Data sets are growing bigger every day and GPUs are getting faster. This means there are more data sets for deep learning researchers and engineers to train and validate their models.
- Many datasets for research in still image recognition are becoming available with 10 million or more images, including OpenImages and Places.
- million YouTube videos (YouTube 8M) consume about 300 TB in 720p, used for research in object recognition, video analytics, and action recognition.
- The Tobacco Corpus consists of about 20 million scanned HD pages, useful for OCR and text analytics research.
Although the most commonly encountered big data sets right now involve images and videos, big datasets occur in many other domains and involve many other kinds of data types: web pages, financial transactions, network traces, brain scans, etc.
However, working with the large amount of data sets presents a number of challenges:
- Dataset Size: datasets often exceed the capacity of node-local disk storage, requiring distributed storage systems and efficient network access.
- Number of Files: datasets often consist of billions of files with uniformly random access patterns, something that often overwhelms both local and network file systems.
- Data Rates: training jobs on large datasets often use many GPUs, requiring aggregate I/O bandwidths to the dataset of many GBytes/s; these can only be satisfied by massively parallel I/O systems.
- Shuffling and Augmentation: training data needs to be shuffled and augmented prior to training.
- Scalability: users often want to develop and test on small datasets and then rapidly scale up to large datasets.
Traditional local and network file systems, and even object storage servers, are not designed for these kinds of applications. The WebDataset I/O library for PyTorch, together with the optional AIStore server and Tensorcom RDMA libraries, provide an efficient, simple, and standards-based solution to all these problems. The library is simple enough for day-to-day use, is based on mature open source standards, and is easy to migrate to from existing file-based datasets.
Using WebDataset is simple and requires little effort, and it will let you scale up the same code from running local experiments to using hundreds of GPUs on clusters or in the cloud with linearly scalable performance. Even on small problems and on your desktop, it can speed up I/O tenfold and simplifies data management and processing of large datasets. The rest of this blog post tells you how to get started with WebDataset and how it works.
The WebDataset Library
The WebDataset library provides a simple solution to the challenges listed above. Currently, it is available as a separate library (github.com/tmbdev/webdataset), but it is on track for being incorporated into PyTorch (see RFC 38419). The WebDataset implementation is small (about 1500 LOC) and has no external dependencies.
Instead of inventing a new format, WebDataset represents large datasets as collections of POSIX tar archive files consisting of the original data files. The WebDataset library can use such tar archives directly for training, without the need for unpacking or local storage.
WebDataset scales perfectly from small, local datasets to petascale datasets and training on hundreds of GPUs and allows data to be stored on local disk, on web servers, or dedicated file servers. For container-based training, WebDataset eliminates the need for volume plugins or node-local storage. As an additional benefit, datasets need not be unpacked prior to training, simplifying the distribution and use of research data.
WebDataset implements PyTorch’s IterableDataset interface and can be used like existing DataLoader-based code. Since data is stored as files inside an archive, existing loading and data augmentation code usually requires minimal modification.
The WebDataset library is a complete solution for working with large datasets and distributed training in PyTorch (and also works with TensorFlow, Keras, and DALI via their Python APIs). Since POSIX tar archives are a standard, widely supported format, it is easy to write other tools for manipulating datasets in this format. E.g., the tarp command is written in Go and can shuffle and process training datasets.
Benefits
The use of sharded, sequentially readable formats is essential for very large datasets. In addition, it has benefits in many other environments. WebDataset provides a solution that scales well from small problems on a desktop machine to very large deep learning problems in clusters or in the cloud. The following table summarizes some of the benefits in different environments.
| Environment | Benefits of WebDataset |
|---|---|
| Local Cluster with AIStore | AIStore can be deployed easily as K8s containers and offers linear scalability and near 100% utilization of network and I/O bandwidth. Suitable for petascale deep learning. |
| Cloud Computing | WebDataset deep learning jobs can be trained directly against datasets stored in cloud buckets; no volume plugins required. Local and cloud jobs work identically. Suitable for petascale learning. |
| Local Cluster with existing distributed FS or object store | WebDataset’s large sequential reads improve performance with existing distributed stores and eliminate the need for dedicated volume plugins. |
| Educational Environments | WebDatasets can be stored on existing web servers and web caches, and can be accessed directly by students by URL |
| Training on Workstations from Local Drives | Jobs can start training as the data still downloads. Data doesn’t need to be unpacked for training. Ten-fold improvements in I/O performance on hard drives over random access file-based datasets. |
| All Environments | Datasets are represented in an archival format and contain metadata such as file types. Data is compressed in native formats (JPEG, MP4, etc.). Data management, ETL-style jobs, and data transformations and I/O are simplified and easily parallelized. |
We will be adding more examples giving benchmarks and showing how to use WebDataset in these environments over the coming months.
High-Performance
For high-performance computation on local clusters, the companion open-source AIStore server provides full disk to GPU I/O bandwidth, subject only to hardware constraints. This Bigdata 2019 Paper contains detailed benchmarks and performance measurements. In addition to benchmarks, research projects at NVIDIA and Microsoft have used WebDataset for petascale datasets and billions of training samples.
Below is a benchmark of AIStore with WebDataset clients using 10 server nodes and 120 rotational drives each.
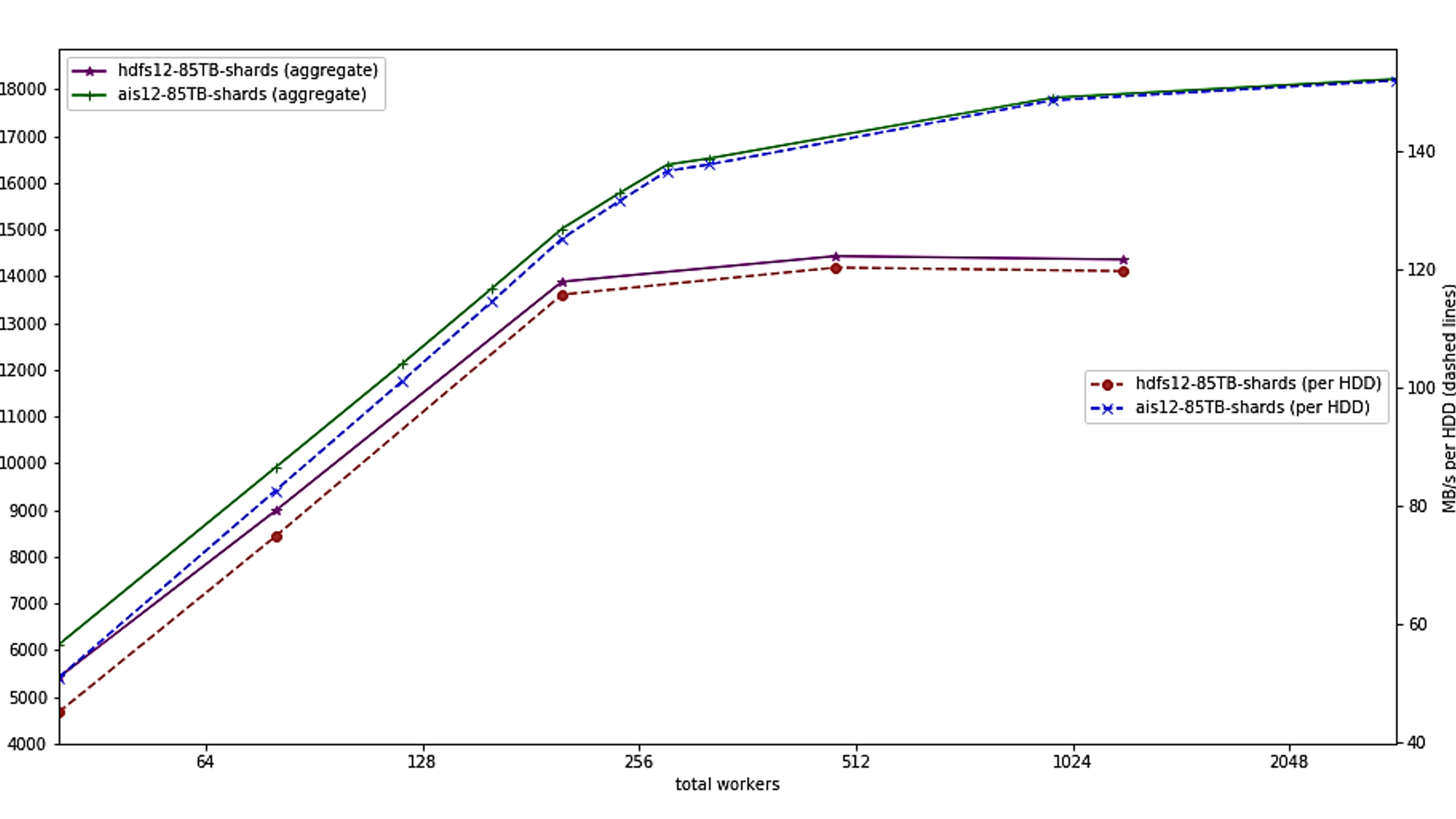
The left axis shows the aggregate bandwidth from the cluster, while the right scale shows the measured per drive I/O bandwidth. WebDataset and AIStore scale linearly to about 300 clients, at which point they are increasingly limited by the maximum I/O bandwidth available from the rotational drives (about 150 MBytes/s per drive). For comparison, HDFS is shown. HDFS uses a similar approach to AIStore/WebDataset and also exhibits linear scaling up to about 192 clients; at that point, it hits a performance limit of about 120 MBytes/s per drive, and it failed when using more than 1024 clients. Unlike HDFS, the WebDataset-based code just uses standard URLs and HTTP to access data and works identically with local files, with files stored on web servers, and with AIStore. For comparison, NFS in similar experiments delivers about 10-20 MBytes/s per drive.
Storing Datasets in Tar Archives
The format used for WebDataset is standard POSIX tar archives, the same archives used for backup and data distribution. In order to use the format to store training samples for deep learning, we adopt some simple naming conventions:
- datasets are POSIX tar archives
- each training sample consists of adjacent files with the same basename
- shards are numbered consecutively
For example, ImageNet is stored in 1282 separate 100 Mbyte shards with names pythonimagenet-train-000000.tar to imagenet-train-001281.tar, the contents of the first shard are:
-r--r--r-- bigdata/bigdata 3 2020-05-08 21:23 n03991062_24866.cls
-r--r--r-- bigdata/bigdata 108611 2020-05-08 21:23 n03991062_24866.jpg
-r--r--r-- bigdata/bigdata 3 2020-05-08 21:23 n07749582_9506.cls
-r--r--r-- bigdata/bigdata 129044 2020-05-08 21:23 n07749582_9506.jpg
-r--r--r-- bigdata/bigdata 3 2020-05-08 21:23 n03425413_23604.cls
-r--r--r-- bigdata/bigdata 106255 2020-05-08 21:23 n03425413_23604.jpg
-r--r--r-- bigdata/bigdata 3 2020-05-08 21:23 n02795169_27274.cls
WebDataset datasets can be used directly from local disk, from web servers (hence the name), from cloud storage and object stores, just by changing a URL. WebDataset datasets can be used for training without unpacking, and training can even be carried out on streaming data, with no local storage.
Shuffling during training is important for many deep learning applications, and WebDataset performs shuffling both at the shard level and at the sample level. Splitting of data across multiple workers is performed at the shard level using a user-provided shard_selection function that defaults to a function that splits based on get_worker_info. (WebDataset can be combined with the tensorcom library to offload decompression/data augmentation and provide RDMA and direct-to-GPU loading; see below.)
Code Sample
Here are some code snippets illustrating the use of WebDataset in a typical PyTorch deep learning application (you can find a full example at http://github.com/tmbdev/pytorch-imagenet-wds.
import webdataset as wds
import ...
sharedurl = "/imagenet/imagenet-train-{000000..001281}.tar"
normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
preproc = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
])
dataset = (
wds.Dataset(sharedurl)
.shuffle(1000)
.decode("pil")
.rename(image="jpg;png", data="json")
.map_dict(image=preproc)
.to_tuple("image", "data")
)
loader = torch.utils.data.DataLoader(dataset, batch_size=64, num_workers=8)
for inputs, targets in loader:
...
This code is nearly identical to the file-based I/O pipeline found in the PyTorch Imagenet example: it creates a preprocessing/augmentation pipeline, instantiates a dataset using that pipeline and a data source location, and then constructs a DataLoader instance from the dataset.
WebDataset uses a fluent API for a configuration that internally builds up a processing pipeline. Without any added processing stages, In this example, WebDataset is used with the PyTorch DataLoader class, which replicates DataSet instances across multiple threads and performs both parallel I/O and parallel data augmentation.
WebDataset instances themselves just iterate through each training sample as a dictionary:
# load from a web server using a separate client process
sharedurl = "pipe:curl -s http://server/imagenet/imagenet-train-{000000..001281}.tar"
dataset = wds.Dataset(sharedurl)
for sample in dataset:
# sample["jpg"] contains the raw image data
# sample["cls"] contains the class
...
For a general introduction to how we handle large scale training with WebDataset, see these YouTube videos.
Related Software
-
AIStore is an open-source object store capable of full-bandwidth disk-to-GPU data delivery (meaning that if you have 1000 rotational drives with 200 MB/s read speed, AIStore actually delivers an aggregate bandwidth of 200 GB/s to the GPUs). AIStore is fully compatible with WebDataset as a client, and in addition understands the WebDataset format, permitting it to perform shuffling, sorting, ETL, and some map-reduce operations directly in the storage system. AIStore can be thought of as a remix of a distributed object store, a network file system, a distributed database, and a GPU-accelerated map-reduce implementation.
-
tarp is a small command-line program for splitting, merging, shuffling, and processing tar archives and WebDataset datasets.
-
tensorcom is a library supporting distributed data augmentation and RDMA to GPU.
-
webdataset-examples contains an example (and soon more examples) of how to use WebDataset in practice.
Check out the library and provide your feedback for RFC 38419.