We’re rolling out NotebookLM, an experimental offering from Google Labs to summarize information, complex ideas and brainstorm new connections.Read More

An open-source gymnasium for machine learning assisted computer architecture design
Computer Architecture research has a long history of developing simulators and tools to evaluate and shape the design of computer systems. For example, the SimpleScalar simulator was introduced in the late 1990s and allowed researchers to explore various microarchitectural ideas. Computer architecture simulators and tools, such as gem5, DRAMSys, and many more have played a significant role in advancing computer architecture research. Since then, these shared resources and infrastructure have benefited industry and academia and have enabled researchers to systematically build on each other’s work, leading to significant advances in the field.
Nonetheless, computer architecture research is evolving, with industry and academia turning towards machine learning (ML) optimization to meet stringent domain-specific requirements, such as ML for computer architecture, ML for TinyML acceleration, DNN accelerator datapath, memory controllers, power consumption, security, and privacy. Although prior work has demonstrated the benefits of ML in design optimization, the lack of strong, reproducible baselines hinders fair and objective comparison across different methods and poses several challenges to their deployment. To ensure steady progress, it is imperative to understand and tackle these challenges collectively.
To alleviate these challenges, in “ArchGym: An Open-Source Gymnasium for Machine Learning Assisted Architecture Design”, accepted at ISCA 2023, we introduced ArchGym, which includes a variety of computer architecture simulators and ML algorithms. Enabled by ArchGym, our results indicate that with a sufficiently large number of samples, any of a diverse collection of ML algorithms are capable of finding the optimal set of architecture design parameters for each target problem; no one solution is necessarily better than another. These results further indicate that selecting the optimal hyperparameters for a given ML algorithm is essential for finding the optimal architecture design, but choosing them is non-trivial. We release the code and dataset across multiple computer architecture simulations and ML algorithms.
Challenges in ML-assisted architecture research
ML-assisted architecture research poses several challenges, including:
- For a specific ML-assisted computer architecture problem (e.g., finding an optimal solution for a DRAM controller) there is no systematic way to identify optimal ML algorithms or hyperparameters (e.g., learning rate, warm-up steps, etc.). There is a wider range of ML and heuristic methods, from random walk to reinforcement learning (RL), that can be employed for design space exploration (DSE). While these methods have shown noticeable performance improvement over their choice of baselines, it is not evident whether the improvements are because of the choice of optimization algorithms or hyperparameters.
Thus, to ensure reproducibility and facilitate widespread adoption of ML-aided architecture DSE, it is necessary to outline a systematic benchmarking methodology.
- While computer architecture simulators have been the backbone of architectural innovations, there is an emerging need to address the trade-offs between accuracy, speed, and cost in architecture exploration. The accuracy and speed of performance estimation widely varies from one simulator to another, depending on the underlying modeling details (e.g., cycle–accurate vs. ML–based proxy models). While analytical or ML-based proxy models are nimble by virtue of discarding low-level details, they generally suffer from high prediction error. Also, due to commercial licensing, there can be strict limits on the number of runs collected from a simulator. Overall, these constraints exhibit distinct performance vs. sample efficiency trade-offs, affecting the choice of optimization algorithm for architecture exploration.
It is challenging to delineate how to systematically compare the effectiveness of various ML algorithms under these constraints.
- Finally, the landscape of ML algorithms is rapidly evolving and some ML algorithms need data to be useful. Additionally, rendering the outcome of DSE into meaningful artifacts such as datasets is critical for drawing insights about the design space.
In this rapidly evolving ecosystem, it is consequential to ensure how to amortize the overhead of search algorithms for architecture exploration. It is not apparent, nor systematically studied how to leverage exploration data while being agnostic to the underlying search algorithm.
ArchGym design
ArchGym addresses these challenges by providing a unified framework for evaluating different ML-based search algorithms fairly. It comprises two main components: 1) the ArchGym environment and 2) the ArchGym agent. The environment is an encapsulation of the architecture cost model — which includes latency, throughput, area, energy, etc., to determine the computational cost of running the workload, given a set of architectural parameters — paired with the target workload(s). The ArchGym agent is an encapsulation of the ML algorithm used for the search and consists of hyperparameters and a guiding policy. The hyperparameters are intrinsic to the algorithm for which the model is to be optimized and can significantly influence performance. The policy, on the other hand, determines how the agent selects a parameter iteratively to optimize the target objective.
Notably, ArchGym also includes a standardized interface that connects these two components, while also saving the exploration data as the ArchGym Dataset. At its core, the interface entails three main signals: hardware state, hardware parameters, and metrics. These signals are the bare minimum to establish a meaningful communication channel between the environment and the agent. Using these signals, the agent observes the state of the hardware and suggests a set of hardware parameters to iteratively optimize a (user-defined) reward. The reward is a function of hardware performance metrics, such as performance, energy consumption, etc.
 |
| ArchGym comprises two main components: the ArchGym environment and the ArchGym agent. The ArchGym environment encapsulates the cost model and the agent is an abstraction of a policy and hyperparameters. With a standardized interface that connects these two components, ArchGym provides a unified framework for evaluating different ML-based search algorithms fairly while also saving the exploration data as the ArchGym Dataset. |
ML algorithms could be equally favorable to meet user-defined target specifications
Using ArchGym, we empirically demonstrate that across different optimization objectives and DSE problems, at least one set of hyperparameters exists that results in the same hardware performance as other ML algorithms. A poorly selected (random selection) hyperparameter for the ML algorithm or its baseline can lead to a misleading conclusion that a particular family of ML algorithms is better than another. We show that with sufficient hyperparameter tuning, different search algorithms, even random walk (RW), are able to identify the best possible normalized reward. However, note that finding the right set of hyperparameters may require exhaustive search or even luck to make it competitive.
 |
| With a sufficient number of samples, there exists at least one set of hyperparameters that results in the same performance across a range of search algorithms. Here the dashed line represents the maximum normalized reward. Cloud-1, cloud-2, stream, and random indicate four different memory traces for DRAMSys (DRAM subsystem design space exploration framework). |
Dataset construction and high-fidelity proxy model training
Creating a unified interface using ArchGym also enables the creation of datasets that can be used to design better data-driven ML-based proxy architecture cost models to improve the speed of architecture simulation. To evaluate the benefits of datasets in building an ML model to approximate architecture cost, we leverage ArchGym’s ability to log the data from each run from DRAMSys to create four dataset variants, each with a different number of data points. For each variant, we create two categories: (a) Diverse Dataset (DD), which represents the data collected from different agents (ACO, GA, RW, and BO), and (b) ACO only, which shows the data collected exclusively from the ACO agent, both of which are released along with ArchGym. We train a proxy model on each dataset using random forest regression with the objective to predict the latency of designs for a DRAM simulator. Our results show that:
- As we increase the dataset size, the average normalized root mean squared error (RMSE) slightly decreases.
- However, as we introduce diversity in the dataset (e.g., collecting data from different agents), we observe 9× to 42× lower RMSE across different dataset sizes.
 |
| Diverse dataset collection across different agents using ArchGym interface. |
 |
| The impact of a diverse dataset and dataset size on the normalized RMSE. |
The need for a community-driven ecosystem for ML-assisted architecture research
While, ArchGym is an initial effort towards creating an open-source ecosystem that (1) connects a broad range of search algorithms to computer architecture simulators in an unified and easy-to-extend manner, (2) facilitates research in ML-assisted computer architecture, and (3) forms the scaffold to develop reproducible baselines, there are a lot of open challenges that need community-wide support. Below we outline some of the open challenges in ML-assisted architecture design. Addressing these challenges requires a well coordinated effort and a community driven ecosystem.
 |
| Key challenges in ML-assisted architecture design. |
We call this ecosystem Architecture 2.0. We outline the key challenges and a vision for building an inclusive ecosystem of interdisciplinary researchers to tackle the long-standing open problems in applying ML for computer architecture research. If you are interested in helping shape this ecosystem, please fill out the interest survey.
Conclusion
ArchGym is an open source gymnasium for ML architecture DSE and enables an standardized interface that can be readily extended to suit different use cases. Additionally, ArchGym enables fair and reproducible comparison between different ML algorithms and helps to establish stronger baselines for computer architecture research problems.
We invite the computer architecture community as well as the ML community to actively participate in the development of ArchGym. We believe that the creation of a gymnasium-type environment for computer architecture research would be a significant step forward in the field and provide a platform for researchers to use ML to accelerate research and lead to new and innovative designs.
Acknowledgements
This blogpost is based on joint work with several co-authors at Google and Harvard University. We would like to acknowledge and highlight Srivatsan Krishnan (Harvard) who contributed several ideas to this project in collaboration with Shvetank Prakash (Harvard), Jason Jabbour (Harvard), Ikechukwu Uchendu (Harvard), Susobhan Ghosh (Harvard), Behzad Boroujerdian (Harvard), Daniel Richins (Harvard), Devashree Tripathy (Harvard), and Thierry Thambe (Harvard). In addition, we would also like to thank James Laudon, Douglas Eck, Cliff Young, and Aleksandra Faust for their support, feedback, and motivation for this work. We would also like to thank John Guilyard for the animated figure used in this post. Amir Yazdanbakhsh is now a Research Scientist at Google DeepMind and Vijay Janapa Reddi is an Associate Professor at Harvard.

Google at ACL 2023
.jpg)
This week, the 61st annual meeting of the Association for Computational Linguistics (ACL), a premier conference covering a broad spectrum of research areas that are concerned with computational approaches to natural language, is taking place online.
As a leader in natural language processing and understanding, and a Diamond Level sponsor of ACL 2023, Google will showcase the latest research in the field with over 50 publications, and active involvement in a variety of workshops and tutorials.
If you’re registered for ACL 2023, we hope that you’ll visit the Google booth to learn more about the projects at Google that go into solving interesting problems for billions of people. You can also learn more about Google’s participation below (Google affiliations in bold).
Board and Organizing Committee
Area chairs include: Dan Garrette
Workshop chairs include: Annie Louis
Publication chairs include: Lei Shu
Program Committee includes: Vinodkumar Prabhakaran, Najoung Kim, Markus Freitag
Spotlight papers
NusaCrowd: Open Source Initiative for Indonesian NLP Resources
Samuel Cahyawijaya, Holy Lovenia, Alham Fikri Aji, Genta Winata, Bryan Wilie, Fajri Koto, Rahmad Mahendra, Christian Wibisono, Ade Romadhony, Karissa Vincentio, Jennifer Santoso, David Moeljadi, Cahya Wirawan, Frederikus Hudi, Muhammad Satrio Wicaksono, Ivan Parmonangan, Ika Alfina, Ilham Firdausi Putra, Samsul Rahmadani, Yulianti Oenang, Ali Septiandri, James Jaya, Kaustubh Dhole, Arie Suryani, Rifki Afina Putri, Dan Su, Keith Stevens, Made Nindyatama Nityasya, Muhammad Adilazuarda, Ryan Hadiwijaya, Ryandito Diandaru, Tiezheng Yu, Vito Ghifari, Wenliang Dai, Yan Xu, Dyah Damapuspita, Haryo Wibowo, Cuk Tho, Ichwanul Karo Karo, Tirana Fatyanosa, Ziwei Ji, Graham Neubig, Timothy Baldwin, Sebastian Ruder, Pascale Fung, Herry Sujaini, Sakriani Sakti, Ayu Purwarianti
Optimizing Test-Time Query Representations for Dense Retrieval
Mujeen Sung, Jungsoo Park, Jaewoo Kang, Danqi Chen, Jinhyuk Lee
PropSegmEnt: A Large-Scale Corpus for Proposition-Level Segmentation and Entailment Recognition
Sihao Chen*, Senaka Buthpitiya, Alex Fabrikant, Dan Roth, Tal Schuster
Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes
Cheng-Yu Hsieh*, Chun-Liang Li, Chih-Kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alex Ratner, Ranjay Krishna, Chen-Yu Lee, Tomas Pfister
Large Language Models with Controllable Working Memory
Daliang Li, Ankit Singh Rawat, Manzil Zaheer, Xin Wang, Michal Lukasik, Andreas Veit, Felix Yu, Sanjiv Kumar
OpineSum: Entailment-Based Self-Training for Abstractive Opinion Summarization
Annie Louis, Joshua Maynez
RISE: Leveraging Retrieval Techniques for Summarization Evaluation
David Uthus, Jianmo Ni
Follow the Leader(board) with Confidence: Estimating p-Values from a Single Test Set with Item and Response Variance
Shira Wein*, Christopher Homan, Lora Aroyo, Chris Welty
SamToNe: Improving Contrastive Loss for Dual Encoder Retrieval Models with Same Tower Negatives
Fedor Moiseev, Gustavo Hernandez Abrego, Peter Dornbach, Imed Zitouni, Enrique Alfonseca, Zhe Dong
Papers
Searching for Needles in a Haystack: On the Role of Incidental Bilingualism in PaLM’s Translation Capability
Eleftheria Briakou, Colin Cherry, George Foster
Prompting PaLM for Translation: Assessing Strategies and Performance
David Vilar, Markus Freitag, Colin Cherry, Jiaming Luo, Viresh Ratnakar, George Foster
Query Refinement Prompts for Closed-Book Long-Form QA
Reinald Kim Amplayo, Kellie Webster, Michael Collins, Dipanjan Das, Shashi Narayan
To Adapt or to Annotate: Challenges and Interventions for Domain Adaptation in Open-Domain Question Answering
Dheeru Dua*, Emma Strubell, Sameer Singh, Pat Verga
FRMT: A Benchmark for Few-Shot Region-Aware Machine Translation (see blog post)
Parker Riley, Timothy Dozat, Jan A. Botha, Xavier Garcia, Dan Garrette, Jason Riesa, Orhan Firat, Noah Constant
Conditional Generation with a Question-Answering Blueprint
Shashi Narayan, Joshua Maynez, Reinald Kim Amplayo, Kuzman Ganchev, Annie Louis, Fantine Huot, Anders Sandholm, Dipanjan Das, Mirella Lapata
Coreference Resolution Through a Seq2Seq Transition-Based System
Bernd Bohnet, Chris Alberti, Michael Collins
Cross-Lingual Transfer with Language-Specific Subnetworks for Low-Resource Dependency Parsing
Rochelle Choenni, Dan Garrette, Ekaterina Shutova
DAMP: Doubly Aligned Multilingual Parser for Task-Oriented Dialogue
William Held*, Christopher Hidey, Fei Liu, Eric Zhu, Rahul Goel, Diyi Yang, Rushin Shah
RARR: Researching and Revising What Language Models Say, Using Language Models
Luyu Gao*, Zhuyun Dai, Panupong Pasupat, Anthony Chen*, Arun Tejasvi Chaganty, Yicheng Fan, Vincent Y. Zhao, Ni Lao, Hongrae Lee, Da-Cheng Juan, Kelvin Guu
Benchmarking Large Language Model Capabilities for Conditional Generation
Joshua Maynez, Priyanka Agrawal, Sebastian Gehrmann
Crosslingual Generalization Through Multitask Fine-Tuning
Niklas Muennighoff, Thomas Wang, Lintang Sutawika, Adam Roberts, Stella Biderman, Teven Le Scao, M. Saiful Bari, Sheng Shen, Zheng Xin Yong, Hailey Schoelkopf, Xiangru Tang, Dragomir Radev, Alham Fikri Aji, Khalid Almubarak, Samuel Albanie, Zaid Alyafeai, Albert Webson, Edward Raff, Colin Raffel
DisentQA: Disentangling Parametric and Contextual Knowledge with Counterfactual Question Answering
Ella Neeman, Roee Aharoni, Or Honovich, Leshem Choshen, Idan Szpektor, Omri Abend
Resolving Indirect Referring Expressions for Entity Selection
Mohammad Javad Hosseini, Filip Radlinski, Silvia Pareti, Annie Louis
SeeGULL: A Stereotype Benchmark with Broad Geo-Cultural Coverage Leveraging Generative Models
Akshita Jha*, Aida Mostafazadeh Davani, Chandan K Reddy, Shachi Dave, Vinodkumar Prabhakaran, Sunipa Dev
The Tail Wagging the Dog: Dataset Construction Biases of Social Bias Benchmarks
Nikil Selvam, Sunipa Dev, Daniel Khashabi, Tushar Khot, Kai-Wei Chang
Character-Aware Models Improve Visual Text Rendering
Rosanne Liu, Dan Garrette, Chitwan Saharia, William Chan, Adam Roberts, Sharan Narang, Irina Blok, RJ Mical, Mohammad Norouzi, Noah Constant
Cold-Start Data Selection for Better Few-Shot Language Model Fine-Tuning: A Prompt-Based Uncertainty Propagation Approach
Yue Yu, Rongzhi Zhang, Ran Xu, Jieyu Zhang, Jiaming Shen, Chao Zhang
Covering Uncommon Ground: Gap-Focused Question Generation for Answer Assessment
Roni Rabin, Alexandre Djerbetian, Roee Engelberg, Lidan Hackmon, Gal Elidan, Reut Tsarfaty, Amir Globerson
FormNetV2: Multimodal Graph Contrastive Learning for Form Document Information Extraction
Chen-Yu Lee, Chun-Liang Li, Hao Zhang, Timothy Dozat, Vincent Perot, Guolong Su, Xiang Zhang, Kihyuk Sohn, Nikolay Glushinev, Renshen Wang, Joshua Ainslie, Shangbang Long, Siyang Qin, Yasuhisa Fujii, Nan Hua, Tomas Pfister
Dialect-Robust Evaluation of Generated Text
Jiao Sun*, Thibault Sellam, Elizabeth Clark, Tu Vu*, Timothy Dozat, Dan Garrette, Aditya Siddhant, Jacob Eisenstein, Sebastian Gehrmann
MISGENDERED: Limits of Large Language Models in Understanding Pronouns
Tamanna Hossain, Sunipa Dev, Sameer Singh
LAMBADA: Backward Chaining for Automated Reasoning in Natural Language
Mehran Kazemi, Najoung Kim, Deepti Bhatia, Xin Xu, Deepak Ramachandran
LAIT: Efficient Multi-Segment Encoding in Transformers with Layer-Adjustable Interaction
Jeremiah Milbauer*, Annie Louis, Mohammad Javad Hosseini, Alex Fabrikant, Donald Metzler, Tal Schuster
Modular Visual Question Answering via Code Generation (see blog post)
Sanjay Subramanian, Medhini Narasimhan, Kushal Khangaonkar, Kevin Yang, Arsha Nagrani, Cordelia Schmid, Andy Zeng, Trevor Darrell, Dan Klein
Towards Understanding Chain-of-Thought Prompting: An Empirical Study of What Matters
Boshi Wang, Sewon Min, Xiang Deng, Jiaming Shen, You Wu, Luke Zettlemoyer and Huan Sun
Better Zero-Shot Reasoning with Self-Adaptive Prompting
Xingchen Wan*, Ruoxi Sun, Hanjun Dai, Sercan Ö. Arik, Tomas Pfister
Factually Consistent Summarization via Reinforcement Learning with Textual Entailment Feedback
Paul Roit, Johan Ferret, Lior Shani, Roee Aharoni, Geoffrey Cideron, Robert Dadashi, Matthieu Geist, Sertan Girgin, Léonard Hussenot, Orgad Keller, Nikola Momchev, Sabela Ramos, Piotr Stanczyk, Nino Vieillard, Olivier Bachem, Gal Elidan, Avinatan Hassidim, Olivier Pietquin, Idan Szpektor
Natural Language to Code Generation in Interactive Data Science Notebooks
Pengcheng Yin, Wen-Ding Li, Kefan Xiao, Abhishek Rao, Yeming Wen, Kensen Shi, Joshua Howland, Paige Bailey, Michele Catasta, Henryk Michalewski, Oleksandr Polozov, Charles Sutton
Teaching Small Language Models to Reason
Lucie Charlotte Magister*, Jonathan Mallinson, Jakub Adamek, Eric Malmi, Aliaksei Severyn
Using Domain Knowledge to Guide Dialog Structure Induction via Neural Probabilistic Soft Logic
Connor Pryor*, Quan Yuan, Jeremiah Liu, Mehran Kazemi, Deepak Ramachandran, Tania Bedrax-Weiss, Lise Getoor
A Needle in a Haystack: An Analysis of High-Agreement Workers on MTurk for Summarization
Lining Zhang, Simon Mille, Yufang Hou, Daniel Deutsch, Elizabeth Clark, Yixin Liu, Saad Mahamood, Sebastian Gehrmann, Miruna Clinciu, Khyathi Raghavi Chandu and João Sedoc
Industry Track papers
Federated Learning of Gboard Language Models with Differential Privacy
Zheng Xu, Yanxiang Zhang, Galen Andrew, Christopher Choquette, Peter Kairouz, Brendan McMahan, Jesse Rosenstock, Yuanbo Zhang
KAFA: Rethinking Image Ad Understanding with Knowledge-Augmented Feature Adaptation of Vision-Language Models
Zhiwei Jia*, Pradyumna Narayana, Arjun Akula, Garima Pruthi, Hao Su, Sugato Basu, Varun Jampani
ACL Findings papers
Multilingual Summarization with Factual Consistency Evaluation
Roee Aharoni, Shashi Narayan, Joshua Maynez, Jonathan Herzig, Elizabeth Clark, Mirella Lapata
Parameter-Efficient Fine-Tuning for Robust Continual Multilingual Learning
Kartikeya Badola, Shachi Dave, Partha Talukdar
FiDO: Fusion-in-Decoder Optimized for Stronger Performance and Faster Inference
Michiel de Jong*, Yury Zemlyanskiy, Joshua Ainslie, Nicholas FitzGerald, Sumit Sanghai, Fei Sha, William Cohen
A Simple, Yet Effective Approach to Finding Biases in Code Generation
Spyridon Mouselinos, Mateusz Malinowski, Henryk Michalewski
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them
Mirac Suzgun, Nathan Scales, Nathanael Scharli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc Le, Ed Chi, Denny Zhou, Jason Wei
QueryForm: A Simple Zero-Shot Form Entity Query Framework
Zifeng Wang*, Zizhao Zhang, Jacob Devlin, Chen-Yu Lee, Guolong Su, Hao Zhang, Jennifer Dy, Vincent Perot, Tomas Pfister
ReGen: Zero-Shot Text Classification via Training Data Generation with Progressive Dense Retrieval
Yue Yu, Yuchen Zhuang, Rongzhi Zhang, Yu Meng, Jiaming Shen, Chao Zhang
Multilingual Sequence-to-Sequence Models for Hebrew NLP
Matan Eyal, Hila Noga, Roee Aharoni, Idan Szpektor, Reut Tsarfaty
Triggering Multi-Hop Reasoning for Question Answering in Language Models Using Soft Prompts and Random Walks
Kanishka Misra*, Cicero Nogueira dos Santos, Siamak Shakeri
Tutorials
Complex Reasoning in Natural Language
Wenting Zhao, Mor Geva, Bill Yuchen Lin, Michihiro Yasunaga, Aman Madaan, Tao Yu
Generating Text from Language Models
Afra Amini, Ryan Cotterell, John Hewitt, Clara Meister, Tiago Pimentel
Workshops
Simple and Efficient Natural Language Processing (SustaiNLP)
Organizers include: Tal Schuster
Workshop on Online Abuse and Harms (WOAH)
Organizers include: Aida Mostafazadeh Davani
Document-Grounded Dialogue and Conversational Question Answering (DialDoc)
Organizers include: Roee Aharoni
NLP for Conversational AI
Organizers include: Abhinav Rastogi
Computation and Written Language (CAWL)
Organizers include: Kyle Gorman, Brian Roark, Richard Sproat
Computational Morphology and Phonology (SIGMORPHON)
Speakers include: Kyle Gorman
Workshop on Narrative Understanding (WNU)
Organizers include: Elizabeth Clark
* Work done while at Google

Modular visual question answering via code generation
Visual question answering (VQA) is a machine learning task that requires a model to answer a question about an image or a set of images. Conventional VQA approaches need a large amount of labeled training data consisting of thousands of human-annotated question-answer pairs associated with images. In recent years, advances in large-scale pre-training have led to the development of VQA methods that perform well with fewer than fifty training examples (few-shot) and without any human-annotated VQA training data (zero-shot). However, there is still a significant performance gap between these methods and state-of-the-art fully supervised VQA methods, such as MaMMUT and VinVL. In particular, few-shot methods struggle with spatial reasoning, counting, and multi-hop reasoning. Furthermore, few-shot methods have generally been limited to answering questions about single images.
To improve accuracy on VQA examples that involve complex reasoning, in “Modular Visual Question Answering via Code Generation,” to appear at ACL 2023, we introduce CodeVQA, a framework that answers visual questions using program synthesis. Specifically, when given a question about an image or set of images, CodeVQA generates a Python program (code) with simple visual functions that allow it to process images, and executes this program to determine the answer. We demonstrate that in the few-shot setting, CodeVQA outperforms prior work by roughly 3% on the COVR dataset and 2% on the GQA dataset.
CodeVQA
The CodeVQA approach uses a code-writing large language model (LLM), such as PALM, to generate Python programs (code). We guide the LLM to correctly use visual functions by crafting a prompt consisting of a description of these functions and fewer than fifteen “in-context” examples of visual questions paired with the associated Python code for them. To select these examples, we compute embeddings for the input question and of all of the questions for which we have annotated programs (a randomly chosen set of fifty). Then, we select questions that have the highest similarity to the input and use them as in-context examples. Given the prompt and question that we want to answer, the LLM generates a Python program representing that question.
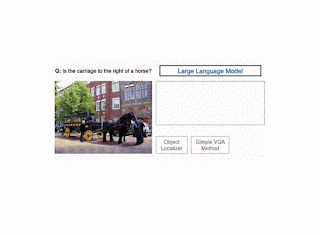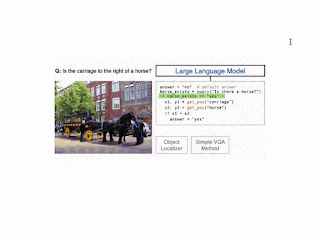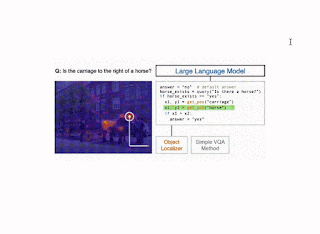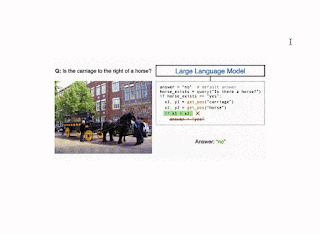
We instantiate the CodeVQA framework using three visual functions: (1) query, (2) get_pos, and (3) find_matching_image.
Query, which answers a question about a single image, is implemented using the few-shot Plug-and-Play VQA (PnP-VQA) method. PnP-VQA generates captions using BLIP — an image-captioning transformer pre-trained on millions of image-caption pairs — and feeds these into a LLM that outputs the answers to the question.Get_pos, which is an object localizer that takes a description of an object as input and returns its position in the image, is implemented using GradCAM. Specifically, the description and the image are passed through the BLIP joint text-image encoder, which predicts an image-text matching score. GradCAM takes the gradient of this score with respect to the image features to find the region most relevant to the text.Find_matching_image, which is used in multi-image questions to find the image that best matches a given input phrase, is implemented by using BLIP text and image encoders to compute a text embedding for the phrase and an image embedding for each image. Then the dot products of the text embedding with each image embedding represent the relevance of each image to the phrase, and we pick the image that maximizes this relevance.
The three functions can be implemented using models that require very little annotation (e.g., text and image-text pairs collected from the web and a small number of VQA examples). Furthermore, the CodeVQA framework can be easily generalized beyond these functions to others that a user might implement (e.g., object detection, image segmentation, or knowledge base retrieval).
 |
Illustration of the CodeVQA method. First, a large language model generates a Python program (code), which invokes visual functions that represent the question. In this example, a simple VQA method (query) is used to answer one part of the question, and an object localizer (get_pos) is used to find the positions of the objects mentioned. Then the program produces an answer to the original question by combining the outputs of these functions. |
Results
The CodeVQA framework correctly generates and executes Python programs not only for single-image questions, but also for multi-image questions. For example, if given two images, each showing two pandas, a question one might ask is, “Is it true that there are four pandas?” In this case, the LLM converts the counting question about the pair of images into a program in which an object count is obtained for each image (using the query function). Then the counts for both images are added to compute a total count, which is then compared to the number in the original question to yield a yes or no answer.
 |
We evaluate CodeVQA on three visual reasoning datasets: GQA (single-image), COVR (multi-image), and NLVR2 (multi-image). For GQA, we provide 12 in-context examples to each method, and for COVR and NLVR2, we provide six in-context examples to each method. The table below shows that CodeVQA improves consistently over the baseline few-shot VQA method on all three datasets.
| Method | GQA | COVR | NLVR2 | ||||||||
| Few-shot PnP-VQA | 46.56 | 49.06 | 63.37 | ||||||||
| CodeVQA | 49.03 | 54.11 | 64.04 |
| Results on the GQA, COVR, and NLVR2 datasets, showing that CodeVQA consistently improves over few-shot PnP-VQA. The metric is exact-match accuracy, i.e., the percentage of examples in which the predicted answer exactly matches the ground-truth answer. |
We find that in GQA, CodeVQA’s accuracy is roughly 30% higher than the baseline on spatial reasoning questions, 4% higher on “and” questions, and 3% higher on “or” questions. The third category includes multi-hop questions such as “Are there salt shakers or skateboards in the picture?”, for which the generated program is shown below.
img = open_image("Image13.jpg")
salt_shakers_exist = query(img, "Are there any salt shakers?")
skateboards_exist = query(img, "Are there any skateboards?")
if salt_shakers_exist == "yes" or skateboards_exist == "yes":
answer = "yes"
else:
answer = "no"
In COVR, we find that CodeVQA’s gain over the baseline is higher when the number of input images is larger, as shown in the table below. This trend indicates that breaking the problem down into single-image questions is beneficial.
| Number of images | |||||||||||
| Method | 1 | 2 | 3 | 4 | 5 | ||||||
| Few-shot PnP-VQA | 91.7 | 51.5 | 48.3 | 47.0 | 46.9 | ||||||
| CodeVQA | 75.0 | 53.3 | 48.7 | 53.2 | 53.4 | ||||||
Conclusion
We present CodeVQA, a framework for few-shot visual question answering that relies on code generation to perform multi-step visual reasoning. Exciting directions for future work include expanding the set of modules used and creating a similar framework for visual tasks beyond VQA. We note that care should be taken when considering whether to deploy a system such as CodeVQA, since vision-language models like the ones used in our visual functions have been shown to exhibit social biases. At the same time, compared to monolithic models, CodeVQA offers additional interpretability (through the Python program) and controllability (by modifying the prompts or visual functions), which are useful in production systems.
Acknowledgements
This research was a collaboration between UC Berkeley’s Artificial Intelligence Research lab (BAIR) and Google Research, and was conducted by Sanjay Subramanian, Medhini Narasimhan, Kushal Khangaonkar, Kevin Yang, Arsha Nagrani, Cordelia Schmid, Andy Zeng, Trevor Darrell, and Dan Klein.

Pic2Word: Mapping pictures to words for zero-shot composed image retrieval
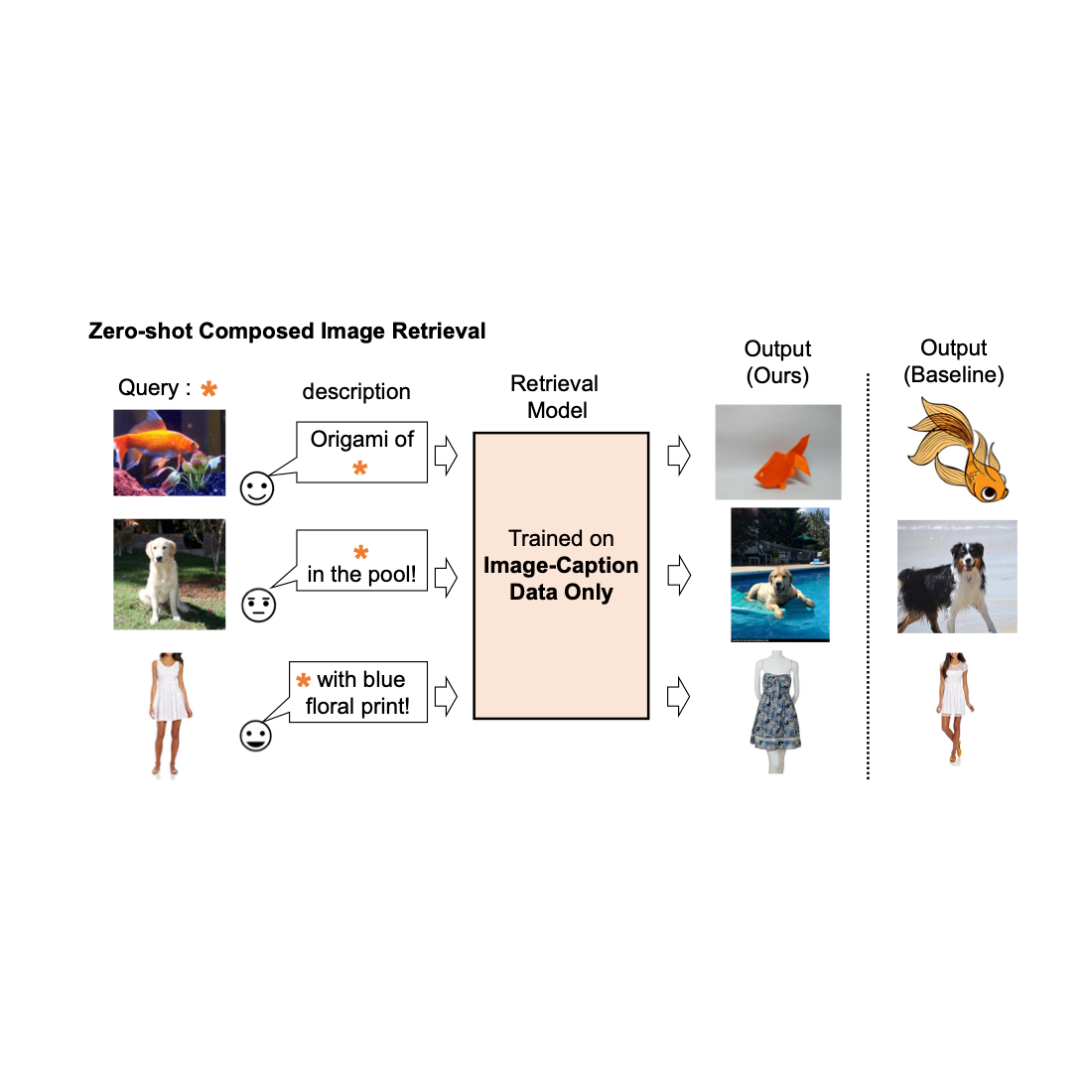
Image retrieval plays a crucial role in search engines. Typically, their users rely on either image or text as a query to retrieve a desired target image. However, text-based retrieval has its limitations, as describing the target image accurately using words can be challenging. For instance, when searching for a fashion item, users may want an item whose specific attribute, e.g., the color of a logo or the logo itself, is different from what they find in a website. Yet searching for the item in an existing search engine is not trivial since precisely describing the fashion item by text can be challenging. To address this fact, composed image retrieval (CIR) retrieves images based on a query that combines both an image and a text sample that provides instructions on how to modify the image to fit the intended retrieval target. Thus, CIR allows precise retrieval of the target image by combining image and text.
However, CIR methods require large amounts of labeled data, i.e., triplets of a 1) query image, 2) description, and 3) target image. Collecting such labeled data is costly, and models trained on this data are often tailored to a specific use case, limiting their ability to generalize to different datasets.
To address these challenges, in “Pic2Word: Mapping Pictures to Words for Zero-shot Composed Image Retrieval”, we propose a task called zero-shot CIR (ZS-CIR). In ZS-CIR, we aim to build a single CIR model that performs a variety of CIR tasks, such as object composition, attribute editing, or domain conversion, without requiring labeled triplet data. Instead, we propose to train a retrieval model using large-scale image-caption pairs and unlabeled images, which are considerably easier to collect than supervised CIR datasets at scale. To encourage reproducibility and further advance this space, we also release the code.
 |
| Description of existing composed image retrieval model. |
 |
| We train a composed image retrieval model using image-caption data only. Our model retrieves images aligned with the composition of the query image and text. |
Method overview
We propose to leverage the language capabilities of the language encoder in the contrastive language-image pre-trained model (CLIP), which excels at generating semantically meaningful language embeddings for a wide range of textual concepts and attributes. To that end, we use a lightweight mapping sub-module in CLIP that is designed to map an input picture (e.g., a photo of a cat) from the image embedding space to a word token (e.g., “cat”) in the textual input space. The whole network is optimized with the vision-language contrastive loss to again ensure the visual and text embedding spaces are as close as possible given a pair of an image and its textual description. Then, the query image can be treated as if it is a word. This enables the flexible and seamless composition of query image features and text descriptions by the language encoder. We call our method Pic2Word and provide an overview of its training process in the figure below. We want the mapped token s to represent the input image in the form of word token. Then, we train the mapping network to reconstruct the image embedding in the language embedding, p. Specifically, we optimize the contrastive loss proposed in CLIP computed between the visual embedding v and the textual embedding p.
 |
| Training of the mapping network (fM) using unlabeled images only. We optimize only the mapping network with a frozen visual and text encoder. |
Given the trained mapping network, we can regard an image as a word token and pair it with the text description to flexibly compose the joint image-text query as shown in the figure below.
 |
| With the trained mapping network, we regard the image as a word token and pair it with the text description to flexibly compose the joint image-text query. |
Evaluation
We conduct a variety of experiments to evaluate Pic2Word’s performance on a variety of CIR tasks.
Domain conversion
We first evaluate the capability of compositionality of the proposed method on domain conversion — given an image and the desired new image domain (e.g., sculpture, origami, cartoon, toy), the output of the system should be an image with the same content but in the new desired image domain or style. As illustrated below, we evaluate the ability to compose the category information and domain description given as an image and text, respectively. We evaluate the conversion from real images to four domains using ImageNet and ImageNet-R.
To compare with approaches that do not require supervised training data, we pick three approaches: (i) image only performs retrieval only with visual embedding, (ii) text only employs only text embedding, and (iii) image + text averages the visual and text embedding to compose the query. The comparison with (iii) shows the importance of composing image and text using a language encoder. We also compare with Combiner, which trains the CIR model on Fashion-IQ or CIRR.
 |
| We aim to convert the domain of the input query image into the one described with text, e.g., origami. |
As shown in figure below, our proposed approach outperforms baselines by a large margin.
 |
| Results (recall@10, i.e., the percentage of relevant instances in the first 10 images retrieved.) on composed image retrieval for domain conversion. |
Fashion attribute composition
Next, we evaluate the composition of fashion attributes, such as the color of cloth, logo, and length of sleeve, using the Fashion-IQ dataset. The figure below illustrates the desired output given the query.
 |
| Overview of CIR for fashion attributes. |
In the figure below, we present a comparison with baselines, including supervised baselines that utilized triplets for training the CIR model: (i) CB uses the same architecture as our approach, (ii) CIRPLANT, ALTEMIS, MAAF use a smaller backbone, such as ResNet50. Comparison to these approaches will give us the understanding on how well our zero-shot approach performs on this task.
Although CB outperforms our approach, our method performs better than supervised baselines with smaller backbones. This result suggests that by utilizing a robust CLIP model, we can train a highly effective CIR model without requiring annotated triplets.
 |
| Results (recall@10, i.e., the percentage of relevant instances in the first 10 images retrieved.) on composed image retrieval for Fashion-IQ dataset (higher is better). Light blue bars train the model using triplets. Note that our approach performs on par with these supervised baselines with shallow (smaller) backbones. |
Qualitative results
We show several examples in the figure below. Compared to a baseline method that does not require supervised training data (text + image feature averaging), our approach does a better job of correctly retrieving the target image.
 |
| Qualitative results on diverse query images and text description. |
Conclusion and future work
In this article, we introduce Pic2Word, a method for mapping pictures to words for ZS-CIR. We propose to convert the image into a word token to achieve a CIR model using only an image-caption dataset. Through a variety of experiments, we verify the effectiveness of the trained model on diverse CIR tasks, indicating that training on an image-caption dataset can build a powerful CIR model. One potential future research direction is utilizing caption data to train the mapping network, although we use only image data in the present work.
Acknowledgements
This research was conducted by Kuniaki Saito, Kihyuk Sohn, Xiang Zhang, Chun-Liang Li, Chen-Yu Lee, Kate Saenko, and Tomas Pfister. Also thanks to Zizhao Zhang and Sergey Ioffe for their valuable feedback.
A principled approach to evolving choice and control for web content
We’re kicking off a public discussion across the web and AI communities to develop new machine-readable means to provide web publisher choice and control.Read More
Unlocking the AI-powered opportunity in the UK
 AI is the most profound technology that humanity is working on today. It’s a critical part of solving big societal challenges and helping to make our everyday lives bett…Read More
AI is the most profound technology that humanity is working on today. It’s a critical part of solving big societal challenges and helping to make our everyday lives bett…Read More

Leonardo da Vinci: Inside a genius mind
 28 institutions from around the world join forces to showcase Leonardo da Vinci’s unparalleled legacy, blending art, science, and AI innovationRead More
28 institutions from around the world join forces to showcase Leonardo da Vinci’s unparalleled legacy, blending art, science, and AI innovationRead More

Announcing the first Machine Unlearning Challenge
Deep learning has recently driven tremendous progress in a wide array of applications, ranging from realistic image generation and impressive retrieval systems to language models that can hold human-like conversations. While this progress is very exciting, the widespread use of deep neural network models requires caution: as guided by Google’s AI Principles, we seek to develop AI technologies responsibly by understanding and mitigating potential risks, such as the propagation and amplification of unfair biases and protecting user privacy.
Fully erasing the influence of the data requested to be deleted is challenging since, aside from simply deleting it from databases where it’s stored, it also requires erasing the influence of that data on other artifacts such as trained machine learning models. Moreover, recent research [1, 2] has shown that in some cases it may be possible to infer with high accuracy whether an example was used to train a machine learning model using membership inference attacks (MIAs). This can raise privacy concerns, as it implies that even if an individual’s data is deleted from a database, it may still be possible to infer whether that individual’s data was used to train a model.
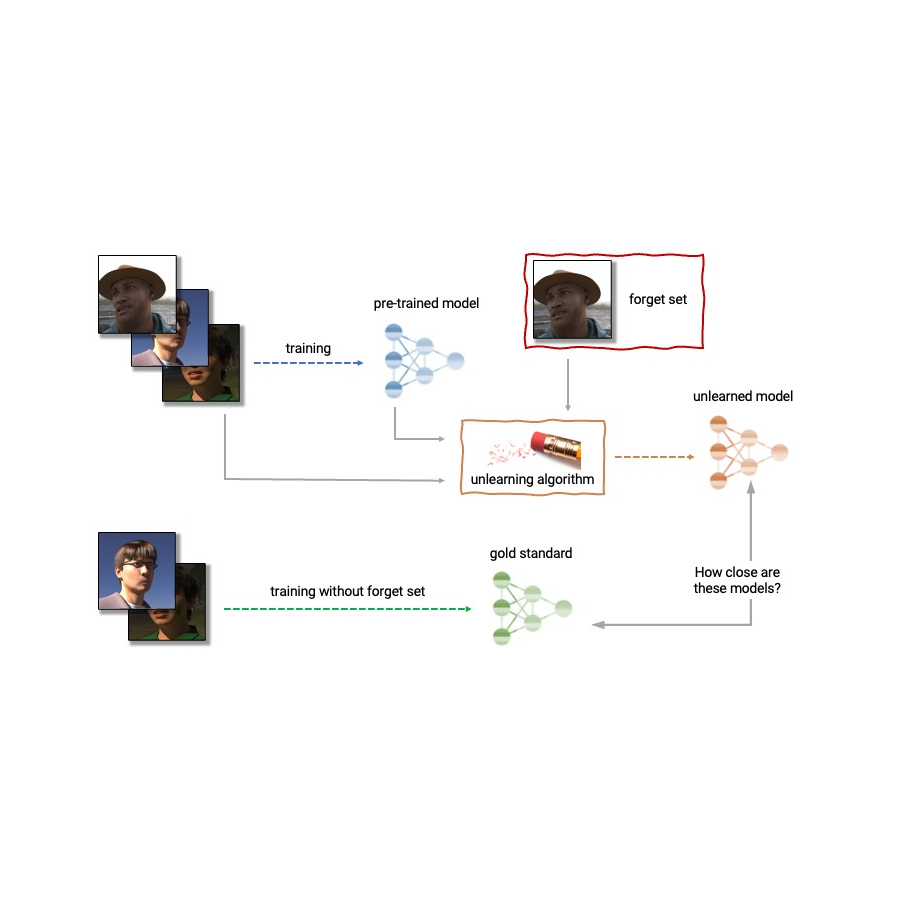
Given the above, machine unlearning is an emergent subfield of machine learning that aims to remove the influence of a specific subset of training examples — the “forget set” — from a trained model. Furthermore, an ideal unlearning algorithm would remove the influence of certain examples while maintaining other beneficial properties, such as the accuracy on the rest of the train set and generalization to held-out examples. A straightforward way to produce this unlearned model is to retrain the model on an adjusted training set that excludes the samples from the forget set. However, this is not always a viable option, as retraining deep models can be computationally expensive. An ideal unlearning algorithm would instead use the already-trained model as a starting point and efficiently make adjustments to remove the influence of the requested data.
Today we’re thrilled to announce that we’ve teamed up with a broad group of academic and industrial researchers to organize the first Machine Unlearning Challenge. The competition considers a realistic scenario in which after training, a certain subset of the training images must be forgotten to protect the privacy or rights of the individuals concerned. The competition will be hosted on Kaggle, and submissions will be automatically scored in terms of both forgetting quality and model utility. We hope that this competition will help advance the state of the art in machine unlearning and encourage the development of efficient, effective and ethical unlearning algorithms.
Machine unlearning applications
Machine unlearning has applications beyond protecting user privacy. For instance, one can use unlearning to erase inaccurate or outdated information from trained models (e.g., due to errors in labeling or changes in the environment) or remove harmful, manipulated, or outlier data.
The field of machine unlearning is related to other areas of machine learning such as differential privacy, life-long learning, and fairness. Differential privacy aims to guarantee that no particular training example has too large an influence on the trained model; a stronger goal compared to that of unlearning, which only requires erasing the influence of the designated forget set. Life-long learning research aims to design models that can learn continuously while maintaining previously-acquired skills. As work on unlearning progresses, it may also open additional ways to boost fairness in models, by correcting unfair biases or disparate treatment of members belonging to different groups (e.g., demographics, age groups, etc.).
 |
| Anatomy of unlearning. An unlearning algorithm takes as input a pre-trained model and one or more samples from the train set to unlearn (the “forget set”). From the model, forget set, and retain set, the unlearning algorithm produces an updated model. An ideal unlearning algorithm produces a model that is indistinguishable from the model trained without the forget set. |
Challenges of machine unlearning
The problem of unlearning is complex and multifaceted as it involves several conflicting objectives: forgetting the requested data, maintaining the model’s utility (e.g., accuracy on retained and held-out data), and efficiency. Because of this, existing unlearning algorithms make different trade-offs. For example, full retraining achieves successful forgetting without damaging model utility, but with poor efficiency, while adding noise to the weights achieves forgetting at the expense of utility.
Furthermore, the evaluation of forgetting algorithms in the literature has so far been highly inconsistent. While some works report the classification accuracy on the samples to unlearn, others report distance to the fully retrained model, and yet others use the error rate of membership inference attacks as a metric for forgetting quality [4, 5, 6].
We believe that the inconsistency of evaluation metrics and the lack of a standardized protocol is a serious impediment to progress in the field — we are unable to make direct comparisons between different unlearning methods in the literature. This leaves us with a myopic view of the relative merits and drawbacks of different approaches, as well as open challenges and opportunities for developing improved algorithms. To address the issue of inconsistent evaluation and to advance the state of the art in the field of machine unlearning, we’ve teamed up with a broad group of academic and industrial researchers to organize the first unlearning challenge.
Announcing the first Machine Unlearning Challenge
We are pleased to announce the first Machine Unlearning Challenge, which will be held as part of the NeurIPS 2023 Competition Track. The goal of the competition is twofold. First, by unifying and standardizing the evaluation metrics for unlearning, we hope to identify the strengths and weaknesses of different algorithms through apples-to-apples comparisons. Second, by opening this competition to everyone, we hope to foster novel solutions and shed light on open challenges and opportunities.
The competition will be hosted on Kaggle and run between mid-July 2023 and mid-September 2023. As part of the competition, today we’re announcing the availability of the starting kit. This starting kit provides a foundation for participants to build and test their unlearning models on a toy dataset.
The competition considers a realistic scenario in which an age predictor has been trained on face images, and, after training, a certain subset of the training images must be forgotten to protect the privacy or rights of the individuals concerned. For this, we will make available as part of the starting kit a dataset of synthetic faces (samples shown below) and we’ll also use several real-face datasets for evaluation of submissions. The participants are asked to submit code that takes as input the trained predictor, the forget and retain sets, and outputs the weights of a predictor that has unlearned the designated forget set. We will evaluate submissions based on both the strength of the forgetting algorithm and model utility. We will also enforce a hard cut-off that rejects unlearning algorithms that run slower than a fraction of the time it takes to retrain. A valuable outcome of this competition will be to characterize the trade-offs of different unlearning algorithms.
 |
| Excerpt images from the Face Synthetics dataset together with age annotations. The competition considers the scenario in which an age predictor has been trained on face images like the above, and, after training, a certain subset of the training images must be forgotten. |
For evaluating forgetting, we will use tools inspired by MIAs, such as LiRA. MIAs were first developed in the privacy and security literature and their goal is to infer which examples were part of the training set. Intuitively, if unlearning is successful, the unlearned model contains no traces of the forgotten examples, causing MIAs to fail: the attacker would be unable to infer that the forget set was, in fact, part of the original training set. In addition, we will also use statistical tests to quantify how different the distribution of unlearned models (produced by a particular submitted unlearning algorithm) is compared to the distribution of models retrained from scratch. For an ideal unlearning algorithm, these two will be indistinguishable.
Conclusion
Machine unlearning is a powerful tool that has the potential to address several open problems in machine learning. As research in this area continues, we hope to see new methods that are more efficient, effective, and responsible. We are thrilled to have the opportunity via this competition to spark interest in this field, and we are looking forward to sharing our insights and findings with the community.
Acknowledgements
The authors of this post are now part of Google DeepMind. We are writing this blog post on behalf of the organization team of the Unlearning Competition: Eleni Triantafillou*, Fabian Pedregosa* (*equal contribution), Meghdad Kurmanji, Kairan Zhao, Gintare Karolina Dziugaite, Peter Triantafillou, Ioannis Mitliagkas, Vincent Dumoulin, Lisheng Sun Hosoya, Peter Kairouz, Julio C. S. Jacques Junior, Jun Wan, Sergio Escalera and Isabelle Guyon.

On-device diffusion plugins for conditioned text-to-image generation
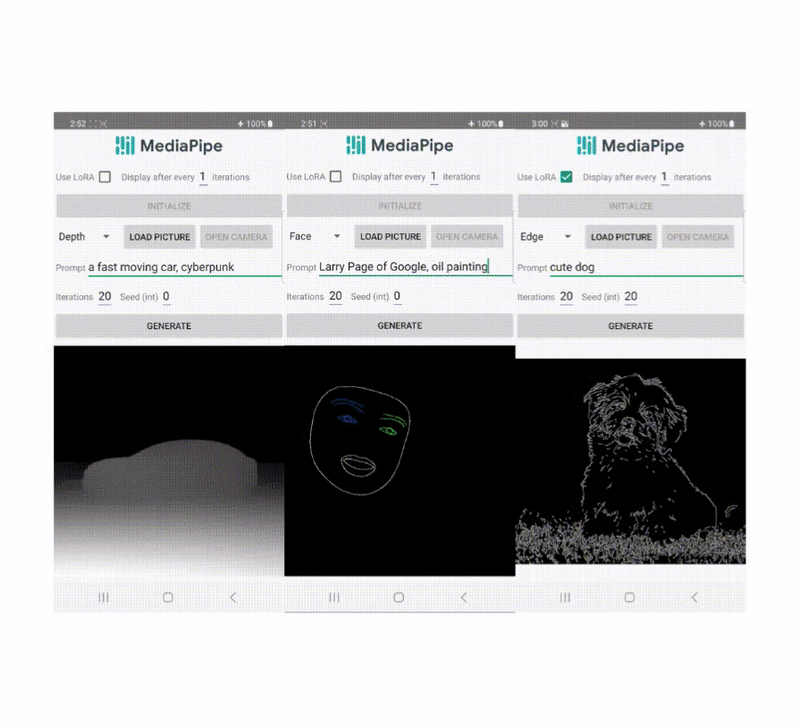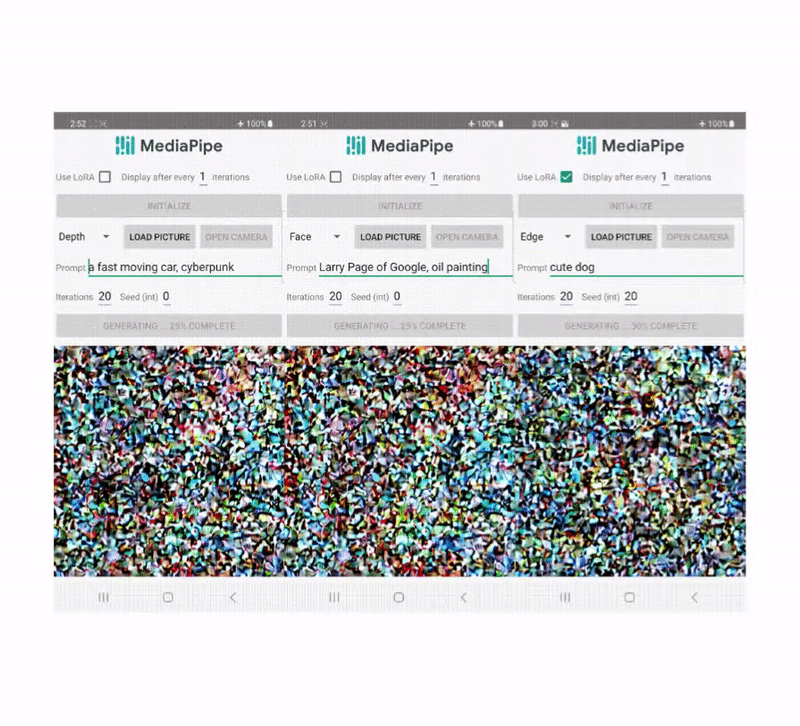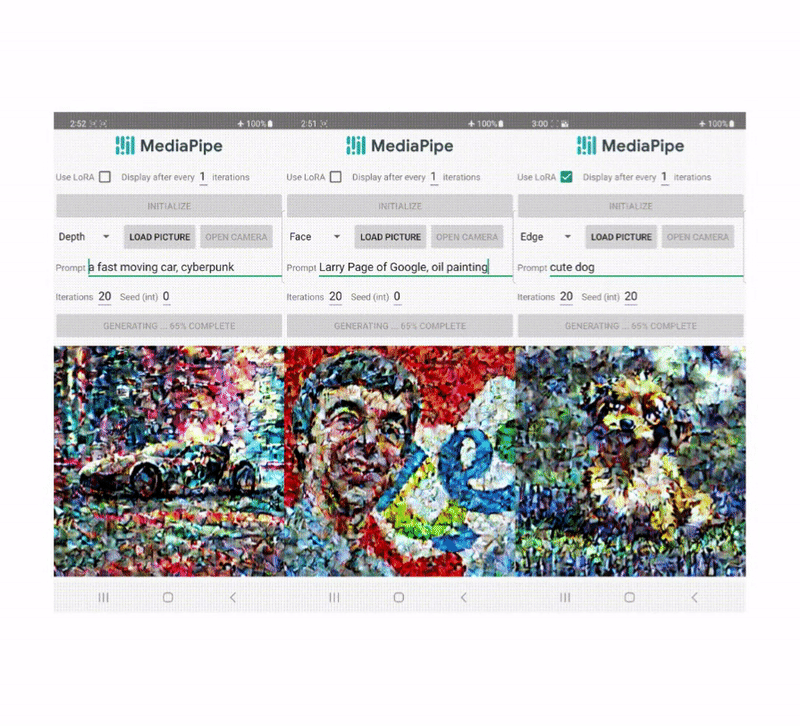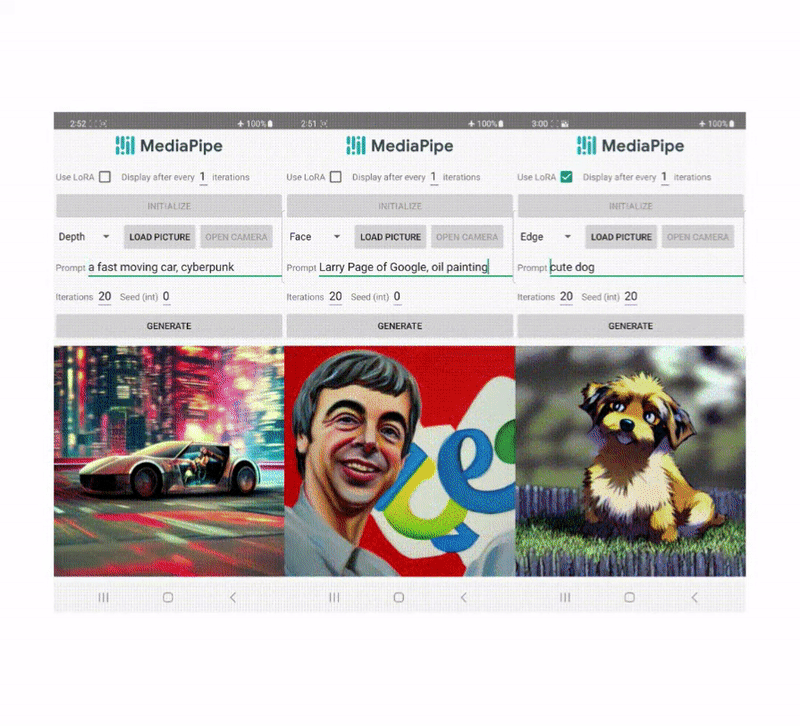
In recent years, diffusion models have shown great success in text-to-image generation, achieving high image quality, improved inference performance, and expanding our creative inspiration. Nevertheless, it is still challenging to efficiently control the generation, especially with conditions that are difficult to describe with text.
Today, we announce MediaPipe diffusion plugins, which enable controllable text-to-image generation to be run on-device. Expanding upon our prior work on GPU inference for on-device large generative models, we introduce new low-cost solutions for controllable text-to-image generation that can be plugged into existing diffusion models and their Low-Rank Adaptation (LoRA) variants.
 |
| Text-to-image generation with control plugins running on-device. |
Background
With diffusion models, image generation is modeled as an iterative denoising process. Starting from a noise image, at each step, the diffusion model gradually denoises the image to reveal an image of the target concept. Research shows that leveraging language understanding via text prompts can greatly improve image generation. For text-to-image generation, the text embedding is connected to the model via cross-attention layers. Yet, some information is difficult to describe by text prompts, e.g., the position and pose of an object. To address this problem, researchers add additional models into the diffusion to inject control information from a condition image.
Common approaches for controlled text-to-image generation include Plug-and-Play, ControlNet, and T2I Adapter. Plug-and-Play applies a widely used denoising diffusion implicit model (DDIM) inversion approach that reverses the generation process starting from an input image to derive an initial noise input, and then employs a copy of the diffusion model (860M parameters for Stable Diffusion 1.5) to encode the condition from an input image. Plug-and-Play extracts spatial features with self-attention from the copied diffusion, and injects them into the text-to-image diffusion. ControlNet creates a trainable copy of the encoder of a diffusion model, which connects via a convolution layer with zero-initialized parameters to encode conditioning information that is conveyed to the decoder layers. However, as a result, the size is large, half that of the diffusion model (430M parameters for Stable Diffusion 1.5). T2I Adapter is a smaller network (77M parameters) and achieves similar effects in controllable generation. T2I Adapter only takes the condition image as input, and its output is shared across all diffusion iterations. Yet, the adapter model is not designed for portable devices.
The MediaPipe diffusion plugins
To make conditioned generation efficient, customizable, and scalable, we design the MediaPipe diffusion plugin as a separate network that is:
- Plugable: It can be easily connected to a pre-trained base model.
- Trained from scratch: It does not use pre-trained weights from the base model.
- Portable: It runs outside the base model on mobile devices, with negligible cost compared to the base model inference.
| Method | Parameter Size | Plugable | From Scratch | Portable | ||||
| Plug-and-Play | 860M* | ✔️ | ❌ | ❌ | ||||
| ControlNet | 430M* | ✔️ | ❌ | ❌ | ||||
| T2I Adapter | 77M | ✔️ | ✔️ | ❌ | ||||
| MediaPipe Plugin | 6M | ✔️ | ✔️ | ✔️ |
| Comparison of Plug-and-Play, ControlNet, T2I Adapter, and the MediaPipe diffusion plugin. * The number varies depending on the particulars of the diffusion model. |
The MediaPipe diffusion plugin is a portable on-device model for text-to-image generation. It extracts multiscale features from a conditioning image, which are added to the encoder of a diffusion model at corresponding levels. When connecting to a text-to-image diffusion model, the plugin model can provide an extra conditioning signal to the image generation. We design the plugin network to be a lightweight model with only 6M parameters. It uses depth-wise convolutions and inverted bottlenecks from MobileNetv2 for fast inference on mobile devices.
 |
| Overview of the MediaPipe diffusion model plugin. The plugin is a separate network, whose output can be plugged into a pre-trained text-to-image generation model. Features extracted by the plugin are applied to the associated downsampling layer of the diffusion model (blue). |
Unlike ControlNet, we inject the same control features in all diffusion iterations. That is, we only run the plugin once for one image generation, which saves computation. We illustrate some intermediate results of a diffusion process below. The control is effective at every diffusion step and enables controlled generation even at early steps. More iterations improve the alignment of the image with the text prompt and generate more detail.
 |
| Illustration of the generation process using the MediaPipe diffusion plugin. |
Examples
In this work, we developed plugins for a diffusion-based text-to-image generation model with MediaPipe Face Landmark, MediaPipe Holistic Landmark, depth maps, and Canny edge. For each task, we select about 100K images from a web-scale image-text dataset, and compute control signals using corresponding MediaPipe solutions. We use refined captions from PaLI for training the plugins.
Face Landmark
The MediaPipe Face Landmarker task computes 478 landmarks (with attention) of a human face. We use the drawing utils in MediaPipe to render a face, including face contour, mouth, eyes, eyebrows, and irises, with different colors. The following table shows randomly generated samples by conditioning on face mesh and prompts. As a comparison, both ControlNet and Plugin can control text-to-image generation with given conditions.
 |
| Face-landmark plugin for text-to-image generation, compared with ControlNet. |
Holistic Landmark
MediaPipe Holistic Landmarker task includes landmarks of body pose, hands, and face mesh. Below, we generate various stylized images by conditioning on the holistic features.
 |
| Holistic-landmark plugin for text-to-image generation. |
Depth
 |
| Depth-plugin for text-to-image generation. |
Canny Edge
 |
| Canny-edge plugin for text-to-image generation. |
Evaluation
We conduct a quantitative study of the face landmark plugin to demonstrate the model’s performance. The evaluation dataset contains 5K human images. We compare the generation quality as measured by the widely used metrics, Fréchet Inception Distance (FID) and CLIP scores. The base model is a pre-trained text-to-image diffusion model. We use Stable Diffusion v1.5 here.
As shown in the following table, both ControlNet and the MediaPipe diffusion plugin produce much better sample quality than the base model, in terms of FID and CLIP scores. Unlike ControlNet, which needs to run at every diffusion step, the MediaPipe plugin only runs once for each image generated. We measured the performance of the three models on a server machine (with Nvidia V100 GPU) and a mobile phone (Galaxy S23). On the server, we run all three models with 50 diffusion steps, and on mobile, we run 20 diffusion steps using the MediaPipe image generation app. Compared with ControlNet, the MediaPipe plugin shows a clear advantage in inference efficiency while preserving the sample quality.
| Model | FID↓ | CLIP↑ | Inference Time (s) | |||||
| Nvidia V100 | Galaxy S23 | |||||||
| Base | 10.32 | 0.26 | 5.0 | 11.5 | ||||
| Base + ControlNet | 6.51 | 0.31 | 7.4 (+48%) | 18.2 (+58.3%) | ||||
| Base + MediaPipe Plugin | 6.50 | 0.30 | 5.0 (+0.2%) | 11.8 (+2.6%) | ||||
| Quantitative comparison on FID, CLIP, and inference time. |
We test the performance of the plugin on a wide range of mobile devices from mid-tier to high-end. We list the results on some representative devices in the following table, covering both Android and iOS.
| Device | Android | iOS | ||||||||||
| Pixel 4 | Pixel 6 | Pixel 7 | Galaxy S23 | iPhone 12 Pro | iPhone 13 Pro | |||||||
| Time (ms) | 128 | 68 | 50 | 48 | 73 | 63 | ||||||
| Inference time (ms) of the plugin on different mobile devices. |
Conclusion
In this work, we present MediaPipe, a portable plugin for conditioned text-to-image generation. It injects features extracted from a condition image to a diffusion model, and consequently controls the image generation. Portable plugins can be connected to pre-trained diffusion models running on servers or devices. By running text-to-image generation and plugins fully on-device, we enable more flexible applications of generative AI.
Acknowledgments
We’d like to thank all team members who contributed to this work: Raman Sarokin and Juhyun Lee for the GPU inference solution; Khanh LeViet, Chuo-Ling Chang, Andrei Kulik, and Matthias Grundmann for leadership. Special thanks to Jiuqiang Tang, Joe Zou and Lu wang, who made this technology and all the demos running on-device.