Editor’s note: This post is part of our weekly In the NVIDIA Studio series, which celebrates featured artists, offers creative tips and tricks, and demonstrates how NVIDIA Studio technology accelerates creative workflows.
The future of content creation is in AI. This week In the NVIDIA Studio, discover how AI-assisted painting is bringing a new level of inspiration to the next generation of artists.
San Francisco-based creator Karen X. Cheng is on the forefront of using AI to design amazing visuals. Her innovative work produces eye-catching effects to social media videos for brands like Adobe, Beats by Dre and Instagram.
Cheng’s work bridges the gap between emerging technologies and creative imagery, and her inspiration can come from anywhere. “I usually get ideas when I’m observing things — whether that’s taking a walk or scrolling in my feed and seeing something cool,” she said. “Then, I’ll start jotting down ideas and sketching them out. I’ve got a messy notebook full of ideas.”
When inspiration hits, it’s important to have the right tools. Cheng’s ASUS Zenbook Pro Duo — an NVIDIA Studio laptop that comes equipped with up to a GeForce RTX 3080 GPU — gives her the power she needs to create anywhere.
Paired with the NVIDIA Canvas app, a free download available to anyone with an NVIDIA RTX or GeForce RTX GPU, Cheng can easily create and share photorealistic imagery. Canvas is powered by the GauGAN2 AI model and accelerated by Tensor Cores found exclusively on RTX GPUs.
“I never had much drawing skill before, so I feel like I have art superpowers.”
The app uses AI to interpret basic lines and shapes, translating them into realistic landscape images and textures. Artists of all skill levels can use this advanced AI to quickly turn simple brushstrokes into realistic images, speeding up concept exploration and allowing for increased iteration, while freeing up valuable time to visualize ideas.
“I’m excited to use NVIDIA Canvas to be able to sketch out the exact landscapes I’m looking for,” said Cheng. “This is the perfect sketch to communicate your vision to an art director or location scout. I never had much drawing skill before, so I feel like I have art superpowers with this thing.”
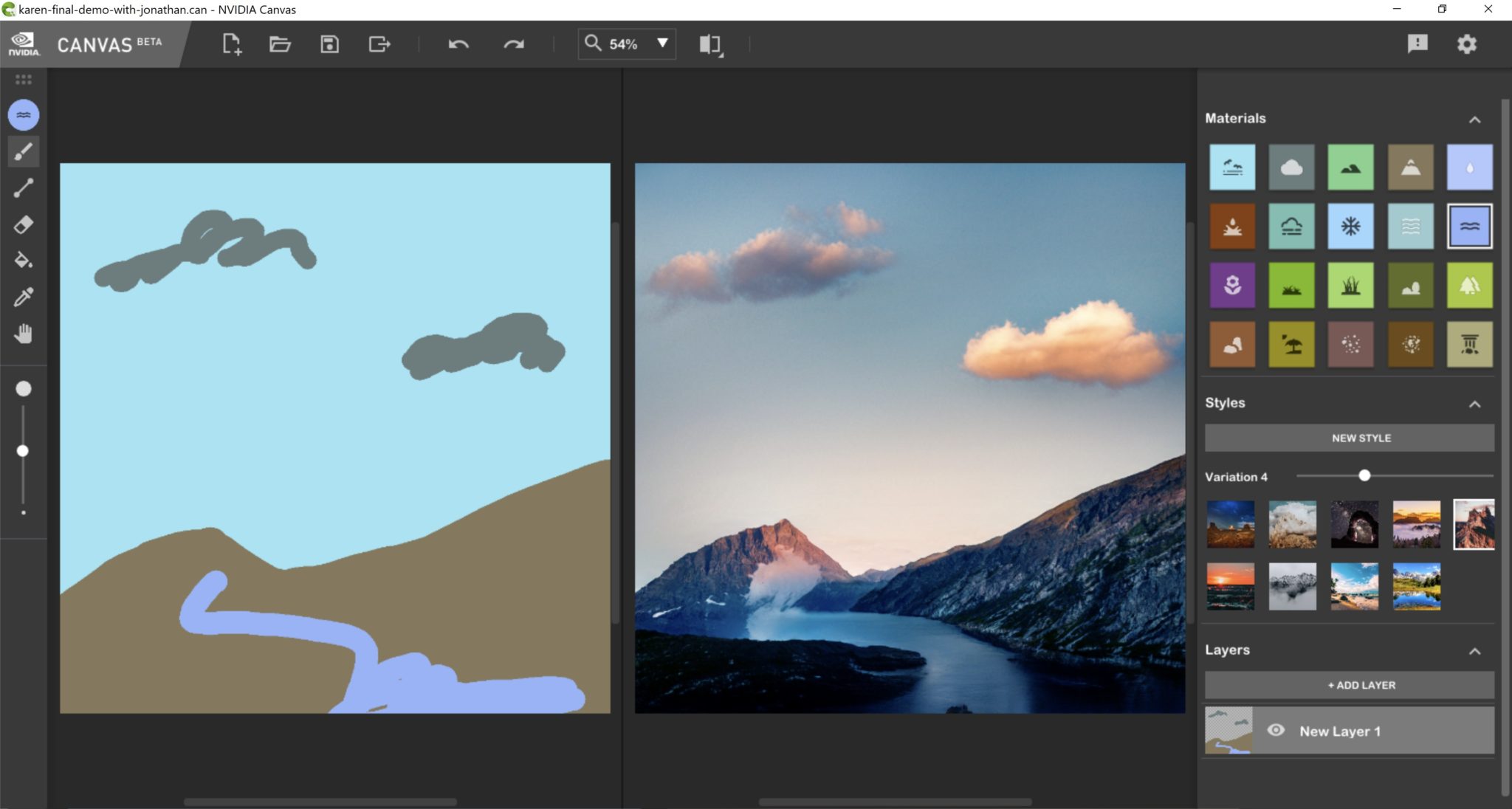
Cheng plans to put these superpowers to the test in an Instagram live stream on Thursday, May 12, where she and her AI Sketchpad collaborator Don Allen Stevenson III will race to paint viewer challenges using Canvas.
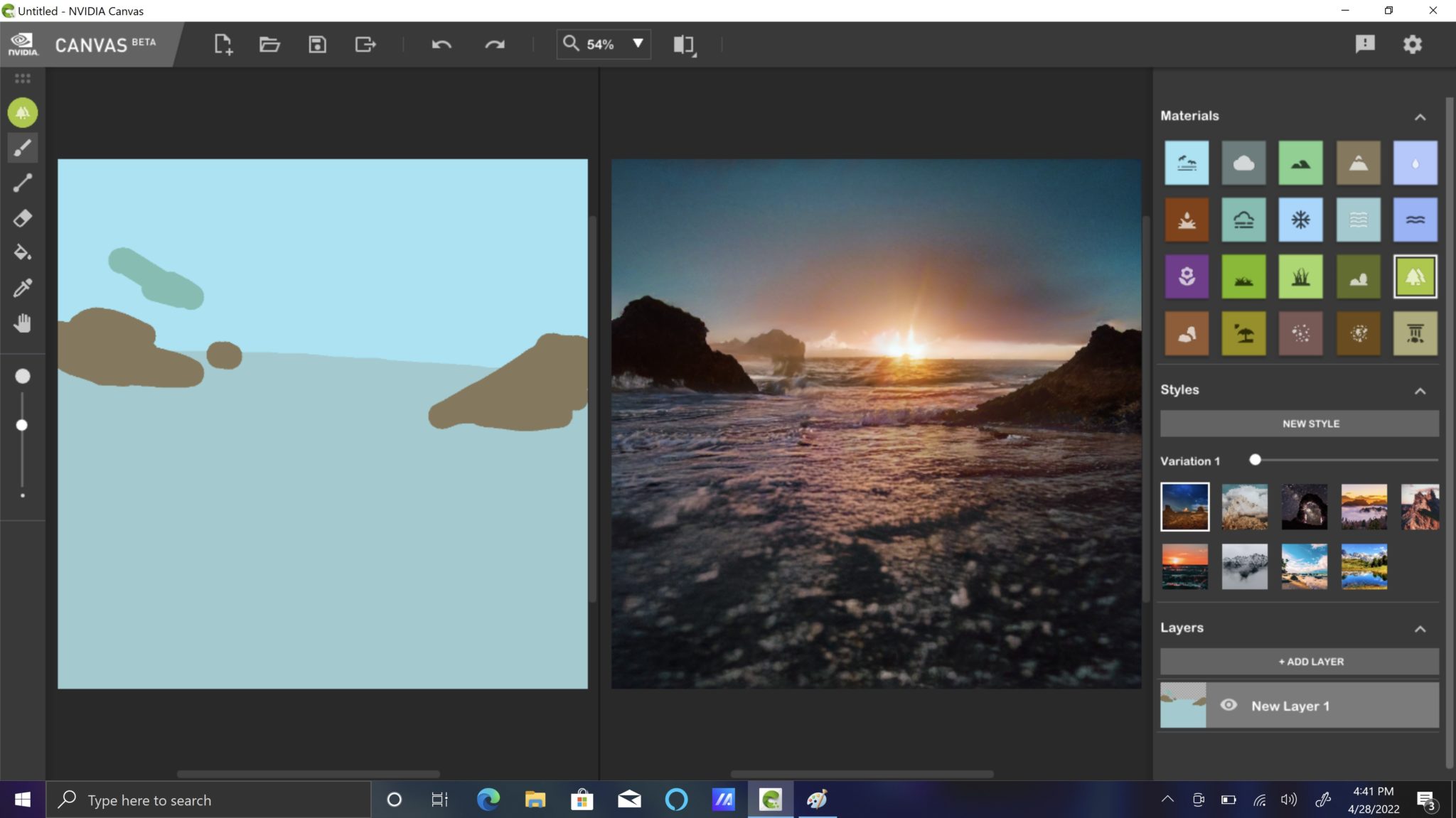
Tune in to contribute, and download NVIDIA Canvas to see how easy it is to paint by AI.
With AI, Anything Is Possible
Empowering scribble-turn-van Gogh painting abilities is just one of the ways that NVIDIA Studio is transforming creative technology through AI.
NVIDIA Broadcast uses AI running on RTX GPUs to improve audio and video for broadcasters and live streamers. The newest version can run multiple neural networks to apply background removal, blur and auto-frame for webcams, and remove noise from incoming and outgoing sound.
3D artists can take advantage of AI denoising in Autodesk Maya and Blender software, refine color detail across high-resolution RAW images with Lightroom’s Enhance Details tool, enable smooth slow motion with retained b-frames using DaVinci Resolve’s SpeedWarp and more.
NVIDIA AI researchers are working on new models and methods to fuel the next generation of creativity. At GTC this year, NVIDIA debuted Instant NeRF technology, which uses AI models to transform 2D images into high-resolution 3D scenes, nearly instantly.
Instant NeRF is an emerging AI technology that Cheng already plans to implement. She and her collaborators have started experimenting with bringing 2D scenes to 3D life.
More AI Tools In the NVIDIA Studio
AI is being used to tackle complex and incredibly challenging problems. Creators can benefit from the same AI technology that’s applied to healthcare, automotive, robotics and countless other fields.
The NVIDIA Studio YouTube channel offers a wide range of tips and tricks, tutorials and sessions for beginning to advanced users.
CGMatter hosts Studio speedhack tutorials for beginners, showing how to use AI viewport denoising and AI render denoising in Blender.
Many of the most popular creative applications from Adobe have AI-powered features to speed up and improve the creative process.
Neural Filters in Photoshop, Auto Reframe and Scene Edit Detection in Premiere Pro, and Image to Material in Substance 3D all make creating quicker and easier through the power of AI.
Follow NVIDIA Studio on Instagram, Twitter and Facebook; access tutorials on the Studio YouTube channel; and get updates directly in your inbox by signing up for the NVIDIA Studio newsletter.
What’s your favorite NVIDIA Canvas creation?
Show us below.
— NVIDIA Studio (@NVIDIACreators) May 9, 2022

The post Creator Karen X. Cheng Brings Keen AI for Design ‘In the NVIDIA Studio’ appeared first on NVIDIA Blog.




 NVIDIA GeForce NOW (@NVIDIAGFN)
NVIDIA GeForce NOW (@NVIDIAGFN)