Data is the fuel that makes artificial intelligence run.
Training machine learning and AI systems requires data. And the quality of datasets has a big impact on the systems’ results.
But compiling quality real-world data for AI and ML can be difficult and expensive.
That’s where synthetic data comes in.
The guest for this week’s AI Podcast episode, Nathan Kundtz, is founder and CEO of Rendered.ai, a platform as a service for creating synthetic data to train AI models. The company is also a member of NVIDIA Inception, a free, global program that nurtures cutting-edge startups.
Kundtz is a physicist by training, holds a Ph.D. from Duke University and previously founded Cometa, a hybrid satellite cellular network company.
Our host, Noah Kravitz, spoke to Kundtz about how AI can be used to generate the data needed to create better AI.
It may seem intuitive that AI and deep learning can speed up workflows — including novel drug discovery, a typically years-long and several-billion-dollar endeavor. However, there is a dearth of recent research reviewing how accelerated computing can impact the process. Professors Artem Cherkasov and Olexandr Isayev discuss how GPUs can help democratize drug discovery.
Is it possible to manipulate things with your mind? Possibly. University of Minnesota postdoctoral researcher Jules Anh Tuan Nguyen discusses allowing amputees to control their prosthetic limbs with their thoughts, using neural decoders and deep learning.
Studying endangered species can be difficult, as they’re elusive, and the act of observing them can disrupt their lives. Sifei Liu, a senior research scientist at NVIDIA, discusses how scientists can avoid these pitfalls by studying AI-generated 3D representations of these endangered species.
Subscribe to the AI Podcast: Now Available on Amazon Music
Reinventing enterprise computing for the modern era, VMware CEO Raghu Raghuram Tuesday announced the availability of the VMware vSphere 8 enterprise workload platform running on NVIDIA DPUs, or data processing units, an initiative formerly known as Project Monterey.
Placing the announcement in context, Raghuram and NVIDIA founder and CEO Jensen Huang discussed how running VMware vSphere 8 for BlueField is a huge moment for enterprise computing and how this reinvents the data center altogether.
“Today, we’ve got customers that are deploying NVIDIA AI in the enterprise, in the data center,” Raghuram said. “Together, we are changing the world for enterprise computing.”
Both agreed AI plays a central role for every company and discussed the growing importance of multi-tenant data centers, hybrid-cloud development, and accelerated infrastructure deployment in a 20-minute conversation at the VMware Explore 2022 conference.
To address this, the companies announced a partnership two years ago to deliver an end-to-end enterprise platform for AI as well as a new architecture for data center, cloud and edge that uses NVIDIA DPUs to support existing and next-generation applications.
The stakes for partners and customers are high: AI has become “mission critical” for every enterprise, Raghuram explained. Yet studies show half of AI projects fail to make it to production, with infrastructure complexity a leading cause, he added.
For example, VMware and NVIDIA are working with healthcare providers to accelerate medical image processing using AI to offer a better quality of service to their patients.
Together with Carilion Clinic, NVIDIA will discuss at VMware Explore how the largest healthcare organization in Virginia is future-proofing their hospitals.
AI for Every Enterprise
New AI-enabled applications include recommender systems, speech and vision analytics, and natural language processing.
This will run on the NVIDIA and VMware AI-Ready Enterprise Platform, which is accelerated by NVIDIA GPUs and DPUs, and optimized and delivered across the breadth of VMware products, Huang said.
Many industries are now embracing VMware and NVIDIA’s joint solutions, Huang said.
VMware vSphere 8 with NVIDIA DPUs will be vital to bringing cloud and multi-tenant cloud, hybrid cloud and zero-trust security to enterprises.
Modern organizations continue to generate and process large amounts of data, Raghuram said.
New waves of workloads are starting to emerge that are highly distributed across the data center, network edge and multi-cloud, he added.
Raghuram said that customers need better performance and security in this new era.
DPUs will play a crucial role in the new infrastructure architecture to accelerate performance, free up CPU cycles and provide better security.
“We have rearchitected vSphere to run on DPUs,” Raghuram said. This offloads software-defined infrastructure tasks like network and storage processing, he added.
“And now you get accelerated I/O, and you can have agility for developers, because all of that storage and network processing is now running in the DPU,” he said.
NVIDIA BlueField DPUs
Huang explained that cloud computing and AI are driving a reinvention of data center architecture, and that data centers are the new unit of compute.
The DPU is a new type of processor to reduce the processing burden on CPUs and provide a zero-trust security model, Huang explained.
The NVIDIA BlueField DPU, an accelerated computing platform, is designed for all enterprise workloads and optimized for NVIDIA AI, Huang explained. The BlueField DPU offloads, accelerates and isolates the software-defined infrastructure of the data center — networking, security, storage and virtualization.
“The return on investment — the benefits that DPU-enabled vSphere 8 with NVIDIA BlueField deliver — will be so fast because it frees up so many resources for computing that the payback is going to be instantaneous,” Huang said. “It’s going to be a really fantastic return.”
Security Isolation
This approach is ideal for today’s security challenges. The traditional approach, Raghuram explained, is based on firewalls that focus on the network perimeter.
With the vSphere platform, VMware NSX and advancements in silicon, “we can now bring intrinsic security to life,” Raghuram said.
This new approach, with the NSX distributed firewall running on BlueField DPUs, enables every node to be more secure at virtually every touch point, Huang explained, and the zero-trust security model is finally realized.
“And this is where BlueField and vSphere 8, with NSX running on BlueField, is such an incredible revolution,” Huang said. “We’re essentially going to have a firewall in every single computer.”
vSphere on DPU
Enterprises can get started now. Raghuram announced the first release of vSphere on DPU is available with the vSphere 8 release, with ESXi and NSX support on BlueField DPU.
It lets users improve infrastructure performance by offloading and accelerating functions on the DPU, providing more host resources to business applications, Raghuram said.
Certain latency- and bandwidth-sensitive workloads that previously used virtualization “pass-thru” can now run fully virtualized with similar performance in this new architecture, without losing key vSphere capabilities like vMotion and DRS, Raghuram said.
Infrastructure admins can rely on vSphere to also manage the DPU lifecycle, thereby reducing operational overhead, Raghuram added. And enterprises can boost infrastructure security by isolating infrastructure domains on a DPU.
“The beauty of what the vSphere engineers have done is they have not changed the management model,” Raghuram said. “And so, it can fit seamlessly into the data center architecture of today, while enabling the future to come about.”
All of this will be available soon running on Dell servers and Dell VxRail hyper-converged infrastructure. It allows customers to use familiar VMware vSphere tools to deploy and manage AI infrastructure.
NVIDIA LaunchPad
VMware vSphere users are able to freely experience these workloads today on NVIDIA LaunchPad, Huang said, adding that “it’s available worldwide.”
With LaunchPad, a free program that gives users access to hands-on AI labs, there’s no need to procure and stand up infrastructure to offload, accelerate and isolate vSphere on a DPU before experiencing the lab, Huang explained.
“I can’t wait to try it out myself,” Raghuram said, adding that “this is just the start.”
Sign up now to try the VMware vSphere platform running on NVIDIA BlueField DPUs.
Watch the fireside chat with NVIDIA CEO Jensen Huang and VMware CEO Raghu Raghuram, below.
Editor’s note: This post is a part of our Meet the Omnivore series, which features individual creators and developers who use NVIDIA Omniverse to accelerate their 3D workflows and create virtual worlds.
Vanessa Rosa
Vanessa Rosa’s art transcends time: it merges traditional and contemporary techniques, gives new life to ancient tales and imagines possible futures.
The U.S.-based 3D artist got her start creating street art in Rio de Janeiro, where she grew up. She’s since undertaken artistic tasks like painting murals for Le Centre in Cotonou, Benin, and publishing children’s books.
Now, her focus is on using NVIDIA Omniverse — a platform for connecting and building custom 3D pipelines — to create what she calls Little Martians, a sci-fi universe in which ceramic humanoids discuss theories related to the past, present and future of humanity.
To kick-start the project, Rosa created the most primitive artwork that she could think of: mask-like ceramics, created with local clay and baked with traditional in-ground kilns.
Then, in a sharply modern twist, she 3D scanned them with applications like Polycam and Regard3D. And to animate them, she recorded herself narrating stories with the motion-capture app Face Cap — as well as generated AI voices from text and used the Omniverse Audio2Face app to create facial animations.
An Accessible, Streamlined Platform for 3D Animation
Prior to the Little Martians project, Rosa seldom relied on technology for her artwork. Only recently did she switch from her laptop to a desktop computer powered by an NVIDIA RTX 5000 GPU, which significantly cut her animation render times.
Omniverse quickly became the springboard for Rosa’s digital workflow.
“I’m new to 3D animation, so NVIDIA applications made it much easier for me to get started rather than having to learn how to rig and animate characters solely in software,” she said. “The power of Omniverse is that it makes 3D simulations accessible to a much larger audience of creators, rather than just 3D professionals.”
After generating animations and voice-overs with Omniverse, she employed an add-on for Blender called Faceit that accepts .json files from Audio2Face.
“This has greatly improved my workflow, as I can continue to develop my projects on Blender after generating animations with Omniverse,” she said.
At the core of Omniverse is Universal Scene Description — an open-source, extensible 3D framework and common language for creating virtual worlds. With USD, creators like Rosa can work with multiple applications and extensions all on a centralized platform, further streamlining workflows.
Considering herself a beginner in 3D animation, Rosa feels she’s “only scratched the surface of what’s possible with Omniverse.” In the future, she plans to use the platform to create more interactive media.
“I love that with this technology, pieces can exist in the physical world, but gain new life in the digital world,” she said. “I’d like to use it to create avatars out of my ceramics, so that a person could interact with it and talk to it using an interface.”
With Little Martians, Rosa hopes to inspire her audience to think about the long processes of history — and empower artists that use traditional techniques to explore the possibilities of design and simulation technology like Omniverse.
“I am always exploring new techniques and sharing my process,” she said. “I believe my work can help other people who love the traditional fine arts to adapt to the digital world.”
Check out artwork from other “Omnivores” and submit projects in the gallery. Connect your workflows to Omniverse with software from Adobe, Autodesk, Epic Games, Maxon, Reallusion and more.
Looking for a change of art? Try using AI — that’s what 3D artist Nikola Damjanov is doing.
Based in Serbia, Damjanov has over 15 years of experience in the graphics industry, from making 3D models and animations to creating high-quality visual effects for music videos and movies. Now an artist at game developer company Nordeus, Damajanov’s hobbies include dabbling in creative projects using the latest technologies, like NVIDIA RTX and AI.
Recently, Damjanov has been experimenting with generative art, which is the process of using algorithms to create new ideas, forms, shapes, colors or patterns. And when Damjanov was invited to participate in his country’s Art Biennale, an exhibit that features creative pieces from local artists, he decided to design something new — a 3D-printed sculpture.
With the help of NVIDIA RTX and AI, Damjanov accelerated his creative workflows and produced a physical 3D sculpture of a flower with intricate details and designs.
An AI for Art
To bring his sculpture to life, Damjanov started with the 3D digital design. His floral sculpture was inspired by the aesthetics of microfossils and radiolaria, which are intricate mineral skeletons.
To capture such elaborate details, Damjanov used the NVIDIA Quadro RTX 6000 GPU, and tapped into the power of NVIDIA RTX rendering and AI denoising. These capabilities helped him easily create the 3D model and achieve the complex details of the flower for the sculpture.
“NVIDIA RTX-powered AI denoising just makes look development way easier, because the feedback loop is much shorter now,” he said. “You can quickly get a very decent approximation of what the final render will look like.”
Damjanov then accomplished most of the RTX rendering and generative modeling in SideFX Houdini, a 3D animation application software, and the OTOY OctaneRender engine.
In generative art, it’s important to set up rules that provide boundaries for the creative process, so the computer can follow those rules to create the new artwork.
For Damjanov, setting up these rules and relationships in the system helped with iterations and design changes. With the rules in place, he could change minor details and aspects, and immediately see how the rest of the design would be affected by the tweaks. For example, Damjanov could alter a petal on the flower to be twice the current size, and everything else connected to the petal would react to the new size.
Once he finalized the design, the most challenging part of the project was testing all the physical parts of the sculpture, the artist said.
“Because it was a very intricate design, we had to test out and print specific parts to see what comes out,” he said. “I ran simulations to try to find an approximate center of mass. I also had to print specific parts to find a design that would be structurally sound when printed.”
After three weeks of printing, Damjanov reached a 3D design that would produce the flower sculpture he envisioned for the Art Biennale.
Damjanov uses RTX-powered AI denoising and rendering in most of his projects. He’s also experimenting with using game engines for his work, and implementing NVIDIA Deep Learning Super Sampling for increased graphics performance.
“I remember when most of my time was spent on waiting for something to finish, such as renders completed, maps baked, mesh processed — it was always a pain,” he said. “But with the sheer power and speed of RTX, artists have more time to spend on creative tasks.”
E-commerce sales have skyrocketed as more people shop remotely, spurred by the pandemic. But this surge has also led fraudsters to use the opportunity to scam retailers and customers, according to David Sutton, director of analytical technology at fintech company Featurespace.
The company, headquartered in the U.K., has developed AI-powered technology to increase the speed and accuracy of fraud detection and prevention. Called ARIC Risk Hub, the platform uses deep learning models trained using NVIDIA GPUs to distinguish between valid and fraudulent transactional behavior.
“Online transactions are a prime target for criminals, as they don’t need to have the physical card to transact,” Sutton said. “With compromised card details readily available through the dark web, fraudsters can target large volumes of cards to commit fraud with very little effort.”
ARIC Risk Hub builds complex behavioral profiles of what it calls “genuine” customers by converging transaction and third-party data from across their lifecycle within a financial institution.
Fraud prevention has traditionally been limited by delays in detection — with customers being notified only after money had already left their bank accounts. But ARIC Risk Hub in less than 30 milliseconds determines anomalies in even the slightest changes in a customer’s behavior. It compares each financial event of a customer to their profile using AI-powered adaptive behavioral analytics.
The technology is deployed across 70 major financial institutions globally — and some have reported that it’s blocked 75% of its fraud attacks, Sutton said.
ARIC Risk Hub helps these institutions identify criminal behavior in near-real time — reducing their financial losses and operational costs, and protecting more than 500 million consumers from fraud and financial crime.
Featurespace is a member of NVIDIA Inception, a free, global program that nurtures cutting-edge startups.
100x Model Training Acceleration With NVIDIA GPUs
Featurespace got its start over a decade ago as a machine learning consultancy. It was rooted in the research of University of Cambridge professor Bill Fitzgerald, who was looking to make a commercial impact with adaptive behavioral analytics, a technology he created.
Applied to the financial services industry, the technology quickly took flight.
“With this technology, you could build a deep learning model that learns from and understands what sorts of actions a person normally takes so that it can look for changes in those actions,” said Sutton.
In the past, it would take weeks for Featurespace to set up and train different deep learning models. With NVIDIA A100 Tensor Core GPUs, the company has seen up to a 100x speedup in model training, Sutton said.
“Compared to when we used CPUs, NVIDIA GPUs give us a really quick research-to-impact loop,” he added. “It’s electrifying to work with something that can have an impact that quickly.”
In the time that they used to run just 10 trials, Featurespace’s researchers and data scientists can now run thousands of tests, which bolsters the statistical confidence of their results, enabling them to deploy only the best, tried-and-tested models.
Sutton said even a 1% increase in fraud detection discovered using the deep learning model could save large enterprises $20 million a year.
Featurespace typically uses recurrent neural-network architectures on data from streams of transactions. This model pipeline allows an individual’s new actions to be assessed via behavioral context learned from their past actions.
Financial Fortifications for All
Featurespace’s deep learning models have prevented all sorts of fraud, including those that involve credit cards, payments, applications and money laundering.
The ARIC Risk Hub interface is customizable, so customers can select the most suitable subset of components for their specific needs. Users can then change analytics settings or review suspicious cases. If upon review a case is deemed to be a false positive, the deep learning model learns from its errors, increasing future accuracy.
Featurespace technology has been making a splash for payment processing companies like TSYS and Worldpay — as well as large banks including Danske Bank, HSBC and NatWest.
As Sutton put it, “Featurespace is using AI to make the world a safer place to transact.”
“Our work is what brings a lot of people at Featurespace into the office every morning,” he said. “If you’re able to reduce the amount of money laundering in the world, for example, you can turn crime into something that doesn’t pay as much, making it a less profitable industry to be in.”
Featurespace will host sessions on preventing fraud, money laundering and cryptocrime at Money 20/20, a fintech conference running Oct. 23-26 in Las Vegas.
Register free for NVIDIA GTC, running online Sept. 19-22, to learn more about the latest technology breakthroughs for the era of AI and the metaverse.
Some weeks, GFN Thursday reveals new or unique features. Other weeks, it’s a cool reward. And every week, it offers its members new games.
This week, it’s all of the above.
First, Saints Row marches into GeForce NOW. Be your own boss in the new reboot of the classic open-world criminal adventure series, now available to stream from nearly any device.
Plus, members asked, and we listened: Genshin Impact is now streaming to iOS, iPadOS and Android mobile devices with touch controls. It’s part of the big Genshin Impact Version 3.0 update, adding a brand-new nation, characters and more.
But that’s not all. Guild Wars 2 comes to Steam, and GeForce NOW members can celebrate with a free in-game reward. Dragons, anyone?
And don’t forget about the 13 new games joining the GeForce NOW library, because the action never stops.
It’s Good to Be the King(pin)
Build a criminal empire and rise up from “Newbie” to “Boss” in Saints Row, streaming today for all GeForce NOW members.
The highly anticipated reboot of the Saints Row franchise follows the Saints, a group of three gang members turned friends who combine forces to take on three warring criminal gangs in the vibrant new city of Santo Ileso. Players can become whoever they want with the all-new “Boss Factory.” Customize characters, their weapons, vehicles and more in true Saints Row fashion.
Meet the new Saints.
Stream every side hustle, criminal venture and blockbuster mission across PCs, Macs, SHIELD TVs, iOS Safari and Android mobile devices and more. Recruiting a friend on a low-powered device into your crew has never been easier.
Jump right into Santo Ileso.
Plus, without any wait times for game downloads, members can jump right into Santo Ileso and spend more time being a boss. The game runs on AMD Threadripper Pro CPUs for GeForce NOW, allowing members to enjoy high-quality graphics. And RTX 3080 members get the added benefits of ultra-low latency, higher streaming frame rates, maximized eight-hour sessions and dedicated RTX 3080 servers.
Tap Into Tevyat With ‘Genshin Impact’ Version 3.0
Travelers rejoice: Genshin Impact is now streaming to iOS, iPadOS and Android mobile devices with touch controls.
The launch of game developer HoYoverse’s free-to-play, open-world, action role-playing game on GeForce NOW has been hugely successful, and members can now continue their journeys with their PCs, Macs or Chromebooks.
Mobile touch controls for Genshin Impact are now available for all GeForce NOW members who prefer gaming on their phones and tablets or only have time to play on the go. Jump in to start playing at PC quality. No downloads or accessories needed – just fingers!
Tap into Tevyat.
The timing for touch controls couldn’t be better, as HoYoverse just released Genshin Impact’s biggest update of the year, “The Morn a Thousand Roses Brings.” It adds Sumeru, the fourth of the game’s seven major nations, and Dendro, the last of the game’s seven-element system. A new nation to explore and Dendro playable characters to recruit for the first time ever — it’s all available to stream on GeForce NOW from nearly any device.
Great things come in threes. Version 3.0 brings the massive region of Sumeru and three new characters from there.
Dragons Are Coming
Guild War 2 comes to Steam this week, and for a limited time members can redeem the “Emblazoned Dragon Throne” in-game reward for free. It’s a heroic seat fit for an adventurer and another perk of being a GeForce NOW member.
Why sit in a standard chair when you could sit on a throne emblazoned with dragons?
Getting membership rewards for streaming games on the cloud is easy. Log in to your NVIDIA account and select “GEFORCE NOW” from the header. Then, scroll down to “REWARDS” and click the “UPDATE REWARDS SETTINGS” button. Check the box in the dialogue window that shows up to start receiving special offers and in-game goodies.
Sign up for the GeForce NOW newsletter, including notifications for when rewards are available, by logging into your NVIDIA account and selecting “PREFERENCES” from the header. Check the “Gaming & Entertainment” box and “GeForce NOW” under topic preferences.
Non-Stop Action
Dragons, dragons, dragons. Century: Age of Ashes is a free-to-play multiplayer dragon battle game.
Check out the 13 new games available to stream on GeForce NOW this week:
With all of these new games to choose from, there’s an option for everyone. Speaking of options, we’ve got a question for you. Let us know your pick on Twitter or in the comments below.
Three doors appear in front of you. Left: You become a crime boss Center: Everything you touch becomes a cloud Right: You get a pet dragon
AI Centers of Excellence are organizational units dedicated to implementing a company-wide AI vision. They help identify business use cases, create an implementation roadmap, accelerate adoption, assess impact and more.
NVIDIA GTC, a global conference on AI and the metaverse, brings together the world’s top business and technology leaders who’ve embraced artificial intelligence to transform their organizations.
The virtual conference, running Sept. 19-22, will feature talks from visionary leaders at companies including ByteDance, Deutsche Bank and Johnson & Johnson. Attend to explore real-world AI use cases, discover implementation strategies and get business tips from subject-matter experts across industries.
About 86% of business and tech executives expect AI to become a mainstream technology in their companies, according to a PwC survey. Such results show that advanced data analytics and AI software will be necessary for businesses to remain competitive across industries.
Industry leaders who take a holistic approach to data science and AI have experienced substantially greater benefits from AI initiatives compared with those who take a piecemeal approach. Reported advantages include about a 40% improvement in decision making, productivity through automation and customer experience, as well as the creation of more innovative products and services.
Accelerated computing platforms and frameworks now allow AI to be deployed quickly and at scale.
Check out the following GTC sessions for an inside look at how executives are driving AI adoption in the world’s most successful companies:
5G Killer App: Making Augmented and Virtual Reality a Reality, featuring Bill Vass, vice president of engineering at AWS; Brian Mecum, vice president of device technology at Verizon; Peter Linder, head of 5G marketing for North America at Ericsson; and Veronica Yip, product manager and product marketing manager at NVIDIA.
Floods in Kentucky and wildfires in California are the kinds of disasters companies of all sorts are trying to address with AI.
Tom Rikert, co-founder and CEO of San Francisco-based startup Masterful AI, is one of many experts helping them manage catastrophe risk.
In the U.S. alone, the National Association of Insurance Commissioners estimates that natural disasters cost $232 billion in 2019. In the face of such costs, regulators worldwide are pressing banks and corporations to be proactive.
“Institutions are expected to understand the impact of climate-related and environmental risks … in order to be able to make informed strategic and business decisions,” Europe’s central bank said in guidelines published in late 2020.
How AI Turns Data Into Insights
The good news is companies can access petabytes of geospatial images from daily satellite and drone feeds to detect and assess these risks.
“Humans can’t review all that data, so they need computer vision to find the patterns,” said Rikert. “That’s why AI’s now essential for managing catastrophe risk.”
Masterful AI uses semi-supervised machine learning, so companies only need to manually label a small fraction of the images they want to use to train AI models. It also supplies software to automate the job of quickly training models that sift through data for actionable insights.
More Flexible, Accurate Models
An analytics company recently used Masterful AI’s tools to detect and classify damaged or rusted transformers that could spark a wildfire, critical insights for utilities.
The software reduced error rates in AI models by over half and cut by two-thirds the time to build new models. Because Masterful can efficiently tap large volumes of unlabeled data for training, it also helped models detect more kinds of component defects across a wider range of background terrains.
“That’s a very high ROI for this field,” said Rikert, who earned a master’s degree from MIT in machine learning and an MBA from Harvard.
Growing Demand and Domains
The startup has worked with several customers and analysis firms that evaluate disasters, pollution and land-use plans. For example, it helped an insurance company improve damage assessments after disasters like hurricanes and hailstorms.
“We see a lot of demand from people who have data and models they’re trying to make more accurate and apply to more domains,” Rikert said.
Masterful AI builds and tests its models on PCs using a mix of NVIDIA GPUs, then runs its largest benchmarks on NVIDIA A100 Tensor Core GPUs in the cloud. Likewise, its customers use the tools locally and in the cloud.
From Laptops to the Cloud
“NVIDIA AI is very portable, so it’s easy to go from local development to a cloud deployment — that’s not the case for some platforms,” Rikert said.
Masterful AI also helps customers maximize their use of the memory packed in NVIDIA GPUs to accelerate training time.
“Without NVIDIA GPUs, we would not be able to accomplish our work,” he said. “It’s not feasible to train our models on CPUs, and we found NVIDIA GPUs have the best combination of operator support, performance and price compared to other accelerators.”
Synthetic Data Fills Gaps
Masterful AI is a member of NVIDIA Inception, a free, global program that helps startups access new technologies, expertise and investors. Thanks to Inception, Rikert’s team aims to test Omniverse Replicator to generate synthetic data that could further improve AI training.
Synthetic data is increasingly used to augment real-world datasets. It can improve AI performance on edge cases and situations where users lack real-world data.
“We see opportunities to improve AI model quality by helping optimize the mix of synthetic, labeled and unlabeled data customers use,” he said.
Broad Ecosystem for Risk Modeling
NVIDIA supports catastrophe-risk products from established software vendors and dozens of startups that are also members of Inception.
For example, Riskthinking.AI, in Toronto, uses probability models, augmented by AI, to create estimates of the financial impact of climate change. In addition, Heavy.ai in San Francisco provides GPU-accelerated analytics and visualization tools to help identify opportunities and risks hidden in massive geospatial and time-series datasets.
Lockheed Martin uses NVIDIA AI to help U.S. agencies fight wildfires. The UN Satellite Centre works with NVIDIA to manage climate risks and train data scientists on how to respond to floods.
Global solution integrators including Accenture, Deloitte and Ernst & Young also deliver NVIDIA-accelerated catastrophe risk products.
It’s a broad ecosystem fighting a growing set of disasters exacerbated by climate change.
“Catastrophes are unfortunately becoming more prevalent, so we’re using our experience working with customers and partners to help others get insights faster by automating their model development,” said Rikert.
Recent AI advances enable modeling of weather forecasting 4-5 magnitudes faster than traditional computing methods.
The brightest leaders, researchers and developers in climate science, high performance computing and AI will discuss such technology breakthroughs — and how they can help foster a greener Earth — at NVIDIA GTC.
The virtual conference, running Sept. 19-22, also includes expert talks about more industries that will be transformed by AI, including healthcare, robotics, graphics and the industrial metaverse.
A dozen sessions will cover how accelerated computing can be used to predict, detect and mitigate climate-related issues. Some can’t-miss speakers include the following:
Editor’s note: This post is part of our weekly In the NVIDIA Studio series, which celebrates featured artists, offers creative tips and tricks, and demonstrates how NVIDIA Studio technology accelerates creative workflows.
A triple threat steps In the NVIDIA Studio this week: a tantalizing trio of talented 3D artists who each reimagined and remastered classic European buildings with individualistic flair.
Robert Lazăr, Dawid Herda and Dalibor Cee have lived unique creative journeys — from their sources of inspiration; to the tricks they employ in their creative workflows; to the insights they’d share with up-and-coming artists.
NVIDIA Studio hardware and software powered the artists’ creative workflows.
While their techniques and styles may differ, they share an NVIDIA Studio-powered workflow. GPU acceleration in creative apps gave them the freedom to fast-track their artistry. AI-powered features accelerated by NVIDIA RTX GPUs reduced repetitive, tedious work, giving back valuable time for them to tinker with and perfect their projects.
Romanian Rendering
Lazăr, who also goes by Eurosadboy, is a self-taught 3D artist with 17 years of experience, as well as an esteemed musician who embarks on a new adventure with each piece that he creates.
While exploring his hometown of Bucharest, Lazăr was delightfully overwhelmed by the Union of Romanian Architects building, with its striking fusion of nostalgia and futurism. Fueled by his passion for science fiction, he saw the opportunity to enhance this iconic building with digital art, featuring elements of the past, present and future.
Lazăr first surveyed the building on site to estimate general sizes, then created a moodboard to gather inspiration from his favorite artists.
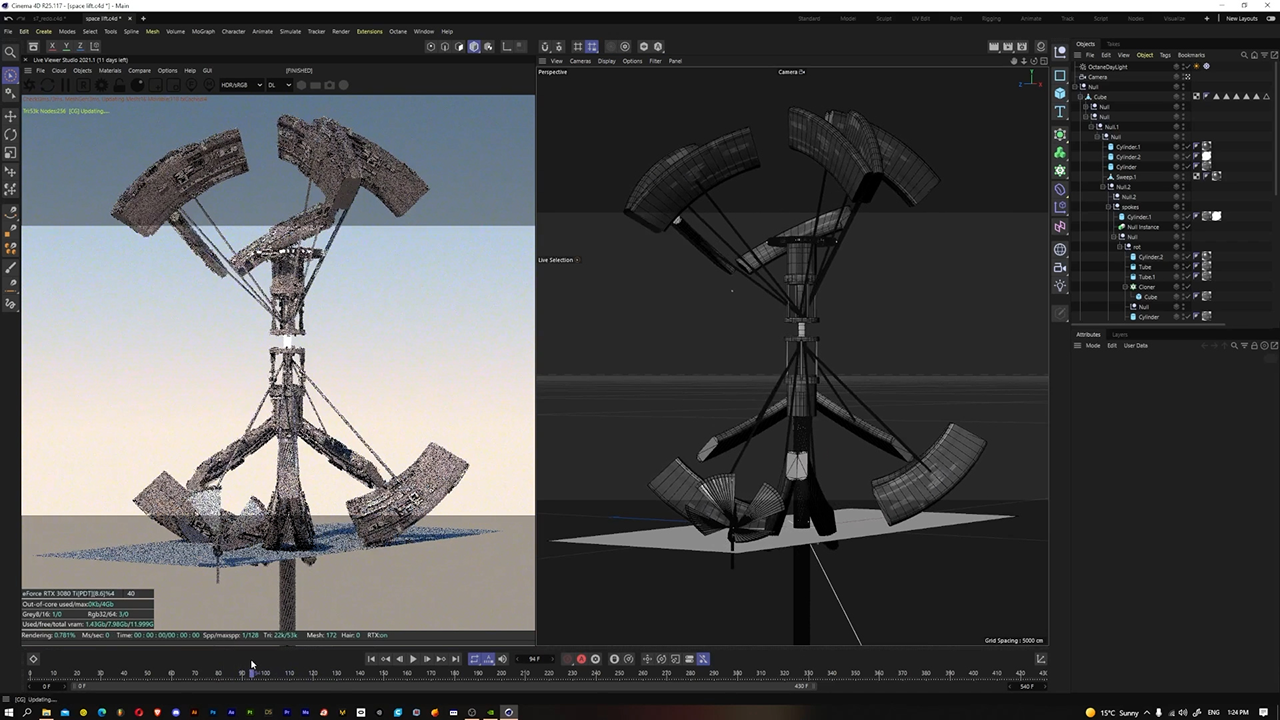
An early iteration of Lazăr’s space lift structure in Cinema 4D.
“Considering that my style trends toward hyperrealism, and given the need for ray tracing in every scene, it was clear the GPU I chose had to be RTX,” Lazăr said.
With his vision in place, Lazăr opened Cinema 4D software and built models to bring the futuristic creation to life. The NVIDIA RTX GPU-accelerated viewport enabled smooth interactivity for these complex 3D shapes while modeling.
He then generated metal, stone and glass textures within the free JSplacement Classic software, then imported them back to Cinema 4D to apply them to his models. Animated elements were added to create his “space elevator” with rotating disks and unfolding arms.
To ensure the scene was lit identically to the original footage, Lazăr used GPU-accelerated ray tracing in Otoy’s Octane to create an ambient-occlusion effect, achieving photorealistic lighting with lightning speed.
Final compositing in Adobe After Effects accelerated by Lazăr’s GeForce RTX 3080 Laptop GPU.
At this stage, Lazăr imported the scene into Adobe After Effects software, then added the digital scene on top of the high-resolution video footage — creating an extraordinarily realistic visual. “The footage was in 4K RAW format, so without the capabilities of the NVIDIA RTX GPU, I wouldn’t have been able to preview in real time — making me spend more time on technical parts and less on creativity,” he said.
Matching colors was critical, the artist added, and thankfully After Effects’ several GPU-accelerated features, including Brightness & Contrast, Change Color and Exposure, helped him get the job done.
Making use of his GeForce 3080 Ti GPU and ASUS ProArt NVIDIA Studio laptop, Lazăr created this work of 3D art faster and more efficiently.
Polish Pride
Dawid Herda, known widely as Graffit, has been an artist for more than a decade. He’s most inspired by his experiences hitchhiking across his home country, Poland.
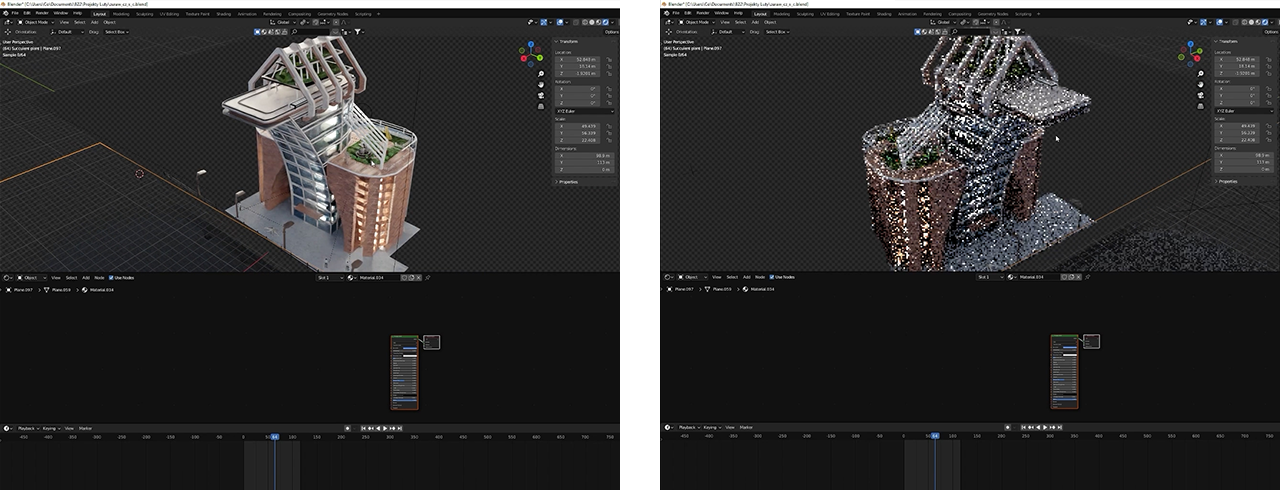
Visiting Gdańsk, Herda found that the architecture of the city’s 600-year-old maritime crane sparked ideas for artistic transformation. He visualized the crane as a futuristic tower of metal and glass, drawing from the newer glass-fronted buildings that flank the old brick structure.
His workflow takes advantage of NVIDIA Omniverse, a platform for 3D design collaboration and world simulation, free for RTX GPU owners. The open-source, extensible Universal Scene Description file format gave Herda the freedom to work within several 3D apps at once, without having to repeatedly import and export between them. Plus, he shared his creation with fellow artists in real time, without his colleagues requiring advanced hardware.
“All these features make the job of complex design much more efficient, saving me a lot of time and freeing me to focus on creativity,” said Herda.
3D motion tracking in Blender.
Herda accessed the Omniverse Connector for Blender to accomplish 3D motion tracking, which is the simulation of live-action camera moves and perspective inside compositing software. From 4K ProRes footage of the crane captured by drone, Herda selected his favorite shots before importing them. He traced the camera movement and mapped perspective in the scene using specific points from the shots.
Blender with the AI denoising feature on vs. off.
“You often have to jump between apps, but thanks to NVIDIA Studio, everything becomes faster and smoother,” Herda said.
Then, Herda added his futuristic building variant, which was created and modeled from scratch. The AI denoising feature in the viewport and RTX GPU-accelerated ray tracing gave Herda instant feedback and crisp, beautiful details.
The artist made the foundational 3D model of the crane using simple blocks that were transformed by modeling and detailing each element. He swapped textures accurately in real time as he interacted with the model, achieving the futuristic look without having to wait for iterations of the model to render.
After animating each building shape, Herda quickly exported final frame renders using RTX-accelerated OptiX ray tracing. Then, he imported the project into After Effects, where GPU-accelerated features were used in the composite stage to round out the project.
His creative setup included a home PC equipped with a GeForce RTX 3090 GPU and an ASUS ZenBook Pro Duo NVIDIA Studio laptop with a GeForce RTX 3080 Laptop GPU. This meant Herda could create his photorealistic content anywhere, anytime.
Czech Craft
Dalibor Cee turned a childhood fascination with 3D into a 20-year career. He started working with 3D architectural models before returning home to Prague to specialize in film special effects like fluid simulations, smoke and explosions.
Dalibor also enjoys projection mapping as a way to bring new light and feeling to old structures, such as the astronomical clock on the iconic Orloj building in Prague’s Old Town Square.
Fascinated by the circular elements of the clock, Dalibor reimagined them in his Czech sci-fi-inspired style by creating a lens effect and using shiny, golden elements and crystal shapes.
Dalibor applies various textures to multiple clock face layers.
The artist started in Blender for motion tracking to align his video footage with the 3D building blocks that would make up the main animation. Dalibor then added textures generated using the JSplacement tool. He experimented with colors, materials and masks to alter the glossiness or roughness, emission and specular aspects of each element.
Link objects on curves captured animations with keyframes in Blender.
“I use apps that need NVIDIA CUDA and PhysX, and generally all software has some advantage when used with NVIDIA RTX GPUs in 3D,” Dalibor said.
The models were then linked onto curves to be animated for forward, backward and rotating movements — similar to those of an optical zoom lens, creating animation depth. Dalibor achieved this with dramatic speed by using Blender Cycles RTX-accelerated OptiX ray tracing in the viewport.
This kind of work is very time and memory intensive, Dalibor said, but his two GeForce RTX 3090 Ti GPUs allow him to complete extra-large projects without having to waste hours on rendering. Blender’s Cycles engine with RTX-accelerated OptiX ray tracing and AI denoising enabled Dalibor to render the entire project in just 20 minutes — nearly 20x faster than with the CPU alone, according to his testing.
These time savings allowed Dalibor to focus on creating and animating the piece’s hundreds of elements. He combined colors and effects to bring the model to life in exactly the way he’d envisioned.
NVIDIA Studio systems have become essential for the next generation of 3D content creators, pushing boundaries to create inspirational, thought-provoking and emotionally intensive art.
Studio Success Stories
For a deeper understanding of their workflows, see how Lazăr, Herda and Dalibor brought their creations from concept to completion in their in-depth videos.
In the spirit of learning, the NVIDIA Studio team is posing a challenge for the community to show off personal growth. Participate in the #CreatorsJourney challenge for a chance to be showcased on NVIDIA Studio social media channels.
Entering is easy. Post an older piece of artwork alongside a more recent one to showcase your growth as an artist. Follow and tag NVIDIA Studio on Instagram, Twitter or Facebook, and use the #CreatorsJourney tag to join.
It’s time to show how you’ve grown as an artist (just like @lowpolycurls)!
Join our #CreatorJourney challenge by sharing something old you created next to something new you’ve made for a chance to be featured on our channels.






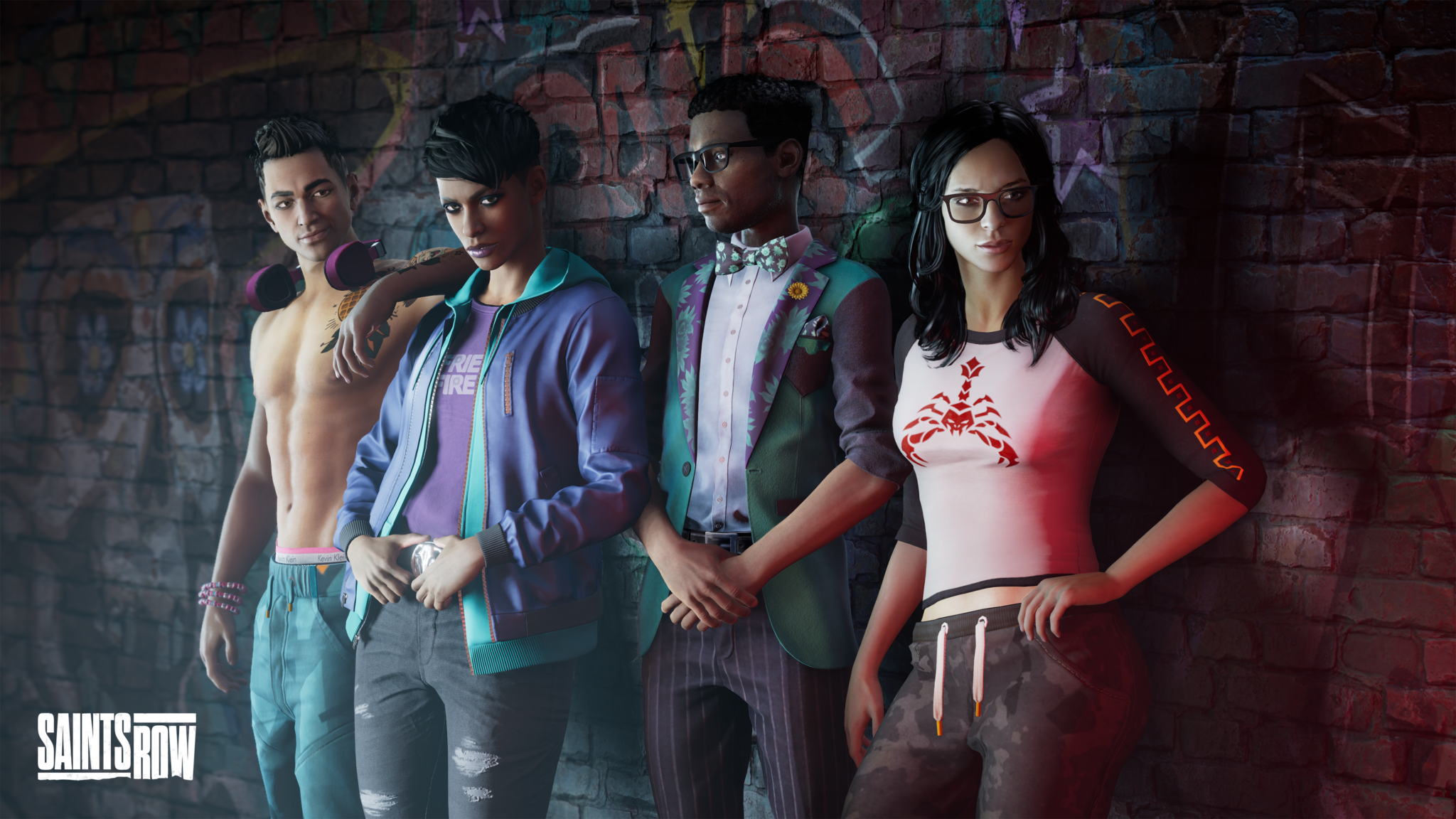






 NVIDIA GeForce NOW (@NVIDIAGFN)
NVIDIA GeForce NOW (@NVIDIAGFN) 



 It’s time to show how you’ve grown as an artist (just like
It’s time to show how you’ve grown as an artist (just like 
