 Explore our collection to find out more about Gemini, the most capable and general model we’ve ever built.Read More
Explore our collection to find out more about Gemini, the most capable and general model we’ve ever built.Read More

Explore our collection to find out more about Gemini, the most capable and general model we’ve ever built.Read More

 We’re starting to bring Gemini’s advanced capabilities into Bard.Read More
We’re starting to bring Gemini’s advanced capabilities into Bard.Read More

 New Feature Drop brings updates to your Pixel hardware. Plus, Gemini Nano now powers on-device generative AI features for Pixel 8 Pro.Read More
New Feature Drop brings updates to your Pixel hardware. Plus, Gemini Nano now powers on-device generative AI features for Pixel 8 Pro.Read More

 Gemini is our most capable and general model, built to be multimodal and optimized for three different sizes: Ultra, Pro and Nano.Read More
Gemini is our most capable and general model, built to be multimodal and optimized for three different sizes: Ultra, Pro and Nano.Read More


Google is proud to be a Diamond Sponsor of Empirical Methods in Natural Language Processing (EMNLP 2023), a premier annual conference, which is being held this week in Sentosa, Singapore. Google has a strong presence at this year’s conference with over 65 accepted papers and active involvement in 11 workshops and tutorials. Google is also happy to be a Major Sponsor for the Widening NLP workshop (WiNLP), which aims to highlight global representations of people, perspectives, and cultures in AI and ML. We look forward to sharing some of our extensive NLP research and expanding our partnership with the broader research community.
We hope you’ll visit the Google booth to chat with researchers who are actively pursuing the latest innovations in NLP, and check out some of the scheduled booth activities (e.g., demos and Q&A sessions listed below). Visit the @GoogleAI X (Twitter) and LinkedIn accounts to find out more about the Google booth activities at EMNLP 2023.
Take a look below to learn more about the Google research being presented at EMNLP 2023 (Google affiliations in bold).
Sponsorship Chair: Shyam Upadyay
Industry Track Chair: Imed Zitouni
Senior Program Committee: Roee Aharoni, Annie Louis, Vinodkumar Prabhakaran, Shruti Rijhwani, Brian Roark, Partha Talukdar
This schedule is subject to change. Please visit the Google booth for more information.
Developing and Utilizing Evaluation Metrics for Machine Translation & Improving Multilingual NLP
Presenter: Isaac Caswell, Dan Deutch, Jan-Thorsten Peter, David Vilar Torres
Fri, Dec 8 | 10:30AM -11:00AM SST
Differentiable Search Indexes & Generative Retrieval
Presenter: Sanket Viabhav Mehta, Vinh Tran
Fri, Dec 8 | 3:30PM -4:00PM SST
Retrieval and Generation in a single pass
Presenter: Palak Jain, Livio Baldini Soares
Sat, Dec 9 | 10:30AM -11:00AM SST
Amplifying Adversarial Attacks
Presenter: Anu Sinha
Sat, Dec 9 | 12:30PM -1:45PM SST
Automate prompt design: Universal Self-Adaptive Prompting (see blog post)
Presenter: Xingchen Qian*, Ruoxi Sun
Sat, Dec 9 | 3:30PM -4:00PM SST
SynJax: Structured Probability Distributions for JAX
Miloš Stanojević, Laurent Sartran
Adapters: A Unified Library for Parameter-Efficient and Modular Transfer Learning
Clifton Poth, Hannah Sterz, Indraneil Paul, Sukannya Purkayastha, Leon Engländer, Timo Imhof, Ivan Vulić, Sebastian Ruder, Iryna Gurevych, Jonas Pfeiffer
DocumentNet: Bridging the Data Gap in Document Pre-training
Lijun Yu, Jin Miao, Xiaoyu Sun, Jiayi Chen, Alexander Hauptmann, Hanjun Dai, Wei Wei
AART: AI-Assisted Red-Teaming with Diverse Data Generation for New LLM-Powered Applications
Bhaktipriya Radharapu, Kevin Robinson, Lora Aroyo, Preethi Lahoti
CRoW: Benchmarking Commonsense Reasoning in Real-World Tasks
Mete Ismayilzada, Debjit Paul, Syrielle Montariol, Mor Geva, Antoine Bosselut
Large Language Models Can Self-Improve
Jiaxin Huang*, Shixiang Shane Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu, Jiawei Han
Dissecting Recall of Factual Associations in Auto-Regressive Language Models
Mor Geva, Jasmijn Bastings, Katja Filippova, Amir Globerson
Stop Uploading Test Data in Plain Text: Practical Strategies for Mitigating Data Contamination by Evaluation Benchmarks
Alon Jacovi, Avi Caciularu, Omer Goldman, Yoav Goldberg
Selective Labeling: How to Radically Lower Data-Labeling Costs for Document Extraction Models
Yichao Zhou, James Bradley Wendt, Navneet Potti, Jing Xie, Sandeep Tata
Measuring Attribution in Natural Language Generation Models
Hannah Rashkin, Vitaly Nikolaev, Matthew Lamm, Lora Aroyo, Michael Collins, Dipanjan Das, Slav Petrov, Gaurav Singh Tomar, Iulia Turc, David Reitter
Inverse Scaling Can Become U-Shaped
Jason Wei*, Najoung Kim, Yi Tay*, Quoc Le
INSTRUCTSCORE: Towards Explainable Text Generation Evaluation with Automatic Feedback
Wenda Xu, Danqing Wang, Liangming Pan, Zhenqiao Song, Markus Freitag, William Yang Wang, Lei Li
On the Robustness of Dialogue History Representation in Conversational Question Answering: A Comprehensive Study and a New Prompt-Based Method
Zorik Gekhman, Nadav Oved, Orgad Keller, Idan Szpektor, Roi Reichart
Investigating Efficiently Extending Transformers for Long-Input Summarization
Jason Phang*, Yao Zhao, Peter J Liu
DSI++: Updating Transformer Memory with New Documents
Sanket Vaibhav Mehta*, Jai Gupta, Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Jinfeng Rao, Marc Najork, Emma Strubell, Donald Metzler
MultiTurnCleanup: A Benchmark for Multi-Turn Spoken Conversational Transcript Cleanup
Hua Shen*, Vicky Zayats, Johann C Rocholl, Daniel David Walker, Dirk Padfield
Adaptation with Self-Evaluation to Improve Selective Prediction in LLMs
Jiefeng Chen*, Jinsung Yoon, Sayna Ebrahimi, Sercan O Arik, Tomas Pfister, Somesh Jha
A Comprehensive Evaluation of Tool-Assisted Generation Strategies
Alon Jacovi*, Avi Caciularu, Jonathan Herzig, Roee Aharoni, Bernd Bohnet, Mor Geva
1-PAGER: One Pass Answer Generation and Evidence Retrieval
Palak Jain, Livio Baldini Soares, Tom Kwiatkowski
MaXM: Towards Multilingual Visual Question Answering
Soravit Changpinyo, Linting Xue, Michal Yarom, Ashish V. Thapliyal, Idan Szpektor, Julien Amelot, Xi Chen, Radu Soricut
SDOH-NLI: A Dataset for Inferring Social Determinants of Health from Clinical Notes
Adam D. Lelkes, Eric Loreaux*, Tal Schuster, Ming-Jun Chen, Alvin Rajkomar
Machine Reading Comprehension Using Case-based Reasoning
Dung Ngoc Thai, Dhruv Agarwal, Mudit Chaudhary, Wenlong Zhao, Rajarshi Das, Jay-Yoon Lee, Hannaneh Hajishirzi, Manzil Zaheer, Andrew McCallum
Cross-lingual Open-Retrieval Question Answering for African Languages
Odunayo Ogundepo, Tajuddeen Gwadabe, Clara E. Rivera, Jonathan H. Clark, Sebastian Ruder, David Ifeoluwa Adelani, Bonaventure F. P. Dossou, Abdou Aziz DIOP, Claytone Sikasote, Gilles HACHEME, Happy Buzaaba, Ignatius Ezeani, Rooweither Mabuya, Salomey Osei, Chris Chinenye Emezue, Albert Kahira, Shamsuddeen Hassan Muhammad, Akintunde Oladipo, Abraham Toluwase Owodunni, Atnafu Lambebo Tonja, Iyanuoluwa Shode, Akari Asai, Anuoluwapo Aremu, Ayodele Awokoya, Bernard Opoku, Chiamaka Ijeoma Chukwuneke, Christine Mwase, Clemencia Siro, Stephen Arthur, Tunde Oluwaseyi Ajayi, Verrah Akinyi Otiende, Andre Niyongabo Rubungo, Boyd Sinkala, Daniel Ajisafe, Emeka Felix Onwuegbuzia, Falalu Ibrahim Lawan, Ibrahim Said Ahmad, Jesujoba Oluwadara Alabi, CHINEDU EMMANUEL MBONU, Mofetoluwa Adeyemi, Mofya Phiri, Orevaoghene Ahia, Ruqayya Nasir Iro, Sonia Adhiambo
On Uncertainty Calibration and Selective Generation in Probabilistic Neural Summarization: A Benchmark Study
Polina Zablotskaia, Du Phan, Joshua Maynez, Shashi Narayan, Jie Ren, Jeremiah Zhe Liu
Epsilon Sampling Rocks: Investigating Sampling Strategies for Minimum Bayes Risk Decoding for Machine Translation
Markus Freitag, Behrooz Ghorbani*, Patrick Fernandes*
Sources of Hallucination by Large Language Models on Inference Tasks
Nick McKenna, Tianyi Li, Liang Cheng, Mohammad Javad Hosseini, Mark Johnson, Mark Steedman
Don’t Add, Don’t Miss: Effective Content Preserving Generation from Pre-selected Text Spans
Aviv Slobodkin, Avi Caciularu, Eran Hirsch, Ido Dagan
What Makes Chain-of-Thought Prompting Effective? A Counterfactual Study
Aman Madaan*, Katherine Hermann, Amir Yazdanbakhsh
Understanding HTML with Large Language Models
Izzeddin Gur, Ofir Nachum, Yingjie Miao, Mustafa Safdari, Austin Huang, Aakanksha Chowdhery, Sharan Narang, Noah Fiedel, Aleksandra Faust
Improving the Robustness of Summarization Models by Detecting and Removing Input Noise
Kundan Krishna*, Yao Zhao, Jie Ren, Balaji Lakshminarayanan, Jiaming Luo, Mohammad Saleh, Peter J. Liu
In-Context Learning Creates Task Vectors
Roee Hendel, Mor Geva, Amir Globerson
Pre-training Without Attention
Junxiong Wang, Jing Nathan Yan, Albert Gu, Alexander M Rush
MUX-PLMs: Data Multiplexing for High-Throughput Language Models
Vishvak Murahari, Ameet Deshpande, Carlos E Jimenez, Izhak Shafran, Mingqiu Wang, Yuan Cao, Karthik R Narasimhan
PaRaDe: Passage Ranking Using Demonstrations with LLMs
Andrew Drozdov*, Honglei Zhuang, Zhuyun Dai, Zhen Qin, Razieh Rahimi, Xuanhui Wang, Dana Alon, Mohit Iyyer, Andrew McCallum, Donald Metzler*, Kai Hui
Long-Form Speech Translation Through Segmentation with Finite-State Decoding Constraints on Large Language Models
Arya D. McCarthy, Hao Zhang, Shankar Kumar, Felix Stahlberg, Ke Wu
Unsupervised Opinion Summarization Using Approximate Geodesics
Somnath Basu Roy Chowdhury*, Nicholas Monath, Kumar Avinava Dubey, Amr Ahmed, Snigdha Chaturvedi
SQLPrompt: In-Context Text-to-SQL with Minimal Labeled Data
Ruoxi Sun, Sercan O. Arik, Rajarishi Sinha, Hootan Nakhost, Hanjun Dai, Pengcheng Yin, Tomas Pfister
Retrieval-Augmented Parsing for Complex Graphs by Exploiting Structure and Uncertainty
Zi Lin, Quan Yuan, Panupong Pasupat, Jeremiah Zhe Liu, Jingbo Shang
A Zero-Shot Language Agent for Computer Control with Structured Reflection
Tao Li, Gang Li, Zhiwei Deng, Bryan Wang*, Yang Li
Pragmatics in Language Grounding: Phenomena, Tasks, and Modeling Approaches
Daniel Fried, Nicholas Tomlin, Jennifer Hu, Roma Patel, Aida Nematzadeh
Improving Classifier Robustness Through Active Generation of Pairwise Counterfactuals
Ananth Balashankar, Xuezhi Wang, Yao Qin, Ben Packer, Nithum Thain, Jilin Chen, Ed H. Chi, Alex Beutel
mmT5: Modular Multilingual Pre-training Solves Source Language Hallucinations
Jonas Pfeiffer, Francesco Piccinno, Massimo Nicosia, Xinyi Wang, Machel Reid, Sebastian Ruder
Scaling Laws vs Model Architectures: How Does Inductive Bias Influence Scaling?
Yi Tay, Mostafa Dehghani, Samira Abnar, Hyung Won Chung, William Fedus, Jinfeng Rao, Sharan Narang, Vinh Q. Tran, Dani Yogatama, Donald Metzler
TaTA: A Multilingual Table-to-Text Dataset for African Languages
Sebastian Gehrmann, Sebastian Ruder, Vitaly Nikolaev, Jan A. Botha, Michael Chavinda, Ankur P Parikh, Clara E. Rivera
XTREME-UP: A User-Centric Scarce-Data Benchmark for Under-Represented Languages
Sebastian Ruder, Jonathan H. Clark, Alexander Gutkin, Mihir Kale, Min Ma, Massimo Nicosia, Shruti Rijhwani, Parker Riley, Jean Michel Amath Sarr, Xinyi Wang, John Frederick Wieting, Nitish Gupta, Anna Katanova, Christo Kirov, Dana L Dickinson, Brian Roark, Bidisha Samanta, Connie Tao, David Ifeoluwa Adelani, Vera Axelrod, Isaac Rayburn Caswell, Colin Cherry, Dan Garrette, Reeve Ingle, Melvin Johnson, Dmitry Panteleev, Partha Talukdar
q2d: Turning Questions into Dialogs to Teach Models How to Search
Yonatan Bitton, Shlomi Cohen-Ganor, Ido Hakimi, Yoad Lewenberg, Roee Aharoni, Enav Weinreb
Emergence of Abstract State Representations in Embodied Sequence Modeling
Tian Yun*, Zilai Zeng, Kunal Handa, Ashish V Thapliyal, Bo Pang, Ellie Pavlick, Chen Sun
Evaluating and Modeling Attribution for Cross-Lingual Question Answering
Benjamin Muller*, John Wieting, Jonathan H. Clark, Tom Kwiatkowski, Sebastian Ruder, Livio Baldini Soares, Roee Aharoni, Jonathan Herzig, Xinyi Wang
Weakly-Supervised Learning of Visual Relations in Multimodal Pre-training
Emanuele Bugliarello, Aida Nematzadeh, Lisa Anne Hendricks
How Do Languages Influence Each Other? Studying Cross-Lingual Data Sharing During LM Fine-Tuning
Rochelle Choenni, Dan Garrette, Ekaterina Shutova
CompoundPiece: Evaluating and Improving Decompounding Performance of Language Models
Benjamin Minixhofer, Jonas Pfeiffer, Ivan Vulić
IC3: Image Captioning by Committee Consensus
David Chan, Austin Myers, Sudheendra Vijayanarasimhan, David A Ross, John Canny
The Curious Case of Hallucinatory (Un)answerability: Finding Truths in the Hidden States of Over-Confident Large Language Models
Aviv Slobodkin, Omer Goldman, Avi Caciularu, Ido Dagan, Shauli Ravfogel
Evaluating Large Language Models on Controlled Generation Tasks
Jiao Sun, Yufei Tian, Wangchunshu Zhou, Nan Xu, Qian Hu, Rahul Gupta, John Wieting, Nanyun Peng, Xuezhe Ma
Ties Matter: Meta-Evaluating Modern Metrics with Pairwise Accuracy and Tie Calibration
Daniel Deutsch, George Foster, Markus Freitag
Transcending Scaling Laws with 0.1% Extra Compute
Yi Tay*, Jason Wei*, Hyung Won Chung*, Vinh Q. Tran, David R. So*, Siamak Shakeri, Xavier Garcia, Huaixiu Steven Zheng, Jinfeng Rao, Aakanksha Chowdhery, Denny Zhou, Donald Metzler, Slav Petrov, Neil Houlsby, Quoc V. Le, Mostafa Dehghani
Data Similarity is Not Enough to Explain Language Model Performance
Gregory Yauney*, Emily Reif, David Mimno
Self-Influence Guided Data Reweighting for Language Model Pre-training
Megh Thakkar*, Tolga Bolukbasi, Sriram Ganapathy, Shikhar Vashishth, Sarath Chandar, Partha Talukdar
ReTAG: Reasoning Aware Table to Analytic Text Generation
Deepanway Ghosal, Preksha Nema, Aravindan Raghuveer
GATITOS: Using a New Multilingual Lexicon for Low-Resource Machine Translation
Alex Jones*, Isaac Caswell, Ishank Saxena
Video-Helpful Multimodal Machine Translation
Yihang Li, Shuichiro Shimizu, Chenhui Chu, Sadao Kurohashi, Wei Li
Symbol Tuning Improves In-Context Learning in Language Models
Jerry Wei*, Le Hou, Andrew Kyle Lampinen, Xiangning Chen*, Da Huang, Yi Tay*, Xinyun Chen, Yifeng Lu, Denny Zhou, Tengyu Ma*, Quoc V Le
“Don’t Take This Out of Context!” On the Need for Contextual Models and Evaluations for Stylistic Rewriting
Akhila Yerukola, Xuhui Zhou, Elizabeth Clark, Maarten Sap
QAmeleon: Multilingual QA with Only 5 Examples
Priyanka Agrawal, Chris Alberti, Fantine Huot, Joshua Maynez, Ji Ma, Sebastian Ruder, Kuzman Ganchev, Dipanjan Das, Mirella Lapata
Speak, Read and Prompt: High-Fidelity Text-to-Speech with Minimal Supervision
Eugene Kharitonov, Damien Vincent, Zalán Borsos, Raphaël Marinier, Sertan Girgin, Olivier Pietquin, Matt Sharifi, Marco Tagliasacchi, Neil Zeghidour
AnyTOD: A Programmable Task-Oriented Dialog System
Jeffrey Zhao, Yuan Cao, Raghav Gupta, Harrison Lee, Abhinav Rastogi, Mingqiu Wang, Hagen Soltau, Izhak Shafran, Yonghui Wu
Selectively Answering Ambiguous Questions
Jeremy R. Cole, Michael JQ Zhang, Daniel Gillick, Julian Martin Eisenschlos, Bhuwan Dhingra, Jacob Eisenstein
PRESTO: A Multilingual Dataset for Parsing Realistic Task-Oriented Dialogs (see blog post)
Rahul Goel, Waleed Ammar, Aditya Gupta, Siddharth Vashishtha, Motoki Sano, Faiz Surani*, Max Chang, HyunJeong Choe, David Greene, Chuan He, Rattima Nitisaroj, Anna Trukhina, Shachi Paul, Pararth Shah, Rushin Shah, Zhou Yu
LM vs LM: Detecting Factual Errors via Cross Examination
Roi Cohen, May Hamri, Mor Geva, Amir Globerson
A Suite of Generative Tasks for Multi-Level Multimodal Webpage Understanding
Andrea Burns*, Krishna Srinivasan, Joshua Ainslie, Geoff Brown, Bryan A. Plummer, Kate Saenko, Jianmo Ni, Mandy Guo
AfriSenti: A Twitter Sentiment Analysis Benchmark for African Languages
Shamsuddeen Hassan Muhammad, Idris Abdulmumin, Abinew Ali Ayele, Nedjma Ousidhoum, David Ifeoluwa Adelani, Seid Muhie Yimam, Ibrahim Said Ahmad, Meriem Beloucif, Saif M. Mohammad, Sebastian Ruder, Oumaima Hourrane, Alipio Jorge, Pavel Brazdil, Felermino D. M. A. Ali, Davis David, Salomey Osei, Bello Shehu-Bello, Falalu Ibrahim Lawan, Tajuddeen Gwadabe, Samuel Rutunda, Tadesse Destaw Belay, Wendimu Baye Messelle, Hailu Beshada Balcha, Sisay Adugna Chala, Hagos Tesfahun Gebremichael, Bernard Opoku, Stephen Arthur
Optimizing Retrieval-Augmented Reader Models via Token Elimination
Moshe Berchansky, Peter Izsak, Avi Caciularu, Ido Dagan, Moshe Wasserblat
SEAHORSE: A Multilingual, Multifaceted Dataset for Summarization Evaluation
Elizabeth Clark, Shruti Rijhwani, Sebastian Gehrmann, Joshua Maynez, Roee Aharoni, Vitaly Nikolaev, Thibault Sellam, Aditya Siddhant, Dipanjan Das, Ankur P Parikh
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel de Jong*, Yury Zemlyanskiy, Federico Lebron, Sumit Sanghai
CoLT5: Faster Long-Range Transformers with Conditional Computation
Joshua Ainslie, Tao Lei, Michiel de Jong, Santiago Ontanon, Siddhartha Brahma, Yury Zemlyanskiy, David Uthus, Mandy Guo, James Lee-Thorp, Yi Tay, Yun-Hsuan Sung, Sumit Sanghai
Improving Diversity of Demographic Representation in Large Language Models via Collective-Critiques and Self-Voting
Preethi Lahoti, Nicholas Blumm, Xiao Ma, Raghavendra Kotikalapudi, Sahitya Potluri, Qijun Tan, Hansa Srinivasan, Ben Packer, Ahmad Beirami, Alex Beutel, Jilin Chen
Universal Self-Adaptive Prompting (see blog post)
Xingchen Wan*, Ruoxi Sun, Hootan Nakhost, Hanjun Dai, Julian Martin Eisenschlos, Sercan O. Arik, Tomas Pfister
TrueTeacher: Learning Factual Consistency Evaluation with Large Language Models
Zorik Gekhman, Jonathan Herzig, Roee Aharoni, Chen Elkind, Idan Szpektor
Hierarchical Pre-training on Multimodal Electronic Health Records
Xiaochen Wang, Junyu Luo, Jiaqi Wang, Ziyi Yin, Suhan Cui, Yuan Zhong, Yaqing Wang, Fenglong Ma
NAIL: Lexical Retrieval Indices with Efficient Non-Autoregressive Decoders
Livio Baldini Soares, Daniel Gillick, Jeremy R. Cole, Tom Kwiatkowski
How Does Generative Retrieval Scale to Millions of Passages?
Ronak Pradeep*, Kai Hui, Jai Gupta, Adam D. Lelkes, Honglei Zhuang, Jimmy Lin, Donald Metzler, Vinh Q. Tran
Make Every Example Count: On the Stability and Utility of Self-Influence for Learning from Noisy NLP Datasets
Irina Bejan*, Artem Sokolov, Katja Filippova
The Seventh Widening NLP Workshop (WiNLP)
Major Sponsor
Organizers: Sunipa Dev
Panelist: Preethi Lahoti
The Sixth Workshop on Computational Models of Reference, Anaphora and Coreference (CRAC)
Invited Speaker: Bernd Bohnet
The 3rd Workshop for Natural Language Processing Open Source Software (NLP-OSS)
Organizer: Geeticka Chauhan
Combined Workshop on Spatial Language Understanding and Grounded Communication for Robotics (SpLU-RoboNLP)
Invited Speaker: Andy Zeng
Natural Language Generation, Evaluation, and Metric (GEM)
Organizer: Elizabeth Clark
The First Arabic Natural Language Processing Conference (ArabicNLP)
Organizer: Imed Zitouni
The Big Picture: Crafting a Research Narrative (BigPicture)
Organizer: Nora Kassner, Sebastian Ruder
BlackboxNLP 2023: The 6th Workshop on Analysing and Interpreting Neural Networks for NLP
Organizer: Najoung Kim
Panelist: Neel Nanda
The SIGNLL Conference on Computational Natural Language Learning (CoNLL)
Co-Chair: David Reitter
Areas and ACs: Kyle Gorman (Speech and Phonology), Fei Liu (Natural Language Generation)
The Third Workshop on Multi-lingual Representation Learning (MRL)
Organizer: Omer Goldman, Sebastian Ruder
Invited Speaker: Orhan Firat
Creative Natural Language Generation
Organizer: Tuhin Chakrabarty*
* Work done while at Google
Quantum computers promise to solve some problems exponentially faster than classical computers, but there are only a handful of examples with such a dramatic speedup, such as Shor’s factoring algorithm and quantum simulation. Of those few examples, the majority of them involve simulating physical systems that are inherently quantum mechanical — a natural application for quantum computers. But what about simulating systems that are not inherently quantum? Can quantum computers offer an exponential advantage for this?
In “Exponential quantum speedup in simulating coupled classical oscillators”, published in Physical Review X (PRX) and presented at the Symposium on Foundations of Computer Science (FOCS 2023), we report on the discovery of a new quantum algorithm that offers an exponential advantage for simulating coupled classical harmonic oscillators. These are some of the most fundamental, ubiquitous systems in nature and can describe the physics of countless natural systems, from electrical circuits to molecular vibrations to the mechanics of bridges. In collaboration with Dominic Berry of Macquarie University and Nathan Wiebe of the University of Toronto, we found a mapping that can transform any system involving coupled oscillators into a problem describing the time evolution of a quantum system. Given certain constraints, this problem can be solved with a quantum computer exponentially faster than it can with a classical computer. Further, we use this mapping to prove that any problem efficiently solvable by a quantum algorithm can be recast as a problem involving a network of coupled oscillators, albeit exponentially many of them. In addition to unlocking previously unknown applications of quantum computers, this result provides a new method of designing new quantum algorithms by reasoning purely about classical systems.
The systems we consider consist of classical harmonic oscillators. An example of a single harmonic oscillator is a mass (such as a ball) attached to a spring. If you displace the mass from its rest position, then the spring will induce a restoring force, pushing or pulling the mass in the opposite direction. This restoring force causes the mass to oscillate back and forth.
 |
| A simple example of a harmonic oscillator is a mass connected to a wall by a spring. [Image Source: Wikimedia] |
Now consider coupled harmonic oscillators, where multiple masses are attached to one another through springs. Displace one mass, and it will induce a wave of oscillations to pulse through the system. As one might expect, simulating the oscillations of a large number of masses on a classical computer gets increasingly difficult.
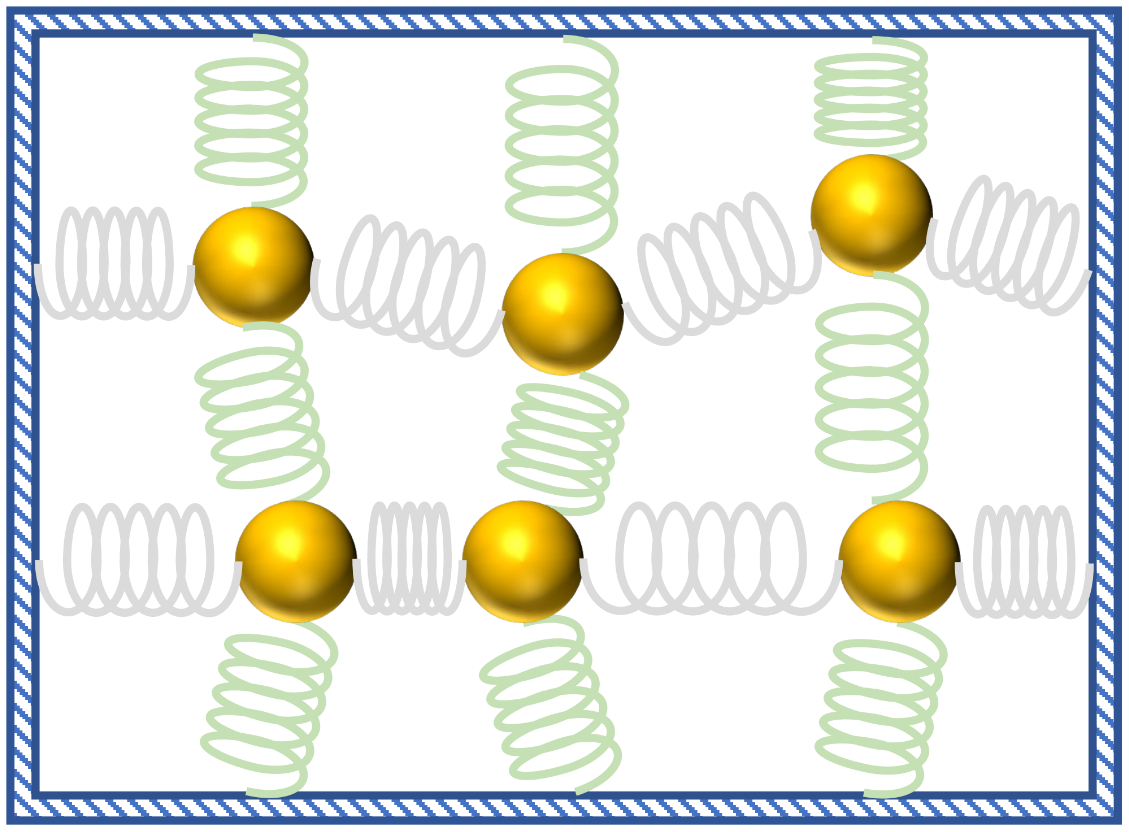 |
| An example system of masses connected by springs that can be simulated with the quantum algorithm. |
To enable the simulation of a large number of coupled harmonic oscillators, we came up with a mapping that encodes the positions and velocities of all masses and springs into the quantum wavefunction of a system of qubits. Since the number of parameters describing the wavefunction of a system of qubits grows exponentially with the number of qubits, we can encode the information of N balls into a quantum mechanical system of only about log(N) qubits. As long as there is a compact description of the system (i.e., the properties of the masses and the springs), we can evolve the wavefunction to learn coordinates of the balls and springs at a later time with far fewer resources than if we had used a naïve classical approach to simulate the balls and springs.
We showed that a certain class of coupled-classical oscillator systems can be efficiently simulated on a quantum computer. But this alone does not rule out the possibility that there exists some as-yet-unknown clever classical algorithm that is similarly efficient in its use of resources. To show that our quantum algorithm achieves an exponential speedup over any possible classical algorithm, we provide two additional pieces of evidence.
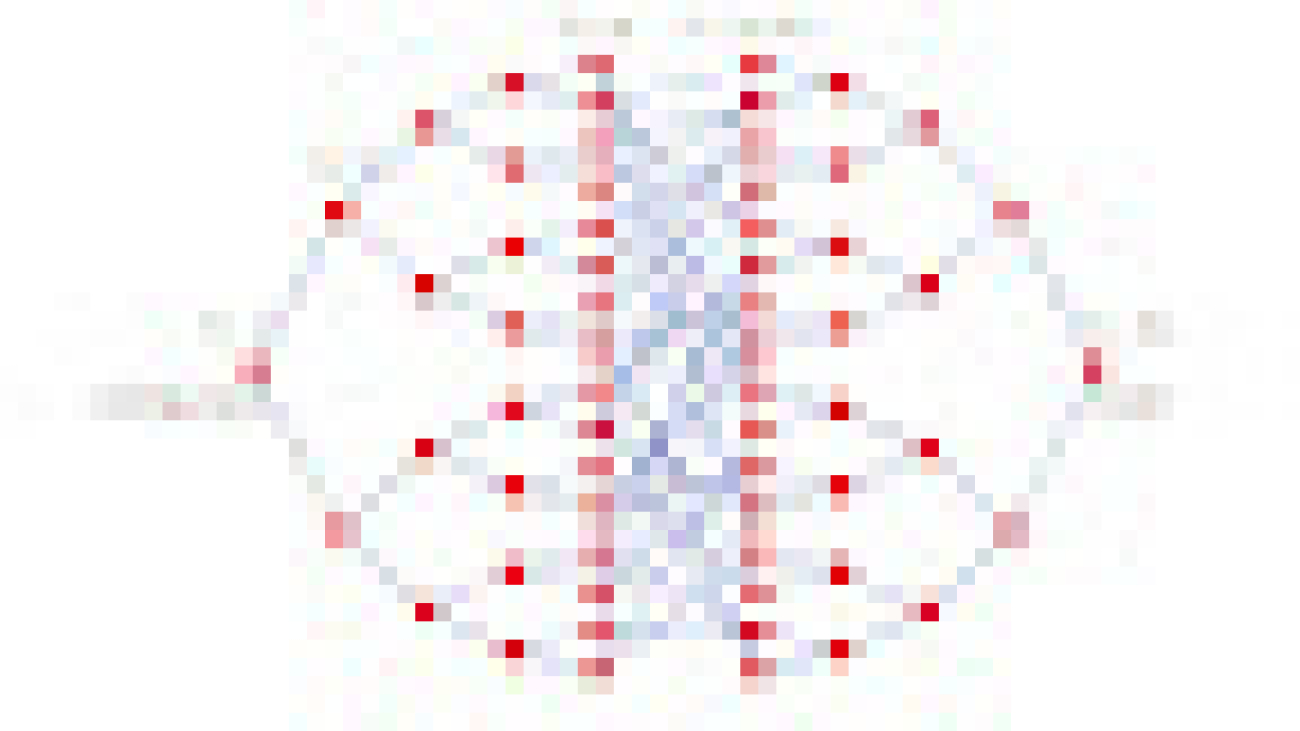
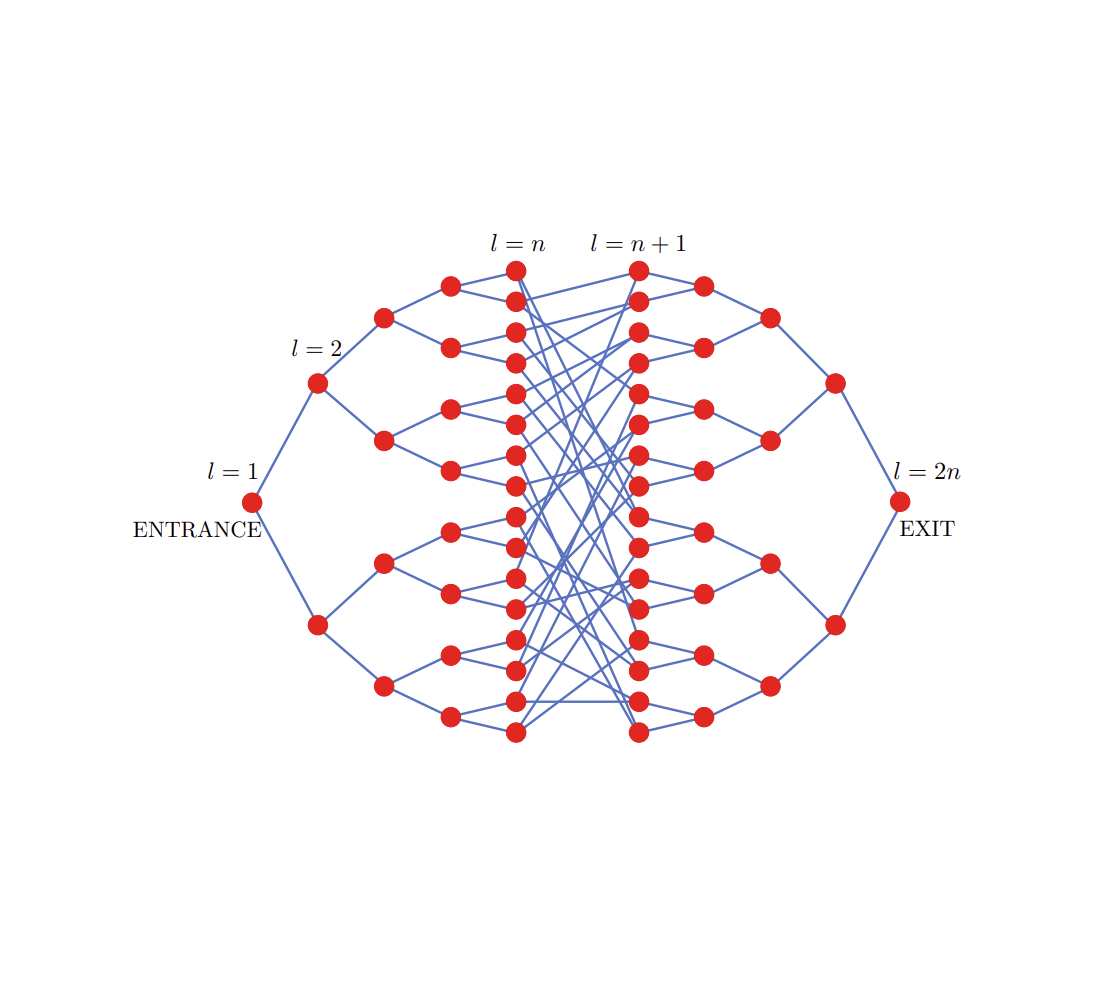
For the first piece of evidence, we use our mapping to show that the quantum algorithm can efficiently solve a famous problem about graphs known to be difficult to solve classically, called the glued-trees problem. The problem takes two branching trees — a graph whose nodes each branch to two more nodes, resembling the branching paths of a tree — and glues their branches together through a random set of edges, as shown in the figure below.
 |
| A visual representation of the glued trees problem. Here we start at the node labeled ENTRANCE and are allowed to locally explore the graph, which is obtained by randomly gluing together two binary trees. The goal is to find the node labeled EXIT. |
The goal of the glued-trees problem is to find the exit node — the “root” of the second tree — as efficiently as possible. But the exact configuration of the nodes and edges of the glued trees are initially hidden from us. To learn about the system, we must query an oracle, which can answer specific questions about the setup. This oracle allows us to explore the trees, but only locally. Decades ago, it was shown that the number of queries required to find the exit node on a classical computer is proportional to a polynomial factor of N, the total number of nodes.
But recasting this as a problem with balls and springs, we can imagine each node as a ball and each connection between two nodes as a spring. Pluck the entrance node (the root of the first tree), and the oscillations will pulse through the trees. It only takes a time that scales with the depth of the tree — which is exponentially smaller than N — to reach the exit node. So, by mapping the glued-trees ball-and-spring system to a quantum system and evolving it for that time, we can detect the vibrations of the exit node and determine it exponentially faster than we could using a classical computer.
The second and strongest piece of evidence that our algorithm is exponentially more efficient than any possible classical algorithm is revealed by examination of the set of problems a quantum computer can solve efficiently (i.e., solvable in polynomial time), referred to as bounded-error quantum polynomial time or BQP. The hardest problems in BQP are called “BQP-complete”.
While it is generally accepted that there exist some problems that a quantum algorithm can solve efficiently and a classical algorithm cannot, this has not yet been proven. So, the best evidence we can provide is that our problem is BQP-complete, that is, it is among the hardest problems in BQP. If someone were to find an efficient classical algorithm for solving our problem, then every problem solved by a quantum computer efficiently would be classically solvable! Not even the factoring problem (finding the prime factors of a given large number), which forms the basis of modern encryption and was famously solved by Shor’s algorithm, is expected to be BQP-complete.
 |
| A diagram showing the believed relationships of the classes BPP and BQP, which are the set of problems that can be efficiently solved on a classical computer and quantum computer, respectively. BQP-complete problems are the hardest problems in BQP. |
To show that our problem of simulating balls and springs is indeed BQP-complete, we start with a standard BQP-complete problem of simulating universal quantum circuits, and show that every quantum circuit can be expressed as a system of many balls coupled with springs. Therefore, our problem is also BQP-complete.
This effort also sheds light on work from 2002, when theoretical computer scientist Lov K. Grover and his colleague, Anirvan M. Sengupta, used an analogy to coupled pendulums to illustrate how Grover’s famous quantum search algorithm could find the correct element in an unsorted database quadratically faster than could be done classically. With the proper setup and initial conditions, it would be possible to tell whether one of N pendulums was different from the others — the analogue of finding the correct element in a database — after the system had evolved for time that was only ~√(N). While this hints at a connection between certain classical oscillating systems and quantum algorithms, it falls short of explaining why Grover’s quantum algorithm achieves a quantum advantage.
Our results make that connection precise. We showed that the dynamics of any classical system of harmonic oscillators can indeed be equivalently understood as the dynamics of a corresponding quantum system of exponentially smaller size. In this way we can simulate Grover and Sengupta’s system of pendulums on a quantum computer of log(N) qubits, and find a different quantum algorithm that can find the correct element in time ~√(N). The analogy we discovered between classical and quantum systems can be used to construct other quantum algorithms offering exponential speedups, where the reason for the speedups is now more evident from the way that classical waves propagate.
Our work also reveals that every quantum algorithm can be equivalently understood as the propagation of a classical wave in a system of coupled oscillators. This would imply that, for example, we can in principle build a classical system that solves the factoring problem after it has evolved for time that is exponentially smaller than the runtime of any known classical algorithm that solves factoring. This may look like an efficient classical algorithm for factoring, but the catch is that the number of oscillators is exponentially large, making it an impractical way to solve factoring.
Coupled harmonic oscillators are ubiquitous in nature, describing a broad range of systems from electrical circuits to chains of molecules to structures such as bridges. While our work here focuses on the fundamental complexity of this broad class of problems, we expect that it will guide us in searching for real-world examples of harmonic oscillator problems in which a quantum computer could offer an exponential advantage.
We would like to thank our Quantum Computing Science Communicator, Katie McCormick, for helping to write this blog post.


In recent years, the Privacy Sandbox initiative was launched to explore responsible ways for advertisers to measure the effectiveness of their campaigns, by aiming to deprecate third-party cookies (subject to resolving any competition concerns with the UK’s Competition and Markets Authority). Cookies are small pieces of data containing user preferences that websites store on a user’s device; they can be used to provide a better browsing experience (e.g., allowing users to automatically sign in) and to serve relevant content or ads. The Privacy Sandbox attempts to address concerns around the use of cookies for tracking browsing data across the web by providing a privacy-preserving alternative.
Many browsers use differential privacy (DP) to provide privacy-preserving APIs, such as the Attribution Reporting API (ARA), that don’t rely on cookies for ad conversion measurement. ARA encrypts individual user actions and collects them in an aggregated summary report, which estimates measurement goals like the number and value of conversions (useful actions on a website, such as making a purchase or signing up for a mailing list) attributed to ad campaigns.
The task of configuring API parameters, e.g., allocating a contribution budget across different conversions, is important for maximizing the utility of the summary reports. In “Summary Report Optimization in the Privacy Sandbox Attribution Reporting API”, we introduce a formal mathematical framework for modeling summary reports. Then, we formulate the problem of maximizing the utility of summary reports as an optimization problem to obtain the optimal ARA parameters. Finally, we evaluate the method using real and synthetic datasets, and demonstrate significantly improved utility compared to baseline non-optimized summary reports.
We use the following example to illustrate our notation. Imagine a fictional gift shop called Du & Penc that uses digital advertising to reach its customers. The table below captures their holiday sales, where each record contains impression features with (i) an impression ID, (ii) the campaign, and (iii) the city in which the ad was shown, as well as conversion features with (i) the number of items purchased and (ii) the total dollar value of those items.
 |
| Impression and conversion feature logs for Du & Penc. |
ARA summary reports can be modeled by four algorithms: (1) Contribution Vector, (2) Contribution Bounding, (3) Summary Reports, and (4) Reconstruct Values. Contribution Bounding and Summary Reports are performed by the ARA, while Contribution Vector and Reconstruct Values are performed by an AdTech provider — tools and systems that enable businesses to buy and sell digital advertising. The objective of this work is to assist AdTechs in optimizing summary report algorithms.
The Contribution Vector algorithm converts measurements into an ARA format that is discretized and scaled. Scaling needs to account for the overall contribution limit per impression. Here we propose a method that clips and performs randomized rounding. The outcome of the algorithm is a histogram of aggregatable keys and values.
Next, the Contribution Bounding algorithm runs on client devices and enforces the contribution bound on attributed reports where any further contributions exceeding the limit are dropped. The output is a histogram of attributed conversions.
The Summary Reports algorithm runs on the server side inside a trusted execution environment and returns noisy aggregate results that satisfy DP. Noise is sampled from the discrete Laplace distribution, and to enforce privacy budgeting, a report may be queried only once.
Finally, the Reconstruct Values algorithm converts measurements back to the original scale. Reconstruct Values and Contribution Vector Algorithms are designed by the AdTech, and both impact the utility received from the summary report.
 |
| Illustrative usage of ARA summary reports, which include Contribution Vector (Algorithm A), Contribution Bounding (Algorithm C), Summary Reports (Algorithm S), and Reconstruct Values (Algorithm R). Algorithms C and S are fixed in the API. The AdTech designs A and R. |
There are several factors to consider when selecting an error metric for evaluating the quality of an approximation. To choose a particular metric, we considered the desirable properties of an error metric that further can be used as an objective function. Considering desired properties, we have chosen 𝜏-truncated root mean square relative error (RMSRE𝜏) as our error metric for its properties. See the paper for a detailed discussion and comparison to other possible metrics.
To optimize utility as measured by RMSRE𝜏, we choose a capping parameter, C, and privacy budget, 𝛼, for each slice. The combination of both determines how an actual measurement (such as two conversions with a total value of $3) is encoded on the AdTech side and then passed to the ARA for Contribution Bounding algorithm processing. RMSRE𝜏 can be computed exactly, since it can be expressed in terms of the bias from clipping and the variance of the noise distribution. Following those steps we find out that RMSRE𝜏 for a fixed privacy budget, 𝛼,or a capping parameter, C, is convex (so the error-minimizing value for the other parameter can be obtained efficiently), while for joint variables (C, 𝛼) it becomes non-convex (so we may not always be able to select the best possible parameters). In any case, any off-the-shelf optimizer can be used to select privacy budgets and capping parameters. In our experiments, we use the SLSQP minimizer from the scipy.optimize library.
Different ARA configurations can be evaluated empirically by testing them on a conversion dataset. However, access to such data can be restricted or slow due to privacy concerns, or simply unavailable. One way to address these limitations is to use synthetic data that replicates the characteristics of real data.
We present a method for generating synthetic data responsibly through statistical modeling of real-world conversion datasets. We first perform an empirical analysis of real conversion datasets to uncover relevant characteristics for ARA. We then design a pipeline that uses this distribution knowledge to create a realistic synthetic dataset that can be customized via input parameters.
The pipeline first generates impressions drawn from a power-law distribution (step 1), then for each impression it generates conversions drawn from a Poisson distribution (step 2) and finally, for each conversion, it generates conversion values drawn from a log-normal distribution (step 3). With dataset-dependent parameters, we find that these distributions closely match ad-dataset characteristics. Thus, one can learn parameters from historical or public datasets and generate synthetic datasets for experimentation.
 |
| Overall dataset generation steps with features for illustration. |
We evaluate our algorithms on three real-world datasets (Criteo, AdTech Real Estate, and AdTech Travel) and three synthetic datasets. Criteo consists of 15M clicks, Real Estate consists of 100K conversions, and Travel consists of 30K conversions. Each dataset is partitioned into a training set and a test set. The training set is used to choose contribution budgets, clipping threshold parameters, and the conversion count limit (the real-world datasets have only one conversion per click), and the error is evaluated on the test set. Each dataset is partitioned into slices using impression features. For real-world datasets, we consider three queries for each slice; for synthetic datasets, we consider two queries for each slice.
For each query we choose the RMSRE𝝉 𝜏 value to be five times the median value of the query on the training dataset. This ensures invariance of the error metric to data rescaling, and allows us to combine the errors from features of different scales by using 𝝉 per each feature.
 |
| Scatter plots of real-world datasets illustrating the probability of observing a conversion value. The fitted curves represent best log-normal distribution models that effectively capture the underlying patterns in the data. |
We compare our optimization-based algorithm to a simple baseline approach. For each query, the baseline uses an equal contribution budget and a fixed quantile of the training data to choose the clipping threshold. Our algorithms produce substantially lower error than baselines on both real-world and synthetic datasets. Our optimization-based approach adapts to the privacy budget and data.
 |
| RMSREτ for privacy budgets {1, 2, 4, 8, 16, 32, 64} for our algorithms and baselines on three real-world and three synthetic datasets. Our optimization-based approach consistently achieves lower error than baselines that use a fixed quantile for the clipping threshold and split the contribution budget equally among the queries. |
We study the optimization of summary reports in the ARA, which is currently deployed on hundreds of millions of Chrome browsers. We present a rigorous formulation of the contribution budgeting optimization problem for ARA with the goal of equipping researchers with a robust abstraction that facilitates practical improvements.
Our recipe, which leverages historical data to bound and scale the contributions of future data under differential privacy, is quite general and applicable to settings beyond advertising. One approach based on this work is to use past data to learn the parameters of the data distribution, and then to apply synthetic data derived from this distribution for privacy budgeting for queries on future data. Please see the paper and accompanying code for detailed algorithms and proofs.
This work was done in collaboration with Badih Ghazi, Pritish Kamath, Ravi Kumar, Pasin Manurangsi, and Avinash Varadarajan. We thank Akash Nadan for his help.


Speech-to-speech translation (S2ST) is a type of machine translation that converts spoken language from one language to another. This technology has the potential to break down language barriers and facilitate communication between people from different cultures and backgrounds.
Previously, we introduced Translatotron 1 and Translatotron 2, the first ever models that were able to directly translate speech between two languages. However they were trained in supervised settings with parallel speech data. The scarcity of parallel speech data is a major challenge in this field, so much that most public datasets are semi- or fully-synthesized from text. This adds additional hurdles to learning translation and reconstruction of speech attributes that are not represented in the text and are thus not reflected in the synthesized training data.
Here we present Translatotron 3, a novel unsupervised speech-to-speech translation architecture. In Translatotron 3, we show that it is possible to learn a speech-to-speech translation task from monolingual data alone. This method opens the door not only to translation between more language pairs but also towards translation of the non-textual speech attributes such as pauses, speaking rates, and speaker identity. Our method does not include any direct supervision to target languages and therefore we believe it is the right direction for paralinguistic characteristics (e.g., such as tone, emotion) of the source speech to be preserved across translation. To enable speech-to-speech translation, we use back-translation, which is a technique from unsupervised machine translation (UMT) where a synthetic translation of the source language is used to translate texts without bilingual text datasets. Experimental results in speech-to-speech translation tasks between Spanish and English show that Translatotron 3 outperforms a baseline cascade system.
Translatotron 3 addresses the problem of unsupervised S2ST, which can eliminate the requirement for bilingual speech datasets. To do this, Translatotron 3’s design incorporates three key aspects:
The model is trained using a combination of the unsupervised MUSE embedding loss, reconstruction loss, and S2S back-translation loss. During inference, the shared encoder is utilized to encode the input into a multilingual embedding space, which is subsequently decoded by the target language decoder.
Translatotron 3 employs a shared encoder to encode both the source and target languages. The decoder is composed of a linguistic decoder, an acoustic synthesizer (responsible for acoustic generation of the translation speech), and a singular attention module, like Translatotron 2. However, for Translatotron 3 there are two decoders, one for the source language and another for the target language. During training, we use monolingual speech-text datasets (i.e., these data are made up of speech-text pairs; they are not translations).
The encoder has the same architecture as the speech encoder in the Translatotron 2. The output of the encoder is split into two parts: the first part incorporates semantic information whereas the second part incorporates acoustic information. By using the MUSE loss, the first half of the output is trained to be the MUSE embeddings of the text of the input speech spectrogram. The latter half is updated without the MUSE loss. It is important to note that the same encoder is shared between source and target languages. Furthermore, the MUSE embedding is multilingual in nature. As a result, the encoder is able to learn a multilingual embedding space across source and target languages. This allows a more efficient and effective encoding of the input, as the encoder is able to encode speech from both languages into a common embedding space, rather than maintaining a separate embedding space for each language.
Like Translatotron 2, the decoder is composed of three distinct components, namely the linguistic decoder, the acoustic synthesizer, and the attention module. To effectively handle the different properties of the source and target languages, however, Translatotron 3 has two separate decoders, for the source and target languages.
The training methodology consists of two parts: (1) auto-encoding with reconstruction and (2) a back-translation term. In the first part, the network is trained to auto-encode the input to a multilingual embedding space using the MUSE loss and the reconstruction loss. This phase aims to ensure that the network generates meaningful multilingual representations. In the second part, the network is further trained to translate the input spectrogram by utilizing the back-translation loss. To mitigate the issue of catastrophic forgetting and enforcing the latent space to be multilingual, the MUSE loss and the reconstruction loss are also applied in this second part of training. To ensure that the encoder learns meaningful properties of the input, rather than simply reconstructing the input, we apply SpecAugment to encoder input at both phases. It has been shown to effectively improve the generalization capabilities of the encoder by augmenting the input data.
During the back-translation training phase (illustrated in the section below), the network is trained to translate the input spectrogram to the target language and then back to the source language. The goal of back-translation is to enforce the latent space to be multilingual. To achieve this, the following losses are applied:
In addition to these losses, SpecAugment is applied to the encoder input at both phases. Before the back-translation training phase, the network is trained to auto-encode the input to a multilingual embedding space using the MUSE loss and reconstruction loss.
To ensure that the encoder generates multilingual representations that are meaningful for both decoders, we employ a MUSE loss during training. The MUSE loss forces the encoder to generate such a representation by using pre-trained MUSE embeddings. During the training process, given an input text transcript, we extract the corresponding MUSE embeddings from the embeddings of the input language. The error between MUSE embeddings and the output vectors of the encoder is then minimized. Note that the encoder is indifferent to the language of the input during inference due to the multilingual nature of the embeddings.
 |
| The training and inference in Translatotron 3. Training includes the reconstruction loss via the auto-encoding path and employs the reconstruction loss via back-translation. |
Following are examples of direct speech-to-speech translation from Translatotron 3:
| Input (Spanish) | |
| TTS-synthesized reference (English) | |
| Translatotron 3 (English) |
| Input (Spanish) | |
| TTS-synthesized reference (English) | |
| Translatotron 3 (English) |
| Input (Spanish) | |
| TTS reference (English) | |
| Translatotron 3 (English) |
To empirically evaluate the performance of the proposed approach, we conducted experiments on English and Spanish using various datasets, including the Common Voice 11 dataset, as well as two synthesized datasets derived from the Conversational and Common Voice 11 datasets.
The translation quality was measured by BLEU (higher is better) on ASR (automatic speech recognition) transcriptions from the translated speech, compared to the corresponding reference translation text. Whereas, the speech quality is measured by the MOS score (higher is better). Furthermore, the speaker similarity is measured by the average cosine similarity (higher is better).
Because Translatotron 3 is an unsupervised method, as a baseline we used a cascaded S2ST system that is combined from ASR, unsupervised machine translation (UMT), and TTS (text-to-speech). Specifically, we employ UMT that uses the nearest neighbor in the embedding space in order to create the translation.
Translatotron 3 outperforms the baseline by large margins in every aspect we measured: translation quality, speaker similarity, and speech quality. It particularly excelled on the conversational corpus. Moreover, Translatotron 3 achieves speech naturalness similar to that of the ground truth audio samples (measured by MOS, higher is better).
 |
| Translation quality (measured by BLEU, where higher is better) evaluated on three Spanish-English corpora. |
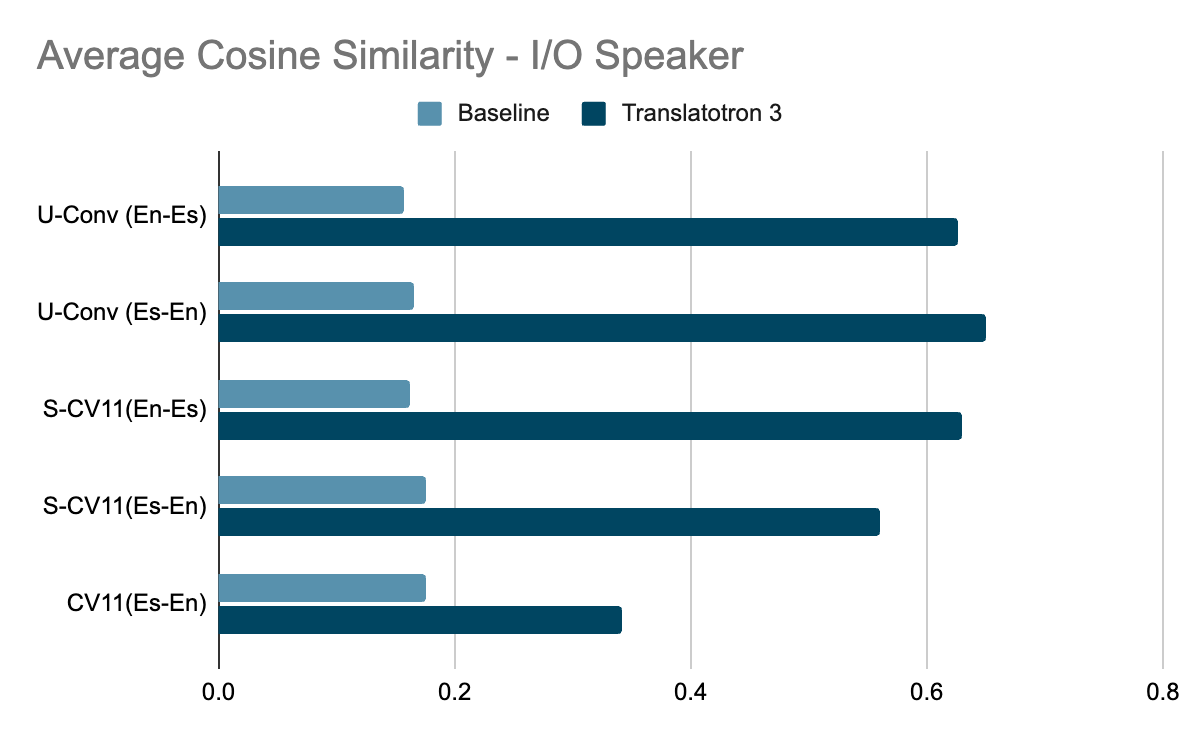 |
| Speech similarity (measured by average cosine similarity between input speaker and output speaker, where higher is better) evaluated on three Spanish-English corpora. |
 |
| Mean-opinion-score (measured by average MOS metric, where higher is better) evaluated on three Spanish-English corpora. |
As future work, we would like to extend the work to more languages and investigate whether zero-shot S2ST can be applied with the back-translation technique. We would also like to examine the use of back-translation with different types of speech data, such as noisy speech and low-resource languages.
The direct contributors to this work include Eliya Nachmani, Alon Levkovitch, Yifan Ding, Chulayutsh Asawaroengchai, Heiga Zhen, and Michelle Tadmor Ramanovich. We also thank Yu Zhang, Yuma Koizumi, Soroosh Mariooryad, RJ Skerry-Ryan, Neil Zeghidour, Christian Frank, Marco Tagliasacchi, Nadav Bar, Benny Schlesinger and Yonghui Wu.
A team of Googlers focused on responsible innovation visited the Fort Peck Tribes in Montana to engage in relationship-building and bidirectional learning.Read More

 Mira Lane explores how AI is empowering creativity with pioneering artist Refik Anadol.Read More
Mira Lane explores how AI is empowering creativity with pioneering artist Refik Anadol.Read More
{kind=link}