Posted by Nikita Namjoshi, Machine Learning Solutions Engineer
For many in the world of data science, distributed training can seem a daunting task. In addition to building and thoughtfully evaluating a high-quality ML model, you have to be aware of how to optimize your model for specific hardware and manage infrastructure. The latter skills are not often included in a data scientist’s toolkit. However, with the help of managed services on the Google Cloud Platform (GCP), you can easily scale your model training job to multiple accelerators or even multiple machines, with no GPU expertise required.
In this tutorial-style article, you’ll get hands-on experience with GCP data science tools and train a TensorFlow model across multiple GPUs. You’ll also learn key terminology in the field of distributed training, such as data parallelism, synchronous training, and AllReduce.
|
| Data parallelism is one of the concepts you will learn about in this article. |
Why Distributed Training?
Every data scientist and machine learning engineer has experienced the agony of sitting and waiting for a model to train. Even if you have access to a GPU, with a large dataset it can take days for a large deep learning model to converge. Using the right hardware configuration can reduce training time to hours, or even minutes. And a shorter training time makes for faster iteration to reach your modeling goals.
If you have a GPU available, TensorFlow will use it automatically with no code changes required. Similarly, TensorFlow can make use of multiple CPU cores out of the box. However, if you want to train with two or more GPUs then you’ll have to do a bit of extra work. This extra work is necessary because TensorFlow needs to know how to coordinate the training process across the multiple GPUs in your runtime. Fortunately, with the tf.distribute module, you have access to different distributed training strategies that you can easily incorporate into your program.
When doing distributed training, it’s important to be clear on the distinction between machines and devices. A device refers to a CPU or accelerator, such as GPUs or TPUs, on some machine that TensorFlow can run operations on. The focus in this article will be training with a single machine that has multiple GPU devices, but the tf.distribute.Strategy API also provides support for multi-worker training. In a multi-worker set up, the training is distributed across multiple machines. These machines can be CPU only, or have one or more GPU devices each.
Single GPU Training
In the following Colab notebook, you’ll find the code to train a ResNet50 architecture on the Cassava dataset. If you execute the cells in the notebook and train the model, you’ll notice that the number of steps taken in each epoch is 89, and each epoch takes around 100 seconds. Make note of these numbers; we will come back to them later.
Multi-GPU Training
You can access a single GPU in colab, but your luck stops there if you want to use multiple GPUs. Moreover, while a Colab notebook is great for quick experimentation you’ll likely want a more secure and reliable set up that offers you more control over your environment. For that, you can turn to the cloud.
There are many different ways to do distributed training on GCP. Picking the best option for your use case will likely involve different considerations if you are a student/researcher running experiments, versus an engineer at a company training models in a production workflow.
In this article you will use the GCP AI Platform Notebooks. This path provides an easy approach to distributed training and also gives you a chance to explore a managed notebook environment running on GCP. As an alternative, if you already have a local environment set up and are looking for a hassle free transition between your local and GCP environments, you can check out the TensorFlow Cloud library. TensorFlow Cloud can automate many of the steps described in this article; however, we will walk through the steps here so you can get a deeper understanding of the key concepts involved in distributed training.
In the following section, you’ll learn how to modify the single GPU training code using the tf.distribute.Strategy API. The resulting code will be cloud platform agnostic so you could run it in a different environment without any changes. You can also run the same code on your own hardware.
Prepare Code for Distributed Training
The first step in using the tf.distribute.Strategy API is to instantiate your strategy. In this tutorial, you will use MirroredStrategy, which is one of several distribution strategies available in TensorFlow.
strategy = tf.distribute.MirroredStrategy()
Next, you need to wrap the creation of your model parameters within the scope of the strategy. This step is crucial because it tells MirroredStrategy which variables to mirror across your GPU devices.
with strategy.scope():
model = create_model()
model.compile(
loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(0.0001),
metrics=['accuracy'])
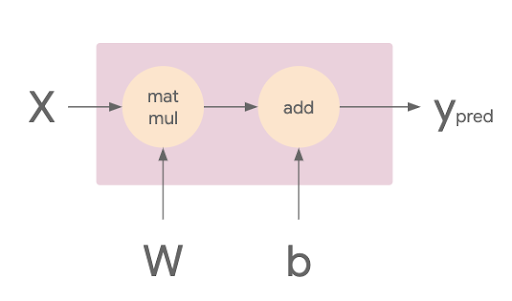
Before we run the updated code, let’s take a brief look at what will actually happen when we call model.fit and how training will differ now that we have added a strategy. For the sake of simplicity, imagine you have a simple linear model instead of the ResNet50 architecture. In TensorFlow, you can think of this simple model in terms of its computational graph.
In the image below, you can see that the matmul op takes in the X and W tensors, which are the training batch and weights respectively. The resulting tensor is then passed to the add op with the tensor b, which is the model’s bias terms. The result of this op is Ypred, which is the model’s predictions.
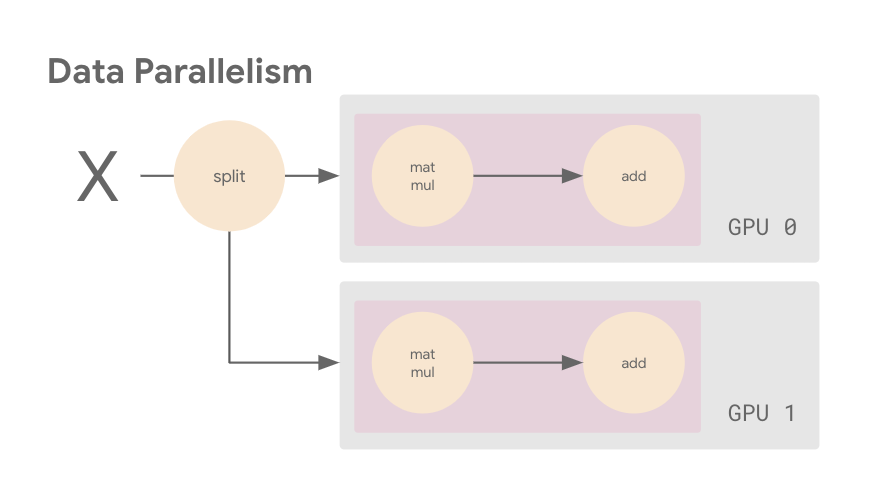
We want a way of executing this computational graph such that we can leverage two GPUs. There are multiple different ways we can achieve this. For example, you could put different layers of your model on different machines or devices, which is one flavor of model parallelism. Alternatively, you could distribute your dataset such that each device processes a portion of the input batch on each training step with the same model, which is known as data parallelism. Or you might do a combination of both. Data parallelism is the most common (and easiest) approach, and that’s what we’ll do here.
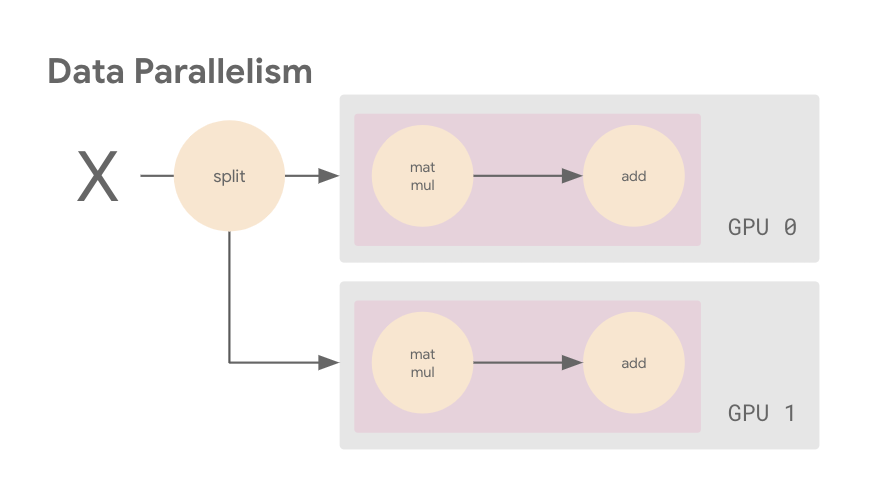
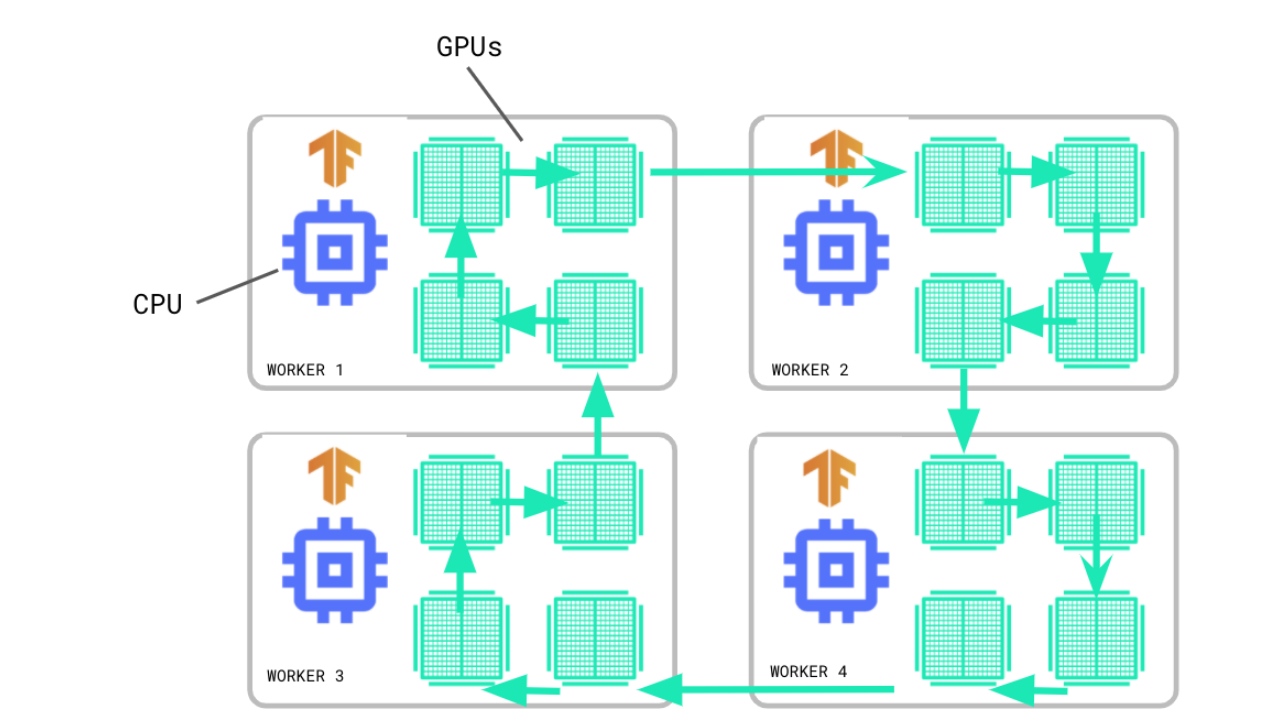
The next image shows an example of data parallelism. The input batch X is split in half, and one slice is sent to GPU 0 and the other to GPU 1. In this case, each GPU calculates the same ops but on different slices of the data.
MirroredStrategy is a data parallelism strategy. So when we call model.fit, MirroredStrategy will make a copy (known as a replica) of the ResNet50 model on both of the GPUs. The CPU (host) is responsible for preparing the tf.data.Dataset batches and sending the data to the GPUs (devices).
The subsequent gradient updates will happen in a synchronous manner. This means that each worker device computes the forward and backward passes through the model on a different slice of the input data. The computed gradients from each of these slices are then aggregated across all of the devices and reduced (usually an average) in a process known as AllReduce. The optimizer then performs the parameter updates with these reduced gradients thereby keeping the devices in sync. Because each worker cannot proceed to the next training step until all the other workers have finished the current step, this gradient calculation becomes the main overhead in distributed training for synchronous strategies.
While MirroredStrategy is a synchronous strategy, data parallelism strategies can also be asynchronous. In an asynchronous data parallelism strategy, each worker computes the gradients from a slice of the input data and makes updates to the parameters in an asynchronous fashion. Compared to synchronous strategies, asynchronous training has the benefit of fault tolerance because the workers are not dependent on one another, but can result in stale gradients. You can learn more about asynchronous training by experimenting with the TensorFlow Parameter Server Strategy.
With the two easy steps of instantiating MirroredStrategy, and then wrapping your model creation within the strategy scope, TensorFlow will do the heavy lifting of distributing your training job across your GPUs through data parallelism and synchronous gradient updates.
The last change you will want to make is to the batch size.
BATCH_SIZE = 64 * strategy.num_replicas_in_sync
Recall that in the single GPU case, the batch size was 64. This means that on each step of model training, 64 images were processed, and the number of resulting steps in each epoch was the total dataset size / batch size, which we noted previously as 89.
When you do distributed training with the tf.distribute.Strategy API and tf.data, the batch size now refers to the global batch size. In other words, if you pass a batch size of 10, and you have two GPUs, then each machine will process 5 examples per step. In this case, 10 is known as the global batch size, and 5 as the per replica batch size. To make the most out of your GPUs, you will want to scale the batch size by the number of replicas, which is two in this case because there is one replica on each GPU.
You can make these code changes yourself, or simply use this other Colab notebook where the changes have been made already. Although MirroredStrategy is designed for a multi-GPU environment, you can actually run this notebook in Colab on a GPU runtime or a CPU runtime without error. TensorFlow will use a single GPU or multiple CPU cores out of the box anyway so you don’t actually need a strategy, but this could come in handy for testing/experimentation purposes.
Set up GCP Project
Now that we’ve made the necessary code changes, the next step is to set up the GCP environment. To do this you will need a GCP project with billing enabled.
- Create your project in the UI
- Create your billing account
Next, you should enable the Cloud Compute Engine API. If you are working in a brand new project, then this process will likely also prompt you to connect the billing account you created. If you are using a GCP project that you have already worked with, then most likely the Compute Engine API will already be enabled.
Request Quota
Google Cloud enforces quotas on resource usage to prevent abuse and accidental usage. If you need access to more of a particular resource than what is available by default, you’ll have to request more quota. For this tutorial, we will use the NVIDIA T4 GPU. By default, you get access to one T4 GPU per location, but in order to do distributed training you’ll need to request quota for an additional GPU in a location.
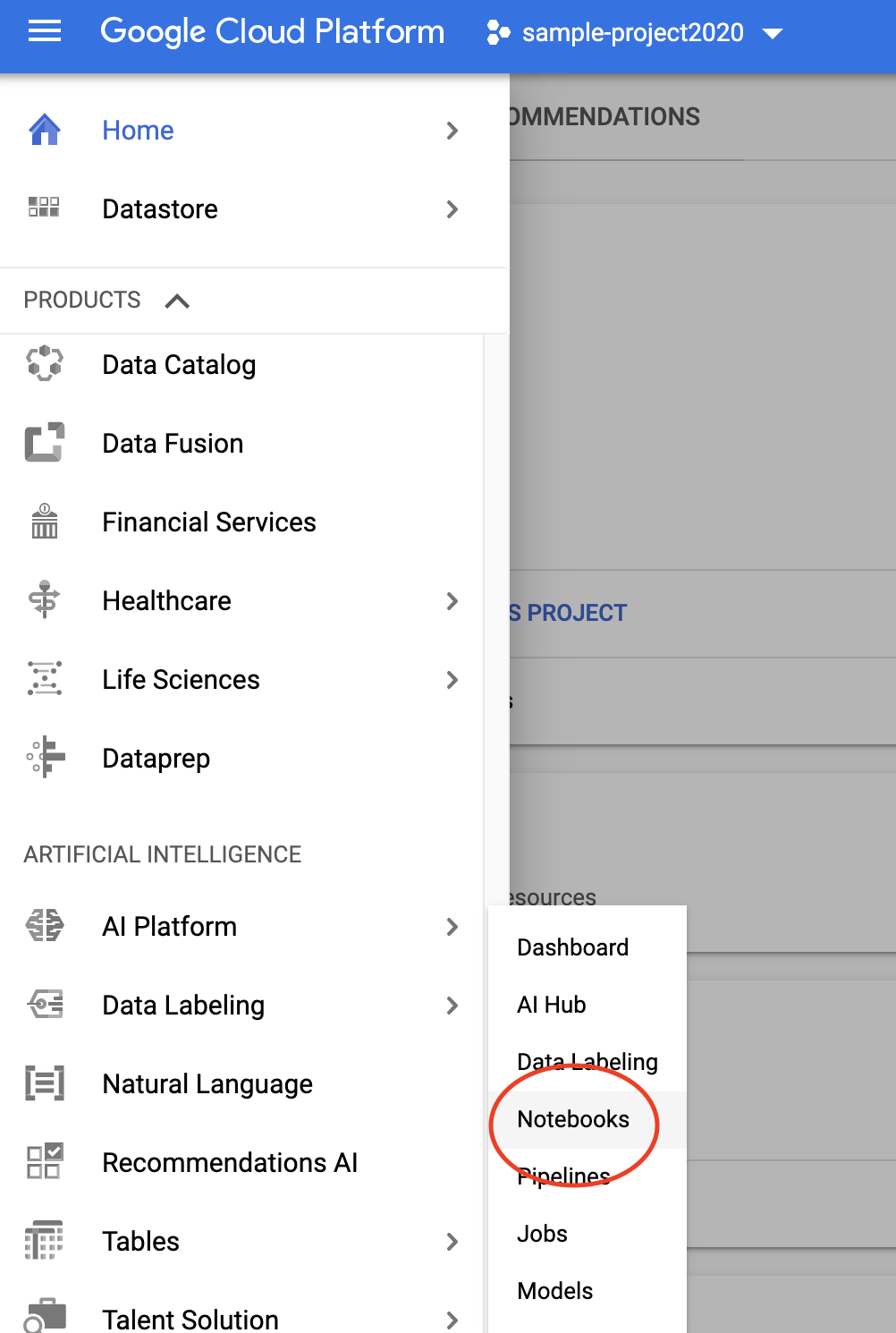
In the GCP console, scroll to the hamburger menu on the left side and navigate to IAM & Admin > Quotas
On the Quotas page you can add a service filter for the Compute Engine API. Note that if you have not enabled the Compute Engine API or enabled billing, you will not see Compute Engine API as a filter option, so be sure you have completed the earlier steps first.
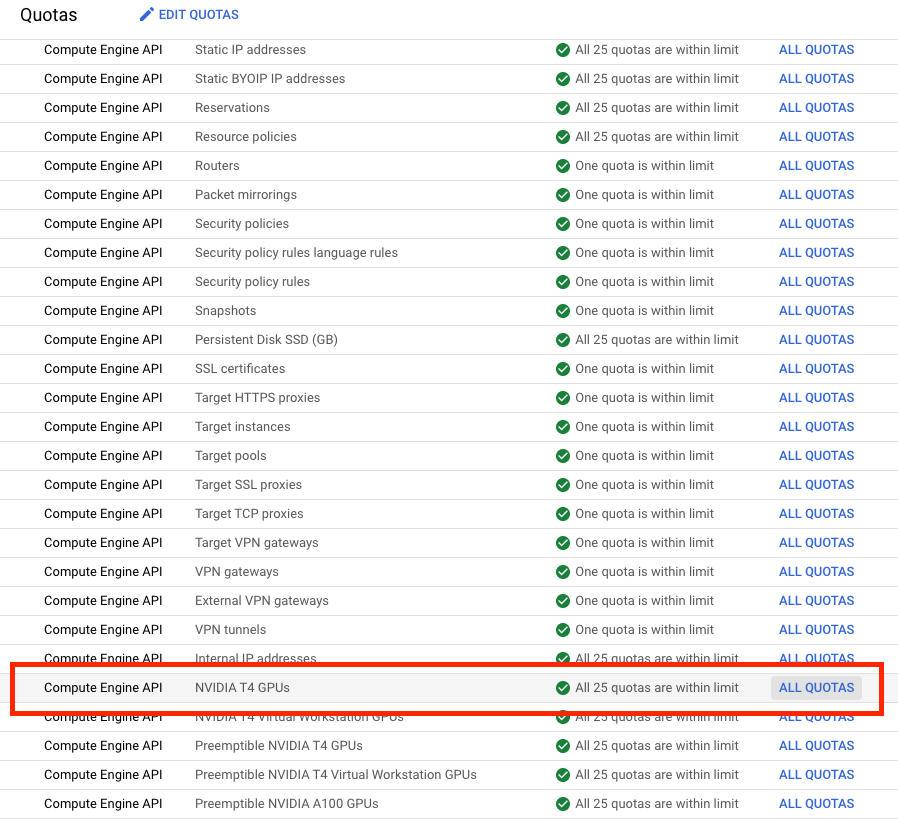
When you find the NVIDIA T4 GPU resource in the list, go ahead and click on ALL QUOTAS for that row.
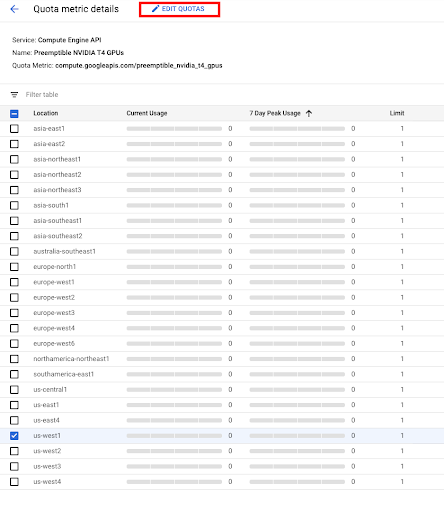
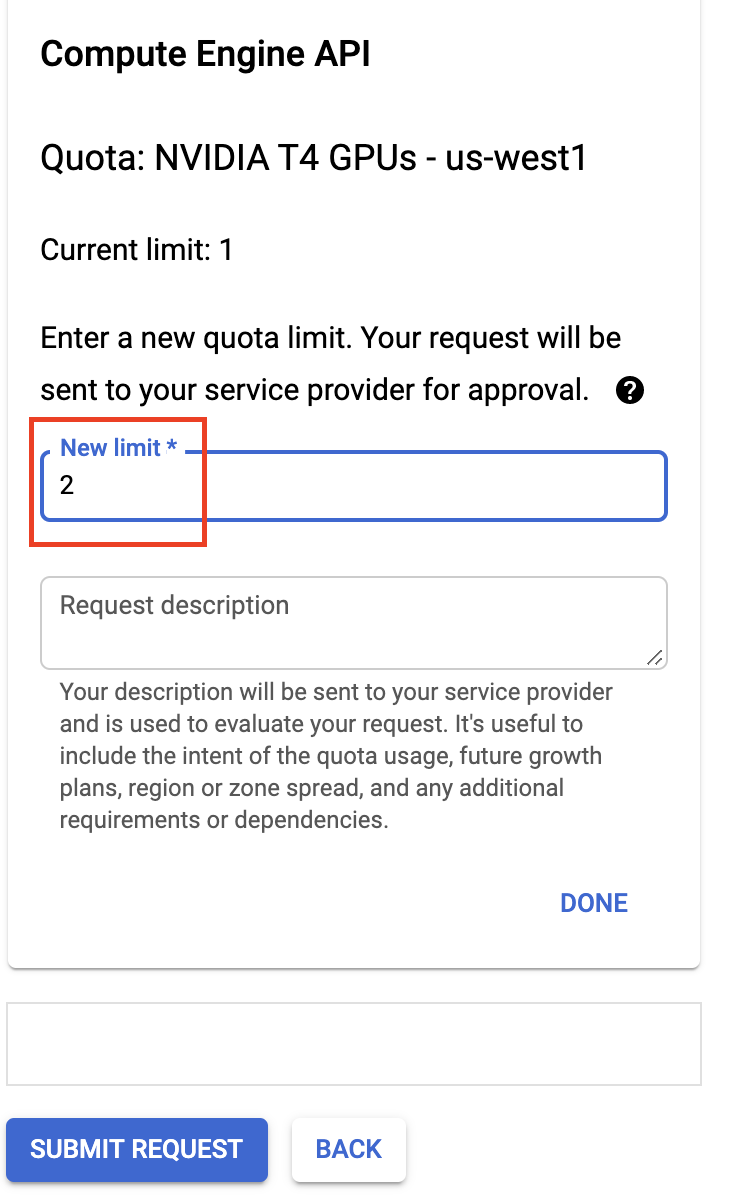
Once you’ve made it to the Quota metric details page for NVIDIA T4 GPUs, select the Location: us-west1 and click edit quotas at the top of the page.
If you already have quota for a different type of GPU, or in a different location, you can easily use those instead. Just make sure you remember the GPU type and location as you will need to specify these parameters when setting up your AI Platform Notebook environment later. Additionally, if you prefer to follow along and just use a single GPU instead of requesting quota for two, you can do that as well. Your code will not be distributed, but you will still get the benefit of learning how to set your GCP environment.
>
Fill in your contact details in the Quota changes menu and then set your New Limit to 2. Then click Done when you’re finished.
You’ll get a confirmation email first when you have submitted the request, and then when your request has been approved.
Create AI Platform Notebook Instance
While you wait for quota approvals, the next step is to get set up with AI Platform Notebooks, which can be found using the same hamburger menu as before in the console and scrolling to Artificial Intelligence > AI Platform > Notebooks
You’ll need to enable the API if this is your first time using the tool.
AI Platform Notebooks is a managed service for doing data science work. This tool is ideal if you like developing in a notebook environment. You can easily add and remove GPUs without having to worry about GPU driver installation, and there are a number of instance images you can choose from depending on your use case so you don’t need to hassle with setting up all the Python packages you need to get your job done.
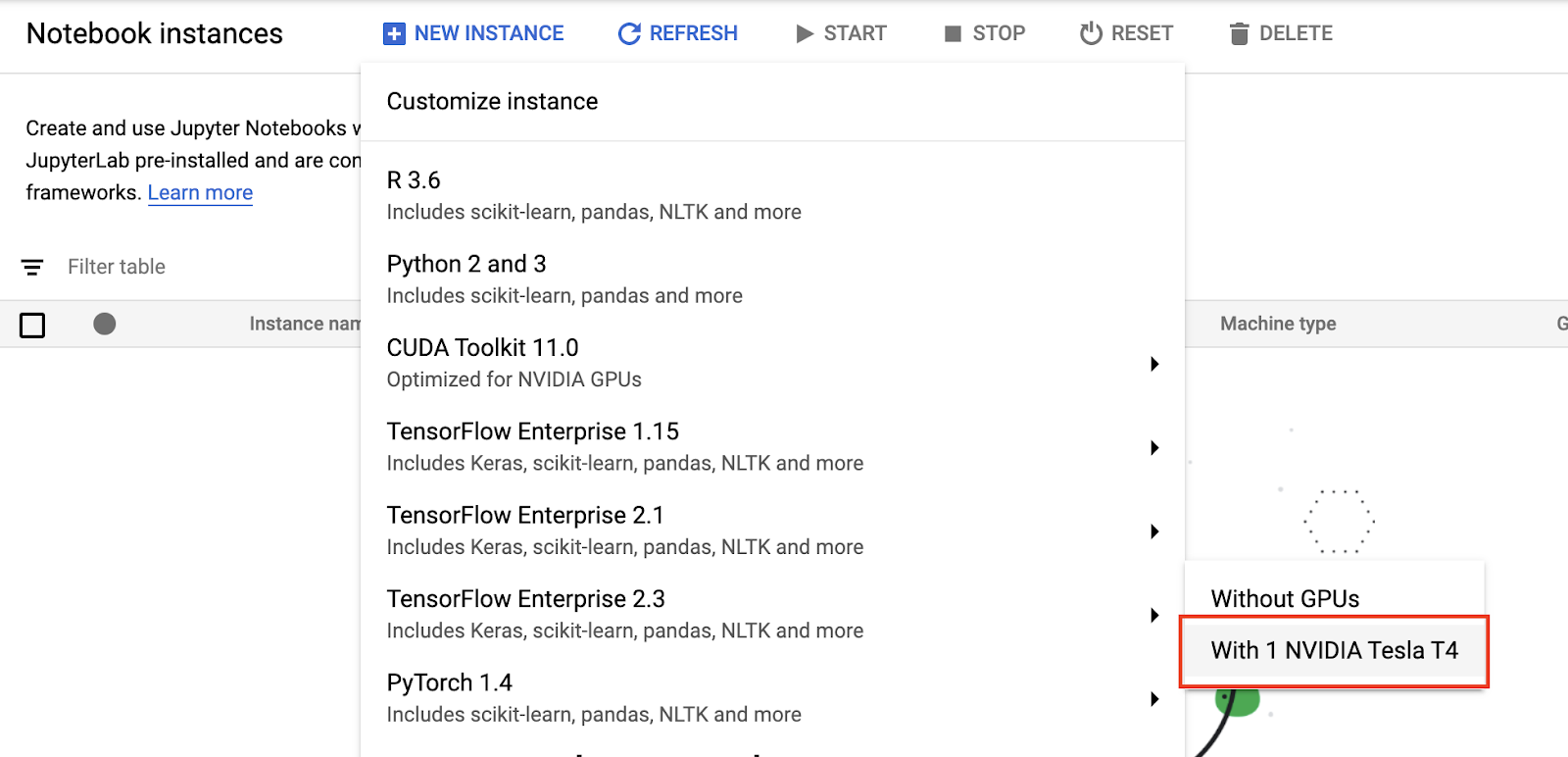
Once the Notebooks API is enabled, the next step is to create your instance. You can do this by clicking the NEW INSTANCE button at the top of the page, and then selecting the TensorFlow Enterprise 2.3 image (or the most recent TensorFlow image if you’re following along at a later date), with the 1 NVIDIA Tesla T4 option. TensorFlow Enterprise is a TensorFlow distribution optimized for GCP.
Click ADVANCED OPTIONS at the bottom of the New notebook instance window, and then change the following fields:
- Instance name: give your instance a name
- Region: us-west1
- GPU type: NVIDIA Tesla T4
- Number of GPUs: 2
- Check the Install NVIDIA GPU driver automatically for me box
Then click CREATE. Note that if you have not yet been approved for the NVIDIA T4 quota, you will get an error message when you click CREATE. So be sure you have received your approval message before completing this step. Additionally, if you plan to use a different GPU type or location other than T4 in us-west1, you will need to change these parameters when creating your notebook.
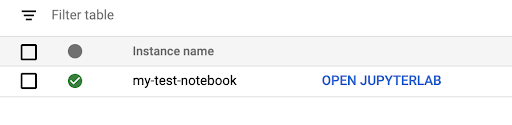
Your instance will take a few minutes to launch, and when it’s done you’ll see the option to OPEN JUPYTERLAB appear in blue letters.
Note that even after you’ve created an AI Platform Notebook instance, you can change the hardware (for example adding or removing GPUs). Should you need to do this in the future, simply stop the instance and follow the steps here.
Train Multi-GPU Model on AI Platform Notebooks
Now that your instance is set up, you can click on OPEN JUPYTERLAB.
Download the Colab Notebook as an .ipynb file, and upload it to your Jupyter Lab environment. When the file is uploaded go to the notebook and run the code.
When you execute the model.fit cell, you should notice that the number of steps per epoch is now 45, which is half of what it was when using a single GPU. This is data parallelism in action. With a global batch size of 64 * 2, your CPU is sending batches of 64 images to each GPU. So while previously the model only saw 64 examples in a single step, it now sees 128 examples on each step and thus each epoch takes less time. Previously each epoch took around 100 seconds, and now each epoch takes around 60 seconds. You’ll notice that adding a second GPU does not cut the time in half, as there is some overhead involved in synchronizing the gradients. The benefits will be more noticeable with a larger dataset (Cassava only has 5656 training images). Additionally, there are lots of techniques you can use to get even more benefit from that second GPU, such as making sure your input pipeline isn’t a bottleneck. To learn more about making the most of your GPUs, see the TensorFlow Performance Debugging guide.
Long Running Jobs on the DLVM
So far you’ve learned how to use the GCP AI Platform Notebooks to run a simple distributed training job. The dataset we used was not very large, and the model achieved fairly high accuracy after only a few epochs. However, in reality your training job will probably run for a lot longer and you might not want to use a notebook.
When you launch an AI Platform Notebook, it creates a Google Compute Engine (GCE) instance using the GCP Deep Learning VM Images. The Deep Learning VM images are Compute Engine virtual machine images optimized for data science and machine learning tasks. In our example we used the TensorFlow Enterprise 2.3 image, but there are many other options available.
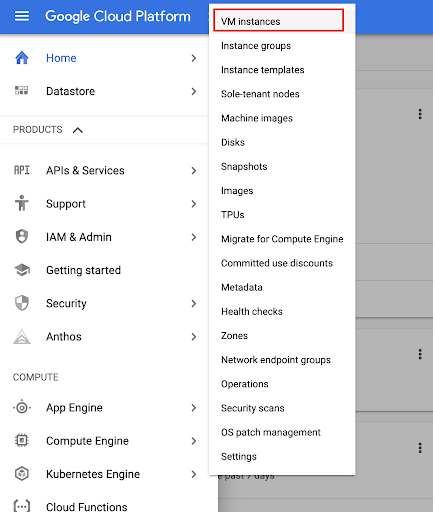
In the console, you can use the menu to navigate to Compute Engine > VM instances
And you should see an instance with the same name as the notebook you created earlier. Because this is a GCE instance, we can ssh into the machine and run the code there.
Install Google SDK
Installing the Google Cloud SDK will allow you to manage GCE resources in your project from your terminal. Follow the steps here to install the SDK and connect to your project.
SSH into the VM
Once the SDK is installed and configured, you can use the following command in your terminal to ssh into your vm. Just be sure to change the instance name and project name.
gcloud compute ssh {your-vm-name} --project={your-project-name}
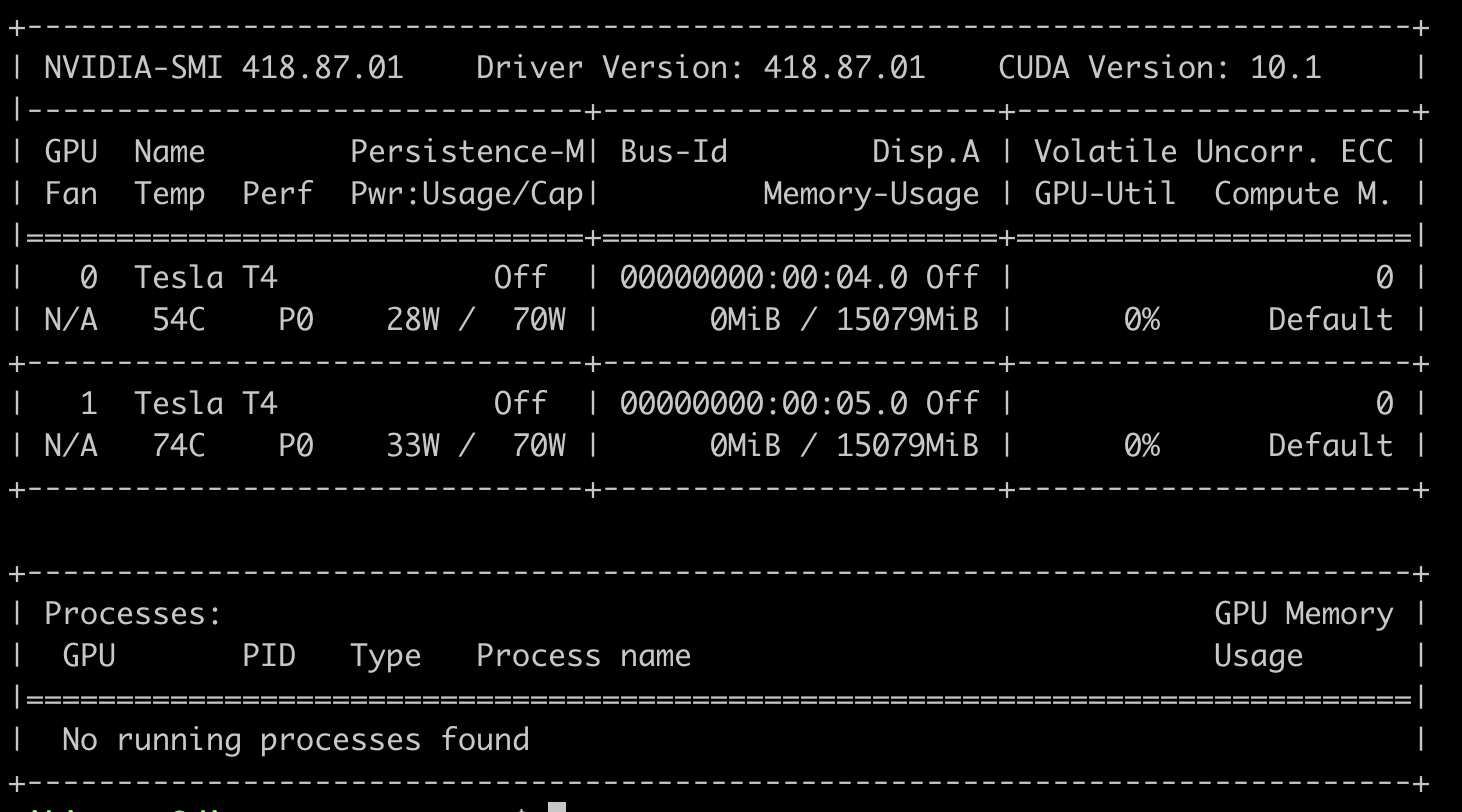
If you run the command nvidia-smi on the vm, you’ll see the two T4 GPUs we provisioned earlier.
To run the distributed training job, simply download the code from the Colab Notebook as a .py file, and use the following command from your local machine to copy it to your vm.
gcloud compute scp --project {your-project-name} {local-path-to-py-file} {your-vm-name}:~/
Finally, you can run the script on your vm with
python dist_strat_blog_multi_gpu.py
And you should see the output of your model training job
If Notebooks are your environment of choice, you can stick with the workflow we used in the previous section. But if you prefer to use vim or emacs, or if you want to run a long running job using Screen for example, you have the option to ssh into the vm from your terminal. Note that you can also launch a Deep Learning VM directly from the command line instead of using the AI Platform Notebooks UI like we did in this tutorial.
When you’re finished experimenting, do not forget to shut your instance down. You can do this by selecting the instance from the Notebook instances page, or GCE Instances page in the console UI and clicking STOP at the top of the window. Shutting down the instance is very important as you will be billed a few dollars for every hour that it is left running. You can easily stop your instance, then restart it when you want to run more experiments and all of your files will still be there.
Take Your Distributed Training Skills to the Next Level
In this article you learned how to use MirroredStrategy, a synchronous data parallelism strategy, to distribute your TensorFlow training job across two GPUs on GCP. You now know the basic mechanics of how to set up your GCP environment and prepare your code, but there’s a lot more to explore in the world of distributed training. For example, if you are interested in building a distributed training job into a production ML pipeline, check out the AI Platform Training Service, which also allows you to configure a training job across multiple machines, each containing multiple GPUs.
On the tensorflow.org site you can check out the other strategies available with the tf.distribute.Strategy API in the overview guide, and also learn how to use a strategy with a custom training loop. For more advanced concepts, there’s a guide on how data gets distributed, and a guide on how to do performance debugging with the TensorFlow Profiler to make sure you are maximizing utilization of your GPUs.
Read More







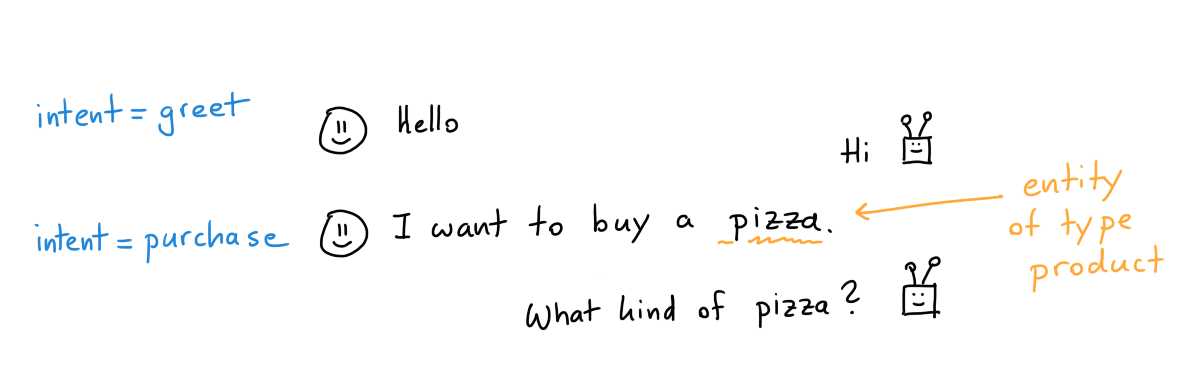










{kind=link}