud Detector is designed specifically to detect fraud. Amazon Fraud Detector combines your data, the latest in ML science, and more than 20 years of fraud detection experience from Amazon.com and AWS to build ML models tailor-made to detect fraud in your business.
This post walks you through how to use Amazon Fraud Detector with Amazon Simple Storage Service (Amazon S3) and AWS Lambda to perform a batch of fraud predictions on event records (such as account registrations and transactions) in a CSV file. This architecture enables you to trigger a batch of predictions automatically upon uploading your CSV file to Amazon S3 and retrieve the fraud prediction results in a newly generated CSV also stored in Amazon S3.
Solution overview
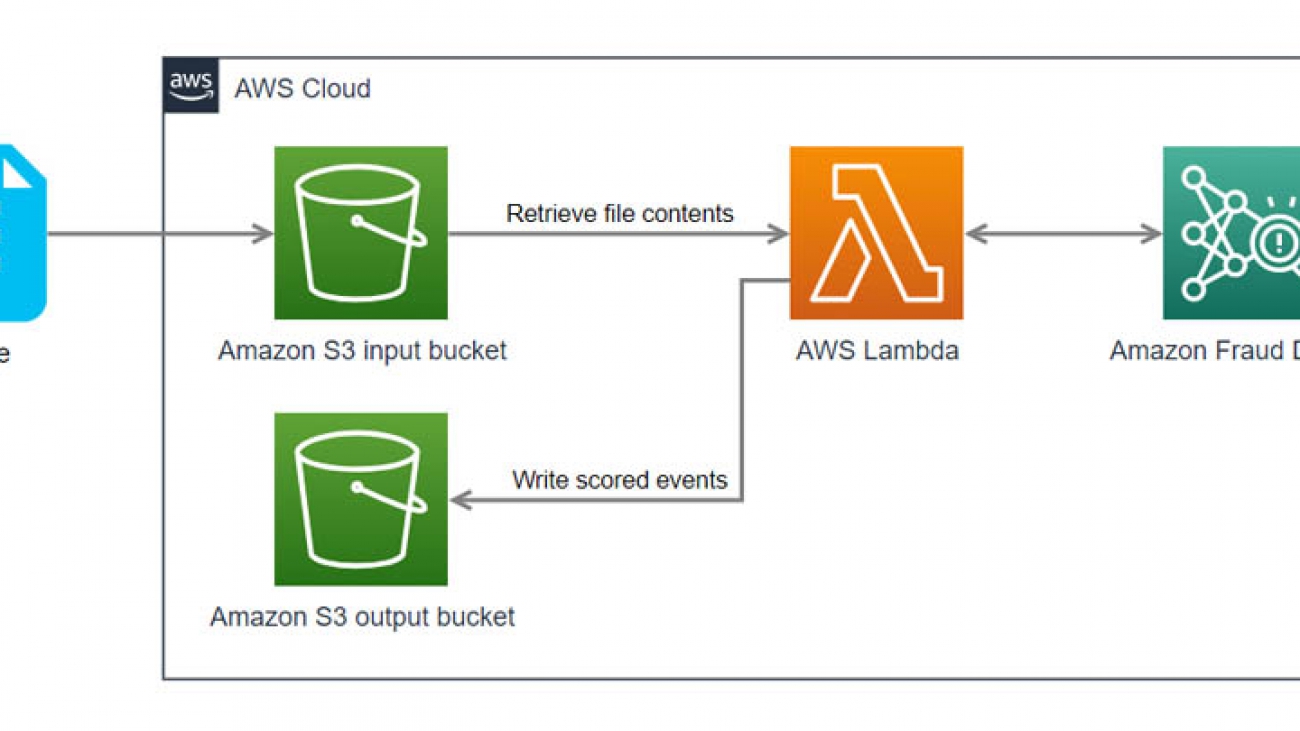
Amazon Fraud Detector can perform low-latency fraud predictions, enabling your company to dynamically adjust the customer experience in your applications based on real-time fraud risk detection. But suppose you want to generate fraud predictions for a batch of events after the fact; perhaps you don’t need a low-latency response and want to evaluate events on an hourly or daily schedule. How do you accomplish this using Amazon Fraud Detector? One approach is to use an Amazon S3 event notification to trigger a Lambda function that processes a CSV file of events stored in Amazon S3 when the file is uploaded to an input S3 bucket. The function runs each event through Amazon Fraud Detector to generate predictions using a detector (ML model and rules) and uploads the prediction results to an S3 output bucket. The following diagram illustrates this architecture.

To create this Lambda-based batch prediction system, you complete the following high-level steps:
- Create and publish a detector version containing a fraud detection model and rules, or simply a ruleset.
- Create two S3 buckets. The first bucket is used to land your CSV file, and the second bucket is where your Lambda function writes the prediction results to.
- Create an AWS Identity and Access Management (IAM) role to use as the execution role in the Lambda function.
- Create a Lambda function that reads in a CSV file from Amazon S3, calls the Amazon Fraud Detector
get_event_predictionfunction for each record in the CSV file, and writes a CSV file to Amazon S3. - Add an Amazon S3 event trigger to invoke your Lambda function whenever a new CSV file is uploaded to the S3 bucket.
- Create a sample CSV file of event records to test the batch prediction process.
- Test the end-to-end process by uploading your sample CSV file to your input S3 bucket and reviewing prediction results in the newly generated CSV file in your output S3 bucket.
Creating and publishing a detector
You can create and publish a detector version using the Amazon Fraud Detector console or via the APIs. For console instructions, see Get started (console) or Amazon Fraud Detector is now Generally Available. After you complete this step, note the following items, which you need in later steps:
- AWS Region you created the detector in
- Detector name and version
- Name of the entity type and event type used by your detector
- List of variables for the entity type used in your detector
The following screenshot shows the detail view of a detector version.

The following screenshot shows the detail view of an event type.

Creating the input and output S3 buckets
Create the following S3 buckets on the Amazon S3 console:
- fraud-detector-input – Where you upload the CSV file containing events for batch predictions
- fraud-detector-output – Where the Lambda function writes the prediction results file
Make sure you create your buckets in the same Region as your detector. For more information, see How do I create an S3 Bucket?
Creating the IAM role
To create the execution role in IAM that gives your Lambda function permission to access the AWS resources required for this solution, complete the following steps:
- On the IAM console, choose Roles.
- Choose Create role.
- Select Lambda.
- Choose Next.
- Attach the following policies:
- AWSLambdaBasicExecutionRole – Provides the Lambda function with write permissions to Amazon CloudWatch Logs.
- AWSXRayDaemonWriteAccess – Allows the AWS X-Ray daemon to relay raw trace data and retrieve sampling data to be used by X-Ray.
- AmazonFraudDetectorFullAccessPolicy – Provides permissions to create resources and generate fraud predictions in Amazon Fraud Detector.
- AmazonS3FullAccess – Provides the Lambda function permissions to read and write objects in Amazon S3. This policy provides broad Amazon S3 access; as a best practice, consider reducing the scope of this policy to the S3 buckets required for this example, or use an inline policy such as the following:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::fraud-detector-input/*",
"arn:aws:s3:::fraud-detector-output/*"
]
}
]
}
- Choose Next.
- Enter a name for your role (for example, lambda-s3-role).
- Choose Create role.
Creating the Lambda function
Now let’s create our Lambda function on the Lambda console.
- On the Lambda console, choose Create function.
- For Function name, enter a name (for example, afd-batch-function).
- For Runtime, choose Python 3.8.
- For Execution role, select Use an existing role.
- For Existing role, choose the role you created.

- Choose Create function
Next, we walk through sections of the code used in the Lambda function. This code goes into the Function code section of your Lambda function. The full Lambda function code is available in the next section.
Packages
import json
import csv
import boto3
Defaults
# -- make a connection to fraud detector --
client = boto3.client("frauddetector")
# -- S3 bucket to write scored data to --
S3_BUCKET_OUT = "fraud-detector-output"
# -- specify event, entity, and detector --
ENTITY_TYPE = "customer"
EVENT_TYPE = "new_account_registration_full_details"
DETECTOR_NAME = "new_account_detector"
DETECTOR_VER = "3"
We have entered the values from the detector we created and the output S3 bucket. Replace these default values with the values you used when creating your output S3 bucket and Amazon Fraud Detector resources.
Functions
We use a few helper functions along with the main lambda_handler() function:
- get_event_variables(EVENT_TYPE) – Returns a list of the variables for the event type. We map these to the input file positions.
- prep_record(record_map, event_map, line) – Returns a record containing just the data required by the detector.
- get_score(event, record) – Returns the fraud prediction risk scores and rule outcomes from the Amazon Fraud Detector
get_event_predictionfunction. Theget_scorefunction uses two extra helper functions to format model scores (prep_scores) and rule outcomes (prep_outcomes).
Finally, the lambda_handler(event, context) drives the whole process. See the following example code:
get_event_variables(EVENT_TYPE)
def get_event_variables(EVENT_TYPE):
""" return list of event variables
"""
response = client.get_event_types(name=EVENT_TYPE)
event_variables = []
for v in response['eventTypes'][0]['eventVariables']:
event_variables.append(v)
return event_variables
prep_record(record_map, event_map, line)
def prep_record(record_map, event_map, line):
""" structure the record for scoring
"""
record = {}
for key in record_map.keys():
record[key] = line[record_map[key]]
event = {}
for key in event_map.keys():
event[key] = line[event_map[key]]
return record, event
prep_scores(model_scores)
def prep_scores(model_scores):
""" return list of models and scores
"""
detector_models = []
for m in model_scores:
detector_models.append(m['scores'])
return detector_models
prep_outcomes(rule_results)
def prep_outcomes(rule_results):
""" return list of rules and outcomes
"""
detector_outcomes = []
for rule in rule_results:
rule_outcomes ={}
rule_outcomes[rule['ruleId']] = rule['outcomes']
detector_outcomes.append(rule_outcomes)
return detector_outcomes
def get_score(event, record):
def get_score(event, record):
""" return the score to the function
"""
pred_rec = {}
try:
pred = client.get_event_prediction(detectorId=DETECTOR_NAME,
detectorVersionId=DETECTOR_VER,
eventId = event['EVENT_ID'],
eventTypeName = EVENT_TYPE,
eventTimestamp = event['EVENT_TIMESTAMP'],
entities = [{'entityType': ENTITY_TYPE, 'entityId':event['ENTITY_ID']}],
eventVariables= record)
pred_rec["score"] = prep_scores(pred['modelScores'])
pred_rec["outcomes"]= prep_outcomes(pred['ruleResults'])
except:
pred_rec["score"] = [-999]
pred_rec["outcomes"]= ["error"]
return pred_rec
The following is the full code for the Lambda function:
import boto3
import csv
import json
# -- make a connection to fraud detector --
client = boto3.client("frauddetector")
# -- S3 bucket to write batch predictions out to --
S3_BUCKET_OUT = "fraud-detector-output"
# -- specify event, entity, and detector --
ENTITY_TYPE = "customer"
EVENT_TYPE = "new_account_registration_full_details"
DETECTOR_NAME = "new_account_detector"
DETECTOR_VER = "3"
def get_event_variables(EVENT_TYPE):
""" return list of event variables
"""
response = client.get_event_types(name=EVENT_TYPE)
event_variables = []
for v in response['eventTypes'][0]['eventVariables']:
event_variables.append(v)
return event_variables
def prep_record(record_map, event_map, line):
""" structure the record for scoring
"""
record = {}
for key in record_map.keys():
record[key] = line[record_map[key]]
event = {}
for key in event_map.keys():
event[key] = line[event_map[key]]
return record, event
def prep_scores(model_scores):
""" return list of models and scores
"""
detector_models = []
for m in model_scores:
detector_models.append(m['scores'])
return detector_models
def prep_outcomes(rule_results):
"""return list of rules and outcomes
"""
detector_outcomes = []
for rule in rule_results:
rule_outcomes = {}
rule_outcomes[rule['ruleId']] = rule['outcomes']
detector_outcomes.append(rule_outcomes)
return detector_outcomes
def get_score(event, record):
""" return the score to the function
"""
pred_rec = {}
try:
pred = client.get_event_prediction(detectorId=DETECTOR_NAME,
detectorVersionId=DETECTOR_VER,
eventId = event['EVENT_ID'],
eventTypeName = EVENT_TYPE,
eventTimestamp = event['EVENT_TIMESTAMP'],
entities = [{'entityType': ENTITY_TYPE, 'entityId':event['ENTITY_ID']}],
eventVariables= record)
pred_rec["score"] = prep_scores(pred['modelScores'])
pred_rec["outcomes"]= prep_outcomes(pred['ruleResults'])
except:
pred_rec["score"] = [-999]
pred_rec["outcomes"]= ["error"]
return pred_rec
def lambda_handler(event, context):
""" the lambda event handler triggers the process.
"""
S3_BUCKET_IN = event['Records'][0]['s3']['bucket']['name']
S3_FILE = event['Records'][0]['s3']['object']['key']
S3_OUT_FILE = "batch_{0}".format(S3_FILE)
# -- open a temp file to write predictions to.
f = open("/tmp/csv_file.csv", "w+")
temp_csv_file = csv.writer(f)
# -- get the input file --
s3 = boto3.resource('s3')
obj = s3.Object(S3_BUCKET_IN, S3_FILE)
data = obj.get()['Body'].read().decode('utf-8').splitlines()
lines = csv.reader(data)
# -- get the file header --
file_variables = next(lines)
# -- write the file header to temporary file --
temp_csv_file.writerow(file_variables + ["MODEL_SCORES", "DETECTOR_OUTCOMES"])
# -- get list of event variables --
event_variables = get_event_variables(EVENT_TYPE)
# -- map event variables to file structure --
record_map = {}
for var in event_variables:
record_map[var] = file_variables.index(var)
# -- map event fields to file structure --
event_map = {}
for var in ['ENTITY_ID', 'EVENT_ID', 'EVENT_TIMESTAMP']:
event_map[var] = file_variables.index(var)
# -- for each record in the file, prep it, score it, write it to temp.
for i,line in enumerate(lines):
record, event = prep_record(record_map, event_map, line)
record_pred = get_score(event, record)
#print(list(record_pred.values()))
temp_csv_file.writerow(line + list(record_pred.values()))
# -- close the temp file and upload it to your OUTPUT bucket
f.close()
s3_client = boto3.client('s3')
s3_client.upload_file('/tmp/csv_file.csv', S3_BUCKET_OUT, "batch_pred_results_" + S3_FILE )
return {
'statusCode': 200,
'body': json.dumps('Batch Complete!')
}
After you add the code to your Lambda function, choose Deploy to save.
Configuring your Lambda settings and creating the Amazon S3 trigger
The batch prediction processes require memory and time to process, so we need to change the Lambda function’s default memory allocation and maximum run time.
- On the Lambda console, locate your function.
- On the function detail page, under Basic settings, choose Edit.
- For Memory, choose 2048 MB.
- For Timeout, enter 15 min.
- Choose Save.

A 15-minute timeout allows the function to process up to roughly 4,000 predictions per batch, so you should keep this in mind as you consider your CSV file creation and upload strategy.
You can now make it so that this Lambda function triggers when a CSV file is uploaded to your input S3 bucket.
- At the top of the Lambda function detail page, in the Designer box, choose Add trigger.
- Choose S3.
- For Bucket, choose your input S3 bucket.
- For Suffix, enter
.csv.

A warning about recursive invocation appears. You don’t want to trigger a read and write to the same bucket, which is why you created a second S3 bucket for the output.
- Select the check-box to acknowledge the recursive invocation warning.
- Choose Add.

Creating a sample CSV file of event records
We need to create a sample CSV file of event records to test the batch prediction process. In this CSV file, include a column for each variable in your event type schema. In addition, include columns for:
- EVENT_ID – An identifier for the event, such as a transaction number. The field values must satisfy the following regular expression pattern:
^[0-9a-z_-]+$. - ENTITY_ID – An identifier for the entity performing the event, such as an account number. The field values must also satisfy the following regular expression pattern:
^[0-9a-z_-]+$. - EVENT_TIMESTAMP – A timestamp, in ISO 8601 format, for when the event occurred.
Column header names must match their corresponding Amazon Fraud Detector variable names exactly.
In your CSV file, each row corresponds to one event that you want to generate a prediction for. The following screenshot shows an example of a test CSV file.

For more information about Amazon Fraud Detector variable data types and formatting, see Create a variable.
Performing a test batch prediction
To test our Lambda function, we simply upload our test file to the fraud-detector-input S3 bucket via the Amazon S3 console. This triggers the Lambda function. We can then check the fraud-detector-output S3 bucket for the results file.
The following screenshot shows that the test CSV file 20_event_test.csv is uploaded to the fraud-detector-input S3 bucket.

When batch prediction is complete, the results CSV file batch_pred_results_20_event_test.csv is uploaded to the fraud-detector-output S3 bucket (see the following screenshot).

The following screenshots show our results CSV file. The new file has two new columns: MODEL_SCORES and DETECTOR_OUTCOMES. MODEL_SCORES contains model names, model details, and prediction scores for any models used in the detector. DETECTOR_OUTCOMES contains all rule results, including any matched rules and their corresponding outcomes.


If the results file doesn’t appear in the output S3 bucket, you can check the CloudWatch log stream to see if the Lambda function ran into any issues. To do this, go to your Lambda function on the Lambda console and choose the Monitoring tab, then choose View logs in CloudWatch. In CloudWatch, choose the log stream covering the time period you uploaded your CSV file.
Conclusion
Congrats! You have successfully performed a batch of fraud predictions. Depending on your use case, you may want to use your prediction results in other AWS services. For example, you can analyze the prediction results in Amazon QuickSight or send results that are high risk to Amazon Augmented AI (Amazon A2I) for a human review of the prediction.
Amazon Fraud Detector has a 2-month free trial that includes 30,000 predictions per month. After that, pricing starts at $0.005 per prediction for rules-only predictions and $0.03 for ML-based predictions. For more information, see Amazon Fraud Detector pricing. For more information about Amazon Fraud Detector, including links to additional blog posts, sample notebooks, user guide, and API documentation, see Amazon Fraud Detector.
The next step is to start dropping files into your S3 bucket! Good luck!
About the Authors
 Nick Tostenrude is a Senior Manager of Product in AWS, where he leads the Amazon Fraud Detector service team. Nick joined Amazon nine years ago. He has spent the past four years as part of the AWS Fraud Prevention organization. Prior to AWS, Nick spent five years in Amazon’s Kindle and Devices organizations, leading product teams focused on the Kindle reading experience, accessibility, and K-12 Education.
Nick Tostenrude is a Senior Manager of Product in AWS, where he leads the Amazon Fraud Detector service team. Nick joined Amazon nine years ago. He has spent the past four years as part of the AWS Fraud Prevention organization. Prior to AWS, Nick spent five years in Amazon’s Kindle and Devices organizations, leading product teams focused on the Kindle reading experience, accessibility, and K-12 Education.
 Mike Ames is a Research Science Manager working on Amazon Fraud Detector. He helps companies use machine learning to combat fraud, waste and abuse. In his spare time, you can find him jamming to 90s metal with an electric mandolin.
Mike Ames is a Research Science Manager working on Amazon Fraud Detector. He helps companies use machine learning to combat fraud, waste and abuse. In his spare time, you can find him jamming to 90s metal with an electric mandolin.
A general approach to solving bandit problems
Applications in product recommendation and natural-language processing demonstrate the approach’s flexibility and ease of use.Read More
AWS Fix This Podcast features Amazon Research Award recipient Philip Stier
What role do clouds play in climate change? In an effort to understand that question, the hosts of Fix This Podcast invited Philip Stier on the program.Read More
AWS Fix This Podcast features Amazon Research Award recipient Philip Stier
What role do clouds play in climate change? In an effort to understand that question, the hosts of Fix This Podcast invited Philip Stier on the program.Read More
Amazon Scholars Michael Kearns and Aaron Roth discuss the ethics of machine learning
Two of the world’s leading experts on algorithmic bias look back at the events of the past year and reflect on what we’ve learned, what we’re still grappling with, and how far we have to go.Read More

Automatically detecting personal protective equipment on persons in images using Amazon Rekognition
Workplace safety hazards can exist in many different forms: sharp edges, falling objects, flying sparks, chemicals, noise, and a myriad of other potentially dangerous situations. Safety regulators such as Occupational Safety and Health Administration (OSHA) and European Commission often require that businesses protect their employees and customers from hazards that can cause injury by providing personal protective equipment (PPE) and ensuring their use. Across many industries, such as manufacturing, construction, food processing, chemical, healthcare, and logistics, workplace safety is usually a top priority. In addition, due to the COVID-19 pandemic, wearing PPE in public places has become important to reduce the spread of the virus. In this post, we show you how you can use Amazon Rekognition PPE detection to improve safety processes by automatically detecting if persons in images are wearing PPE. We start with an overview of the PPE detection feature, explain how it works, and then discuss the different ways to deploy a PPE detection solution based on your camera and networking requirements.
Amazon Rekognition PPE detection overview
Even when people do their best to follow PPE guidelines, sometimes they inadvertently forget to wear PPE or don’t realize it’s required in the area they’re in. This puts their safety at potential risk and opens the business to possible regulatory compliance issues. Businesses usually rely on site supervisors or superintendents to individually check and remind all people present in the designated areas to wear PPE, which isn’t reliable, effective, or cost-efficient at scale. With Amazon Rekognition PPE detection, businesses can augment manual checks with automated PPE detection.
With Amazon Rekognition PPE detection, you can analyze images from your on-premises cameras at scale to automatically detect if people are wearing the required protective equipment, such as face covers (surgical masks, N95 masks, cloth masks), head covers (hard hats or helmets), and hand covers (surgical gloves, safety gloves, cloth gloves). Using these results, you can trigger timely alarms or notifications to remind people to wear PPE before or during their presence in a hazardous area to help improve or maintain everyone’s safety.
You can also aggregate the PPE detection results and analyze them by time and place to identify how safety warnings or training practices can be improved or generate reports for use during regulatory audits. For example, a construction company can check if construction workers are wearing head covers and hand covers when they’re on the construction site and remind them if one or more PPE isn’t detected to support their safety in case of accidents. A food processing company can check for PPE such as face covers and hand covers on employees working in non-contamination zones to comply with food safety regulations. Or a manufacturing company can analyze PPE detection results across different sites and plants to determine where they should add more hazard warning signage and conduct additional safety training.
With Amazon Rekognition PPE detection, you receive a detailed analysis of an image, which includes bounding boxes and confidence scores for persons (up to 15 per image) and PPE detected, confidence scores for the body parts detected, and Boolean values and confidence scores for whether the PPE covers the corresponding body part. The following image shows an example of PPE bounding boxes for head cover, hand covers, and face cover annotated using the analysis provided by the Amazon Rekognition PPE detection feature.

Often just detecting the presence of PPE in an image isn’t very useful. It’s important to detect if the PPE is worn by the customer or employee. Amazon Rekognition PPE detection also predicts a confidence score for whether the protective equipment is covering the corresponding body part of the person. For example, if a person’s nose is covered by face cover, head is covered by head cover, and hands are covered by hand covers. This prediction helps filter out cases where the PPE is in the image but not actually on the person.
You can also supply a list of required PPE (such as face cover or face cover and head cover) and a minimum confidence threshold (such as 80%) to receive a consolidated list of persons on the image that are wearing the required PPE, not wearing the required PPE, and when PPE can not be determined (such as when a body part isn’t visible). This reduces the amount of code developers need to write to high level counts or reference a person’s information in the image to further drill down.
Now, let’s take a closer look at how Amazon Rekognition PPE detection works.
How it works
To detect PPE in an image, you call the DetectProtectiveEquipment API and pass an input image. You can provide the input image (in JPG or PNG format) either as raw bytes or as an object stored in an Amazon Simple Storage Service (Amazon S3) bucket. You can optionally use the SummarizationAttributes (ProtectiveEquipmentSummarizationAttributes) input parameter to request summary information about persons that are wearing the required PPE, not wearing the required PPE, or are indeterminate.
The following image shows an example input image and its corresponding output from the DetectProtectiveEquipment as seen on the Amazon Rekognition PPE detection console. In this example, we supply face cover as the required PPE and 80% as the required minimum confidence threshold as part of summarizationattributes. We receive a summarization result that indicates that there are four persons in the image that are wearing face covers at a confidence score of over 80% [person identifiers 0, 1,2, 3]. It also provides the full fidelity API response in the per-person results. Note that this feature doesn’t perform facial recognition or facial comparison and can’t identify the detected persons.

Following is the DetectProtectiveEquipment API request JSON for this sample image in the console:
{
"Image": {
"S3Object": {
"Bucket": "console-sample-images",
"Name": "ppe_group_updated.jpg"
}
},
"SummarizationAttributes": {
"MinConfidence": 80,
"RequiredEquipmentTypes": [
"FACE_COVER"
]
}
}
The response of the DetectProtectiveEquipment API is a JSON structure that includes up to 15 persons detected per image and for each person, the body parts detected (face, head, left hand, and right hand), the types of PPE detected, and if the PPE covers the corresponding body part. The full JSON response from DetectProtectiveEquipment API for this image is as follows:
"ProtectiveEquipmentModelVersion": "1.0",
"Persons": [
{
"BodyParts": [
{
"Name": "FACE",
"Confidence": 99.07738494873047,
"EquipmentDetections": [
{
"BoundingBox": {
"Width": 0.06805413216352463,
"Height": 0.09381836652755737,
"Left": 0.7537466287612915,
"Top": 0.26088595390319824
},
"Confidence": 99.98419189453125,
"Type": "FACE_COVER",
"CoversBodyPart": {
"Confidence": 99.76295471191406,
"Value": true
}
}
]
},
{
"Name": "LEFT_HAND",
"Confidence": 99.25702667236328,
"EquipmentDetections": []
},
{
"Name": "RIGHT_HAND",
"Confidence": 80.11490631103516,
"EquipmentDetections": []
},
{
"Name": "HEAD",
"Confidence": 99.9693374633789,
"EquipmentDetections": [
{
"BoundingBox": {
"Width": 0.09358207136392593,
"Height": 0.10753925144672394,
"Left": 0.7455776929855347,
"Top": 0.16204142570495605
},
"Confidence": 98.4826889038086,
"Type": "HEAD_COVER",
"CoversBodyPart": {
"Confidence": 99.99744415283203,
"Value": true
}
}
]
}
],
"BoundingBox": {
"Width": 0.22291666269302368,
"Height": 0.82421875,
"Left": 0.7026041746139526,
"Top": 0.15703125298023224
},
"Confidence": 99.97362518310547,
"Id": 0
},
{
"BodyParts": [
{
"Name": "FACE",
"Confidence": 99.71298217773438,
"EquipmentDetections": [
{
"BoundingBox": {
"Width": 0.05732834339141846,
"Height": 0.07323434203863144,
"Left": 0.5775181651115417,
"Top": 0.33671364188194275
},
"Confidence": 99.96135711669922,
"Type": "FACE_COVER",
"CoversBodyPart": {
"Confidence": 96.60395050048828,
"Value": true
}
}
]
},
{
"Name": "LEFT_HAND",
"Confidence": 98.09618377685547,
"EquipmentDetections": []
},
{
"Name": "RIGHT_HAND",
"Confidence": 95.69132995605469,
"EquipmentDetections": []
},
{
"Name": "HEAD",
"Confidence": 99.997314453125,
"EquipmentDetections": [
{
"BoundingBox": {
"Width": 0.07994530349969864,
"Height": 0.08479492366313934,
"Left": 0.5641391277313232,
"Top": 0.2394576370716095
},
"Confidence": 97.718017578125,
"Type": "HEAD_COVER",
"CoversBodyPart": {
"Confidence": 99.9454345703125,
"Value": true
}
}
]
}
],
"BoundingBox": {
"Width": 0.21979166567325592,
"Height": 0.742968738079071,
"Left": 0.49427083134651184,
"Top": 0.24296875298023224
},
"Confidence": 99.99588012695312,
"Id": 1
},
{
"BodyParts": [
{
"Name": "FACE",
"Confidence": 98.42090606689453,
"EquipmentDetections": [
{
"BoundingBox": {
"Width": 0.05756797641515732,
"Height": 0.07883334159851074,
"Left": 0.22534936666488647,
"Top": 0.35751715302467346
},
"Confidence": 99.97816467285156,
"Type": "FACE_COVER",
"CoversBodyPart": {
"Confidence": 95.9388656616211,
"Value": true
}
}
]
},
{
"Name": "LEFT_HAND",
"Confidence": 92.42487335205078,
"EquipmentDetections": []
},
{
"Name": "RIGHT_HAND",
"Confidence": 96.88029479980469,
"EquipmentDetections": []
},
{
"Name": "HEAD",
"Confidence": 99.98686218261719,
"EquipmentDetections": [
{
"BoundingBox": {
"Width": 0.0872764065861702,
"Height": 0.09496871381998062,
"Left": 0.20529428124427795,
"Top": 0.2652358412742615
},
"Confidence": 90.25578308105469,
"Type": "HEAD_COVER",
"CoversBodyPart": {
"Confidence": 99.99089813232422,
"Value": true
}
}
]
}
],
"BoundingBox": {
"Width": 0.19479165971279144,
"Height": 0.72265625,
"Left": 0.12187500298023224,
"Top": 0.2679687440395355
},
"Confidence": 99.98648071289062,
"Id": 2
},
{
"BodyParts": [
{
"Name": "FACE",
"Confidence": 99.32310485839844,
"EquipmentDetections": [
{
"BoundingBox": {
"Width": 0.055801939219236374,
"Height": 0.06405147165060043,
"Left": 0.38087061047554016,
"Top": 0.393160879611969
},
"Confidence": 99.98370361328125,
"Type": "FACE_COVER",
"CoversBodyPart": {
"Confidence": 98.56526184082031,
"Value": true
}
}
]
},
{
"Name": "LEFT_HAND",
"Confidence": 96.11709594726562,
"EquipmentDetections": []
},
{
"Name": "RIGHT_HAND",
"Confidence": 80.49284362792969,
"EquipmentDetections": []
},
{
"Name": "HEAD",
"Confidence": 99.91870880126953,
"EquipmentDetections": [
{
"BoundingBox": {
"Width": 0.08105235546827316,
"Height": 0.07952981442213058,
"Left": 0.36679577827453613,
"Top": 0.2875025272369385
},
"Confidence": 98.80988311767578,
"Type": "HEAD_COVER",
"CoversBodyPart": {
"Confidence": 99.6932144165039,
"Value": true
}
}
]
}
],
"BoundingBox": {
"Width": 0.18541666865348816,
"Height": 0.6875,
"Left": 0.3187499940395355,
"Top": 0.29218751192092896
},
"Confidence": 99.98927307128906,
"Id": 3
}
],
"Summary": {
"PersonsWithRequiredEquipment": [
0,
1,
2,
3
],
"PersonsWithoutRequiredEquipment": [],
"PersonsIndeterminate": []
}
}
Deploying Amazon Rekognition PPE detection
Depending on your use case, cameras, and environment setup, you can use different approaches to analyze your on-premises camera feeds for PPE detection. Because DetectProtectiveEquipment API only accepts images as input, you can extract frames from streaming or stored videos at the desired frequency (such as every 1, 2 or 5 seconds or every time motion is detected) and analyze those frames using the DetectProtectiveEquipment API. You can also set different frequencies of frame ingestion for cameras covering different areas. For example, you can set a higher frequency for busy or important locations and a lower frequency for areas that see light activity. This allows you to control the network bandwidth requirements because you only send images to the AWS cloud for processing.
The following architecture shows how you can design a serverless workflow to process frames from camera feeds for PPE detection.

We have included a demo web application that implements this reference architecture in the Amazon Rekognition PPE detection GitHub repo. This web app extracts frames from a webcam video feed and sends them to the solution deployed in the AWS Cloud. As images get analyzed with the DetectProtectiveEquipment API, a summary output is displayed in the web app in near-real time. Following are a few example GIFs showing the detection of face cover, head cover, and hand covers as they are worn by a person in front of the webcam that is sampling a frame every two seconds. Depending on your use case, you can adjust the sampling rate to a higher or lower frequency. A screenshot showing the full demo application output, including the PPE and PPE worn or not predictions is also shown below.

Face cover detection

Hand cover detection

Head cover detection

Full demo web application output
Using this application and solution, you can generate notifications with Amazon Simple Notification Service. Although not implemented in the demo solution (but shown in the reference architecture), you can store the PPE detection results to create anonymized reports of PPE detection events using AWS services such as AWS Glue, Amazon Athena, and Amazon QuickSight. You can also optionally store ingested images in Amazon S3 for a limited time for regulatory auditing purposes. For instructions on deploying the demo web application and solution, see the Amazon Rekognition PPE detection GitHub repo.
Instead of sending images via Amazon API Gateway, you can also send images directly to an S3 bucket. This allows you to store additional metadata, including camera location, time, and other camera information, as Amazon S3 object metadata. As images get processed, you can delete them immediately or set them to expire within a time window using a lifecycle policy for an S3 bucket as required by your organization’s data retention policy. You can use the following reference architecture diagram to design this alternate workflow.

Extracting frames from your video systems
Depending on your camera setup and video management system, you can use the SDK provided by the manufacturer to extract frames. For cameras that support HTTP(s) or RTSP streams, the following code sample shows how you can extract frames at a desired frequency from the camera feed and process them using DetectProtectiveEquipment API.
import cv2
import boto3
import time
from datetime import datetime
import json
def processFrame(videoStreamUrl):
cap = cv2.VideoCapture(videoStreamUrl)
ret, frame = cap.read()
if ret:
hasFrame, imageBytes = cv2.imencode(".jpg", frame)
if hasFrame:
session = boto3.session.Session()
rekognition = session.client('rekognition')
response = rekognition. detect_protective_equipment(
Image={
'Bytes': imageBytes.tobytes(),
}
)
print(response)
cap.release()
# Video stream
videoStreamUrl = "rtsp://@192.168.10.100"
frameCaptureThreshold = 300
while (True):
try:
processFrame(videoStreamUrl)
except Exception as e:
print("Error: {}.".format(e))
time.sleep(frameCaptureThreshold)
To extract frames from stored videos, you can use AWS Elemental MediaConvert or other tools such as FFmpeg or OpenCV. The following code shows you how to extract frames from stored video and process them using the DetectProtectiveEquipment API:
import json
import boto3
import cv2
import math
import io
videoFile = "video file"
rekognition = boto3.client('rekognition')
ppeLabels = []
cap = cv2.VideoCapture(videoFile)
frameRate = cap.get(5) #frame rate
while(cap.isOpened()):
frameId = cap.get(1) #current frame number
print("Processing frame id: {}".format(frameId))
ret, frame = cap.read()
if (ret != True):
break
if (frameId % math.floor(frameRate) == 0):
hasFrame, imageBytes = cv2.imencode(".jpg", frame)
if(hasFrame):
response = rekognition. detect_protective_equipment(
Image={
'Bytes': imageBytes.tobytes(),
}
)
for person in response["Persons"]:
person["Timestamp"] = (frameId/frameRate)*1000
ppeLabels.append(person)
print(ppeLabels)
with open(videoFile + ".json", "w") as f:
f.write(json.dumps(ppeLabels))
cap.release()
Detecting other and custom PPE
Although the DetectProtectiveEquipment API covers the most common PPE, if your use case requires identifying additional equipment specific to your business needs, you can use Amazon Rekognition Custom Labels. For example, you can use Amazon Rekognition Custom Labels to quickly train a custom model to detect safety goggles, high visibility vests, or other custom PPE by simply supplying some labelled images of what to detect. No machine learning expertise is required to use Amazon Rekognition Custom Labels. When you have a custom model trained and ready for inference, you can then make parallel calls to DetectProtectiveEquipment and to the Amazon Rekognition Custom Labels model to detect all the required PPE and combine the results for further processing. For more information about using Amazon Rekognition Custom Labels to detect high-visibility vests including a sample solution with instructions, please visit the Custom PPE detection GitHub repository. You can use the following reference architecture diagram to design a combined DetectProtectiveEquipment and Amazon Rekognition Custom Labels PPE detection solution.

Conclusion
In this post, we showed how to use Amazon Rekognition PPE detection (the DetectProtectiveEquipment API) to automatically analyze images and video frames to check if employees and customers are wearing PPE such as face covers, hand covers, and head covers. We covered different implementation approaches, including frame extraction from cameras, stored video, and streaming videos. Finally, we covered how you can use Amazon Rekognition Custom Labels to identify additional equipment that is specific to your business needs.
To test PPE detection with your own images, sign in to the Amazon Rekognition console and upload your images in the Amazon Rekognition PPE detection console demo. For more information about the API inputs, outputs, limits, and recommendations, see Amazon Rekognition PPE detection documentation. To find out what our customers think about the feature or if you need a partner to help build an end-to-end PPE detection solution for your organization, see the Amazon Rekognition workplace safety web-page.
About the Authors
 Tushar Agrawal leads Outbound Product Management for Amazon Rekognition. In this role, he focuses on making customers successful by solving their business challenges with the right solution and go-to-market capabilities. In his spare time, he loves listening to music and re-living his childhood with his kindergartener.
Tushar Agrawal leads Outbound Product Management for Amazon Rekognition. In this role, he focuses on making customers successful by solving their business challenges with the right solution and go-to-market capabilities. In his spare time, he loves listening to music and re-living his childhood with his kindergartener.
 Kashif Imran is a Principal Solutions Architect at Amazon Web Services. He works with some of the largest AWS customers who are taking advantage of AI/ML to solve complex business problems. He provides technical guidance and design advice to implement computer vision applications at scale. His expertise spans application architecture, serverless, containers, NoSQL and machine learning.
Kashif Imran is a Principal Solutions Architect at Amazon Web Services. He works with some of the largest AWS customers who are taking advantage of AI/ML to solve complex business problems. He provides technical guidance and design advice to implement computer vision applications at scale. His expertise spans application architecture, serverless, containers, NoSQL and machine learning.
 Matteo Figus is an AWS Solution Engineer based in the UK. Matteo works with the AWS Solution Architects to create standardized tools, code samples, demonstrations and quickstarts. He is passionate about open-source software and in his spare time he likes to cook and play the piano.
Matteo Figus is an AWS Solution Engineer based in the UK. Matteo works with the AWS Solution Architects to create standardized tools, code samples, demonstrations and quickstarts. He is passionate about open-source software and in his spare time he likes to cook and play the piano.
 Connor Kirkpatrick is an AWS Solution Engineer based in the UK. Connor works with the AWS Solution Architects to create standardised tools, code samples, demonstrations and quickstarts. He is an enthusiastic squash player, wobbly cyclist, and occasional baker.
Connor Kirkpatrick is an AWS Solution Engineer based in the UK. Connor works with the AWS Solution Architects to create standardised tools, code samples, demonstrations and quickstarts. He is an enthusiastic squash player, wobbly cyclist, and occasional baker.