Online trust has come a long way since the time of centralized databases, where information was concentrated in one location and the security and validation of that information relied on a core set of people and systems. While convenient, this model of centralized management and oversight had a number of drawbacks. Trust depended on how the workflows of those systems were established and the skillset and integrity of the people involved. It created opportunities for such issues as duplicate digital transactions, human error, and bias, as witnessed in recent history in the financial industry. In response to these systemic issues, a now-famous paper published in late 2008 proposed a distributed ledger, where new transactions could be added and validated only through participant consensus. This model of decentralized trust and execution would become known as distributed ledger technology, or blockchain, and it offered a more trustworthy alternative to centrally managed databases and a new way to store and decentralize data.
In a distributed trust model, network participants validate transactions over a network by performing computation on those transactions themselves and comparing the outputs. While their identities are private and those performing the transactions typically have pseudonyms, the transactions themselves are public, greatly limiting the use cases for decentralized computation systems. One use case where decentralized computation doesn’t work involves handling financial transactions so that they’re compliant with Know Your Client (KYC) standards and anti-money laundering (AML) regulations while also respecting privacy laws. Another involves managing medical records, where multiple organizations, such as healthcare providers and insurers, jointly govern the system.
Distributed trust with centralized confidential computation
While blockchain provided a more reliable option to centralized databases, it isn’t a perfect solution. The Confidential Computing team at Microsoft Research wanted to build a system that retained the advantages of decentralized trust while keeping transactions confidential. This meant we had to develop a way to centralize computation. At the time, no system offered these capabilities.
To tackle this issue, we developed Confidential Consortium Framework (CCF), a framework for building highly available stateful services that require centralized computation while providing decentralized trust. CCF is based on a distributed trust model like that of blockchain while maintaining data confidentiality through secure centralized computation. This centralized confidential computation model also provides another benefit—it addresses the substantial amount of energy used in blockchain and other distributed computation environments.
As widely reported in the media, blockchain comes at a great environmental cost. Cryptocurrency—the most widespread implementation of blockchain—requires a significant amount of computing power to verify transactions. According to the Cambridge Center for Alternative Finance (CCAF), bitcoin, the most common cryptocurrency, as of this writing, currently consumes slightly over 92 terawatt hours per year—0.41 percent of global electricity production, more than the annual energy draw of countries like Belgium or the Philippines.
Our goal was to develop a framework that reduced the amount of computing power it takes to run a distributed system and make it much more efficient, requiring no more energy than the cost of running the actual computation.
To apply the technology in a way that people can use, we worked with the Azure Security team to build Azure confidential ledger, an Azure service developed on CCF that manages sensitive data records in a highly secure way. In this post, we discuss the motivations behind CCF, the problems we set out to solve, and the approaches we took to solve them. We also explain our approach in supporting the development of Azure confidential ledger using CCF.
Overcoming a bias for blockchain
We discovered a strong bias for blockchain as we explained our research to different groups that were interested in this technology, including other teams at Microsoft, academic researchers exploring blockchain consensus, and external partners looking for enterprise-ready blockchain solutions. This bias was in the form of certain assumptions about what was needed to build a distributed ledger: that all transactions had to be public, that computation had to be geographically distributed, and that it had to be resilient to Byzantine faults from executors. First recognizing these biases and then countering them were some of the biggest challenges we had to surmount.
We worked to show how CCF broke from each of these assumptions while still providing an immutable ledger with distributed trust. We also had to prove that there were important use cases for maintaining confidentiality in a distributed trust system. We went through multiple rounds of discussion, explaining how the technology we wanted to build was different from traditional blockchains, why it was a worthwhile investment, and what the benefits were. Through these conversations, we discovered that many of our colleagues were just as frustrated as we were by the very issues in blockchain we were setting out to solve.
Additionally, we encountered skepticism from internal partner teams, who needed more than a research paper to be convinced that we could successfully accomplish our research goals and support our project. There were healthy doubts about the performance that was possible when executing inside an encrypted and isolated memory space, the ability to build a functional and useable system with minimal components that needed to be trusted, and how much of the internal complexity it was possible to hide from operators and users. Early versions of CCF and sample apps were focused on proving we could overcome those risks. We built basic proofs of concept and gave numerous demonstrations showing how we could implement distributed trust with centralized confidential computation. In the end, it was the strength of these demos that helped us get the resources we needed to pursue our research.
Building the compute stack
Another challenge involved was reimagining a secure compute stack for an enclave—the secured portion of the hardware’s processor and memory. At the time, enclaves were very resource constrained compared with traditional hardware, and we could run only small amounts of code on very little memory.
In addition, capabilities are limited when performing computation in an enclave. For example, the code can’t access anything outside the enclave, and it’s difficult to get the code to communicate with an external system. This challenge required us to design and build an entire compute stack from scratch with all the elements needed to establish consensus, implement transactional storage, establish runtimes for user languages, and so on.
Another consideration was the need to build a system that people could use. As researchers, we wanted our work to have real impact, but it was tempting to push the state of the art in the area of confidential computing research and develop very elaborate technology in these enclaves. However, these types of innovations cannot be deployed in actual products because they’re exceedingly difficult to explain and apply. We had committed to creating something that product teams could implement and use as a foundation for building real systems and products, so we worked to calibrate the guarantees and threat model so that our system could be used in actual products.
Establishing a root of trust with CCF
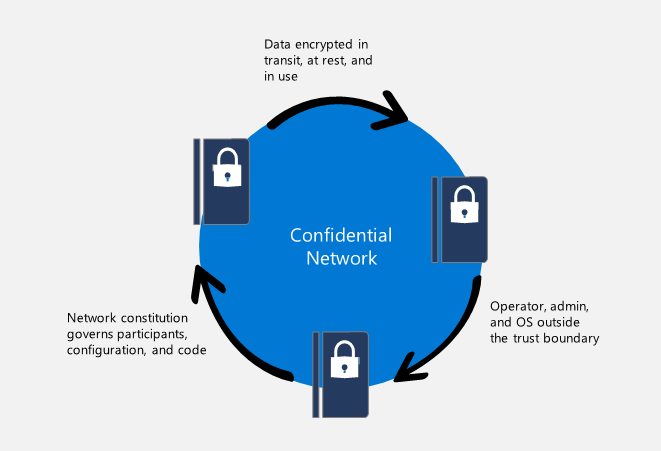
CCF strengthens the trust boundary in scenarios in which both distributed trust and data confidentiality are needed by decreasing the size of the trusted computing base (TCB)—the components of a computing environment that must be trusted for the appropriate level of security to be applied—reducing the attack surface. Specifically, CCF allows operators to greatly decrease or even eliminate their presence in the TCB, depending on the governance configuration.
Instead of a social root of trust—such as a cloud service provider or the participant consensus used in blockchain networks—CCF relies on trusted hardware to enforce transaction integrity and confidentiality, which creates a trusted execution environment (TEE). These TEEs are isolated memory spaces that are kept encrypted at all times, even when data is executing. The memory chip itself strictly enforces this memory encryption. Data in TEEs is never readable.
Decentralized trust is underpinned by remote attestation, providing the guarantee to a remote entity that all computation of user data takes place in a publicly verifiable TEE. The combination of this attestation with the isolated and encrypted TEE creates a distributed trust environment. Nodes in the network establish mutual trust by verifying their respective attestations, which affirm that they’re running the expected code in a TEE. The operator starting the nodes, which can be automated or manual, indicates where in the network they can find each other.
Service governance is performed by a flexible consortium, which is separate from the operator. CCF uses a ledger to provide offline trust. All transactions are reflected in a tamper-protected ledger that users can review to audit service governance and obtain universally verifiable transaction receipts, which can verify the consistency of the service and prove the execution of transactions to other users. This is particularly valuable for users who need to comply with specific laws and regulations.
Laying the foundation for Azure confidential ledger
We collaborated with the Azure Security team to refine and improve CCF so that it could be used as a foundation for building new Azure services for confidential computing. We applied Azure API standards and ensured that CCF complied with Azure best practices, including enabling it to log operations and perform error reporting and long-running queries. We then developed a prototype of an Azure application, and from this, the Azure Security team developed Azure confidential ledger, the first generally available managed service built on CCF, which provides tamper-protected audit logging that can be cryptographically verified.
Looking forward
We were pleasantly surprised by how quickly we discovered new use cases for CCF and Azure confidential ledger, both within Microsoft and with third-party users. Now, most of the use cases are those we had not initially foreseen, from atmospheric carbon removal to securing machine learning logs. We’re extremely excited by the potential for CCF to have much more impact than we had originally planned or expected when we first started on this journey, and we’re looking forward to discovering some of the countless ways in which it can be applied.
The post CCF: Bringing efficiency and usability to a decentralized trust model appeared first on Microsoft Research.