In today’s ever-evolving world of ecommerce, the influence of a compelling product description cannot be overstated. It can be the decisive factor that turns a potential visitor into a paying customer or sends them clicking off to a competitor’s site. The manual creation of these descriptions across a vast array of products is a labor-intensive process, and it can slow down the velocity of new innovation. This is where Amazon Bedrock with its generative AI capabilities steps in to reshape the game. In this post, we dive into how Amazon Bedrock is transforming the product description generation process, empowering e-retailers to efficiently scale their businesses while conserving valuable time and resources.
Unlocking the power of generative AI in retail
Generative AI has captured the attention of boards and CEOs worldwide, prompting them to ask, “How can we leverage generative AI for our business?” One of the most promising applications of generative AI in ecommerce is using it to craft product descriptions. Retailers and brands have invested significant resources in testing and evaluating the most effective descriptions, and generative AI excels in this area.
Creating engaging and informative product descriptions for a vast catalog is a monumental task, especially for global ecommerce platforms. Manual translation and adaptation of product descriptions for each market consumes time and resources. This results in generic or incomplete descriptions, leading to reduced sales and customer satisfaction.
The power of Amazon Bedrock: AI-generated product descriptions
Amazon Bedrock is a fully managed service that simplifies generative AI development, offering high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API. It provides a comprehensive set of capabilities for building generative AI applications while ensuring privacy and security are maintained. With Amazon Bedrock, you can experiment with various FMs and customize them privately using techniques like fine-tuning and Retrieval Augmented Generation (RAG). The platform enables you to create managed agents for complex business tasks without the need for coding, such as booking travel, processing insurance claims, creating ad campaigns, and managing inventory.
For example, ecommerce platforms can initially generate basic product descriptions that include size, color, and price. However, Amazon Bedrock’s flexibility allows these descriptions to be fine-tuned to incorporate customer reviews, integrate brand-specific language, and highlight specific product features, resulting in tailored descriptions that resonate with the target audience. Moreover, Amazon Bedrock offers access to foundation models from Amazon and leading AI startups through an intuitive API, making the entire process seamless and efficient.
Using AI can have the following impact on the product description process:
- Faster approvals – Vendors experience a streamlined process, moving from product listing to approval in under an hour, eliminating frustrating delays
- Improved product listing velocity – When automated, your ecommerce marketplace sees a surge in product listings, offering consumers access to the latest merchandise nearly instantaneously
- Future-proofing – By embracing cutting-edge AI, you secure your position as a forward-looking platform ready to meet evolving market demands
- Innovation – This solution liberates teams from mundane tasks, allowing them to focus on higher-value work and fostering a culture of innovation
Solution overview
Before we dive into the technical details, let’s see the high-level preview of what this solution offers. This solution will allow you to create and manage product descriptions for your ecommerce platform. It empowers your platform to:
- Generate descriptions from text – With the power of generative AI, Amazon Bedrock can convert plain text descriptions into vivid, informative, and captivating product descriptions.
- Craft images – Beyond text, it can also craft images that align perfectly with the product descriptions, enhancing the visual appeal of your listings.
- Enhance existing content – Do you have existing product descriptions that need a fresh perspective? Amazon Bedrock can take your current content and make it even more compelling and engaging.
This solution is available in the AWS Solutions Library. We’ve provided detailed instructions in the accompanying README file. The README file contains all the information you need to get started, from requirements to deployment guidelines.
The system architecture comprises several core components:
- UI portal – This is the user interface (UI) designed for vendors to upload product images.
- Amazon Rekognition – Amazon Rekognition is an image analysis service that detects objects, text, and labels in images.
- Amazon Bedrock – Foundation models in Amazon Bedrock use the labels detected by Amazon Rekognition to generate product descriptions.
- AWS Lambda – AWS Lambda provides serverless compute for processing.
- Product database – The central repository stores vendor products, images, labels, and generated descriptions. This could be any database of your choice. Note that in this solution, all of the storage is in the UI.
- Admin portal – This portal provides oversight of the system and product listings, ensuring smooth operation. This is not part of the solution; we’ve added it for understanding.
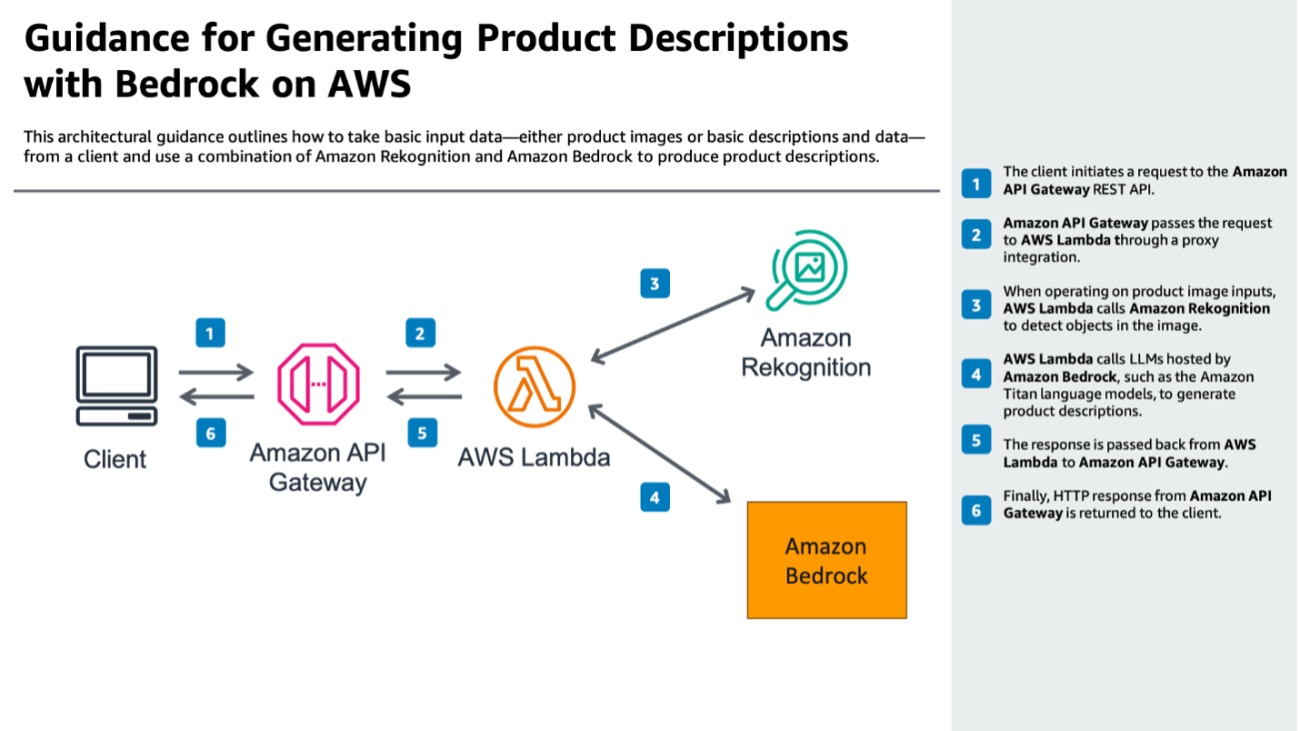
The following diagram illustrates the flow of data and interactions within the system

The workflow includes the following steps:
- The client initiates a request to the Amazon API Gateway REST API.
- Amazon API Gateway passes the request to AWS Lambda through a proxy integration.
- When operating on product image inputs, AWS Lambda calls Amazon Rekognition to detect objects in the image.
- AWS Lambda calls LLMs hosted by Amazon Bedrock, such as the Amazon Titan language models, to generate product descriptions.
- The response is passed back from AWS Lambda to Amazon API Gateway.
- Finally, HTTP response from Amazon API Gateway is returned to the client.
Example use case
Imagine a vendor uploads a product image of shoes, and Amazon Rekognition identifies key attributes like “white shoes,” “sneaker,” and “durable.” The Amazon Bedrock Titan AI takes this information and generates a product description like, “Here is a draft product description for a canvas running shoe based on the product photo: Introducing the Canvas Runner, the perfect lightweight sneaker for your active lifestyle. This running shoe features a breathable canvas upper with leather accents for a stylish, classic look. The lace-up design provides a secure fit, while the padded tongue and collar add comfort. Inside, a removable cushioned insole supports and comforts your feet. The EVA midsole absorbs shock with each step, reducing fatigue. Flex grooves in the rubber outsole ensure flexibility and traction. With its simple, retro-inspired style, the Canvas Runner seamlessly transitions from workouts to everyday wear. Whether you’re running errands or running miles, this versatile sneaker will keep you moving in comfort and style.”
Design details
Let’s explore the components in more detail:
- User interface:
- Front end – The front end of the vendor portal allows vendors to upload product images and displays product listings.
- API calls – The portal communicates with the backend through APIs to process images and generate descriptions.
- Amazon Rekognition:
- Image analysis – Triggered by API calls, Amazon Rekognition analyzes images and detects objects, text, and labels.
- Label output – It outputs label data derived from the analysis.
- Amazon Bedrock:
- NLP text generation – Amazon Bedrock uses the Amazon Titan natural language processing (NLP) model to generate textual descriptions.
- Label integration – It takes the labels detected by Amazon Rekognition as input to generate product descriptions.
- Style matching – Amazon Bedrock provides fine-tuning capabilities for Amazon Titan models to ensure that the generated descriptions match the style of the platform.
- AWS Lambda:
- Processing – Lambda handles the API calls to services.
- Product database:
- Flexible database – The product database is chosen based on customer preferences and requirements. Note this is not provided as part of the solution.
Additional capabilities
This solution goes beyond just generating product descriptions. It offers two more incredible options:
- Image and description generation from text – With the power of generative AI, Amazon Bedrock can take text descriptions and create corresponding images along with detailed product descriptions. Consider the potential:
- Instantly visualizing products from text.
- Automating image creation for large catalogs.
- Enhancing customer experience with rich visuals.
- Reducing content creation time and costs.
- Description enhancement – If you already have existing product descriptions, Amazon Bedrock can enhance them. Simply supply the text and the prompt, and Amazon Bedrock will skillfully enhance and enrich the content, rendering it highly captivating and engaging for your customers.
Conclusion
In the fiercely competitive world of ecommerce, staying at the forefront of innovation is imperative. Amazon Bedrock offers a transformative capability for e-retailers looking to enhance their product content, optimize their listing process, and drive sales. With the power of AI-generated product descriptions, businesses can create compelling, informative, and culturally relevant content that resonates deeply with customers. The future of ecommerce has arrived, and it’s driven by machine learning with Amazon Bedrock.
Are you ready to unlock the full potential of AI-powered product descriptions? Take the next step in revolutionizing your ecommerce platform. Visit the AWS Solutions Library and explore how Amazon Bedrock can transform your product descriptions, streamline your processes, and boost your sales. It’s time to supercharge your ecommerce with Amazon Bedrock!
About the Authors
 Dhaval Shah is a Senior Solutions Architect at AWS, specializing in Machine Learning. With a strong focus on digital native businesses, he empowers customers to leverage AWS and drive their business growth. As an ML enthusiast, Dhaval is driven by his passion for creating impactful solutions that bring positive change. In his leisure time, he indulges in his love for travel and cherishes quality moments with his family.
Dhaval Shah is a Senior Solutions Architect at AWS, specializing in Machine Learning. With a strong focus on digital native businesses, he empowers customers to leverage AWS and drive their business growth. As an ML enthusiast, Dhaval is driven by his passion for creating impactful solutions that bring positive change. In his leisure time, he indulges in his love for travel and cherishes quality moments with his family.
 Doug Tiffan is the Head of World Wide Solution Strategy for Fashion & Apparel at AWS. In his role, Doug works with Fashion & Apparel executives to understand their goals and align with them on the best solutions. Doug has over 30 years of experience in retail, holding several merchandising and technology leadership roles. Doug holds a BBA from Texas A&M University and is based in Houston, Texas.
Doug Tiffan is the Head of World Wide Solution Strategy for Fashion & Apparel at AWS. In his role, Doug works with Fashion & Apparel executives to understand their goals and align with them on the best solutions. Doug has over 30 years of experience in retail, holding several merchandising and technology leadership roles. Doug holds a BBA from Texas A&M University and is based in Houston, Texas.
 Nikhil Sharma is a Solutions Architecture Leader at Amazon Web Services (AWS) where he and his team of Solutions Architects help AWS customers solve critical business challenges using AWS cloud technologies and services.
Nikhil Sharma is a Solutions Architecture Leader at Amazon Web Services (AWS) where he and his team of Solutions Architects help AWS customers solve critical business challenges using AWS cloud technologies and services.
 Kevin Bell is a Sr. Solutions Architect at AWS based in Seattle. He has been building things in the cloud for about 10 years. You can find him online as @bellkev on GitHub.
Kevin Bell is a Sr. Solutions Architect at AWS based in Seattle. He has been building things in the cloud for about 10 years. You can find him online as @bellkev on GitHub.
 Nipun Chagari is a Principal Solutions Architect based in the Bay Area, CA. Nipun is passionate about helping customers adopt Serverless technology to modernize applications and achieve their business objectives. His recent focus has been on assisting organizations in adopting modern technologies to enable digital transformation. Apart from work, Nipun finds joy in playing volleyball, cooking and traveling with his family.
Nipun Chagari is a Principal Solutions Architect based in the Bay Area, CA. Nipun is passionate about helping customers adopt Serverless technology to modernize applications and achieve their business objectives. His recent focus has been on assisting organizations in adopting modern technologies to enable digital transformation. Apart from work, Nipun finds joy in playing volleyball, cooking and traveling with his family.
 Marshall Bunch is a Solutions Architect at AWS helping North American customers design secure, scalable and cost-effective workloads in the cloud. His passion lies in solving age-old business problems where data and the newest technologies enable novel solutions. Beyond his professional pursuits, Marshall enjoys hiking and camping in Colorado’s beautiful Rocky Mountains.
Marshall Bunch is a Solutions Architect at AWS helping North American customers design secure, scalable and cost-effective workloads in the cloud. His passion lies in solving age-old business problems where data and the newest technologies enable novel solutions. Beyond his professional pursuits, Marshall enjoys hiking and camping in Colorado’s beautiful Rocky Mountains.
 Altaaf Dawoodjee is a Solutions Architect Leader that supports AdTech customers in the Digital Native Business (DNB) segment at Amazon Web Service (AWS). He has over 20 years of experience in Technology and has deep expertise in Analytics. He is passionate about helping drive successful business outcomes for his customers leveraging the AWS cloud.
Altaaf Dawoodjee is a Solutions Architect Leader that supports AdTech customers in the Digital Native Business (DNB) segment at Amazon Web Service (AWS). He has over 20 years of experience in Technology and has deep expertise in Analytics. He is passionate about helping drive successful business outcomes for his customers leveraging the AWS cloud.
 Scott Bell is a dynamic leader and innovator with 25+ years of technology management experience. He is passionate about leading and developing teams in providing technology to meet the challenges of global users and businesses. He has extensive experience in leading technology teams which provide global technology solutions supporting 35+ languages. He is also passionate about the way the AI and Generative AI transform businesses and the way they support customer’s current unmet needs.
Scott Bell is a dynamic leader and innovator with 25+ years of technology management experience. He is passionate about leading and developing teams in providing technology to meet the challenges of global users and businesses. He has extensive experience in leading technology teams which provide global technology solutions supporting 35+ languages. He is also passionate about the way the AI and Generative AI transform businesses and the way they support customer’s current unmet needs.
 Sachin Shetti is a Principal Customer Solution Manager at AWS. He is passionate about helping enterprises succeed and realize significant benefits from cloud adoption, driving everything from basic migration to large-scale cloud transformation across people, processes, and technology. Prior to joining AWS, Sachin worked as a software developer for over 12 years and held multiple senior leadership positions leading technology delivery and transformation in healthcare, financial services, retail, and insurance. He has an Executive MBA and a Bachelor’s degree in Mechanical Engineering.
Sachin Shetti is a Principal Customer Solution Manager at AWS. He is passionate about helping enterprises succeed and realize significant benefits from cloud adoption, driving everything from basic migration to large-scale cloud transformation across people, processes, and technology. Prior to joining AWS, Sachin worked as a software developer for over 12 years and held multiple senior leadership positions leading technology delivery and transformation in healthcare, financial services, retail, and insurance. He has an Executive MBA and a Bachelor’s degree in Mechanical Engineering.










 Greg Benson is a Professor of Computer Science at the University of San Francisco and Chief Scientist at SnapLogic. He joined the USF Department of Computer Science in 1998 and has taught undergraduate and graduate courses including operating systems, computer architecture, programming languages, distributed systems, and introductory programming. Greg has published research in the areas of operating systems, parallel computing, and distributed systems. Since joining SnapLogic in 2010, Greg has helped design and implement several key platform features including cluster processing, big data processing, the cloud architecture, and machine learning. He currently is working on Generative AI for data integration.
Greg Benson is a Professor of Computer Science at the University of San Francisco and Chief Scientist at SnapLogic. He joined the USF Department of Computer Science in 1998 and has taught undergraduate and graduate courses including operating systems, computer architecture, programming languages, distributed systems, and introductory programming. Greg has published research in the areas of operating systems, parallel computing, and distributed systems. Since joining SnapLogic in 2010, Greg has helped design and implement several key platform features including cluster processing, big data processing, the cloud architecture, and machine learning. He currently is working on Generative AI for data integration. Aaron Kesler is the Senior Product Manager for AI products and services at SnapLogic, Aaron applies over ten years of product management expertise to pioneer AI/ML product development and evangelize services across the organization. He is the author of the upcoming book “What’s Your Problem?” aimed at guiding new product managers through the product management career. His entrepreneurial journey began with his college startup, STAK, which was later acquired by Carvertise with Aaron contributing significantly to their recognition as Tech Startup of the Year 2015 in Delaware. Beyond his professional pursuits, Aaron finds joy in golfing with his father, exploring new cultures and foods on his travels, and practicing the ukulele.
Aaron Kesler is the Senior Product Manager for AI products and services at SnapLogic, Aaron applies over ten years of product management expertise to pioneer AI/ML product development and evangelize services across the organization. He is the author of the upcoming book “What’s Your Problem?” aimed at guiding new product managers through the product management career. His entrepreneurial journey began with his college startup, STAK, which was later acquired by Carvertise with Aaron contributing significantly to their recognition as Tech Startup of the Year 2015 in Delaware. Beyond his professional pursuits, Aaron finds joy in golfing with his father, exploring new cultures and foods on his travels, and practicing the ukulele. Rich Dill is a Principal Solutions Architect with experience cutting broadly across multiple areas of specialization. A track record of success spanning multi-platform enterprise software and SaaS. Well known for turning customer advocacy (serving as the voice of the customer) into revenue-generating new features and products. Proven ability to drive cutting-edge products to market and projects to completion on schedule and under budget in fast-paced onshore and offshore environments. A simple way to describe me: the mind of a scientist, the heart of an explorer and the soul of an artist.
Rich Dill is a Principal Solutions Architect with experience cutting broadly across multiple areas of specialization. A track record of success spanning multi-platform enterprise software and SaaS. Well known for turning customer advocacy (serving as the voice of the customer) into revenue-generating new features and products. Proven ability to drive cutting-edge products to market and projects to completion on schedule and under budget in fast-paced onshore and offshore environments. A simple way to describe me: the mind of a scientist, the heart of an explorer and the soul of an artist. Clay Elmore is an AI/ML Specialist Solutions Architect at AWS. After spending many hours in a materials research lab, his background in chemical engineering was quickly left behind to pursue his interest in machine learning. He has worked on ML applications in many different industries ranging from energy trading to hospitality marketing. Clay’s current work at AWS centers around helping customers bring software development practices to ML and generative AI workloads, allowing customers to build repeatable, scalable solutions in these complex environments. In his spare time, Clay enjoys skiing, solving Rubik’s cubes, reading, and cooking.
Clay Elmore is an AI/ML Specialist Solutions Architect at AWS. After spending many hours in a materials research lab, his background in chemical engineering was quickly left behind to pursue his interest in machine learning. He has worked on ML applications in many different industries ranging from energy trading to hospitality marketing. Clay’s current work at AWS centers around helping customers bring software development practices to ML and generative AI workloads, allowing customers to build repeatable, scalable solutions in these complex environments. In his spare time, Clay enjoys skiing, solving Rubik’s cubes, reading, and cooking. Sina Sojoodi is a technology executive, systems engineer, product leader, ex-founder and startup advisor. He joined AWS in March 2021 as a Principal Solutions Architect. Sina is currently the US-West ISV area lead Solutions Architect. He works with SaaS and B2B software companies to build and grow their businesses on AWS. Previous to his role at Amazon, Sina was a technology executive at VMware, and Pivotal Software (IPO in 2018, VMware M&A in 2020) and served multiple leadership roles including founding engineer at Xtreme Labs (Pivotal acquisition in 2013). Sina has dedicated the past 15 years of his work experience to building software platforms and practices for enterprises, software businesses and the public sector. He is an industry leader with a passion for innovation. Sina holds a BA from the University of Waterloo where he studied Electrical Engineering and Psychology.
Sina Sojoodi is a technology executive, systems engineer, product leader, ex-founder and startup advisor. He joined AWS in March 2021 as a Principal Solutions Architect. Sina is currently the US-West ISV area lead Solutions Architect. He works with SaaS and B2B software companies to build and grow their businesses on AWS. Previous to his role at Amazon, Sina was a technology executive at VMware, and Pivotal Software (IPO in 2018, VMware M&A in 2020) and served multiple leadership roles including founding engineer at Xtreme Labs (Pivotal acquisition in 2013). Sina has dedicated the past 15 years of his work experience to building software platforms and practices for enterprises, software businesses and the public sector. He is an industry leader with a passion for innovation. Sina holds a BA from the University of Waterloo where he studied Electrical Engineering and Psychology.



 A.K Roy is a Director of Product Management at Qualcomm, for Cloud and Datacenter AI products and solutions. He has over 20 years of experience in product strategy and development, with the current focus of best-in-class performance and performance/$ end-to-end solutions for AI inference in the Cloud, for the broad range of use-cases, including GenAI, LLMs, Auto and Hybrid AI.
A.K Roy is a Director of Product Management at Qualcomm, for Cloud and Datacenter AI products and solutions. He has over 20 years of experience in product strategy and development, with the current focus of best-in-class performance and performance/$ end-to-end solutions for AI inference in the Cloud, for the broad range of use-cases, including GenAI, LLMs, Auto and Hybrid AI. Jianying Lang is a Principal Solutions Architect at AWS Worldwide Specialist Organization (WWSO). She has over 15 years of working experience in HPC and AI field. At AWS, she focuses on helping customers deploy, optimize, and scale their AI/ML workloads on accelerated computing instances. She is passionate about combining the techniques in HPC and AI fields. Jianying holds a PhD degree in Computational Physics from the University of Colorado at Boulder.
Jianying Lang is a Principal Solutions Architect at AWS Worldwide Specialist Organization (WWSO). She has over 15 years of working experience in HPC and AI field. At AWS, she focuses on helping customers deploy, optimize, and scale their AI/ML workloads on accelerated computing instances. She is passionate about combining the techniques in HPC and AI fields. Jianying holds a PhD degree in Computational Physics from the University of Colorado at Boulder.













 Paxton Hall is a Marketing Program Manager for the AWS AI/ML Community on the AI/ML Education team at AWS. He has worked in retail and experiential marketing for the past 7 years, focused on developing communities and marketing campaigns. Out of the office, he’s passionate about public lands access and conservation, and enjoys backcountry skiing, climbing, biking, and hiking throughout Washington’s Cascade mountains.
Paxton Hall is a Marketing Program Manager for the AWS AI/ML Community on the AI/ML Education team at AWS. He has worked in retail and experiential marketing for the past 7 years, focused on developing communities and marketing campaigns. Out of the office, he’s passionate about public lands access and conservation, and enjoys backcountry skiing, climbing, biking, and hiking throughout Washington’s Cascade mountains.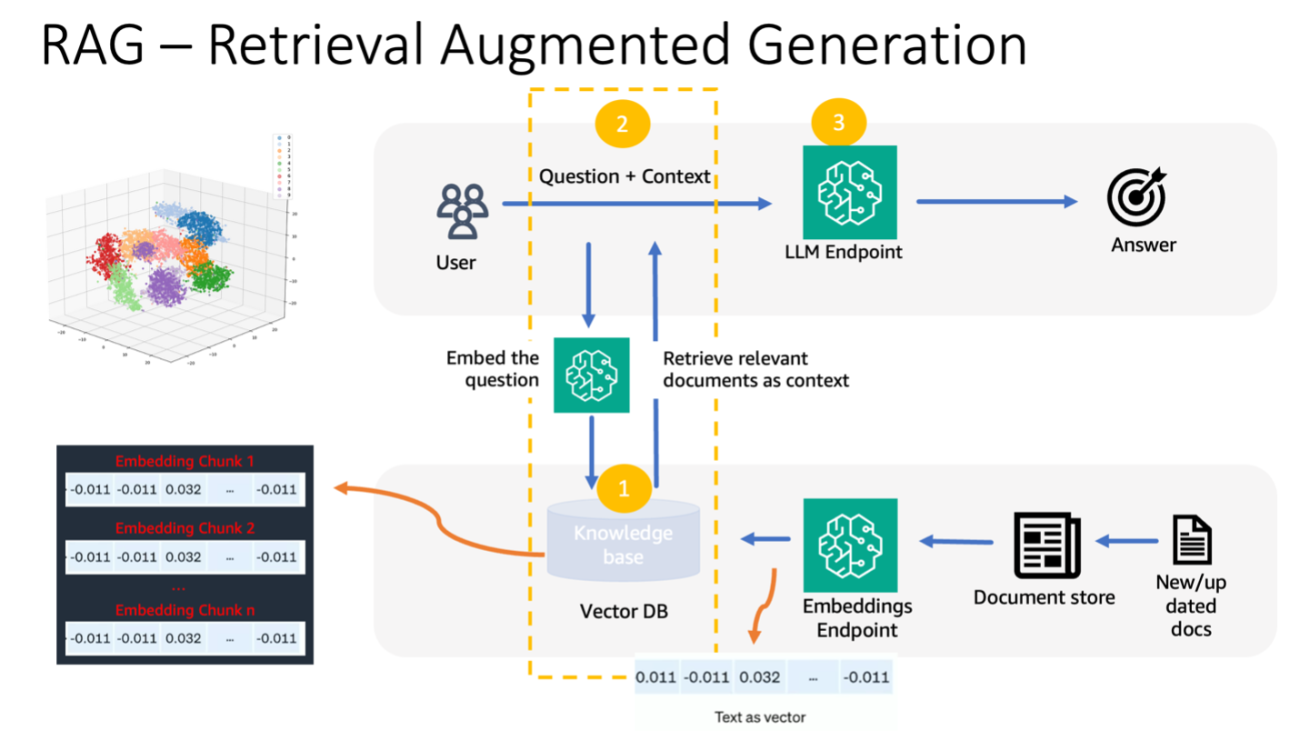

 Sunil Padmanabhan is a Startup Solutions Architect at AWS. As a former startup founder and CTO, he is passionate about machine learning and focuses on helping startups leverage AI/ML for their business outcomes and design and deploy ML/AI solutions at scale.
Sunil Padmanabhan is a Startup Solutions Architect at AWS. As a former startup founder and CTO, he is passionate about machine learning and focuses on helping startups leverage AI/ML for their business outcomes and design and deploy ML/AI solutions at scale. Suleman Patel is a Senior Solutions Architect at Amazon Web Services (AWS), with a special focus on Machine Learning and Modernization. Leveraging his expertise in both business and technology, Suleman helps customers design and build solutions that tackle real-world business problems. When he’s not immersed in his work, Suleman loves exploring the outdoors, taking road trips, and cooking up delicious dishes in the kitchen.
Suleman Patel is a Senior Solutions Architect at Amazon Web Services (AWS), with a special focus on Machine Learning and Modernization. Leveraging his expertise in both business and technology, Suleman helps customers design and build solutions that tackle real-world business problems. When he’s not immersed in his work, Suleman loves exploring the outdoors, taking road trips, and cooking up delicious dishes in the kitchen.
 Brijesh Pati is an Enterprise Solutions Architect at AWS. His primary focus is helping enterprise customers adopt cloud technologies for their workloads. He has a background in application development and enterprise architecture and has worked with customers from various industries such as sports, finance, energy and professional services. His interests include serverless architectures and AI/ML.
Brijesh Pati is an Enterprise Solutions Architect at AWS. His primary focus is helping enterprise customers adopt cloud technologies for their workloads. He has a background in application development and enterprise architecture and has worked with customers from various industries such as sports, finance, energy and professional services. His interests include serverless architectures and AI/ML. Mia Chang is a ML Specialist Solutions Architect for Amazon Web Services. She works with customers in EMEA and shares best practices for running AI/ML workloads on the cloud with her background in applied mathematics, computer science, and AI/ML. She focuses on NLP-specific workloads, and shares her experience as a conference speaker and a book author. In her free time, she enjoys hiking, board games, and brewing coffee.
Mia Chang is a ML Specialist Solutions Architect for Amazon Web Services. She works with customers in EMEA and shares best practices for running AI/ML workloads on the cloud with her background in applied mathematics, computer science, and AI/ML. She focuses on NLP-specific workloads, and shares her experience as a conference speaker and a book author. In her free time, she enjoys hiking, board games, and brewing coffee. Rui Cardoso is a partner solutions architect at Amazon Web Services (AWS). He is focusing on AI/ML and IoT. He works with AWS Partners and support them in developing solutions in AWS. When not working, he enjoys cycling, hiking and learning new things.
Rui Cardoso is a partner solutions architect at Amazon Web Services (AWS). He is focusing on AI/ML and IoT. He works with AWS Partners and support them in developing solutions in AWS. When not working, he enjoys cycling, hiking and learning new things. Tim Condello is a senior artificial intelligence (AI) and machine learning (ML) specialist solutions architect at Amazon Web Services (AWS). His focus is natural language processing and computer vision. Tim enjoys taking customer ideas and turning them into scalable solutions.
Tim Condello is a senior artificial intelligence (AI) and machine learning (ML) specialist solutions architect at Amazon Web Services (AWS). His focus is natural language processing and computer vision. Tim enjoys taking customer ideas and turning them into scalable solutions. Sherry Ding is a senior artificial intelligence (AI) and machine learning (ML) specialist solutions architect at Amazon Web Services (AWS). She has extensive experience in machine learning with a PhD degree in computer science. She mainly works with public sector customers on various AI/ML related business challenges, helping them accelerate their machine learning journey on the AWS Cloud. When not helping customers, she enjoys outdoor activities.
Sherry Ding is a senior artificial intelligence (AI) and machine learning (ML) specialist solutions architect at Amazon Web Services (AWS). She has extensive experience in machine learning with a PhD degree in computer science. She mainly works with public sector customers on various AI/ML related business challenges, helping them accelerate their machine learning journey on the AWS Cloud. When not helping customers, she enjoys outdoor activities. Suyin Wang is an AI/ML Specialist Solutions Architect at AWS. She has an interdisciplinary education background in Machine Learning, Financial Information Service and Economics, along with years of experience in building Data Science and Machine Learning applications that solved real-world business problems. She enjoys helping customers identify the right business questions and building the right AI/ML solutions. In her spare time, she loves singing and cooking.
Suyin Wang is an AI/ML Specialist Solutions Architect at AWS. She has an interdisciplinary education background in Machine Learning, Financial Information Service and Economics, along with years of experience in building Data Science and Machine Learning applications that solved real-world business problems. She enjoys helping customers identify the right business questions and building the right AI/ML solutions. In her spare time, she loves singing and cooking.
 Sherry Ding is a senior artificial intelligence (AI) and machine learning (ML) specialist solutions architect at Amazon Web Services (AWS). She has extensive experience in machine learning with a PhD degree in computer science. She mainly works with public sector customers on various AI/ML related business challenges, helping them accelerate their machine learning journey on the AWS Cloud. When not helping customers, she enjoys outdoor activities.
Sherry Ding is a senior artificial intelligence (AI) and machine learning (ML) specialist solutions architect at Amazon Web Services (AWS). She has extensive experience in machine learning with a PhD degree in computer science. She mainly works with public sector customers on various AI/ML related business challenges, helping them accelerate their machine learning journey on the AWS Cloud. When not helping customers, she enjoys outdoor activities. Brijesh Pati is an Enterprise Solutions Architect at AWS. His primary focus is helping enterprise customers adopt cloud technologies for their workloads. He has a background in application development and enterprise architecture and has worked with customers from various industries such as sports, finance, energy and professional services. His interests include serverless architectures and AI/ML.
Brijesh Pati is an Enterprise Solutions Architect at AWS. His primary focus is helping enterprise customers adopt cloud technologies for their workloads. He has a background in application development and enterprise architecture and has worked with customers from various industries such as sports, finance, energy and professional services. His interests include serverless architectures and AI/ML. Rui Cardoso is a partner solutions architect at Amazon Web Services (AWS). He is focusing on AI/ML and IoT. He works with AWS Partners and support them in developing solutions in AWS. When not working, he enjoys cycling, hiking and learning new things.
Rui Cardoso is a partner solutions architect at Amazon Web Services (AWS). He is focusing on AI/ML and IoT. He works with AWS Partners and support them in developing solutions in AWS. When not working, he enjoys cycling, hiking and learning new things. Mia Chang is a ML Specialist Solutions Architect for Amazon Web Services. She works with customers in EMEA and shares best practices for running AI/ML workloads on the cloud with her background in applied mathematics, computer science, and AI/ML. She focuses on NLP-specific workloads, and shares her experience as a conference speaker and a book author. In her free time, she enjoys hiking, board games, and brewing coffee.
Mia Chang is a ML Specialist Solutions Architect for Amazon Web Services. She works with customers in EMEA and shares best practices for running AI/ML workloads on the cloud with her background in applied mathematics, computer science, and AI/ML. She focuses on NLP-specific workloads, and shares her experience as a conference speaker and a book author. In her free time, she enjoys hiking, board games, and brewing coffee. Suyin Wang is an AI/ML Specialist Solutions Architect at AWS. She has an interdisciplinary education background in Machine Learning, Financial Information Service and Economics, along with years of experience in building Data Science and Machine Learning applications that solved real-world business problems. She enjoys helping customers identify the right business questions and building the right AI/ML solutions. In her spare time, she loves singing and cooking.
Suyin Wang is an AI/ML Specialist Solutions Architect at AWS. She has an interdisciplinary education background in Machine Learning, Financial Information Service and Economics, along with years of experience in building Data Science and Machine Learning applications that solved real-world business problems. She enjoys helping customers identify the right business questions and building the right AI/ML solutions. In her spare time, she loves singing and cooking. Tim Condello is a senior artificial intelligence (AI) and machine learning (ML) specialist solutions architect at Amazon Web Services (AWS). His focus is natural language processing and computer vision. Tim enjoys taking customer ideas and turning them into scalable solutions.
Tim Condello is a senior artificial intelligence (AI) and machine learning (ML) specialist solutions architect at Amazon Web Services (AWS). His focus is natural language processing and computer vision. Tim enjoys taking customer ideas and turning them into scalable solutions.