Amazon Q Business recently added support for administrators to modify the default access control list (ACL) crawling feature for data source connectors.
Amazon Q Business is a fully managed, AI powered assistant with enterprise-grade security and privacy features. It includes over 40 data source connectors that crawl and index documents. By default, Amazon Q Business indexes ACL information attached to documents along with the documents themselves and uses this to filter chat responses based on the user’s document access. With this new feature, you can enable or disable ACL crawling as required by their business use case.
This post introduces the new ACL toggle feature for Amazon Q Business, which you can use to enable or disable ACL crawling. We’ll explore use cases for disabling ACLs and discuss how to safely enable or disable ACL crawling.
Overview of access control list crawling
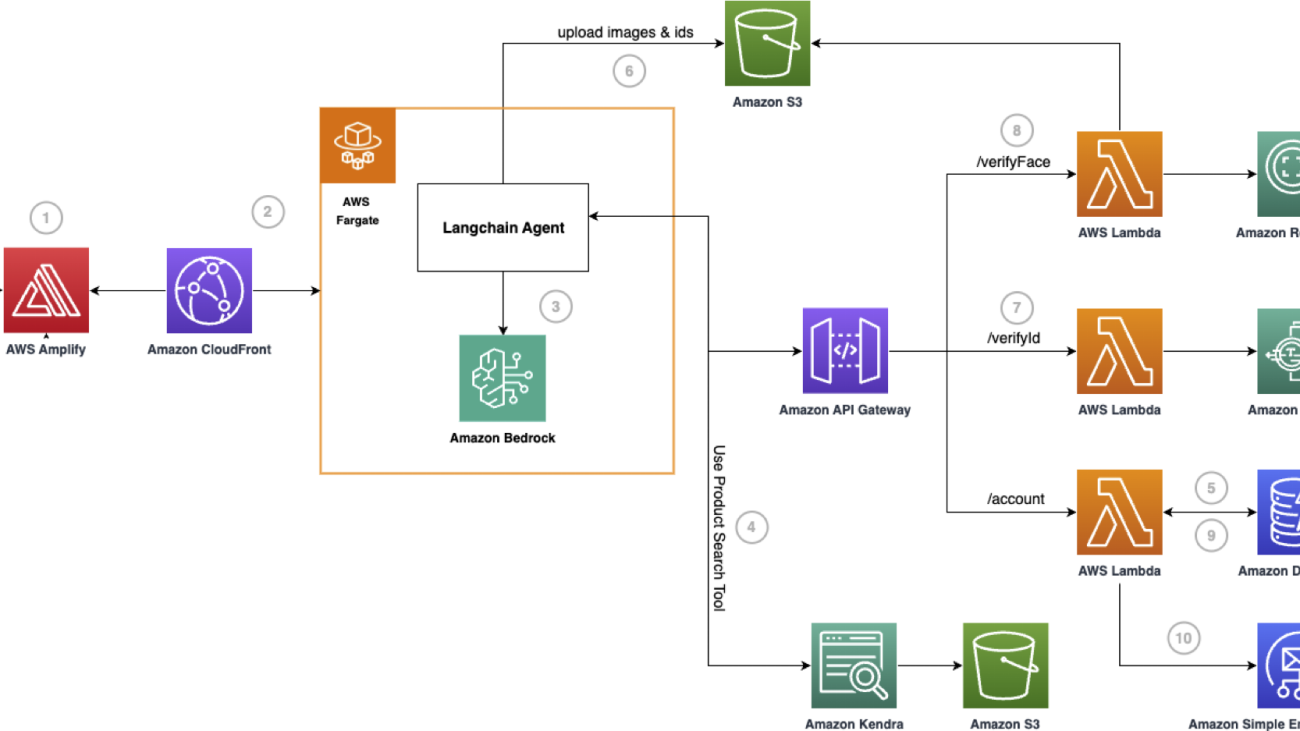
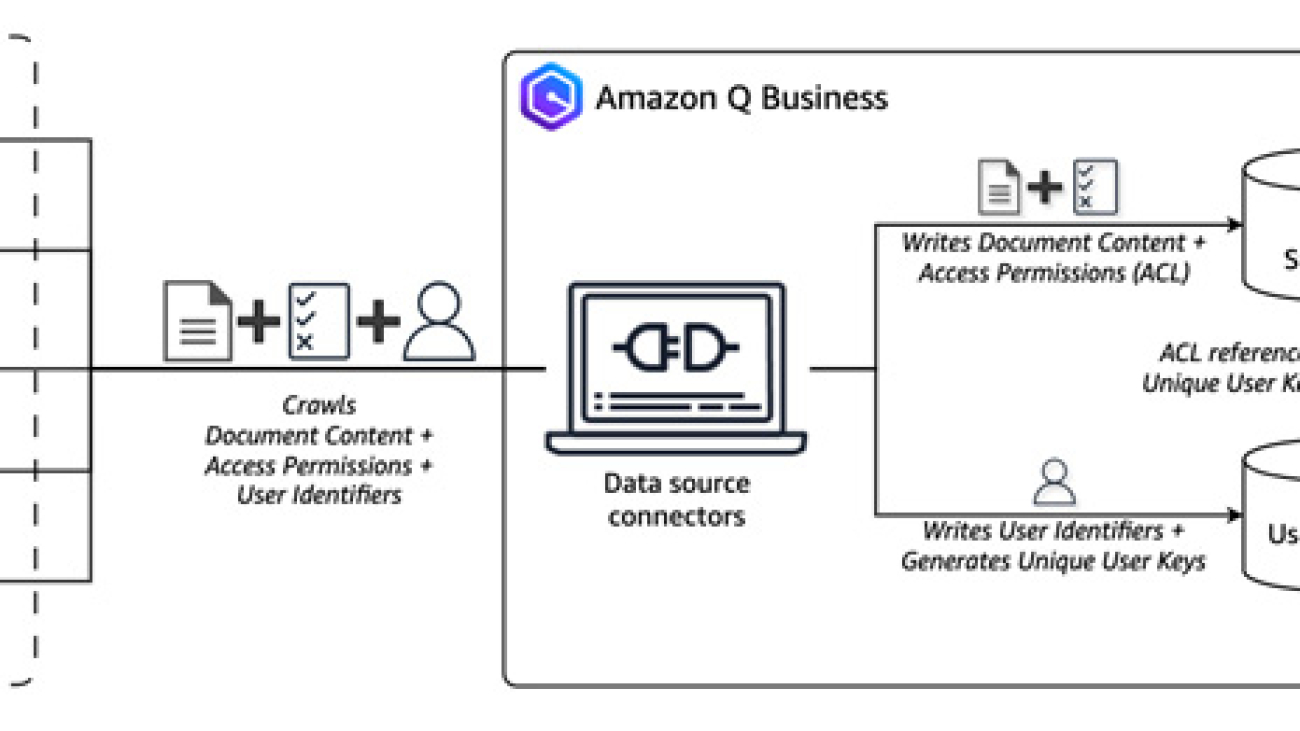
Amazon Q Business data source connectors help crawl various data sources to collect and index content in Amazon Q Business for fast discovery and retrieval when answering user queries. These data sources often contain documents with different classifications such as public, internal public, private, and confidential. To provide fine-grained control over access rights, you can attach ACLs to documents, allowing you to specify different levels of access for various users or groups. To verify that Amazon Q Business respects access control policies and that users only receive responses for content they’re authorized to access, the data source connectors automatically crawl for access permissions associated with the content, user identifiers, and groups.

The preceding figure illustrates the Amazon Q Business data source crawler with ACL crawling enabled. As the connector retrieves content from the data source, it examines the associated ACL and compiles a list of users and groups with read permissions for each document. The connector also collects user identifiers, which are stored in the Amazon Q Business user store for quick matching during query execution. Both the ACL and content are optimized and stored in the Amazon Q Business index storage, enabling secure and efficient retrieval when answering user queries. For more information on the user store, see Understanding Amazon Q Business User Store.
When to disable ACL crawling?
ACL crawling builds a security-aware index that respects access control policies in the primary data source. This process helps maintain data privacy and access control required for regulatory compliance, making sure that sensitive information isn’t inadvertently exposed through user query results. It provides a scalable mechanism to handle large amounts of content while maintaining consistency between the actual access controls on the data and what’s discoverable through search. Because of these advantages, ACL crawling is strongly recommended for all data sources. However, there are some circumstances when you might need to disable it. The following are some reasons why you might disable ACL crawling.
Internally public content
Organizations often designate certain data sources as internally public, including HR policies, IT knowledge bases, and wiki pages. For instance, a company might allocate an entire Microsoft SharePoint site for policies accessible to all employees, classifying it as internal-public. In such cases, crawling ACLs for permissions that include all employees can be costly and create unnecessary overhead. Turning off ACL crawling might be advantageous in these scenarios.
Data source contains irreconcilable identities
Amazon Q Business requires all users to authenticate with an enterprise-approved identity provider (IdP). After successful authentication, Amazon Q Business uses the IdP-provided user identifier to match against the user identifier fetched from the data source during ACL crawling. This process validates user access to content before retrieving it for query responses.
However, because of legacy issues such as mergers and acquisitions, data source configuration limitations, or other constraints, the primary user identifier from the IdP might differ from the one in the data source. This discrepancy can prevent Amazon Q Business from retrieving relevant content from the index and answering user queries effectively.
In such cases, it might be necessary to disable ACL crawling and use alternative options. These include implementing attribute filters or building dedicated restricted applications with access limited to specific audiences and content. For more information on attribute filters, see Filtering chat responses using document attributes.
Use case-driven targeted deployments
As a fully managed service, Amazon Q Business can be quickly deployed in multiple instances for scoped down targeted use cases. Examples include an HR bot in Slack or an AI assistant for customer support agents in a contact center. Because these AI assistants might be deployed for a limited audience, and the indexed content might be generally available to all users with application access, ACL crawling can be turned off.
Note of caution
Amazon Q Business cannot enforce access controls if ACL crawling is disabled. When ACL crawling is disabled for a data source, indexed content in that source will be considered accessible to users with access to the Amazon Q Business application. Therefore, disabling ACL crawling should be done with caution and due diligence. The following are some recommended best practices:
- Notify data source content owners and administrators of your intent to disable ACL crawling and obtain their approval beforehand.
- If applicable, consider implementing alternative options such as attribute filtering to restrict content retrieval or deploying a scoped-down, use-case-driven deployment to a limited audience.
- Maintain a decision document that clearly articulates the reasons for disabling ACL crawling, the scope of affected content, and precautions taken to prevent indexing of sensitive information.
Note: As a precaution, you cannot disable ACL crawling for an existing Amazon Q Business data source that already has ACL crawling enabled. To disable ACL crawling, you must delete the data source and recreate it. You can only disable ACL crawling during the data source creation process, and this requires an account administrator to grant permission for disabling ACL crawling when configuring the data source.
Procedures for configuring ACL crawling
Amazon Q Business ACL crawling helps protect your data. Amazon Q Business provides safeguards to help administrators and developers mitigate accidentally disabling ACL crawling. In this section, we will cover how you can allow or deny the ACL crawling disable feature, explore procedures to enable or disable ACL crawling, explain how to monitor logs for ACL crawling configuration changes, and troubleshoot common issues.
Personas for configuring ACL crawling
ACL crawling configuration typically involves multiple roles, depending on your organizational structure. To maximize safeguards, it’s recommended that these roles are filled by different individuals. For faster deployments, identify the necessary personnel within your organization before starting the project and ensure they collaborate to complete the configuration. Here are the common roles needed for ACL crawling configuration:
- AWS account administrator – An AWS account administrator is a user with full access to AWS services and the ability to manage IAM resources and permissions in the account. They can create and manage organizations, enabling centralized management of multiple AWS accounts.
- Amazon Q Business administrator – An Amazon Q Business administrator is typically a user or role responsible for managing and configuring the Amazon Q Business service. Their duties include creating and optimizing Amazon Q Business indexes, setting up guardrails, and tuning relevance. They also set up and maintain connections to various data sources that Amazon Q Business will index, such as Amazon Simple Storage Service (Amazon S3) buckets, SharePoint, Salesforce, and Confluence.
Prerequisites for ACL crawling
- Amazon Q Business application.
- For information on configuring a starter application, see Creating a sample Amazon Q Business application.
- Amazon Q Business data source connector that supports ACL crawling configuration.
- For a complete list of connectors that support disabling ACL crawling, see Connecting Amazon Q Business data sources.
- Data source authentication that meets the permissions required for crawling content and ACLs.
Process to disallow the option to disable ACL crawling
By default, the option to disable ACL crawling is enabled for an account. AWS account administrators can disallow this feature by setting up an account-level policy. It’s recommended to configure an explicit deny for production accounts by default. The following below shows the associated actions in relation to the personas involved in the configuration process.

Administrators can attach the IAM action qbusiness:DisableAclOnDataSource to the Amazon Q Business administrator user or role policy to deny or allow the option to disable ACL crawling. The example IAM policy code snippet that follows demonstrates how to set up an explicit deny.
Note that even if the option to disable ACL crawling is denied, the user interface might not gray out this option. However, if you attempt to create a data source with this option disabled, it will fail the validation check, and Amazon Q Business will not create the data source.
Process to disable ACL crawling for a data source connector
Before setting up a data source connector with ACL crawling disabled in your Amazon Q Business application deployment, make sure that you have no sensitive content in the data source or have implemented controls to help prevent accidental content exposure. Verify that the data source connector supports the option to disable ACL crawling. Notify information custodians, content owners, and data source administrators of your intent to disable ACL crawling and obtain their documented approvals, if necessary. If your account administrator has explicitly denied the option to disable ACL crawling, request temporary permission. After you have secured all approvals and exceptions, create a new data source with ACL crawling disabled and sync the data. With ACL crawling disabled, Amazon Q Business users will be able to discover knowledge and obtain answers from the indexed documents through this connector. Notify the account administrator to revert the account policy back to explicitly denying the disable ACL crawling option. The process and interaction between different roles are shown in the following chart.

The following is an overview of the procedure to create a data source with ACL crawling disabled using AWS Console:
- Navigate to the Amazon Q Business console.
- Select the Amazon Q Business application that you want to add a data source connector to.
- Choose Add data source in the Data sources section and select the desired connector.
- Update the connector configuration information. See Connecting Amazon Q Business data sources for configuration details.
- In the Authorization section, choose Disable ACLs and check the acknowledgment to accept the risks of disabling ACL crawling.

- Complete the remaining connector configuration and choose Save.
- Sync the data source.
Note: You cannot disable ACL crawling for an existing data source connector that was created with ACL crawling enabled. You must create a new data source connector instance with ACL disabled and delete the older instance that has ACL crawling enabled.
Process to enable ACL crawling for a data source connector
Creating a data source connector with ACL crawling enabled is recommended and doesn’t require additional allow listing from AWS account administrators. To enable ACL crawling, you follow steps similar to disabling ACLs as described in the previous section. When configuring the data source connector using the console, choose Enable ACLs in the Authorization section to create a connector with ACL crawling enabled. You can also enable ACL crawling at any time for an existing data source connector that was created with this option disabled. Sync the data source connector for the ACL enforcement to take effect. Amazon Q Business users can only query and obtain answers from documents to which they have access in the original data source.
It’s important to review that the data source administrator has set up the required permissions properly, making sure that the crawler has permission to crawl for ACLs in the data source before enabling ACL crawling. You can find the required permissions in the prerequisite section of the connector in Connecting Amazon Q Business data sources. The following shows the process for setting up a data source connector with ACL crawling enabled.
Logging and monitoring the ACL crawling configuration
Amazon Q Business uses AWS CloudTrail for logging API calls related to ACL crawling configuration. You can monitor the CloudTrail log for CreateDataSource and UpdateDataSource API calls to identify ACL crawling-related changes made to data source configuration. For a complete list of Amazon Q Business APIs that are logged to CloudTrail, see Logging Amazon Q Business API calls using AWS CloudTrail.
Administrators can configure Amazon CloudWatch alarms to generate automated alert notifications if ACL crawling is disabled for a data source connector, allowing them to initiate corrective action. For step-by-step instructions on setting up CloudWatch alarms based on CloudTrail events, see How do I use CloudWatch alarms to monitor CloudTrail events.
The example CloudWatch alarm code snippet that follows shows the filter pattern for identifying events related to disabling ACL crawling in a data source connector.
Tips for troubleshooting
When configuring Amazon Q Business data source connectors, you might occasionally encounter issues. The following are some common errors and their possible resolutions.
Not authorized to disable ACL crawling
When creating a new data source connector with ACL crawling disabled, you might see an error message stating not authorized to perform: qbusiness:DisableAclOnDataSource as shown in the following image.

This error indicates that your administrator has explicitly denied the option to disable ACL crawling for your AWS account. Contact your administrator to allow-list this action for your account. For more details, see the Process to disable ACL crawling for a data source connector section earlier in this post.
Data source connection errors
Data source connectors might also fail to connect to your data source or crawl data. In such cases, verify that Amazon Q Business can reach the data source through the public internet or through a VPC private network. See Connecting Amazon Q Business data sources to make sure that your data source authentication has the permissions needed to crawl content and ACLs, if enabled.
Identity and ACL mismatch errors
Finally, after successfully syncing data with ACL crawling enabled, some users might still be unable to get answers to queries, even though the relevant documents were indexed. This issue commonly occurs when the user lacks access to the indexed content in the original data source, or when the user identity obtained from the data source doesn’t match the sign-in identity. To troubleshoot such ACL mismatch issues, examine the data source sync report. For more information, see Introducing document-level sync reports: Enhanced data sync visibility in Amazon Q Business.
Key considerations and recommendations
Given the impact that disabling ACL crawling can have on content security, consider these restrictions and best practices when disabling ACL crawling in Amazon Q Business data source connectors:
- ACL crawling enablement is a one-way control mechanism. After it’s enabled, you cannot disable it. This helps prevent accidentally disabling ACL crawling in production environments.
- Keep ACL crawling enabled by default and disable it only for the subset of data source connectors that require it.
- If necessary, consider splitting the indexing of a data source by setting up multiple data source connectors and limiting ACL crawling disablement to a smaller content segment. Use the document
Inclusion and Exclusionfeature of data source connectors to define the indexing scope. - When ACL crawling is disabled because of irreconcilable identities, consider alternative options. These include implementing attribute filters, restricting access to the Amazon Q Business application, and setting up guardrails.
- As a security best practice, AWS Organizations and account administrators should add a service control policy to
explicitly deny the qbusiness:DisableAclOnDataSourcepermission for all accounts. Grant this permission only when requested by an Amazon Q Business administrator. After configuring a data source connector with ACL crawling disabled, revert to an explicit deny. Use a ticketing system to maintain a record of exception approvals. For more information, see <link>. - Currently, disabling ACL crawling is available for limited connectors, including ServiceNow, Confluence, SharePoint, Jira, Google Drive, OneDrive, Salesforce, Zendesk, GitHub, MS Teams, and Slack. For the latest list of connectors that support disabling ACL crawling, see Connecting Amazon Q Business data sources.
Clean up
To avoid incurring additional charges, make sure you delete any resources created in this post.
- To delete any data source created in Amazon Q Business, follow the instructions in Deleting an Amazon Q Business data source connector to delete the same.
- To delete any Amazon Q Business application created, follow the instructions in Deleting an application.
Conclusion
Amazon Q Business data source connector ACL crawling is an essential feature that helps organizations build, manage, and scale secure AI assistants. It plays a crucial role in enforcing regulatory and compliance policies and protecting sensitive content. With the introduction of a self-service feature to disable ACL crawling, Amazon Q Business now provides you more autonomy to choose deployment options that suit your organization’s business needs. To start building secure AI assistants with Amazon Q Business, explore the Getting started guide.
About the Authors
 Rajesh Kumar Ravi, a Senior Solutions Architect at Amazon Web Services, specializes in building generative AI solutions using Amazon Q Business, Amazon Bedrock, and Amazon Kendra. He helps businesses worldwide implement these technologies to enhance efficiency, innovation, and competitiveness. An accomplished technology leader, Rajesh has experience developing innovative AI products, nurturing the builder community, and contributing to new ideas. Outside of work, he enjoys walking and short hiking trips.
Rajesh Kumar Ravi, a Senior Solutions Architect at Amazon Web Services, specializes in building generative AI solutions using Amazon Q Business, Amazon Bedrock, and Amazon Kendra. He helps businesses worldwide implement these technologies to enhance efficiency, innovation, and competitiveness. An accomplished technology leader, Rajesh has experience developing innovative AI products, nurturing the builder community, and contributing to new ideas. Outside of work, he enjoys walking and short hiking trips.
 Meenakshisundaram Thandavarayan works for AWS as an AI/ML Specialist. He has a passion to design, create, and promote human-centered data and analytics experiences. Meena focuses on developing sustainable systems that deliver measurable, competitive advantages for strategic customers of AWS. Meena is a connector and design thinker and strives to drive business to new ways of working through innovation, incubation, and democratization.
Meenakshisundaram Thandavarayan works for AWS as an AI/ML Specialist. He has a passion to design, create, and promote human-centered data and analytics experiences. Meena focuses on developing sustainable systems that deliver measurable, competitive advantages for strategic customers of AWS. Meena is a connector and design thinker and strives to drive business to new ways of working through innovation, incubation, and democratization.
 Amit Choudhary is a Product Manager for Amazon Q Business connectors. He loves to build products that make it easy for customers to use privacy-preserving technologies (PETs) such as differential privacy
Amit Choudhary is a Product Manager for Amazon Q Business connectors. He loves to build products that make it easy for customers to use privacy-preserving technologies (PETs) such as differential privacy
 Keerthi Kumar Kallur is a Software Development Engineer at AWS. He is part of the Amazon Q Business team and worked on various features with customers. In his spare time, he likes to do outdoor activities such as hiking and sports such as volleyball.
Keerthi Kumar Kallur is a Software Development Engineer at AWS. He is part of the Amazon Q Business team and worked on various features with customers. In his spare time, he likes to do outdoor activities such as hiking and sports such as volleyball.


 Sungmin Hong is a Senior Applied Scientist at AWS Generative AI Innovation Center where he helps expedite the variety of use cases of AWS customers. Before joining Amazon, Sungmin was a postdoctoral research fellow at Harvard Medical School. He holds Ph.D. in Computer Science from New York University. Outside of work, Sungmin enjoys hiking, reading and cooking.
Sungmin Hong is a Senior Applied Scientist at AWS Generative AI Innovation Center where he helps expedite the variety of use cases of AWS customers. Before joining Amazon, Sungmin was a postdoctoral research fellow at Harvard Medical School. He holds Ph.D. in Computer Science from New York University. Outside of work, Sungmin enjoys hiking, reading and cooking. Sujeong Cha is a Deep Learning Architect at the AWS Generative AI Innovation Center, where she specializes in model customization and optimization. She has extensive hands-on experience in solving customers’ business use cases by utilizing generative AI as well as traditional AI/ML solutions. Sujeong holds a M.S. degree in Data Science from New York University.
Sujeong Cha is a Deep Learning Architect at the AWS Generative AI Innovation Center, where she specializes in model customization and optimization. She has extensive hands-on experience in solving customers’ business use cases by utilizing generative AI as well as traditional AI/ML solutions. Sujeong holds a M.S. degree in Data Science from New York University. Arijit Ghosh Chowdhury is a Scientist with the AWS Generative AI Innovation Center, where he works on model customization and optimization. In his role, he works on applied research in fine-tuning and model evaluations to enable GenAI for various industries. He has a Master’s degree in Computer Science from the University of Illinois at Urbana Champaign, where his research focused on question answering, search and domain adaptation.
Arijit Ghosh Chowdhury is a Scientist with the AWS Generative AI Innovation Center, where he works on model customization and optimization. In his role, he works on applied research in fine-tuning and model evaluations to enable GenAI for various industries. He has a Master’s degree in Computer Science from the University of Illinois at Urbana Champaign, where his research focused on question answering, search and domain adaptation. Yiyue Qian is an Applied Scientist II at the AWS Generative AI Innovation Center, where she supports providing generative AI solutions to AWS customers. In this role, she collaborates with a team of experts to develop innovative AI-driven models for AWS customers across various industries. Yiyue holds a Ph.D. in Computer Science from the University of Notre Dame, where her research focused on advanced machine learning and deep learning techniques.
Yiyue Qian is an Applied Scientist II at the AWS Generative AI Innovation Center, where she supports providing generative AI solutions to AWS customers. In this role, she collaborates with a team of experts to develop innovative AI-driven models for AWS customers across various industries. Yiyue holds a Ph.D. in Computer Science from the University of Notre Dame, where her research focused on advanced machine learning and deep learning techniques. Wei-Chih Chen is a Machine Learning Engineer at the AWS Generative AI Innovation Center, where he works on model customization and optimization for LLMs. He also builds tools to help his team tackle various aspects of the LLM development life cycle—including fine-tuning, benchmarking, and load-testing—that accelerating the adoption of diverse use cases for AWS customers. He holds an M.S. degree in Computer Science from UC Davis.
Wei-Chih Chen is a Machine Learning Engineer at the AWS Generative AI Innovation Center, where he works on model customization and optimization for LLMs. He also builds tools to help his team tackle various aspects of the LLM development life cycle—including fine-tuning, benchmarking, and load-testing—that accelerating the adoption of diverse use cases for AWS customers. He holds an M.S. degree in Computer Science from UC Davis. Hannah Marlowe is a Senior Manager of Model Customization at the AWS Generative AI Innovation Center. Her team specializes in helping customers develop differentiating Generative AI solutions using their unique and proprietary data to achieve key business outcomes. She holds a Ph.D in Physics from the University of Iowa, with a focus on astronomical X-ray analysis and instrumentation development. Outside of work, she can be found hiking, mountain biking, and skiing around the mountains in Colorado.
Hannah Marlowe is a Senior Manager of Model Customization at the AWS Generative AI Innovation Center. Her team specializes in helping customers develop differentiating Generative AI solutions using their unique and proprietary data to achieve key business outcomes. She holds a Ph.D in Physics from the University of Iowa, with a focus on astronomical X-ray analysis and instrumentation development. Outside of work, she can be found hiking, mountain biking, and skiing around the mountains in Colorado. Seunghyeon Jeong (Steve) is a team leader of the Platform Application team at SKT. He is responsible for commercializing the Global Intelligence Platform (GIP), which provides AI models and tools. For most of his career, he has been a PM developing various mobile services such as mobile wallet, fashion streaming, and unified login services for SK. His team is expanding the delivery of models and features to make it easier for internal teams to apply AI, contributing to SKT’s AI Transformation. Before entering the AI space, he was a Product Manager, developing and operating various mobile services such as mobile wallet, fashion streaming, and unified login services for the US and Korea.
Seunghyeon Jeong (Steve) is a team leader of the Platform Application team at SKT. He is responsible for commercializing the Global Intelligence Platform (GIP), which provides AI models and tools. For most of his career, he has been a PM developing various mobile services such as mobile wallet, fashion streaming, and unified login services for SK. His team is expanding the delivery of models and features to make it easier for internal teams to apply AI, contributing to SKT’s AI Transformation. Before entering the AI space, he was a Product Manager, developing and operating various mobile services such as mobile wallet, fashion streaming, and unified login services for the US and Korea. Sunwoo Lee (Lois) is the team leader of the Data Construction and Evaluation Team within SK Telecom’s Global AI Tech division. She oversees the design and construction of training data for language models, the model performance evaluation process, and its application to services. Her career has focused on NLP within IT, which is a great fit with her background in Linguistics and Korean language education. Alongside her world-class team, she continues to explore and solve fascinating problems such as how to optimize the design of data for language model training, which tasks and methods to implement for validating language model performance, and the best design of AI-human conversations.
Sunwoo Lee (Lois) is the team leader of the Data Construction and Evaluation Team within SK Telecom’s Global AI Tech division. She oversees the design and construction of training data for language models, the model performance evaluation process, and its application to services. Her career has focused on NLP within IT, which is a great fit with her background in Linguistics and Korean language education. Alongside her world-class team, she continues to explore and solve fascinating problems such as how to optimize the design of data for language model training, which tasks and methods to implement for validating language model performance, and the best design of AI-human conversations. Eric Davis is the vice president of the AI Tech Collaboration Group at SKT. Eric oversees tech collaborations with worldwide tech partners to customize large language models (LLMs) for the telecommunications domain. His teams are responsible for designing and building the datasets to tune LLMs, as well as benchmarking LLMs in general and for the telecommunications domain. Eric holds a Master of Science degree in Computer Science from Carnegie Mellon from the Language Technologies Institute and a Bachelor of Arts in Linguistics and Psychology from the University of California, Los Angeles.
Eric Davis is the vice president of the AI Tech Collaboration Group at SKT. Eric oversees tech collaborations with worldwide tech partners to customize large language models (LLMs) for the telecommunications domain. His teams are responsible for designing and building the datasets to tune LLMs, as well as benchmarking LLMs in general and for the telecommunications domain. Eric holds a Master of Science degree in Computer Science from Carnegie Mellon from the Language Technologies Institute and a Bachelor of Arts in Linguistics and Psychology from the University of California, Los Angeles.


 James Park is a Solutions Architect at Amazon Web Services. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In his spare time, he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends.
James Park is a Solutions Architect at Amazon Web Services. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In his spare time, he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends. RJ is an Engineer within Amazon. He builds and optimizes systems for distributed systems for training and works on optimizing adopting systems to reduce latency for ML Inference. Outside work, he is exploring using Generative AI for building food recipes.
RJ is an Engineer within Amazon. He builds and optimizes systems for distributed systems for training and works on optimizing adopting systems to reduce latency for ML Inference. Outside work, he is exploring using Generative AI for building food recipes. Yang Zhou is a software engineer working on building and optimizing machine learning systems. His recent focus is enhancing the performance and cost efficiency of generative AI inference. Beyond work, he enjoys traveling and has recently discovered a passion for running long distances.
Yang Zhou is a software engineer working on building and optimizing machine learning systems. His recent focus is enhancing the performance and cost efficiency of generative AI inference. Beyond work, he enjoys traveling and has recently discovered a passion for running long distances. Adam (Hongshen) Zhao is a Software Development Manager at Amazon Stores Foundational AI. In his current role, Adam is leading Rufus Inference team to build GenAI inference optimization solutions and inference system at scale for fast inference at low cost. Outside work, he enjoys traveling with his wife and art creations.
Adam (Hongshen) Zhao is a Software Development Manager at Amazon Stores Foundational AI. In his current role, Adam is leading Rufus Inference team to build GenAI inference optimization solutions and inference system at scale for fast inference at low cost. Outside work, he enjoys traveling with his wife and art creations. Faqin Zhong is a software engineer at Amazon Stores Foundational AI, working on Large Language Model (LLM) inference infrastructure and optimizations. Passionate about Generative AI technology, Faqin collaborates with leading teams to drive innovations, making LLMs more accessible and impactful, ultimately enhancing customer experiences across diverse applications. Outside of work she enjoys cardio exercise and baking with her son.
Faqin Zhong is a software engineer at Amazon Stores Foundational AI, working on Large Language Model (LLM) inference infrastructure and optimizations. Passionate about Generative AI technology, Faqin collaborates with leading teams to drive innovations, making LLMs more accessible and impactful, ultimately enhancing customer experiences across diverse applications. Outside of work she enjoys cardio exercise and baking with her son. Nicolas Trown is an engineer in Amazon Stores Foundational AI. His recent focus is lending his systems expertise across Rufus to aid Rufus Inference team and efficient utilization across the Rufus experience. Outside of work he enjoys spending time with his wife and day trips to nearby coast, Napa, and Sonoma areas.
Nicolas Trown is an engineer in Amazon Stores Foundational AI. His recent focus is lending his systems expertise across Rufus to aid Rufus Inference team and efficient utilization across the Rufus experience. Outside of work he enjoys spending time with his wife and day trips to nearby coast, Napa, and Sonoma areas. Bing Yin is a director of science at Amazon Stores Foundational AI. He leads the effort to build LLMs that are specialized for shopping use cases and optimized for inference at Amazon scale. Outside of work, he enjoys running marathon races.
Bing Yin is a director of science at Amazon Stores Foundational AI. He leads the effort to build LLMs that are specialized for shopping use cases and optimized for inference at Amazon scale. Outside of work, he enjoys running marathon races.
 Tim Westman is the Product Manager and Go-to-Market Lead for Edge Machine Learning, AWS. Tim leads the Product Management and Business Development for the Edge Machine Learning business at Amazon Web Services. In this role, he works with customers to help build computer vision solutions at the edge to solve complex operational challenges. Tim has more than 30 years of experience in sales, business development and product management roles for leading hardware and software companies, with the last 8 years specializing in AI and computer vision for IoT applications.
Tim Westman is the Product Manager and Go-to-Market Lead for Edge Machine Learning, AWS. Tim leads the Product Management and Business Development for the Edge Machine Learning business at Amazon Web Services. In this role, he works with customers to help build computer vision solutions at the edge to solve complex operational challenges. Tim has more than 30 years of experience in sales, business development and product management roles for leading hardware and software companies, with the last 8 years specializing in AI and computer vision for IoT applications.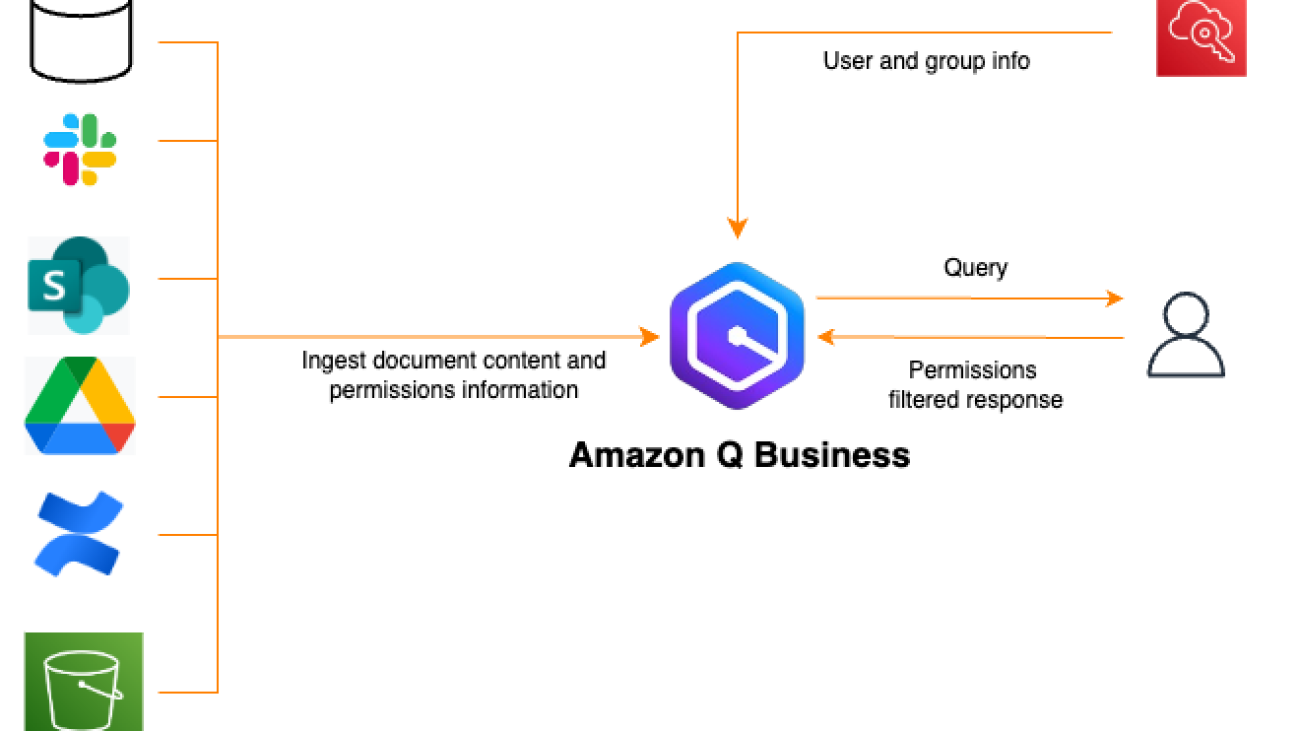
































 Akshara Shah is a Senior Solutions Architect at Amazon Web Services. She provides strategic technical guidance to help customers design and build cloud solutions. She is currently focused on machine learning and AI technologies.
Akshara Shah is a Senior Solutions Architect at Amazon Web Services. She provides strategic technical guidance to help customers design and build cloud solutions. She is currently focused on machine learning and AI technologies. Roshan Thomas is a Senior Solutions Architect at Amazon Web Services. He is based in Melbourne, Australia and works closely with enterprise customers to accelerate their journey in the cloud. He is passionate about technology and helping customers architect and build solutions on AWS.
Roshan Thomas is a Senior Solutions Architect at Amazon Web Services. He is based in Melbourne, Australia and works closely with enterprise customers to accelerate their journey in the cloud. He is passionate about technology and helping customers architect and build solutions on AWS.
 Nirmal Kumar is Sr. Product Manager for the Amazon SageMaker service. Committed to broadening access to AI/ML, he steers the development of no-code and low-code ML solutions. Outside work, he enjoys travelling and reading non-fiction.
Nirmal Kumar is Sr. Product Manager for the Amazon SageMaker service. Committed to broadening access to AI/ML, he steers the development of no-code and low-code ML solutions. Outside work, he enjoys travelling and reading non-fiction.



 Roy Allela is a Senior AI/ML Specialist Solutions Architect at AWS.He helps AWS customers—from small startups to large enterprises—train and deploy foundation models efficiently on AWS. He is passionate about computational optimization problems and improving the performance of AI workloads.
Roy Allela is a Senior AI/ML Specialist Solutions Architect at AWS.He helps AWS customers—from small startups to large enterprises—train and deploy foundation models efficiently on AWS. He is passionate about computational optimization problems and improving the performance of AI workloads. Kanwaljit Khurmi is a Principal Solutions Architect at Amazon Web Services. He works with AWS customers to provide guidance and technical assistance, helping them improve the value of their solutions when using AWS. Kanwaljit specializes in helping customers with containerized and machine learning applications.
Kanwaljit Khurmi is a Principal Solutions Architect at Amazon Web Services. He works with AWS customers to provide guidance and technical assistance, helping them improve the value of their solutions when using AWS. Kanwaljit specializes in helping customers with containerized and machine learning applications. Trevor Harvey is a Principal Specialist in Generative AI at Amazon Web Services (AWS) and an AWS Certified Solutions Architect – Professional. He serves as a voting member of the PyTorch Foundation Governing Board, where he contributes to the strategic advancement of open-source deep learning frameworks. At AWS, Trevor works with customers to design and implement machine learning solutions and leads go-to-market strategies for generative AI services.
Trevor Harvey is a Principal Specialist in Generative AI at Amazon Web Services (AWS) and an AWS Certified Solutions Architect – Professional. He serves as a voting member of the PyTorch Foundation Governing Board, where he contributes to the strategic advancement of open-source deep learning frameworks. At AWS, Trevor works with customers to design and implement machine learning solutions and leads go-to-market strategies for generative AI services. Less Wright is an AI/Partner Engineer in PyTorch. He works on Triton/CUDA kernels (
Less Wright is an AI/Partner Engineer in PyTorch. He works on Triton/CUDA kernels ( Wei Feng is a Software Engineer on the PyTorch distributed team. He has worked on float8 all-gather for FSDP2, TP (Tensor Parallel) in TorchTitan, and 4-bit quantization for distributed QLoRA in TorchTune. He is also a core maintainer of FSDP2.
Wei Feng is a Software Engineer on the PyTorch distributed team. He has worked on float8 all-gather for FSDP2, TP (Tensor Parallel) in TorchTitan, and 4-bit quantization for distributed QLoRA in TorchTune. He is also a core maintainer of FSDP2.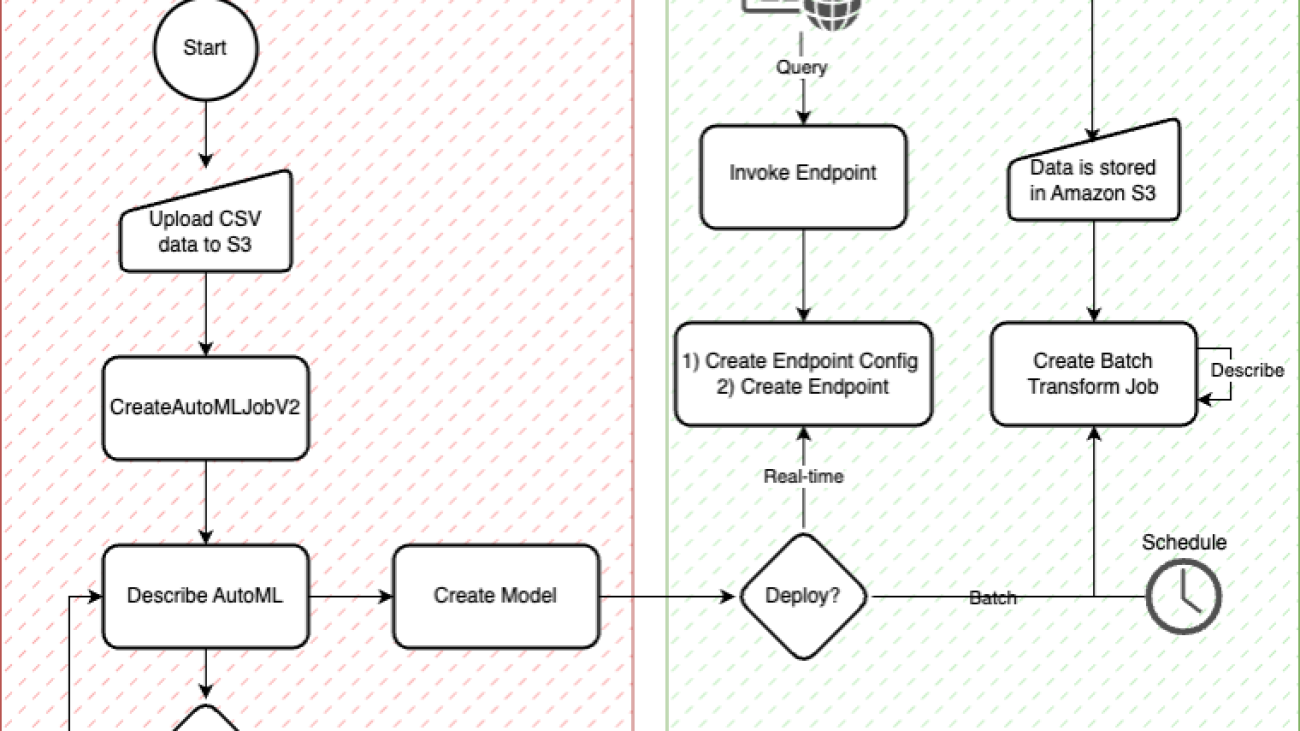
 Nick McCarthy is a Senior Machine Learning Engineer at AWS, based in London. He has worked with AWS clients across various industries including healthcare, finance, sports, telecoms and energy to accelerate their business outcomes through the use of AI/ML. Outside of work he loves to spend time travelling, trying new cuisines and reading about science and technology. Nick has a Bachelors degree in Astrophysics and a Masters degree in Machine Learning.
Nick McCarthy is a Senior Machine Learning Engineer at AWS, based in London. He has worked with AWS clients across various industries including healthcare, finance, sports, telecoms and energy to accelerate their business outcomes through the use of AI/ML. Outside of work he loves to spend time travelling, trying new cuisines and reading about science and technology. Nick has a Bachelors degree in Astrophysics and a Masters degree in Machine Learning. Davide Gallitelli is a Senior Specialist Solutions Architect for AI/ML in the EMEA region. He is based in Brussels and works closely with customers throughout Benelux. He has been a developer since he was very young, starting to code at the age of 7. He started learning AI/ML at university, and has fallen in love with it since then.
Davide Gallitelli is a Senior Specialist Solutions Architect for AI/ML in the EMEA region. He is based in Brussels and works closely with customers throughout Benelux. He has been a developer since he was very young, starting to code at the age of 7. He started learning AI/ML at university, and has fallen in love with it since then.