A guest post by Sandeep Mistry, Arm
|
|
| Some tools you’ll need for this project (learn more below!) |
Introduction
Machine learning enables developers and engineers to unlock new capabilities in their applications. Instead of explicitly defining instructions and rules for a computer to execute, you can collect large amounts of data for a classification task that your application requires, and train an ML model to learn from the patterns in the data.
Training typically happens in the cloud on computers equipped with one or more GPUs. Once a model has been trained, depending on its size, it can be deployed for inference on a wide range of devices. These devices range from large computers in the cloud with gigabytes of memory, to tiny microcontrollers (or MCUs) which typically have just kilobytes of memory.
Microcontrollers are low-power, self-contained, cost-effective computer systems that are embedded in devices that you use everyday, such as your microwave, electric toothbrush, or smart door lock. Microcontroller based systems typically interact with their surrounding environment via one or more sensors (think buttons, microphones, motion sensors) and perform an action using one or more actuators (think LEDs, motors, speakers).
Microcontrollers also offer privacy advantages, and can perform inference locally on the device, without needing to send any data to the cloud. This can have power advantages too for devices running off batteries.
In this article, we will demonstrate how an Arm Cortex-M based microcontroller can be used for local on-device ML to detect audio events from its surrounding environment. This is a tutorial-style article, and we’ll guide you through training a TensorFlow based audio classification model to detect a fire alarm sound.
We’ll show you how to use TensorFlow Lite for Microcontrollers with Arm CMSIS-NN accelerated kernels to deploy the ML model to an Arm Cortex-M0+ based microcontroller board for local on-device ML inference. Arm’s CMSIS-DSP library, which provides optimized Digital Signal Processing (DSP) function implementations for Arm Cortex-M processors, will also be used to extract features from the real-time audio data before inference.
While this guide focuses on detecting a fire alarm sound, it can be adapted for other sound classification tasks. You may also need to adapt the feature extraction stages and/or adjust ML model architecture for your use case.
An interactive version of this tutorial is available on Google Colab and all technical assets for this guide can be found on GitHub.
What you need to to get started
Development Environment
Hardware
You’ll need one of the following development boards that are based on Raspberry Pi’s RP2040 MCU chip that was released early in 2021.
SparkFun RP2040 MicroMod and MicroMod ML Carrier
This board is great for folks new to electronics and microcontrollers. It does not require a soldering iron, knowing how to solder, or how to wire up breadboards.
Raspberry Pi Pico and PDM microphone board
This option is great if you know how to solder (or would like to learn). It requires a soldering iron and knowledge of how to wire a breadboard with electronic components. You’ll need:
Both of the options above will allow you to collect real-time 16 kHz audio from a digital microphone and process the audio signal on the development board’s Arm Cortex-M0+ processor, which operates at 125 MHz. The application running on the Arm Cortex-M0+ will have a Digital Signal Processing (DSP) stage to extract features from the audio signal. The extracted features will then be fed into a neural network to perform a classification task to determine if a fire alarm sound is present in the board’s environment.
Dataset
We will start by training a sound classifier (for many events) with TensorFlow using the ESC-50: Dataset for Environmental Sound Classification. After training on this broad dataset, we will use Transfer Learning to fine tune it for our specific audio classification task.
This model will be trained on the ESC-50 dataset, which contains 50 types of sounds. Each sound category has 40 audio files that are 5 seconds each in length. Each audio file will be split into 1 second soundbites, and any soundbites that contain pure silence will be discarded.
|
|
| A sample waveform from the data set of a dog barking. |
Spectrograms
Rather than passing in the time series data directly into our TensorFlow model, we will transform the audio data into an audio spectrogram representation. This will create a 2D representation of the audio signal’s frequency content over time.
The input audio signal we will use will have a sampling rate of 16kHz, this means one second of audio will contain 16,000 samples. Using TensorFlow’s tf.signal.stft(…) function we can transform a 1 second audio signal into a 2D tensor representation. We will choose a frame length of 256 and a frame step of 128, so the output of this feature extraction stage will be a Tensor that has a shape of (124, 129).
|
|
| An audio spectrogram representation of a dog barking. |
The ML model
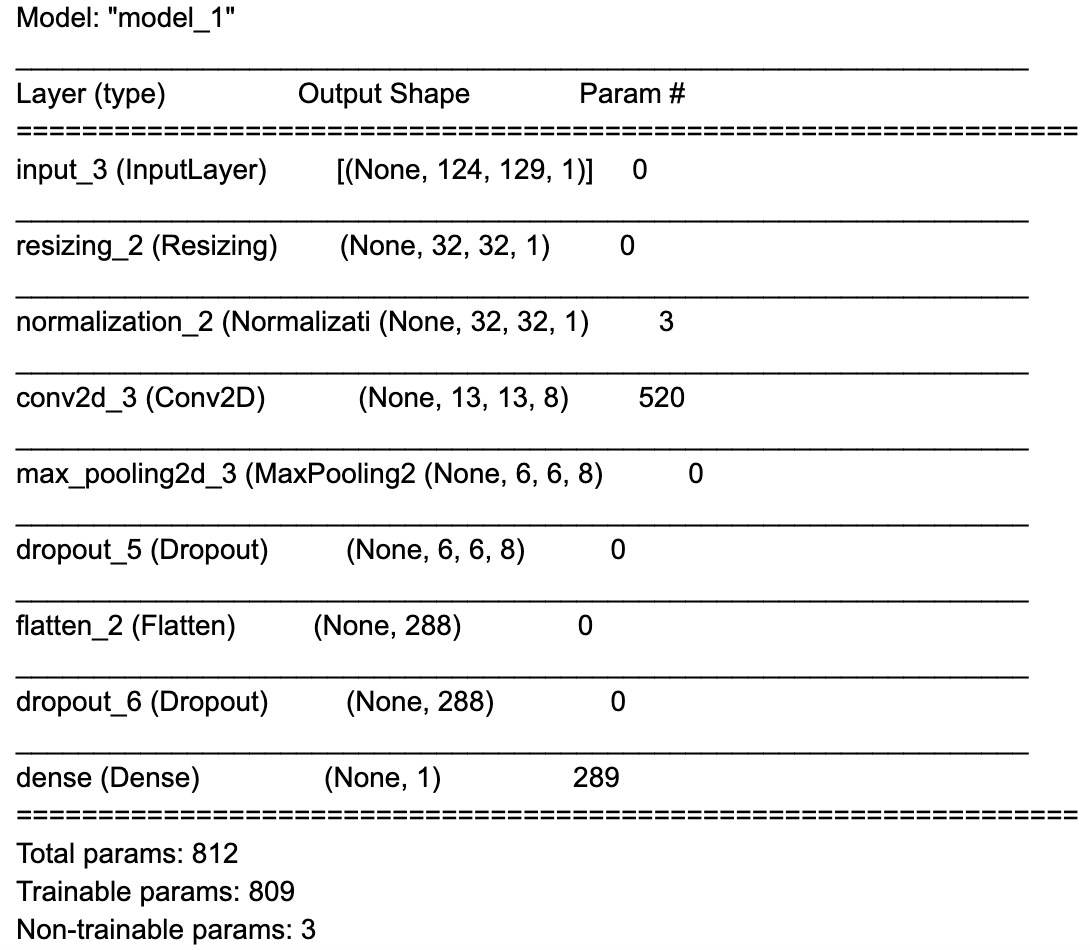
Now that we have the features extracted from the audio signal, we can create a model using TensorFlow’s Keras API. You can find the complete code linked above. The model will consist of 8 layers:
- An input layer.
- A preprocessing layer, that will resize the input tensor from 124x129x1 to 32x32x1.
- A normalization layer, that will scale the input values between -1 and 1
- A 2D convolution layer with: 8 filters, a kernel size of 8×8, and stride of 2×2, and ReLU activation function.
- A 2D max pooling layer with size of 2×2
- A flatten layer to flatten the 2D data to 1D
- A dropout layer, that will help reduce overfitting during training
- A dense layer with 50 outputs and a softmax activation function, which outputs the likelihood of the sound category (between 0 and 1).
The model summary can be found below:
Notice that this model only has about 15K parameters (this is quite small!)
Fine tuning
Now we will use transfer learning and change the classification head (the last Dense layer) of the model to train a binary classification model for fire alarm sounds. We have collected 10 fire alarm clips from freesound.org and BigSoundBank.com. Background noise clips from the SpeechCommands dataset will be used for non-fire alarm sounds. This dataset is small, and enough for us to get started. Data augmentation techniques will be used to supplement the training data we’ve collected.
For real-world applications, it’s important to collect a much larger dataset (you can learn more about best practices on TensorFlow’s Responsible AI website).
Data Augmentation
Data augmentation is a set of techniques used to increase the size of a dataset. This is done by slightly modifying samples from the dataset or by creating synthetic data. In this situation we are using audio and we will create a few functions to augment different samples. We will use three techniques:
- Adding white noise to the audio samples.
- Adding random silence to the audio.
- Mixing two audio samples together.
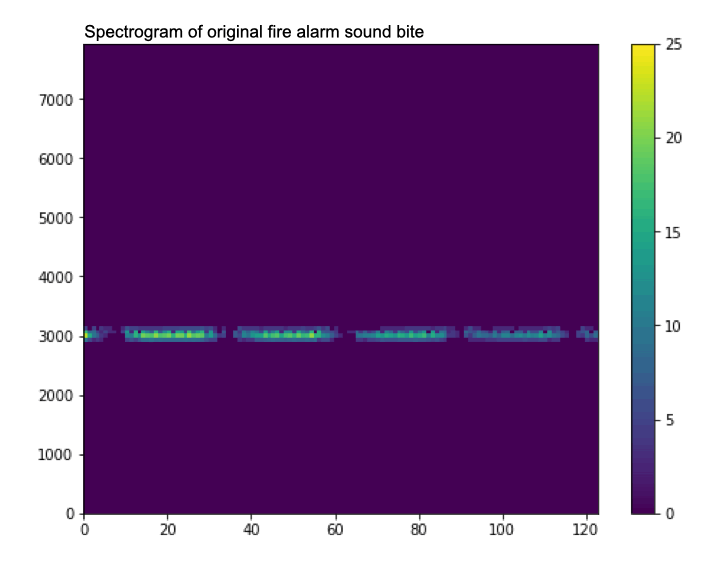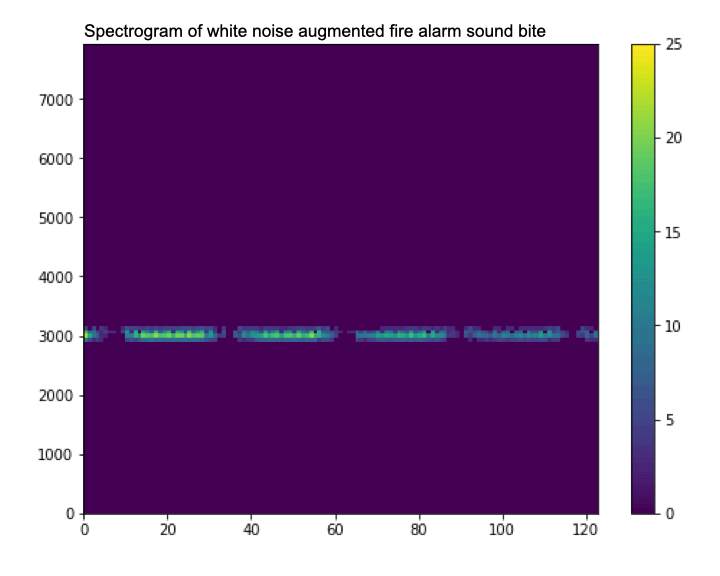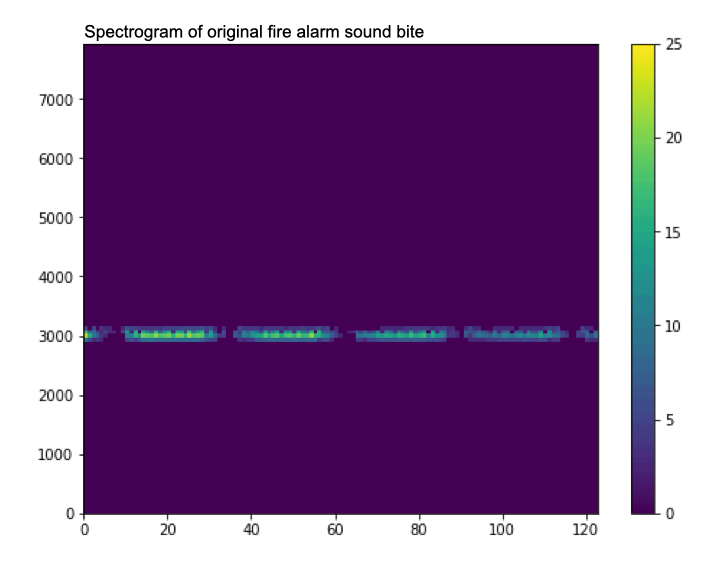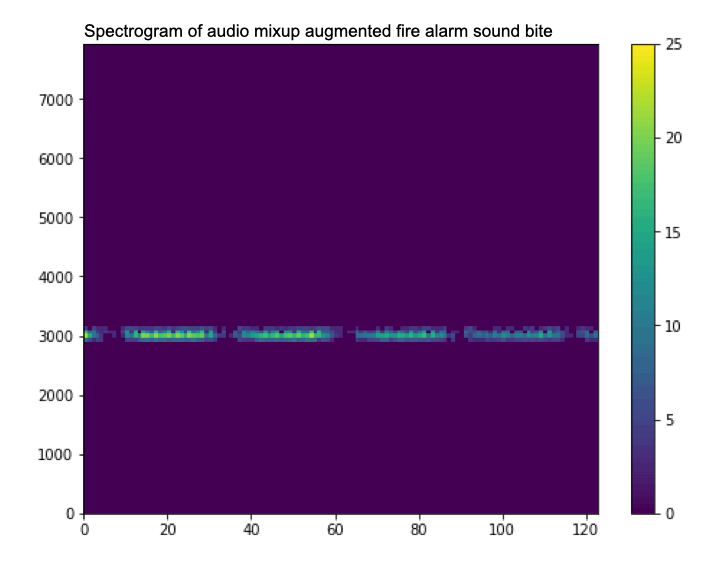
As well as increasing the size of the dataset, data augmentation also helps to reduce overfitting by training the model on different (not perfect) data samples. For example, on a microcontroller you are unlikely to have perfect high quality audio, and so a technique like adding white noise can help the model work in situations where your microphone might every so often have noise in there.
|
|
| A gif showing how data augmentation slightly changes the spectrogram by adding noise (watch it closely, it can be a bit hard to see). |
Feature Extraction
TensorFlow Lite for Microcontroller (TFLu) provides a subset of TensorFlow operations, so we are unable to use the tf.signal.sft(…) API we’ve used for feature extraction of the baseline model on our MCU. However, we can leverage Arm’s CMSIS-DSP library to generate spectrograms on the MCU. CMSIS-DSP contains support for both floating-point and fixed-point DSP operations which are optimized for Arm Cortex-M processors, including the Arm Cortex-M0+ that we will be deploying the ML model to. The Arm Cortex-M0+ does not contain a floating-point unit (FPU) so it would be better to leverage a 16-bit fixed-point DSP based feature extraction pipeline on the board.
We can leverage CMSIS-DSP’s Python Wrapper in the notebook to perform the same operations on our training pipeline using 16-bit fixed-point math. At a high level we can replicate the TensorFlow SFT API with the following CMSIS-DSP based operations:
- Manually creating a Hanning Window of length 256 using the Hanning Window formula along with CMSIS-DSP’s arm_cos_f32 API.
- Creating a CMSIS-DSP arm_rfft_instance_q15 instance and initializing it using CMSIS-DSP’s arm_rfft_init_q15 API.
- Looping through the audio data 256 samples at a time, with a stride of 128 (this matches the parameters we’ve passed into the TF sft API)
- Multiplying the 256 samples by the Hanning Window, using CMSIS-DSP’s arm_mult_q15 API
- Calculating the FFT of the output of the previous step, using CMSIS-DSP’s arm_rfft_q15 API
- Calculating the magnitude of the previous step, using CMSIS-DSP’s arm_cmplx_mag_q15 API
- Each audio soundbites’s FFT magnitude represents the one column of the spectrogram.
- Since our baseline model expects a floating point input, instead of the 16-bit quantized value we were using, the CMSIS-DSP arm_q15_to_float API can be used to convert the spectrogram data from a 16-bit fixed-point value to a floating-point value for training.
The complete Python code for this is a bit long, but can be found in the “Transfer Learning -> Load dataset” section of the Google Colab notebook.
|
|
| Waveform and audio spectrogram of a smoke alarm sound. |
For an in-depth description of how to create audio spectrograms using fixed-point operations with CMSIS-DSP, please see Towards Data Science “Fixed-point DSP for Data Scientists” guide.
Loading the baseline model and changing the classification head
The model we previously trained on the ESC-50 dataset, predicted the presence of 50 sound types, and which resulted in the final dense layer of the model having 50 outputs. The new model we would like to create is a binary classifier, and needs to have a single output value.
We will load the baseline model, and swap out the final dense layer to match our needs:
# We need a new head with one neuron.
model_body = tf.keras.Model(inputs=model.input, outputs=model.layers[-2].output)
classifier_head = tf.keras.layers.Dense(1, activation="sigmoid")(model_body.output)
fine_tune_model = tf.keras.Model(model_body.input, classifier_head)
This results in the following model.summary():
Transfer Learning
Transfer Learning is the process of retraining a model that has been developed for a task to complete a new similar task. The idea is that the model has learned transferable “skills” and the weights and biases can be used in other models as a starting point.
As humans we use transfer learning too. The skills you developed to learn to walk could also be used to learn to run later on.
In a neural network, the first few layers of a model start to perform a “feature extraction” such as finding shapes, edges and colours. The layers later on are used as classifiers; they take the extracted features and classify them.
Because of this, we can assume the first few layers have learned quite general feature extraction techniques that can be applied to similar tasks, and so we can freeze all these layers and use them on a new task in the future. The classifier layer will need to be trained based on the new task.
To do this, we break the process into two steps:
- Freeze the “backbone” of the model and train the head with a fairly high learning rate. We slowly reduce the learning rate.
- Unfreeze the “backbone” and fine-tune the model with a low learning rate.
To freeze a layer in TensorFlow we can set layer.trainable=False. Let’s loop through all the layers and do this:
for layer in fine_tune_model.layers:
layer.trainable = False
and now unfreeze the last layer (the head):
fine_tune_model.layers[-1].trainable = True
We can now train the model using a binary crossentropy loss function. Keras callbacks for early stopping (to avoid overfitting) and a dynamic learning rate scheduler will also be used.
After we’ve trained with the frozen layers, we can unfreeze them:
for layer in fine_tune_model.layers:
layer.trainable = True
And train again for up to 10 epochs. You can find the complete code for this in the “Transfer Learning -> ”Train Model” section of Colab notebook.
Recording your own training data
We now have an ML model which can classify the presence of fire alarm sound. However this model was trained on publicly available sound recordings which might not match the sound characteristics of the hardware microphone we will use for inferencing.
The Raspberry Pi RP2040 MCU has a native USB feature that allows it to act like a custom USB device. We can flash an application to the board to enable it to act like a USB microphone to our PC. Then we can extend Google Colab’s capabilities with the Web Audio API on a modern Web browser like Google Chrome to collect live data samples (all from within Google Colab!)
Hardware Setup
SparkFun MicroMod RP2040
For assembly, remove the screw on the carrier board, at an angle, slide in the MicroMod RP2040 Processor board into the socket and secure it in place with the screw. See the MicroMod Machine Learning Carrier Board Hookup Guide for more details.
Raspberry Pi Pico
Follow the instructions from the Hardware Setup section of the “Create a USB Microphone with the Raspberry Pi Pico” guide for assembly instructions.
|
|
| Top: Fritzing wiring diagram Bottom: Assembled breadboard |
Setting up the firmware applications toolchains
Rather than setting up the Raspberry Pi Pico’s SDK on your personal computer. We can leverage Colab’s built-in Linux shell command feature to set up the Pico SDK development environment with CMake and GNU Arm Embedded Toolchain.
The pico-sdk will also have to be downloaded to the Colab instance using git:
%%shell
git clone https://github.com/raspberrypi/pico-sdk.git
cd pico-sdk
git submodule init
git submodule update
Compiling and flashing the USB microphone application
Now we can use the USB microphone example from the Microphone Library for Pico. The example application can be compiled using cmake and make. Then we can flash the example application to the board over USB by putting the board into “boot ROM mode” which will allow us to upload an application to the board.
SparkFun
- Plug the USB-C cable into the board and your PC to power the board.
- While holding down the BOOT button on the board, tap the RESET button.
Raspberry Pi Pico
- Plug the USB Micro cable into your PC, but do NOT plug in the Pico side.
- While holding down the white BOOTSEL button, plug in the micro USB cable to the Pico.
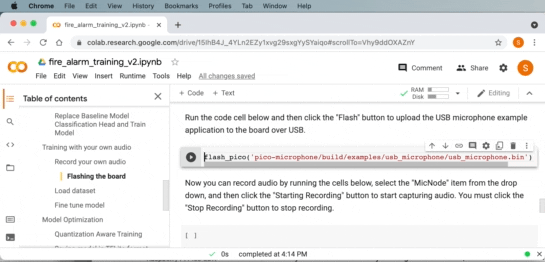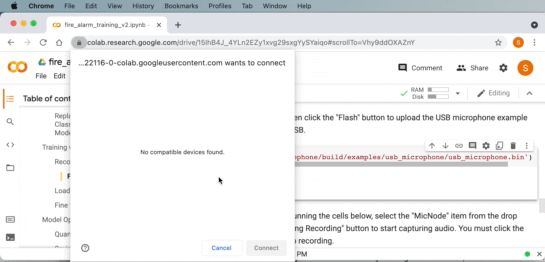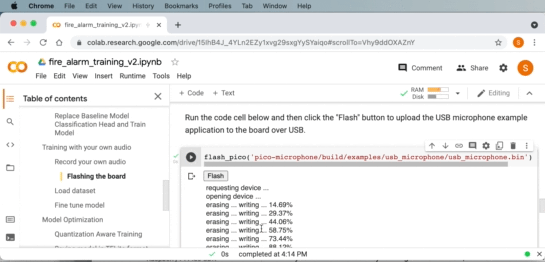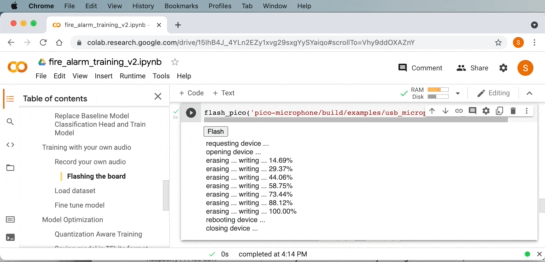
If you are using a WebUSB API enabled browser like Google Chrome, you can directly flash the image onto the board from within Google Collab!
|
|
| Downloading USB microphone application to the board from within Google Colab and WebUSB. |
Otherwise, you can manually download the .uf2 file to your computer and then drag it onto the USB disk for the RP2040 board.
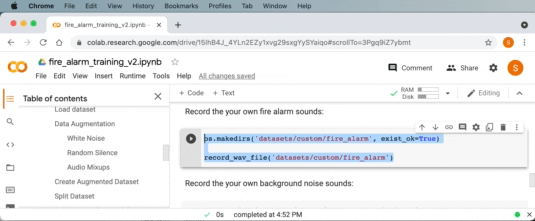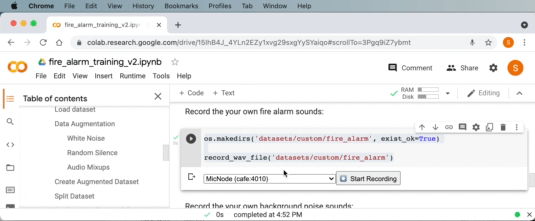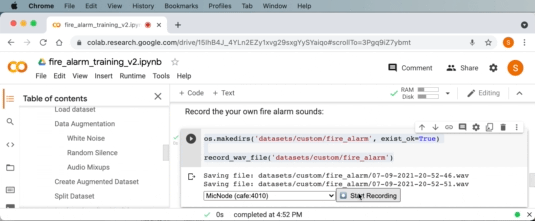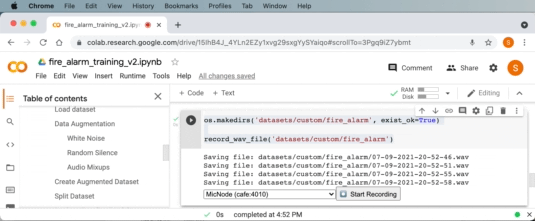
Collecting training data
Now that you have flashed the USB microphone application to the board, it will appear as a USB audio input on your PC.
We can now use Google Colab to record a fire alarm sound, select “MicNode ” as the audio input source in the drop down. Then while pressing the test button on a smoke alarm, click the record button on Google Colab to record a 1 second audio clip. Repeat this process a few times.
Similarly, we can also do the same to collect background audio samples in the next code cell in Google Colab. Repeat this a few times for non-fire alarm sounds like silence, yourself talking, or any other normal sounds for the environment.
Final model training
Now that we’ve collected additional samples with the microphone that will be used during inference. We can tune the model again with the new data.
Converting the Model to run on the MCU
We will need to convert the Keras model we’ve used to TensorFlow Lite format so that we can use it for inference on the device.
Quantization
To optimize the model to run on the Arm Cortex-M0+ processor, we will use a process called model quantization. Model quantization converts the model’s weights and bias from 32-bit floating point values to 8-bit values. The pico-tflmicro library, which is a port of TFLu for the RP2040’s Pico SDK contains Arm’s CMSIS-NN library, which supports optimized kernel operations for quantized 8-bit weights on Arm Cortex-M processors.
We can use TensorFlow’s Quantization Aware Training (QAT) feature to easily convert the floating-point model to quantized.
Converting the model to TF Lite format
We will now use the tf.lite.TFLiteConverter.from_keras_model(…) API to convert the quantized Keras model to TF Lite format, and then save it to disk as a .tflite file.
converter = tf.lite.TFLiteConverter.from_keras_model(quant_aware_model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
train_ds = train_ds.unbatch()
def representative_data_gen():
for input_value, output_value in train_ds.batch(1).take(100):
# Model has only one input so each data point has one element.
yield [input_value]
converter.representative_dataset = representative_data_gen
# Ensure that if any ops can't be quantized, the converter throws an error
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
# Set the input and output tensors to uint8 (APIs added in r2.3)
converter.inference_input_type = tf.int8
converter.inference_output_type = tf.int8
tflite_model_quant = converter.convert()
with open("tflite_model.tflite", "wb") as f:
f.write(tflite_model_quant)
Since TensorFlow also supports loading TF Lite models using tf.lite, we can also verify the functionality of the quantized model and compare its accuracy with the regular unquantized model inside Google Colab.
The RP2040 MCU on the boards we are deploying to, does not have a built-in file system, which means we cannot use the .tflite file directly on the board. However, we can use the Linux `xxd` command to convert the .tflite file to a .h file which can then be compiled in the inference application in the next step.
%%shell
echo "alignas(8) const unsigned char tflite_model[] = {" > tflite_model.h
cat tflite_model.tflite | xxd -i >> tflite_model.h
echo "};"
Deploy the model to the device
We now have a model that is ready to be deployed to the device. We’ve created an application template for inference which can be compiled with the .h file that we’ve generated for the model.
The C++ application uses the pico-sdk as the base, along with the CMSIS-DSP, pico-tflmicro, and Microphone Library for Pico libraries. It’s general structure is as follows:
- Initialization
- Configure the board’s built-in LED for output. The application will map the brightness of the LED to the output of the model. (0.0 LED off, 1.0 LED on with full brightness)
- Setup the TF Lite library and TF Lite model for inference
- Setup the CMSIS-DSP based DSP pipeline
- Setup and start the microphone for real-time audio
- Inference loop
- Wait for 128 * 4 = 512 new audio samples from the microphone
- Shift the spectrogram array over by 4 columns
- Shift the audio input buffer over by 128 * 4 = 512 samples and copy in the new samples
- Calculate 4 new spectrogram columns for the updated input buffer
- Perform inference on the spectrogram data
- Map the inference output value to the on-board LED’s brightness and output the status to the USB port
In-order to run in real-time each cycle of the inference loop must take under (512 / 16000) = 0.032 seconds or 32 milliseconds. The model we’ve trained and converted takes 24 ms for inference, which gives us ~8 ms for the other operations in the loop.
128 was used above to match the stride of 128 used in the training pipeline for the spectrogram. We used a shift of 4 in the spectrogram to fit within the real-time constraints we had.
Compiling the Firmware
Now we can use CMake to generate the build files required for compilation followed by make to compile.
The “cmake ..” line will have to be changed based on the board you are using:
- SparkFun: cmake .. -DPICO_BOARD=sparkfun_micromod
- Raspberry Pi Pico: cmake .. -DPICO_BOARD=pico
Flashing the Inference Application to the board
You’ll need to put the board into “boot ROM mode” again to load the new application to it.
SparkFun
- Plug the USB-C cable into the board and your PC to power the board.
- While holding down the BOOT button on the board, tap the RESET button.
Raspberry Pi Pico
- Plug the USB Micro cable into your PC, but do NOT plug in the Pico side.
- While holding down the white BOOTSEL button, plug in the micro USB cable to the Pico.
If you are using a WebUSB API enabled browser like Google Chrome, you can directly flash the image onto the board from within Google Colab. Otherwise, you can manually download the .uf2 file to your computer and then drag it onto the USB disk for the RP2040 board.
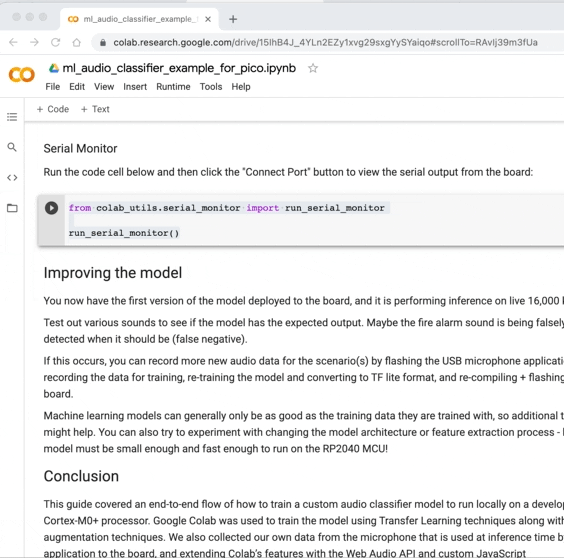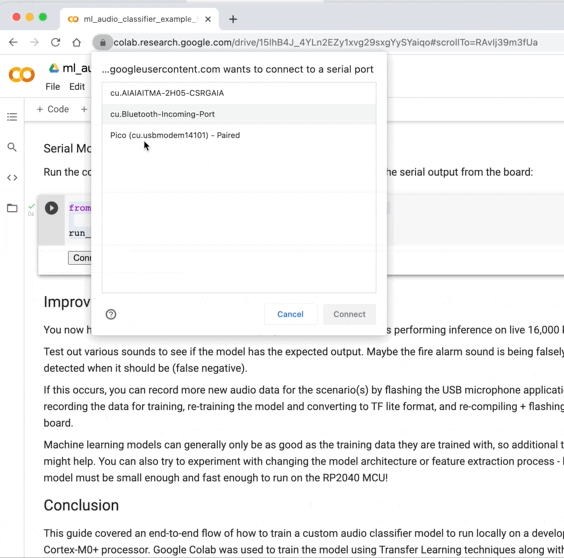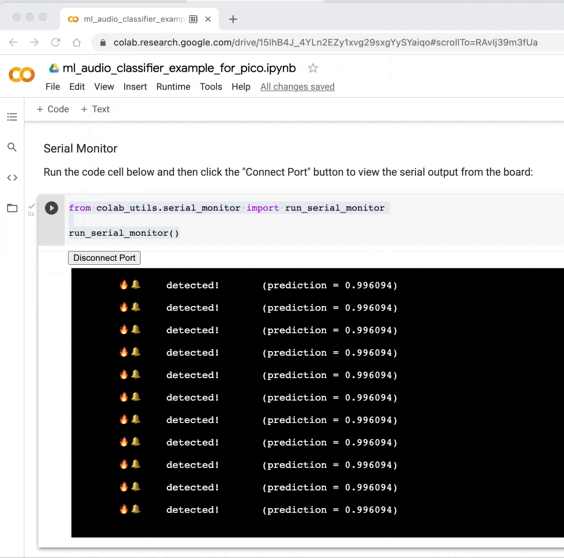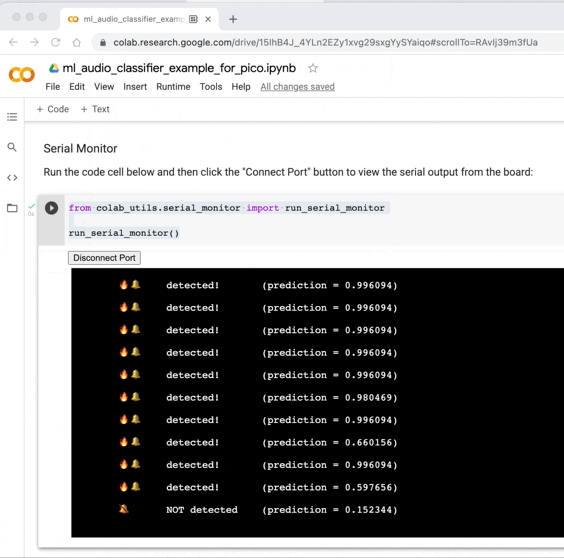
Monitoring the Inference on the board
Now that the inference application is running on the board you can observe it in action in two ways:
Visually by observing the brightness of the LED on the board. It should remain off or dim when no fire alarm sound is present – and be on when a fire alarm sound is present:
Connecting to the board’s USB serial port to view output from the inference application. If you are using a Web Serial API enabled browser like Google Chrome, this can be done directly from Google Colab:
Improving the model
You now have the first version of the model deployed to the board, and it is performing inference on live 16,000 kHz audio data!
Test out various sounds to see if the model has the expected output. Maybe the fire alarm sound is being falsely detected (false positive) or not detected when it should be (false negative).
If this occurs, you can record more new audio data for the scenario(s) by flashing the USB microphone application firmware to the board, recording the data for training, re-training the model and converting to TF lite format, and re-compiling + flashing the inference application to the board.
Supervised machine learning models can generally only be as good as the training data they are trained with, so additional training data for these scenarios might help. You can also try to experiment with changing the model architecture or feature extraction process – but keep in mind that your model must be small enough and fast enough to run on the RP2040 MCU.
Conclusion
This article covered an end-to-end flow of how to train a custom audio classifier model to run locally on a development board that uses an Arm Cortex-M0+ processor. TensorFlow was used to train the model using transfer learning techniques along with a smaller dataset and data augmentation techniques. We also collected our own data from the microphone that is used at inference time by loading an USB microphone application to the board, and extending Colab’s features with the Web Audio API and JavaScript.
The training side of the project combined Google’s Colab service and Chrome browser, with the open source TensorFlow library. The inference application captured audio data from a digital microphone, used Arm’s CMSIS-DSP library for the feature extraction stage, then used TensorFlow Lite for Microcontrollers with Arm CMSIS-NN accelerated kernels to perform inference with a 8-bit quantized model that classified a real-time 16 kHz audio input on an Arm Cortex-M0+ processor.
The Web Audio API, Web USB API, and Web Serial API features of Google Chrome were used to extend Google Colab’s functionality to interact with the development board. This allowed us to experiment with and develop our application entirely with a web browser and deploy it to a constrained development board for on-device inference.
Since the ML processing was performed on the development boards RP2040 MCU, no audio data left the device at inference time.
Learn more
You can learn more and get hands-on experience using TinyML at the upcoming Arm DevSummit, a 3-day virtual event between October 19 – 21. The event includes workshops on tinyML computer vision for real-world embedded devices and building large vocabulary voice control with Arm Cortex-M based MCUs. We hope to see you there!
Read More


















 Posted by
Posted by