Generative artificial intelligence (AI) not only empowers innovation through ideation, content creation, and enhanced customer service, but also streamlines operations and boosts productivity across various domains. To effectively harness this transformative technology, Amazon Bedrock offers a fully managed service that integrates high-performing foundation models (FMs) from leading AI companies, such as AI21 Labs, Anthropic, Cohere, Meta, Stability AI, Mistral AI, and Amazon. By providing access to these advanced models through a single API and supporting the development of generative AI applications with an emphasis on security, privacy, and responsible AI, Amazon Bedrock enables you to use AI to explore new avenues for innovation and improve overall offerings.
Enterprise customers can unlock significant value by harnessing the power of intelligent document processing (IDP) augmented with generative AI. By infusing IDP solutions with generative AI capabilities, organizations can revolutionize their document processing workflows, achieving exceptional levels of automation and reliability. This combination enables advanced document understanding, highly effective structured data extraction, automated document classification, and seamless information retrieval from unstructured text. With these capabilities, organizations can achieve scalable, efficient, and high-value document processing that drives business transformation and competitiveness, ultimately leading to improved productivity, reduced costs, and enhanced decision-making.
In this post, we show how to develop an IDP solution using Anthropic Claude 3 Sonnet on Amazon Bedrock. We demonstrate how to extract data from a scanned document and insert it into a database.
The Anthropic Claude 3 Sonnet model is optimized for speed and efficiency, making it an excellent choice for intelligent tasks—particularly for enterprise workloads. It also possesses sophisticated vision capabilities, demonstrating a strong aptitude for understanding a wide range of visual formats, including photos, charts, graphs, and technical diagrams. Although we demonstrate this solution using the Anthropic Claude 3 Sonnet model, you can alternatively use the Haiku and Opus models if your use case requires them.
Solution overview
The proposed solution uses Amazon Bedrock and the powerful Anthropic Claude 3 Sonnet model to enable IDP capabilities. The architecture consists of several AWS services seamlessly integrated with the Amazon Bedrock, enabling efficient and accurate extraction of data from scanned documents.
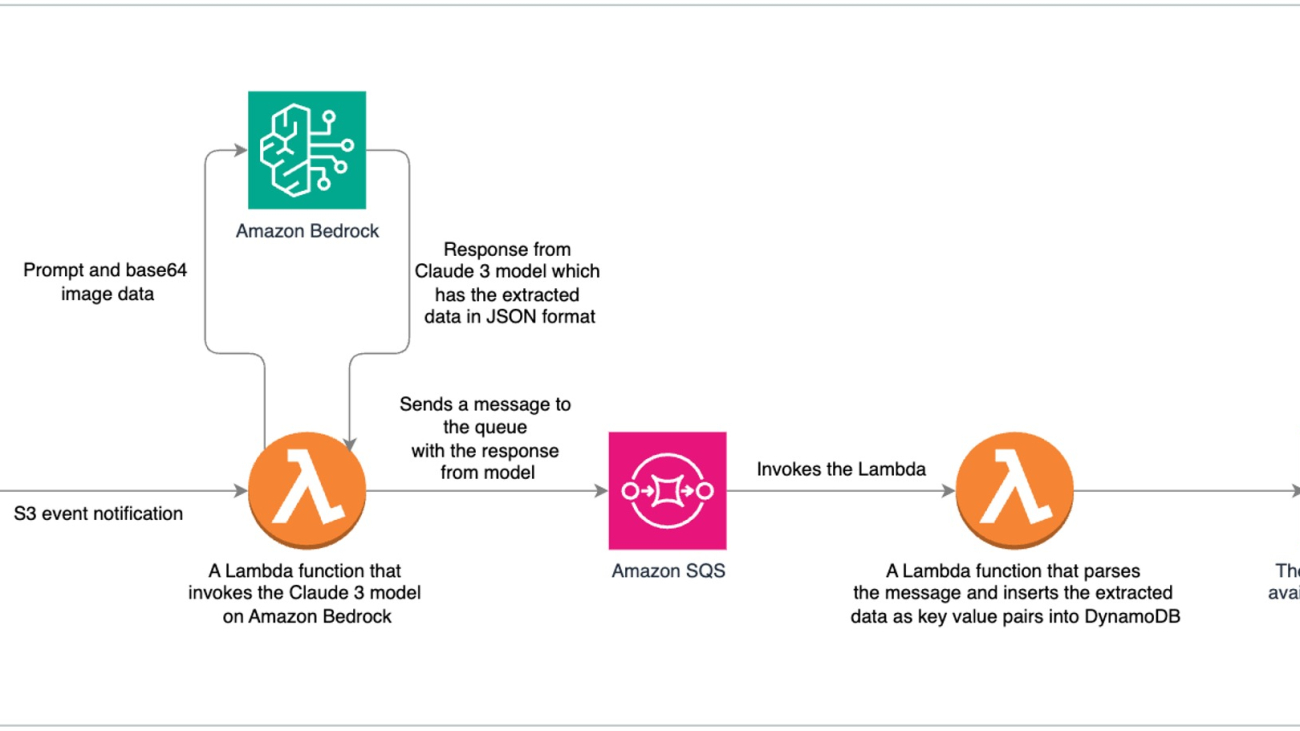
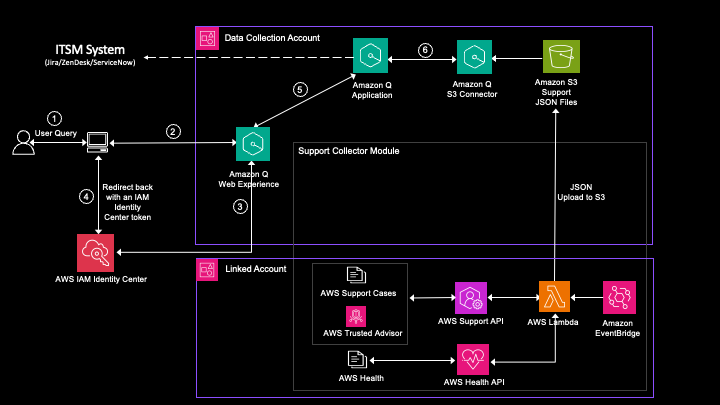
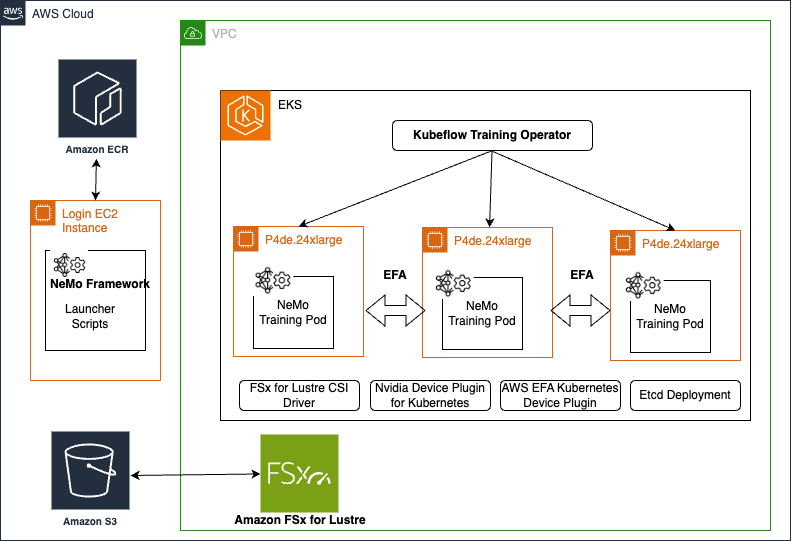
The following diagram illustrates our solution architecture.

The solution consists of the following steps:
- The process begins with scanned documents being uploaded and stored in an Amazon Simple Storage Service (Amazon S3) bucket, which invokes an S3 Event Notification on object upload.
- This event invokes an AWS Lambda function, responsible for invoking the Anthropic Claude 3 Sonnet model on Amazon Bedrock.
- The Anthropic Claude 3 Sonnet model, with its advanced multimodal capabilities, processes the scanned documents and extracts relevant data in a structured JSON format.
- The extracted data from the Anthropic Claude 3 model is sent to an Amazon Simple Queue Service (Amazon SQS) queue. Amazon SQS acts as a buffer, allowing components to send and receive messages reliably without being directly coupled, providing scalability and fault tolerance in the system.
- Another Lambda function consumes the messages from the SQS queue, parses the JSON data, and stores the extracted key-value pairs in an Amazon DynamoDB table for retrieval and further processing.
This serverless architecture takes advantage of the scalability and cost-effectiveness of AWS services while harnessing the cutting-edge intelligence of Anthropic Claude 3 Sonnet. By combining the robust infrastructure of AWS with Anthropic’s FMs, this solution enables organizations to streamline their document processing workflows, extract valuable insights, and enhance overall operational efficiency.
The solution uses the following services and features:
- Amazon Bedrock is a fully managed service that provides access to large language models (LLMs), allowing developers to build and deploy their own customized AI applications.
- The Anthropic Claude 3 family offers a versatile range of models tailored to meet diverse needs. With three options—Opus, Sonnet, and Haiku—you can choose the perfect balance of intelligence, speed, and cost. These models excel at understanding complex enterprise content, including charts, graphs, technical diagrams, and reports.
- Amazon DynamoDB is a fully managed, serverless, NoSQL database service.
- AWS Lambda is a serverless computing service that allows you to run code without provisioning or managing servers.
- Amazon SQS is a fully managed message queuing service.
- Amazon S3 is a highly scalable, durable, and secure object storage service.
In this solution, we use the generative AI capabilities in Amazon Bedrock to efficiently extract data. As of writing of this post, Anthropic Claude 3 Sonnet only accepts images as input. The supported file types are GIF, JPEG, PNG, and WebP. You can choose to save images during the scanning process or convert the PDF to images.
You can also enhance this solution by implementing human-in-the-loop and model evaluation features. The goal of this post is to demonstrate how you can build an IDP solution using Amazon Bedrock, but to use this as a production-scale solution, additional considerations should be taken into account, such as testing for edge case scenarios, better exception handling, trying additional prompting techniques, model fine-tuning, model evaluation, throughput requirements, number of concurrent requests to be supported, and carefully considering cost and latency implications.
Prerequisites
You need the following prerequisites before you can proceed with this solution. For this post, we use the us-east-1 AWS Region. For details on available Regions, see Amazon Bedrock endpoints and quotas.
- An AWS account with an AWS Identity and Access Management (IAM) user who has permissions to DynamoDB, Lambda, Amazon Bedrock, Amazon S3, Amazon SQS, Lambda, and IAM.
- Access to the Anthropic Claude 3 Sonnet model in Amazon Bedrock. For instructions, see Manage model access.
Use case and dataset
For our example use case, let’s look at a state agency responsible for issuing birth certificates. The agency may receive birth certificate applications through various methods, such as online applications, forms completed at a physical location, and mailed-in completed paper applications. Today, most agencies spend a considerable amount of time and resources to manually extract the application details. The process begins with scanning the application forms, manually extracting the details, and then entering them into an application that eventually stores the data into a database. This process is time-consuming, inefficient, not scalable, and error-prone. Additionally, it adds complexity if the application form is in a different language (such as Spanish).
For this demonstration, we use sample scanned images of birth certificate application forms. These forms don’t contain any real personal data. Two examples are provided: one in English (handwritten) and another in Spanish (printed). Save these images as .jpeg files to your computer. You need them later for testing the solution.
Create an S3 bucket
On the Amazon S3 console, create a new bucket with a unique name (for example, bedrock-claude3-idp-{random characters to make it globally unique}) and leave the other settings as default. Within the bucket, create a folder named images and a sub-folder named birth_certificates.

Create an SQS queue
On the Amazon SQS console, create a queue with the Standard queue type, provide a name (for example, bedrock-idp-extracted-data), and leave the other settings as default.

Create a Lambda function to invoke the Amazon Bedrock model
On the Lambda console, create a function (for example, invoke_bedrock_claude3), choose Python 3.12 for the runtime, and leave the remaining settings as default. Later, you configure this function to be invoked every time a new image is uploaded into the S3 bucket. You can download the entire Lambda function code from invoke_bedrock_claude3.py. Replace the contents of the lambda_function.py file with the code from the downloaded file. Make sure to substitute {SQS URL} with the URL of the SQS queue you created earlier, then choose Deploy.
The Lambda function should perform the following actions:
s3 = boto3.client('s3')
sqs = boto3.client('sqs')
bedrock = boto3.client('bedrock-runtime', region_name='us-east-1')
QUEUE_URL = {SQS URL}
MODEL_ID = "anthropic.claude-3-sonnet-20240229-v1:0"
The following code gets the image from the S3 bucket using the get_object method and converts it to base64 data:
image_data = s3.get_object(Bucket=bucket_name, Key=object_key)['Body'].read()
base64_image = base64.b64encode(image_data).decode('utf-8')
Prompt engineering is a critical factor in unlocking the full potential of generative AI applications like IDP. Crafting well-structured prompts makes sure that the AI system’s outputs are accurate, relevant, and aligned with your objectives, while mitigating potential risks.
With the Anthropic Claude 3 model integrated into the Amazon Bedrock IDP solution, you can use the model’s impressive visual understanding capabilities to effortlessly extract data from documents. Simply provide the image or document as input, and Anthropic Claude 3 will comprehend its contents, seamlessly extracting the desired information and presenting it in a human-readable format. All Anthropic Claude 3 models are capable of understanding non-English languages such as Spanish, Japanese, and French. In this particular use case, we demonstrate how to translate Spanish application forms into English by providing the appropriate prompt instructions.
However, LLMs like Anthropic Claude 3 can exhibit variability in their response formats. To achieve consistent and structured output, you can tailor your prompts to instruct the model to return the extracted data in a specific format, such as JSON with predefined keys. This approach enhances the interoperability of the model’s output with downstream applications and streamlines data processing workflows.
The following is the prompt with the specific JSON output format:
prompt = """
This image shows a birth certificate application form.
Please precisely copy all the relevant information from the form.
Leave the field blank if there is no information in corresponding field.
If the image is not a birth certificate application form, simply return an empty JSON object.
If the application form is not filled, leave the fees attributes blank.
Translate any non-English text to English.
Organize and return the extracted data in a JSON format with the following keys:
{
"applicantDetails":{
"applicantName": "",
"dayPhoneNumber": "",
"address": "",
"city": "",
"state": "",
"zipCode": "",
"email":""
},
"mailingAddress":{
"mailingAddressApplicantName": "",
"mailingAddress": "",
"mailingAddressCity": "",
"mailingAddressState": "",
"mailingAddressZipCode": ""
},
"relationToApplicant":[""],
"purposeOfRequest": "",
"BirthCertificateDetails":
{
"nameOnBirthCertificate": "",
"dateOfBirth": "",
"sex": "",
"cityOfBirth": "",
"countyOfBirth": "",
"mothersMaidenName": "",
"fathersName": "",
"mothersPlaceOfBirth": "",
"fathersPlaceOfBirth": "",
"parentsMarriedAtBirth": "",
"numberOfChildrenBornInSCToMother": "",
"diffNameAtBirth":""
},
"fees":{
"searchFee": "",
"eachAdditionalCopy": "",
"expediteFee": "",
"totalFees": ""
}
}
"""
Invoke the Anthropic Claude 3 Sonnet model using the Amazon Bedrock API. Pass the prompt and the base64 image data as parameters:
def invoke_claude_3_multimodal(prompt, base64_image_data):
request_body = {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 2048,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt,
},
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/png",
"data": base64_image_data,
},
},
],
}
],
}
try:
response = bedrock.invoke_model(modelId=MODEL_ID, body=json.dumps(request_body))
return json.loads(response['body'].read())
except bedrock.exceptions.ClientError as err:
print(f"Couldn't invoke Claude 3 Sonnet. Here's why: {err.response['Error']['Code']}: {err.response['Error']['Message']}")
raise
Send the Amazon Bedrock API response to the SQS queue using the send_message method:
def send_message_to_sqs(message_body):
try:
sqs.send_message(QueueUrl=QUEUE_URL, MessageBody=json.dumps(message_body))
except sqs.exceptions.ClientError as e:
print(f"Error sending message to SQS: {e.response['Error']['Code']}: {e.response['Error']['Message']}")
Next, modify the IAM role of the Lambda function to grant the required permissions:
- On the Lambda console, navigate to the function.
- On the Configuration tab, choose Permissions in the left pane.
- Choose the IAM role (for example,
invoke_bedrock_claude3-role-{random chars}).

This will open the role on a new tab.
- In the Permissions policies section, choose Add permissions and Create inline policy.
- On the Create policy page, switch to the JSON tab in the policy editor.
- Enter the policy from the following code block, replacing
{AWS Account ID}with your AWS account ID and{S3 Bucket Name}with your S3 bucket name. - Choose Next.
- Enter a name for the policy (for example,
invoke_bedrock_claude3-role-policy), and choose Create policy.
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Action": "bedrock:InvokeModel",
"Resource": "arn:aws:bedrock:us-east-1::foundation-model/*"
}, {
"Effect": "Allow",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::{S3 Bucket Name}/*"
}, {
"Effect": "Allow",
"Action": "sqs:SendMessage",
"Resource": "arn:aws:sqs:us-east-1:{AWS Account ID}:bedrock-idp-extracted-data"
}]
}
The policy will grant the following permissions:
- Invoke model access to Amazon Bedrock FMs
- Retrieve objects from the
bedrock-claude3-idp...S3 bucket - Send messages to the
bedrock-idp-extracted-dataSQS queue for processing the extracted data
Additionally, modify the Lambda function’s timeout to 2 minutes. By default, it’s set to 3 seconds.
Create an S3 Event Notification
To create an S3 Event Notification, complete the following steps:
- On the Amazon S3 console, open the
bedrock-claude3-idp...S3 bucket. - Navigate to Properties, and in the Event notifications section, create an event notification.
- Enter a name for Event name (for example,
bedrock-claude3-idp-event-notification). - Enter
images/birth_certificates/for the prefix. - For
Event Type, select Put in the Object creation section. - For Destination, select Lambda function and choose
invoke_bedrock_claude3. - Choose Save changes.
Create a DynamoDB table
To store the extracted data in DynamoDB, you need to create a table. On the DynamoDB console, create a table called birth_certificates with Id as the partition key, and keep the remaining settings as default.
Create a Lambda function to insert records into the DynamoDB table
On the Lambda console, create a Lambda function (for example, insert_into_dynamodb), choose Python 3.12 for the runtime, and leave the remaining settings as default. You can download the entire Lambda function code from insert_into_dynamodb.py. Replace the contents of the lambda_function.py file with the code from the downloaded file and choose Deploy.
The Lambda function should perform the following actions:
Get the message from the SQS queue that contains the response from the Anthropic Claude 3 Sonnet model:
data = json.loads(event['Records'][0]['body'])['content'][0]['text']
event_id = event['Records'][0]['messageId']
data = json.loads(data)
Create objects representing DynamoDB and its table:
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('birth_certificates')Get the key objects from the JSON data:
applicant_details = data.get('applicantDetails', {})
mailing_address = data.get('mailingAddress', {})
relation_to_applicant = data.get('relationToApplicant', [])
birth_certificate_details = data.get('BirthCertificateDetails', {})
fees = data.get('fees', {})
Insert the extracted data into DynamoDB table using put_item() method:
table.put_item(Item={
'Id': event_id,
'applicantName': applicant_details.get('applicantName', ''),
'dayPhoneNumber': applicant_details.get('dayPhoneNumber', ''),
'address': applicant_details.get('address', ''),
'city': applicant_details.get('city', ''),
'state': applicant_details.get('state', ''),
'zipCode': applicant_details.get('zipCode', ''),
'email': applicant_details.get('email', ''),
'mailingAddressApplicantName': mailing_address.get('mailingAddressApplicantName', ''),
'mailingAddress': mailing_address.get('mailingAddress', ''),
'mailingAddressCity': mailing_address.get('mailingAddressCity', ''),
'mailingAddressState': mailing_address.get('mailingAddressState', ''),
'mailingAddressZipCode': mailing_address.get('mailingAddressZipCode', ''),
'relationToApplicant': ', '.join(relation_to_applicant),
'purposeOfRequest': data.get('purposeOfRequest', ''),
'nameOnBirthCertificate': birth_certificate_details.get('nameOnBirthCertificate', ''),
'dateOfBirth': birth_certificate_details.get('dateOfBirth', ''),
'sex': birth_certificate_details.get('sex', ''),
'cityOfBirth': birth_certificate_details.get('cityOfBirth', ''),
'countyOfBirth': birth_certificate_details.get('countyOfBirth', ''),
'mothersMaidenName': birth_certificate_details.get('mothersMaidenName', ''),
'fathersName': birth_certificate_details.get('fathersName', ''),
'mothersPlaceOfBirth': birth_certificate_details.get('mothersPlaceOfBirth', ''),
'fathersPlaceOfBirth': birth_certificate_details.get('fathersPlaceOfBirth', ''),
'parentsMarriedAtBirth': birth_certificate_details.get('parentsMarriedAtBirth', ''),
'numberOfChildrenBornInSCToMother': birth_certificate_details.get('numberOfChildrenBornInSCToMother', ''),
'diffNameAtBirth': birth_certificate_details.get('diffNameAtBirth', ''),
'searchFee': fees.get('searchFee', ''),
'eachAdditionalCopy': fees.get('eachAdditionalCopy', ''),
'expediteFee': fees.get('expediteFee', ''),
'totalFees': fees.get('totalFees', '')
})
Next, modify the IAM role of the Lambda function to grant the required permissions. Follow the same steps you used to modify the permissions for the invoke_bedrock_claude3 Lambda function, but enter the following JSON as the inline policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "dynamodb:PutItem",
"Resource": "arn:aws:dynamodb:us-east-1::{AWS Account ID}:table/birth_certificates"
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": [
"sqs:DeleteMessage",
"sqs:ReceiveMessage",
"sqs:GetQueueAttributes"
],
"Resource": "arn:aws:sqs:us-east-1::{AWS Account ID}:bedrock-idp-extracted-data"
}
]
}
Enter a policy name (for example, insert_into_dynamodb-role-policy) and choose Create policy.

The policy will grant the following permissions:
- Put records into the DynamoDB table
- Read and delete messages from the SQS queue
Configure the Lambda function trigger for SQS
Complete the following steps to create a trigger for the Lambda function:
- On the Amazon SQS console, open the
bedrock-idp-extracted-dataqueue. - On the Lambda triggers tab, choose Configure Lambda function trigger.
- Select the
insert_into_dynamodbLambda function and choose Save.

Test the solution
Now that you have created all the necessary resources, permissions, and code, it’s time to test the solution.
In the S3 folder birth_certificates, upload the two scanned images that you downloaded earlier. Then open the DynamoDB console and explore the items in the birth_certificates table.
If everything is configured properly, you should see two items in DynamoDB in just a few seconds, as shown in the following screenshots. For the Spanish form, Anthropic Claude 3 automatically translated the keys and labels from Spanish to English based on the prompt.


Troubleshooting
If you don’t see the extracted data in the DynamoDB table, you can investigate the issue:
- Check CloudWatch logs – Review the Amazon CloudWatch log streams of the Lambda functions involved in the data extraction and ingestion process. Look for any error messages or exceptions that may indicate the root cause of the issue.
- Identify missing permissions – In many cases, errors can occur due to missing permissions. Confirm that the Lambda functions have the necessary permissions to access the required AWS resources, such as DynamoDB tables, S3 buckets, or other services involved in the solution.
- Implement a dead-letter queue – In a production-scale solution, it is recommended to implement a dead letter queue (DLQ) to catch and handle any events or messages that fail to process or encounter errors.
Clean up
Clean up the resources created as part of this post to avoid incurring ongoing charges:
- Delete all the objects from the
bedrock-claude3-idp...S3 bucket, then delete the bucket. - Delete the two Lambda functions named
invoke_bedrock_claude3andinsert_into_dynamodb. - Delete the SQS queue named
bedrock-idp-extracted-data. - Delete the DynamoDB table named
birth_certificates.
Example use cases and business value
The generative AI-powered IDP solution demonstrated in this post can benefit organizations across various industries, such as:
- Government and public sector – Process and extract data from citizen applications, immigration documents, legal contracts, and other government-related forms, enabling faster turnaround times and improved service delivery
- Healthcare – Extract and organize patient information, medical records, insurance claims, and other health-related documents, improving data accuracy and accessibility for better patient care
- Finance and banking – Automate the extraction and processing of financial documents, loan applications, tax forms, and regulatory filings, reducing manual effort and increasing operational efficiency
- Logistics and supply chain – Extract and organize data from shipping documents, invoices, purchase orders, and inventory records, streamlining operations and enhancing supply chain visibility
- Retail and ecommerce – Automate the extraction and processing of customer orders, product catalogs, and marketing materials, enabling personalized experiences and efficient order fulfillment
By using the power of generative AI and Amazon Bedrock, organizations can unlock the true potential of their data, driving operational excellence, enhancing customer experiences, and fostering continuous innovation.
Conclusion
In this post, we demonstrated how to use Amazon Bedrock and the powerful Anthropic Claude 3 Sonnet model to develop an IDP solution. By harnessing the advanced multimodal capabilities of Anthropic Claude 3, we were able to accurately extract data from scanned documents and store it in a structured format in a DynamoDB table.
Although this solution showcases the potential of generative AI in IDP, it may not be suitable for all IDP use cases. The effectiveness of the solution may vary depending on the complexity and quality of the documents, the amount of training data available, and the specific requirements of the organization.
To further enhance the solution, consider implementing a human-in-the-loop workflow to review and validate the extracted data, especially for mission-critical or sensitive applications. This will provide data accuracy and compliance with regulatory requirements. You can also explore the model evaluation feature in Amazon Bedrock to compare model outputs, and then choose the model best suited for your downstream generative AI applications.
For further exploration and learning, we recommend checking out the following resources:
- Amazon Bedrock Developer Guide
- Anthropic’s Claude 3 Opus model is now available on Amazon Bedrock
- Anthropic Claude 3
About the Authors
 Govind Palanisamy is a Solutions Architect at AWS, where he helps government agencies migrate and modernize their workloads to increase citizen experience. He is passionate about technology and transformation, and he helps customers transform their businesses using AI/ML and generative AI-based solutions.
Govind Palanisamy is a Solutions Architect at AWS, where he helps government agencies migrate and modernize their workloads to increase citizen experience. He is passionate about technology and transformation, and he helps customers transform their businesses using AI/ML and generative AI-based solutions.
 Bharath Gunapati is a Sr. Solutions architect at AWS, where he helps clinicians, researchers, and staff at academic medical centers to adopt and use cloud technologies. He is passionate about technology and the impact it can make on healthcare and research.
Bharath Gunapati is a Sr. Solutions architect at AWS, where he helps clinicians, researchers, and staff at academic medical centers to adopt and use cloud technologies. He is passionate about technology and the impact it can make on healthcare and research.






 Tanay Chowdhury is a Data Scientist at Generative AI Innovation Center at Amazon Web Services. He helps customers to solve their business problem using Generative AI and Machine Learning.
Tanay Chowdhury is a Data Scientist at Generative AI Innovation Center at Amazon Web Services. He helps customers to solve their business problem using Generative AI and Machine Learning.


 Doron Bleiberg is a senior AWS Startups Solution Architect helping Fintech customers in their cloud journey.
Doron Bleiberg is a senior AWS Startups Solution Architect helping Fintech customers in their cloud journey. Liran Zelkha is the co-founder and CTO at Lili, leading our development and data efforts.
Liran Zelkha is the co-founder and CTO at Lili, leading our development and data efforts. Eyal Solnik is the head of Data at Lili and leads our AccountantAI product.
Eyal Solnik is the head of Data at Lili and leads our AccountantAI product.
 Hemmy Yona is a Solutions Architect at Amazon Web Services based in Israel. With 20 years of experience in software development and group management, Hemmy is passionate about helping customers build innovative, scalable, and cost-effective solutions. Outside of work, you’ll find Hemmy enjoying sports and traveling with family.
Hemmy Yona is a Solutions Architect at Amazon Web Services based in Israel. With 20 years of experience in software development and group management, Hemmy is passionate about helping customers build innovative, scalable, and cost-effective solutions. Outside of work, you’ll find Hemmy enjoying sports and traveling with family. Tzahi Mizrahi is a Solutions Architect at Amazon Web Services, specializing in container solutions with over 10 years of experience in development and DevOps lifecycle processes. His expertise includes designing scalable, container-based architectures and optimizing deployment workflows. In his free time, he enjoys music and plays the guitar.
Tzahi Mizrahi is a Solutions Architect at Amazon Web Services, specializing in container solutions with over 10 years of experience in development and DevOps lifecycle processes. His expertise includes designing scalable, container-based architectures and optimizing deployment workflows. In his free time, he enjoys music and plays the guitar. Gili Nachum is a Principal solutions architect at AWS, specializing in Generative AI and Machine Learning. Gili is helping AWS customers build new foundation models, and to leverage LLMs to innovate in their business. In his spare time Gili enjoys family time and Calisthenics.
Gili Nachum is a Principal solutions architect at AWS, specializing in Generative AI and Machine Learning. Gili is helping AWS customers build new foundation models, and to leverage LLMs to innovate in their business. In his spare time Gili enjoys family time and Calisthenics. Maciej Mensfeld is a principal product architect at Mend, focusing on data acquisition, aggregation, and AI/LLM security research. He’s the creator of diffend.io (acquired by Mend) and Karafka. As a Software Architect, Security Researcher, and conference speaker, he teaches Ruby, Rails, and Kafka. Passionate about OSS, Maciej actively contributes to various projects, including Karafka, and is a member of the RubyGems security team.
Maciej Mensfeld is a principal product architect at Mend, focusing on data acquisition, aggregation, and AI/LLM security research. He’s the creator of diffend.io (acquired by Mend) and Karafka. As a Software Architect, Security Researcher, and conference speaker, he teaches Ruby, Rails, and Kafka. Passionate about OSS, Maciej actively contributes to various projects, including Karafka, and is a member of the RubyGems security team.







 Shashi Raina is a Senior Partner Solutions Architect at Amazon Web Services (AWS), where he specializes in supporting generative AI (GenAI) startups. With close to 6 years of experience at AWS, Shashi has developed deep expertise across a range of domains, including DevOps, analytics, and generative AI.
Shashi Raina is a Senior Partner Solutions Architect at Amazon Web Services (AWS), where he specializes in supporting generative AI (GenAI) startups. With close to 6 years of experience at AWS, Shashi has developed deep expertise across a range of domains, including DevOps, analytics, and generative AI. James Yi is a Senior AI/ML Partner Solutions Architect in the Emerging Technologies team at Amazon Web Services. He is passionate about working with enterprise customers and partners to design, deploy and scale AI/ML applications to derive their business values. Outside of work, he enjoys playing soccer, traveling and spending time with his family.
James Yi is a Senior AI/ML Partner Solutions Architect in the Emerging Technologies team at Amazon Web Services. He is passionate about working with enterprise customers and partners to design, deploy and scale AI/ML applications to derive their business values. Outside of work, he enjoys playing soccer, traveling and spending time with his family. Pradeep Prabhakaran is a Customer Solutions Architect at Cohere. In his current role at Cohere, Pradeep acts as a trusted technical advisor to customers and partners, providing guidance and strategies to help them realize the full potential of Cohere’s cutting-edge Generative AI platform. Prior to joining Cohere, Pradeep was a Principal Customer Solutions Manager at Amazon Web Services, where he led Enterprise Cloud transformation programs for large enterprises. Prior to AWS, Pradeep has held various leadership positions at consulting companies such as Slalom, Deloitte, and Wipro. Pradeep holds a Bachelor’s degree in Engineering and is based in Dallas, TX.
Pradeep Prabhakaran is a Customer Solutions Architect at Cohere. In his current role at Cohere, Pradeep acts as a trusted technical advisor to customers and partners, providing guidance and strategies to help them realize the full potential of Cohere’s cutting-edge Generative AI platform. Prior to joining Cohere, Pradeep was a Principal Customer Solutions Manager at Amazon Web Services, where he led Enterprise Cloud transformation programs for large enterprises. Prior to AWS, Pradeep has held various leadership positions at consulting companies such as Slalom, Deloitte, and Wipro. Pradeep holds a Bachelor’s degree in Engineering and is based in Dallas, TX.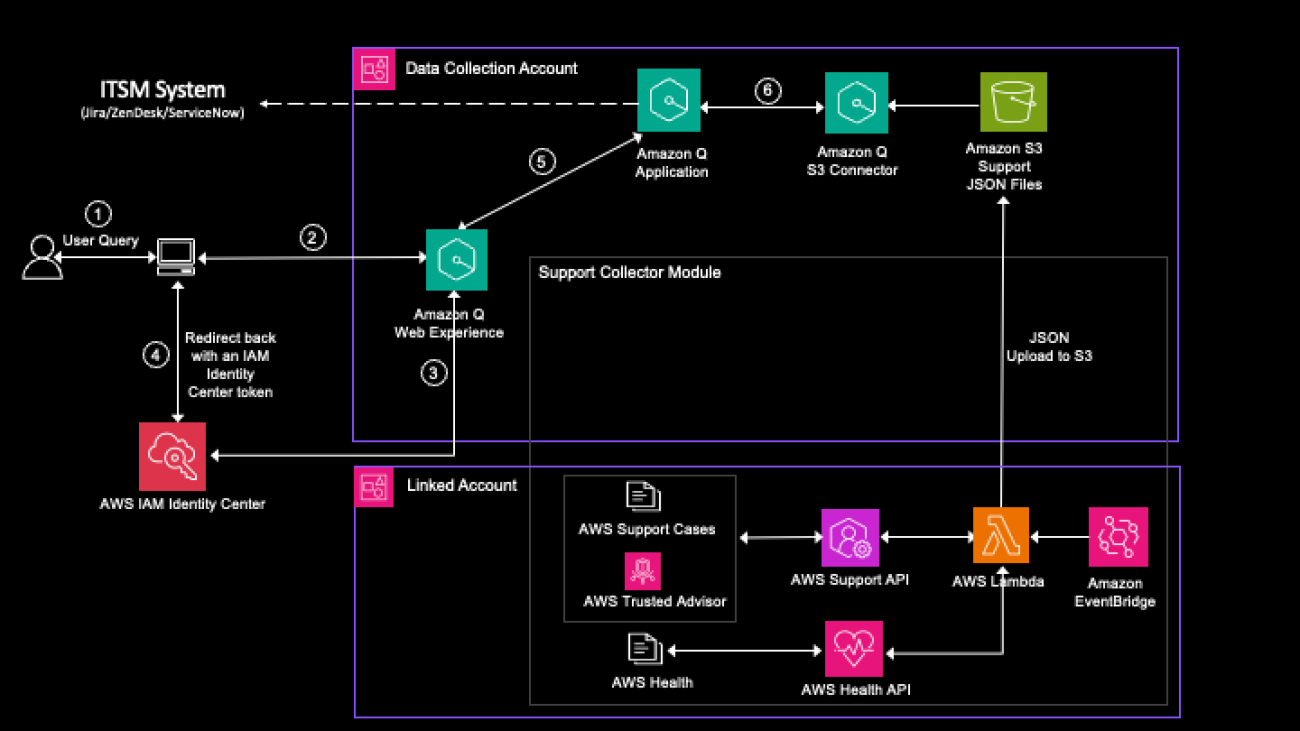



 Chitresh Saxena is a Sr. Technical Account Manager specializing in generative AI solutions and dedicated to helping customers successfully adopt AI/ML on AWS. He excels at understanding customer needs and provides technical guidance to build, launch, and scale AI solutions that solve complex business problems.
Chitresh Saxena is a Sr. Technical Account Manager specializing in generative AI solutions and dedicated to helping customers successfully adopt AI/ML on AWS. He excels at understanding customer needs and provides technical guidance to build, launch, and scale AI solutions that solve complex business problems. Jonathan Delfour is a Principal Technical Account Manager supporting Energy customers, providing top-notch support as part of the AWS Enterprise Support team. His technical guidance and unwavering commitment to excellence ensure that customers can leverage the full potential of AWS, optimizing their operations and driving success.
Jonathan Delfour is a Principal Technical Account Manager supporting Energy customers, providing top-notch support as part of the AWS Enterprise Support team. His technical guidance and unwavering commitment to excellence ensure that customers can leverage the full potential of AWS, optimizing their operations and driving success. Krishna Atluru is an Enterprise Support Lead at AWS. He provides customers with in-depth guidance on improving security posture and operational excellence for their workloads. Outside of work, Krishna enjoys cooking, swimming and travelling.
Krishna Atluru is an Enterprise Support Lead at AWS. He provides customers with in-depth guidance on improving security posture and operational excellence for their workloads. Outside of work, Krishna enjoys cooking, swimming and travelling. Arish Labroo is a Principal Specialist Technical Account Manager – Builder supporting large AWS customers. He is focused on building strategic tools that help customers get the most value out of Enterprise Support.
Arish Labroo is a Principal Specialist Technical Account Manager – Builder supporting large AWS customers. He is focused on building strategic tools that help customers get the most value out of Enterprise Support. Manik Chopra is a Principal Technical Account Manager at AWS. He helps customers adopt AWS services and provides guidance in various areas around Data Analytics and Optimization. His areas of expertise include delivering solutions using Amazon QuickSight, Amazon Athena, and various other automation techniques. Outside of work, he enjoys spending time outdoors and traveling.
Manik Chopra is a Principal Technical Account Manager at AWS. He helps customers adopt AWS services and provides guidance in various areas around Data Analytics and Optimization. His areas of expertise include delivering solutions using Amazon QuickSight, Amazon Athena, and various other automation techniques. Outside of work, he enjoys spending time outdoors and traveling.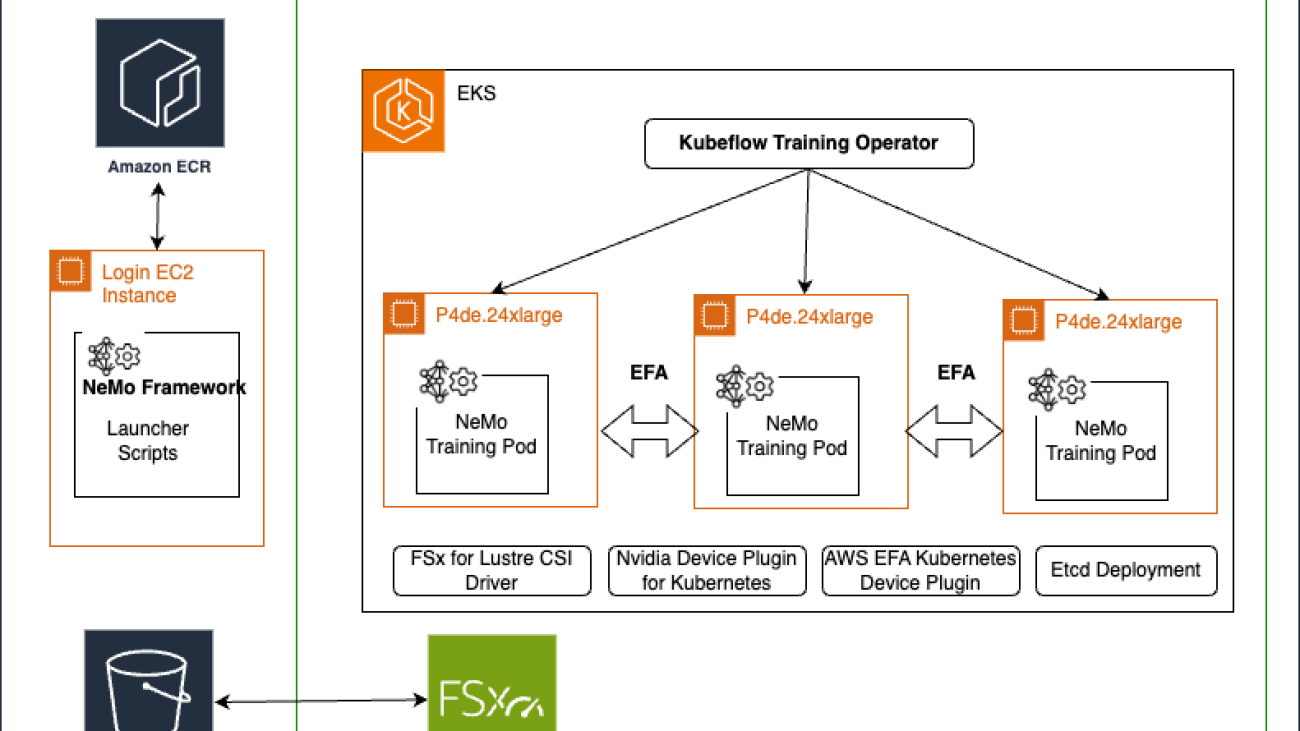








 Ankur Srivastava is a Sr. Solutions Architect in the ML Frameworks Team. He focuses on helping customers with self-managed distributed training and inference at scale on AWS. His experience includes industrial predictive maintenance, digital twins, probabilistic design optimization and has completed his doctoral studies from Mechanical Engineering at Rice University and post-doctoral research from Massachusetts Institute of Technology.
Ankur Srivastava is a Sr. Solutions Architect in the ML Frameworks Team. He focuses on helping customers with self-managed distributed training and inference at scale on AWS. His experience includes industrial predictive maintenance, digital twins, probabilistic design optimization and has completed his doctoral studies from Mechanical Engineering at Rice University and post-doctoral research from Massachusetts Institute of Technology. Akshit Arora is a senior data scientist at NVIDIA, where he works on deploying conversational AI models on GPUs at scale. He’s a graduate of University of Colorado at Boulder, where he applied deep learning to improve knowledge tracking on a K-12 online tutoring platform. His work spans multilingual text-to-speech, time series classification, ed-tech, and practical applications of deep learning.
Akshit Arora is a senior data scientist at NVIDIA, where he works on deploying conversational AI models on GPUs at scale. He’s a graduate of University of Colorado at Boulder, where he applied deep learning to improve knowledge tracking on a K-12 online tutoring platform. His work spans multilingual text-to-speech, time series classification, ed-tech, and practical applications of deep learning. Eliuth Triana Isaza is a Developer Relations Manager at NVIDIA empowering Amazon’s AI MLOps, DevOps, Scientists and AWS technical experts to master the NVIDIA computing stack for accelerating and optimizing Generative AI Foundation models spanning from data curation, GPU training, model inference and production deployment on AWS GPU instances. In addition, Eliuth is a passionate mountain biker, skier, tennis and poker player.
Eliuth Triana Isaza is a Developer Relations Manager at NVIDIA empowering Amazon’s AI MLOps, DevOps, Scientists and AWS technical experts to master the NVIDIA computing stack for accelerating and optimizing Generative AI Foundation models spanning from data curation, GPU training, model inference and production deployment on AWS GPU instances. In addition, Eliuth is a passionate mountain biker, skier, tennis and poker player. Wenhan Tan is a Solutions Architect at Nvidia assisting customers to adopt Nvidia AI solutions at large-scale. His work focuses on accelerating deep learning applications and addressing inference and training challenges.
Wenhan Tan is a Solutions Architect at Nvidia assisting customers to adopt Nvidia AI solutions at large-scale. His work focuses on accelerating deep learning applications and addressing inference and training challenges.










 Alberto Menendez is a DevOps Consultant in Professional Services at AWS. He helps accelerate customers’ journeys to the cloud and achieve their digital transformation goals. In his free time, he enjoys playing sports, especially basketball and padel, spending time with family and friends, and learning about technology.
Alberto Menendez is a DevOps Consultant in Professional Services at AWS. He helps accelerate customers’ journeys to the cloud and achieve their digital transformation goals. In his free time, he enjoys playing sports, especially basketball and padel, spending time with family and friends, and learning about technology. Ram Vittal is a Principal ML Solutions Architect at AWS. He has over 3 decades of experience architecting and building distributed, hybrid, and cloud applications. He is passionate about building secure, scalable, reliable AI/ML and big data solutions to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he rides motorcycle and walks with his three-year old sheep-a-doodle!
Ram Vittal is a Principal ML Solutions Architect at AWS. He has over 3 decades of experience architecting and building distributed, hybrid, and cloud applications. He is passionate about building secure, scalable, reliable AI/ML and big data solutions to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he rides motorcycle and walks with his three-year old sheep-a-doodle! Liam Izar is Solutions Architect at AWS, where he helps customers work backward from business outcomes to develop innovative solutions on AWS. Liam has led multiple projects with customers migrating, transforming, and integrating data to solve business challenges. His core area of expertise includes technology strategy, data migrations, and machine learning. In his spare time, he enjoys boxing, hiking, and vacations with the family.
Liam Izar is Solutions Architect at AWS, where he helps customers work backward from business outcomes to develop innovative solutions on AWS. Liam has led multiple projects with customers migrating, transforming, and integrating data to solve business challenges. His core area of expertise includes technology strategy, data migrations, and machine learning. In his spare time, he enjoys boxing, hiking, and vacations with the family.