This holiday season, feast on the bounty of food-themed stories NVIDIA Blog readers gobbled up in 2022.
Startups in the retail industry — and particularly in quick-service restaurants — are using NVIDIA AI and robotics technology to make it easier to order food in drive-thrus, find beverages on store shelves and have meals delivered. They’re accelerated by NVIDIA Inception, a program that offers go-to-market support, expertise and technology for cutting-edge startups.
For those who prefer eye candy, artists also recreated a ramen restaurant using the NVIDIA Omniverse platform for creating and operating metaverse applications.
Toronto startup HuEx is developing a conversational AI assistant to handle order requests at the drive-thru speaker box. The real-time voice service, which runs on the NVIDIA Jetson edge AI platform, transcribes voice orders to text for staff members to fulfill.
The technology, integrated with the existing drive-thru headset system, allows for team members to hear the orders and jump in to assist if needed. It’s in pilot tests to help support service at popular Canadian fast-service chains.
San Diego-based startup Vistry is tackling a growing labor shortage among quick-service restaurants with an AI-enabled, automated order-taking solution. The system, built with the NVIDIA Riva software development kit, uses natural language processing for menu understanding and speech — plus recommendation systems to enable faster, more accurate order-taking and more relevant, personalized offers.
Vistry is also using the NVIDIA Metropolis application framework to create computer vision applications that can help automate curbside check-ins, speed up drive-thrus and predict the time it takes to prepare a customer’s order. Its tools are powered by NVIDIA Jetson and NVIDIA A2 Tensor Core GPUs.
Oakland-based startup Cartken is deploying NVIDIA Jetson-enabled sidewalk robots for last-mile deliveries of coffee and meals. Its autonomous mobile robot technology is used to deliver Grubhub orders to students at the University of Arizona and Ohio State — and Starbucks goods in malls in Japan.
The Inception member relies on the NVIDIA Jetson AGX Orin module to run six cameras that aid in simultaneous localization and mapping, navigation, and wheel odometry.
Telexistence, an Inception startup based in Tokyo, is deploying hundreds of NVIDIA AI-powered robots to restock shelves at FamilyMart, a leading Japanese convenience store chain. The robots handle repetitive tasks like refilling beverage displays, which frees up retail staff to interact with customers.
NVIDIA technology isn’t just accelerating food-related applications for the restaurant industry — it’s also powering tantalizing virtual scenes complete with mouth-watering, calorie-free dishes.
Two dozen NVIDIA artists and freelancers around the globe showcased the capabilities of NVIDIA Omniverse by recreating a Tokyo ramen shop in delicious detail — including simmering pots of noodles, steaming dumplings and bottled drinks.
The scene, created to highlight NVIDIA RTX-powered real-time rendering and physics simulation capabilities, consists of more than 22 million triangles, 350 unique textured models and 3,000 4K-resolution texture maps.
In a moment of pure serendipity, Lah Yileh Lee and Xinting Lee, a pair of talented singers who often stream their performances online, found themselves performing in a public square in Taipei when NVIDIA founder and CEO Jensen Huang happened upon them.
Toy Jensen Created Using NVIDIA Omniverse Avatar Cloud Engine
Now, with the help of his AI-driven avatar, Toy Jensen, Huang has come up with a playful holiday-themed response.
NVIDIA’s creative team quickly developed a holiday performance by TJ, a tech demo showcasing core technologies that are part of the NVIDIA Omniverse Avatar Cloud Engine, or ACE, platform.
Omniverse ACE is a collection of cloud-native AI microservices and workflows for developers to easily build, customize and deploy engaging and interactive avatars.
Unlike current avatar development, which requires expertise, specialized equipment, and manually intensive workflows, Omniverse ACE is built on top of the Omniverse platform and NVIDIA’s Unified Compute Framework, or UCF, which makes it possible to quickly create and configure AI pipelines with minimal coding.
“It’s a really amazing technology, and the fact that we can do this is phenomenal,” said Cyrus Hogg, an NVIDIA technical program manager.
To make it happen, NVIDIA’s team used a recently developed voice conversion model to extract the voice of a professional singer from a sample provided by them and turn it into TJ’s voice – originally developed by training on hours of real world recordings. They used the musical notes from that sample and applied them to the digital voice of TJ to make the avatar sing the same notes and with the same rhythm as the original singer.
NVIDIA Omniverse Generative AI – Audio2Face, Audio2Gesture Enable Realistic Facial Expressions, Body Movements
Then the team used NVIDIA Omniverse ACE along with Omniverse Audio2Face and Audio2Gesture technologies to generate realistic facial expressions and body movements for the animated performance based on TJ’s audio alone.
While the team behind Omniverse ACE technologies spent years developing and fine-tuning the technology showcased in the performance, turning the music track they created into a polished video took just hours.
Toy Jensen Delights Fans With ‘Jingle Bells’ Performance
That gave them plenty of time to ensure an amazing performance.
They even collaborated with Jochem van der Saag, a composer and producer who has worked with Michael Bublé and David Foster, to create the perfect backing track for TJ to sing along to.
“We have van der Saag composing the song, and he’s gonna also orchestrate it for us,” said Hogg. “So that’s a really great addition to the team. And we’re really excited to have him on board.”
ACE Could Revolutionize Virtual Experiences
The result is the perfect showcase for NVIDIA Omniverse ACE and the applications it could have in various industries — for virtual events, online education and customer service, as well as in creating personalized avatars for video games, social media and virtual reality experiences. NVIDIA Omniverse ACE will be available soon to early-access partners.
Gear up for some festive fun this GFN Thursday with some of the GeForce NOW community’s top picks of games to play during the holidays, as well as a new title joining the GeForce NOW library this week.
And, following the recent update that enabled Ubisoft Connect account syncing with GeForce NOW, select Ubisoft+ Multi-Access subscribers are receiving a one-month GeForce NOW Priority membership for free. Keep an eye out for an email from Ubisoft to subscribers eligible for the promotion and read more details.
Top Picks to Play During the Holidays
With over 1,400 titles streaming from the cloud and more coming every week, there’s a game for everyone to enjoy this holiday. We asked which games members were most looking forward to playing, and the GeForce NOW community responded with their top picks.
Gamers are diving into all of the action with hit games like the next-gen update for The Witcher 3: Wild Hunt,Battlefield 2042 and Mass Effect.
“Battlefield 2042 highlights what the RTX 3080 tier is ALL about,” said Project Storm. “High performance in the cloud with ultra-low latency.”
“The Mass Effect saga is an epic journey,” said Tartan Troot. “Certainly some of the best role-playing games you can play GeForce NOW.”
For some, it’s all about the immersion. Members are visiting darker and fantastic worlds in Marvel’s Midnight Suns and Warhammer 40,000: Darktide. Many are fighting zombie hoards in Dying Light 2, while others are taking the path of revenge in SIFU.
“For me, it’s the story that draws me into a game,” said N7_Spectres. “So those games that I’ve been playing this year have been Marvel’s Midnight Suns and Warhammer 40,000: Darktide.”
“I’ve had so many good experiences in the cloud with GeForce NOW this year … games such as Dying Light 2 and SIFU have been in their element on the RTX 3080 membership,” said ParamedicGames from Cloudy With Games.
Gamers who crave competition called out favorites like Destiny 2 and Rocket League. Many mentioned their love for Fortnite, streaming with touch controls on mobile devices.
“The best game to stream on GFN this year has been Destiny 2,” said Nads614. “Being able to set those settings to the maximum and see the quality and the performance is great — I love it.”
“Rocket League still remains the best game I’ve ever played on GFN,” said Aluneth. “Started playing on a bad laptop in 2017 and then moved on to GFN for a better experience.”
“GeForce NOW RTX 3080 works so well to play Fortnite with support for 120 frames per second and ridiculously fast response time, making the cloud gaming platform an affordable, very competitive platform like no other,” said DrSpaceman.
Other titles mentioned frequently include Genshin Impact, Apex Legends and Marvel’s Midnight Suns for gamers wanting to play characters with fantastic abilities. Games like the Assassin’s Creed series and Cyberpunk 2077 are popular options for immersive worlds. And members wanting to partner up and play with others should try It Takes Two for a fun-filled, collaborative experience.
Share the joy of great gaming this season with a GeForce NOW gift card.
Speaking of playing together, the perfect last-minute present for a gamer in your life is the gift of being able to play all of these titles on any device.
Grab a GeForce NOW RTX 3080 or Priority membership digital gift card to power up devices with the kick of a full gaming rig, priority access to gaming servers, extended session lengths and RTX ON to take supported games to the next level of rendering quality. Check out the GeForce NOW membership page for more information on benefits.
Here for the Holidays
Fight against other players to collect money, lava and bones to buy and upgrade properties.
This GFN Thursday brings new in-game content. Roam around explosive Jurassic streets with dinosaurs and buy properties to become the most famous real-estate mogul of Dino City in the new MONOPOLY Madnessdownloadable content.
And, as the perfect tree topper, members can look for the following new title streaming this week:
Robots have rolled into action for sustainability in farms, lower energy in food delivery, efficiency in retail inventory, improved throughput in warehouses and just about everything in between — what’s not to love?
In addition to reshaping industries and helping end users, robots play a vital role in the transition away from fossil fuels. The first commercially available electric tractors with autonomy also launched this year, packing AI to support more sustainable farming practices.
Take a peek at some of the top robots of the year.
Monarch Tractor Plows New Path
Developers have been digging into agriculture technologies for the past several years, but Monarch Tractor in December released a revolutionary new electric tractor that checks a lot of boxes.
Monarch, based in Livermore, Calif., unveiled the first commercially available tractor with autonomy, which is compatible with computer vision-guided smart implements like precision sprayers for herbicides.
Using six NVIDIA Jetson Xavier NX system-on-modules, Monarch’s Founder Series MK-V tractors are essentially roving robots.
Farmers won’t get range anxiety with these either. The highly capable sustainable farming tractor can run all day on a charge. The NVIDIA Jetson platform provides energy-efficient computing to the MK-V, which offers advances in battery performance.
With plans to scale up production in 2023, Monarch’s debut marks a Tesla moment for tractors.
Cartken Puts Delivery Bots in Reach
Food delivery has been a hot ticket with consumers, driving mobile apps that deliver from restaurants. An offshoot of this, robot food delivery startups are assisting some of these companies.
Cartken, based in Oakland, Calif., is serving Grubhub and Starbucks deliveries with its robot. It’s among a growing pack of robots-as-a-service companies that harness NVIDIA Jetson for edge AI.
The startup relies on the Jetson AGX Orin module to run six cameras to support mapping and navigation as well as the complete sense, perceive and control stack.
Cartken joins the food party as startup Kiwibot is making a splash here, too.
Robot deliveries are poised to boom. Robotic last-mile delivery is expected to grow more than 9x to $670 million in revenue in 2030, up from $70 million in 2022, according to ABI Research.
Fraunhofer IML Aims at Warehouse Efficiencies
Robots, particularly autonomous mobile robots (AMRs), are playing a big role in creating supply chain efficiencies.
Like many working on robotics innovations — including BMW, Amazon and Siemens — German research firm Fraunhofer IML relies on the NVIDIA Omniverse platform for building and operating metaverse applications. It’s harnessing the platform to make advances in applied research in logistics for fulfillment and manufacturing.
Fraunhofer IML taps into the NVIDIA Isaac Sim application to make leaps in robot design with simulation. Fraunhofer’s O3dyn robot uses NVIDIA simulation and robotics technologies to create an indoor-outdoor AMR.
It aims to deliver fast-moving AMRs that aren’t yet available on the market.
Telexistence Deploying Hundreds of Restocking Bots
Lockdowns and labor shortages of the past few years put empty retail store shelves around the world in the spotlight.
Telexistence, based in Tokyo, recently announced plans to deploy NVIDIA AI-driven robots for restocking shelves at hundreds of FamilyMart convenience stores in Japan. They are also using the power of simulation with Isaac Sim so the developers are not left waiting to develop and debug the product.
The startup is helping to create efficiencies and keep shelves fresh by applying robots to repetitive tasks like beverage restocking. This frees up retail employees to handle more complex challenges, like customer service.
Next up, it plans to expand to U.S convenience stores.
Scythe Rolls Out Autonomous Lawn Mower
Scythe, based in Boulder, Colo., is taking reservations for its M.52 autonomous electric lawn mower.
The startup’s M.52 mower gathers data from eight cameras and more than a dozen sensors, processed by NVIDIA Jetson AGX Xavier edge AI computing modules.
Scythe plans to rent its machines to customers in a software-as-as-service model, based on acreage of cut grass, reducing upfront costs.
The lawn robot company is a member of the NVIDIA Inception program for cutting-edge startups, as are Cartken and Monarch Tractor.
Cartken has thousands of reservations for its on-demand robot service, according to the company.
All of us recycle. Or, at least, all of us should. Now, AI is joining the effort.
On the latest episode of the NVIDIA AI Podcast, host Noah Kravitz spoke with JD Ambadti, founder and CEO of EverestLabs, developer of RecycleOS, the first AI-enabled operating system for recycling.
The company reports that an average of 25-40% more waste is being recovered in recycling facilities around the world that use its tech.
In the latest example of how researchers are using the latest technologies to track animals less invasively, a team of researchers has proposed harnessing high-flying AI-equipped drones to track the endangered black rhino through the wilds of Namibia.
Fewer than 4,000 tigers remain worldwide, according to Tigers United, a university consortium that recently began using AI to help save the species. Jeremy Dertien is a conservation biologist with Tigers United and a Ph.D. candidate in wildlife biology and conservation planning at Clemson University.
What do radiology and wastewater have in common? Hopefully, not much. But at startup Opseyes, founder Bryan Arndt and data scientist Robin Schlenga are putting the AI that’s revolutionizing medical imaging to work on analyzing wastewater samples.
Editor’s note: This post is part of our weekly In the NVIDIA Studio series, which celebrates featured artists, offers creative tips and tricks, and demonstrates how NVIDIA Studio technology improves creative workflows. We’re also deep diving on new GeForce RTX 40 Series GPU features, technologies and resources, and how they dramatically accelerate content creation.
3D artist Edward McEvenue shares his imaginative, holiday-themed short film The Great Candy Inquisition this week In the NVIDIA Studio. The artist, recently featured in our Meet the Omnivore series, is creating the film with Autodesk 3ds Max, Houdini, Adobe Substance 3D and Unreal Engine — as well as the NVIDIA Omniverse Create app.
In addition, NVIDIA artist Michael Johnson brings holiday cheer with more winter-themed artwork built in Omniverse Create.
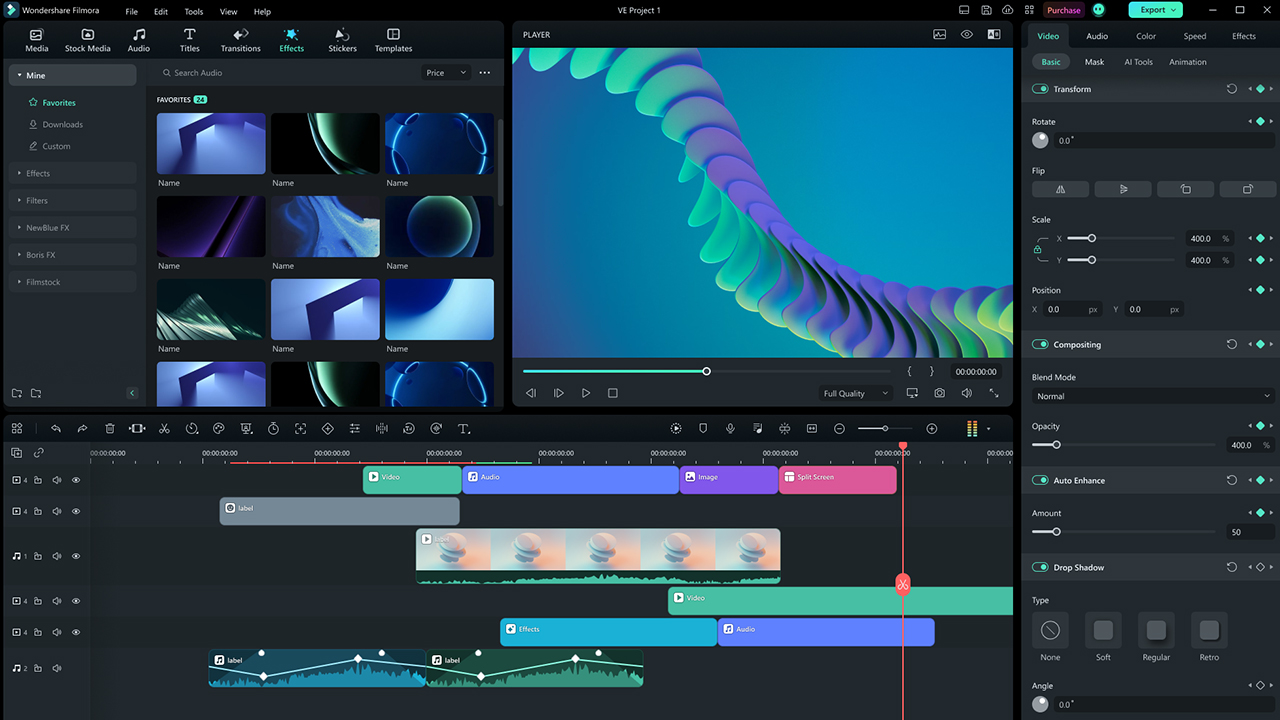
Santa brought creative app upgrades and optimizations early, as video-editing app Filmora added NVIDIA AV1 dual encoder support with GeForce RTX 40 Series GPUs, slashing export times in half.
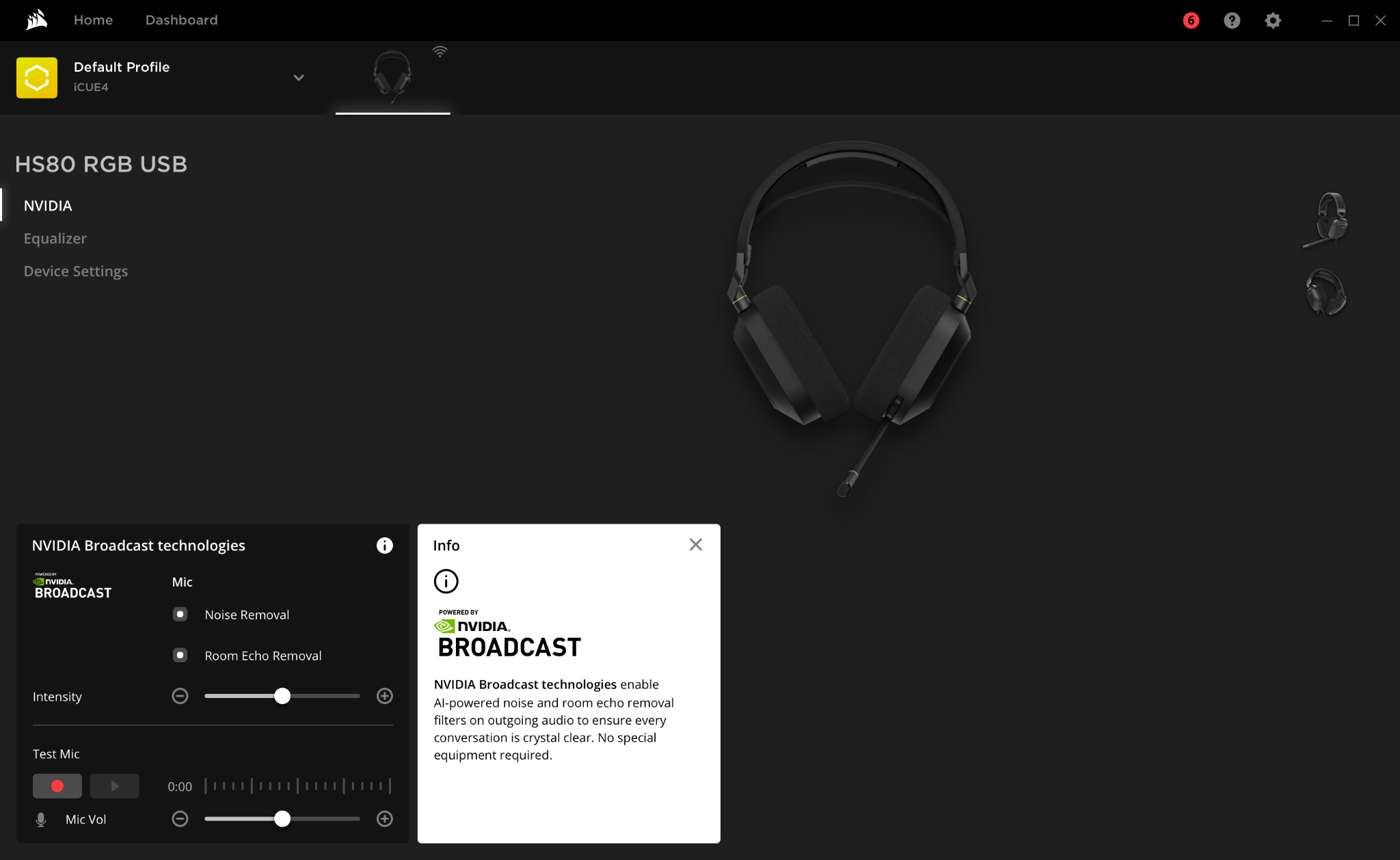
Technology company CORSAIR’s iCUE software release 4.31 enabled NVIDIA Broadcast integration, unlocking Noise Reduction and Room Echo cancellation features in systems powered by RTX 40 Series GPUs.
Get into the holiday mood with incredible wintery art in the latest “Studio Standouts,” featuring pieces from the #WinterArtChallenge.
There’s still time to enter by sharing winter-themed art on Instagram, Twitter or Facebook for a chance to be featured on NVIDIA Studio’s social media channels. Be sure to tag #WinterArtChallenge to join.
Hide Your Candy
The Great Candy Inquisition is a whimsical short film full of childlike wonder. Jealous that children often only want candy, the reindeer toys, nutcrackers and other animated characters in the film go on a sticky, sweet inquisition to remove candy from the toy kingdom. Will the gingerbread boy, whose gingerbread parents are sent to the “gulnog” for refusing to comply, be able to stop them?
Find out by watching the final video next year, being beautifully pieced together in NVIDIA Omniverse, a platform for building and operating metaverse applications, using the Omniverse Create app for large-scale world-building and scene composition.
Virtually all of McEvenue’s creative workflow is accelerated by his GeForce RTX 3080 Ti GPU. As the founder of EDSTUDIOS, McEvenue takes on freelance work for which it’s critical that he and his team complete tasks quickly and efficiently.
Modeling for The Great Candy Inquisition is being split between Houdini, which has an RTX-accelerated Karma XPU renderer that enables fast rendering of complex 3D models and simulations, and Autodesk 3ds Max, which uses RTX-accelerated AI denoising to unlock smooth, interactive rendering. 3D assets were sourced from Sketchfab and Turbosquid, using the built-in asset browser within Omniverse Create.
McEvenue then built textures and materials in Adobe Substance 3D Painter and Designer, which he baked (rather than gingerbread men or women) in seconds, thanks to RTX-accelerated light and ambient occlusion.
Animations in Unreal Engine 5 were quick and easy, McEvenue said. RTX-accelerated rendering guaranteed photorealistic detail, further enhanced by AI features in NVIDIA DLSS to upscale frames rendered at lower resolution while still retaining high-fidelity details.
At this juncture, McEvenue imported 3D elements into Omniverse Create to piece together stunning scenes.
Omniverse Create houses the advanced, multi-GPU-enabled, path-traced RTX Renderer capable of global illumination, reflections and refractions — all at the speed of light, powered by an RTX GPU. McEvenue tickled and touched up scenes without changes in the stunning level of detail. Omniverse Create includes access to NVIDIA vMaterials for even more realistic scenes and true-to-reality visualizations.
“The ability to progressively iterate on designs and see your work rendered in real time in the viewport, with full-fidelity lighting, materials and post-production effects like DOF, Bloom and atmospheric fog makes all the difference in finalizing artwork,” said McEvenue.
With The Great Candy Inquisition close to completion, the team applied final details in their preferred 3D apps by live-syncing Omniverse Connectors in Autodesk 3ds Max, Adobe Substance 3D Painter and Unreal Engine, simultaneously, despite working in several different physical locations. Working in such a cohesive virtual environment eliminated the need to download, reupload and redownload files.
EDSTUDIOS’ upcoming projects will be completed much quicker thanks to GeForce RTX GPUs, McEvenue said. “Real-time rendering is the future, and only possible with GPU-powered systems — and NVIDIA GPUs lead the pack,” the artist said.
3D artist Edward McEvenue.
Check out Edward McEvenue’s website for more inspirational artwork.
It’s Beginning to Look a Lot Like Omniverse
NVIDIA artist Michael Johnson is a big fan of the holiday season. Unable to resist the temptation to create winter-themed art in Omniverse Create, he decided to work on a piece for the #WinterArtChallenge, which runs through the end of the month and is open to creatives from around the globe. Johnson spent a week creating different assets and assembled the image.
Who wants hot cocoa?
A steaming mug of hot cocoa — studded with creamy marshmallows and emblazoned with “Happy Holidays, From Ours to Yours” — sets the scene. Scattered around the mug are squares of chocolate, gingerbread cookies, shimmering ornaments and a furry throw, all aglow from twinkling holiday lights.
“The holiday season tends to make me feel warm inside,” Johnson said. “Listening to music, decorating a tree with family and wearing cozy clothes while eating sweet treats — this is the feeling I wanted to give off with this piece of art.”
Like McEvenue, Johnson maneuvered his piece quickly, changing angles and lighting in the viewport with little to no delay, while incredibly realistic visuals populated the scene.
Johnson manipulates ornaments, in the video below, resizing assets and adding fine detail.
He then easily applied colors and textures with the Adobe Substance 3D Painter Connector.
Creative App Updates Come Early This Holiday Season
Wondershare’s intuitive video-editing app, Filmora, with over 100 million users, has integrated NVIDIA AV1 dual encoders in the latest version 12 update, powered by GeForce RTX 40 Series GPUs. The dual encoders can work in tandem, dividing work automatically to double output and cut export times in half.
GeForce RTX 40 Series GPUs also unlock faster decoding with NVIDIA decoder (NVDEC) for smooth playback of high-resolution and high-dynamic-range videos, plus faster rendering of GPU-accelerated video effects.
A leader in high-performance gear and systems for gamers, content creators and PC enthusiasts, CORSAIR has released iCUE software now with support for the new GeForce RTX 40 Series GPUs.
NVIDIA Broadcast features are now accessible directly in CORSAIR’s iCUE software for GeForce RTX 40 Series GPUs.
iCUE Version 4.31 and later updates will integrate NVIDIA Broadcast technology to take advantage of AI-powered features. Noise Reduction and Room Echo cancellation eliminate keyboard typing, annoying microphone static, loud PC fans and more, ensuring content creators and creative professionals can find a quiet place to work with their systems powered by GeForce RTX 40 Series GPUs.
With the state of the world under constant flux in 2022, some technology trends were put on hold while others were accelerated. Supply chain challenges, labor shortages and economic uncertainty had companies reevaluating their budgets for new technology.
For many organizations, AI is viewed as the solution to a lot of the uncertainty bringing improved efficiency, differentiation, automation and reduced cost.
Until now, AI has operated almost exclusively in the cloud. But increasingly diverse streams of data are being generated around the clock from sensors at the edge. These require real-time inference, which is leading more AI deployments to move to edge computing.
For airports, stores, hospitals and more, AI brings advanced efficiency, automation and even cost reduction, which is why edge AI adoption accelerated last year.
In 2023, expect to see a similarly challenging environment, which will drive the following edge AI trends.
1. Focus on AI Use Cases With High ROI
Return on investment is always an important factor for technology purchases. But with companies looking for new ways to reduce cost and gain a competitive advantage, expect AI projects to become more common.
A few years ago, AI was often viewed as experimental, but, according to research from IBM, 35% of companies today report using AI in their business, and an additional 42% report they’re exploring AI. Edge AI use cases, in particular, can help increase efficiency and reduce cost, making them a compelling place to focus new investments.
For example, supermarkets and big box stores are investing heavily in AI at self-checkout machines to reduce loss from theft and human error. With solutions that can detect errors with 98% accuracy, companies can quickly see a return of investment in a matter of months.
AI industrial inspection also has an immediate return, helping augment human inspectors on factory lines. Bootstrapped with synthetic data, AI can detect defects at a much higher rate and address a variety of defects that simply cannot be captured manually, resulting in more products with fewer false negative or positive detections.
2. Growth in Human and Machine Collaboration
Often seen as a far-off use case of edge AI, the use of intelligent machines and autonomous robots is on the rise. From automated distribution facilities to meet the demands of same-day deliveries, to robots monitoring grocery stores for spills and stock outs, to robot arms working alongside humans on a production line, these intelligent machines are becoming more common.
According to Gartner, the use of robotics and intelligent machines is expected to grow significantly by the end of the decade. “By 2030, 80% of humans will engage with smart robots on a daily basis, due to smart robot advancements in intelligence, social interactions and human augmentation capabilities, up from less than 10% today.” (Gartner, “Emerging Technologies: AI Roadmap for Smart Robots — Journey to a Super Intelligent Humanoid Robot”, G00761328, June 2022)
For this future to happen, one area of focus that needs attention in 2023 is aiding human and machine collaboration. Automated processes benefit from the strength and repeatable actions performed by robots, leaving humans to perform specialized and dexterous tasks that are more suited to our skills. Expect organizations to invest more in this human-machine collaboration in 2023 as a way to alleviate labor shortages and supply chain issues.
3. New AI Use Cases for Safety
Related to the trend of human and machine collaboration is that of AI functional safety. First seen in autonomous vehicles, more companies are looking to use AI to add proactive and flexible safety measures to industrial environments.
Historically, functional safety has been applied in industrial environments in a binary way, with the primary role of the safety function to immediately stop the equipment from causing any harm or damage when an event is triggered. AI, on the other hand, works in combination with context awareness to predict an event happening. This allows AI to proactively send alerts regarding future potential safety events, preventing the events before they happen, which can drastically reduce safety incidents and related downtime in industrial environments.
New functional safety standards that define the use of AI in safety are expected to be released in 2023 and will open the door for early adoption in factories, warehouses, agricultural use cases and more. One of the first areas for AI safety adoption will focus on improved worker safety, including worker posture detection, falling object prevention and personal protection equipment detection.
4. IT Focus on Cybersecurity at the Edge
Cyber attacks rose 50% in 2021 and haven’t slowed down since, making this a top focus for IT organizations. Edge computing, particularly when combined with AI use cases, can increase cybersecurity risk for many organizations by creating a wider attack surface outside of the traditional data center and its firewalls.
Edge AI in industries like manufacturing, energy, and transportation requires IT teams to expand their security footprint into environments traditionally managed by operational technology teams. Operational technology teams typically focus on operational efficiency as their main metric, relying on air-gapped systems with no network connectivity to the outside world. Edge AI use cases will start to break down these restrictions, requiring IT to enable cloud connectivity while still maintaining strict security standards.
With billions of devices and sensors around the world that will all be connected to the internet, IT organizations have to both protect edge devices from direct attack and consider network and cloud security. In 2023, expect to see AI applied to cybersecurity. Log data generated from IoT networks can now be fed through intelligent security models that can flag suspicious behavior and notify security teams to take action.
5. Connecting Digital Twins to the Edge
The term digital twin refers to perfectly synchronized, physically accurate virtual representations of real-world assets, processes or environments. Last year, NVIDIA partnered with Siemens to enable industrial metaverse use cases, helping customers accelerate their adoption of industrial automation technologies. Leading companies spanning manufacturing, retail, consumer packaged goods and telco, such as BMW, Lowe’s, PepsiCo and Heavy.AI, have also begun building operational digital twins allowing them to simulate and optimize their production environments.
What connects digital twins to the physical world and edge computing is the explosion of IoT sensors and data that is driving both these trends. In 2023, we’ll see organizations increasingly connect live data from their physical environment into their virtual simulations. They’ll move away from historical data-based simulations toward a live, digital environment — a true digital twin.
By connecting live data from the physical world to their digital twins, organizations can gain real-time insight into their environment, allowing them to make faster and more informed decisions. While still early, expect to see massive growth in this space next year for ecosystem providers and in customer adoption.
The Year of Edge AI
While the 2023 economic environment remains uncertain, edge AI will certainly be an area of investment for organizations looking to drive automation and efficiency. Many of the trends we saw take off last year continue to accelerate with the new focus on initiatives that help drive sales, reduce costs, grow customer satisfaction and enhance operational efficiency.
Visit NVIDIA’s Edge Computing Solutions page to learn more about edge AI and how we’re helping organizations implement it in their environments today.
The channel showcases the latest breakthroughs in artificial intelligence, with demos, keynotes and other videos that help viewers see and believe the astonishing ways in which the technology is changing the world.
NVIDIA’s most popular videos of 2022 put spotlights on photorealistically animated data centers, digital twins for climate science, AI for healthcare and more.
And the latest GTC keynote address by NVIDIA founder and CEO Jensen Huang racked up 19 million views in just three months, making it the channel’s most-watched video of all time.
It all demonstrates the power of AI, its growth and applications.
But don’t just take our word for it — watch NVIDIA’s top five YouTube videos of the year:
Meet NVIDIA — the Engine of AI
While watching graphics cards dance and autonomous vehicles cruise, learn more about how NVIDIA’s body of work is fueling all things AI.
NVIDIA DGX A100 — Bringing AI to Every Industry
In a dazzling clip that unpacks NVIDIA DGX A100, the universal system for AI workloads, check out the many applications for the world’s first 5 petaFLOPS AI system.
A New Era of Digital Twins and Virtual Worlds With NVIDIA Omniverse
Watch stunning demos and hear about how the NVIDIA Omniverse platform enables real-time 3D simulation, design collaboration and the creation of virtual worlds.
Optimizing an Ultrarapid DNA Sequencing Technique for Critical Care Patients
A collaboration including NVIDIA led to a record-breaking AI technique where a whole genome was sequenced in just about seven hours.
Maximizing Wind Energy Production Using Wake Optimization
Dive into how Siemens Gamesa is using NVIDIA-powered, physics-informed, super-resolution AI models to simulate wind farms and boost energy production.
A national initiative in semiconductors provides a once-in-a-generation opportunity to energize manufacturing in the U.S.
The CHIPS and Science Act includes an $13 billion R&D investment in the chip industry. Done right, it’s a recipe for bringing advanced manufacturing techniques to every industry and cultivating a highly skilled workforce.
The semiconductor industry uses the most complex manufacturing processes and equipment in human history. To produce each chip inside a car or computer, hundreds of steps must be executed perfectly, most already automated with robotics.
The U.S. government asked industry where it should focus its efforts on improving this sector. In response, NVIDIA released a 12-page document with its best ideas.
Supercharged with accelerated computing and AI, a modern fab is also a guidepost for all other types of complex manufacturing — from making smartphones to shoes — flexibly and efficiently.
The World’s Most Expensive Factories
Semiconductors are made in factories called fabs. Building and outfitting a new one costs as much as $20 billion.
The latest factories rely heavily on computers that are built, programmed and operated by skilled workers armed with machine learning for the next generation of manufacturing processes.
For example, AI can find patterns no human can see, including tiny defects in a product on a fast-moving assembly line. The semiconductor industry needs this technology to create tomorrow’s increasingly large and complex chips. Other industries will be able to use it to make better products faster, too.
Efficiency Through Simulation
We can now create a digital copy of an entire factory. Using NVIDIA technologies, BMW is already building a digital twin of one of its automotive plants to bring new efficiencies to its business.
No one has built anything as complex as a digital twin of a chip fab yet, but that goal is now within reach.
A virtual fab would let specialists design and test new processes much more quickly and cheaply without stopping production in a physical plant. A simulation also can use AI to analyze data from sensors inside physical factories, finding new ways to route materials that reduce waste and speed operations.
Soon, any manufacturing plant with a digital twin will be more economically competitive than a plant without one.
Virtual Factories, Real Operators
Digital twins enable remote specialists to collaborate as if they were in the same room. They also take worker training to a new level.
Some of the most vital tools in a fab are the size of a shipping container and cost as much as $200 million each. Digital twins let workers train on these expensive systems before they’re even installed.
Once trained, workers can qualify, operate and service them without needing to set foot in the ultra-clean rooms where they’re installed. This kind of work represents the future of all manufacturing.
Factories designed with virtual twins also can optimize energy efficiency, water consumption and maximize reuse, reducing environmental impact.
Wanted: More Performance per Watt
Tomorrow’s factories will need more computing muscle than ever. To deliver it, we need investments in energy-efficient technologies at every level.
The circuits inside chips need to use and waste significantly less energy. The signals they send to nearby chips and across global networks must move faster while consuming less power.
Computers will need to tackle more data-intensive jobs while increasing productivity. To design and build these systems, we need research on new kinds of accelerator chips, accelerated systems and the software that will run on them.
NVIDIA and others have made great progress in green computing. Now we have an opportunity to take another big step forward.
A Broad Agenda and Partnerships
These are just some of the ways NVIDIA wants to help advance the U.S. semiconductor industry and by extension all manufacturers.
No company can do this work alone. Industry, academia and government must collaborate to get this right.
NVIDIA is at the center of a vibrant ecosystem of 3.5 million developers and more than 12,000 global startups registered in the NVIDIA Inception program.
The University of Florida provides a model for advancing AI and data science education across every field of study.
In 2020, it kicked off a plan to become one of the nation’s first AI universities. Today it’s infusing its entire curriculum with machine learning. At its heart, UF’s AI supercomputer is already advancing research in fields such as healthcare, agriculture and engineering.
It’s one more example of the transformative power of accelerated computing and AI. We look forward to the opportunity to take part in this grand adventure in U.S. manufacturing.
To learn more about NVIDIA’s ideas on the future of semiconductor manufacturing, including how AI is critical to advancing lithography, electronic design tools and cybersecurity processes, read the full document.
To make transportation safer, autonomous vehicles (AVs) must have processes and underlying systems that meet the highest standards.
NVIDIA DRIVE OS is the operating system for in-vehicle accelerated computing powered by the NVIDIA DRIVE platform. DRIVE OS 5.2 is now functional safety-certified by TÜV SÜD, one of the most experienced and rigorous assessment bodies in the automotive industry.
TÜV SÜD has determined that the software meets the International Organization for Standardization (ISO) 26262 ASIL B standard, which targets functional safety, or “the absence of unreasonable risk due to hazards caused by malfunctioning behavior of electrical or electronic systems.”
Based in Munich, Germany, TÜV SÜD assesses compliance to national and international standards for safety, durability and quality in cars, as well as for factories, buildings, bridges and other infrastructure.
Safety architecture, design and methodologies are pervasive throughout NVIDIA DRIVE solutions, from the data center to the car. NVIDIA has invested 15,000 engineering years in safety systems and processes.
A Strong Foundation
DRIVE OS is the foundation of the NVIDIA DRIVE SDK and is the first functionally safe operating system for complex in-vehicle accelerated computing platforms.
It includes NVIDIA CUDA libraries for efficient parallel computing, the NVIDIA TensorRT SDK for real-time AI inferencing, the NvMedia library for sensor input processing and other developer tools and modules for access to hardware engines.
NVIDIA is working across the industry to ensure the safe deployment of AVs. It participates in standardization and regulation bodies worldwide, including ISO, the Society of Automotive Engineers (SAE), the Institute of Electrical and Electronics Engineers (IEEE) and more.
Measuring Up
NVIDIA DRIVE is an open platform, meaning experts at top car companies can build upon this industrial-strength system.
TÜV SÜD, among the world’s most respected safety experts, measured DRIVE OS against industry safety standards, specifically ISO 26262, the definitive global standard for functional safety of road vehicles’ systems, hardware and software.
To meet that standard, software must detect failures during operation, as well as be developed in a process that handles potential systematic faults along the whole V-model — from safety-requirements definition to coding, analysis, verification and validation.
That is, the software must avoid failures whenever possible, but detect and respond to them if they cannot be avoided.
TÜV SÜD’s team determined DRIVE OS 5.2 complies with the testing criteria and is suitable for safety-related use in applications up to ASIL B.
Safety Across the Stack
Safety is NVIDIA’s first priority in AV development.
This certification builds on TÜV SÜD’s 2020 assessment of the NVIDIA DRIVE Xavier system-on-a-chip, which determined that it meets ISO 26262 random hardware integrity of ASIL C and a systematic capability of ASIL D for process — the strictest standard for functional safety.
These processes all contribute to our dedication to a comprehensive safety approach that extends from the SoC to the operating system, the application software and the cloud.


 San Diego-based startup Vistry is tackling a growing labor shortage among quick-service restaurants with an AI-enabled, automated order-taking solution. The system, built with the NVIDIA Riva software development kit, uses natural language processing for menu understanding and speech — plus recommendation systems to enable faster, more accurate order-taking and more relevant, personalized offers.
San Diego-based startup Vistry is tackling a growing labor shortage among quick-service restaurants with an AI-enabled, automated order-taking solution. The system, built with the NVIDIA Riva software development kit, uses natural language processing for menu understanding and speech — plus recommendation systems to enable faster, more accurate order-taking and more relevant, personalized offers. Oakland-based startup Cartken is deploying NVIDIA Jetson-enabled sidewalk robots for last-mile deliveries of coffee and meals. Its autonomous mobile robot technology is used to deliver Grubhub orders to students at the University of Arizona and Ohio State — and Starbucks goods in malls in Japan.
Oakland-based startup Cartken is deploying NVIDIA Jetson-enabled sidewalk robots for last-mile deliveries of coffee and meals. Its autonomous mobile robot technology is used to deliver Grubhub orders to students at the University of Arizona and Ohio State — and Starbucks goods in malls in Japan.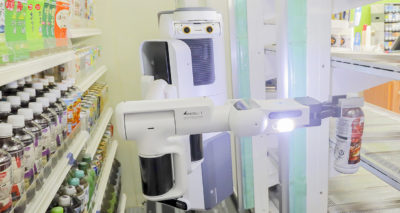 Telexistence, an Inception startup based in Tokyo, is deploying hundreds of NVIDIA AI-powered robots to restock shelves at FamilyMart, a leading Japanese convenience store chain. The robots handle repetitive tasks like refilling beverage displays, which frees up retail staff to interact with customers.
Telexistence, an Inception startup based in Tokyo, is deploying hundreds of NVIDIA AI-powered robots to restock shelves at FamilyMart, a leading Japanese convenience store chain. The robots handle repetitive tasks like refilling beverage displays, which frees up retail staff to interact with customers.








 NVIDIA GeForce NOW (@NVIDIAGFN)
NVIDIA GeForce NOW (@NVIDIAGFN)