 A recap of the some of the biggest scientific breakthroughs over the past two years.Read More
A recap of the some of the biggest scientific breakthroughs over the past two years.Read More

A recap of the some of the biggest scientific breakthroughs over the past two years.Read More

 Google is committed to make benefits of AI more accessible and inclusive for everyone in the Middle East and North Africa.Read More
Google is committed to make benefits of AI more accessible and inclusive for everyone in the Middle East and North Africa.Read More

 We’re expanding flood forecasting to over 100 countries and making our breakthrough AI model available to researchers and partners.Read More
We’re expanding flood forecasting to over 100 countries and making our breakthrough AI model available to researchers and partners.Read More
 Here are 7 of Google’s latest AI updates from October.Read More
Here are 7 of Google’s latest AI updates from October.Read More
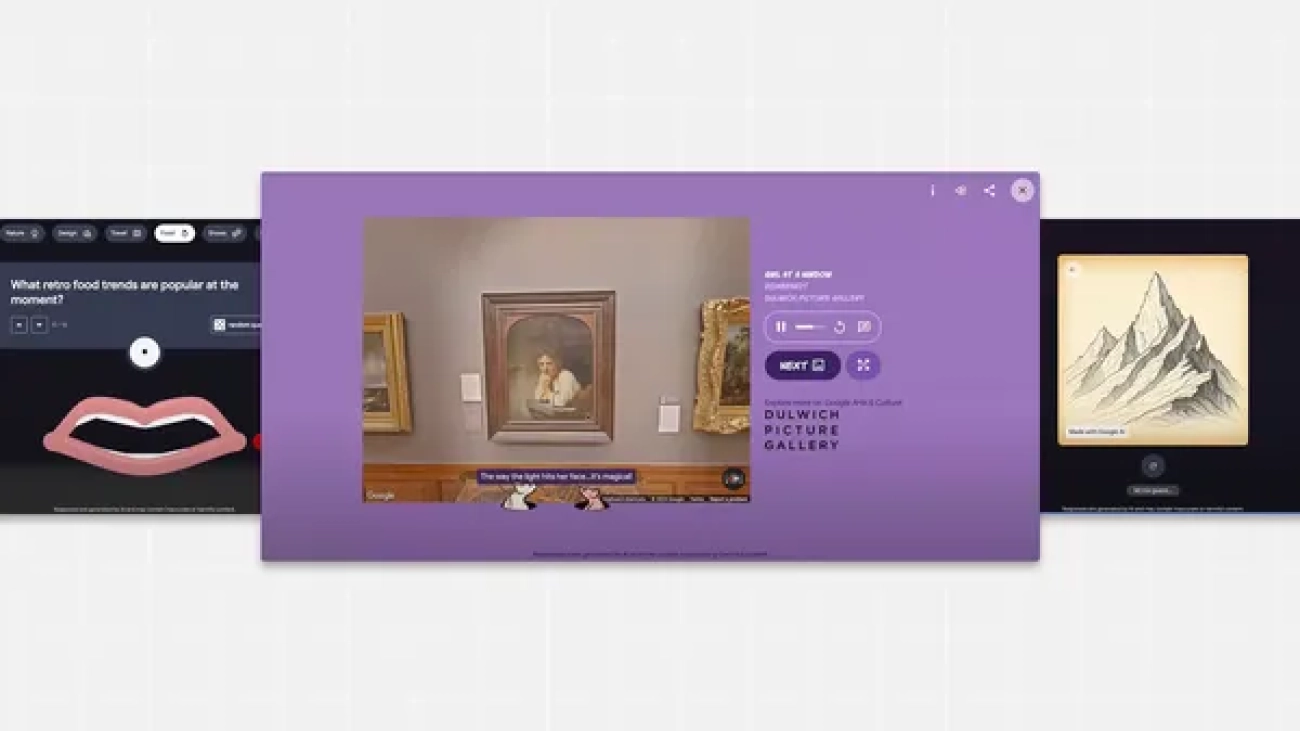
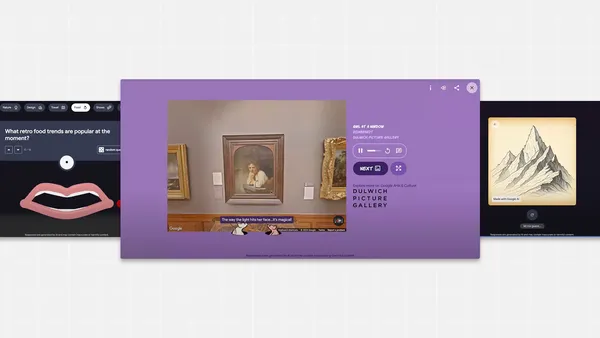 Here are four AI voice models from Google Arts & Culture that offer a new way to experience and engage with art, history and culture.Read More
Here are four AI voice models from Google Arts & Culture that offer a new way to experience and engage with art, history and culture.Read More
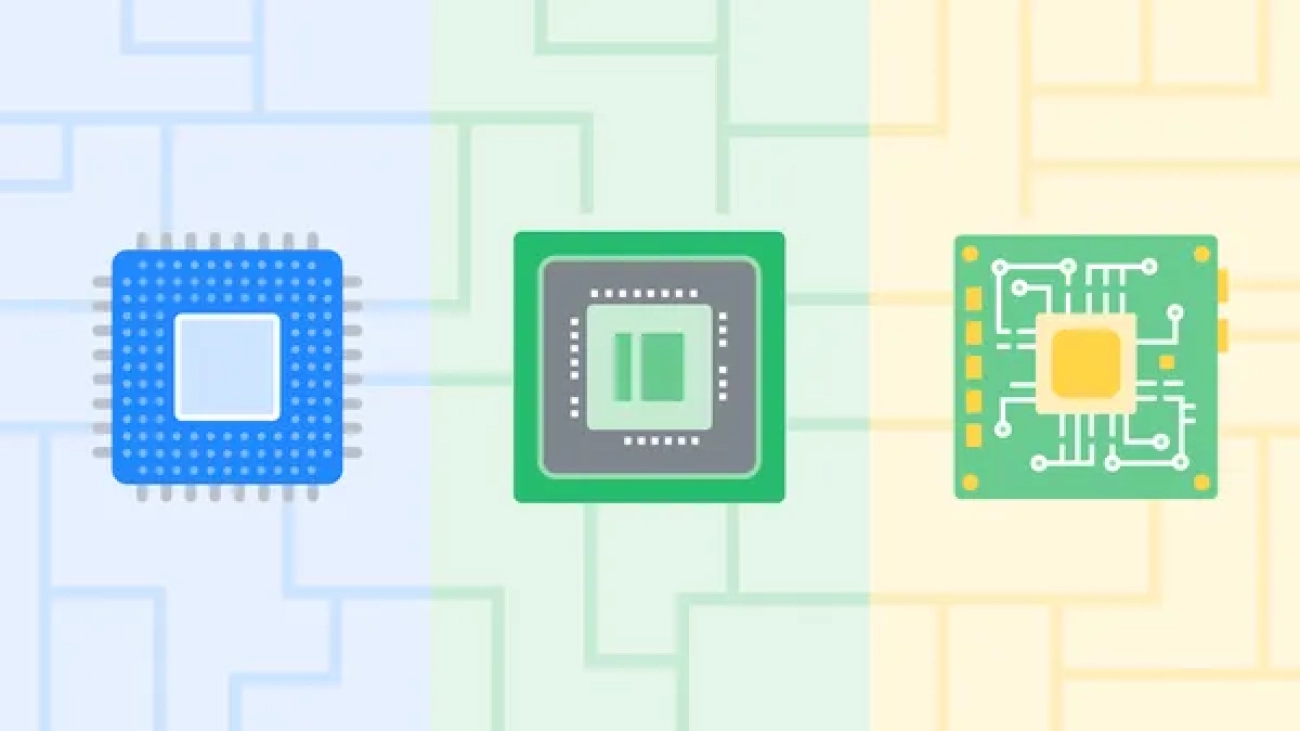
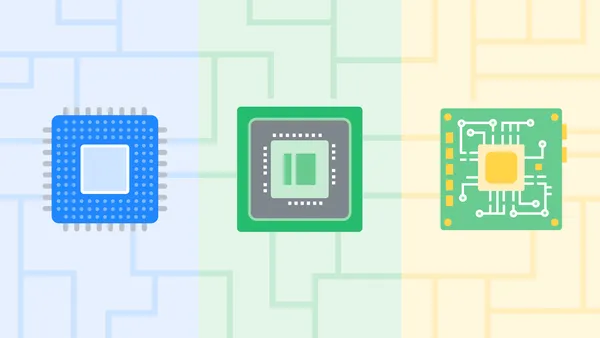 Learn more from a Google expert about CPUs, GPUs and TPUs — and Google latest TPU, Trillium.Read More
Learn more from a Google expert about CPUs, GPUs and TPUs — and Google latest TPU, Trillium.Read More
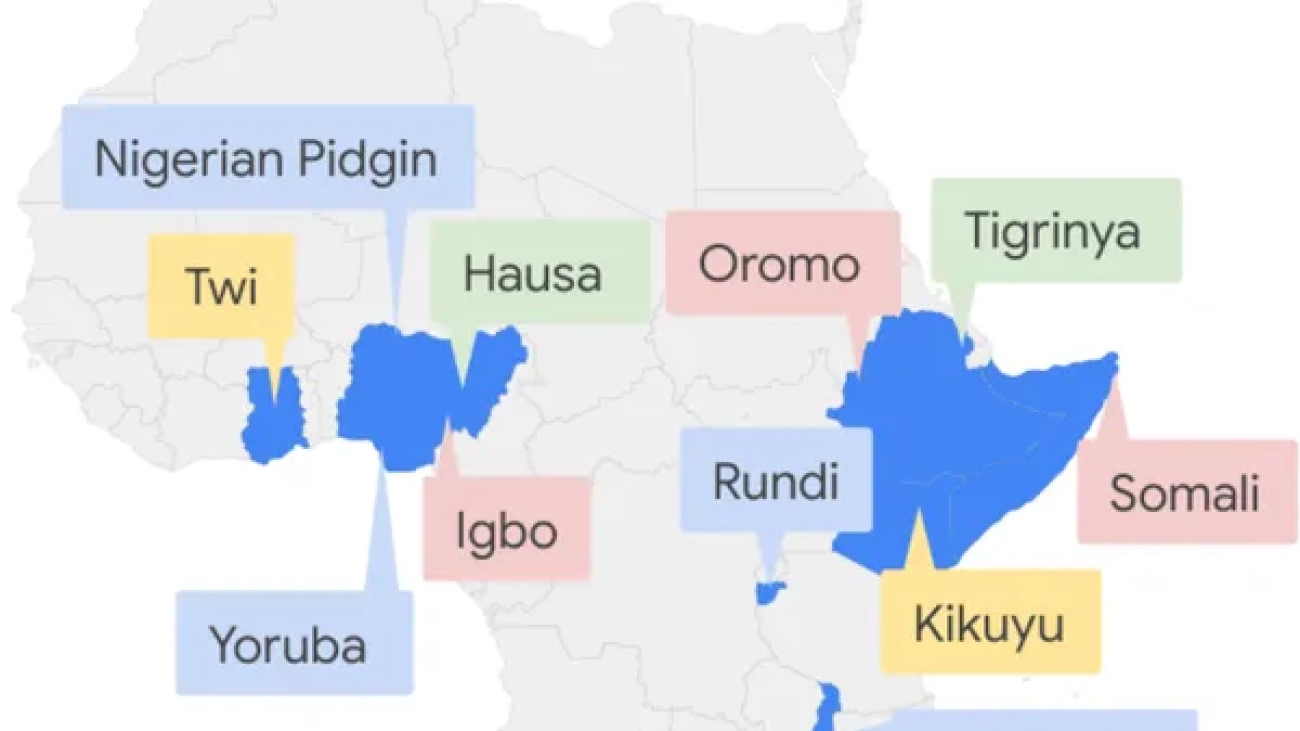
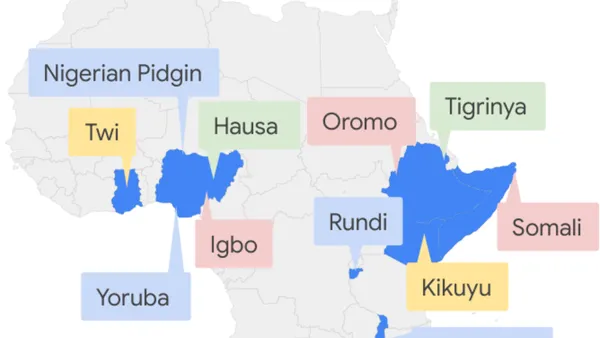 As Sub-Saharan Africa looks to its ‘digital decade’, President of Google EMEA Matt Brittin discusses the big opportunities and some new announcements from Google.Read More
As Sub-Saharan Africa looks to its ‘digital decade’, President of Google EMEA Matt Brittin discusses the big opportunities and some new announcements from Google.Read More

 Google Labs worked with Jacob Collier to improve and simplify MusicFX DJ.Read More
Google Labs worked with Jacob Collier to improve and simplify MusicFX DJ.Read More
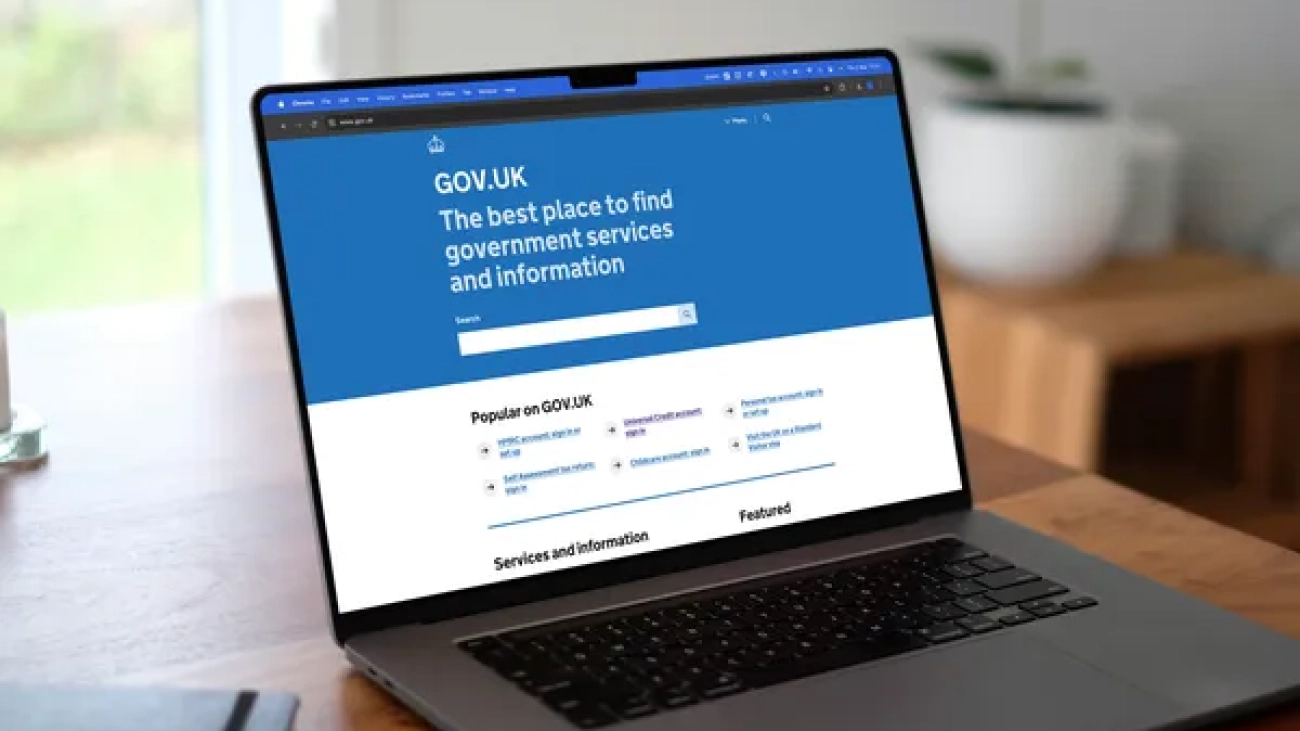
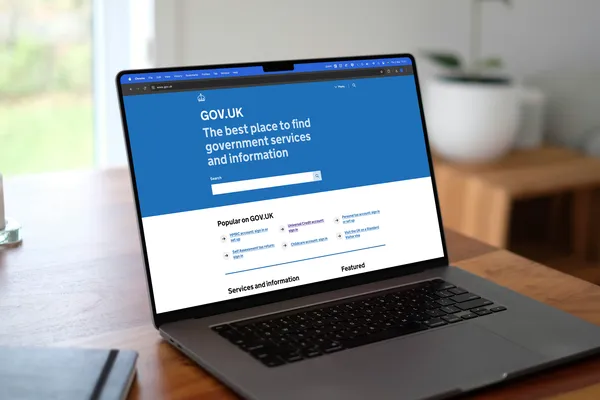 GOV.UK, the official website of the UK government, partnered with consultancy Kin + Carta and Google Cloud to improve its user experience and transform its search engine…Read More
GOV.UK, the official website of the UK government, partnered with consultancy Kin + Carta and Google Cloud to improve its user experience and transform its search engine…Read More
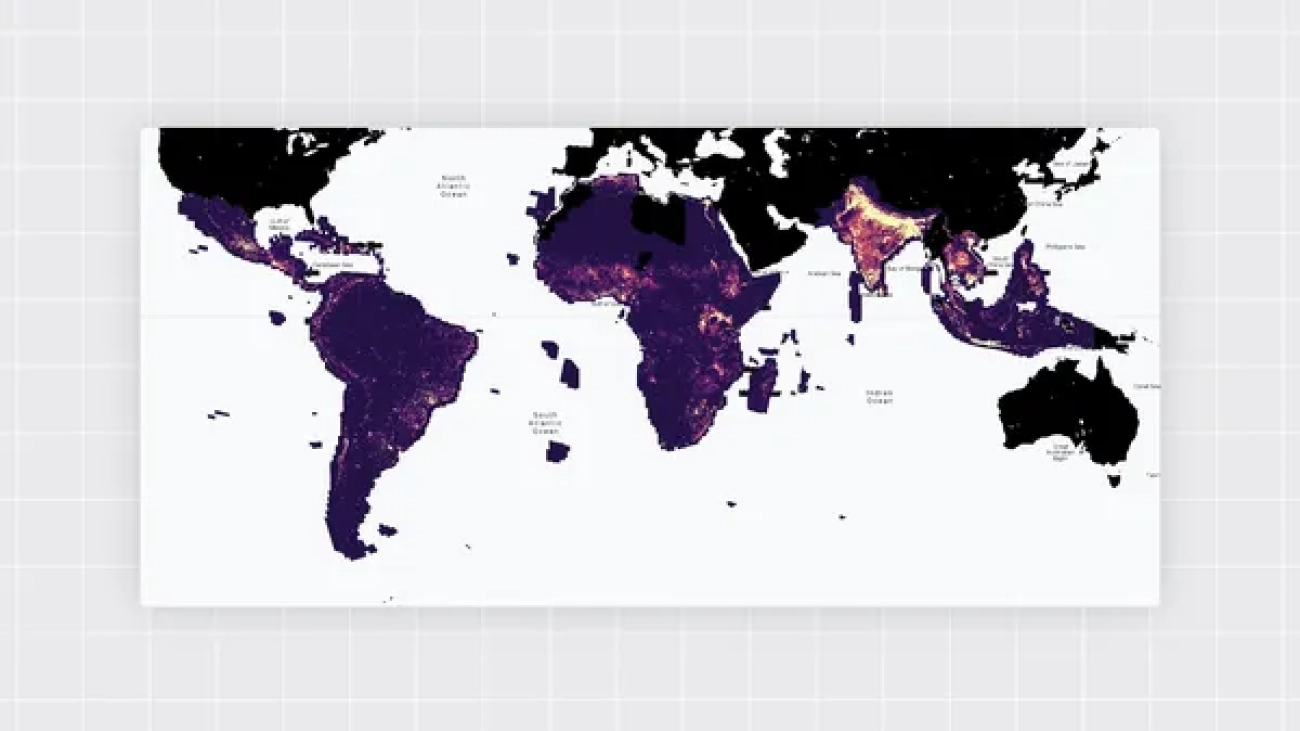
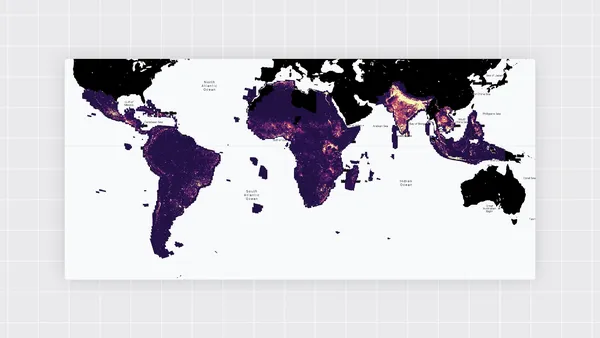 Google’s Open Buildings 2.5D Temporal Dataset is helping to fill a major gap in data for population and density in the developing world.Read More
Google’s Open Buildings 2.5D Temporal Dataset is helping to fill a major gap in data for population and density in the developing world.Read More