Self-supervised method for learning when to retrieve contextual information from a code repository speeds up code completion times by 70% while increasing accuracy.Read More
Using Amazon Q Business with AWS HealthScribe to gain insights from patient consultations
With the advent of generative AI and machine learning, new opportunities for enhancement became available for different industries and processes. During re:Invent 2023, we launched AWS HealthScribe, a HIPAA eligible service that empowers healthcare software vendors to build their clinical applications to use speech recognition and generative AI to automatically create preliminary clinician documentation. In addition to AWS HealthScribe, we also launched Amazon Q Business, a generative AI-powered assistant that can perform functions such as answer questions, provide summaries, generate content, and securely complete tasks based on data and information that are in your enterprise systems.
AWS HealthScribe combines speech recognition and generative AI trained specifically for healthcare documentation to accelerate clinical documentation and enhance the consultation experience.
Key features of AWS HealthScribe include:
- Rich consultation transcripts with word-level timestamps.
- Speaker role identification (clinician or patient).
- Transcript segmentation into relevant sections such as subjective, objective, assessment, and plan.
- Summarized clinical notes for sections such as chief complaint, history of present illness, assessment, and plan.
- Evidence mapping that references the original transcript for each sentence in the AI-generated notes.
- Extraction of structured medical terms for entries such as conditions, medications, and treatments.
AWS HealthScribe provides a suite of AI-powered features to streamline clinical documentation while maintaining security and privacy. It doesn’t retain audio or output text, and users have control over data storage with encryption in transit and at rest.
With Amazon Q Business, we provide a new generative AI-powered assistant designed specifically for business and workplace use cases. It can be customized and integrated with an organization’s data, systems, and repositories. Amazon Q allows users to have conversations, help solve problems, generate content, gain insights, and take actions through its AI capabilities. Amazon Q offers user-based pricing plans tailored to how the product is used. It can adapt interactions based on individual user identities, roles, and permissions within the organization. Importantly, AWS never uses customer content from Amazon Q to train its underlying AI models, making sure that company information remains private and secure.
In this blog post, we’ll show you how AWS HealthScribe and Amazon Q Business together analyze patient consultations to provide summaries and trends from clinician conversations, simplifying documentation workflows. This automation and use of machine learning from clinician-patient interactions with Amazon HealthScribe and Amazon Q can help improve patient outcomes by enhancing communication, leading to more personalized care for patients and increased efficiency for clinicians.
Benefits and use cases
Gaining insight from patient-clinician interactions alongside a chatbot can help in a variety of ways such as:
- Enhanced communication: In analyzing consultations, clinicians using AWS HealthScribe can more readily identify patterns and trends in large patient datasets, which can help improve communication between clinicians and patients. An example would be a clinician understanding common trends in their patient’s symptoms that they can then consider for new consultations.
- Personalized care: Using machine learning, clinicians can tailor their care to individual patients by analyzing the specific needs and concerns of each patient. This can lead to more personalized and effective care.
- Streamlined workflows: Clinicians can use machine learning to help streamline their workflows by automating tasks such as appointment scheduling and consultation summarization. This can give clinicians more time to focus on providing high-quality care to their patients. An example would be using clinician summaries together with agentic workflows to perform these tasks on a routine basis.
Architecture diagram

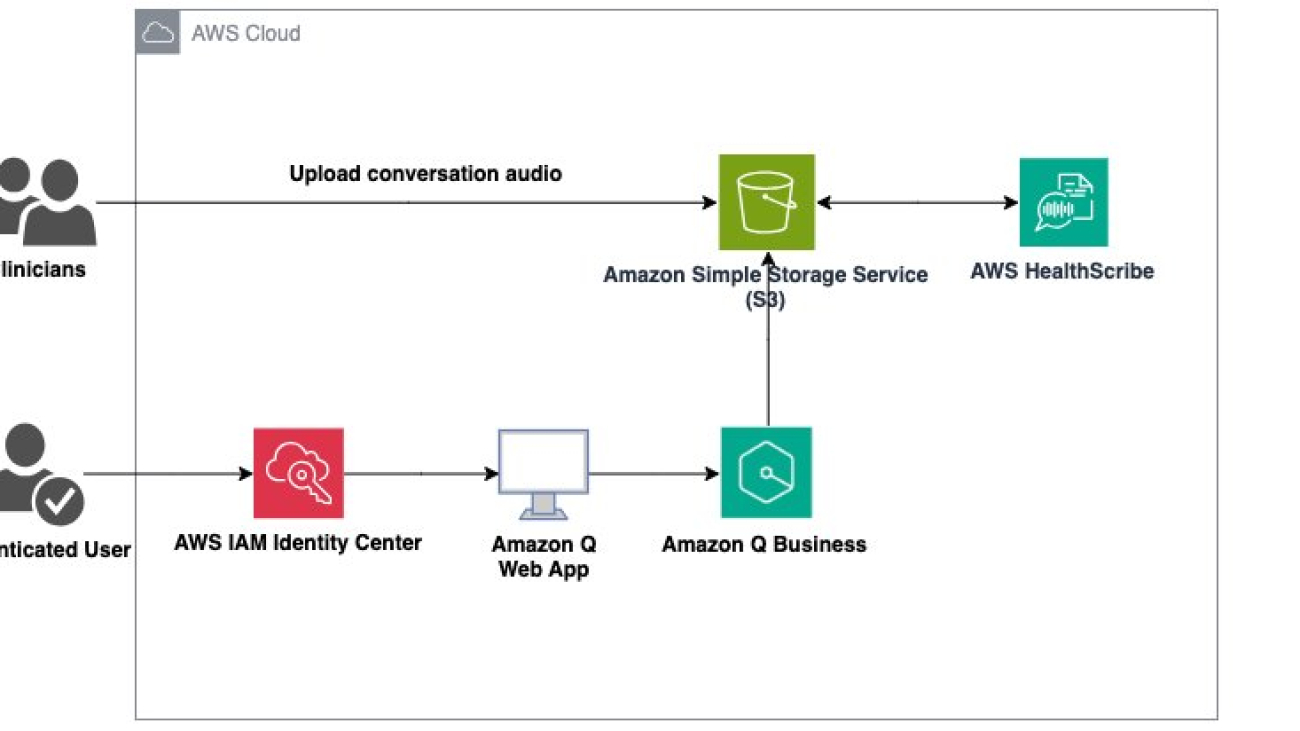
In the architecture diagram we present for this demo, two user workflows are shown. To kickoff the process, a clinician uploads the recording of a consultation to Amazon Simple Storage Service (Amazon S3). This audio file is then ingested by AWS HealthScribe and used to analyze consultation conversations. AWS HealthScribe will then output two files which are also stored on Amazon S3. In the second workflow, an authenticated user logs in via AWS IAM Identity Center to an Amazon Q web front end hosted by Amazon Q Business. In this scenario, Amazon Q Business is given the output Amazon S3 bucket as the data source for use in its web app.
Prerequisites
- AWS IAM Identity Center will be used as the SAML 2.0-compliant identity provider (IdP). You’ll need to enable an IAM Identity Center instance. Under this instance, be sure to provision a user with a valid email address because this will be the user you will use to sign in to Amazon Q Business. For more details, see Configure user access with the default IAM Identity Center directory.
- Amazon Simple Storage Service (Amazon S3) buckets that will be the input and output buckets for the clinician-patient conversations and AWS HealthScribe.
Implementation
To start using AWS HealthScribe you must first start a transcription job that takes a source audio file and outputs summary and transcription JSON files with the analyzed conversation. You’ll then connect these output files to Amazon Q.
Creating the AWS HealthScribe job
- In the AWS HealthScribe console, choose Transcription jobs in the navigation pane, and then choose Create job to get started.

- Enter a name for the job—in this example, we use
FatigueConsult—and select the S3 bucket where the audio file of the clinician-patient conversation is stored.
- Next, use the S3 URI search field to find and point the transcription job to the Amazon S3 bucket you want the output files to be saved to. Maintain the default options for audio settings, customization, and content removal.

- Create a new AWS Identity and Access Management (IAM) role for AWS HealthScribe to use for access to the S3 input and output buckets by choosing Create an IAM role. In our example, we entered
HealthScribeRoleas the Role name. To complete the job creation, choose Create job.
- This will take a few minutes to finish. When it’s complete, you will see the status change from In Progress to Complete and can inspect the results by selecting the job name.
 AWS HealthScribe will create two files: a word-for-word transcript of the conversation with the suffix
AWS HealthScribe will create two files: a word-for-word transcript of the conversation with the suffix /transcript.jsonand a summary of the conversation with the suffix/summary.json. This summary uses the underlying power of generative AI to highlight key topics in the conversation, extract medical terminology, and more.

In this workflow, AWS HealthScribe analyzes the patient-clinician conversation audio to:
- Transcribe the consultation
- Identify speaker roles (for example, clinician and patient)
- Segment the transcript (for example, small talk, visit flow management, assessment, and treatment plan)
- Extract medical terms (for example, medication name and medical condition name)
- Summarize notes for key sections of the clinical document (for example, history of present illness and treatment plan)
- Create evidence mapping (linking every sentence in the AI-generated note with corresponding transcript dialogues).
Connecting an AWS HealthScribe job to Amazon Q
To use Amazon Q with the summarized notes and transcripts from AWS HealthScribe, we need to first create an Amazon Q business application and set the data source as the S3 bucket where the output files were stored in the HealthScribe jobs workflow. This will allow Amazon Q to index the files and give users the ability to ask questions of the data.
- In the Amazon Q Business console, choose Get Started, then choose Create Application.
- Enter a name for your application and select Create and use a new service-linked role (SLR).

- Choose Create when you’re ready to select a data source.
- In the Add data source pane select Amazon S3.

- To configure the S3 bucket with Amazon Q, enter a name for the data source. In our example we use
my-s3-bucket.
- Next, locate the S3 bucket with the JSON outputs from HealthScribe using the Browse S3 button. Select Full sync for the sync mode and select a cadence of your preference. Once you complete these steps, Amazon Q Business will run a full sync of the objects in your S3 bucket and be ready for use.

- In the main applications dashboard, navigate to the URL under Web experience URL. This is how you will access the Amazon Q web front end to interact with the assistant.

After a user signs in to the web experience, they can start asking questions directly in the chat box as shown in the sample frontend that follows.
Sample frontend workflow
With the AWS HealthScribe results integrated into Amazon Q Business, users can go to the web experience to gain insights from their patient conversations. For example, you can use Q to determine information such as trends in patient symptoms, checking which medications patients are taking and so on as shown in the following figures.
The workflow starts with a question and answer about issues patients had, as shown in the following figure.  In the example above, a clinician is asking what the symptoms were of patients who complained of stomach pain. Q responds with common symptoms, like bloating and bowel problems, from the data it has access to. The answers generated cite the source files from Amazon S3 that led to its summary and can be inspected by choosing Sources.
In the example above, a clinician is asking what the symptoms were of patients who complained of stomach pain. Q responds with common symptoms, like bloating and bowel problems, from the data it has access to. The answers generated cite the source files from Amazon S3 that led to its summary and can be inspected by choosing Sources.
In the following example, a clinician asks what medications patients with knee pain are taking. Using our sample data of various consultations for knee pain, Q tells us patients are taking over the counter ibuprofen, but that it is not often providing patients relief.
This application can also help clinicians understand common trends in their patient data, such as asking what the common symptoms are for patients with chest pain.
 In the final example for this post, a clinician asks Q if there are common symptoms for patients complaining of knee and elbow pain. Q responds that both sets of patients describe their pain being exacerbated by movement, but that it cannot conclusively point to any common symptoms across both consultation types. In this case Amazon Q is correctly using source data to prevent a hallucination from occurring.
In the final example for this post, a clinician asks Q if there are common symptoms for patients complaining of knee and elbow pain. Q responds that both sets of patients describe their pain being exacerbated by movement, but that it cannot conclusively point to any common symptoms across both consultation types. In this case Amazon Q is correctly using source data to prevent a hallucination from occurring.
Considerations
The UI for Amazon Q has limited customization. At the time of writing this post, the Amazon Q frontend cannot be embedded in other tools. Supported customization of the web experience includes the addition of a title and subtitle, adding a welcome message, and displaying sample prompts. For updates on web experience customizations, see Customizing an Amazon Q Business web experience. If this kind of customization is critical to your application and business needs, you can explore custom large language model chatbot designs using Amazon Bedrock or Amazon SageMaker.
AWS HealthScribe uses conversational and generative AI to transcribe patient-clinician conversations and generate clinical notes. The results produced by AWS HealthScribe are probabilistic and might not always be accurate because of various factors, including audio quality, background noise, speaker clarity, the complexity of medical terminology, and context-specific language nuances. AWS HealthScribe is designed to be used in an assistive role for clinicians and medical scribes rather than as a substitute for their clinical expertise. As such, AWS HealthScribe output should not be employed to fully automate clinical documentation workflows, but rather to provide additional assistance to clinicians or medical scribes in their documentation process. Please ensure that your application provides the workflow for reviewing the clinical notes produced by AWS HealthScribe and establishes expectation of the need for human review before finalizing clinical notes.
Amazon Q Business uses machine learning models that generate predictions based on patterns in data, and generate insights and recommendations from your content. Outputs are probabilistic and should be evaluated for accuracy as appropriate for your use case, including by employing human review of the output. You and your users are responsible for all decisions made, advice given, actions taken, and failures to take action based on your use of these features.
This proof-of-concept can be extrapolated to create a patient-facing application as well, with the notion that a patient can review their own conversations with physicians and be given access to their medical records and consultation notes in a way that makes it easy for them to ask questions of the trends and data for their own medical history.
AWS HealthScribe is only available for English-US language at this time in the US East (N. Virginia) Region. Amazon Q Business is only available in US East (N. Virginia) and US West (Oregon).
Clean up
To ensure that you don’t continue to accrue charges from this solution, you must complete the following clean-up steps.
AWS HealthScribe
Navigate to the AWS HealthScribe the console and choose Transcription jobs. Select whichever HealthScribe jobs you want to clean up and choose Delete at the top right corner of the console page.
Amazon S3
To clean up your Amazon S3 resources, navigate to the Amazon S3 console and choose the buckets that you used or created while going through this post. To empty the buckets, follow the instructions for Emptying a bucket. After you empty the bucket, you delete the entire bucket.
Amazon Q Business
To delete your Amazon Q Business application, follow the instructions on Managing Amazon Q Business applications.
Conclusion
In this post, we discussed how you can use AWS HealthScribe with Amazon Q Business to create a chatbot to quickly gain insights into patient clinician conversations. To learn more, reach out to your AWS account team or check out the links that follow.
About the Authors
 Laura Salinas is a Startup Solution Architect supporting customers whose core business involves machine learning. She is passionate about guiding her customers on their cloud journey and finding solutions that help them innovate. Outside of work she loves boxing, watching the latest movie at the theater and playing competitive dodgeball.
Laura Salinas is a Startup Solution Architect supporting customers whose core business involves machine learning. She is passionate about guiding her customers on their cloud journey and finding solutions that help them innovate. Outside of work she loves boxing, watching the latest movie at the theater and playing competitive dodgeball.
 Tiffany Chen is a Solutions Architect on the CSC team at AWS. She has supported AWS customers with their deployment workloads and currently works with Enterprise customers to build well-architected and cost-optimized solutions. In her spare time, she enjoys traveling, gardening, baking, and watching basketball.
Tiffany Chen is a Solutions Architect on the CSC team at AWS. She has supported AWS customers with their deployment workloads and currently works with Enterprise customers to build well-architected and cost-optimized solutions. In her spare time, she enjoys traveling, gardening, baking, and watching basketball.
 Art Tuazon is a Partner Solutions Architect focused on enabling AWS Partners through technical best practices and is passionate about helping customers build on AWS. In her free time, she enjoys running and cooking.
Art Tuazon is a Partner Solutions Architect focused on enabling AWS Partners through technical best practices and is passionate about helping customers build on AWS. In her free time, she enjoys running and cooking.
 Winnie Chen is a Solutions Architect currently on the CSC team at AWS supporting greenfield customers. She supports customers of all industries as well as sizes such as enterprise and small to medium businesses. She has helped customers migrate and build their infrastructure on AWS. In her free time, she enjoys traveling and spending time outdoors through activities like hiking, biking and rock climbing.
Winnie Chen is a Solutions Architect currently on the CSC team at AWS supporting greenfield customers. She supports customers of all industries as well as sizes such as enterprise and small to medium businesses. She has helped customers migrate and build their infrastructure on AWS. In her free time, she enjoys traveling and spending time outdoors through activities like hiking, biking and rock climbing.
Use Amazon SageMaker Studio with a custom file system in Amazon EFS
Amazon SageMaker Studio is the latest web-based experience for running end-to-end machine learning (ML) workflows. SageMaker Studio offers a suite of integrated development environments (IDEs), which includes JupyterLab, Code Editor, as well as RStudio. Data scientists and ML engineers can spin up SageMaker Studio private and shared spaces, which are used to manage the storage and resource needs of the JupyterLab and Code Editor applications, enable stopping the applications when not in use to save on compute costs, and resume the work from where they stopped.
The storage resources for SageMaker Studio spaces are Amazon Elastic Block Store (Amazon EBS) volumes, which offer low-latency access to user data like notebooks, sample data, or Python/Conda virtual environments. However, there are several scenarios where using a distributed file system shared across private JupyterLab and Code Editor spaces is convenient, which is enabled by configuring an Amazon Elastic File System (Amazon EFS) file system in SageMaker Studio. Amazon EFS provides a scalable fully managed elastic NFS file system for AWS compute instances.
Amazon SageMaker supports automatically mounting a folder in an EFS volume for each user in a domain. Using this folder, users can share data between their own private spaces. However, users can’t share data with other users in the domain; they only have access to their own folder user-default-efs in the $HOME directory of the SageMaker Studio application.
In this post, we explore three distinct scenarios that demonstrate the versatility of integrating custom Amazon EFS with SageMaker Studio.
For further information on configuring Amazon EFS in SageMaker Studio, refer to Attaching a custom file system to a domain or user profile.
Solution overview
In the first scenario, an AWS infrastructure admin wants to set up an EFS file system that can be shared across the private spaces of a given user profile in SageMaker Studio. This means that each user within the domain will have their own private space on the EFS file system, allowing them to store and access their own data and files. The automation described in this post will enable new team members joining the data science team can quickly set up their private space on the EFS file system and access the necessary resources to start contributing to the ongoing project.
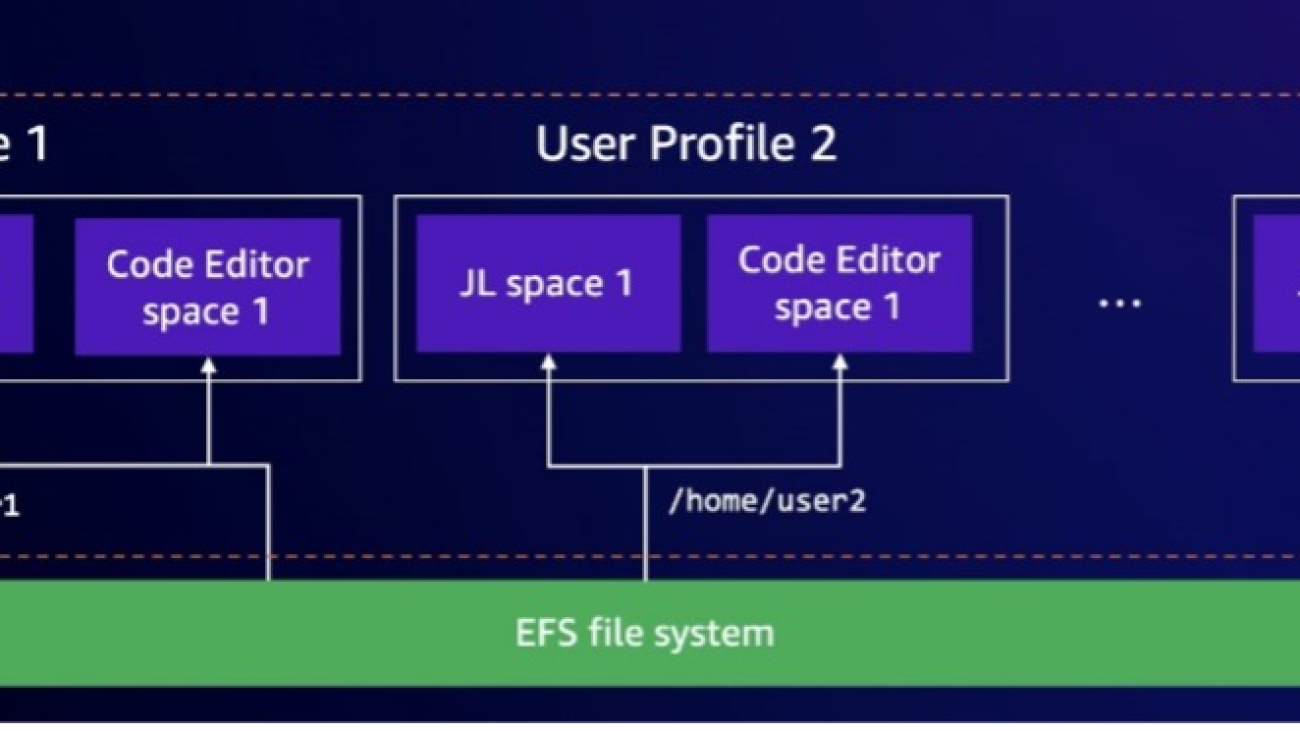
The following diagram illustrates this architecture.

This scenario offers the following benefits:
- Individual data storage and analysis – Users can store their personal datasets, models, and other files in their private spaces, allowing them to work on their own projects independently. Segregation is made by their user profile.
- Centralized data management – The administrator can manage the EFS file system centrally, maintaining data security, backup, and direct access for all users. By setting up an EFS file system with a private space, users can effortlessly track and maintain their work.
- Cross-instance file sharing – Users can access their files from multiple SageMaker Studio spaces, because the EFS file system provides a persistent storage solution.
The second scenario is related to the creation of a single EFS directory that is shared across all the spaces of a given SageMaker Studio domain. This means that all users within the domain can access and use the same shared directory on the EFS file system, allowing for better collaboration and centralized data management (for example, to share common artifacts). This is a more generic use case, because there is no specific segregated folder for each user profile.
The following diagram illustrates this architecture.

This scenario offers the following benefits:
- Shared project directories – Suppose the data science team is working on a large-scale project that requires collaboration among multiple team members. By setting up a shared EFS directory at project level, the team can collaborate on the same projects by accessing and working on files in the shared directory. The data science team can, for example, use the shared EFS directory to store their Jupyter notebooks, analysis scripts, and other project-related files.
- Simplified file management – Users don’t need to manage their own private file storage, because they can rely on the shared directory for their file-related needs.
- Improved data governance and security – The shared EFS directory, being centrally managed by the AWS infrastructure admin, can provide improved data governance and security. The admin can implement access controls and other data management policies to maintain the integrity and security of the shared resources.
The third scenario explores the configuration of an EFS file system that can be shared across multiple SageMaker Studio domains within the same VPC. This allows users from different domains to access and work with the same set of files and data, enabling cross-domain collaboration and centralized data management.
The following diagram illustrates this architecture.

This scenario offers the following benefits:
- Enterprise-level data science collaboration – Imagine a large organization with multiple data science teams working on various projects across different departments or business units. By setting up a shared EFS file system accessible across the organization’s SageMaker Studio domains, these teams can collaborate on cross-functional projects, share artifacts, and use a centralized data repository for their work.
- Shared infrastructure and resources – The EFS file system can be used as a shared resource across multiple SageMaker Studio domains, promoting efficiency and cost-effectiveness.
- Scalable data storage – As the number of users or domains increases, the EFS file system automatically scales to accommodate the growing storage and access requirements.
- Data governance – The shared EFS file system, being managed centrally, can be subject to stricter data governance policies, access controls, and compliance requirements. This can help the organization meet regulatory and security standards while still enabling cross-domain collaboration and data sharing.
Prerequisites
This post provides an AWS CloudFormation template to deploy the main resources for the solution. In addition to this, the solution expects that the AWS account in which the template is deployed already has the following configuration and resources:
- You should have a SageMaker Studio domain. Refer to Quick setup to Amazon SageMaker for instructions to set up a domain with default settings.
- You should have an AWS CloudTrail log file that logs the SageMaker API CreateUserProfile. Refer to Creating a trail for your AWS account for additional information.
- The CloudFormation resources are deployed in a virtual private cloud (VPC). Make sure the selected VPC allows outbound traffic through a NAT gateway and has proper routing Amazon Simple Storage Service (Amazon S3) endpoint access, which will be required for AWS CloudFormation. Refer to How do I troubleshoot custom resource failures in CloudFormation? for additional information.
- The CloudFormation template deploys an AWS Lambda function in a VPC. If the access to AWS services in the selected VPC is restricted using AWS PrivateLink, make sure the Lambda security group can connect to the interface VPC endpoints for SageMaker (API), Amazon EFS, and Amazon Elastic Compute Cloud (Amazon EC2). Refer to Connecting inbound interface VPC endpoints for Lambda for additional information.
- You should have the necessary AWS Identity and Access Management permissions to deploy the CloudFormation template in your account.
Refer to Attaching a custom file system to a domain or user profile for additional prerequisites.
Configure an EFS directory shared across private spaces of a given user profile
In this scenario, an administrator wants to provision an EFS file system for all users of a SageMaker Studio domain, creating a private file system directory for each user. We can distinguish two use cases:
- Create new SageMaker Studio user profiles – A new team member joins a preexisting SageMaker Studio domain and wants to attach a custom EFS file system to the JupyterLab or Code Editor spaces
- Use preexisting SageMaker Studio user profiles – A team member is already working on a specific SageMaker Studio domain and wants to attach a custom EFS file system to the JupyterLab or Code Editor spaces
The solution provided in this post focuses on the first use case. We discuss how to adapt the solution for preexisting SageMaker Studio domain user profiles later in this post.
The following diagram illustrates the high-level architecture of the solution.

In this solution, we use CloudTrail, Amazon EventBridge, and Lambda to automatically create a private EFS directory when a new SageMaker Studio user profile is created. The high-level steps to set up this architecture are as follows:
- Create an EventBridge rule that invokes the Lambda function when a new SageMaker user profile is created and logged in CloudTrail.
- Create an EFS file system with an access point for the Lambda function and with a mount target in every Availability Zone that the SageMaker Studio domain is located.
- Use a Lambda function to create a private EFS directory with the required POSIX permissions for the profile. The function will also update the profile with the new file system configuration.
Deploy the solution using AWS CloudFormation
To use the solution, you can deploy the infrastructure using the following CloudFormation template. This template deploys three main resources in your account: Amazon EFS resources (file system, access points, mount targets), an EventBridge rule, and a Lambda function.
Refer to Create a stack from the CloudFormation console for additional information. The input parameters for this template are:
- SageMakerDomainId – The SageMaker Studio domain ID that will be associated with the EFS file system.
- SageMakerStudioVpc – The VPC associated to the SageMaker Studio domain.
- SageMakerStudioSubnetId – One or multiple subnets associated to the SageMaker Studio domain. The template deploys its resources in these subnets.
- SageMakerStudioSecurityGroupId – The security group associated to the SageMaker Studio domain. The template configures the Lambda function with this security group.
Amazon EFS resources
After you deploy the template, navigate to the Amazon EFS console and confirm that the EFS file system has been created. The file system has a mount target in every Availability Zone that your SageMaker domain connects to.
Note that each mount target uses the EC2 security group that SageMaker created in your AWS account when you first created the domain, which allows NFS traffic at port 2049. The provided template automatically retrieves this security group when it is first deployed, using a Lambda backed custom resource.

You can also observe that the file system has an EFS access point. This access point grants root access on the file system for the Lambda function that will create the directories for the SageMaker Studio user profiles.

EventBridge rule
The second main resource is an EventBridge rule invoked when a new SageMaker Studio user profile is created. Its target is the Lambda function that creates the folder in the EFS file system and updates the profile that has been just created. The input of the Lambda function is the event matched, where you can get the SageMaker Studio domain ID and the SageMaker user profile name.

Lambda function
Lastly, the template creates a Lambda function that creates a directory in the EFS file system with the required POSIX permissions for the user profile and updates the user profile with the new file system configuration.
At a POSIX permissions level, you can control which users can access the file system and which files or data they can access. The POSIX user and group ID for SageMaker apps are:
UID– The POSIX user ID. The default is 200001. A valid range is a minimum value of 10000 and maximum value of 4000000.GID– The POSIX group ID. The default is 1001. A valid range is a minimum value of 1001 and maximum value of 4000000.
The Lambda function is in the same VPC as the EFS file system and it has attached the file system and access point previously created.

Adapt the solution for preexisting SageMaker Studio domain user profiles
We can reuse the previous solution for scenarios in which the domain already has user profiles created. For that, you can create an additional Lambda function in Python that lists all the user profiles for the given SageMaker Studio domain and creates a dedicated EFS directory for each user profile.
The Lambda function should be in the same VPC as the EFS file system and it has attached the file system and access point previously created. You need to add the efs_id and domain_id values as environment variables for the function.
You can include the following code as part of this new Lambda function and run it manually:
Configure an EFS directory shared across all spaces of a given domain
In this scenario, an administrator wants to provision an EFS file system for all users of a SageMaker Studio domain, using the same file system directory for all the users.
To achieve this, in addition to the prerequisites described earlier in this post, you need to complete the following steps.
Create the EFS file system
The file system needs to be in the same VPC as the SageMaker Studio domain. Refer to Creating EFS file systems for additional information.

Add mount targets to the EFS file system
Before SageMaker Studio can access the new EFS file system, the file system must have a mount target in each of the subnets associated with the domain. For more information about assigning mount targets to subnets, see Managing mount targets. You can get the subnets associated to the domain on the SageMaker Studio console under Network. You need to create a mount target for each subnet.

Additionally, for each mount target, you must add the security group that SageMaker created in your AWS account when you created the SageMaker Studio domain. The security group name has the format security-group-for-inbound-nfs-domain-id.
The following screenshot shows an example of an EFS file system with two mount targets for a SageMaker Studio domain associated to two subnets. Note the security group associated to both mount targets.

Create an EFS access point
The Lambda function accesses the EFS file system as root using this access point. See Creating access points for additional information.

Create a new Lambda function
Define a new Lambda function with the name LambdaManageEFSUsers. This function updates the default space settings of the SageMaker Studio domain, configuring the file system settings to use a specific EFS file system shared repository path. This configuration is automatically applied to all spaces within the domain.
The Lambda function is in the same VPC as the EFS file system and it has attached the file system and access point previously created. Additionally, you need to add efs_id and domain_id as environment variables for the function.
At a POSIX permissions level, you can control which users can access the file system and which files or data they can access. The POSIX user and group ID for SageMaker apps are:
UID– The POSIX user ID. The default is 200001.GID– The POSIX group ID. The default is 1001.
The function updates the default space settings of the SageMaker Studio domain, configuring the EFS file system to be used by all users. See the following code:
The execution role of the Lambda function needs to have permissions to update the SageMaker Studio domain:
Configure an EFS directory shared across multiple domains under the same VPC
In this scenario, an administrator wants to provision an EFS file system for all users of multiple SageMaker Studio domains, using the same file system directory for all the users. The idea in this case is to assign the same EFS file system to all users of all domains that are within the same VPC. To test the solution, the account should ideally have two SageMaker Studio domains inside the VPC and subnet.
Create the EFS file system, add mount targets, and create an access point
Complete the steps in the previous section to set up your file system, mount targets, and access point.
Create a new Lambda function
Define a Lambda function called LambdaManageEFSUsers. This function is responsible for automating the configuration of SageMaker Studio domains to use a shared EFS file system within a specific VPC. This can be useful for organizations that want to provide a centralized storage solution for their ML projects across multiple SageMaker Studio domains. See the following code:
The execution role of the Lambda function needs to have permissions to describe and update the SageMaker Studio domain:
Clean up
To clean up the solution you implemented and avoid further costs, delete the CloudFormation template you deployed in your AWS account. When you delete the template, you also delete the EFS file system and its storage. For additional information, refer to Delete a stack from the CloudFormation console.
Conclusion
In this post, we have explored three scenarios demonstrating the versatility of integrating Amazon EFS with SageMaker Studio. These scenarios highlight how Amazon EFS can provide a scalable, secure, and collaborative data storage solution for data science teams.
The first scenario focused on configuring an EFS directory with private spaces for individual user profiles, allowing users to store and access their own data while the administrator manages the EFS file system centrally.
The second scenario showcased a shared EFS directory across all spaces within a SageMaker Studio domain, enabling better collaboration and centralized data management.
The third scenario explored an EFS file system shared across multiple SageMaker Studio domains, empowering enterprise-level data science collaboration and promoting efficient use of shared resources.
By implementing these Amazon EFS integration scenarios, organizations can unlock the full potential of their data science teams, improve data governance, and enhance the overall efficiency of their data-driven initiatives. The integration of Amazon EFS with SageMaker Studio provides a versatile platform for data science teams to thrive in the evolving landscape of ML and AI.
About the Authors
 Irene Arroyo Delgado is an AI/ML and GenAI Specialist Solutions Architect at AWS. She focuses on bringing out the potential of generative AI for each use case and productionizing ML workloads, to achieve customers’ desired business outcomes by automating end-to-end ML lifecycles. In her free time, Irene enjoys traveling and hiking.
Irene Arroyo Delgado is an AI/ML and GenAI Specialist Solutions Architect at AWS. She focuses on bringing out the potential of generative AI for each use case and productionizing ML workloads, to achieve customers’ desired business outcomes by automating end-to-end ML lifecycles. In her free time, Irene enjoys traveling and hiking.
 Itziar Molina Fernandez is an AI/ML Consultant in the AWS Professional Services team. In her role, she works with customers building large-scale machine learning platforms and generative AI use cases on AWS. In her free time, she enjoys exploring new places.
Itziar Molina Fernandez is an AI/ML Consultant in the AWS Professional Services team. In her role, she works with customers building large-scale machine learning platforms and generative AI use cases on AWS. In her free time, she enjoys exploring new places.
 Matteo Amadei is a Data Scientist Consultant in the AWS Professional Services team. He uses his expertise in artificial intelligence and advanced analytics to extract valuable insights and drive meaningful business outcomes for customers. He has worked on a wide range of projects spanning NLP, computer vision, and generative AI. He also has experience with building end-to-end MLOps pipelines to productionize analytical models. In his free time, Matteo enjoys traveling and reading.
Matteo Amadei is a Data Scientist Consultant in the AWS Professional Services team. He uses his expertise in artificial intelligence and advanced analytics to extract valuable insights and drive meaningful business outcomes for customers. He has worked on a wide range of projects spanning NLP, computer vision, and generative AI. He also has experience with building end-to-end MLOps pipelines to productionize analytical models. In his free time, Matteo enjoys traveling and reading.
 Giuseppe Angelo Porcelli is a Principal Machine Learning Specialist Solutions Architect for Amazon Web Services. With several years of software engineering and an ML background, he works with customers of any size to understand their business and technical needs and design AI and ML solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. He has worked on projects in different domains, including MLOps, computer vision, and NLP, involving a broad set of AWS services. In his free time, Giuseppe enjoys playing football.
Giuseppe Angelo Porcelli is a Principal Machine Learning Specialist Solutions Architect for Amazon Web Services. With several years of software engineering and an ML background, he works with customers of any size to understand their business and technical needs and design AI and ML solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. He has worked on projects in different domains, including MLOps, computer vision, and NLP, involving a broad set of AWS services. In his free time, Giuseppe enjoys playing football.
Summarize call transcriptions securely with Amazon Transcribe and Amazon Bedrock Guardrails
Given the volume of meetings, interviews, and customer interactions in modern business environments, audio recordings play a crucial role in capturing valuable information. Manually transcribing and summarizing these recordings can be a time-consuming and tedious task. Fortunately, advancements in generative AI and automatic speech recognition (ASR) have paved the way for automated solutions that can streamline this process.
Customer service representatives receive a high volume of calls each day. Previously, calls were recorded and manually reviewed later for compliance, regulations, and company policies. Call recordings had to be transcribed, summarized, and then redacted for personal identifiable information (PII) before analyzing calls, resulting in delayed access to insights.
Redacting PII is a critical practice in security for several reasons. Maintaining the privacy and protection of individuals’ personal information is not only a matter of ethical responsibility, but also a legal requirement. In this post, we show you how to use Amazon Transcribe to get near real-time transcriptions of calls sent to Amazon Bedrock for summarization and sensitive data redaction. We’ll walk through an architecture that uses AWS Step Functions to orchestrate the process, providing seamless integration and efficient processing
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading model providers such as AI21 Labs, Anthropic, Cohere, Meta, Stability AI, Mistral AI, and Amazon through a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI. You can use Amazon Bedrock Guardrails to redact sensitive information such as PII found in the generated call transcription summaries. Clean, summarized transcripts are then sent to analysts. This provides quicker access to call trends while protecting customer privacy.
Solution overview
The architecture of this solution is designed to be scalable, efficient, and compliant with privacy regulations. It includes the following key components:
- Recording – An audio file, such as a meeting or support call, to be transcribed and summarized
- Step Functions workflow – Coordinates the transcription and summarization process
- Amazon Transcribe – Converts audio recordings into text
- Amazon Bedrock – Summarizes the transcription and removes PII
- Amazon SNS – Delivers the summary to the designated recipient
- Recipient – Receives the summarized, PII-redacted transcript
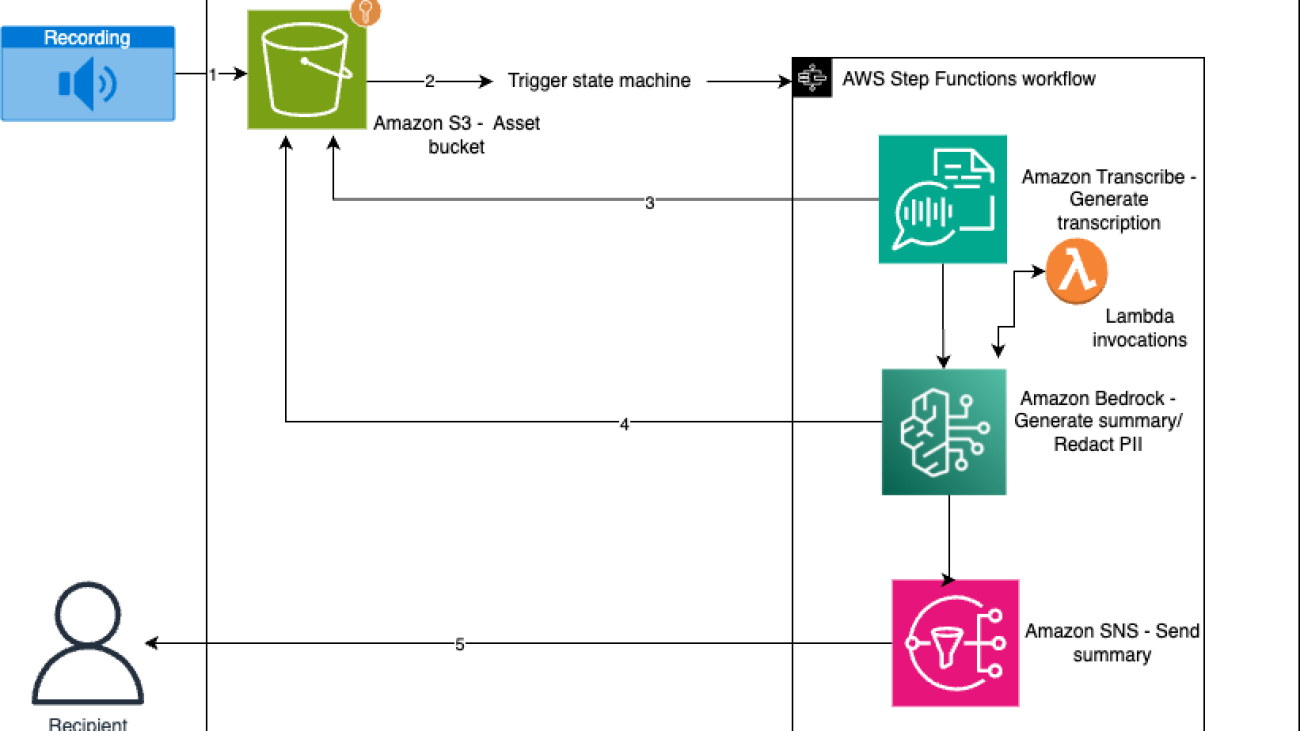
The following diagram shows the architecture overflow –

The workflow orchestrated by Step Functions is as follows:
- An audio recording is provided as an input to the Step Functions workflow. This could be done manually or automatically depending on the specific use case and integration requirements.
- The workflow invokes Amazon Transcribe, which converts the multi-speaker audio recording into a textual, speaker-partition transcription. Amazon Transcribe uses advanced speech recognition algorithms and machine learning (ML) models to accurately partition speakers and transcribe the audio, handling various accents, background noise, and other challenges.
- The transcription output from Amazon Transcribe is then passed to Anthropic’s Claude 3 Haiku model on Amazon Bedrock through AWS Lambda. This model was chosen because it has relatively lower latency and cost than other models. The model first summarizes the transcript according to its summary instructions, and then the summarized output (the model response) is evaluated by Amazon Bedrock Guardrails to redact PII. To learn how it blocks harmful content, refer to How Amazon Bedrock Guardrails works. The instructions and transcript are both passed to the model as context.
- The output from Amazon Bedrock is stored in Amazon Simple Storage Service (Amazon S3) and sent to the designated recipient using Amazon Simple Notification Service (Amazon SNS). Amazon SNS supports various delivery channels, including email, SMS, and mobile push notifications, making sure that the summary reaches the intended recipient in a timely and reliable manner
The recipient can then review the concise summary, quickly grasping the key points and insights from the original audio recording. Additionally, sensitive information has been redacted, maintaining privacy and compliance with relevant regulations.
The following diagram shows the Step Functions workflow –

Prerequisites
Follow these steps before starting:
- Amazon Bedrock users need to request access to models before they’re available for use. This is a one-time action. For this solution, you need to enable access to Anthropic’s Claude 3 Haiku model on Amazon Bedrock. For more information, refer to Access Amazon Bedrock foundation models. Deployment, as described below, is currently supported only in the US West (Oregon) us-west-2 AWS Region. Users may explore other models if desired. You might need some customizations to deploy to alternative Regions with different model availability (such as us-east-1, which hosts Anthropic’s Claude 3.5 Sonnet). Make sure you consider model quality, speed, and cost tradeoffs before choosing a model.
- Create a guardrail for PII redaction. Configure filters to block or mask sensitive information. This option can be found on the Amazon Bedrock console on the Add sensitive information filters page when creating a guardrail. To learn how to configure filters for other use cases, refer to Remove PII from conversations by using sensitive information filters.
Deploy solution resources
To deploy the solution, download an AWS CloudFormation template to automatically provision the necessary resources in your AWS account. The template sets up the following components:
- A Step Functions workflow
- Lambda functions
- An SNS topic
- An S3 bucket
- AWS Key Management Service (AWS KMS) keys for data encryption and decryption
By using this template, you can quickly deploy the sample solution with minimal manual configuration. The template requires the following parameters:
- Email address used to send summary – The summary will be sent to this address. You must acknowledge the initial Amazon SNS confirmation email before receiving additional notifications.
- Summary instructions – These are the instructions given to the Amazon Bedrock model to generate the summary
- Guardrail ID – This is the ID of your recently created guardrail, which can be found on the Amazon Bedrock Guardrails console in Guardrail overview
The Summary instructions are read into your Lambda function as an environment variable.
Deploy the solution
After you deploy the resources using AWS CloudFormation, complete these steps:
- Add a Lambda layer.
Although AWS Lambda regularly updates the version of AWS Boto3 included, at the time of writing this post, it still provides version 1.34.126. To use Amazon Bedrock Guardrails, you need version 1.34.90 or higher, for which we’ll add a Lambda layer that updates the Boto3. You can follow the official developer guide on how to add a Lambda layer.
There are different ways to create a Lambda layer. A simple method is to use the steps outlined in Packaging the layer content, which references a sample application repo. You should be able to replace requests==2.31.0 within requirements.txt content to boto3, which will install the latest available version, then create the layer.
To add the layer to Lambda, make sure that the parameters specified in Creating the layer match the deployed Lambda. That is, you need to update compatible-architectures to x86_64.
- Acknowledge the Amazon SNS email confirmation that you should receive a few moments after creating the CloudFormation stack
- On the AWS CloudFormation console, find the stack you just created
- On the stack’s Outputs tab, look for the value associated with
AssetBucketName. It will look something likesummary-generator-assetbucket-xxxxxxxxxxxxx. - On the Amazon S3 console, find your S3 assets bucket.
This is where you’ll upload your recordings. Valid file formats are MP3, MP4, WAV, FLAC, AMR, OGG, and WebM.
- Upload your recording to the recordings folder in Amazon S3
Uploading recordings will automatically trigger the AWS Step Functions state machine. For this example, we use a sample team meeting recording from the sample recording.
- On the AWS Step Functions console, find the summary-generator state machine. Choose the name of the state machine run with the status Running.
Here, you can watch the progress of the state machine as it processes the recording. After it reaches its Success state, you should receive an emailed summary of the recording. Alternatively, you can navigate to the S3 assets bucket and view the transcript there in the transcripts folder.
Expand the solution
Now that you have a working solution, here are some potential ideas to customize the solution for your specific use cases:
- Try altering the process to fit your available source content and desired outputs:
- For situations where transcripts are available, create an alternate AWS Step Functions workflow to ingest existing text-based or PDF-based transcriptions
- Instead of using Amazon SNS to notify recipients through email, you can use it to send the output to a different endpoint, such as a team collaboration site or to the team’s chat channel
- Try changing the summary instructions for the AWS CloudFormation stack parameter provided to Amazon Bedrock to produce outputs specific to your use case. The following are some examples:
- When summarizing a company’s earnings call, you could have the model focus on potential promising opportunities, areas of concern, and things that you should continue to monitor
- If you’re using the model to summarize a course lecture, it could identify upcoming assignments, summarize key concepts, list facts, and filter out small talk from the recording
- For the same recording, create different summaries for different audiences:
- Engineers’ summaries focus on design decisions, technical challenges, and upcoming deliverables
- Project managers’ summaries focus on timelines, costs, deliverables, and action items
- Project sponsors get a brief update on project status and escalations
- For longer recordings, try generating summaries for different levels of interest and time commitment. For example, create a single sentence, single paragraph, single page, or in-depth summary. In addition to the prompt, you might want to adjust the
max_tokens_to_sampleparameter to accommodate different content lengths.
Clean up
Clean up the resources you created for this solution to avoid incurring costs. You can use an AWS SDK, the AWS Command Line Interface (AWS CLI), or the console.
- Delete Amazon Bedrock Guardrails and the Lambda layer you created
- Delete the CloudFormation stack
To use the console, follow these steps:
- On the Amazon Bedrock console, in the navigation menu, select Guardrails. Choose your guardrail, then select Delete.
- On the AWS Lambda console, in the navigation menu, select Layers. Choose your layer, then select Delete.
- On the AWS CloudFormation console, in the navigation menu, select Stacks. Choose the stack you created, then select Delete.
Deleting the stack won’t delete the associated S3 bucket. If you no longer require the recordings or transcripts, you can delete the bucket separately. Amazon Transcribe is designed to automatically delete transcription jobs after 90 days. However, you can opt to manually delete these jobs before the 90-day retention period expires.
Conclusion
As businesses turn to data as a foundation for decision-making, having the ability to efficiently extract insights from audio recordings is invaluable. By using the power of generative AI with Amazon Bedrock and Amazon Transcribe, your organization can create concise summaries of audio recordings while maintaining privacy and compliance. The proposed architecture demonstrates how AWS services can be orchestrated using AWS Step Functions to streamline and automate complex workflows, enabling organizations to focus on their core business activities.
This solution not only saves time and effort, but also makes sure that sensitive information is redacted, mitigating potential risks and promoting compliance with data protection regulations. As organizations continue to generate and process large volumes of audio data, solutions like this will become increasingly important for gaining insights, making informed decisions, and maintaining a competitive edge.
About the authors
 Yash Yamsanwar is a Machine Learning Architect at Amazon Web Services (AWS). He is responsible for designing high-performance, scalable machine learning infrastructure that optimizes the full lifecycle of machine learning models, from training to deployment. Yash collaborates closely with ML research teams to push the boundaries of what is possible with LLMs and other cutting-edge machine learning technologies.
Yash Yamsanwar is a Machine Learning Architect at Amazon Web Services (AWS). He is responsible for designing high-performance, scalable machine learning infrastructure that optimizes the full lifecycle of machine learning models, from training to deployment. Yash collaborates closely with ML research teams to push the boundaries of what is possible with LLMs and other cutting-edge machine learning technologies.
 Sawyer Hirt is a Solutions Architect at AWS, specializing in AI/ML and cloud architectures, with a passion for helping businesses leverage cutting-edge technologies to overcome complex challenges. His expertise lies in designing and optimizing ML workflows, enhancing system performance, and making advanced AI solutions more accessible and cost-effective, with a particular focus on Generative AI. Outside of work, Sawyer enjoys traveling, spending time with family, and staying current with the latest developments in cloud computing and artificial intelligence.
Sawyer Hirt is a Solutions Architect at AWS, specializing in AI/ML and cloud architectures, with a passion for helping businesses leverage cutting-edge technologies to overcome complex challenges. His expertise lies in designing and optimizing ML workflows, enhancing system performance, and making advanced AI solutions more accessible and cost-effective, with a particular focus on Generative AI. Outside of work, Sawyer enjoys traveling, spending time with family, and staying current with the latest developments in cloud computing and artificial intelligence.
How DPG Media uses Amazon Bedrock and Amazon Transcribe to enhance video metadata with AI-powered pipelines
This post was co-written with Lucas Desard, Tom Lauwers, and Sam Landuydt from DPG Media.
DPG Media is a leading media company in Benelux operating multiple online platforms and TV channels. DPG Media’s VTM GO platform alone offers over 500 days of non-stop content.
With a growing library of long-form video content, DPG Media recognizes the importance of efficiently managing and enhancing video metadata such as actor information, genre, summary of episodes, the mood of the video, and more. Having descriptive metadata is key to providing accurate TV guide descriptions, improving content recommendations, and enhancing the consumer’s ability to explore content that aligns with their interests and current mood.
This post shows how DPG Media introduced AI-powered processes using Amazon Bedrock and Amazon Transcribe into its video publication pipelines in just 4 weeks, as an evolution towards more automated annotation systems.
The challenge: Extracting and generating metadata at scale
DPG Media receives video productions accompanied by a wide range of marketing materials such as visual media and brief descriptions. These materials often lack standardization and vary in quality. As a result, DPG Media Producers have to run a screening process to consume and understand the content sufficiently to generate the missing metadata, such as brief summaries. For some content, additional screening is performed to generate subtitles and captions.
As DPG Media grows, they need a more scalable way of capturing metadata that enhances the consumer experience on online video services and aids in understanding key content characteristics.
The following were some initial challenges in automation:
- Language diversity – The services host both Dutch and English shows. Some local shows feature Flemish dialects, which can be difficult for some large language models (LLMs) to understand.
- Variability in content volume – They offer a range of content volume, from single-episode films to multi-season series.
- Release frequency – New shows, episodes, and movies are released daily.
- Data aggregation – Metadata needs to be available at the top-level asset (program or movie) and must be reliably aggregated across different seasons.
Solution overview
To address the challenges of automation, DPG Media decided to implement a combination of AI techniques and existing metadata to generate new, accurate content and category descriptions, mood, and context.
The project focused solely on audio processing due to its cost-efficiency and faster processing time. Video data analysis with AI wasn’t required for generating detailed, accurate, and high-quality metadata.
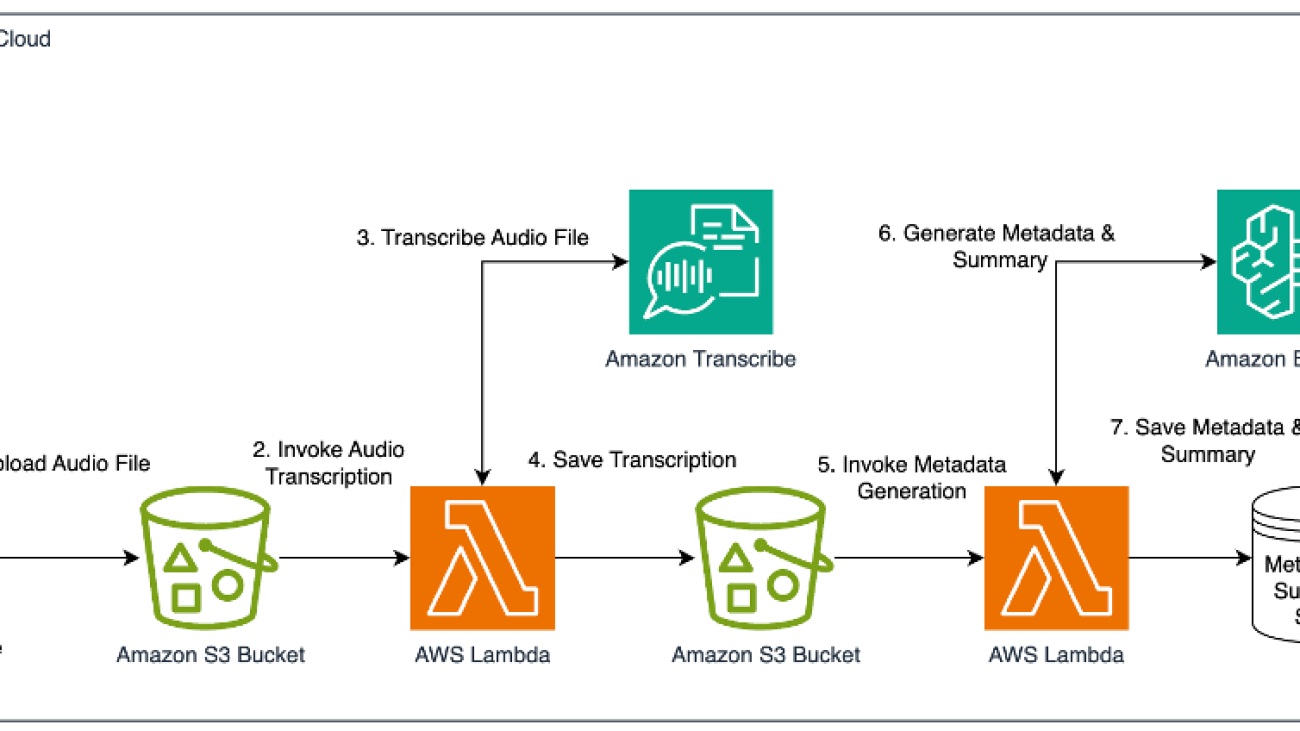
The following diagram shows the metadata generation pipeline from audio transcription to detailed metadata.

The general architecture of the metadata pipeline consists of two primary steps:
- Generate transcriptions of audio tracks: use speech recognition models to generate accurate transcripts of the audio content.
- Generate metadata: use LLMs to extract and generate detailed metadata from the transcriptions.
In the following sections, we discuss the components of the pipeline in more detail.
Step 1. Generate transcriptions of audio tracks
To generate the necessary audio transcripts for metadata extraction, the DPG Media team evaluated two different transcription strategies: Whisper-v3-large, which requires at least 10 GB of vRAM and high operational processing, and Amazon Transcribe, a managed service with the added benefit of automatic model updates from AWS over time and speaker diarization. The evaluation focused on two key factors: price-performance and transcription quality.
To evaluate the transcription accuracy quality, the team compared the results against ground truth subtitles on a large test set, using the following metrics:
- Word error rate (WER) – This metric measures the percentage of words that are incorrectly transcribed compared to the ground truth. A lower WER indicates a more accurate transcription.
- Match error rate (MER) – MER assesses the proportion of correct words that were accurately matched in the transcription. A lower MER signifies better accuracy.
- Word information lost (WIL) – This metric quantifies the amount of information lost due to transcription errors. A lower WIL suggests fewer errors and better retention of the original content.
- Word information preserved (WIP) – WIP is the opposite of WIL, indicating the amount of information correctly captured. A higher WIP score reflects more accurate transcription.
- Hits – This metric counts the number of correctly transcribed words, giving a straightforward measure of accuracy.
Both experiments transcribing audio yielded high-quality results without the need to incorporate video or further speaker diarization. For further insights into speaker diarization in other use cases, see Streamline diarization using AI as an assistive technology: ZOO Digital’s story.
Considering the varying development and maintenance efforts required by different alternatives, DPG Media chose Amazon Transcribe for the transcription component of their system. This managed service offered convenience, allowing them to concentrate their resources on obtaining comprehensive and highly accurate data from their assets, with the goal of achieving 100% qualitative precision.
Step 2. Generate metadata
Now that DPG Media has the transcription of the audio files, they use LLMs through Amazon Bedrock to generate the various categories of metadata (summaries, genre, mood, key events, and so on). Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Through Amazon Bedrock, DPG Media selected the Anthropic Claude 3 Sonnet model based on internal testing, and the Hugging Face LMSYS Chatbot Arena Leaderboard for its reasoning and Dutch language performance. Working closely with end-consumers, the DPG Media team tuned the prompts to make sure the generated metadata matched the expected format and style.
After the team had generated metadata at the individual video level, the next step was to aggregate this metadata across an entire series of episodes. This was a critical requirement, because content recommendations on a streaming service are typically made at the series or movie level, rather than the episode level.
To generate summaries and metadata at the series level, the DPG Media team reused the previously generated video-level metadata. They fed the summaries in an ordered and structured manner, along with a specifically tailored system prompt, back through Amazon Bedrock to Anthropic Claude 3 Sonnet.
Using the summaries instead of the full transcriptions of the episodes was sufficient for high-quality aggregated data and was more cost-efficient, because many of DPG Media’s series have extended runs.
The solution also stores the direct association between each type of metadata and its corresponding system prompt, making it straightforward to tune, remove, or add prompts as needed—similar to the adjustments made during the development process. This flexibility allows them to tailor the metadata generation to evolving business requirements.
To evaluate the metadata quality, the team used reference-free LLM metrics, inspired by LangSmith. This approach used a secondary LLM to evaluate the outputs based on tailored metrics such as if the summary is simple to understand, if it contains all important events from the transcription, and if there are any hallucinations in the generated summary. The secondary LLM is used to evaluate the summaries on a large scale.
Results and lessons learned
The implementation of the AI-powered metadata pipeline has been a transformative journey for DPG Media. Their approach saves days of work generating metadata for a TV series.
DPG Media chose Amazon Transcribe for its ease of transcription and low maintenance, with the added benefit of incremental improvements by AWS over the years. For metadata generation, DPG Media chose Anthropic Claude 3 Sonnet on Amazon Bedrock, instead of building direct integrations to various model providers. The flexibility to experiment with multiple models was appreciated, and there are plans to try out Anthropic Claude Opus when it becomes available in their desired AWS Region.
DPG Media decided to strike a balance between AI and human expertise by having the results generated by the pipeline validated by humans. This approach was chosen because the results would be exposed to end-customers, and AI systems can sometimes make mistakes. The goal was not to replace people but to enhance their capabilities through a combination of human curation and automation.
Transforming the video viewing experience is not merely about adding more descriptions, it’s about creating a richer, more engaging user experience. By implementing AI-driven processes, DPG Media aims to offer better-recommended content to users, foster a deeper understanding of its content library, and progress towards more automated and efficient annotation systems. This evolution promises not only to streamline operations but also to align content delivery with modern consumption habits and technological advancements.
Conclusion
In this post, we shared how DPG Media introduced AI-powered processes using Amazon Bedrock into its video publication pipelines. This solution can help accelerate audio metadata extraction, create a more engaging user experience, and save time.
We encourage you to learn more about how to gain a competitive advantage with powerful generative AI applications by visiting Amazon Bedrock and trying this solution out on a dataset relevant to your business.
About the Authors
 Lucas Desard is GenAI Engineer at DPG Media. He helps DPG Media integrate generative AI efficiently and meaningfully into various company processes.
Lucas Desard is GenAI Engineer at DPG Media. He helps DPG Media integrate generative AI efficiently and meaningfully into various company processes.
 Tom Lauwers is a machine learning engineer on the video personalization team for DPG Media. He builds and architects the recommendation systems for DPG Media’s long-form video platforms, supporting brands like VTM GO, Streamz, and RTL play.
Tom Lauwers is a machine learning engineer on the video personalization team for DPG Media. He builds and architects the recommendation systems for DPG Media’s long-form video platforms, supporting brands like VTM GO, Streamz, and RTL play.
 Sam Landuydt is the Area Manager Recommendation & Search at DPG Media. As the manager of the team, he guides ML and software engineers in building recommendation systems and generative AI solutions for the company.
Sam Landuydt is the Area Manager Recommendation & Search at DPG Media. As the manager of the team, he guides ML and software engineers in building recommendation systems and generative AI solutions for the company.
 Irina Radu is a Prototyping Engagement Manager, part of AWS EMEA Prototyping and Cloud Engineering. She helps customers get the most out of the latest tech, innovate faster, and think bigger.
Irina Radu is a Prototyping Engagement Manager, part of AWS EMEA Prototyping and Cloud Engineering. She helps customers get the most out of the latest tech, innovate faster, and think bigger.
 Fernanda Machado, AWS Prototyping Architect, helps customers bring ideas to life and use the latest best practices for modern applications.
Fernanda Machado, AWS Prototyping Architect, helps customers bring ideas to life and use the latest best practices for modern applications.
 Andrew Shved, Senior AWS Prototyping Architect, helps customers build business solutions that use innovations in modern applications, big data, and AI.
Andrew Shved, Senior AWS Prototyping Architect, helps customers build business solutions that use innovations in modern applications, big data, and AI.
How SailPoint uses Anthropic’s Claude on Amazon Bedrock to automatically generate TypeScript code for SaaS connectors
Generative AI is revolutionizing the way developers approach programming by providing intelligent assistance and automation throughout the coding process. With the power of advanced language models and machine learning (ML) algorithms, generative AI can understand the context and intent behind a programmer’s code, offering valuable suggestions, completing code snippets, and even generating entire functions or modules based on high-level descriptions. This technology empowers developers to focus on higher-level problem-solving and architecture, while the AI handles the tedious and repetitive aspects of coding. One of the key advantages of large language models (LLMs) in programming is their ability to learn from the vast amounts of existing code and programming patterns they were trained on. This knowledge allows them to generate context-aware code, detect potential bugs or vulnerabilities, and offer optimizations to improve code quality and performance.
In this post, we highlight how the AWS Generative AI Innovation Center collaborated with SailPoint Technologies to build a generative AI-based coding assistant that uses Anthropic’s Claude Sonnet on Amazon Bedrock to help accelerate the development of software as a service (SaaS) connectors.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
SailPoint specializes in enterprise identity security solutions. Over 3,000 enterprises worldwide use SailPoint to help defend against today’s dynamic, identity-centric cyber threats while enhancing productivity and efficiency. Their products are designed to manage and secure access to applications and data through the lens of identity, at speed and scale, for users inside an organization and for external parties such as non-employees. SailPoint’s unified, intelligent, and extensible environment provides comprehensive identity governance capabilities, including access certifications, policy management, access request and provisioning, password management, and data access governance. This helps organizations make sure the right individuals have the right access to the right resources at the right times, thereby enforcing security policies and compliance requirements. Founded in 2005, SailPoint has grown to be a key player in identity security, serving customers globally across various industries.
SailPoint connectors and SaaS connectivity
SailPoint’s identity security solutions interface with various software as a service (SaaS) applications to retrieve the necessary information, such as account and access information, from an identity security standpoint. Each SaaS application implements these functionalities in slightly different ways and might expose their implementation through REST-based web APIs that are typically supported by OpenAPI specifications. SailPoint connectors are TypeScript modules that interface with a SaaS application and map the relevant identity security information (such as accounts and entitlements) to a standardized format understood by SailPoint. Based on the APIs exposed by the application, SailPoint connectors can create, update, and delete access on those accounts. SailPoint connectors help manage user identities and their access rights across different environments within an organization, supporting the organization’s compliance and security efforts.
Although a typical connector exposes several functions, for this post, we focus on developing the list user function of a connector that connects to an API endpoint for listing users, retrieving all the users, and transforming them into the format required by SailPoint.
In the following sections, we detail how we used Anthropic’s Claude Sonnet on Amazon Bedrock to automatically create the list user connector, a critical component of the broader SaaS connectivity.
Understanding the list user connector
Connectors are modules that can connect to an external service and retrieve and update relevant information from a SaaS application. To better understand how connectors are built, we give an example of the connector function that connects to DocuSign’s REST API’s getUsers endpoint. The following TypeScript code defines an asynchronous function listUsers that retrieves a list of user accounts from an external API and constructs a structured output for each user:
The following is a breakdown of what each part of the code does:
- Imports – The code imports several types and interfaces from
@sailpoint/connector-sdk. These includeContext, Response, StdAccountListHandler, and StdAccountListOutput, which are used to handle the input and output of the function in a standardized way within a SailPoint environment. - Function definition –
listUsersis defined as an asynchronous function compatible with theStdAccountListHandlerIt uses theContextto access configuration details like API keys and the base URL, and aResponseto structure the output. - Retrieve API key and host URL – These are extracted from the
contextparameter. They are used to authenticate and construct the request URL. - URL construction – The function constructs the initial URL using the hostUrl and
organizationIdfrom thecontext. This URL points to an endpoint that returns users associated with a specific organization. - Loop through pages – The
whileloop continues as long as there are more pages of data (hasMoreis true). It serves the following functions:- Fetch data – Inside the
whileloop, afetchrequest is made to the API endpoint. The request includes anAuthorizationheader that uses theapiKey. The API’s response is converted to JSON format. - Process users – Inside the
whileloop, it extracts user data from the API response. The process loops through each user, constructing anStdAccountListOutputobject for each one. This object includes user identifiers and attributes like user names, names, status, email, and group IDs. - Pagination – Inside the while loop, it checks if there is a next page URL in the pagination information (
results.paging.next). If it exists, it updates theurlfor the next iteration of the loop. If not, it sets hasMore to false to stop the loop.
- Fetch data – Inside the
Understanding this example helps us understand the step-by-step process of building this function in a connector. We aim to reproduce this process using an LLM with a prompt chaining strategy.
Generate a TypeScript connector using an LLM prompt chain
There are several approaches to using pre-trained LLMs for code generation, with varying levels of complexity:
- Single prompt – You can use models like Anthropic’s Claude to generate code by direct prompting. These models can generate code in a variety of languages, including TypeScript, but they don’t inherently possess domain-specific knowledge relevant to the task of building a connector. All the required information, including API specifications and formatting instructions, must be provided in the prompt, similar to the instructions that would be given to a developer. However, LLMs tend to struggle when given a long list of complex instructions. It’s also difficult for the prompt engineer to understand which steps are challenging for the LLM.
- Agentic frameworks with LLMs – Agents are a sophisticated framework that can use tools to perform a sequence of complex tasks. In this case, the agent starts by breaking down the user requests into steps, searches for necessary information using tools (a knowledge base or web browser), and autonomously generates code from start to finish. Although they’re powerful, these frameworks are complex to implement, often unstable in their behavior, and less controllable compared to other methods. Agents also require many LLM calls to perform a task, which makes them rather slow in practice. In the case where the logic to perform a task is a fixed sequence of steps, agents are not an efficient option.
- Prompt chain – A solution that finds a good trade-off between the two previous approaches involves using a prompt chaining technique. This method breaks the complex problem into a series of more manageable steps and integrates them to craft the final code. Each step has clear instructions that are easier for the LLM to follow, and a human in the loop can control the output of each step and correct the LLM if needed. This approach strikes a balance between flexibility and control, avoiding the extremes of the other two methods.
We initially tested the LLM’s ability to generate connector code based on a single prompt and realized that it struggles to generate code that addresses all aspects of the problem, such as pagination or nested data structures. To make sure the LLM would cover all the necessary components of the connector functions, and because creating a connector follows a fixed sequence of steps, prompt chaining was the most natural approach to improve the generated code.
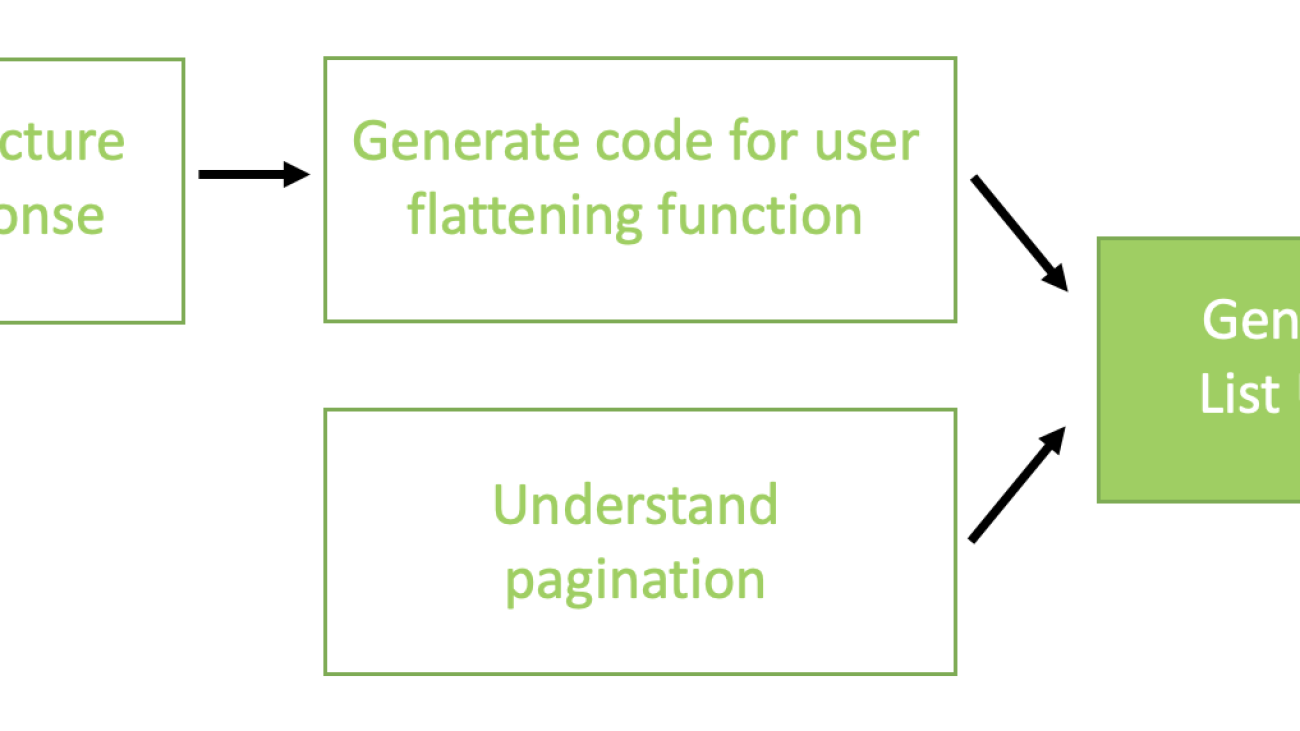
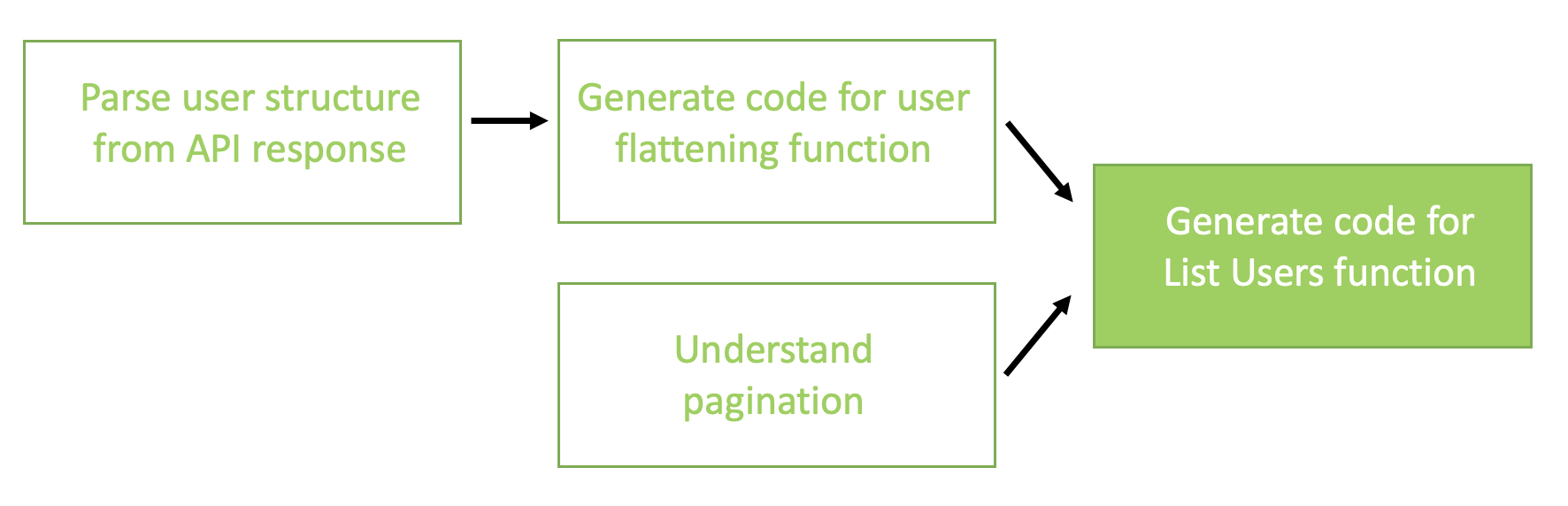
The chain we used for connector generation consists of the following high-level steps:
- Parse the data model of the API response into prescribed TypeScript classes.
- Generate the function for user flattening in the format expected by the connector interface.
- Understand the pagination of the API specs and formulate a high-level solution.
- Generate the code for the
ListUsersfunction by combining all the intermediate steps.
Step 1 is used as an input to Step 2, but Step 3 is separate. Both Step 2 and Step 3 results are fed to Step 4 for the final result. The following diagram illustrates this workflow.
In the following sections, we will dive into the prompting techniques we used for each of these steps.
System prompt
The system prompt is an essential component of LLM prompting that typically provides the initial context to guide the model’s response. For all the prompts in the chain, we used the following system prompt:
More specifically, the system prompt is used to establish the role of the LLM (expert web developer), give it a general goal (understand API specs and write TypeScript code), give high-level instructions (add comments in the code) and set boundaries (do not make up information).
Data model parsing
In this step, we prompt the LLM to understand the structure of the API response and create TypeScript classes corresponding to the objects in the response. Although this step isn’t strictly necessary for generating the response, it can help the LLM immensely in generating a correct connector. Similar to chain-of-thought reasoning for arithmetic problems, it is forcing the LLM to “think” before responding.
This step offers two primary benefits:
- Verbose API response simplification – API responses specified in the documentation can be quite verbose. By converting the response structure into TypeScript classes, we compress the information into fewer lines of code, making it more concise and less complicated for the LLM to comprehend. This step helps ensure that the essential information is prominently displayed at the start.
- Handling fragmented user responses – In some APIs, the user response is composed of several fragments because of the reuse of data structures. The OpenAPI specification uses the
$reftag to reference these reusable components. By converting the user response into TypeScript classes, we can consolidate all the relevant information into a single location. This consolidation simplifies the downstream steps by providing a centralized source of information.
We use the following task prompt to convert the API response into prescribed TypeScript classes:
In the preceding prompt template, the variable {api_spec} is replaced with the API specification of the endpoint. A specific example for a DocuSign ListUsers endpoint is provided in the appendix.
The following code is an example of the LLM-generated classes when applied to the DocuSign API specs. This has been parsed out of the <data-model> tags.
User flattening function generation
The expected structure for each user is an object consisting of two properties: an identifier and a dictionary of attributes. The attributes dictionary is a map that associates string keys with either primitive attributes (number, Boolean, or string) or an array of primitive attributes. because of the potential for arbitrarily nested JSON object structures in the response, we use the capabilities of an LLM to generate a user flattening and conversion function. Both the user ID and the attributes are extracted from the response. By employing this approach, we effectively separate the intricate task of converting the user structure from the REST API response into the required format for the SailPoint connector SDK (hereafter referred to as the connector SDK).
The benefits of this approach are twofold. First, it allows for a cleaner and more modular code design, because the complex conversion process is abstracted away from the main code base. Second, it enables greater flexibility and adaptability, because the conversion function can be modified or regenerated to accommodate changes in the API response structure or the connector SDK requirements, without necessitating extensive modifications to the surrounding code base.
We use the following prompt to generate the conversion function, which takes as input the data model generated in the previous step:
In the preceding prompt template, we replace the {data_model} variable with the data model of TypeScript classes extracted in the previous generation step of parsing the data model.
The following code is an example of the LLM-generated user flattening function when applied to the DocuSign API:
Pagination understanding
As mentioned earlier, the REST API can implement one or more pagination schemes. Often, the pagination details aren’t explicitly mentioned. During the development of the chain, we found that when there are multiple pagination schemes, the LLM would mix up elements of different pagination schemes and output code that isn’t coherent and sometimes also contains errors. Because looping over the paged results is a crucial step, we separate out this step in the code generation to let the LLM understand the pagination scheme implemented by the API and formulate its response at a high level before outputting the code. This allows the LLM to think step by step in formulating the response. This step generates the intermediate reasoning, which is fed into the next and final step: generating the list users function code.
We use the following prompt to get the pagination logic. Because we’re using Anthropic’s Claude Sonnet on Amazon Bedrock, we ask the LLM to output the logic in XML format, which is known to be an efficient way to structure information for that model.
In the preceding prompt template, the variable {api_spec} is replaced with the API specification. An example of the DocuSign API is provided in the appendix at the end of this post. The variable {api_info} can be replaced with additional API documentation in natural language, which is left as an empty string in the DocuSign example.
The following is the LLM’s response for the pagination logic extraction in the case of the DocuSign API, parsed out of the <pagination-logic> tags:
ListUsers function generation
This final step in the chain combines the information extracted in the previous steps in addition to the user flattening function generated in the previous steps to formulate the final response, which is the TypeScript function that retrieves a list of users from the provided API.
We use the following prompt to generate the complete TypeScript function:
In this prompt, we replace {flatten_user_function} with the flattenUser that was generated earlier and {pagination_logic} with the one that was generated earlier. We provide a template for the listUsers function to make sure the final output meets the requirements for the connector function. The resulting output is the following listUsers function, which uses the flattenUser function from earlier:
Lessons learned
In this post, we demonstrated how LLMs can address complex code generation problems by employing various core prompting principles and the prompt chaining technique. Although LLMs excel at following clearly defined instructions and generating small code snippets, this use case involved a substantial amount of contextual information in the form of API specifications and user instructions. Our findings from this exercise are the following:
- Decomposing complex problems – Breaking down a complex code generation problem into several intermediate steps of lower complexity enhances the LLM’s performance. Providing a single complex prompt can result in the LLM missing some instructions. The prompt chaining approach enhances the robustness of the generation, maintaining better adherence to instructions.
- Iterative optimization – This method allows for iterative optimization of intermediate steps. Each part of the chain can be refined independently before moving to the next step. LLMs can be sensitive to minor changes in instructions, and adjusting one aspect can unintentionally affect other objectives. Prompt chaining offers a systematic way to optimize each step independently.
- Handling complex decisions – In the section on understanding pagination, we illustrated how LLMs can reason through various options and make complex decisions before generating code. For instance, when the input API specification supports multiple pagination schemes, we prompted the LLM to decide on the pagination approach before implementing the code. With direct code generation, without using an intermediate reasoning step, the LLM tended to mix elements of different pagination schemes, resulting in inconsistent output. By forcing decision-making first, in natural language, we achieved more consistent and accurate code generation.
Through automated code generation, SailPoint was able to dramatically reduce connector development time from hours or days to mere minutes. The approach also democratizes code development, so you don’t need deep TypeScript expertise or intimate familiarity with SailPoint’s connector SDK. By accelerating connector generation, SailPoint significantly shortens the overall customer onboarding process. This streamlined workflow not only saves valuable developer time but also enables faster integration of diverse systems, ultimately allowing customers to use SailPoint’s identity security solutions more rapidly and effectively.
Conclusion
Our AI-powered solution for generating connector code opens up new possibilities for integrating with REST APIs. By automating the creation of connectors from API specifications, developers can rapidly build robust connections to any REST API, saving developer time and reducing the time to value for onboarding new customers. As demonstrated in this post, this technology can significantly streamline the process of working with diverse APIs, allowing teams to focus on using the data and functionality these APIs provide rather than getting overwhelmed by connector code details. Consider how such a solution could enhance your own API integration efforts—it could be the key to more efficient and effective use of the myriad APIs available in today’s interconnected digital landscape.
About the Authors
 Erik Huckle is the product lead for AI at SailPoint, where he works to solve critical customer problems in the identity security ecosystem through generative AI and data technologies. Prior to SailPoint, Erik co-founded a startup in robotic automation and later joined AWS as the first product hire at Amazon One. Erik mentors local startups and serves as a board member and tech committee lead for a EdTech nonprofit organization.
Erik Huckle is the product lead for AI at SailPoint, where he works to solve critical customer problems in the identity security ecosystem through generative AI and data technologies. Prior to SailPoint, Erik co-founded a startup in robotic automation and later joined AWS as the first product hire at Amazon One. Erik mentors local startups and serves as a board member and tech committee lead for a EdTech nonprofit organization.
 Tyler McDonnell is the engineering head of AI at SailPoint, where he leads the development of AI solutions to drive innovation and impact in identity security world. Prior to SailPoint, Tyler led machine learning research and engineering teams at several early to late-stage startups and published work in domains spanning software maintenance, information retrieval, and deep learning. He’s passionate about building products that use AI to bring positive impact to real people and problems.
Tyler McDonnell is the engineering head of AI at SailPoint, where he leads the development of AI solutions to drive innovation and impact in identity security world. Prior to SailPoint, Tyler led machine learning research and engineering teams at several early to late-stage startups and published work in domains spanning software maintenance, information retrieval, and deep learning. He’s passionate about building products that use AI to bring positive impact to real people and problems.
 Anveshi Charuvaka is a Senior Applied Scientist at the Generative AI Innovation Center, where he helps customers adopt Generative AI by implementing solutions for their critical business challenges. With a PhD in Machine Learning and over a decade of experience, he specializes in applying innovative machine learning and generative AI techniques to address complex real-world problems.
Anveshi Charuvaka is a Senior Applied Scientist at the Generative AI Innovation Center, where he helps customers adopt Generative AI by implementing solutions for their critical business challenges. With a PhD in Machine Learning and over a decade of experience, he specializes in applying innovative machine learning and generative AI techniques to address complex real-world problems.
 Aude Genevay is a Senior Applied Scientist at the Generative AI Innovation Center, where she helps customers tackle critical business challenges and create value using generative AI. She holds a PhD in theoretical machine learning and enjoys turning cutting-edge research into real-world solutions.
Aude Genevay is a Senior Applied Scientist at the Generative AI Innovation Center, where she helps customers tackle critical business challenges and create value using generative AI. She holds a PhD in theoretical machine learning and enjoys turning cutting-edge research into real-world solutions.
 Mofijul Islam is an Applied Scientist II at the AWS Generative AI Innovation Center, where he helps customers tackle complex, customer-centric research challenges using generative AI, large language models (LLM), multi-agent learning, and multimodal learning. He holds a PhD in machine learning from the University of Virginia, where his work focused on multimodal machine learning, multilingual NLP, and multitask learning. His research has been published in top-tier conferences like NeurIPS, ICLR, AISTATS, and AAAI, as well as IEEE and ACM Transactions.
Mofijul Islam is an Applied Scientist II at the AWS Generative AI Innovation Center, where he helps customers tackle complex, customer-centric research challenges using generative AI, large language models (LLM), multi-agent learning, and multimodal learning. He holds a PhD in machine learning from the University of Virginia, where his work focused on multimodal machine learning, multilingual NLP, and multitask learning. His research has been published in top-tier conferences like NeurIPS, ICLR, AISTATS, and AAAI, as well as IEEE and ACM Transactions.
 Yasin Khatami is a Senior Applied Scientist at the Generative AI Innovation Center. With more than a decade of experience in artificial intelligence (AI), he implements state-of-the-art AI products for AWS customers to drive efficiency and value for customer platforms. His expertise is in generative AI, large language models (LLM), multi-agent techniques, and multimodal learning.
Yasin Khatami is a Senior Applied Scientist at the Generative AI Innovation Center. With more than a decade of experience in artificial intelligence (AI), he implements state-of-the-art AI products for AWS customers to drive efficiency and value for customer platforms. His expertise is in generative AI, large language models (LLM), multi-agent techniques, and multimodal learning.
 Karthik Ram is a Principal Solutions Architect with Amazon Web Services based in Columbus, Ohio. He works with Independent Software Vendors (ISVs) to build secure and innovative cloud solutions, including helping with their products and solving their business problems using data-driven approaches. Karthik’s area of depth is Cloud Security with a focus on Infrastructure Security and threat detection.
Karthik Ram is a Principal Solutions Architect with Amazon Web Services based in Columbus, Ohio. He works with Independent Software Vendors (ISVs) to build secure and innovative cloud solutions, including helping with their products and solving their business problems using data-driven approaches. Karthik’s area of depth is Cloud Security with a focus on Infrastructure Security and threat detection.
Appendix
The following API specifications were used for the experiments in this post:
Map Earth’s vegetation in under 20 minutes with Amazon SageMaker
In today’s rapidly changing world, monitoring the health of our planet’s vegetation is more critical than ever. Vegetation plays a crucial role in maintaining an ecological balance, providing sustenance, and acting as a carbon sink. Traditionally, monitoring vegetation health has been a daunting task. Methods such as field surveys and manual satellite data analysis are not only time-consuming, but also require significant resources and domain expertise. These traditional approaches are cumbersome. This often leads to delays in data collection and analysis, making it difficult to track and respond swiftly to environmental changes. Furthermore, the high costs associated with these methods limit their accessibility and frequency, hindering comprehensive and ongoing global vegetation monitoring efforts at a planetary scale. In light of these challenges, we have developed an innovative solution to streamline and enhance the efficiency of vegetation monitoring processes on a global scale.
Transitioning from the traditional, labor-intensive methods of monitoring vegetation health, Amazon SageMaker geospatial capabilities offer a streamlined, cost-effective solution. Amazon SageMaker supports geospatial machine learning (ML) capabilities, allowing data scientists and ML engineers to build, train, and deploy ML models using geospatial data. These geospatial capabilities open up a new world of possibilities for environmental monitoring. With SageMaker, users can access a wide array of geospatial datasets, efficiently process and enrich this data, and accelerate their development timelines. Tasks that previously took days or even weeks to accomplish can now be done in a fraction of the time.
In this post, we demonstrate the power of SageMaker geospatial capabilities by mapping the world’s vegetation in under 20 minutes. This example not only highlights the efficiency of SageMaker, but also its impact how geospatial ML can be used to monitor the environment for sustainability and conservation purposes.
Identify areas of interest
We begin by illustrating how SageMaker can be applied to analyze geospatial data at a global scale. To get started, we follow the steps outlined in Getting Started with Amazon SageMaker geospatial capabilities. We start with the specification of the geographical coordinates that define a bounding box covering the areas of interest. This bounding box acts as a filter to select only the relevant satellite images that cover the Earth’s land masses.

Data acquisition
SageMaker geospatial capabilities provide access to a wide range of public geospatial datasets, including Sentinel-2, Landsat 8, Copernicus DEM, and NAIP. For our vegetation mapping project, we’ve selected Sentinel-2 for its global coverage and update frequency. The Sentinel-2 satellite captures images of Earth’s land surface at a resolution of 10 meters every 5 days. We pick the first week of December 2023 in this example. To make sure we cover most of the visible earth surface, we filter for images with less than 10% cloud coverage. This way, our analysis is based on clear and reliable imagery.
By utilizing the search_raster_data_collection function from SageMaker geospatial, we identified 8,581 unique Sentinel-2 images taken in the first week of December 2023. To validate the accuracy in our selection, we plotted the footprints of these images on a map, confirming that we had the correct images for our analysis.

SageMaker geospatial processing jobs
When querying data with SageMaker geospatial capabilities, we received comprehensive details about our target images, including the data footprint, properties around spectral bands, and hyperlinks for direct access. With these hyperlinks, we can bypass traditional memory and storage-intensive methods of first downloading and subsequently processing images locally—a task made even more daunting by the size and scale of our dataset, spanning over 4 TB. Each of the 8,000 images are large in size, have multiple channels, and are individually sized at approximately 500 MB. Processing multiple terabytes of data on a single machine would be time-prohibitive. Although setting up a processing cluster is an alternative, it introduces its own set of complexities, from data distribution to infrastructure management. SageMaker geospatial streamlines this with Amazon SageMaker Processing. We use the purpose-built geospatial container with SageMaker Processing jobs for a simplified, managed experience to create and run a cluster. With just a few lines of code, you can scale out your geospatial workloads with SageMaker Processing jobs. You simply specify a script that defines your workload, the location of your geospatial data on Amazon Simple Storage Service (Amazon S3), and the geospatial container. SageMaker Processing provisions cluster resources for you to run city-, country-, or continent-scale geospatial ML workloads.
For our project, we’re using 25 clusters, with each cluster comprising 20 instances, to scale out our geospatial workload. Next, we divided the 8,581 images into 25 batches for efficient processing. Each batch contains approximately 340 images. These batches are then evenly distributed across the machines in a cluster. All batch manifests are uploaded to Amazon S3, ready for the processing job, so each segment is processed swiftly and efficiently.
With our input data ready, we now turn to the core analysis that will reveal insights into vegetation health through the Normalized Difference Vegetation Index (NDVI). NDVI is calculated from the difference between Near-infrared (NIR) and Red reflectances, normalized by their sum, yielding values that range from -1 to 1. Higher NDVI values signal dense, healthy vegetation, a value of zero indicates no vegetation, and negative values usually point to water bodies. This index serves as a critical tool for assessing vegetation health and distribution. The following is an example of what NDVI looks like.

Now we have the compute logic defined, we’re ready to start the geospatial SageMaker Processing job. This involves a straightforward three-step process: setting up the compute cluster, defining the computation specifics, and organizing the input and output details.
First, to set up the cluster, we decide on the number and type of instances required for the job, making sure they’re well-suited for geospatial data processing. The compute environment itself is prepared by selecting a geospatial image that comes with all commonly used packages for processing geospatial data.
Next, for the input, we use the previously created manifest that lists all image hyperlinks. We also designate an S3 location to save our results.
With these elements configured, we’re able to initiate multiple processing jobs at once, allowing them to operate concurrently for efficiency.
After you launch the job, SageMaker automatically spins up the required instances and configures the cluster to process the images listed in your input manifest. This entire setup operates seamlessly, without needing your hands-on management. To monitor and manage the processing jobs, you can use the SageMaker console. It offers real-time updates on the status and completion of your processing tasks. In our example, it took under 20 minutes to process all 8,581 images with 500 instances. The scalability of SageMaker allows for faster processing times if needed, simply by increasing the number of instances.

Conclusion
The power and efficiency of SageMaker geospatial capabilities have opened new doors for environmental monitoring, particularly in the realm of vegetation mapping. Through this example, we showcased how to process over 8,500 satellite images in less than 20 minutes. We not only demonstrated the technical feasibility, but also showcased the efficiency gains from using the cloud for environmental analysis. This approach illustrates a significant leap from traditional, resource-intensive methods to a more agile, scalable, and cost-effective approach. The flexibility to scale processing resources up or down as needed, combined with the ease of accessing and analyzing vast datasets, positions SageMaker as a transformative tool in the field of geospatial analysis. By simplifying the complexities associated with large-scale data processing, SageMaker enables scientists, researchers, and businesses stakeholders to focus more on deriving insights and less on infrastructure and data management.
As we look to the future, the integration of ML and geospatial analytics promises to further enhance our understanding of the planet’s ecological systems. The potential to monitor changes in real time, predict future trends, and respond with more informed decisions can significantly contribute to global conservation efforts. This example of vegetation mapping is just the beginning for running planetary-scale ML. See Amazon SageMaker geospatial capabilities to learn more.
About the Author
 Xiong Zhou is a Senior Applied Scientist at AWS. He leads the science team for Amazon SageMaker geospatial capabilities. His current area of research includes LLM evaluation and data generation. In his spare time, he enjoys running, playing basketball and spending time with his family.
Xiong Zhou is a Senior Applied Scientist at AWS. He leads the science team for Amazon SageMaker geospatial capabilities. His current area of research includes LLM evaluation and data generation. In his spare time, he enjoys running, playing basketball and spending time with his family.
 Anirudh Viswanathan is a Sr Product Manager, Technical – External Services with the SageMaker geospatial ML team. He holds a Masters in Robotics from Carnegie Mellon University, an MBA from the Wharton School of Business, and is named inventor on over 40 patents. He enjoys long-distance running, visiting art galleries and Broadway shows.
Anirudh Viswanathan is a Sr Product Manager, Technical – External Services with the SageMaker geospatial ML team. He holds a Masters in Robotics from Carnegie Mellon University, an MBA from the Wharton School of Business, and is named inventor on over 40 patents. He enjoys long-distance running, visiting art galleries and Broadway shows.
 Janosch Woschitz is a Senior Solutions Architect at AWS, specializing in AI/ML. With over 15 years of experience, he supports customers globally in leveraging AI and ML for innovative solutions and building ML platforms on AWS. His expertise spans machine learning, data engineering, and scalable distributed systems, augmented by a strong background in software engineering and industry expertise in domains such as autonomous driving.
Janosch Woschitz is a Senior Solutions Architect at AWS, specializing in AI/ML. With over 15 years of experience, he supports customers globally in leveraging AI and ML for innovative solutions and building ML platforms on AWS. His expertise spans machine learning, data engineering, and scalable distributed systems, augmented by a strong background in software engineering and industry expertise in domains such as autonomous driving.
 Li Erran Li is the applied science manager at humain-in-the-loop services, AWS AI, Amazon. His research interests are 3D deep learning, and vision and language representation learning. Previously he was a senior scientist at Alexa AI, the head of machine learning at Scale AI and the chief scientist at Pony.ai. Before that, he was with the perception team at Uber ATG and the machine learning platform team at Uber working on machine learning for autonomous driving, machine learning systems and strategic initiatives of AI. He started his career at Bell Labs and was adjunct professor at Columbia University. He co-taught tutorials at ICML’17 and ICCV’19, and co-organized several workshops at NeurIPS, ICML, CVPR, ICCV on machine learning for autonomous driving, 3D vision and robotics, machine learning systems and adversarial machine learning. He has a PhD in computer science at Cornell University. He is an ACM Fellow and IEEE Fellow.
Li Erran Li is the applied science manager at humain-in-the-loop services, AWS AI, Amazon. His research interests are 3D deep learning, and vision and language representation learning. Previously he was a senior scientist at Alexa AI, the head of machine learning at Scale AI and the chief scientist at Pony.ai. Before that, he was with the perception team at Uber ATG and the machine learning platform team at Uber working on machine learning for autonomous driving, machine learning systems and strategic initiatives of AI. He started his career at Bell Labs and was adjunct professor at Columbia University. He co-taught tutorials at ICML’17 and ICCV’19, and co-organized several workshops at NeurIPS, ICML, CVPR, ICCV on machine learning for autonomous driving, 3D vision and robotics, machine learning systems and adversarial machine learning. He has a PhD in computer science at Cornell University. He is an ACM Fellow and IEEE Fellow.
 Amit Modi is the product leader for SageMaker MLOps, ML Governance, and Responsible AI at AWS. With over a decade of B2B experience, he builds scalable products and teams that drive innovation and deliver value to customers globally.
Amit Modi is the product leader for SageMaker MLOps, ML Governance, and Responsible AI at AWS. With over a decade of B2B experience, he builds scalable products and teams that drive innovation and deliver value to customers globally.
 Kris Efland is a visionary technology leader with a successful track record in driving product innovation and growth for over 20 years. Kris has helped create new products including consumer electronics and enterprise software across many industries, at both startups and large companies. In his current role at Amazon Web Services (AWS), Kris leads the Geospatial AI/ML category. He works at the forefront of Amazon’s fastest-growing ML service, Amazon SageMaker, which serves over 100,000 customers worldwide. He recently led the launch of Amazon SageMaker’s new geospatial capabilities, a powerful set of tools that allow data scientists and machine learning engineers to build, train, and deploy ML models using satellite imagery, maps, and location data. Before joining AWS, Kris was the Head of Autonomous Vehicle (AV) Tools and AV Maps for Lyft, where he led the company’s autonomous mapping efforts and toolchain used to build and operate Lyft’s fleet of autonomous vehicles. He also served as the Director of Engineering at HERE Technologies and Nokia and has co-founded several startups..
Kris Efland is a visionary technology leader with a successful track record in driving product innovation and growth for over 20 years. Kris has helped create new products including consumer electronics and enterprise software across many industries, at both startups and large companies. In his current role at Amazon Web Services (AWS), Kris leads the Geospatial AI/ML category. He works at the forefront of Amazon’s fastest-growing ML service, Amazon SageMaker, which serves over 100,000 customers worldwide. He recently led the launch of Amazon SageMaker’s new geospatial capabilities, a powerful set of tools that allow data scientists and machine learning engineers to build, train, and deploy ML models using satellite imagery, maps, and location data. Before joining AWS, Kris was the Head of Autonomous Vehicle (AV) Tools and AV Maps for Lyft, where he led the company’s autonomous mapping efforts and toolchain used to build and operate Lyft’s fleet of autonomous vehicles. He also served as the Director of Engineering at HERE Technologies and Nokia and has co-founded several startups..
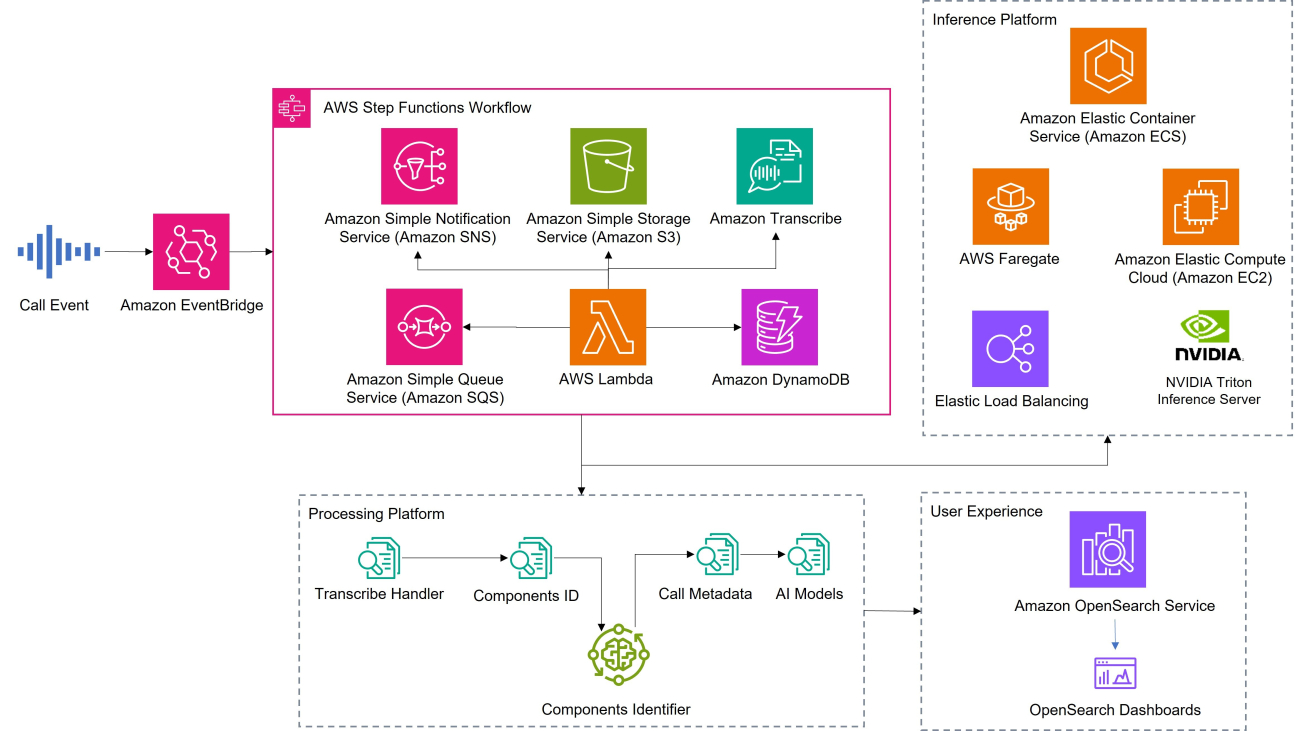
Unlocking insights and enhancing customer service: Intact’s transformative AI journey with AWS
Intact Financial Corporation is the leading provider of property and casualty insurance in Canada, a leading provider of global specialty insurance, and a leader in commercial lines in the UK and Ireland. Intact faced a challenge in managing its vast network of customer support call centers and required a workable solution within 6 months and long-term solution within 1 year. With up to 20,000 calls per day, the manual auditing process was inefficient and struggled to keep up with increasing call traffic and rising customer service expectations. Quality control agents had to manually pick calls to audit, which was not a scalable solution. To address this, Intact turned to AI and speech-to-text technology to unlock insights from calls and improve customer service. The company developed an automated solution called Call Quality (CQ) using AI services from Amazon Web Services (AWS). The implementation of CQ allowed Intact to handle 1,500% more calls (15 times more calls per auditor), reduce agent handling time by 10%, and generate valuable insights about agent behavior, leading to improved customer service.
Amazon Transcribe is a fully managed automatic speech recognition (ASR) service that helps developers add speech-to-text capabilities to applications. It uses deep learning to convert audio to text quickly and accurately. In this post, we demonstrate how the CQ solution used Amazon Transcribe and other AWS services to improve critical KPIs with AI-powered contact center call auditing and analytics.
This allowed Intact to transcribe customer calls accurately, train custom language models, simplify the call auditing process, and extract valuable customer insights more efficiently.
Solution overview
Intact aimed to develop a cost-effective and efficient call analytics platform for their contact centers by using speech-to-text and machine learning technologies. The goal was to refine customer service scripts, provide coaching opportunities for agents, and improve call handling processes. By doing so, Intact hoped to improve agent efficiency, identify business opportunities, and analyze customer satisfaction, potential product issues, and training gaps. The following figure shows the architecture of the solution, which is described in the following sections.

Intact selected Amazon Transcribe as their speech-to-text AI solution for its accuracy in handling both English and Canadian French. This was a key factor in Intact’s decision, because the company sought a versatile platform capable of adapting to their diverse business needs. Amazon Transcribe offers deep learning capabilities, which can handle a wide range of speech and acoustic characteristics, in addition to its scalability to process anywhere from a few hundred to over tens of thousands of calls daily, also played a pivotal role. Additionally, Intact was impressed that Amazon Transcribe could adapt to various post-call analytics use cases across their organization.
Call processing and model serving
Intact has on-premises contact centers and cloud contact centers, so they built a call acquisition process to ingest calls from both sources. The architecture incorporates a fully automated workflow, powered by Amazon EventBridge, which triggers an AWS Step Functions workflow when an audio file is uploaded to a designated Amazon Simple Storage Service (Amazon S3) bucket. This serverless processing pipeline is built around Amazon Transcribe, which processes the call recordings and converts them from speech to text. Notifications of processed transcriptions are sent to an Amazon Simple Queue Service (Amazon SQS) queue, which aids in decoupling the architecture and resuming the Step Functions state machine workflow. AWS Lambda is used in this architecture as a transcription processor to store the processed transcriptions into an Amazon OpenSearch Service table.
The call processing workflow uses custom machine learning (ML) models built by Intact that run on Amazon Fargate and Amazon Elastic Compute Cloud (Amazon EC2). The transcriptions in OpenSearch are then further enriched with these custom ML models to perform components identification and provide valuable insights such as named entity recognition, speaker role identification, sentiment analysis, and personally identifiable information (PII) redaction. Regular improvements on existing and new models added valuable insights to be extracted such as reason for call, script adherence, call outcome, and sentiment analysis across various business departments from claims to personal lines. Amazon DynamoDB is used in this architecture to control the limits of the queues. The call transcriptions are then compressed from WAV to an MP3 format to optimize storage costs on Amazon S3.
Machine learning operations (MLOps)
Intact also built an automated MLOps pipeline that use Step Functions, Lambda, and Amazon S3. This pipeline provides self-serving capabilities for data scientists to track ML experiments and push new models to an S3 bucket. It offers flexibility for data scientists to conduct shadow deployments and capacity planning, enabling them to seamlessly switch between models for both production and experimentation purposes. Additionally, the application offers backend dashboards tailored to MLOps functionalities, ensuring smooth monitoring and optimization of machine learning models.
Frontend and API
The CQ application offers a robust search interface specially crafted for call quality agents, equipping them with powerful auditing capabilities for call analysis. The application’s backend is powered by Amazon OpenSearch Service for the search functionality. The application also uses Amazon Cognito to provide single sign-on for secure access. Lastly, Lambda functions are used for orchestration to fetch dynamic content from OpenSearch.
The application offers trend dashboards customized to deliver actionable business insights, aiding in identifying key areas where agents allocate their time. Using data from sources like Amazon S3 and Snowflake, Intact builds comprehensive business intelligence dashboards showcasing key performance metrics such as periods of silence and call handle time. This capability enables call quality agents to delve deeper into call components, facilitating targeted agent coaching opportunities.
Call Quality Trend Dashboard
The following figure is an example of the Call Quality Trend Dashboard, showing the information available to agents. This includes the ability to filter on multiple criteria including Dates and Languages, Average Handle Time per Components and Unit Managers, and Speech time vs. Silence Time.

Results
The implementation of the new system has led to a significant increase in efficiency and productivity. There has been a 1,500% increase in auditing speed and a 1,500% increase in the number of calls reviewed. Additionally, by building the MLOps on AWS alongside the CQ solution, the team has reduced the delivery of new ML models for providing analytics from days to mere hours, making auditors 65% more efficient. This has also resulted in a 10% reduction in agents’ time per call and a 10% reduction of average hold time as they receive targeted coaching to improve their customer conversations. This efficiency has allowed for more effective use of auditors’ time in devising coaching strategies, improving scripts, and agent training.
Additionally, the solution has provided intangible benefits such as extremely high availability with no major downtime since 2020 and high-cost predictability. The solution’s modular design has also led to robust deployments, which significantly reduced the time for new releases to less than an hour. This has also contributed to a near-zero failure rate during deployment.
Conclusion
In conclusion, Intact Financial Corporation’s implementation of the CQ, powered by AWS AI services has revolutionized their customer service approach. This case study serves as a testament to the transformative power of AI and speech-to-text technology in enhancing customer service efficiency and effectiveness. The solution’s design and capabilities position Intact well to use generative AI for future transcription projects. As next steps, Intact plans to further use this technology by processing calls using Amazon Transcribe streaming for real-time transcription and deploying a virtual agent to provide human agents with relevant information and recommended responses.
The journey of Intact Financial Corporation is one example of how embracing AI can lead to significant improvements in service delivery and customer satisfaction. For customers looking to quickly get started on their call analytics journey, explore Amazon Transcribe Call Analytics for live call analytics and agent assist and post call analytics.
About the Authors
 Étienne Brouillard is an AWS AI Principal Architect at Intact Financial Corporation, Canada’s largest provider of property and casualty insurance.
Étienne Brouillard is an AWS AI Principal Architect at Intact Financial Corporation, Canada’s largest provider of property and casualty insurance.
 Ami Dani is a Senior Technical Program Manager at AWS focusing on AI/ML services. During her career, she has focused on delivering transformative software development projects for the federal government and large companies in industries as diverse as advertising, entertainment, and finance. Ami has experience driving business growth, implementing innovative training programs and successfully managing complex, high-impact projects.
Ami Dani is a Senior Technical Program Manager at AWS focusing on AI/ML services. During her career, she has focused on delivering transformative software development projects for the federal government and large companies in industries as diverse as advertising, entertainment, and finance. Ami has experience driving business growth, implementing innovative training programs and successfully managing complex, high-impact projects.
 Prabir Sekhri is a Senior Solutions Architect at AWS in the enterprise financial services sector. During his career, he has focused on digital transformation projects within large companies in industries as diverse as finance, multimedia, telecommunications as well as the energy and gas sectors. His background includes DevOps, security, and designing and architecting enterprise storage solutions. Besides technology, Prabir has always been passionate about playing music. He leads a jazz ensemble in Montreal as a pianist, composer and arranger.
Prabir Sekhri is a Senior Solutions Architect at AWS in the enterprise financial services sector. During his career, he has focused on digital transformation projects within large companies in industries as diverse as finance, multimedia, telecommunications as well as the energy and gas sectors. His background includes DevOps, security, and designing and architecting enterprise storage solutions. Besides technology, Prabir has always been passionate about playing music. He leads a jazz ensemble in Montreal as a pianist, composer and arranger.
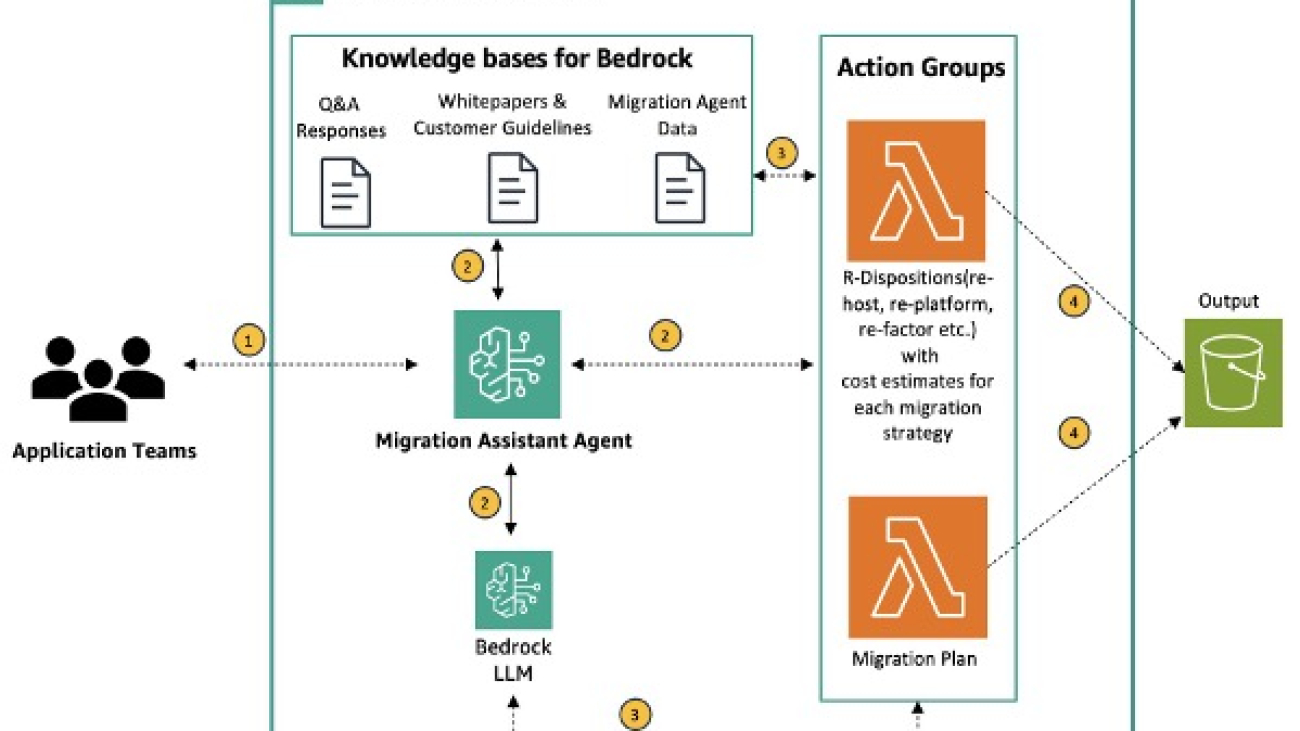
Accelerate migration portfolio assessment using Amazon Bedrock
Conducting assessments on application portfolios that need to be migrated to the cloud can be a lengthy endeavor. Despite the existence of AWS Application Discovery Service or the presence of some form of configuration management database (CMDB), customers still face many challenges. These include time taken for follow-up discussions with application teams to review outputs and understand dependencies (approximately 2 hours per application), cycles needed to generate a cloud architecture design that meets security and compliance requirements, and the effort needed to provide cost estimates by selecting the right AWS services and configurations for optimal application performance in the cloud. Typically, it takes 6–8 weeks to carry out these tasks before actual application migrations begin.
In this blog post, we will harness the power of generative AI and Amazon Bedrock to help organizations simplify, accelerate, and scale migration assessments. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI. By using Amazon Bedrock Agents, action groups, and Amazon Bedrock Knowledge Bases, we demonstrate how to build a migration assistant application that rapidly generates migration plans, R-dispositions, and cost estimates for applications migrating to AWS. This approach enables you to scale your application portfolio discovery and significantly accelerate your planning phase.
General requirements for a migration assistant
The following are some key requirements that you should consider when building a migration assistant.
Accuracy and consistency
Is your migration assistant application able to render accurate and consistent responses?
Guidance: To ensure accurate and consistent responses from your migration assistant, implement Amazon Bedrock Knowledge Bases. The knowledge base should contain contextual information based on your company’s private data sources. This enables the migration assistant to use Retrieval-Augmented Generation (RAG), which enhances the accuracy and consistency of responses. Your knowledge base should comprise multiple data sources, including:
- Responses for an application discovery questionnaire (See example)
- Output from the configuration management database (CMDB) or AWS Application Discovery Agent data (See example)
- Best practices and white-papers on migration to AWS (for example, Migration Lens – AWS Well-Architected Framework and Container Migration Methodology)
- Any organization-specific guidelines, migration patterns, or application patterns
Handle hallucinations
How are you reducing the hallucinations from the large language model (LLM) for your migration assistant application?
Guidance: Reducing hallucinations in LLMs involves implementation of several key strategies. Implement customized prompts based on your requirements and incorporate advanced prompting techniques to guide the model’s reasoning and provide examples for more accurate responses. These techniques include chain-of-thought prompting, zero-shot prompting, multishot prompting, few-shot prompting, and model-specific prompt engineering guidelines (see Anthropic Claude on Amazon Bedrock prompt engineering guidelines). RAG combines information retrieval with generative capabilities to enhance contextual relevance and reduce hallucinations. Finally, a feedback loop or human-in-the-loop when fine-tuning LLMs on specific datasets will help align the responses with accurate and relevant information, mitigating errors and outdated content.
Modular design
Is the design of your migration assistant modular?
Guidance: Building a migration assistant application using Amazon Bedrock action groups, which have a modular design, offers three key benefits.
- Customization and adaptability: Action groups allow users to customize migration workflows to suit specific AWS environments and requirements. For instance, if a user is migrating a web application to AWS, they can customize the migration workflow to include specific actions tailored to web server setup, database migration, and network configuration. This customization ensures that the migration process aligns with the unique needs of the application being migrated.
- Maintenance and troubleshooting: Simplifies maintenance and troubleshooting tasks by isolating issues to individual components. For example, if there’s an issue with the database migration action within the migration workflow, it can be addressed independently without affecting other components. This isolation streamlines the troubleshooting process and minimizes the impact on the overall migration operation, ensuring a smoother migration and faster resolution of issues.
- Scalability and reusability: Promote scalability and reusability across different AWS migration projects. For instance, if a user successfully migrates an application to AWS using a set of modular action groups, they can reuse those same action groups to migrate other applications with similar requirements. This reusability saves time and effort when developing new migration workflows and ensures consistency across multiple migration projects. Additionally, modular design facilitates scalability by allowing users to scale the migration operation up or down based on workload demands. For example, if they need to migrate a larger application with higher resource requirements, they can easily scale up the migration workflow by adding more instances of relevant action groups, without needing to redesign the entire workflow from scratch.
Overview of solution
Before we dive deep into the deployment, let’s walk through the key steps of the architecture that will be established, as shown in Figure 1.

- Users interact with the migration assistant through the Amazon Bedrock chat console to input their requests. For example, a user might request to Generate R-disposition with cost estimates or Generate Migration plan for specific application IDs (for example, A1-CRM or A2-CMDB).
- The migration assistant, which uses Amazon Bedrock agents, is configured with instructions, action groups, and knowledge bases. When processing the user’s request, the migration assistant invokes relevant action groups such as R Dispositions and Migration Plan, which in turn invoke specific AWS Lambda
- The Lambda functions process the request using RAG to produce the required output.
- The resulting output documents (R-Dispositions with cost estimates and Migration Plan) are then uploaded to a designated Amazon Simple Storage Service (Amazon S3)
The following image is a screenshot of a sample user interaction with the migration assistant.

Prerequisites
You should have the following:
- Understanding of Amazon Bedrock Agents, prompt engineering, Amazon Bedrock Knowledge Bases, Lambda functions, and AWS Identity and Access Management (IAM).
- Familiarity with basic cloud migration concepts, including application discovery and migration strategies.
- An AWS account with the appropriate IAM permissions to create Amazon Bedrock agents and knowledge bases, Lambda functions, and IAM roles.
- Access to Amazon Bedrock models. For more information, refer to Model access.
- Access to create and configure Amazon Simple Storage Service (S3) buckets, which will be used for storing generated migration plans and other outputs.
- Create a service role for Amazon Bedrock Agents.
Deployment steps
- Configure a knowledge base:
- Open the AWS Management Console for Amazon Bedrock and navigate to Amazon Bedrock Knowledge Bases.
- Choose Create knowledge base and enter a name and optional description.
- Select the vector database (for example, Amazon OpenSearch Serverless).
- Select the embedding model (for example, Amazon Titan Embedding G1 – Text).
- Add data sources:
- For Amazon S3: Specify the S3 bucket and prefix, file types, and chunking configuration.
- For custom data: Use the API to ingest data programmatically.
- Review and create the knowledge base.
- Set up Amazon Bedrock Agents:
- In the Amazon Bedrock console, go to the Agents section and chose Create agent.
- Enter a name and optional description for the agent.
- Select the foundation model (for example, Anthropic Claude V3).
- Configure the agent’s AWS Identity and Access Management (IAM) role to grant necessary permissions.
- Add instructions to guide the agent’s behavior.
- Optionally, add the previously created Amazon Bedrock Knowledge Base to enhance the agent’s responses.
- Configure additional settings such as maximum tokens and temperature.
- Review and create the agent.
- Configure actions groups for the agent:
- On the agent’s configuration page, navigate to the Action groups
- Choose Add action group for each required group (for example, Create R-disposition Assessment and Create Migration Plan).
- For each action group:
- Enter a name and description.
- Define the API schema using OpenAPI 3.0 specification, detailing the endpoints and expected request and response formats.
- Create and associate a Lambda function to handle the action’s logic. See the sample Lambda logic for Create R-disposition Assessment and Create Migration Plan action groups.
- Configure the Lambda function with the appropriate permissions and environment variables.
- Test the action group using the provided test console to ensure proper functionality.
- After adding all action groups, review the entire agent configuration and deploy the agent.
Clean up
To avoid unnecessary charges, delete the resources created during testing. Use the following steps to clean up the resources:
- Delete the Amazon Bedrock knowledge base: Open the Amazon Bedrock console.
Delete the knowledge base from any agents that it’s associated with.- From the left navigation pane, choose Agents.
- Select the Name of the agent that you want to delete the knowledge base from.
- A red banner appears to warn you to delete the reference to the knowledge base, which no longer exists, from the agent.
- Select the radio button next to the knowledge base that you want to remove. Choose More and then choose Delete.
- From the left navigation pane, choose Knowledge base.
- To delete a source, either choose the radio button next to the source and select Delete or select the Name of the source and then choose Delete in the top right corner of the details page.
- Review the warnings for deleting a knowledge base. If you accept these conditions, enter delete in the input box and choose Delete to confirm.
- Delete the Agent
- In the Amazon Bedrock console, choose Agents from the left navigation pane.
- Select the radio button next to the agent to delete.
- A modal appears warning you about the consequences of deletion. Enter delete in the input box and choose Delete to confirm.
- A blue banner appears to inform you that the agent is being deleted. When deletion is complete, a green success banner appears.
- Delete all the other resources including the Lambda functions and any AWS services used for account customization.
Conclusion
Conducting assessments on application portfolios for AWS cloud migration can be a time-consuming process, involving analyzing data from various sources, discovery and design discussions to develop an AWS Cloud architecture design, and cost estimates.
In this blog post, we demonstrated how you can simplify, accelerate, and scale migration assessments by using generative AI and Amazon Bedrock. We showcased using Amazon Bedrock Agents, action groups, and Amazon Bedrock Knowledge Bases for a migration assistant application that renders migration plans, R-dispositions, and cost estimates. This approach significantly reduces the time and effort required for portfolio assessments, helping organizations to scale and expedite their journey to the AWS Cloud.
Ready to improve your cloud migration process with generative AI in Amazon Bedrock? Begin by exploring the Amazon Bedrock User Guide to understand how it can streamline your organization’s cloud journey. For further assistance and expertise, consider using AWS Professional Services (contact sales) to help you streamline your cloud migration journey and maximize the benefits of Amazon Bedrock.
About the Authors
 Ebbey Thomas is a Senior Cloud Architect at AWS, with a strong focus on leveraging generative AI to enhance cloud infrastructure automation and accelerate migrations. In his role at AWS Professional Services, Ebbey designs and implements solutions that improve cloud adoption speed and efficiency while ensuring secure and scalable operations for AWS users. He is known for solving complex cloud challenges and driving tangible results for clients. Ebbey holds a BS in Computer Engineering and an MS in Information Systems from Syracuse University.
Ebbey Thomas is a Senior Cloud Architect at AWS, with a strong focus on leveraging generative AI to enhance cloud infrastructure automation and accelerate migrations. In his role at AWS Professional Services, Ebbey designs and implements solutions that improve cloud adoption speed and efficiency while ensuring secure and scalable operations for AWS users. He is known for solving complex cloud challenges and driving tangible results for clients. Ebbey holds a BS in Computer Engineering and an MS in Information Systems from Syracuse University.
 Shiva Vaidyanathan is a Principal Cloud Architect at AWS. He provides technical guidance, design and lead implementation projects to customers ensuring their success on AWS. He works towards making cloud networking simpler for everyone. Prior to joining AWS, he has worked on several NSF funded research initiatives on performing secure computing in public cloud infrastructures. He holds a MS in Computer Science from Rutgers University and a MS in Electrical Engineering from New York University.
Shiva Vaidyanathan is a Principal Cloud Architect at AWS. He provides technical guidance, design and lead implementation projects to customers ensuring their success on AWS. He works towards making cloud networking simpler for everyone. Prior to joining AWS, he has worked on several NSF funded research initiatives on performing secure computing in public cloud infrastructures. He holds a MS in Computer Science from Rutgers University and a MS in Electrical Engineering from New York University.
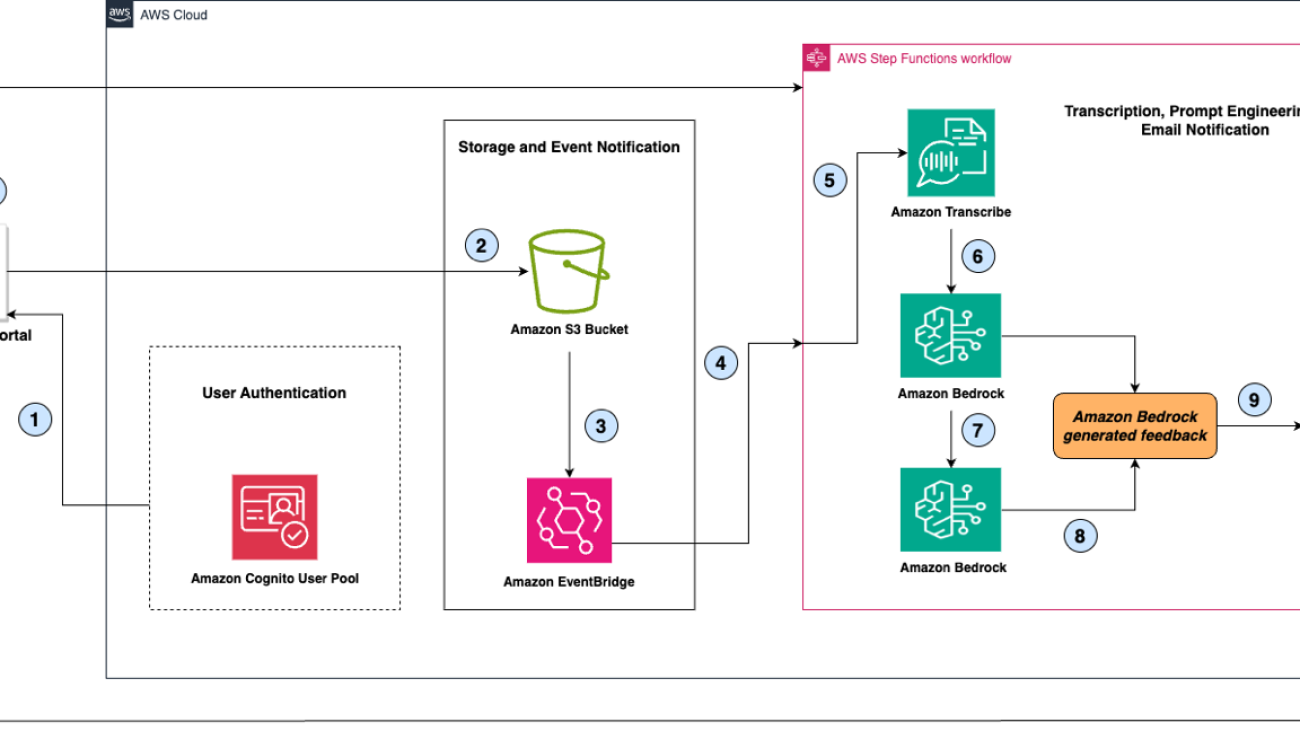
Improve public speaking skills using a generative AI-based virtual assistant with Amazon Bedrock
Public speaking is a critical skill in today’s world, whether it’s for professional presentations, academic settings, or personal growth. By practicing it regularly, individuals can build confidence, manage anxiety in a healthy way, and develop effective communication skills leading to successful public speaking engagements. Now, with the advent of large language models (LLMs), you can use generative AI-powered virtual assistants to provide real-time analysis of speech, identification of areas for improvement, and suggestions for enhancing speech delivery.
In this post, we present an Amazon Bedrock powered virtual assistant that can transcribe presentation audio and examine it for language use, grammatical errors, filler words, and repetition of words and sentences to provide recommendations as well as suggest a curated version of the speech to elevate the presentation. This solution helps refine communication skills and empower individuals to become more effective and impactful public speakers. Organizations across various sectors, including corporations, educational institutions, government entities, and social media personalities, can use this solution to provide automated coaching for their employees, students, and public speaking engagements.
In the following sections, we walk you through constructing a scalable, serverless, end-to-end Public Speaking Mentor AI Assistant with Amazon Bedrock, Amazon Transcribe, and AWS Step Functions using provided sample code. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Overview of solution
The solution consists of four main components:
- An Amazon Cognito user pool for user authentication. Authenticated users are granted access to the Public Speaking Mentor AI Assistant web portal to upload audio and video recordings.
- A simple web portal created using Streamlit to upload audio and video recordings. The uploaded files are stored in an Amazon Simple Storage Service (Amazon S3) bucket for later processing, retrieval, and analysis.
- A Step Functions standard workflow to orchestrate converting the audio to text using Amazon Transcribe and then invoking Amazon Bedrock with AI prompt chaining to generate speech recommendations and rewrite suggestions.
- Amazon Simple Notification Service (Amazon SNS) to send an email notification to the user with Amazon Bedrock generated recommendations.
This solution uses Amazon Transcribe for speech-to-text conversion. When an audio or video file is uploaded, Amazon Transcribe transcribes the speech into text. This text is passed as an input to Anthropic’s Claude 3.5 Sonnet on Amazon Bedrock. The solution sends two prompts to Amazon Bedrock: one to generate feedback and recommendations on language usage, grammar, filler words, repetition, and more, and another to obtain a curated version of the original speech. Prompt chaining is performed with Amazon Bedrock for these prompts. The solution then consolidates the outputs, displays recommendations on the user’s webpage, and emails the results.
The generative AI capabilities of Amazon Bedrock efficiently process user speech inputs. It uses natural language processing to analyze the speech and provides tailored recommendations. Using LLMs trained on extensive data, Amazon Bedrock generates curated speech outputs to enhance the presentation delivery.
The following diagram shows our solution architecture.

Let’s explore the architecture step by step:
- The user authenticates to the Public Speaking Mentor AI Assistant web portal (a Streamlit application hosted on user’s local desktop) using the Amazon Cognito user pool authentication mechanism.
- The user uploads an audio or video file to the web portal, which is stored in an S3 bucket encrypted using server-side encryption with Amazon S3 managed keys (SSE-S3).
- The S3 service triggers an
s3:ObjectCreatedevent for each file that is saved to the bucket. - Amazon EventBridge invokes the Step Functions state machine based on this event. Because the state machine execution could exceed 5 minutes, we use a standard workflow. Step Functions state machine logs are sent to Amazon CloudWatch for logging and troubleshooting purposes.
- The Step Functions workflow uses AWS SDK integrations to invoke Amazon Transcribe and initiates a
StartTranscriptionJob, passing the S3 bucket, prefix path, and object name in theMediaFileUriThe workflow waits for the transcription job to complete and saves the transcript in another S3 bucket prefix path. - The Step Functions workflow uses the optimized integrations to invoke the Amazon Bedrock
InvokeModelAPI, which specifies the Anthropic Claude 3.5 Sonnet model, the system prompt, maximum tokens, and the transcribed speech text as inputs to the API. The system prompt instructs the Anthropic Claude 3.5 Sonnet model to provide suggestions on how to improve the speech by identifying incorrect grammar, repetitions of words or content, use of filler words, and other recommendations. - After receiving a response from Amazon Bedrock, the Step Functions workflow uses prompt chaining to craft another input for Amazon Bedrock, incorporating the previous transcribed speech and the model’s previous response, and requesting the model to provide suggestions for rewriting the speech.
- The workflow combines these outputs from Amazon Bedrock and crafts a message that is displayed on the logged-in user’s webpage.
- The Step Functions workflow invokes the Amazon SNS
Publishoptimized integration to send an email to the user with the Amazon Bedrock generated message. - The Streamlit application queries Step Functions to display output results on the Amazon Cognito user’s webpage.
Prerequisites
For implementing the Public Speaking Mentor AI Assistant solution, you should have the following prerequisites:
- An AWS account with sufficient AWS Identity and Access Management (IAM) permissions for the following AWS services to deploy the solution and run the Streamlit application web portal:
-
- Amazon Bedrock
- AWS CloudFormation
- Amazon CloudWatch
- Amazon Cognito
- Amazon EventBridge
- Amazon Transcribe
- Amazon SNS
- Amazon S3
- AWS Step Functions
- Model access enabled for Anthropic’s Claude 3.5 Sonnet on Amazon Bedrock in your desired AWS Region.
- A local desktop environment with the AWS Command Line Interface (AWS CLI) installed, Python 3.8 or above, and the AWS Cloud Development Kit (AWS CDK) for Python and Git installed.
- The AWS CLI set up with necessary AWS credentials and desired Region.
Deploy the Public Speaking Mentor AI Assistant solution
Complete the following steps to deploy the Public Speaking Mentor AI Assistant AWS infrastructure:
- Clone the repository to your local desktop environment with the following command:
- Change to the
appdirectory in the cloned repository: - Create a Python virtual environment:
- Activate your virtual environment:
- Install the required dependencies:
- Optionally, synthesize the CloudFormation template using the AWS CDK:
You may need to perform a one-time AWS CDK bootstrapping using the following command. See AWS CDK bootstrapping for more details.
- Deploy the CloudFormation template in your AWS account and selected Region:
After the AWS CDK is deployed successfully, you can follow the steps in the next section to create an Amazon Cognito user.
Create an Amazon Cognito user for authentication
Complete the following steps to create a user in the Amazon Cognito user pool to access the web portal. The user created doesn’t need AWS permissions.
- Sign in to the AWS Management Console of your account and select the Region for your deployment.
- On the Amazon Cognito console, choose User pools in the navigation pane.
- Choose the user pool created by the CloudFormation template. (The user pool name should have the prefix
PSMBUserPoolfollowed by a string of random characters as one word.) - Choose Create user.

- Enter a user name and password, then choose Create user.

Subscribe to an SNS topic for email notifications
Complete the following steps to subscribe to an SNS topic to receive speech recommendation email notifications:
- Sign in to the console of your account and select the Region for your deployment.
- On the Amazon SNS console, choose Topics in the navigation pane.
- Choose the topic created by the CloudFormation template. (The name of the topic should look like
InfraStack-PublicSpeakingMentorAIAssistantTopicfollowed by a string of random characters as one word.) - Choose Create subscription.

- For Protocol, choose Email.
- For Endpoint, enter your email address.
- Choose Create subscription.

Run the Streamlit application to access the web portal
Complete the following steps to run the Streamlit application to access the Public Speaking Mentor AI Assistant web portal:
- Change the directory to
webappinside theappdirectory: - Launch the Streamlit server on port 8080:
- Make note of the Streamlit application URL for further use. Depending on your environment setup, you could choose one of the URLs out of three (Local, Network, or External) provided by Streamlit server’s running process.
- Make sure incoming traffic on
port 8080is allowed on your local machine to access the Streamlit application URL.
Use the Public Speaking Mentor AI Assistant
Complete the following steps to use the Public Speaking Mentor AI Assistant to improve your speech:
- Open the Streamlit application URL in your browser (Google Chrome, preferably) that you noted in the previous steps.
- Log in to the web portal using the Amazon Cognito user name and password created earlier for authentication.

- Choose Browse files to locate and choose your recording.
- Choose Upload File to upload your file to an S3 bucket.

As soon as the file upload finishes, the Public Speaking Mentor AI Assistant processes the audio transcription and prompt engineering steps to generate speech recommendations and rewrite results.

When the processing is complete, you can see the Speech Recommendations and Speech Rewrite sections on the webpage as well as in your email through Amazon SNS notifications.
On the right pane of the webpage, you can review the processing steps performed by the Public Speaking Mentor AI Assistant solution to get your speech results.

Clean up
Complete the following steps to clean up your resources:
- Shut down your Streamlit application server process running in your environment using Ctrl+C.
- Change to the
appdirectory in your repository. - Destroy the resources created with AWS CloudFormation using the AWS CDK:
Optimize for functionality, accuracy, and cost
Let’s conduct an analysis of this proposed solution architecture to identify opportunities for functionality enhancements, accuracy improvements, and cost optimization.
Starting with prompt engineering, our approach involves analyzing users’ speech based on several criteria, such as language usage, grammatical errors, filler words, and repetition of words and sentences. Individuals and organizations have the flexibility to customize the prompt by including additional analysis parameters or adjusting existing ones to align with their requirements and company policies. Furthermore, you can set the inference parameters to control the response from the LLM deployed on Amazon Bedrock.
To create a lean architecture, we have primarily chosen serverless technologies, such as Amazon Bedrock for prompt engineering and natural language generation, Amazon Transcribe for speech-to-text conversion, Amazon S3 for storage, Step Functions for orchestration, EventBridge for scalable event handling to process audio files, and Amazon SNS for email notifications. Serverless technologies enable you to run the solution without provisioning or managing servers, allowing for automatic scaling and pay-per-use billing, which can lead to cost savings and increased agility.
For the web portal component, we are currently deploying the Streamlit application in a local desktop environment. Alternatively, you have the option to use Amazon S3 Website Hosting, which would further contribute to a serverless architecture.
To enhance the accuracy of audio-to-text translation, it’s recommended to record your presentation audio in a quiet environment, away from noise and distractions.
In cases where your media contains domain-specific or non-standard terms, such as brand names, acronyms, and technical words, Amazon Transcribe might not accurately capture these terms in your transcription output. To address transcription inaccuracies and customize your output for your specific use case, you can create custom vocabularies and custom language models.
At the time of writing, our solution analyzes only the audio component. Uploading audio files alone can optimize storage costs. You may consider converting your video files into audio using third-party tools prior to uploading them to the Public Speaking Mentor AI Assistant web portal.
Our solution currently uses the standard tier of Amazon S3. However, you have the option to choose the S3 One Zone-IA storage class for storing files that don’t require high availability. Additionally, configuring an Amazon S3 lifecycle policy can further help reduce costs.
You can configure Amazon SNS to send speech recommendations to other destinations, such as email, webhook, and Slack. Refer to Configure Amazon SNS to send messages for alerts to other destinations for more information.
To estimate the cost of implementing the solution, you can use the AWS Pricing Calculator. For larger workloads, additional volume discounts may be available. We recommend contacting AWS pricing specialists or your account manager for more detailed pricing information.
Security best practices
Security and compliance is a shared responsibility between AWS and the customer, as outlined in the Shared Responsibility Model. We encourage you to review this model for a comprehensive understanding of the respective responsibilities. Refer to Security in Amazon Bedrock and Build generative AI applications on Amazon Bedrock to learn more about building secure, compliant, and responsible generative AI applications on Amazon Bedrock. OWASP Top 10 For LLMs outlines the most common vulnerabilities. We encourage you to enable Amazon Bedrock Guardrails to implement safeguards for your generative AI applications based on your use cases and responsible AI policies.
With AWS, you manage the privacy controls of your data, control how your data is used, who has access to it, and how it is encrypted. Refer to Data Protection in Amazon Bedrock and Data Protection in Amazon Transcribe for more information. Similarly, we strongly recommend referring to the data protection guidelines for each AWS service used in our solution architecture. Furthermore, we advise applying the principle of least privilege when granting permissions, because this practice enhances the overall security of your implementation.
Conclusion
By harnessing the capabilities of LLMs in Amazon Bedrock, our Public Speaking Mentor AI Assistant offers a revolutionary approach to enhancing public speaking abilities. With its personalized feedback and constructive recommendations, individuals can develop effective communication skills in a supportive and non-judgmental environment.
Unlock your potential as a captivating public speaker. Embrace the power of our Public Speaking Mentor AI Assistant and embark on a transformative journey towards mastering the art of public speaking. Try out our solution today by cloning the GitHub repository and experience the difference our cutting-edge technology can make in your personal and professional growth.
About the Authors
 Nehal Sangoi is a Sr. Technical Account Manager at Amazon Web Services. She provides strategic technical guidance to help independent software vendors plan and build solutions using AWS best practices. Connect with Nehal on LinkedIn.
Nehal Sangoi is a Sr. Technical Account Manager at Amazon Web Services. She provides strategic technical guidance to help independent software vendors plan and build solutions using AWS best practices. Connect with Nehal on LinkedIn.
 Akshay Singhal is a Sr. Technical Account Manager at Amazon Web Services supporting Enterprise Support customers focusing on the Security ISV segment. He provides technical guidance for customers to implement AWS solutions, with expertise spanning serverless architectures and cost optimization. Outside of work, Akshay enjoys traveling, Formula 1, making short movies, and exploring new cuisines. Connect with him on LinkedIn.
Akshay Singhal is a Sr. Technical Account Manager at Amazon Web Services supporting Enterprise Support customers focusing on the Security ISV segment. He provides technical guidance for customers to implement AWS solutions, with expertise spanning serverless architectures and cost optimization. Outside of work, Akshay enjoys traveling, Formula 1, making short movies, and exploring new cuisines. Connect with him on LinkedIn.