Posted by Pete Florence, Research Scientist and Corey Lynch, Research Engineer, Robotics at Google
Despite considerable progress in robot learning over the past several years, some policies for robotic agents can still struggle to decisively choose actions when trying to imitate precise or complex behaviors. Consider a task in which a robot tries to slide a block across a table to precisely position it into a slot. There are many possible ways to solve this task, each requiring precise movements and corrections. The robot must commit to just one of these options, but must also be capable of changing plans each time the block ends up sliding farther than expected. Although one might expect such a task to be easy, that is often not the case for modern learning-based robots, which often learn behavior that expert observers describe as indecisive or imprecise.
| Example of a baseline explicit behavior cloning model struggling on a task where the robot needs to slide a block across a table and then precisely insert it into a fixture. |
To encourage robots to be more decisive, researchers often utilize a discretized action space, which forces the robot to choose option A or option B, without oscillating between options. For example, discretization was a key element of our recent Transporter Networks architecture, and is also inherent in many notable achievements by game-playing agents, such as AlphaGo, AlphaStar, and OpenAI’s Dota bot. But discretization brings its own limitations — for robots that operate in the spatially continuous real world, there are at least two downsides to discretization: (i) it limits precision, and (ii) it triggers the curse of dimensionality, since considering discretizations along many different dimensions can dramatically increase memory and compute requirements. Related to this, in 3D computer vision much recent progress has been powered by continuous, rather than discretized, representations.
With the goal of learning decisive policies without the drawbacks of discretization, today we announce our open source implementation of Implicit Behavioral Cloning (Implicit BC), which is a new, simple approach to imitation learning and was presented last week at CoRL 2021. We found that Implicit BC achieves strong results on both simulated benchmark tasks and on real-world robotic tasks that demand precise and decisive behavior. This includes achieving state-of-the-art (SOTA) results on human-expert tasks from our team’s recent benchmark for offline reinforcement learning, D4RL. On six out of seven of these tasks, Implicit BC outperforms the best previous method for offline RL, Conservative Q Learning. Interestingly, Implicit BC achieves these results without requiring any reward information, i.e., it can use relatively simple supervised learning rather than more-complex reinforcement learning.
Implicit Behavioral Cloning
Our approach is a type of behavior cloning, which is arguably the simplest way for robots to learn new skills from demonstrations. In behavior cloning, an agent learns how to mimic an expert’s behavior using standard supervised learning. Traditionally, behavior cloning involves training an explicit neural network (shown below, left), which takes in observations and outputs expert actions.
The key idea behind Implicit BC is to instead train a neural network to take in both observations and actions, and output a single number that is low for expert actions and high for non-expert actions (below, right), turning behavioral cloning into an energy-based modeling problem. After training, the Implicit BC policy generates actions by finding the action input that has the lowest score for a given observation.
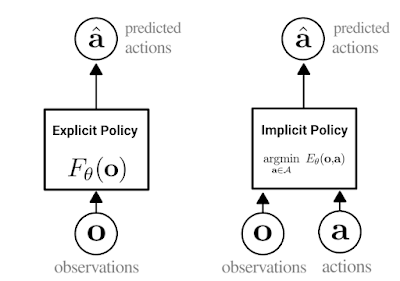 |
| Depiction of the difference between explicit (left) and implicit (right) policies. In the implicit policy, the “argmin” means the action that, when paired with a particular observation, minimizes the value of the energy function. |
To train Implicit BC models, we use an InfoNCE loss, which trains the network to output low energy for expert actions in the dataset, and high energy for all others (see below). It is interesting to note that this idea of using models that take in both observations and actions is common in reinforcement learning, but not so in supervised policy learning.
| Animation of how implicit models can fit discontinuities — in this case, training an implicit model to fit a step (Heaviside) function. Left: 2D plot fitting the black (X) training points — the colors represent the values of the energies (blue is low, brown is high). Middle: 3D plot of the energy model during training. Right: Training loss curve. |
Once trained, we find that implicit models are particularly good at precisely modeling discontinuities (above) on which prior explicit models struggle (as in the first figure of this post), resulting in policies that are newly capable of switching decisively between different behaviors.
But why do conventional explicit models struggle? Modern neural networks almost always use continuous activation functions — for example, Tensorflow, Jax, and PyTorch all only ship with continuous activation functions. In attempting to fit discontinuous data, explicit networks built with these activation functions cannot represent discontinuities, so must draw continuous curves between data points. A key aspect of implicit models is that they gain the ability to represent sharp discontinuities, even though the network itself is composed only of continuous layers.
We also establish theoretical foundations for this aspect, specifically a notion of universal approximation. This proves the class of functions that implicit neural networks can represent, which can help justify and guide future research.
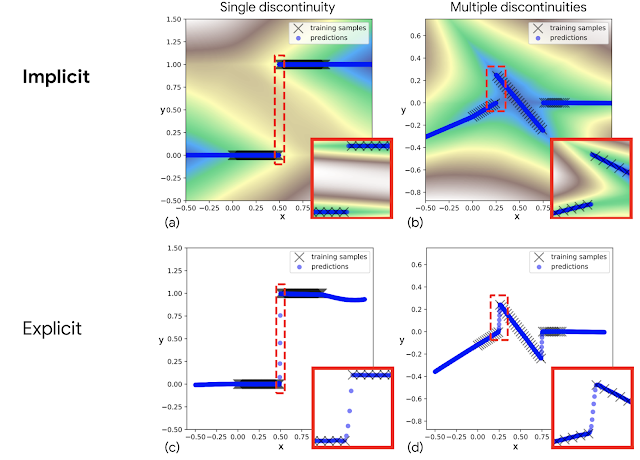 |
| Examples of fitting discontinuous functions, for implicit models (top) compared to explicit models (bottom). The red highlighted insets show that implicit models represent discontinuities (a) and (b) while the explicit models must draw continuous lines (c) and (d) in between the discontinuities. |
One challenge faced by our initial attempts at this approach was “high action dimensionality”, which means that a robot must decide how to coordinate many motors all at the same time. To scale to high action dimensionality, we use either autoregressive models or Langevin dynamics.
Highlights
In our experiments, we found Implicit BC does particularly well in the real world, including an order of magnitude (10x) better on the 1mm-precision slide-then-insert task compared to a baseline explicit BC model. On this task the implicit model does several consecutive precise adjustments (below) before sliding the block into place. This task demands multiple elements of decisiveness: there are many different possible solutions due to the symmetry of the block and the arbitrary ordering of push maneuvers, and the robot needs to discontinuously decide when the block has been pushed far “enough” before switching to slide it in a different direction. This is in contrast to the indecisiveness that is often associated with continuous-controlled robots.
| Example task of sliding a block across a table and precisely inserting it into a slot. These are autonomous behaviors of our Implicit BC policies, using only images (from the shown camera) as input. |
| A diverse set of different strategies for accomplishing this task. These are autonomous behaviors from our Implicit BC policies, using only images as input. |
In another challenging task, the robot needs to sort blocks by color, which presents a large number of possible solutions due to the arbitrary ordering of sorting. On this task the explicit models are customarily indecisive, while implicit models perform considerably better.
| Comparison of implicit (left) and explicit (right) BC models on a challenging continuous multi-item sorting task. (4x speed) |
In our testing, implicit BC models can also exhibit robust reactive behavior, even when we try to interfere with the robot, despite the model never seeing human hands.
| Robust behavior of the implicit BC model despite interfering with the robot. |
Overall, we find that Implicit BC policies can achieve strong results compared to state of the art offline reinforcement learning methods across several different task domains. These results include tasks that, challengingly, have either a low number of demonstrations (as few as 19), high observation dimensionality with image-based observations, and/or high action dimensionality up to 30 — which is a large number of actuators to have on a robot.
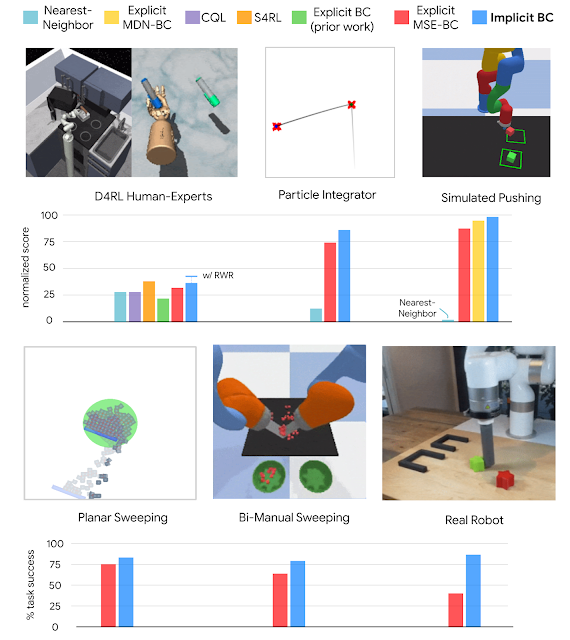 |
| Policy learning results of Implicit BC compared to baselines across several domains. |
Conclusion
Despite its limitations, behavioral cloning with supervised learning remains one of the simplest ways for robots to learn from examples of human behaviors. As we showed here, replacing explicit policies with implicit policies when doing behavioral cloning allows robots to overcome the “struggle of decisiveness”, enabling them to imitate much more complex and precise behaviors. While the focus of our results here was on robot learning, the ability of implicit functions to model sharp discontinuities and multimodal labels may have broader interest in other application domains of machine learning as well.
Acknowledgements
Pete and Corey summarized research performed together with other co-authors: Andy Zeng, Oscar Ramirez, Ayzaan Wahid, Laura Downs, Adrian Wong, Johnny Lee, Igor Mordatch, and Jonathan Tompson. The authors would also like to thank Vikas Sindwhani for project direction advice; Steve Xu, Robert Baruch, Arnab Bose for robot software infrastructure; Jake Varley, Alexa Greenberg for ML infrastructure; and Kamyar Ghasemipour, Jon Barron, Eric Jang, Stephen Tu, Sumeet Singh, Jean-Jacques Slotine, Anirudha Majumdar, Vincent Vanhoucke for helpful feedback and discussions.
