Saildrone is making a splash in autonomous oceanic monitoring.
The startup’s nautical data collection technology has tracked hurricanes up close in the North Atlantic, discovered a 3,200-foot underwater mountain in the Pacific Ocean and begun to help map the entirety of the world’s ocean floor.
Based in the San Francisco Bay Area, the company develops autonomous uncrewed surface vehicles (USVs) that carry a wide range of sensors. Its data streams are processed on NVIDIA Jetson modules for AI at the edge and are being optimized in prototypes with the NVIDIA DeepStream software development kit for intelligent video analytics.
Saildrone is seeking to make ocean intelligence collection cost-effective, offering data-gathering systems for science, fisheries, weather forecasting, ocean mapping and maritime security.
It has three different USVs, and its Mission Portal control center service is used for monitoring customized missions and visualizing data in near real time. Also, some of Saildrone’s historical data is freely available to the public.
“We’ve sailed into three major hurricanes, and right through the eye of Hurricane Sam, and all the vehicles came out the other side — they are pretty robust platforms,” said Blythe Towal, vice president of software engineering at Saildrone, referring to a powerful cyclone that threatened Bermuda in 2021 .
Saildrone, founded in 2012, has raised $190 million in funding. The startup is a member of NVIDIA Inception, a program that provides companies with technology support and AI platforms guidance.
Keeping an AI on Earth’s Waters
Saildrone is riding a wave of interest for use of its crewless data collection missions in environmental studies of oceans and lakes.
The University of Hawaii at Manoa has enlisted the help of three 23-foot Saildrone Explorer USVs to study the impact of ocean acidification on climate change. The six-month mission around the islands of Hawaii, Maui, Oahu and Kaui will be used to help evaluate the ocean’s health around the state.
Ocean acidification is a reduction in its pH, and contributing factors include the burning of fossil fuels and farming. These can have an impact on coral, oysters, clams, sea urchins and calcareous plankton, which can threaten marine ecosystems.
Saildrone recently partnered with Seabed 2030 to completely map the world’s oceans. Seabed 2030 is a collaboration between the Nippon Foundation and the General Bathymetric Chart of the Oceans, or GEBCO, to map ocean floors worldwide by 2030.
“Saildrone’s vision is of a healthy ocean and a sustainable planet,” said Saildrone founder and CEO Richard Jenkins. “A complete map of the ocean floor is fundamental to achieving that vision.”
Saildrone USVs enable researchers to collect more data using fewer resources than traditional boats and crews, conserving energy and keeping crews out of danger.
The USVs are built for harsh weather and long missions. One of its USVs recently completed a 370-day voyage monitoring carbon dioxide, sailing from Rhode Island across the North Atlantic to Cabo Verde, down to the equator off the west coast of Africa, and back to Florida.
Running mostly on solar and wind power requires energy-efficient computing to handle so much data processing.
“With solar power, being able to keep our compute load power efficiency lower than a typical computing platform running GPUs by implementing NVIDIA Jetson is important for enabling us to do these kinds of missions,” said Towal.
Oceanic Surveying Meets Edge AI
Saildrone relies on the NVIDIA JetPack SDK for access to a full development environment for hardware-accelerated edge AI on the Jetson platform. It runs machine learning on the module for image-based vessel detection to aid navigation.
Saildrone pilots set waypoints and optimize the routes using metocean data — which includes meteorological and oceanographic information — returned from the vehicle. All of the USVs are monitored around the clock, and operators can change course remotely via the cloud if needed.
Machine learning is mostly run locally on the Jetson module— but can run on the cloud as well with a satellite connection — because bandwidth can be limited and costly to shuttle from its robust suite of sensors producing high-resolution imagery.
The USVs have oceanographic sensors for measurement of wind, temperature, salinity and dissolved carbon. The company also enables research of ocean and lake floors with bathymetric sensors, including deep sonar mapping with single- or multi-beam for going deeper or wider. And its perceptual sensor suite includes radar and visual underwater acoustic sensors.
DeepStream Goes Deep Sea
Saildrone taps into the NVIDIA DeepStream SDK for its vision AI applications and services. Developers can build seamless streaming pipelines for AI-based video, audio and image analytics using the kit.
Offering a 10x throughput improvement, DeepStream can be applied from edge to cloud to develop optimized intelligent video applications that handle multiple video, image and audio streams.
Saildrone will rely on DeepStream for image preprocessing and model inference, which enables machine learning at the edge, even at sea while powered by sun and wind.
Editor’s note: This post is part of our weekly In the NVIDIA Studio series, which celebrates featured artists, offers creative tips and tricks, and demonstrates how NVIDIA Studio technology improves creative workflows. We’re also deep diving on new GeForce RTX 40 Series GPU features, technologies and resources, and how they dramatically accelerate content creation.
The Portal: Prelude RTX gaming mod — a remastering of the popular unofficial Portal prequel — comes with full ray tracing, DLSS 3 and RTX IO technology for cutting-edge, AI-powered graphics that rejuvenate the legendary mod for gamers, creators, developers and others to experience it anew.
Nicolas “NykO18” Grevet, a software engineer behind Portal: Prelude, collaborated with modder David Driver-Gomm to create the project — which launched today as a free download on Steam — using NVIDIA RTX Remix. The free modding platform enables users to quickly create and share RTX mods for classic games. Learn about the duo’s workflow this week In the NVIDIA Studio.
Plus, this month, graphics card partners will begin to offer the 16GB version of the GeForce RTX 4060 Ti GPU, featuring the state-of-the-art NVIDIA Ada Lovelace architecture that supercharges creative apps and productivity while delivering immersive, AI-accelerated gaming with ray tracing and DLSS 3. The GPUs are well-suited for working in larger 3D scenes, editing videos in up to 12K resolution and running native AI foundation models.
All of this is backed by the July NVIDIA Studio Driver, which supports these latest updates and more, available for download today.
In addition, the NVIDIA Studio #StartToFinish community challenge is in full swing. Use the hashtag to submit a screenshot of a favorite project featuring its beginning and ending stages for a chance to be featured on the @NVIDIAStudio and @NVIDIAOmniverse social channels.
A Portal Into Creativity
Portal: Prelude’s storyline revolves around what’s called the Genetic Lifeform and Disk Operating System, or GlaDOS, an AI created by Aperture Science, the fictional scientific research corporation key to the original game’s plot.
With extra chapters, test chambers, challenges and an extended storyline, the most popular Portal mod of all time was recognized by Mod DB with a “Mod of the Year” award. Check out the original game trailer below.
“Modders have to wear many hats — they’re simultaneously level designers, 2D artists, scripters, writers, web developers, quality-assurance analysts and so much more,” said Grevet. “This demands resilience and adaptability.”
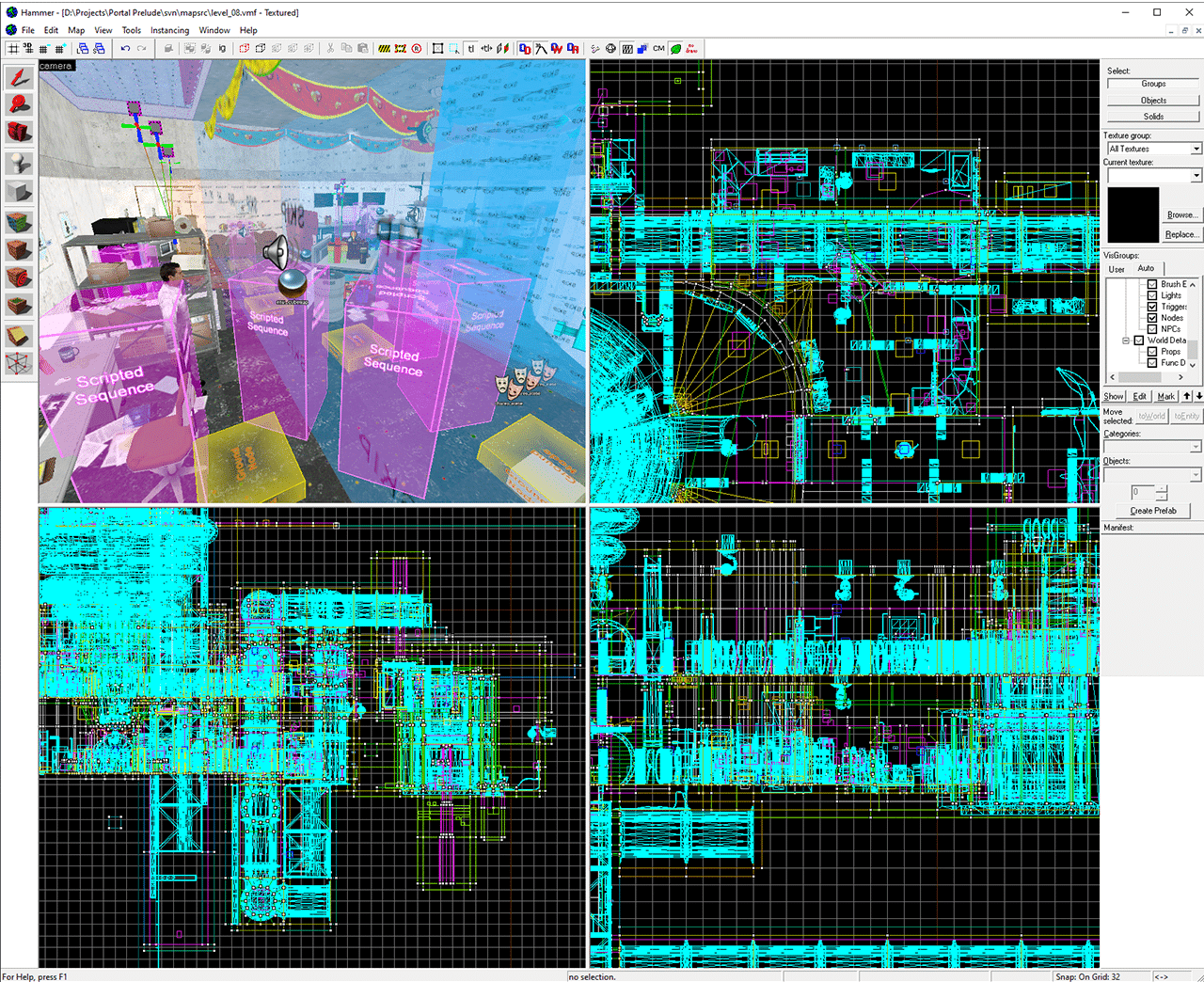
3D mapping in Valve’s Hammer engine.
Grevet and Driver-Gomm transformed Portal: Prelude’s older, lower-resolution assets into new, high-resolution assets using RTX Remix. Both creators used a GeForce RTX 40 Series GPU, which enabled full ray tracing and DLSS 3.
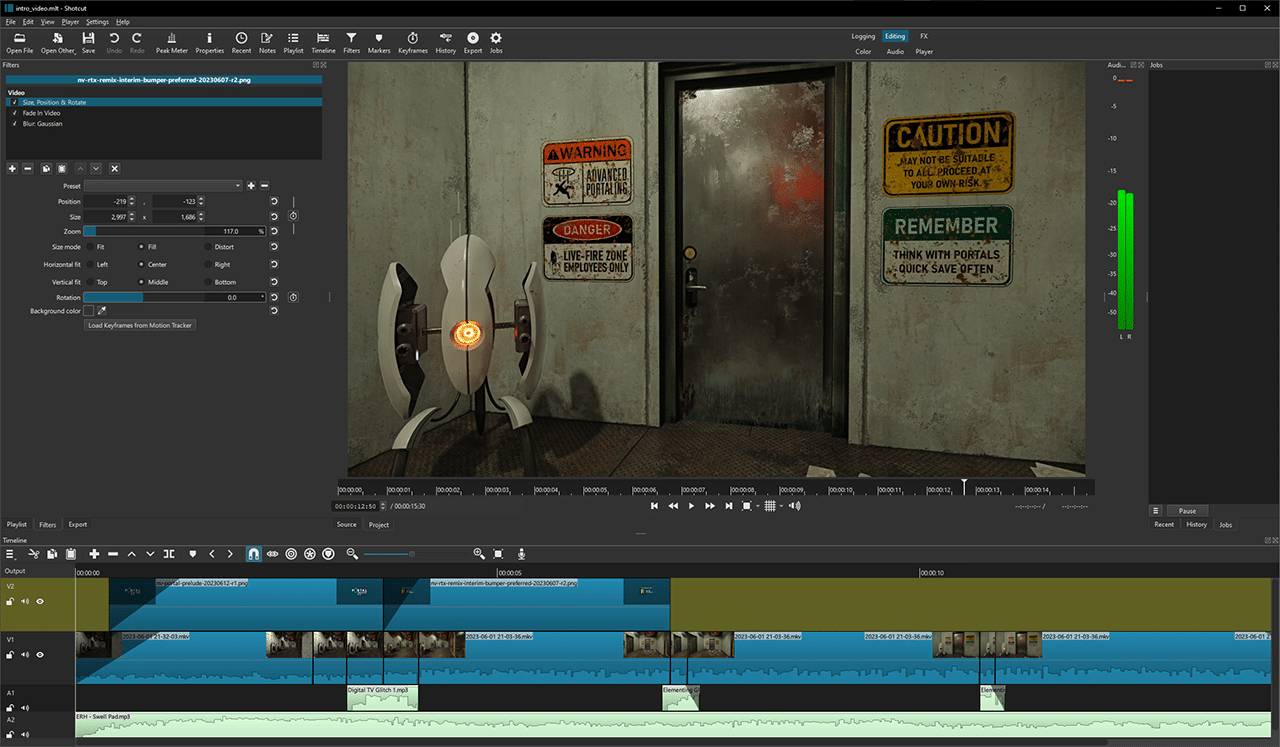
Reviewing 360-degree captures in the Shotcut video-editing platform.
The duo first gathered 360-degree screenshots of entire scene levels with RTX Remix.
Next, they used a component of RTX Remix called RTX Remix Runtime to capture game scenes and replace assets during playback while adding RTX technology to the game, including NVIDIA Reflex for low-latency responsiveness.
“We could take virtual, in-game 3D screenshots of a level and all of its assets, load the captures in RTX Remix, and literally replace every single asset, texture, geometry and light with up to 100x higher fidelity using open-source 2D and 3D formats.” — Nicolas “NykO18” Grevet
“We played with AI upscaling a lot,” said Grevet. “It was tremendously helpful in cutting down on early work and enabled sharper focus on the hero assets that required more hands-on treatment, like characters and non-playable character models, as well as large, predominant textures.”
These higher-resolution assets in the OpenUSD format were uploaded to NVIDIA Omniverse, a platform for connecting and building 3D tools and applications, through the Blender Connector. This allowed the team to use their 3D app of choice for modeling new geometry and beveling out edges, all in real time, with full ray-traced fidelity for ultra-photorealistic lighting and shadows. Blender Cycles’ RTX-accelerated OptiX ray tracing enabled smooth movement in the viewport.
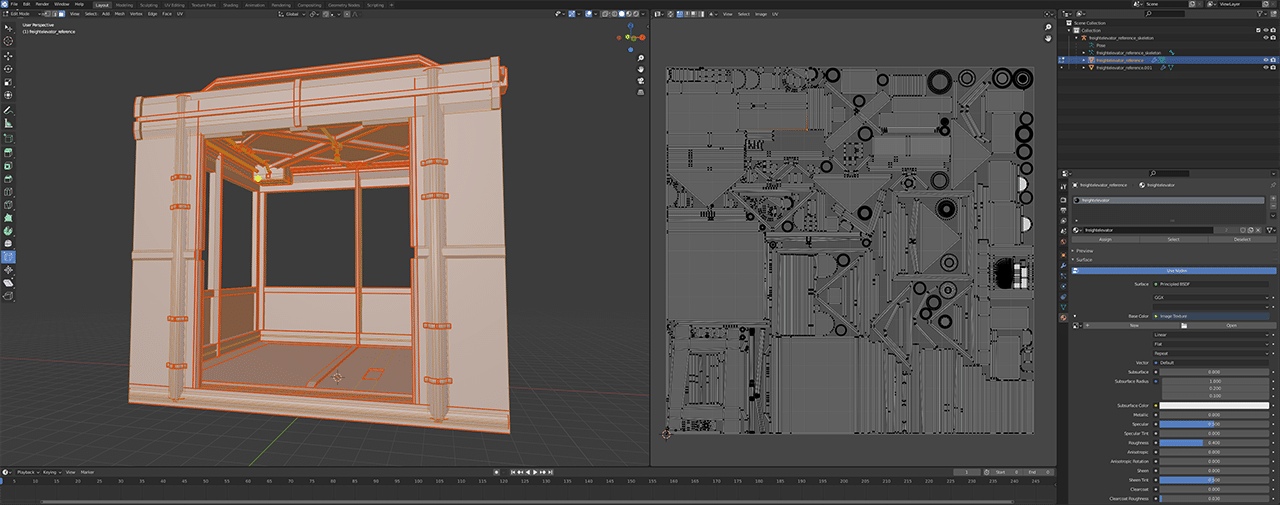
Modeling a freight elevator with the Omniverse Connector for Blender.
“Some assets were practically modeled from scratch, whereas others — like pipes — mostly just had their edges beveled out so they were higher poly and smoother,” said Driver-Gomm. “Either way, it was exponentially faster in Omniverse.” All refined assets work from captured meshes rather than by applying new meshes for individual assets, saving an incredible amount of time.
The team then UV unwrapped the assets, which is the process of opening a mesh to make a 2D texture that can blanket a 3D object for the precise application of textures and materials.
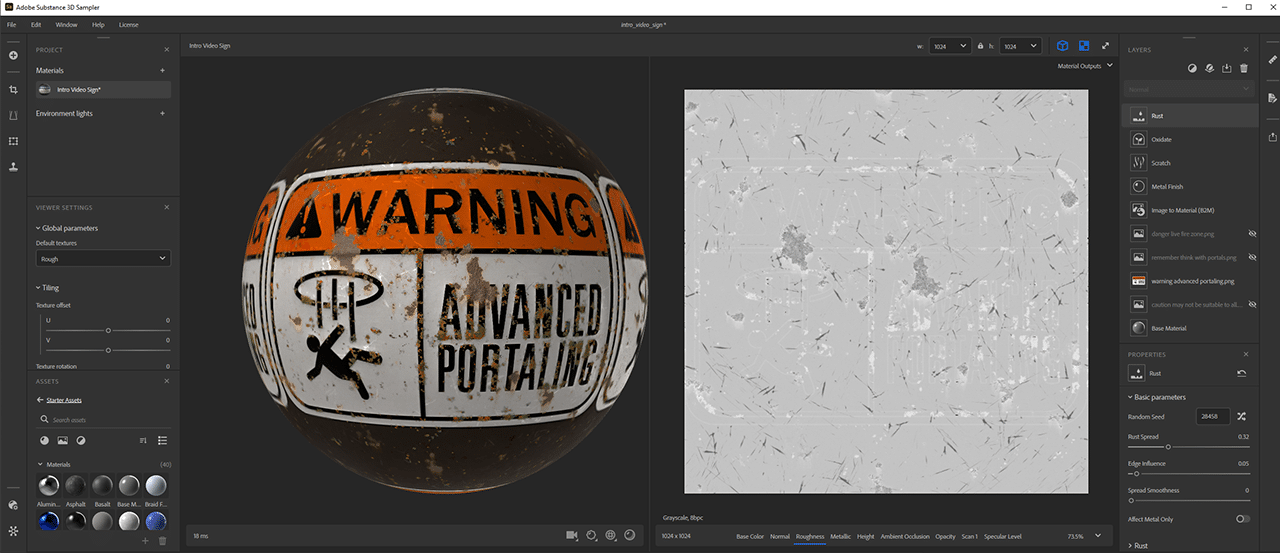
Grevet and Driver-Gomm then moved to Adobe Substance 3D Painter and Sampler to create high-quality physically based render models. This means images were rendered modeling lights and surfaces with real-world optics. GPU-accelerated filters sped up and simplified material creation, while RTX-accelerated light and ambient occlusion baked assets in seconds.
Lifelike textures built in Adobe 3D Substance Sampler.
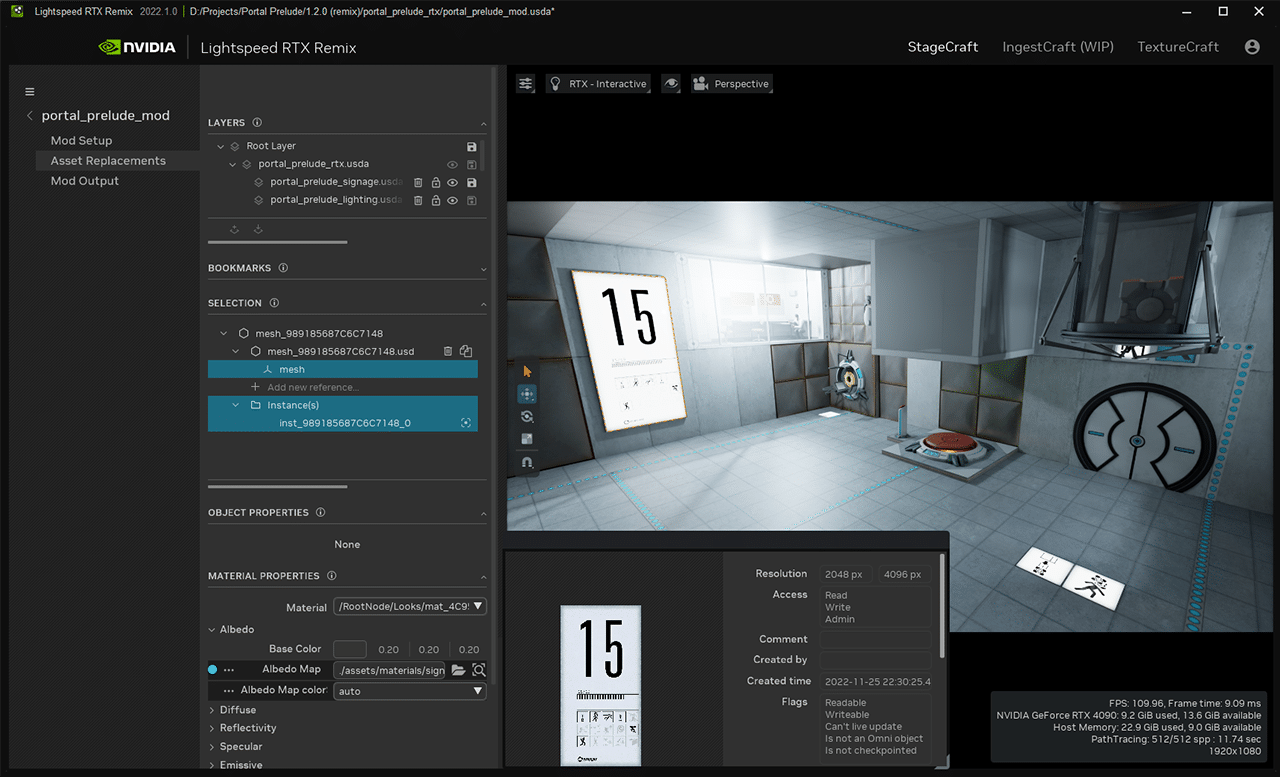
With all assets in place, the team used RTX Remix to swap older ones with these newer, higher-fidelity models. But the creators weren’t ready to rest on their laurels just yet — RTX Remix allowed them to relight every single level with realistic, path-traced lighting.
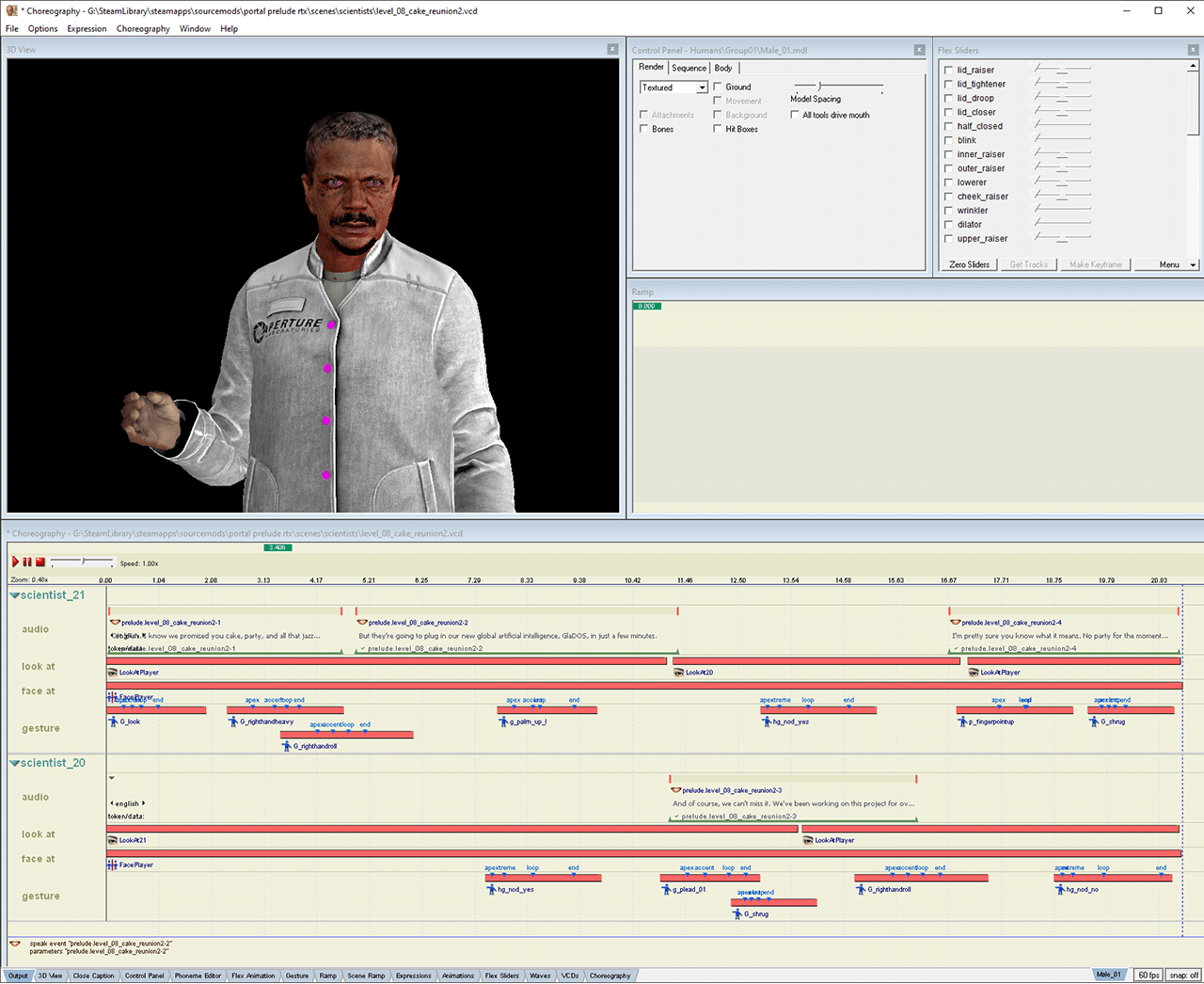
Valve’s Faceposer software development kit produced choreographed sequences that included facial expressions, lip-syncing and skeletal animations.
The final result of Portal: Prelude RTX is “light-years ahead of what I could do on my own,” said Grevet. “Having the opportunity to remaster these levels in the way I’d intended for them to look and behave was a nice cherry on top.”
Relight levels with realistic path-traced lighting in RTX Remix.
“The RTX Remix tool is insanely powerful and almost comes across as magic to me,” said Grevet. “The ability to capture any part of a game, load it in a 3D tool and chip away at it as if this was being done using the original game’s level editor is insane.”
Hammering out final details in RTX Remix.
Pick up Portal: Prelude RTX for free for Portal owners on Steam.
Game modders Nicolas “NykO18” Grevet and David Driver-Gomm.
A watershed moment on Nov. 22, 2022, was mostly virtual, yet it shook the foundations of nearly every industry on the planet.
On that day, OpenAI released ChatGPT, the most advanced artificial intelligence chatbot ever developed. This set off demand for generative AI applications that help businesses become more efficient, from providing consumers with answers to their questions to accelerating the work of researchers as they seek scientific breakthroughs, and much, much more.
Businesses that previously dabbled in AI are now rushing to adopt and deploy the latest applications. Generative AI — the ability of algorithms to create new text, images, sounds, animations, 3D models and even computer code — is moving at warp speed, transforming the way people work and play.
By employing large language models (LLMs) to handle queries, the technology can dramatically reduce the time people devote to manual tasks like searching for and compiling information.
The stakes are high. AI could contribute more than $15 trillion to the global economy by 2030, according to PwC. And the impact of AI adoption could be greater than the inventions of the internet, mobile broadband and the smartphone — combined.
The engine driving generative AI is accelerated computing. It uses GPUs, DPUs and networking along with CPUs to accelerate applications across science, analytics, engineering, as well as consumer and enterprise use cases.
Click to view the infographic: Generating the Next Wave of AI Transformation
Generative AI for Drug Discovery
Today, radiologists use AI to detect abnormalities in medical images, doctors use it to scan electronic health records to uncover patient insights, and researchers use it to accelerate the discovery of novel drugs.
Traditional drug discovery is a resource-intensive process that can require the synthesis of over 5,000 chemical compounds and yields an average success rate of just 10%. And it takes more than a decade for most new drug candidates to reach the market.
Researchers are now using generative AI models to read a protein’s amino acid sequence and accurately predict the structure of target proteins in seconds, rather than weeks or months.
Using NVIDIA BioNeMo models, Amgen, a global leader in biotechnology, has slashed the time it takes to customize models for molecule screening and optimization from three months to just a few weeks. This type of trainable foundation model enables scientists to create variants for research into specific diseases, allowing them to develop target treatments for rare conditions.
Whether predicting protein structures or securely training algorithms on large real-world and synthetic datasets, generative AI and accelerated computing are opening new areas of research that can help mitigate the spread of disease, enable personalized medical treatments and boost patient survival rates.
Generative AI for Financial Services
According to a recent NVIDIA survey, the top AI use cases in the financial services industry are customer services and deep analytics, where natural language processing and LLMs are used to better respond to customer inquiries and uncover investment insights. Another common application is in recommender systems that power personalized banking experiences, marketing optimization and investment guidance.
Advanced AI applications have the potential to help the industry better prevent fraud and transform every aspect of banking, from portfolio planning and risk management to compliance and automation.
Eighty percent of business-relevant information is in an unstructured format — primarily text — which makes it a prime candidate for generative AI. Bloomberg News produces 5,000 stories a day related to the financial and investment community. These stories represent a vast trove of unstructured market data that can be used to make timely investment decisions.
NVIDIA, Deutsche Bank, Bloomberg and others are creating LLMs trained on domain-specific and proprietary data to power finance applications.
Financial Transformers, or “FinFormers,” can learn context and understand the meaning of unstructured financial data. They can power Q&A chatbots, summarize and translate financial texts, provide early warning signs of counterparty risk, quickly retrieve data and identify data-quality issues.
These generative AI tools rely on frameworks that can integrate proprietary data into model training and fine-tuning, integrate data curation to prevent bias and use guardrails to keep conversations finance-specific.
Expect fintech startups and large international banks to expand their use of LLMs and generative AI to develop sophisticated virtual assistants to serve internal and external stakeholders, create hyper-personalized customer content, automate document summarization to reduce manual work, and analyze terabytes of public and private data to generate investment insights.
Generative AI for Retail
With 60% of all shopping journeys starting online and consumers more connected and knowledgeable than ever, AI has become a vital tool to help retailers match shifting expectations and differentiate from a rising tide of competition.
Retailers are using AI to improve customer experiences, power dynamic pricing, create customer segmentation, design personalized recommendations and perform visual search.
Generative AI can support customers and employees at every step through the buyer journey.
With AI models trained on specific brand and product data, they can generate robust product descriptions that improve search engine optimization rankings and help shoppers find the exact product they’re looking for. For example, generative AI can use metatags containing product attributes to generate more comprehensive product descriptions that include various terms like “low sugar” or “gluten free.”
AI virtual assistants can check enterprise resource planning systems and generate customer service messages to inform shoppers about which items are available and when orders will ship, and even assist customers with order change requests.
Fashable, a member of NVIDIA Inception’s global network of technology startups, is using generative AI to create virtual clothing designs, eliminating the need for physical fabric during product development. With the models trained on both proprietary and market data, this reduces the environmental impact of fashion design and helps retailers design clothes according to current market trends and tastes.
Expect retailers to use AI to capture and retain customer attention, deliver superior shopping experiences, and drive revenue by matching shoppers with the right products at the right time.
Whether improving customer service, streamlining network operations and design, supporting field technicians or creating new monetization opportunities, generative AI has the potential to reinvent the telecom industry.
Telcos can train diagnostic AI models with proprietary data on network equipment and services, performance, ticket issues, site surveys and more. These models can accelerate troubleshooting of technical performance issues, recommend network designs, check network configurations for compliance, predict equipment failures, and identify and respond to security threats.
Generative AI applications on handheld devices can support field technicians by scanning equipment and generating virtual tutorials to guide them through repairs. Virtual guides can then be enhanced with augmented reality, enabling technicians to analyze equipment in a 3D immersive environment or call on a remote expert for support.
New revenue opportunities will also open for telcos. With large edge infrastructure and access to vast datasets, telcos around the world are now offering generative AI as a service to enterprise and government customers.
As generative AI advances, expect telecommunications providers to use the technology to optimize network performance, improve customer support, detect security intrusions and enhance maintenance operations.
Generative AI for Energy
In the energy industry, AI is powering predictive maintenance and asset optimization, smart grid management, renewable energy forecasting, grid security and more.
To meet growing data needs across aging infrastructure and new government compliance regulations, energy operators are looking to generative AI.
In the U.S., electric utility companies spend billions of dollars every year to inspect, maintain and upgrade power generation and transmission infrastructure.
Until recently, using vision AI to support inspection required algorithms to be trained on thousands of manually collected and tagged photos of grid assets, with training data constantly updated for new components. Now, generative AI can do the heavy lifting.
With a small set of image training data, algorithms can generate thousands of physically accurate images to train computer vision models that help field technicians identify grid equipment corrosion, breakage, obstructions and even detect wildfires. This type of proactive maintenance enhances grid reliability and resiliency by reducing downtime, while diminishing the need to dispatch teams to the field.
Generative AI can also reduce the need for manual research and analysis. According to McKinsey, employees spend up to 1.8 hours per day searching for information — nearly 20% of the work week. To increase productivity, energy companies can train LLMs on proprietary data, including meeting notes, SAP records, emails, field best practices and public data such as standard material data sheets.
With this type of knowledge repository connected to an AI chatbot, engineers and data scientists can get instant answers to highly technical questions. For example, a maintenance engineer troubleshooting pitch control issues on a turbine’s hydraulic system could ask a bot: “How should I adjust the hydraulic pressure or flow to rectify pitch control issues on a model turbine from company X?” A properly trained model would deliver specific instructions to the user, who wouldn’t have to look through a bulky manual to find answers.
With AI applications for new system design, customer service and automation, expect generative AI to enhance safety and energy efficiency, as well as reduce operational expenses in the energy industry.
Generative AI for Higher Education and Research
From intelligent tutoring systems to automated essay grading, AI has been employed in education for decades. As universities use AI to improve teacher and student experiences, they’re increasingly dedicating resources to build AI-focused research initiatives.
For example, researchers at the University of Florida have access to one of the world’s fastest supercomputers in academia. They’ve used it to develop GatorTron — a natural language processing model that enables computers to read and interpret medical language in clinical notes that are stored in electronic health records. With a model that understands medical context, AI developers can create numerous medical applications, such as speech-to-text apps that support doctors with automated medical charting.
In Europe, an industry-university collaboration involving the Technical University of Munich is demonstrating that LLMs trained on genomics data can generalize across a plethora of genomic tasks, unlike previous approaches that required specialized models. The genomics LLM is expected to help scientists understand the dynamics of how DNA is translated into RNA and proteins, unlocking new clinical applications that will benefit drug discovery and health.
To conduct this type of groundbreaking research and attract the most motivated students and qualified academic professionals, higher education institutes should consider a whole-university approach to pool budget, plan AI initiatives, and distribute AI resources and benefits across disciplines.
Generative AI for the Public Sector
Today, the biggest opportunity for AI in the public sector is helping public servants to perform their jobs more efficiently and save resources.
These administrative roles often involve time-consuming manual tasks, including drafting, editing and summarizing documents, updating databases, recording expenditures for auditing and compliance, and responding to citizen inquiries.
To control costs and bring greater efficiency to routine job functions, government agencies can use generative AI.
Generative AI’s ability to summarize documents has great potential to boost the productivity of policymakers and staffers, civil servants, procurement officers and contractors. Consider a 756-page report recently released by the National Security Commission on Artificial Intelligence. With reports and legislation often spanning hundreds of pages of dense academic or legal text, AI-powered summaries generated in seconds can quickly break down complex content into plain language, saving the human resources otherwise needed to complete the task.
AI virtual assistants and chatbots powered by LLMs can instantly deliver relevant information to people online, taking the burden off of overstretched staff who work phone banks at agencies like the Treasury Department, IRS and DMV.
With simple text inputs, AI content generation can help public servants create and distribute publications, email correspondence, reports, press releases and public service announcements.
The analytical capabilities of AI can also help process documents to speed the delivery of vital services provided by organizations like Medicare, Medicaid, Veterans Affairs, USPS and the State Department.
Generative AI could be a pivotal tool to help government bodies work within budget constraints, deliver government services more quickly and achieve positive public sentiment.
Generative AI – A Key Ingredient for Business Success
Across every field, organizations are transforming employee productivity, improving products and delivering higher-quality services with generative AI.
To put generative AI into practice, businesses need expansive amounts of data, deep AI expertise and sufficient compute power to deploy and maintain models quickly. Enterprises can fast-track adoption with the NeMo generative AI framework, part of NVIDIA AI Enterprise software, running on DGX Cloud. NVIDIA’s pretrained foundation models offer a simplified approach to building and running customized generative AI solutions for unique business use cases.
Learn more about powerful generative AI tools to help your business increase productivity, automate tasks, and unlock new opportunities for employees and customers.
Arise, members! Capcom’s legendary role-playing game Dragon’s Dogma: Dark Arisen joins the GeForce NOW library today.
The RPG and THQ Nordic’s Jagged Alliance 3 are newly supported on GeForce NOW, playable on nearly any device.
From Dusk Till Pawn
It’s dangerous to go alone, so bring a Pawn along in “Dragon’s Dogma: Dark Arisen.”
Become the Arisen and take up the challenge in Capcom’s critically acclaimed RPG. Set in a huge open world, Dragon’s Dogma: Dark Arisen brings players on an epic adventure filled with challenging battles and action.
But there’s no need to go it alone: Adventure with up to three Pawns. These customizable AI companions fight independently, demonstrating prowess and ability they’ve developed based on traits learned from each player.
Players can share their Pawns online and reap rewards of treasures, tips and strategy hints for taking down terrifying enemies. Pawns can also be borrowed when specific skills are needed to complete various challenging quests.
Revisit Gransys or experience Dragon’s Dogma for the first time. Members can play the real Steam version of this RPG classic with support for stunning visuals and high-resolution graphics, even on devices like Macs, mobile devices and smart TVs. Priority members can adventure at up to 1080p 60 frames per second, or upgrade to an Ultimate membership for gameplay at up to 4K 120 fps, longer streaming sessions and RTX ON for supported games.
Game On
The cloud is locked and loaded.
Another week means new games.
THQ Nordic’s tactical RPG Jagged Alliance 3 joins the cloud this week. Chaos reigns when the elected president of Grand Chien — a nation of rich natural resources and deep political divides — goes missing and a paramilitary force known as “The Legion” seizes control of the countryside. Recruit from a large cast of unique mercenaries and make choices to impact the country’s fate.
Members can look forward to the following this week:
On top of that, in collaboration with EE, the U.K.’s biggest and fastest mobile network, GeForce NOW launched new cloud gaming bundles featuring Priority and Ultimate memberships. To celebrate, check out how streamer Leah ‘Leahviathan’ Alexandra showcased GeForce NOW in action at the U.K.’s highest-altitude gaming den on the slopes of Ben Nevis, 1,500 feet above sea level in the clouds of the Scottish Highlands.
What are you planning to play this weekend? Let us know on Twitter or in the comments below.
A crack NVIDIA team of five machine learning experts spread across four continents won all three tasks in a hotly contested, prestigious competition to build state-of-the-art recommendation systems.
The results reflect the group’s savvy applying the NVIDIA AI platform to real-world challenges for these engines of the digital economy. Recommenders serve up trillions of search results, ads, products, music and news stories to billions of people daily.
More than 450 teams of data scientists competed in the Amazon KDD Cup ‘23. The three-month challenge had its share of twists and turns and a nail-biter of a finish.
Shifting Into High Gear
In the first 10 weeks of the competition, the team had a comfortable lead. But in the final phase, organizers switched to new test datasets and other teams surged ahead.
The NVIDIANs shifted into high gear, working nights and weekends to catch up. They left a trail of round-the-clock Slack messages from team members living in cities from Berlin to Tokyo.
“We were working nonstop, it was pretty exciting,” said Chris Deotte, a team member in San Diego.
A Product by Any Other Name
The last of the three tasks was the hardest.
Participants had to predict which products users would buy based on data from their browsing sessions. But the training data didn’t include brand names of many possible choices.
“I knew from the beginning, this would be a very, very difficult test,” said Gilberto “Giba” Titericz.
KGMON to the Rescue
Based in Curitaba, Brazil, Titericz was one of four team members ranked as grandmasters in Kaggle competitions, the online Olympics of data science. They’re part of a team of machine learning ninjas who’ve won dozens of competitions. NVIDIA founder and CEO Jensen Huang calls them KGMON (Kaggle Grandmasters of NVIDIA), a playful takeoff on Pokémon.
In dozens of experiments, Titericz used large language models (LLMs) to build generative AIs to predict product names, but none worked.
In a creative flash, the team discovered a work-around. Predictions using their new hybrid ranking/classifier model were spot on.
Down to the Wire
In the last hours of the competition, the team raced to package all their models together for a few final submissions. They’d been running overnight experiments across as many as 40 computers.
Kazuki Onodera, a KGMON in Tokyo, was feeling jittery. “I really didn’t know if our actual scores would match what we were estimating,” he said.
The four KGMON (clockwise from upper left) Onodera, Titericz, Deotte and Puget.
Deotte, also a KGMON, remembered it as “something like 100 different models all working together to produce a single output … we submitted it to the leaderboard, and POW!”
The team inched ahead of its closest rival in the AI equivalent of a photo finish.
The Power of Transfer Learning
In another task, the team had to take lessons learned from large datasets in English, German and Japanese and apply them to meager datasets a tenth the size in French, Italian and Spanish. It’s the kind of real-world challenge many companies face as they expand their digital presence around the globe.
Jean-Francois Puget, a three-time Kaggle grandmaster based outside Paris, knew an effective approach to transfer learning. He used a pretrained multilingual model to encode product names, then fine-tuned the encodings.
“Using transfer learning improved the leaderboard scores enormously,” he said.
Blending Savvy and Smart Software
The KGMON efforts show the field known as recsys is sometimes more art than science, a practice that combines intuition and iteration.
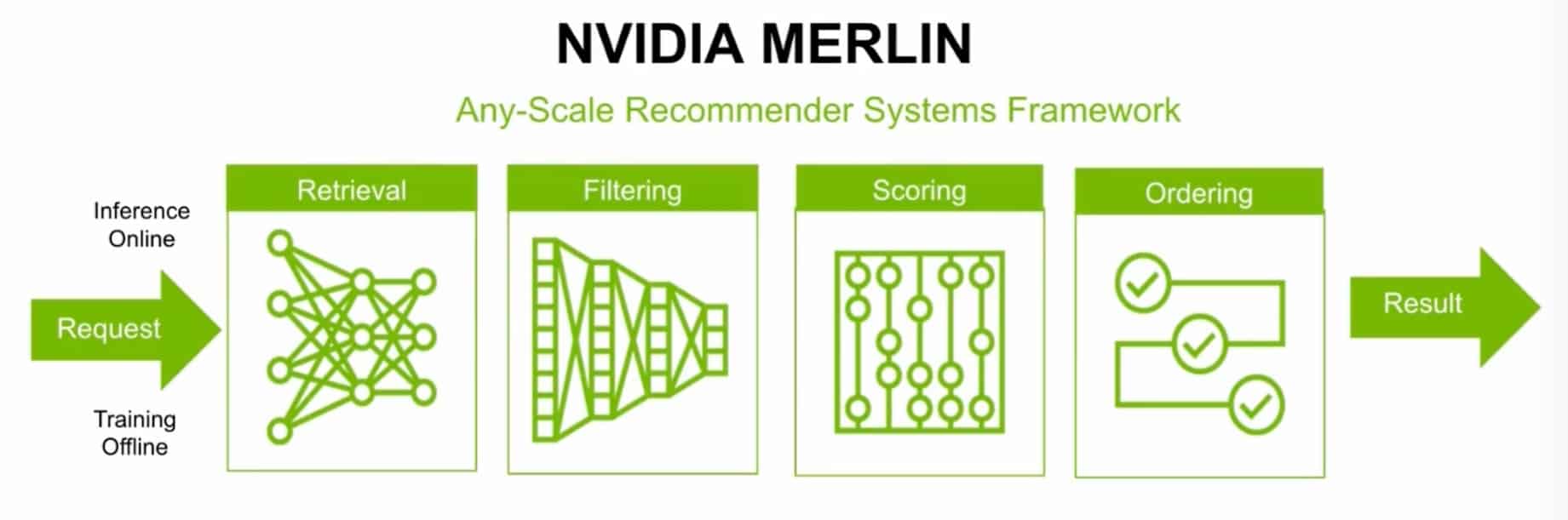
It’s expertise that’s encoded into software products like NVIDIA Merlin, a framework to help users quickly build their own recommendation systems.
The Merlin framework provides an end-to-end solution for building recommendation systems.
Benedikt Schifferer, a Berlin-based teammate who helps design Merlin, used the software to train transformer models that crushed the competition’s classic recsys task.
“Merlin provides great results right out of the box, and the flexible design lets me customize models for the specific challenge,” he said.
Riding the RAPIDS
Like his teammates, he also used RAPIDS, a set of open-source libraries for accelerating data science on GPUs.
For example, Deotte accessed code from NGC, NVIDIA’s hub for accelerated software. Called DASK XGBoost, the code helped spread a large, complex task across eight GPUs and their memory.
For his part, Titericz used a RAPIDS library called cuML to search through millions of product comparisons in seconds.
The team focused on session-based recommenders that don’t require data from multiple user visits. It’s a best practice these days when many users want to protect their privacy.
To learn more:
Watch a GTC session on building session-based recommenders with Merlin.
Startup MosaicML is on a mission to help the AI community improve prediction accuracy, decrease costs and save time by providing tools for easy training and deployment of large AI models.
In this episode of NVIDIA’s AI Podcast, host Noah Kravitz speaks with MosaicML CEO and co-founder Naveen Rao about how the company aims to democratize access to large language models.
MosaicML, a member of NVIDIA’s Inception program, has identified two key barriers to widespread adoption: the difficulty of coordinating a large number of GPUs to train a model and the costs associated with this process.
MosaicML was in the news earlier this month when Databricks announced an agreement to acquire MosaicML for $1.3 billion.
Making training of models accessible is key for many companies that need control over model behavior, respect data privacy and iterate fast to develop new products based on AI.
A postdoctoral researcher at the University of Minnesota discusses his efforts to allow amputees to control their prosthetic limb — right down to the finger motions — with their minds.
Overjet, a member of NVIDIA Inception, is moving fast to bring AI to dentists’ offices. Dr. Wardah Inam, CEO of the company, discusses using AI to improve patient care.
Luis Voloch, co-founder and chief technology officer of Immunai, talks about tackling the challenges of the immune system with a machine learning and data science mindset.
Editor’s note: This post is part of our weekly In the NVIDIA Studio series, which celebrates featured artists, offers creative tips and tricks, and demonstrates how NVIDIA Studio technology improves creative workflows. We’re also deep diving on new GeForce RTX 40 Series GPU features, technologies and resources, and how they dramatically accelerate content creation.
Jacob Norris is a 3D artist and the president, co-founder and creative director of Sierra Division Studios — an outsource studio specializing in digital 3D content creation. The studio was founded with a single goal in mind: to make groundbreaking artwork at the highest level.
His team is entirely remote — giving employees added flexibility to work from anywhere in the world while increasing the pool of prospective artists who have a vast array of experiences and skill sets that the studio can draw from.
Norris envisions a future where incredible 3D content can be made regardless of location, time or even language, he said. It’s a future in which NVIDIA Omniverse, a platform for connecting and building custom 3D tools and metaverse applications, will play a critical role.
Omniverse is also a powerful tool for making SimReady assets — 3D objects with accurate physical properties. Combined with synthetic data, these assets can help solve real-world problems in simulation, including for AI-powered 3D artists. Learn more about AI and access creative resources to level up your passion projects on the NVIDIA Studio creative side hustle page.
Plus, check out the new community challenge, #StartToFinish. Use the hashtag to submit a screenshot of a favorite project featuring both its beginning and ending stages for a chance to be showcased on the @NVIDIAStudio and @NVIDIAOmniverse social channels.
“Omniverse is an incredibly powerful tool for our team in the collaboration process,” said Norris. He noted that the Universal Scene Description format, aka OpenUSD, is key to achieving efficient content creation.
“We used OpenUSD to build a massive library of all the assets from our team,” Norris said. “We accomplished this by adding every mesh and element of a single model into a large, easily viewable overview scene for kitbashing, which is the process of combining elements from several assets into an entirely new model.”
The byproduct of kitbashing.
“Since everything is shared in OpenUSD, our asset library is easily accessible and reduces the time needed to access materials and make edits on the fly,” Norris added. “This helps spur inspirational and imaginational forces.”
During the review phase, the team can compare photorealistic models with incredible visual fidelity side by side in a shared space, ensuring the models are “created to the highest set of standards,” said Norris.
The Last Oil Rig on Earth
Sierra Division’s The Oil Rig video is set on Earth’s last operational fossil fuel rig, which is visited by a playful drone named Quark. The piece’s storytelling takes the audience through an impeccably detailed environment.
Real or rendered?
A scene as complex as the one above required blockouts in Unreal Engine. The team snapped models together from a set of greybox modular pieces, ensuring the environment bits were easy to work with. Once satisfied with the environment concept and layout, the team added further detail to the models.
Building blocks in Unreal Engine.
Norris’ Lenovo ThinkPad P73 NVIDIA Studio laptop with NVIDIA RTX A5000 graphics powered NVIDIA DLSS technology to increase the interactivity of the viewport — by using AI to upscale frames rendered at lower resolution while retaining high-fidelity detail.
Sierra Division then created tiling textures, trim sheets and materials to apply to near-finalized models. The studio used Adobe Substance 3D Painter to design custom textures with edge wear and grunge, taking advantage of RTX-accelerated light and ambient occlusion for baking and optimizing assets in seconds.
Oil rig ocean materials refined in Adobe Substance 3D Painter and Designer.
Next, lighting scenarios were tested in the Omniverse USD Composer app with the Unreal Engine Connector, which eliminates the need to upload, download and refile formats, thanks to OpenUSD.
Stunning detail.
“With OpenUSD, it’s very easy to open the same file you’re viewing in the engine and quickly make edits without having to re-import,” said Norris.
Team-wide review of renders made easier with Omniverse USD Composer.
Sierra Division analyzed daytime, nighttime, rainy and cloudy scenarios to see how the scene resonated emotionally, helping to decide the mood of the story they wanted to tell with their in-progress assets. They settled on a cloudy environment with well-placed lights to evoke feelings of mystery and intrigue.
Don’t underestimate the value of emotion. ‘Oil Rig’ re-light artwork by Ted Mebratu.
“From story-building to asset and scene creation to final renders with RTX, AI and GPU-accelerated features helped us every step of the way.” — Jacob Norris
From here, the team added cameras to the scene to determine compositions for final renders.
“If we were to try to compose the entire environment without cameras or direction, it would take much longer, and we wouldn’t have perfectly laid-out camera shots nor specifically lit renders,” said Norris. “It’s just much easier and more fun to do it this way and to pick camera shots earlier on.”
Final renders were exported lightning fast with Norris’ RTX A5000 GPU into Adobe Photoshop. Over 30 GPU-accelerated features gave Norris plenty of options to play with colors and contrast, and make final image adjustments smoothly and quickly.
Pick camera angles before final composition.
The Oil Rig modular set is available for purchase on Epic Games Unreal Marketplace. Sierra Division donates a portion of every sale to Ocean Conservancy — a nonprofit working to reduce trash, create sustainable fisheries and preserve wildlife.
The Explorer’s Room
For another video, called “The Explorer’s Room,” Sierra Division collaborated with 3D artist Mostafa Sohbi. An environment originally created by Sohbi was a great starting point to expand on the idea of an “explorer” that collects artifacts, gets into precarious situations and uses tools to help him out.
Norris and Sierra Division’s creative workflow for this piece closely mirrored the team’s work on The Oil Rig.
The Explorer’s Room.
“We all know Nathan Drake, Lara Croft, Indiana Jones and other adventurous characters,” said Norris. “They were big inspirations for us to create a living environment that tells our version of the story, while also allowing others to take the same assets and work on their own versions of the story, adding or changing elements in it.”
Don’t lose your way.
Norris stressed the importance of GPU technology in his creative workflow. “Having the fastest-performing GPU allowed us to focus more on the creative process and telling our story, instead of trying to work around slow technology or accommodating for poor performance with lower-quality artwork,” said Norris.
It’s the little details that make this render extraordinary.
“We simply made what we thought was awesome, looked awesome and felt great to share with others,” Norris said. “So it was a no-brainer for us to use NVIDIA RTX GPUs.”
Traveling soon?
Money Heist
Norris said much of the content Sierra Division creates offers the opportunity for others to use the studio’s assets to tell their own stories. “We don’t always want to over impose our own ideas into a scene or an environment, but we do want to show what is possible,” he added.
Don’t get any ideas.
Sierra Division created the Heist Essentials and Tools Collection set of props to share with game developers, content creators and virtual production teams.
Photorealistic detail.
“It’s always a thrill to recreate props inspired by movies like Ocean’s Eleven and Mission Impossible, and create assets someone might use during these types of missions and sequences,” said Norris.
How much money is that?
Try to spot all of the hidden treasures.
Jacob Norris, president, co-founder and creative director of Sierra Division Studios.
NVIDIA RTX is spinning new cycles for designs. Trek Bicycle is using GPUs to bring design concepts to life.
The Wisconsin-based company, one of the largest bicycle manufacturers in the world, aims to create bikes with the highest-quality craftsmanship. With its new partner Lidl, an international retailer chain, Trek Bicycle also owns a cycling team, now called Lidl-Trek. The team is competing in the annual Tour de France stage race on Trek Bicycle’s flagship lineup, which includes the Emonda, Madone and Speed Concept. Many of the team’s accessories and equipment, such as the wheels and road race helmets, were also designed at Trek.
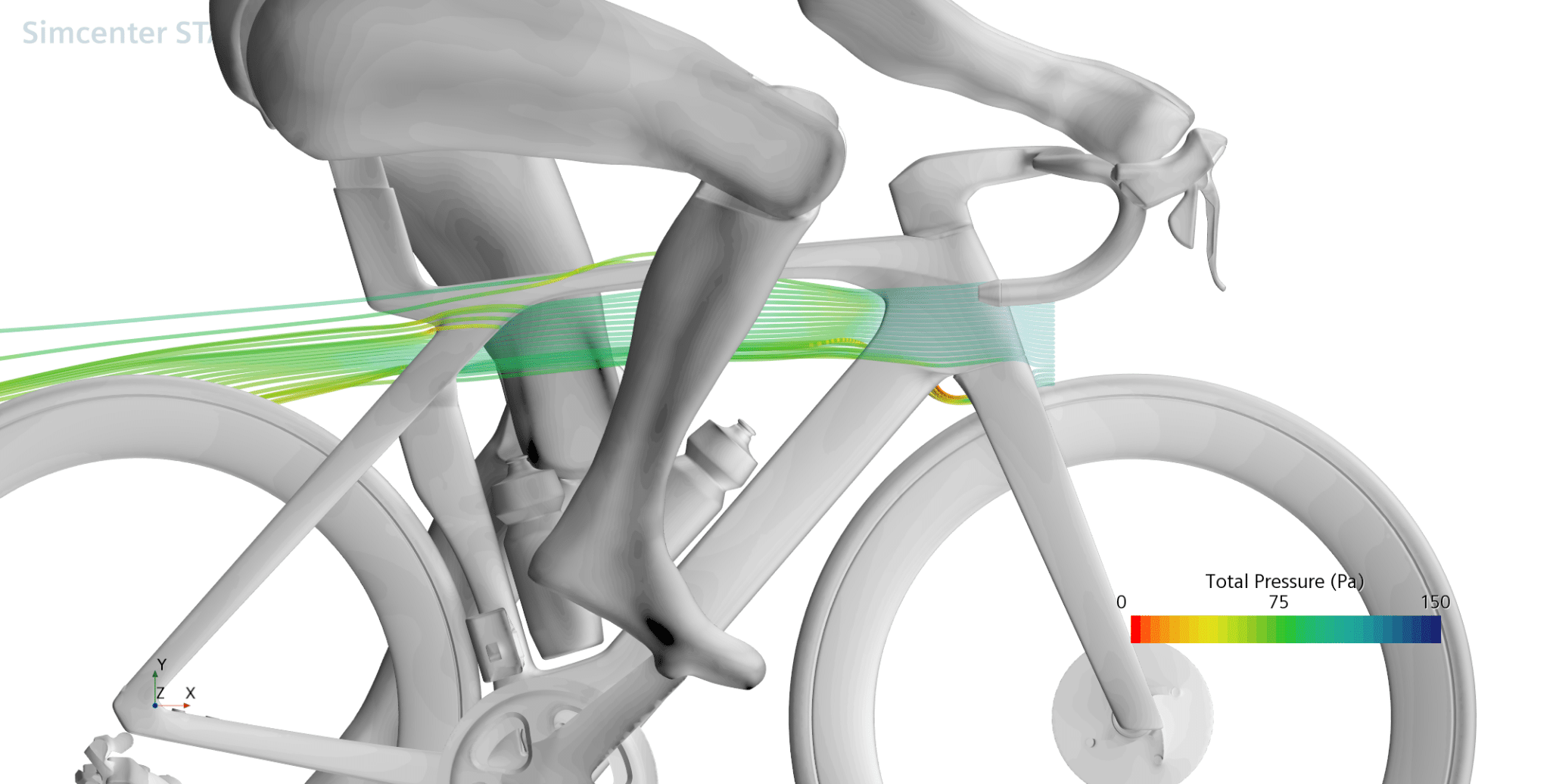
Bicycle design involves complex physics — and a key challenge is balancing aerodynamic efficiency with comfort and ride quality. To address this, the team at Trek is using NVIDIA A100 Tensor Core GPUs to run high-fidelity computational fluid dynamics (CFD) simulations, setting new benchmarks for aerodynamics in a bicycle that’s also comfortable to ride and handles smoothly.
The designers and engineers are further enhancing their workflows using NVIDIA RTX technology in Dell Precision workstations, including the NVIDIA RTX A5500 GPU, as well as a Dell Precision 7920 running dual RTX A6000 GPUs.
Visualizing Bicycle Designs in Real Time
To kick off the product design process, the team starts with user research to generate early design concepts and develop a range of ideas. Then, they build prototypes and iterate the design as needed.
To improve performance, the bikes need to feel a certain way, whether riders are taking it on the road or the trail. So Trek spends a lot of time with athletes to figure out where to make critical changes, including tweaks to geometry and the flexibility of the frame and taking the edge off of bumps.
The designers use graphics-intensive applications tools for their computer-aided design workflows, including Adobe Substance 3D, Cinema 4D, KeyShot, Redshift and SOLIDWORKS. For CFD simulations, the Trek Performance Research team uses Simcenter STAR-CCM+ from Siemens Digital Industries Software to take advantage of the GPU processing capabilities.
NVIDIA RTX GPUs provided Trek with a giant leap forward for design and engineering. The visualization team can easily tap into RTX technology to iterate quicker and show more options in designs. They can also use Cinema 4D and Redshift with RTX to produce high-quality renderings and even to visualize different designs in near real time.
Michael Hammond, the lead for digital visual communications at Trek Bicycle, explains the importance of having time for iterations. “The faster we can render an image or animation, the faster we can improve it,” he said. “But at the same time, we don’t want to lose details or spend time recreating models.”
With the help of the RTX A5500, Trek’s digital visual team can push past creative limits and reach the final design much faster. “On average, the RTX GPU performs 12x faster than our network rendering, which is on CPU cores,” said Hammond. “For a render that takes about two hours to complete on our network, it only takes around 10-12 minutes on the RTX A5500 — that means I can do 12x the iterations, which leads to better quality rendering and animation in less time.”
Accelerating CFD Simulations
Over the past decade, adoption of CFD has grown as a critical tool for engineers and equipment designers because it allows them to gain better insights into the behavior of their designs. But CFD is more than an analysis tool — it’s used to make improvements without having to resort to time-consuming and expensive physical testing for every design. This is why Trek has integrated CFD into its product development workflows.
The aerodynamics team at Trek relies on Simcenter STAR-CCM+ to optimize the performance of each bike. To provide a comfortable ride and smooth handling while achieving the best aerodynamic performance, the Trek engineers designed the latest generation Madone to use IsoFlow, a unique feature designed to increase rider comfort while reducing drag.
The Simcenter STAR-CCM+ simulations benefit from the speed of accelerated GPU computing, and it enabled the engineers to cut down simulation runtimes by 85 days, as they could run CFD simulations 4-5x faster on NVIDIA A100 GPUs compared to their 128-core CPU-based HPC server.
The team can also analyze more complex physics in CFD to better understand how the air is moving in real-world unsteady conditions.
“Now that we can run higher fidelity and more accurate simulations and still meet deadlines, we are able to reduce wind tunnel testing time for significant cost savings,” said John Davis, the aerodynamics lead at Trek Bicycle. “Within the first two months of running CFD on our GPUs, we were able to cancel a planned wind tunnel test due to the increased confidence we had in simulation results.”
Editor’s note: This post is part of our weekly In the NVIDIA Studio series, which celebrates featured artists, offers creative tips and tricks, and demonstrates how NVIDIA Studio technology improves creative workflows. We’re also deep diving on new GeForce RTX 40 Series GPU features, technologies and resources, and how they dramatically accelerate content creation.
A diverse range of artists, fashionistas, musicians and the cinematic arts inspired the creative journey of Pedro Soares, aka Blendeered, and helped him fall in love with using 3D to create art.
Now, the Porto, Portugal-based artist uses his own life experiences and interactions with people, regardless of their artistic background, to realize his artistic vision.
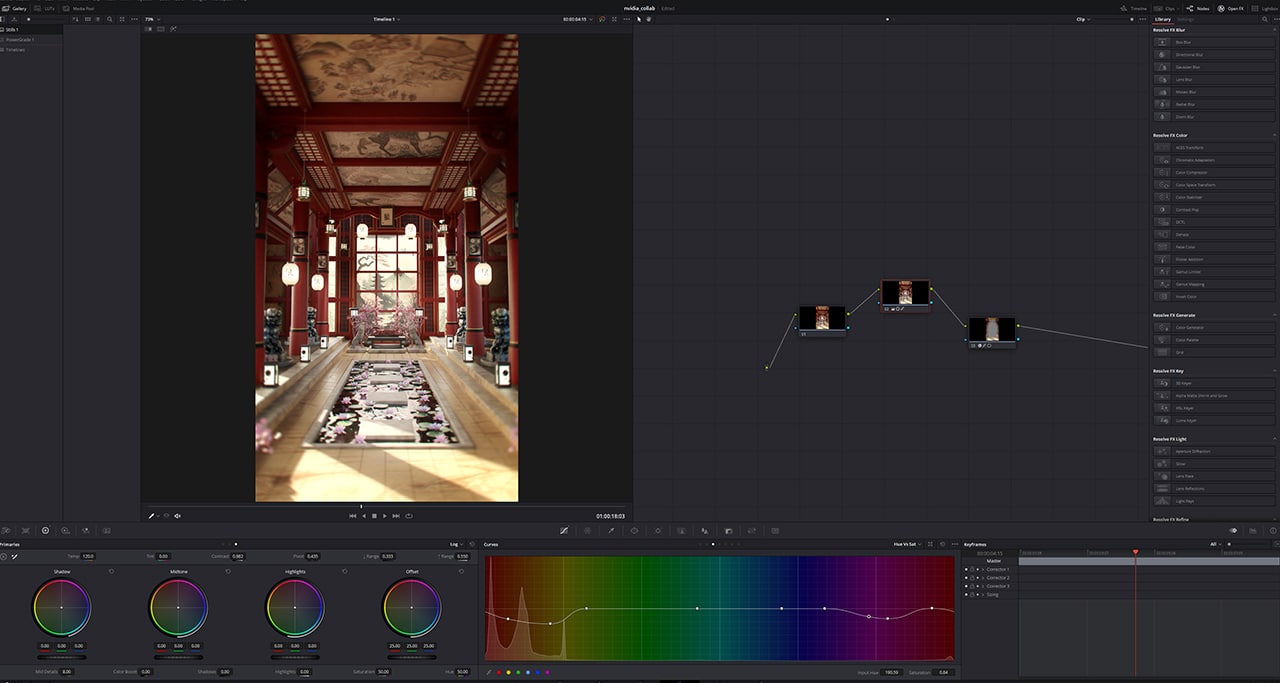
Enamored by Japanese culture, Blendeered sought to make a representation of an old Japanese temple, dedicated to an animal that has consistently delivered artistic inspiration — the mighty wolf. The result is Japanese Temple Set, a short animation that is the subject of this week’s edition of In the NVIDIA Studio, built with Blender and Blackmagic Design’s DaVinci Resolve.
In addition, get a glimpse of two cloud-based AI apps, Wondershare Filmora and Trimble SketchUp Go, powered by NVIDIA RTX GPUs, and learn how they can elevate and automate content creation.
Finally, the #SetTheScene challenge has come to an end. Check out highlights from some of the many incredible submissions.
Thank you to everyone who participated in the #SetTheScene challenge!
We were blown away by your creativity and artistic skill.
Week by week, AI becomes more ubiquitous within the content creation workflows of aspiring artists and creative professionals. Those who own NVIDIA or GeForce RTX GPUs can take advantage of Tensor Cores that utilize AI to accelerate over 100 apps. For others yet to upgrade and seeking more versatility, NVIDIA is working with the top creative app publishers to accelerate their apps on RTX GPUs from the cloud.
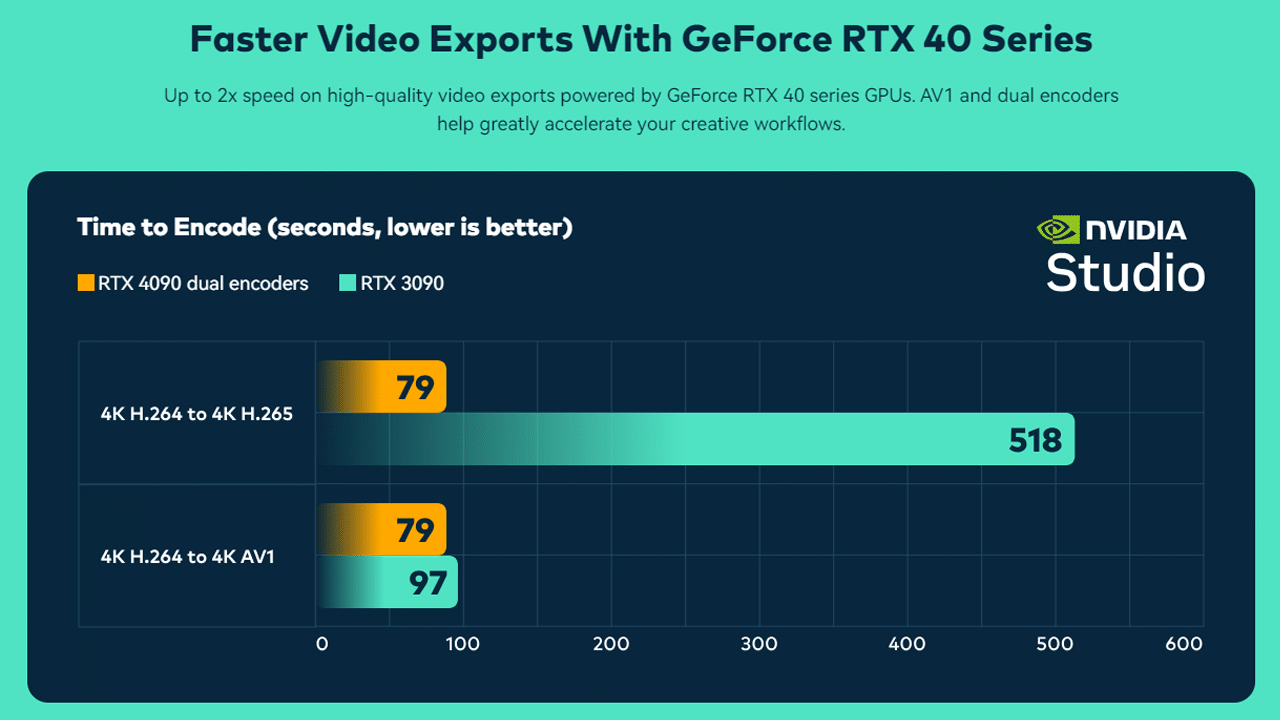
Take the Wondershare Filmora app, which creators can use to capture and touch up video on their mobile devices. They can, for example, add photos and transform them into an animated video with the app’s AI Image feature. Those with a PC powered by RTX GPUs can send files to the Filmora desktop app and continue to edit with local RTX acceleration, such as by exporting video at double the speed with dual encoders on RTX 4070 Ti or above GPUs.
Data is based on tests carried out by Filmora technical experts. To test the export of 4K footage in H.265 and AV1 formats, Wondershare Filmora 12 has been performed on computers with RTX 3090 and 4090 graphics cards respectively.
With the Trimble SketchUp Go app, architects can design structures on any device — such as an iPad — without loss in performance thanks to RTX acceleration in the cloud. Projects can be synced in the cloud using Trimble Connect, allowing users to refine projects on their RTX-powered PC using the SketchUp Pro app. There’s even an Omniverse Connector for Trimble, enabling SketchUp Pro compatibility with all apps on NVIDIA Omniverse, a development platform for connecting and building 3D tools and applications.
Cloud-based AI support with Trimble SketchUp Go.
Hungry Like the Wolf
To gather inspiration, and reference materials, to fuel his Japanese temple project, Blendeered browsed Google, Pinterest and PureRef, a stand-alone app for creating mood boards. He sought wolf-inspired and Japanese open-source 3D assets to enrich the scene he envisions before modeling.
“Little details in the scene are a celebration of wolves, for example, the paintings on the ceiling and the statues,” said Blendeered. “I did this scene with the goal of invoking calm and relaxing emotions, giving people a moment to breathe and catch their breath.”
Work began in Blender with the block-out phase — creating a rough-draft level built using simple 3D shapes, without details or polished art assets. This helped to keep base meshes clean, eliminating the need to create new meshes in the next round, which required only minor edits.
Experimenting with camera angles.
Blender is the most popular open-source 3D app in the world as it supports the entirety of the 3D pipeline. Blendeered uses it to apply textures, adjust lighting and animate the scene with ease.
“Blender, my ultimate 3D app, captivates with its friendly interface, speed, power, real-time rendering, diverse addons, vibrant community, and the best part — it’s free!” said Blendeered, whose moniker underscores his enthusiasm.
Aided by his NVIDIA Studio laptop powered by GeForce RTX graphics, Blendeered used RTX-accelerated OptiX ray tracing in the viewport for interactive, photoreal rendering for his modeling and animation needs.
Blendeered can view footage through an Instagram aspect ratio.
“GPU acceleration for real-time rendering in Blender helps a lot by allowing instant feedback on how scenes look and what needs to be changed and improved,” said the artist.
With final renders ready, Blendeered accessed the Blender Cycles renderer and OptiX ray tracing to export final frames quickly, importing the project into DaVinci Resolve for post-production.
Here, his RTX card was put to work again, refining the scene with GPU-accelerated color grading, video editing and color scopes.
Node application in DaVinci Resolve.
The GPU-accelerated decoder (NVDEC) unlocked smoother playback and scrubbing of high-resolution and multistream videos, saving Blendeered massive amounts of time.
Blendeered had numerous RTX-accelerated AI-effects at his disposal, including Cut Scene Detection for automatically tagging clips and tracking of effects, SpeedWarp for smooth slow motion, and seamless video Super Resolution. Even non-GPU-powered effects such as Neural Engine text-basedediting can prove to be tremendously useful.
Once satisfied with the animation, Blendeered used the GPU-accelerated encoder (NVENC) to speed up the exporting of his video.
Reflecting on the role his GPU had to play, Blendeered was matter-of-fact: “I chose a GeForce RTX-powered system because of the processing power and compatibility with the software I use.”
GFN Thursday arrives alongside the sweet Steam Summer Sale — with hundreds of PC games playable on GeForce NOW available during Valve’s special event for PC gamers.
Also on sale, OCTOPATH TRAVELER and OCTOPATH TRAVELER II join the GeForce NOW library as a part of five new games coming to the service this week.
Saved by the Sale
Get great games at great deals to stream across your devices during the Steam Summer Sale. In total, more than 1,000 titles can be found at discounts of up to 90% through July 13.
Grow your game collection with some top picks.
Get to the gaming while also saving.
Enjoy iconic Xbox Game Studios hits from the Age of Empires series — even on Mac — thanks to the cloud. Control an empire with the goal of expanding to become a flourishing civilization. Age of Empires II arrives to the GeForce NOW library this week, joining Age of Empires, Age of Empires III and Age of Empires IV.
Stream Square Enix games at beautiful quality on underpowered PCs with heart-wrenching single-player stories like Life is Strange 2 and Life is Strange: True Colors, or battle it out with a squad in the dark sci-fi universe of Outriders.
Become a Viking, sail the open sea and fight monsters in the world of Valheim, or play a spooky game of hide-and-seek as a Ghost or a Hunter in Midnight Ghost Hunt. Take these titles from publisher Coffee Stain Studios on the go playing on nearly any Android or iOS mobile device.
Tune in on the big screen with NVIDIA SHIELD TVs for THQ Nordic favorites. Return to an apocalyptic Earth in the hack-n-slash adventure Darksiders III, or terrorize the people of 1950s Earth as an evil alien in Destroy All Humans!
Experience these titles and 1,600+ other games on GeForce NOW with all of the perks of an Ultimate membership, including RTX 4080 quality, support for 4K 120 frames per second gameplay and ultrawide resolutions, and the longest gaming sessions on the cloud.
Priority and Ultimate members can also experience DLSS 3 and RTX ON for real-time cinematic lighting in supported games.
Choose Your Path
Eight travelers, eight stories, one very powerful cloud to stream from.
Visit faraway realms playing OCTOPATH TRAVELER and OCTOPATH TRAVELER II from Square Enix — also on sale on Steam. Members can even start their traveler journey with the OCTOPATH TRAVELER II Prologue demo.
Explore the story of eight travelers hailing from different regions who are set on vastly different ventures. Step into their shoes and use their unique talents to make decisions that will shape your path and aid you along your journey in these two award-winning role-playing games.
In OCTOPATH TRAVELER, engage in side quests and thrilling battles where every choice made by players shapes the storylines and destinies of these remarkable characters. Continue the adventure with OCTOPATH TRAVELER II and a fresh new set of eight travelers in the land of Solistia, a land comprising eastern and western continents divided by the sea.
It’s Good to Be the King
And that’s not all — five new games are joining the GeForce NOW library this week.
The (Industrial) Revolution will be streaming from the cloud.
Age of Empires II: Definitive Edition celebrates the 20th anniversary of one of the world’s most popular real-time strategy games. Explore all the original campaigns like never before, spanning over 200 hours of gameplay and 1,000 years of human history. Rise to the challenge of leading four new civilizations, exclusive to the Definitive Edition, and head online to challenge other players in a bid for world domination throughout the ages.
Catch the full list of new titles available to find your next adventure:
The Legend of Heroes: Trails into Reverie (New release on Steam, July 7)
Members can also experience Major League Baseball’s new Virtual Ballpark and be a part of MLB’s interactive All-Star Celebrity Softball Watch Party on Saturday, July 8. Supported by NVIDIA’s global cloud streaming infrastructure, fans will have frictionless access to high-fidelity interactive experiences. Register for the event.
What are you planning to play this weekend? Let us know on Twitter or in the comments below.
If you could 𝒕𝒓𝒂𝒗𝒆𝒍 to any video game land, where would it be?










 NVIDIA GeForce NOW (@NVIDIAGFN)
NVIDIA GeForce NOW (@NVIDIAGFN)