As personal transportation becomes electrified and automated, time in the vehicle has begun to resemble that of a living space rather than a mind-numbing commute.
Companies are creating innovative ways for drivers and passengers to make the most of this experience, using the flexibility and modularity of NVIDIA DRIVE IX. In-vehicle technology companies Cerence, Smart Eye, Rightware and DSP Concepts are now using the platform to deliver intelligent features for every vehicle occupant.
These partners are joining a diverse ecosystem of companies developing on DRIVE IX, including Soundhound, Jungo and VisionLabs, providing cutting-edge solutions for any in-vehicle need.
DRIVE IX provides an open software stack for cockpit solution providers to build and deploy features that will turn personal vehicles into interactive environments, enabling intelligent assistants, graphic user interfaces and immersive media and entertainment.
Intelligent Assistants
AI isn’t just transforming the way people drive, but also how they interact with cars.
Using speech, gestures and advanced graphical user interfaces, passengers can communicate with the vehicle through an AI assistant as naturally as they would with a human.
An intelligent assistant will help to operate vehicle functions more intuitively, warn passengers in critical situations and provide services such as giving local updates like the weather forecast, making reservations and phone calls, and managing calendars.
Conversational AI Interaction
Software partnerCerence is enabling AI-powered, voice-based interaction with the Cerence Assistant, its intelligent in-car assistant platform.
Cerence Assistant uses sensor data to serve drivers throughout their daily journeys, notifying them, for example, when fuel or battery levels are low and navigating to the nearest gas or charging station.
It features robust speech recognition, natural language understanding and text-to-speech capabilities, enhancing the driver experience.
Courtesy of Cerence
Using DRIVE IX, it can empower both embedded and cloud-based natural language processing on the same architecture, ensuring drivers have access to important capabilities regardless of connectivity.
Cerence Assistant also supports major global markets and related languages, and is customizable for brand-specific speech recognition and personalization.
Gesture Recognition
In addition to speech, passengers can interact with AI assistants via gesture, which relies on interior sensing technologies.
Smart Eye is a global leader in AI-based driver monitoring and interior sensing solutions. Its production driver-monitoring system is already in 1 million vehicles on the roads around the world, and will be incorporated in the upcoming Polestar 3, set to be revealed in October.
Working with DRIVE IX, Smart Eye’s technology makes it possible to detect eye movements, facial expressions, body posture and gestures, bringing insight into people’s behavior, activities and mood.
Courtesy of Smart Eye
Using NVIDIA GPU technology, Smart Eye has been able to speed up its cabin-monitoring system — which consists of 10 deep neural networks running in parallel — by more than 10x.
This interior sensing is critical for safety — ensuring driver attention is on the road when it should be and detecting left-behind children or pets — and it customizes and enhances the entire mobility experience for comfort, wellness and entertainment.
Graphical User Interface
AI assistants can communicate relevant information easily and clearly with high-resolution graphical interfaces. Using DRIVE IX, Rightware is creating a seamless visual experience across all cockpit and infotainment domains.
Caption: Courtesy of Rightware
Rightware’s automotive human-machine interface tool Kanzi One helps designers bring amazing real-time 3D graphical user interfaces into the car and hides the underlying operating system and framework complexity. Automakers can completely customize the vehicle’s user interface with Kanzi One, providing a brand-specific signature UI.
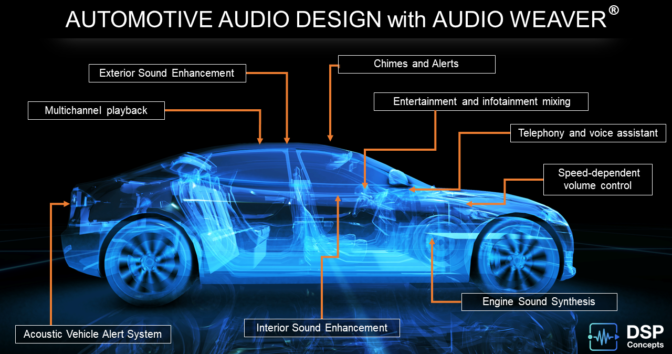
Enhancing visual user interfaces by audio features is equally important for interacting with the vehicle. The Audio Weaver development platform from DSP Concepts can be integrated into the DRIVE IX advanced sound engine. It provides a sound design toolchain and audio framework to graphically design features.
Courtesy of DSP Concepts.
Creators and sound artists can design a car- and brand-specific sound experience without the hassle of writing complex code for low-level audio features from scratch.
Designing in Simulation
With NVIDIA DRIVE Sim on Omniverse, developers can integrate, refine and test all these new features in the virtual world before implementing them in vehicles.
Interior sensing companies can build driver- or occupant-monitoring models in the cockpit using the DRIVE Replicator synthetic-data generation tool on DRIVE Sim. Partners providing content for vehicle displays can first develop on a rich, simulated screen configuration.
Access to this virtual vehicle platform can significantly accelerate end-to-end development of intelligent in-vehicle technology.
By combining the flexibility of DRIVE IX with leading in-cabin solutions providers, spending time in the car can become a luxury rather than a chore.
Breakthroughs in centralized, high performance computing aren’t just opening up new functionality for autonomous driving, but for the in-vehicle experience as well.
With the introduction of NVIDIA DRIVE Thor, automakers can build unified AI compute platforms that combine advanced driver-assistance systems and in-vehicle infotainment. The centralized NVIDIA DRIVE architecture supports novel features in the vehicle, including the ability to support content across multiple displays.
HARMAN, a global leader in rich, connected in-vehicle solutions, will be working with the NVIDIA DRIVE platform to develop multi-domain infotainment solutions. HARMAN is using the DRIVE IX intelligent experience software stack to bring immersive cinematic experiences to every seat in the vehicle, including with individual sound zones for personalized audio.
U.S. drivers collectively whiled away 3.6 billion hours in their vehicles last year, according to a study from INRIX. With AI-assisted automated-driving systems, these hours can become valuable downtime.
Electric vehicle charging could also add to time spent in vehicles, as owners wait for their car to charge during longer trips. Current EVs take at least 30 minutes to charge — making it a prime opportunity to catch up on the latest video game release.
With the high performance of NVIDIA DRIVE and the open DRIVE IX platform, HARMAN can build and deploy multi-domain features that will turn personal vehicles into an entirely new living space.
Sit Back and Relax
HARMAN’s innovative technologies combine and orchestrate various in-vehicle domains, such as cockpit, sound, telematics and cloud services to create personalized, road-ready solutions that meet the demands of automakers and their customers.
With this curated approach, HARMAN delivers consumer experiences at automotive grade, including premium car audio, connectivity and visualization solutions that create meaningful experiences for consumers.
DRIVE IX enables HARMAN to make every screen — whether in the cockpit or the rear passenger seats — display high-resolution video content, as well as 3D audio, creating a virtual concert hall.
HARMAN’s long-term expertise in both the consumer and automotive categories uniquely positions it to bolster the use of vehicles as a living space.
With the open, flexible and high-performance DRIVE platform, HARMAN is poised to completely transform the vehicle experience, turning rush-hour dread into a thing of the past.
Whether for virtual assistants, transcriptions or contact centers, voice AI services are turning words and conversations into bits and bytes of business magic.
At GTC this week, NVIDIA announced new additions to NVIDIA Riva, a GPU-accelerated software development kit for building and deploying speech AI applications.
Riva’s pretrained models are now offered in seven languages, including French and Hindi. Additional languages on the horizon: Arabic, Italian, Japanese, Korean and Portuguese. Riva also brings improvements in accuracy for English, German, Mandarin, Russian and Spanish. Additionally, it adds capabilities like word-level confidence scores and speaker diarization — the process of identifying speakers in audio streams.
Riva is built to be fully customizable at every stage of the speech AI pipeline to help solve unique problems efficiently. Developers can also deploy it where they want their data to be: on premises, for hybrid multiclouds, at the edge or in embedded devices. It’s used by enterprises to bolster services, efficiency and competitive advantage.
While AI for voice services has been in high demand, development tools have lagged. More people are working and learning from home, shopping online and seeking remote customer support, which strains call centers and pushes voice applications to their limits. Customer service wait times have recently tripled as staffing shortages have hit call centers hard, according to a 2022 Bloomberg report.
Advances in speech AI offer the way forward. NVIDIA Riva enables companies to explore larger deep learning models and develop more nuanced voice systems. Speech AI applications built on Riva provide an accelerated path to better services, promising improved customer experiences and engagement.
Rising Demand for Voice AI Applications
The worldwide market for contact center software reached about $27 billion in 2021, a figure expected to nearly triple to $79 billion by 2029, according to Fortune Business Insights.
This increase is due to the benefits that customized voice applications offer businesses of any size, in almost every industry — from global enterprises, to original equipment manufacturers delivering speech AI-based systems and cloud services, to systems integrators and independent software vendors.
Riva SDK Accelerates AI Workflows
NVIDIA Riva includes pretrained language models that can be used as is or fine-tuned using transfer learning from the NVIDIA TAO Toolkit, which allows for custom datasets in a no-code environment. Riva automated speech recognition (ASR) and text-to-speech (TTS) models can be optimized, exported and deployed as speech services.
Voice AI is making its way into ever more types of applications, such as customer support virtual assistants and chatbots, video conferencing systems, drive-thru convenience food orders, retail by phone, and media and entertainment. Global organizations have adopted Riva to drive voice AI efforts, including T-Mobile, Deloitte, HPE, Interactions, 1-800-Flowers.com, Quantiphi and Kore.ai.
T-Mobile adopted Riva for its T-Mobile Expert Assist — a custom-built call center application that uses AI to transcribe real-time customer conversations and recommend solutions — for 17,000 customer service agents. T-Mobile plans to deploy Riva worldwide soon.
Hewlett Packard Enterprise offers HPE ProLiant servers that include NVIDIA GPUs and NVIDIA Riva software in a system capable of developing and running challenging speech AI and natural language processing workloads that can easily turn audio into insights. HPE ProLiant systems and NVIDIA Riva form a world-class, full-stack solution for running financial services and other industry applications.
“To deliver the capabilities of NVIDIA Riva, HPE offers a Kubernetes-based NLP reference architecture based on HPE Ezmeral software,” said Scott Ramsay, vice president of HPE GreenLake solutions at HPE. “Delivered through the HPE GreenLake cloud platform, this system enables developers to accelerate the development and deployment of next-generation speech AI applications.”
Deloitte supports clients looking to deploy ASR and TTS use cases, such as for order-taking systems in some of the world’s largest quick-order restaurants. It’s also developing chatbot services for healthcare providers that will enable accurate and efficient transcriptions for patient questions and chat summarizations.
“Advances in natural language processing make it possible to design cost-efficient experiences that enable purposeful, simple and natural customer conversations,” said Christine Ahn, principal at Deloitte US. “Our clients are looking for a streamlined path to conversational AI deployment, and NVIDIA Riva supports that path.”
Interactions has integrated Riva with its Curo software platform to create seamless, personalized engagements for customers in a broad range of industries that include telecommunications, as well as for companies such as 1-800-Flowers.com, which has deployed a speech AI order-taking system.
Kore.ai is integrating Riva with its SmartAssist speech AI contact-center-as-a-service, which powers its BankAssist, HealthAssist, AgentAssist, HR Assist and IT Assist products. Proof of concepts with NVIDIA Riva are in progress.
Quantiphi is a solution-delivery partner that is developing closed-captioning solutions using Riva for customers in media and entertainment, including Fox News. It’s also developing digital avatars with Riva for telecommunications and other industries.
Complex Speech AI Pipelines, Easier Solutions
Speech AI pipelines can be complex and require coordination across multiple services. Microservices are required to run at scale with ASR models, natural language understanding, TTS and domain-specific apps. NVIDIA GPUs are ideal for acceleration of these types of specialized tasks.
Riva offers software libraries for building speech AI applications and includes GPU-optimized services for ASR and TTS that use the latest deep learning models. Developers can meld these multiple speech AI skills within their applications.
Developers can easily access Riva and pretrained models through NVIDIA NGC, a hub for GPU-optimized AI software, models and Jupyter Notebook examples.
Support for Riva is available through NVIDIA AI Enterprise, a cloud-native suite of AI and data analytics software that’s optimized to enable any organization to use AI. It’s certified to deploy anywhere — from the enterprise data center to the public cloud — and includes global enterprise support to keep AI projects on track.
Try NVIDIA Riva with guided labs on ready-to-run infrastructure in NVIDIA LaunchPad.
Dentists get a bad rap. Dentists also get more people out of more aggravating pain than just about anyone.
Which is why the more technology dentists have, the better.
Overjet, a member of the NVIDIA Inception program for startups, is moving fast to bring AI to dentists’ offices.
On this episode of the NVIDIA AI Podcast, host Noah Kravitz talks to Dr. Wardha Inam, CEO of Overjet, about how her company uses AI to improve patient care.
Overjet’s AI-powered technology analyzes and annotates X-rays for dentists and insurance providers.
It’s a step that promises to take the subjectivity out of X-ray interpretations, boosting medical services.
It may seem intuitive that AI and deep learning can speed up workflows — including novel drug discovery, a typically years-long and several-billion-dollar endeavor. However, there is a dearth of recent research reviewing how accelerated computing can impact the process. Professors Artem Cherkasov and Olexandr Isayev discuss how GPUs can help democratize drug discovery.
Is it possible to manipulate things with your mind? Possibly. University of Minnesota postdoctoral researcher Jules Anh Tuan Nguyen discusses allowing amputees to control their prosthetic limbs with their thoughts, using neural decoders and deep learning.
Studying endangered species can be difficult, as they’re elusive, and the act of observing them can disrupt their lives. Sifei Liu, a senior research scientist at NVIDIA, discusses how scientists can avoid these pitfalls by studying AI-generated 3D representations of these endangered species.
Subscribe to the AI Podcast: Now Available on Amazon Music
South Korea’s most popular AI voice assistant, GiGA Genie, converses with 8 million people each day.
The AI-powered speaker from telecom company KT can control TVs, offer real-time traffic updates and complete a slew of other home-assistance tasks based on voice commands. It has mastered its conversational skills in the highly complex Korean language thanks to large language models (LLMs) — machine learning algorithms that can recognize, understand, predict and generate human languages based on huge text datasets.
The company’s models are built using the NVIDIA DGX SuperPOD data center infrastructure platform and the NeMo Megatron framework for training and deploying LLMs with billions of parameters.
The Korean language, known as Hangul, reliably shows up in lists of the world’s most challenging languages. It includes four types of compound verbs, and words are often composed of two or more roots.
KT — South Korea’s leading mobile operator with over 22 million subscribers — improved the smart speaker’s understanding of such words by developing LLMs with around 40 billion parameters. And through integration with Amazon Alexa, GiGA Genie can converse with users in English, too.
“With transformer-based models, we’ve achieved significant quality improvements for the GiGA Genie smart speaker, as well as our customer services platform AI Contact Center, or AICC,” said Hwijung Ryu, LLM development team lead at KT.
AICC is an all-in-one, cloud-based platform that offers AI voice agents and other customer service-related applications.
It can receive calls and provide requested information — or quickly connect customers to human agents for answers to more detailed inquiries. AICC without human intervention manages more than 100,000 calls daily across Korea, according to Ryu.
“LLMs enable GiGA Genie to gain better language understanding and generate more human-like sentences, and AICC to reduce consultation times by 15 seconds as it summarizes and classifies inquiry types more quickly,” he added.
Training Large Language Models
Developing LLMs can be an expensive, time-consuming process that requires deep technical expertise and full-stack technology investments.
The NVIDIA AI platform simplified and sped up this process for KT.
“We trained our LLM models more effectively with NVIDIA DGX SuperPOD’s powerful performance — as well as NeMo Megatron’s optimized algorithms and 3D parallelism techniques,” Ryu said. “NeMo Megatron is continuously adopting new features, which is the biggest advantage we think it offers in improving our model accuracy.”
3D parallelism — a distributed training method in which an extremely large-scale deep learning model is partitioned across multiple devices — was crucial for training KT’s LLMs. NeMo Megatron enabled the team to easily accomplish this task with the highest throughput, according to Ryu.
“We considered using other platforms, but it was difficult to find an alternative that provides full-stack environments — from the hardware level to the inference level,” he added. “NVIDIA also provides exceptional expertise from product, engineering teams and more, so we easily solved several technical issues.”
Using hyperparameter optimization tools in NeMo Megatron, KT trained its LLMs 2x faster than with other frameworks, Ryu said. These tools allow users to automatically find the best configurations for LLM training and inference, easing and speeding the development and deployment process.
“Thanks to LLMs, KT can release competitive products faster than ever,” Ryu said. “We also believe that our technology can drive innovation from other companies, as it can be used to improve their value and create innovative products.”
KT plans to release more than 20 natural language understanding and natural language generation APIs for developers in November. The application programming interfaces can be used for tasks including document summarization and classification, emotion recognition, and filtering of potentially inappropriate content.
Learn more about breakthrough technologies for the era of AI and the metaverse at NVIDIA GTC, running online through Thursday, Sept. 22.
Watch NVIDIA founder and CEO Jensen Huang’s keynote address in replay below:
At GTC today, NVIDIA unveiled a number of updates to its DGX portfolio to power new breakthroughs in enterprise AI development.
NVIDIA DGX H100 systems are now available for order. These infrastructure building blocks support NVIDIA’s full-stack enterprise AI solutions.
With 32 petaflops of performance at FP8 precision, NVIDIA DGX H100 delivers a leap in efficiency for enterprise AI development. It offers 3x lower total cost of ownership and 3.5x more energy efficiency compared to the previous generation.
New NVIDIA Base Command software, which simplifies and speeds AI development, powers every DGX system — from single nodes to DGX SuperPODs.
Also unveiled was NVIDIA DGX BasePOD — the evolution of DGX POD — which makes enterprise data-center AI deployments simpler and faster for IT teams to acquire, deploy and manage.
Many of the world’s AI leaders are building technological breakthroughs — from self-driving cars to voice assistants — using NVIDIA DGX systems and software, and the pace of innovation is not slowing down.
New NVIDIA Base Command Features
NVIDIA Base Command provides enterprise-grade orchestration and cluster management, and it now features a full software stack for maximizing AI developer productivity, IT manageability and workload performance.
The workflow management features of Base Command now include support for on-premises DGX SuperPOD environments, enabling businesses to gain centralized control of AI development projects with simplified collaboration for project teams, and integrated monitoring and reporting dashboards.
Base Command works with the NVIDIA AI Enterprise software suite, which is now included with every DGX system. The NVIDIA AI software enables end-to-end AI development and deployment with supported AI and data science tools, optimized frameworks and pretrained models.
Additionally, it offers enterprise-workflow management and MLOps integrations with DGX-Ready Software providers Domino Data Lab, Run.ai, Weights & Biases and NVIDIA Inception member Rescale. It also includes libraries that optimize and accelerate compute, storage and network infrastructure — while ensuring maximized system uptime, security and reliability.
New DGX BasePOD Reference Architecture
DGX BasePOD provides a reference architecture for DGX systems that incorporates design best practices for integrating compute, networking, storage and software.
Customers are already using NVIDIA DGX POD to power the development of a broad range of enterprise applications. DGX BasePOD builds on the success of DGX POD with new industry solutions targeting the biggest AI opportunities, including natural language processing, healthcare and life sciences, and fraud detection.
Delivered as fully integrated, ready-to-deploy offerings through the NVIDIA Partner Network, DGX BasePOD solutions range in size, from two to hundreds of DGX systems, with certified high-performance storage from NVIDIA DGX storage technology partners including DDN, Dell, NetApp, Pure Storage, VAST Data and WEKA.
Leaders Power AI Breakthroughs With DGX Systems
Enterprises around the world choose NVIDIA DGX systems to power their most advanced AI workloads. Among the AI innovators developing mission-critical AI capabilities on DGX A100 systems:
ML research and product lab Adept is building an AI teammate powered by a large language model prototyped on NVIDIA DGX Foundry, and then scaled with NVIDIA A100 GPUs and NVIDIA Megatron on Oracle Cloud Infrastructure.
Hyundai Motor Group is using a 40-node DGX SuperPOD to explore hyperscale AI workloads.
Telecom company KT is developing a LLM with around 40 billion parameters for a variety of Korean-language applications, including the GiGA Genie smart speaker, using the NVIDIA NeMo Megatron framework, NVIDIA DGX SuperPOD and NVIDIA Base Command software.
The University of Wisconsin-Madison is quickly bringing AI to medical imaging devices using NVIDIA DGX systems with the Flywheel research platform and the NVIDIA Clara healthcare application framework. Using the NVIDIA Federated Learning Application Runtime Environment, or NVIDIA FLARE, in collaboration with other hospitals, the university is securely training AI models on DGX systems for medical imaging, annotation and classification.
Learn more about the AI breakthroughs powered by NVIDIA DGX systems by watching NVIDIA founder and CEO Jensen Huang’s GTC keynote in replay. And join the GTC session, “Designing Your AI Center of Excellence,” with Charlie Boyle, vice president of DGX systems at NVIDIA.
New cloud services to support AI workflows and the launch of a new generation of GeForce RTX GPUs featured today in NVIDIA CEO Jensen Huang’s GTC keynote, which was packed with new systems, silicon, and software.
“Computing is advancing at incredible speeds, the engine propelling this rocket is accelerated computing, and its fuel is AI,” Huang said during a virtual presentation as he kicked off NVIDIA GTC.
Again and again, Huang connected new technologies to new products to new opportunities – from harnessing AI to delight gamers with never-before-seen graphics to building virtual proving grounds where the world’s biggest companies can refine their products.
Driving the deluge of new ideas, new products and new applications: a singular vision of accelerated computing unlocking advances in AI, which, in turn will touch industries around the world.
First out of the blocks at the keynote was the launch of next-generation GeForce RTX 40 Series GPUs powered by Ada, which Huang called a “quantum leap” that paves the way for creators of fully simulated worlds.
NVIDIA CEO Jensen Huang launched the next-generation GeForce RTX 40 Series GPUs.
Huang gave his audience a taste of what that makes possible by offering up a look at Racer RTX, a fully interactive simulation that’s entirely ray traced, with all the action physically modeled.
Ada’s advancements include a new Streaming Multiprocessor, a new RT Core with twice the ray-triangle intersection throughput, and a new Tensor Core with the Hopper FP8 Transformer Engine and 1.4 petaflops of Tensor processor power.
Ada also introduces the latest version of NVIDIA DLSS technology, DLSS 3, which uses AI to generate new frames by comparing new frames with prior frames to understand how a scene is changing. The result: boosting game performance by up to 4x over brute force rendering.
DLSS 3 has received support from many of the world’s leading game developers, with more than 35 games and applications announcing support. “DLSS 3 is one of our greatest neural rendering inventions,” Huang said.
Together, Huang said, these innovations help deliver 4x more processing throughput with the new GeForce RTX 4090 versus its forerunner, the RTX 3090 Ti. “The new heavyweight champ” starts at $1,599 and will be available Oct. 12.
Additionally, the new GeForce RTX 4080 is launching in November with two configurations.
The GeForce RTX 4080 16GB, priced at $1,199, has 9,728 CUDA cores and 16GB of high-speed Micron GDDR6X memory. With DLSS 3, it’s twice as fast in today’s games as the GeForce RTX 3080 Ti, and more powerful than the GeForce RTX 3090 Ti at lower power.
The GeForce RTX 4080 12GB has 7,680 CUDA cores and 12GB of Micron GDDR6X memory, and with DLSS 3 is faster than the RTX 3090 Ti, the previous-generation flagship GPU. It’s priced at $899.
Huang also announced that NVIDIA Lightspeed Studios used Omniverse to reimagine Portal, one of the most celebrated games in history. With NVIDIA RTX Remix, an AI-assisted toolset, users can mod their favorite games, enabling them to up-res textures and assets, and give materials physically accurate properties.
NVIDIA Lightspeed Studios used Omniverse to reimagine Portal, one of the most celebrated games in history.
Powering AI Advances, H100 GPU in Full Production
Once more tying systems and software to broad technology trends, Huang explained that large language models, or LLMs, and recommender systems are the two most important AI models today.
Recommenders “run the digital economy,” powering everything from e-commerce to entertainment to advertising, he said. “They’re the engines behind social media, digital advertising, e-commerce and search.”
And large language models based on the Transformer deep learning model first introduced in 2017 are now among the most vibrant areas for research in AI, and able to learn to understand human language without supervision or labeled datasets.
“A single pre-trained model can perform multiple tasks, like question answering, document summarization, text generation, translation and even software programming,” Huang said.
Delivering the computing muscle needed to power these enormous models, Huang said the NVIDIA H100 Tensor Core GPU, with Hopper’s next-generation Transformer Engine, is in full production, with systems shipping in the coming weeks.
“Hopper is in full production and coming soon to power the world’s AI factories,” Huang said.
Partners building systems include Atos, Cisco, Dell Technologies, Fujitsu, GIGABYTE, Hewlett Packard Enterprise, Lenovo and Supermicro. And Amazon Web Services, Google Cloud, Microsoft Azure and Oracle Cloud Infrastructure will be among the first to deploy H100-based instances in the cloud starting next year.
And Grace Hopper, which combines NVIDIA’s Arm-based Grace data center CPU with Hopper GPUs, with its 7x increase in fast-memory capacity, will deliver a “giant leap” for recommender systems, Huang said. Systems incorporating Grace Hopper will be available in the first half of 2023.
Weaving Together the Metaverse, L40 Data Center GPUs in Full Production
The next evolution of the internet, called the metaverse, will be extended with 3D, Huang explained. Omniverse is NVIDIA’s platform for building and running metaverse applications.
Here, too, Huang explained how connecting and simulating these worlds will require powerful, flexible new computers. And NVIDIA OVX servers are built for scaling out metaverse applications.
NVIDIA’s 2nd-generation OVX systems will be powered by Ada Lovelace L40 data center GPUs, which are now in full production, Huang announced.
Thor for Autonomous Vehicles, Robotics, Medical Instruments and More
In today’s vehicles, active safety, parking, driver monitoring, camera mirrors, cluster and infotainment are driven by different computers. In the future, they’ll be delivered by software that improves over time, running on a centralized computer, Huang said.
To power this, Huang introduced DRIVE Thor, which combines the transformer engine of Hopper, the GPU of Ada, and the amazing CPU of Grace.
The new Thor superchip delivers 2,000 teraflops of performance, replacing Atlan on the DRIVE roadmap, and providing a seamless transition from DRIVE Orin, which has 254 TOPS of performance and is currently in production vehicles. Thor will be the processor for robotics, medical instruments, industrial automation and edge AI systems, Huang said.
3.5 Million Developers, 3,000 Accelerated Applications
Bringing NVIDIA’s systems and silicon, and the benefits of accelerated computing, to industries around the world, is a software ecosystem with more than 3.5 million developers creating some 3,000 accelerated apps using NVIDIA’s 550 software development kits, or SDKs, and AI models, Huang announced.
And it’s growing fast. Over the past 12 months, NVIDIA has updated more than 100 SDKs and introduced 25 new ones.
“New SDKs increase the capability and performance of systems our customers already own, while opening new markets for accelerated computing,” Huang said.
New Services for AI, Virtual Worlds
Large language models “are the most important AI models today,” Huang said. Based on the transformer architecture, these giant models can learn to understand meanings and languages without supervision or labeled datasets, unlocking remarkable new capabilities.
To make it easier for researchers to apply this “incredible” technology to their work, Huang announced the Nemo LLM Service, an NVIDIA-managed cloud service to adapt pretrained LLMs to perform specific tasks.
To accelerate the work of drug and bioscience researchers, Huang also announced BioNeMo LLM, a service to create LLMs that understand chemicals, proteins, DNA and RNA sequences.
Huang announced that NVIDIA is working with The Broad Institute, the world’s largest producer of human genomic information, to make NVIDIA Clara libraries, such as NVIDIA Parabricks, the Genome Analysis Toolkit, and BioNeMo, available on Broad’s Terra Cloud Platform.
NVIDIA is working with The Broad Institute, the world’s largest producer of human genomic information, to make NVIDIA Clara libraries available on Broad’s Terra Cloud Platform.
New Omniverse containers – Replicator for synthetic data generation, Farm for scaling render farms, and Isaac Sim for building and training AI robots – are now available for cloud deployment, Huang announced.
Omniverse is seeing wide adoption, and Huang shared several customer stories and demos:
Lowe’s, which has nearly 2,000 retail outlets, is using Omniverse to design, build and operate digital twins of their stores;
Charter, a $50 billion dollar telecoms provider, and interactive data analytics provider HeavyAI, are using Omniverse to create digital twins of Charter’s 4G and 5G networks;
GM is creating a digital twin of its Michigan Design Studio in Omniverse where designers, engineers and marketers can collaborate.
Home improvement retailer Lowe’s is using Omniverse to design, build and operate digital twins of their stores.
New Jetson Orin Nano for Robotics
Shifting from virtual worlds to machines that will move through their world, robotic computers “are the newest types of computers,” Huang said, describing NVIDIA’s second-generation processor for robotics, Orin, as a homerun.
To bring Orin to more markets, he announced the Jetson Orin Nano, a tiny robotics computer that is 80x faster than the previous super-popular Jetson Nano.
Jetson Orin Nano runs the NVIDIA Isaac robotics stack and features the ROS 2 GPU-accelerated framework, and NVIDIA Iaaac Sim, a robotics simulation platform, is available on the cloud.
Most of the world’s internet traffic is video, and user-generated video streams will be increasingly augmented by AI special effects and computer graphics, Huang explained.
“Avatars will do computer vision, speech AI, language understanding and computer graphics in real time and at cloud scale,” Huang said.
Deloitte to Bring AI, Omniverse Services to Enterprises
And to speed the adoption of all these technologies to the world’s enterprises, Deloitte, the world’s largest professional services firm, is bringing new services built on NVIDIA AI and NVIDIA Omniverse to the world’s enterprises, Huang announced.
He said that Deloitte’s professionals will help the world’s enterprises use NVIDIA application frameworks to build modern multi-cloud applications for customer service, cybersecurity, industrial automation, warehouse and retail automation and more.
Just Getting Started
Huang ended his keynote by recapping a talk that moved from outlining new technologies to product announcements and back — uniting scores of different parts into a singular vision.
“Today, we announced new chips, new advances to our platforms, and, for the very first time, new cloud services,” Huang said as he wrapped up. “These platforms propel new breakthroughs in AI, new applications of AI, and the next wave of AI for science and industry.”
Meet Violet, an AI-powered customer service assistant ready to take your order.
Unveiled this week at GTC, Violet is a cloud-based avatar that represents the latest evolution in avatar development through NVIDIA Omniverse Avatar Cloud Engine (ACE), a suite of cloud-native AI microservices that make it easier to build and deploy intelligent virtual assistants and digital humans at scale.
To animate interactive avatars like Violet, developers need to ensure the 3D character can see, hear, understand and communicate with people. But bringing these avatars to life can be incredibly challenging, as traditional methods typically require expensive equipment, specific expertise and time-consuming workflows.
The Violet demo showcases how Omniverse ACE eases avatar development, delivering all the AI building blocks necessary to create, customize and deploy interactive avatars. Whether taking restaurant orders or answering questions about the universe, these AI assistants are easily customizable for virtually any industry, and can help organizations enhance existing workflows and unlock new business opportunities.
Watch the video below to see Violet interact with users, respond to speech prompts and make intelligent recommendations:
How Omniverse ACE Brings Violet to Life
The demo showcases Violet as a fully rigged avatar with basic animation. To create Violet, NVIDIA’s creative team used the company’s Unified Compute Framework, a fully accelerated framework that enables developers to combine optimized and accelerated microservices into real-time AI applications. UCF helped the team build a graph of microservices for Violet that were deployed in the cloud.
Omniverse ACE powers the backend of interactive avatars, essentially acting as Violet’s brain. Additionally, two reference applications are built on ACE: NVIDIA Tokkio and NVIDIA Maxine.
Violet was developed using the Tokkio application workflow, which enables interactive avatars to see, perceive, converse intelligently and provide recommendations to enhance customer service, both online and in places like restaurants and stores.
NVIDIA Maxine delivers a suite of GPU-accelerated AI software development kits and cloud-native microservices for deploying AI features to enhance real-time video communications. Maxine integrates the NVIDIA Riva SDK’s real-time automatic speech recognition and text-to-speech capabilities with real-time “live portrait” photo animation and eye contact features, which enable better communication and understanding.
With UCF, NVIDIA’s creative team built a graph of microservices for Violet that were deployed in the cloud.
Latest Microservices Expand Possibilities for Avatars
The demo with Violet highlights how developers of digital humans and virtual assistants can use Omniverse ACE to accelerate their avatar development workflows. Omniverse ACE also delivers microservices that enable developers to access the best NVIDIA AI technology, with no coding required.
Some of the latest microservices include:
Animation AI:Omniverse Audio2Face simplifies animation of a 3D character to match any voice-over track, helping users animate characters for games, films or real-time digital assistants.
Conversational AI: Includes the NVIDIA Riva SDK for speech AI and NVIDIA NeMo Megatron framework for natural language processing, allowing developers to quickly build and deploy cutting-edge applications that deliver high-accuracy, expressive voices and respond in real time.
AI Avatars Deliver New Transformations Across Industries
The AI avatars that ACE enables will enhance interactive experiences in industries such as gaming, entertainment, transportation and hospitality.
Leading professional-services company Deloitte has worked with NVIDIA to help enterprises deploy transformative applications. At GTC, Deloitte announced that new hybrid-cloud offerings for NVIDIA AI and NVIDIA Omniverse services and platforms, including Omniverse ACE, will be added to the existing Deloitte Center for AI Computing.
NVIDIA Omniverse ACE brings all three versions of Violet to life, from customer service Violet (left), to intelligent Violet (right) to Ultra Violet (center).
“Cloud-based AI models and services are opening up new ways for digital humans to make people feel more connected, and today’s interaction with Violet in the NVIDIA GTC keynote shows a glimpse into the future of AI-powered avatars,” said Vladimir Mastilović, vice president of digital humans technology at Epic Games. “We are delighted to see NVIDIA Omniverse ACE using MetaHumans in Unreal Engine 5 to make it even easier to deploy engaging high-fidelity 3D avatars.”
NVIDIA Omniverse ACE will be available to early-access partners starting later this year, along with the Tokkio reference application for simplified customer-service avatar implementation.
Learn more about Omniverse ACE by joining this session at GTC, and explore all the technologies that go into the creation and animation of realistic, interactive digital humans.
The latest release of NVIDIA Maxine is paving the way for real-time audio and video communications. Whether for a video conference, a call made to a customer service center, or a live stream, Maxine enables clear communications to enhance virtual interactions.
NVIDIA Maxine is a suite of GPU-accelerated AI software development kits (SDKs) and cloud-native microservices for deploying optimized and accelerated AI features that enhance audio, video and augmented-reality (AR) effects in real time.
And with Maxine’s state-of-the-art models, end users don’t need expensive gear to improve audio and video. Using NVIDIA AI-based technology, these high-quality effects can be achieved with standard microphones and camera equipment.
At GTC, NVIDIA announced the re-architecture of Maxine for cloud-native microservices, with the early-access release of Maxine’s audio-effects microservice. Additionally, new Maxine SDK features were unveiled, including Speaker Focus and Face Expression Estimation, as well as the general availability of Eye Contact. NVIDIA Maxine now also includes enhanced versions of existing SDK features.
Maxine Goes Cloud Native
Maxine’s cloud-native microservices allow developers to build real-time AI applications. Microservices can be independently managed and deployed seamlessly in the cloud, accelerating development timelines.
The Audio Effects microservice, available in early access, contains four state-of-the-art audio features:
Background Noise Removal: Removes several common background noises using AI models, while preserving the speaker’s natural voice.
Room Echo Removal: Removes reverberations from audio using AI models, restoring clarity of a speaker’s voice.
Audio Super Resolution: Improves audio quality by increasing the temporal resolution of audio signal. It currently supports upsampling from 8 kHz to 16 kHz and from 16 kHz to 48 kHz.
Acoustic Echo Cancellation: Cancels real-time acoustic device echo from the input-audio stream, eliminating mismatched acoustic pairs and double-talk. With AI-based technology, more effective cancellation is achieved than with traditional digital signal processing.
Pexip, a leading provider of enterprise video conferencing and collaboration solutions, is using NVIDIA AI technologies to take virtual meetings to the next level with advanced features for the modern workforce.
“With Maxine’s move to cloud-native microservices, it will be even easier to combine NVIDIA’s advanced AI technologies with our own unique server-side architecture,” said Eddie Clifton, senior vice president of Strategic Alliances at Pexip. “This allows our teams at Pexip to deliver an enhanced experience for virtual meetings.”
Maxine offers three GPU-accelerated SDKs that reinvent real-time communications with AI: audio, video and AR effects.
The audio effects SDK delivers multi-effect, low-latency, AI-based audio-quality enhancement algorithms. Speaker Focus, available in early access, is a new feature that separates the audio tracks of foreground and background speakers, making each voice more intelligible. Additionally, the Audio Super Resolution SDK feature has been updated with enhanced quality.
The video effects SDK creates AI-based video effects with standard webcam input. The Virtual Background feature, which segments a person’s profile and applies AI-powered background removal, replacement or blur, has been updated with enhanced temporal stability.
And the AR SDK provides AI-powered, real-time 3D face tracking and body pose estimation based on a standard web camera feed. Latest features include:
Eye Contact: Simulates eye contact by estimating and aligning gaze with the camera.
Face Expression Estimation: Tracks the face and infers what expression is presented by the subject.
The following AR features have been updated:
Body Pose Estimation: Predicts and tracks 34 key points of the human body in 2D and 3D — now with support for multi-person tracking.
Face Landmark Tracking: Recognizes facial features and contours using 126 key points. Tracks head pose and facial deformation due to head movement and expression — in three degrees of freedom in real time — now with Quality mode to achieve even higher-quality tracking.
Experience State-of-the-Art Effects With the Power of AI
Maxine SDKs and microservices provide a suite of low-latency AI effects that can be integrated with existing customer infrastructures. Developers can tap into cutting-edge AI capabilities with Maxine, as the technology is built on the NVIDIA AI platform and has world-class pretrained models for users to create, customize and deploy premium audio- and video-quality features.
Maxine is also part of the NVIDIA Omniverse Avatar Cloud Engine, a collection of cloud-based AI models and services for developers to build, customize and deploy interactive avatars. Maxine’s customizable cloud-native microservices allow for independent deployment into AI-effects pipelines. Maxine can be deployed on premises, in the cloud or at the edge.
Learn more about NVIDIA Maxine and other technology breakthroughs by watching the GTC keynote by NVIDIA founder and CEO Jensen Huang:
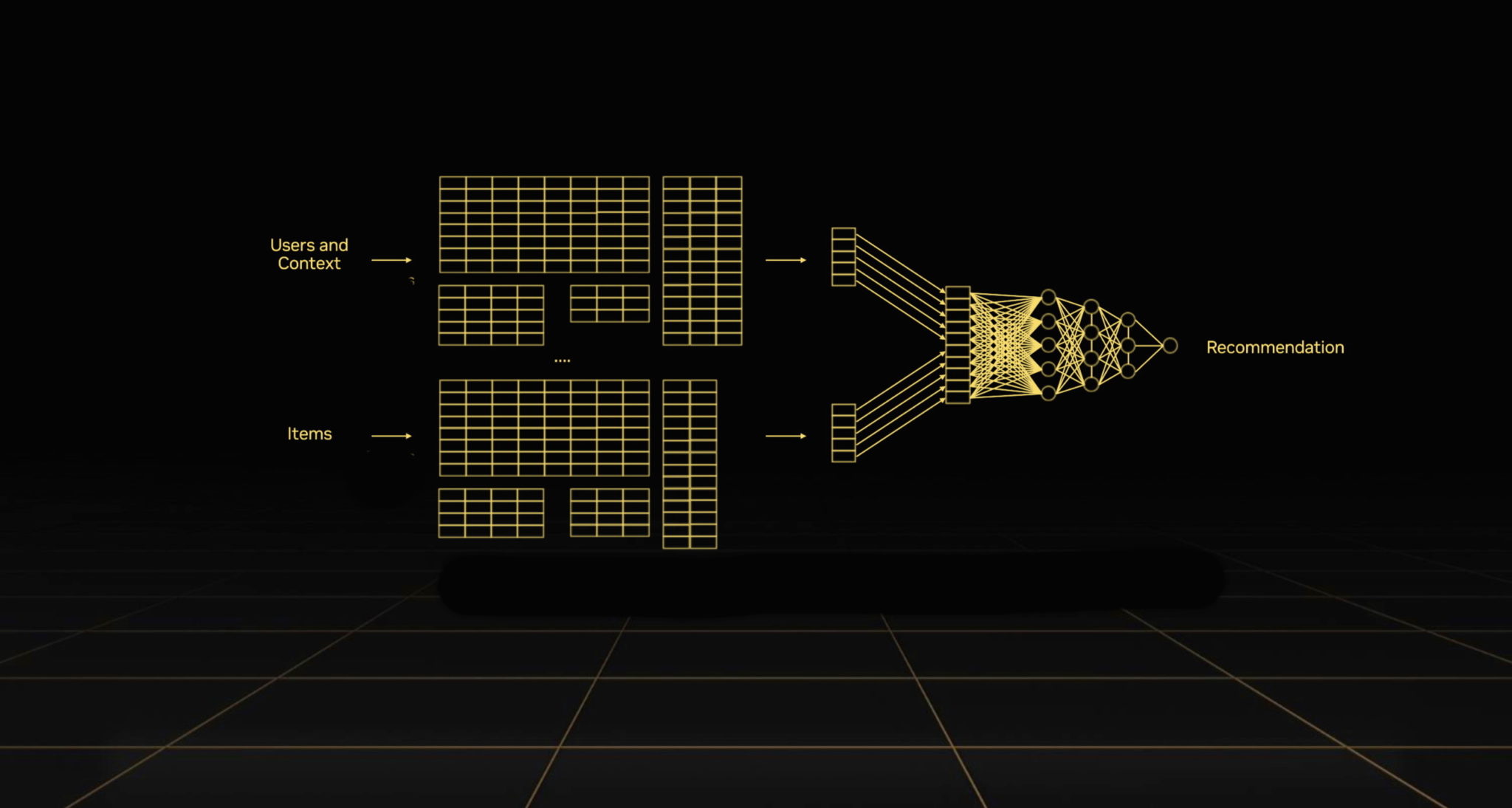
Recommender systems, the economic engines of the internet, are getting a new turbocharger: the NVIDIA Grace Hopper Superchip.
Every day, recommenders serve up trillions of search results, ads, products, music and news stories to billions of people. They’re among the most important AI models of our time because they’re incredibly effective at finding in the internet’s pandemonium the pearls users want.
These machine learning pipelines run on data, terabytes of it. The more data recommenders consume, the more accurate their results and the more return on investment they deliver.
To process this data tsunami, companies are already adopting accelerated computing to personalize services for their customers. Grace Hopper will take their advances to the next level.
GPUs Drive 16% More Engagement
Pinterest, the image-sharing social media company, was able to move to 100x larger recommender models by adopting NVIDIA GPUs. That increased engagement by 16% for its more than 400 million users.
“Normally, we would be happy with a 2% increase, and 16% is just a beginning,” a software engineer at the company said in a recent blog. “We see additional gains — it opens a lot of doors for opportunities.”
Recommenders consume tens of terabytes of embeddings, data tables that provide context for making accurate predictions.
The next generation of the NVIDIA AI platform promises even greater gains for companies processing massive datasets with super-sized recommender models.
Because data is the fuel of AI, Grace Hopper is designed to pump more data through recommender systems than any other processor on the planet.
NVLink Accelerates Grace Hopper
Grace Hopper achieves this because it’s a superchip — two chips in one unit, sharing a superfast chip-to-chip interconnect. It’s an Arm-based NVIDIA Grace CPU and a Hopper GPU that communicate over NVIDIA NVLink-C2C.
What’s more, NVLink also connects many superchips into a super system, a computing cluster built to run terabyte-class recommender systems.
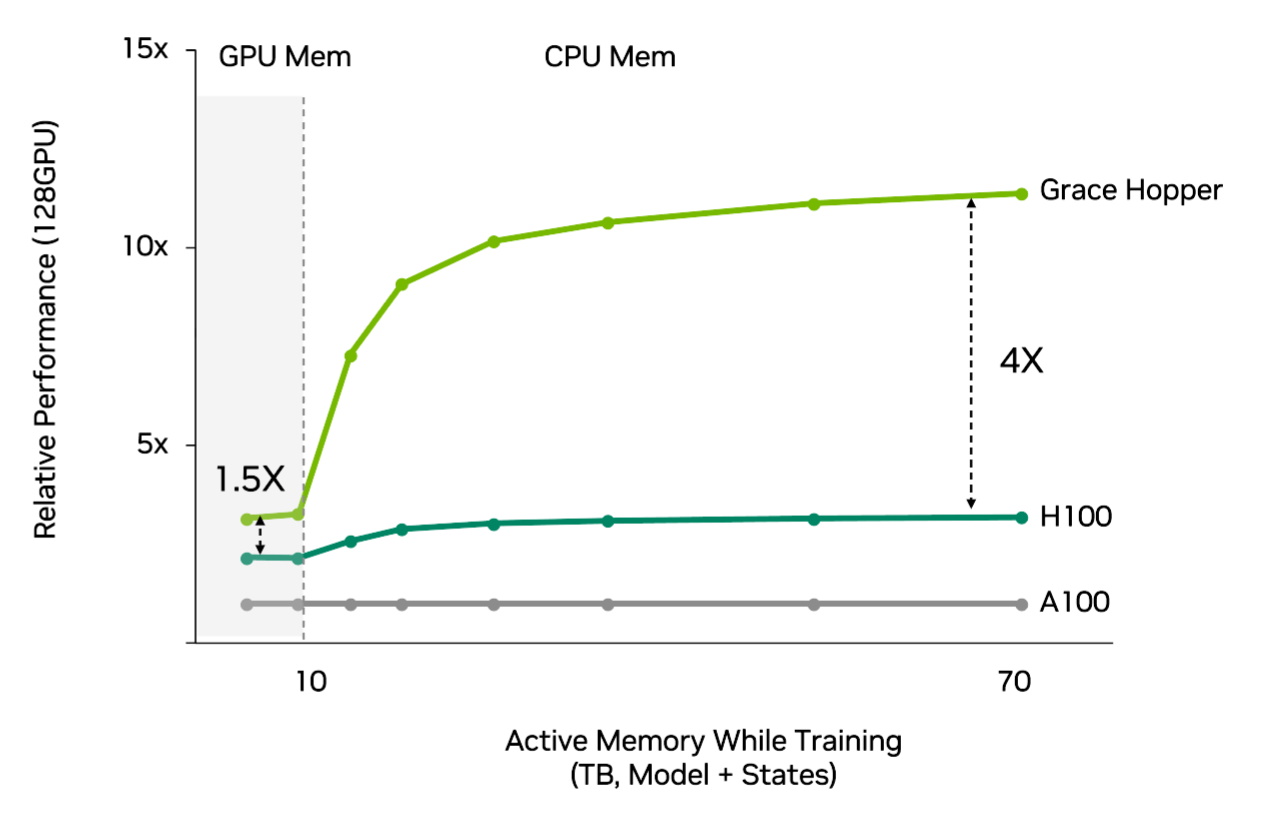
NVLink carries data at a whopping 900 gigabytes per second — 7x the bandwidth of PCIe Gen 5, the interconnect most leading edge upcoming systems will use.
That means Grace Hopper feeds recommenders 7x more of the embeddings — data tables packed with context — that they need to personalize results for users.
More Memory, Greater Efficiency
The Grace CPU uses LPDDR5X, a type of memory that strikes the optimal balance of bandwidth, energy efficiency, capacity and cost for recommender systems and other demanding workloads. It provides 50% more bandwidth while using an eighth of the power per gigabyte of traditional DDR5 memory subsystems.
Any Hopper GPU in a cluster can access Grace’s memory over NVLink. It’s a feature of Grace Hopper that provides the largest pools of GPU memory ever.
In addition, NVLink-C2C requires just 1.3 picojoules per bit transferred, giving it more than 5x the energy efficiency of PCIe Gen 5.
The overall result is recommenders get a further up to 4x more performance and greater efficiency using Grace Hopper than using Hopper with traditional CPUs (see chart below).
All the Software You Need
The Grace Hopper Superchip runs the full stack of NVIDIA AI software used in some of the world’s largest recommender systems today.
NVIDIA Merlin is the rocket fuel of recommenders, a collection of models, methods and libraries for building AI systems that can provide better predictions and increase clicks.