From classic problems like image segmentation and object detection to theoretical topics like data representation and “machine unlearning”, Amazon researchers’ ICCV papers showcase the diversity of their work in computer vision.Read More
Accenture creates a Knowledge Assist solution using generative AI services on AWS
This post is co-written with Ilan Geller and Shuyu Yang from Accenture.
Enterprises today face major challenges when it comes to using their information and knowledge bases for both internal and external business operations. With constantly evolving operations, processes, policies, and compliance requirements, it can be extremely difficult for employees and customers to stay up to date. At the same time, the unstructured nature of much of this content makes it time consuming to find answers using traditional search.
Internally, employees can often spend countless hours hunting down information they need to do their jobs, leading to frustration and reduced productivity. And when they can’t find answers, they have to escalate issues or make decisions without complete context, which can create risk.
Externally, customers can also find it frustrating to locate the information they are seeking. Although enterprise knowledge bases have, over time, improved the customer experience, they can still be cumbersome and difficult to use. Whether seeking answers to a product-related question or needing information about operating hours and locations, a poor experience can lead to frustration, or worse, a customer defection.
In either case, as knowledge management becomes more complex, generative AI presents a game-changing opportunity for enterprises to connect people to the information they need to perform and innovate. With the right strategy, these intelligent solutions can transform how knowledge is captured, organized, and used across an organization.
To help tackle this challenge, Accenture collaborated with AWS to build an innovative generative AI solution called Knowledge Assist. By using AWS generative AI services, the team has developed a system that can ingest and comprehend massive amounts of unstructured enterprise content.
Rather than traditional keyword searches, users can now ask questions and extract precise answers in a straightforward, conversational interface. Generative AI understands context and relationships within the knowledge base to deliver personalized and accurate responses. As it fields more queries, the system continuously improves its language processing through machine learning (ML) algorithms.
Since launching this AI assistance framework, companies have seen dramatic improvements in employee knowledge retention and productivity. By providing quick and precise access to information and enabling employees to self-serve, this solution reduces training time for new hires by over 50% and cuts escalations by up to 40%.
With the power of generative AI, enterprises can transform how knowledge is captured, organized, and shared across the organization. By unlocking their existing knowledge bases, companies can boost employee productivity and customer satisfaction. As Accenture’s collaboration with AWS demonstrates, the future of enterprise knowledge management lies in AI-driven systems that evolve through interactions between humans and machines.
Accenture is working with AWS to help clients deploy Amazon Bedrock, utilize the most advanced foundational models such as Amazon Titan, and deploy industry-leading technologies such as Amazon SageMaker JumpStart and Amazon Inferentia alongside other AWS ML services.
This post provides an overview of an end-to-end generative AI solution developed by Accenture for a production use case using Amazon Bedrock and other AWS services.
Solution overview
A large public health sector client serves millions of citizens every day, and they demand easy access to up-to-date information in an ever-changing health landscape. Accenture has integrated this generative AI functionality into an existing FAQ bot, allowing the chatbot to provide answers to a broader array of user questions. Increasing the ability for citizens to access pertinent information in a self-service manner saves the department time and money, lessening the need for call center agent interaction. Key features of the solution include:
- Hybrid intent approach – Uses generative and pre-trained intents
- Multi-lingual support – Converses in English and Spanish
- Conversational analysis – Reports on user needs, sentiment, and concerns
- Natural conversations – Maintains context with human-like natural language processing (NLP)
- Transparent citations – Guides users to the source information
Accenture’s generative AI solution provides the following advantages over existing or traditional chatbot frameworks:
- Generates accurate, relevant, and natural-sounding responses to user queries quickly
- Remembers the context and answers follow-up questions
- Handles queries and generates responses in multiple languages (such as English and Spanish)
- Continuously learns and improves responses based on user feedback
- Is easily integrable with your existing web platform
- Ingests a vast repository of enterprise knowledge base
- Responds in a human-like manner
- The evolution of the knowledge is continuously available with minimal to no effort
- Uses a pay-as-you-use model with no upfront costs
The high-level workflow of this solution involves the following steps:
- Users create a simple integration with existing web platforms.
- Data is ingested into the platform as a bulk upload on day 0 and then incremental uploads day 1+.
- User queries are processed in real time with the system scaling as required to meet user demand.
- Conversations are saved in application databases (Amazon Dynamo DB) to support multi-round conversations.
- The Anthropic Claude foundation model is invoked via Amazon Bedrock, which is used to generate query responses based on the most relevant content.
- The Anthropic Claude foundation model is used to translate queries as well as responses from English to other desired languages to support multi-language conversations.
- The Amazon Titan foundation model is invoked via Amazon Bedrock to generate vector embeddings.
- Content relevance is determined through similarity of raw content embeddings and the user query embedding by using Pinecone vector database embeddings.
- The context along with the user’s question is appended to create a prompt, which is provided as input to the Anthropic Claude model. The generated response is provided back to the user via the web platform.
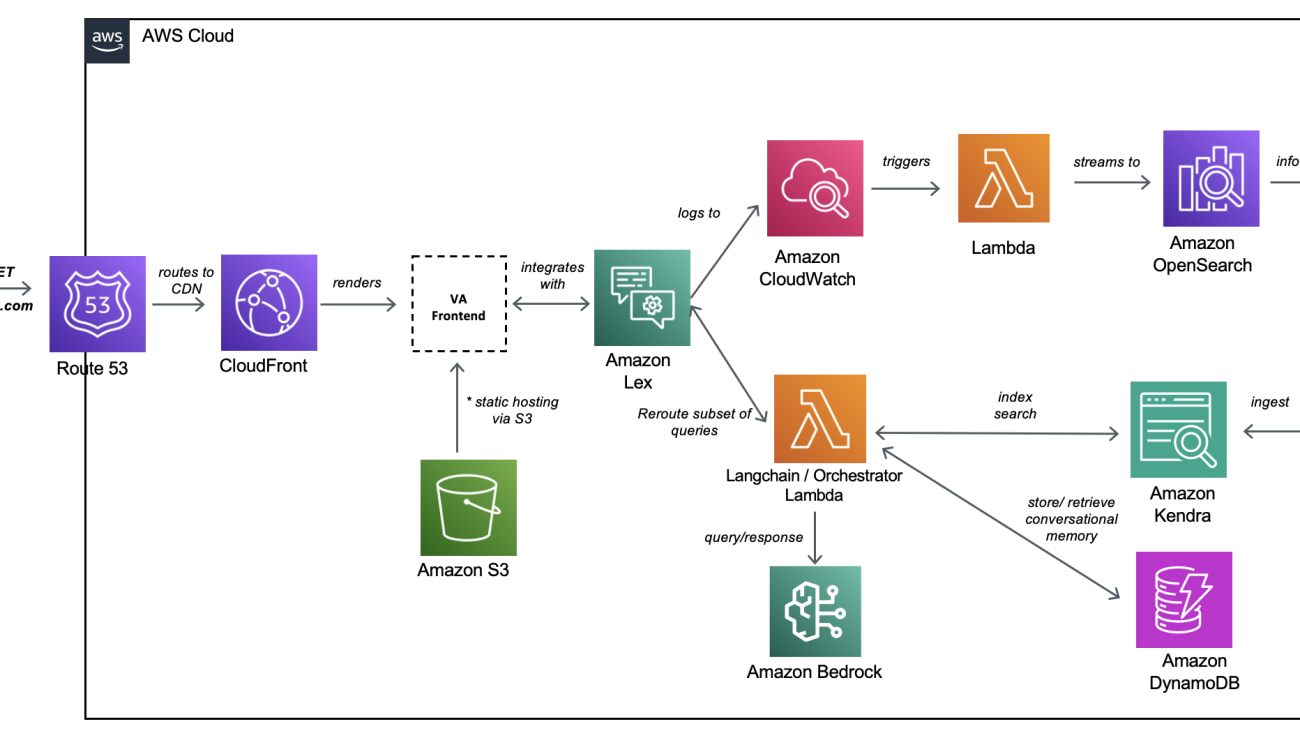
The following diagram illustrates the solution architecture.

The architecture flow can be understood in two parts:
- Offline data loading to Amazon Kendra
- End-user online flow
In the following sections, we discuss different aspects of the solution and its development in more detail.
Model selection
The process for model selection included regress testing of various models available in Amazon Bedrock, which included AI21 Labs, Cohere, Anthropic, and Amazon foundation models. We checked for supported use cases, model attributes, maximum tokens, cost, accuracy, performance, and languages. Based on this, we selected Claude-2 as best suited for this use case.
Data source
We created an Amazon Kendra index and added a data source using web crawler connectors with a root web URL and directory depth of two levels. Several webpages were ingested into the Amazon Kendra index and used as the data source.
GenAI chatbot request and response process
Steps in this process consist of an end-to-end interaction with a request from Amazon Lex and a response from a large language model (LLM):
- The user submits the request to the conversational front-end application hosted in an Amazon Simple Storage Service (Amazon S3) bucket through Amazon Route 53 and Amazon CloudFront.
- Amazon Lex understands the intent and directs the request to the orchestrator hosted in an AWS Lambda function.
- The orchestrator Lambda function performs the following steps:
- The function interacts with the application database, which is hosted in a DynamoDB-managed database. The database stores the session ID and user ID for conversation history.
- Another request is sent to the Amazon Kendra index to get the top five relevant search results to build the relevant context. Using this context, modified prompt is constructed required for the LLM model.
- The connection is established between Amazon Bedrock and the orchestrator. A request is posted to the Amazon Bedrock Claude-2 model to get the response from the LLM model selected.
- The data is post-processed from the LLM response and a response is sent to the user.
Online reporting
The online reporting process consists of the following steps:
- End-users interact with the chatbot via a CloudFront CDN front-end layer.
- Each request/response interaction is facilitated by the AWS SDK and sends network traffic to Amazon Lex (the NLP component of the bot).
- Metadata about the request/response pairings are logged to Amazon CloudWatch.
- The CloudWatch log group is configured with a subscription filter that sends logs into Amazon OpenSearch Service.
- Once available in OpenSearch Service, logs can be used to generate reports and dashboards using Kibana.
Conclusion
In this post, we showcased how Accenture is using AWS generative AI services to implement an end-to-end approach towards digital transformation. We identified the gaps in traditional question answering platforms and augmented generative intelligence within its framework for faster response times and continuously improving the system while engaging with the users across the globe. Reach out to the Accenture Center of Excellence team to dive deeper into the solution and deploying this solution for your clients.
This Knowledge Assist platform can be applied to different industries, including but not limited to health sciences, financial services, manufacturing, and more. This platform provides natural, human-like responses to questions using knowledge that is secured. This platform enables efficiency, productivity, and more accurate actions for its users can take.
The joint effort builds on the 15-year strategic relationship between the companies and uses the same proven mechanisms and accelerators built by the Accenture AWS Business Group (AABG).
Connect with the AABG team at accentureaws@amazon.com to drive business outcomes by transforming to an intelligent data enterprise on AWS.
For further information about generative AI on AWS using Amazon Bedrock or Amazon SageMaker, we recommend the following resources:
- Generative AI on AWS: Technology
- Get started with generative AI on AWS using Amazon SageMaker JumpStart
You can also sign up for the AWS generative AI newsletter, which includes educational resources, blogs, and service updates.
About the Authors
 Ilan Geller is the Managing Director at Accenture with focus on Artificial Intelligence, helping clients Scale Artificial Intelligence applications and the Global GenAI COE Partner Lead for AWS.
Ilan Geller is the Managing Director at Accenture with focus on Artificial Intelligence, helping clients Scale Artificial Intelligence applications and the Global GenAI COE Partner Lead for AWS.
 Shuyu Yang is Generative AI and Large Language Model Delivery Lead and also leads CoE (Center of Excellence) Accenture AI (AWS DevOps professional) teams.
Shuyu Yang is Generative AI and Large Language Model Delivery Lead and also leads CoE (Center of Excellence) Accenture AI (AWS DevOps professional) teams.
 Shikhar Kwatra is an AI/ML specialist solutions architect at Amazon Web Services, working with a leading Global System Integrator. He has earned the title of one of the Youngest Indian Master Inventors with over 500 patents in the AI/ML and IoT domains. Shikhar aids in architecting, building, and maintaining cost-efficient, scalable cloud environments for the organization, and supports the GSI partner in building strategic industry solutions on AWS.
Shikhar Kwatra is an AI/ML specialist solutions architect at Amazon Web Services, working with a leading Global System Integrator. He has earned the title of one of the Youngest Indian Master Inventors with over 500 patents in the AI/ML and IoT domains. Shikhar aids in architecting, building, and maintaining cost-efficient, scalable cloud environments for the organization, and supports the GSI partner in building strategic industry solutions on AWS.
 Jay Pillai is a Principal Solution Architect at Amazon Web Services. In this role, he functions as the Global Generative AI Lead Architect and also the Lead Architect for Supply Chain Solutions with AABG. As an Information Technology Leader, Jay specializes in artificial intelligence, data integration, business intelligence, and user interface domains. He holds 23 years of extensive experience working with several clients across supply chain, legal technologies, real estate, financial services, insurance, payments, and market research business domains.
Jay Pillai is a Principal Solution Architect at Amazon Web Services. In this role, he functions as the Global Generative AI Lead Architect and also the Lead Architect for Supply Chain Solutions with AABG. As an Information Technology Leader, Jay specializes in artificial intelligence, data integration, business intelligence, and user interface domains. He holds 23 years of extensive experience working with several clients across supply chain, legal technologies, real estate, financial services, insurance, payments, and market research business domains.
 Karthik Sonti leads a global team of Solutions Architects focused on conceptualizing, building, and launching horizontal, functional, and vertical solutions with Accenture to help our joint customers transform their business in a differentiated manner on AWS.
Karthik Sonti leads a global team of Solutions Architects focused on conceptualizing, building, and launching horizontal, functional, and vertical solutions with Accenture to help our joint customers transform their business in a differentiated manner on AWS.
Speed up your time series forecasting by up to 50 percent with Amazon SageMaker Canvas UI and AutoML APIs
We’re excited to announce that Amazon SageMaker Canvas now offers a quicker and more user-friendly way to create machine learning models for time-series forecasting. SageMaker Canvas is a visual point-and-click service that enables business analysts to generate accurate machine learning (ML) models without requiring any machine learning experience or having to write a single line of code.
SageMaker Canvas supports a number of use cases, including time-series forecasting used for inventory management in retail, demand planning in manufacturing, workforce and guest planning in travel and hospitality, revenue prediction in finance, and many other business-critical decisions where highly-accurate forecasts are important. As an example, time-series forecasting allows retailers to predict future sales demand and plan for inventory levels, logistics, and marketing campaigns. Time-series forecasting models in SageMaker Canvas use advanced technologies to combine statistical and machine learning algorithms, and deliver highly accurate forecasts.
In this post, we describe the enhancements to the forecasting capabilities of SageMaker Canvas and guide you on using its user interface (UI) and AutoML APIs for time-series forecasting. While the SageMaker Canvas UI offers a code-free visual interface, the APIs empower developers to interact with these features programmatically. Both can be accessed from the SageMaker console.
Improvements in forecasting experience
With today’s launch, SageMaker Canvas has upgraded its forecasting capabilities using AutoML, delivering up to 50 percent faster model building performance and up to 45 percent quicker predictions on average compared to previous versions across various benchmark datasets. This reduces the average model training duration from 186 to 73 minutes and the average prediction time from 33 to 18 minutes for a typical batch of 750 time series with data size up to 100 MB. Users can now also programmatically access model construction and prediction functions through Amazon SageMaker Autopilot APIs, which come with model explainability and performance reports.
Previously, introducing incremental data required retraining the entire model, which was time-consuming and caused operational delays. Now, in SageMaker Canvas, you can add recent data to generate future forecasts without retraining the entire model. Just input your incremental data to your model to use the latest insights for upcoming forecasts. Eliminating retraining accelerates the forecasting process, allowing you to more quickly apply those results to your business processes.
With SageMaker Canvas now using AutoML for forecasting, you can harness model building and prediction functions through SageMaker Autopilot APIs, ensuring consistency across the UI and APIs. For example, you can start with building models in the UI, then switch to using APIs for generating predictions. This updated modeling approach also enhances model transparency in several ways:
- Users can access an explainability report that offers clearer insights into factors influencing predictions. This is valuable for risk, compliance teams, and external regulators. The report elucidates how dataset attributes influence specific time series forecasts. It employs impact scores to measure each attribute’s relative effect, indicating whether they amplify or reduce forecast values.
- You can now access the trained models and deploy them to SageMaker Inference or your preferred infrastructure for predictions.
- A performance report is available, granting deeper insights into optimal models chosen by AutoML for specific time series and the hyperparameters used during training.
Generate time-series forecasts using the SageMaker Canvas UI
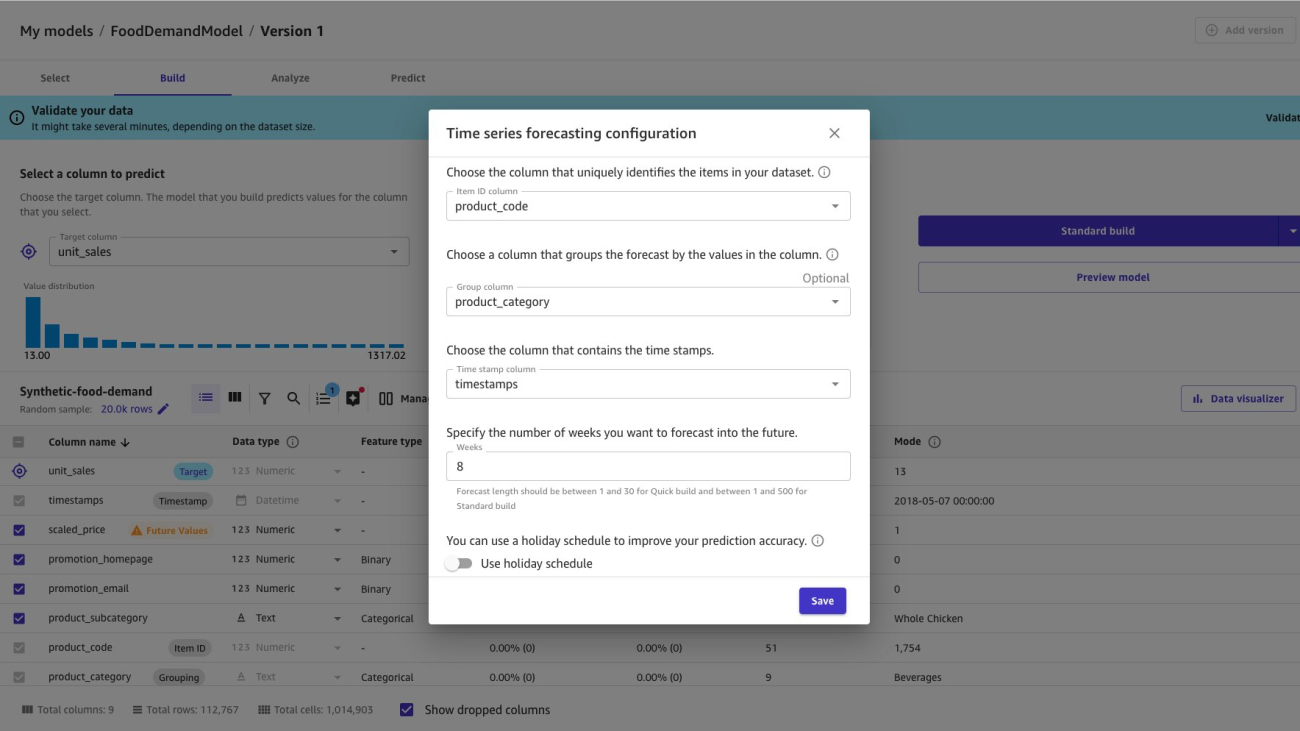
The SageMaker Canvas UI lets you seamlessly integrate data sources from the cloud or on-premises, merge datasets effortlessly, train precise models, and make predictions with emerging data—all without coding. Let’s explore generating a time-series forecast using this UI.
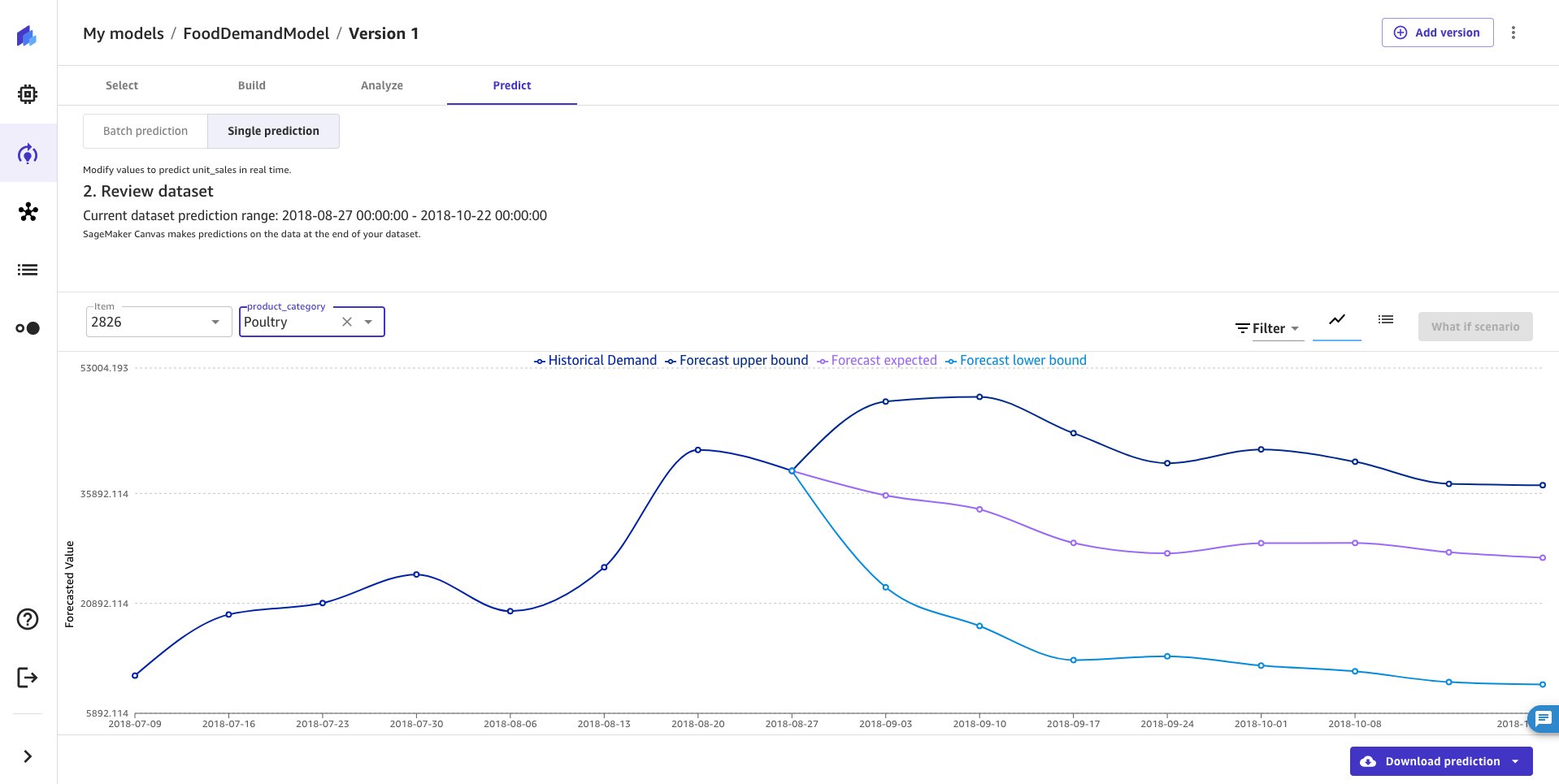
First, you import data into SageMaker Canvas from various sources, including from local files from your computer, Amazon Simple Storage Service (Amazon S3) buckets, Amazon Athena, Snowflake, and over 40 other data sources. After importing data, you can explore and visualize it to get additional insights, such as with scatterplots or bar charts. After you’re ready to create a model, you can do it with just a few clicks after configuring necessary parameters, such as selecting a target column to forecast and specifying how many days into the future you want to forecast. The following screenshots show an example visualization of predicting product demand based on historical weekly demand data for specific products in different store locations:

The following image shows weekly forecasts for a specific product in different store locations:
For a comprehensive guide on how to use the SageMaker Canvas UI for forecasting, check out this blog post.
If you need an automated workflow or direct ML model integration into apps, our forecasting functions are accessible through APIs. In the following section, we provide a sample solution detailing how to employ our APIs for automated forecasting.
Generate time-series forecast using APIs
Let’s dive into how to use the APIs to train the model and generate predictions. For this demonstration, consider a situation where a company needs to predict product stock levels at various stores to meet customer demand. At a high level, the API interactions break down into the following steps:
- Prepare the dataset.
- Create a SageMaker Autopilot job.
- Evaluate the Autopilot job:
- Explore the model accuracy metrics and backtest results.
- Explore the model explainability report.
- Generate predictions from the model:
- Use the real-time inference endpoint created as part of the Autopilot job; or
- Use a batch transform job.

Sample Amazon SageMaker Studio notebook showcasing forecasting with APIs
We’ve provided a sample SageMaker Studio notebook on GitHub to help accelerate your time-to-market when your business prefers to orchestrate forecasting through programmatic APIs. The notebook offers a sample synthetic dataset available through a public S3 bucket. The notebook guides you through all the steps outlined in the workflow image mentioned above. While the notebook provides a basic framework, you can tailor the code sample to fit your specific use case. This includes modifying it to match your unique data schema, time-resolution, forecasting horizon, and other necessary parameters to achieve your desired results.
Conclusion
SageMaker Canvas democratizes time-series forecasting by offering a user-friendly, code-free experience that empowers business analysts to create highly accurate machine learning models. With today’s AutoML upgrades, it delivers up to 50 percent faster model building, up to 45 percent quicker predictions, and introduces API access for both model construction and prediction functions, enhancing its transparency and consistency. The unique ability of SageMaker Canvas to seamlessly handle incremental data without retraining ensures swift adaptation to ever-changing business demands.
Whether you prefer the intuitive UI or versatile APIs, SageMaker Canvas simplifies data integration, model training, and prediction, making it a pivotal tool for data-driven decision-making and innovation across industries.
To learn more, review the documentation, or explore the notebook available in our GitHub repository. Pricing information for time-series forecasting using SageMaker Canvas is available on the SageMaker Canvas Pricing page, and for SageMaker training and inference pricing when using SageMaker Autopilot APIs please see the SageMaker Pricing page.
These capabilities are available in all AWS Regions where SageMaker Canvas and SageMaker Autopilot are publicly accessible. For more information about Region availability, see AWS Services by Region.
About the Authors
 Nirmal Kumar is Sr. Product Manager for the Amazon SageMaker service. Committed to broadening access to AI/ML, he steers the development of no-code and low-code ML solutions. Outside work, he enjoys travelling and reading non-fiction.
Nirmal Kumar is Sr. Product Manager for the Amazon SageMaker service. Committed to broadening access to AI/ML, he steers the development of no-code and low-code ML solutions. Outside work, he enjoys travelling and reading non-fiction.
 Charles Laughlin is a Principal AI/ML Specialist Solution Architect who works on the Amazon SageMaker service team at AWS. He helps shape the service roadmap and collaborates daily with diverse AWS customers to help transform their businesses using cutting-edge AWS technologies and thought leadership. Charles holds a M.S. in Supply Chain Management and a Ph.D. in Data Science.
Charles Laughlin is a Principal AI/ML Specialist Solution Architect who works on the Amazon SageMaker service team at AWS. He helps shape the service roadmap and collaborates daily with diverse AWS customers to help transform their businesses using cutting-edge AWS technologies and thought leadership. Charles holds a M.S. in Supply Chain Management and a Ph.D. in Data Science.
 Ridhim Rastogi a Software Development Engineer who works on Amazon SageMaker service team at AWS. He is passionate about building scalable distributed systems with a focus on solving real-world problems through AI/ML. In his spare time, he likes to solve puzzles, read fiction, and explore his surroundings.
Ridhim Rastogi a Software Development Engineer who works on Amazon SageMaker service team at AWS. He is passionate about building scalable distributed systems with a focus on solving real-world problems through AI/ML. In his spare time, he likes to solve puzzles, read fiction, and explore his surroundings.
 Ahmed Raafat is a Principal Solutions Architect at AWS, with 20 years of field experience and a dedicated focus of 5 years within the AWS ecosystem. He specializes in AI/ML solutions. His extensive experience extends across various industry verticals, rendering him a trusted advisor for numerous enterprise customers, facilitating their seamless navigation and acceleration of their cloud journey.
Ahmed Raafat is a Principal Solutions Architect at AWS, with 20 years of field experience and a dedicated focus of 5 years within the AWS ecosystem. He specializes in AI/ML solutions. His extensive experience extends across various industry verticals, rendering him a trusted advisor for numerous enterprise customers, facilitating their seamless navigation and acceleration of their cloud journey.
 John Oshodi is a Senior Solutions Architect at Amazon Web Services based in London, UK. He specializes in data and analytics and serves as a technical advisor for numerous AWS enterprise customers, supporting and accelerating their cloud journey. Outside of work, he enjoys travelling to new places and experiencing new cultures with his family.
John Oshodi is a Senior Solutions Architect at Amazon Web Services based in London, UK. He specializes in data and analytics and serves as a technical advisor for numerous AWS enterprise customers, supporting and accelerating their cloud journey. Outside of work, he enjoys travelling to new places and experiencing new cultures with his family.
Robust time series forecasting with MLOps on Amazon SageMaker
In the world of data-driven decision-making, time series forecasting is key in enabling businesses to use historical data patterns to anticipate future outcomes. Whether you are working in asset risk management, trading, weather prediction, energy demand forecasting, vital sign monitoring, or traffic analysis, the ability to forecast accurately is crucial for success.
In these applications, time series data can have heavy-tailed distributions, where the tails represent extreme values. Accurate forecasting in these regions is important in determining how likely an extreme event is and whether to raise an alarm. However, these outliers significantly impact the estimation of the base distribution, making robust forecasting challenging. Financial institutions rely on robust models to predict outliers such as market crashes. In energy, weather, and healthcare sectors, accurate forecasts of infrequent but high-impact events such as natural disasters and pandemics enable effective planning and resource allocation. Neglecting tail behavior can lead to losses, missed opportunities, and compromised safety. Prioritizing accuracy at the tails helps lead to reliable and actionable forecasts. In this post, we train a robust time series forecasting model capable of capturing such extreme events using Amazon SageMaker.
To effectively train this model, we establish an MLOps infrastructure to streamline the model development process by automating data preprocessing, feature engineering, hyperparameter tuning, and model selection. This automation reduces human error, improves reproducibility, and accelerates the model development cycle. With a training pipeline, businesses can efficiently incorporate new data and adapt their models to evolving conditions, which helps ensure that forecasts remain reliable and up to date.
After the time series forecasting model is trained, deploying it within an endpoint grants real-time prediction capabilities. This empowers you to make well-informed and responsive decisions based on the most recent data. Furthermore, deploying the model in an endpoint enables scalability, because multiple users and applications can access and utilize the model simultaneously. By following these steps, businesses can harness the power of robust time series forecasting to make informed decisions and stay ahead in a rapidly changing environment.
Overview of solution
This solution showcases the training of a time series forecasting model, specifically designed to handle outliers and variability in data using a Temporal Convolutional Network (TCN) with a Spliced Binned Pareto (SBP) distribution. For more information about a multimodal version of this solution, refer to The science behind NFL Next Gen Stats’ new passing metric. To further illustrate the effectiveness of the SBP distribution, we compare it with the same TCN model but using a Gaussian distribution instead.
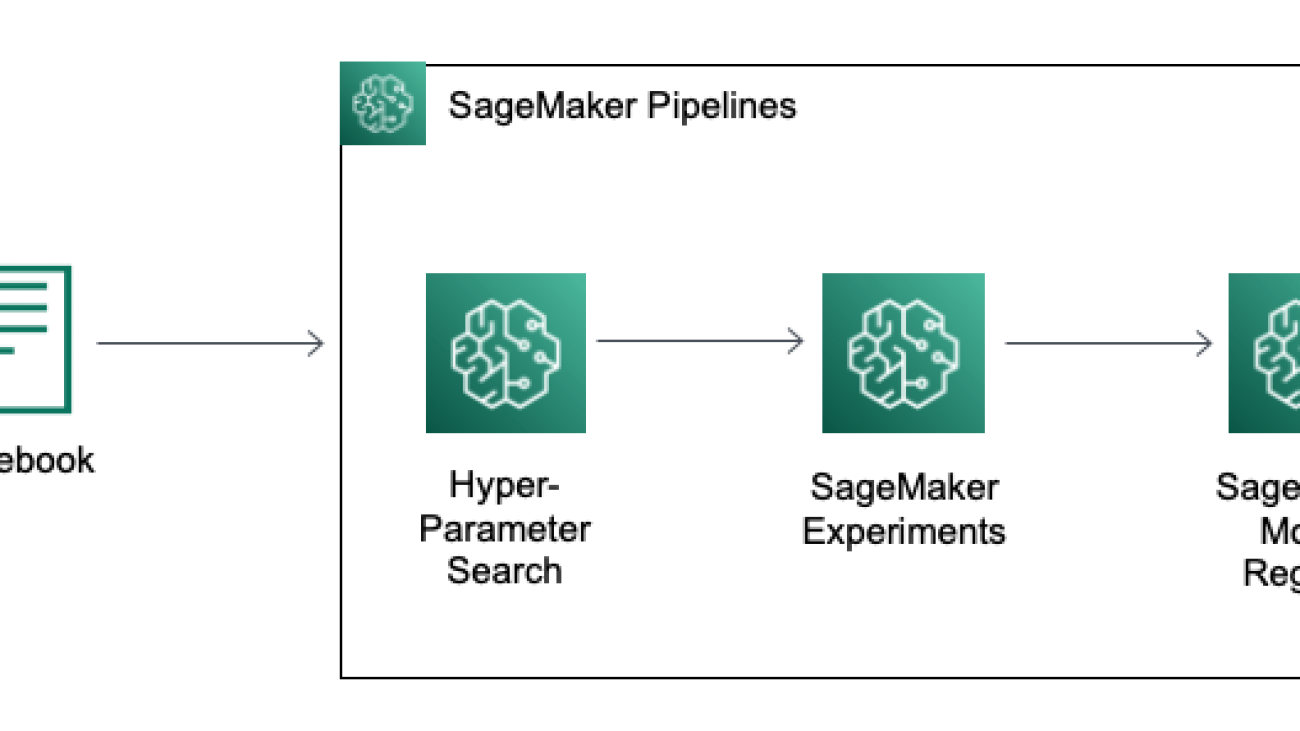
This process significantly benefits from the MLOps features of SageMaker, which streamline the data science workflow by harnessing the powerful cloud infrastructure of AWS. In our solution, we use Amazon SageMaker Automatic Model Tuning for hyperparameter search, Amazon SageMaker Experiments for managing experiments, Amazon SageMaker Model Registry to manage model versions, and Amazon SageMaker Pipelines to orchestrate the process. We then deploy our model to a SageMaker endpoint to obtain real-time predictions.
The following diagram illustrates the architecture of the training pipeline.

The following diagram illustrates the inference pipeline.

You can find the complete code in the GitHub repo. To implement the solution, run the cells in SBP_main.ipynb.
Click here to open the AWS console and follow along.
SageMaker pipeline
SageMaker Pipelines offers a user-friendly Python SDK to create integrated machine learning (ML) workflows. These workflows, represented as Directed Acyclic Graphs (DAGs), consist of steps with various types and dependencies. With SageMaker Pipelines, you can streamline the end-to-end process of training and evaluating models, enhancing efficiency and reproducibility in your ML workflows.
The training pipeline begins with generating a synthetic dataset that is split into training, validation, and test sets. The training set is used to train two TCN models, one utilizing Spliced Binned-Pareto distribution and the other employing Gaussian distribution. Both models go through hyperparameter tuning using the validation set to optimize each model. Afterward, an evaluation against the test set is conducted to determine the model with the lowest root mean squared error (RMSE). The model with the best accuracy metric is uploaded to the model registry.
The following diagram illustrates the pipeline steps.
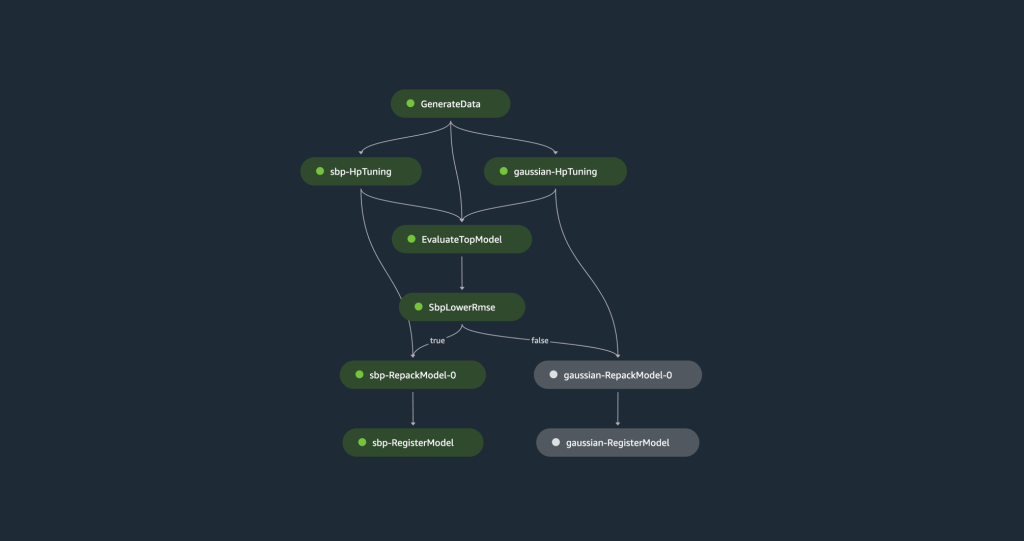
Let’s discuss the steps in more detail.
Data generation
The first step in our pipeline generates a synthetic dataset, which is characterized by a sinusoidal waveform and asymmetric heavy-tailed noise. The data was created using a number of parameters, such as degrees of freedom, a noise multiplier, and a scale parameter. These elements influence the shape of the data distribution, modulate the random variability in our data, and adjust the spread of our data distribution, respectively.
This data processing job is accomplished using a PyTorchProcessor, which runs PyTorch code (generate_data.py) within a container managed by SageMaker. Data and other relevant artifacts for debugging are located in the default Amazon Simple Storage Service (Amazon S3) bucket associated with the SageMaker account. Logs for each step in the pipeline can be found in Amazon CloudWatch.
The following figure is a sample of the data generated by the pipeline.
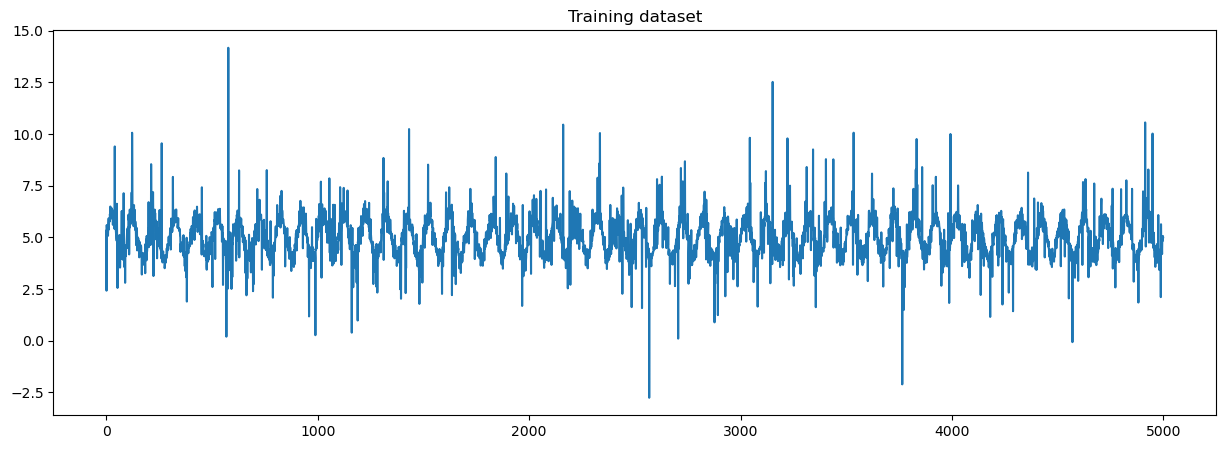
You can replace the input with a wide variety of time series data, such as symmetric, asymmetric, light-tailed, heavy-tailed, or multimodal distribution. The model’s robustness allows it to be applicable to a broad range of time series problems, provided sufficient observations are available.
Model training
After data generation, we train two TCNs: one using SBP distribution and other using Gaussian distribution. SBP distribution employs a discrete binned distribution as its predictive base, where the real axis is divided into discrete bins, and the model predicts the likelihood of an observation falling within each bin. This methodology enables the capture of asymmetries and multiple modes because the probability of each bin is independent. An example of the binned distribution is shown in the following figure.
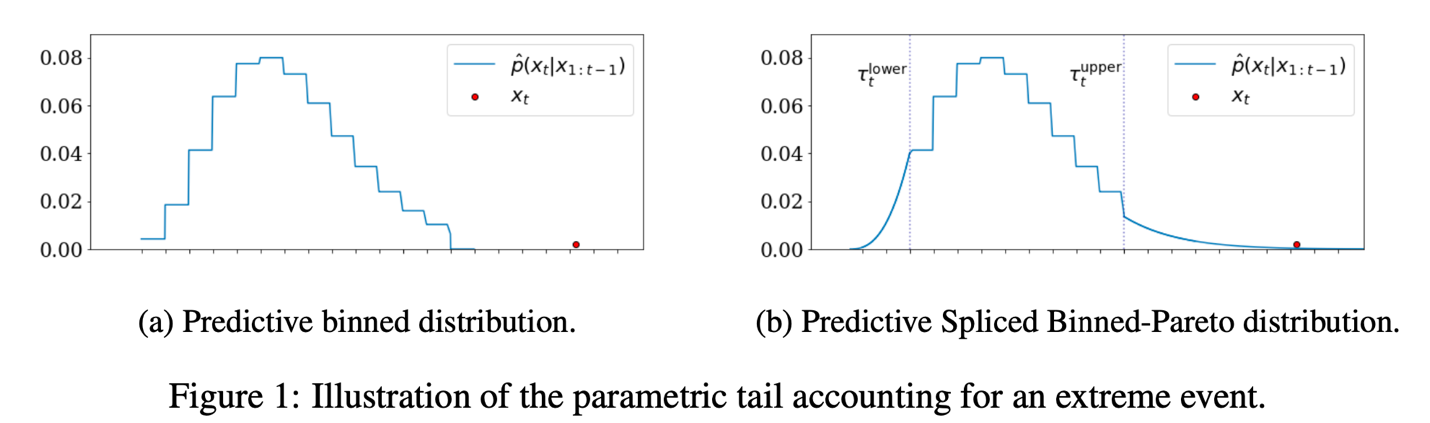
The predictive binned distribution on the left is robust to extreme events because the log-likelihood is not dependent on the distance between the predicted mean and observed point, differing from parametric distributions like Gaussian or Student’s t. Therefore, the extreme event represented by the red dot will not bias the learned mean of the distribution. However, the extreme event will have zero probability. To capture extreme events, we form an SBP distribution by defining the lower tail at the 5th quantile and the upper tail at the 95th quantile, replacing both tails with weighted Generalized Pareto Distributions (GPD), which can quantify the likeliness of the event. The TCN will output the parameters for the binned distribution base and GPD tails.
Hyperparameter search
For optimal output, we use automatic model tuning to find the best version of a model through hyperparameter tuning. This step is integrated into SageMaker Pipelines and allows for the parallel run of multiple training jobs, employing various methods and predefined hyperparameter ranges. The result is the selection of the best model based on the specified model metric, which is RMSE. In our pipeline, we specifically tune the learning rate and number of training epochs to optimize our model’s performance. With the hyperparameter tuning capability in SageMaker, we increase the likelihood that our model achieves optimal accuracy and generalization for the given task.
Due to the synthetic nature of our data, we are keeping Context Length and Lead Time as static parameters. Context Length refers to the number of historical time steps inputted into the model, and Lead Time represents the number of time steps in our forecast horizon. For the sample code, we are only tuning Learning Rate and the number of epochs to save on time and cost.
SBP-specific parameters are kept constant based on extensive testing by the authors on the original paper across different datasets:
- Number of Bins (100) – This parameter determines the number of bins used to model the base of the distribution. It is kept at 100, which has proven to be most effective across multiple industries.
- Percentile Tail (0.05) – This denotes the size of the generalized Pareto distributions at the tail. Like the previous parameter, this has been exhaustively tested and found to be most efficient.
Experiments
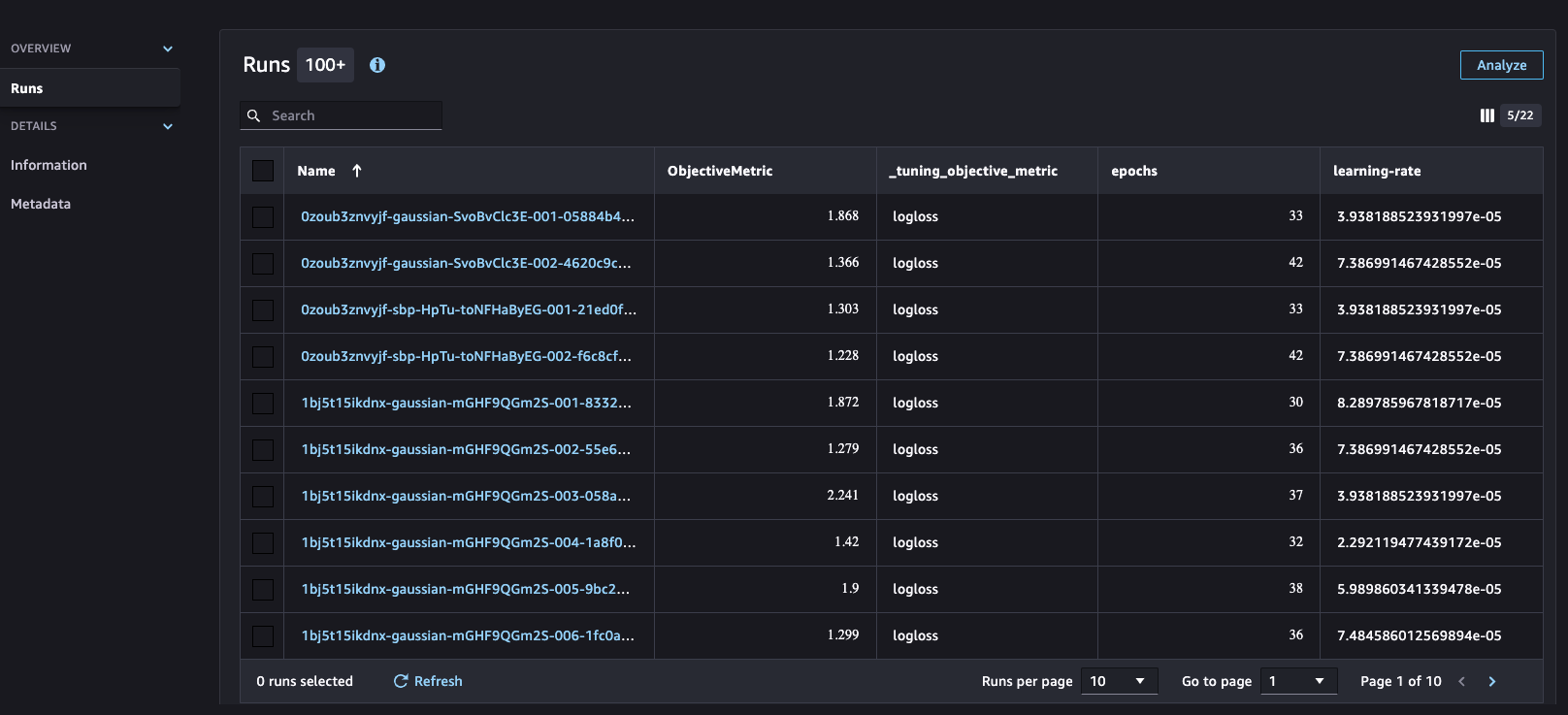
The hyperparameter process is integrated with SageMaker Experiments, which helps organize, analyze, and compare iterative ML experiments, providing insights and facilitating tracking of the best-performing models. Machine learning is an iterative process involving numerous experiments encompassing data variations, algorithm choices, and hyperparameter tuning. These experiments serve to incrementally refine model accuracy. However, the large number of training runs and model iterations can make it challenging to identify the best-performing models and make meaningful comparisons between current and past experiments. SageMaker Experiments addresses this by automatically tracking our hyperparameter tuning jobs and allowing us to gain further details and insight into the tuning process, as shown in the following screenshot.
Model evaluation
The models undergo training and hyperparameter tuning, and are subsequently evaluated via the evaluate.py script. This step utilizes the test set, distinct from the hyperparameter tuning stage, to gauge the model’s real-world accuracy. RMSE is used to assess the accuracy of the predictions.
For distribution comparison, we employ a probability-probability (P-P) plot, which assesses the fit between the actual vs. predicted distributions. The closeness of the points to the diagonal indicates a perfect fit. Our comparisons between SBP’s and Gaussian’s predicted distributions against the actual distribution show that SBP’s predictions align more closely with the actual data.
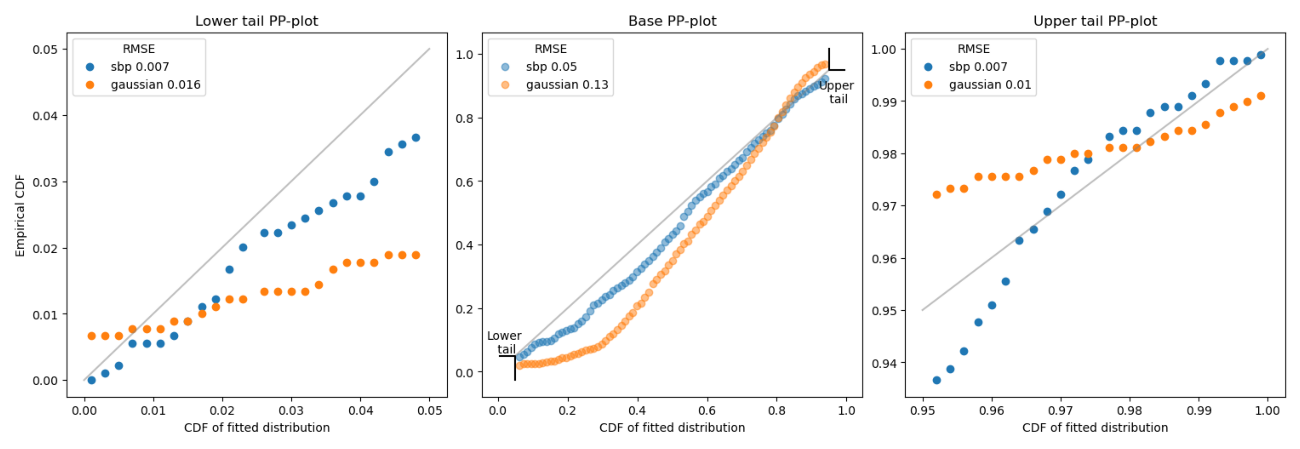
As we can observe, SBP has lower RMSE on the base, lower tail, and upper tail. The SBP distribution improved the accuracy of the Gaussian distribution by 61% on the base, 56% on the lower tail, and 30% on the upper tail. Overall, the SBP distribution has significantly better results.
Model selection
We use a condition step in SageMaker Pipelines to analyze model evaluation reports, opting for the model with the lowest RMSE for improved distribution accuracy. The selected model is converted into a SageMaker model object, readying it for deployment. This involves creating a model package with crucial parameters and packaging it into a ModelStep.
Model registry
The selected model is then uploaded to SageMaker Model Registry, which plays a critical role in managing models ready for production. It stores models, organizes model versions, captures essential metadata and artifacts such as container images, and governs the approval status of each model. By using the registry, we can efficiently deploy models to accessible SageMaker environments and establish a foundation for continuous integration and continuous deployment (CI/CD) pipelines.
Inference
Upon completion of our training pipeline, our model is then deployed using SageMaker hosting services, which enables the creation of an inference endpoint for real-time predictions. This endpoint allows seamless integration with applications and systems, providing on-demand access to the model’s predictive capabilities through a secure HTTPS interface. Real-time predictions can be used in scenarios such as stock price and energy demand forecast. Our endpoint provides a single-step forecast for the provided time series data, presented as percentiles and the median, as shown in the following figure and table.
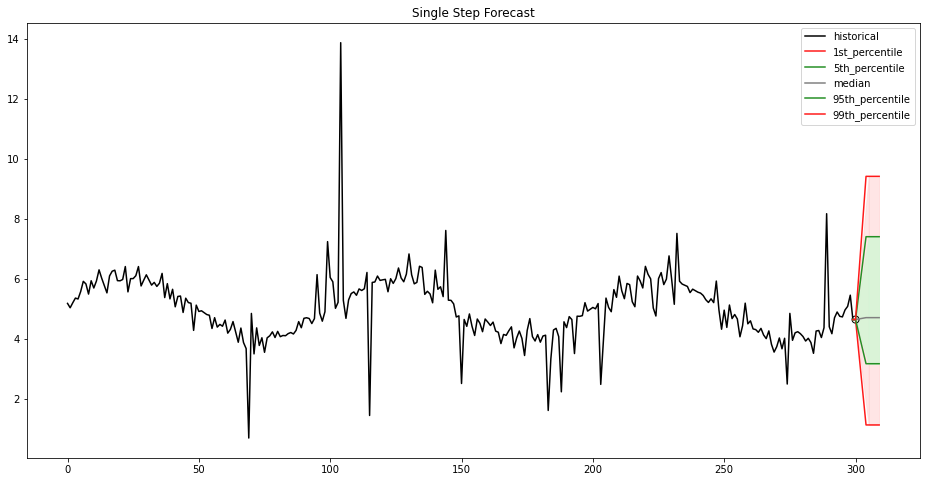
| 1st percentile | 5th percentile | Median | 95th percentile | 99th percentile |
| 1.12 | 3.16 | 4.70 | 7.40 | 9.41 |
Clean up
After you run this solution, make sure you clean up any unnecessary AWS resources to avoid unexpected costs. You can clean up these resources using the SageMaker Python SDK, which can be found at the end of the notebook. By deleting these resources, you prevent further charges for resources you are no longer using.
Conclusion
Having an accurate forecast can highly impact a business’s future planning and can also provide solutions to a variety of problems in different industries. Our exploration of robust time series forecasting with MLOps on SageMaker has demonstrated a method to obtain an accurate forecast and the efficiency of a streamlined training pipeline.
Our model, powered by a Temporal Convolutional Network with Spliced Binned Pareto distribution, has shown accuracy and adaptability to outliers by improving the RMSE by 61% on the base, 56% on the lower tail, and 30% on the upper tail over the same TCN with Gaussian distribution. These figures make it a reliable solution for real-world forecasting needs.
The pipeline demonstrates the value of automating MLOps features. This can reduce manual human effort, enable reproducibility, and accelerate model deployment. SageMaker features such as SageMaker Pipelines, automatic model tuning, SageMaker Experiments, SageMaker Model Registry, and endpoints make this possible.
Our solution employs a miniature TCN, optimizing just a few hyperparameters with a limited number of layers, which are sufficient for effectively highlighting the model’s performance. For more complex use cases, consider using PyTorch or other PyTorch-based libraries to construct a more customized TCN that aligns with your specific needs. Additionally, it would be beneficial to explore other SageMaker features to enhance your pipeline’s functionality further. To fully automate the deployment process, you can use the AWS Cloud Development Kit (AWS CDK) or AWS CloudFormation.
For more information on time series forecasting on AWS, refer to the following:
- Amazon Forecast
- Deep demand forecasting with Amazon SageMaker
- Hierarchical Forecasting using Amazon SageMaker
- Build a cold start time series forecasting engine using AutoGluon
Feel free to leave a comment with any thoughts or questions!
About the Authors
 Nick Biso is a Machine Learning Engineer at AWS Professional Services. He solves complex organizational and technical challenges using data science and engineering. In addition, he builds and deploys AI/ML models on the AWS Cloud. His passion extends to his proclivity for travel and diverse cultural experiences.
Nick Biso is a Machine Learning Engineer at AWS Professional Services. He solves complex organizational and technical challenges using data science and engineering. In addition, he builds and deploys AI/ML models on the AWS Cloud. His passion extends to his proclivity for travel and diverse cultural experiences.
 Alston Chan is a Software Development Engineer at Amazon Ads. He builds machine learning pipelines and recommendation systems for product recommendations on the Detail Page. Outside of work, he enjoys game development and rock climbing.
Alston Chan is a Software Development Engineer at Amazon Ads. He builds machine learning pipelines and recommendation systems for product recommendations on the Detail Page. Outside of work, he enjoys game development and rock climbing.
 Maria Masood specializes in building data pipelines and data visualizations at AWS Commerce Platform. She has expertise in Machine Learning, covering natural language processing, computer vision, and time-series analysis. A sustainability enthusiast at heart, Maria enjoys gardening and playing with her dog during her downtime.
Maria Masood specializes in building data pipelines and data visualizations at AWS Commerce Platform. She has expertise in Machine Learning, covering natural language processing, computer vision, and time-series analysis. A sustainability enthusiast at heart, Maria enjoys gardening and playing with her dog during her downtime.
Create a Generative AI Gateway to allow secure and compliant consumption of foundation models
In the rapidly evolving world of AI and machine learning (ML), foundation models (FMs) have shown tremendous potential for driving innovation and unlocking new use cases. However, as organizations increasingly harness the power of FMs, concerns surrounding data privacy, security, added cost, and compliance have become paramount. Regulated and compliance-oriented industries, such as financial services, healthcare and life sciences, and government institutes, face unique challenges in ensuring the secure and responsible consumption of these models. To strike a balance between agility, innovation, and adherence to standards, a robust platform becomes essential. In this post, we propose Generative AI Gateway as platform for an enterprise to allow secure access to FMs for rapid innovation.
In this post, we define what a Generative AI Gateway is, its benefits, and how to architect one on AWS. A Generative AI Gateway can help large enterprises control, standardize, and govern FM consumption from services such as Amazon Bedrock, Amazon SageMaker JumpStart, third-party model providers (such as Anthropic and their APIs), and other model providers outside of the AWS ecosystem.
What is a Generative AI Gateway?
For traditional APIs (such as REST or gRPC), API Gateway has established itself as a design pattern that enables enterprises to standardize and control how APIs are externalized and consumed. In addition, API Registries enabled centralized governance, control, and discoverability of APIs.
Similarly, Generative AI Gateway is a design pattern that aims to expand on API Gateway and Registry patterns with considerations specific to serving and consuming foundation models in large enterprise settings. For example, handling hallucinations, managing company-specific IPs and EULAs (End User License Agreements), as well as moderating generations are new responsibilities that go beyond the scope of traditional API Gateways.
In addition to requirements specific for generative AI, the technological and regulatory landscape for foundation models is changing fast. This creates unique challenges for organizations to balance innovation speed and compliance. For example:
- The state-of-the-art (SOTA) of models, architectures, and best practices are constantly changing. This means companies need loose coupling between app clients (model consumers) and model inference endpoints, which ensures easy switch among large language model (LLM), vision, or multi-modal endpoints if needed. An abstraction layer over model inference endpoints provides such loose coupling.
- Regulatory uncertainty, especially over IP and data privacy, requires observability, monitoring, and trace of generations. For example, if Retrieval Augmented Generation (RAG)-based applications accidentally include personally identifiable information (PII) data in context, such issues need to be detected in real time. This becomes challenging if large enterprises with multiple data science teams use bespoke, distributed platforms for deploying foundation models.
Generative AI Gateway aims to solve for these new requirements while providing the same benefits of traditional API Gateways and Registries, such as centralized governance and observability, and reuse of common components.
Solution overview
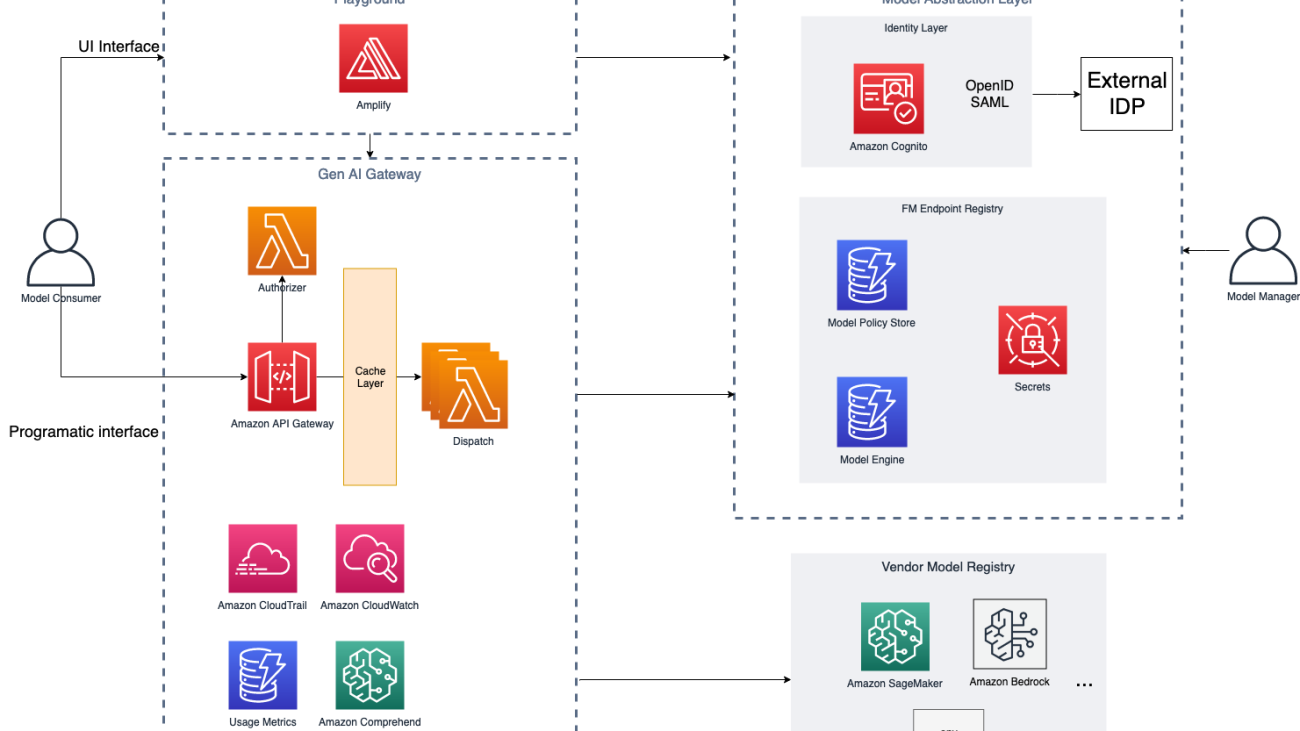
Specifically, Generative AI Gateway provides the following key components:
- A model abstraction layer for approved FMs
- An API Gateway for FMs (AI Gateway)
- A playground for FMs for internal model discoverability
The following diagram illustrates the solution architecture.
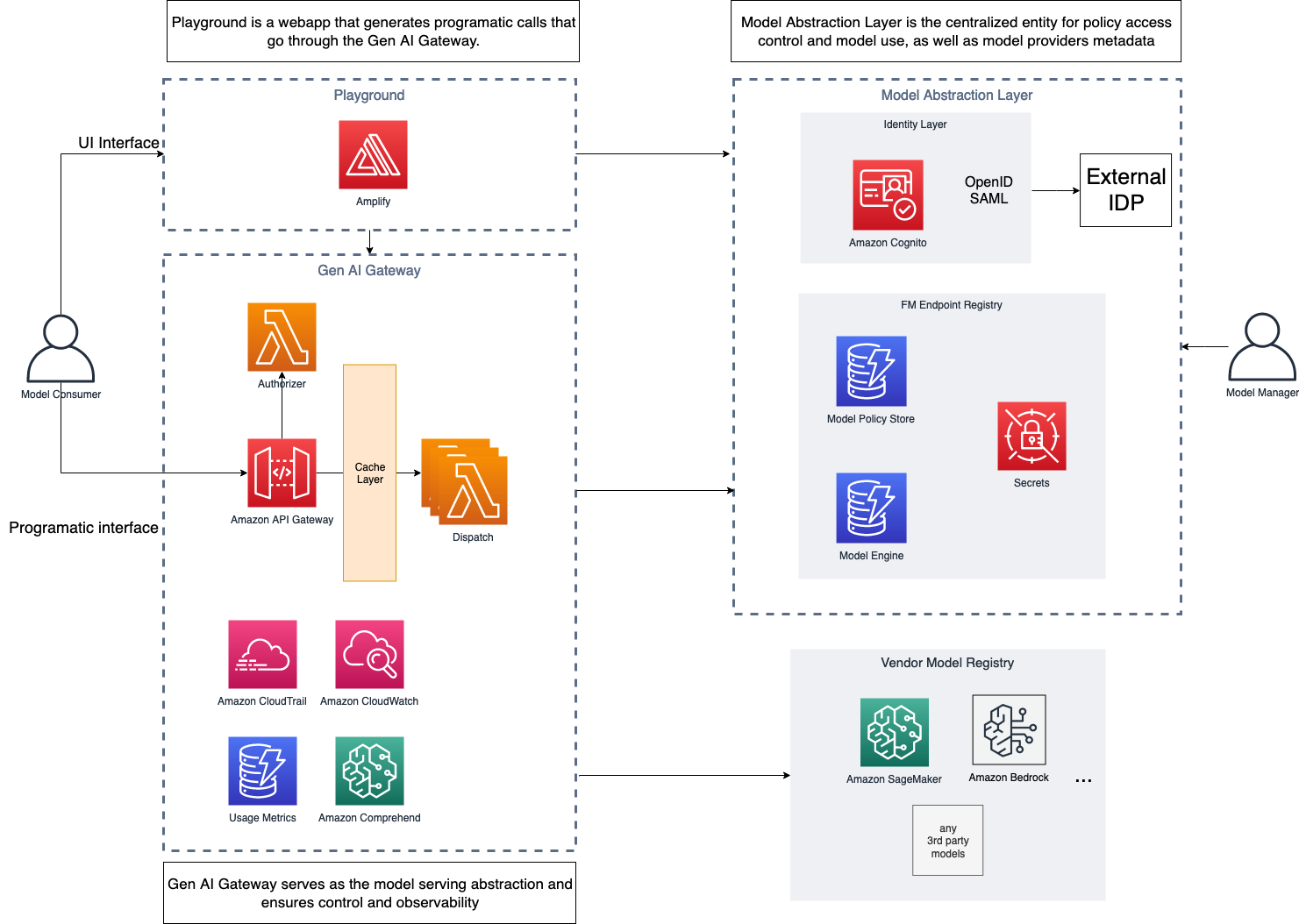
For added resilience, the suggested solution can be deployed in a Multi-AZ environment. The dotted lines in the preceding diagram represent network boundaries, although the entire solution can be deployed in a single VPC.
Model abstraction layer
The model abstraction layer serves as the foundation for secure and controlled access to the organization’s pool of FMs. The layer serves a single source of truth on which models are available to the company, team, and employee, as well as how to access each model by storing endpoint information for each model.
This layer serves as the cornerstone for secure, compliant, and agile consumption of FMs through the Generative AI Gateway, promoting responsible AI practices within the organization.
The layer itself consists of four main components:
- FM endpoint registry – After the FMs are evaluated, approved, and deployed for usage, their endpoints are added to the FM endpoint registry—a centralized repository of all deployed or externally accessible API endpoints. The registry contains metadata about generative AI service endpoints that an organization consumes, whether it’s an internally deployed FM or an externally provided generative AI API from a vendor. The metadata includes information such as service endpoint information for each foundation model and their configuration, and access policies (based on role, team, and so on).
- Model policy store and engine – For FMs to be consumed in a compliant manner, the model abstraction layer must track qualitative and quantitative rules for model generations. For example, some generations might be subject to certain regulations such as CCPA (California Consumer Privacy Act), which requires custom generation behavior per geo. Therefore, the policies should be country and geo aware, to ensure compliance across changing regulatory environments across locales.
- Identity layer – After the models are available to be consumed, the identity layer plays a pivotal role in access management, ensuring that only authorized users or roles within the organization can interact with specific FMs through the AI Gateway. Role-based access control (RBAC) mechanisms help define granular access permissions, ensuring that users can access models based on their roles and responsibilities.
- Integration with vendor model registries – FMS can be available in different ways, either deployed in organization accounts under VPCs or available as APIs through different vendors. After passing the initial checks mentioned earlier, the endpoint registry holds the necessary information about these models from vendors and their versions exposed via APIs. This abstracts way the underlying complexities from the end-user.
To populate the AI model endpoint registry, the Generative AI Gateway team collaborates with a cross-function team of domain experts and business line stakeholders to carefully select and onboard FMs to the platform. During this onboarding phase, factors like model performance, cost, ethical alignment, compliance with industry regulations, and the vendor’s reputation are carefully considered. By conducting thorough evaluations, organizations ensure that the selected FMs align with their specific business needs and adhere to security and privacy requirements.
The following diagram illustrates the architecture of this layer.

AWS services can help in building a model abstraction layer (MAL) as follows:
- The generative AI manager creates a registry table using Amazon DynamoDB. This table is populated with information about the FMs either deployed internally in the organization account or accessible via an API from vendors. This table will hold the endpoint, metadata, and configuration parameters for the model. It can also store the information if a custom AWS Lambda function is needed to invoke the underlying FM with vendor-specific API clients.
- The generative AI manager then determines access for the user, adds limits, adds a policy for what type of generations the user can perform (images, text, multi-modality, and so on), and adds other organization specific policies such as responsible AI and content filters that will be added as a separate policy table in DynamoDB.
- When the user makes a request using the AI Gateway, it’s routed to Amazon Cognito to determine access for the client. A Lambda authorizer helps determine the access from the identity layer, which will be managed by the DynamoDB table policy. If the client has access, the relevant access such as the AWS Identity and Access Management (IAM) role or API key for the FM endpoint are fetched from AWS Secrets Manager. Also, the registry is explored to find the relevant endpoint and configuration at this stage.
- After all the necessary information related to the request is fetched, such as the endpoint, configuration, access keys, and custom function, it’s handed back to the AI Gateway to be used with the dispatcher Lambda function that calls a specific model endpoint.
AI Gateway
The AI Gateway serves as a crucial component that facilitates secure and efficient consumption of FMs within the organization. It operates on top of the model abstraction layer, providing an API-based interface to internal users, including developers, data scientists, and business analysts.
Through this user-friendly interface (programmatic and playground UI-based), internal users can seamlessly access, interact with, and use the organization’s curated models, ensuring relevant models are made available based on their identities and responsibilities. An AI Gateway can comprise the following:
- A unified API interface across all FMs – The AI Gateway presents a unified API interface and SDK that abstracts the underlying technical complexities, enabling internal users to interact with the organization’s pool of FMs effortlessly. Users can use the APIs to invoke different models and send in their prompts to get model generation.
- API quota, limits, and usage management – This includes the following:
- Consumed quota – To enable efficient resource allocation and cost control, the AI Gateway provides users with insights into their consumed quota for each model. This transparency allows users to manage their AI resource usage effectively, ensuring optimal utilization and preventing resource waste.
- Request for dedicated hosting – Recognizing the importance of resource allocation for critical use cases, the AI Gateway allows users to request dedicated hosting of specific models. Users with high-priority or latency-sensitive applications can use this feature to ensure a consistent and dedicated environment for their model inference needs.
- Access control and model governance – Using the identity layer from the model abstraction layer, the AI Gateway enforces stringent access controls. Each user’s identity and assigned roles determine the models they can access. This granular access control ensures that users are presented with only the models relevant to their domains, maintaining data security and privacy while promoting responsible AI usage.
- Content, privacy, and responsible AI policy enforcement – The API Gateway employs both the preprocessing and postprocessing of all inputs to the model as well as the model generations to filter and moderate for toxicity, violence, harmfulness, PII data, and more that are specified by the model abstraction layer for filtering. Centralizing this function in the AI Gateway ensures enforcement and easy audit.
By integrating the AI Gateway with the model abstraction layer and incorporating features such as identity-based access control, model listing and metadata display, consumed quota monitoring, and dedicated hosting requests, organizations can create a powerful AI consumption platform.
In addition, the AI Gateway provides the standard benefits of API Gateways, such as the following:
- Cost control mechanism – To optimize resource allocation and manage costs effectively, a robust cost control mechanism can be implemented. This mechanism monitors resource usage, model inference costs, and data transfer expenses. It allows organizations to gain insights into generative AI resource expenditure, identify cost-saving opportunities, and make informed decisions on resource allocation.
- Cache – Inference from FMs can become expensive, especially during testing and development phases of the application. A cache layer can help reduce that cost and even improve the speed by maintaining a cache for frequent requests. The cache also offloads the inference burden on the endpoint, which makes room for other requests.
- Observability – This plays a crucial role in capturing activities performed on the AI Gateway and the Discovery Playground. Detailed logs record user interactions, model requests, and system responses. These logs provide valuable information for troubleshooting, tracking user behavior, and reinforcing transparency and accountability.
- Quotas, rate limits, and throttling – The governance aspect of this layer can incorporate the application of quotas, rate limits, and throttling to manage and control AI resource usage. Quotas define the maximum number of requests a user or team can make within a specific time frame, ensuring fair resource distribution. Rate limits prevent excessive usage of resources by enforcing a maximum request rate. Throttling mitigates the risk of system overload by controlling the frequency of incoming requests, preventing service disruptions.
- Audit trails and usage monitoring – The team assumes responsibility of maintaining detailed audit trails of the entire ecosystem. These logs enable comprehensive usage monitoring, allowing the central team to track user activities, identify potential risks, and maintain transparency in AI consumption.
The following diagram illustrates this architecture.

AWS services can help in building an AI Gateway as follows:
- The user makes the request using Amazon API Gateway, which is routed to the model abstraction layer after the request has been authenticated and authorized.
- The AI Gateway enforces usage limits for each user’s request using usage limit policies returned by the MAL. For easy enforcement, we use the native capability of API Gateway to enforce metering. In addition, we perform standard API Gateway validations on request using a JSON schema.
- After the usage limits are validated, both the endpoint configuration and credentials received from the MAL form the actual inference payload using native interfaces provided by each of the approved model vendors. The dispatch layer normalizes the differences across vendors’ SDKs and API interfaces to provide a unified interface to the client. Issues such as DNS changes, load balancing, and caching could also be handled by a more sophisticated dispatch service.
- After the response is received from the underlying model endpoints, postprocessing Lambda functions use the policies from the MAL pertaining to content (toxicity, nudity, and so on) as well as compliance (CCPA, GDPR, and so on) to filter or mask generations as a whole or in part.
- Throughout the lifecycle of the request, all generations and inference payloads are logged through Amazon CloudWatch Logs, which can be organized via log groups depending on tags as well as policies retrieved from MAL. For example, logs can be separated per model vendor and geo. This allows for further model improvement and troubleshooting.
- Finally, a retroactive audit is available through AWS CloudTrail.
Discovery Playground
The last component is to introduce a Discovery Playground, which presents a user-friendly interface built on top of the model abstraction layer and the AI Gateway, offering a dynamic environment for users to explore, test, and unleash the full potential of available FMs. Beyond providing access to AI capabilities, the playground empowers users to interact with models using a rich UI interface, provide valuable feedback, and share their discoveries with other users within the organization. It offers the following key features:
- Playground interface – You can effortlessly input prompts and receive model outputs in real time. The UI streamlines the interaction process, making generative AI exploration accessible to users with varying levels of technical expertise.
- Model cards – You can access a comprehensive list of available models along with their corresponding metadata. You can explore detailed information about each model, such as its capabilities, performance metrics, and supported use cases. This feature facilitates informed decision-making, empowering you to select the most suitable model for your specific needs.
- Feedback mechanism – A differentiating aspect of the playground would be its feedback mechanism, allowing you to provide insights on model outputs. You can report issues like hallucination (fabricated information), inappropriate language, or any unintended behavior observed during interactions with the models.
- Recommendations for use cases – The Discovery Playground can be designed to facilitate learning and understanding of FMs’ capabilities for different use cases. You can experiment with various prompts and discover which models excel in specific scenarios.
By offering a rich UI interface, model cards, feedback mechanism, use case recommendations, and the optional Example Store, the Discovery Playground becomes a powerful platform for generative AI exploration and knowledge sharing within the organization.
Process considerations
Whereas the previous modules of the Generative AI Gateway offer a platform, this layer is more practical, ensuring the responsible and compliant consumption of FMs within the organization. It encompasses additional measures that go beyond the technical aspects, focusing on legal, practical, and regulatory considerations. This layer presents crucial responsibilities for the central team to address data security, licenses, organizational regulations, and audit trails, fostering a culture of trust and transparency:
- Data security and privacy – Because FMs can process vast amounts of data, data security and privacy become paramount concerns. The central team is responsible for implementing robust data security measures, including encryption, access controls, and data anonymization. Compliance with data protection regulations, such as GDPR, HIPAA, or other industry-specific standards, is diligently ensured to safeguard sensitive information and user privacy.
- Data monitoring – A comprehensive data monitoring system should be established to track incoming and outgoing information through the AI Gateway and Discovery Playground. This includes monitoring the prompts provided by users and the corresponding model outputs. The data monitoring mechanism enables the organization to observe data patterns, detect anomalies, and ensure that sensitive information remains secure.
- Model licenses and agreements – The central team should take the lead in managing licenses and agreements associated with the use of models. Vendor-provided models may come with specific usage agreements, usage restrictions, or licensing terms. The team ensures compliance with these agreements and maintains a comprehensive repository of all licenses, ensuring a clear understanding of the rights and limitations pertaining to each model.
- Ethical considerations – As AI systems become increasingly sophisticated, the central team assumes the responsibility of ensuring ethical alignment in AI usage. They assess models for potential biases, harmful outputs, or unethical behavior. Steps are taken to mitigate such issues and foster responsible AI development and deployment within the organization.
- Proactive adaptation – To stay ahead of emerging challenges and ever-changing regulations, the central team takes a proactive approach to governance. They continuously update policies, model standards, and compliance measures to align with the latest industry practices and legal requirements. This ensures the organization’s AI ecosystem remains in compliance and upholds ethical standards.
Conclusion
The Generative AI Gateway enables organizations to use foundation models responsibly and securely. Through the integration of the model abstraction layer, AI Gateway, and Discovery Playground powered with monitoring, observability, governance, and security, compliance, and audit layers, organizations can strike a balance between innovation and compliance. The AI Gateway empowers you with seamless access to curated models, while the Discovery Playground fosters exploration and feedback. Monitoring and governance provide insights for optimized resource allocation and proactive decision-making. With a focus on security, compliance, and ethical AI practices, the Generative AI Gateway opens doors to a future where AI-driven applications thrive responsibly, unlocking new realms of possibilities for organizations.
About the Authors
 Talha Chattha is an AI/ML Specialist Solutions Architect at Amazon Web Services, based in Stockholm, serving Nordic enterprises and digital native businesses. Talha holds a deep passion for Generative AI technologies, He works tirelessly to deliver innovative, scalable and valuable ML solutions in the space of Large Language Models and Foundation Models for his customers. When not shaping the future of AI, he explores the scenic European landscapes and delicious cuisines.
Talha Chattha is an AI/ML Specialist Solutions Architect at Amazon Web Services, based in Stockholm, serving Nordic enterprises and digital native businesses. Talha holds a deep passion for Generative AI technologies, He works tirelessly to deliver innovative, scalable and valuable ML solutions in the space of Large Language Models and Foundation Models for his customers. When not shaping the future of AI, he explores the scenic European landscapes and delicious cuisines.
 John Hwang is a Generative AI Architect at AWS with special focus on Large Language Model (LLM) applications, vector databases, and generative AI product strategy. He is passionate about helping companies with AI/ML product development, and the future of LLM agents and co-pilots. Prior to joining AWS, he was a Product Manager at Alexa, where he helped bring conversational AI to mobile devices, as well as a derivatives trader at Morgan Stanley. He holds a B.S. in Computer Science from Stanford University.
John Hwang is a Generative AI Architect at AWS with special focus on Large Language Model (LLM) applications, vector databases, and generative AI product strategy. He is passionate about helping companies with AI/ML product development, and the future of LLM agents and co-pilots. Prior to joining AWS, he was a Product Manager at Alexa, where he helped bring conversational AI to mobile devices, as well as a derivatives trader at Morgan Stanley. He holds a B.S. in Computer Science from Stanford University.
 Paolo Di Francesco is a Senior Solutions Architect at Amazon Web Services (AWS). He holds a PhD in Telecommunication Engineering and has experience in software engineering. He is passionate about machine learning and is currently focusing on using his experience to help customers reach their goals on AWS, in particular in discussions around MLOps. Outside of work, he enjoys playing football and reading.
Paolo Di Francesco is a Senior Solutions Architect at Amazon Web Services (AWS). He holds a PhD in Telecommunication Engineering and has experience in software engineering. He is passionate about machine learning and is currently focusing on using his experience to help customers reach their goals on AWS, in particular in discussions around MLOps. Outside of work, he enjoys playing football and reading.
Beyond forecasting: The delicate balance of serving customers and growing your business
Companies use time series forecasting to make core planning decisions that help them navigate through uncertain futures. This post is meant to address supply chain stakeholders, who share a common need of determining how many finished goods are needed over a mixed variety of planning time horizons. In addition to planning how many units of goods are needed, businesses often need to know where they will be needed, to create a geographically optimal inventory.
The delicate balance of oversupply and undersupply
If manufacturers produce too few parts or finished goods, the resulting undersupply can cause them to make tough choices of rationing available resources among their trading partners or business units. As a result, purchase orders may have lower acceptance rates with fewer profits realized. Further down the supply chain, if a retailer has too few products to sell, relative to demand, they can disappoint shoppers due to out-of-stocks. When the retail shopper has an immediate need, these shortfalls can result in the purchase from an alternate retailer or substitutable brand. This substitution can be a churn risk if the alternate becomes the new default.
On the other end of the supply pendulum, an oversupply of goods can also incur penalties. Surplus items must now be carried in inventory until sold. Some degree of safety stock is expected to help navigate through expected demand uncertainty; however, excess inventory leads to inefficiencies that can dilute an organization’s bottom line. Especially when products are perishable, an oversupply can lead to the loss of all or part of the initial investment made to acquire the sellable finished good.
Even when products are not perishable, during storage they effectively become an idle resource that could be available on the balance sheet as free cash or used to pursue other investments. Balance sheets aside, storage and carrying costs are not free. Organizations typically have a finite amount of arranged warehouse and logistics capabilities. They must operate within these constraints, using available resources efficiently.
Faced with choosing between oversupply and undersupply, on average, most organizations prefer to oversupply by explicit choice. The measurable cost of undersupply is often higher, sometimes by several multiples, when compared to the cost of oversupply, which we discuss in sections that follow.
The main reason for the bias towards oversupply is to avoid the intangible cost of losing goodwill with customers whenever products are unavailable. Manufacturers and retailers think about long-term customer value and want to foster brand loyalty—this mission helps inform their supply chain strategy.
In this section, we examined inequities resulting from allocating too many or too few resources following a demand planning process. Next, we investigate time series forecasting and how demand predictions can be optimally matched with item-level supply strategies.
Classical approaches to sales and operations planning cycles
Historically, forecasting has been achieved with statistical methods that result in point forecasts, which provide a most-likely value for the future. This approach is often based on forms of moving averages or linear regression, which seeks to fit a model using an ordinary least squares approach. A point forecast consists of a single mean prediction value. Because the point forecast value is centered on a mean, it is expected that the true value will be above the mean, approximately 50% of the time. This leaves a remaining 50% of the time when the true number will fall below the point forecast.
Point forecasts may be interesting, but they can result in retailers running out of must-have items 50% of the time if followed without expert review. To prevent underserving customers, supply and demand planners apply manual judgement overrides or adjust point forecasts by a safety stock formula. Companies may use their own interpretation of a safety stock formula, but the idea is to help ensure product supply is available through an uncertain short-term horizon. Ultimately, planners will need to decide whether to inflate or deflate the mean point forecast predictions, according to their rules, interpretations, and subjective view of the future.
Modern, state-of-the-art time series forecasting enables choice
To meet real-world forecasting needs, AWS provides a broad and deep set of capabilities that deliver a modern approach to time series forecasting. We offer machine learning (ML) services that include but are not limited to Amazon SageMaker Canvas (for details, refer to Train a time series forecasting model faster with Amazon SageMaker Canvas Quick build), Amazon Forecast (Start your successful journey with time series forecasting with Amazon Forecast), and Amazon SageMaker built-in algorithms (Deep demand forecasting with Amazon SageMaker). In addition, AWS developed an open-source software package, AutoGluon, which supports diverse ML tasks, including those in the time series domain. For more information, refer to Easy and accurate forecasting with AutoGluon-TimeSeries.
Consider the point forecast discussed in the prior section. Real-world data is more complicated than can be expressed with an average or a straight regression line estimate. In addition, because of the imbalance of over and undersupply, you need more than a single point estimate. AWS services address this need by the use of ML models coupled with quantile regression. Quantile regression enables you to select from a wide range of planning scenarios, which are expressed as quantiles, rather than rely on single point forecasts. It is these quantiles that offer choice, which we describe in more detail in the next section.
Forecasts designed to serve customers and generate business growth
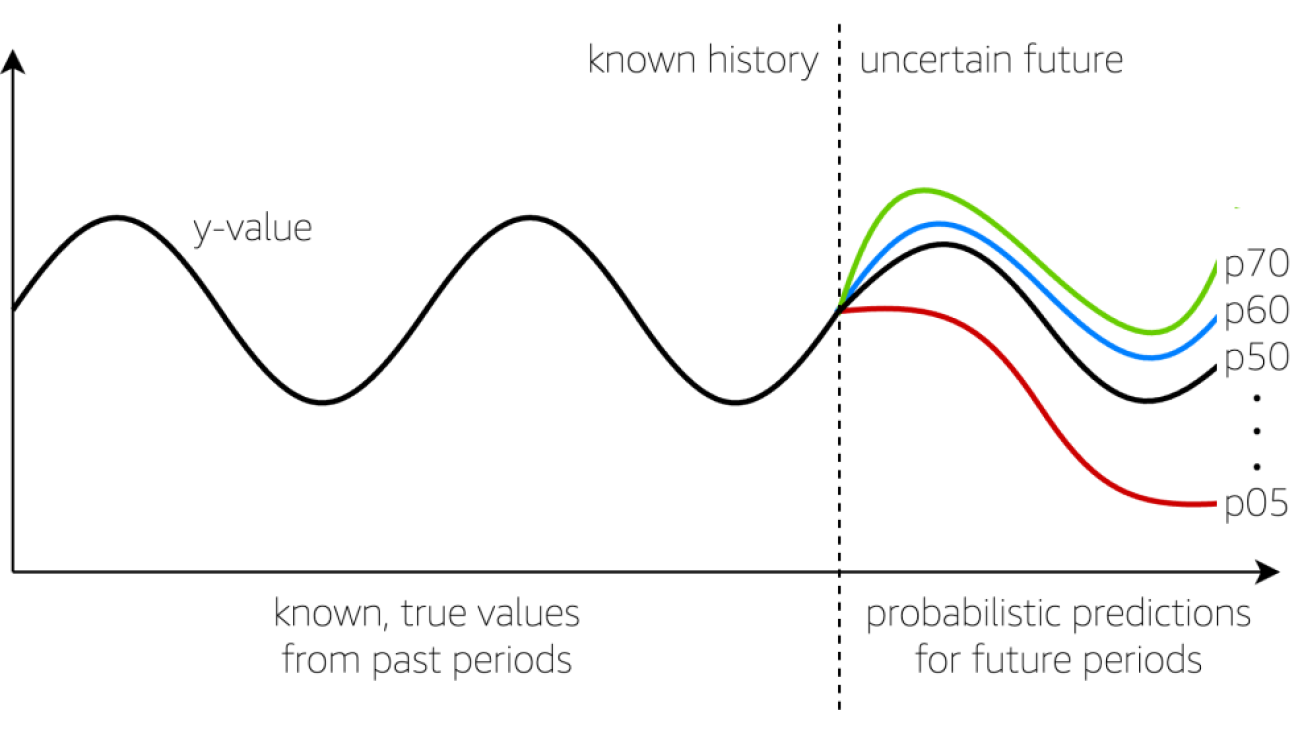
The following figure provides a visual of a time series forecast with multiple outcomes, made possible through quantile regression. The red line, denoted with p05, offers a probability that the real number, whatever it may be, is expected to fall below the p05 line, about 5% of the time. Conversely, this means 95% of the time, the true number will likely fall above the p05 line.
Next, observe the green line, denoted with p70. The true value will fall below the p70 line about 70% of the time, leaving a 30% chance it will exceed the p70. The p50 line provides a mid-point perspective about the future, with a 50/50 chance values will fall above or below the p50, on average. These are examples, but any quantile can be interpreted in the same manner.
In the following section, we examine how to measure if the quantile predictions produce an over or undersupply by item.
Measuring oversupply and undersupply from historic data
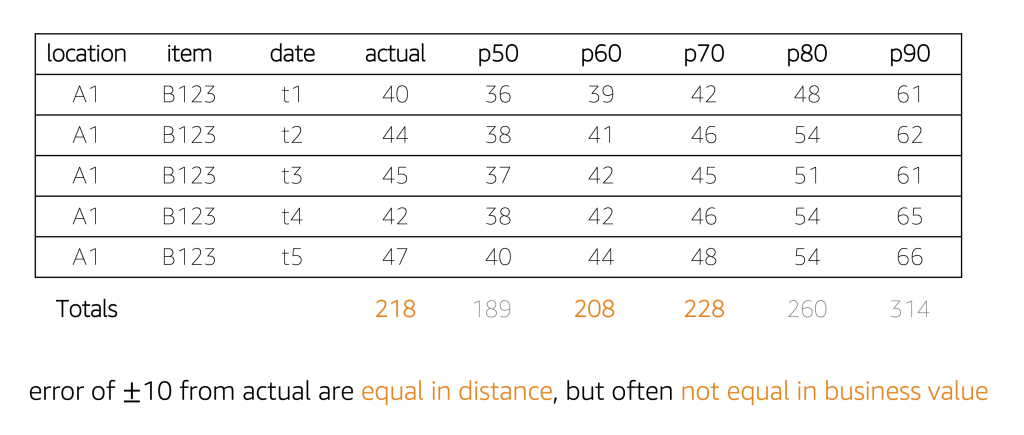
The previous section demonstrated a graphical way to observe predictions; another way to view them is in a tabular way, as shown in the following table. When creating time series models, part of the data is held back from the training operation, which allows accuracy metrics to be generated. Although the future is uncertain, the main idea here is that accuracy during a holdback period is the best approximation of how tomorrow’s predictions will perform, all other things being equal.
The table doesn’t show accuracy metrics; rather, it shows true values known from the past, alongside several quantile predictions from p50 through p90 in steps of 10. During the recent historic five time periods, the true demand was 218 units. Quantile predictions offer a range of values, from a low of 189 units, to a high of 314 units. With the following table, it’s easy to see p50 and p60 result in an undersupply, and the last three quantiles result in an oversupply.
We previously pointed out that there is an asymmetry in over and undersupply. Most businesses who make a conscious choice to oversupply do so to avoid disappointing customers. The critical question becomes: “For the future ahead, which quantile prediction number should the business plan against?” Given the asymmetry that exists, a weighted decision needs to be made. This need is addressed in the next section where forecasted quantities, as units, are converted to their respective financial meanings.
Automatically selecting correct quantile points based on maximizing profit or customer service goals
To convert quantile values to business values, we must find the penalty associated with each unit of overstock and with each unit of understock, because these are rarely equal. A solution for this need is well-documented and studied in the field of operations research, referred to as a newsvendor problem. Whitin (1955) was the first to formulate a demand model with pricing effects included. The newsvendor problem is named from a time when news sellers had to decide how many newspapers to purchase for the day. If they chose a number too low, they would sell out early and not reach their income potential the day. If they chose a number too high, they were stuck with “yesterday’s news” and would risk losing part of their early morning speculative investment.
To compute per-unit the over and under penalties, there are a few pieces of data necessary for each item you wish to forecast. You may also increase the complexity by specifying the data as an item+location pair, item+customer pair, or other combinations according to business need.
- Expected sales value for the item.
- All-in cost of goods to purchase or manufacture the item.
- Estimated holding costs associated with carrying the item in inventory, if unsold.
- Salvage value of the item, if unsold. If highly perishable, the salvage value could approach zero, resulting in a full loss of the original cost of goods investment. When shelf stable, the salvage value can fall anywhere under the expected sales value for the item, depending on the nature of a stored and potentially aged item.
The following table demonstrates how the quantile points were self-selected from among the available forecast points in known historical periods. Consider the example of item 3, which had a true demand of 1,578 units in prior periods. A p50 estimate of 1,288 units would have undersupplied, whereas a p90 value of 2,578 units would have produced a surplus. Among the observed quantiles, the p70 value produces a maximum profit of $7,301. Knowing this, you can see how a p50 selection would result in a near $1,300 penalty, compared to the p70 value. This is only one example, but each item in the table has a unique story to tell.

Solution overview
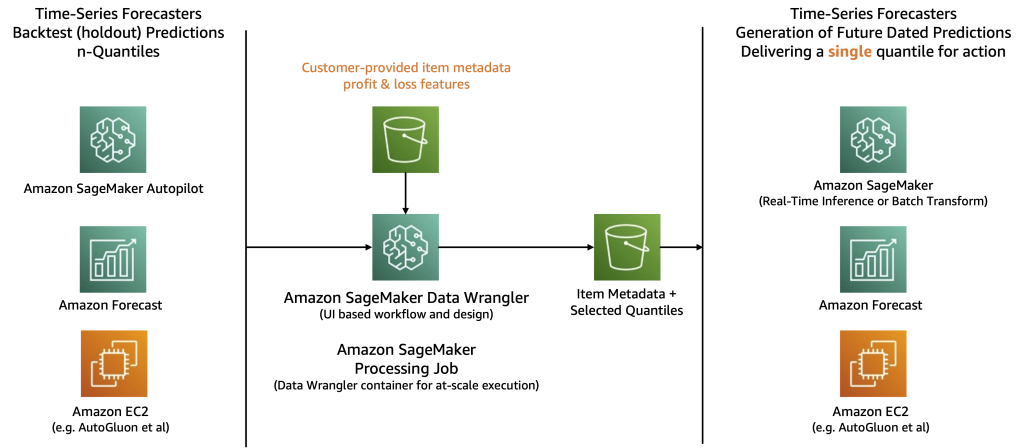
The following diagram illustrates a proposed workflow. First, Amazon SageMaker Data Wrangler consumes backtest predictions produced by a time series forecaster. Next, backtest predictions and known actuals are joined with financial metadata on an item basis. At this point, using backtest predictions, a SageMaker Data Wrangler transform computes the unit cost for under and over forecasting per item.
SageMaker Data Wrangler translates the unit forecast into a financial context and automatically selects the item-specific quantile that provides the highest amount of profit among quantiles examined. The output is a tabular set of data, stored on Amazon S3, and is conceptually similar to the table in the previous section.
Finally, a time series forecaster is used to produce future-dated forecasts for future periods. Here, you may also choose to drive inference operations, or act on inference data, according to which quantile was chosen. This may allow you to reduce computational costs while also removing the burden of manual review of every single item. Experts in your company can have more time to focus on high-value items while thousands of items in your catalog can have automatic adjustments applied. As a point of consideration, the future has some degree of uncertainty. However, all other things being equal, a mixed selection of quantiles should optimize outcomes in an overall set of time series. Here at AWS, we advise you to use two holdback prediction cycles to quantify the degree of improvements found with mixed quantile selection.
Solution guidance to accelerate your implementation
If you wish to recreate the quantile selection solution discussed in this post and adapt it to your own dataset, we provide a synthetic sample set of data and a sample SageMaker Data Wrangler flow file to get you started on GitHub. The entire hands-on experience should take you less than an hour to complete.
We provide this post and sample solution guidance to help accelerate your time to market. The primary enabler for recommending specific quantiles is SageMaker Data Wrangler, a purpose-built AWS service meant to reduce the time it takes to prepare data for ML use cases. SageMaker Data Wrangler provides a visual interface to design data transformations, analyze data, and perform feature engineering.
If you are new to SageMaker Data Wrangler, refer to Get Started with Data Wrangler to understand how to launch the service through Amazon SageMaker Studio. Independently, we have more than 150 blog posts that help discover diverse sample data transformations addressed by the service.
Conclusion
In this post, we discussed how quantile regression enables multiple business decision points in time series forecasting. We also discussed the imbalanced cost penalties associated with over and under forecasting—often the penalty of undersupply is several multiples of the oversupply penalty, not to mention undersupply can cause the loss of goodwill with customers.
The post discussed how organizations can evaluate multiple quantile prediction points with a consideration for the over and undersupply costs of each item to automatically select the quantile likely to provide the most profit in future periods. When necessary, you can override the selection when business rules desire a fixed quantile over a dynamic one.
The process is designed to help meet business and financial goals while removing the friction of having to manually apply judgment calls to each item forecasted. SageMaker Data Wrangler helps the process run on an ongoing basis because quantile selection must be dynamic with changing real-world data.
It should be noted that quantile selection is not a one-time event. The process should be evaluated during each forecasting cycle as well, to account for changes including increased cost of goods, inflation, seasonal adjustments, new product introduction, shifting consumer demands, and more. The proposed optimization process is positioned after the time series model generation, referred to as the model training step. Quantile selections are made and used with the future forecast generation step, sometimes called the inference step.
If you have any questions about this post or would like a deeper dive into your unique organizational needs, please reach out to your AWS account team, your AWS Solutions Architect, or open a new case in our support center.
References
- DeYong, G. D. (2020). The price-setting newsvendor: review and extensions. International Journal of Production Research, 58(6), 1776–1804.
- Liu, C., Letchford, A. N., & Svetunkov, I. (2022). Newsvendor problems: An integrated method for estimation and optimisation. European Journal of Operational Research, 300(2), 590–601.
- Punia, S., Singh, S. P., & Madaan, J. K. (2020). From predictive to prescriptive analytics: A data-driven multi-item newsvendor model. Decision Support Systems, 136.
- Trapero, J. R., Cardós, M., & Kourentzes, N. (2019). Quantile forecast optimal combination to enhance safety stock estimation. International Journal of Forecasting, 35(1), 239–250.
- Whitin, T. M. (1955). Inventory control and price theory. Management Sci. 2 61–68.
About the Author
Charles Laughlin is a Principal AI/ML Specialist Solution Architect and works in the Amazon SageMaker service team at AWS. He helps shape the service roadmap and collaborates daily with diverse AWS customers to help transform their businesses using cutting-edge AWS technologies and thought leadership. Charles holds a M.S. in Supply Chain Management and a Ph.D. in Data Science.

Announcing New Tools to Help Every Business Embrace Generative AI
From startups to enterprises, organizations of all sizes are getting started with generative AI. They want to capitalize on generative AI and translate the momentum from betas, prototypes, and demos into real-world productivity gains and innovations. But what do organizations need to bring generative AI into the enterprise and make it real? When we talk to customers, they tell us they need security and privacy, scale and price-performance, and most importantly tech that is relevant to their business. We are excited to announce new capabilities and services today to allow organizations big and small to use generative AI in creative ways, building new applications and improving how they work. At AWS, we are hyper-focused on helping our customers in a few ways:
- Making it easy to build generative AI applications with security and privacy built in
- Focusing on the most performant, low cost infrastructure for generative AI so you can train your own models and run inference at scale
- Providing generative AI-powered applications for the enterprise to transform how work gets done
- Enabling data as your differentiator to customize foundation models (FMs) and make them an expert on your business, your data, and your company
To help a broad range of organizations build differentiated generative AI experiences, AWS has been working hand-in-hand with our customers, including BBVA, Thomson Reuters, Philips, and LexisNexis Legal & Professional. And with the new capabilities launched today, we look forward to enhanced productivity, improved customer engagement, and more personalized experiences that will transform how companies get work done.

Announcing the general availability of Amazon Bedrock, the easiest way to build generative AI applications with security and privacy built in
Customers are excited and optimistic about the value that generative AI can bring to the enterprise. They are diving deep into the technology to learn the steps they need to take to build a generative AI system in production. While recent advancements in generative AI have captured widespread attention, many businesses have not been able to take part in this transformation. Customers tell us they need a choice of models, security and privacy assurances, a data-first approach, cost-effective ways to run models, and capabilities like prompt engineering, retrieval augmented generation (RAG), agents, and more to create customized applications. That is why on April 13, 2023, we announced Amazon Bedrock, the easiest way to build and scale generative AI applications with foundation models. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models from leading providers like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon, along with a broad set of capabilities that customers need to build generative AI applications, simplifying development while maintaining privacy and security. Additionally, as part of a recently announced strategic collaboration, all future FMs from Anthropic will be available within Amazon Bedrock with early access to unique features for model customization and fine-tuning capabilities.
Since April, we have seen firsthand how startups like Coda, Hurone AI, and Nexxiot; large enterprises like adidas, GoDaddy, and Broadridge; and partners like Accenture, BCG, Leidos, and Mission Cloud are already using Amazon Bedrock to securely build generative AI applications across industries. Independent software vendors (ISVs) like Salesforce are now securely integrating with Amazon Bedrock to enable their customers to power generative AI applications. Customers are applying generative AI to new use cases; for example, Lonely Planet, a premier travel media company, worked with our Generative AI Innovation Center to introduce a scalable AI platform that organizes book content in minutes to deliver cohesive, highly accurate travel recommendations, reducing itinerary generation costs by nearly 80%. And since then, we have continued to add new capabilities, like agents for Amazon Bedrock, as well as support for new models, like Cohere and the latest models from Anthropic, to offer our customers more choice and make it easier to create generative AI-based applications. Agents for Bedrock are a game changer, allowing LLMs to complete complex tasks based on your own data and APIs, privately, securely, with setup in minutes (no training or fine tuning required).
Today, we are excited to share new announcements that make it easier to bring generative AI to your organization:
- General availability of Amazon Bedrock to help even more customers build and scale generative AI applications
- Expanded model choice with Llama 2 (coming in the next few weeks) and Amazon Titan Embeddings gives customers greater choice and flexibility to find the right model for each use case and power RAG for better results
- Amazon Bedrock is a HIPAA eligible service and can be used in compliance with GDPR, allowing even more customers to benefit from generative AI.
- Provisioned throughput to ensure a consistent user experience even during peak traffic times
With the general availability of Amazon Bedrock, more customers will have access to Bedrock’s comprehensive capabilities. Customers can easily experiment with a variety of top FMs, customize them privately with their data using techniques such as fine tuning and RAG, and create managed agents that execute complex business tasks—from booking travel and processing insurance claims to creating ad campaigns and managing inventory—all without writing any code. Since Amazon Bedrock is serverless, customers don’t have to manage any infrastructure, and they can securely integrate and deploy generative AI capabilities into their applications using the AWS services they are already familiar with.
Second, model choice has been a cornerstone of what makes Amazon Bedrock a unique, differentiated service for our customers. This early in the adoption of generative AI, there is no single model that unlocks all the value of generative AI, and customers need the ability to work with a range of high-performing models. We are excited to announce the general availability of Amazon Titan Embeddings and coming in the next few weeks availability of Llama 2, Meta’s next generation large language model (LLM) – joining existing model providers AI21 Labs, Anthropic, Cohere, Stability AI, and Amazon in further expanding choice and flexibility for customers. Amazon Bedrock is the first fully managed generative AI service to offer Llama 2, Meta’s next-generation LLM, through a managed API. Llama 2 models come with significant improvements over the original Llama models, including being trained on 40% more data and having a longer context length of 4,000 tokens to work with larger documents. Optimized to provide a fast response on AWS infrastructure, the Llama 2 models available via Amazon Bedrock are ideal for dialogue use cases. Customers can now build generative AI applications powered by Llama 2 13B and 70B parameter models, without the need to set up and manage any infrastructure.
Amazon Titan FMs are a family of models created and pretrained by AWS on large datasets, making them powerful, general purpose capabilities built to support a variety of use cases. The first of these models generally available to customers, Amazon Titan Embeddings, is an LLM that converts text into numerical representations (known as embeddings) to power RAG use cases. FMs are well suited for a wide variety of tasks, but they can only respond to questions based on learnings from the training data and contextual information in a prompt, limiting their effectiveness when responses require timely knowledge or proprietary data. Data is the difference between a general generative AI application and one that truly knows your business and your customer. To augment FM responses with additional data, many organizations turn to RAG, a popular model-customization technique where an FM connects to a knowledge source that it can reference to augment its responses. To get started with RAG, customers first need access to an embedding model to convert their data into vectors that allow the FM to more easily understand the semantic meaning and relationships between data. Building an embeddings model requires massive amounts of data, resources, and ML expertise, putting RAG out of reach for many organizations. Amazon Titan Embeddings makes it easier for customers to get started with RAG to extend the power of any FM using their proprietary data. Amazon Titan Embeddings supports more than 25 languages and a context length of up to 8,192 tokens, making it well suited to work with single words, phrases, or entire documents based on the customer’s use case. The model returns output vectors of 1,536 dimensions, giving it a high degree of accuracy, while also optimizing for low-latency, cost-effective results. With new models and capabilities, it’s easy to use your organization’s data as a strategic asset to customize foundation models and build more differentiated experiences.
Third, because the data customers want to use for customization is such valuable IP, they need it to remain secure and private. With security and privacy built in since day one, Amazon Bedrock customers can trust that their data remains protected. None of the customer’s data is used to train the original base FMs. All data is encrypted at rest and in transit. And you can expect the same AWS access controls that you have with any other AWS service. Today, we are excited to build on this foundation and introduce new security and governance capabilities – Amazon Bedrock is now a HIPAA eligible service and can be used in compliance with GDPR, allowing even more customers to benefit from generative AI. New governance capabilities include integration with Amazon CloudWatch to track usage metrics and build customized dashboards and integration with AWS CloudTrail to monitor API activity and troubleshoot issues. These new governance and security capabilities help organizations unlock the potential of generative AI, even in highly regulated industries, and ensure that data remains protected.
Finally, certain periods of the year, like the holidays, are critical for customers to make sure their users can get uninterrupted service from applications powered by generative AI. During these periods, customers want to ensure their service is available to all of its customers regardless of the demand. Amazon Bedrock now allows customers to reserve throughput (in terms of tokens processed per minute) to maintain a consistent user experience even during peak traffic times.
Together, the new capabilities and models we announced today for Amazon Bedrock will accelerate how quickly enterprises can build more personalized applications and enhance employee productivity. In concert with our ongoing investments in ML infrastructure, Amazon Bedrock is the best place for customers to build and scale generative AI applications.
To help customers get started quickly with these new features, we are adding a new generative AI training for Amazon Bedrock to our collection of digital, on-demand training courses. Amazon Bedrock – Getting Started is a free, self-paced digital course that introduces learners to the service. This 60-minute course will introduce developers and technical audiences to Amazon Bedrock’s benefits, features, use cases, and technical concepts.
Announcing Amazon CodeWhisperer customization capability to generate more relevant code recommendations informed by your organization’s code base
At AWS, we are building powerful new applications that transform how our customers get work done with generative AI. In April 2023, we announced the general availability of Amazon CodeWhisperer, an AI coding companion that helps developers build software applications faster by providing code suggestions across 15 languages, based on natural language comments and code in a developer’s integrated developer environment (IDE). CodeWhisperer has been trained on billions of lines of publicly available code to help developers be more productive across a wide range of tasks. We have specially trained CodeWhisperer on high-quality Amazon code, including AWS APIs and best practices, to help developers be even faster and more accurate generating code that interacts with AWS services like Amazon Elastic Compute Cloud (Amazon EC2), Amazon Simple Storage Service (Amazon S3), and AWS Lambda. Customers from Accenture to Persistent to Bundesliga have been using CodeWhisperer to help make their developers more productive.
Many customers also want CodeWhisperer to include their own internal APIs, libraries, best practices, and architectural patterns in its suggestions, so they can speed up development even more. Today, AI coding companions are not able to include these APIs in their code suggestions because they are typically trained on publicly available code, and so aren’t aware of a company’s internal code. For example, to build a feature for an ecommerce website that lists items in a shopping cart, developers have to find and understand existing internal code, such as the API that provides the description of items, so they can display the description in the shopping cart. Without a coding companion capable of suggesting the correct, internal code for them, developers have to spend hours digging through their internal code base and documentation to complete their work. Even after developers are able to find the right resources, they have to spend more time reviewing the code to make sure it follows their company’s best practices.
Today, we are excited to announce a new Amazon CodeWhisperer customization capability, which enables CodeWhisperer to generate even better suggestions than before, because it can now include your internal APIs, libraries, best practices, and architectural patterns. This capability uses the latest model and context customization techniques and will be available in preview soon as part of a new CodeWhisperer Enterprise Tier. With this capability, you can securely connect your private repositories to CodeWhisperer, and with a few clicks, customize CodeWhisperer to generate real-time recommendations that include your internal code base. For example, with a CodeWhisperer customization, a developer working in a food delivery company can ask CodeWhisperer to provide recommendations that include specific code related to the company’s internal services, such as “Process a list of unassigned food deliveries around the driver’s current location.” Previously, CodeWhisperer would not know the correct internal APIs for “unassigned food deliveries” or “driver’s current location” because this isn’t publicly available information. Now, once customized on the company’s internal code base, CodeWhisperer understands the intent, determines which internal and public APIs are best suited to the task, and generates code recommendations for the developer. The CodeWhisperer customization capability can save developers hours spent searching and modifying sparsely documented code, and helps onboard developers who are new to the company faster.
In the following example, after creating a private customization, AnyCompany (a food delivery company) developers get CodeWhisperer code recommendations that include their internal APIs and libraries.

We conducted a recent study with Persistent, a global services and solutions company delivering digital engineering and enterprise modernization services to customers, to measure the productivity benefits of the CodeWhisperer customization capability. Persistent found that developers using the customization capability were able to complete their coding tasks up to 28% faster, on average, than developers using standard CodeWhisperer.
We designed this customization capability with privacy and security at the forefront. Administrators can easily manage access to a private customization from the AWS Management Console, so that only specific developers have access. Administrators can also ensure that only repositories that meet their standards are eligible for use in a CodeWhisperer customization. Using high-quality repositories helps CodeWhisperer make suggestions that promote security and code quality best practices. Each customization is completely isolated from other customers and none of the customizations built with this new capability will be used to train the FM underlying CodeWhisperer, protecting customers’ valuable intellectual property.
Announcing the preview of Generative BI authoring capabilities in Amazon QuickSight to help business analysts easily create and customize visuals using natural-language commands
AWS has been on a mission to democratize access to insights for all users in the organization. Amazon QuickSight, our unified business intelligence (BI) service built for the cloud, allows insights to be shared across all users in the organization. With QuickSight, we’ve been using generative models to power Amazon QuickSight Q, which enable any user to ask questions of their data using natural language, without having to write SQL queries or learn a BI tool, since 2020. In July 2023, we announced that we are furthering the early innovation in QuickSight Q with the new LLM capabilities to provide Generative BI capabilities in QuickSight. Current QuickSight customers like BMW Group and Traeger Grills are looking forward to further increasing productivity of their analysts using the Generative BI authoring experience.
Today, we are excited to make these LLM capabilities available in preview with Generative BI dashboard authoring capabilities for business analysts. The new Generative BI authoring capabilities extend the natural-language querying of QuickSight Q beyond answering well-structured questions (such as “what are the top 10 products sold in California?”) to help analysts quickly create customizable visuals from question fragments (such as “top 10 products”), clarify the intent of a query by asking follow-up questions, refine visualizations, and complete complex calculations. Business analysts simply describe the desired outcome, and QuickSight generates compelling visuals that can be easily added to a dashboard or report with a single click. QuickSight Q also offers related questions to help analysts clarify ambiguous cases when multiple data fields match their query. When the analyst has the initial visualization, they can add complex calculations, change chart types, and refine visuals using natural language prompts. The new Generative BI authoring capabilities in QuickSight Q make it fast and easy for business analysts to create compelling visuals and reduce the time to deliver the insights needed to inform data-driven decisions at scale.
Creating visuals using Generative BI capabilities in Amazon QuickSight
Generative AI tools and capabilities for every business
Today’s announcements open generative AI up to any customer. With enterprise-grade security and privacy, choice of leading FMs, a data-first approach, and a highly performant, cost-effective infrastructure, organizations trust AWS to power their innovations with generative AI solutions at every layer of the stack. We have seen exciting innovation from Bridgewater Associates to Omnicom to Rocket Mortgage, and with these new announcements, we look forward to new use cases and applications of the technology to boost productivity. This is just the beginning—across the technology stack, we are innovating with new services and capabilities built for your organization to help tackle some of your largest challenges and change how we work.
Resources
To learn more, check out the following resources:
- Explore generative AI on AWS
- Learn about Amazon Bedrock, the easiest way to build and scale generative AI applications with FMs
- Learn more about Llama2 on Amazon Bedrock
- Learn about Amazon Titan, high-performing FMs from Amazon to innovate responsibly
- Learn how you can use the Amazon CodeWhisperer customization capability
- Learn more about Generative BI features for QuickSight
- Discover generative AI solutions from AWS Partners in AWS Marketplace
About the author
 Swami Sivasubramanian is Vice President of Data and Machine Learning at AWS. In this role, Swami oversees all AWS Database, Analytics, and AI & Machine Learning services. His team’s mission is to help organizations put their data to work with a complete, end-to-end data solution to store, access, analyze, and visualize, and predict.
Swami Sivasubramanian is Vice President of Data and Machine Learning at AWS. In this role, Swami oversees all AWS Database, Analytics, and AI & Machine Learning services. His team’s mission is to help organizations put their data to work with a complete, end-to-end data solution to store, access, analyze, and visualize, and predict.
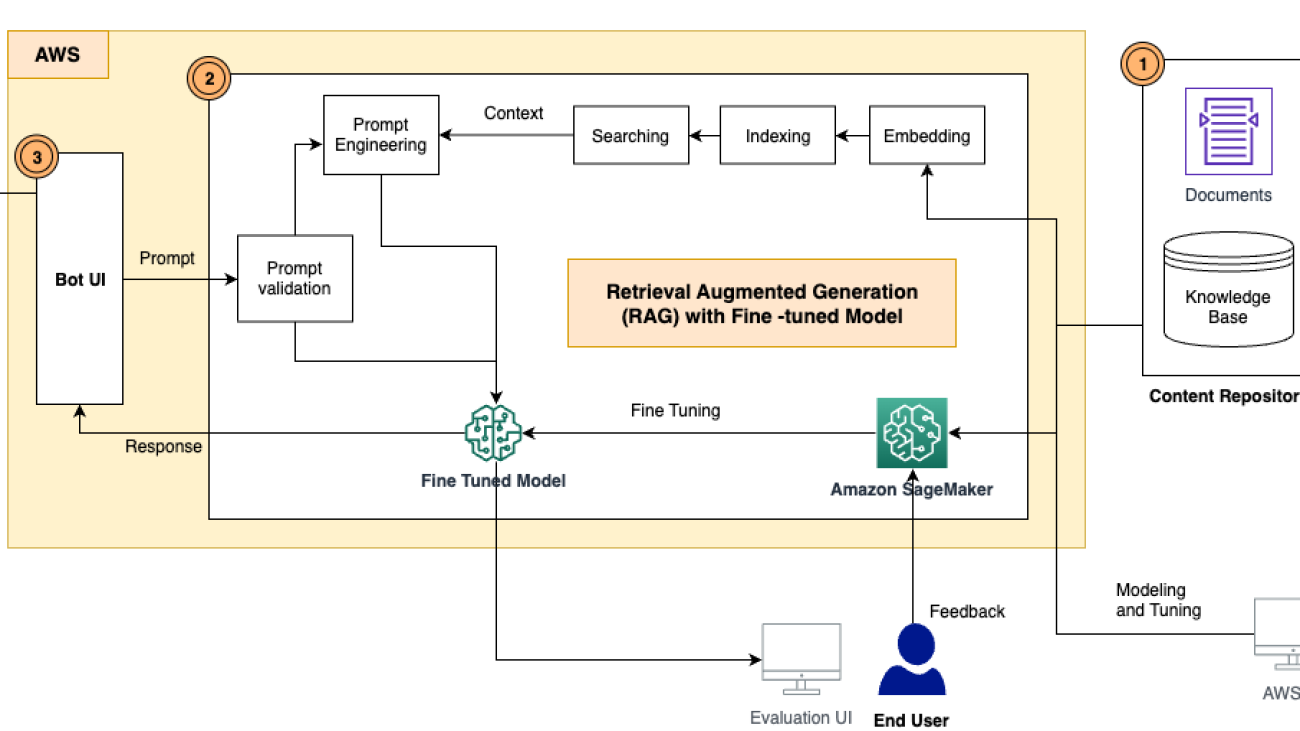
A generative AI-powered solution on Amazon SageMaker to help Amazon EU Design and Construction
The Amazon EU Design and Construction (Amazon D&C) team is the engineering team designing and constructing Amazon Warehouses across Europe and the MENA region. The design and deployment processes of projects involve many types of Requests for Information (RFIs) about engineering requirements regarding Amazon and project-specific guidelines. These requests range from simple retrieval of baseline design values, to review of value engineering proposals, to analysis of reports and compliance checks. Today, these are addressed by a Central Technical Team, comprised of subject matter experts (SMEs) who can answer such highly technical specialized questions, and provide this service to all stakeholders and teams throughout the project lifecycle. The team is looking for a generative AI question answering solution to quickly get information and proceed with their engineering design. Notably, these use cases are not limited to the Amazon D&C team alone but are applicable to the broader scope of Global Engineering Services involved in project deployment. The entire range of stakeholders and teams engaged in the project lifecycle can benefit from a generative AI question-answering solution, as it will enable quick access to critical information, streamlining the engineering design and project management processes.
The existing generative AI solutions for question answering are mainly based on Retrieval Augmented Generation (RAG). RAG searches documents through large language model (LLM) embedding and vectoring, creates the context from search results through clustering, and uses the context as an augmented prompt to inference a foundation model to get the answer. This method is less efficient for the highly technical documents from Amazon D&C, which contains significant unstructured data such as Excel sheets, tables, lists, figures, and images. In this case, the question answering task works better by fine-tuning the LLM with the documents. Fine-tuning adjusts and adapts the weights of the pre-trained LLM to improve the model quality and accuracy.
To address these challenges, we present a new framework with RAG and fine-tuned LLMs. The solution uses Amazon SageMaker JumpStart as the core service for the model fine-tuning and inference. In this post, we not only provide the solution, but also discuss the lessons learned and best practices when implementing the solution in real-world use cases. We compare and contrast how different methodologies and open-source LLMs performed in our use case and discuss how to find the trade-off between model performance and compute resource costs.
Solution overview
The solution has the following components, as shown in the architecture diagram:
- Content repository – The D&C contents include a wide range of human-readable documents with various formats, such as PDF files, Excel sheets, wiki pages, and more. In this solution, we stored these contents in an Amazon Simple Storage Service (Amazon S3) bucket and used them as a knowledge base for information retrieval as well as inference. In the future, we will build integration adapters to access the contents directly from where they live.
- RAG framework with a fine-tuned LLM – This consists of the following subcomponents:
- RAG framework – This retrieves the relevant data from documents, augments the prompts by adding the retrieved data in context, and passes it to a fine-tuned LLM to generate outputs.
- Fine-tuned LLM – We constructed the training dataset from the documents and contents and conducted fine-tuning on the foundation model. After the tuning, the model learned the knowledge from the D&C contents, and therefore can respond to the questions independently.
- Prompt validation module – This measures the semantic match between the user’s prompt and the dataset for fine-tuning. If the LLM is fine-tuned to answer this question, then you can inference the fine-tuned model for a response. If not, you can use RAG to generate the response.
- LangChain – We use LangChain to build a workflow to respond to the incoming questions.
- End-user UI – This is the chatbot UI to capture users’ questions and queries, and present the answer from the RAG and LLM response.

In the next sections, we demonstrate how to create the RAG workflow and build the fine-tuned models.
RAG with foundation models by SageMaker JumpStart
RAG combines the powers of pre-trained dense retrieval and sequence-to-sequence (seq2seq) foundation models. For question answering from Amazon D&C documents, we need to prepare the following in advance:
- Embedding and indexing the documents using an LLM embedding model – We split the multiple documents into small chunks based on the document chapter and section structure, tested with the Amazon GPT-J-6B model on SageMaker JumpStart to generate the indexes, and stored the indexes in a FAISS vector store
- A pre-trained foundation model to generate responses from prompts – We tested with Flan-T5 XL, Flan-T5 XXL, and Falcon-7B models on SageMaker JumpStart
The question answering process is implemented by LangChain, which is a framework for developing applications powered by language models. The workflow in the chain contains the following steps:
- Get a question from the user.
- Perform semantic search on the indexed documents through FAISS to get the top K most-relevant document chunks.
- Define the prompt template, such as
- Augment the retrieved document chunks as the
{context}and the user question as the{question}in the prompt. - Prompt the foundation model with the constructed zero-shot prompt.
- Return the model output to the user.
We tested 125 questions on Amazon D&C requirements and specifications, and RAG returned a good response for some questions. In the following example, RAG with the Flan-T5-XXL model provided accurate response from the right sections of the documents.
| Question | What are the PLUMBING requirements for Drinking Fountains and Water Coolers? (Section 22 47 00) |
| Expected answer | The Developer shall provide water dispensing bars, floor standing at the Warehouse wall space immediately adjacent to the entrance of each toilet block serving the Warehouse and in the equivalent location adjacent to the Lockers Room toilet block. Units shall be in accordance with Amazon standard. Final numbers and placement to be agreed with Amazon prior to installation. Minimum of two units dispensing cooled and room temperature water to be provided at each location. Water Coolers or Water Bars – The Developer shall provide potable water supplies as required for remote water coolers or water bars throughout the facility. The Developer shall provide water points, drainage and any electrical services required in the Break Rooms for the Water Bars which will be provided by the Catering Contractor. |
| RAG answer (GPT-J-6B embedding with Flan-T5-XXL) | The Developer shall provide water dispensing bars, floor standing at the Warehouse wall space immediately adjacent to the entrance of each toilet block serving the Warehouse and in the equivalent location adjacent to the Lockers Room toilet block. Units shall be in accordance with Amazon standard. Final numbers and placement to be agreed with Amazon prior to installation. Minimum of two units dispensing cooled and room temperature water to be provided at each location. Water Coolers or Water Bars – The Developer shall provide potable water supplies as required for remote water coolers or water bars throughout the facility. The Developer shall provide water points, drainage and any electrical services required in the Break Rooms for the Water Bars which will be provided by the Catering Contractor. |
However, we observed that RAG doesn’t provide clear and crisp answers to the questions that are more specific and highly technical, such as guidelines, numbers, and figures. As shown in the following example, when a technical dimension output is expected, RAG can’t provide the specific answer, mainly because the embedding and searching process can’t return a concise context.
| Question | What is the Floor Heights requirement for P2 First Floor level Concrete? |
| Expected answer | 7,50 m AFFL |
| RAG answer (GPT-J-6B embedding with Flan-T5-XXL) | P2 First Floor level Concrete |
This needs to be improved because hallucination is not tolerated due to the criticality of the consequences in this use case.
Fine-tune LLMs on SageMaker
To address this challenge and improve the response quality, we take a new approach to fine-tune the LLM model using the documents for a question answering task. The model will be trained to learn the corresponding knowledge from the documents directly. Unlike RAG, it’s not dependent on whether the documents are properly embedded and indexed, and whether the semantic search algorithm is effective enough to return the most relevant contents from the vector database.
To prepare the training dataset for fine-tuning, we extract the information from the D&C documents and construct the data in the following format:
- Instruction – Describes the task and provides partial prompt
- Input – Provides further context to be consolidated into the prompt
- Response – The output of the model
During the training process, we add an instruction key, input key, and response key to each part, combine them into the training prompt, and tokenize it. Then the data is fed to a trainer in SageMaker to generate the fine-tuned model.
To accelerate the training process and reduce the cost of compute resources, we employed Parameter Efficient Fine-Tuning (PEFT) with the Low-Rank Adaptation (LoRA) technique. PEFT allows us to only fine-tune a small number of extra model parameters, and LoRA represents the weight updates with two smaller matrices through low-rank decomposition. With PEFT and LoRA on 8-bit quantization (a compression operation that further reduces the memory footprint of the model and accelerates the training and inference performance), we are able to fit the training of 125 question-answer pairs within a g4dn.x instance with a single GPU.
To prove the effectiveness of the fine-tuning, we tested with multiple LLMs on SageMaker. We selected five small-size models: Bloom-7B, Flan-T5-XL, GPT-J-6B, and Falcon-7B on SageMaker JumpStart, and Dolly-3B from Hugging Face on SageMaker.
Through 8-bit LoRA-based training, we are able to reduce the trainable parameters to no more than 5% of the full weights of each model. The training takes 10–20 epochs to converge, as shown in the following figure. For each model, the fine-tuning processes can fit on a single GPU of a g4dn.x instance, which optimized the costs of compute resources.

Inference the fine-tuned model deployed on SageMaker
We deployed the fine-tuned model along with the RAG framework in a single GPU g4dn.x node on SageMaker and compared the inference results for the 125 questions. The model performance is measured by two metrics. One is the ROUGE (Recall-Oriented Understudy for Gisting Evaluation) score, a popular natural language processing (NLP) model evaluation method that calculates the quotient of the matching words under the total count of words in the reference sentence. The other is the semantic (textual) similarity score, which measures how close the meaning of two pieces of text meanings are by using a transformer model to encode sentences to get their embeddings, then using a cosine similarity metric to compute their similarity score. From the experiments, we can see these two metrics are fairly consistent in presenting the quality of answers to the questions.
In the following table and figure, we can see that the fine-tuned Falcon-7B model provides the best quality of answering, and the Flan-T5-XL and Dolly-3B models also generate accurate responses.
| . | RAG_GPT-J-6B_Flan-T5-XL | RAG_GPT-J-6B_Flan-T5-XXL | Fine-tuned Bloom-7B1 | Fine-tuned Flan-T5-XL | Fine-tuned GPT-J-6B | Fine-tuned Dolly-3B | Fine-tuned Falcon-7B |
| ROUGE Score | 0.1938 | 0.2747 | 0.3914 | 0.4977 | 0.3740 | 0.6991 | 0.9459 |
| Semantic Similarity Score | 0.4121 | 0.4786 | 0.5666 | 0.7205 | 0.5414 | 0.8147 | 0.9774 |

The following is one example answer from the models. RAG with the Flan-T5-XL model provided a highly hallucinated response, whereas the response from RAG with the larger Flan-T5-XXL model was more relevant but still not able to cover the full expected message. Comparatively, all the fine-tuned models (Flan-T5-XL, Dolly-3B, and Falcon-7B) were able to provide the most accurate response as the expected answer.
| Question | What are the requirements for Post Grinding Sealer/Hardener? (TS0004 – section 2.8) |
| Expected answer | A Lithium based sealer/hardener will be used post any grinding/sanding procedures undertaken on the AR Floor. Please refer to TGC /0007 AR Floor SCA Procedures. Alternatives will be considered but must be approved by Amazon and the Flooring Consultant. |
| Answer from RAG (GPT-J-6B embedding with Flan-T5-XL) | The Penetrating Concrete Hardener must be discussed at the pre-pour meeting and must be approved by the Flooring Consultant and Amazon |
| Answer from RAG (GPT-J-6B embedding with Flan-T5-XXL) | The proposed compound must be discussed at the pre – pour meeting and must be approved by the Flooring Consultant and Amazon. Alternatives will be considered but must be approved by Amazon and the Flooring Consultant. |
| Answer from fine-tuned Flan-T5-XL | A Lithium based sealer/hardener will be used post any grinding/sanding procedures undertaken on the AR Floor. Please refer to TGC /0007 AR Floor SCA Procedures. Alternatives will be considered but must be approved by Amazon and the Flooring Consultant. |
| Answer from fine-tuned Dolly-3B | A Lithium based sealer/hardener will be used post any grinding/sanding procedures undertaken on the AR Floor. Please refer to TGC /0007 AR Floor SCA Procedures. Alternatives will be considered but must be approved by Amazon and the Flooring Consultant. |
| Answer from fine-tuned Falcon-7B | A Lithium based sealer/hardener will be used post any grinding/sanding procedures undertaken on the AR Floor. Please refer to TGC /0007 AR Floor SCA Procedures. Alternatives will be considered but must be approved by Amazon and the Flooring Consultant. |
Solution prototype and outcome
We developed a prototype based on the presented architecture and conducted a proof of concept to demonstrate the outcome. To take advantage of both the RAG framework and the fine-tuned LLM, and also to reduce the hallucination, we first semantically validate the incoming question. If the question is among the training data for the fine-tuning (the fine-tuned model already has the knowledge to provide a high-quality answer), then we direct the question as a prompt to inference the fine-tuned model. Otherwise, the question goes through LangChain and gets the response from RAG. The following diagram illustrates this workflow.

We tested the architecture with a test dataset of 166 questions, which contains the 125 questions used to fine-tune the model and an additional 41 questions that the fine-tuned model wasn’t trained with. The RAG framework with the embedding model and fine-tuned Falcon-7B model provided high-quality results with a ROUGE score of 0.7898 and a semantic similarity score of 0.8781. As shown in the following examples, the framework is able to generate responses to users’ questions that are well matched with the D&C documents.
The following image is our first example document.

The following screenshot shows the bot output.

The bot is also able to respond with data from a table or list and display figures for the corresponding questions. For example, we use the following document.

The following screenshot shows the bot output.

We can also use a document with a figure, as in the following example.

The following screenshot shows the bot output with text and the figure.

The following screenshot shows the bot output with just the figure.

Lessons learned and best practices
Through the solution design and experiments with multiple LLMs, we learned how to ensure the quality and performance for the question answering task in a generative AI solution. We recommend the following best practices when you apply the solution to your question answering use cases:
- RAG provides reasonable responses to engineering questions. The performance is heavily dependent on document embedding and indexing. For highly unstructured documents, you may need some manual work to properly split and augment the documents before LLM embedding and indexing.
- The index search is important to determine the RAG final output. You should properly tune the search algorithm to achieve a good level of accuracy and ensure RAG generates more relevant responses.
- Fine-tuned LLMs are able to learn additional knowledge from highly technical and unstructured documents, and possess the knowledge within the model with no dependency on the documents after training. This is especially useful for use cases where hallucination is not tolerated.
- To ensure the quality of model response, the training dataset format for fine-tuning should utilize a properly defined, task-specific prompt template. The inference pipeline should follow the same template in order to generate human-like responses.
- LLMs often come with a substantial price tag and demand considerable resources and exorbitant costs. You can use PEFT and LoRA and quantization techniques to reduce the demand of compute power and avoid high training and inference costs.
- SageMaker JumpStart provides easy-to-access pre-trained LLMs for fine-tuning, inference, and deployment. It can significantly accelerate your generative AI solution design and implementation.
Conclusion
With the RAG framework and fine-tuned LLMs on SageMaker, we are able to provide human-like responses to users’ questions and prompts, thereby enabling users to efficiently retrieve accurate information from a large volume of highly unstructured and unorganized documents. We will continue to develop the solution, such as providing a higher level of contextual response from previous interactions, and further fine-tuning the models from human feedback.
Your feedback is always welcome; please leave your thoughts and questions in the comments section.
About the authors
 Yunfei Bai is a Senior Solutions Architect at AWS. With a background in AI/ML, data science, and analytics, Yunfei helps customers adopt AWS services to deliver business results. He designs AI/ML and data analytics solutions that overcome complex technical challenges and drive strategic objectives. Yunfei has a PhD in Electronic and Electrical Engineering. Outside of work, Yunfei enjoys reading and music.
Yunfei Bai is a Senior Solutions Architect at AWS. With a background in AI/ML, data science, and analytics, Yunfei helps customers adopt AWS services to deliver business results. He designs AI/ML and data analytics solutions that overcome complex technical challenges and drive strategic objectives. Yunfei has a PhD in Electronic and Electrical Engineering. Outside of work, Yunfei enjoys reading and music.
 Burak Gozluklu is a Principal ML Specialist Solutions Architect located in Boston, MA. Burak has over 15 years of industry experience in simulation modeling, data science, and ML technology. He helps global customers adopt AWS technologies and specifically AI/ML solutions to achieve their business objectives. Burak has a PhD in Aerospace Engineering from METU, an MS in Systems Engineering, and a post-doc in system dynamics from MIT in Cambridge, MA. Burak is passionate about yoga and meditation.
Burak Gozluklu is a Principal ML Specialist Solutions Architect located in Boston, MA. Burak has over 15 years of industry experience in simulation modeling, data science, and ML technology. He helps global customers adopt AWS technologies and specifically AI/ML solutions to achieve their business objectives. Burak has a PhD in Aerospace Engineering from METU, an MS in Systems Engineering, and a post-doc in system dynamics from MIT in Cambridge, MA. Burak is passionate about yoga and meditation.
![]() Elad Dwek is a Construction Technology Manager at Amazon. With a background in construction and project management, Elad helps teams adopt new technologies and data-based processes to deliver construction projects. He identifies needs and solutions, and facilitates the development of the bespoke attributes. Elad has an MBA and a BSc in Structural Engineering. Outside of work, Elad enjoys yoga, woodworking, and traveling with his family.
Elad Dwek is a Construction Technology Manager at Amazon. With a background in construction and project management, Elad helps teams adopt new technologies and data-based processes to deliver construction projects. He identifies needs and solutions, and facilitates the development of the bespoke attributes. Elad has an MBA and a BSc in Structural Engineering. Outside of work, Elad enjoys yoga, woodworking, and traveling with his family.
MDaudit uses AI to improve revenue outcomes for healthcare customers
MDaudit provides a cloud-based billing compliance and revenue integrity software as a service (SaaS) platform to more than 70,000 healthcare providers and 1,500 healthcare facilities, ensuring healthcare customers maintain regulatory compliance and retain revenue. Working with the top 60+ US healthcare networks, MDaudit needs to be able to scale its artificial intelligence (AI) capabilities to improve end-user productivity to meet growing demand and adapt to the changing healthcare landscape. MDaudit recognized that in order to meet its healthcare customers’ unique business challenges, it would benefit from automating its external auditing workflow (EAW) using AI to reduce dependencies on legacy IT frameworks and reduce manual activities needed to manage external payer audits. The end goal was to empower its customers to quickly respond to a large volume of external audit requests and improve revenue outcomes with AI-driven automation. MDaudit also recognized the opportunity to evolve its existing architecture into a solution that could scale with the growing demand for its EAW module.
In this post, we discuss MDaudit’s solution to this challenge, the benefits for their customers, and the architecture involved.
Solution overview
MDaudit built an intelligent document processing (IDP) solution, SmartScan.ai. The solution automates the extraction and formatting of data elements from unstructured PDFs that are part of the Additional Documentation Requests (ADR) service for Payment Review that customers of MDaudit receive from commercial and federal payers across the country.
Designed with client-level isolation at the document level, MDaudit customers start by uploading their ADR documents via a web portal to Amazon Simple Storage Service (Amazon S3).

This prompts an AWS Lambda function to initiate Amazon Textract. Using Amazon Textract for optical character recognition (OCR) to convert text images into machine-readable text, MDaudits’s SmartScan.ai can process scanned PDFs without manual review. The solution also uses Amazon Comprehend, which uses natural language processing (NLP) to identify and extract key entities from the ADR documents, such as name, date of birth, and date of service. The OCR extract from Amazon Textract and the output from Amazon Comprehend are then compared against preexisting configurations of data objects stored in Amazon DynamoDB. If the format isn’t recognized, the solution conducts a generalized search to extract relevant data points from the PDFs uploaded by the customer. The new configuration is then sent to the human-in-the-loop using Amazon Augmented AI (Amazon A2I). After the configuration has been approved, it’s stored and made available for future scans, thus enhancing security. By using Amazon CloudWatch in the solution, MDaudit monitors metrics, events, and logs throughout the end-to-end solution.
Benefits
In the post pandemic era, the healthcare sector is still grappling with financial hardships characterized by thin margins as a result of staffing shortages, reduced patient volumes and the upsurge in inflation. Simultaneously, Payer’s post payment recovery audits have skyrocketed by more than 900% and aggravating the situation further, Revenue cycle management (RCM) workforce reductions by 50-70% have put them in a precarious position to defend against the overwhelming impact of these post payment audits. The external audit workflow offered by MDaudit streamlines the management and response to external audits through automated workflows, successfully safeguarding millions of dollars in revenue. With the integration of AI-driven capabilities, using AWS AI/ML services, their innovative solution SmartScan.ai introduces further time savings and enhanced data accuracy by automatically extracting pertinent patient information from lengthy audit letters, which can vary from tens to hundreds of pages. As a result, customers are now capable of managing a much higher volume of demand letters from Payers, increasing their productivity by an estimated tenfold. These advancements lead to improved efficiencies, significant cost savings, faster response to external audits and the retention of revenue in a timely manner.
The Initial adaptation statistics indicate that the average processing time for an ADR letter is approximately 40 seconds, with accuracy rates approaching 90%. Within the first couple months of launching SmartScan.ai, MDaudit’s customers have successfully responded to the audit requests and safeguarded approximately $3 million in revenue.
Our approach to innovation centers on collaboration with our ecosystem partners, and AWS has proven to be a valuable strategic ally in our healthcare transformation mission.” says Nisheet Goenka, VP of Engineering at MDaudit. “Our close cooperation with AWS and our extended account team not only expedited the development process but also spared us four months of dedicated engineering efforts. This has resulted in the creation of a solution that provides us with meaningful data to support our Healthcare customers.”
Summary
This post discussed the unique business challenges faced by customers in the healthcare industry. We also reviewed how MDaudit is solving those challenges, the architecture MDaudit used, and how AI and machine learning played a part in their solution. To start exploring ML and AI today, refer to Machine Learning on AWS, and see where it can help you in your next solution.
About the Authors

Jake Bernstein is a Solutions Architect at Amazon Web Services with a passion for modernization and serverless first architecture. And a focus on helping customers optimize their architecture and accelerate their cloud journey.

Guy Loewy is a Senior Solutions Architect At Amazon Web Services with a focus on serverless and event driven architecture.

Justin Leto is a Senior Solutions Architect At Amazon Web Services with a focus on Machine Learning and Analytics.

Build and deploy ML inference applications from scratch using Amazon SageMaker
As machine learning (ML) goes mainstream and gains wider adoption, ML-powered inference applications are becoming increasingly common to solve a range of complex business problems. The solution to these complex business problems often requires using multiple ML models and steps. This post shows you how to build and host an ML application with custom containers on Amazon SageMaker.
Amazon SageMaker offers built-in algorithms and pre-built SageMaker docker images for model deployment. But, if these don’t fit your needs, you can bring your own containers (BYOC) for hosting on Amazon SageMaker.
There are several use cases where users might need to BYOC for hosting on Amazon SageMaker.
- Custom ML frameworks or libraries: If you plan on using a ML framework or libraries that aren’t supported by Amazon SageMaker built-in algorithms or pre-built containers, then you’ll need to create a custom container.
- Specialized models: For certain domains or industries, you may require specific model architectures or tailored preprocessing steps that aren’t available in built-in Amazon SageMaker offerings.
- Proprietary algorithms: If you’ve developed your own proprietary algorithms inhouse, then you’ll need a custom container to deploy them on Amazon SageMaker.
- Complex inference pipelines: If your ML inference workflow involves custom business logic — a series of complex steps that need to be executed in a particular order — then BYOC can help you manage and orchestrate these steps more efficiently.
Solution overview
In this solution, we show how to host a ML serial inference application on Amazon SageMaker with real-time endpoints using two custom inference containers with latest scikit-learn and xgboost packages.
The first container uses a scikit-learn model to transform raw data into featurized columns. It applies StandardScaler for numerical columns and OneHotEncoder to categorical ones.

The second container hosts a pretrained XGboost model (i.e., predictor). The predictor model accepts the featurized input and outputs predictions.

Lastly, we deploy the featurizer and predictor in a serial-inference pipeline to an Amazon SageMaker real-time endpoint.
Here are few different considerations as to why you may want to have separate containers within your inference application.
- Decoupling – Various steps of the pipeline have a clearly defined purpose and need to be run on separate containers due to the underlying dependencies involved. This also helps keep the pipeline well structured.
- Frameworks – Various steps of the pipeline use specific fit-for-purpose frameworks (such as scikit or Spark ML) and therefore need to be run on separate containers.
- Resource isolation – Various steps of the pipeline have varying resource consumption requirements and therefore need to be run on separate containers for more flexibility and control.
- Maintenance and upgrades – From an operational standpoint, this promotes functional isolation and you can continue to upgrade or modify individual steps much more easily, without affecting other models.
Additionally, local build of the individual containers helps in the iterative process of development and testing with favorite tools and Integrated Development Environments (IDEs). Once the containers are ready, you can use deploy them to the AWS cloud for inference using Amazon SageMaker endpoints.
Full implementation, including code snippets, is available in this Github repository here.
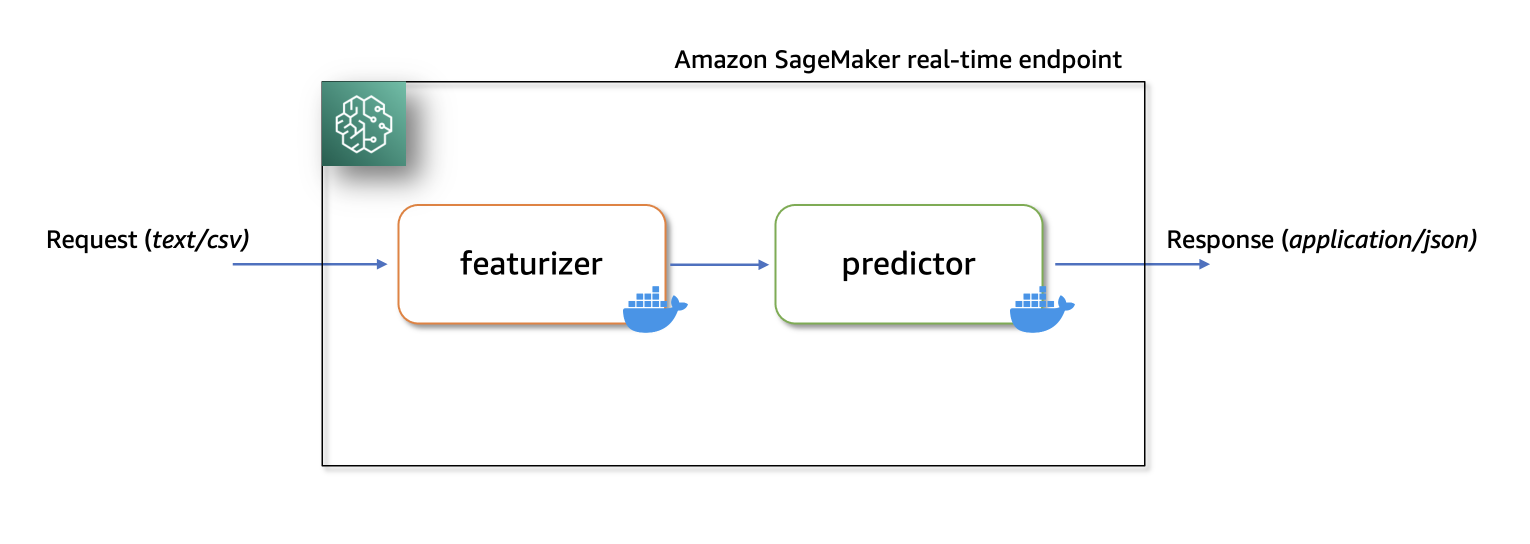
Prerequisites
As we test these custom containers locally first, we’ll need docker desktop installed on your local computer. You should be familiar with building docker containers.
You’ll also need an AWS account with access to Amazon SageMaker, Amazon ECR and Amazon S3 to test this application end-to-end.
Ensure you have the latest version of Boto3 and the Amazon SageMaker Python packages installed:
Solution Walkthrough
Build custom featurizer container
To build the first container, the featurizer container, we train a scikit-learn model to process raw features in the abalone dataset. The preprocessing script uses SimpleImputer for handling missing values, StandardScaler for normalizing numerical columns, and OneHotEncoder for transforming categorical columns. After fitting the transformer, we save the model in joblib format. We then compress and upload this saved model artifact to an Amazon Simple Storage Service (Amazon S3) bucket.
Here’s a sample code snippet that demonstrates this. Refer to featurizer.ipynb for full implementation:
Next, to create a custom inference container for the featurizer model, we build a Docker image with nginx, gunicorn, flask packages, along with other required dependencies for the featurizer model.
Nginx, gunicorn and the Flask app will serve as the model serving stack on Amazon SageMaker real-time endpoints.
When bringing custom containers for hosting on Amazon SageMaker, we need to ensure that the inference script performs the following tasks after being launched inside the container:
- Model loading: Inference script (
preprocessing.py) should refer to/opt/ml/modeldirectory to load the model in the container. Model artifacts in Amazon S3 will be downloaded and mounted onto the container at the path/opt/ml/model. - Environment variables: To pass custom environment variables to the container, you must specify them during the Model creation step or during Endpoint creation from a training job.
- API requirements: The Inference script must implement both
/pingand/invocationsroutes as a Flask application. The/pingAPI is used for health checks, while the/invocationsAPI handles inference requests. - Logging: Output logs in the inference script must be written to standard output (stdout) and standard error (stderr) streams. These logs are then streamed to Amazon CloudWatch by Amazon SageMaker.
Here’s a snippet from preprocessing.py that show the implementation of /ping and /invocations.
Refer to preprocessing.py under the featurizer folder for full implementation.
Build Docker image with featurizer and model serving stack
Let’s now build a Dockerfile using a custom base image and install required dependencies.
For this, we use python:3.9-slim-buster as the base image. You can change this any other base image relevant to your use case.
We then copy the nginx configuration, gunicorn’s web server gateway file, and the inference script to the container. We also create a python script called serve that launches nginx and gunicorn processes in the background and sets the inference script (i.e., preprocessing.py Flask application) as the entry point for the container.
Here’s a snippet of the Dockerfile for hosting the featurizer model. For full implementation refer to Dockerfile under featurizer folder.
Test custom inference image with featurizer locally
Now, build and test the custom inference container with featurizer locally, using Amazon SageMaker local mode. Local mode is perfect for testing your processing, training, and inference scripts without launching any jobs on Amazon SageMaker. After confirming the results of your local tests, you can easily adapt the training and inference scripts for deployment on Amazon SageMaker with minimal changes.
To test the featurizer custom image locally, first build the image using the previously defined Dockerfile. Then, launch a container by mounting the directory containing the featurizer model (preprocess.joblib) to the /opt/ml/model directory inside the container. Additionally, map port 8080 from container to the host.
Once launched, you can send inference requests to http://localhost:8080/invocations.
To build and launch the container, open a terminal and run the following commands.
Note that you should replace the <IMAGE_NAME>, as shown in the following code, with the image name of your container.
The following command also assumes that the trained scikit-learn model (preprocess.joblib) is present under a directory called models.
After the container is up and running, we can test both the /ping and /invocations routes using curl commands.
Run the below commands from a terminal
When raw (untransformed) data is sent to http://localhost:8080/invocations, the endpoint responds with transformed data.
You should see response something similar to the following:
We now terminate the running container, and then tag and push the local custom image to a private Amazon Elastic Container Registry (Amazon ECR) repository.
See the following commands to login to Amazon ECR, which tags the local image with full Amazon ECR image path and then push the image to Amazon ECR. Ensure you replace region and account variables to match your environment.
Refer to create a repository and push an image to Amazon ECR AWS Command Line Interface (AWS CLI) commands for more information.
Optional step
Optionally, you could perform a live test by deploying the featurizer model to a real-time endpoint with the custom docker image in Amazon ECR. Refer to featurizer.ipynb notebook for full implementation of buiding, testing, and pushing the custom image to Amazon ECR.
Amazon SageMaker initializes the inference endpoint and copies the model artifacts to the /opt/ml/model directory inside the container. See How SageMaker Loads your Model artifacts.
Build custom XGBoost predictor container
For building the XGBoost inference container we follow similar steps as we did while building the image for featurizer container:
- Download pre-trained
XGBoostmodel from Amazon S3. - Create the
inference.pyscript that loads the pretrainedXGBoostmodel, converts the transformed input data received from featurizer, and converts toXGBoost.DMatrixformat, runspredicton the booster, and returns predictions in json format. - Scripts and configuration files that form the model serving stack (i.e.,
nginx.conf,wsgi.py, andserveremain the same and needs no modification. - We use
Ubuntu:18.04as the base image for the Dockerfile. This isn’t a prerequisite. We use the ubuntu base image to demonstrate that containers can be built with any base image. - The steps for building the customer docker image, testing the image locally, and pushing the tested image to Amazon ECR remain the same as before.
For brevity, as the steps are similar shown previously; however, we only show the changed coding in the following.
First, the inference.py script. Here’s a snippet that show the implementation of /ping and /invocations. Refer to inference.py under the predictor folder for full implementation of this file.
Here’s a snippet of the Dockerfile for hosting the predictor model. For full implementation refer to Dockerfile under predictor folder.
We then continue to build, test, and push this custom predictor image to a private repository in Amazon ECR. Refer to predictor.ipynb notebook for full implementation of building, testing and pushing the custom image to Amazon ECR.
Deploy serial inference pipeline
After we have tested both the featurizer and predictor images and have pushed them to Amazon ECR, we now upload our model artifacts to an Amazon S3 bucket.
Then, we create two model objects: one for the featurizer (i.e., preprocess.joblib) and other for the predictor (i.e., xgboost-model) by specifying the custom image uri we built earlier.
Here’s a snippet that shows that. Refer to serial-inference-pipeline.ipynb for full implementation.
Now, to deploy these containers in a serial fashion, we first create a PipelineModel object and pass the featurizer model and the predictor model to a python list object in the same order.
Then, we call the .deploy() method on the PipelineModel specifying the instance type and instance count.
At this stage, Amazon SageMaker deploys the serial inference pipeline to a real-time endpoint. We wait for the endpoint to be InService.
We can now test the endpoint by sending some inference requests to this live endpoint.
Refer to serial-inference-pipeline.ipynb for full implementation.
Clean up
After you are done testing, please follow the instructions in the cleanup section of the notebook to delete the resources provisioned in this post to avoid unnecessary charges. Refer to Amazon SageMaker Pricing for details on the cost of the inference instances.
Conclusion
In this post, I showed how we can build and deploy a serial ML inference application using custom inference containers to real-time endpoints on Amazon SageMaker.
This solution demonstrates how customers can bring their own custom containers for hosting on Amazon SageMaker in a cost-efficient manner. With BYOC option, customers can quickly build and adapt their ML applications to be deployed on to Amazon SageMaker.
We encourage you to try this solution with a dataset relevant to your business Key Performance Indicators (KPIs). You can refer to the entire solution in this GitHub repository.
References
- Model hosting patterns in Amazon SageMaker
- Amazon SageMaker Bring your own containers
- Hosting models as serial inference pipeline on Amazon SageMaker
About the Author
 Praveen Chamarthi is a Senior AI/ML Specialist with Amazon Web Services. He is passionate about AI/ML and all things AWS. He helps customers across the Americas to scale, innovate, and operate ML workloads efficiently on AWS. In his spare time, Praveen loves to read and enjoys sci-fi movies.
Praveen Chamarthi is a Senior AI/ML Specialist with Amazon Web Services. He is passionate about AI/ML and all things AWS. He helps customers across the Americas to scale, innovate, and operate ML workloads efficiently on AWS. In his spare time, Praveen loves to read and enjoys sci-fi movies.