From scaling mountains in the annual California Death Ride bike challenge to creating a low-cost, open-source ventilator in the early days of the COVID-19 pandemic, NVIDIA Chief Scientist Bill Dally is no stranger to accomplishing near-impossible feats.
The aim of the council — a coalition of engineering societies, including the Institute of Electrical and Electronics Engineers, SAE International and the Association for Computing Machinery — is to promote engineering programs and enhance society through science.
Since 1990, its Hall of Fame has honored engineers who have accomplished significant professional achievements while serving their profession and the wider community.
Previous inductees include industry luminaries such as Intel founders Robert Noyce and Gordon Moore, former president of Stanford University and MIPS founder John Hennessy, and Google distinguished engineer and professor emeritus at UC Berkeley David Patterson.
Recognizing ‘an Industry Leader’
In accepting the distinction, Dally said, “I am honored to be inducted into the Silicon Valley Hall of Fame. The work for which I am being recognized is part of a large team effort. Many faculty and students participated in the stream processing research at Stanford, and a very large team at NVIDIA was involved in translating this research into GPU computing. It is a really exciting time to be a computer engineer.”
“The future is bright with a lot more demanding applications waiting to be accelerated using the principles of stream processing and accelerated computing.”
His induction kicked off with a video featuring colleagues and friends, spanning his career across Caltech, MIT, Stanford and NVIDIA.
In the video, NVIDIA founder and CEO Jensen Huang describes Dally as “an extraordinary scientist, engineer, leader and amazing person.”
Fei-Fei Li, professor of computer science at Stanford and co-director of the Stanford Institute for Human-Centered AI, commended Dally’s journey “from an academic scholar and a world-class researcher to an industry leader” who is spearheading one of the “biggest digital revolutions of our time in terms of AI — both software and hardware.”
Following the tribute video, Fred Barez, chair of the Hall of Fame committee and professor of mechanical engineering at San Jose State University, took the stage. He said of Dally: “This year’s inductee has made significant contributions, not just to his profession, but to Silicon Valley and beyond.”
Underpinning the GPU Revolution
As the leader of NVIDIA Research for nearly 15 years, Dally has built a team of more than 300 scientists around the globe, with groups covering a wide range of topics, including AI, graphics, simulation, computer vision, self-driving cars and robotics.
Prior to NVIDIA, Dally advanced the state of the art in engineering at some of the world’s top academic institutions. His development of stream processing at Stanford led directly to GPU computing, and his contributions are responsible for much of the technology used today in high-performance computing networks.
Telcos are seeking industry-standard solutions that can run 5G, AI applications and immersive graphics workloads on the same server — including for computer vision and the metaverse.
To meet this need, NVIDIA is developing a new AI-on-5G solution that combines 5G vRAN, edge AI and digital twin workloads on an all-in-one, hyperconverged and GPU-accelerated system.
The lower cost of ownership enabled by such a system would help telcos drive revenue growth in smart cities, as well as the retail, entertainment and manufacturing industries, to support a multitrillion-dollar, 5G-enabled ecosystem.
The AI-on-5G system consists of:
Fujitsu’s virtualized 5G Open RAN product suite, which was developed as part of the 5G Open RAN ecosystem experience (OREX) project promoted by NTT DOCOMO. It also includes Fujitsu’s virtualized central unit (vCU) and distributed unit (vDU), plus other virtualized software functions of vRAN from Fujitsu.
Hardware includes the NVIDIA A100X and L40 converged accelerators.
OREC has supported performance verification and evaluation tests for this system.
Collaborating With Fujitsu
“Fujitsu is delivering a fully virtualized 5G vRAN together with multi-access edge computing on the same high-performance, energy-efficient, versatile and scalable computing infrastructure,” said Masaki Taniguchi, senior vice president and head of mobile systems at Fujitsu. “This combination, powered by AI and XR applications, enables telcos to deliver ultra-low latency services, highly optimized TCO and energy-efficient performance.”
The announcement is a step toward accomplishing the O-RAN alliance’s goal of enabling software-defined, AI-driven, cloud-native, fully programmable, energy-efficient and commercially ready telco-grade 5G Open RAN solutions. It’s also consistent with OREC’s goal of implementing a widely adopted, high-performance and multi-vendor 5G vRAN for both public and enterprise 5G deployments.
The all-in-one system uses GPUs to accelerate the software-defined 5G vRAN, as well as the edge AI and graphics applications, without bespoke hardware accelerators nor a specific telecom CPU. This ensures that the GPUs can accelerate the vRAN (based on NVIDIA Aerial), AI video analytics (based on NVIDIA Metropolis), streaming immersive extended reality (XR) experiences (based on NVIDIA CloudXR) and digital twins (based on NVIDIA Omniverse).
“Telcos and their customers are exploring new ways to boost productivity, efficiency and creativity through immersive experiences delivered over 5G networks,” said Ronnie Vasishta, senior vice president of telecom at NVIDIA. “At Mobile World Congress, we are bringing those visions into reality, showcasing how a single GPU-enabled server can support workloads such as NVIDIA Aerial for 5G, CloudXR for streaming virtual reality and Omniverse for digital twins.”
The AI-on-5G system is part of a growing portfolio of 5G solutions from NVIDIA that are driving transformation in the telecommunications industry. Anchored on the NVIDIA Aerial SDK and A100X converged accelerators — combined with BlueField DPUs and a suite of AI frameworks — NVIDIA provides a high-performance, software-defined, cloud-native, AI-enabled 5G for on-premises and telco operators’ RAN.
Telcos working with NVIDIA can gain access to thousands of software vendors and applications in the ecosystem, which can help address enterprise needs in smart cities, retail, manufacturing, industrial and mining.
NVIDIA and Fujitsu will demonstrate the new AI-on-5G system at Mobile World Congress in Barcelona, running Feb. 27-March 2, at hall 4, stand 4E20.
But genome sequencing is just the first step. Analyzing genome sequencing data requires accelerated compute, data science and AI to read and understand the genome. With the end of Moore’s law, the observation that there’s a doubling every two years in the number of transistors in an integrated circuit, new computing approaches are necessary to lower the cost of data analysis, increase the throughput and accuracy of reads, and ultimately unlock the full potential of the human genome.
An Explosion in Bioinformatics Data
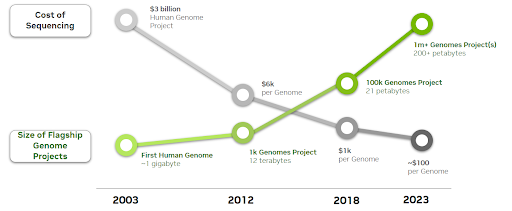
Sequencing an individual’s whole genome generates roughly 100 gigabytes of raw data. That more than doubles after the genome is sequenced using complex algorithms and applications such as deep learning and natural language processing.
As the cost of sequencing a human genome continues to decrease, volumes of sequencing data are exponentially increasing.
An estimated 40 exabytes will be required to store all human genome data by 2025. As a reference, that’s 8x more storage than would be required to store every word spoken in history.
Many genome analysis pipelines are struggling to keep up with the expansive levels of raw data being generated.
Accelerated Genome Sequencing AnalysisWorkflows
Sequencing analysis is complicated and computationally intensive, with numerous steps required to identify genetic variants in a human genome.
Deep learning is becoming important for base calling right within the genomic instrument using RNN- and convolutional neural network (CNN)-based models. Neural networks interpret image and signal data generated by instruments and infer the 3 billion nucleotide pairs of the human genome. This is improving the accuracy of the reads and ensuring that base calling occurs closer to real time, further hastening the entire genomics workflow, from sample to variant call format to final report.
For secondary genomic analysis, alignment technologies use a reference genome to assist with piecing a genome back together after the sequencing of DNA fragments.
BWA-MEM, a leading algorithm for alignment, is helping researchers rapidly map DNA sequence reads to a reference genome. STAR is another gold-standard alignment algorithm used for RNA-seq data that delivers accurate, ultrafast alignment to better understand gene expressions.
The dynamic programming algorithm Smith-Waterman is also widely used for alignment, a step that’s accelerated 35x on the NVIDIA H100 Tensor Core GPU, which includes a dynamic programming accelerator.
Uncovering Genetic Variants
One of the most critical stages of sequencing projects is variant calling, where researchers identify differences between a patient’s sample and the reference genome. This helps clinicians determine what genetic disease a critically ill patient might have, or helps researchers look across a population to discover new drug targets. These variants can be single-nucleotide changes, small insertions and deletions, or complex rearrangements.
GPU-optimized and -accelerated callers such as the Broad Institute’s GATK — a genome analysis toolkit for germline variant calling — increase speed of analysis. To help researchers remove false positives in GATK results, NVIDIA collaborated with the Broad Institute to introduce NVScoreVariants, a deep learning tool for filtering variants using CNNs.
Deep learning-based variant callers such as Google’s DeepVariant increase accuracy of calls, without the need for a separate filtering step. DeepVariant uses a CNN architecture to call variants. It can be retrained to fine-tune for enhanced accuracy with each genomic platform’s outputs.
Secondary analysis software in the NVIDIA Clara Parabricks suite of tools has accelerated these variant callers up to 80x. For example, germline HaplotypeCaller’s runtime is reduced from 16 hours in a CPU-based environment to less than five minutes with GPU-accelerated Clara Parabricks.
Accelerating the Next Wave of Genomics
NVIDIA is helping to enable the next wave of genomics by powering both short- and long-read sequencing platforms with accelerated AI base calling and variant calling. Industry leaders and startups are working with NVIDIA to push the boundaries of whole genome sequencing.
For example, biotech company PacBio recently announced the Revio system, a new long-read sequencing system featuring NVIDIA Tensor Core GPUs. Enabled by a 20x increase in computing power relative to prior systems, Revio is designed to sequence human genomes with high-accuracy long reads at scale for under $1,000.
Oxford Nanopore Technologies offers the only single technology that can sequence any-length DNA or RNA fragments in real time. These features allow the rapid discovery of more genetic variation. Seattle Children’s Hospital recently used the high-throughput nanopore sequencing instrument PromethION to understand a genetic disorder in the first few hours of a newborn’s life.
Ultima Genomics is offering high-throughput whole genome sequencing at just $100 per sample, and Singular Genomics’ G4 is the most powerful benchtop system.
Learn More
At NVIDIA GTC, a free AI conference taking place online March 20-23, speakers from PacBio, Oxford Nanopore, Genomic England, KAUST, Stanford, Argonne National Labs and other leading institutions will share the latest AI advances in genomic sequencing, analysis and genomic large language models for understanding gene expression.
Cloudy British weather is the butt of many jokes — but the United Kingdom’s national power grid is making the most of its sunshine.
With the help of Open Climate Fix, a nonprofit product lab, the control room of the National Grid Electricity System Operator (ESO) is testing AI models that provide granular, near-term forecasts of sunny and cloudy conditions over the country’s solar panels.
These insights can help ESO, the U.K.’s electric grid operator, address a key challenge in renewable energy: Sudden cloud cover can cause a significant dip in solar power generation, so grid operators ask fossil fuel plants to overproduce energy as backup.
With better forecasts, ESO could cut down on the extra fossil fuel energy held as reserve — improving efficiency while decreasing carbon footprint.
“Traditional weather models aren’t very good at predicting clouds, but using AI and satellite imagery, we can bring a lot more accuracy to solar forecasting,” said Dan Travers, co-founder of Open Climate Fix, a U.K.-based startup. “Solar energy is really effective at displacing coal, but grid operators need accurate forecasts to make it possible to integrate large amounts of solar generation — so we see a lot of opportunity in bringing this solution to coal-heavy electric grids worldwide.”
Open Climate Fix is a member of NVIDIA Inception, a global program that offers cutting-edge startups expertise, technology and go-to-market support. The team publishes its datasets, dozens of models and open-source code to HuggingFace and GitHub.
Each colored dot on the map represents a solar photovoltaic system. Blue dots represent low solar-energy output, yellow dots signify high output and black dots are systems with no data.
AI to Catch a Cloud and Pin It Down
Before the advent of renewable energy, the experts managing the electric grid day-to-day only had to worry about the variability of demand across the network — making sure there was enough power generated to keep up with air conditioners during a heat wave, or electric stoves and appliances on weekday evenings.
By adding renewables such as wind and solar energy to the mix, the energy grid must also account for weather-related variation in the level of supply. Satellite images provide the most up-to-date view to determine when clouds are coming between photovoltaic panels and the sun.
Open Climate Fix’s AI models are trained on terabytes of satellite data captured at five-minute intervals over Europe, the Middle East and North Africa. Additional data sources include years’ worth of hourly weather predictions at ten-kilometer resolution, topographic maps, information about the time of day and the sun’s position in the sky, and live readings from around solar panels across the U.K.
The team is using some of the most recent deep learning models for weather modeling including MetNet, GraphCast and Deep Generative Model of Radar. They’ve shown that their transformer-based AI models are 3x better at predicting solar energy generation than the forecasts generated by ESO’s traditional methods. The increased precision can help ESO reach its goal of being able to operate a zero-carbon electric grid by 2025.
“The physics-based forecasting models are powerful for predicting weather on the scale of days and weeks, but take hours to produce — making them ill-suited for predictions at the hour or minute level,” said Travers. “But with satellite images captured at intervals of a few minutes, we can get closer to a live view of cloud cover.”
AI’s Working on Sunshine
Cloud cover is of particular concern in the U.K., where cities including London, Birmingham and Glasgow receive an average of 1,400 or fewer hours of sunshine each year — less than half that of Los Angeles. But even in desert climates where cloudy days are rare, Open Climate Fix’s AI models could be repurposed to detect when solar panels would be covered by dust from a sandstorm.
In addition to forecasting for the entire U.K., the nonprofit is also developing models that can forecast how much energy individual solar panels will capture. This data could help large solar farm operators understand and maximize their energy output. Smart home companies, too, could use the information to optimize energy use from solar panels on customers’ roofs — giving homeowners insights about when to run power-hungry devices or schedule electric vehicle charging.
“The hardware grants have helped us develop and iterate on our models more easily,” said Jacob Bieker, a machine learning researcher at Open Climate Fix. “When our team is first debugging and training a model, it’s two or three times faster to do so locally.”
To learn more about AI accelerating decarbonization, boosting grid resiliency and driving energy efficiency, register free for NVIDIA GTC, which takes place online, March 20-23.
The do-it-yourself climate modeling movement is here.
Researchers from Northwestern University and Argonne National Laboratory have been launching NVIDIA Jetson-driven edge computing Waggle devices across the globe to collect hyper-local climate information. Waggle is an open source sensor platform for edge computing developed by Argonne.
Working with this, scientists share open-source AI code designed for the edge at an app store within the Sage web portal, funded by the National Science Foundation (NSF).
The pioneering work is supporting environmental studies around the world. As a result, more and more researchers and scientists are jumping in to study climate issues with edge computing and sensors.
Waggle’s installed base studies everything from micro-local Chicago weather to help understand urban heat islands and their impact on residents, to climate effects on wild rice on the Ojibwe tribe’s lands in Wisconsin.
More recently, the University of Oregon’s Hazards Lab began using edge computing with Waggle. This work aims to help understand and identify wildfires as part of the ALERTWildfire system that provides local residents, firefighters and municipalities live data streams from smart cameras.
The efforts, on several continents, underscore the accessibility of edge computing paired with a digital infrastructure for delivering open AI models for use in these climate-related applications.
“Many climate models focus on large geographic scales — and therefore the impact can be difficult to understand for specific communities — but the Department of Energy wants to understand how our changing climate will impact humans, especially in an urban environment,” said Pete Beckman, an Argonne distinguished fellow and co-director of the Northwestern University Argonne Institute of Science and Engineering.
NVIDIA announced at GTC 2021 the Earth-2 AI supercomputer for climate research worldwide.
Waggle Nodes Plus Sage AI
It all began in 2015 with an NSF project called the “Array of Things,” or AoT, led by Charlie Catlett, which introduced advanced sensors and edge computing for studying urban environments.
The AoT was built using the Waggle edge computing platform that had been recently developed internally at Argonne National Laboratory. Waggle brings together powerful edge AI computing like NVIDIA Jetson with industry-standard software toolkits like Kubernetes, PyTorch and TensorFlow to provide a programmable intelligent platform that can support cameras, microphones, software-defined radios, lidar and infrared imagers. To support the rapidly growing AI and sensor landscape, the NVIDIA platform was the obvious choice, offering the largest ecosystem, the most flexibility and industry-leading performance.
The energy efficiency of Jetson is key, as Waggle nodes are often mounted outside of buildings or on light posts.
The Sage project began with a grant from the NSF in 2022 to build a national-scale, software-defined sensor network to support AI at the edge.
Sage nodes are open resources for scientific exploration. Scientists can develop new AI models, upload them to the Sage app store and then deploy them to mountaintops in Oregon or prairies in Illinois.
Monitoring Chicago for Heat Waves
The same core technology is being deployed in Chicago, which uses the Waggle-Sage platform.
The U.S. Department of Energy wanted to understand what was happening with climate change in the urban environment. It put out a call for proposals for an urban integrated field lab. The effort pairs the supercomputing of the Waggle nodes with the open-source Sage models for hyper-local data analysis.
Argonne and partners are establishing an urban integrated field lab, dubbed Community Research on Climate and Urban Science (CROCUS), to focus on the Chicago region. The plans are for it to take community input to identify questions and specific areas of urban climate change to study, ensuring that research results directly benefit local residents.
“How do we build AI systems that are hyperlocal, that can give us real insight into an urban environment?” said Beckman.
Modeling Wild Rice Migration
In Wisconsin, researchers deployed a node with the Ojibwe tribe, in efforts to help understand wild rice, a food source with important cultural significance.
“Wild rice is a species that is shifting because of climate change, so they want to understand what is happening,” said Beckman.
Identifying Birds by Sounds
What else do you get when you combine open AI models, edge computing and researchers on a climate mission?
A lot of useful applications for many people, including bird identification AI.
Now, birders can download the Merlin Bird ID app — available for iOS and Android devices — and start identifying birds by the sounds they make. The models have also been moved to some Waggle devices and can identify birds wherever Sage is deployed.
A million developers across the globe are now using the NVIDIA Jetson platform for edge AI and robotics to build innovative technologies. Plus, more than 6,000 companies — a third of which are startups — have integrated the platform with their products.
These milestones and more will be celebrated during the NVIDIA Jetson Edge AI Developer Days at GTC, a global conference for the era of AI and the metaverse, taking place online March 20-23.
Register free to learn more about the Jetson platform and begin developing the next generation of edge AI and robotics.
One in a Million
Atlanta-based Kris Kersey, the mind behind the popular YouTube channel Kersey Fabrications, is one developer using the NVIDIA Jetson platform for his one-in-a-million technological innovations.
He created a fully functional Iron Man helmet that could be straight out of the Marvel Comics films. It uses the NVIDIA Jetson Xavier NX 8GB developer kit as the core of the “Arc Reactor” powering its heads-up display — a transparent display that presents information wherever the user’s looking.
In just over two years, Kersey built from scratch the wearable helmet, complete with object detection and other on-screen sensors that would make Tony Stark proud.
“The software design was more than half the work on the project, and for me, this is the most exciting, interesting part,” Kersey said. “The software takes all of the discrete hardware components and makes them into a remarkable system.”
To get started, Kersey turned to GitHub where he found “Hello AI World,” a guide for deploying deep-learning inference networks and deep vision primitives with the NVIDIA TensorRT software development kit and NVIDIA Jetson. He then wrote a wrapper code to connect his own project.
Watch Kersey document his Iron Man project from start to finish:
This 3D-printed helmet is just the beginning for Kersey, who’s aiming to build a full Iron Man suit later this year. He plans to make the entire project’s code open source, so anyone who dreams of becoming a superhero can try it for themselves.
Jetson Edge AI Developer Days at GTC
Developers like Kersey can register for the free Jetson Edge AI Developer Days at GTC, which feature NVIDIA experts who’ll cover the latest Jetson hardware, software and partners. Sessions include:
Level Up Edge AI and Robotics With NVIDIA Jetson Orin Platform
Accelerate Edge AI With NVIDIA Jetson Software
Getting the Most Out of Your Jetson Orin Using NVIDIA Nsight Developer Tools
Bring Your Products to Market Faster With the NVIDIA Jetson Ecosystem
Design a Complex Architecture on NVIDIA Isaac ROS
Plus, there’ll be a Connect with Experts session focusing on the Jetson platform that provides a deep-dive Q&A with embedded platform engineers from NVIDIA on Tuesday, March 21, at 12 p.m. PT. This interactive session offers a unique opportunity to meet, in a group or individually, with the minds behind NVIDIA products and get your questions answered. Space is limited and on a first-come, first-served basis.
Additional Sessions by Category
GTC sessions will also cover robotics, intelligent video analytics and smart spaces. Below are some of the top sessions in these categories.
Grab the latest Jetson modules and developer kits from the NVIDIA Jetson store.
And sign up for the NVIDIA Developer Program to connect with Jetson developers from around the world and get access to the latest software and software development kits, including NVIDIA JetPack.
To drive the automotive industry forward, NVIDIA and Mercedes-Benz are taking the virtual road.
NVIDIA founder and CEO Jensen Huang joined Mercedes-Benz CEO Ola Källenius on stage at the automaker’s strategy update event yesterday in Silicon Valley, showcasing progress in their landmark partnership to digitalize the entire product lifecycle, plus the ownership and automated driving experience.
The automotive industry is undergoing a massive transformation, which is driven by advancements in accelerated computing, AI and the industrial metaverse.
“Digitalization is streamlining every aspect of the automotive lifecycle: from styling and design, software development and engineering, manufacturing, simulation and safety testing, to customer buying and driving experiences,” said Huang.
Since its founding, Mercedes-Benz has set the bar in automotive innovation and ingenuity, backed by superior craftsmanship. The automaker is shaping the future with its intelligent and software-defined vehicles, which are powered by NVIDIA’s end-to-end solutions.
The Fleet of the Future
Next-generation Mercedes-Benz vehicles will be built on a revolutionary centralized computing architecture that includes sophisticated software and features that will turn these future vehicles into high-performance, perpetually upgradable supercomputers on wheels.
During the event, the automaker took the wraps off its new operating system, MB.OS, a purpose-built, chip-to-cloud architecture that will be standard across its entire vehicle portfolio — delivering exceptional software capabilities and ease of use.
MB.OS benefits from full access to all vehicle domains, including infotainment, automated driving, body and comfort, driving and charging — an approach that allows Mercedes-Benz customers a differentiated, superior product experience.
“MB.OS is a platform that connects all parts of our business,” Källenius noted during the event.
Safe Has Never Felt So Powerful
At the heart of this architecture is NVIDIA DRIVE Orin, which delivers high-performance, energy-efficient AI compute to support a comprehensive sensor suite and software to safely enable enhanced assisted driving and, ultimately, level 3 conditionally automated driving.
Running on DRIVE Orin is the flexible and scalable software stack jointly developed by NVIDIA and Mercedes-Benz. Sarah Tariq, NVIDIA vice president of autonomous driving software, joined Magnus Östberg, chief software officer at Mercedes-Benz, on stage to delve deeper into this full-stack software architecture, which includes the MB.OS, middleware and deep neural networks to enable advanced autonomy.
Tariq said, “The companies are working in close collaboration to develop a software stack that can comfortably and safely handle all the complexities that the automaker’s customers may encounter during day-to-day commutes all over the world.”
This includes enhanced level 2 features in urban environments where there are pedestrians or dense, complex traffic patterns. Using advanced AI, Mercedes-Benz can deliver a comfortable driving experience that consumers have come to expect, backed by uncompromised safety and security.
With the ability to perform 254 trillion operations per second, DRIVE Orin has ample compute headroom to continuously advance this software with new capabilities and subscription services over the life of the vehicle, through over-the-air software updates, via an app, web or from inside the car.
Additionally, Mercedes-Benz is accelerating the development of these systems with the high-fidelity NVIDIA DRIVE Sim platform, built on NVIDIA Omniverse. This cloud-native platform delivers physically based, scalable simulation for automakers to develop and test autonomous vehicle systems on a wide range of rare and hazardous scenarios.
Manufacturing in the Industrial Metaverse
This software-defined platform is just one piece of Mercedes-Benz intelligent vehicle strategy.
At CES last month, Mercedes-Benz previewed its first step in digitalization of its production process using NVIDIA Omniverse — a platform for building and operating metaverse applications — to plan and operate its manufacturing and assembly facilities.
With Omniverse, Mercedes-Benz can create an AI-enabled digital twin of the factory to review and optimize floor layouts, unlocking operational efficiencies. With enhanced predictive analysis, software and process automation, the digital twin can maximize productivity and help maintain faultless operation.
By implementing a digital-first approach to its operations, Mercedes-Benz can also ensure production activities won’t be disrupted as new models and architectures are introduced. And this blueprint can be deployed to other areas within the automaker’s global production network for scalable, more agile vehicle manufacturing.
Revolutionizing the Customer Experience
Digitalization is also improving the car-buying experience, migrating from physical retail showrooms to immersive online digital spaces.
With Omniverse, automakers can bridge the gap between the digital and physical worlds, making the online car-research experience more realistic and interactive. These tools include online car configurators, 3D visualizations of vehicles, demonstration of cars in augmented reality and virtual test drives.
Östberg summed up, “The partnership with NVIDIA is already living up to its promise, and the potential is huge.”
The cloud just got bigger. NVIDIA and Microsoft announced this week they’re working to bring top PC Xbox Game Studios games to the GeForce NOW library, including titles from Bethesda, Mojang Studios and Activision, pending closure of Microsoft’s acquisition.
With six new games joining the cloud this week for members to stream, it’s a jam-packed GFN Thursday.
Plus, Ultimate members can now access cloud-based RTX 4080-class servers in and around Paris, the latest city to light up on the update map. Keep checking GFN Thursday to see which RTX 4080 SuperPOD upgrade is completed next.
Game On
GeForce NOW beyond fast gaming expands to Xbox PC Games.
NVIDIA and Microsoft’s 10-year deal to bring the Xbox PC game library to GeForce NOW is a major boost for cloud gaming and brings incredible choice to gamers. It’s the perfect bow to wrap up GeForce NOW’s anniversary month, expanding the over 1,500 titles available to stream.
Work to bring top Xbox PC game franchises and titles to GeForce NOW, such as Halo, Minecraft and Elder Scrolls, will begin immediately. Games from Activision like Call of Duty and Overwatch are on the horizon once Microsoft’s acquisition of Activision closes. GeForce NOW members will be able to stream these titles across their devices, with the flexibility to easily switch between underpowered PCs, Macs, Chromebooks, smartphones and more.
Xbox Game Studios PC games available on third-party stores, like Steam or Epic Games Store, will be among the first streamed through GeForce NOW. The partnership also marks the first games that will be available on the Windows Store, support for which will begin soon.
It’s an exciting time for all gamers, as the partnership will give people more choice and higher performance. Stay tuned to GFN Thursdays for news on the latest Microsoft titles coming to GeForce NOW.
Ready, Set, Action!
Find a way to survive alone or with a buddy.
A new week means new GFN Thursday games. Sons of the Forest, the highly anticipated sequel to The Forest from Endnight Games, places gamers on a cannibal-infested island after crash-landing. Survive alone or pair up online with a buddy online.
Earlier in the week, members started streaming Atomic Heart, the action role-playing game from Mundfish, day-and-date from the cloud. Check out the full list of new titles available to stream this week:
With the wrap up of GeForce NOW’s #3YearsOfGFN celebrations, members are sharing their winning GeForce NOW moments on Twitter and Facebook for a chance to win an MSI Ultrawide Gaming monitor — the perfect companion with an Ultimate membership. Join the conversation and add your own favorite moments.
Editor’s note: This post is part of our weekly In the NVIDIA Studio series, which celebrates featured artists, offers creative tips and tricks, and demonstrates how NVIDIA Studio technology improves creative workflows. We’re also deep diving on new GeForce RTX 40 Series GPU features, technologies and resources, and how they dramatically accelerate content creation.
Laptops equipped with NVIDIA GeForce RTX 4070, 4060 and 4050 GPUs are now available. The new lineup — including NVIDIA Studio-validated laptops from ASUS, GIGABYTE and Samsung — gives creators more options to create from anywhere with lighter, thinner devices that dramatically exceed the performance of the last generation.
These new GeForce RTX Laptop GPUs bring increased efficiency, thanks to the NVIDIA Ada Lovelace GPU architecture and fifth-generation Max-Q technology.
The laptops are fueled by powerful NVIDIA Studio technologies, including hardware acceleration for 3D, video and AI workflows; optimizations for RTX hardware in over 110 popular creative apps; and exclusive NVIDIA Studio apps like Omniverse, Canvas and Broadcast. And when the creating ends to let the gaming begin, DLSS 3 technology doubles frame rates.
Plus, the making of 3D artist Shangyu Wang’s short film, called Most Precious Gift, is highlighted In the NVIDIA Studio this week. The film was staged in NVIDIA Omniverse, a platform for creating and operating metaverse applications.
And don’t forget to sign up for creator and Omniverse sessions, tutorials and more at NVIDIA GTC, a free, global conference for the era of AI and the metaverse running online March 20-23.
A GPU Class of Their Own
The new Studio laptops, equipped with powerful GeForce RTX 4070, 4060 and 4050 Laptop GPUs and fifth-generation Max-Q technology, revolutionize content creation on the go.
These advancements enable extreme efficiencies that allow creators to get the best of both worlds: small size and high performance. The thinner, lighter, quieter laptops retain extraordinary performance — letting users complete complex creative tasks in a fraction of the time needed before.
GeForce RTX 4070 GPUs unlock advanced video editing and 3D rendering capabilities. Work in 6K RAW high-dynamic range video files with lightning-fast decoding, export in AV1 with the new eighth-generation encoder, and gain a nearly 40% performance boost over the previous generation with GPU-accelerated effects in Blackmagic Design’s DaVinci Resolve. Advanced 3D artists can tackle large projects with ease across essential 3D apps using new third-generation RT Cores.
The GeForce RTX 4060 GPU-class laptops equipped with 8GB of video memory are great for video editing and artists looking to get started in 3D modeling and animation. In the popular open-source 3D app Blender, render times are a whopping 38% faster than the last generation.
Get started with GPU acceleration for photography, graphic design and video editing workflows using GeForce RTX 4050 GPUs, which provide a massive upgrade from integrated graphics. Access accelerated AI features, including 54% faster performance in Topaz Video for upscaling and deinterlacing footage. And turn home offices into professional-grade studios with NVIDIA’s encoder and the AI-powered NVIDIA Broadcast app for livestreaming.
Freelancers, hobbyists, aspiring artists and others can find a GeForce RTX GPU to fit their needs, now available in the new lineup of NVIDIA Studio laptops.
Potent, Portable, Primed for Creating
Samsung’s Galaxy Book3 Ultra comes with a choice of the GeForce RTX 4070 or 4050 GPU, alongside a vibrant 16-inch, 3K, AMOLED display.
The Samsung Galaxy Book3 Ultra houses the GeForce RTX 4070 or 4050 GPU.
GIGABYTE upgraded its Aero 16 Studio laptop with up to a GeForce RTX 4070 GPU and a 16-inch, thin-bezel, 60Hz, OLED display. The Aero 14 features a GeForce RTX 4050 GPU with a 14-inch, thin-bezel, 90Hz, OLED display.
Purchase the Aero 14 from Amazon, and find both laptops on GIGABYTE.com.
GIGABYTE’s Aero 16 and 14 models with up to a GeForce RTX 4070 GPU are content-creation beasts.
The ASUS ROG FLOW Z13 comes with up to a GeForce RTX 4060 GPU, QHD, 165Hz, 13.4-inch Nebula display, as well as a 170-degree kickstand and detachable full-sized keyboard for portable creating, plus a stylus with NVIDIA Canvas support to turn simple brushstrokes into realistic images powered by AI.
The ASUS ROG FLOW Z13 is equipped with up to a GeForce RTX 4060 GPU.
MSI’s Stealth 17 Studio and Razer’s 16 and 18 models, with up to GeForce RTX 4090 Laptop GPUs, are also available to pick up today.
All Aboard the Creative Ship
Studio laptops power the imaginations of the world’s most creative minds, including this week’s In the NVIDIA Studio artist, Shangyu Wang.
From the moment his movie’s opening credits roll, viewers can expect to be captivated by a spellbinding journey in space and an intricately designed world, complemented by engaging music and voice-overs.
The film, Most Precious Gift, centers on humanity attempting to make peace with another intelligent lifeform holding the key to survival. It’s an extension of Wang’s interests in alien civilizations and their potential conflicts with humankind.
Wang usually jumps directly into 3D modeling, bypassing the concept stage that most artists go through. He sculpts and shapes the models in Autodesk Maya and Autodesk Fusion 360.
Ultra-fine details modeled in Autodesk Maya.
By selecting the default Autodesk Arnold renderer, using his GeForce RTX 3080 Ti-powered Studio laptop, Wang was able to use RTX-accelerated ray tracing and AI denoising, which let him tinker with and add details to highly interactive, photorealistic visuals. This was a boon for his efficiency.
Clothing segments combined and applied to the 3D model in Autodesk Maya.
Wang built textures in Adobe Substance 3D Painter and placed extra care on the fine details, noting the app was the “best option for the most realistic, original materials.” RTX-accelerated light and ambient occlusion guaranteed fully baked assets in mere seconds.
Realistic textures applied to 3D models in Adobe Substance 3D Painter.
For final renders, Wang said it was a no-brainer to assemble, simulate and stage his 3D scenes in Omniverse Create. “Because of the powerful path-tracing rendering, I can modify scene lights and materials in real time,” he said.
And when it came to final exports, Wang could use his preferred renderer within the Omniverse Create viewport, which has support for Pixar HD Storm, Chaos V-Ray, Maxon’s Redshift, OTOY OctaneRender, Blender Cycles and more.
Realistic lighting and shadows, manipulated and tinkered with in Omniverse Create.
Wang wrapped up compositing in NUKE software, where he adjusted colors and added depth-of-field visuals to the lens. The artist finally moved to DaVinci Resolve to add sound effects, music and subtitles.
The telecommunications industry has for decades helped advance revolutionary change – enabling everything from telephones and television to online streaming and self-driving cars. Yet the industry has long been considered an evolutionary mover in its own business.
A recent survey of more than 400 telecommunications industry professionals from around the world found that same cautious tone in how they plan to define and execute on their AI strategies.
To fill in a more complete picture of how the telecommunications industry is using AI, and where it’s headed, NVIDIA’s first “State of AI in Telecommunications” survey consisted of questions covering a range of AI topics, infrastructure spending, top use cases, biggest challenges and deployment models.
Survey respondents included C-suite leaders, managers, developers and IT architects from mobile telecoms, fixed and cable companies. The survey was conducted over eight weeks between mid-November 2022 and mid-January 2023.
Dial AI for Motivation
The survey results revealed two consistent themes: industry players (73%) see AI as a tool to grow revenue, improve operations and sustainability, or boost customer retention. Amid skepticism about the money-making potential of 5G, telecoms see efficiencies driven by AI as the most likely path for returns on investment.
Yet, 93% of those responding to questions about undertaking AI projects at their own companies appear to be substantially underinvesting in AI as a percentage of annual capital spending.
Some 50% of respondents reported spending less than $1 million last year on AI projects; a year earlier, 60% of respondents said they spent less than $1 million on AI. Just 3% of respondents spent over $50 million on AI in 2022.
The reasons cited for such cautious spending? Some 44% of respondents reported an inability to adequately quantify return on investment, which illustrates a mismatch between aspirations and the reality in introducing AI-driven solutions.
Technical challenges — whether from lack of enough skilled personnel or poor infrastructure — are also obstructing AI adoption. Of respondents, 34% cited an insufficient number of data scientists as the second-biggest challenge. Given that data scientists are sought after across industries, the response suggests that the telecoms industry needs to push harder to woo them.
With 33% of respondents also citing a lack of budget for AI projects, the results suggest that AI advocates need to work harder with decision-makers to develop a convincing case for AI adoption.
Likewise, for a technology solution that relies on data, concerns about the availability, handling, privacy and security of data were all critical issues to be addressed, especially in the light of data privacy and data residency laws around the globe, for example GDPR.
AI Engagement
Some 95% of telecommunications industry respondents said they were engaged with AI. But only 34% of respondents reported using AI for more than six months, while 23% said they’re still learning about the different options for AI. Eighteen percent reported being in a trial or pilot phase of an AI project.
For respondents at the trial or implementation stage, a clear majority acknowledged that there had been a positive impact on both revenue and cost. About 73% of respondents reported that implementation of AI had led to increased revenue in the last year, with 17% noting revenue gains of more than 10% in specific parts of the business.
Likewise, 80% of respondents reported that their implementation of AI led to reduced annual costs in the last year, with 15% noting that this cost reduction is above 10% — again, in specific parts of their business.
AI, AI Everywhere
The telecommunications industry has a deep and multilayered view on where best to allocate resources to AI: cost reduction, revenue increase, customer experience enhancement and creating operational efficiencies were all cited as key priorities.
In terms of deployment, however, AI focused on improving operational efficiency was a clear winner. This is somewhat expected, as the operational complexity of new telecommunications networks like 5G lend themselves to new solutions like AI. The industry is responsible for critical national infrastructure in every country, supports over 5 billion customer end points, and is expected to constantly deliver above 99% reliability. Telcos have also discussed AI-enabled solutions for network operations, cell sites planning, truck-routing optimization and machine learning data analytics. To improve the customer experience, some are adopting recommendation engines, virtual assistants and digital avatars.
In the near term, the focus appears to be on building more effective telecom infrastructure and unlocking new revenue-generating opportunities, especially together with partners.
The trick will be moving from early testing to widespread adoption.


 software development kit
software development kit









 NVIDIA GeForce NOW (@NVIDIAGFN)
NVIDIA GeForce NOW (@NVIDIAGFN)