Posted by Brian Ichter and Karol Hausman, Research Scientists, Google Research, Brain Team
Over the last several years, we have seen significant progress in applying machine learning to robotics. However, robotic systems today are capable of executing only very short, hard-coded commands, such as “Pick up an apple,” because they tend to perform best with clear tasks and rewards. They struggle with learning to perform long-horizon tasks and reasoning about abstract goals, such as a user prompt like “I just worked out, can you get me a healthy snack?”
Meanwhile, recent progress in training language models (LMs) has led to systems that can perform a wide range of language understanding and generation tasks with impressive results. However, these language models are inherently not grounded in the physical world due to the nature of their training process: a language model generally does not interact with its environment nor observe the outcome of its responses. This can result in it generating instructions that may be illogical, impractical or unsafe for a robot to complete in a physical context. For example, when prompted with “I spilled my drink, can you help?” the language model GPT-3 responds with “You could try using a vacuum cleaner,” a suggestion that may be unsafe or impossible for the robot to execute. When asking the FLAN language model the same question, it apologizes for the spill with “I’m sorry, I didn’t mean to spill it,” which is not a very useful response. Therefore, we asked ourselves, is there an effective way to combine advanced language models with robot learning algorithms to leverage the benefits of both?
In “Do As I Can, Not As I Say: Grounding Language in Robotic Affordances”, we present a novel approach, developed in partnership with Everyday Robots, that leverages advanced language model knowledge to enable a physical agent, such as a robot, to follow high-level textual instructions for physically-grounded tasks, while grounding the language model in tasks that are feasible within a specific real-world context. We evaluate our method, which we call PaLM-SayCan, by placing robots in a real kitchen setting and giving them tasks expressed in natural language. We observe highly interpretable results for temporally-extended complex and abstract tasks, like “I just worked out, please bring me a snack and a drink to recover.” Specifically, we demonstrate that grounding the language model in the real world nearly halves errors over non-grounded baselines. We are also excited to release a robot simulation setup where the research community can test this approach.
<!–
 |
| With PaLM-SayCan, the robot acts as the language model’s “hands and eyes,” while the language model supplies high-level semantic knowledge about the task. |
–>
|
|
| With PaLM-SayCan, the robot acts as the language model’s “hands and eyes,” while the language model supplies high-level semantic knowledge about the task. |
A Dialog Between User and Robot, Facilitated by the Language Model
Our approach uses the knowledge contained in language models (Say) to determine and score actions that are useful towards high-level instructions. It also uses an affordance function (Can) that enables real-world-grounding and determines which actions are possible to execute in a given environment. Using the the PaLM language model, we call this PaLM-SayCan.
 |
| Our approach selects skills based on what the language model scores as useful to the high level instruction and what the affordance model scores as possible. |
Our system can be seen as a dialog between the user and robot, facilitated by the language model. The user starts by giving an instruction that the language model turns into a sequence of steps for the robot to execute. This sequence is filtered using the robot’s skillset to determine the most feasible plan given its current state and environment. The model determines the probability of a specific skill successfully making progress toward completing the instruction by multiplying two probabilities: (1) task-grounding (i.e., a skill language description) and (2) world-grounding (i.e., skill feasibility in the current state).
There are additional benefits of our approach in terms of its safety and interpretability. First, by allowing the LM to score different options rather than generate the most likely output, we effectively constrain the LM to only output one of the pre-selected responses. In addition, the user can easily understand the decision making process by looking at the separate language and affordance scores, rather than a single output.
|
|
| PaLM-SayCan is also interpretable: at each step, we can see the top options it considers based on their language score (blue), affordance score (red), and combined score (green). |
Training Policies and Value Functions
Each skill in the agent’s skillset is defined as a policy with a short language description (e.g., “pick up the can”), represented as embeddings, and an affordance function that indicates the probability of completing the skill from the robot’s current state. To learn the affordance functions, we use sparse reward functions set to 1.0 for a successful execution, and 0.0 otherwise.
We use image-based behavioral cloning (BC) to train the language-conditioned policies and temporal-difference-based (TD) reinforcement learning (RL) to train the value functions. To train the policies, we collected data from 68,000 demos performed by 10 robots over 11 months and added 12,000 successful episodes, filtered from a set of autonomous episodes of learned policies. We then learned the language conditioned value functions using MT-Opt in the Everyday Robots simulator. The simulator complements our real robot fleet with a simulated version of the skills and environment, which is transformed using RetinaGAN to reduce the simulation-to-real gap. We bootstrapped simulation policies’ performance by using demonstrations to provide initial successes, and then continuously improved RL performance with online data collection in simulation.
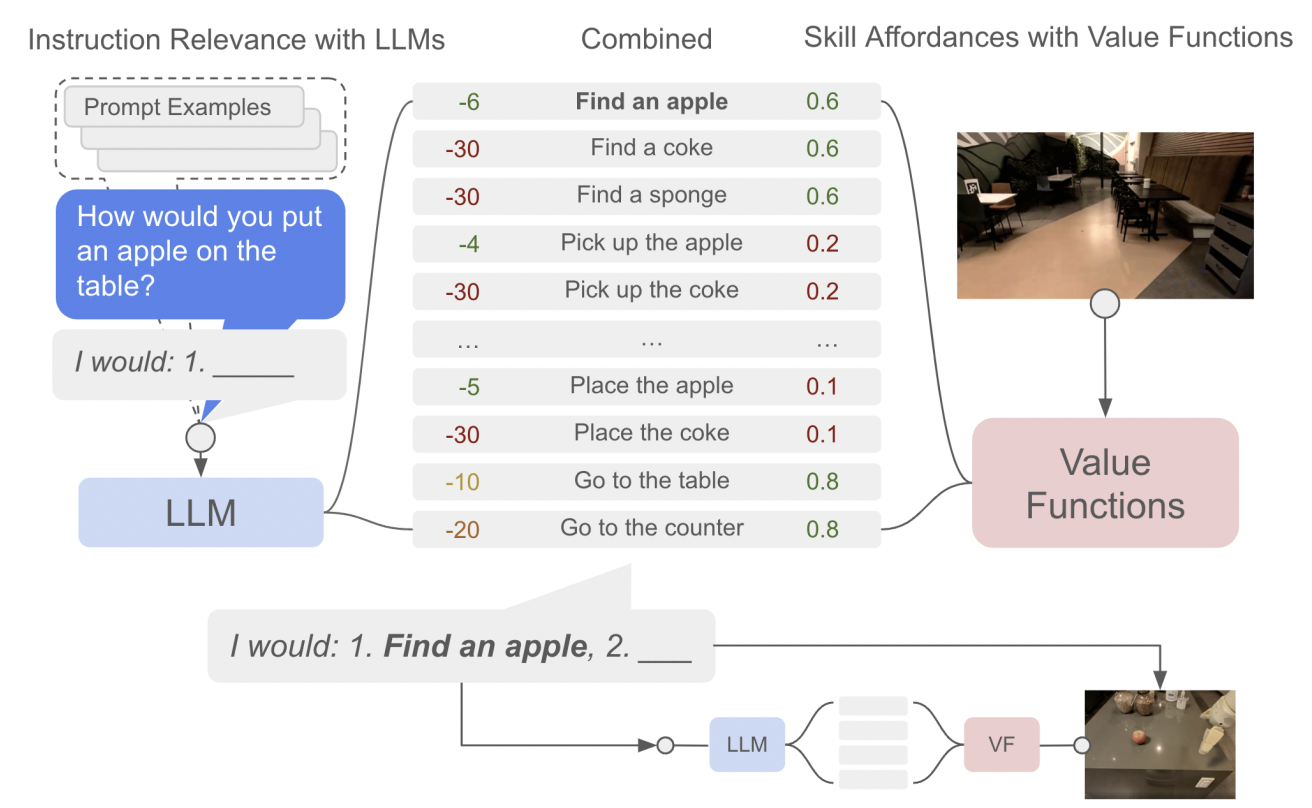 |
| Given a high-level instruction, our approach combines the probabilities from the language model with the probabilities from the value function (VF) to select the next skill to perform. This process is repeated until the high-level instruction is successfully completed. |
Performance on Temporally-Extended, Complex, and Abstract Instructions
To test our approach, we use robots from Everyday Robots paired with PaLM. We place the robots in a kitchen environment containing common objects and evaluate them on 101 instructions to test their performance across various robot and environment states, instruction language complexity and time horizon. Specifically, these instructions were designed to showcase the ambiguity and complexity of language rather than to provide simple, imperative queries, enabling queries such as “I just worked out, how would you bring me a snack and a drink to recover?” instead of “Can you bring me water and an apple?”
We use two metrics to evaluate the system’s performance: (1) the plan success rate, indicating whether the robot chose the right skills for the instruction, and (2) the execution success rate, indicating whether it performed the instruction successfully. We compare two language models, PaLM and FLAN (a smaller language model fine-tuned on instruction answering) with and without the affordance grounding as well as the underlying policies running directly with natural language (Behavioral Cloning in the table below). The results show that the system using PaLM with affordance grounding (PaLM-SayCan) chooses the correct sequence of skills 84% of the time and executes them successfully 74% of the time, reducing errors by 50% compared to FLAN and compared to PaLM without robotic grounding. This is particularly exciting because it represents the first time we can see how an improvement in language models translates to a similar improvement in robotics. This result indicates a potential future where robotics is able to ride the wave of progress that we have been observing in language models, bringing these subfields of research closer together.
|
Algorithm |
|
Plan |
|
Execute |
|
PaLM-SayCan |
|
84% |
|
74% |
|
PaLM |
|
67% |
|
– |
|
FLAN-SayCan |
|
70% |
|
61% |
|
FLAN |
|
38% |
|
– |
|
Behavioral Cloning |
|
0% |
|
0% |
| PaLM-SayCan halves errors compared to PaLM without affordances and compared to FLAN over 101 tasks. |
<!–
|
| SayCan demonstrated successful planning for 84% of the 101 test instructions when combined with PaLM. |
–>
|
|
| SayCan demonstrated successful planning for 84% of the 101 test instructions when combined with PaLM. |
<!–<
| SayCan demonstrated successful planning for 84% of the 101 test instructions when combined with PaLM. |
–>
If you’re interested in learning more about this project from the researchers themselves, please check out the video below:
Conclusion and Future Work
We’re excited about the progress that we’ve seen with PaLM-SayCan, an interpretable and general approach to leveraging knowledge from language models that enables a robot to follow high-level textual instructions to perform physically-grounded tasks. Our experiments on a number of real-world robotic tasks demonstrate the ability to plan and complete long-horizon, abstract, natural language instructions at a high success rate. We believe that PaLM-SayCan’s interpretability allows for safe real-world user interaction with robots. As we explore future directions for this work, we hope to better understand how information gained via the robot’s real-world experience could be leveraged to improve the language model and to what extent natural language is the right ontology for programming robots. We have open-sourced a robot simulation setup, which we hope will provide researchers with a valuable resource for future research that combines robotic learning with advanced language models. The research community can visit the project’s GitHub page and website to learn more.
Acknowledgements
We’d like to thank our coauthors Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Kelly Fu, Keerthana Gopalakrishnan, Alex Herzog, Daniel Ho, Jasmine Hsu, Julian Ibarz, Alex Irpan, Eric Jang, Rosario Jauregui Ruano, Kyle Jeffrey, Sally Jesmonth, Nikhil J Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Kuang-Huei Lee, Sergey Levine, Yao Lu, Linda Luu, Carolina Parada, Peter Pastor, Jornell Quiambao, Kanishka Rao, Jarek Rettinghouse, Diego Reyes, Pierre Sermanet, Nicolas Sievers, Clayton Tan, Alexander Toshev, Vincent Vanhoucke, Fei Xia, Ted Xiao, Peng Xu, Sichun Xu, Mengyuan Yan, and Andy Zeng. We’d also like to thank Yunfei Bai, Matt Bennice, Maarten Bosma, Justin Boyd, Bill Byrne, Kendra Byrne, Noah Constant, Pete Florence, Laura Graesser, Rico Jonschkowski, Daniel Kappler, Hugo Larochelle, Benjamin Lee, Adrian Li, Suraj Nair, Krista Reymann, Jeff Seto, Dhruv Shah, Ian Storz, Razvan Surdulescu, and Vincent Zhao for their help and support in various aspects of the project. And we’d like to thank Tom Small for creating many of the animations in this post.
Read More













.jpg)
.jpg)

















{kind=link}
{kind=link}