With personalized content more likely to drive customer engagement, businesses continuously seek to provide tailored content based on their customer’s profile and behavior. Recommendation systems in particular seek to predict the preference an end-user would give to an item. Some common use cases include product recommendations on online retail stores, personalizing newsletters, generating music playlist recommendations, or even discovering similar content on online media services.
However, it can be challenging to create an effective recommendation system due to complexities in model training, algorithm selection, and platform management. Amazon Personalize enables developers to improve customer engagement through personalized product and content recommendations with no machine learning (ML) expertise required. Developers can start to engage customers right away by using captured user behavior data. Behind the scenes, Amazon Personalize examines this data, identifies what is meaningful, selects the right algorithms, trains and optimizes a personalization model that is customized for your data, and provides recommendations via an API endpoint.
Although providing recommendations in real time can help boost engagement and satisfaction, sometimes this might not actually be required, and performing this in batch on a scheduled basis can simply be a more cost-effective and manageable option.
This post shows you how to use AWS services to not only create recommendations but also operationalize a batch recommendation pipeline. We walk through the end-to-end solution without a single line of code. We discuss two topics in detail:
- Preparing your data using AWS Glue
- Orchestrating the Amazon Personalize batch inference jobs using AWS Step Functions
Solution overview
In this solution, we use the MovieLens dataset. This dataset includes 86,000 ratings of movies from 2,113 users. We attempt to use this data to generate recommendations for each of these users.
Data preparation is very important to ensure we get customer behavior data into a format that is ready for Amazon Personalize. The architecture described in this post uses AWS Glue, a serverless data integration service, to perform the transformation of raw data into a format that is ready for Amazon Personalize to consume. The solution uses Amazon Personalize to create batch recommendations for all users by using a batch inference. We then use a Step Functions workflow so that the automated workflow can be run by calling Amazon Personalize APIs in a repeatable manner.
The following diagram demonstrates this solution.
We will build this solution with the following steps:
- Build a data transformation job to transform our raw data using AWS Glue.
- Build an Amazon Personalize solution with the transformed dataset.
- Build a Step Functions workflow to orchestrate the generation of batch inferences.
Prerequisites
You need the following for this walkthrough:
- An AWS account
- Permissions to create new AWS Identity and Access Management (IAM) roles
Build a data transformation job to transform raw data with AWS Glue
With Amazon Personalize, input data needs to have a specific schema and file format. Data from interactions between users and items must be in CSV format with specific columns, whereas the list of users for which you want to generate recommendations for must be in JSON format. In this section, we use AWS Glue Studio to transform raw input data into the required structures and format for Amazon Personalize.
AWS Glue Studio provides a graphical interface that is designed for easy creation and running of extract, transform, and load (ETL) jobs. You can visually create data transformation workloads through simple drag-and-drop operations.
We first prepare our source data in Amazon Simple Storage Service (Amazon S3), then we transform the data without code.
- On the Amazon S3 console, create an S3 bucket with three folders: raw, transformed, and curated.
- Download the MovieLens dataset and upload the uncompressed file named user_ratingmovies-timestamp.dat to your bucket under the raw folder.
- On the AWS Glue Studio console, choose Jobs in the navigation pane.
- Select Visual with a source and target, then choose Create.

- Choose the first node called Data source – S3 bucket. This is where we specify our input data.
- On the Data source properties tab, select S3 location and browse to your uploaded file.
- For Data format, choose CSV, and for Delimiter, choose Tab.

- We can choose the Output schema tab to verify that the schema has inferred the columns correctly.
- If the schema doesn’t match your expectations, choose Edit to edit the schema.



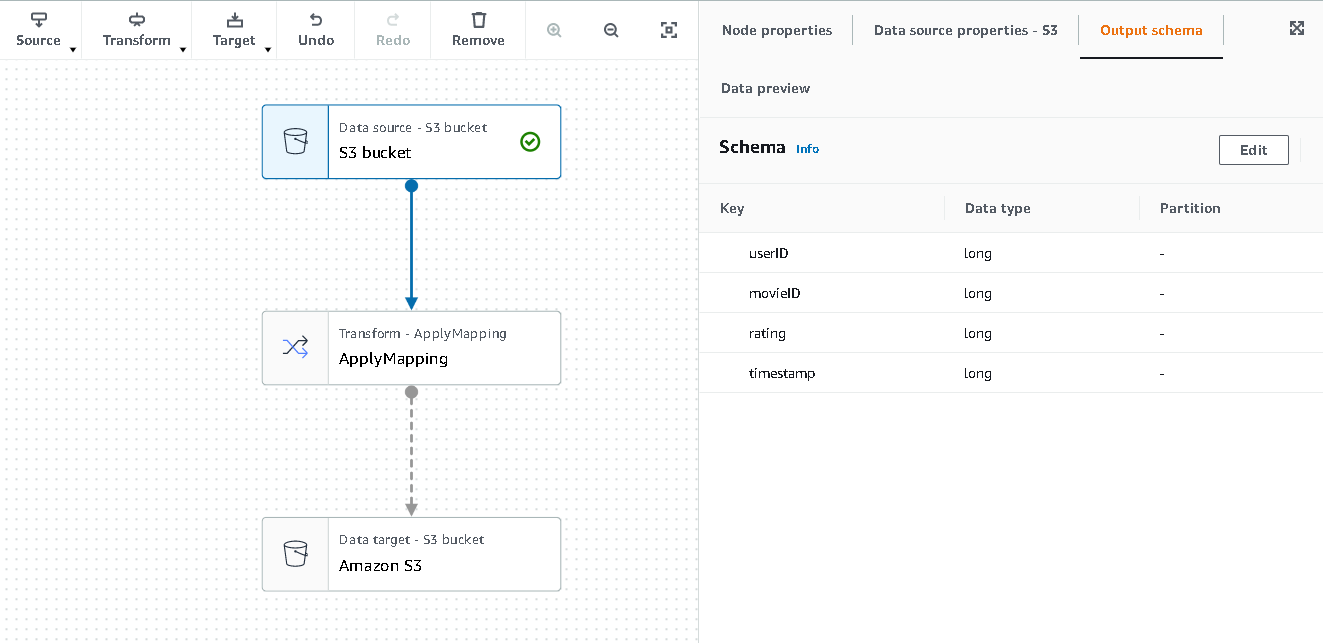
Next, we transform this data to follow the schema requirements for Amazon Personalize.
- Choose the Transform – Apply Mapping node and, on the Transform tab, update the target key and data types.
Amazon Personalize, at minimum, expects the following structure for the interactions dataset:
-
-
user_id(string) -
item_id(string) -
timestamp(long, in Unix epoch time format)

-
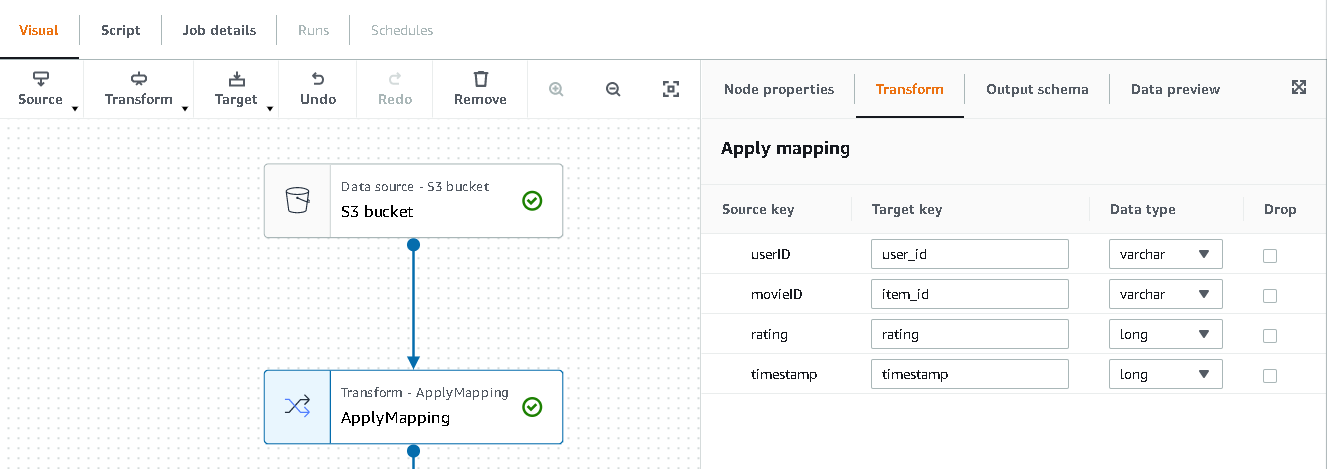
In this example, we exclude the poorly rated movies in the dataset.
- To do so, remove the last node called S3 bucket and add a filter node on the Transform tab.
- Choose Add condition and filter out data where rating < 3.5.


We now write the output back to Amazon S3.
- Expand the Target menu and choose Amazon S3.
- For S3 Target Location, choose the folder named
transformed. - Choose CSV as the format and suffix the Target Location with
interactions/.
Next, we output a list of users that we want to get recommendations for.
- Choose the ApplyMapping node again, and then expand the Transform menu and choose ApplyMapping.
- Drop all fields except for
user_idand rename that field touserId. Amazon Personalize expects that field to be named userId. - Expand the Target menu again and choose Amazon S3.
- This time, choose JSON as the format, and then choose the transformed S3 folder and suffix it with
batch_users_input/.
This produces a JSON list of users as input for Amazon Personalize. We should now have a diagram that looks like the following.
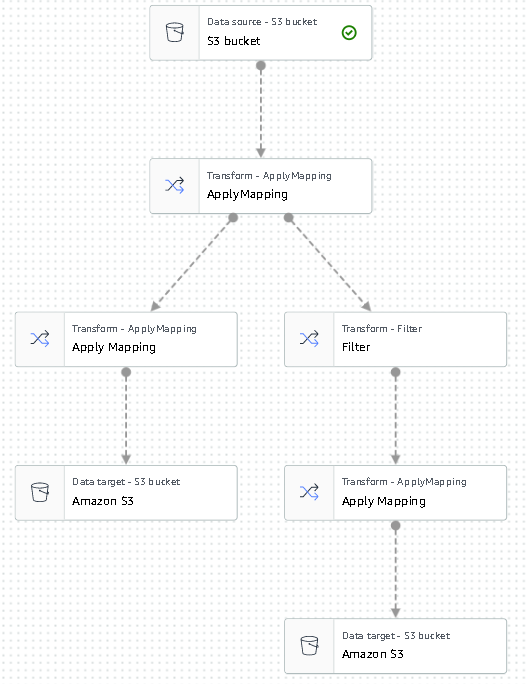
We are now ready to run our transform job.
- On the IAM console, create a role called glue-service-role and attach the following managed policies:
AWSGlueServiceRoleAmazonS3FullAccess
For more information on how to create IAM service roles, refer to the Creating a role to delegate permissions to an AWS service.
- Navigate back to your AWS Glue Studio job, and choose the Job details tab.
- Set the job name as
batch-personalize-input-transform-job. - Choose the newly created IAM role.
- Keep the default values for everything else.
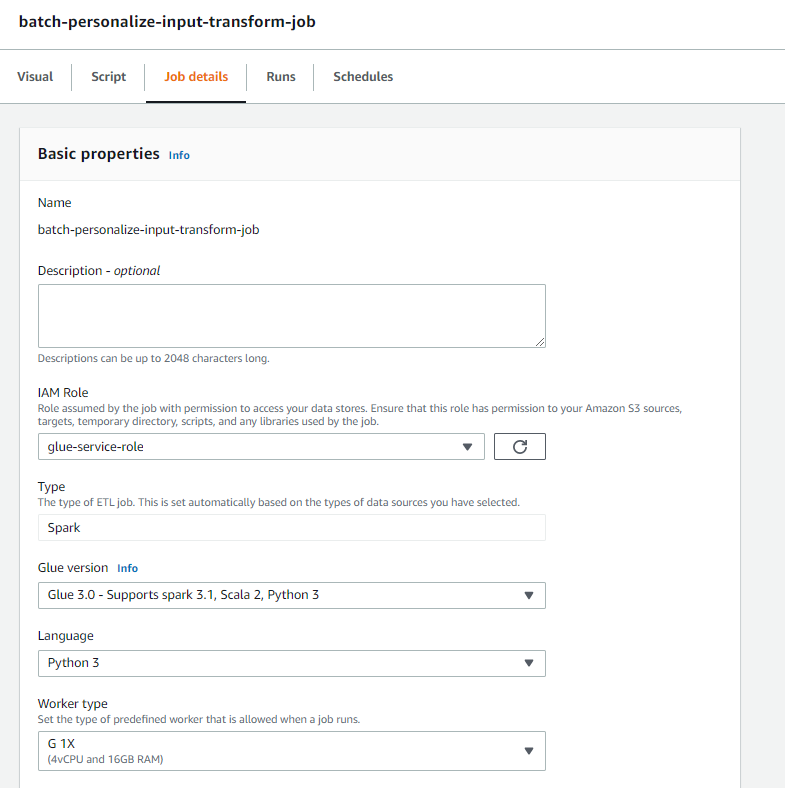
- Choose Save.
- When you’re ready, choose Run and monitor the job in the Runs tab.
- When the job is complete, navigate to the Amazon S3 console to validate that your output file has been successfully created.
We have now shaped our data into the format and structure that Amazon Personalize requires. The transformed dataset should have the following fields and format:
-
Interactions dataset – CSV format with fields
USER_ID,ITEM_ID,TIMESTAMP -
User input dataset – JSON format with element
userId
Build an Amazon Personalize solution with the transformed dataset
With our interactions dataset and user input data in the right format, we can now create our Amazon Personalize solution. In this section, we create our dataset group, import our data, and then create a batch inference job. A dataset group organizes resources into containers for Amazon Personalize components.
- On the Amazon Personalize console, choose Create dataset group.
- For Domain, select Custom.
- Choose Create dataset group and continue.

Next, create the interactions dataset.
- Enter a dataset name and select Create new schema.
- Choose Create dataset and continue.
We now import the interactions data that we had created earlier.
- Navigate to the S3 bucket in which we created our interactions CSV dataset.
- On the Permissions tab, add the following bucket access policy so that Amazon Personalize has access. Update the policy to include your bucket name.
Navigate back to Amazon Personalize and choose Create your dataset import job. Our interactions dataset should now be importing into Amazon Personalize. Wait for the import job to complete with a status of Active before continuing to the next step. This should take approximately 8 minutes.
- On the Amazon Personalize console, choose Overview in the navigation pane and choose Create solution.

- Enter a solution name.
- For Solution type, choose Item recommendation.
- For Recipe, choose the
aws-user-personalizationrecipe. - Choose Create and train solution.


The solution now trains against the interactions dataset that was imported with the user personalization recipe. Monitor the status of this process under Solution versions. Wait for it to complete before proceeding. This should take approximately 20 minutes.

We now create our batch inference job, which generates recommendations for each of the users present in the JSON input.
- In the navigation pane, under Custom resources, choose Batch inference jobs.
- Enter a job name, and for Solution, choose the solution created earlier.
- Choose Create batch inference job.

- For Input data configuration, enter the S3 path of where the
batch_users_inputfile is located.

This is the JSON file that contains userId.
- For Output data configuration path, choose the curated path in S3.
- Choose Create batch inference job.
This process takes approximately 30 minutes. When the job is finished, recommendations for each of the users specified in the user input file are saved in the S3 output location.
We have successfully generated a set of recommendations for all of our users. However, we have only implemented the solution using the console so far. To make sure that this batch inferencing runs regularly with the latest set of data, we need to build an orchestration workflow. In the next section, we show you how to create an orchestration workflow using Step Functions.
Build a Step Functions workflow to orchestrate the batch inference workflow
To orchestrate your pipeline, complete the following steps:
- On the Step Functions console, choose Create State Machine.
- Select Design your workflow visually, then choose Next.

- Drag the
CreateDatasetImportJobnode from the left (you can search for this node in the search box) onto the canvas. - Choose the node, and you should see the configuration API parameters on the right. Record the ARN.
- Enter your own values in the API Parameters text box.

This calls the CreateDatasetImportJob API with the parameter values that you specify.

- Drag the
CreateSolutionVersionnode onto the canvas. - Update the API parameters with the ARN of the solution that you noted down.
This creates a new solution version with the newly imported data by calling the CreateSolutionVersion API.
- Drag the
CreateBatchInferenceJobnode onto the canvas and similarly update the API parameters with the relevant values.
Make sure that you use the $.SolutionVersionArn syntax to retrieve the solution version ARN parameter from the previous step. These API parameters are passed to the CreateBatchInferenceJob API.

We need to build a wait logic in the Step Functions workflow to make sure the recommendation batch inference job finishes before the workflow completes.
- Find and drag in a Wait node.
- In the configuration for Wait, enter 300 seconds.
This is an arbitrary value; you should alter this wait time according to your specific use case.
- Choose the
CreateBatchInferenceJobnode again and navigate to the Error handling tab. - For Catch errors, enter
Personalize.ResourceInUseException. - For Fallback state, choose Wait.
This step enables us to periodically check the status of the job and it only exits the loop when the job is complete.
- For ResultPath, enter
$.errorMessage.
This effectively means that when the “resource in use” exception is received, the job waits for x seconds before trying again with the same inputs.

- Choose Save, and then choose Start the execution.
We have successfully orchestrated our batch recommendation pipeline for Amazon Personalize. As an optional step, you can use Amazon EventBridge to schedule a trigger of this workflow on a regular basis. For more details, refer to EventBridge (CloudWatch Events) for Step Functions execution status changes.
Clean up
To avoid incurring future charges, delete the resources that you created for this walkthrough.
Conclusion
In this post, we demonstrated how to create a batch recommendation pipeline by using a combination of AWS Glue, Amazon Personalize, and Step Functions, without needing a single line of code or ML experience. We used AWS Glue to prep our data into the format that Amazon Personalize requires. Then we used Amazon Personalize to import the data, create a solution with a user personalization recipe, and create a batch inferencing job that generates a default of 25 recommendations for each user, based on past interactions. We then orchestrated these steps using Step Functions so that we can run these jobs automatically.
For steps to consider next, user segmentation is one of the newer recipes in Amazon Personalize, which you might want to explore to create user segments for each row of the input data. For more details, refer to Getting batch recommendations and user segments.
About the author

Maxine Wee is an AWS Data Lab Solutions Architect. Maxine works with customers on their use cases, designs solutions to solve their business problems, and guides them through building scalable prototypes. Prior to her journey with AWS, Maxine helped customers implement BI, data warehousing, and data lake projects in Australia.