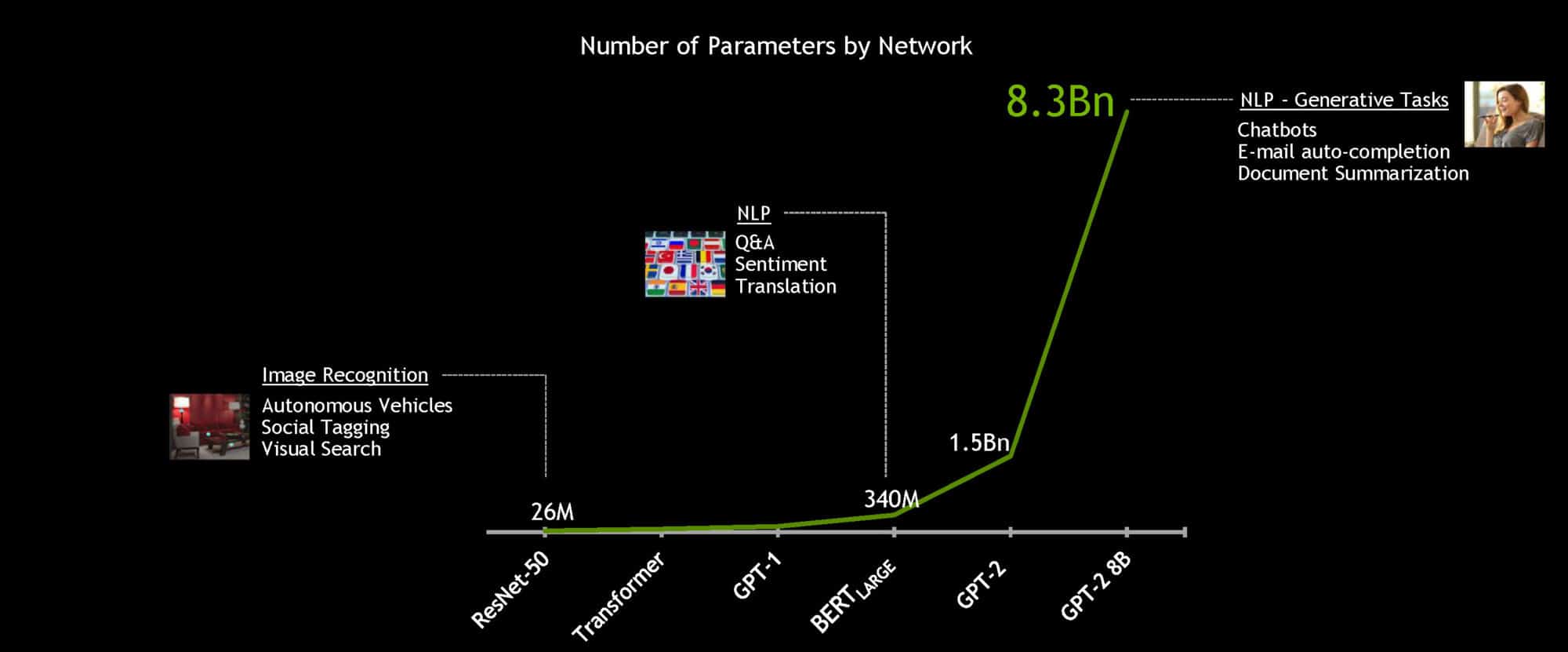
Everything we do on the internet — which is just about everything we do these days — depends on the work of clusters, which are also called pods.
When we stream a hot new TV show, order a pair of jeans or Zoom with grandma, we use clusters. You’re reading this story thanks to pods.
So, What Is a Cluster? What Is a Pod?
A cluster or a pod is simply a set of computers linked by high-speed networks into a single unit.
Computer architects must have reached, at least unconsciously, for terms rooted in nature. Pea pods and dolphin superpods, like today’s computer clusters, show the power of many individuals working as a team.
The Roots of Pods and Superpods
The links go deeper. Botanists say pods not only protect and nourish individual peas, they can reallocate resources from damaged seeds to thriving ones. Similarly, a load balancer moves jobs off a failed compute node to a functioning one.
The dynamics aren’t much different for dolphins.
Working off the coast of the Bahamas, veteran marine biologist Denise Herzing often sees every day the same pods, family groups of perhaps 20 dolphins. And once she encountered a vastly larger group.
“Years ago, off the Baja peninsula, I saw a superpod. It was very exciting and a little overwhelming because as a researcher I want to observe a small group closely, not a thousand animals spread over a large area,” said the founder of the Wild Dolphin Project.
For dolphins, superpods are vital. “They protect the travelers by creating a huge sensory system, a thousand sets of ears that listen for predators like one super-sensor,” she said, noting the parallels with the clusters used in cloud computing today.

Pods Sprout in Early Data Centers
As companies began computerizing their accounting systems in the early 1960s, they instinctively ganged multiple computers together so they would have backups in case one failed, according to Greg Pfister, a former IBM technologist and an expert on clusters.
“I’m pretty sure NCR, MetLife and a lot of people did that kind of thing,” said Pfister, author of In Search of Clusters, considered by some the bible of the field.
In May 1983, Digital Equipment Corp. packed several of its popular 32-bit VAX minicomputers into what it called a VAXcluster. Each computer ran its own operating system, but they shared other resources, providing IT users with a single system image.

By the late 1990s, the advent of low-cost PC processors, Ethernet networks and Linux inspired at least eight major research projects that built clusters. NASA designed one with 16 PC motherboards on two 10 Mbit/second networks and dubbed it Beowulf, imagining it slaying the giant mainframes and massively parallel systems of the day.
Cluster Networks Need Speed
Researchers found clusters could be assembled quickly and offered high performance at low cost, as long as they used high-speed networks to eliminate bottlenecks.
Another late ‘90’s project, Berkeley’s Network of Workstations (NoW), linked dozens of Sparc workstations on the fastest interconnects of the day. They created an image of a pod of small fish eating a larger fish to illustrate their work.

One researcher, Eric Brewer, saw clusters were ideal for emerging internet apps, so he used the 100-server NoW system as a search engine.
“For a while we had the best search engine in the world running on the Berkeley campus,” said David Patterson, a veteran of NoW and many computer research projects at Berkeley.
The work was so successful, Brewer co-founded Inktomi, an early search engine built on a NoW-inspired cluster of 1,000 systems. It had many rivals, including a startup called Google with roots at Stanford.
“They built their network clusters out of PCs and defined a business model that let them grow and really improve search quality — the rest was history,” said Patterson, co-author of a popular textbook on computing.
Today, clusters or pods are the basis of most of the world’s TOP500 supercomputers as well as virtually all cloud computing services. And most use NVIDIA GPUs, but we’re getting ahead of the story.
Pods vs. Clusters: A War of Words
While computer architects called these systems clusters, some networking specialists preferred the term pod. Turning the biological term into a tech acronym, they said POD stood for a “point of delivery” of computing services.
The term pod gained traction in the early days of cloud computing. Service providers raced to build ever larger, warehouse-sized systems often ordering entire shipping containers, aka pods, of pre-configured systems they could plug together like Lego blocks.

More recently, the Kubernetes group adopted the term pod. They define a software pod as “a single container or a small number of containers that are tightly coupled and that share resources.”
Industries like aerospace and consumer electronics adopted the term pod, too, perhaps to give their concepts an organic warmth. Among the most iconic examples are the iPod, the forerunner of the iPhone, and the single-astronaut vehicle from the movie 2001: A Space Odyssey.
When AI Met Clusters
In 2012, cloud computing services heard the Big Bang of AI, the genesis of a powerful new form of computing. They raced to build giant clusters of GPUs that, thanks to their internal clusters of accelerator cores, could process huge datasets to train and run neural networks.
To help spread AI to any enterprise data center, NVIDIA packs GPU clusters on InfiniBand networks into NVIDIA DGX Systems. A reference architecture lets users easily scale from a single DGX system to an NVIDIA DGX POD or even a supercomputer-class NVIDIA DGX SuperPOD.
For example, Cambridge-1, in the United Kingdom, is an AI supercomputer based on a DGX SuperPOD, dedicated to advancing life sciences and healthcare. It’s one of many AI-ready clusters and pods spreading like never before. They’re sprouting like AI itself, in many shapes and sizes in every industry and business.
The post What Is a Cluster? What Is a Pod? appeared first on The Official NVIDIA Blog.


 Cloud gaming streams the latest games from powerful GPUs in remote data centers to nearly any device.
Cloud gaming streams the latest games from powerful GPUs in remote data centers to nearly any device. GeForce NOW empowers you to take your PC games with you, wherever you go.
GeForce NOW empowers you to take your PC games with you, wherever you go. Over 80 percent of GeForce NOW members are playing on devices that don’t meet the min spec for the games they’re playing.
Over 80 percent of GeForce NOW members are playing on devices that don’t meet the min spec for the games they’re playing. NVIDIA RTX servers provide the backbone for GeForce NOW.
NVIDIA RTX servers provide the backbone for GeForce NOW.