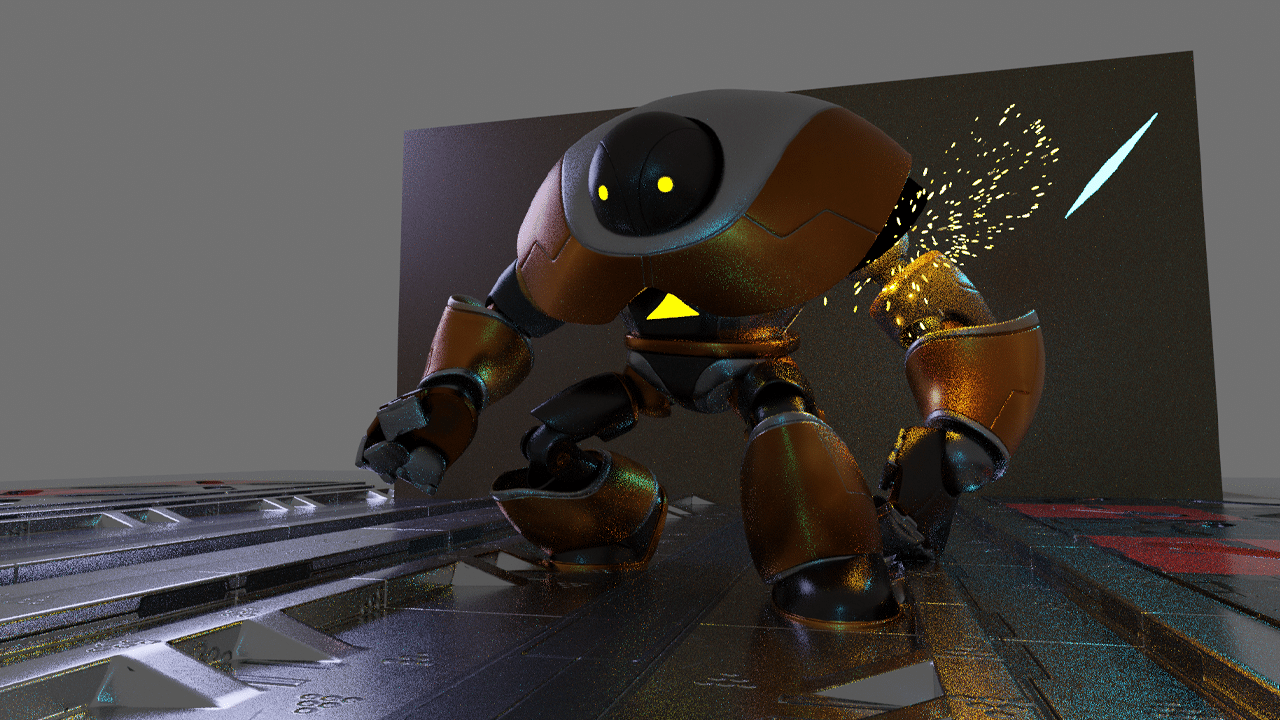The fastest way to give the gift of cloud gaming starts this GFN Thursday: For a limited time, every six-month GeForce NOW Ultimate membership includes three months of PC Game Pass.
Also, the newest GeForce NOW app update is rolling out to members, including Xbox Game Syncing and more improvements.
Plus, take advantage of a heroic, new members-only Guild Wars 2 reward. It’s all topped off by support for 18 more games in the GeForce NOW library this week.
Give the Gift of Gaming
Pair PC Game Pass with a GeForce NOW Ultimate bundle for the ultimate gaming gift.
Unwrap the gift of gaming: For a limited time, gamers who sign up for the six-month GeForce NOW Ultimate membership will also receive three free months of PC Game Pass — a $30 value.
With it, Ultimate members can play a collection of high-quality Xbox PC titles with the power of a GeForce RTX 4080 rig in the cloud. Jump into the action in iconic franchises like Age of Empires, DOOM, Forza and more, with support for more titles added every GFN Thursday.
Seamlessly launch supported favorites across nearly any device at up to 4K and 120 frames per second or at up to 240 fps with NVIDIA Reflex technology in supported titles for lowest-latency streaming.
This special offer is only here for a limited time, so upgrade today.
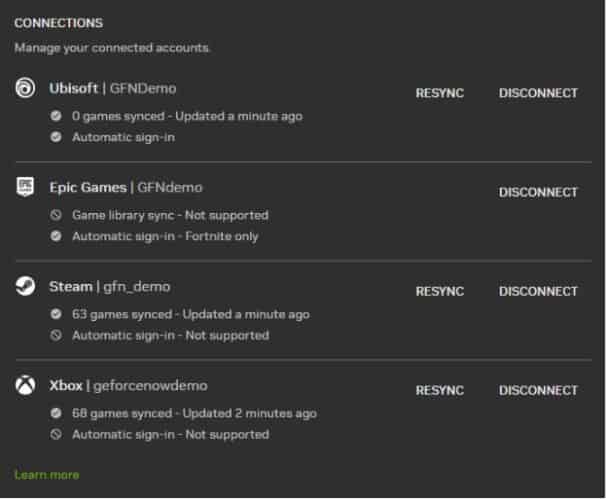
Sync’d Up
Look who just joined the party!
With so many games ready to stream, it might be hard to decide what to play next. The latest GeForce NOW app update, currently rolling out to members, is here to help.
Members can now connect their Xbox accounts to GeForce NOW to sync the games they own to their GeForce NOW library. Game syncing lets members connect their digital game store accounts to GeForce NOW, so all of their supported games are part of their streaming library. Syncing an Xbox account will also add any supported titles a member has access to via PC Game Pass — perfect for members taking advantage of the latest Ultimate bundle.
The new update also adds benefits for Ubisoft+ subscribers. With a linked Ubisoft+ account, members can now launch supported Ubisoft+ games they already own from the GeForce NOW app, and the game will be automatically added to “My Library.” Get more details on Ubisoft account linking.
Version 2.0.58 also includes an expansion of the new game session diagnostic tools to help members ensure they’re streaming at optimal quality. It adds codec information to the in-stream statistics overlay and includes other miscellaneous bug fixes. The update should be available for all members soon.
A Heroic Offering
Rewards fit for a hero.
This week, members can receive Guild Wars 2 “Heroic Edition,” which includes a treasure trove of goodies, such as the base game, Legacy Armor, an 18-slot inventory expansion and four heroic Boosters. It’s the perfect way to jump into ArenaNet’s critically acclaimed, free-to-play, massively multiplayer online role-playing game.
It’s easy to get membership rewards for streaming games on the cloud. Visit the GeForce NOW Rewards portal and update the settings to receive special offers and in-game goodies.
Members can also sign up for the GeForce NOW newsletter, which includes reward notifications, by logging into their NVIDIA account and selecting “Preferences” from the header. Check the “Gaming & Entertainment” box and “GeForce NOW” under topic preferences.
Ready, Set, Go
A new DLC awakens.
The first downloadable content for Gearbox’s Remnant 2 arrives in the cloud. The Awakened King brings a new storyline, area, archetype and more to the dark fantasy co-op shooter — stream it today to experience the awakening of the One True King as he seeks revenge against all who oppose him.
Catch even more action with the 18 newly supported games in the cloud:
The telecommunications industry — the backbone of today’s interconnected world — is valued at a staggering $1.7 trillion globally, according to IDC.
It’s a massive operation, as telcos process hundreds of petabytes of data in their networks each day. That magnitude is only increasing, as the total amount of data transacted globally is forecast to grow to more than 180 zettabytes by 2025.
To meet this demand for data processing and analysis, telcos are turning to generative AI, which is improving efficiency and productivity across industries.
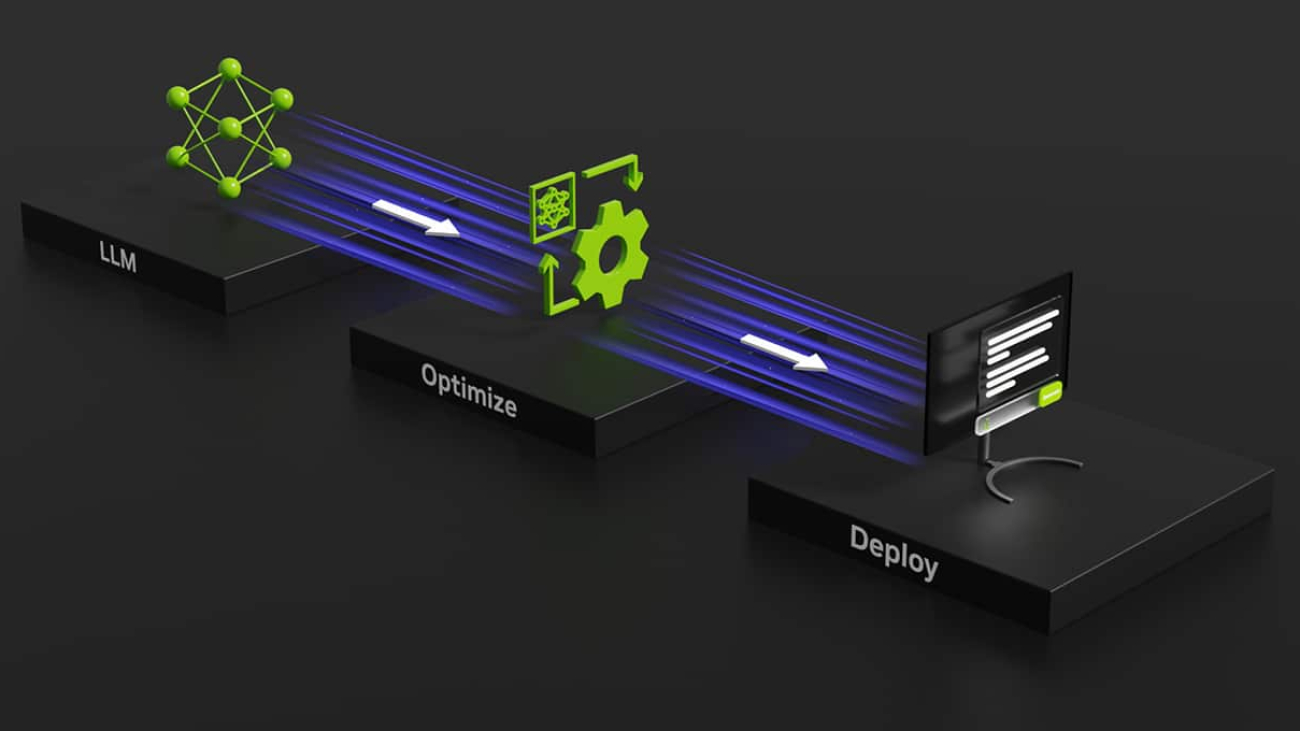
NVIDIA announced an AI foundry service — a collection of NVIDIA AI Foundation Models, NVIDIA NeMo framework and tools, and NVIDIA DGX Cloud AI supercomputing and services — that gives enterprises an end-to-end solution for creating and optimizing custom generative AI models.
Using the AI foundry service, Amdocs, a leading provider of software and services for communications and media providers, will optimize enterprise-grade large language models for the telco and media industries to efficiently deploy generative AI use cases across their businesses, from customer experiences to network operations and provisioning. The LLMs will run on NVIDIA accelerated computing as part of the Amdocs amAIz framework.
The collaboration builds on the previously announced Amdocs-Microsoft partnership, enabling service providers to adopt these applications in secure, trusted environments, including on premises and in the cloud.
Custom Models for Custom Results
While preliminary applications of generative AI used broad datasets, enterprises have become increasingly focused on developing custom models to perform specialized, industry-specific skills.
By training models on proprietary data, telcos can deliver tailored solutions that produce more accurate results for their use cases.
To simplify the development, tuning and deployment of such custom models, Amdocs is integrating the new NVIDIA AI foundry service.
Equipped with these new generative AI capabilities — including guardrail features — service providers can enhance performance, optimize resource utilization and flexibly scale to meet future needs.
Amdocs’ Global Telco Ecosystem Footprint
More than 350 of the world’s leading telecom and media companies across 90 countries take advantage of Amdocs services each day, including 27 of the world’s top 30 service providers, according to OMDIA.(1) Powering more than 1.7 billion daily digital journeys, Amdocs platforms impact more than 3 billion people around the world.
NVIDIA and Amdocs are exploring several generative AI use cases to simplify and improve operations by providing secure, cost-effective, and high-performance generative AI capabilities.
Initial use cases span customer care, including accelerating resolution of customer inquiries by drawing information from across company data.
And in network operations, the companies are exploring ways to generate solutions to address configuration, coverage or performance issues as they arise.
Automotive companies are transforming every phase of their product lifecycle — evolving their primarily physical, manual processes into software-driven, AI-enhanced digital systems.
To help them save costs and reduce lead times, NVIDIA is announcing two new simulation engines on Omniverse Cloud: the virtual factory simulation engine and the autonomous vehicle (AV) simulation engine.
Omniverse Cloud, a platform-as-a-service for developing and deploying applications for industrial digitalization, is hosted on Microsoft Azure. This one-stop shop enables automakers worldwide to unify digitalization across their core product and business processes. It allows enterprises to achieve faster production and more efficient operations, improving time to market and enhancing sustainability initiatives.
For design, engineering and manufacturing teams, digitalization streamlines their work, converting once primarily manual industrial processes into efficient systems for concept and styling; AV development, testing and validation; and factory planning.
Virtual Factory Simulation Engine
The Omniverse Cloud virtual factory simulation engine is a collection of customizable developer applications and services that enable factory planning teams to connect large-scale industrial datasets while collaborating, navigating and reviewing them in real time.
Design teams working with 3D data can assemble virtual factories and share their work with thousands of planners who can view, annotate and update the full-fidelity factory dataset from lightweight devices. By simulating virtual factories on Omniverse Cloud, automakers can increase throughput and production quality while saving years of effort and millions of dollars that would result from making changes once construction is underway.
On Omniverse Cloud, teams can create interoperability between existing software applications such as Autodesk Factory Planning, which supports the entire lifecycle for building, mechanical, electrical, and plumbing and factory lines, as well as Siemens’ NX, Process Simulate and Teamcenter Visualization software and the JT file format. They can share knowledge and data in real time in live, virtual factory reviews across 2D devices or in extended reality.
T-Systems, a leading IT solutions provider for Europe’s largest automotive manufacturers, is building and deploying a custom virtual factory application that its customers can deploy in Omniverse Cloud.
SoftServe, an elite member of the NVIDIA Service Delivery Partner program, is also developing custom factory simulation and visualization solutions on this Omniverse Cloud engine, covering factory design, production planning and control.
AV Simulation Engine
The AV simulation engine is a service that delivers physically based sensor simulation, enabling AV and robotics developers to run autonomous systems in a closed-loop virtual environment.
The next generation of AV architectures will be built on large, unified AI models that combine layers of the vehicle stack, including perception, planning and control. Such new architectures call for an integrated approach to development.
With previous architectures, developers could train and test these layers independently, as they were governed by different models. For example, simulation could be used to develop a vehicle’s planning and control system, which only needs basic information about objects in a scene — such as the speed and distance of surrounding vehicles — while perception networks could be trained and tested on recorded sensor data.
However, using simulation to develop an advanced unified AV architecture requires sensor data as the input. For a simulator to be effective, it must be able to simulate vehicle sensors, such as cameras, radars and lidars, with high fidelity.
To address this challenge, NVIDIA is bringing state-of-the-art sensor simulation pipelines used in DRIVE Sim and Isaac Sim to Omniverse Cloud on Microsoft Azure.
Omniverse Cloud sensor simulation provides AV and robotics workflows with high-fidelity, physically based simulation for cameras, radars, lidars and other types of sensors. It can be connected to existing simulation applications, whether developed in-house or provided by a third party, via Omniverse Cloud application programming interfaces for integration into workflows.
Fast Track to Digitalization
The factory simulation engine is now available to customers via an Omniverse Cloud enterprise private offer through the Azure Marketplace, which provides access to NVIDIA OVX systems and fully managed Omniverse software, reference applications and workflows. The sensor simulation engine is coming soon.
As NVIDIA continues to collaborate with Microsoft to build state-of-the-art AI infrastructure, Microsoft is introducing additional H100-based virtual machines to Microsoft Azure to accelerate demanding AI workloads.
At its Ignite conference in Seattle today, Microsoft announced its new NC H100 v5 VM series for Azure, the industry’s first cloud instances featuring NVIDIA H100 NVL GPUs.
This offering brings together a pair of PCIe-based H100 GPUs connected via NVIDIA NVLink, with nearly 4 petaflops of AI compute and 188GB of faster HBM3 memory. The NVIDIA H100 NVL GPU can deliver up to 12x higher performance on GPT-3 175B over the previous generation and is ideal for inference and mainstream training workloads.
Additionally, Microsoft announced plans to add the NVIDIA H200 Tensor Core GPU to its Azure fleet next year to support larger model inferencing with no increase in latency. This new offering is purpose-built to accelerate the largest AI workloads, including LLMs and generative AI models.
The H200 GPU brings dramatic increases both in memory capacity and bandwidth using the latest-generation HBM3e memory. Compared to the H100, this new GPU will offer 141GB of HBM3e memory (1.8x more) and 4.8 TB/s of peak memory bandwidth (a 1.4x increase).
Cloud Computing Gets Confidential
Further expanding availability of NVIDIA-accelerated generative AI computing for Azure customers, Microsoft announced another NVIDIA-powered instance: the NCC H100 v5.
These Azure confidential VMs with NVIDIA H100 Tensor Core GPUs allow customers to protect the confidentiality and integrity of their data and applications in use, in memory, while accessing the unsurpassed acceleration of H100 GPUs. These GPU-enhanced confidential VMs will be coming soon to private preview.
To learn more about the new confidential VMs with NVIDIA H100 Tensor Core GPUs, and sign up for the preview, read the blog.
Today’s landscape of free, open-source large language models (LLMs) is like an all-you-can-eat buffet for enterprises. This abundance can be overwhelming for developers building custom generative AI applications, as they need to navigate unique project and business requirements, including compatibility, security and the data used to train the models.
NVIDIA AI Foundation Models — a curated collection of enterprise-grade pretrained models — give developers a running start for bringing custom generative AI to their enterprise applications.
NVIDIA-Optimized Foundation Models Speed Up Innovation
NVIDIA AI Foundation Models can be experienced through a simple user interface or API, directly from a browser. Additionally, these models can be accessed from NVIDIA AI Foundation Endpoints to test model performance from within their enterprise applications.
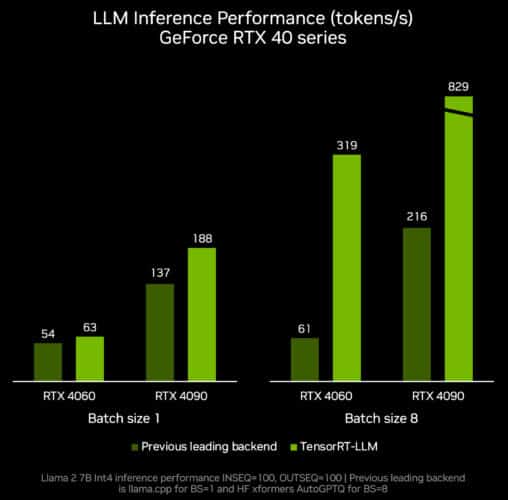
Available models include leading community models such as Llama 2, Stable Diffusion XL and Mistral, which are formatted to help developers streamline customization with proprietary data. Additionally, models have been optimized with NVIDIA TensorRT-LLM to deliver the highest throughput and lowest latency and to run at scale on any NVIDIA GPU-accelerated stack. For instance, the Llama 2 model optimized with TensorRT-LLM runs nearly 2x faster on NVIDIA H100.
The new NVIDIA family of Nemotron-3 8B foundation models supports the creation of today’s most advanced enterprise chat and Q&A applications for a broad range of industries, including healthcare, telecommunications and financial services.
The models are a starting point for customers building secure, production-ready generative AI applications, are trained on responsibly sourced datasets and operate at comparable performance to much larger models. This makes them ideal for enterprise deployments.
Multilingual capabilities are a key differentiator of the Nemotron-3 8B models. Out of the box, the models are proficient in over 50 languages, including English, German, Russian, Spanish, French, Japanese, Chinese, Korean, Italian and Dutch.
Fast-Track Customization to Deployment
Enterprises leveraging generative AI across business functions need an AI foundry to customize models for their unique applications. NVIDIA’s AI foundry features three elements — NVIDIA AI Foundation Models, NVIDIA NeMo framework and tools, and NVIDIA DGX Cloud AI supercomputing services. Together, these provide an end-to-end enterprise offering for creating custom generative AI models.
Importantly, enterprises own their customized models and can deploy them virtually anywhere on accelerated computing with enterprise-grade security, stability and support using NVIDIA AI Enterprise software.
To understand the latest advance in generative AI, imagine a courtroom.
Judges hear and decide cases based on their general understanding of the law. Sometimes a case — like a malpractice suit or a labor dispute — requires special expertise, so judges send court clerks to a law library, looking for precedents and specific cases they can cite.
Like a good judge, large language models (LLMs) can respond to a wide variety of human queries. But to deliver authoritative answers that cite sources, the model needs an assistant to do some research.
The court clerk of AI is a process called retrieval-augmented generation, or RAG for short.
The Story of the Name
Patrick Lewis, lead author of the 2020 paper that coined the term, apologized for the unflattering acronym that now describes a growing family of methods across hundreds of papers and dozens of commercial services he believes represent the future of generative AI.
Patrick Lewis
“We definitely would have put more thought into the name had we known our work would become so widespread,” Lewis said in an interview from Singapore, where he was sharing his ideas with a regional conference of database developers.
“We always planned to have a nicer sounding name, but when it came time to write the paper, no one had a better idea,” said Lewis, who now leads a RAG team at AI startup Cohere.
So, What Is Retrieval-Augmented Generation?
Retrieval-augmented generation is a technique for enhancing the accuracy and reliability of generative AI models with facts fetched from external sources.
In other words, it fills a gap in how LLMs work. Under the hood, LLMs are neural networks, typically measured by how many parameters they contain. An LLM’s parameters essentially represent the general patterns of how humans use words to form sentences.
That deep understanding, sometimes called parameterized knowledge, makes LLMs useful in responding to general prompts at light speed. However, it does not serve users who want a deeper dive into a current or more specific topic.
Combining Internal, External Resources
Lewis and colleagues developed retrieval-augmented generation to link generative AI services to external resources, especially ones rich in the latest technical details.
The paper, with coauthors from the former Facebook AI Research (now Meta AI), University College London and New York University, called RAG “a general-purpose fine-tuning recipe” because it can be used by nearly any LLM to connect with practically any external resource.
Building User Trust
Retrieval-augmented generation gives models sources they can cite, like footnotes in a research paper, so users can check any claims. That builds trust.
What’s more, the technique can help models clear up ambiguity in a user query. It also reduces the possibility a model will make a wrong guess, a phenomenon sometimes called hallucination.
Another great advantage of RAG is it’s relatively easy. A blog by Lewis and three of the paper’s coauthors said developers can implement the process with as few as five lines of code.
That makes the method faster and less expensive than retraining a model with additional datasets. And it lets users hot-swap new sources on the fly.
How People Are Using Retrieval-Augmented Generation
With retrieval-augmented generation, users can essentially have conversations with data repositories, opening up new kinds of experiences. This means the applications for RAG could be multiple times the number of available datasets.
For example, a generative AI model supplemented with a medical index could be a great assistant for a doctor or nurse. Financial analysts would benefit from an assistant linked to market data.
In fact, almost any business can turn its technical or policy manuals, videos or logs into resources called knowledge bases that can enhance LLMs. These sources can enable use cases such as customer or field support, employee training and developer productivity.
The broad potential is why companies including AWS, IBM, Glean, Google, Microsoft, NVIDIA, Oracle and Pinecone are adopting RAG.
Getting Started With Retrieval-Augmented Generation
The software components are all part of NVIDIA AI Enterprise, a software platform that accelerates development and deployment of production-ready AI with the security, support and stability businesses need.
Getting the best performance for RAG workflows requires massive amounts of memory and compute to move and process data. The NVIDIA GH200 Grace Hopper Superchip, with its 288GB of fast HBM3e memory and 8 petaflops of compute, is ideal — it can deliver a 150x speedup over using a CPU.
Once companies get familiar with RAG, they can combine a variety of off-the-shelf or custom LLMs with internal or external knowledge bases to create a wide range of assistants that help their employees and customers.
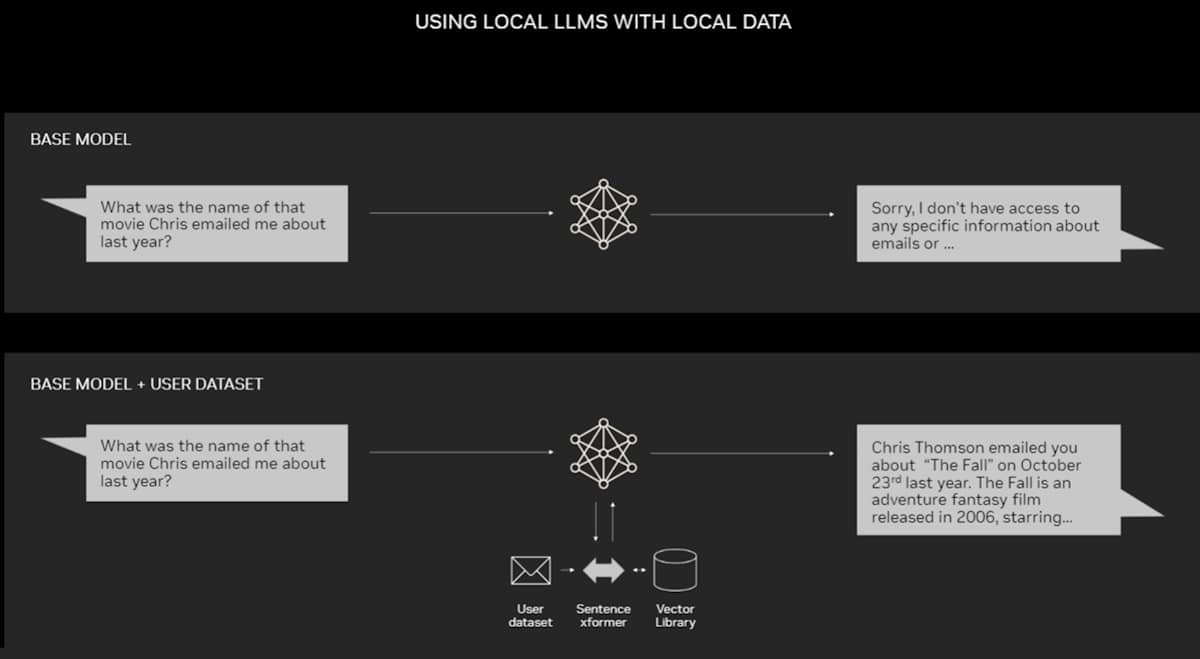
RAG doesn’t require a data center. LLMs are debuting on Windows PCs, thanks to NVIDIA software that enables all sorts of applications users can access even on their laptops.
An example application for RAG on a PC.
PCs equipped with NVIDIA RTX GPUs can now run some AI models locally. By using RAG on a PC, users can link to a private knowledge source – whether that be emails, notes or articles – to improve responses. The user can then feel confident that their data source, prompts and response all remain private and secure.
A recent blog provides an example of RAG accelerated by TensorRT-LLM for Windows to get better results fast.
The History of Retrieval-Augmented Generation
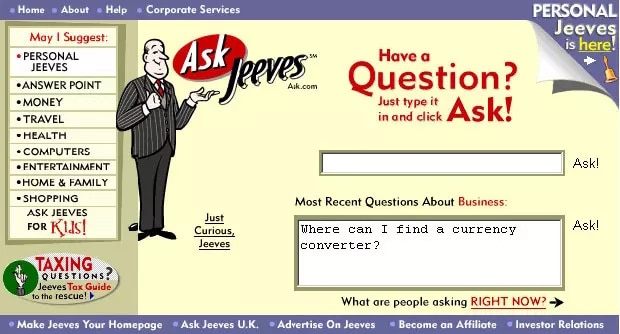
The roots of the technique go back at least to the early 1970s. That’s when researchers in information retrieval prototyped what they called question-answering systems, apps that use natural language processing (NLP) to access text, initially in narrow topics such as baseball.
The concepts behind this kind of text mining have remained fairly constant over the years. But the machine learning engines driving them have grown significantly, increasing their usefulness and popularity.
In the mid-1990s, the Ask Jeeves service, now Ask.com, popularized question answering with its mascot of a well-dressed valet. IBM’s Watson became a TV celebrity in 2011 when it handily beat two human champions on the Jeopardy! game show.
Today, LLMs are taking question-answering systems to a whole new level.
Insights From a London Lab
The seminal 2020 paper arrived as Lewis was pursuing a doctorate in NLP at University College London and working for Meta at a new London AI lab. The team was searching for ways to pack more knowledge into an LLM’s parameters and using a benchmark it developed to measure its progress.
Building on earlier methods and inspired by a paper from Google researchers, the group “had this compelling vision of a trained system that had a retrieval index in the middle of it, so it could learn and generate any text output you wanted,” Lewis recalled.
The IBM Watson question-answering system became a celebrity when it won big on the TV game show Jeopardy!
When Lewis plugged into the work in progress a promising retrieval system from another Meta team, the first results were unexpectedly impressive.
“I showed my supervisor and he said, ‘Whoa, take the win. This sort of thing doesn’t happen very often,’ because these workflows can be hard to set up correctly the first time,” he said.
Lewis also credits major contributions from team members Ethan Perez and Douwe Kiela, then of New York University and Facebook AI Research, respectively.
When complete, the work, which ran on a cluster of NVIDIA GPUs, showed how to make generative AI models more authoritative and trustworthy. It’s since been cited by hundreds of papers that amplified and extended the concepts in what continues to be an active area of research.
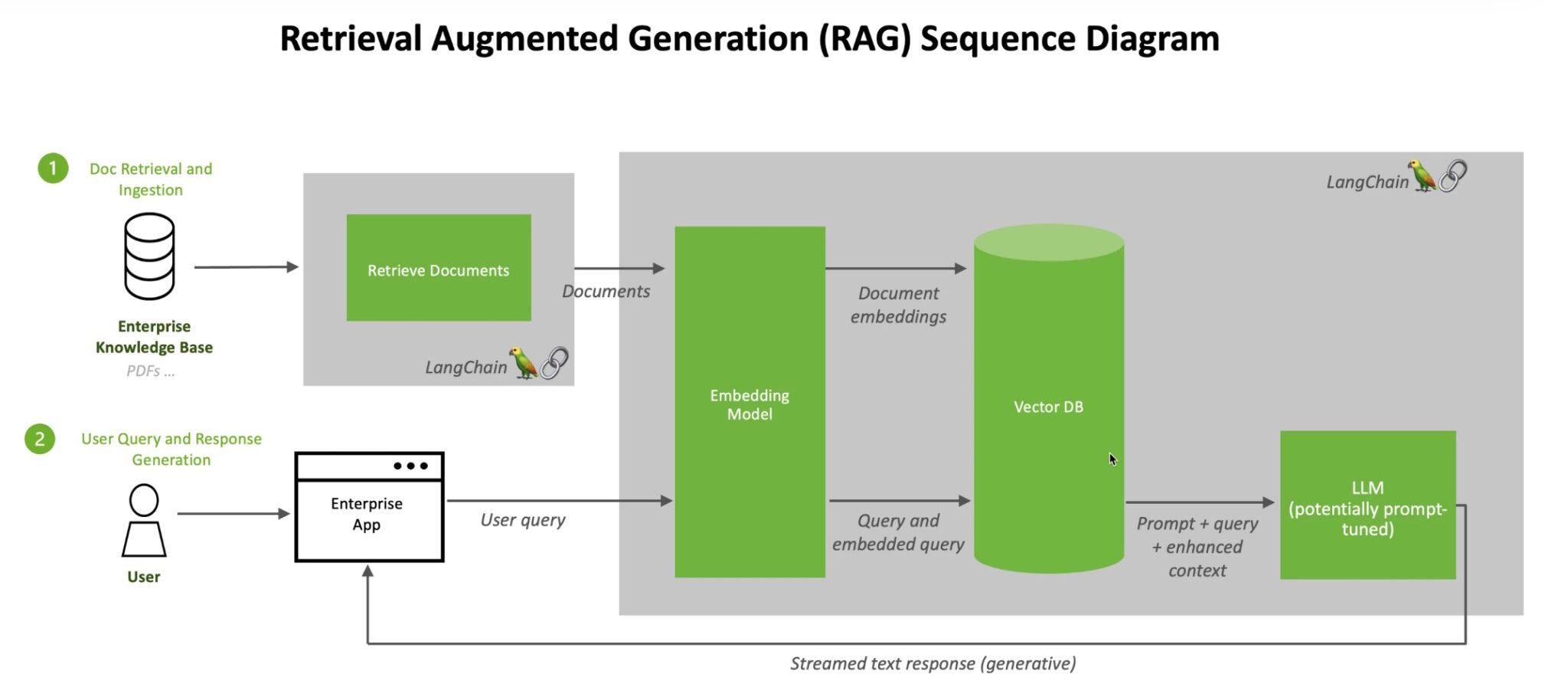
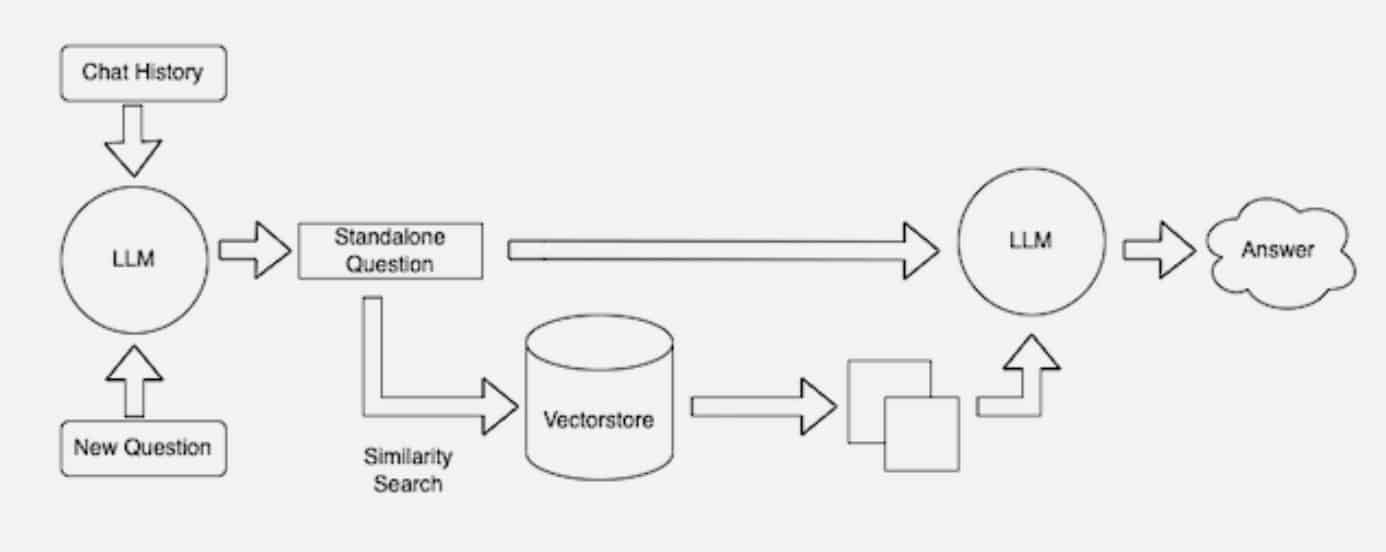
When users ask an LLM a question, the AI model sends the query to another model that converts it into a numeric format so machines can read it. The numeric version of the query is sometimes called an embedding or a vector.
Retrieval-augmented generation combines LLMs with embedding models and vector databases.
The embedding model then compares these numeric values to vectors in a machine-readable index of an available knowledge base. When it finds a match or multiple matches, it retrieves the related data, converts it to human-readable words and passes it back to the LLM.
Finally, the LLM combines the retrieved words and its own response to the query into a final answer it presents to the user, potentially citing sources the embedding model found.
Keeping Sources Current
In the background, the embedding model continuously creates and updates machine-readable indices, sometimes called vector databases, for new and updated knowledge bases as they become available.
Retrieval-augmented generation combines LLMs with embedding models and vector databases.
Many developers find LangChain, an open-source library, can be particularly useful in chaining together LLMs, embedding models and knowledge bases. NVIDIA uses LangChain in its reference architecture for retrieval-augmented generation.
Looking forward, the future of generative AI lies in creatively chaining all sorts of LLMs and knowledge bases together to create new kinds of assistants that deliver authoritative results users can verify.
Get a hands on using retrieval-augmented generation with an AI chatbot in this NVIDIA LaunchPad lab.
Artificial intelligence on Windows 11 PCs marks a pivotal moment in tech history, revolutionizing experiences for gamers, creators, streamers, office workers, students and even casual PC users.
It offers unprecedented opportunities to enhance productivity for users of the more than 100 million Windows PCs and workstations that are powered by RTX GPUs. And NVIDIA RTX technology is making it even easier for developers to create AI applications to change the way people use computers.
New optimizations, models and resources announced at Microsoft Ignite will help developers deliver new end-user experiences, quicker.
An upcoming update to TensorRT-LLM — open-source software that increases AI inference performance — will add support for new large language models and make demanding AI workloads more accessible on desktops and laptops with RTX GPUs starting at 8GB of VRAM.
TensorRT-LLM for Windows will soon be compatible with OpenAI’s popular Chat API through a new wrapper. This will enable hundreds of developer projects and applications to run locally on a PC with RTX, instead of in the cloud — so users can keep private and proprietary data on Windows 11 PCs.
Custom generative AI requires time and energy to maintain projects. The process can become incredibly complex and time-consuming, especially when trying to collaborate and deploy across multiple environments and platforms.
AI Workbench is a unified, easy-to-use toolkit that allows developers to quickly create, test and customize pretrained generative AI models and LLMs on a PC or workstation. It provides developers a single platform to organize their AI projects and tune models to specific use cases.
This enables seamless collaboration and deployment for developers to create cost-effective, scalable generative AI models quickly. Join the early access list to be among the first to gain access to this growing initiative and to receive future updates.
To support AI developers, NVIDIA and Microsoft will release are releasing DirectML enhancements to accelerate one two of the most popular foundational AI models,: Llama 2 and Stable Diffusion. Developers now have more options for cross-vendor deployment, in addition to setting a new standard for performance.
Portable AI
Last month, NVIDIA announced TensorRT-LLM for Windows, a library for accelerating LLM inference.
The next TensorRT-LLM release, v0.6.0 coming later this month, will bring improved inference performance — up to 5x faster — and enable support for additional popular LLMs, including the new Mistral 7B and Nemotron-3 8B. Versions of these LLMs will run on any GeForce RTX 30 Series and 40 Series GPU with 8GB of RAM or more, making fast, accurate, local LLM capabilities accessible even in some of the most portable Windows devices.
Up to 5X performance with the new TensorRT-LLM v0.6.0.
The new release of TensorRT-LLM will be available for install on the /NVIDIA/TensorRT-LLM GitHub repo. New optimized models will be available on ngc.nvidia.com.
Conversing With Confidence
Developers and enthusiasts worldwide use OpenAI’s Chat API for a wide range of applications — from summarizing web content and drafting documents and emails to analyzing and visualizing data and creating presentations.
One challenge with such cloud-based AIs is that they require users to upload their input data, making them impractical for private or proprietary data or for working with large datasets.
To address this challenge, NVIDIA is soon enabling TensorRT-LLM for Windows to offer a similar API interface to OpenAI’s widely popular ChatAPI, through a new wrapper, offering a similar workflow to developers whether they are designing models and applications to run locally on a PC with RTX or in the cloud. By changing just one or two lines of code, hundreds of AI-powered developer projects and applications can now benefit from fast, local AI. Users can keep their data on their PCs and not worry about uploading datasets to the cloud.
Perhaps the best part is that many of these projects and applications are open source, making it easy for developers to leverage and extend their capabilities to fuel the adoption of generative AI on Windows, powered by RTX.
The wrapper will work with any LLM that’s been optimized for TensorRT-LLM (for example, Llama 2, Mistral and NV LLM) and is being released as a reference project on GitHub, alongside other developer resources for working with LLMs on RTX.
Model Acceleration
Developers can now leverage cutting-edge AI models and deploy with a cross-vendor API. As part of an ongoing commitment to empower developers, NVIDIA and Microsoft have been working together to accelerate Llama on RTX via the DirectML API.
Building on the announcements for the fastest inference performance for these models announced last month, this new option for cross-vendor deployment makes it easier than ever to bring AI capabilities to PC.
Developers and enthusiasts can experience the latest optimizations by downloading the latest ONNX runtime and following the installation instructions from Microsoft, and installing the latest driver from NVIDIA, which will be available on Nov. 21.
These new optimizations, models and resources will accelerate the development and deployment of AI features and applications to the 100 million RTX PCs worldwide, joining the more than 400 partners shipping AI-powered apps and games already accelerated by RTX GPUs.
As models become even more accessible and developers bring more generative AI-powered functionality to RTX-powered Windows PCs, RTX GPUs will be critical for enabling users to take advantage of this powerful technology.
Editor’s note: This post is part of our weekly In the NVIDIA Studio series, which celebrates featured artists, offers creative tips and tricks, and demonstrates how NVIDIA Studio technology improves creative workflows. We’re also deep diving on new GeForce RTX 40 Series GPU features, technologies and resources, and how they dramatically accelerate content creation.
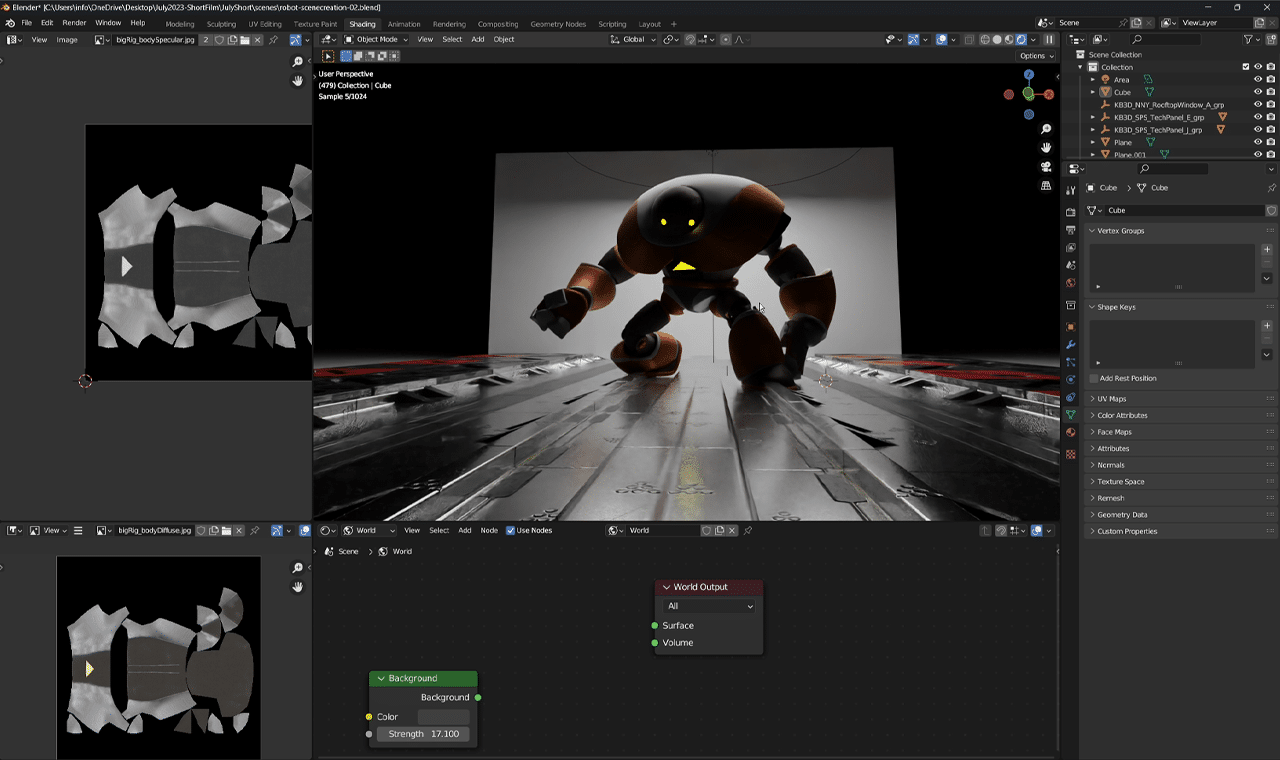
Character animator Sir Wade Neistadt works to make animation and 3D education more accessible for aspiring and professional artists alike through video tutorials and industry training.
The YouTube creator, who goes by Sir Wade, also likes a challenge. When electronics company Razer recently asked him to create something unique and creative using the new Razer Blade 18 laptop with GeForce RTX 4090 graphics, Sir Wade obliged.
“I said yes because I thought it’d be a great opportunity to try something creatively risky and make something I didn’t yet know how to achieve,” the artist said.
I, Robot
One of the hardest parts of getting started on a project is needing to be creative on demand, said Sir Wade. For the Razer piece, the animator started by asking himself two questions: “What am I inspired by?” and “What do I have to work with?”
Sir Wade finds inspiration in games, technology, movies, people-watching and conversations. Fond of tech — and having eyed characters from the ProRigs library for some time — he decided his short animation should feature robots.
When creating a concept for the animation, Sir Wade took an unorthodox approach, skipping the popular step of 2D sketching. Instead, he captured video references by acting out the animations himself.
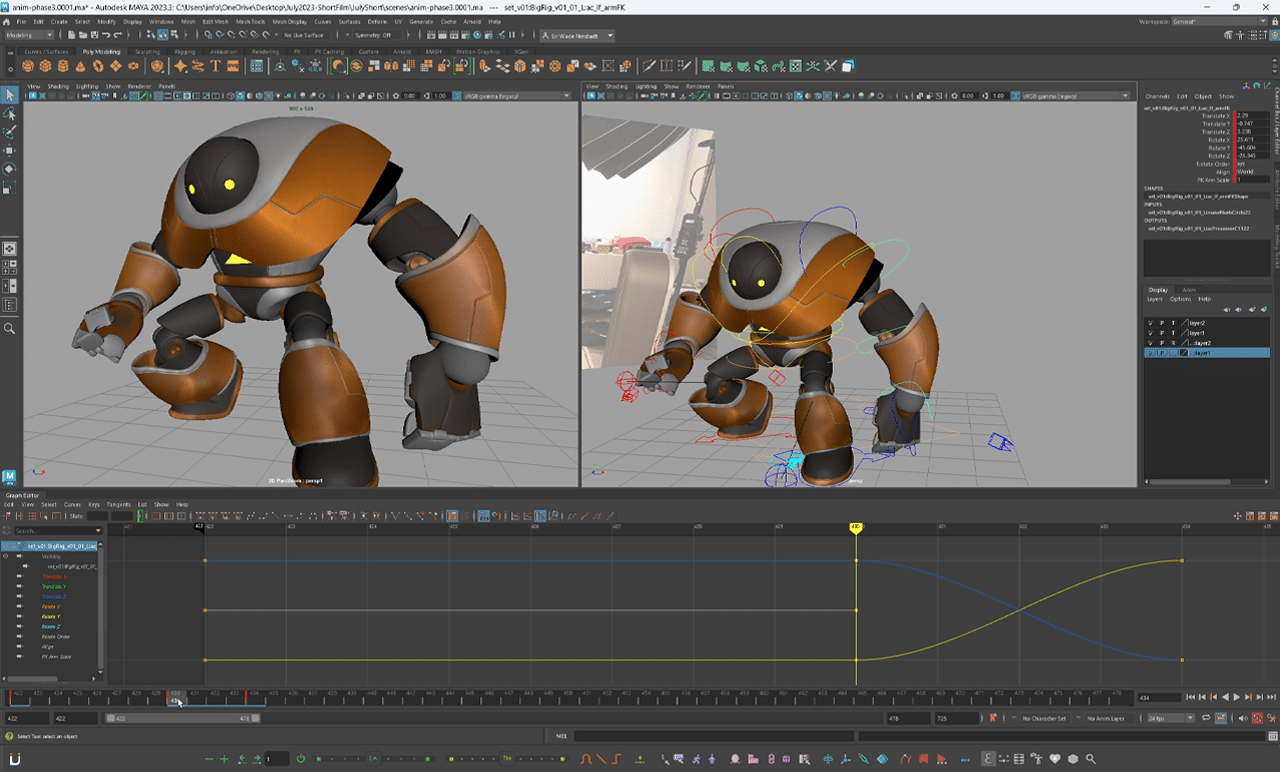
This gave Sir Wade the opportunity to quickly try a bunch of movements and preview body mechanics for the animation phase. Since ProRigs characters are rigs based on Autodesk Maya, he naturally began his animation work using this 3D software.
“YOU SHALL NOT (RENDER) PASS.”
His initial approach was straightforward: mimicking the main robot character’s movements with the edited reference footage. This worked fairly well, as NVIDIA RTX-accelerated ray tracing and AI denoising with the default Autodesk Arnold renderer resulted in smooth viewport movement and photorealistic visuals.
Then, Sir Wade continued tinkering with the piece, focusing on how the robot’s arm plates crashed into each other and how its feet moved. This was a great challenge, but he kept moving on the project. The featured artist would advise, “Don’t wait for everything to be perfect.”
The video reference footage captured earlier paid off later in Sir Wade’s creative workflow.
Next, Sir Wade exported files into Blender software with the Universal Scene Description (OpenUSD) framework, unlocking an open and extensible ecosystem, including the ability to make edits in NVIDIA Omniverse, a development platform for building and connecting 3D tools and applications. The edits could then be captured in the original native files, eliminating the need for tedious uploading, downloading and file reformatting.
AI-powered RTX-accelerated OptiX ray tracing in the viewport allowed Sir Wade to manipulate the scene with ease.
Sir Wade browsed the Kitbash3D digital platform with the new asset browser Cargo to compile kits, models and materials, and drag them into Blender with ease. It’s important at this stage to get base-level models in the scene, he said, so the environment can be further refined.
Dubbed the “ultimate desktop replacement,” the Razer Blade 18 offers NVIDIA GeForce RTX 4090 graphics.
Sir Wade raved about the Razer Blade 18’s quad-high-definition (QHD+) 18″ screen and 16:10 aspect ratio, which gives him more room to create, as well as its color-calibrated display, which ensures uploads to social media are as accurate as possible and require minimal color correction.
The preinstalled NVIDIA Studio Drivers, free to RTX GPU owners, are extensively tested with the most popular creative software to deliver maximum stability and performance.
“This is by far the best laptop I’ve ever used for this type of work.” — Sir Wade Neistadt
Returning to the action, Sir Wade used an emission shader to form the projectiles aimed at the robot. He also tweaked various textures, such as surface imperfections, to make the robot feel more weathered and battle-worn, before moving on to visual effects (VFX).
The artist used basic primitives as particle emitters in Blender to achieve the look of bursting particles over a limited number of frames. This, combined with the robot and floor surfaces containing surface nodes, creates sparks when the robot moves or gets hit by objects.
Sir Wade’s GeForce RTX 4090 Laptop GPU with Blender Cycles RTX-accelerated OptiX ray tracing in the viewport provides interactive, photorealistic rendering for modeling and animation.
Particle and collusion effects in Blender enable compelling VFX.
To further experiment with VFX, Sir Wade imported the project into the EmberGen simulation tool to test out various preset and physics effects.
VFX in EmberGen.
He added dust and debris VFX, and exported the scene as an OpenVDB file back to Blender to perfect the lighting.
Final lighting elements in Blender.
“I chose an NVIDIA RTX GPU-powered system for its reliable speed, performance and stability, as I had a very limited window to complete this project.” — Sir Wade Neistadt
Finally, Sir Wade completed sound-design effects in Blackmagic Design’s DaVinci Resolve software.
Sir Wade’s video tutorials resonate with diverse audiences because of their fresh approach to solving problems and individualistic flair.
“Creativity for me doesn’t come naturally like for other artists,” Sir Wade explained. “I reverse engineer the process by seeing a tool or a concept, evaluating what’s interesting, then either figuring out a way to use it uniquely or explaining the discovery in a relatable way.”
Sir Wade Neistadt.
Check out Sir Wade’s animation workshops on his website.
Less than two days remain in Sir Wade’s Fall 2023 Animation Challenge. Download the challenge template and Maya character rig files, and submit a custom 3D scene to win an NVIDIA RTX GPU or other prizes by end of day on Wednesday, Nov. 15.
NVIDIA today unveiled at SC23 the next wave of technologies that will lift scientific and industrial research centers worldwide to new levels of performance and energy efficiency.
“NVIDIA hardware and software innovations are creating a new class of AI supercomputers,” said Ian Buck, vice president of the company’s high performance computing and hyperscale data center business, in a special address at the conference.
Buck described the new NVIDIA HGX H200 as “the world’s leading AI computing platform.”
NVIDIA H200 Tensor Core GPUs pack HBM3e memory to run growing generative AI models.
It packs up to 141GB of HBM3e, the first AI accelerator to use the ultrafast technology. Running models like GPT-3, NVIDIA H200 Tensor Core GPUs provide an 18x performance increase over prior-generation accelerators.
Among other generative AI benchmarks, they zip through 12,000 tokens per second on a Llama2-13B large language model (LLM).
Buck also revealed a server platform that links four NVIDIA GH200 Grace Hopper Superchips on an NVIDIA NVLink interconnect. The quad configuration puts in a single compute node a whopping 288 Arm Neoverse cores and 16 petaflops of AI performance with up to 2.3 terabytes of high-speed memory.
Server nodes based on the four GH200 Superchips will deliver 16 petaflops of AI performance.
Demonstrating its efficiency, one GH200 Superchip using the NVIDIA TensorRT-LLM open-source library is 100x faster than a dual-socket x86 CPU system and nearly 2x more energy efficient than an X86 + H100 GPU server.
“Accelerated computing is sustainable computing,” Buck said. “By harnessing the power of accelerated computing and generative AI, together we can drive innovation across industries while reducing our impact on the environment.”
NVIDIA Powers 38 of 49 New TOP500 Systems
The latest TOP500 list of the world’s fastest supercomputers reflects the shift toward accelerated, energy-efficient supercomputing.
Thanks to new systems powered by NVIDIA H100 Tensor Core GPUs, NVIDIA now delivers more than 2.5 exaflops of HPC performance across these world-leading systems, up from 1.6 exaflops in the May rankings. NVIDIA’s contribution on the top 10 alone reaches nearly an exaflop of HPC and 72 exaflops of AI performance.
The new list contains the highest number of systems ever using NVIDIA technologies, 379 vs. 372 in May, including 38 of 49 new supercomputers on the list.
Microsoft Azure leads the newcomers with its Eagle system using H100 GPUs in NDv5 instances to hit No. 3 with 561 petaflops. Mare Nostrum5 in Barcelona ranked No. 8, and NVIDIA Eos — which recently set new AI training records on the MLPerf benchmarks — came in at No. 9.
Showing their energy efficiency, NVIDIA GPUs power 23 of the top 30 systems on the Green500. And they retained the No. 1 spot with the H100 GPU-based Henri system, which delivers 65.09 gigaflops per watt for the Flatiron Institute in New York.
Gen AI Explores COVID
Showing what’s possible, the Argonne National Laboratory used NVIDIA BioNeMo, a generative AI platform for biomolecular LLMs, to develop GenSLMs, a model that can generate gene sequences that closely resemble real-world variants of the coronavirus. Using NVIDIA GPUs and data from 1.5 million COVID genome sequences, it can also rapidly identify new virus variants.
It’s “just the tip of the iceberg — the future is brimming with possibilities, as generative AI continues to redefine the landscape of scientific exploration,” said Kimberly Powell, vice president of healthcare at NVIDIA, in the special address.
Saving Time, Money and Energy
Using the latest technologies, accelerated workloads can see an order-of-magnitude reduction in system cost and energy used, Buck said.
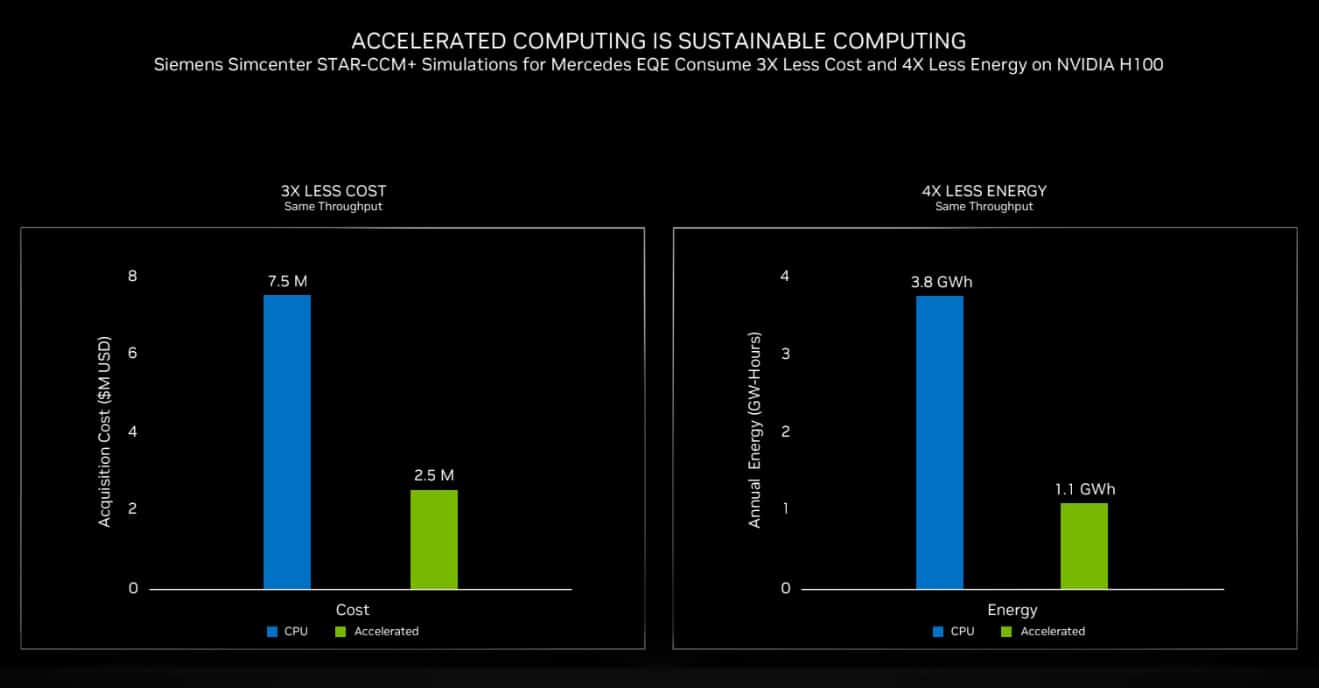
For example, Siemens teamed with Mercedes to analyze aerodynamics and related acoustics for its new electric EQE vehicles. The simulations that took weeks on CPU clusters ran significantly faster using the latest NVIDIA H100 GPUs. In addition, Hopper GPUs let them reduce costs by 3x and reduce energy consumption by 4x (below).
Switching on 200 Exaflops Beginning Next Year
Scientific and industrial advances will come from every corner of the globe where the latest systems are being deployed.
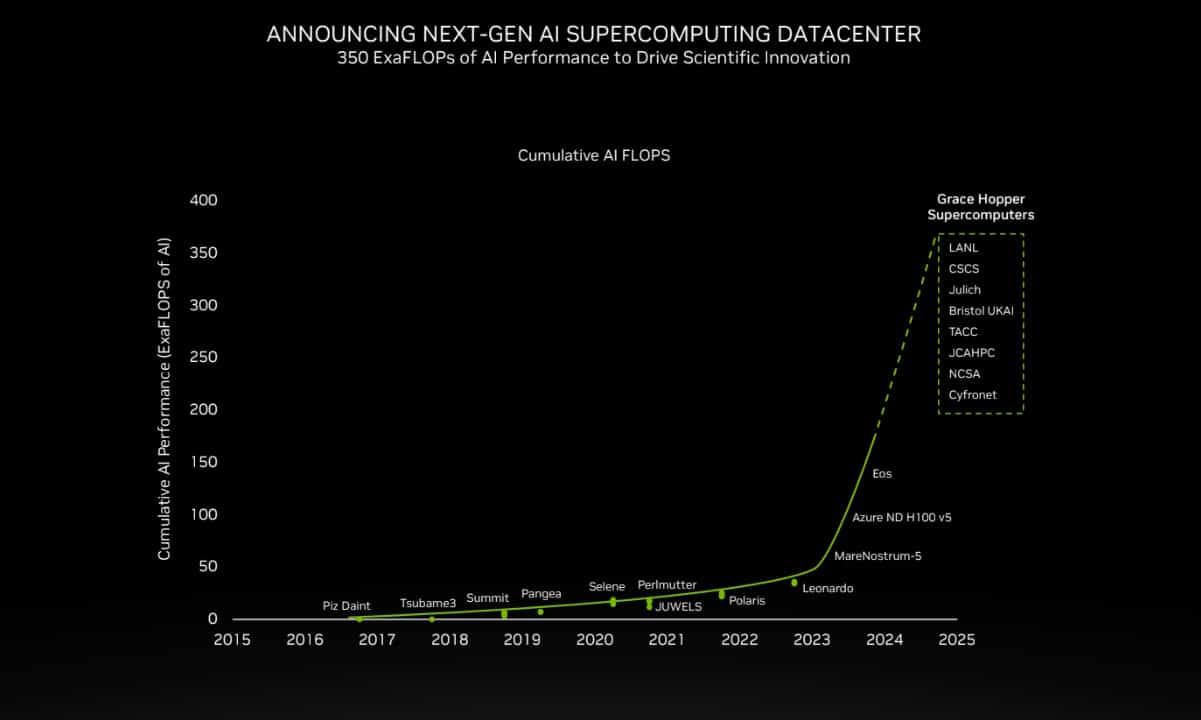
“We already see a combined 200 exaflops of AI on Grace Hopper supercomputers going to production 2024,” Buck said.
They include the massive JUPITER supercomputer at Germany’s Jülich center. It can deliver 93 exaflops of performance for AI training and 1 exaflop for HPC applications, while consuming only 18.2 megawatts of power.
Research centers are poised to switch on a tsunami of GH200 performance.
Based on Eviden’s BullSequana XH3000 liquid-cooled system, JUPITER will use the NVIDIA quad GH200 system architecture and NVIDIA Quantum-2 InfiniBand networking for climate and weather predictions, drug discovery, hybrid quantum computing and digital twins. JUPITER quad GH200 nodes will be configured with 864GB of high-speed memory.
It’s one of several new supercomputers using Grace Hopper that NVIDIA announced at SC23.
The HPE Cray EX2500 system from Hewlett Packard Enterprise will use the quad GH200 to power many AI supercomputers coming online next year.
For example, HPE uses the quad GH200 to power OFP-II, an advanced HPC system in Japan shared by the University of Tsukuba and the University of Tokyo, as well as the DeltaAI system, which will triple computing capacity for the U.S. National Center for Supercomputing Applications.
HPE is also building the Venado system for the Los Alamos National Laboratory, the first GH200 to be deployed in the U.S. In addition, HPE is building GH200 supercomputers in the Middle East, Switzerland and the U.K.
Grace Hopper in Texas and Beyond
At the Texas Advanced Computing Center (TACC), Dell Technologies is building the Vista supercomputer with NVIDIA Grace Hopper and Grace CPU Superchips.
More than 100 global enterprises and organizations, including NASA Ames Research Center and Total Energies, have already purchased Grace Hopper early-access systems, Buck said.
They join previously announced GH200 users such as SoftBank and the University of Bristol, as well as the massive Leonardo system with 14,000 NVIDIA A100 GPUs that delivers 10 exaflops of AI performance for Italy’s Cineca consortium.
The View From Supercomputing Centers
Leaders from supercomputing centers around the world shared their plans and work in progress with the latest systems.
“We’ve been collaborating with MeteoSwiss ECMWP as well as scientists from ETH EXCLAIM and NVIDIA’s Earth-2 project to create an infrastructure that will push the envelope in all dimensions of big data analytics and extreme scale computing,” said Thomas Schultess, director of the Swiss National Supercomputing Centre of work on the Alps supercomputer.
“There’s really impressive energy-efficiency gains across our stacks,” Dan Stanzione, executive director of TACC, said of Vista.
It’s “really the stepping stone to move users from the kinds of systems we’ve done in the past to looking at this new Grace Arm CPU and Hopper GPU tightly coupled combination and … we’re looking to scale out by probably a factor of 10 or 15 from what we are deploying with Vista when we deploy Horizon in a couple years,” he said.
Accelerating the Quantum Journey
Researchers are also using today’s accelerated systems to pioneer a path to tomorrow’s supercomputers.
In Germany, JUPITER “will revolutionize scientific research across climate, materials, drug discovery and quantum computing,” said Kristel Michelson, who leads Julich’s research group on quantum information processing.
“JUPITER’s architecture also allows for the seamless integration of quantum algorithms with parallel HPC algorithms, and this is mandatory for effective quantum HPC hybrid simulations,” she said.
CUDA Quantum Drives Progress
The special address also showed how NVIDIA CUDA Quantum — a platform for programming CPUs, GPUs and quantum computers also known as QPUs — is advancing research in quantum computing.
For example, researchers at BASF, the world’s largest chemical company, pioneered a new hybrid quantum-classical method for simulating chemicals that can shield humans against harmful metals. They join researchers at Brookhaven National Laboratory and HPE who are separately pushing the frontiers of science with CUDA Quantum.
NVIDIA also announced a collaboration with Classiq, a developer of quantum programming tools, to create a life sciences research center at the Tel Aviv Sourasky Medical Center, Israel’s largest teaching hospital. The center will use Classiq’s software and CUDA Quantum running on an NVIDIA DGX H100 system.
Separately, Quantum Machines will deploy the first NVIDIA DGX Quantum, a system using Grace Hopper Superchips, at the Israel National Quantum Center that aims to drive advances across scientific fields. The DGX system will be connected to a superconducting QPU by Quantware and a photonic QPU from ORCA Computing, both powered by CUDA Quantum.
“In just two years, our NVIDIA quantum computing platform has amassed over 120 partners [above], a testament to its open, innovative platform,” Buck said.
Overall, the work across many fields of discovery reveals a new trend that combines accelerated computing at data center scale with NVIDIA’s full-stack innovation.
“Accelerated computing is paving the path for sustainable computing with advancements that provide not just amazing technology but a more sustainable and impactful future,” he concluded.
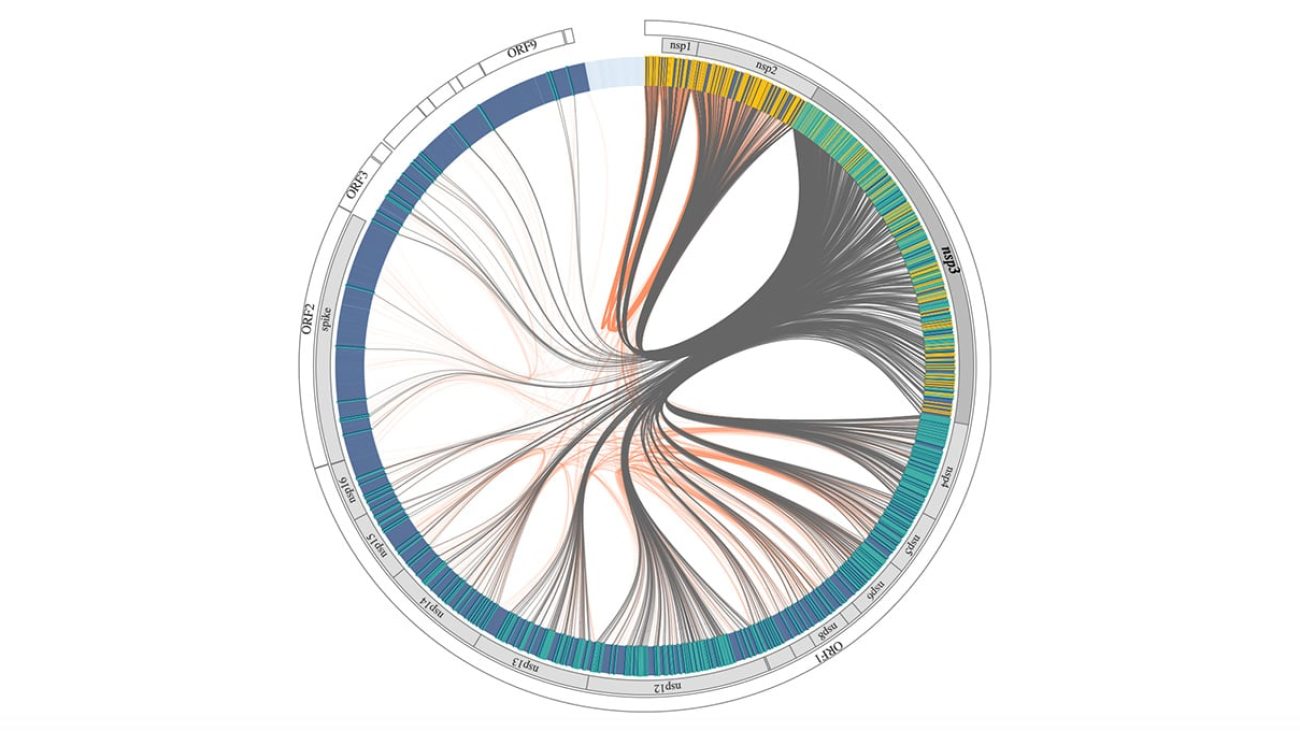
A widely acclaimed large language model for genomic data has demonstrated its ability to generate gene sequences that closely resemble real-world variants of SARS-CoV-2, the virus behind COVID-19.
Called GenSLMs, the model, which last year won the Gordon Bell special prize for high performance computing-based COVID-19 research, was trained on a dataset of nucleotide sequences — the building blocks of DNA and RNA. It was developed by researchers from Argonne National Laboratory, NVIDIA, the University of Chicago and a score of other academic and commercial collaborators.
When the researchers looked back at the nucleotide sequences generated by GenSLMs, they discovered that specific characteristics of the AI-generated sequences closely matched the real-world Eris and Pirola subvariants that have been prevalent this year — even though the AI was only trained on COVID-19 virus genomes from the first year of the pandemic.
“Our model’s generative process is extremely naive, lacking any specific information or constraints around what a new COVID variant should look like,” said Arvind Ramanathan, lead researcher on the project and a computational biologist at Argonne. “The AI’s ability to predict the kinds of gene mutations present in recent COVID strains — despite having only seen the Alpha and Beta variants during training — is a strong validation of its capabilities.”
In addition to generating its own sequences, GenSLMs can also classify and cluster different COVID genome sequences by distinguishing between variants. In a demo coming soon to NGC, NVIDIA’s hub for accelerated software, users can explore visualizations of GenSLMs’ analysis of the evolutionary patterns of various proteins within the COVID viral genome.
Reading Between the Lines, Uncovering Evolutionary Patterns
A key feature of GenSLMs is its ability to interpret long strings of nucleotides — represented with sequences of the letters A, T, G and C in DNA, or A, U, G and C in RNA — in the same way an LLM trained on English text would interpret a sentence. This capability enables the model to understand the relationship between different areas of the genome, which in coronaviruses consists of around 30,000 nucleotides.
In the demo, users will be able to choose from among eight different COVID variants to understand how the AI model tracks mutations across various proteins of the viral genome. The visualization depicts evolutionary couplings across the viral proteins — highlighting which snippets of the genome are likely to be seen in a given variant.
“Understanding how different parts of the genome are co-evolving gives us clues about how the virus may develop new vulnerabilities or new forms of resistance,” Ramanathan said. “Looking at the model’s understanding of which mutations are particularly strong in a variant may help scientists with downstream tasks like determining how a specific strain can evade the human immune system.”
GenSLMs was trained on more than 110 million prokaryotic genome sequences and fine-tuned with a global dataset of around 1.5 million COVID viral sequences using open-source data from the Bacterial and Viral Bioinformatics Resource Center. In the future, the model could be fine-tuned on the genomes of other viruses or bacteria, enabling new research applications.
The GenSLMs research team’s Gordon Bell special prize was awarded at last year’s SC22 supercomputing conference. At this week’s SC23, in Denver, NVIDIA is sharing a new range of groundbreaking work in the field of accelerated computing. View the full schedule.
NVIDIA Research comprises hundreds of scientists and engineers worldwide, with teams focused on topics including AI, computer graphics, computer vision, self-driving cars and robotics. Learn more about NVIDIA Research and subscribe to NVIDIA healthcare news.
Main image courtesy of Argonne National Laboratory’s Bharat Kale.
This research was supported by the Exascale Computing Project (17-SC-20-SC), a collaborative effort of the U.S. DOE Office of Science and the National Nuclear Security Administration. Research was supported by the DOE through the National Virtual Biotechnology Laboratory, a consortium of DOE national laboratories focused on response to COVID-19, with funding from the Coronavirus CARES Act.




NVIDIA GeForce NOW (@NVIDIAGFN) November 15, 2023