 Google’s Be Internet Legends programme launches a new school assembly teaching about AI literacy and online safety.Read More
Google’s Be Internet Legends programme launches a new school assembly teaching about AI literacy and online safety.Read More

Google’s Be Internet Legends programme launches a new school assembly teaching about AI literacy and online safety.Read More

 NotebookLM is an AI-powered tool for more deeply understanding something — we asked a Google expert to give us a few tips on how to use it.Read More
NotebookLM is an AI-powered tool for more deeply understanding something — we asked a Google expert to give us a few tips on how to use it.Read More

 NotebookLM is piloting a way for teams to collaborate, and introducing a new way to customize Audio Overviews.Read More
NotebookLM is piloting a way for teams to collaborate, and introducing a new way to customize Audio Overviews.Read More

 A study published by Google Cloud and Harris Poll sheds light on healthcare’s administrative burden, and how AI can help.Read More
A study published by Google Cloud and Harris Poll sheds light on healthcare’s administrative burden, and how AI can help.Read More

 These new grants to the Partnership for Public Service and InnovateUS will help public sector workers develop responsible AI skills.Read More
These new grants to the Partnership for Public Service and InnovateUS will help public sector workers develop responsible AI skills.Read More
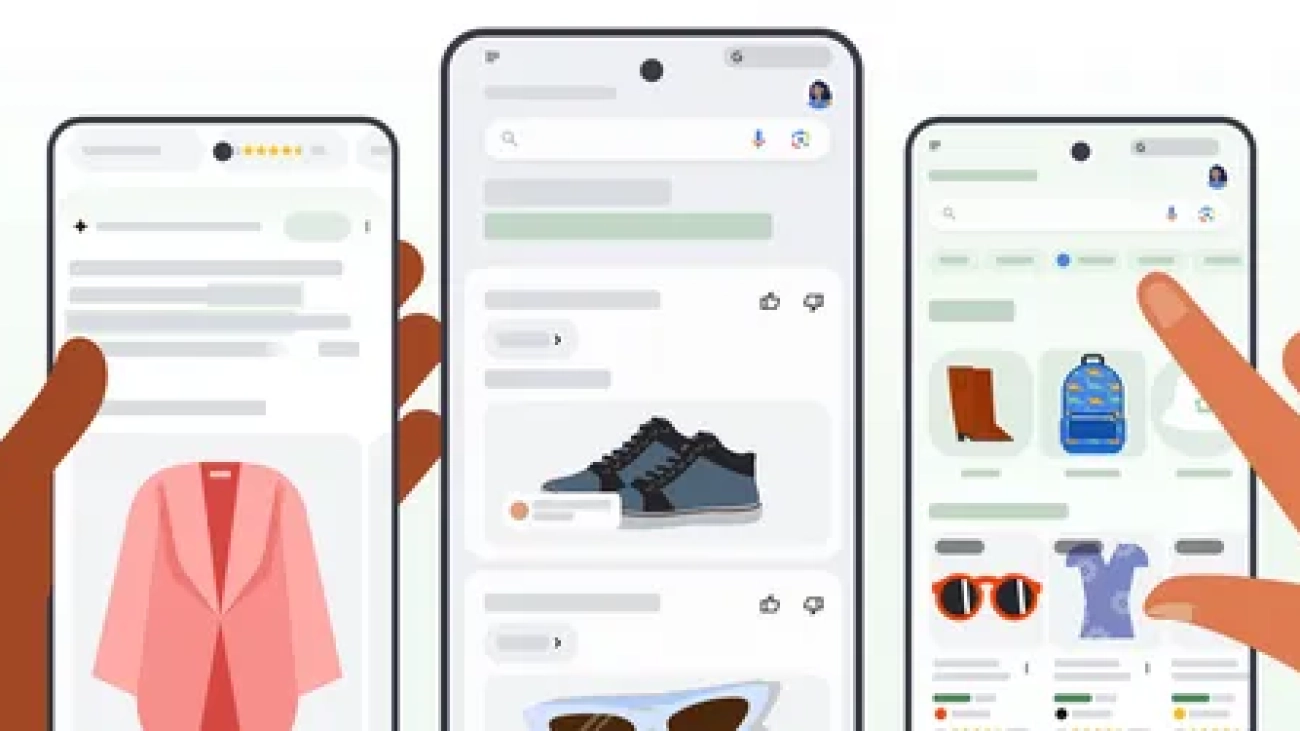
 Google Shopping uses AI to help you find more relevant products, discover personalized options and find the lowest prices.Read More
Google Shopping uses AI to help you find more relevant products, discover personalized options and find the lowest prices.Read More

 Here’s a breakdown of on-device processing and how we’re working to make your devices better with local AI features.Read More
Here’s a breakdown of on-device processing and how we’re working to make your devices better with local AI features.Read More

 Learn how startups in Growth Academy: AI for Health program are leveraging tech to improve access to care, personalize treatment, and enhance the effectiveness of therap…Read More
Learn how startups in Growth Academy: AI for Health program are leveraging tech to improve access to care, personalize treatment, and enhance the effectiveness of therap…Read More
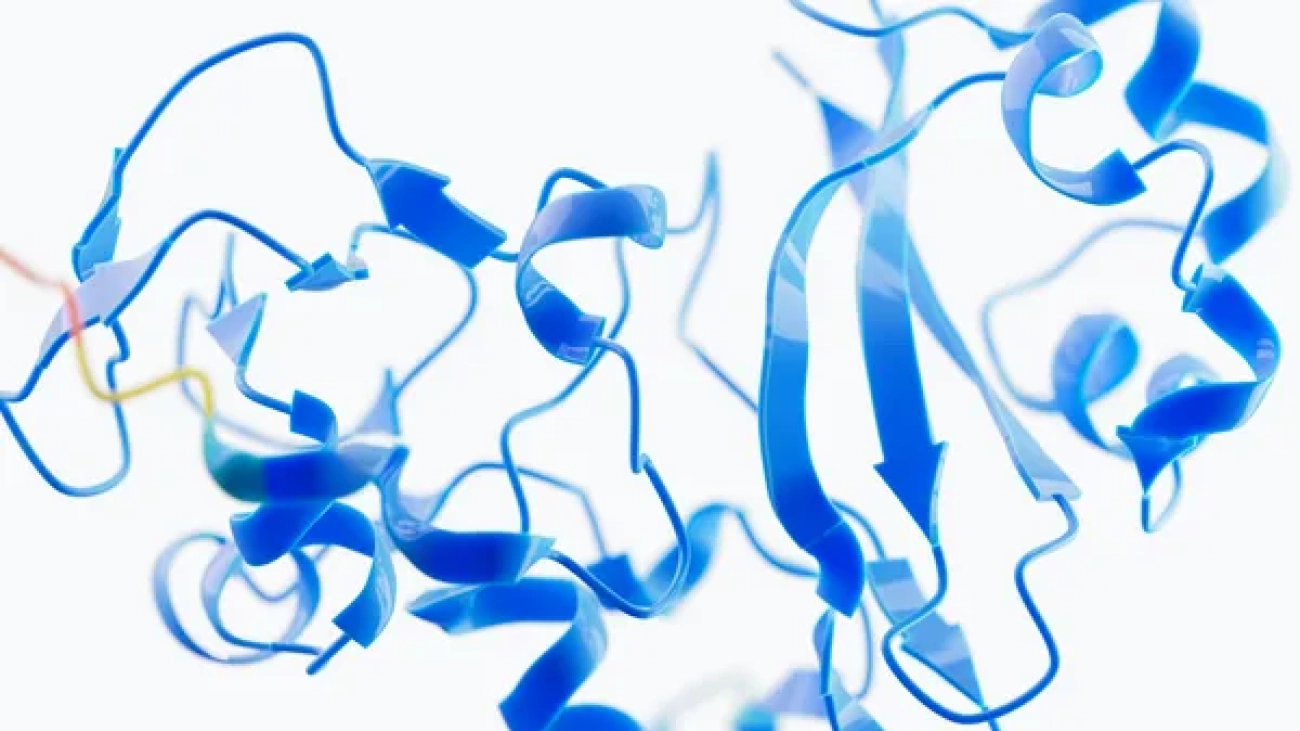
 The award is for their work on AlphaFold, a groundbreaking AI system that predicts the 3D structure of proteins from their amino acid sequences.Read More
The award is for their work on AlphaFold, a groundbreaking AI system that predicts the 3D structure of proteins from their amino acid sequences.Read More

 Starting next month Google Cloud will expand our data residency commitment, enabling customers to conduct machine learning processing for Gemini 1.5 Flash within the UK.Read More
Starting next month Google Cloud will expand our data residency commitment, enabling customers to conduct machine learning processing for Gemini 1.5 Flash within the UK.Read More