Unlocking accurate and insightful answers from vast amounts of text is an exciting capability enabled by large language models (LLMs). When building LLM applications, it is often necessary to connect and query external data sources to provide relevant context to the model. One popular approach is using Retrieval Augmented Generation (RAG) to create Q&A systems that comprehend complex information and provide natural responses to queries. RAG allows models to tap into vast knowledge bases and deliver human-like dialogue for applications like chatbots and enterprise search assistants.
In this post, we explore how to harness the power of LlamaIndex, Llama 2-70B-Chat, and LangChain to build powerful Q&A applications. With these state-of-the-art technologies, you can ingest text corpora, index critical knowledge, and generate text that answers users’ questions precisely and clearly.
Llama 2-70B-Chat
Llama 2-70B-Chat is a powerful LLM that competes with leading models. It is pre-trained on two trillion text tokens, and intended by Meta to be used for chat assistance to users. Pre-training data is sourced from publicly available data and concludes as of September 2022, and fine-tuning data concludes July 2023. For more details on the model’s training process, safety considerations, learnings, and intended uses, refer to the paper Llama 2: Open Foundation and Fine-Tuned Chat Models. Llama 2 models are available on Amazon SageMaker JumpStart for a quick and straightforward deployment.
LlamaIndex
LlamaIndex is a data framework that enables building LLM applications. It provides tools that offer data connectors to ingest your existing data with various sources and formats (PDFs, docs, APIs, SQL, and more). Whether you have data stored in databases or in PDFs, LlamaIndex makes it straightforward to bring that data into use for LLMs. As we demonstrate in this post, LlamaIndex APIs make data access effortless and enables you to create powerful custom LLM applications and workflows.
If you are experimenting and building with LLMs, you are likely familiar with LangChain, which offers a robust framework, simplifying the development and deployment of LLM-powered applications. Similar to LangChain, LlamaIndex offers a number of tools, including data connectors, data indexes, engines, and data agents, as well as application integrations such as tools and observability, tracing, and evaluation. LlamaIndex focuses on bridging the gap between the data and powerful LLMs, streamlining data tasks with user-friendly features. LlamaIndex is specifically designed and optimized for building search and retrieval applications, such as RAG, because it provides a simple interface for querying LLMs and retrieving relevant documents.
Solution overview
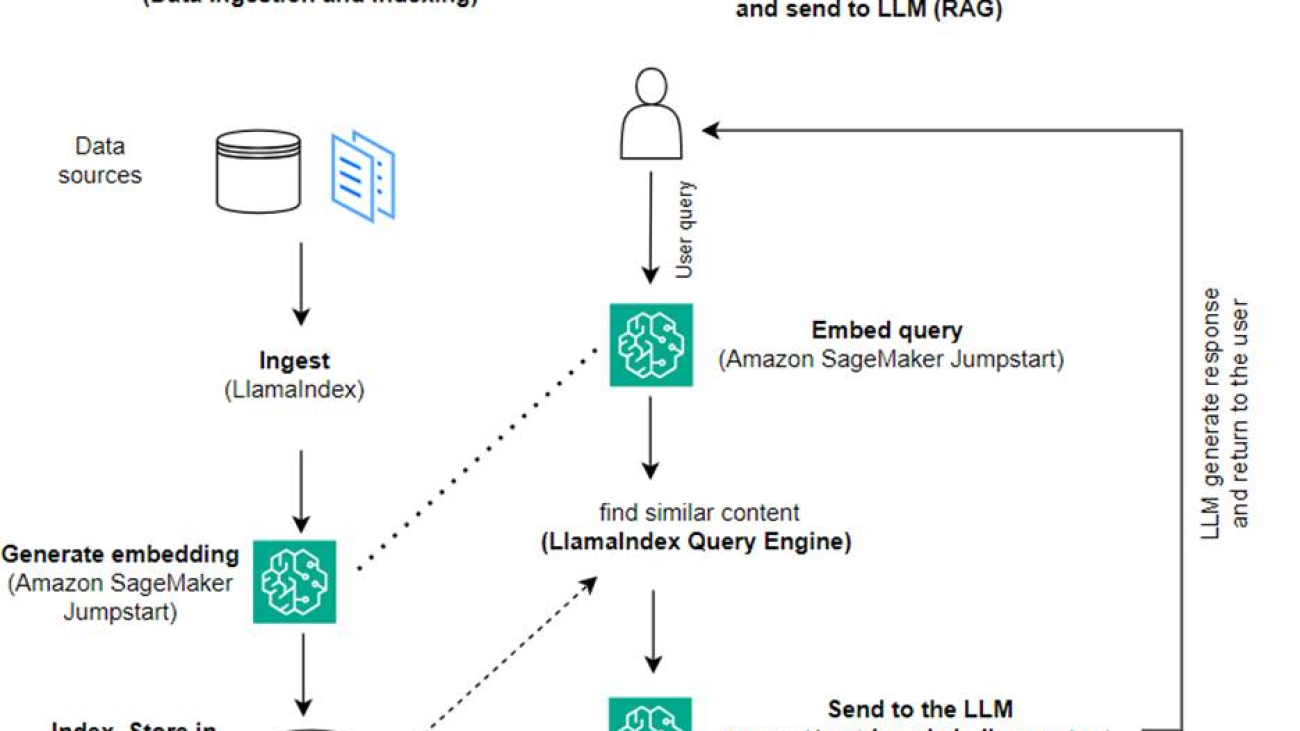
In this post, we demonstrate how to create a RAG-based application using LlamaIndex and an LLM. The following diagram shows the step-by-step architecture of this solution outlined in the following sections.

RAG combines information retrieval with natural language generation to produce more insightful responses. When prompted, RAG first searches text corpora to retrieve the most relevant examples to the input. During response generation, the model considers these examples to augment its capabilities. By incorporating relevant retrieved passages, RAG responses tend to be more factual, coherent, and consistent with context compared to basic generative models. This retrieve-generate framework takes advantage of the strengths of both retrieval and generation, helping address issues like repetition and lack of context that can arise from pure autoregressive conversational models. RAG introduces an effective approach for building conversational agents and AI assistants with contextualized, high-quality responses.
Building the solution consists of the following steps:
- Set up Amazon SageMaker Studio as the development environment and install the required dependencies.
- Deploy an embedding model from the Amazon SageMaker JumpStart hub.
- Download press releases to use as our external knowledge base.
- Build an index out of the press releases to be able to query and add as additional context to the prompt.
- Query the knowledge base.
- Build a Q&A application using LlamaIndex and LangChain agents.
All the code in this post is available in the GitHub repo.
Prerequisites
For this example, you need an AWS account with a SageMaker domain and appropriate AWS Identity and Access Management (IAM) permissions. For account setup instructions, see Create an AWS Account. If you don’t already have a SageMaker domain, refer to Amazon SageMaker domain overview to create one. In this post, we use the AmazonSageMakerFullAccess role. It is not recommended that you use this credential in a production environment. Instead, you should create and use a role with least-privilege permissions. You can also explore how you can use Amazon SageMaker Role Manager to build and manage persona-based IAM roles for common machine learning needs directly through the SageMaker console.
Additionally, you need access to a minimum of the following instance sizes:
- ml.g5.2xlarge for endpoint usage when deploying the Hugging Face GPT-J text embeddings model
- ml.g5.48xlarge for endpoint usage when deploying the Llama 2-Chat model endpoint
To increase your quota, refer to Requesting a quota increase.
Deploy a GPT-J embedding model using SageMaker JumpStart
This section gives you two options when deploying SageMaker JumpStart models. You can use a code-based deployment using the code provided, or use the SageMaker JumpStart user interface (UI).
Deploy with the SageMaker Python SDK
You can use the SageMaker Python SDK to deploy the LLMs, as shown in the code available in the repository. Complete the following steps:
- Set the instance size that is to be used for deployment of the embeddings model using
instance_type = "ml.g5.2xlarge"
- Locate the ID the model to use for embeddings. In SageMaker JumpStart, it is identified as
model_id = "huggingface-textembedding-gpt-j-6b-fp16"
- Retrieve the pre-trained model container and deploy it for inference.
SageMaker will return the name of the model endpoint and the following message when the embeddings model has been deployed successfully:
Deploy with SageMaker JumpStart in SageMaker Studio
To deploy the model using SageMaker JumpStart in Studio, complete the following steps:
- On the SageMaker Studio console, choose JumpStart in the navigation pane.

- Search for and choose the GPT-J 6B Embedding FP16 model.
- Choose Deploy and customize the deployment configuration.

- For this example, we need an ml.g5.2xlarge instance, which is the default instance suggested by SageMaker JumpStart.
- Choose Deploy again to create the endpoint.
The endpoint will take approximately 5–10 minutes to be in service.

After you have deployed the embeddings model, in order to use the LangChain integration with SageMaker APIs, you need to create a function to handle inputs (raw text) and transform them to embeddings using the model. You do this by creating a class called ContentHandler, which takes a JSON of input data, and returns a JSON of text embeddings: class ContentHandler(EmbeddingsContentHandler).
Pass the model endpoint name to the ContentHandler function to convert the text and return embeddings:
embeddings = SagemakerEndpointEmbeddings(endpoint_name='huggingface-textembedding-gpt-j-6b-fp16', region_name= aws_region, content_handler=emb_content_handler).
You can locate the endpoint name in either the output of the SDK or in the deployment details in the SageMaker JumpStart UI.
You can test that the ContentHandler function and endpoint are working as expected by inputting some raw text and running the embeddings.embed_query(text) function. You can use the example provided text = "Hi! It's time for the beach" or try your own text.
Deploy and test Llama 2-Chat using SageMaker JumpStart
Now you can deploy the model that is able to have interactive conversations with your users. In this instance, we choose one of the Llama 2-chat models, that is identified via
my_model = JumpStartModel(model_id = "meta-textgeneration-llama-2-70b-f")
The model needs to be deployed to a real-time endpoint using predictor = my_model.deploy(). SageMaker will return the model’s endpoint name, which you can use for the endpoint_name variable to reference later.
You define a print_dialogue function to send input to the chat model and receive its output response. The payload includes hyperparameters for the model, including the following:
- max_new_tokens – Refers to the maximum number of tokens that the model can generate in its outputs.
- top_p – Refers to the cumulative probability of the tokens that can be retained by the model when generating its outputs
- temperature – Refers to the randomness of the outputs generated by the model. A temperature greater than 0 or equal to 1 increases the level of randomness, whereas a temperature of 0 will generate the most likely tokens.
You should select your hyperparameters based on your use case and test them appropriately. Models such as the Llama family require you to include an additional parameter indicating that you have read and accepted the End User License Agreement (EULA):
response = predictor.predict(payload, custom_attributes='accept_eula=true')
To test the model, replace the content section of the input payload: "content": "what is the recipe of mayonnaise?". You can use your own text values and update the hyperparameters to understand them better.
Similar to the deployment of the embeddings model, you can deploy Llama-70B-Chat using the SageMaker JumpStart UI:
- On the SageMaker Studio console, choose JumpStart in the navigation pane
- Search for and choose the
Llama-2-70b-Chat model
- Accept the EULA and choose Deploy, using the default instance again
Similar to the embedding model, you can use LangChain integration by creating a content handler template for the inputs and outputs of your chat model. In this case, you define the inputs as those coming from a user, and indicate that they are governed by the system prompt. The system prompt informs the model of its role in assisting the user for a particular use case.
This content handler is then passed when invoking the model, in addition to the aforementioned hyperparameters and custom attributes (EULA acceptance). You parse all these attributes using the following code:
llm = SagemakerEndpoint(
endpoint_name=endpoint_name,
region_name="us-east-1",
model_kwargs={"max_new_tokens":500, "top_p": 0.1, "temperature": 0.4, "return_full_text": False},
content_handler=content_handler,
endpoint_kwargs = {"CustomAttributes": "accept_eula=true"}
)
When the endpoint is available, you can test that it is working as expected. You can update llm("what is amazon sagemaker?") with your own text. You also need to define the specific ContentHandler to invoke the LLM using LangChain, as shown in the code and the following code snippet:
class ContentHandler(LLMContentHandler):
content_type = "application/json"
accepts = "application/json"
def transform_input(self, prompt: str, model_kwargs: dict) -> bytes:
payload = {
"inputs": [
[
{
"role": "system",
"content": system_prompt,
},
{"role": "user", "content": prompt},
],
],
"parameters": model_kwargs,
}
input_str = json.dumps(
payload,
)
return input_str.encode("utf-8")
def transform_output(self, output: bytes) -> str:
response_json = json.loads(output.read().decode("utf-8"))
content = response_json[0]["generation"]["content"]
return content
content_handler = ContentHandler()
Use LlamaIndex to build the RAG
To continue, install LlamaIndex to create the RAG application. You can install LlamaIndex using the pip: pip install llama_index
You first need to load your data (knowledge base) onto LlamaIndex for indexing. This involves a few steps:
- Choose a data loader:
LlamaIndex provides a number of data connectors available on LlamaHub for common data types like JSON, CSV, and text files, as well as other data sources, allowing you to ingest a variety of datasets. In this post, we use SimpleDirectoryReader to ingest a few PDF files as shown in the code. Our data sample is two Amazon press releases in PDF version in the press releases folder in our code repository. After you load the PDFs, you can see that they been converted to a list of 11 elements.
Instead of loading the documents directly, you can also covert the Document object into Node objects before sending them to the index. The choice between sending the entire Document object to the index or converting the Document into Node objects before indexing depends on your specific use case and the structure of your data. The nodes approach is generally a good choice for long documents, where you want to break and retrieve specific parts of a document rather than the entire document. For more information, refer to Documents / Nodes.
- Instantiate the loader and load the documents:
This step initializes the loader class and any needed configuration, such as whether to ignore hidden files. For more details, refer to SimpleDirectoryReader.
- Call the loader’s
load_data method to parse your source files and data and convert them into LlamaIndex Document objects, ready for indexing and querying. You can use the following code to complete the data ingestion and preparation for full-text search using LlamaIndex’s indexing and retrieval capabilities:
docs = SimpleDirectoryReader(input_dir="pressrelease").load_data()
- Build the index:
The key feature of LlamaIndex is its ability to construct organized indexes over data, which is represented as documents or nodes. The indexing facilitates efficient querying over the data. We create our index with the default in-memory vector store and with our defined setting configuration. The LlamaIndex Settings is a configuration object that provides commonly used resources and settings for indexing and querying operations in a LlamaIndex application. It acts as a singleton object, so that it allows you to set global configurations, while also allowing you to override specific components locally by passing them directly into the interfaces (such as LLMs, embedding models) that use them. When a particular component is not explicitly provided, the LlamaIndex framework falls back to the settings defined in the Settings object as a global default. To use our embedding and LLM models with LangChain and configuring the Settings we need to install llama_index.embeddings.langchain and llama_index.llms.langchain. We can configure the Settings object as in the following code:
Settings.embed_model = LangchainEmbedding(embeddings)
Settings.llm = LangChainLLM(llm)
By default, VectorStoreIndex uses an in-memory SimpleVectorStore that’s initialized as part of the default storage context. In real-life use cases, you often need to connect to external vector stores such as Amazon OpenSearch Service. For more details, refer to Vector Engine for Amazon OpenSearch Serverless.
index = VectorStoreIndex.from_documents(docs, service_context=service_context)
Now you can run Q&A over your documents by using the query_engine from LlamaIndex. To do so, pass the index you created earlier for queries and ask your question. The query engine is a generic interface for querying data. It takes a natural language query as input and returns a rich response. The query engine is typically built on top of one or more indexes using retrievers.
query_engine = index.as_query_engine() print(query_engine.query("Since migrating to AWS in May, how much in operational cost Yellow.ai has reduced?"))
You can see that the RAG solution is able to retrieve the correct answer from the provided documents:
According to the provided information, Yellow.ai has reduced its operational costs by 20% since migrating to AWS in May
Use LangChain tools and agents
Loader class. The loader is designed to load data into LlamaIndex or subsequently as a tool in a LangChain agent. This gives you more power and flexibility to use this as part of your application. You start by defining your tool from the LangChain agent class. The function that you pass on to your tool queries the index you built over your documents using LlamaIndex.
tools = [
Tool(
name="Pressrelease",
func=lambda q: str(index.as_query_engine().query(q)),
description="useful pressreleases for answering relevnat questions",
return_direct=True,
),
]
Then you select the right type of the agent that you would like to use for your RAG implementation. In this case, you use the chat-zero-shot-react-description agent. With this agent, the LLM will take use the available tool (in this scenario, the RAG over the knowledge base) to provide the response. You then initialize the agent by passing your tool, LLM, and agent type:
agent= initialize_agent(tools, llm, agent="chat-zero-shot-react-description", verbose=True)
You can see the agent going through thoughts, actions, and observation , use the tool (in this scenario, querying your indexed documents); and return a result:
'According to the provided press release, Yellow.ai has reduced its operational costs by 20%, driven performance improvements by 15%, and cut infrastructure costs by 10% since migrating to AWS. However, the specific cost savings from the migration are not mentioned in the provided information. It only states that the company has been able to reinvest the savings into innovation and AI research and development.'
You can find the end-to-end implementation code in the accompanying GitHub repo.
Clean up
To avoid unnecessary costs, you can clean up your resources, either via the following code snippets or the Amazon JumpStart UI.
To use the Boto3 SDK, use the following code to delete the text embedding model endpoint and the text generation model endpoint, as well as the endpoint configurations:
client = boto3.client('sagemaker', region_name=aws_region)
client.delete_endpoint(EndpointName=endpoint_name)
client.delete_endpoint_config(EndpointConfigName=endpoint_configuration)
To use the SageMaker console, complete the following steps:
- On the SageMaker console, under Inference in the navigation pane, choose Endpoints
- Search for the embedding and text generation endpoints.
- On the endpoint details page, choose Delete.
- Choose Delete again to confirm.
Conclusion
For use cases focused on search and retrieval, LlamaIndex provides flexible capabilities. It excels at indexing and retrieval for LLMs, making it a powerful tool for deep exploration of data. LlamaIndex enables you to create organized data indexes, use diverse LLMs, augment data for better LLM performance, and query data with natural language.
This post demonstrated some key LlamaIndex concepts and capabilities. We used GPT-J for embedding and Llama 2-Chat as the LLM to build a RAG application, but you could use any suitable model instead. You can explore the comprehensive range of models available on SageMaker JumpStart.
We also showed how LlamaIndex can provide powerful, flexible tools to connect, index, retrieve, and integrate data with other frameworks like LangChain. With LlamaIndex integrations and LangChain, you can build more powerful, versatile, and insightful LLM applications.
About the Authors
 Dr. Romina Sharifpour is a Senior Machine Learning and Artificial Intelligence Solutions Architect at Amazon Web Services (AWS). She has spent over 10 years leading the design and implementation of innovative end-to-end solutions enabled by advancements in ML and AI. Romina’s areas of interest are natural language processing, large language models, and MLOps.
Dr. Romina Sharifpour is a Senior Machine Learning and Artificial Intelligence Solutions Architect at Amazon Web Services (AWS). She has spent over 10 years leading the design and implementation of innovative end-to-end solutions enabled by advancements in ML and AI. Romina’s areas of interest are natural language processing, large language models, and MLOps.
 Nicole Pinto is an AI/ML Specialist Solutions Architect based in Sydney, Australia. Her background in healthcare and financial services gives her a unique perspective in solving customer problems. She is passionate about enabling customers through machine learning and empowering the next generation of women in STEM.
Nicole Pinto is an AI/ML Specialist Solutions Architect based in Sydney, Australia. Her background in healthcare and financial services gives her a unique perspective in solving customer problems. She is passionate about enabling customers through machine learning and empowering the next generation of women in STEM.
Read More


 Anthony Liguori is an AWS VP and Distinguished Engineer for EC2
Anthony Liguori is an AWS VP and Distinguished Engineer for EC2 Colm MacCárthaigh is an AWS VP and Distinguished Engineer for EC2
Colm MacCárthaigh is an AWS VP and Distinguished Engineer for EC2


 Sumit Bhati is a Senior Customer Solutions Manager at AWS, specializes in expediting the cloud journey for enterprise customers. Sumit is dedicated to assisting customers through every phase of their cloud adoption, from accelerating migrations to modernizing workloads and facilitating the integration of innovative practices.
Sumit Bhati is a Senior Customer Solutions Manager at AWS, specializes in expediting the cloud journey for enterprise customers. Sumit is dedicated to assisting customers through every phase of their cloud adoption, from accelerating migrations to modernizing workloads and facilitating the integration of innovative practices. David Girling is a Senior AI/ML Solutions Architect with over 20 years of experience in designing, leading, and developing enterprise systems. David is part of a specialist team that focuses on helping customers learn, innovate, and utilize these highly capable services with their data for their use cases.
David Girling is a Senior AI/ML Solutions Architect with over 20 years of experience in designing, leading, and developing enterprise systems. David is part of a specialist team that focuses on helping customers learn, innovate, and utilize these highly capable services with their data for their use cases. Ravi Avula is a Senior Solutions Architect in AWS focusing on Enterprise Architecture. Ravi has 20 years of experience in software engineering and has held several leadership roles in software engineering and software architecture working in the payments industry.
Ravi Avula is a Senior Solutions Architect in AWS focusing on Enterprise Architecture. Ravi has 20 years of experience in software engineering and has held several leadership roles in software engineering and software architecture working in the payments industry. George Belsian is a Senior Cloud Application Architect at AWS. He is passionate about helping customers accelerate their modernization and cloud adoption journey. In his current role, George works alongside customer teams to strategize, architect, and develop innovative, scalable solutions.
George Belsian is a Senior Cloud Application Architect at AWS. He is passionate about helping customers accelerate their modernization and cloud adoption journey. In his current role, George works alongside customer teams to strategize, architect, and develop innovative, scalable solutions.



 Julie Tang is the Senior Global Partner Marketing Manager for Generative AI at Amazon Web Services (AWS), where she collaborates closely with NVIDIA to plan and execute partner marketing initiatives focused on generative AI. Throughout her tenure at AWS, she has held various partner marketing roles, including Global IoT Solutions, AWS Partner Solution Factory, and Sr. Campaign Manager in Americas Field Marketing. Prior to AWS, Julie served as the Marketing Director at Segway. She holds a Master’s degree in Communications Management with a focus on marketing and entertainment management from the University of Southern California, and dual Bachelor’s degrees in Law and Broadcast Journalism from Fudan University.
Julie Tang is the Senior Global Partner Marketing Manager for Generative AI at Amazon Web Services (AWS), where she collaborates closely with NVIDIA to plan and execute partner marketing initiatives focused on generative AI. Throughout her tenure at AWS, she has held various partner marketing roles, including Global IoT Solutions, AWS Partner Solution Factory, and Sr. Campaign Manager in Americas Field Marketing. Prior to AWS, Julie served as the Marketing Director at Segway. She holds a Master’s degree in Communications Management with a focus on marketing and entertainment management from the University of Southern California, and dual Bachelor’s degrees in Law and Broadcast Journalism from Fudan University.








 Yanxiang Yu is an Applied Scientist at at the Amazon Generative AI Innovation Center. With over 9 years of experience building AI and machine learning solutions for industrial applications, he specializes in generative AI, computer vision, and time series modeling.
Yanxiang Yu is an Applied Scientist at at the Amazon Generative AI Innovation Center. With over 9 years of experience building AI and machine learning solutions for industrial applications, he specializes in generative AI, computer vision, and time series modeling. Tianyi Mao is an Applied Scientist at AWS based out of Chicago area. He has 5+ years of experience in building machine learning and deep learning solutions and focuses on computer vision and reinforcement learning with human feedbacks. He enjoys working with customers to understand their challenges and solve them by creating innovative solutions using AWS services.
Tianyi Mao is an Applied Scientist at AWS based out of Chicago area. He has 5+ years of experience in building machine learning and deep learning solutions and focuses on computer vision and reinforcement learning with human feedbacks. He enjoys working with customers to understand their challenges and solve them by creating innovative solutions using AWS services. Yanru Xiao is an Applied Scientist at the Amazon Generative AI Innovation Center, where he builds AI/ML solutions for customers’ real-world business problems. He has worked in several fields, including manufacturing, energy, and agriculture. Yanru obtained his Ph.D. in Computer Science from Old Dominion University.
Yanru Xiao is an Applied Scientist at the Amazon Generative AI Innovation Center, where he builds AI/ML solutions for customers’ real-world business problems. He has worked in several fields, including manufacturing, energy, and agriculture. Yanru obtained his Ph.D. in Computer Science from Old Dominion University. Paul George is an accomplished product leader with over 15 years of experience in automotive technologies. He is adept at leading product management, strategy, Go-to-Market and systems engineering teams. He has incubated and launched several new sensing and perception products globally. At AWS, he is leading strategy and go-to-market for autonomous vehicle workloads.
Paul George is an accomplished product leader with over 15 years of experience in automotive technologies. He is adept at leading product management, strategy, Go-to-Market and systems engineering teams. He has incubated and launched several new sensing and perception products globally. At AWS, he is leading strategy and go-to-market for autonomous vehicle workloads. Caroline Chung is an engineering manager at Veoneer (acquired by Magna International), she has over 14 years of experience developing sensing and perception systems. She currently leads interior sensing pre-development programs at Magna International managing a team of compute vision engineers and data scientists.
Caroline Chung is an engineering manager at Veoneer (acquired by Magna International), she has over 14 years of experience developing sensing and perception systems. She currently leads interior sensing pre-development programs at Magna International managing a team of compute vision engineers and data scientists.











 Sandeep Singh is a Senior Generative AI Data Scientist at Amazon Web Services, helping businesses innovate with generative AI. He specializes in Generative AI, Artificial Intelligence, Machine Learning, and System Design. He is passionate about developing state-of-the-art AI/ML-powered solutions to solve complex business problems for diverse industries, optimizing efficiency and scalability.
Sandeep Singh is a Senior Generative AI Data Scientist at Amazon Web Services, helping businesses innovate with generative AI. He specializes in Generative AI, Artificial Intelligence, Machine Learning, and System Design. He is passionate about developing state-of-the-art AI/ML-powered solutions to solve complex business problems for diverse industries, optimizing efficiency and scalability. Suyin Wang is an AI/ML Specialist Solutions Architect at AWS. She has an interdisciplinary education background in Machine Learning, Financial Information Service and Economics, along with years of experience in building Data Science and Machine Learning applications that solved real-world business problems. She enjoys helping customers identify the right business questions and building the right AI/ML solutions. In her spare time, she loves singing and cooking.
Suyin Wang is an AI/ML Specialist Solutions Architect at AWS. She has an interdisciplinary education background in Machine Learning, Financial Information Service and Economics, along with years of experience in building Data Science and Machine Learning applications that solved real-world business problems. She enjoys helping customers identify the right business questions and building the right AI/ML solutions. In her spare time, she loves singing and cooking. Sherry Ding is a senior artificial intelligence (AI) and machine learning (ML) specialist solutions architect at Amazon Web Services (AWS). She has extensive experience in machine learning with a PhD degree in computer science. She mainly works with public sector customers on various AI/ML related business challenges, helping them accelerate their machine learning journey on the AWS Cloud. When not helping customers, she enjoys outdoor activities.
Sherry Ding is a senior artificial intelligence (AI) and machine learning (ML) specialist solutions architect at Amazon Web Services (AWS). She has extensive experience in machine learning with a PhD degree in computer science. She mainly works with public sector customers on various AI/ML related business challenges, helping them accelerate their machine learning journey on the AWS Cloud. When not helping customers, she enjoys outdoor activities.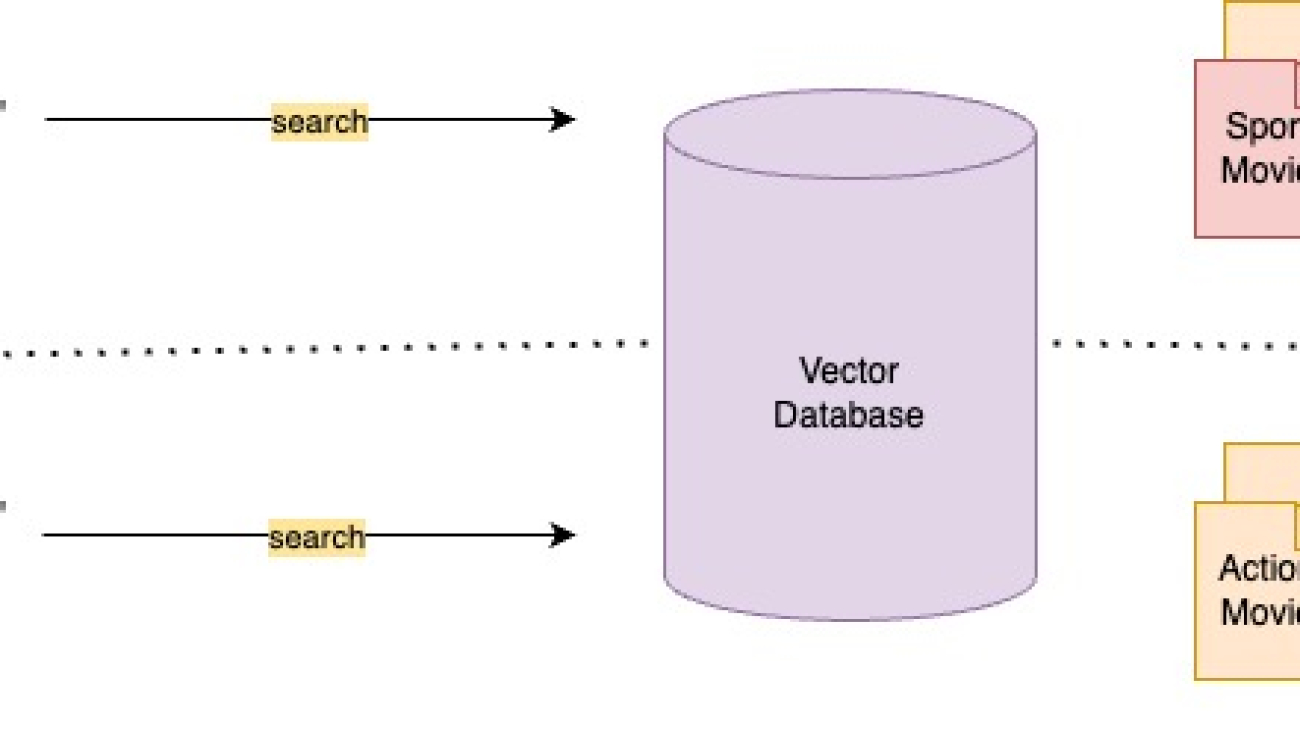



 Corvus Lee is a Senior GenAI Labs Solutions Architect based in London. He is passionate about designing and developing prototypes that use generative AI to solve customer problems. He also keeps up with the latest developments in generative AI and retrieval techniques by applying them to real-world scenarios.
Corvus Lee is a Senior GenAI Labs Solutions Architect based in London. He is passionate about designing and developing prototypes that use generative AI to solve customer problems. He also keeps up with the latest developments in generative AI and retrieval techniques by applying them to real-world scenarios. Ahmed Ewis is a Senior Solutions Architect at AWS GenAI Labs, helping customers build generative AI prototypes to solve business problems. When not collaborating with customers, he enjoys playing with his kids and cooking.
Ahmed Ewis is a Senior Solutions Architect at AWS GenAI Labs, helping customers build generative AI prototypes to solve business problems. When not collaborating with customers, he enjoys playing with his kids and cooking. Chris Pecora is a Generative AI Data Scientist at Amazon Web Services. He is passionate about building innovative products and solutions while also focusing on customer-obsessed science. When not running experiments and keeping up with the latest developments in GenAI, he loves spending time with his kids.
Chris Pecora is a Generative AI Data Scientist at Amazon Web Services. He is passionate about building innovative products and solutions while also focusing on customer-obsessed science. When not running experiments and keeping up with the latest developments in GenAI, he loves spending time with his kids.