
In the rapidly evolving landscape of AI, generative models have emerged as a transformative technology, empowering users to explore new frontiers of creativity and problem-solving. These advanced AI systems have transcended their traditional text-based capabilities, now seamlessly integrating multimodal functionalities that expand their reach into diverse applications. models have become increasingly powerful, enabling a wide range of applications beyond just text generation. These models can now create striking images, generate engaging summaries, answer complex questions, and even produce code—all while maintaining a high level of accuracy and coherence. The integration of these multimodal capabilities has unlocked new possibilities for businesses and individuals, revolutionizing fields such as content creation, visual analytics, and software development.
In this post, we showcase how to fine-tune a text and vision model, such as Meta Llama 3.2, to better perform at visual question answering tasks. The Meta Llama 3.2 Vision Instruct models demonstrated impressive performance on the challenging DocVQA benchmark for visual question answering. The non-fine-tuned 11B and 90B models achieved strong ANLS (Aggregated Normalized Levenshtein Similarity) scores of 88.4 and 90.1, respectively, on the DocVQA test set. ANLS is a metric used to evaluate the performance of models on visual question answering tasks, which measures the similarity between the model’s predicted answer and the ground truth answer. However, by using the power of Amazon SageMaker JumpStart, we demonstrate the process of adapting these generative AI models to excel at understanding and responding to natural language questions about images. By fine-tuning these models using SageMaker JumpStart, we were able to further enhance their abilities, boosting the ANLS scores to 91 and 92.4. This significant improvement showcases how the fine-tuning process can equip these powerful multimodal AI systems with specialized skills for excelling at understanding and answering natural language questions about complex, document-based visual information.
For a detailed walkthrough on fine-tuning the Meta Llama 3.2 Vision models, refer to the accompanying notebook.
Overview of Meta Llama 3.2 11B and 90B Vision models
The Meta Llama 3.2 collection of multimodal and multilingual large language models (LLMs) is a collection of pre-trained and instruction-tuned generative models in a variety of sizes. The 11B and 90B models are multimodal—they support text in/text out, and text+image in/text out.
Meta Llama 3.2 11B and 90B are the first Llama models to support vision tasks, with a new model architecture that integrates image encoder representations into the language model. The new models are designed to be more efficient for AI workloads, with reduced latency and improved performance, making them suitable for a wide range of applications. All Meta Llama 3.2 models support a 128,000 context length, maintaining the expanded token capacity introduced in Meta Llama 3.1. Additionally, the models offer improved multilingual support for eight languages, including English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai.
DocVQA dataset
The DocVQA (Document Visual Question Answering) dataset is a widely used benchmark for evaluating the performance of multimodal AI models on visual question answering tasks involving document-style images. This dataset consists of a diverse collection of document images paired with a series of natural language questions that require both visual and textual understanding to answer correctly. By fine-tuning a generative AI model like Meta Llama 3.2 on the DocVQA dataset using Amazon SageMaker, you can equip the model with the specialized skills needed to excel at answering questions about the content and structure of complex, document-based visual information.
For more information on the dataset used in this post, see DocVQA – Datasets.
Dataset preparation for visual question and answering tasks
The Meta Llama 3.2 Vision models can be fine-tuned on image-text datasets for vision and language tasks such as visual question answering (VQA). The training data should be structured with the image, the question about the image, and the expected answer. This data format allows the fine-tuning process to adapt the model’s multimodal understanding and reasoning abilities to excel at answering natural language questions about visual content.
The input includes the following:
- A train and an optional validation directory. Train and validation directories should contain one directory named
imageshosting all the image data and one JSON Lines (.jsonl) file namedmetadata.jsonl. - In the
metadata.jsonlfile, each example is a dictionary that contains three keys namedfile_name,prompt, andcompletion. Thefile_namedefines the path to image data.promptdefines the text input prompt andcompletiondefines the text completion corresponding to the input prompt. The following code is an example of the contents in themetadata.jsonlfile:
SageMaker JumpStart
SageMaker JumpStart is a powerful feature within the SageMaker machine learning (ML) environment that provides ML practitioners a comprehensive hub of publicly available and proprietary foundation models (FMs). With this managed service, ML practitioners get access to a growing list of cutting-edge models from leading model hubs and providers that you can deploy to dedicated SageMaker instances within a network isolated environment, and customize models using SageMaker for model training and deployment.
Solution overview
In the following sections, we discuss the steps to fine-tune Meta Llama 3.2 Vision models. We cover two approaches: using the Amazon SageMaker Studio UI for a no-code solution, and using the SageMaker Python SDK.
Prerequisites
To try out this solution using SageMaker JumpStart, you need the following prerequisites:
- An AWS account that will contain all of your AWS resources.
- An AWS Identity and Access Management (IAM) role to access SageMaker. To learn more about how IAM works with SageMaker, refer to Identity and Access Management for Amazon SageMaker.
- Access to SageMaker Studio or a SageMaker notebook instance, or an interactive development environment (IDE) such as PyCharm or Visual Studio Code. We recommend using SageMaker Studio for straightforward deployment and inference.
No-code fine-tuning through the SageMaker Studio UI
SageMaker JumpStart provides access to publicly available and proprietary FMs from third-party and proprietary providers. Data scientists and developers can quickly prototype and experiment with various ML use cases, accelerating the development and deployment of ML applications. It helps reduce the time and effort required to build ML models from scratch, allowing teams to focus on fine-tuning and customizing the models for their specific use cases. These models are released under different licenses designated by their respective sources. It’s essential to review and adhere to the applicable license terms before downloading or using these models to make sure they’re suitable for your intended use case.
You can access the Meta Llama 3.2 FMs through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. In this section, we cover how to discover these models in SageMaker Studio.
SageMaker Studio is an IDE that offers a web-based visual interface for performing the ML development steps, from data preparation to model building, training, and deployment. For instructions on getting started and setting up SageMaker Studio, refer to Amazon SageMaker Studio.
When you’re in SageMaker Studio, you can access SageMaker JumpStart by choosing JumpStart in the navigation pane.

In the JumpStart view, you’re presented with the list of public models offered by SageMaker. You can explore other models from other providers in this view. To start using the Meta Llama 3 models, under Providers, choose Meta.

You’re presented with a list of the models available. Choose one of the Vision Instruct models, for example the Meta Llama 3.2 90B Vision Instruct model.

Here you can view the model details, as well as train, deploy, optimize, and evaluate the model. For this demonstration, we choose Train.

On this page, you can point to the Amazon Simple Storage Service (Amazon S3) bucket containing the training and validation datasets for fine-tuning. In addition, you can configure deployment configuration, hyperparameters, and security settings for fine-tuning. Choose Submit to start the training job on a SageMaker ML instance.

Deploy the model
After the model is fine-tuned, you can deploy it using the model page on SageMaker JumpStart. The option to deploy the fine-tuned model will appear when fine-tuning is finished, as shown in the following screenshot.

You can also deploy the model from this view. You can configure endpoint settings such as the instance type, number of instances, and endpoint name. You will need to accept the End User License Agreement (EULA) before you can deploy the model.
Fine-tune using the SageMaker Python SDK
You can also fine-tune Meta Llama 3.2 Vision Instruct models using the SageMaker Python SDK. A sample notebook with the full instructions can be found on GitHub. The following code example demonstrates how to fine-tune the Meta Llama 3.2 11B Vision Instruct model:
The code sets up a SageMaker JumpStart estimator for fine-tuning the Meta Llama 3.2 Vision Instruct model on a custom training dataset. It configures the estimator with the desired model ID, accepts the EULA, sets the number of training epochs as a hyperparameter, and initiates the fine-tuning process.
When the fine-tuning process is complete, you can review the evaluation metrics for the model. These metrics will provide insights into the performance of the fine-tuned model on the validation dataset, allowing you to assess how well the model has adapted. We discuss these metrics more in the following sections.
You can then deploy the fine-tuned model directly from the estimator, as shown in the following code:
As part of the deploy settings, you can define the instance type you want to deploy the model on. For the full list of deployment parameters, refer to the deploy parameters in the SageMaker SDK documentation.
After the endpoint is up and running, you can perform an inference request against it using the predictor object as follows:
For the full list of predictor parameters, refer to the predictor object in the SageMaker SDK documentation.
Fine-tuning quantitative metrics
SageMaker JumpStart automatically outputs various training and validation metrics, such as loss, during the fine-tuning process to help evaluate the model’s performance.


The DocVQA dataset is a widely used benchmark for evaluating the performance of multimodal AI models on visual question answering tasks involving document-style images. As shown in the following table, the non-fine-tuned Meta Llama 3.2 11B and 90B models achieved ANLS scores of 88.4 and 90.1 respectively on the DocVQA test set, as reported in the post Llama 3.2: Revolutionizing edge AI and vision with open, customizable models on the Meta AI website. After fine-tuning the 11B and 90B Vision Instruct models using SageMaker JumpStart, the fine-tuned models achieved improved ANLS scores of 91 and 92.4, demonstrating that the fine-tuning process significantly enhanced the models’ ability to understand and answer natural language questions about complex document-based visual information.
| DocVQA test set (5138 examples, metric: ANLS) | 11B-Instruct | 90B-Instruct |
|---|---|---|
| Non-fine-tuned | 88.4 | 90.1 |
| SageMaker JumpStart Fine-tuned | 91 | 92.4 |
For the fine-tuning results shown in the table, the models were trained using the DeepSpeed framework on a single P5.48xlarge instance with multi-GPU distributed training. The fine-tuning process used Low-Rank Adaptation (LoRA) on all linear layers, with a LoRA alpha of 8, LoRA dropout of 0.05, and a LoRA rank of 16. The 90B Instruct model was trained for 6 epochs, while the 11B Instruct model was trained for 4 epochs. Both models used a learning rate of 5e-5 with a linear learning rate schedule. Importantly, the Instruct models were fine-tuned using the built-in chat template format, where the loss was computed on the last turn of the conversation (the assistant’s response)
For the base model fine-tuning, you have the choice of using chat completion format or text completion format, controlled by the hyperparameter chat_template. For text completion, it is simply a concatenation of image token, prompt, and completion, where the prompt and completion part are connected by a response key ###Response:nn and loss values are computed on the completion part only.
Fine-tuning qualitative results
In addition to the quantitative evaluation metrics, you can observe qualitative differences in the model’s outputs after the fine-tuning process.
For the non-Instruct models, the fine-tuning was performed using a specific prompt template that doesn’t use the chat format. The prompt template was structured as follows:
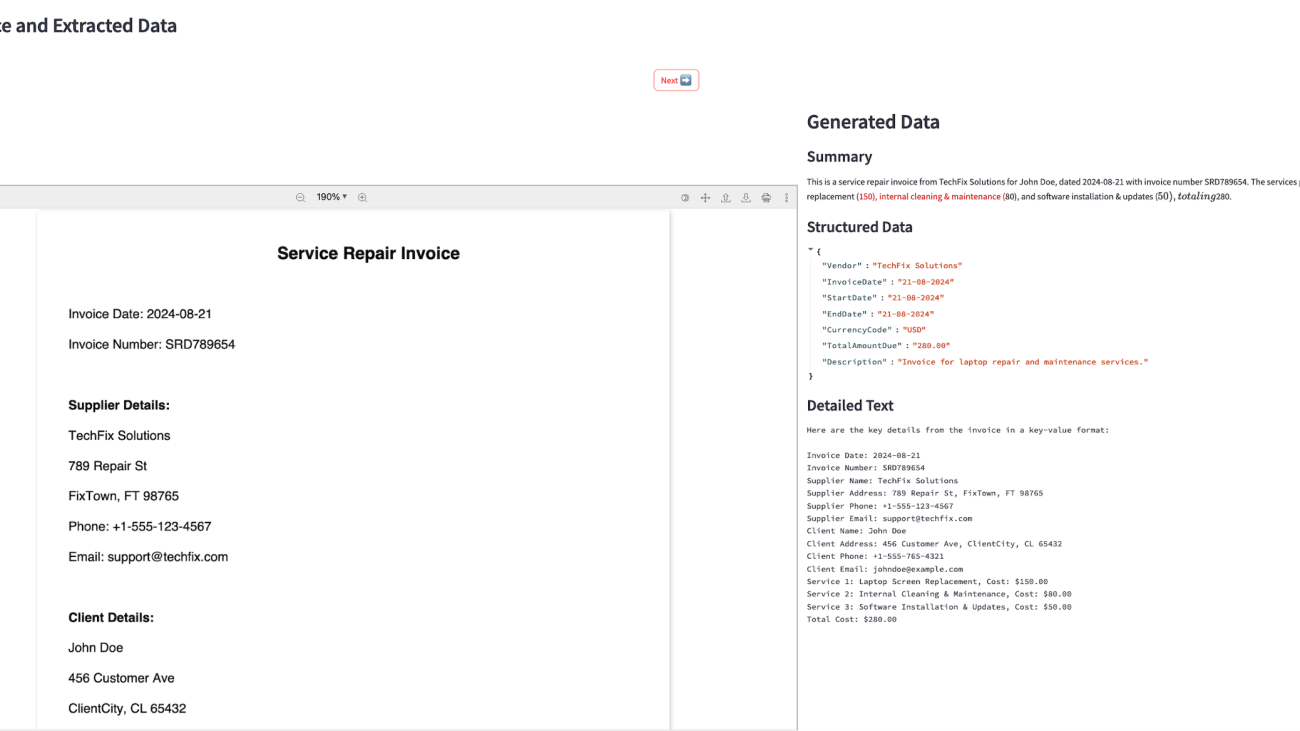
This prompt template required the model to generate a direct, concise response based on the visual information in the image, without producing additional context or commentary. The results of fine-tuning a 11 B Vision non-Instruct base model using this prompt template are shown in the following qualitative examples, demonstrating how the fine-tuning process improved the models’ ability to accurately extract and reproduce the relevant information from the document images.
| Image | Input prompt | Pre-trained response | Fine-tuned response | Ground truth |
 |
What is the name of the company? | ### Response: ### Response: ### Response: ### Response: ### Response: ### Response: ### Response: ### |
ITC Limited | itc limited |
 |
Where is the company located? | 1) Opening Stock : a) Cigarette Filter Rods Current Year Previous year b) Poly Propelene |
CHENNAI | chennai |
 |
What the location address of NSDA? | Source: https://www. industrydocuments.ucsf .edu/docs/qqvf0227. <OCR/> The best thing between |
1128 SIXTEENTH ST., N. W., WASHINGTON, D. C. 20036 | 1128 SIXTEENTH ST., N. W., WASHINGTON, D. C. 20036 |
 |
What is the ‘no. of persons present’ for the sustainability committee meeting held on 5th April, 2012? | 1 2 3 4 5 6 7 8 9 10 11 12 13 |
6 | 6 |
Clean up
After you’re done running the notebook, make sure to delete all the resources that you created in the process so your billing is stopped:
Conclusion
In this post, we discussed fine-tuning Meta Llama 3.2 Vision Instruct models using SageMaker JumpStart. We showed that you can use the SageMaker JumpStart console in SageMaker Studio or the SageMaker Python SDK to fine-tune and deploy these models. We also discussed the fine-tuning technique, instance types, and supported hyperparameters. Finally, we showcased both the quantitative metrics and qualitative results of fine-tuning the Meta Llama 3.2 Vision model on the DocVQA dataset, highlighting the model’s improved performance on visual question answering tasks involving complex document-style images.
As a next step, you can try fine-tuning these models on your own dataset using the code provided in the notebook to test and benchmark the results for your use cases.
About the Authors
 Marc Karp is an ML Architect with the Amazon SageMaker Service team. He focuses on helping customers design, deploy, and manage ML workloads at scale. In his spare time, he enjoys traveling and exploring new places.
Marc Karp is an ML Architect with the Amazon SageMaker Service team. He focuses on helping customers design, deploy, and manage ML workloads at scale. In his spare time, he enjoys traveling and exploring new places.
 Dr. Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A.
Dr. Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A.
Appendix
Language models such as Meta Llama are more than 10 GB or even 100 GB in size. Fine-tuning such large models requires instances with significantly higher CUDA memory. Furthermore, training these models can be very slow due to their size. Therefore, for efficient fine-tuning, we use the following optimizations:
- Low-Rank Adaptation (LoRA) – To efficiently fine-tune the LLM, we employ LoRA, a type of parameter-efficient fine-tuning (PEFT) technique. Instead of training all the model parameters, LoRA introduces a small set of adaptable parameters that are added to the pre-trained model. This significantly reduces the memory footprint and training time compared to fine-tuning the entire model.
- Mixed precision training (bf16) – To further optimize memory usage, we use mixed precision training using bfloat16 (bf16) data type. bf16 provides similar performance to full-precision float32 while using only half the memory, enabling us to train larger batch sizes and fit the model on available hardware.
The default hyperparameters are as follows:
- Peft Type: lora – LoRA fine-tuning, which can efficiently adapt a pre-trained language model to a specific task
- Chat Template: True – Enables the use of a chat-based template for the fine-tuning process
- Gradient Checkpointing: True – Reduces the memory footprint during training by recomputing the activations during the backward pass, rather than storing them during the forward pass
- Per Device Train Batch Size: 2 – The batch size for training on each device
- Per Device Evaluation Batch Size: 2 – The batch size for evaluation on each device
- Gradient Accumulation Steps: 2 – The number of steps to accumulate gradients for before performing an update
- Bf16 16-Bit (Mixed) Precision Training: True – Enables the use of bfloat16 (bf16) data type for mixed precision training, which can speed up training and reduce memory usage
- Fp16 16-Bit (Mixed) Precision Training: False – Disables the use of float16 (fp16) data type for mixed precision training
- Deepspeed: True – Enables the use of the Deepspeed library for efficient distributed training
- Epochs: 10 – The number of training epochs
- Learning Rate: 6e-06 – The learning rate to be used during training
- Lora R: 64 – The rank parameter for the LoRA fine-tuning
- Lora Alpha: 16 – The alpha parameter for the LoRA fine-tuning
- Lora Dropout: 0 – The dropout rate for the LoRA fine-tuning
- Warmup Ratio: 0.1 – The ratio of the total number of steps to use for a linear warmup from 0 to the learning rate
- Evaluation Strategy: steps – The strategy for evaluating the model during training
- Evaluation Steps: 20 – The number of steps to use for evaluating the model during training
- Logging Steps: 20 – The number of steps between logging training metrics
- Weight Decay: 0.2 – The weight decay to be used during training
- Load Best Model At End: False – Disables loading the best performing model at the end of training
- Seed: 42 – The random seed to use for reproducibility
- Max Input Length: -1 – The maximum length of the input sequence
- Validation Split Ratio: 0.2 – The ratio of the training dataset to use for validation
- Train Data Split Seed: 0 – The random seed to use for splitting the training data
- Preprocessing Num Workers: None – The number of worker processes to use for data preprocessing
- Max Steps: -1 – The maximum number of training steps to perform
- Adam Beta1: 0.9 – The beta1 parameter for the Adam optimizer
- Adam Beta2: 0.999 – The beta2 parameter for the Adam optimizer
- Adam Epsilon: 1e-08 – The epsilon parameter for the Adam optimizer
- Max Grad Norm: 1.0 – The maximum gradient norm to be used for gradient clipping
- Label Smoothing Factor: 0 – The label smoothing factor to be used during training
- Logging First Step: False – Disables logging the first step of training
- Logging Nan Inf Filter: True – Enables filtering out NaN and Inf values from the training logs
- Saving Strategy: no – Disables automatic saving of the model during training
- Save Steps: 500 – The number of steps between saving the model during training
- Save Total Limit: 1 – The maximum number of saved models to keep
- Dataloader Drop Last: False – Disables dropping the last incomplete batch during data loading
- Dataloader Num Workers: 32 – The number of worker processes to use for data loading
- Eval Accumulation Steps: None – The number of steps to accumulate gradients for before performing an evaluation
- Auto Find Batch Size: False – Disables automatically finding the optimal batch size
- Lr Scheduler Type: constant_with_warmup – The type of learning rate scheduler to use (for example, constant with warmup)
- Warm Up Steps: 0 – The number of steps to use for linear warmup of the learning rate

 Ajay Swamy is the Global Product Leader for Data, AIML and Generative AI AWS Solutions. He specializes in building AWS Solutions (production-ready software packages) that deliver compelling value to customers by solving for their unique business needs. Other than
Ajay Swamy is the Global Product Leader for Data, AIML and Generative AI AWS Solutions. He specializes in building AWS Solutions (production-ready software packages) that deliver compelling value to customers by solving for their unique business needs. Other than  Dr. Nicki Susman is a Senior Machine Learning Engineer and the Technical Lead of the Principal AI Enablement team. She has extensive experience in data and analytics, application development, infrastructure engineering, and DevSecOps.
Dr. Nicki Susman is a Senior Machine Learning Engineer and the Technical Lead of the Principal AI Enablement team. She has extensive experience in data and analytics, application development, infrastructure engineering, and DevSecOps. Joel Elscott is a Senior Data Engineer on the Principal AI Enablement team. He has over 20 years of software development experience in the financial services industry, specializing in ML/AI application development and cloud data architecture. Joel lives in Des Moines, Iowa, with his wife and five children, and is also a group fitness instructor.
Joel Elscott is a Senior Data Engineer on the Principal AI Enablement team. He has over 20 years of software development experience in the financial services industry, specializing in ML/AI application development and cloud data architecture. Joel lives in Des Moines, Iowa, with his wife and five children, and is also a group fitness instructor. Bob Strahan is a Principal Solutions Architect in the AWS Generative AI Innovation Center team.
Bob Strahan is a Principal Solutions Architect in the AWS Generative AI Innovation Center team. Austin Johnson is a Solutions Architect, maintaining the Lex Web UI open source library.
Austin Johnson is a Solutions Architect, maintaining the Lex Web UI open source library.




 Deepika Kumar is a Solution Architect at AWS. She has over 13 years of experience in the technology industry and has helped enterprises and SaaS organizations build and securely deploy their workloads on the cloud securely. She is passionate about using Generative AI in a responsible manner whether that is driving product innovation, boost productivity or enhancing customer experiences.
Deepika Kumar is a Solution Architect at AWS. She has over 13 years of experience in the technology industry and has helped enterprises and SaaS organizations build and securely deploy their workloads on the cloud securely. She is passionate about using Generative AI in a responsible manner whether that is driving product innovation, boost productivity or enhancing customer experiences. Jobandeep Singh is an Associate Solution Architect at AWS specializing in Machine Learning. He supports customers across a wide range of industries to leverage AWS, driving innovation and efficiency in their operations. In his free time, he enjoys playing sports, with a particular love for hockey.
Jobandeep Singh is an Associate Solution Architect at AWS specializing in Machine Learning. He supports customers across a wide range of industries to leverage AWS, driving innovation and efficiency in their operations. In his free time, he enjoys playing sports, with a particular love for hockey. Ratan Kumar is a solutions architect based out of Auckland, New Zealand. He works with large enterprise customers helping them design and build secure, cost-effective, and reliable internet scale applications using the AWS cloud. He is passionate about technology and likes sharing knowledge through blog posts and twitch sessions.
Ratan Kumar is a solutions architect based out of Auckland, New Zealand. He works with large enterprise customers helping them design and build secure, cost-effective, and reliable internet scale applications using the AWS cloud. He is passionate about technology and likes sharing knowledge through blog posts and twitch sessions.

 Ram Vittal is a Principal ML Solutions Architect at AWS. He has over 3 decades of experience architecting and building distributed, hybrid, and cloud applications. He is passionate about building secure and scalable AI/ML and big data solutions to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he rides his motorcycle and walks with his 3-year-old Sheepadoodle.
Ram Vittal is a Principal ML Solutions Architect at AWS. He has over 3 decades of experience architecting and building distributed, hybrid, and cloud applications. He is passionate about building secure and scalable AI/ML and big data solutions to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he rides his motorcycle and walks with his 3-year-old Sheepadoodle. Anastasia Tzeveleka is a Senior Generative AI/ML Specialist Solutions Architect at AWS. As part of her work, she helps customers across EMEA build foundation models and create scalable generative AI and machine learning solutions using AWS services.
Anastasia Tzeveleka is a Senior Generative AI/ML Specialist Solutions Architect at AWS. As part of her work, she helps customers across EMEA build foundation models and create scalable generative AI and machine learning solutions using AWS services. Siamak Nariman is a Senior Product Manager at AWS. He is focused on AI/ML technology, ML model management, and ML governance to improve overall organizational efficiency and productivity. He has extensive experience automating processes and deploying various technologies.
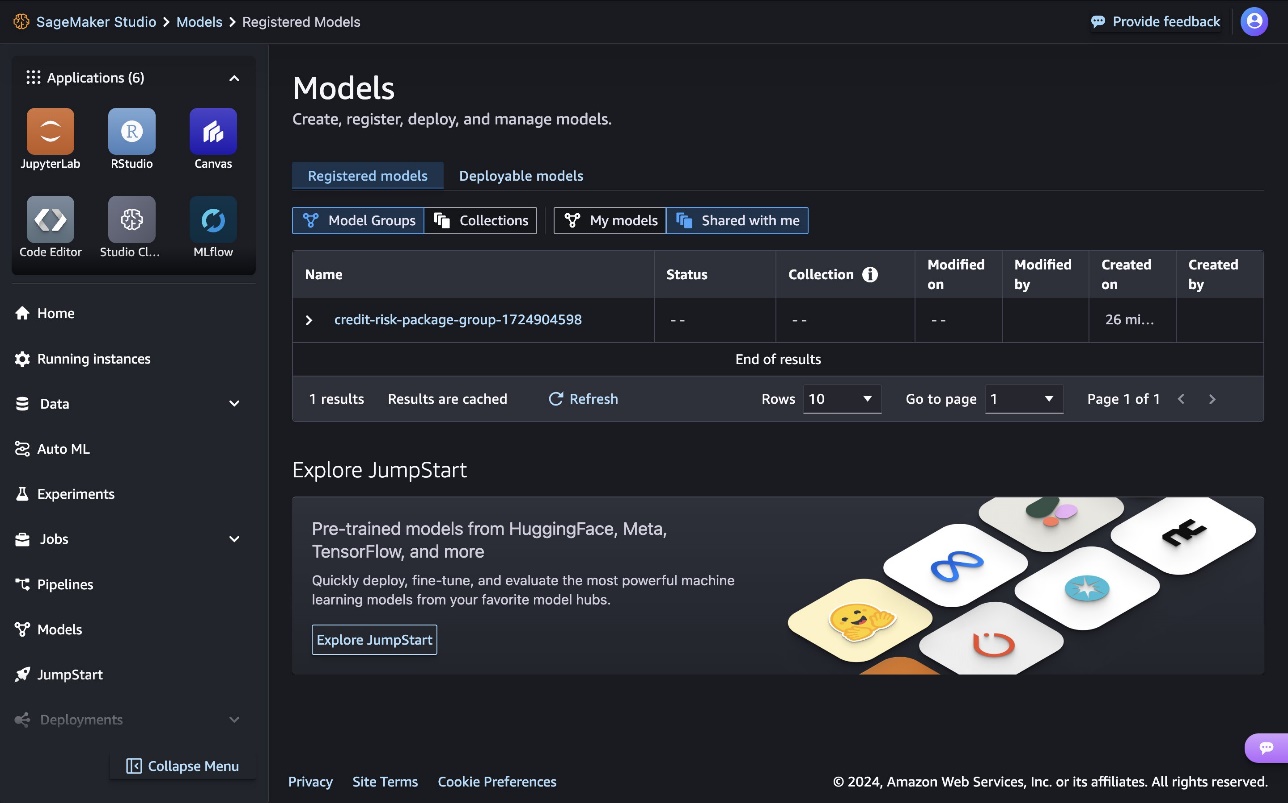
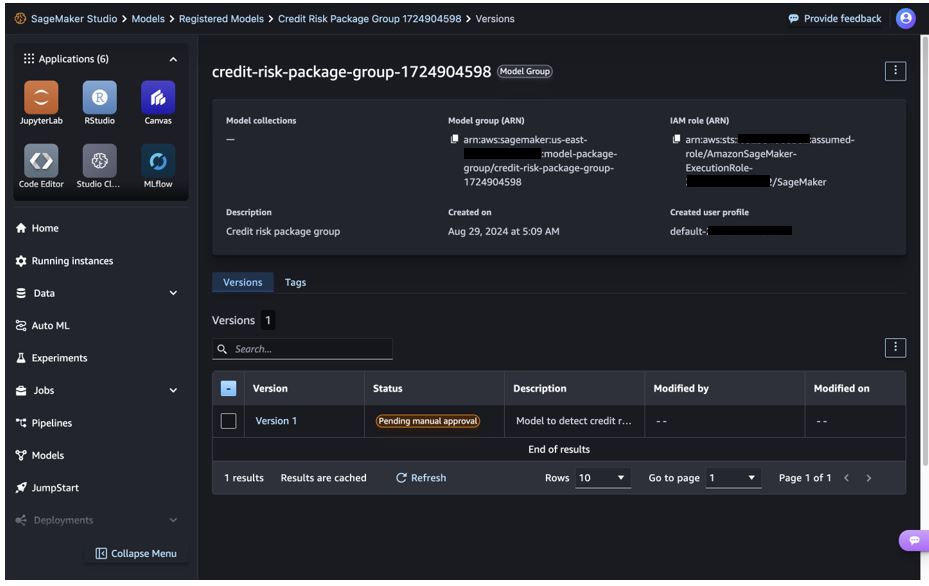
Siamak Nariman is a Senior Product Manager at AWS. He is focused on AI/ML technology, ML model management, and ML governance to improve overall organizational efficiency and productivity. He has extensive experience automating processes and deploying various technologies. Madhubalasri B. is a Software Development Engineer at Amazon Web Services (AWS), focusing on the SageMaker Model Registry and machine learning governance domain. She has expertise in cross-account access and model sharing, ensuring secure, scalable, and compliant deployment of machine learning models. Madhubalasri is dedicated to driving innovation in ML governance and optimizing model management processes
Madhubalasri B. is a Software Development Engineer at Amazon Web Services (AWS), focusing on the SageMaker Model Registry and machine learning governance domain. She has expertise in cross-account access and model sharing, ensuring secure, scalable, and compliant deployment of machine learning models. Madhubalasri is dedicated to driving innovation in ML governance and optimizing model management processes Saumitra Vikaram is a Senior Software Engineer at AWS. He is focused on AI/ML technology, ML model management, ML governance, and MLOps to improve overall organizational efficiency and productivity.
Saumitra Vikaram is a Senior Software Engineer at AWS. He is focused on AI/ML technology, ML model management, ML governance, and MLOps to improve overall organizational efficiency and productivity. Keshav Chandakis a Software Engineer at AWS with a focus on the SageMaker Repository Service. He specializes in developing capabilities to enhance governance and management of ML models.
Keshav Chandakis a Software Engineer at AWS with a focus on the SageMaker Repository Service. He specializes in developing capabilities to enhance governance and management of ML models.




 Yao Cong (YC) Yeo is a Solutions Architect at Amazon Web Services, empowering Singapore’s ISVs and SMBs in their cloud transformation journeys, guiding customers to optimize workloads and maximize their AWS cloud potential. YC specialises in the Application Security domain in Cloud Security, ensuring robust and secure cloud implementations. In the Generative AI space, YC delivers thought leadership content to bridge the gap between technical possibilities and business objectives in the evolving digital landscape.
Yao Cong (YC) Yeo is a Solutions Architect at Amazon Web Services, empowering Singapore’s ISVs and SMBs in their cloud transformation journeys, guiding customers to optimize workloads and maximize their AWS cloud potential. YC specialises in the Application Security domain in Cloud Security, ensuring robust and secure cloud implementations. In the Generative AI space, YC delivers thought leadership content to bridge the gap between technical possibilities and business objectives in the evolving digital landscape. Loke Jun Kai is an AI/ML Specialist Solutions Architect in AWS. He works on Go-To-Market motions and Strategic Opportunities in the ASEAN Region. Jun Kai have provided technical and visionary guidance for customers across industries and segments, from large enterprises to Startups. Outside of work, he enjoys looking at all things related to Venture Capital, or having Tennis sessions.
Loke Jun Kai is an AI/ML Specialist Solutions Architect in AWS. He works on Go-To-Market motions and Strategic Opportunities in the ASEAN Region. Jun Kai have provided technical and visionary guidance for customers across industries and segments, from large enterprises to Startups. Outside of work, he enjoys looking at all things related to Venture Capital, or having Tennis sessions. Abhi Fabhian is a Solutions Architect at Amazon Web Services based in Indonesia, providing expert technical guidance on cloud technologies to clients across various sectors in Indonesia, helping them optimize their cloud experience. Outside of work he enjoys sports, cars, music and playing games.
Abhi Fabhian is a Solutions Architect at Amazon Web Services based in Indonesia, providing expert technical guidance on cloud technologies to clients across various sectors in Indonesia, helping them optimize their cloud experience. Outside of work he enjoys sports, cars, music and playing games. Tung Cao is a Solutions Architect at Amazon Web Services based in Vietnam, covering Vietnam’s SMB and ISVs on their journey to the cloud, helping them optimize and innovate their business processes. Tung specializes in AI/ML, which helps in providing cutting-edge solutions to enhance customer experiences, streamline operations, and drive data-driven decision-making. enabling businesses to leverage advanced technologies like machine learning and deep learning to gain competitive advantages.
Tung Cao is a Solutions Architect at Amazon Web Services based in Vietnam, covering Vietnam’s SMB and ISVs on their journey to the cloud, helping them optimize and innovate their business processes. Tung specializes in AI/ML, which helps in providing cutting-edge solutions to enhance customer experiences, streamline operations, and drive data-driven decision-making. enabling businesses to leverage advanced technologies like machine learning and deep learning to gain competitive advantages. Siraphop (Fufu) Thaisangsa-nga is a Solutions Architect at Amazon Web Services based in Thailand, dedicated to guiding local businesses through their cloud transformation journeys. With a deep understanding of the Thai market, Fufu helps companies leverage AWS services to innovate, scale, and improve their operational efficiency, excelling in tailoring cloud solutions to meet the unique needs of Thai businesses across various industries.
Siraphop (Fufu) Thaisangsa-nga is a Solutions Architect at Amazon Web Services based in Thailand, dedicated to guiding local businesses through their cloud transformation journeys. With a deep understanding of the Thai market, Fufu helps companies leverage AWS services to innovate, scale, and improve their operational efficiency, excelling in tailoring cloud solutions to meet the unique needs of Thai businesses across various industries.



 Vinicius Pedroni is a Senior Solutions Architect at AWS for the Travel and Hospitality Industry, with focus on Edge Services and Generative AI. Vinicius is also passionate about assisting customers on their Cloud Journey, allowing them to adopt the right strategies at the right moment.
Vinicius Pedroni is a Senior Solutions Architect at AWS for the Travel and Hospitality Industry, with focus on Edge Services and Generative AI. Vinicius is also passionate about assisting customers on their Cloud Journey, allowing them to adopt the right strategies at the right moment. Manikanth Pasumarti is a Solutions Architect based out of New York City. He works with enterprise customers to architect and design solutions for their business needs. He is passionate about math and loves to teach kids in his free time.
Manikanth Pasumarti is a Solutions Architect based out of New York City. He works with enterprise customers to architect and design solutions for their business needs. He is passionate about math and loves to teach kids in his free time.























 Isha Dua is a Senior Solutions Architect based in the San Francisco Bay Area working with GENAI Model providers and helping customer optimize their GENAI workloads on AWS. She helps enterprise customers grow by understanding their goals and challenges, and guides them on how they can architect their applications in a cloud-native manner while ensuring resilience and scalability. She’s passionate about machine learning technologies and environmental sustainability.
Isha Dua is a Senior Solutions Architect based in the San Francisco Bay Area working with GENAI Model providers and helping customer optimize their GENAI workloads on AWS. She helps enterprise customers grow by understanding their goals and challenges, and guides them on how they can architect their applications in a cloud-native manner while ensuring resilience and scalability. She’s passionate about machine learning technologies and environmental sustainability. Sanwal Yousaf is a Solutions Engineer at Stability AI. His work at Stability AI focuses on working with enterprises to architect solutions using Stability AI’s Generative models to solve pressing business problems. He is passionate about creating accessible resources for people to learn and develop proficiency with AI.
Sanwal Yousaf is a Solutions Engineer at Stability AI. His work at Stability AI focuses on working with enterprises to architect solutions using Stability AI’s Generative models to solve pressing business problems. He is passionate about creating accessible resources for people to learn and develop proficiency with AI.









 Tom Yemington is a Senior GenAI Models Specialist focused on helping model providers and customers scale generative AI solutions in AWS. Tom is a Certified Information Systems Security Professional (CISSP). Outside of work, you can find Tom racing vintage cars or teaching people how to race as an instructor at track-day events.
Tom Yemington is a Senior GenAI Models Specialist focused on helping model providers and customers scale generative AI solutions in AWS. Tom is a Certified Information Systems Security Professional (CISSP). Outside of work, you can find Tom racing vintage cars or teaching people how to race as an instructor at track-day events. Boshi Huang is a Senior Applied Scientist in Generative AI at Amazon Web Services, where he collaborates with customers to develop and implement generative AI solutions. Boshi’s research focuses on advancing the field of generative AI through automatic prompt engineering, adversarial attack and defense mechanisms, inference acceleration, and developing methods for responsible and reliable visual content generation.
Boshi Huang is a Senior Applied Scientist in Generative AI at Amazon Web Services, where he collaborates with customers to develop and implement generative AI solutions. Boshi’s research focuses on advancing the field of generative AI through automatic prompt engineering, adversarial attack and defense mechanisms, inference acceleration, and developing methods for responsible and reliable visual content generation.