The post New Z-code Mixture of Experts models improve quality, efficiency in Translator and Azure AI appeared first on The AI Blog.

Powering the next generation of trustworthy AI in a confidential cloud using NVIDIA GPUs
Cloud computing is powering a new age of data and AI by democratizing access to scalable compute, storage, and networking infrastructure and services. Thanks to the cloud, organizations can now collect data at an unprecedented scale and use it to train complex models and generate insights.
While this increasing demand for data has unlocked new possibilities, it also raises concerns about privacy and security, especially in regulated industries such as government, finance, and healthcare. One area where data privacy is crucial is patient records, which are used to train models to aid clinicians in diagnosis. Another example is in banking, where models that evaluate borrower creditworthiness are built from increasingly rich datasets, such as bank statements, tax returns, and even social media profiles. This data contains very personal information, and to ensure that it’s kept private, governments and regulatory bodies are implementing strong privacy laws and regulations to govern the use and sharing of data for AI, such as the General Data Protection Regulation (GDPR) and the proposed EU AI Act. You can learn more about some of the industries where it’s imperative to protect sensitive data in this Microsoft Azure Blog post.
Commitment to a confidential cloud
Microsoft recognizes that trustworthy AI requires a trustworthy cloud—one in which security, privacy, and transparency are built into its core. A key component of this vision is confidential computing—a set of hardware and software capabilities that give data owners technical and verifiable control over how their data is shared and used. Confidential computing relies on a new hardware abstraction called trusted execution environments (TEEs). In TEEs, data remains encrypted not just at rest or during transit, but also during use. TEEs also support remote attestation, which enables data owners to remotely verify the configuration of the hardware and firmware supporting a TEE and grant specific algorithms access to their data.
At Microsoft, we are committed to providing a confidential cloud, where confidential computing is the default for all cloud services. Today, Azure offers a rich confidential computing platform comprising different kinds of confidential computing hardware (Intel SGX, AMD SEV-SNP), core confidential computing services like Azure Attestation and Azure Key Vault managed HSM, and application-level services such as Azure SQL Always Encrypted, Azure confidential ledger, and confidential containers on Azure. However, these offerings are limited to using CPUs. This poses a challenge for AI workloads, which rely heavily on AI accelerators like GPUs to provide the performance needed to process large amounts of data and train complex models.
-
Publication
Graviton: Trusted Execution Environments on GPUs
The Confidential Computing group at Microsoft Research identified this problem and defined a vision for confidential AI powered by confidential GPUs, proposed in two papers, “Oblivious Multi-Party Machine Learning on Trusted Processors” and “Graviton: Trusted Execution Environments on GPUs.” In this post, we share this vision. We also take a deep dive into the NVIDIA GPU technology that’s helping us realize this vision, and we discuss the collaboration among NVIDIA, Microsoft Research, and Azure that enabled NVIDIA GPUs to become a part of the Azure confidential computing ecosystem.
Vision for confidential GPUs
Today, CPUs from companies like Intel and AMD allow the creation of TEEs, which can isolate a process or an entire guest virtual machine (VM), effectively eliminating the host operating system and the hypervisor from the trust boundary. Our vision is to extend this trust boundary to GPUs, allowing code running in the CPU TEE to securely offload computation and data to GPUs.
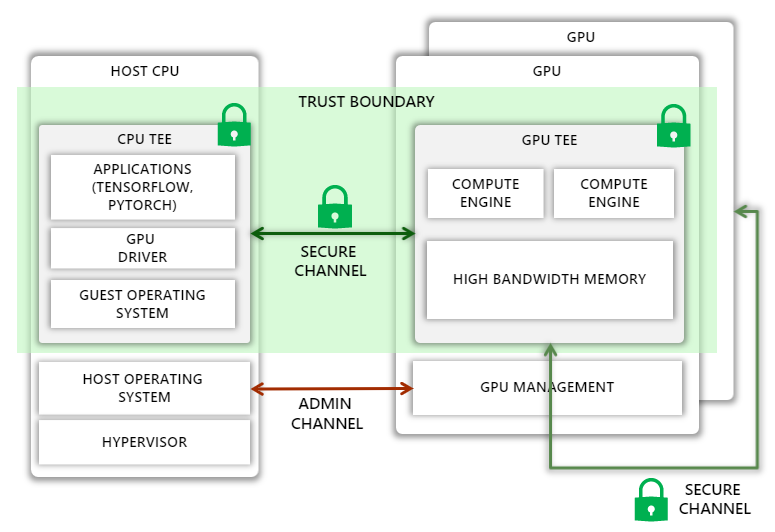
Unfortunately, extending the trust boundary is not straightforward. On the one hand, we must protect against a variety of attacks, such as man-in-the-middle attacks where the attacker can observe or tamper with traffic on the PCIe bus or on a NVIDIA NVLink connecting multiple GPUs, as well as impersonation attacks, where the host assigns an incorrectly configured GPU, a GPU running older versions or malicious firmware, or one without confidential computing support for the guest VM. At the same time, we must ensure that the Azure host operating system has enough control over the GPU to perform administrative tasks. Furthermore, the added protection must not introduce large performance overheads, increase thermal design power, or require significant changes to the GPU microarchitecture.
Our research shows that this vision can be realized by extending the GPU with the following capabilities:
- A new mode where all sensitive state on the GPU, including GPU memory, is isolated from the host
- A hardware root-of-trust on the GPU chip that can generate verifiable attestations capturing all security sensitive state of the GPU, including all firmware and microcode
- Extensions to the GPU driver to verify GPU attestations, set up a secure communication channel with the GPU, and transparently encrypt all communications between the CPU and GPU
- Hardware support to transparently encrypt all GPU-GPU communications over NVLink
- Support in the guest operating system and hypervisor to securely attach GPUs to a CPU TEE, even if the contents of the CPU TEE are encrypted
Confidential computing with NVIDIA A100 Tensor Core GPUs
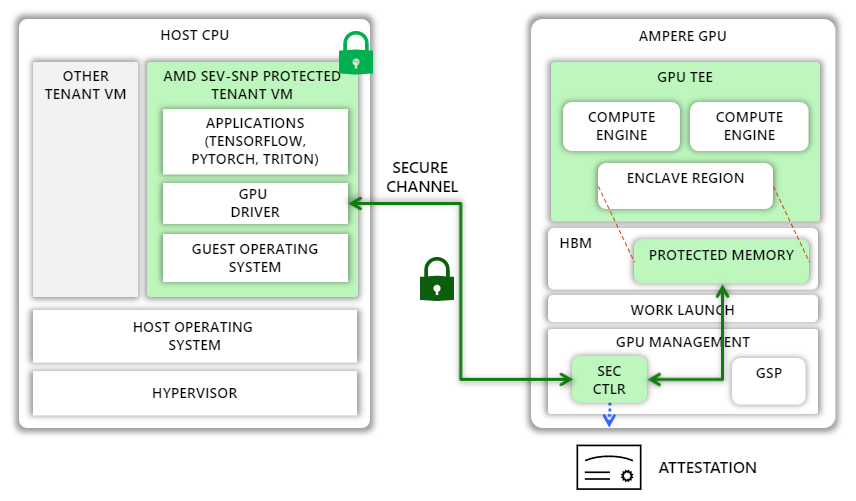
NVIDIA and Azure have taken a significant step toward realizing this vision with a new feature called Ampere Protected Memory (APM) in the NVIDIA A100 Tensor Core GPUs. In this section, we describe how APM supports confidential computing within the A100 GPU to achieve end-to-end data confidentiality.
APM introduces a new confidential mode of execution in the A100 GPU. When the GPU is initialized in this mode, the GPU designates a region in high-bandwidth memory (HBM) as protected and helps prevent leaks through memory-mapped I/O (MMIO) access into this region from the host and peer GPUs. Only authenticated and encrypted traffic is permitted to and from the region.
In confidential mode, the GPU can be paired with any external entity, such as a TEE on the host CPU. To enable this pairing, the GPU includes a hardware root-of-trust (HRoT). NVIDIA provisions the HRoT with a unique identity and a corresponding certificate created during manufacturing. The HRoT also implements authenticated and measured boot by measuring the firmware of the GPU as well as that of other microcontrollers on the GPU, including a security microcontroller called SEC2. SEC2, in turn, can generate attestation reports that include these measurements and that are signed by a fresh attestation key, which is endorsed by the unique device key. These reports can be used by any external entity to verify that the GPU is in confidential mode and running last known good firmware.
When the NVIDIA GPU driver in the CPU TEE loads, it checks whether the GPU is in confidential mode. If so, the driver requests an attestation report and checks that the GPU is a genuine NVIDIA GPU running known good firmware. Once confirmed, the driver establishes a secure channel with the SEC2 microcontroller on the GPU using the Security Protocol and Data Model (SPDM)-backed Diffie-Hellman-based key exchange protocol to establish a fresh session key. When that exchange completes, both the GPU driver and SEC2 hold the same symmetric session key.
The GPU driver uses the shared session key to encrypt all subsequent data transfers to and from the GPU. Because pages allocated to the CPU TEE are encrypted in memory and not readable by the GPU DMA engines, the GPU driver allocates pages outside the CPU TEE and writes encrypted data to those pages. On the GPU side, the SEC2 microcontroller is responsible for decrypting the encrypted data transferred from the CPU and copying it to the protected region. Once the data is in high bandwidth memory (HBM) in cleartext, the GPU kernels can freely use it for computation.
Accelerating innovation with confidential AI
The implementation of APM is an important milestone toward achieving broader adoption of confidential AI in the cloud and beyond. APM is the foundational building block of Azure Confidential GPU VMs, now in private preview. These VMs, designed in collaboration with NVIDIA, Azure, and Microsoft Research, feature up to four A100 GPUs with 80 GB of HBM and APM technology and enable users to host AI workloads on Azure with a new level of security.
But this is just the beginning. We look forward to taking our collaboration with NVIDIA to the next level with NVIDIA’s Hopper architecture, which will enable customers to protect both the confidentiality and integrity of data and AI models in use. We believe that confidential GPUs can enable a confidential AI platform where multiple organizations can collaborate to train and deploy AI models by pooling together sensitive datasets while remaining in full control of their data and models. Such a platform can unlock the value of large amounts of data while preserving data privacy, giving organizations the opportunity to drive innovation.
A real-world example involves Bosch Research, the research and advanced engineering division of Bosch, which is developing an AI pipeline to train models for autonomous driving. Much of the data it uses includes personal identifiable information (PII), such as license plate numbers and people’s faces. At the same time, it must comply with GDPR, which requires a legal basis for processing PII, namely, consent from data subjects or legitimate interest. The former is challenging because it is practically impossible to get consent from pedestrians and drivers recorded by test cars. Relying on legitimate interest is challenging too because, among other things, it requires showing that there is a no less privacy-intrusive way of achieving the same result. This is where confidential AI shines: Using confidential computing can help reduce risks for data subjects and data controllers by limiting exposure of data (for example, to specific algorithms), while enabling organizations to train more accurate models.
At Microsoft Research, we are committed to working with the confidential computing ecosystem, including collaborators like NVIDIA and Bosch Research, to further strengthen security, enable seamless training and deployment of confidential AI models, and help power the next generation of technology.
About confidential computing at Microsoft Research
The Confidential Computing team at Microsoft Research Cambridge conducts pioneering research in system design that aims to guarantee strong security and privacy properties to cloud users. We tackle problems around secure hardware design, cryptographic and security protocols, side channel resilience, and memory safety. We are also interested in new technologies and applications that security and privacy can uncover, such as blockchains and multiparty machine learning. Please visit our careers page to learn about opportunities for both researchers and engineers. We’re hiring.
Related GTC Conference sessions
The post Powering the next generation of trustworthy AI in a confidential cloud using NVIDIA GPUs appeared first on Microsoft Research.
Microsoft Translator enhanced with Z-code Mixture of Experts models
Translator, a Microsoft Azure Cognitive Service, is adopting Z-code Mixture of Experts models, a breakthrough AI technology that significantly improves the quality of production translation models. As a component of Microsoft’s larger XYZ-code initiative to combine AI models for text, vision, audio, and language, Z-code supports the creation of AI systems that can speak, see, hear, and understand. This effort is a part of Azure AI and Project Turing, focusing on building multilingual, large-scale language models that support various production teams. Translator is using NVIDIA GPUs and Triton Inference Server to deploy and scale these models efficiently for high-performance inference. Translator is the first machine translation provider to introduce this technology live for customers.
Z-code MoE boosts efficiency and quality
Z-code models utilize a new architecture called Mixture of Experts (MoE), where different parts of the models can learn different tasks. The models learn to translate between multiple languages at the same time. The Z-code MoE model utilizes more parameters while dynamically selecting which parameters to use for a given input. This enables the model to specialize a subset of the parameters (experts) during training. At runtime, the model uses the relevant experts for the task, which is more computationally efficient than utilizing all model’s parameters.
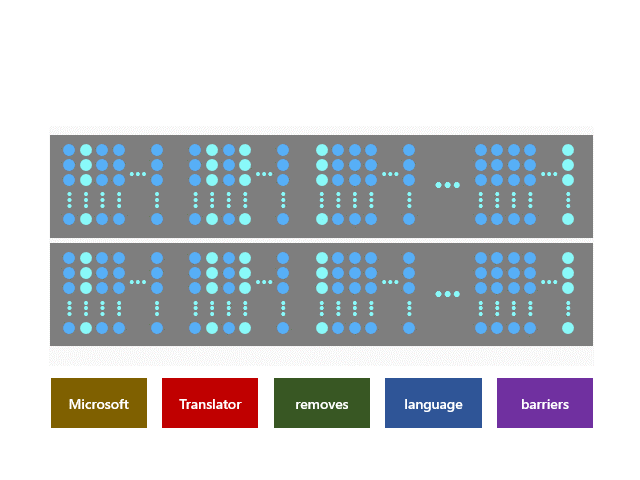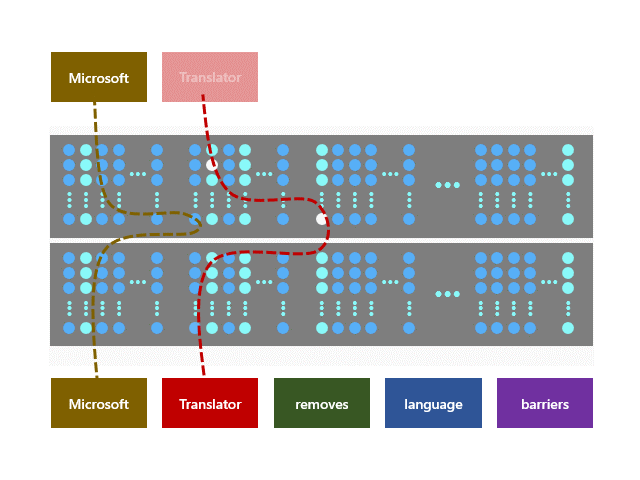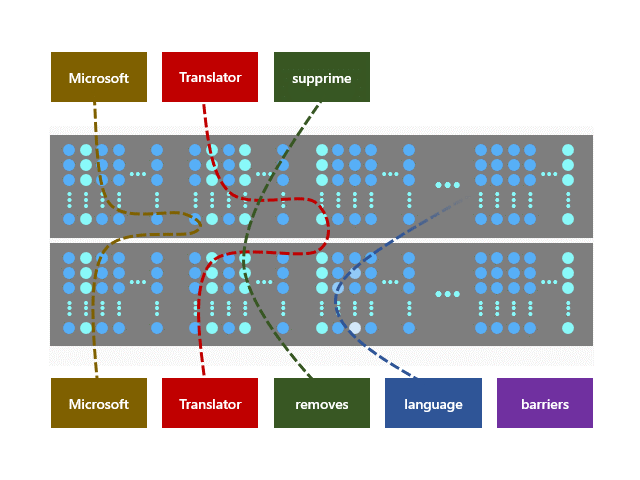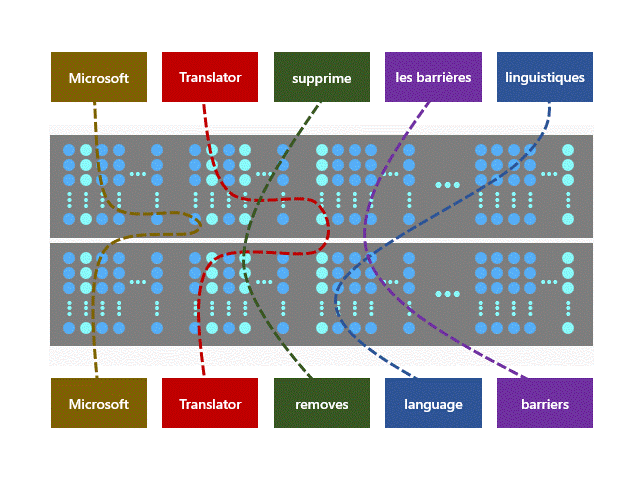
Newly introduced Z-code MoE models leverage transfer learning, which enables efficient knowledge sharing across similar languages. Moreover, the models utilize both parallel and monolingual data during the training process. This opens the way to high quality machine translation beyond the high-resource languages and improves the quality of low-resource languages that lack significant training data. This approach can provide a positive impact on AI fairness, since both high-resource and low-resource languages see improvements.
We have trained translation systems for research purposes with 200 billion parameters supporting 100 language pairs. Though such large systems significantly improved the translation quality, this also introduced challenges to deploy them in a production environment cost effectively. For our production model deployment, we opted for training a set of 5 billion parameter models, which are 80 times larger than our currently deployed models. We trained a multilingual model per set of languages, where each model can serve up to 20 language pairs and therefore replace up to 20 of the current systems. This enabled our model to maximize the transfer learning among languages while being deployable with effective runtime cost. We compared the quality improvements of the new MoE to the current production system using human evaluation. The figure below shows the results of the models on various language pairs. The Z-code-MoE systems outperformed individual bilingual systems, with average improvements of 4%. For instance, the models improved English to French translations by 3.2 percent, English to Turkish by 5.8 percent, Japanese to English by 7.6 percent, English to Arabic by 9.3 percent, and English to Slovenian by 15 percent.
Training large models with billions of parameters is challenging. The Translator team collaborated with Microsoft DeepSpeed to develop a high-performance system that helped train massive scale Z-code MoE models, enabling us to efficiently scale and deploy Z-code models for translation.
We partnered with NVIDIA to optimize faster engines that can be used at runtime to deploy the new Z-code/MoE models on GPUs. NVIDIA developed custom CUDA kernels and leveraged the CUTLASS and FasterTransformer libraries to efficiently implement MoE layers on a single V100 GPU. This implementation achieved up to 27x throughput improvements over standard GPU (PyTorch) runtimes. We used NVIDIA’s open source Triton Inference Server to serve Z-code MoE models. We used Triton’s dynamic batching feature to pool several requests into a big batch for higher throughput that enabled us to ship large models with relatively low runtime costs.
How can you use the new Z-code models?
Z-code models are available now by invitation to customers using Document Translation, a feature that translates entire documents, or volumes of documents, in a variety of different file formats preserving their original formatting. Z-code models will be made available to all customers and to other Translator products in phases. Please fill out this form to request access to Document Translation using Z-code models.
Learn more
- New Z-code Mixture of Experts models improve quality, efficiency in Translator and Azure AI
- Cognitive Services—APIs for AI Solutions | Microsoft Azure
- Scalable and Efficient MoE Training for Multitask Multilingual Models
- Fast and Scalable AI Model Deployment with NVIDIA Triton Inference Server | NVIDIA Technical Blog
Acknowledgements
The following people contributed to this work: Abdelrahman Abouelenin, Ahmed Salah, Akiko Eriguchi, Alex Cheng, Alex Muzio, Amr Hendy, Arul Menezes, Brad Ballinger, Christophe Poulain, Evram Narouz, Fai Sigalov, Hany Hassan Awadalla, Hitokazu Matsushita, Mohamed Afify, Raffy Bekhit, Rohit Jain, Steven Nguyen, Vikas Raunak, Vishal Chowdhary, and Young Jin Kim.
The post Microsoft Translator enhanced with Z-code Mixture of Experts models appeared first on Microsoft Research.

Microsoft has demonstrated the underlying physics required to create a new kind of qubit
Quantum computing promises to help us solve some of humanity’s greatest challenges. Yet as an industry, we are still in the early days of discovering what’s possible. Today’s quantum computers are enabling researchers to do interesting work. However, these researchers often find themselves limited by the inadequate scale of these systems and are eager to do more. Today’s quantum computers are based on a variety of qubit types, but none so far have been able to scale to enough qubits to fully realize the promise of quantum.
Microsoft is taking a more challenging, but ultimately more promising approach to scaled quantum computing with topological qubits that are theorized to be inherently more stable than qubits produced with existing methods without sacrificing size or speed. We have discovered that we can produce the topological superconducting phase and its concomitant Majorana zero modes, clearing a significant hurdle toward building a scaled quantum machine. The explanation of our work and methods below shows that the underlying physics behind a topological qubit are sound—the observation of a 30 μeV topological gap is a first in this work, and one that lays groundwork for the potential future of topological quantum computing. While engineering challenges remain, this discovery proves out a fundamental building block for our approach to a scaled quantum computer and puts Microsoft on the path to deliver a quantum machine in Azure that will help solve some of the world’s toughest problems.
Dr. Chetan Nayak and Dr. Sankar Das Sarma recently sat down to discuss these results and why they matter in the video below. Learn more about our journey and visit Azure Quantum to get started with quantum computing today.
Microsoft Quantum team reports observation of a 30 μeV topological gap in indium arsenide-aluminum heterostructures
Topological quantum computation is a route to hardware-level fault tolerance, potentially enabling a quantum computing system with high fidelity qubits, fast gate operations, and a single module architecture. The fidelity, speed, and size of a topological qubit is controlled by a characteristic energy called the topological gap. This path is only open if one can reliably produce a topological phase of matter and experimentally verify that the sub-components of a qubit are in a topological phase (and ready for quantum information processing). Doing so is not trivial because topological phases are characterized by the long-ranged entanglement of their ground states, which is not readily accessible to conventional experimental probes.
This difficulty was addressed by the “topological gap protocol” (TGP), which our team set forth a year ago as a criterion for identifying the topological phase with quantum transport measurements. Topological superconducting wires have Majorana zero modes at their ends. There is a real fermionic operator localized at each end of the wire, analogous to the real fermionic wave equation constructed by Ettore Majorana in 1937.
Consequently, there are two quantum states of opposite fermion parity that can only be measured through a phase-coherent probe coupled to both ends. In electrical measurements, the Majorana zero modes (see Figure 1) cause zero-bias peaks (ZBPs) in the local conductance. However, local Andreev bound states and disorder can also cause zero-bias peaks. Thus, the TGP focuses on ZBPs that are highly stable and, crucially, uses the non-local conductance to detect a bulk phase transition. Such a transition must be present at the boundary between the trivial superconducting phase and the topological phase because these are two distinct phases of matter, as different as water and ice.
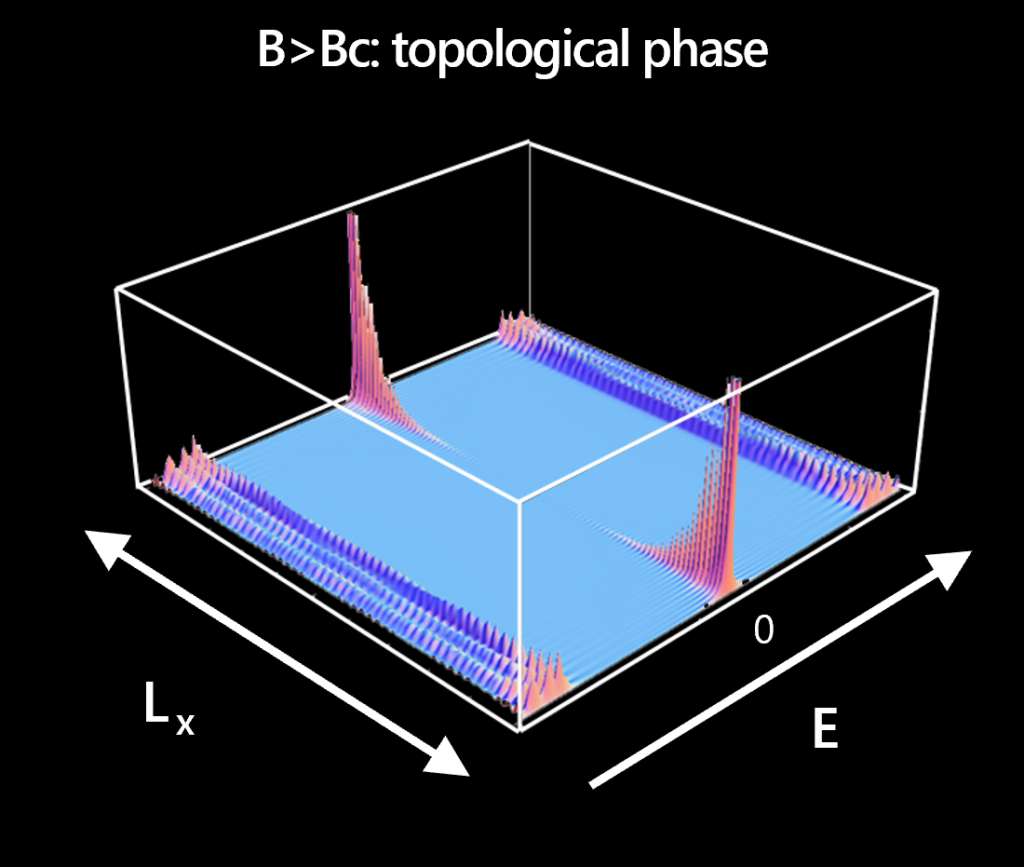
We have simulated our devices using models that incorporate the details of the materials stack, geometry, and imperfections. Our simulations have demonstrated that the TGP is a very stringent criterion, rendering it a reliable method for detecting the topological phase in a device. Crucially, the conditions for passing the protocol—the presence of stable ZBPs at both ends of the device over a gapped region with gapless boundary, as established via the non-local conductance—were established before any devices had been measured. Given the subtleties involved in identifying a topological phase, which stem from the absence of a local order parameter, one of the design principles of the TGP was to avoid confirmation bias. In particular, the device is scanned over its entire operating range instead of ‘hunting’ for a specific desired feature, such as a ZBP.
Microsoft’s Station Q, in Santa Barbara, CA, is the birthplace of Microsoft’s quantum program. For the last 16 years, it has been the host of a biannual conference on topological phases and quantum computing. After a two-year hiatus of in-person meetings due to the pandemic, the Station Q meetings resumed in early March. At this meeting with leaders in quantum computing from across industry and academia, we reported that we have multiple devices that have passed the TGP.
Our team has measured topological gaps exceeding 30 μeV. This is more than triple the noise level in the experiment and larger than the temperature by a similar factor. This shows that it is a robust feature. This is both a landmark scientific advance and a crucial step on the journey to topological quantum computation, which relies on the fusion and braiding of anyons (the two primitive operations on topological quasiparticles). The topological gap controls the fault-tolerance that the underlying state of matter affords to these operations. More complex devices enabling these operations require multiple topological wire segments and rely on TGP as part of their initialization procedure. Our success was predicated on very close collaboration between our simulation, growth, fabrication, measurement, and data analysis teams. Every device design was simulated in order to optimize it over 23 different parameters prior to fabrication. This enabled us to determine the device tuning procedure during design.
Our results are backed by exhaustive measurements and rigorous data validation procedures. We obtained the large-scale phase diagram of multiple devices, derived from a combination of local and non-local conductances. Our analysis procedure was validated on simulated data in which we attempted to fool the TGP. This enabled us to rule out various null hypotheses with high confidence. Moreover, data analysis was led by a different team than the one who took the data, as part of our checks and balances between different groups within the team. Additionally, an expert council of independent consultants is vetting our results, and the response to date is overwhelmingly positive.
With the underlying physics demonstrated, the next step is a topological qubit. We hypothesize that the topological qubit will have a favorable combination of speed, size, and stability compared to other qubits. We believe ultimately it will power a fully scalable quantum machine in the future, which will in turn enable us to realize the full promise of quantum to solve the most complex and pressing challenges our society faces.
The post Microsoft has demonstrated the underlying physics required to create a new kind of qubit appeared first on Microsoft Research.

PeopleLens: Using AI to support social interaction between children who are blind and their peers
For children born blind, social interaction can be particularly challenging. A child may have difficulty aiming their voice at the person they’re talking to and put their head on their desk instead. Linguistically advanced young people may struggle with maintaining a topic of conversation, talking only about something of interest to them. Most noticeably, many children and young people who are blind struggle with engaging and befriending those in their age group despite a strong desire to do so. This is often deeply frustrating for the child or young person and can be equally so for their support network of family members and teachers who want to help them forge these important connections.
-
PUBLICATION
PeopleLens
The PeopleLens is an open-ended AI system that offers people who are blind or who have low vision further resources to make sense of and engage with their immediate social surroundings.
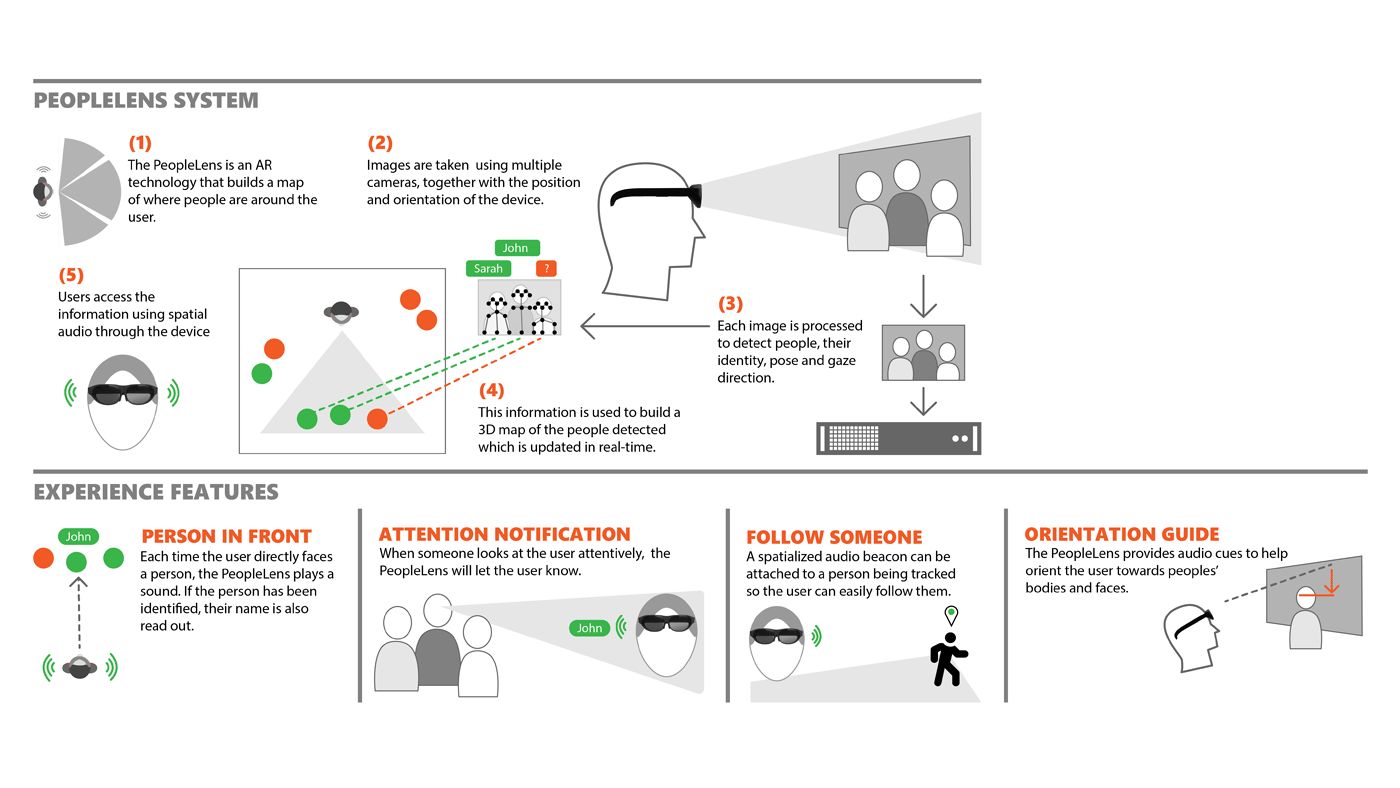
The PeopleLens is a new research technology that we’ve created to help young people who are blind (referred to as learners in our work) and their peers interact more easily. A head-worn device, the PeopleLens reads aloud in spatialized audio the names of known individuals when the learner looks at them. That means the sound comes from the direction of the person, assisting the learner in understanding both the relative position and distance of their peers. The PeopleLens helps learners build a People Map, a mental map of those around them needed to effectively signal communicative intent. The technology, in turn, indicates to the learner’s peers when the peers have been “seen” and can interact—a replacement for the eye contact that usually initiates interaction between people.
For children and young people who are blind, the PeopleLens is a way to find their friends; however, for teachers and parents, it’s a way for these children and young people to develop competence and confidence in social interaction. An accompanying scheme of work aims to guide the development of spatial attention skills believed to underpin social interaction through a series of games that learners using the PeopleLens can play with peers. It also sets up situations in which learners can experience agency in social interaction. A child’s realization that they can choose to initiate a conversation because they spot someone first or that they can stop a talkative brother from speaking by looking away is a powerful moment, motivating them to delve deeper into directing their own and others’ attention.
The PeopleLens is an advanced research prototype that works on Nreal Light augmented reality glasses tethered to a phone. While it’s not available for purchase, we are recruiting learners in the United Kingdom aged 5 to 11 who have the support of a teacher to explore the technology as part of a multistage research study. For the study, led by the University of Bristol, learners will be asked to use the PeopleLens for a three-month period beginning in September 2022. For more information, visit the research study information page.
Research foundation
The scheme of work, coauthored by collaborators Professor Linda Pring and Dr. Vasiliki Kladouchou, draws on research and practice from psychology and speech and language therapy in providing activities to do with the technology. The PeopleLens builds on the hypothesis that many social interaction difficulties for children who are blind stem from differences in the ways children with and without vision acquire fundamental attentional processes as babies and young children. For example, growing up, children with vision learn to internalize a joint visual dialogue of attention. A young child points at something in the sky, and the parent says, “Bird.” Through these dialogues, young children learn how to direct the attention of others. However, there isn’t enough research to understand how joint attention manifests in children who are blind. A review of the literature suggests that most research doesn’t account for a missing sense and that research specific to visual impairment doesn’t provide a framework for joint attention beyond the age of 3. We’re carrying out research to better understand how the development of joint attention can be improved in early education and augmented with technology.
How does the PeopleLens work?
The PeopleLens is a sophisticated AI prototype system that is intended to provide people who are blind or have low vision with a better understanding of their immediate social environment. It uses a head-mounted augmented reality device in combination with four state-of-the-art computer vision algorithms to continuously locate, identify, track, and capture the gaze directions of people in the vicinity. It then presents this information to the wearer through spatialized audio—sound that comes from the direction of the person. The real-time nature of the system gives a sense of immersion in the People Map.
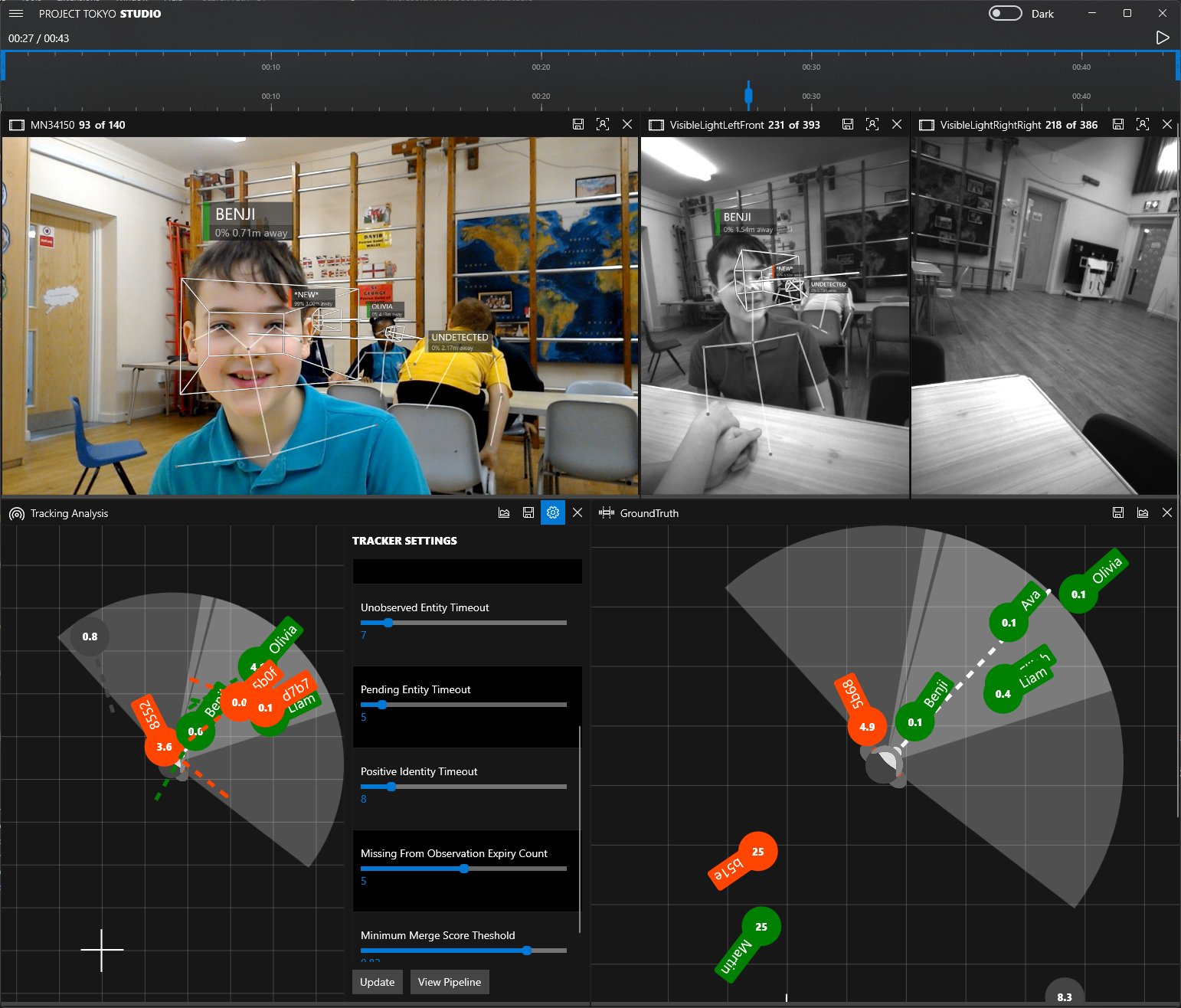
The PeopleLens is a ground-breaking technology that has also been designed to protect privacy. Among the algorithms underpinning the system is facial recognition of people who’ve been registered in the system. A person registers by taking several photographs of themselves with the phone attached to the PeopleLens. Photographs aren’t stored, instead converted into a vector of numbers that represent a face. These differ from any vectors used in other systems, so recognition by the PeopleLens doesn’t lead to recognition by any other system. No video or identifying information is captured by the system, ensuring that the images can’t be maliciously used.
The system employs a series of sounds to assist the wearer in placing people in the surrounding space: A percussive bump indicates when their gaze has crossed a person up to 10 meters away. The bump is followed by the person’s name if the person is registered in the system, is within 4 meters of the wearer, and both the person’s ears can be detected. The sound of woodblocks guides the wearer in finding and centering the face of a person the system has seen for 1 second but hasn’t identified, changing in pitch to help the wearer adjust their gaze accordingly. (Those people who are unregistered are acknowledged with a click sound.) Gaze notification can alert the wearer to when they’re being looked at.
Community collaboration
The success of the PeopleLens, as well as systems like it, is dependent on a prototyping process that includes close collaboration with the people it is intended to serve. Our work with children who are blind and their support systems has put us on a path toward building a tool that can have practical value and empower those using it. We encourage those interested in the PeopleLens to reach out about participating in our study and help us further evolve the technology.
To learn more about the PeopleLens and its development, check out the Innovation Stories blog about the technology.
The post PeopleLens: Using AI to support social interaction between children who are blind and their peers appeared first on Microsoft Research.
µTransfer: A technique for hyperparameter tuning of enormous neural networks
Great scientific achievements cannot be made by trial and error alone. Every launch in the space program is underpinned by centuries of fundamental research in aerodynamics, propulsion, and celestial bodies. In the same way, when it comes to building large-scale AI systems, fundamental research forms the theoretical insights that drastically reduce the amount of trial and error necessary and can prove very cost-effective.
In this post, we relay how our fundamental research enabled us, for the first time, to tune enormous neural networks that are too expensive to train more than once. We achieved this by showing that a particular parameterization preserves optimal hyperparameters across different model sizes. This is the µ-Parametrization (or µP, pronounced “myu-P”) that we introduced in a previous paper, where we showed that it uniquely enables maximal feature learning in the infinite-width limit. In collaboration with researchers at OpenAI, we verified its practical advantage on a range of realistic scenarios, which we describe in our new paper, “Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer.”
By greatly reducing the need to guess which training hyperparameters to use, this technique can accelerate research on enormous neural networks, such as GPT-3 and potentially larger successors in the future. We also released a PyTorch package that facilitates the integration of our technique in existing models, available on the project GitHub page or by simply running (texttt{pip install mup}).
“µP provides an impressive step toward removing some of the black magic from scaling up neural networks. It also provides a theoretically backed explanation of some tricks used by past work, like the T5 model. I believe both practitioners and researchers alike will find this work valuable.”
— Colin Raffel, Assistant Professor of Computer Science, University of North Carolina at Chapel Hill and co-creator of T5
Scaling the initialization is easy, but scaling training is hard
Large neural networks are hard to train partly because we don’t understand how their behavior changes as their size increases. Early work on deep learning, such as by Glorot & Bengio and He et al., generated useful heuristics that deep learning practitioners widely use today. In general, these heuristics try to keep the activation scales consistent at initialization. However, as training starts, this consistency breaks at different model widths, as illustrated on the left in Figure 1.
Unlike at random initialization, behavior during training is much harder to mathematically analyze. Our goal is to obtain a similar consistency so that as model width increases, the change in activation scales during training stay consistent and similar to initialization to avoid numerical overflow and underflow. Our solution, µP, achieves this goal, as seen on the right in Figure 1, which shows the stability of network activation scales for the first few steps of training across increasing model width.

Our parameterization, which maintains this consistency during training, follows two pieces of crucial insight. First, gradient updates behave differently from random weights when the width is large. This is because gradient updates are derived from data and contain correlations, whereas random initializations do not. Therefore, they need to be scaled differently. Second, parameters of different shapes also behave differently when the width is large. While we typically divide parameters into weights and biases, with the former being matrices and the latter vectors, some weights behave like vectors in the large-width setting. For example, the embedding matrix in a language model is of size vocabsize x width. While the width tends to infinity, vocabsize stays constant and finite. During matrix multiplication, the difference in behavior between summing along a finite dimension and an infinite one cannot be more different.
These insights, which we discuss in detail in a previous blog post, motivated us to develop µP. In fact, beyond just keeping the activation scale consistent throughout training, µP ensures that neural networks of different and sufficiently large widths behave similarly during training such that they converge to a desirable limit, which we call the feature learning limit.
A theory-guided approach to scaling width
Our theory of scaling enables a procedure to transfer training hyperparameters across model sizes. If, as discussed above, µP networks of different widths share similar training dynamics, they likely also share similar optimal hyperparameters. Consequently, we can simply apply the optimal hyperparameters of a small model directly onto a scaled-up version. We call this practical procedure µTransfer. If our hypothesis is correct, the training loss-hyperparameter curves for µP models of different widths would share a similar minimum.
Conversely, our reasoning suggests that no scaling rule of initialization and learning rate other than µP can achieve the same result. This is supported by the animation below. Here, we vary the parameterization by interpolating the initialization scaling and the learning rate scaling between PyTorch default and µP. As shown, µP is the only parameterization that preserves the optimal learning rate across width, achieves the best performance for the model with width 213 = 8192, and where wider models always do better for a given learning rate—that is, graphically, the curves don’t intersect.
Building on the theoretical foundation of Tensor Programs, µTransfer works automatically for advanced architectures, such as Transformer and ResNet. It can also simultaneously transfer a wide range of hyperparameters. Using Transformer as an example, we demonstrate in Figure 3 how the optima of key hyperparameters are stable across widths.

“I am excited about µP advancing our understanding of large models. µP’s principled way of parameterizing the model and selecting the learning rate make it easier for anybody to scale the training of deep neural networks. Such an elegant combination of beautiful theory and practical impact.”
— Johannes Gehrke, Technical Fellow, Lab Director of Research at Redmond, and CTO and Head of Machine Learning for the Intelligent Communications and Conversations Cloud (IC3)
Beyond width: Empirical scaling of model depth and more
Modern neural network scaling involves many more dimensions than just width. In our work, we also explore how µP can be applied to realistic training scenarios by combining it with simple heuristics for nonwidth dimensions. In Figure 4, we use the same transformer setup to show how the optimal learning rate remains stable within reasonable ranges of nonwidth dimensions. For hyperparameters other than learning rate, see Figure 19 in our paper.

Testing µTransfer
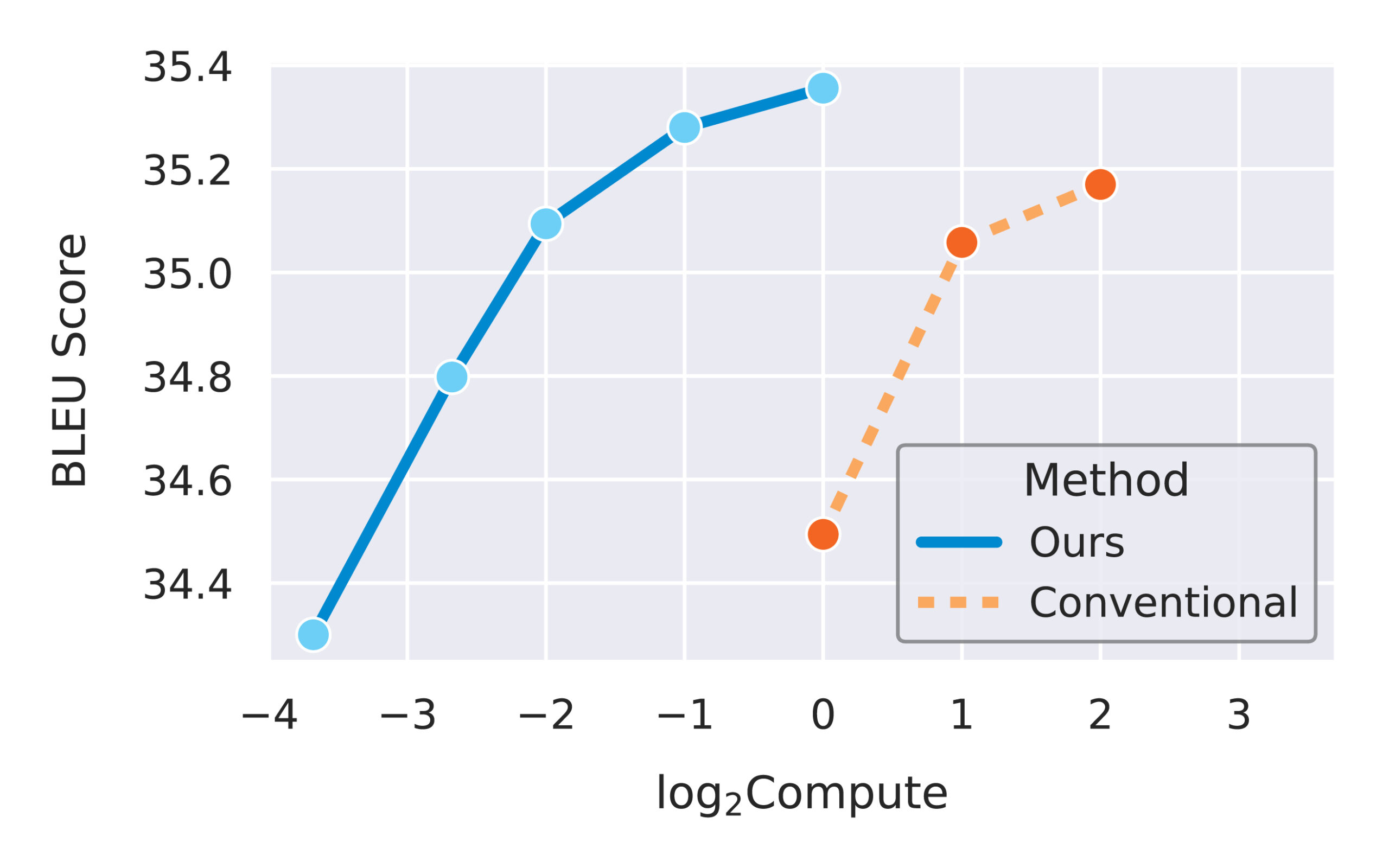
Now that we have verified the transfer of individual hyperparameters, it is time to combine them in a more realistic scenario. In Figure 5, we compare µTransfer, which transfers tuned hyperparameters from a small proxy model, with directly tuning the large target model. In both cases, the tuning is done via random search. Figure 5 illustrates a Pareto frontier of the relative tuning compute budget compared with the tuned model quality (BLEU score) on IWSLT14 De-En, a machine translation dataset. Across all compute budget levels, µTransfer is about an order of magnitude (in base 10) more compute-efficient for tuning. We expect this efficiency gap to dramatically grow as we move to larger target model sizes.
A glimpse of the future: µP + GPT-3
Before this work, the larger a model was, the less well-tuned we expected it to be due to the high cost of tuning. Therefore, we expected that the largest models could benefit the most from µTransfer, which is why we partnered with OpenAI to evaluate it on GPT-3.
After parameterizing a version of GPT-3 with relative attention in µP, we tuned a small proxy model with 40 million parameters before copying the best hyperparameter combination to the 6.7-billion parameter variant of GPT-3, as prescribed by µTransfer. The total compute used during this tuning stage was only 7 percent of the compute used in the pretraining of the final 6.7-billion model. This µTransferred model outperformed the model of the same size (with absolute attention) in the original GPT-3 paper. In fact, it performs similarly to the model (with absolute attention) with double the parameter count from the same paper, as shown in Figure 6.

Implications for deep learning theory
As shown previously, µP gives a scaling rule which uniquely preserves the optimal hyperparameter combination across models of different widths in terms of training loss. Conversely, other scaling rules, like the default in PyTorch or the NTK parameterization studied in the theoretical literature, are looking at regions in the hyperparameter space farther and farther from the optimum as the network gets wider. In that regard, we believe that the feature learning limit of µP, rather than the NTK limit, is the most natural limit to study if our goal is to derive insights that are applicable to feature learning neural networks used in practice. As a result, more advanced theories on overparameterized neural networks should reproduce the feature learning limit of µP in the large width setting.
Theory of Tensor Programs
The advances described above are made possible by the theory of Tensor Programs (TPs) developed over the last several years. Just as autograd helps practitioners compute the gradient of any general computation graph, TP theory enables researchers to compute the limit of any general computation graph when its matrix dimensions become large. Applied to the underlying graphs for neural network initialization, training, and inference, the TP technique yields fundamental theoretical results, such as the architectural universality of the Neural Network-Gaussian Process correspondence and the Dynamical Dichotomy theorem, in addition to deriving µP and the feature learning limit that led to µTransfer. Looking ahead, we believe extensions of TP theory to depth, batch size, and other scale dimensions hold the key to the reliable scaling of large models beyond width.
Applying µTransfer to your own models
Even though the math can be intuitive, we found that implementing µP (which enables µTransfer) from scratch can be error prone. This is similar to how autograd is tricky to implement from scratch even though the chain rule for taking derivatives is very straightforward. For this reason, we created the mup package to enable practitioners to easily implement µP in their own PyTorch models, just as how frameworks like PyTorch, TensorFlow, and JAX have enabled us to take autograd for granted. Please note that µTransfer works for models of any size, not just those with billions of parameters.
The journey has just begun
While our theory explains why models of different widths behave differently, more investigation is needed to build a theoretical understanding of the scaling of network depth and other scale dimensions. Many works have addressed the latter, such as the research on batch size by Shallue et al., Smith et al., and McCandlish et al., as well as research on neural language models in general by Rosenfield et al. and Kaplan et al. We believe µP can remove a confounding variable for such investigations. Furthermore, recent large-scale architectures often involve scale dimensions beyond those we have talked about in our work, such as the number of experts in a mixture-of-experts system. Another high-impact domain to which µP and µTransfer have not been applied is fine tuning a pretrained model. While feature learning is crucial in that domain, the need for regularization and the finite-width effect prove to be interesting challenges.
We firmly believe in fundamental research as a cost-effective complement to trial and error and plan to continue our work to derive more principled approaches to large-scale machine learning. To learn about our other deep learning projects or opportunities to work with us and even help us expand µP, please go to our Deep Learning Group page.
The post µTransfer: A technique for hyperparameter tuning of enormous neural networks appeared first on Microsoft Research.

COMPASS: COntrastive Multimodal Pretraining for AutonomouS Systems
Humans have the fundamental cognitive ability to perceive the environment through multimodal sensory signals and utilize this to accomplish a wide variety of tasks. It is crucial that an autonomous agent can similarly perceive the underlying state of an environment from different sensors and appropriately consider how to accomplish a task. For example, localization (or “where am I?”) is a fundamental question that needs to be answered by an autonomous agent prior to navigation, often addressed via visual odometry. Highly dynamic tasks, such as vehicle racing, necessitate collision avoidance and understanding of the temporal evolution of their state with respect to the environment. Agents must learn perceptual representations of geometric and semantic information from the environment so that their actions can influence the world.
Task-driven approaches are appealing, but learning representations that are suitable only for a specific task limits their ability to generalize to new scenarios, thus confining their utility. For example, as shown in Figure 1, to achieve tasks of drone navigation and vehicle racing, people usually need to specifically design different models to encode representations from very different sensor modalities, e.g., different environments, sensory signals, sampling rate, etc. Such models must also cope with different dynamics and controls for each application scenario. Therefore, we ask the question if it is possible to build general-purpose pretrained models for autonomous systems that are agnostic to tasks and individual form factor.
In our recent work, COMPASS: Contrastive Multimodal Pretraining for Autonomous Systems, we introduce a general-purpose pretraining pipeline, built to overcome such limitations arising from task-specific models. The code can be viewed on GitHub.
COMPASS features three key aspects:
- COMPASS is a general-purpose large-scale pretraining pipeline for perception-action loops in autonomous systems. Representations learned by COMPASS generalize to different environments and significantly improve performance on relevant downstream tasks.
- COMPASS is designed to handle multimodal data. Given the prevalence of multitudes of sensors in autonomous systems, the framework is designed to utilize rich information from different sensor modalities.
- COMPASS is trained in a self-supervised manner which does not require manual labels, and hence can leverage large scale data for pretraining.
We demonstrate how COMPASS can be used to solve various downstream tasks across three different scenarios: Drone Navigation, Vehicle Racing, and Visual Odometry tasks.
Challenges in learning generic representations for autonomous systems
Although general-purpose pretrained models have made breakthroughs in natural language processing (NLP) and in computer vision, building such models for autonomous systems has its own challenges.
- Autonomous systems deal with complex perception-action interplay. The target learning space is highly variable due to a wide range of environmental factors and application scenarios. This is in stark contrast to language models, which focus on underlying linguistic representations, or visual models, which focus on object-centric semantics. These aspects make existing pretraining approaches inadequate for autonomous systems.
- The environments are usually perceived through multimodal sensors, so the model must be able to make sense of multimodal data. Existing multimodal learning approaches focus primarily on mapping multimodal data into joint latent spaces. Though they have shown promising results in applications of video, audio, and text, they are suboptimal for autonomous systems. Approaches that learn a single joint latent space fail to respect different properties of multimodal data, such as sampling rate and temporal dynamics. On the other hand, mapping into disjoint latent spaces loses the connection among the modalities and limits the usage in complex autonomous systems, because different autonomous systems can be equipped with a wide variety of sensor configurations.
- Unlike NLP and computer vision, there is scarcity of multimodal data that can be used to train large pretrained representations for autonomous systems.
Factorized spatiotemporal latent spaces for learning representations
COMPASS is a multimodal pretraining framework for perception and action in autonomous systems. COMPASS builds general-purpose multimodal representations that can generalize to different environments and tasks.
Two questions inform our design choices in COMPASS:
- What essential pieces of information are common for all tasks of autonomous systems?
- How can we effectively learn representations from complex multimodal data to capture the desired information?
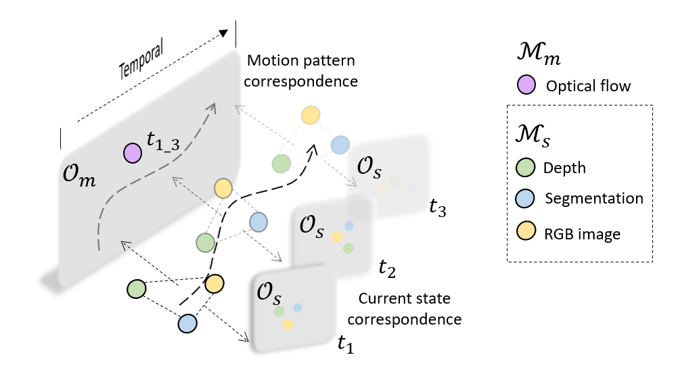
The network architecture design must adhere to the spatiotemporal constraints of autonomous systems. The representation needs to account for the motion (ego-motion or environmental) and its temporal aspects as well as the spatial, geometric, and semantic cues perceived through the sensors. Therefore, we propose a multimodal graph that captures the spatiotemporal properties of the modalities (Fig. 2). The graph is designed to map each of the modalities into two factorized spatiotemporal latent subspaces: 1) the motion pattern space and 2) the current state space. The self-supervised training then uses multimodal correspondence to associate the modality to the different latent spaces. Such a factorized representation further allows systems equipped with different sensors to use the same pretrained model.
While plenty of sensor modalities are rich in spatial and semantic cues, such as RGB images, depth sensors), we note that certain modalities primarily contain information about the temporal aspect, such as IMU, Optical Flow). Given such a partition of modalities between spatially informative ((mathcal{M}_{s})) and temporally informative (mathcal{M}_{m}) data, we jointly learn two latent spaces, a “motion pattern space” (mathcal{O}_{m}) and a “current state space” (mathcal{O}_{s}).
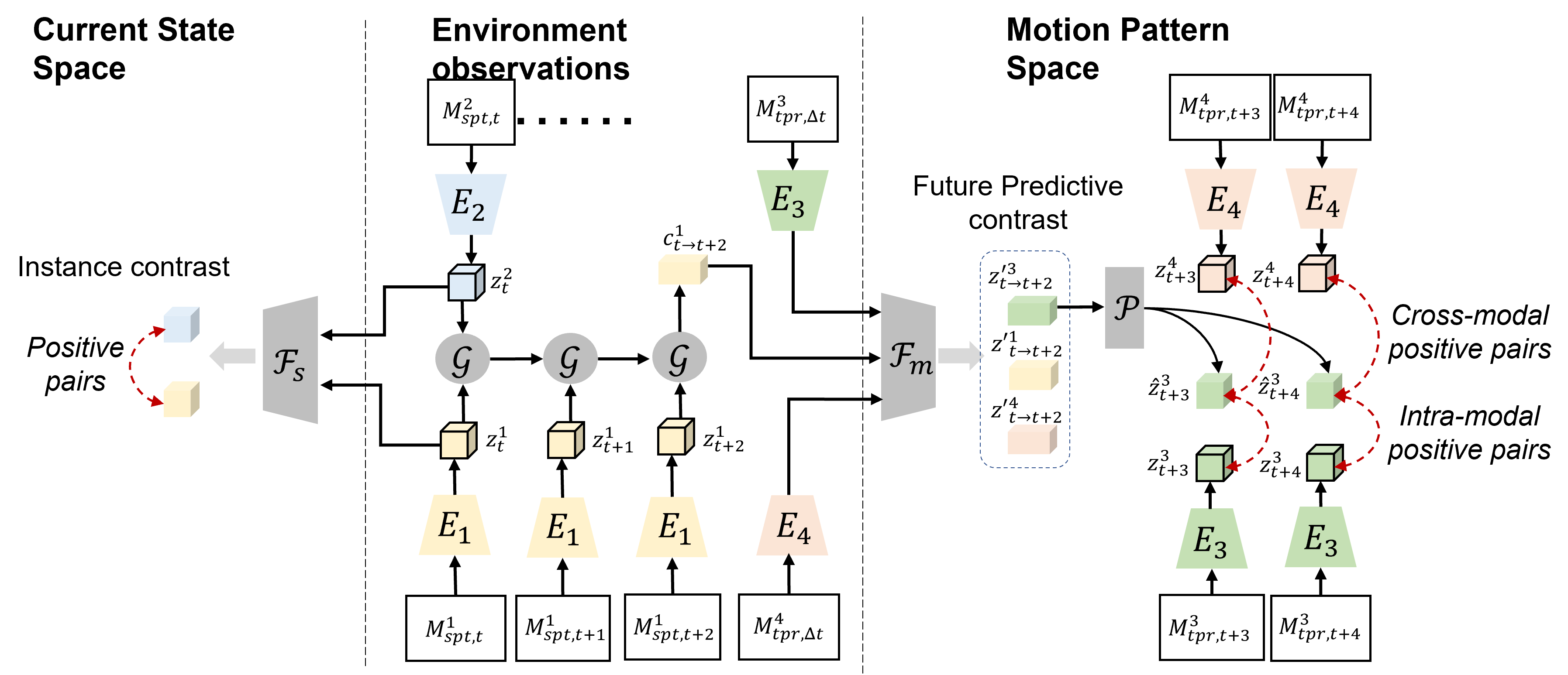
Contrastive learning via multimodal graph connections
The key intuition behind the self-supervised objective for training COMPASS is that if the representation successfully captures spatiotemporal information across multiple modalities, then each modality should have some predictive capacity both for itself as well as the others. We formulate this intuition into a contrastive learning objective. Figure 3 graphically depicts the idea where the modality-specific encoders (E) extract embeddings from each modality. These are then mapped to the common motion pattern space (mathcal{O}_{m}) through the motion pattern projection head (mathcal{F}_m). A prediction head (mathcal{P}) is added on top to perform future prediction. The contrastive loss is computed between the predicted future representations and their corresponding encoded true representations. Similarly, the contrastive objective also associates the data between distinct spatial modalities (mathcal{M}_{s}) projected onto the current state space (mathcal{O}_s) at every time step.
Note that modalities that are primarily temporal are projected to the motion pattern space through (mathcal{F}_m) only. Modalities that are only spatial are first projected onto the current state space by (mathcal{F}_s). To better associate spatial modalities with the temporal ones, we introduce a spatiotemporal connection where spatial modalities from multiple timesteps are aggregated via an aggregator head (mathcal{G}) and projected into the motion pattern space. Such as multimodal graph with spatial, temporal, and spatiotemporal connections serves as a framework for learning multimodal representations by encoding the underlying properties of modalities (such as static, dynamic) as well as any common information shared between them (for example, geometry, motion).
Finally, we tackle the challenge of data scarcity by resorting to simulation. In particular, we build upon our previous work in high-fidelity simulation with AirSim and use the TartanAir dataset (TartanAir: A Dataset to Push the Limits of Visual SLAM – Microsoft Research) to train the model.
Deploying COMPASS to downstream tasks
After pretraining, the COMPASS model can be finetuned for several downstream tasks. Based on the sensor modalities available for the task of interest, we connect the appropriate pretrained COMPASS encoders to small neural network modules responsible for task-specific predictions such as robot actions, camera poses etc. This combined model is then finetuned given data and objectives from the specific task.
We demonstrate the effectiveness of COMPASS as a general-purpose pretraining approach on three downstream tasks: simulated drone navigation, simulated vehicle racing, and visual odometry. Figure 4 and Table 1 show some details about both our pretraining as well as downstream task datasets.

| Dataset | Usage | Scale | Env. |
|---|---|---|---|
| TartanAIR | Pretraining | 1M | 16 |
| Soccer-gate | Drone Navigation. | 3k | 1 |
| KITTI | Visual Odometry | 23K | 11 |
| AirSim-Car | Car racing | 17K | 9 |
Drone Navigation
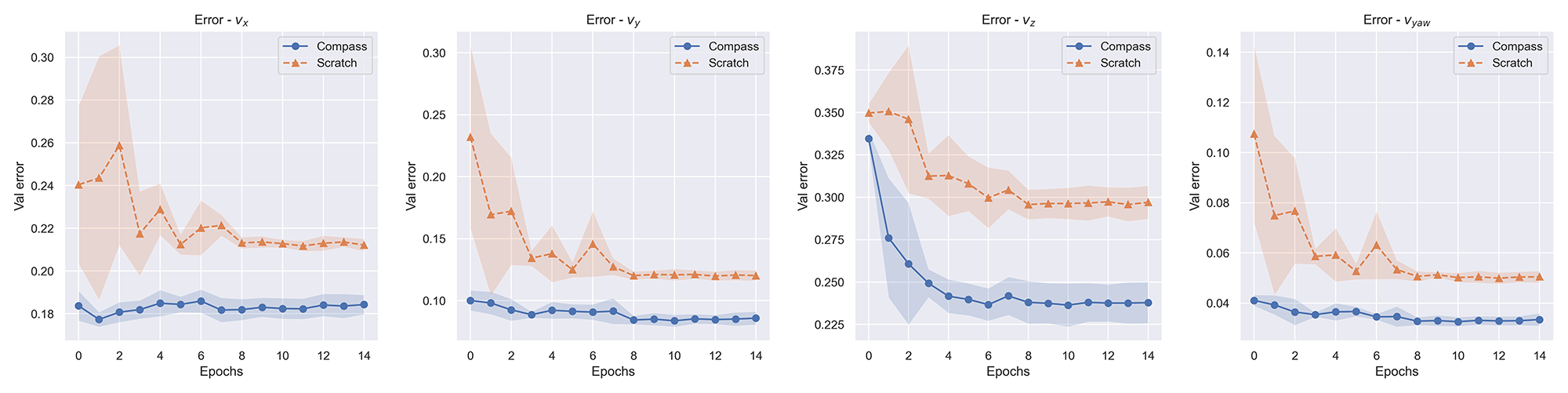
The goal of this task is to enable a quadrotor drone to navigate through a series of gates whose locations are unknown to it a priori. The simulated environment contains a diverse set of gates varying in shape, sizes, color, and texture. Given RGB images from the camera onboard the drone in this environment, the model is asked to predict velocity commands to make the drone successfully go through a series of gates. Figure 5 highlights that finetuning COMPASS for this velocity prediction task results in better performance than training a model from scratch.
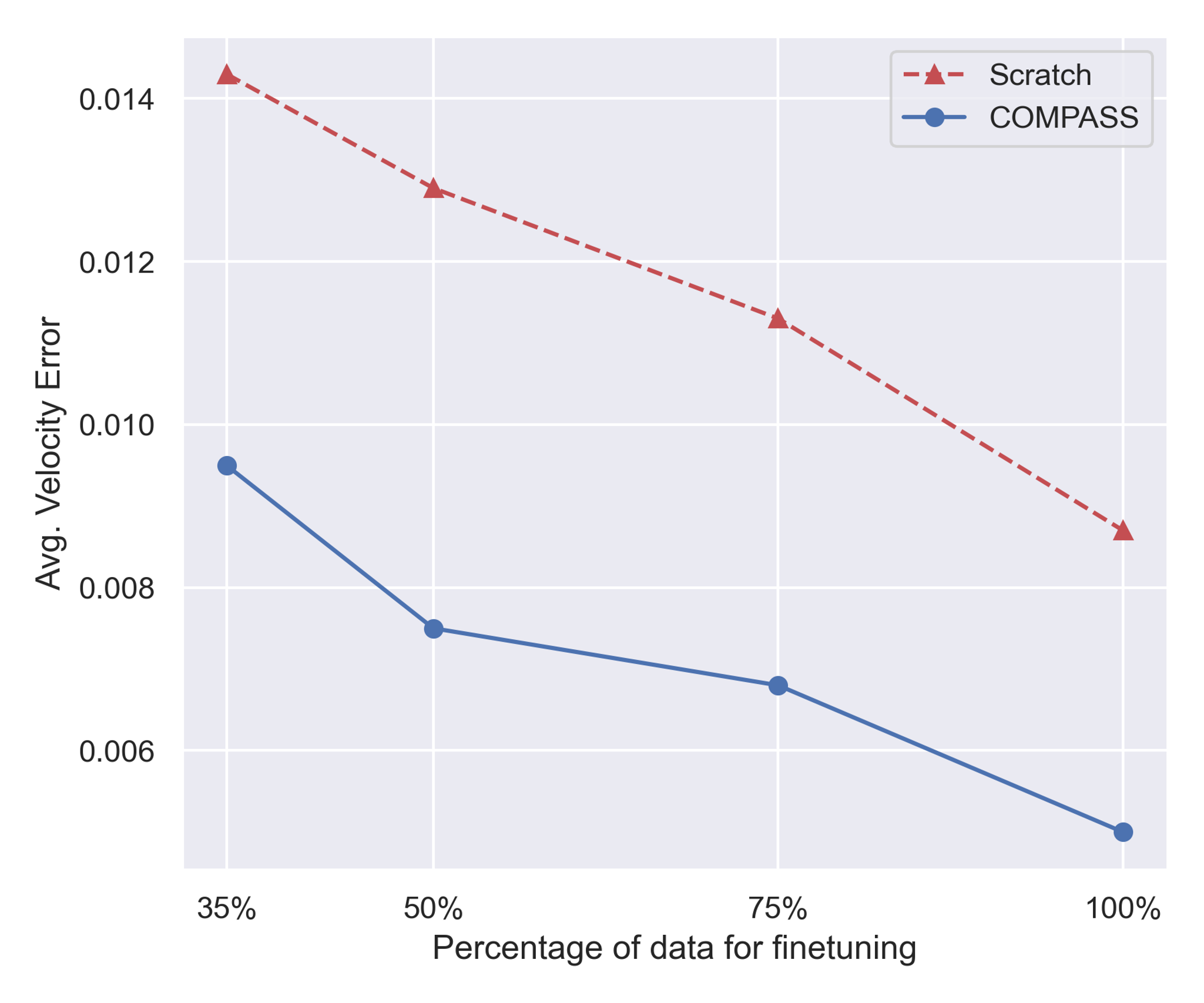
COMPASS can improve data efficiency. Furthermore, finetuning over pretrained COMPASS models exhibits more data efficient learning than training models from scratch. Figure 6 compares finetuning performance with different amounts of data to training from scratch. We see that COMPASS finetuning consistently produces fewer errors than training from scratch, even with less data.
Visual Odometry
Visual odometry (VO) aims to estimate camera motion from consecutive image frames. This is a fundamental component in visual SLAM which is widely used for localization in robotics. We evaluate COMPASS for the VO task on a widely used real-world dataset (The KITTI Vision Benchmark Suite (cvlibs.net)). We first use an off-the-shelf optical flow model (PWC-Net) to generate optical flow data given consecutive image frames, which are then inputted to the optical flow encoder of COMPASS, eventually resulting in predicted camera motion.
| Methods | Sequence 9 | Sequence 10 | ||
| (t_{rel}) | (r_{rel}) | (t_{rel}) | (r_{rel}) | |
| ORB-SLAM2 | 15.3 | 0.26 | 3.71 | 0.3 |
| DVSO | 0.83 | 0.21 | 0.74 | 0.21 |
| D3VO | 0.78 | – | 0.62 | – |
| VISO2-M | 4.04 | 1.43 | 25.2 | 3.8 |
| DeepVO | N/A | N/A | 8.11 | 8.83 |
| Wang et al. | 8.04 | 1.51 | 6.23 | 0.97 |
| TartanVO | 6.00 | 3.11 | 6.89 | 2.73 |
| UnDeepVO | N/A | N/A | 10.63 | 4.65 |
| GeoNet | 26.93 | 9.54 | 20.73 | 9.04 |
| COMPASS (ours) | 2.79 | 0.98 | 2.41 | 1.00 |
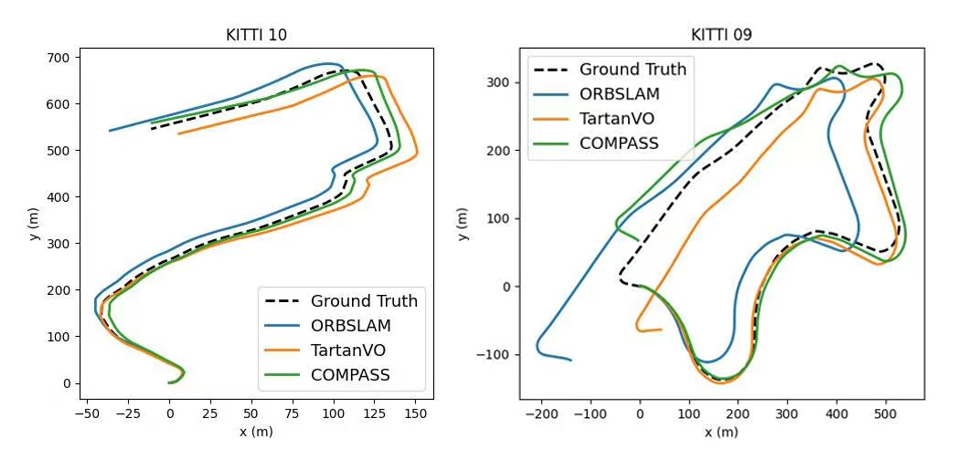
COMPASS can adapt to real-world scenarios. In this experiment, we finetune the model on sequence 00-08 of KITTI and test it on sequence 09 and 10. For comprehensive investigation, we compare COMPASS with both SLAM methods and visual odometry methods. The results are shown in Table 2, where we list the relative pose error (RPE), which is the same metric used on KITTI benchmark. Using the pretrained flow encoder from COMPASS within this VO pipeline achieves better results than several other VO methods and is even comparable to SLAM methods. Figure 7 shows the predicted trajectories of sequences 09 and 10 compared to ground truth. For clarity, we also select one representative model from the geometry-based and learning-based approaches each. We can see that, although pretrained purely on simulation data, COMPASS adapts well to finetuning on real-world scenarios.
Vehicle Racing
The goal here is to enable autonomous vehicles to drive in a competitive Formula racing environment. The simulated environment contains visual distractors such as advertising signs, tires, grandstands, and fences, which help add realism and increase task difficulty. Given RGB images from the environment as input, the control module must predict the steering wheel angle for a car to successfully maneuver around the track and avoid obstacles.
| Model | Seen env. | Unseen env. |
|---|---|---|
| SCRATCH | 0.085 ± 0.025 | 0.120 ± 0.009 |
| CPC | 0.037 ±0.012 | 0.101 ± 0.017 |
| CMC | 0.039 ± 0.013 | 0.102 ± 0.012 |
| JOINT | 0.055 ± 0.016 | 0.388 ± 0.018 |
| DISJOINT | 0.039 ± 0.017 | 0.131 ± 0.016 |
| COMPASS | 0.041 ± 0.013 | 0.071 ± 0.023 |

COMPASS can generalize to unseen environments. We hypothesize that better perception, enabled by pretraining, improves generalization to unseen environments. To show this, we evaluate models in two settings: 1) trained and evaluated on all nine scenarios (“seen”); 2) trained on eight scenarios and evaluated on one scenario (“unseen”). Table 3 shows that the performance degradation in the unseen environment is relatively marginal with (texttt{COMPASS}), which suggests its effectiveness compared to the other pretraining approaches.
COMPASS can benefit from multimodal training regime. We investigate the effectiveness of pretraining on multimodal data by analyzing loss curves from different pretrained models on the same ‘unseen’ environments. Figure 8(b) compares the validation loss curves of (texttt{COMPASS}), (texttt{RGB}), and (texttt{Scratch}), where (texttt{RGB}) is the model that is pretrained only with RGB images. As we can see, by pretraining on multimodal data, COMPASS achieves the best performance overall. Also, both of these pretraining models show large gaps when compared to a model trained from scratch ((texttt{Scratch})). When comparing Figure 8(a) to Figure 8(b), we see that (texttt{Scratch}) suffers more from the overfitting issue than the other two models.
Conclusion
We introduce COntrastive Multimodal pretraining for AutonomouS Systems (COMPASS), a ‘general’ pretraining framework that learns multimodal representations to tackle various downstream autonomous system tasks. In contrast to existing task-specific approaches in autonomous systems, COMPASS is trained entirely agnostic to any downstream tasks, with the primary goal of extracting information that is common to multiple scenarios. COMPASS learns to associate multimodal data with respect to their properties, allowing it to encode the spatio-temporal nature of data commonly observed in autonomous systems. We demonstrated that COMPASS generalizes well to different downstream tasks—drone navigation, vehicle racing and visual odometry—even in unseen environments, real-world environments and in the low-data regime.
The post COMPASS: COntrastive Multimodal Pretraining for AutonomouS Systems appeared first on Microsoft Research.

Using reinforcement learning to identify high-risk states and treatments in healthcare
As the pandemic overburdens medical facilities and clinicians become increasingly overworked, the ability to make quick decisions on providing the best possible treatment is even more critical. In urgent health situations, such decisions can mean life or death. However, certain treatment protocols can pose a considerable risk to patients who have serious medical conditions and can potentially contribute to unintended outcomes.
In this research project, we built a machine learning (ML) model that works with scenarios where data is limited, such as healthcare. This model was developed to recognize treatment protocols that could contribute to negative outcomes and to alert clinicians when a patient’s health could decline to a dangerous level. You can explore the details of this research project in our research paper, “Medical Dead-ends and Learning to Identify High-risk States and Treatments,” which was presented at the 2021 Conference on Neural Information Processing Systems (NeurIPS 2021).
Reinforcement learning for healthcare
To build our model, we decided to use reinforcement learning—an ML framework that’s uniquely well-suited for advancing safety-critical domains such as healthcare. This is because at its core, healthcare is a sequential decision-making domain, and reinforcement learning is the formal paradigm for modeling and solving problems in such domains. In healthcare, clinicians base their treatment decisions on an overall understanding of a patient’s health; they observe how the patient responds to this treatment, and the process repeats. Likewise, in reinforcement learning, an algorithm, or agent, interprets the state of its environment and takes an action, which, coupled with the internal dynamics of the environment, causes it to transition to a new state, as shown in Figure 1. A reward signal is then assigned to account for the immediate impact of this change. For example, in a healthcare scenario, if a patient recovers or is discharged from the intensive care unit (ICU), the agent may receive a positive reward. However, if the patient does not survive, the agent receives a negative reward, or penalty.

Reinforcement learning is widely used in gaming, for example, to determine the best sequence of chess moves and maximize an AI system’s chances of winning. Over time, due to trial-and-error experimentation, the desired actions are maximized and the undesired ones are minimized until the optimal solution is identified. Normally, this experimentation is made possible by the proactive collection of extensive amounts of diverse data. However, unlike in gaming, exploratory data collection and experimentation are not possible in healthcare, and our only option in this realm is to work with previously collected datasets, providing very limited opportunities to explore alternative choices. This is where offline reinforcement learning comes into focus. A subarea of reinforcement learning, offline reinforcement learning works only with data that already exists—instead of proactively taking in new data, we’re using a fixed dataset. Even so, to propose the best course of action, an offline reinforcement learning algorithm still requires sufficient trial-and-error with alternatives, and this necessitates a very large dataset, something not feasible in safety-critical domains with limited data, like healthcare.
In the current research literature, when reinforcement learning is applied to healthcare, the focus is on what to do to support the best possible patient outcome, an infeasible objective. In our paper, we propose inverting this paradigm in offline settings to investigate high-risk treatments and identify when the state of patients’ health reaches a critical point. To enable this approach, we developed a methodology called Dead-end Discovery (DeD), which identifies treatments to avoid in order to prevent a medical dead-end—the point at which the patient is most likely to die regardless of future treatment. DeD provably requires exponentially less data than the standard methods, making it significantly more reliable in limited-data situations. By identifying known high-risk treatments, DeD could assist clinicians in making trustworthy decisions in highly stressful situations, where minutes count. Moreover, this methodology could also raise an early warning flag and alert clinicians when a patient’s condition reveals outstanding risk, often before it becomes obvious. We go into more detail on the DeD methodology later in this post.
Medical dead-ends and rescue states
At ICUs, patients experience a trajectory which sequentially tracks the state of their health. It starts with the patient’s condition upon admission, followed by the administration of treatment and then by their response to the treatment. This sequence repeats until the patient reaches a terminal state—the final observation of the patient’s condition that’s still relevant within the ICU. To learn what treatments to avoid, we focus on two types of terminal states: patient recovery and patient death. Other terminal states can also exist. For example, when playing chess, a loss or a win are not the only possible outcomes; draws can also occur. While our framework can encompass additional terminal states, this work focuses on only two possibilities: positive outcomes and negative outcomes.
Building on these two terminal states, we define medical dead-ends as patient states from which all possible future trajectories will lead to the terminal state of the patient’s death. If applied in acute care settings, it’s critical to both avoid medical dead-ends and identify the probability with which any selected treatment will lead to them. It’s also important to note that medical dead-ends can occur considerably earlier than clinicians are able to observe. This makes DeD particularly valuable, as every hour counts when it comes to critical conditions.
To contrast with medical dead-ends, we also propose the concept of rescue states, where recovery is fully reachable. At each rescue state, there exists at least one treatment that would lead, with the probability of 1, either to another rescue state or to recovery. In most cases, a patient’s condition is neither a medical dead-end nor a rescue state, as the minimum and maximum probability of future mortality or recovery is not always 0 and 1, but somewhere in between. Therefore, it’s important to have an alert when a patient is likely to enter a medical dead-end.
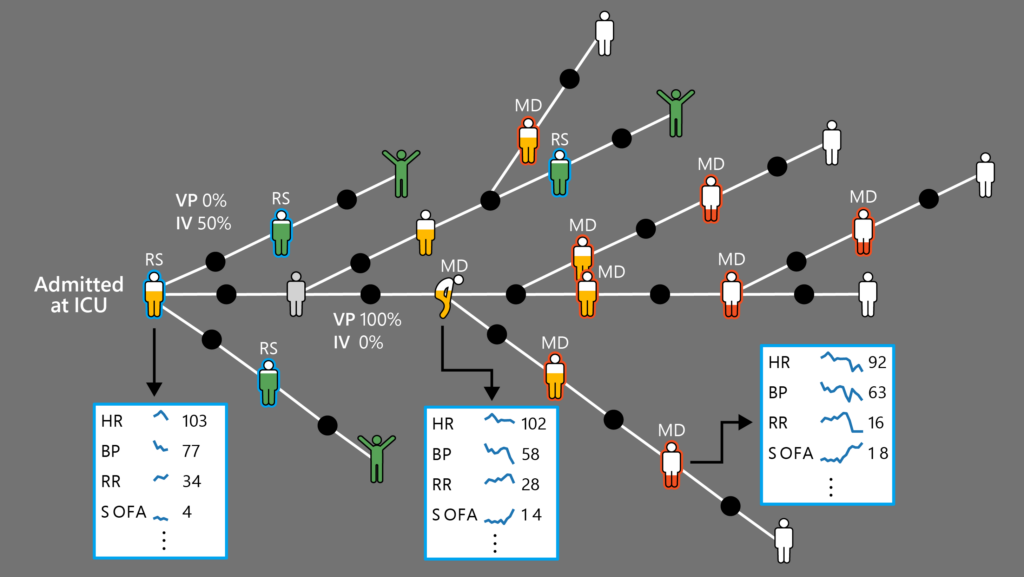
Patient vital signs taken at the ICU: HR=heart rate; BP=blood pressure; RR=respiration rate; SOFA=sequential organ failure assessment score
Treatment security: How to help doctors
To develop our model, we considered a generic condition that guarantees the merit and reliability of a given treatment-selection policy. In particular, we postulated the following condition we called treatment security:
If at state (s), treatment (a) causes transitioning to a medical dead-end with any given level of certainty, then the policy must refrain from selecting (a) at (s) with the same level of certainty.
For example, if a certain treatment leads to a medical dead-end or immediate death with a probability of more than 80 percent, that treatment should be selected for administration no more than 20 percent of the time.
While treatment security is a desired property, it’s not easy to directly enforce because the required probabilities are not known a priori, nor are they directly measurable from the data. Therefore, we developed a theoretical framework at the core of our method that enables treatment security from data by mapping it to proper learning problems.
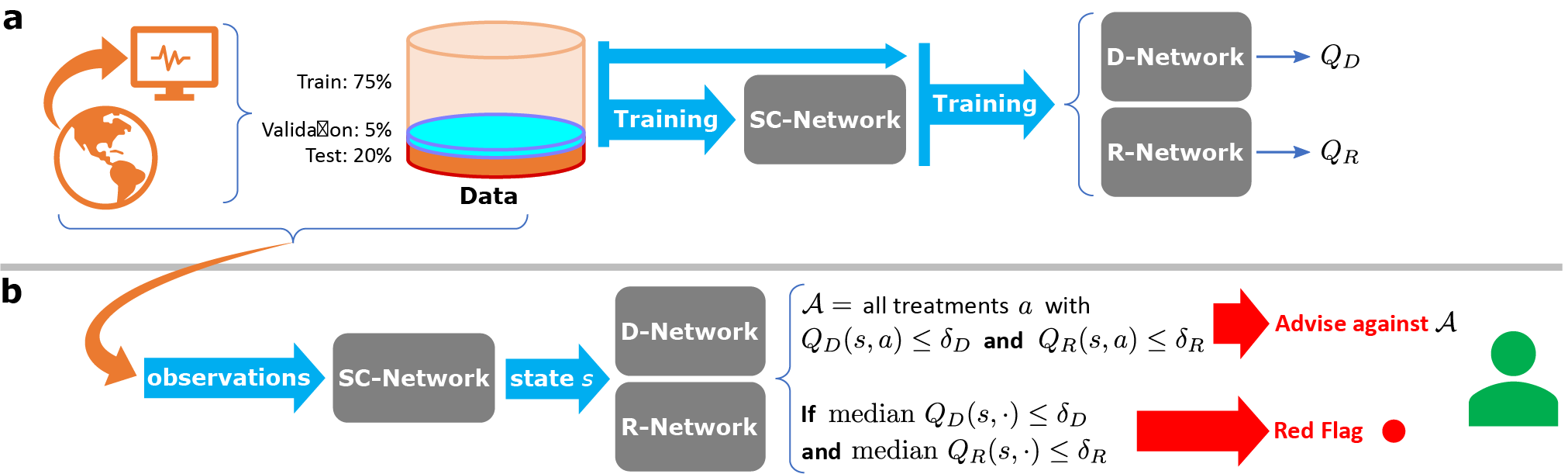
DeD: Dead-end Discovery methodology
To precisely define the learning problems, we based our DeD methodology on three core ideas: 1) separating the outcomes, 2) learning the optimal value function of each outcome in isolation without discounting, and 3) proving important properties for these particular value functions, which enable treatment security.
We constructed two simple reward signals for independent learning problems:
- -1 in the case of a negative outcome; 0 at all other transitions
- +1 in the case of a positive outcome; 0 at all other transitions
Next, we learned their corresponding optimal value functions, (Q_{D}^{*}(s, a)) and (Q_{R}^{*}(s, a)) both with no discounting. It turns out that these value functions are intrinsically important. In fact, we show that:
–(Q_{D}^{*}(s, a)) corresponds to the minimum probability of a future negative outcome if treatment (a) is selected at state (s). Equivalently, (1 + Q_{D}^{*}(s, a)) corresponds to the maximum hope of a positive outcome.
Moreover, the quantity (1 + Q_{D}^{*}(s, a)) proves to be a meaningful threshold for a policy to make it secure. We formally show that: for treatment security, it is sufficient to abide by the maximum hope of recovery.
We further proved that if the probability of treatment selection can be higher than (Q_{R}^{*}(s, a)), the patient is guaranteed to remain in a rescue state when possible. Finally, we also showed that such thresholds for limiting the treatment selection probabilities exist.
Building from these results, we defined a training and deployment pipeline, illustrated in Figure 3.
Applying the DeD methodology to sepsis
To demonstrate the utility of DeD in safety-critical domains and to honor the underlying healthcare motivations behind its development, we applied DeD on publicly available real-world medical data. Specifically, our data pertained to critically ill patients who had developed sepsis and were treated in an ICU.
Sepsis is a syndrome characterized by organ dysfunction due to a patient’s dysregulated response to an infection. In the United States alone, sepsis is responsible for more than 200,000 deaths each year, contributing to over 10 percent of in-hospital mortality, and accounting for over $23 billion in hospitalization costs. Globally, sepsis is a leading cause of mortality, with an estimated 11 million deaths each year, accounting for almost 20 percent of all deaths. It’s also an end-stage to many health conditions. In a recent retrospective study of hospitalized COVID-19 patients, all the fatal cases and more than 40 percent of survivors were septic.
In our study, we envisioned a way to help clinicians identify which subset of treatments could statistically cause further health deterioration so that they could eliminate them when deciding on the next steps. To estimate the value functions of possible treatments, we used the publicly available Medical Information Mart for Intensive Care III (MIMIC-III) dataset (v 1.4), sourced from the Beth Israel Deaconess Medical Center in Boston, Massachusetts. MIMIC-III is comprised of deidentified electronic health records (EHR) of consenting patients admitted to critical care units, collected from 53,423 distinct hospital admissions between 2001 and 2012. Following standard extraction and preprocessing methods, we derived an experimental cohort of 19,611 patients who are presumed to have developed sepsis during their initial admission to the ICU, with an observed mortality rate of approximately 10 percent. We studied 72 hours of the patients’ stay at the ICU—24 hours before the presumed onset of sepsis and 48 hours afterwards. We used 44 observation variables, including various health records and demographic information, and 25 distinct treatment options (five discrete levels for IV fluid and vasopressor volumes in combination), aggregated over four hours.
With this dataset, we sought to demonstrate that medical dead-ends exist in medical data and show the effect of treatment selection on the development of medical dead-ends. We also sought to identify whether alternative treatments were available that could have prevented the occurrence of a medical dead-end.
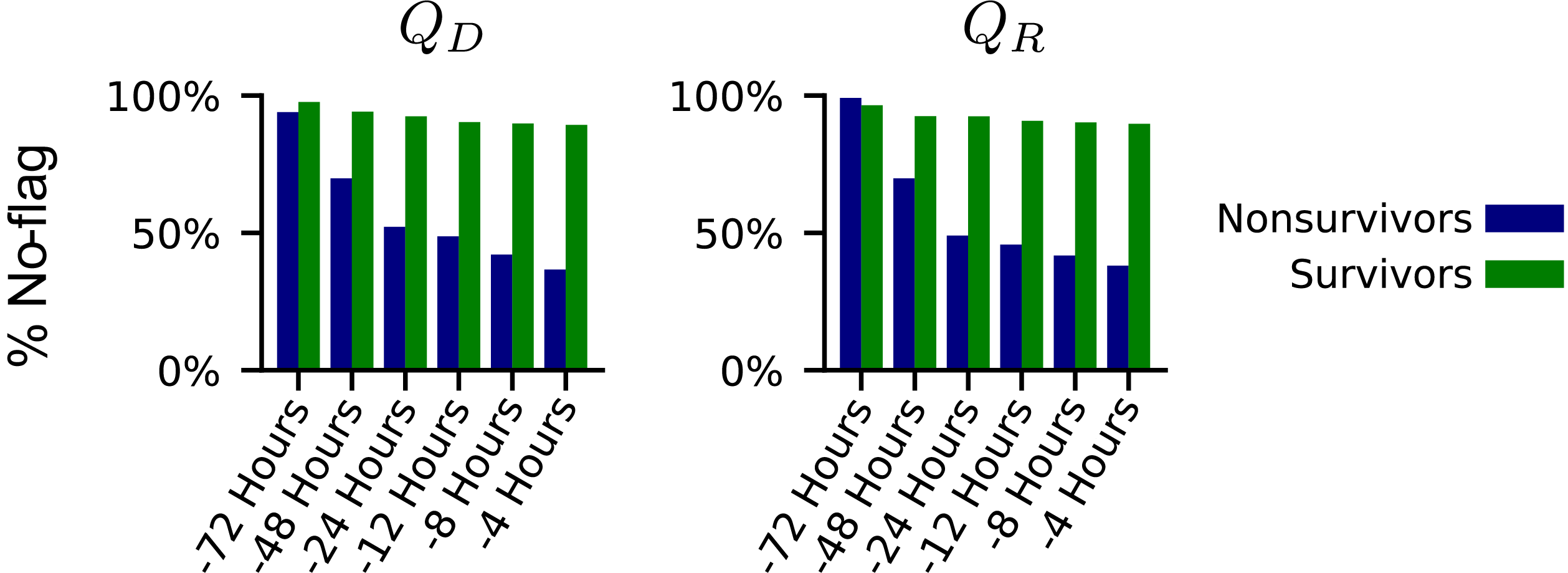
To flag potentially nonsecure treatments, we examined whether the values estimated ((Q_{D}(s, a)) and (Q_{R}(s, a))) for each treatment passed certain thresholds. To flag potential medical dead-end states, we looked at the median values of available treatments against these same thresholds. Using the median helped mitigate approximation errors due to generalization from potentially insufficient data and extrapolations made by the reinforcement learning formulation. With the specified thresholds, DeD identified increasing percentages of patients raising fatal flags, particularly among the subpopulation that died in the hospital. In Figure 4, note the distinctive difference between the trend of estimated values for surviving and non-surviving patients. Over the course of 72 hours in the ICU, surviving patients rarely raised a flag, while flags were raised at an increased rate for patients who did not survive as they proceeded toward the final observations of their time in the ICU.
To further support our hypothesis that medical dead-ends exist among septic patients and may be preventable, we aligned patients according to the point in their care when a flag was first raised by our DeD framework. As shown in Figure 5, we selected all trajectories with at least 24 hours prior to and 16 hours after this flag. The DeD estimates of (V) and (Q) values for administered treatments had similar behavior in both the surviving and non-surviving subpopulations prior to this first flag, but the values quickly diverged afterwards. We observed that the advent of this first flag also corresponded to a similar divergence among various clinical measures and vital signs, shown in Figure 5, sections a and b.
DeD identified a clear critical point in these patients’ care, where non-surviving patients experienced an irreversible negative change to their health, as shown in Figure 5, section c. Additionally, there was a significant gap in the estimated value between the treatments administered to the non-surviving patients and those treatments deemed to be more secure by DeD, shown in Figure 5, section e. There was a clear inflection in the estimated values four to eight hours before this first flag was raised, shown in Figure 5, section c.
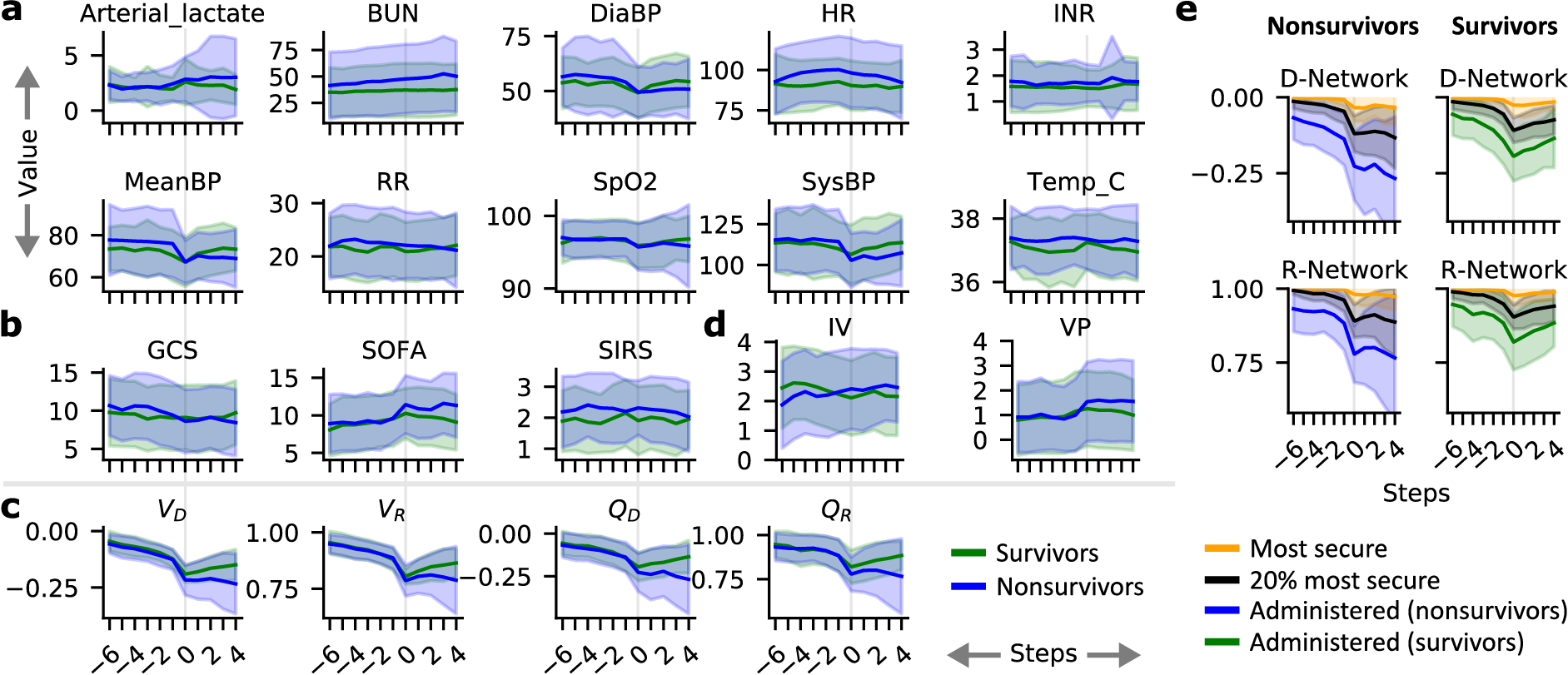
Further analysis of our results, which we describe in detail in our paper, indicates that more than 12 percent of treatments given to non-surviving patients could be detrimental 24 hours before death. We also identified that 2.7 percent of non-surviving patients entered medical dead-end trajectories with a sharply increasing rate up to 48 hours before death, and close to 10 percent when we slightly relaxed our thresholds for predicting medical dead-ends. While these percentages may seem small, more than 200,000 patients die of sepsis every year in US hospitals alone, and any reduction of this rate would result in possibly tens of thousands of individuals who would otherwise survive. We’re excited about the possibility that DeD could help clinicians provide their patients with the best care and that many more patients could potentially survive sepsis.
Looking ahead: Further uses of DeD and offline reinforcement learning
We view DeD as a powerful tool that could magnify human expertise in healthcare by supporting clinicians with predictive models as they make critical decisions. There is significant potential for researchers to use the DeD method to expand on this research and look at other measures, such as the relationship between patient demographics and sepsis treatment, with the goal of preventing certain treatment profiles for particular subgroups of patients.
The principles of offline reinforcement learning and the DeD methodology can also be applied to other clinical conditions, as well as to safety-critical areas beyond healthcare that also rely on sequential decision-making. For example, the domain of finance entails similar core concepts as it is analogously based on sequential decision-making processes. DeD could be used to alert financial professionals when specific actions, such as buying or selling certain assets, are likely to result in unavoidable future loss, or a financial dead-end. We hope our work will inspire active research and discussion in the community. You can learn more about the research and access the code here.
The post Using reinforcement learning to identify high-risk states and treatments in healthcare appeared first on Microsoft Research.

Advancing AI trustworthiness: Updates on responsible AI research
Editor’s note: This year in review is a sampling of responsible AI research compiled by Aether, a Microsoft cross-company initiative on AI Ethics and Effects in Engineering and Research, as outreach from their commitment to advancing the practice of human-centered responsible AI. Although each paper includes authors who are participants in Aether, the research presented here expands beyond, encompassing work from across Microsoft, as well as with collaborators in academia and industry.
Inflated expectations around the capabilities of AI technologies may lead people to believe that computers can’t be wrong. The truth is AI failures are not a matter of if but when. AI is a human endeavor that combines information about people and the physical world into mathematical constructs. Such technologies typically rely on statistical methods, with the possibility for errors throughout an AI system’s lifespan. As AI systems become more widely used across domains, especially in high-stakes scenarios where people’s safety and wellbeing can be affected, a critical question must be addressed: how trustworthy are AI systems, and how much and when should people trust AI?
-

Explore responsible AI resources
Designed to help you responsibly use AI at every stage of development.
As part of their ongoing commitment to building AI responsibly, research scientists and engineers at Microsoft are pursuing methods and technologies aimed at helping builders of AI systems cultivate appropriate trust—that is, building trustworthy models with reliable behaviors and clear communication that set proper expectations. When AI builders plan for failures, work to understand the nature of the failures, and implement ways to effectively mitigate potential harms, they help engender trust that can lead to a greater realization of AI’s benefits.
Pursuing trustworthiness across AI systems captures the intent of multiple projects on the responsible development and fielding of AI technologies. Numerous efforts at Microsoft have been nurtured by its Aether Committee, a coordinative cross-company council comprised of working groups focused on technical leadership at the frontiers of innovation in responsible AI. The effort is led by researchers and engineers at Microsoft Research and from across the company and is chaired by Chief Scientific Officer Eric Horvitz. Beyond research, Aether has advised Microsoft leadership on responsible AI challenges and opportunities since the committee’s inception in 2016.
-

Explore the HAX Toolkit
The Human-AI eXperience (HAX) Toolkit helps builders of AI systems create fluid, responsible human-AI experiences.
-
Explore the Responsible AI Toolbox
Customizable dashboards that help builders of AI systems identify, diagnose, and mitigate model errors, as well as debug models and understand causal relationships in data.
The following is a sampling of research from the past year representing efforts across the Microsoft responsible AI ecosystem that highlight ways for creating appropriate trust in AI. Facilitating trustworthy measurement, improving human-AI collaboration, designing for natural language processing (NLP), advancing transparency and interpretability, and exploring the open questions around AI safety, security, and privacy are key considerations for developing AI responsibly. The goal of trustworthy AI requires a shift in perspective at every stage of the AI development and deployment life cycle. We’re actively developing a growing number of best practices and tools to help with the shift to make responsible AI more available to a broader base of users. Many open questions remain, but as innovators, we are committed to tackling these challenges with curiosity, enthusiasm, and humility.
Facilitating trustworthy measurement
AI technologies influence the world through the connection of machine learning models—that provide classifications, diagnoses, predictions, and recommendations—with larger systems that drive displays, guide controls, and activate effectors. But when we use AI to help us understand patterns in human behavior and complex societal phenomena, we need to be vigilant. By creating models for assessing or measuring human behavior, we’re participating in the very act of shaping society. Guidelines for ethically navigating technology’s impacts on society—guidance born out of considering technologies for COVID-19—prompt us to start by weighing a project’s risk of harm against its benefits. Sometimes an important step in the practice of responsible AI may be the decision to not build a particular model or application.
Human behavior and algorithms influence each other in feedback loops. In a recent Nature publication, Microsoft researchers and collaborators emphasize that existing methods for measuring social phenomena may not be up to the task of investigating societies where human behavior and algorithms affect each other. They offer five best practices for advancing computational social science. These include developing measurement models that are informed by social theory and that are fair, transparent, interpretable, and privacy preserving. For trustworthy measurement, it’s crucial to document and justify the model’s underlying assumptions, plus consider who is deciding what to measure and how those results will be used.

In line with these best practices, Microsoft researchers and collaborators have proposed measurement modeling as a framework for anticipating and mitigating fairness-related harms caused by AI systems. This framework can help identify mismatches between theoretical understandings of abstract concepts—for example, socioeconomic status—and how these concepts get translated into mathematics and code. Identifying mismatches helps AI practitioners to anticipate and mitigate fairness-related harms that reinforce societal biases and inequities. A study applying a measurement modeling lens to several benchmark datasets for surfacing stereotypes in NLP systems reveals considerable ambiguity and hidden assumptions, demonstrating (among other things) that datasets widely trusted for measuring the presence of stereotyping can, in fact, cause stereotyping harms.
-

VIDEO
Discovering and measuring harms in NLP
Examining pitfalls in state-of-the-art approaches to measuring computational harms in language technologies.
Flaws in datasets can lead to AI systems with unfair outcomes, such as poor quality of service or denial of opportunities and resources for different groups of people. AI practitioners need to understand how their systems are performing for factors like age, race, gender, and socioeconomic status so they can mitigate potential harms. In identifying the decisions that AI practitioners must make when evaluating an AI system’s performance for different groups of people, researchers highlight the importance of rigor in the construction of evaluation datasets.
Making sure that datasets are representative and inclusive means facilitating data collection from different groups of people, including people with disabilities. Mainstream AI systems are often non-inclusive. For example, speech recognition systems do not work for atypical speech, while input devices are not accessible for people with limited mobility. In pursuit of inclusive AI, a study proposes guidelines for designing an accessible online infrastructure for collecting data from people with disabilities, one that is built to respect, protect, and motivate those contributing data.
Related papers
- Responsible computing during COVID-19 and beyond
- Measuring algorithmically infused societies
- Measurement and fairness
- Stereotyping Norwegian salmon: An inventory of pitfalls in fairness benchmark datasets
- Understanding the representation and representativeness of age in AI data sets
- Designing disaggregated evaluations of AI systems: Choices, considerations, and tradeoffs
- Designing an online infrastructure for collecting AI data from People with Disabilities
Improving human-AI collaboration
When people and AI collaborate on solving problems, the benefits can be impressive. But current practice can be far from establishing a successful partnership between people and AI systems. A promising advance and direction of research is developing methods that learn about ideal ways to complement people with problem solving. In the approach, machine learning models are optimized to detect where people need the most help versus where people can solve problems well on their own. We can additionally train the AI systems to make decisions as to when a system should ask an individual for input and to combine the human and machine abilities to make a recommendation. In related work, studies have shown that people will too often accept an AI system’s outputs without question, relying on them even when they are wrong. Exploring how to facilitate appropriate trust in human-AI teamwork, experiments with real-world datasets for AI systems show that retraining a model with a human-centered approach can better optimize human-AI team performance. This means taking into account human accuracy, human effort, the cost of mistakes—and people’s mental models of the AI.
In systems for healthcare and other high-stakes scenarios, a break with the user’s mental model can have severe impacts. An AI system can compromise trust when, after an update for better overall accuracy, it begins to underperform in some areas. For instance, an updated system for predicting cancerous skin moles may have an increase in accuracy overall but a significant decrease for facial moles. A physician using the system may either lose confidence in the benefits of the technology or, with more dire consequences, may not notice this drop in performance. Techniques for forcing an updated system to be compatible with a previous version produce tradeoffs in accuracy. But experiments demonstrate that personalizing objective functions can improve the performance-compatibility tradeoff for specific users by as much as 300 percent.
System updates can have grave consequences when it comes to algorithms used for prescribing recourse, such as how to fix a bad credit score to qualify for a loan. Updates can lead to people who have dutifully followed a prescribed recourse being denied their promised rights or services and damaging their trust in decision makers. Examining the impact of updates caused by changes in the data distribution, researchers expose previously unknown flaws in the current recourse-generation paradigm. This work points toward rethinking how to design these algorithms for robustness and reliability.
Complementarity in human-AI performance, where the human-AI team performs better together by compensating for each other’s weaknesses, is a goal for AI-assisted tasks. You might think that if a system provided an explanation of its output, this could help an individual identify and correct an AI failure, producing the best of human-AI teamwork. Surprisingly, and in contrast to prior work, a large-scale study shows that explanations may not significantly increase human-AI team performance. People often over-rely on recommendations even when the AI is incorrect. This is a call to action: we need to develop methods for communicating explanations that increase users’ understanding rather than to just persuade.
Related papers
- Learning to complement humans
- Is the most accurate AI the best teammate? Optimizing AI for teamwork
- Improving the performance-compatibility tradeoff with personalized objective functions
- Algorithmic recourse in the wild: Understanding the impact of data and model shift
- Does the whole exceed its parts? The effect of AI explanations on complementary team performance
- A Bayesian approach to identifying representational errors
Designing for natural language processing
The allure of natural language processing’s potential, including rash claims of human parity, raises questions of how we can employ NLP technologies in ways that are truly useful, as well as fair and inclusive. To further these and other goals, Microsoft researchers and collaborators hosted the first workshop on bridging human-computer interaction and natural language processing, considering novel questions and research directions for designing NLP systems to align with people’s demonstrated needs.
Language shapes minds and societies. Technology that wields this power requires scrutiny as to what harms may ensue. For example, does an NLP system exacerbate stereotyping? Does it exhibit the same quality of service for people who speak the same language in different ways? A survey of 146 papers analyzing “bias” in NLP observes rampant pitfalls of unstated assumptions and conceptualizations of bias. To avoid these pitfalls, the authors outline recommendations based on the recognition of relationships between language and social hierarchies as fundamentals for fairness in the context of NLP. We must be precise in how we articulate ideas about fairness if we are to identify, measure, and mitigate NLP systems’ potential for fairness-related harms.
-
Launch the HAX Playbook
A low-cost way to proactively identify, design for, and test human-AI interaction failures.
The open-ended nature of language—its inherent ambiguity, context-dependent meaning, and constant evolution—drives home the need to plan for failures when developing NLP systems. Planning for NLP failures with the AI Playbook introduces a new tool for AI practitioners to anticipate errors and plan human-AI interaction so that the user experience is not severely disrupted when errors inevitably occur.
Related papers
- Proceedings of the first workshop on bridging human-computer interaction and natural language processing
- Language (technology) is power: A critical survey of “bias” in NLP
- Planning for natural language failures with the AI Playbook
- Invariant language modeling
- On the relationships between the grammatical genders of inanimate nouns and their co-occurring adjectives and verbs
Improving transparency
To build AI systems that are reliable and fair—and to assess how much to trust them—practitioners and those using these systems need insight into their behavior. If we are to meet the goal of AI transparency, the AI/ML and human-computer interaction communities need to integrate efforts to create human-centered interpretability methods that yield explanations that can be clearly understood and are actionable by people using AI systems in real-world scenarios.
As a case in point, experiments investigating whether simple models that are thought to be interpretable achieve their intended effects rendered counterintuitive findings. When participants used an ML model considered to be interpretable to help them predict the selling prices of New York City apartments, they had difficulty detecting when the model was demonstrably wrong. Providing too many details of the model’s internals seemed to distract and cause information overload. Another recent study found that even when an explanation helps data scientists gain a more nuanced understanding of a model, they may be unwilling to make the effort to understand it if it slows down their workflow too much. As both studies show, testing with users is essential to see if people clearly understand and can use a model’s explanations to their benefit. User research is the only way to validate what is or is not interpretable by people using these systems.
Explanations that are meaningful to people using AI systems are key to the transparency and interpretability of black-box models. Introducing a weight-of-evidence approach to creating machine-generated explanations that are meaningful to people, Microsoft researchers and colleagues highlight the importance of designing explanations with people’s needs in mind and evaluating how people use interpretability tools and what their understanding is of the underlying concepts. The paper also underscores the need to provide well-designed tutorials.
Traceability and communication are also fundamental for demonstrating trustworthiness. Both AI practitioners and people using AI systems benefit from knowing the motivation and composition of datasets. Tools such as datasheets for datasets prompt AI dataset creators to carefully reflect on the process of creation, including any underlying assumptions they are making and potential risks or harms that might arise from the dataset’s use. And for dataset consumers, seeing the dataset creators’ documentation of goals and assumptions equips them to decide whether a dataset is suitable for the task they have in mind.
Related papers
- A human-centered agenda for intelligible machine learning
- Datasheets for datasets
- Manipulating and measuring model interpretability
- From human explanation to model interpretability: A framework based on weight of evidence
- Summarize with caution: Comparing global feature attributions
Advancing algorithms for interpretability
Interpretability is vital to debugging and mitigating the potentially harmful impacts of AI processes that so often take place in seemingly impenetrable black boxes—it is difficult (and in many settings, inappropriate) to trust an AI model if you can’t understand the model and correct it when it is wrong. Advanced glass-box learning algorithms can enable AI practitioners and stakeholders to see what’s “under the hood” and better understand the behavior of AI systems. And advanced user interfaces can make it easier for people using AI systems to understand these models and then edit the models when they find mistakes or bias in them. Interpretability is also important to improve human-AI collaboration—it is difficult for users to interact and collaborate with an AI model or system if they can’t understand it. At Microsoft, we have developed glass-box learning methods that are now as accurate as previous black-box methods but yield AI models that are fully interpretable and editable.
-
VIDEO
Editing GAMs with interactive visualization
Machine learning interpretability techniques reveal that many accurate models learn some problematic and dangerous patterns from the training data. GAM Changer helps address these issues.
Recent advances at Microsoft include a new neural GAM (generalized additive model) for interpretable deep learning, a method for using dropout rates to reduce spurious interaction, an efficient algorithm for recovering identifiable additive models, the development of glass-box models that are differentially private, and the creation of tools that make editing glass-box models easy for those using them so they can correct errors in the models and mitigate bias.
Related papers
- NODE-GAM: Neural generalized additive model for interpretable deep learning
- Dropout as a regularizer of interaction effects
- Purifying interaction effects with the Functional ANOVA: An efficient algorithm for recovering identifiable additive models
- Accuracy, interpretability, and differential privacy via explainable boosting
- GAM changer: Editing generalized additive models with interactive visualization
- Neural additive models: Interpretable machine learning with neural nets
- How interpretable and trustworthy are GAMs?
- Extracting clinician’s goals by What-if interpretable modeling
- Automated interpretable discovery of heterogeneous treatment effectiveness: A Covid-19 case study
Exploring open questions for safety, security, and privacy in AI
When considering how to shape appropriate trust in AI systems, there are many open questions about safety, security, and privacy. How do we stay a step ahead of attackers intent on subverting an AI system or harvesting its proprietary information? How can we avoid a system’s potential for inferring spurious correlations?
With autonomous systems, it is important to acknowledge that no system operating in the real world will ever be complete. It’s impossible to train a system for the many unknowns of the real world. Unintended outcomes can range from annoying to dangerous. For example, a self-driving car may splash pedestrians on a rainy day or erratically swerve to localize itself for lane-keeping. An overview of emerging research in avoiding negative side effects due to AI systems’ incomplete knowledge points to the importance of giving users the means to avoid or mitigate the undesired effects of an AI system’s outputs as essential to how the technology will be viewed or used.
When dealing with data about people and our physical world, privacy considerations take a vast leap in complexity. For example, it’s possible for a malicious actor to isolate and re-identify individuals from information in large, anonymized datasets or from their interactions with online apps when using personal devices. Developments in privacy-preserving techniques face challenges in usability and adoption because of the deeply theoretical nature of concepts like homomorphic encryption, secure multiparty computation, and differential privacy. Exploring the design and governance challenges of privacy-preserving computation, interviews with builders of AI systems, policymakers, and industry leaders reveal confidence that the technology is useful, but the challenge is to bridge the gap from theory to practice in real-world applications. Engaging the human-computer interaction community will be a critical component.
Related papers
Reliability and safety
- Avoiding negative side effects due to incomplete knowledge of AI systems
- Split-treatment analysis to rank heterogeneous causal effects for prospective interventions
- Out-of-distribution prediction with invariant risk minimization: The limitation and an effective fix
- Causal transfer random forest: Combining logged data and randomized experiments for robust prediction
- Understanding failures of deep networks via robust feature extraction
- DoWhy: Addressing challenges in expressing and validating causal assumptions
Privacy and security
- Exploring design and governance challenges in the development of privacy-preserving computation
- Accuracy, interpretability, and differential privacy via explainable boosting
- Labeled PSI from homomorphic encryption with reduced computation and communication
- EVA improved: Compiler and extension library for CKKS
- Aggregate measurement via oblivious shuffling
A call to personal action
AI is not an end-all, be-all solution; it’s a powerful, albeit fallible, set of technologies. The challenge is to maximize the benefits of AI while anticipating and minimizing potential harms.
Admittedly, the goal of appropriate trust is challenging. Developing measurement tools for assessing a world in which algorithms are shaping our behaviors, exposing how systems arrive at decisions, planning for AI failures, and engaging the people on the receiving end of AI systems are important pieces. But what we do know is change can happen today with each one of us as we pause and reflect on our work, asking: what could go wrong, and what can I do to prevent it?
The post Advancing AI trustworthiness: Updates on responsible AI research appeared first on Microsoft Research.