 Four artists use Google DeepMind’s AI to reimagine the visual world of “Alice’s Adventures in Wonderland.”Read More
Four artists use Google DeepMind’s AI to reimagine the visual world of “Alice’s Adventures in Wonderland.”Read More

Four artists use Google DeepMind’s AI to reimagine the visual world of “Alice’s Adventures in Wonderland.”Read More
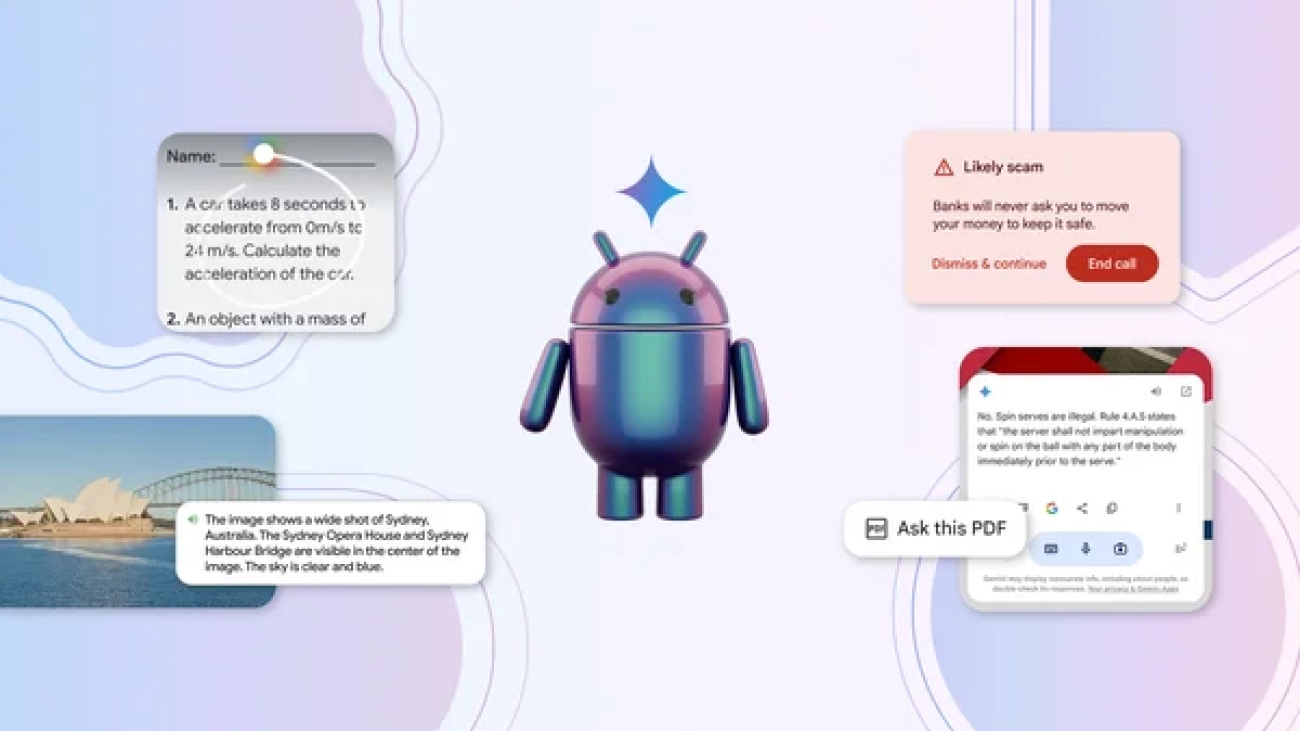
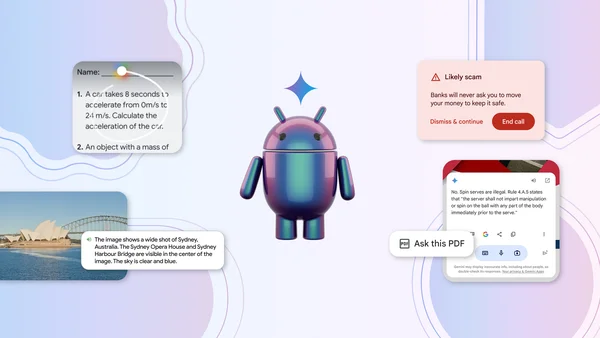 Here’s more ways you can experience Google AI on Android. Learn how on-device AI is changing what your phone can do.Read More
Here’s more ways you can experience Google AI on Android. Learn how on-device AI is changing what your phone can do.Read More

 Today we’re introducing VideoFX, plus new features for ImageFX and MusicFX that are now available in 110 countries.Read More
Today we’re introducing VideoFX, plus new features for ImageFX and MusicFX that are now available in 110 countries.Read More

 Get more done across Workspace with Gemini 1.5 Pro in the side panel and new features in the Gmail mobile app.Read More
Get more done across Workspace with Gemini 1.5 Pro in the side panel and new features in the Gmail mobile app.Read More

 Today we’re updating Gemini 1.5 Pro, introducing 1.5 Flash, rolling out new Gemini API features and adding two new Gemma models.Read More
Today we’re updating Gemini 1.5 Pro, introducing 1.5 Flash, rolling out new Gemini API features and adding two new Gemma models.Read More

 We introduced Veo for video generation, Imagen 3 for image generation, and released demos recordings from our AI music collaborations.Read More
We introduced Veo for video generation, Imagen 3 for image generation, and released demos recordings from our AI music collaborations.Read More

 We’re announcing new AI safeguards and new tools that use AI to make learning more engaging and accessible.Read More
We’re announcing new AI safeguards and new tools that use AI to make learning more engaging and accessible.Read More
 We’re sharing updates across our Gemini family of models and a glimpse of Project Astra, our vision for the future of AI assistants.Read More
We’re sharing updates across our Gemini family of models and a glimpse of Project Astra, our vision for the future of AI assistants.Read More

 LearnLM is our new Gemini-based family of models for better learning and teaching experiences.Read More
LearnLM is our new Gemini-based family of models for better learning and teaching experiences.Read More
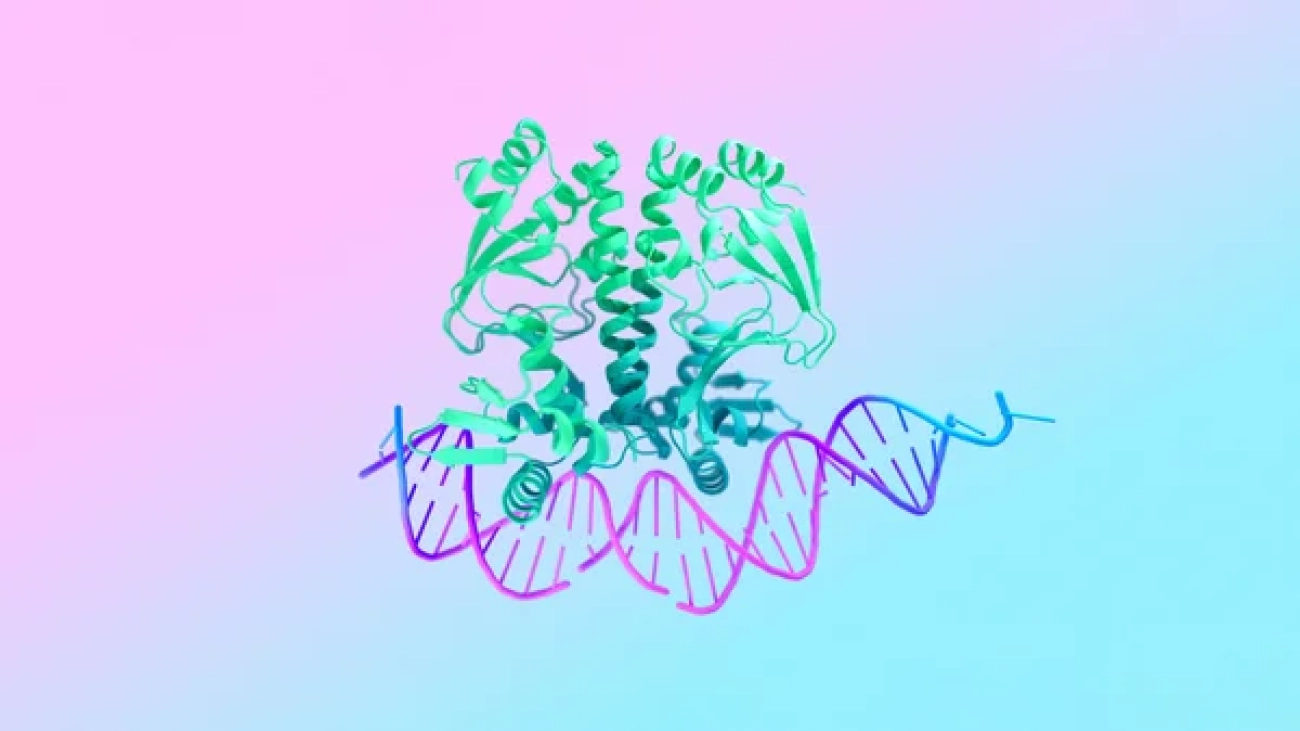
 Our new AI model AlphaFold 3 can predict the structure and interactions of all life’s molecules with unprecedented accuracy.Read More
Our new AI model AlphaFold 3 can predict the structure and interactions of all life’s molecules with unprecedented accuracy.Read More