Last year, we announced the general availability of RStudio on Amazon SageMaker, the industry’s first fully managed RStudio Workbench integrated development environment (IDE) in the cloud. You can quickly launch the familiar RStudio IDE and dial up and down the underlying compute resources without interrupting your work, making it easy to build machine learning (ML) and analytics solutions in R at scale.
Many of the RStudio on SageMaker users are also users of Amazon Redshift, a fully managed, petabyte-scale, massively parallel data warehouse for data storage and analytical workloads. It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Users can also interact with data with ODBC, JDBC, or the Amazon Redshift Data API.
The use of RStudio on SageMaker and Amazon Redshift can be helpful for efficiently performing analysis on large data sets in the cloud. However, working with data in the cloud can present challenges, such as the need to remove organizational data silos, maintain security and compliance, and reduce complexity by standardizing tooling. AWS offers tools such as RStudio on SageMaker and Amazon Redshift to help tackle these challenges.
In this blog post, we will show you how to use both of these services together to efficiently perform analysis on massive data sets in the cloud while addressing the challenges mentioned above. This blog focuses on the Rstudio on Amazon SageMaker language, with business analysts, data engineers, data scientists, and all developers that use the R Language and Amazon Redshift, as the target audience.
If you’d like to use the traditional SageMaker Studio experience with Amazon Redshift, refer to Using the Amazon Redshift Data API to interact from an Amazon SageMaker Jupyter notebook.
Solution overview
In the blog today, we will be executing the following steps:
- Cloning the sample repository with the required packages.
- Connecting to Amazon Redshift with a secure ODBC connection (ODBC is the preferred protocol for RStudio).
- Running queries and SageMaker API actions on data within Amazon Redshift Serverless through RStudio on SageMaker
This process is depicted in the following solutions architecture:
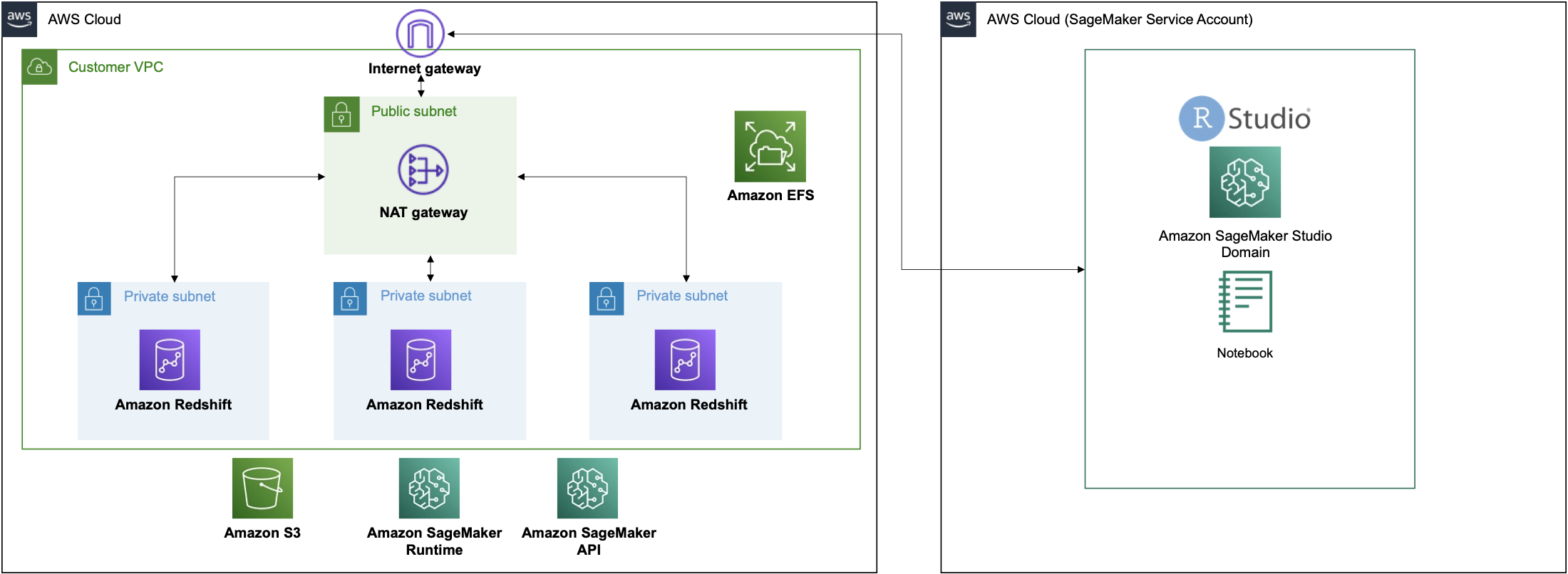
Solution walkthrough
Prerequisites
Prior to getting started, ensure you have all requirements for setting up RStudio on Amazon SageMaker and Amazon Redshift Serverless, such as:
We will be using a CloudFormation stack to generate the required infrastructure.
Note: If you already have an RStudio domain and Amazon Redshift cluster you can skip this step
Launching this stack creates the following resources:
- 3 Private subnets
- 1 Public subnet
- 1 NAT gateway
- Internet gateway
- Amazon Redshift Serverless cluster
- SageMaker domain with RStudio
- SageMaker RStudio user profile
- IAM service role for SageMaker RStudio domain execution
- IAM service role for SageMaker RStudio user profile execution
This template is designed to work in a Region (ex. us-east-1, us-west-2) with three Availability Zones, RStudio on SageMaker, and Amazon Redshift Serverless. Ensure your Region has access to those resources, or modify the templates accordingly.
Press the Launch Stack button to create the stack.
![]()
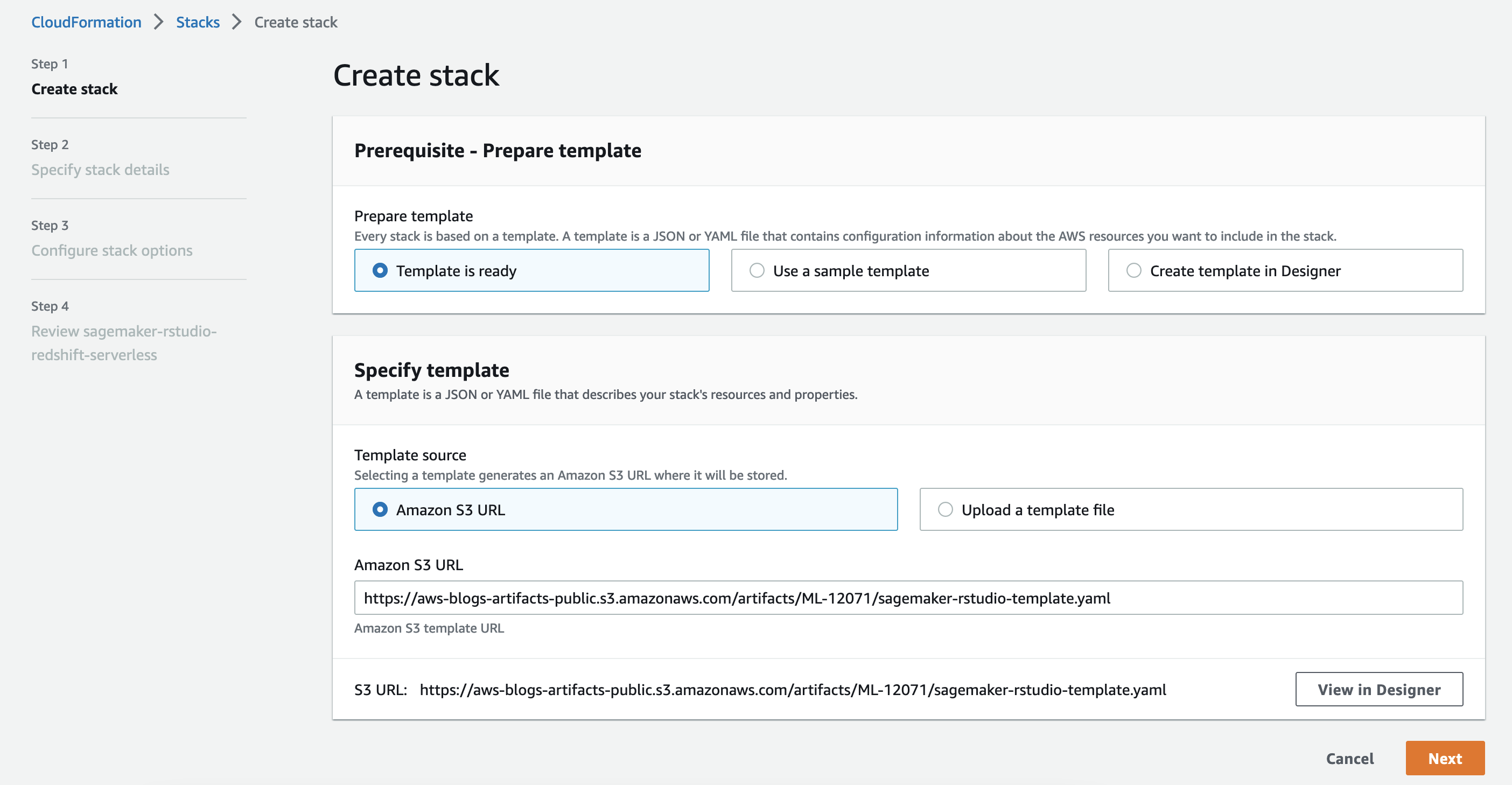
- On the Create stack page, choose Next.
- On the Specify stack details page, provide a name for your stack and leave the remaining options as default, then choose Next.
- On the Configure stack options page, leave the options as default and press Next.
- On the Review page, select the
- I acknowledge that AWS CloudFormation might create IAM resources with custom names
- I acknowledge that AWS CloudFormation might require the following capability: CAPABILITY_AUTO_EXPANDcheckboxes and choose Submit.

The template will generate five stacks.
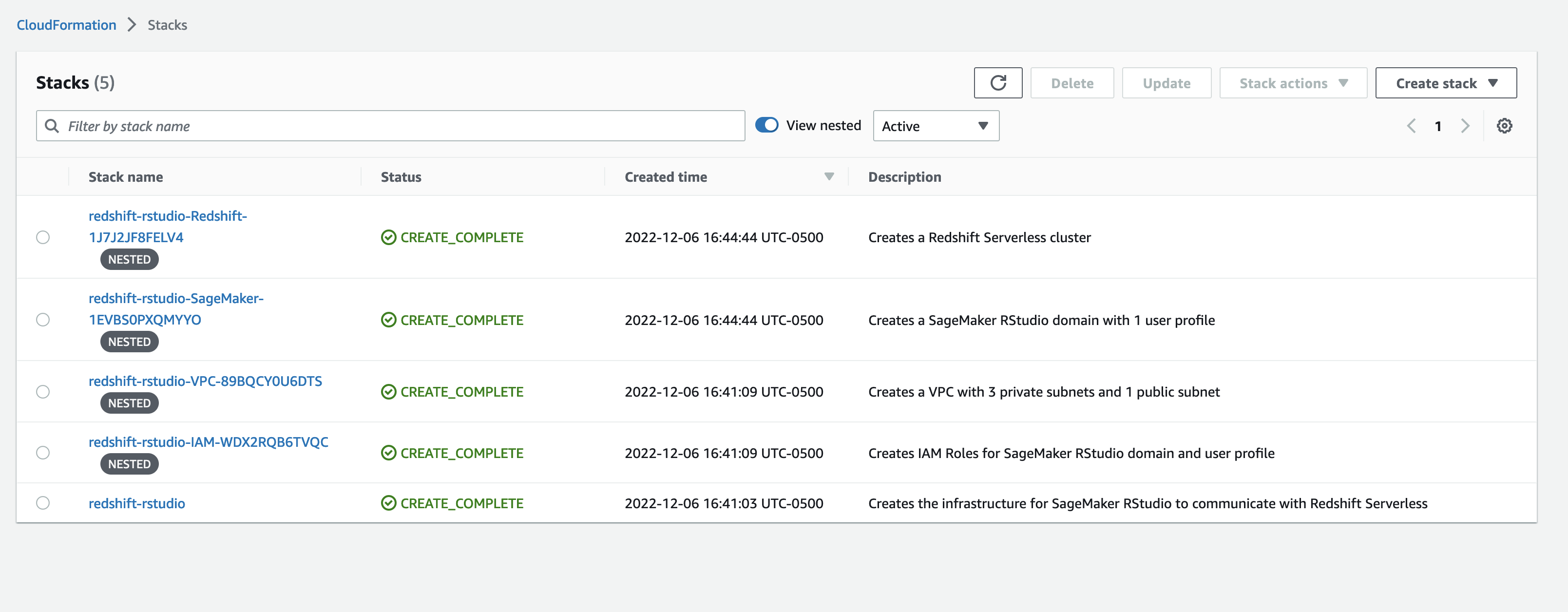
Once the stack status is CREATE_COMPLETE, navigate to the Amazon Redshift Serverless console. This is a new capability that makes it super easy to run analytics in the cloud with high performance at any scale. Just load your data and start querying. There is no need to set up and manage clusters.
Note: The pattern demonstrated in this blog integrating Amazon Redshift and RStudio on Amazon SageMaker will be the same regardless of Amazon Redshift deployment pattern (serverless or traditional cluster).
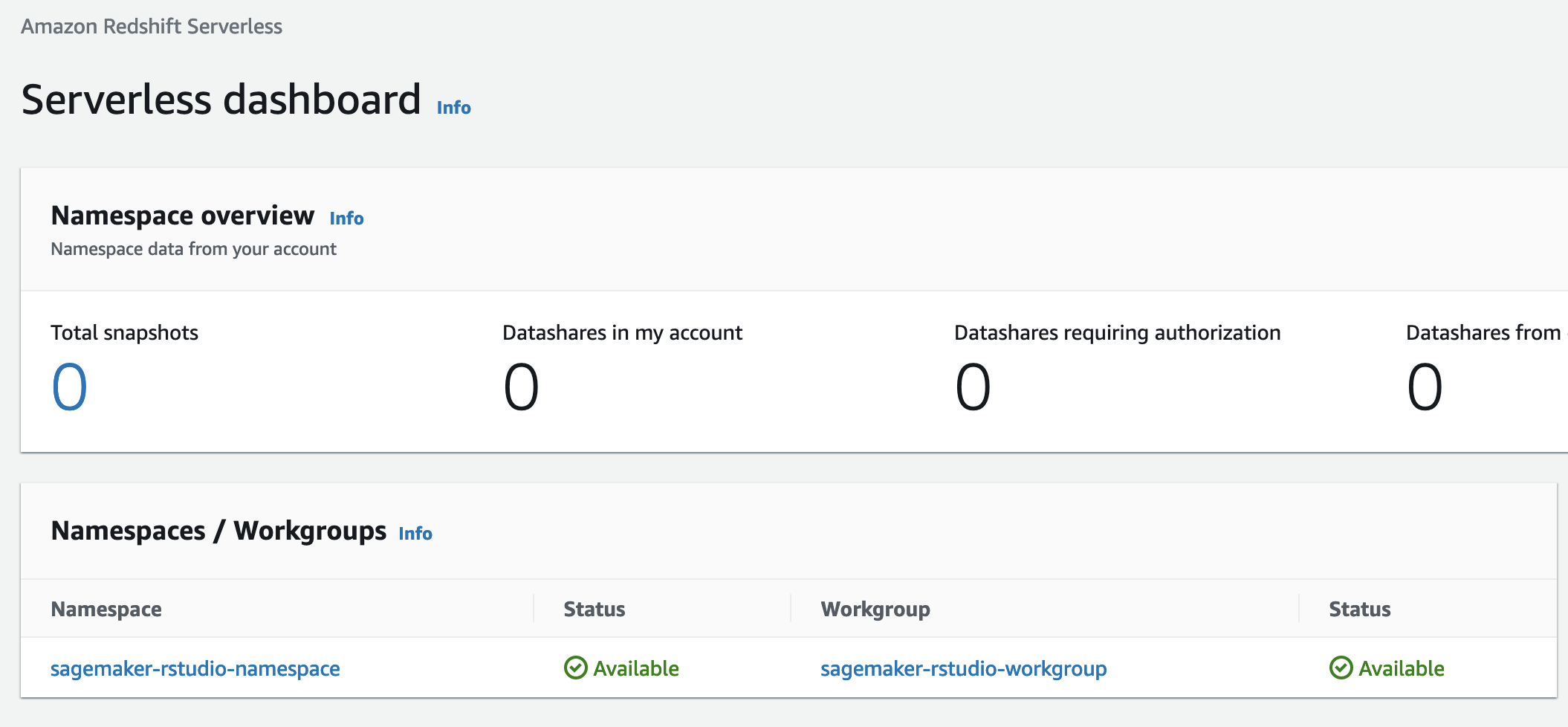
Loading data in Amazon Redshift Serverless
The CloudFormation script created a database called sagemaker. Let’s populate this database with tables for the RStudio user to query. Create a SQL editor tab and be sure the sagemaker database is selected. We will be using the synthetic credit card transaction data to create tables in our database. This data is part of the SageMaker sample tabular datasets s3://sagemaker-sample-files/datasets/tabular/synthetic_credit_card_transactions.
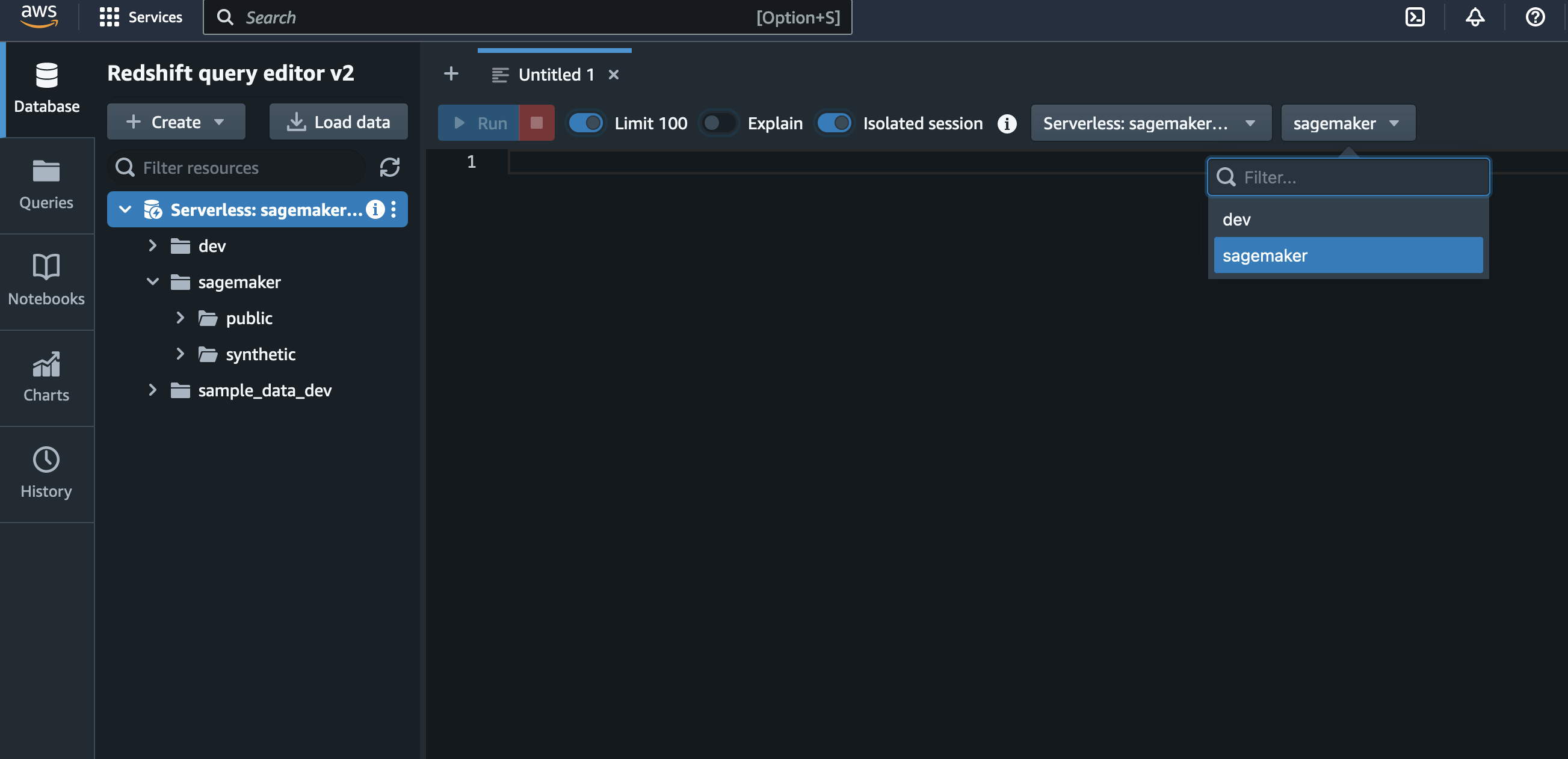
We are going to execute the following query in the query editor. This will generate three tables, cards, transactions, and users.
You can validate that the query ran successfully by seeing three tables within the left-hand pane of the query editor.
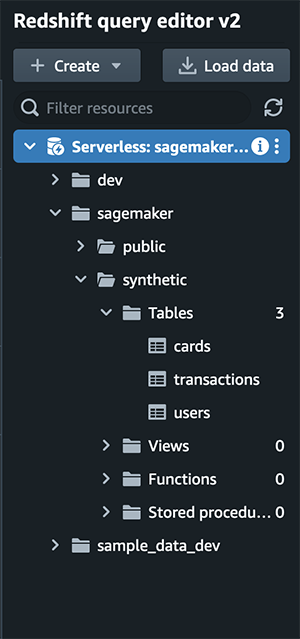
Once all of the tables are populated, navigate to SageMaker RStudio and start a new session with RSession base image on an ml.m5.xlarge instance.
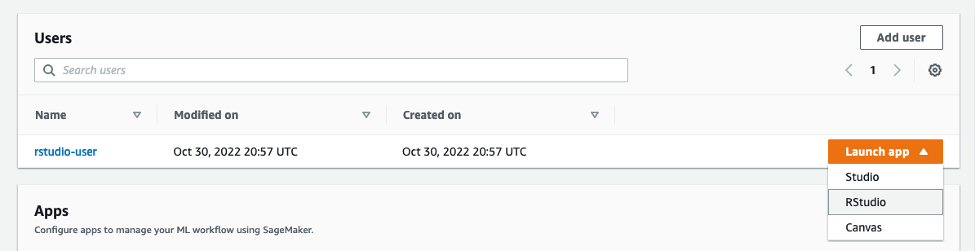
Once the session is launched, we will run this code to create a connection to our Amazon Redshift Serverless database.
In order to view the tables in the synthetic schema, you will need to grant access in Amazon Redshift via the query editor.

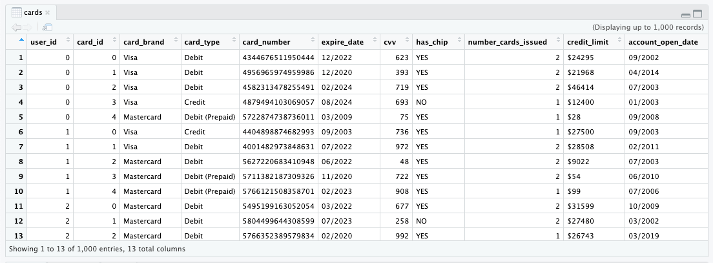
The RStudio Connections pane should show the sagemaker database with schema synthetic and tables cards, transactions, users.
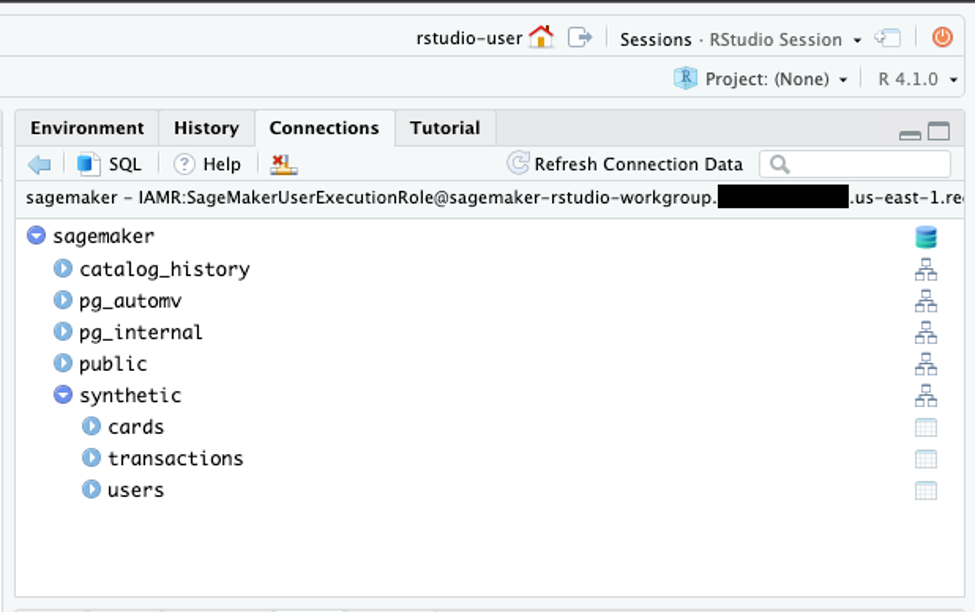
You can click the table icon next to the tables to view 1,000 records.
Note: We have created a pre-built R Markdown file with all the code-blocks pre-built that can be found at the project GitHub repo.
Now let’s use the DBI package function dbListTables() to view existing tables.
Use dbGetQuery() to pass a SQL query to the database.
We can also use the dbplyr and dplyr packages to execute queries in the database. Let’s count() how many transactions are in the transactions table. But first, we need to install these packages.
Use the tbl() function while specifying the schema.
Let’s run a count of the number of rows for each table.
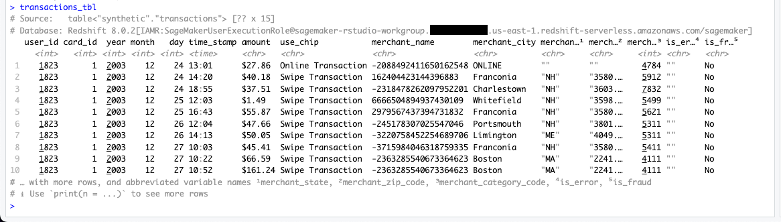
So we have 2,000 users; 6,146 cards; and 24,386,900 transactions. We can also view the tables in the console.
transactions_tbl
We can also view what dplyr verbs are doing under the hood.
Let’s visually explore the number of transactions by year.
![]()
We can also summarize data in the database as follows:
Suppose we want to view fraud using card information. We just need to join the tables and then group them by the attribute.
Now let’s prepare a dataset that could be used for machine learning. Let’s filter the transaction data to just include Discover credit cards while only keeping a subset of columns.
And now let’s do some cleaning using the following transformations:
- Convert
is_fraudto binary attribute - Remove transaction string from
use_chipand rename it to type - Combine year, month, and day into a data object
- Remove $ from amount and convert to a numeric data type
Now that we have filtered and cleaned our dataset, we are ready to collect this dataset into local RAM.
Now we have a working dataset to start creating features and fitting models. We will not cover those steps in this blog, but if you want to learn more about building models in RStudio on SageMaker refer to Announcing Fully Managed RStudio on Amazon SageMaker for Data Scientists.
Cleanup
To clean up any resources to avoid incurring recurring costs, delete the root CloudFormation template. Also delete all EFS mounts created and any S3 buckets and objects created.
Conclusion
Data analysis and modeling can be challenging when working with large datasets in the cloud. Amazon Redshift is a popular data warehouse that can help users perform these tasks. RStudio, one of the most widely used integrated development environments (IDEs) for data analysis, is often used with R language. In this blog post, we showed how to use Amazon Redshift and RStudio on SageMaker together to efficiently perform analysis on massive datasets. By using RStudio on SageMaker, users can take advantage of the fully managed infrastructure, access control, networking, and security capabilities of SageMaker, while also simplifying integration with Amazon Redshift. If you would like to learn more about using these two tools together, check out our other blog posts and resources. You can also try using RStudio on SageMaker and Amazon Redshift for yourself and see how they can help you with your data analysis and modeling tasks.
Please add your feedback to this blog, or create a pull request on the GitHub.
About the Authors
 Ryan Garner is a Data Scientist with AWS Professional Services. He is passionate about helping AWS customers use R to solve their Data Science and Machine Learning problems.
Ryan Garner is a Data Scientist with AWS Professional Services. He is passionate about helping AWS customers use R to solve their Data Science and Machine Learning problems.
 Raj Pathak is a Senior Solutions Architect and Technologist specializing in Financial Services (Insurance, Banking, Capital Markets) and Machine Learning. He specializes in Natural Language Processing (NLP), Large Language Models (LLM) and Machine Learning infrastructure and operations projects (MLOps).
Raj Pathak is a Senior Solutions Architect and Technologist specializing in Financial Services (Insurance, Banking, Capital Markets) and Machine Learning. He specializes in Natural Language Processing (NLP), Large Language Models (LLM) and Machine Learning infrastructure and operations projects (MLOps).
 Aditi Rajnish is a Second-year software engineering student at University of Waterloo. Her interests include computer vision, natural language processing, and edge computing. She is also passionate about community-based STEM outreach and advocacy. In her spare time, she can be found rock climbing, playing the piano, or learning how to bake the perfect scone.
Aditi Rajnish is a Second-year software engineering student at University of Waterloo. Her interests include computer vision, natural language processing, and edge computing. She is also passionate about community-based STEM outreach and advocacy. In her spare time, she can be found rock climbing, playing the piano, or learning how to bake the perfect scone.
 Saiteja Pudi is a Solutions Architect at AWS, based in Dallas, Tx. He has been with AWS for more than 3 years now, helping customers derive the true potential of AWS by being their trusted advisor. He comes from an application development background, interested in Data Science and Machine Learning.
Saiteja Pudi is a Solutions Architect at AWS, based in Dallas, Tx. He has been with AWS for more than 3 years now, helping customers derive the true potential of AWS by being their trusted advisor. He comes from an application development background, interested in Data Science and Machine Learning.