

Posted by Jen Person, Senior Developer Relations Engineer, TensorFlow
Welcome to part 2 of my dual approach to content moderation! In this post, I show you how to implement content moderation using machine learning in a server-side environment. If you’d like to see how to implement this moderation client-side, check out part 1.
Remind me: what are we doing here again?
In short, anonymity can create some distance between people in a way that allows them to say things they wouldn’t say in person. That is to say, there are tons of trolls out there. And let’s be honest: we’ve all typed something online we wouldn’t actually say IRL at least once! Any website that takes public text input can benefit from some form of moderation. Client-side moderation has the benefit of instant feedback, but server-side moderation cannot be bypassed like client-side might, so I like to have both.
This project picks up where part 1 left off, but you can also start here with a fresh copy of the Firebase Text Moderation demo code. The website in the Firebase demo showcases content moderation through a basic guestbook using a server-side content moderation system implemented through a Realtime Database-triggered Cloud Function. This means that the guestbook data is stored in the Firebase Realtime Database, a NoSQL database. The Cloud Function is triggered whenever data is written to a certain area of the database. We can choose what code runs when that event is triggered. In our case, we will use the Text Toxicity Classifier model to determine if the text written to the database is inappropriate, and then remove it from the database if needed. With this model, you can evaluate text on different labels of unwanted content, including identity attacks, insults, and obscenity. You can try out the demo to see the classifier in action.
If you prefer to start at the end, you can follow along in a completed version of the project on GitHub.
Server-side moderation
The Firebase text moderation example I used as my starting point doesn’t include any machine learning. Instead, it checks for the presence of profanity from a list of words and then replaces them with asterisks using the bad-words npm package. I thought about blending this approach with machine learning (more on that later), but I decided to just wipe the slate clean and replace the code of the Cloud Function altogether. Start by navigating to the Cloud Functions folder of the Text Moderation example:
|
cd text–moderation/functions |
Open index.js and delete its contents. In index.js, add the following code:
|
const functions = require(‘firebase-functions’); const toxicity = require(‘@tensorflow-models/toxicity’); exports.moderator = functions.database.ref(‘/messages/{messageId}’).onCreate(async (snapshot, context) => { const message = snapshot.val(); // Verify that the snapshot has a value if (!message) { return; } functions.logger.log(‘Retrieved message content: ‘, message); // Run moderation checks on the message and delete if needed. const moderateResult = await moderateMessage(message.text); functions.logger.log( ‘Message has been moderated. Does message violate rules? ‘, moderateResult ); }); |
This code runs any time a message is added to the database. It gets the text of the message, and then passes it to a function called `moderateResult`. If you’re interested in learning more about Cloud Functions and the Realtime Database, then check out the Firebase documentation.
Add the Text Toxicity Classifier model
|
|
This function does the following:
- Sets the threshold for the model to 0.9. The threshold of the model is the minimum prediction confidence you want to use to set the model’s predictions to true or false–that is, how confident the model is that the text does or does not contain the given type of toxic content. The scale for the threshold is 0-1.0. In this case, I set the threshold to .9, which means the model will predict true or false if it is 90% confident in its findings.
- Loads the model, passing the threshold. Once loaded, it sets toxicity_model to the model` value.
- Puts the message into an array called messages, as an array is the object type that the classify function accepts.
- Calls classify on the messages array.
- Iterates through the prediction results. predictions is an array of objects each representing a different language label. You may want to know about only specific labels rather than iterating through them all. For example, if your use case is a website for hosting the transcripts of rap battles, you probably don’t want to detect and remove insults.
- Checks if the content is a match for that label. if the match value is true, then the model has detected the given type of unwanted language. If the unwanted language is detected, the function returns true. There’s no need to keep checking the rest of the results, since the content has already been deemed inappropriate.
- If the function iterates through all the results and no label match is set to true, then the function returns false – meaning no undesirable language was found. The match label can also be null. In that case, its value isn’t true, so it’s considered acceptable language. I will talk more about the null option in a future post.
Complete the Cloud Functions code
Back in your Cloud Function, you now know that based on the code we wrote for moderateMessage, the value of moderateResult will be true or false: true if the message is considered toxic by the model, and false if it does not detect toxicity with certainty greater than 90%. Now add code to delete the message from the database if it is deemed toxic:
|
// Run moderation checks on the message and delete if needed. const moderateResult = await moderateMessage(message.text); functions.logger.log( ‘Message has been moderated. Does message violate rules? ‘, moderateResult ); if (moderateResult === true) { var modRef = snapshot.ref; try { await modRef.remove(); } catch (error) { functions.logger.error(‘Remove failed: ‘ + error.message); } } |
This code does the following:
- Checks if moderateResult is true, meaning that the message written to the guestbook is inappropriate.
- If the value is true, it removes the data from the database using the remove function from the Realtime Database SDK.
- Logs an error if one occurs.
Deploy the code
To deploy the Cloud Function, you can use the Firebase CLI. If you don’t have it, you can install it using the following npm command:
|
npm install –g firebase–tools |
|
firebase login |
Run this command to connect the app to your Firebase project:
|
firebase use —add |
From here, you can select your project in the list, connect Firebase to an existing Google Cloud project, or create a new Firebase project.
Once the project is configured, use the following command to deploy your Cloud Function:
|
firebase deploy |
Once deployment is complete, the logs include the link to your hosted guestbook. Write some guestbook entries. If you followed part 1 of the blog, you will need to either delete the moderation code from the website and deploy again, or manually add guestbook entries to the Realtime Database in the Firebase console.
You can view your Cloud Functions logs in the Firebase console.
Building on the example
I have a bunch of ideas for ways to build on this example. Here are just a few. Let me know which ideas you would like to see me build, and share your suggestions as well! The best ideas come from collaboration.
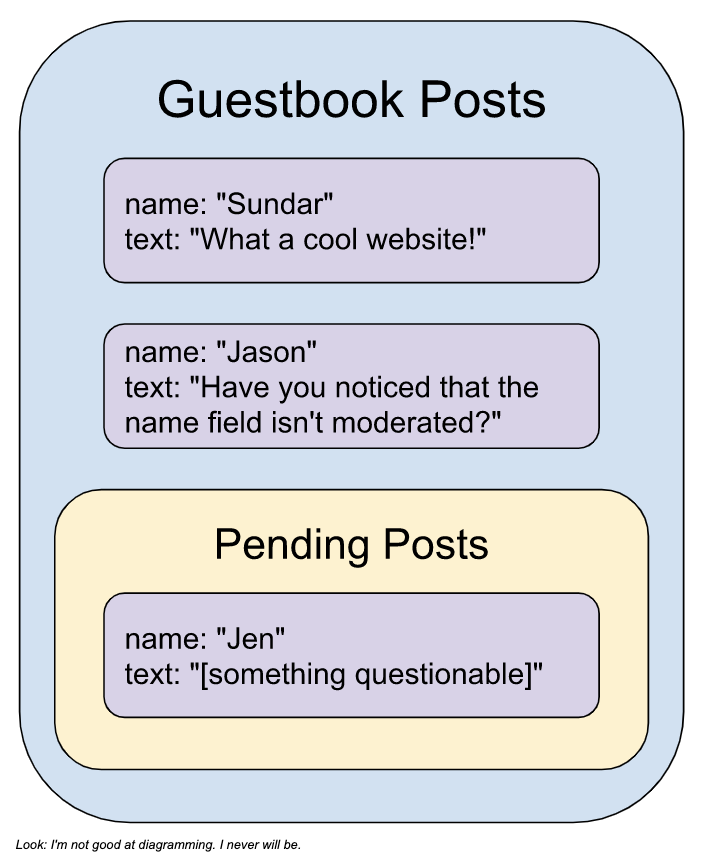
I mentioned that the “match” value of a language label can be true, false, or null without going into detail on the significance of the null value. If the label is null, then the model cannot determine if the language is toxic within the given threshold. One way to limit the number of null values is to lower this threshold. For example, if you change the threshold value to 0.8, then the model will label the match value as true if it is at least 80% certain that the text contains language that fits the label. My website example assigns labels of value null the same as those labeled false, allowing that text through the filter. But since the model isn’t sure if that text is appropriate, it’s probably a good idea to get some eyes on it. You could add these posts to a queue for review, and then approve or deny them as needed. I said “you” here, but I guess I mean “me”. If you think this would be an interesting use case to explore, let me know! I’m happy to write about it if it would be useful.
The Firebase moderation sample that I used as the foundation of my project uses Realtime Database. I prefer to use Firestore because of its structure, scalability, and security. Firestore’s structure is well suited for implementing a queue because I could have a collection of posts to review within the collection of posts. If you’d like to see the website using Firestore, let me know.
Don’t just eliminate – moderate!
One of the things I like about the original Firebase moderation sample is that it sanitizes the text rather than just deleting the post. You could run text through the sanitizer before checking for toxic language through the text toxicity model. If the sanitized text is deemed appropriate, then it could overwrite the original text. If it still doesn’t meet the standards of decent discourse, then you could still delete it. This might save some posts from otherwise being deleted.
What’s in a name?
You’ve probably noticed that my moderation functionality doesn’t extend to the name field. This means that even a halfway-clever troll could easily get around the filter by cramming all of their expletives into that name field. That’s a good point and I trust that you will use some type of moderation on all fields that users interact with. Perhaps you use an authentication method to identify users so they aren’t provided a field for their name. Anyway, you get it: I didn’t add moderation to the name field, but in a production environment, you definitely want moderation on all fields.
Build a better fit
When you test out real-world text samples on your website, you might find that the text toxicity classifier model doesn’t quite fit your needs. Since each social space is unique, there will be specific language that you are looking to include and exclude. You can address these needs by training the model on new data that you provide.
If you enjoyed this article and would like to learn more about TensorFlow.js, then there are a ton of things you can do:
- Check out the TensorFlow.js edX course by Jason Mayes. If you are even remotely interested in using TensorFlow.js, I cannot recommend this enough. It might look like a lot at first, but the course is broken up into easy-to-follow manageable pieces.
- View all the TensorFlow.js pretrained models in the TFJS repository on GitHub.
- Play around with TensorFlow.js projects on Glitch.