This post was written in collaboration with Ankur Goyal and Karthikeyan Chokappa from PwC Australia’s Cloud & Digital business.
Artificial intelligence (AI) and machine learning (ML) are becoming an integral part of systems and processes, enabling decisions in real time, thereby driving top and bottom-line improvements across organizations. However, putting an ML model into production at scale is challenging and requires a set of best practices. Many businesses already have data scientists and ML engineers who can build state-of-the-art models, but taking models to production and maintaining the models at scale remains a challenge. Manual workflows limit ML lifecycle operations to slow down the development process, increase costs, and compromise the quality of the final product.
Machine learning operations (MLOps) applies DevOps principles to ML systems. Just like DevOps combines development and operations for software engineering, MLOps combines ML engineering and IT operations. With the rapid growth in ML systems and in the context of ML engineering, MLOps provides capabilities that are needed to handle the unique complexities of the practical application of ML systems. Overall, ML use cases require a readily available integrated solution to industrialize and streamline the process that takes an ML model from development to production deployment at scale using MLOps.
To address these customer challenges, PwC Australia developed Machine Learning Ops Accelerator as a set of standardized process and technology capabilities to improve the operationalization of AI/ML models that enable cross-functional collaboration across teams throughout ML lifecycle operations. PwC Machine Learning Ops Accelerator, built on top of AWS native services, delivers a fit-for-purpose solution that easily integrates into the ML use cases with ease for customers across all industries. In this post, we focus on building and deploying an ML use case that integrates various lifecycle components of an ML model, enabling continuous integration (CI), continuous delivery (CD), continuous training (CT), and continuous monitoring (CM).
Solution overview
In MLOps, a successful journey from data to ML models to recommendations and predictions in business systems and processes involves several crucial steps. It involves taking the result of an experiment or prototype and turning it into a production system with standard controls, quality, and feedback loops. It’s much more than just automation. It’s about improving organization practices and delivering outcomes that are repeatable and reproducible at scale.
Only a small fraction of a real-world ML use case comprises the model itself. The various components needed to build an integrated advanced ML capability and continuously operate it at scale is shown in Figure 1. As illustrated in the following diagram, PwC MLOps Accelerator comprises seven key integrated capabilities and iterative steps that enable CI, CD, CT, and CM of an ML use case. The solution takes advantage of AWS native features from Amazon SageMaker, building a flexible and extensible framework around this.
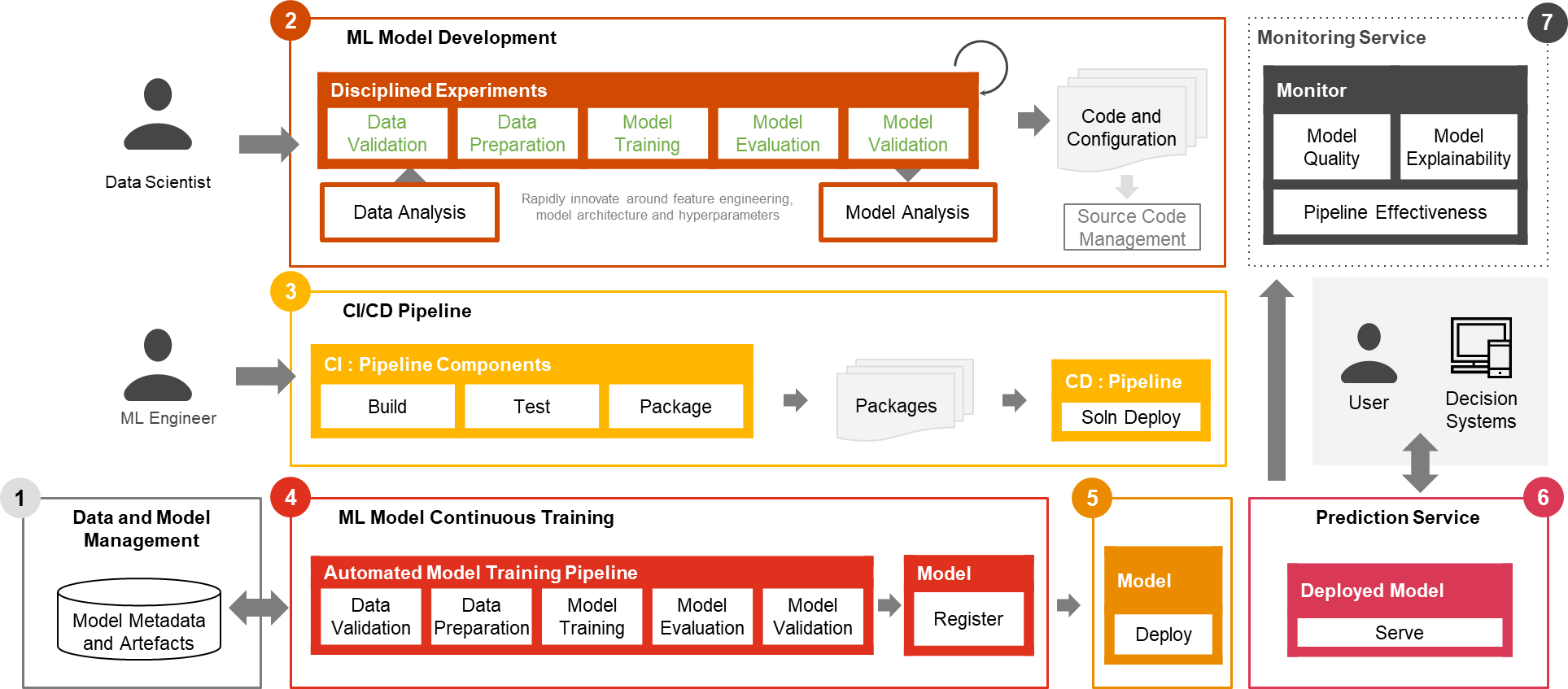
Figure 1 -– PwC Machine Learning Ops Accelerator capabilities
In a real enterprise scenario, additional steps and stages of testing may exist to ensure rigorous validation and deployment of models across different environments.
- Data and model management provide a central capability that governs ML artifacts throughout their lifecycle. It enables auditability, traceability, and compliance. It also promotes the shareability, reusability, and discoverability of ML assets.
- ML model development allows various personas to develop a robust and reproducible model training pipeline, which comprises a sequence of steps, from data validation and transformation to model training and evaluation.
- Continuous integration/delivery facilitates the automated building, testing, and packaging of the model training pipeline and deploying it into the target execution environment. Integrations with CI/CD workflows and data versioning promote MLOps best practices such as governance and monitoring for iterative development and data versioning.
- ML model continuous training capability executes the training pipeline based on retraining triggers; that is, as new data becomes available or model performance decays below a preset threshold. It registers the trained model if it qualifies as a successful model candidate and stores the training artifacts and associated metadata.
- Model deployment allows access to the registered trained model to review and approve for production release and enables model packaging, testing, and deploying into the prediction service environment for production serving.
- Prediction service capability starts the deployed model to provide prediction through online, batch, or streaming patterns. Serving runtime also captures model serving logs for continuous monitoring and improvements.
- Continuous monitoring monitors the model for predictive effectiveness to detect model decay and service effectiveness (latency, pipeline throughout, and execution errors)
PwC Machine Learning Ops Accelerator architecture
The solution is built on top of AWS-native services using Amazon SageMaker and serverless technology to keep performance and scalability high and running costs low.
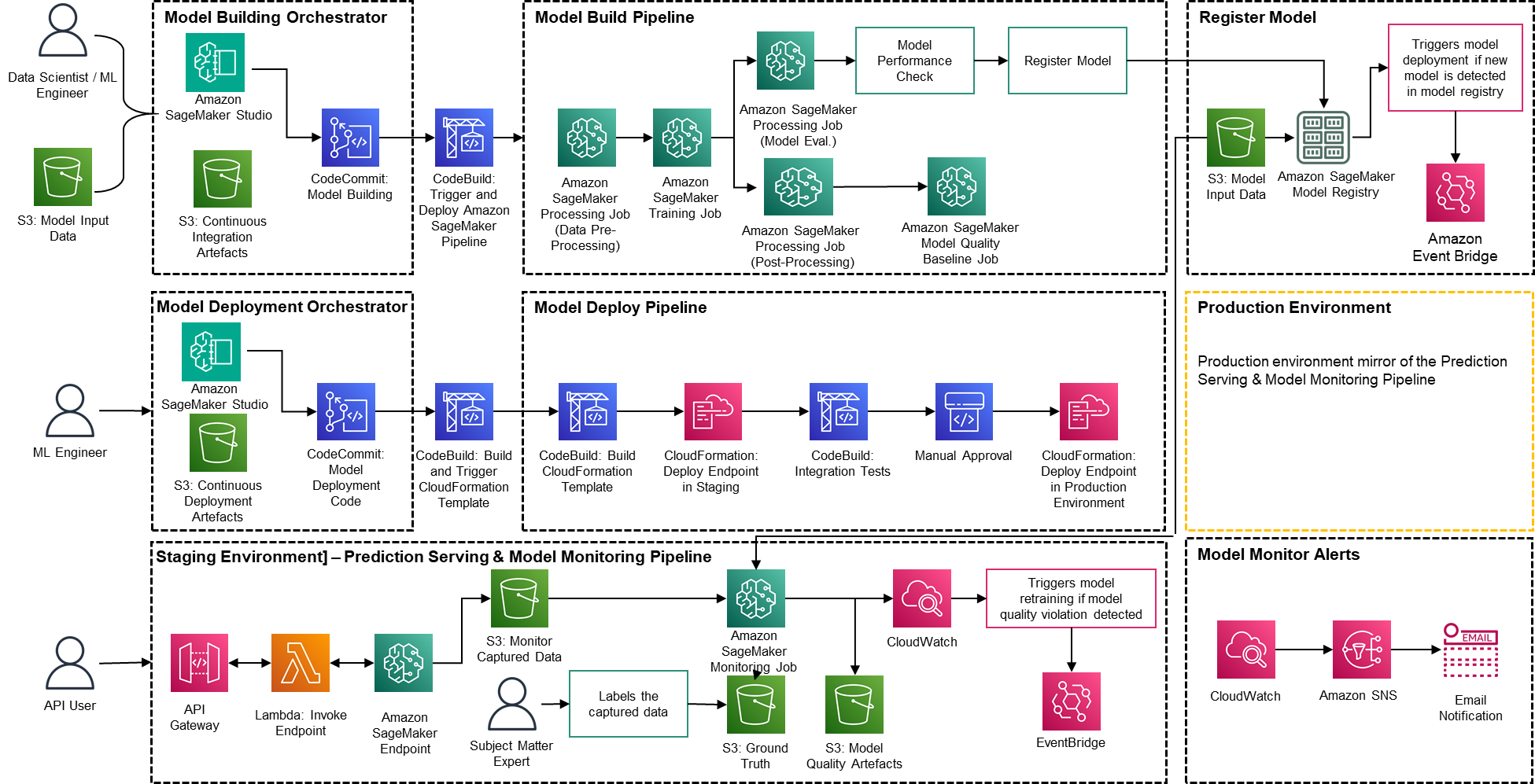
Figure 2 – PwC Machine Learning Ops Accelerator architecture
- PwC Machine Learning Ops Accelerator provides a persona-driven access entitlement for build-out, usage, and operations that enables ML engineers and data scientists to automate deployment of pipelines (training and serving) and rapidly respond to model quality changes. Amazon SageMaker Role Manager is used to implement role-based ML activity, and Amazon S3 is used to store input data and artifacts.
- Solution uses existing model creation assets from the customer and builds a flexible and extensible framework around this using AWS native services. Integrations have been built between Amazon S3, Git, and AWS CodeCommit that allow dataset versioning with minimal future management.
- AWS CloudFormation template is generated using AWS Cloud Development Kit (AWS CDK). AWS CDK provides the ability to manage changes for the complete solution. The automated pipeline includes steps for out-of-the-box model storage and metric tracking.
- PwC MLOps Accelerator is designed to be modular and delivered as infrastructure-as-code (IaC) to allow automatic deployments. The deployment process uses AWS CodeCommit, AWS CodeBuild, AWS CodePipeline, and AWS CloudFormation template. Complete end-to-end solution to operationalize an ML model is available as deployable code.
- Through a series of IaC templates, three distinct components are deployed: model build, model deployment , and model monitoring and prediction serving, using Amazon SageMaker Pipelines
- Model build pipeline automates the model training and evaluation process and enables approval and registration of the trained model.
- Model deployment pipeline provisions the necessary infrastructure to deploy the ML model for batch and real-time inference.
- Model monitoring and prediction serving pipeline deploys the infrastructure required to serve predictions and monitor model performance.
- PwC MLOps Accelerator is designed to be agnostic to ML models, ML frameworks, and runtime environments. The solution allows for the familiar use of programming languages like Python and R, development tools such as Jupyter Notebook, and ML frameworks through a configuration file. This flexibility makes it straightforward for data scientists to continuously refine models and deploy them using their preferred language and environment.
- The solution has built-in integrations to use either pre-built or custom tools to assign the labeling tasks using Amazon SageMaker Ground Truth for training datasets to provide continuous training and monitoring.
- End-to-end ML pipeline is architected using SageMaker native features (Amazon SageMaker Studio , Amazon SageMaker Model Building Pipelines, Amazon SageMaker Experiments, and Amazon SageMaker endpoints).
- The solution uses Amazon SageMaker built-in capabilities for model versioning, model lineage tracking, model sharing, and serverless inference with Amazon SageMaker Model Registry.
- Once the model is in production, the solution continuously monitors the quality of ML models in real time. Amazon SageMaker Model Monitor is used to continuously monitor models in production. Amazon CloudWatch Logs is used to collect log files monitoring the model status, and notifications are sent using Amazon SNS when the quality of the model hits certain thresholds. Native loggers such as (boto3) are used to capture run status to expedite troubleshooting.
Solution walkthrough
The following walkthrough dives into the standard steps to create the MLOps process for a model using PwC MLOps Accelerator. This walkthrough describes a use case of an MLOps engineer who wants to deploy the pipeline for a recently developed ML model using a simple definition/configuration file that is intuitive.
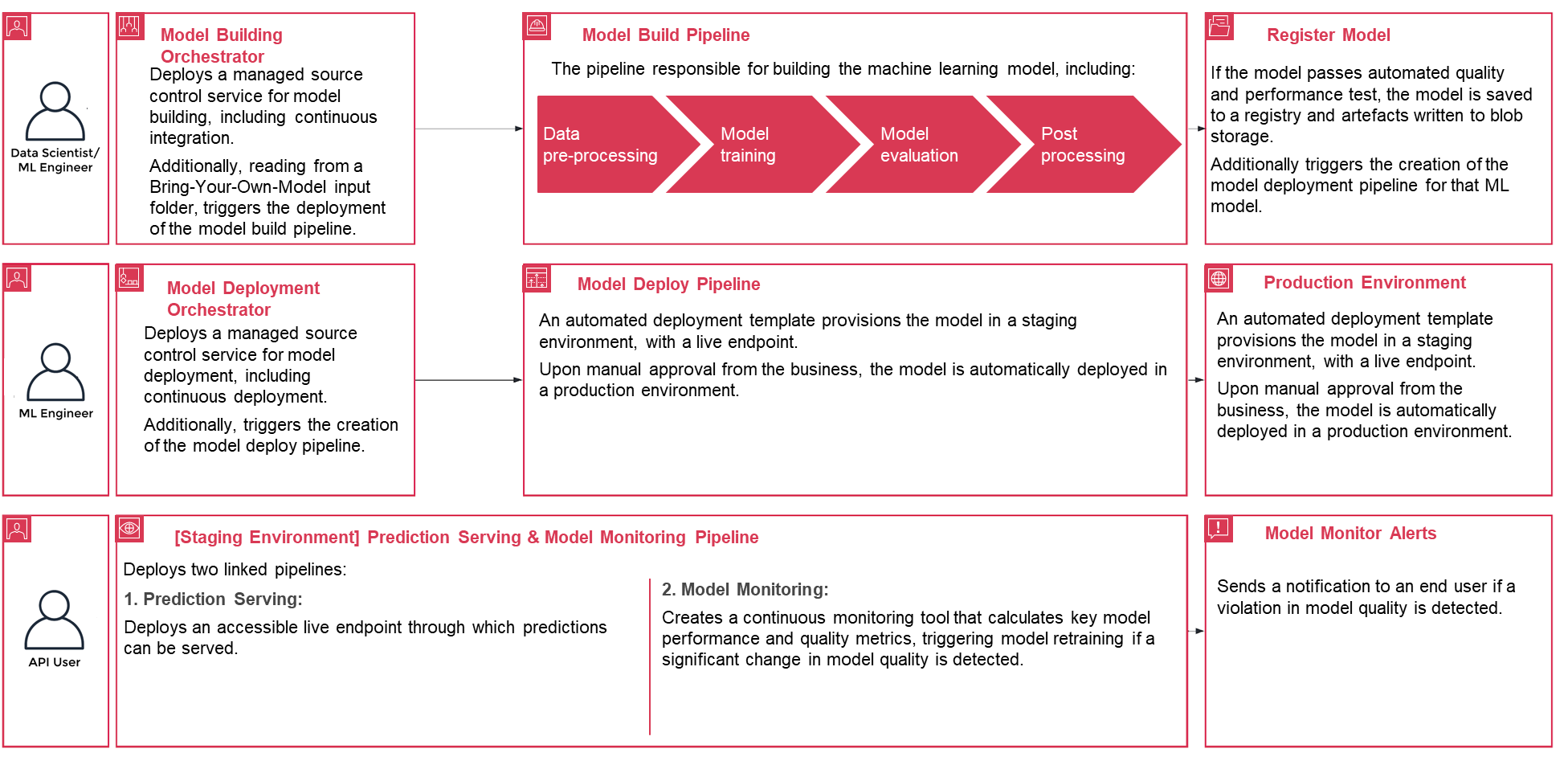
Figure 3 – PwC Machine Learning Ops Accelerator process lifecycle
- To get started, enroll in PwC MLOps Accelerator to get access to solution artifacts. The entire solution is driven from one configuration YAML file (
config.yaml) per model. All the details required to run the solution are contained within that config file and stored along with the model in a Git repository. The configuration file will serve as input to automate workflow steps by externalizing important parameters and settings outside of code. - The ML engineer is required to populate
config.yamlfile and trigger the MLOps pipeline. Customers can configure an AWS account, the repository, the model, the data used, the pipeline name, the training framework, the number of instances to use for training, the inference framework, and any pre- and post-processing steps and several other configurations to check the model quality, bias, and explainability.

Figure 4 – Machine Learning Ops Accelerator configuration YAML
- A simple YAML file is used to configure each model’s training, deployment, monitoring, and runtime requirements. Once the
config.yamlis configured appropriately and saved alongside the model in its own Git repository, the model-building orchestrator is invoked. It also can read from a Bring-Your-Own-Model that can be configured through YAML to trigger deployment of the model build pipeline. - Everything after this point is automated by the solution and does not need the involvement of either the ML engineer or data scientist. The pipeline responsible for building the ML model includes data preprocessing, model training, model evaluation, and ost-processing. If the model passes automated quality and performance tests, the model is saved to a registry, and artifacts are written to Amazon S3 storage per the definitions in the YAML files. This triggers the creation of the model deployment pipeline for that ML model.
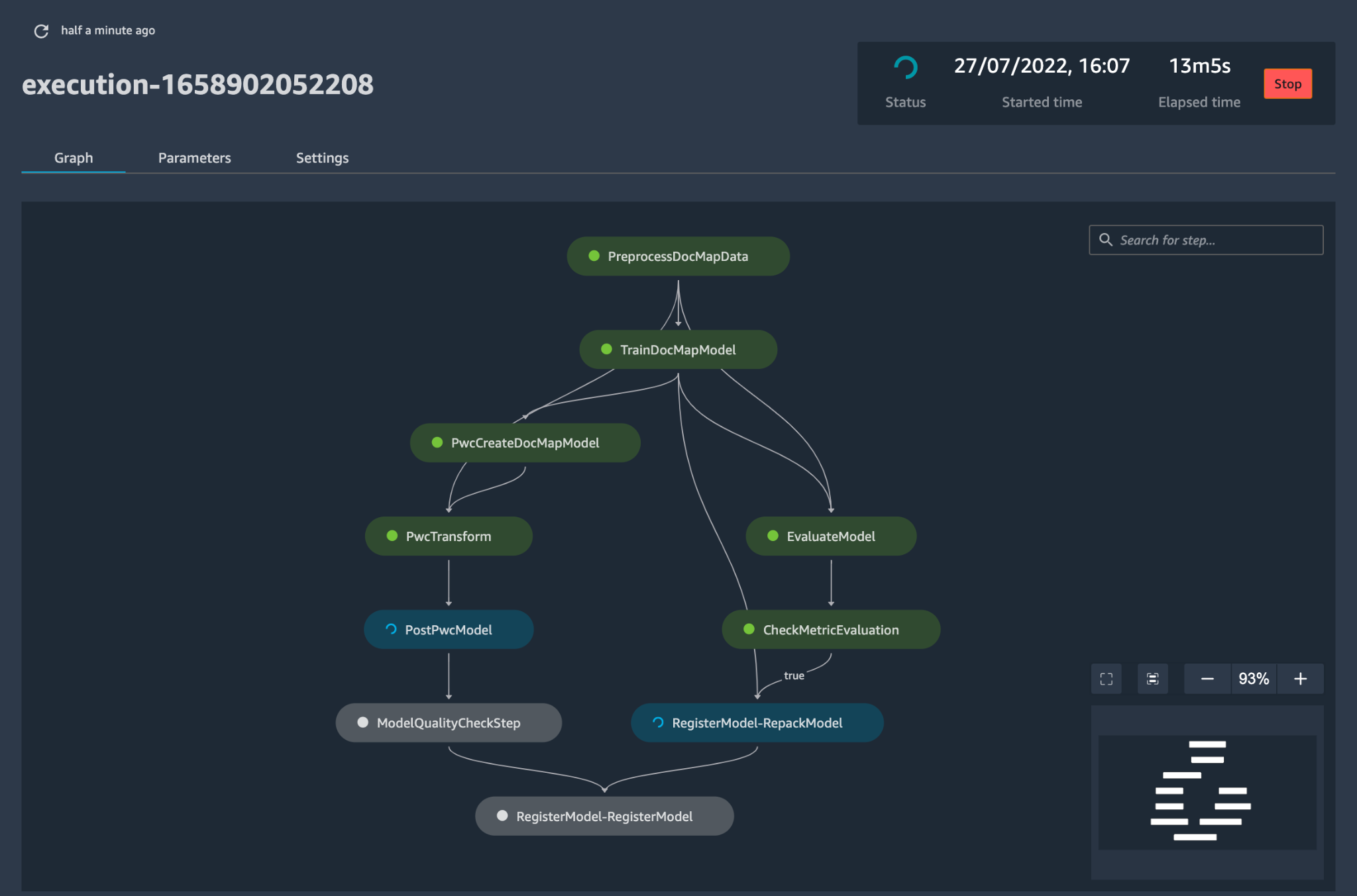
Figure 5 – Sample model deployment workflow
- Next, an automated deployment template provisions the model in a staging environment with a live endpoint. Upon approval, the model is automatically deployed into the production environment.
- The solution deploys two linked pipelines. Prediction serving deploys an accessible live endpoint through which predictions can be served. Model monitoring creates a continuous monitoring tool that calculates key model performance and quality metrics, triggering model retraining if a significant change in model quality is detected.
- Now that you’ve gone through the creation and initial deployment, the MLOps engineer can configure failure alerts to be alerted for issues, for example, when a pipeline fails to do its intended job.
- MLOps is no longer about packaging, testing, and deploying cloud service components similar to a traditional CI/CD deployment; it’s a system that should automatically deploy another service. For example, the model training pipeline automatically deploys the model deployment pipeline to enable prediction service, which in turn enables the model monitoring service.
Conclusion
In summary, MLOps is critical for any organization that aims to deploy ML models in production systems at scale. PwC developed an accelerator to automate building, deploying, and maintaining ML models via integrating DevOps tools into the model development process.
In this post, we explored how the PwC solution is powered by AWS native ML services and helps to adopt MLOps practices so that businesses can speed up their AI journey and gain more value from their ML models. We walked through the steps a user would take to access the PwC Machine Learning Ops Accelerator, run the pipelines, and deploy an ML use case that integrates various lifecycle components of an ML model.
To get started with your MLOps journey on AWS Cloud at scale and run your ML production workloads, enroll in PwC Machine Learning Operations.
About the Authors
 Kiran Kumar Ballari is a Principal Solutions Architect at Amazon Web Services (AWS). He is an evangelist who loves to help customers leverage new technologies and build repeatable industry solutions to solve their problems. He is especially passionate about software engineering , Generative AI and helping companies with AI/ML product development.
Kiran Kumar Ballari is a Principal Solutions Architect at Amazon Web Services (AWS). He is an evangelist who loves to help customers leverage new technologies and build repeatable industry solutions to solve their problems. He is especially passionate about software engineering , Generative AI and helping companies with AI/ML product development.
 Ankur Goyal is a director in PwC Australia’s Cloud and Digital practice, focused on Data, Analytics & AI. Ankur has extensive experience in supporting public and private sector organizations in driving technology transformations and designing innovative solutions by leveraging data assets and technologies.
Ankur Goyal is a director in PwC Australia’s Cloud and Digital practice, focused on Data, Analytics & AI. Ankur has extensive experience in supporting public and private sector organizations in driving technology transformations and designing innovative solutions by leveraging data assets and technologies.
 Karthikeyan Chokappa (KC) is a Manager in PwC Australia’s Cloud and Digital practice, focused on Data, Analytics & AI. KC is passionate about designing, developing, and deploying end-to-end analytics solutions that transform data into valuable decision assets to improve performance and utilization and reduce the total cost of ownership for connected and intelligent things.
Karthikeyan Chokappa (KC) is a Manager in PwC Australia’s Cloud and Digital practice, focused on Data, Analytics & AI. KC is passionate about designing, developing, and deploying end-to-end analytics solutions that transform data into valuable decision assets to improve performance and utilization and reduce the total cost of ownership for connected and intelligent things.
 Rama Lankalapalli is a Sr. Partner Solutions Architect at AWS, working with PwC to accelerate their clients’ migrations and modernizations into AWS. He works across diverse industries to accelerate their adoption of AWS Cloud. His expertise lies in architecting efficient and scalable cloud solutions, driving innovation and modernization of customer applications by leveraging AWS services, and establishing resilient cloud foundations.
Rama Lankalapalli is a Sr. Partner Solutions Architect at AWS, working with PwC to accelerate their clients’ migrations and modernizations into AWS. He works across diverse industries to accelerate their adoption of AWS Cloud. His expertise lies in architecting efficient and scalable cloud solutions, driving innovation and modernization of customer applications by leveraging AWS services, and establishing resilient cloud foundations.
 Jeejee Unwalla is a Senior Solutions Architect at AWS who enjoys guiding customers in solving challenges and thinking strategically. He is passionate about tech and data and enabling innovation.
Jeejee Unwalla is a Senior Solutions Architect at AWS who enjoys guiding customers in solving challenges and thinking strategically. He is passionate about tech and data and enabling innovation.